Python训练营打卡 Day46
道注意力(SE注意力)
知识点回顾:
- 不同CNN层的特征图:不同通道的特征图
- 什么是注意力:注意力家族,类似于动物园,都是不同的模块,好不好试了才知道。
- 通道注意力:模型的定义和插入的位置
- 通道注意力后的特征图和热力图
SE注意力机制(Squeeze-and-Excitation Networks)
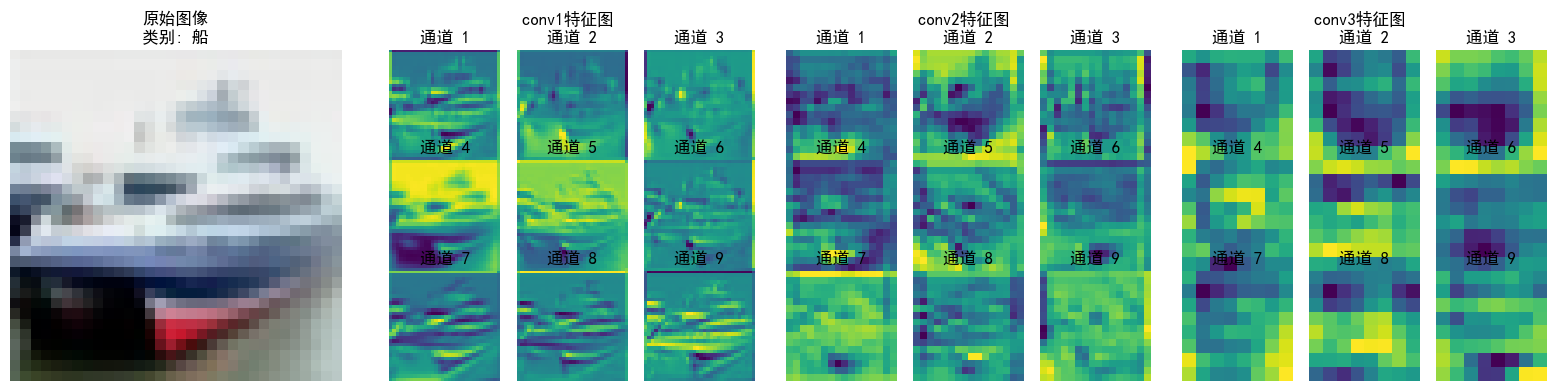
1. 不同CNN层的特征图:不同通道的特征图
-
特征图:就像餐厅中每种食材都含有不同的营养成分,CNN的每个通道的特征图都捕捉了图像的不同特征。
-
通道注意力:关注哪些特征(食材)对当前任务更重要。
2. 什么是注意力:注意力家族,类似于动物园,都是不同的模块,好不好试了才知道
-
注意力概念:如同在嘈杂的餐厅中,顾客注意力集中在某道菜上,深度学习模型的注意力机制让模型集中精力在输入数据的关键部分。
-
注意力家族:有不同的注意力机制,如同动物园中有多种动物,各有特点,如SE注意力、空间注意力等,需通过实验确定哪种更有效。
3. 通道注意力:模型的定义和插入的位置
-
模型的定义:类似于在餐厅中制定烹饪流程,通道注意力定义了如何动态调整不同特征通道的重要性。
-
插入的位置:通常紧接着卷积层或池化层后,如在ResNet中,将SE模块插入每个残差块中。
4. 通道注意力后的特征图和热力图
-
特征图:调整后的图显示各通道特征重要性,如同食材经调味后的“增强版”。
-
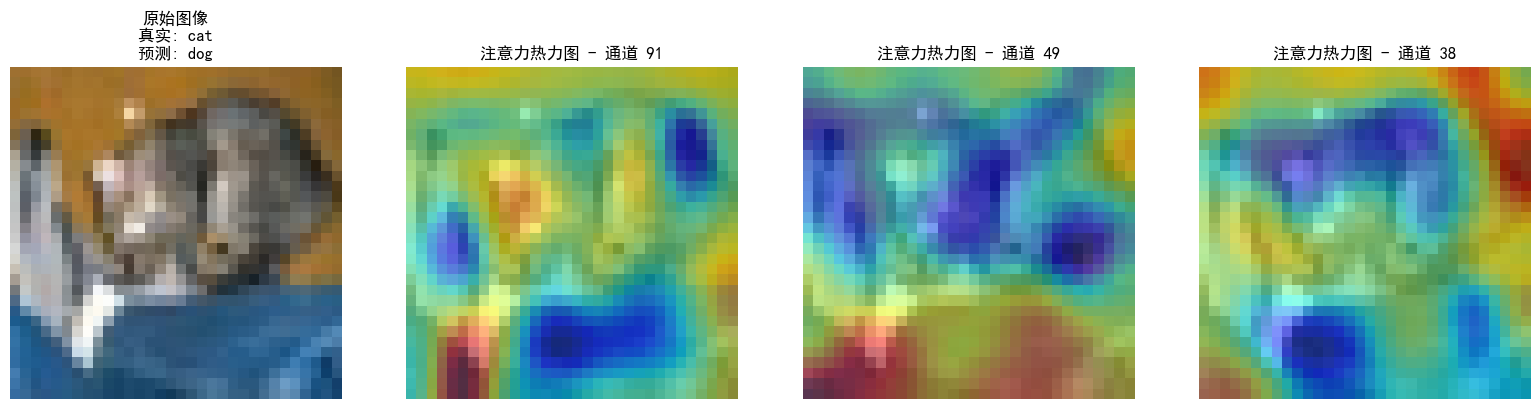
热力图:可视化通道注意力后的特征图,如同在餐厅中用热成像仪显示食材热度,颜色越亮表示对应区域特征越重要。
内容参考

作业:
- 今日代码较多,理解逻辑即可
- 对比不同卷积层特征图可视化的结果(可选)
原始代码,特征图可视化
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 设置替代中文字体(适用于Linux)
plt.rcParams["font.family"] = ["WenQuanYi Micro Hei", "sans-serif"]
plt.rcParams['axes.unicode_minus'] = False
# # 设置中文字体支持
# plt.rcParams["font.family"] = ["SimHei"]
# plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 1. 数据预处理
# 训练集:使用多种数据增强方法提高模型泛化能力
train_transform = transforms.Compose([# 随机裁剪图像,从原图中随机截取32x32大小的区域transforms.RandomCrop(32, padding=4),# 随机水平翻转图像(概率0.5)transforms.RandomHorizontalFlip(),# 随机颜色抖动:亮度、对比度、饱和度和色调随机变化transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),# 随机旋转图像(最大角度15度)transforms.RandomRotation(15),# 将PIL图像或numpy数组转换为张量transforms.ToTensor(),# 标准化处理:每个通道的均值和标准差,使数据分布更合理transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 测试集:仅进行必要的标准化,保持数据原始特性,标准化不损失数据信息,可还原
test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./cifar_data/cifar_data',train=True,download=True,transform=train_transform # 使用增强后的预处理
)test_dataset = datasets.CIFAR10(root='./cifar_data/cifar_data',train=False,transform=test_transform # 测试集不使用增强
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 4. 定义CNN模型的定义(替代原MLP)
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__() # 继承父类初始化# ---------------------- 第一个卷积块 ----------------------# 卷积层1:输入3通道(RGB),输出32个特征图,卷积核3x3,边缘填充1像素self.conv1 = nn.Conv2d(in_channels=3, # 输入通道数(图像的RGB通道)out_channels=32, # 输出通道数(生成32个新特征图)kernel_size=3, # 卷积核尺寸(3x3像素)padding=1 # 边缘填充1像素,保持输出尺寸与输入相同)# 批量归一化层:对32个输出通道进行归一化,加速训练self.bn1 = nn.BatchNorm2d(num_features=32)# ReLU激活函数:引入非线性,公式:max(0, x)self.relu1 = nn.ReLU()# 最大池化层:窗口2x2,步长2,特征图尺寸减半(32x32→16x16)self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # stride默认等于kernel_size# ---------------------- 第二个卷积块 ----------------------# 卷积层2:输入32通道(来自conv1的输出),输出64通道self.conv2 = nn.Conv2d(in_channels=32, # 输入通道数(前一层的输出通道数)out_channels=64, # 输出通道数(特征图数量翻倍)kernel_size=3, # 卷积核尺寸不变padding=1 # 保持尺寸:16x16→16x16(卷积后)→8x8(池化后))self.bn2 = nn.BatchNorm2d(num_features=64)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:16x16→8x8# ---------------------- 第三个卷积块 ----------------------# 卷积层3:输入64通道,输出128通道self.conv3 = nn.Conv2d(in_channels=64, # 输入通道数(前一层的输出通道数)out_channels=128, # 输出通道数(特征图数量再次翻倍)kernel_size=3,padding=1 # 保持尺寸:8x8→8x8(卷积后)→4x4(池化后))self.bn3 = nn.BatchNorm2d(num_features=128)self.relu3 = nn.ReLU() # 复用激活函数对象(节省内存)self.pool3 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:8x8→4x4# ---------------------- 全连接层(分类器) ----------------------# 计算展平后的特征维度:128通道 × 4x4尺寸 = 128×16=2048维self.fc1 = nn.Linear(in_features=128 * 4 * 4, # 输入维度(卷积层输出的特征数)out_features=512 # 输出维度(隐藏层神经元数))# Dropout层:训练时随机丢弃50%神经元,防止过拟合self.dropout = nn.Dropout(p=0.5)# 输出层:将512维特征映射到10个类别(CIFAR-10的类别数)self.fc2 = nn.Linear(in_features=512, out_features=10)def forward(self, x):# 输入尺寸:[batch_size, 3, 32, 32](batch_size=批量大小,3=通道数,32x32=图像尺寸)# ---------- 卷积块1处理 ----------x = self.conv1(x) # 卷积后尺寸:[batch_size, 32, 32, 32](padding=1保持尺寸)x = self.bn1(x) # 批量归一化,不改变尺寸x = self.relu1(x) # 激活函数,不改变尺寸x = self.pool1(x) # 池化后尺寸:[batch_size, 32, 16, 16](32→16是因为池化窗口2x2)# ---------- 卷积块2处理 ----------x = self.conv2(x) # 卷积后尺寸:[batch_size, 64, 16, 16](padding=1保持尺寸)x = self.bn2(x)x = self.relu2(x)x = self.pool2(x) # 池化后尺寸:[batch_size, 64, 8, 8]# ---------- 卷积块3处理 ----------x = self.conv3(x) # 卷积后尺寸:[batch_size, 128, 8, 8](padding=1保持尺寸)x = self.bn3(x)x = self.relu3(x)x = self.pool3(x) # 池化后尺寸:[batch_size, 128, 4, 4]# ---------- 展平与全连接层 ----------# 将多维特征图展平为一维向量:[batch_size, 128*4*4] = [batch_size, 2048]x = x.view(-1, 128 * 4 * 4) # -1自动计算批量维度,保持批量大小不变x = self.fc1(x) # 全连接层:2048→512,尺寸变为[batch_size, 512]x = self.relu3(x) # 激活函数(复用relu3,与卷积块3共用)x = self.dropout(x) # Dropout随机丢弃神经元,不改变尺寸x = self.fc2(x) # 全连接层:512→10,尺寸变为[batch_size, 10](未激活,直接输出logits)return x # 输出未经过Softmax的logits,适用于交叉熵损失函数# 初始化模型
model = CNN()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 引入学习率调度器,在训练过程中动态调整学习率--训练初期使用较大的 LR 快速降低损失,训练后期使用较小的 LR 更精细地逼近全局最优解。
# 在每个 epoch 结束后,需要手动调用调度器来更新学习率,可以在训练过程中调用 scheduler.step()
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, # 指定要控制的优化器(这里是Adam)mode='min', # 监测的指标是"最小化"(如损失函数)patience=3, # 如果连续3个epoch指标没有改善,才降低LRfactor=0.5 # 降低LR的比例(新LR = 旧LR × 0.5)
)
# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs):model.train() # 设置为训练模式# 记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号# 记录每个 epoch 的准确率和损失train_acc_history = []test_acc_history = []train_loss_history = []test_loss_history = []for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计准确率和损失running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次打印一次训练信息if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totaltrain_acc_history.append(epoch_train_acc)train_loss_history.append(epoch_train_loss)# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testtest_acc_history.append(epoch_test_acc)test_loss_history.append(epoch_test_loss)# 更新学习率调度器scheduler.step(epoch_test_loss)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)# 绘制每个 epoch 的准确率和损失曲线plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)return epoch_test_acc # 返回最终测试准确率# 6. 绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 7. 绘制每个 epoch 的准确率和损失曲线
def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):epochs = range(1, len(train_acc) + 1)plt.figure(figsize=(12, 4))# 绘制准确率曲线plt.subplot(1, 2, 1)plt.plot(epochs, train_acc, 'b-', label='训练准确率')plt.plot(epochs, test_acc, 'r-', label='测试准确率')plt.xlabel('Epoch')plt.ylabel('准确率 (%)')plt.title('训练和测试准确率')plt.legend()plt.grid(True)# 绘制损失曲线plt.subplot(1, 2, 2)plt.plot(epochs, train_loss, 'b-', label='训练损失')plt.plot(epochs, test_loss, 'r-', label='测试损失')plt.xlabel('Epoch')plt.ylabel('损失值')plt.title('训练和测试损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 8. 执行训练和测试
epochs = 50 # 增加训练轮次为了确保收敛
print("开始使用CNN训练模型...")
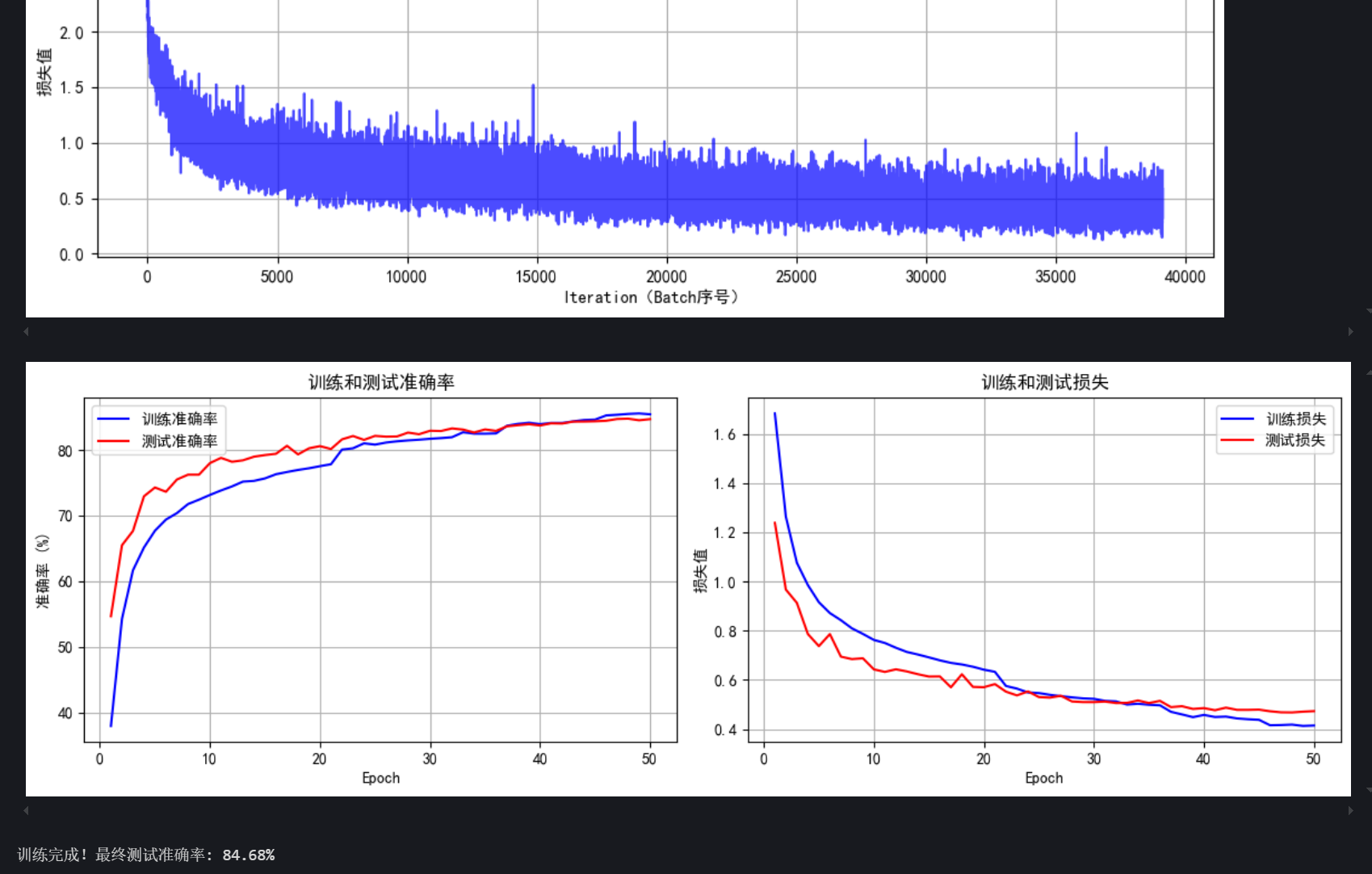
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")# # 保存模型
torch.save(model.state_dict(), 'cifar10_cnn_model.pth')
print("模型已保存为: cifar10_cnn_model.pth")# 设置替代中文字体(适用于Linux)
plt.rcParams["font.family"] = ["WenQuanYi Micro Hei", "sans-serif"]
plt.rcParams['axes.unicode_minus'] = False
def visualize_feature_maps(model, test_loader, device, layer_names, num_images=3, num_channels=9):"""可视化指定层的特征图(修复循环冗余问题)参数:model: 模型test_loader: 测试数据加载器layer_names: 要可视化的层名称(如['conv1', 'conv2', 'conv3'])num_images: 可视化的图像总数num_channels: 每个图像显示的通道数(取前num_channels个通道)"""model.eval() # 设置为评估模式class_names = ['飞机', '汽车', '鸟', '猫', '鹿', '狗', '青蛙', '马', '船', '卡车']# 从测试集加载器中提取指定数量的图像(避免嵌套循环)images_list, labels_list = [], []for images, labels in test_loader:images_list.append(images)labels_list.append(labels)if len(images_list) * test_loader.batch_size >= num_images:break# 拼接并截取到目标数量# torch.cat(images_list, dim=0) 将多个图像张量在批次维度(dim=0)拼接成一个大张量images = torch.cat(images_list, dim=0)[:num_images].to(device)labels = torch.cat(labels_list, dim=0)[:num_images].to(device)with torch.no_grad():# 存储各层特征图feature_maps = {}# 保存钩子句柄hooks = []# 定义钩子函数,捕获指定层的输出def hook(module, input, output, name):feature_maps[name] = output.cpu() # 保存特征图到字典# 为每个目标层注册钩子,并保存钩子句柄for name in layer_names:# getattr(model, name):通过层名称动态获取模型中的模块(如卷积层、ReLU 层等)。module = getattr(model, name)hook_handle = module.register_forward_hook(lambda m, i, o, n=name: hook(m, i, o, n))hooks.append(hook_handle)# 前向传播触发钩子_ = model(images)# 正确移除钩子for hook_handle in hooks:hook_handle.remove()# 可视化每个图像的各层特征图(仅一层循环)for img_idx in range(num_images):img = images[img_idx].cpu().permute(1, 2, 0).numpy()# 反标准化处理(恢复原始像素值)img = img * np.array([0.2023, 0.1994, 0.2010]).reshape(1, 1, 3) + np.array([0.4914, 0.4822, 0.4465]).reshape(1, 1, 3)img = np.clip(img, 0, 1) # 确保像素值在[0,1]范围内# 创建子图num_layers = len(layer_names)fig, axes = plt.subplots(1, num_layers + 1, figsize=(4 * (num_layers + 1), 4))# 显示原始图像axes[0].imshow(img)axes[0].set_title(f'原始图像\n类别: {class_names[labels[img_idx]]}')axes[0].axis('off')# 显示各层特征图# layer_names: 要可视化的层名称(如['conv1', 'conv2', 'conv3'])for layer_idx, layer_name in enumerate(layer_names):fm = feature_maps[layer_name][img_idx] # 取第img_idx张图像的特征图fm = fm[:num_channels] # 仅取前num_channels个通道num_rows = int(np.sqrt(num_channels))num_cols = num_channels // num_rows if num_rows != 0 else 1# 创建子图网格layer_ax = axes[layer_idx + 1]layer_ax.set_title(f'{layer_name}特征图 \n')# 加个换行让文字分离上去layer_ax.axis('off') # 关闭大子图的坐标轴# 在大子图内创建小网格for ch_idx, channel in enumerate(fm):ax = layer_ax.inset_axes([ch_idx % num_cols / num_cols, (num_rows - 1 - ch_idx // num_cols) / num_rows, 1/num_cols, 1/num_rows])ax.imshow(channel.numpy(), cmap='viridis')ax.set_title(f'通道 {ch_idx + 1}')ax.axis('off')plt.tight_layout()plt.show()# 调用示例(按需修改参数)
layer_names = ['conv1', 'conv2', 'conv3']
visualize_feature_maps(model=model,test_loader=test_loader,device=device,layer_names=layer_names,num_images=5, # 可视化5张测试图像 → 输出5张大图num_channels=9 # 每张图像显示前9个通道的特征图
)

引入通道注意力机制后,特征图可视化
# ===================== 新增:通道注意力模块(SE模块) =====================
class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_ratio=16):"""参数:in_channels: 输入特征图的通道数reduction_ratio: 降维比例,用于减少参数量"""super(ChannelAttention, self).__init__()# 全局平均池化 - 将空间维度压缩为1x1,保留通道信息self.avg_pool = nn.AdaptiveAvgPool2d(1)# 全连接层 + 激活函数,用于学习通道间的依赖关系self.fc = nn.Sequential(# 降维:压缩通道数,减少计算量nn.Linear(in_channels, in_channels // reduction_ratio, bias=False),nn.ReLU(inplace=True),# 升维:恢复原始通道数nn.Linear(in_channels // reduction_ratio, in_channels, bias=False),# Sigmoid将输出值归一化到[0,1],表示通道重要性权重nn.Sigmoid())def forward(self, x):"""参数:x: 输入特征图,形状为 [batch_size, channels, height, width]返回:加权后的特征图,形状不变"""batch_size, channels, height, width = x.size()# 1. 全局平均池化:[batch_size, channels, height, width] → [batch_size, channels, 1, 1]avg_pool_output = self.avg_pool(x)# 2. 展平为一维向量:[batch_size, channels, 1, 1] → [batch_size, channels]avg_pool_output = avg_pool_output.view(batch_size, channels)# 3. 通过全连接层学习通道权重:[batch_size, channels] → [batch_size, channels]channel_weights = self.fc(avg_pool_output)# 4. 重塑为二维张量:[batch_size, channels] → [batch_size, channels, 1, 1]channel_weights = channel_weights.view(batch_size, channels, 1, 1)# 5. 将权重应用到原始特征图上(逐通道相乘)return x * channel_weights # 输出形状:[batch_size, channels, height, width]class CNN(nn.Module):def __init__(self):super(CNN, self).__init__() # ---------------------- 第一个卷积块 ----------------------self.conv1 = nn.Conv2d(3, 32, 3, padding=1)self.bn1 = nn.BatchNorm2d(32)self.relu1 = nn.ReLU()# 新增:插入通道注意力模块(SE模块)self.ca1 = ChannelAttention(in_channels=32, reduction_ratio=16) self.pool1 = nn.MaxPool2d(2, 2) # ---------------------- 第二个卷积块 ----------------------self.conv2 = nn.Conv2d(32, 64, 3, padding=1)self.bn2 = nn.BatchNorm2d(64)self.relu2 = nn.ReLU()# 新增:插入通道注意力模块(SE模块)self.ca2 = ChannelAttention(in_channels=64, reduction_ratio=16) self.pool2 = nn.MaxPool2d(2) # ---------------------- 第三个卷积块 ----------------------self.conv3 = nn.Conv2d(64, 128, 3, padding=1)self.bn3 = nn.BatchNorm2d(128)self.relu3 = nn.ReLU()# 新增:插入通道注意力模块(SE模块)self.ca3 = ChannelAttention(in_channels=128, reduction_ratio=16) self.pool3 = nn.MaxPool2d(2) # ---------------------- 全连接层(分类器) ----------------------self.fc1 = nn.Linear(128 * 4 * 4, 512)self.dropout = nn.Dropout(p=0.5)self.fc2 = nn.Linear(512, 10)def forward(self, x):# ---------- 卷积块1处理 ----------x = self.conv1(x) x = self.bn1(x) x = self.relu1(x) x = self.ca1(x) # 应用通道注意力x = self.pool1(x) # ---------- 卷积块2处理 ----------x = self.conv2(x) x = self.bn2(x) x = self.relu2(x) x = self.ca2(x) # 应用通道注意力x = self.pool2(x) # ---------- 卷积块3处理 ----------x = self.conv3(x) x = self.bn3(x) x = self.relu3(x) x = self.ca3(x) # 应用通道注意力x = self.pool3(x) # ---------- 展平与全连接层 ----------x = x.view(-1, 128 * 4 * 4) x = self.fc1(x) x = self.relu3(x) x = self.dropout(x) x = self.fc2(x) return x # 重新初始化模型,包含通道注意力模块
model = CNN()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 引入学习率调度器,在训练过程中动态调整学习率--训练初期使用较大的 LR 快速降低损失,训练后期使用较小的 LR 更精细地逼近全局最优解。
# 在每个 epoch 结束后,需要手动调用调度器来更新学习率,可以在训练过程中调用 scheduler.step()
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, # 指定要控制的优化器(这里是Adam)mode='min', # 监测的指标是"最小化"(如损失函数)patience=3, # 如果连续3个epoch指标没有改善,才降低LRfactor=0.5 # 降低LR的比例(新LR = 旧LR × 0.5)
)# 5. 训练函数(支持学习率调度器)
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs):model.train() # 设置为训练模式train_loss_history = []test_loss_history = []train_acc_history = []test_acc_history = []all_iter_losses = []iter_indices = []for epoch in range(epochs):running_loss = 0.0correct_train = 0total_train = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()# 记录Iteration损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计训练指标running_loss += iter_loss_, predicted = output.max(1)total_train += target.size(0)correct_train += predicted.eq(target).sum().item()# 每100批次打印进度if (batch_idx + 1) % 100 == 0:print(f"Epoch {epoch+1}/{epochs} | Batch {batch_idx+1}/{len(train_loader)} "f"| 单Batch损失: {iter_loss:.4f}")# 计算 epoch 级指标epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct_train / total_train# 测试阶段model.eval()correct_test = 0total_test = 0test_loss = 0.0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_test# 记录历史数据train_loss_history.append(epoch_train_loss)test_loss_history.append(epoch_test_loss)train_acc_history.append(epoch_train_acc)test_acc_history.append(epoch_test_acc)# 更新学习率调度器if scheduler is not None:scheduler.step(epoch_test_loss)# 打印 epoch 结果print(f"Epoch {epoch+1} 完成 | 训练损失: {epoch_train_loss:.4f} "f"| 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%")# 绘制损失和准确率曲线plot_iter_losses(all_iter_losses, iter_indices)plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)return epoch_test_acc # 返回最终测试准确率# 训练模型(复用原有的train函数)
print("开始训练带通道注意力的CNN模型...")
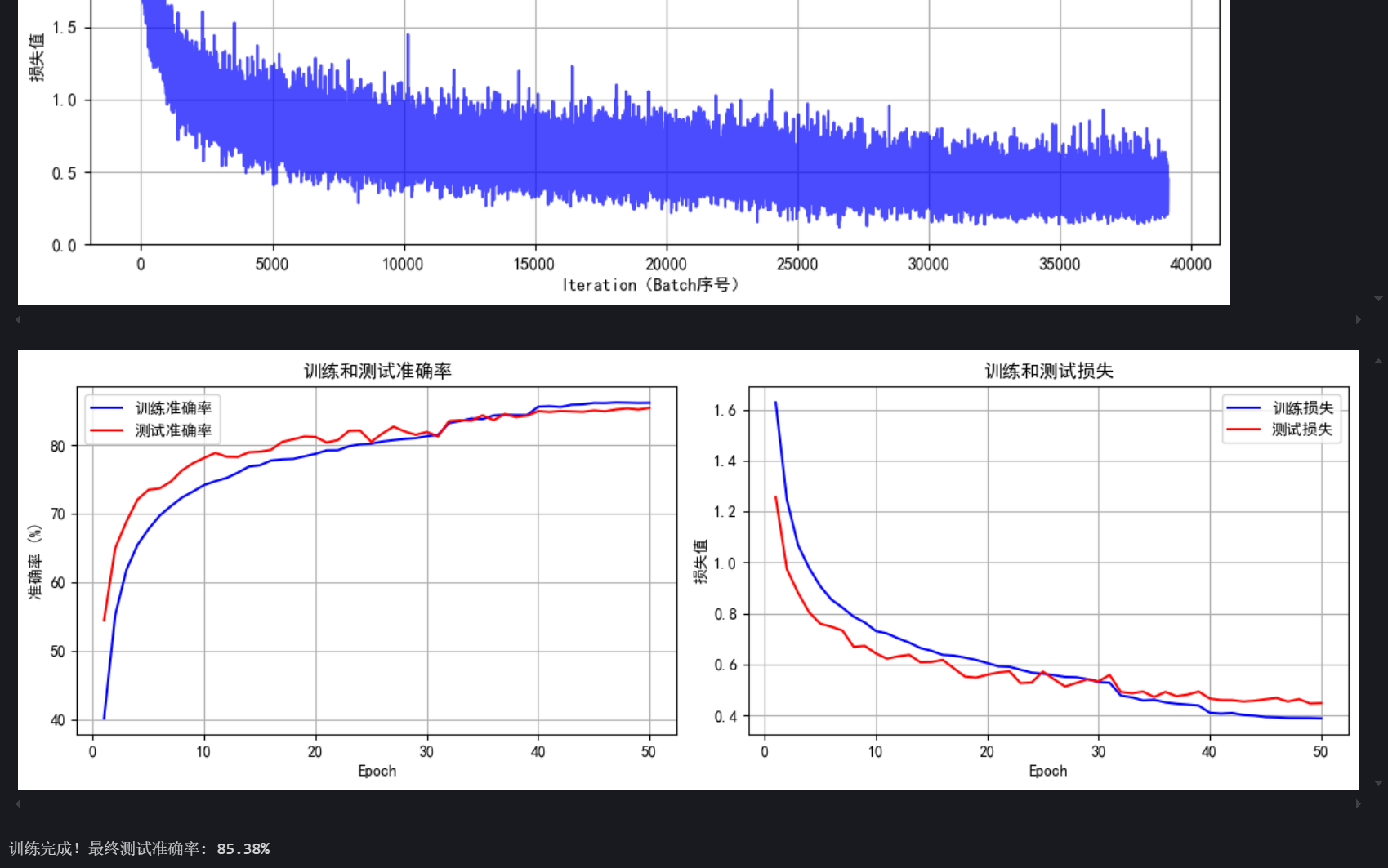
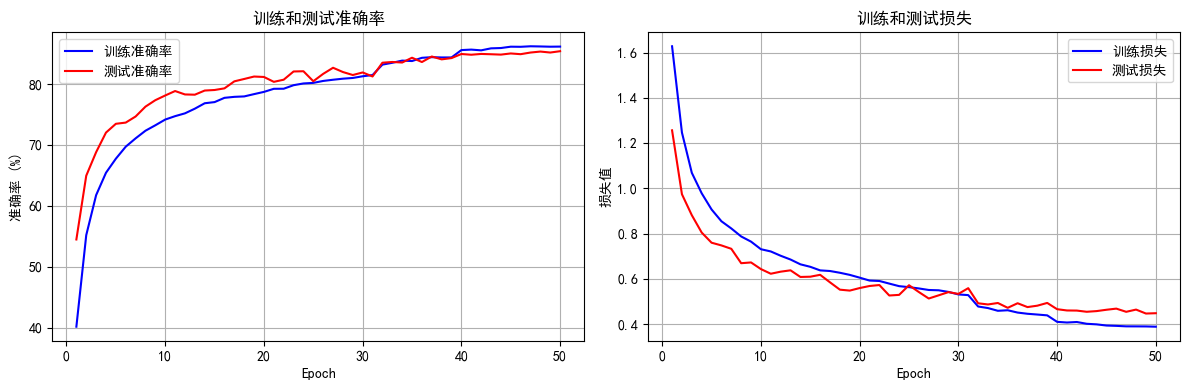
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs=50)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")
ps:
- 我这里列出来的是通道注意力中的一种,SE注意力
- 为了保证收敛方便对比性能,今日代码训练轮数较多,比较耗时
- 目前我们终于接触到了模块,模块本质上也是对特征的进一步提取,整个深度学习就是在围绕特征提取展开的,后面会是越来越复杂的特征提取和组合步骤
- 新增八股部分,在本讲义目录中可以看到----用问答的形式记录知识点
@浙大疏锦行
相关文章:
Python训练营打卡 Day46
道注意力(SE注意力) 知识点回顾: 不同CNN层的特征图:不同通道的特征图什么是注意力:注意力家族,类似于动物园,都是不同的模块,好不好试了才知道。通道注意力:模型的定义和插入的位置通道注意力后…...
解决微软应用商店 (Microsoft store) 打不开,无网络连接的问题!
很多小伙伴都会遇见微软应用商店 (Microsoft store)打开后出现无网络的问题,一般出现这种问题基本都是因为你的电脑安装了某些银行的网银工具,因为网银工具为了安全会关闭Internet 选项中的最新版本的TLS协议,而微软商店又需要最新的TLS协议才…...

《影像引导下骨盆创伤手术的术前骨折复位规划:基于学习的综合流程》|文献速递-深度学习医疗AI最新文献
Title 题目 Preoperative fracture reduction planning for image-guided pelvic trauma surgery: A comprehensive pipeline with learning 《影像引导下骨盆创伤手术的术前骨折复位规划:基于学习的综合流程》 01 文献速递介绍 《影像引导下骨盆创伤手术的术前…...
如何使用Webhook触发器,在 ONLYOFFICE 协作空间构建智能工作流
在数字化办公中,ONLYOFFICE 协作空间作为一款功能强大的文档协作平台,提供了丰富的自动化功能。对于开发者而言,Webhook 触发器是实现业务流程自动化与系统集成的关键工具。本文将深入探讨如何在 ONLYOFFICE 协作空间中高效利用 Webhook&…...

跟我学c++中级篇——理解类型推导和C++不同版本的支持
一、类型推导 在前面反复分析过类型推导(包括前面提到的类模板参数推导CTAD),类型推导其实就是满足C语言这种强类型语言的要求即编译期必须确定对象的数据类型。换一句话说,理论上如果编译器中能够自动推导所有的相关数据类型&am…...

什么是DevOps智能平台的核心功能?
在数字化转型的浪潮中,DevOps智能平台已成为企业提升研发效能、加速产品迭代的核心工具。然而,许多人对“DevOps智能平台”的理解仍停留在“自动化工具链”的表层概念。今天,我们从一个真实场景切入:假设你是某互联网公司的技术负…...
Windows账户管理,修改密码,创建帐户...(无需密码)
前言 我们使用wWindows操作系统时,账户是非常重要的概念 它不仅能够帮助我们区分文档主题权限等等 嗯还有最重要的解锁电脑的作用! 但想要管理他,不仅需要原本的密码,而且设置中的管理项也非常的不全。 Windows有一款netplwi…...

软件功能模块归属论证方法
文章目录 **一、核心设计原则****二、论证方法****三、常见决策模式****四、验证方法****五、反模式警示****总结** 在讨论软件功能点应该归属哪些模块时,并没有放之四海而皆准的固定方法,但可以通过系统化的论证和设计原则来做出合理决策。以下是常见的…...

【Java后端基础 005】ThreadLocal-线程数据共享和安全
📚博客主页:代码探秘者 ✨专栏:文章正在持续更新ing… ✅C语言/C:C(详细版) 数据结构) 十大排序算法 ✅Java基础:JavaSE基础 面向对象大合集 JavaSE进阶 Java版数据结构JDK新特性…...
【C语言】C语言经典小游戏:贪吃蛇(下)
文章目录 一、游戏前准备二、游戏开始1、游戏开始函数(GameStart)1)打印欢迎界⾯(WelcomeToGame)2)创建地图(CreateMap)3)初始化蛇⾝(InitSnake)4…...

NTT印地赛车:数字孪生技术重构赛事体验范式,驱动观众参与度革命
引言:数字孪生技术赋能体育赛事,开启沉浸式观赛新纪元 在传统体育赛事观赛模式遭遇体验天花板之际,NTT与印地赛车系列赛(NTT INDYCAR SERIES)的深度合作,通过数字孪生(Digital Twin)…...
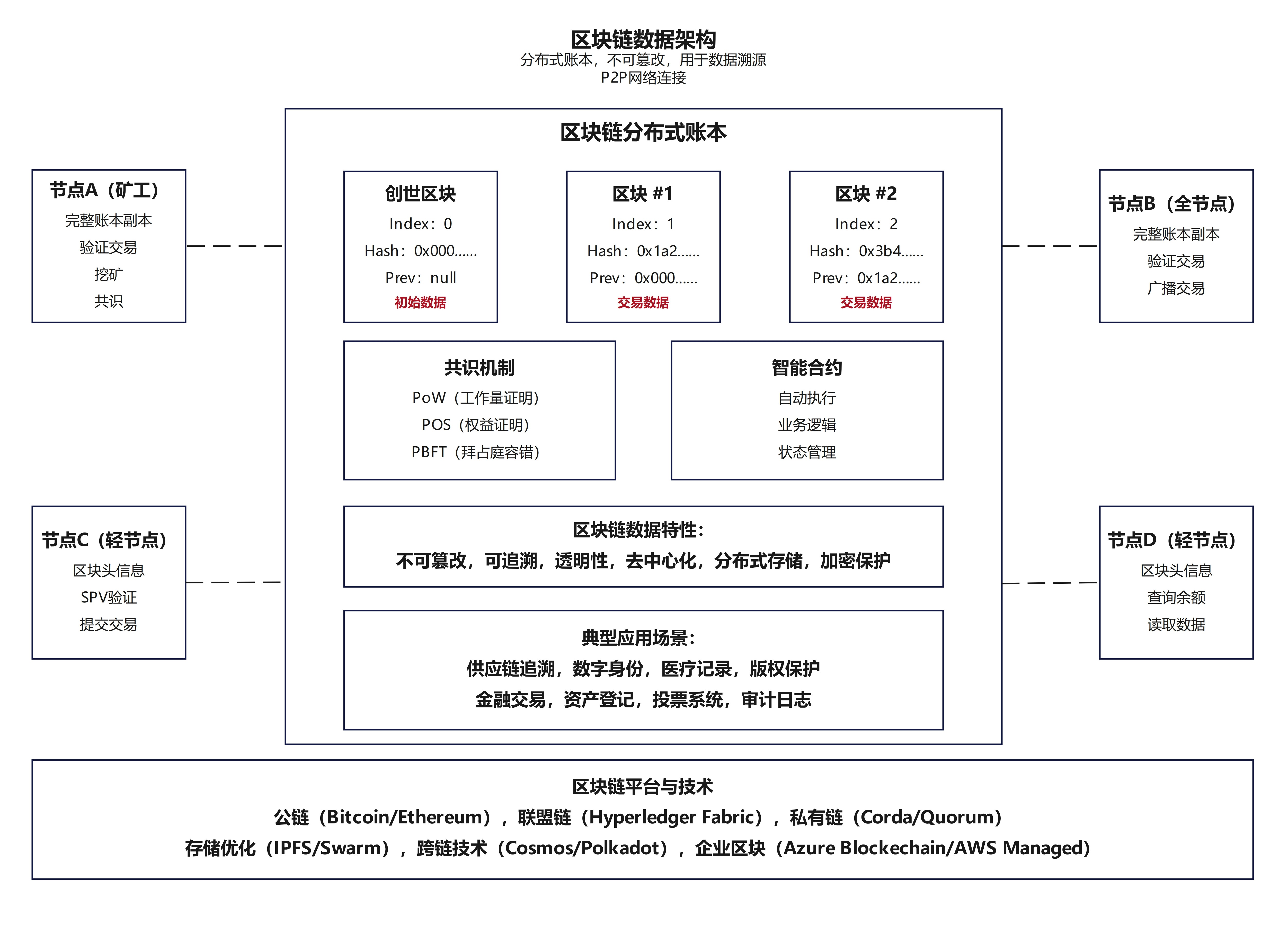
30.【新型数据架构】-区块链数据架构
30.【新型数据架构】-区块链数据架构:分布式账本,不可篡改性,用于数据溯源 一、区块链数据架构的本质:分布式账本的革新 区块链的核心是分布式账本技术(Distributed Ledger Technology, DLT),它颠覆了传统中心化数据库的架构模式: 去中心化存储: 账本数据不再集中存储…...
版本)
使用docker 安装Redis 带配置文件(x86和arm)版本
一、安装redis 1.1 拉去ARM镜像(7.4.2) docker pull registry.cn-hangzhou.aliyuncs.com/qiluo-images/linux_arm64_redis:latest1.2 拉去x86镜像(8.0.1)版本 docker pull registry.cn-hangzhou.aliyuncs.com/qiluo-images/redis:latest新建文件夹 mkd…...
在CSDN发布AWS Proton解决方案:实现云原生应用的标准化部署
引言:云原生时代的部署挑战 在云原生应用开发中,基础设施管理的复杂性已成为团队面临的核心挑战。随着微服务架构的普及,每个服务可能包含数十个AWS资源(如Lambda、API Gateway、ECS集群等),传统的手动配置…...

小白的进阶之路系列之十----人工智能从初步到精通pytorch综合运用的讲解第三部分
本文将介绍Autograd基础。 PyTorch的Autograd特性是PyTorch灵活和快速构建机器学习项目的一部分。它允许在一个复杂的计算中快速而简单地计算多个偏导数(也称为梯度)。这个操作是基于反向传播的神经网络学习的核心。 autograd的强大之处在于它在运行时动态地跟踪你的计算,…...

[蓝桥杯]整理玩具
整理玩具 题目描述 小明有一套玩具,一共包含 NMNM 个部件。这些部件摆放在一个包含 NMNM 个小格子的玩具盒中,每个小格子中恰好摆放一个部件。 每一个部件上标记有一个 0 ~ 9 的整数,有可能有多个部件标记相同的整数。 小明对玩具的摆放有…...

C++11 Move Constructors and Move Assignment Operators 从入门到精通
文章目录 一、引言二、基本概念2.1 右值引用(Rvalue References)2.2 移动语义(Move Semantics) 三、移动构造函数(Move Constructors)3.1 定义和语法3.2 示例代码3.3 使用场景 四、移动赋值运算符ÿ…...

JavaScript 中的单例内置对象:Global 与 Math 的深度解析
JavaScript 中的单例内置对象:Global 与 Math 的深度解析 在 JavaScript 的世界中,单例内置对象是开发者必须了解的核心概念之一。它们是语言规范中预定义的对象,无需显式创建即可直接使用。本文将深入解析 JavaScript 中最重要的两个单例内…...

11 - ArcGIS For JavaScript -- 高程分析
这里写自定义目录标题 描述代码实现结果 描述 高程分析是地理信息系统(GIS)中的核心功能之一,主要涉及对地表高度数据(数字高程模型, DEM)的处理和分析。 ArcGIS For JavaScript4.32版本的发布,提供了Web端的针对高程分析的功能。 代码实现 <!doct…...
通道注意力
一、 什么是注意力 其中注意力机制是一种让模型学会「选择性关注重要信息」的特征提取器,就像人类视觉会自动忽略背景,聚焦于图片中的主体(如猫、汽车)。 transformer中的叫做自注意力机制,他是一种自己学习自己的机制…...

2048游戏的技术实现分析-完全Java和Processing版
目录 简介Processing库基础项目构建指南项目结构核心数据结构游戏核心机制图形界面实现性能优化代码详解设计模式分析测试策略总结与展望简介 2048是一款由Gabriele Cirulli开发的经典益智游戏。本文将深入分析其Java实现版本的技术细节。该实现使用了Processing库来创建图形界…...
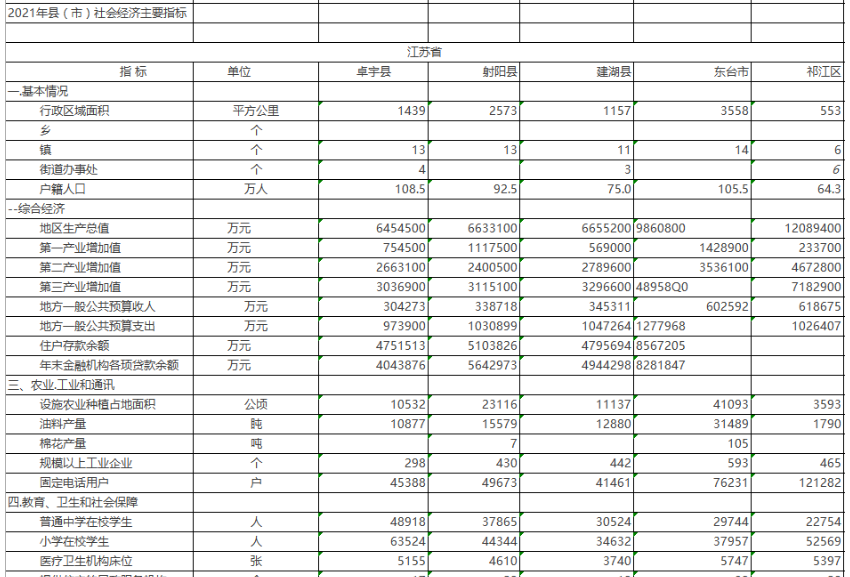
全国县域统计年鉴PDF-Excel电子版-2022年
全国县域统计年鉴PDF-Excel电子版-2022年.ziphttps://download.csdn.net/download/2401_84585615/89784662 https://download.csdn.net/download/2401_84585615/89784662 《中国县域统计年鉴》是一部全面反映中国县域社会经济发展状况的资料性年鉴。自2014年起,该年…...
)
平滑技术(数据处理,持续更新...)
一.介绍 “平滑”是一种用于减少数据中的短期波动、噪声或者异常值的技术,从而更清晰地揭示数据的长期趋势或周期性特征。 平滑的主要作用: 1.减少噪声。数据中常常包含各种随机噪声或误差,这些误差可能会掩盖数据的真实趋势。平滑可以降低…...
)
App 上线后还能加固吗?iOS 应用的动态安全补强方案实战分享(含 Ipa Guard 等工具组合)
很多开发者以为 App 一旦上线,安全策略也就定型了。但现实是,App 上线只是攻击者的起点——从黑产扫描符号表、静态分析资源文件、注入调试逻辑,到篡改功能模块,这些行为都可能在你“以为很安全”的上线版本里悄然发生。 本篇文章…...
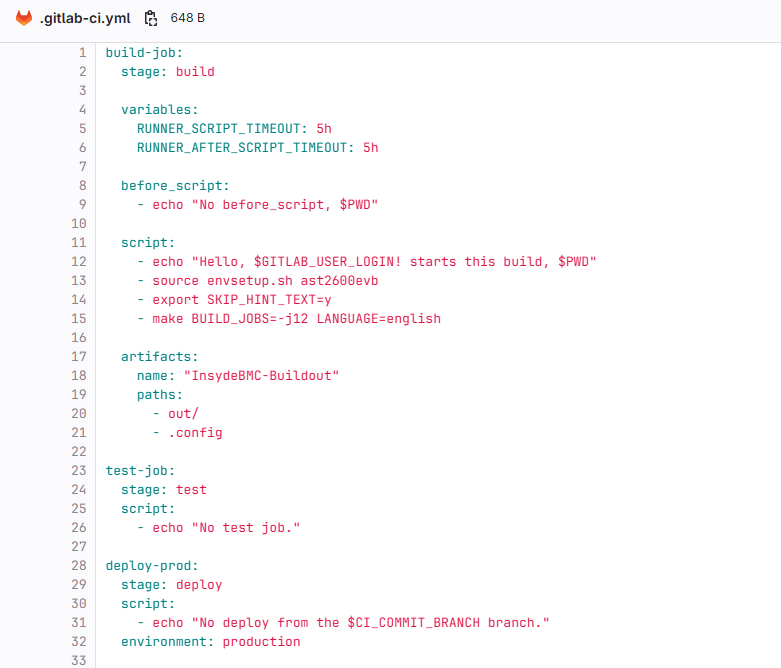
gitlab CI/CD本地部署配置
背景: 代码管理平台切换为公司本地服务器的gitlab server。为了保证commit的代码至少编译ok,也为了以后能拓展test cases,现在先搭建本地gitlab server的CI/CD基本的编译job pipeline。 配置步骤: 先安装gitlab-runner: curl -L "ht…...
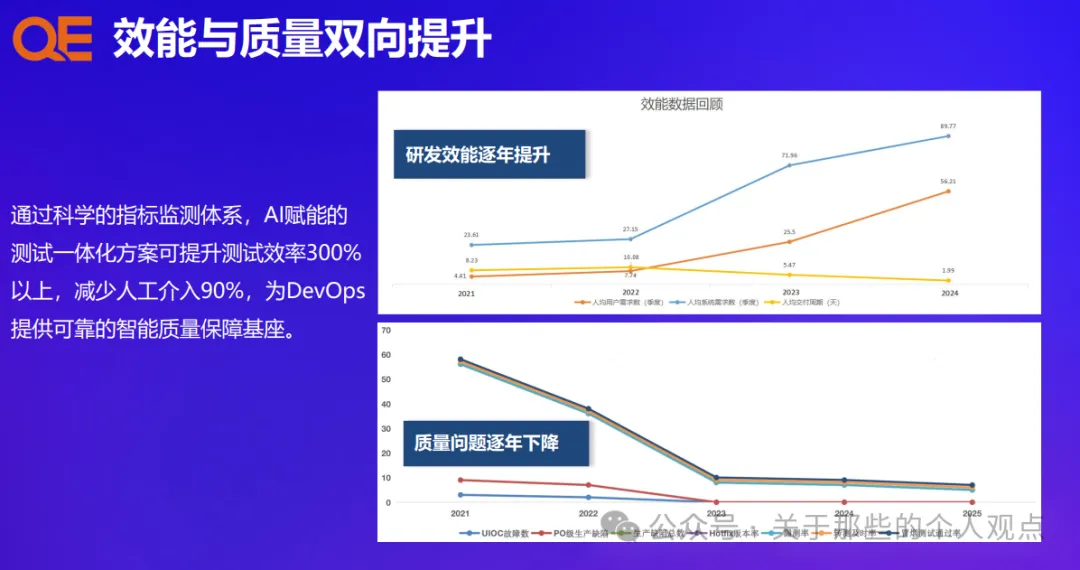
AI大模型在测试领域应用案例拆解:AI赋能的软件测试效能跃迁的四大核心引擎(顺丰科技)
导语 5月份QECon深圳大会已经结束,继续更新一下案例拆解,本期是来自顺丰科技。 文末附完整版材料获取方式。 首先来看一下这个案例的核心内容,涵盖了测四用例设计、CI/CD辅助、测试执行、监控预警四大方面,也是算大家比较熟悉的…...
从零搭建uniapp项目
目录 创建uni-app项目 基础架构 安装 uni-ui 组件库 安装sass依赖 easycom配置组件自动导入 配置view等标签高亮声明 配置uni-ui组件类型声明 解决 标签 错误 关于tsconfig.json中提示报错 关于非原生标签错误(看运气) 安装 uview-plus 组件库…...

数据库密码加密
数据库密码加密 添加jar包构建工具类具体使用优缺点 添加jar包 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-security</artifactId> </dependency>构建工具类 public class PasswordUtil …...

GaLore:基于梯度低秩投影的大语言模型高效训练方法详解一
📘 GaLore:基于梯度低秩投影的大语言模型高效训练方法详解 一、论文背景与动机 随着大语言模型(LLM)参数规模的不断增长,例如 GPT-3(175B)、LLaMA(65B)、Qwenÿ…...
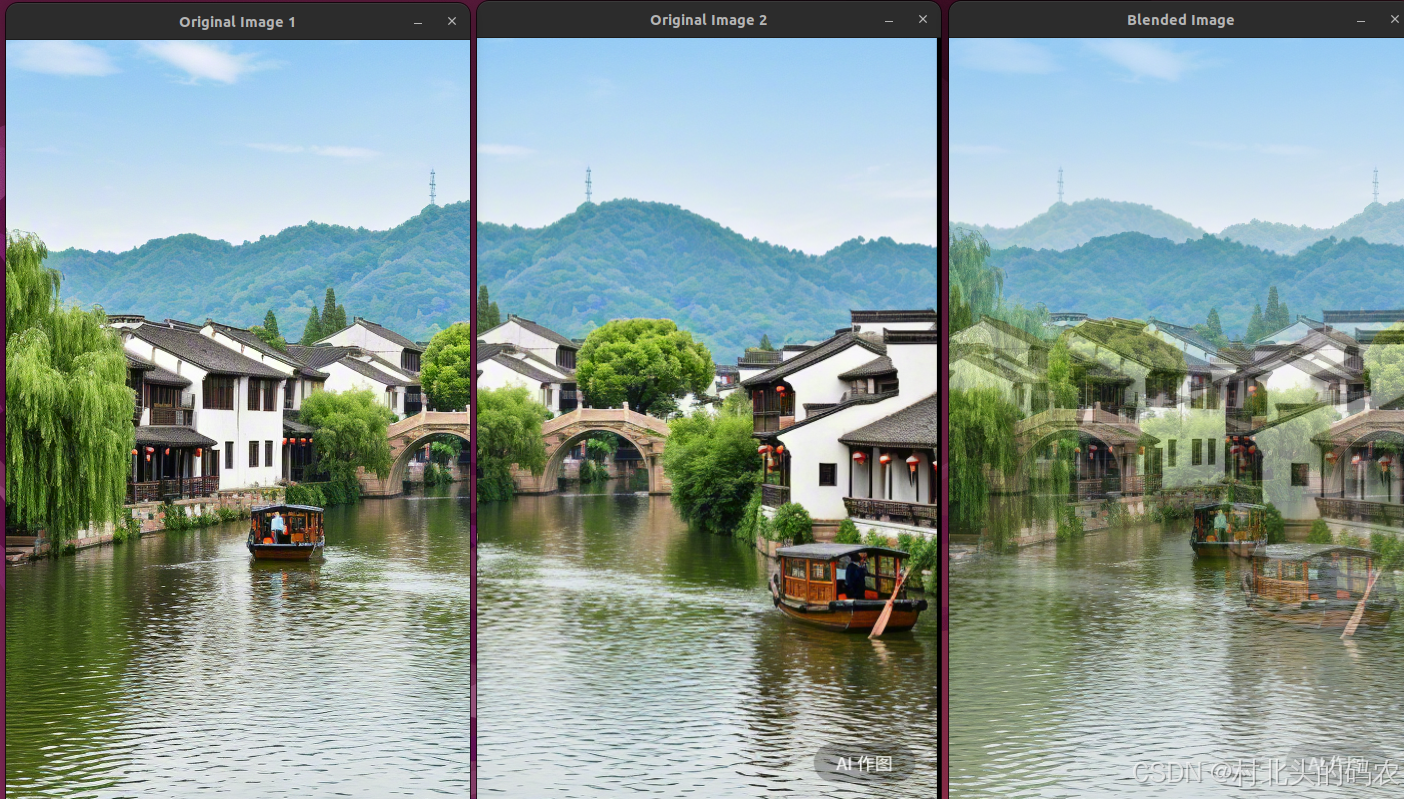
OpenCV CUDA模块图像处理------图像融合函数blendLinear()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 该函数执行 线性融合(加权平均) 两个图像 img1 和 img2,使用对应的权重图 weights1 和 weights2。 融合公式…...