Spring中循环依赖问题的解决机制总结
一、解决机制
1. 什么是循环依赖
循环依赖是指两个或多个Bean之间相互依赖对方,形成一个闭环的依赖关系。最常见的情况是当Bean A依赖Bean B,而Bean B又依赖Bean A时,就形成了循环依赖。在Spring容器初始化过程中,如果不加以特殊处理,这种循环依赖会导致Bean的创建过程陷入死循环,最终导致应用启动失败。
例如以下代码展示了一个典型的循环依赖场景:
@Service
public class A {@Autowiredprivate B b;
}@Service
public class B {@Autowiredprivate A a;
}
2. Spring三级缓存机制概述
Spring框架通过巧妙的"三级缓存"机制解决了循环依赖问题。这三级缓存在Spring源码中是通过三个Map集合实现的:
// 一级缓存:存放完全初始化好的Bean
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);// 二级缓存:存放原始的Bean对象(尚未填充属性),用于解决循环依赖
private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(16);// 三级缓存:存放Bean工厂对象,用于解决循环依赖
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
这三级缓存的作用分别是:
-
一级缓存(singletonObjects):用于存储完全初始化好的Bean,即已经完成实例化、属性填充和初始化的Bean,可以直接被其他对象使用。
-
二级缓存(earlySingletonObjects):用于存储早期曝光的Bean对象,这些Bean已经完成实例化但还未完成属性填充和初始化。当出现循环依赖时,其他Bean可以引用这个未完全初始化的Bean。
-
三级缓存(singletonFactories):用于存储Bean的工厂对象,主要用于处理需要AOP代理的Bean的循环依赖问题。它存储的是一个Lambda表达式,这个表达式会返回Bean的早期引用,并在需要时将其放入二级缓存。
3. 三级缓存的查找顺序
当Spring需要获取一个单例Bean时,会按照以下顺序查找:
- 首先从一级缓存(singletonObjects)中查找,如果找到直接返回
- 如果一级缓存没有,再从二级缓存(earlySingletonObjects)中查找
- 如果二级缓存也没有,则从三级缓存(singletonFactories)中查找对应的工厂,如果找到则通过工厂获取对象,并将其放入二级缓存,同时从三级缓存中移除
这种层级查找的机制确保了在循环依赖的情况下,Bean能够被正确地创建和注入。
4. Spring解决循环依赖的详细流程
以A、B两个类相互依赖为例,Spring解决循环依赖的流程如下:
-
创建Bean A:
- Spring首先创建Bean A的实例(仅完成实例化,未进行属性填充)
- 将A的创建工厂放入三级缓存singletonFactories中
- 开始给A填充属性,发现依赖了B
-
创建Bean B:
- Spring开始创建B(因为A依赖B)
- 实例化B,并将B的创建工厂放入三级缓存
- 开始给B填充属性,发现依赖了A
-
处理循环依赖:
- 此时需要注入A,但A正在创建中
- Spring尝试从一级缓存查找A,未找到
- 继续从二级缓存查找A,未找到
- 最后从三级缓存中找到A的工厂对象
- 通过工厂获取A的早期引用(可能是原始对象,也可能是代理对象)
- 将A的早期引用放入二级缓存,并从三级缓存中移除A的工厂
- 将A的早期引用注入到B中
-
完成Bean创建:
- B完成属性填充和初始化,放入一级缓存
- 返回到A的属性填充流程,将B注入到A中
- A完成属性填充和初始化,放入一级缓存
通过这个流程,Spring成功解决了循环依赖问题,关键在于提前暴露了Bean的早期引用。
5. 为什么需要三级缓存
很多人会疑惑,为什么需要三级缓存?二级缓存不能解决循环依赖问题吗?
实际上,在不考虑AOP的情况下,二级缓存确实可以解决循环依赖问题。但Spring设计三级缓存的主要目的是为了处理AOP代理的情况。
在Spring中,AOP代理是在Bean生命周期的最后阶段(初始化后)创建的。但如果出现循环依赖,就需要提前创建代理对象。三级缓存中的工厂对象可以在需要时(即真正出现循环依赖时)才创建代理对象,而不是对所有Bean都提前创建代理。
这种设计有以下优势:
- 延迟代理对象的创建:只有在真正需要时才创建代理对象,避免了不必要的性能开销
- 保持Bean生命周期的一致性:尽可能地保持Bean的标准生命周期流程
- 灵活处理各种代理场景:适应不同的AOP实现和代理方式
6. 三级缓存的局限性
虽然三级缓存机制能够解决大多数循环依赖问题,但它仍有一些局限性:
-
不能解决构造器注入的循环依赖:因为构造器注入发生在实例化阶段,此时Bean还未被放入三级缓存,所以无法解决
-
不能解决prototype作用域的循环依赖:三级缓存机制只对单例Bean有效,对于prototype作用域的Bean,Spring不会缓存其实例,因此无法解决其循环依赖
-
不能解决多例Bean之间的循环依赖:原因同上,Spring不会缓存非单例Bean
7. 源码分析
Spring解决循环依赖的核心源码主要在DefaultSingletonBeanRegistry类中,关键方法包括:
getSingleton(String beanName):按照一级、二级、三级缓存的顺序查找BeanaddSingletonFactory(String beanName, ObjectFactory<?> singletonFactory):将Bean的工厂对象放入三级缓存doGetBean(String name, Class<T> requiredType, Object[] args, boolean typeCheckOnly):获取Bean的主要逻辑
在AbstractAutowireCapableBeanFactory的doCreateBean方法中,会在Bean实例化后立即将其工厂对象放入三级缓存,为解决循环依赖做准备。
8. 总结
Spring通过三级缓存机制巧妙地解决了循环依赖问题,其核心思想是将Bean的实例化和初始化分离,提前暴露实例化但未完全初始化的对象。三级缓存的设计不仅解决了基本的循环依赖问题,还优雅地处理了AOP代理场景下的循环依赖。
这种机制体现了Spring框架设计的精妙之处,通过缓存分层和提前暴露对象的方式,在不影响Bean正常生命周期的前提下解决了看似棘手的循环依赖问题。
二、实际示例与解析
为了更直观地理解Spring如何通过三级缓存解决循环依赖问题,我们来看一个具体的示例,并详细分析整个过程。
1. 示例代码
首先,我们创建两个相互依赖的Service类:
@Service
public class UserService {@Autowiredprivate OrderService orderService;public void findUserOrders(Long userId) {System.out.println("查询用户订单");orderService.getOrdersByUserId(userId);}
}@Service
public class OrderService {@Autowiredprivate UserService userService;public List<Order> getOrdersByUserId(Long userId) {System.out.println("获取用户订单");return new ArrayList<>();}public void notifyUser(Long orderId) {System.out.println("通知用户订单状态");userService.findUserOrders(1L); // 调用UserService的方法}
}
在这个示例中,UserService依赖OrderService,而OrderService又依赖UserService,形成了典型的循环依赖。
2. 详细解析Spring处理流程
让我们详细分析Spring如何处理这个循环依赖:
2.1 创建UserService
当Spring容器启动时,会按照Bean定义顺序开始创建Bean。假设先创建UserService:
1. 实例化UserService对象(仅调用构造函数,此时内部属性尚未赋值)
2. 将UserService实例的创建工厂添加到三级缓存(singletonFactories)中singletonFactories.put("userService", () -> getEarlyBeanReference(beanName, mbd, userService实例))
3. 开始填充UserService的属性,发现需要注入OrderService
2.2 创建OrderService
由于UserService依赖OrderService,Spring开始创建OrderService:
1. 实例化OrderService对象(仅调用构造函数)
2. 将OrderService实例的创建工厂添加到三级缓存中singletonFactories.put("orderService", () -> getEarlyBeanReference(beanName, mbd, orderService实例))
3. 开始填充OrderService的属性,发现需要注入UserService
2.3 处理循环依赖
此时出现了关键的循环依赖处理步骤:
1. OrderService需要注入UserService,但UserService正在创建中
2. Spring尝试从一级缓存(singletonObjects)查找UserService,未找到
3. 继续从二级缓存(earlySingletonObjects)查找UserService,未找到
4. 最后从三级缓存(singletonFactories)中找到UserService的工厂对象
5. 调用工厂对象的getObject()方法获取UserService的早期引用- 如果UserService需要被代理(如有@Transactional注解),此时会创建代理对象- 如果不需要代理,则返回原始对象
6. 将获取到的UserService早期引用放入二级缓存,同时从三级缓存中移除earlySingletonObjects.put("userService", userService早期引用)singletonFactories.remove("userService")
7. 将UserService的早期引用注入到OrderService中
2.4 完成Bean创建
接下来完成两个Bean的创建过程:
1. OrderService完成属性填充(已注入UserService的早期引用)
2. OrderService完成初始化(调用各种初始化方法)
3. 如果OrderService需要被代理,创建代理对象(AOP)
4. 将完全初始化好的OrderService放入一级缓存singletonObjects.put("orderService", 完全初始化的orderService)
5. 返回到UserService的属性填充流程,将完全初始化好的OrderService注入到UserService中
6. UserService完成初始化
7. 如果UserService需要被代理且之前没有提前创建代理,创建代理对象
8. 将完全初始化好的UserService放入一级缓存singletonObjects.put("userService", 完全初始化的userService)
3. 关键源码执行分析
让我们看一下在这个过程中涉及的关键源码执行流程:
3.1 从getSingleton方法开始
当Spring尝试获取一个Bean时,首先会调用getSingleton方法:
protected Object getSingleton(String beanName, boolean allowEarlyReference) {// 首先从一级缓存查找Object singletonObject = this.singletonObjects.get(beanName);// 如果一级缓存没有,且该Bean正在创建中if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {// 从二级缓存查找singletonObject = this.earlySingletonObjects.get(beanName);// 如果二级缓存也没有,且允许早期引用if (singletonObject == null && allowEarlyReference) {// 从三级缓存获取工厂ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);if (singletonFactory != null) {// 通过工厂获取早期引用singletonObject = singletonFactory.getObject();// 放入二级缓存this.earlySingletonObjects.put(beanName, singletonObject);// 从三级缓存移除this.singletonFactories.remove(beanName);}}}return singletonObject;
}
3.2 添加Bean到三级缓存
在Bean实例化后,Spring会将其添加到三级缓存中:
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {Assert.notNull(singletonFactory, "Singleton factory must not be null");synchronized (this.singletonObjects) {// 如果一级缓存中不存在if (!this.singletonObjects.containsKey(beanName)) {// 添加到三级缓存this.singletonFactories.put(beanName, singletonFactory);// 确保二级缓存中不存在this.earlySingletonObjects.remove(beanName);// 记录注册的单例this.registeredSingletons.add(beanName);}}
}
3.3 创建早期引用
当需要处理循环依赖时,Spring会通过getEarlyBeanReference方法获取早期引用:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {Object exposedObject = bean;if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {for (BeanPostProcessor bp : getBeanPostProcessors()) {if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;// 这里可能创建代理对象exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);}}}return exposedObject;
}
4. AOP场景下的循环依赖
特别值得注意的是,当涉及到AOP代理时,循环依赖的处理会更加复杂。例如,如果我们的示例中添加了事务注解:
@Service
@Transactional
public class UserService {// ...
}@Service
@Transactional
public class OrderService {// ...
}
在这种情况下:
- 当从三级缓存获取UserService的早期引用时,会通过
AbstractAutoProxyCreator.getEarlyBeanReference方法创建代理对象 - 这个代理对象会被放入二级缓存,并最终注入到OrderService中
- 这就确保了OrderService依赖的是UserService的代理对象,而不是原始对象
这也解释了为什么需要三级缓存而不是二级缓存:三级缓存中存储的工厂可以在需要时(出现循环依赖时)才创建代理对象,而不是对所有Bean都提前创建代理。
5. 总结
通过这个实际示例,我们可以清晰地看到Spring如何通过三级缓存机制解决循环依赖问题:
- 实例化Bean后立即将其工厂对象放入三级缓存
- 当出现循环依赖时,通过三级缓存获取早期引用(可能是代理对象)
- 将早期引用放入二级缓存,并从三级缓存中移除
- 使用早期引用完成依赖注入
- 最终将完全初始化的Bean放入一级缓存
这种机制既解决了循环依赖问题,又保持了Spring Bean生命周期的完整性,同时还能灵活处理AOP代理场景,体现了Spring框架设计的精妙之处。
相关文章:

Spring中循环依赖问题的解决机制总结
一、解决机制 1. 什么是循环依赖 循环依赖是指两个或多个Bean之间相互依赖对方,形成一个闭环的依赖关系。最常见的情况是当Bean A依赖Bean B,而Bean B又依赖Bean A时,就形成了循环依赖。在Spring容器初始化过程中,如果不加以特殊…...

青少年编程与数学 01-011 系统软件简介 04 Linux操作系统
青少年编程与数学 01-011 系统软件简介 04 Linux操作系统 一、Linux 的发展历程(一)起源(二)早期发展(三)成熟与普及(四)移动与嵌入式领域的拓展 二、Linux 的内核与架构(…...

微软PowerBI考试 PL300-使用适用于 Power BI 的 Copilot 创建交互式报表
微软PowerBI考试 PL300-使用适用于 Power BI 的 Copilot 创建交互式报表 Microsoft Power BI 可帮助您通过交互式报表准备数据并对数据进行可视化。 如果您是 Power BI 的新用户,可能很难知道从哪里开始,并且创建报表可能很耗时。 通过适用于 Power BI …...

损坏的RAID5 第十六次CCF-CSP计算机软件能力认证
纯大模拟 提前打好板子 我只通过4个用例点 然后就超时了。 #include<iostream> #include<cstring> #include<algorithm> #include<unordered_map> #include<bits/stdc.h> using namespace std; int n, s, l; unordered_map<int, string>…...

Android USB 通信开发
Android USB 通信开发主要涉及两种模式:主机模式(Host Mode)和配件模式(Accessory Mode)。以下是开发USB通信应用的关键知识点和步骤。 1. 基本概念 主机模式(Host Mode) Android设备作为USB主机,控制连接的USB设备 需要设备支持USB主机功能(通常需要O…...

Prompt提示工程指南#Kontext图像到图像
重要提示:单个prompt的最大token数为512 # 核心能力 Kontext图像编辑系统能够: 理解图像上下文语义实现精准的局部修改保持原始图像风格一致性支持复杂的多步迭代编辑 # 基础对象修改 示例场景:改变汽车颜色 Prompt设计: Change …...
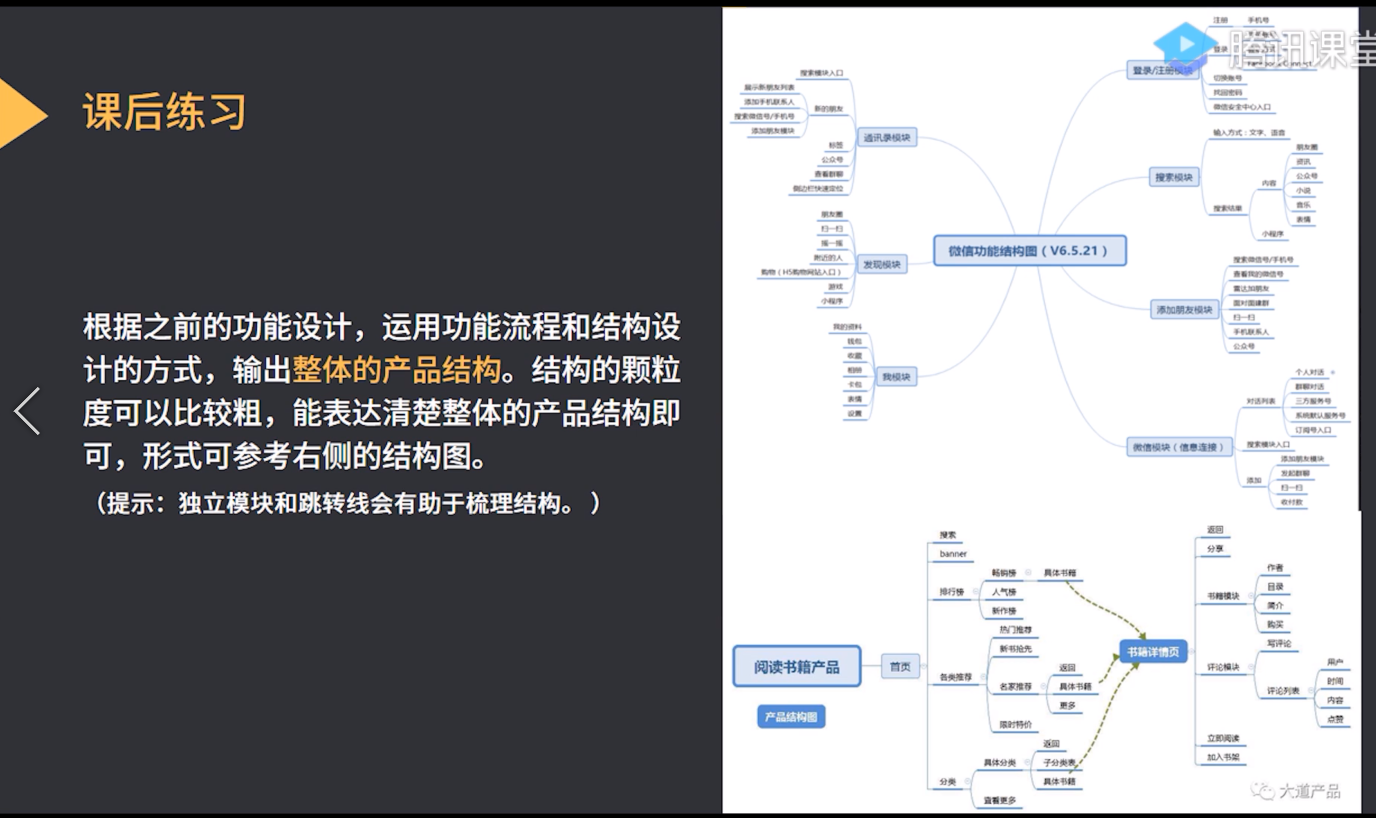
产品经理课程(十一)
(一)复习 1、用户需求不等于产品需求,挖掘用户的本质需求 2、功能设计的前提:不违背我们的产品的基础定位(用一句话阐述我们的产品:工具:产品画布) 3、判断设计好坏的标准…...
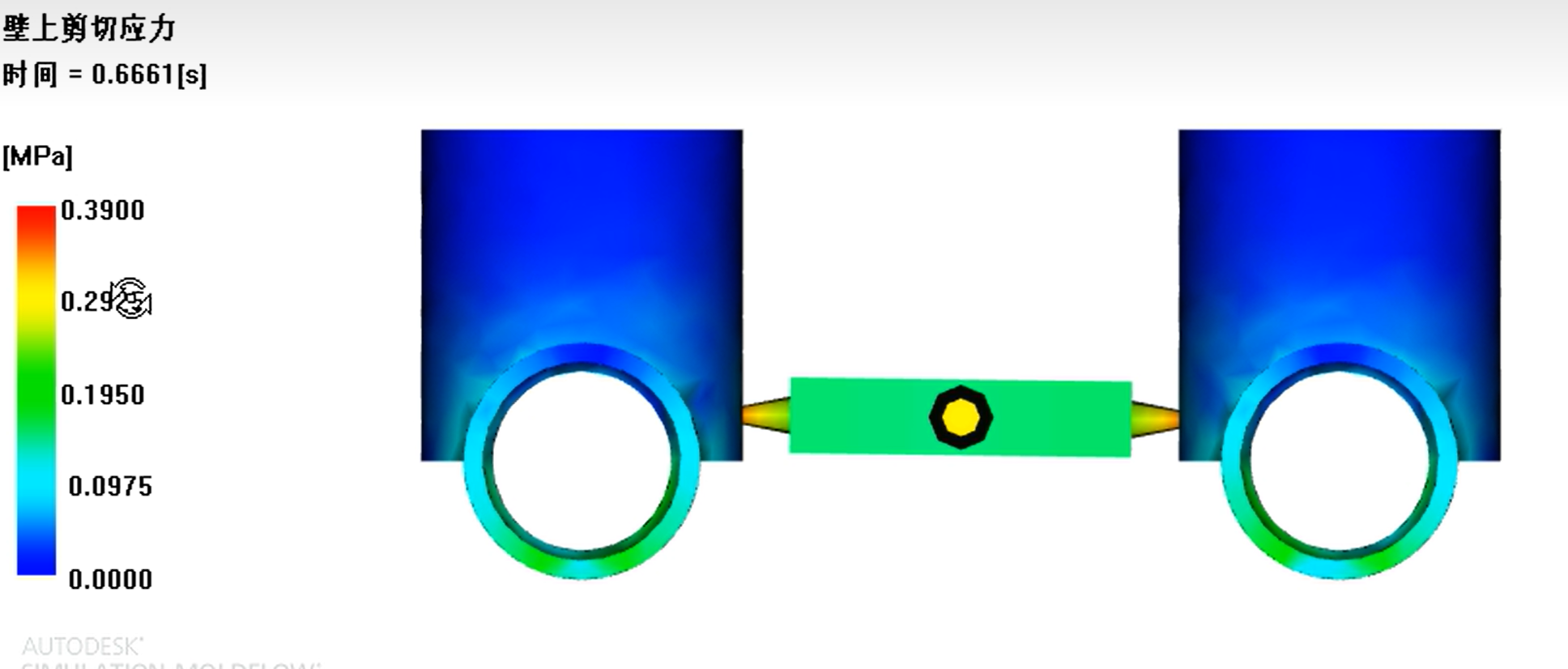
Moldflow充填分析设置
1. 如何选择注塑机: 注塑机初选按注射量来选择: 点网格统计;选择三角形, 三角形体积就是产品的体积 47.7304 cm^3 点网格统计;选择柱体, 柱体的体积就是浇注系统的体积2.69 cm^3 所以总体积产品体积浇注系统体积 47.732.69 cm^3 材料的熔体密度与固体…...
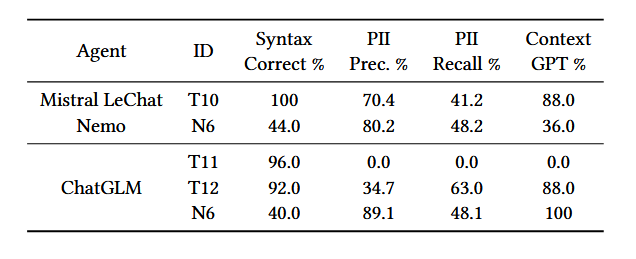
Imprompter: Tricking LLM Agents into Improper Tool Use
原文:Imprompter: Tricking LLM Agents into Improper Tool Use 代码:Reapor-Yurnero/imprompter: Codebase of https://arxiv.org/abs/2410.14923 实机演示:Imprompter 摘要: 新兴发展的Agent可以将LLM与外部资源工具相结合&a…...

python asyncio的作用
协程是可以暂停运行和恢复运行的函数。协程函数是用async定义的函数。它与普通的函数最大的区别是,当执行的时候不会真的执行里面的代码,而是返回一个协程对象,在执行协程对象时才执行里面真正的代码。 例如代码: async def cor…...
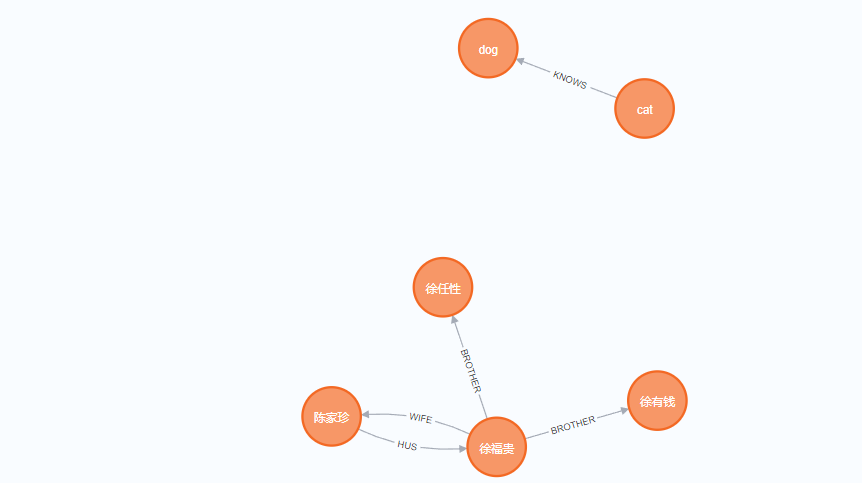
【大模型:知识图谱】--3.py2neo连接图数据库neo4j
【图数据库】--Neo4j 安装_neo4j安装-CSDN博客 需要打开图数据库Neo4j, neo4j console 目录 1.图数据库--连接 2.图数据库--操作 2.1.创建节点 2.2.删除节点 2.3.增改属性 2.4.建立关系 2.5.查询节点 2.6.查询关系 3.图数据库--实例 1.图数据库--连接 fr…...
如何理解机器人课程的技术壁垒~壁垒和赚钱是两件不同的事情
答疑: 有部分朋友私聊说博客内容,越来越不适合人类阅读习惯…… 可以做这种理解,我从23年之后,博客会不会就是写给机器看的。 或者说我在以黑盒方式测试AI推荐的风格。 主观-客观-主观螺旋式发展过程。 2015最早的一篇博客重…...

如何从零开始建设一个网站?
当你没有建站的基础和建站的知识,那么应该如何开展网站建设和网站管理。而今天的教程是不管你是为自己建站还是为他人建站都适合的。本教程会指导你如何进入建站,将建站的步骤给大家分解: 首先我们了解一下,建站需要那些步骤和流程…...
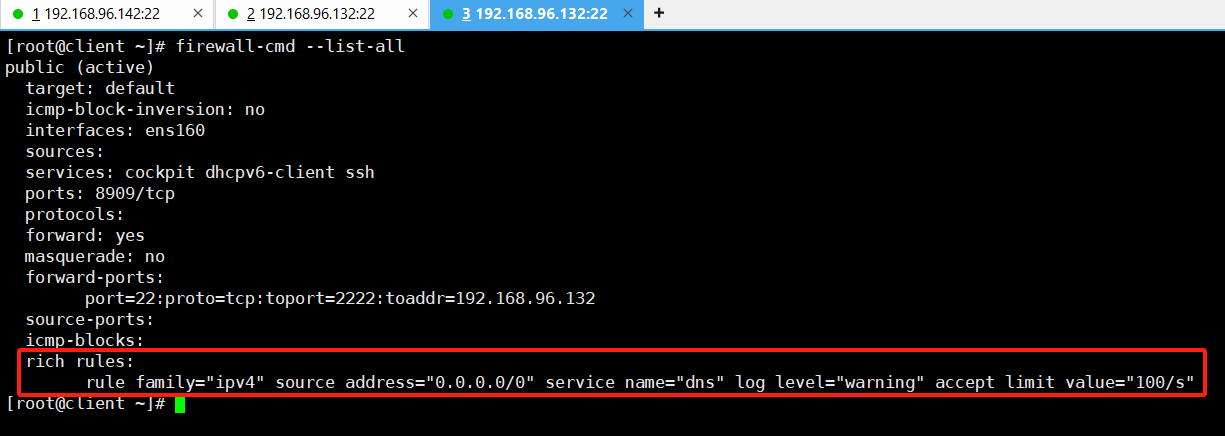
selinux firewalld
一、selinux 1.说明 SELinux 是 Security-Enhanced Linux 的缩写,意思是安全强化的 linux; SELinux 主要由美国国家安全局(NSA)开发,当初开发的目的是为了避免资源的误用 DAC(Discretionary Access Cont…...
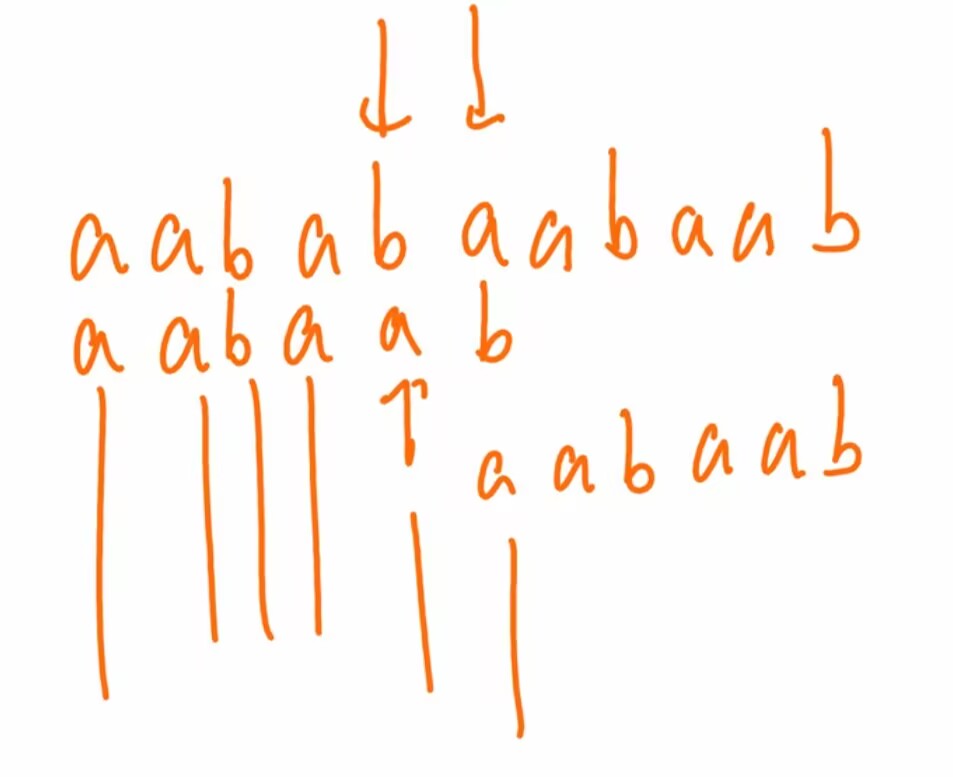
408第一季 - 数据结构 - 字符串和KMP算法
闲聊 这章属于难点但考频低 3个名词记一下:模式匹配,主串,字串(模式串) 举个例子 主串 aabaaaabaab 字串 aabaab 模式匹配 从主串找到字串 暴力解法 也是不多说 很暴力就是了 KMP算法 next数组 它只和字串有关 先…...

如何查看自己电脑安装的Java——JDK
开始->运行->然后输入cmd进入dos界面 (快捷键windows->输入cmd) 输入java -version,回车 出现了一下信息就是安装了jdk 输入java -verbose,回车 查看安装目录...

青少年编程与数学 01-011 系统软件简介 07 iOS操作系统
青少年编程与数学 01-011 系统软件简介 07 iOS操作系统 一、发展历程(一)诞生初期(2007 - 2008年)(二)功能拓展与升级(2009 - 2013年)(三)持续优化与创新&…...

电力系统时间同步系统之三
2.6 电力系统时间同步装置 时间同步装置主要完成时间信号和时间信息的同步传递,并提供相应的时间格式和物理接口。时间同步装置主要由三大部分组成:时间输入、内部时钟和时间输出,如图 2-25 所示。输入装置的时间信号和时间信息的精度必须不…...
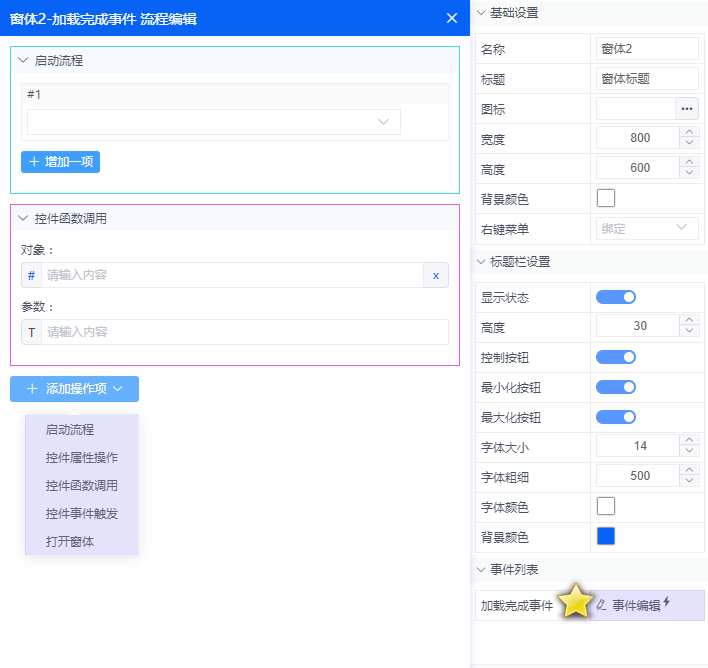
火语言RPA--界面应用详解
新建一个界面应用后,软件将自动弹出一个界面设计器,本篇将介绍下流程设计器中各部分的功能。 UI控件列表 显示软件中自带的所有UI控件流程库 流程是颗粒组件的容器,可在建立的流程中添加颗粒组件编写成规则流程。 流程编辑好后再绑定UI控件…...
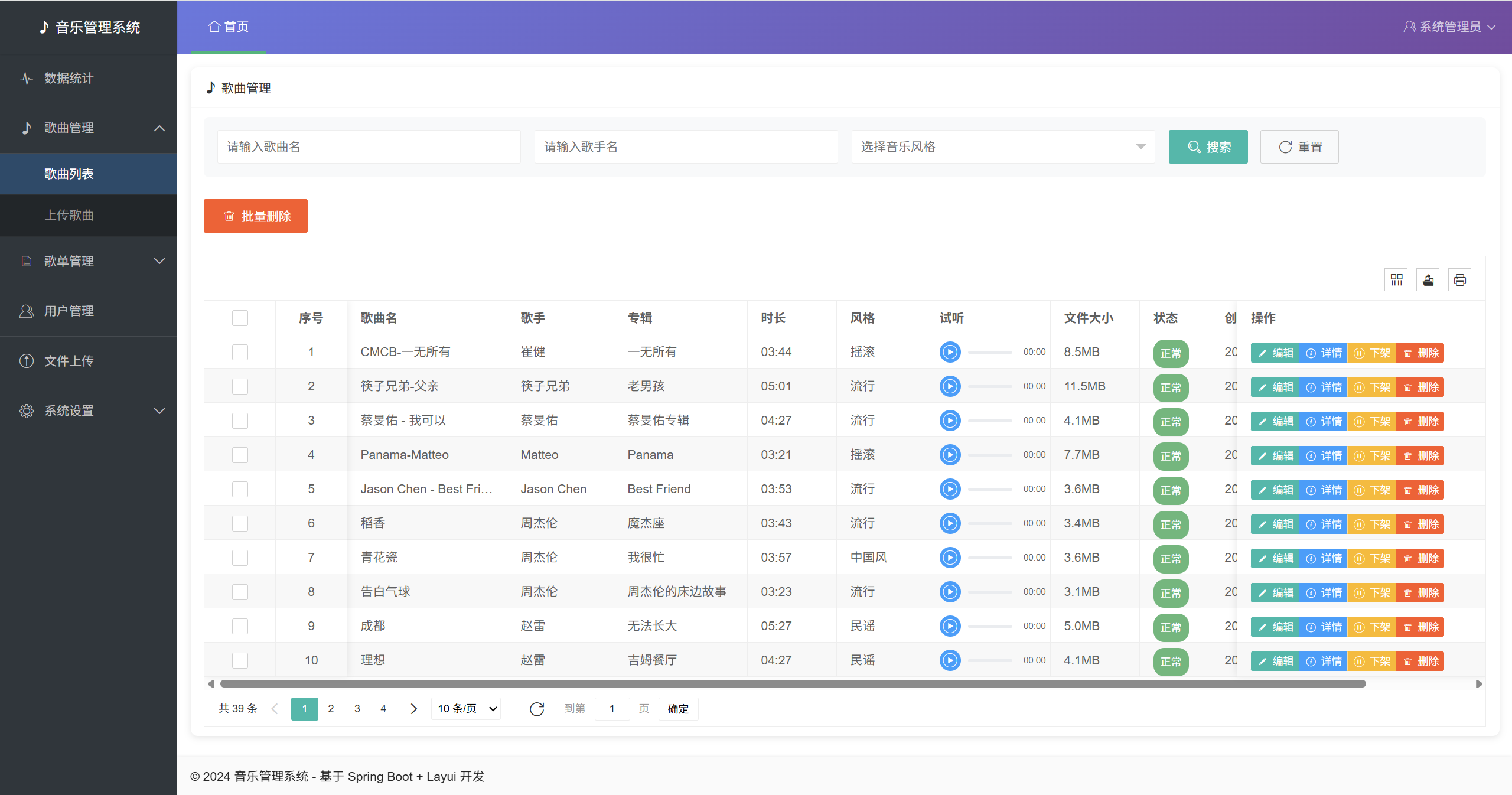
基于Spring Boot的云音乐平台设计与实现
基于Spring Boot的云音乐平台设计与实现——集成协同过滤推荐算法的全栈项目实战 📖 文章目录 项目概述技术选型与架构设计数据库设计后端核心功能实现推荐算法设计与实现前端交互设计系统优化与性能提升项目部署与测试总结与展望 项目概述 🎯 项目背…...
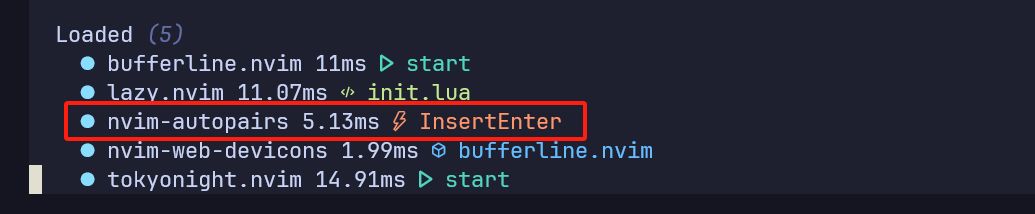
Neovim - 打造一款属于自己的编辑器(一)
文章目录 前言(劝退)neovim 安装neovim 配置配置文件位置第一个 hello world 代码拆分 neovim 配置正式配置 neovim基础配置自定义键位Lazy 插件管理器配置tokyonight 插件配置BufferLine 插件配置自动补全括号 / 引号 插件配置 前言(劝退&am…...
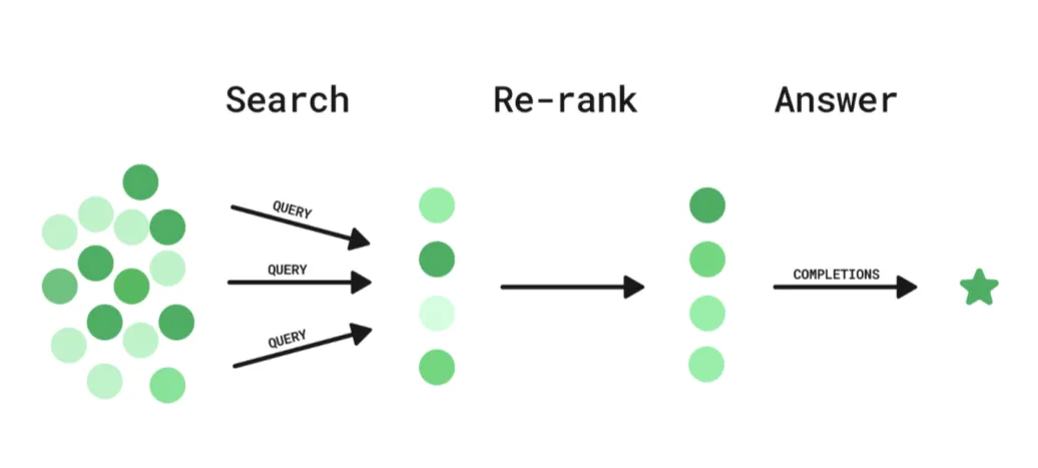
RAG检索系统的两大核心利器——Embedding模型和Rerank模型
在RAG系统中,有两个非常重要的模型一个是Embedding模型,另一个则是Rerank模型;这两个模型在RAG中扮演着重要角色。 Embedding模型的作用是把数据向量化,通过降维的方式,使得可以通过欧式距离,余弦函数等计算…...
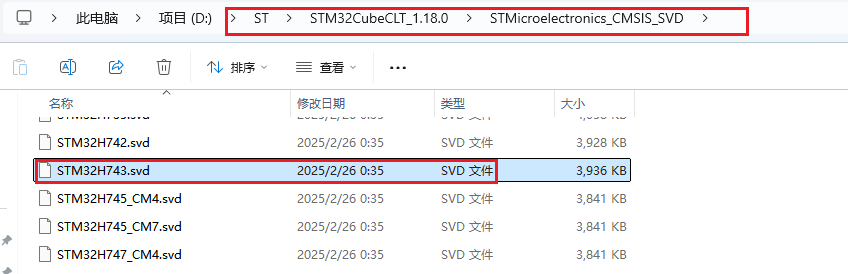
CLion社区免费后,使用CLion开发STM32相关工具资源汇总与入门教程
Clion下载与配置 Clion推出社区免费,就是需要注册一个账号使用,大家就不用去找破解版版本了,jetbrains家的IDEA用过的都说好,这里嵌入式领域也推荐使用。 CLion官网下载地址 安装没有什么特别,下一步就好。 启动登录…...
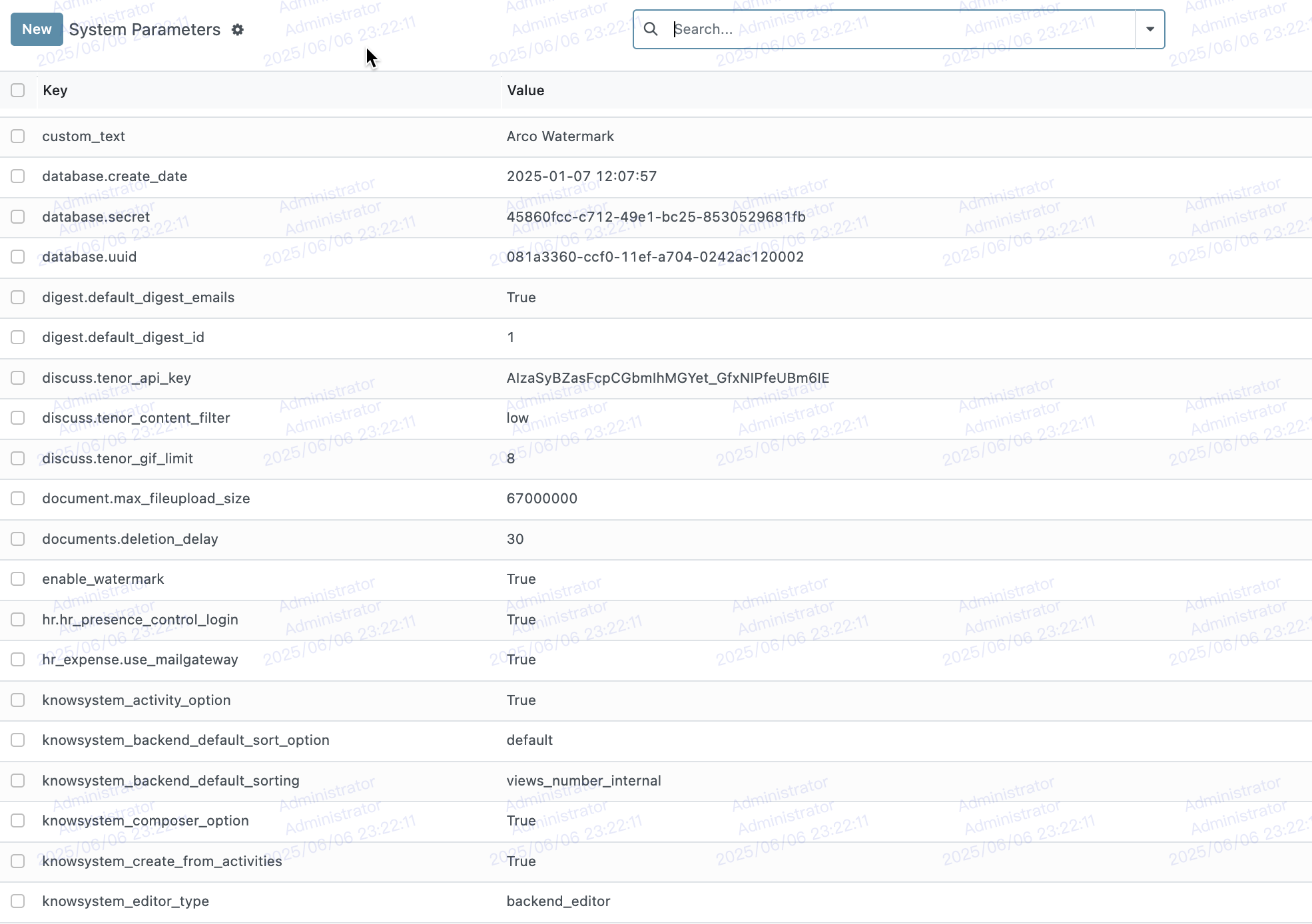
第21讲、Odoo 18 配置机制详解
Odoo 18 配置机制详解:res.config.settings 与 ir.config_parameter 原理与实战指南 在现代企业信息化系统中,灵活且可维护的系统参数配置是模块开发的核心能力之一。Odoo 作为一款高度模块化的企业管理软件,其参数配置机制主要依赖于两个关…...

LinkedList、Vector、Set
LinkedList 基本概念 LinkedList 是一个双向链表的实现类,它实现了 List、Deque、Queue 和 Cloneable 接口,底层使用双向链表结构,适合频繁插入和删除操作。 主要特点 有序,可重复。 查询速度较慢,插入/删除速度较…...

SQL 基础入门
SQL 基础入门 SQL(全称 Structured Query Language,结构化查询语言)是用于操作关系型数据库的标准语言,主要用于数据的查询、新增、修改和删除。本文面向初学者,介绍 SQL 的基础概念和核心操作。 1. 常见的 SQL 数据…...
)
GitHub 趋势日报 (2025年06月05日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 1472 onlook 991 HowToCook 752 ChinaTextbook 649 quarkdown 451 scrapy 324 age…...

基于Flask框架的前后端分离项目开发流程是怎样的?
基于Flask框架的前后端分离项目开发流程可分为需求分析、架构设计、并行开发、集成测试和部署上线五个阶段。以下是详细步骤和技术要点: 一、需求分析与规划 1. 明确项目边界 功能范围:确定核心功能(如用户认证、数据管理、支付流程&#…...

Delphi SetFileSecurity 设置安全描述符
在Delphi中,使用Windows API函数SetFileSecurity来设置文件或目录的安全描述符时,你需要正确地构建一个安全描述符(SECURITY_DESCRIPTOR结构)。这个过程涉及到几个步骤,包括创建或修改安全描述符、设置访问控制列表&am…...
)
rec_pphgnetv2完整代码学习(二)
六、TheseusLayer PaddleOCRv5 中的 TheseusLayer 深度解析 TheseusLayer 是 PaddleOCRv5 中 rec_pphgnetv2 模型的核心网络抽象层,提供了强大的网络结构调整和特征提取能力。以下是对其代码的详细解读: 1. 整体设计思想 核心概念: 网络…...