NLP学习路线图(二十七):Transformer编码器/解码器
一、Transformer概览:抛弃循环,拥抱注意力
传统RNN及其变体(如LSTM、GRU)处理序列数据时存在顺序依赖的瓶颈:必须逐个处理序列元素,难以并行计算,且对长程依赖建模能力较弱。Transformer的革命性在于:
-
完全基于自注意力机制:直接计算序列中任意两个元素之间的关系强度,无视距离。
-
并行化计算:序列所有元素同时参与计算,极大提升训练效率。
-
堆叠层结构:通过多层堆叠(通常6层或更多),逐步提取更复杂的特征和表示。
Transformer的整体架构图是其精髓的直观体现:
输入序列 -> [编码器] -> 中间表示 -> [解码器] -> 输出序列(N个相同层) (N个相同层)-
编码器:负责理解和压缩输入序列(如源语言句子),将其转化为富含上下文信息的中间表示(Context Representation)。
-
解码器:负责生成输出序列(如目标语言句子)。它利用编码器提供的中间表示,并结合自身已生成的部分,一步步预测下一个元素(自回归生成)。
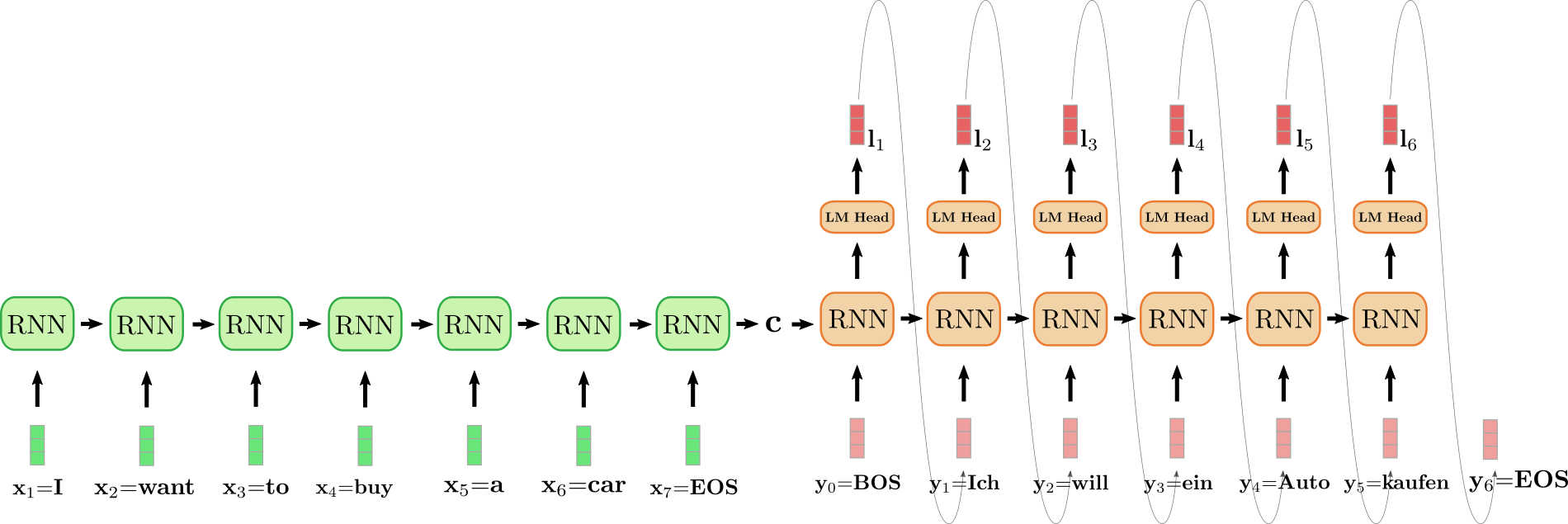
二、编码器(Encoder):信息的深度理解与融合
编码器由 N 个(通常N=6)结构完全相同的层堆叠而成。每一层都包含两个核心子层:
-
多头自注意力机制层(Multi-Head Self-Attention Layer)
-
前馈神经网络层(Position-wise Feed-Forward Network, FFN)
每个子层周围都应用了关键的残差连接(Residual Connection) 和 层归一化(Layer Normalization)。即每个子层的输出是 LayerNorm(Sublayer(x) + x)。
1. 输入嵌入与位置编码(Input Embedding & Positional Encoding)
-
输入嵌入:将输入序列中的每个词(或子词)token映射为一个
d_model维(如512、768、1024)的稠密向量(词向量)。例如:# 假设词汇表大小 vocab_size=10000, d_model=512 embedding_layer = nn.Embedding(10000, 512) input_embeddings = embedding_layer(input_ids) # shape: [batch_size, seq_len, 512]位置编码(Positional Encoding, PE):由于Transformer本身没有循环或卷积结构,它无法感知序列元素的顺序。位置编码将序列中每个位置的索引信息注入到输入嵌入中。其公式为:
PE(pos, 2i) = sin(pos / 10000^(2i/d_model)) PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model)) -
-
pos:词在序列中的位置(0, 1, 2, ..., seq_len-1)。 -
i:维度索引(0 <= i < d_model/2)。 -
使用正弦和余弦函数能保证模型轻松学习到相对位置关系(如
PE(pos+k)可以表示为PE(pos)的线性变换)。 -
最终输入:
Input = Input_Embedding + Positional_Encoding。相加后输入张量维度为[batch_size, seq_len, d_model]。
-
2. 核心组件:自注意力机制(Self-Attention)
自注意力让序列中的每个词都能直接关注到序列中的所有其他词(包括自身),动态计算它们之间的相关性权重,并据此加权聚合信息。
-
核心概念:Query, Key, Value (Q, K, V)
-
每个输入词向量(
Input)通过三个独立的线性变换生成:-
Query(Q):代表当前词在“询问”什么信息。
-
Key(K):代表其他词能“提供”什么信息的关键标识。
-
Value(V):代表其他词实际“携带”的信息内容。
-
-
线性变换:
Q = Input * W^Q,K = Input * W^K,V = Input * W^V。W^Q, W^K, W^V是可学习参数矩阵,维度通常为[d_model, d_k](Q, K)和[d_model, d_v](V),常设d_k = d_v = d_model / h,h是头数。
-
-
注意力分数计算与权重分配
-
计算
Q与K的点积:Scores = Q * K^T(维度:[batch_size, h, seq_len, seq_len])。点积越大表示Query和Key越相关。 -
缩放(Scale):
Scores = Scores / sqrt(d_k)。防止点积结果过大导致softmax梯度消失。 -
掩码(可选,在编码器自注意力中通常不需要):在解码器中会用到,防止看到未来信息。
-
Softmax归一化:
Attention_Weights = softmax(Scores, dim=-1)。将分数转换为和为1的概率分布,表示每个Key(对应每个词)对当前Query(当前词)的重要性权重。 -
加权求和:
Output = Attention_Weights * V(维度:[batch_size, h, seq_len, d_v])。这一步就是用权重对Value向量进行加权求和,得到当前Query词的新表示,它融合了所有其他词的信息。
公式总结:
Attention(Q, K, V) = softmax(Q * K^T / sqrt(d_k)) * V -
-
多头注意力(Multi-Head Attention):这是Transformer性能强大的关键。
-
将
d_model维的Q, K, V分割成h个头(如h=8),每个头在降维后的空间(d_k, d_k, d_v)中进行独立的注意力计算。 -
好处:
-
并行计算:多个头可并行计算。
-
捕捉不同子空间信息:不同的头可以学习关注序列中不同类型的关系(如语法关系、指代关系、语义关系)。一个头可能关注局部依赖,另一个头可能关注长距离依赖。
-
-
合并输出:将
h个头的输出拼接(concat)起来,再通过一个线性层W^O映射回d_model维:MultiHead(Q, K, V) = Concat(head1, ..., headh) * W^O。W^O维度为[h * d_v, d_model]。
-
3. 前馈神经网络(Position-wise FFN)
自注意力层输出后,会经过一个前馈神经网络。它对序列中的每个位置独立、相同地进行变换。
-
结构:通常是两层线性变换,中间加一个ReLU激活函数:
FFN(x) = max(0, x * W1 + b1) * W2 + b2 -
-
W1维度[d_model, d_ff](如d_ff=2048)。 -
W2维度[d_ff, d_model]。 -
b1, b2是偏置项。
-
-
作用:为每个位置的特征提供非线性变换能力,增强模型的表示能力。可以看作是在每个词的位置上独立应用一个小型MLP。
4. 残差连接与层归一化(Add & Norm)
-
残差连接(Add):将子层(自注意力层或FFN层)的输入直接加到其输出上:
y = Sublayer(x) + x。-
核心作用:
-
缓解梯度消失:深层网络中,梯度可以直接通过残差路径回传。
-
保留原始信息:即使子层没学到新东西,输入信息也能无损传递。
-
-
-
层归一化(LayerNorm):对单个样本在特征维度(
d_model)上进行归一化。LayerNorm(x) = γ * (x - μ) / sqrt(σ² + ε) + β -
μ, σ²是特征维度上的均值和方差。 -
γ, β是可学习的缩放和偏移参数。 -
ε是防止除零的小常数。 -
作用:稳定训练过程,加速收敛。它作用于每个样本的每个位置的特征向量上。
5. 编码器层堆叠
经过 N 个这样的编码器层(每层包含自注意力 + FFN,以及Add&Norm)处理后,输入序列被逐步转化为高度抽象、富含全局上下文信息的表示。最后一层编码器的输出即为整个输入序列的中间表示(Context Representation),它将被传递给解码器使用。
三、解码器(Decoder):自回归生成的艺术
解码器同样由 N 个(通常与编码器层数相同)结构相同的层堆叠而成。解码器层结构与编码器层相似,但包含三个核心子层:
-
(带掩码的)多头自注意力层(Masked Multi-Head Self-Attention Layer)
-
多头编码器-解码器注意力层(Multi-Head Encoder-Decoder Attention Layer)
-
前馈神经网络层(Position-wise FFN)
同样,每个子层周围都有残差连接和层归一化。
1. 输入:目标序列嵌入与位置编码
-
解码器的输入是目标序列(如待生成的翻译句子)的嵌入表示(加上位置编码)。
-
关键点:在训练时,我们使用完整的目标序列右移一位(Shifted Right)作为输入(例如,输入是
<sos> I love NLP,期望输出是I love NLP <eos>)。在推理时,则是自回归的:输入起始符(如<sos>),预测第一个词;然后将预测出的词作为输入,预测下一个词,依此类推。
2. 核心组件1:掩码多头自注意力(Masked Multi-Head Self-Attention)
-
目的:让解码器在预测位置
i时,只能看到位置 1 到 i-1 的信息(即只能看到已生成的部分),而不能看到位置 i 及之后的信息(未来信息)。 -
实现机制 - 注意力掩码:在计算
Q * K^T得到注意力分数矩阵后,在softmax之前,将未来位置对应的分数设置为一个极大的负数(如 -1e9)。# 伪代码示例:创建下三角掩码矩阵(主对角线及以下为0,以上为 -inf) mask = torch.tril(torch.ones(seq_len, seq_len)) # 下三角矩阵,元素为1 mask = mask.masked_fill(mask == 0, float('-inf')) # 将0的位置替换为 -inf Scores = Q * K^T / sqrt(d_k) + mask # 加上掩码 Attention_Weights = softmax(Scores, dim=-1) -
作用:确保解码器的自回归生成特性,使其在训练和推理时的行为一致。
3. 核心组件2:编码器-解码器注意力(Encoder-Decoder Attention)
-
目的:让解码器在生成目标序列的每个词时,能够聚焦于输入序列(源序列)中最相关的部分。
-
Q, K, V的来源:
-
Query (Q):来自解码器上一子层(掩码自注意力层)的输出。代表解码器当前要生成词的位置在“询问”什么。
-
Key (K) 和 Value (V):来自编码器最后一层的输出(即整个输入序列的中间表示)。代表源序列提供的所有信息。
-
-
计算过程:与多头注意力机制完全一致:
EncoderDecoderAttention(Q, K, V) = softmax(Q * K^T / sqrt(d_k)) * V。这里没有掩码。 -
意义:这是连接源语言和目标语言的桥梁。解码器通过此机制动态地、有选择地从源序列中提取信息,指导当前目标词的生成。例如,在翻译时,生成某个目标词时,注意力权重可能高度集中在源句中对应的词或相关词上。
4. 前馈神经网络(FFN)与 Add & Norm
-
与编码器中的FFN子层完全相同,独立作用于每个位置。
-
同样应用残差连接和层归一化。
5. 解码器层堆叠与输出
经过 N 个解码器层处理后,得到解码器顶层的输出(维度 [batch_size, target_seq_len, d_model])。该输出通过一个线性层(将 d_model 维映射到目标词汇表大小维)和一个 Softmax层,计算出在目标词汇表上每个位置的概率分布:
# 伪代码
output_logits = linear(decoder_output) # shape: [batch_size, target_seq_len, target_vocab_size]
output_probs = softmax(output_logits, dim=-1)模型的目标是最大化正确目标词序列的似然概率,通常使用交叉熵损失函数进行训练。
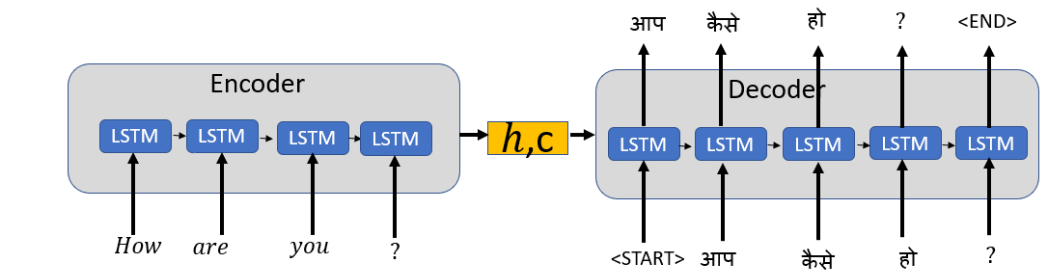
四、编码器与解码器的协同工作流程(以机器翻译为例)
-
输入处理(编码器):
-
源语言句子 "I love NLP" 被分词、嵌入并添加位置编码。
-
输入序列
[<sos>, I, love, NLP, <eos>]送入编码器。 -
经过多层编码器处理,得到富含整个源句信息的中间表示(Context Tensor)。
-
-
初始化解码器:
-
解码器初始输入通常只包含起始符
<sos>(及其位置编码)。
-
-
自回归生成(解码器):
- Step 1 (输入:
<sos>): - 解码器掩码自注意力层:仅关注
<sos>。 - 编码器-解码器注意力层:基于
<sos>的 Query,从编码器的中间表示(Context Tensor)中计算注意力权重,聚焦于源句的相关部分(可能整个句子的信息都会被加权考虑)。 - FFN层处理。
- 输出层预测第一个目标词的概率分布。假设概率最高的是中文词 "我"。
- Step 2 (输入:
<sos>, "我"): - 掩码自注意力:关注
<sos>和 "我"。 - 编码器-解码器注意力:基于 "我" 的 Query,再次从 Context Tensor 中计算注意力权重(此时权重分布可能与 Step 1 不同)。
- FFN层处理。
- 输出层预测第二个词。假设预测为 "喜欢"。
- Step 3 (输入:
<sos>, "我", "喜欢"): - 掩码自注意力:关注
<sos>, "我", "喜欢"。 - 编码器-解码器注意力:基于 "喜欢" 的 Query,从 Context Tensor 中提取信息(可能高度聚焦于源句的 "love")。
- FFN层处理。
- 输出层预测第三个词。预测为 "NLP"。
- Step 4 (输入:
<sos>, "我", "喜欢", "NLP"): - ... 过程同上。
- 输出层预测下一个词。预测为结束符
<eos>。 - 结束:生成序列
<sos> 我 喜欢 NLP <eos>,去除起始符得到最终翻译 "我喜欢 NLP"。
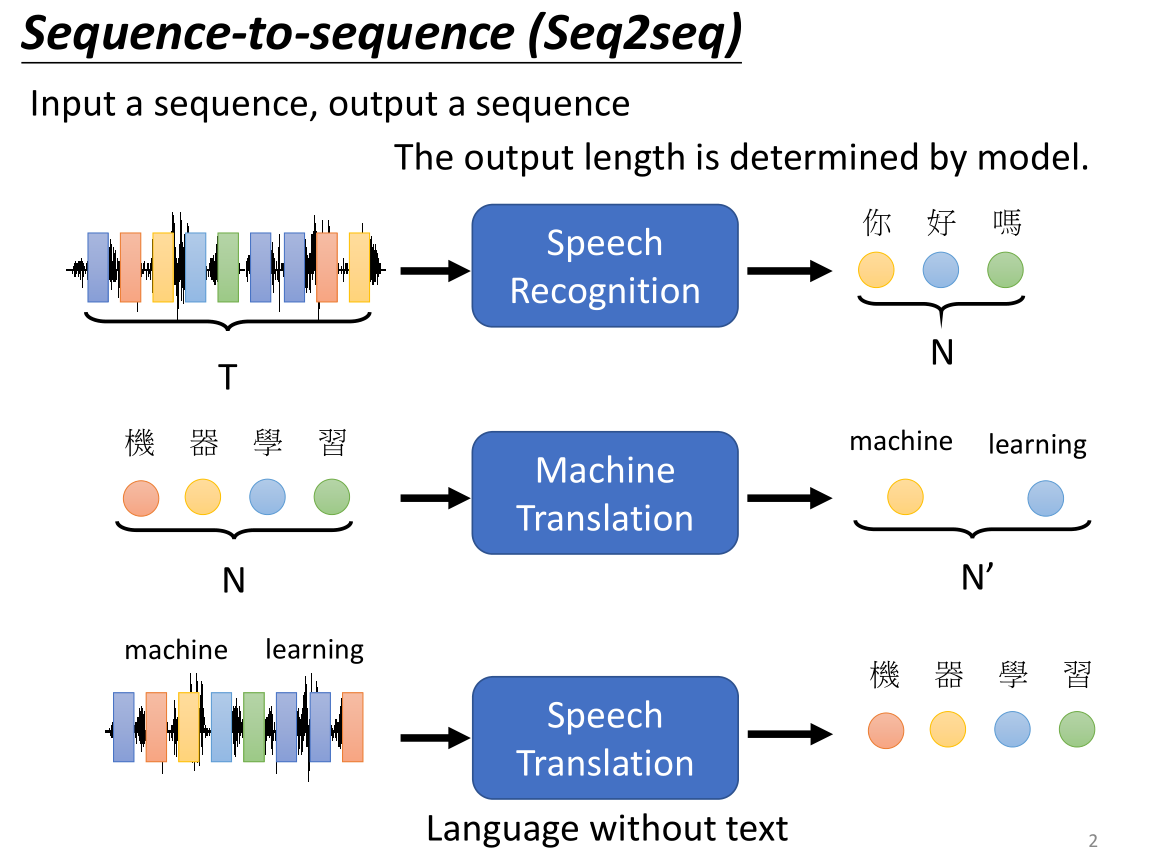
五、Transformer架构的核心优势
-
强大的长程依赖建模:自注意力机制允许序列中任意两个元素直接交互,彻底克服了RNN处理长序列时信息衰减的难题。
-
卓越的并行计算能力:序列所有元素在自注意力层和FFN层中同时计算,训练速度远超RNN/CNN。
-
灵活的注意力机制:多头注意力可捕获不同语义子空间的关系;编码器-解码器注意力实现动态源-目标对齐。
-
可扩展性强:堆叠更多层(如12、24、48层)、增大
d_model、增加头数h等,能显著提升模型容量和性能,为大模型时代奠定基础。 -
通用性:虽然最初为机器翻译设计,但其架构通用性使其在文本分类、问答、摘要、语音识别、图像生成(ViT)等众多领域大放异彩。
六、总结:理解与生成的完美协奏
Transformer的编码器和解码器是理解其强大能力的关键:
-
编码器如同一位精通源语言的读者,通过层层递进的自注意力阅读整个输入序列,抽丝剥茧,最终形成一个蕴含全局语义和细节的“思维导图”(中间表示)。
-
解码器如同一位精通目标语言的作者,在创作(生成目标序列)时:
-
时刻回顾自己已经写了什么(掩码自注意力)。
-
不断参考编码器提供的“思维导图”,精准找到与当前要写内容最相关的源信息(编码器-解码器注意力)。
-
融合这两部分信息,构思并写下最合适的下一个词(FFN + 输出层)。
-
相关文章:
NLP学习路线图(二十七):Transformer编码器/解码器
一、Transformer概览:抛弃循环,拥抱注意力 传统RNN及其变体(如LSTM、GRU)处理序列数据时存在顺序依赖的瓶颈:必须逐个处理序列元素,难以并行计算,且对长程依赖建模能力较弱。Transformer的革命…...
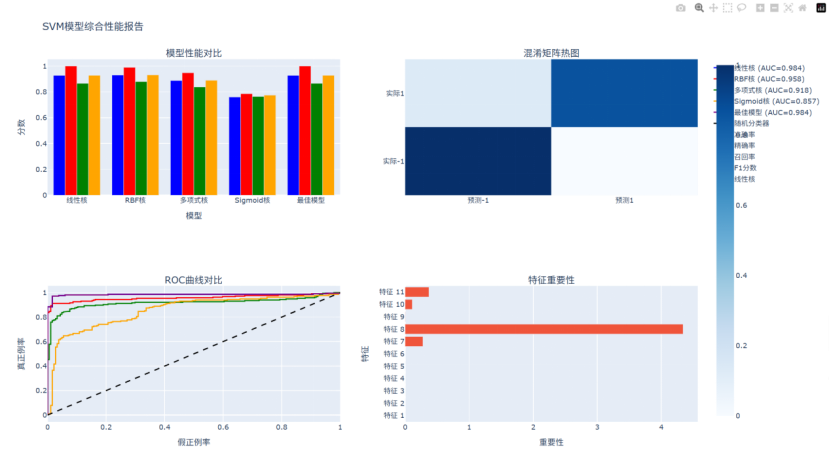
【机器学习】支持向量机实验报告——基于SVM进行分类预测
目录 一、实验题目描述 二、实验步骤 三、Python代码实现基于SVM进行分类预测 四、我的收获 五、我的感受 一、实验题目描述 实验题目:基于SVM进行分类预测 实验要求:通过给定数据,使用支持向量机算法(SVM)实现分…...

策略模式实战:Spring中动态选择商品处理策略的实现
概念 可以在运行时期动态的选择需要的具体策略类,处理具体的问题 组成元素 策略接口 public interface GoodsStrategy {void handleGoods(); } 具体策略类 Service(Constants.BEAN_GOODS) public class BeanGoodsStrategy implements GoodsStrategy {Override…...

主流信创数据库对向量功能的支持对比
主流信创数据库对向量功能的支持对比 版本支持对比向量索引支持对比距离函数支持对比使用限制对比OceanBase向量数据库GaussDB向量数据库TiDB向量数据库VastBase向量数据库 ⭐️ 本文章引用数据截止于2025年5月31日。 版本支持对比 数据库产品支持向量功能的版本OceanBaseOce…...

Matlab | matlab中的画图工具详解
二维图形到高级三维可视化 **一、基础二维绘图****二、三维可视化****三、图形修饰工具****四、高级功能****五、交互式工具****六、面向对象绘图(推荐)****七、常用技巧****学习资源**在MATLAB中,画图工具(绘图功能)是其核心优势之一,涵盖从基础二维图形到高级三维可视化…...
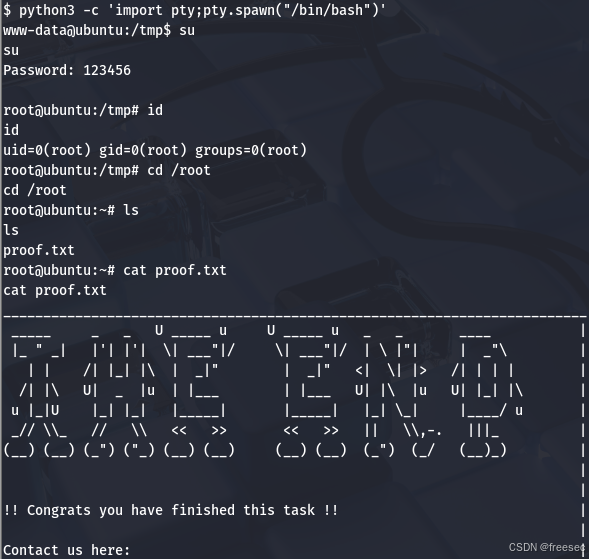
HA: Wordy靶场
HA: Wordy 来自 <HA: Wordy ~ VulnHub> 1,将两台虚拟机网络连接都改为NAT模式 2,攻击机上做namp局域网扫描发现靶机 nmap -sn 192.168.23.0/24 那么攻击机IP为192.168.23.128,靶场IP192.168.23.130 3,对靶机进行端口服务探…...

6.7本日总结
一、英语 复习默写list10list19,07年第3篇阅读 二、数学 学习线代第一讲,写15讲课后题 三、408 学习计组第二章,写计组习题 四、总结 本周结束线代第一讲和计组第二章,之后学习计网4.4,学完计网4.4之后开操作系…...

中国移动6周年!
基站超过250万个 网络规模全球最大、质量最优 覆盖全国96%人口 在全国率先实现乡乡双千兆 服务用户超5.7亿 网络上下行均值接入速率均居行业首位 行业应用快速推广,数量超5万个 3CC、RedCap、通感一体、 无线AI改造等技术成熟商用 客户品牌持续升级&#x…...

Svelte 核心语法详解:Vue/React 开发者如何快速上手?
在很多地方早就听到过svelte的大名了,不少工具都有针对svelte的配置插件,比如vite \ unocss \ svelte. 虽然还没使用过,但是发现它的star82.9k数很高哦,学习一下它与众不同的魔法。 这名字有点别扭,好几次都写错。 sve…...

Fullstack 面试复习笔记:HTML / CSS 基础梳理
Fullstack 面试复习笔记:HTML / CSS 基础梳理 之前的笔记: Fullstack 面试复习笔记:操作系统 / 网络 / HTTP / 设计模式梳理Fullstack 面试复习笔记:Java 基础语法 / 核心特性体系化总结Fullstack 面试复习笔记:项目…...

408第一季 - 数据结构 - 树与二叉树II
二叉树的先中后序遍历 理解 那主播,请问你有没有更快的遍历方式呢 有的,兄弟有的 以中序遍历为例啊 找左边有没有东西,左边没东西那它就自由了,就按上面的图举例子 A左边有东西,是B,B左边没东西…...

打卡第47天
作业:对比不同卷积层热图可视化的结果 核心差异总结 浅层卷积层(如第 1-3 层) 关注细节:聚焦输入图像的边缘、纹理、颜色块等基础特征(例:猫脸的胡须边缘、树叶的脉络)。热图特点:区…...
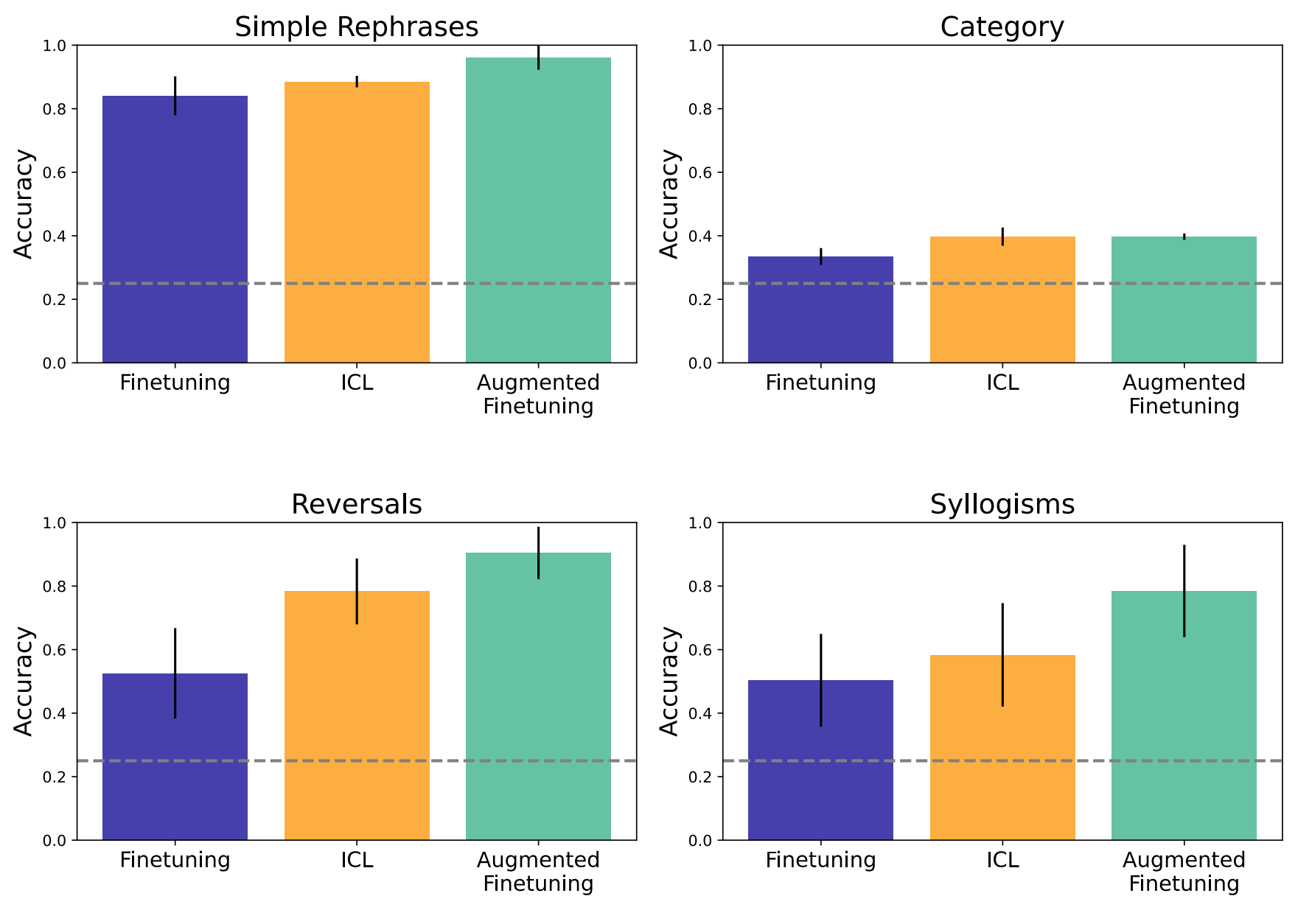
从上下文学习和微调看语言模型的泛化:一项对照研究
大型语言模型表现出令人兴奋的能力,但也可以从微调中表现出令人惊讶的狭窄泛化。例如,他们可能无法概括为简单的关系反转,或者无法根据训练信息进行简单的逻辑推理。这些未能从微调中概括出来的失败可能会阻碍这些模型的实际应用。另一方面&a…...

智慧城市建设方案
第1章 总体说明 1.1 建设背景 1.2 建设目标 1.3 项目建设主要内容 1.4 设计原则 第2章 对项目的理解 2.1 现状分析 2.2 业务需求分析 2.3 功能需求分析 第3章 大数据平台建设方案 3.1 大数据平台总体设计 3.2 大数据平台功能设计 3.3 平台应用 第4章 政策标准保障…...

phosphobot开源程序是控制您的 SO-100 和 SO-101 机器人并训练 VLA AI 机器人开源模型
一、软件介绍 文末提供程序和源码下载 phosphobot开源程序是控制您的 SO-100 和 SO-101 机器人并训练 VLA AI 机器人开源模型。 二、Overview 概述 🕹️ Control your robot with the keyboard, a leader arm, a Meta Quest headset or via API 🕹️…...
pygame开发的坦克大战
使用Python和Pygame开发的精美坦克大战游戏。这个游戏包含玩家控制的坦克、敌方坦克、各种障碍物、爆炸效果和完整的游戏机制。 游戏说明 这个坦克大战游戏包含以下功能: 游戏特点 玩家控制:使用方向键移动坦克,空格键射击 敌人AI&#x…...

C++2025.6.7 C++五级考题
城市商业街主干道是一条笔直的道路,商业街里有 n 家店铺,现给定 n 个店铺的位置,请在这条道路上找到一个中心点,使得所有店铺到这个中心点的距离之和最小,并输出这个最小值。 #include <bits/stdc.h> using nam…...

【原神 × 二叉树】角色天赋树、任务分支和圣遗物强化路径的算法秘密!
【原神 二叉树】角色天赋树、任务分支和圣遗物强化路径的算法秘密! 作者:星之辰 标签:#原神 #二叉树 #天赋树 #任务分支 #圣遗物强化 #算法科普 发布时间:2025年6月 总字数:6000+ 一、引子:提瓦特大陆的“树型奥秘” 你是否曾留意过《原神》角色面板的天赋树? 升级技能…...
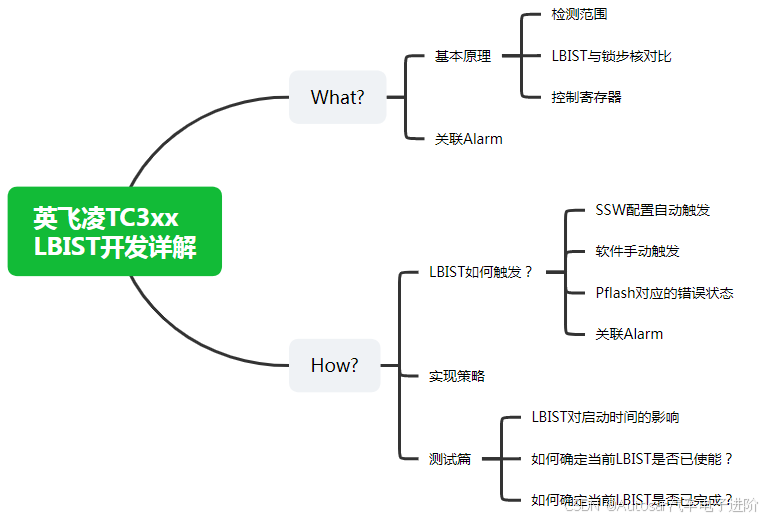
功能安全实战系列09-英飞凌TC3xx LBIST开发详解
本文框架 0. 前言1.What?1.1 基本原理1.1.1 检测范围1.1.2 LBIST与锁步核对比1.1.3 控制寄存器1.2 关联Alarm2. How?2.1 LBIST触发?2.1.1 SSW配置自动触发2.1.2 软件手动触发LBIST2.2 实现策略2.3 测试篇LBIST对启动时间的影响如何确定当前LBIST是否已使能?如何确定当前LBI…...
一个完整的日志收集方案:Elasticsearch + Logstash + Kibana+Filebeat (二)
📄 本地 Windows 部署 Logstash 连接本地 Elasticsearch 指南 ✅ 目标 在本地 Windows 上安装并运行 Logstash配置 Logstash 将数据发送至本地 Elasticsearch测试数据采集与 ES 存储流程 🧰 前提条件 软件版本要求安装说明Java17Oracle JDK 下载 或 O…...
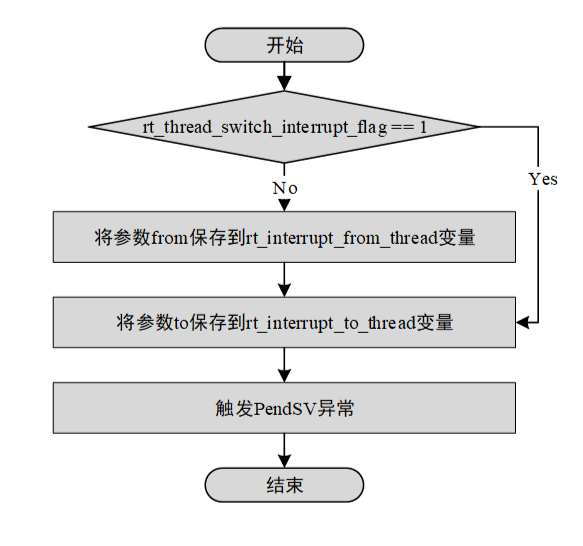
RT-Thread内核组成——内核移植
内核移植就是指将 RT-Thread 内核在不同的芯片架构、不同的板卡上运行起来,能够具备线程管理和调度,内存管理,线程间同步和通信、定时器管理等功能。移植可分为 CPU 架构移植和 BSP(Board support package,板级支持包&…...

Docker_Desktop开启k8s
Docker_Desktop开启k8s 原文地址:在 Docker Desktop 中启用 K8s 服务 - 墨墨墨墨小宇 - 博客园 开启k8s服务 打开docker的设置界面,选择Docker Engine,修改如下: {"debug": false,"experimental": false,…...

MS2691 全频段、多模导航、射频低噪声放大器芯片,应用于导航仪 双频测量仪
MS2691 全频段、多模导航、射频低噪声放大器芯片,应用于导航仪 双频测量仪 产品简述 MS2691 是一款具有 1164MHz 1615MHz 全频段、低功耗的低噪声放大器芯片。该芯片通过对外围电路的简单配置,使得频带具有宽带或窄带特性。支持不同频段的各种导…...
基于Java(SpringBoot、Mybatis、SpringMvc)+MySQL实现(Web)小二结账系统
结账系统 1.引言 1.1.编写目的 此说明书在概要设计的基础上,对小二结账系统的各个模块、程序分别进行了实现层面上的要求和说明。在以下的详细设计报告中将对在本阶段中对系统所做的所有详细设计进行说明。在本阶段中,确定应该如何具体的实现所要求的…...

Java泛型中的通配符详解
无界通配符 通配符的必要性 通过WrapperUtil类的示例可以清晰展示通配符的使用场景。假设我们需要为Wrapper类创建一个工具类WrapperUtil,其中包含一个静态方法printDetails(),该方法需要处理任意类型的Wrapper对象。最初的实现尝试如下: …...

Java方法引用深度解析:从匿名内部类到函数式编程的演进
文章目录 前言问题场景第一种:传统的匿名内部类技术解析优缺点分析 第二种:Lambda表达式的革命技术解析Lambda表达式的本质性能优势 第三种:方法引用的极致简洁技术解析 方法引用的四种类型1. 静态方法引用2. 实例方法引用3. 特定类型的任意对…...
三维GIS开发cesium智慧地铁教程(4)城市白模加载与样式控制
一、添加3D瓦片 <!-- 核心依赖引入 --> <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"><!-- 模型数据路径 --> u…...

越狱蒸馏-可再生安全基准测试
大家读完觉得有帮助记得关注!!! 摘要 大型语言模型(LLMs)正迅速部署在关键应用中,这引发了对稳健安全基准测试的迫切需求。我们提出了越狱提炼(JBDISTILL),这是一种新颖…...

64、js 中require和import有何区别?
在 JavaScript 中,require 和 import 都是用于模块导入的语法,但它们属于不同的模块系统,具有显著的区别: 1. 模块系统不同 require 属于 CommonJS 模块系统(Node.js 默认使用)。 语法:const…...

手机号段数据库与网络安全应用
手机号段数据库的构成与原理 手机号段数据库存储着海量手机号段及其关联信息,包括号段起始与结束号码、运营商归属、地区编码、卡类型等核心数据。这些数据主要来源于通信管理机构的官方分配信息、运营商的业务更新数据以及合法采集的使用数据。经过数据清洗、校验…...