从上下文学习和微调看语言模型的泛化:一项对照研究
大型语言模型表现出令人兴奋的能力,但也可以从微调中表现出令人惊讶的狭窄泛化。例如,他们可能无法概括为简单的关系反转,或者无法根据训练信息进行简单的逻辑推理。这些未能从微调中概括出来的失败可能会阻碍这些模型的实际应用。另一方面,语言模型的语境学习表现出不同的归纳偏差,在某些情况下可以更好地概括。在这里,我们将探讨基于上下文和基于微调的学习之间在泛化方面的差异。为此,我们构建了几个新的数据集,以评估和提高模型从微调数据中概括的能力。这些数据集旨在通过将数据集中的知识与预训练中的知识隔离开来,来创建干净的泛化测试。我们将预训练的大型模型暴露给这些数据集中的受控信息子集-无论是在上下文中,还是通过微调-并评估它们在需要各种类型泛化的测试集上的性能。总体而言,我们发现在数据匹配的环境中,情境学习可以比微调更灵活地推广(尽管我们也发现了先前发现的一些限制,例如微调可以推广到嵌入在更大知识结构中的逆转)。基于这些发现,我们提出了一种方法,使改进的泛化从微调:添加上下文推理微调数据。我们表明,这种方法提高了我们的数据集和其他基准的各种分裂的泛化。我们的研究结果对于理解语言模型中不同学习模式的归纳偏差,并实际提高其性能具有重要意义。
简介
在庞大的互联网文本语料库上预先训练的语言模型(LM)成为高效的上下文学习器;它们可以从一个任务的几个例子中归纳出答案来回答新的例子(Brown等人,2020年;双子座团队Google,2023年)。预训练的LM还可以使用相对较少的示例针对下游任务进行微调--尽管通过微调实现良好的泛化通常需要数百到数千个示例(例如Kirstain等人,2022年;维埃拉等人,2024年)的报告。事实上,对一个特定例子进行微调所得到的概括是非常有限的;例如,对“B的母亲是A”这样的陈述进行微调的学习模型,就不能概括出“谁是A的儿子”这样的答案。(Berglund等人,2024年;参见Allen Zhu和Li,2025)。然而,LM可以很容易地回答关于这些类型的反向响应的问题。在上下文中的引用(例如Lampinen等人,第2024段b)。此外,当从权重和从上下文进行归纳时,transformers显示出不同的归纳偏差(参见Chan等人,2022 b; Russin等人;Shen等,2023年)的报告。情境学习和微调之间的概括模式有何不同?对于我们应该如何适应新任务或新信息的模型,有什么启示?本文就这些问题进行了探讨。
为此,我们构建了事实知识的受控合成数据集。我们将这些数据集设计为具有复杂和自洽的结构,同时避免与预训练语料库中可能存在的知识重叠。我们创建这些数据集的训练和测试分割,这些数据集涉及不同类型的泛化:反转或将多个逻辑推理链接到三段论中。然后,我们评估大的预训练的语言模型通过微调或通过在上下文中学习(通过将整个训练集(或其大子集)置于上下文中)来推广到这些测试集。我们还探索了各种改进泛化的方法,例如数据增强。总的来说,我们发现在各种数据集中,上下文学习(ICL)比微调更好地推广。然而,通过使用上下文推理花费更多的训练时间计算来增强训练数据集,可以改进微调泛化,实际上甚至可以超过ICL泛化。
我们的贡献如下:
- 我们研究了预先训练的LM从上下文学习和微调中表现出的不同的泛化模式。
- 我们发现,在整个训练数据集上的上下文学习通常比微调更好地概括,当对逆转,三段论推理,合成等系统性顽固进行评估时。
- 我们建议通过数据集增强来弥合这一差距-促使LM在上下文中生成数据集的增强,然后将这些增强的数据添加到训练集中。
- 我们表明,数据集增强可以弥合差距,从而通过微调来提高泛化能力。
- 我们还提出了一种微调方法,打破了句子之间的相关性,放大了增强的好处。
数据集
我们评估了几个数据集的学习和泛化能力,这些数据集是为了隔离泛化的不同方面,或者在更广泛的学习挑战中进行泛化。我们还利用了以前工作中的数据集。
简单的反转和三段论
首先,我们用两个简单的数组1测试我们的方法,这些数组包含以下独立的示例:逆向推理和三段论推理。
简单的反转:
每个训练示例都由一个前序(例如“你知道吗”)和一个比较两个实体的语句组成,例如“femp比glon更危险”。提供了一百个这样的比较(其中比较词从28个的集合中采样,例如“更亮”、“更重”)。每个比较在10个不同的训练示例中重复,每次与随机采样的前导码配对。测试集由正确的反转和矛盾关系之间的强制选择组成,例如:“glon比femp危险性小/大。”
简单的三段论:
有69个训练案例。每一个例子都由一个序言(它规定了所讨论的实体),后面跟着两个形成三段论的陈述组成。例如:“glon、troff和yomp之间的关系是:所有glon都是yomp。所有的troff是glon。”测试示例评估模型是否从该三段论形式做出正确的推断。它们提供了一个指定来自训练示例的两个实体的前序,然后对关于这两个实体之间的关系的所有可能的语句进行评分,这些语句涉及数据集中的量词和关系。根据Lampinen等人(2024 b),我们省略了部分否定形式(有些X不是Y);因此,有6个这样的可能陈述(“all”、“some”和“no”的乘积,以及这些关系中的每一个可能采取的两个方向)。例如,对应于上述三段论的测试示例的序言将是“The relationships between yomp and troff are:“,而正确答案将是“All troff are yomp.”。
反转诅咒报纸
我们使用Berglund et al.(2024)提出的反转数据集,其中包含对虚构名人的一句话描述。数据集示例可以在描述之前具有名人姓名(例如,“Daphne Barrington”)(例如,“A Journey Through Time的导演”)。”')反之亦然。在微调过程中,训练数据集以一种顺序呈现,例如名称在描述之前,然后以相反的顺序进行测试,其中名称在描述之后。
根据Berglund等人(2024),我们使用两组独立的名人- 'A'和'B'。在微调期间,我们呈现来自集合“A”的名人,其中名称在描述之前,并且来自集合“B”,其中名称和描述以两种顺序出现,但是在单独的示例中。总的来说,训练集由3600个示例组成。测试集评估模型是否可以从仅给出其描述的集合“A”中推断出名人姓名。为了在测试示例中添加干扰项,我们在选项列表中随机选择三个不正确的名人名字进行评分。
语义结构基准
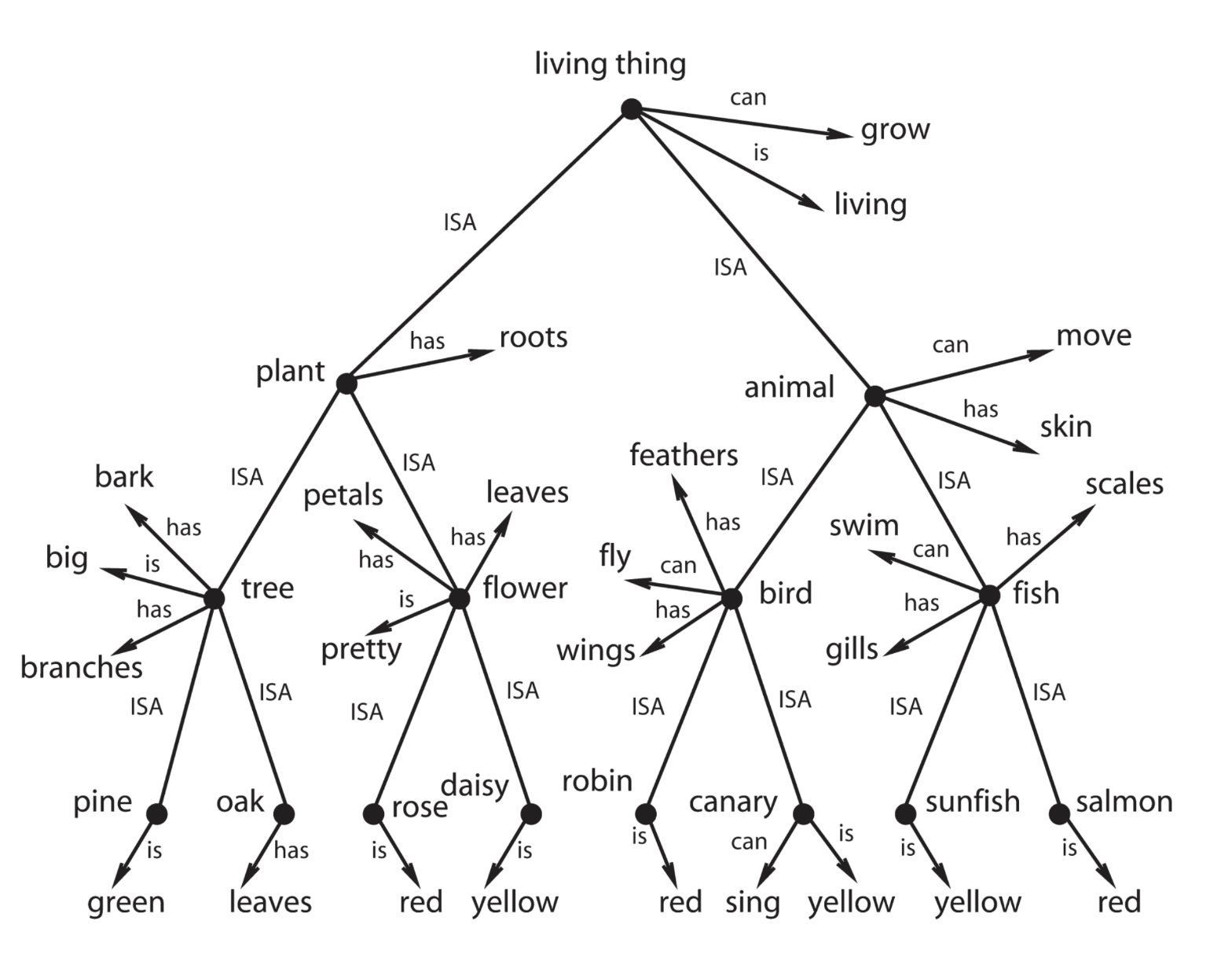
图1|具有属性和关系层次结构的语义结构。(经Rogers和McClelland(2008)许可转载。
基准测试是围绕一个关系语义层次结构,允许演绎推理和抽象。这种层次结构是基于现实世界的范畴和关系,并从认知科学中研究丰富语义层次结构学习的先前工作中汲取灵感(参见图1,其中有一个直观的例子,构成了现实世界结构的一部分)。我们同样创建了一个分层的知识结构,涉及110个动物和物体的类别,以及属性(每个类别1-6个,加上继承的)和关系。这个基础结构是从真实的世界中衍生出来的。
为了使结构对于预训练的模型来说是新颖的,我们用无意义的术语替换所有的名词、形容词和动词。这消除了与预训练数据的潜在重叠,从而确保数据属性遵循某些真实世界的分布特征,但不会受到污染。
无意义术语的使用可能会带来标记化的挑战;然而,我们通过使用英语音素的合理组合生成4-5个字母的短无意义词来改善这些挑战(通过Gao等人,2023年)的报告。此外,我们将在接下来的章节中说明,在实践中,模型可以很容易地对上下文中这些无意义的实体进行推断,因此使用不熟悉的单词并不是模型性能的主要瓶颈。
训练集
为了进行训练,我们将有关此语义层次结构的训练集事实组装成简短的、模糊的、类似维基百科的合成文章,具有不同的格式和风格,以及一些QA示例(以确保对数据的微调不会降低问题回答能力)。我们确保测试问题(以下)所需的所有事实都在至少一个训练文档中列出。但是,某些事实将在多个文档中冗余地呈现。我们总共创建了2200个长度为4-20句的训练文档。
测试集
在语义结构中,我们的测试集容纳了关系的反转(gruds [狗]是abmes [哺乳动物]的一种=> abmes包括gruds; cf.Berglund等人,2024),三段论式演绎推理(例如,gruds [狗]是abmes [哺乳动物]; abmes是rony [温血动物] => gruds是rony),以及更长的演绎。具体来说,我们专注于以下分组(以粗略的难度顺序):
- 对训练过的事实的重述,但不改变措辞的方向:用于验证材料是否已学习。
- 训练事实的反转,即两个实体处于相反的顺序,并且相应地调整关系词。
- 对训练过的事实的三段论。
- 类别拒不接受:在训练中,关于一个类别只有一个事实:它的父类别是什么。所有可能的推论来自检验过的事实。这与三段论分组的某些方面重叠,除了关于目标类别的信息受到更严格的限制,从而限制了其他有助于概括的线索。
在创建评估问题时,我们通过选择与数据集中的不同实体具有目标关系的实体或属性,为不正确的答案选择困难的干扰项。例如,如果正确答案是“gruds are rony”,则其中一个干扰项可能是“gruds are zept”,其中数据集中存在其他有效语句,例如“telk are zept”。因此,不可能简单地通过单词的局部上下文来猜测哪个答案是正确的。
方法
评估
我们使用多项选择似然评分进行评估。我们不提供上下文中的答案选项。
微调
我们的微调实验主要涉及在我们的数据集上调整Gemini 1.5 Flash(Gemini Team Google,2024)。我们通常使用批量大小为8或16,学习率为3 · 10−4,进行200-1000步的微调(取决于数据集大小和损失)。
情境评价
为了执行完整的数据集上下文评估,我们将训练数据集中的文档连接起来,并将它们作为上下文提供给(预调)模型。然后,我们提示模型使用该上下文来回答问题。当在最大的数据集上评估模型时,我们将文档随机子采样8倍,因为数据集中存在一些冗余,并且我们发现模型会随着上下文长度的变化而受到干扰。
数据集增强
我们的数据集增强的关键方法是利用模型的上下文泛化,以提高微调数据集的覆盖率。我们通过几种方法来实现这一点,但所有方法都主要针对花费训练时间计算上下文推理以创建更多微调数据的目标,以便改善上下文外的泛化(即,而训练的时候不需要上下文中的附加信息)。
具体地说,我们考虑两种类型的增强:一种是试图增加特定信息使用灵活性的局部策略,另一种是试图在不同信息之间建立联系的全局策略。这些策略中的每一个都使用不同的上下文和提示(附录A.第1段)。
局部(句子)扩增:
我们提示LM增强每个训练数据点(例如句子),以增强模型编码的灵活性。我们的提示包括改写和反转的示例。
全局(文档)增强:
我们将完整的训练数据集作为上下文连接起来,然后提供一个特定的文档,并提示模型通过链接该文档和上下文中的其余文档来生成推理。这导致相关推论的推理痕迹更长
句子分割
一些数据集,例如Berglund等人(2024)的虚构名人数据集和我们的语义结构数据集,包含包含逻辑或语义链接的多个句子的文档。我们发现,在文档级别将这些文档拆分为多个微调示例,可以大大提高微调性能-即使在考虑了总数据集大小和梯度步长之后。我们探索了两种分割文档的方法:1)独立分割:其中文档的所有重复句子被独立地分割成两个独立的训练示例,2)累积拆分:其中,将多句文档拆分为𝑛示例,其中第个示例包含到第i个句子的所有句子。我们在附录B.1中分析了句子分裂对模型泛化的影响。在下面的章节中,我们假设独立的句子分割,除非另有说明。
实验
反转诅咒
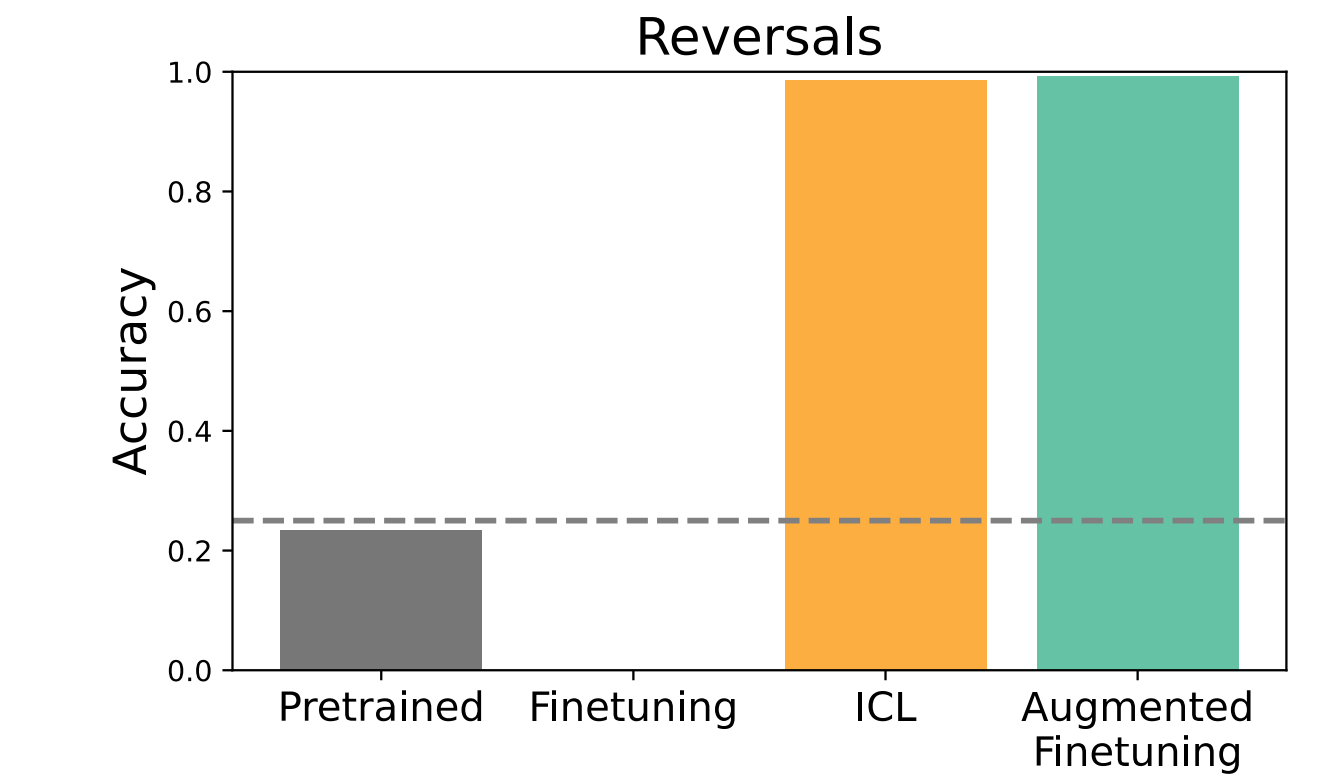
图2| 反转诅咒文件的结果。
在图2中,我们首先在Berglund等人(2024)发布的逆转诅咒现象和数据集的背景下探索概括。我们重复的发现,微调的正向方向不会产生泛化的逆转。这项工作的作者简要地指出,在上下文中,模型可以更好地执行这项任务。我们通过在上下文中呈现整个数据集来更系统地研究这一点,并发现该模型在反向上几乎达到了天花板,从而有力地证明了上下文学习优于微调的好处。用上下文推理增强的数据进行微调,也会产生类似的高测试性能。另一方面,简单的微调具有接近零的准确性,因为微调模型总是更喜欢那些在训练期间被视为目标的(不正确的)名人姓名完成,而不管上下文如何。最后,预训练的模型在测试集上的表现接近偶然,表明没有污染。
简单的无意义反转
然后,我们相应地在反向数据集的简单无意义版本上测试模型(图3,左)。我们发现,在这种情况下,ICL比微调的好处更弱,但仍然值得注意,而增强微调的好处也更强。与上述实验相比,益处的差异可能是由于所讨论的关系的可信度的差异,例如,无意义单词在某种程度上干扰模型在较长上下文中的推理的可能性(参见附录B.第2款)。
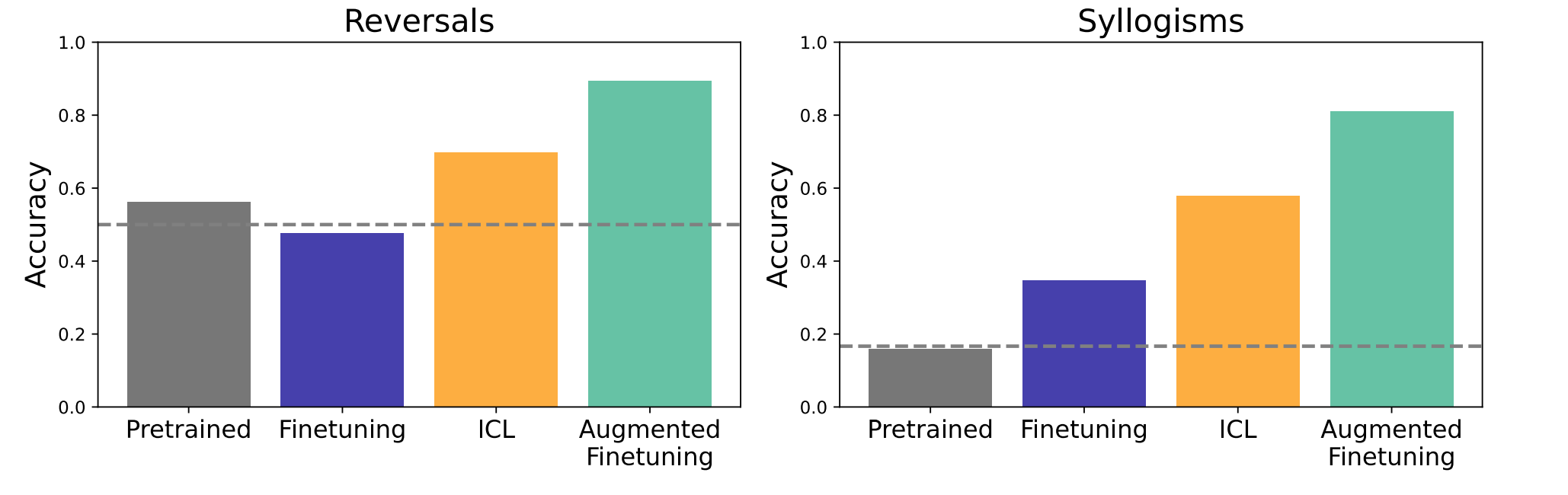
图3|在我们的简单反转(左)和三段论(右)数据集上,上下文学习优于微调。此外,增加微调数据集会大大提高模型性能。预训练模型的表现接近偶然,表明数据集不能基于表面特征猜测。
简单三段论
接下来我们测试简单的推论数据集(图3,右)。同样,预训练的模型表现出偶然性,表明缺乏污染。在数据集上进行微调确实会产生一些非平凡的机会上的概括;也许是因为对于某些类型的三段论,逻辑推理与更简单的语言模式兼容-例如,比如“所有X都包括Y”“所有的Y都包括Z”可能会使模型更有可能从纯关联中预测“所有X包括Z”。然而,以下简单的联想模式对大多数三段论形式都是无效的,例如,如果全称量词在上面的例子中被存在量词替换。也许正因为如此,上下文学习产生了更强的性能;使用上下文学习来增强训练数据集进一步提高了整体性能。
语义结构基准
然后,我们测试了语义结构基准(图4),它在更丰富的学习环境中集成了多种泛化。在这种情况下,我们评估以下方面的性能:a)重新措辞的训练语句(保留关系的方向),在图中表示为“train”,B)反转,c)三段论推理,以及d)关于保持类别的命题。在这些设置中,我们发现ICL优于微调的总体好处,尽管这种好处的大小取决于分裂。我们发现在泛化方面有一些改进,甚至是从训练中重新措辞的信息,和更戏剧性的对反证法和三段论的改进。然而,类别保持分裂仍然很困难,ICL的改进微乎其微。此外,我们继续发现,用上下文推理增强微调数据可以提高微调的性能,在许多情况下甚至优于ICL。(N.B.,在此设置中,我们不对微调基线使用句子拆分,因为我们发现它会损害性能,并且我们希望与最强的基线进行比较;基线句子拆分的结果以及其他消融的结果可以在Appx中找到。沿着。B.4.)
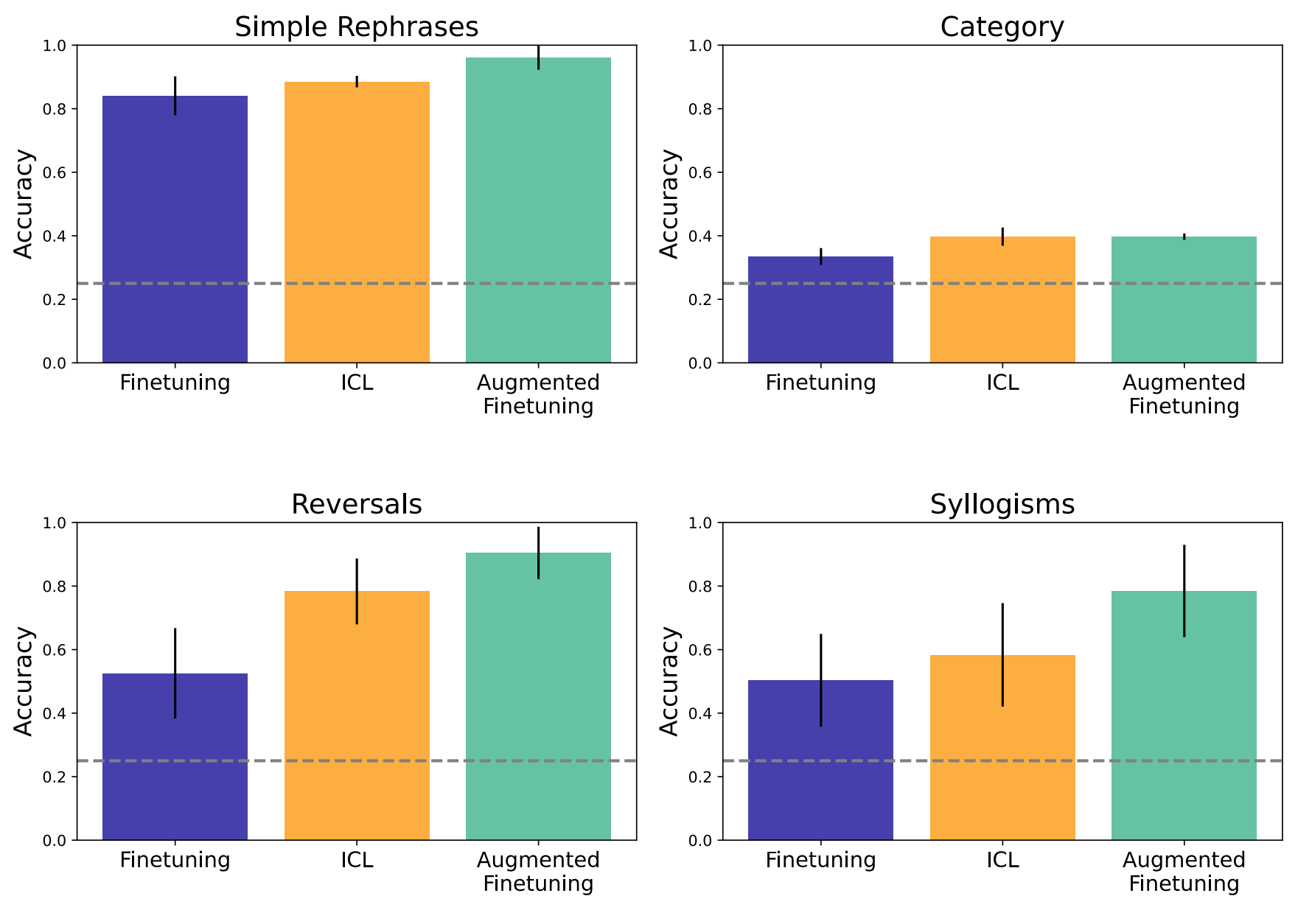
图4|在结构更丰富的语义数据集上,上下文学习仍然适度优于微调。此外,增强继续显示出微调对泛化的好处-即使是在关于不涉及反转的训练事实的重新措辞的问题中(左上)。然而,一些泛化分裂,如类别级别的坚持,仍然非常具有挑战性。(误差线是在具有不同类型的所讨论的推理的任务子集上计算的标准误差,例如,属性关系的反转与类别包含关系的反转。
我们在本节中的结果也突出了与先前关于反转诅咒的结果的重要细微差别(Berglund等人,2024年)的报告。当被测试的信息构成了一个更广泛的连贯知识结构(比如我们的语义结构)的一部分时,微调本身确实会表现出某种高于偶然性的对反转的概括。这一概括可能是由于训练集中的其他信息可以支持相反的结论;例如,如果反转是从“鸟类包括鹰”到“鹰是一种鸟类”,但训练集还包括“鹰有翅膀”的陈述,则该信息可以实现推断反转的替代途径(如果不是逻辑上的,则是关联性的)。然而,上下文内学习和增强的微调继续比单独的微调表现得更好。
处理知识
我们还进行了一些初步实验,探索过程类型(而不是语义)知识的学习和泛化,即将新程序应用于输入的能力。具体来说,我们专注于执行一个简单的伪数学过程,我们称之为“derivatoids”,它以类似于计算导数的方式转换类似数学的表达式。我们创建了一个训练-测试组合泛化分组,其中某些规则组合在训练中可见(再次,无论是在上下文中还是通过微调),但其他组合则用于测试。结果的总体格局与上述情况基本一致。ICL优于微调,特别是在低拍摄区域,并且增强提高微调性能。然而,过程知识需要不同的评估方法,与上述语义知识实验相比,效果相应地似乎由不同的因素驱动;因此,我们在附录B.5中详细介绍了实验和结果。
相关工作
上下文学习:
各种各样的工作已经探索了上下文学习(Brown等人,2020年; Dong等人,2022年; Lampinen等人,第2024条a款)。一些研究工作已经研究了ICL的学习和概括的模式,或者是经验性的(Chan等人,2022 a; Garg等人,2022),机械地(Olsson等人,2022),或理论上(Elmoznino等人,2024; Xie等人,2023; Zhang等人,2024年)的报告。最近的几项工作已经发现即使缩放到数百或数千个上下文无关的示例也可以提高LM在具有挑战性的数据集上的性能(Agarwal等人,2024年; Anil等人,2024年; Bertsch等人,2024年)的报告。我们的工作同样依赖于模型从上下文中的许多文档中学习的能力,以便生成用于扩充的推断。
断章取义学习:
其他几篇论文(例如Berglund等人,二零二三年; Meinke和Evans,2023)已经考虑了模型如何泛化“上下文外”-也就是说,它们如何在测试时以灵活的方式使用未直接包含在提示中的信息。我们的结果可能与这些有关,例如,即使在语义结构数据集上进行微调,也可以看到部分泛化的模式。然而,我们通常不会发现上下文外信息的可靠使用,即,情境学习往往优于微调。
事实学习和概括:
各种各样的工作已经研究了语言模型是如何学习和概括事实信息的,无论是在预训练中(例如Allen-Zhu和Li,2024,2025; Zucchet等人,2025)和在微调期间(例如Berglund等人,2024年; Gekhman等人,2024年)的报告。这些著作中的许多集中于未能像“逆转诅咒”那样概括(Berglund等人,2024),而其他人研究了LLM经过预训练时幻觉的增加(Zucchet等人,2025)或根据新知识进行微调(Gekhman等人,2024年)的报告。然而,这些工作通常没有进行数据匹配实验,比较了在上下文学习和微调的泛化。
数据增强:
各种各样的工作已经探索了如何使用LLM来增强数据,以改善来自小的或窄的数据集的性能,例如,改善零触发任务性能(Maini等人,2024)或改进跨语言概括(例如怀特豪斯等人,2023年)的报告。Ding等人(2024)综述了一些更广泛的文献。也已经有针对性地尝试用硬编码的增强来修复诸如反转诅咒之类的特定问题(Golovneva等人,2024年)的报告。Akyürek等人(2024年)的一项密切相关的工作提出了“演绎闭包训练”,通过促使语言模型从训练文档中生成演绎推理来提高覆盖率。Padmanabhan等人(2024)同样提出了生成延拓,然后将其提取到模型中的方法。一些同时进行的工作Chen et al.(2024); Ruan et al.(2025)提出,让学习机产生额外的推理方向,并使用这些方向来扩充他们的训练数据,可以提高推理任务的表现。Yang等人(2024)使用语言模型提取训练文档中的实体,并生成关于这些实体之间链接的合成数据推理;与我们的结果一样,他们发现这种在合成数据中“重新排列”知识的方法有助于提高下游性能。我们的实验表明,在受控环境中,在没有数据集污染的可能性的情况下,类似的方法来扩充小的微调数据集可以产生改进的泛化,并将性能与通过更基本的微调和上下文学习所实现的性能相关联。
合成数据:
同样广泛的文献已经探索了合成数据在改善LM性能方面的其他应用;最近的调查见Liu et al.(2024)。早期的工作考虑手工设计的合成数据使用诸如语言学或数学的领域的领域知识来改进概括(例如Pratapa等人,2018年; Wu等人,2021年)的报告。最近的方法集中于直接从语言模型生成数据,或者用地面实况分数过滤(Zelikman等人,2022)或简单地通过自我一致性(Huang等人,2023; Wang等人,2023年)的报告。虽然最近的一篇著名文章认为对合成数据的训练会导致模型崩溃(Shumailov等人,2024),其它著作已经注意到在合成数据与原始数据混合的设置中性能继续提高(Gerstgrasser等人,2024年)的报告。我们相应地发现,在我们的设置中,将扩充数据与模型合成一致地提高了性能,而不是有害的(即使在来自语义结构数据集中的训练分裂的重新措辞的信息上)。这些结果有助于正在进行的关于合并合成数据如何影响模型性能的讨论。
讨论
在本文中,我们对语言模型如何从上下文学习和微调中概括各种类型的新信息进行了对照实验。总的来说,我们发现模型平均沿着几个维度从上下文学习中推广得更好。使用上下文学习来增强微调数据集可以利用两者的互补优势来获得更好的性能。
情境学习和微调的不同归纳偏差:
许多著作研究了情境学习中的归纳偏差。一个共同的主题是强调在上下文中的学习可以近似梯度下降(例如Von Oswald等人,2023),在该行为是最佳的设置中。然而,许多其他研究发现,情境学习的归纳偏差可能会因数据集多样性等因素而异(Raventós等人,2024)或模型比例(Wei等人,2023年)的报告。事实上,Elmoznino等人(2024)认为,在上下文学习的一些工作已经明确指出,不同的归纳偏差的上下文与权重学习(如“基于规则”对比“基于范例”概括)(Awadalla等人,2022年; Chan等人,2022 b; Shen等人,2023)-而另一些人则认为它们比看起来更相似(Mosbach等人,2023年)的报告。我们的工作有助于这一系列的发现,但超出了这些工作中考虑的典型输入-输出任务,考虑了其他类型的知识。
可获取的信息和通过思考学习:
Lombrozo(2024)强调了“通过思考学习”如何成为认知科学和人工智能最新进展的统一主题-系统可以纯粹通过计算获得新的信息和技能,而无需进一步的输入。Lombrozo强调,虽然从表面上看,这似乎是矛盾的-信息不能被创建-这种进一步的计算可以增加信息的可访问性,从而提高实践中的性能。这一论点与Xu et al.(2020)关于计算如何增加信息可访问性的理论观点相似。我们使用上下文推理来提高微调性能,超越原始数据,遵循这种模式。例如,关于反转和三段论的信息总是隐藏在数据中,但是对上下文推理的微调使这些信息更加明确,从而在测试时更容易访问。
训练时间推断缩放:
最近,各种工作已经开始探索测试时间推断缩放以提高性能(例如Guo等人,2025年; Jaech等人,2024年)的报告。这些发现补充了探索缩放训练计算(例如,通过更大的模型或更多的数据)如何提高性能的先前研究(例如,Hoffmann等人,2022年;卡普兰等人,2020年)的报告。我们的结果表明,通过上下文推理方法缩放训练时间计算有助于改善模型泛化的某些方面。
不足之处
我们的工作受到几个限制。首先,我们的主要实验依赖于无意义的词语和难以置信的操作。虽然这些反事实任务使我们能够避免数据集污染的可能性,但它们可能会在一定程度上干扰模型的性能。例如,初步实验(Appx.B.2)建议如果名称被替换为无意义,则反转诅咒数据集上模型的ICL性能会降低。因此,具有更合理实体的任务可能会从ICL中获得更大的好处。有可能微调使无意义的术语更熟悉,这导致了增强微调和ICL之间的差距。然而,在这种情况下,我们可能会低估ICL和基础微调之间的差距(因为后者将有效地受益于无意义实体的增加的“熟悉度”)。第二,我们没有使用其他语言模型进行实验,这将增强我们的结果的普遍性。然而,由于我们所建立的个别现象-例如微调时的反向诅咒(Berglund等人,2024)与在上下文中进行反转的能力(例如Lampinen等人,2024 b)-已在多个模型中记录,我们认为将我们的结果外推到其他环境是合理的。然而,未来的工作应该更仔细地研究模型在这些环境中如何学习和推广的差异,包括更新的推理模型(如Guo等人,2025年)的报告。
结论:
我们已经探讨了在上下文学习和微调时,LM暴露于各种类型的新的信息结构的泛化。我们发现显着的差异-通常与ICL更好地概括某些类型的推理-并提出了通过添加上下文推理来微调数据来实现更好性能的方法。我们希望这项工作将有助于理解基础模型中的学习和泛化的科学,以及使它们适应下游任务的实用性。
相关文章:
从上下文学习和微调看语言模型的泛化:一项对照研究
大型语言模型表现出令人兴奋的能力,但也可以从微调中表现出令人惊讶的狭窄泛化。例如,他们可能无法概括为简单的关系反转,或者无法根据训练信息进行简单的逻辑推理。这些未能从微调中概括出来的失败可能会阻碍这些模型的实际应用。另一方面&a…...

智慧城市建设方案
第1章 总体说明 1.1 建设背景 1.2 建设目标 1.3 项目建设主要内容 1.4 设计原则 第2章 对项目的理解 2.1 现状分析 2.2 业务需求分析 2.3 功能需求分析 第3章 大数据平台建设方案 3.1 大数据平台总体设计 3.2 大数据平台功能设计 3.3 平台应用 第4章 政策标准保障…...

phosphobot开源程序是控制您的 SO-100 和 SO-101 机器人并训练 VLA AI 机器人开源模型
一、软件介绍 文末提供程序和源码下载 phosphobot开源程序是控制您的 SO-100 和 SO-101 机器人并训练 VLA AI 机器人开源模型。 二、Overview 概述 🕹️ Control your robot with the keyboard, a leader arm, a Meta Quest headset or via API 🕹️…...
pygame开发的坦克大战
使用Python和Pygame开发的精美坦克大战游戏。这个游戏包含玩家控制的坦克、敌方坦克、各种障碍物、爆炸效果和完整的游戏机制。 游戏说明 这个坦克大战游戏包含以下功能: 游戏特点 玩家控制:使用方向键移动坦克,空格键射击 敌人AI&#x…...

C++2025.6.7 C++五级考题
城市商业街主干道是一条笔直的道路,商业街里有 n 家店铺,现给定 n 个店铺的位置,请在这条道路上找到一个中心点,使得所有店铺到这个中心点的距离之和最小,并输出这个最小值。 #include <bits/stdc.h> using nam…...

【原神 × 二叉树】角色天赋树、任务分支和圣遗物强化路径的算法秘密!
【原神 二叉树】角色天赋树、任务分支和圣遗物强化路径的算法秘密! 作者:星之辰 标签:#原神 #二叉树 #天赋树 #任务分支 #圣遗物强化 #算法科普 发布时间:2025年6月 总字数:6000+ 一、引子:提瓦特大陆的“树型奥秘” 你是否曾留意过《原神》角色面板的天赋树? 升级技能…...
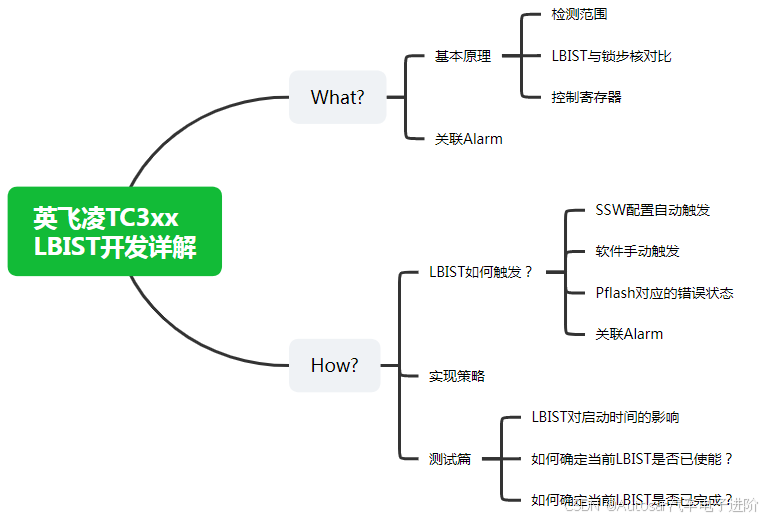
功能安全实战系列09-英飞凌TC3xx LBIST开发详解
本文框架 0. 前言1.What?1.1 基本原理1.1.1 检测范围1.1.2 LBIST与锁步核对比1.1.3 控制寄存器1.2 关联Alarm2. How?2.1 LBIST触发?2.1.1 SSW配置自动触发2.1.2 软件手动触发LBIST2.2 实现策略2.3 测试篇LBIST对启动时间的影响如何确定当前LBIST是否已使能?如何确定当前LBI…...
一个完整的日志收集方案:Elasticsearch + Logstash + Kibana+Filebeat (二)
📄 本地 Windows 部署 Logstash 连接本地 Elasticsearch 指南 ✅ 目标 在本地 Windows 上安装并运行 Logstash配置 Logstash 将数据发送至本地 Elasticsearch测试数据采集与 ES 存储流程 🧰 前提条件 软件版本要求安装说明Java17Oracle JDK 下载 或 O…...
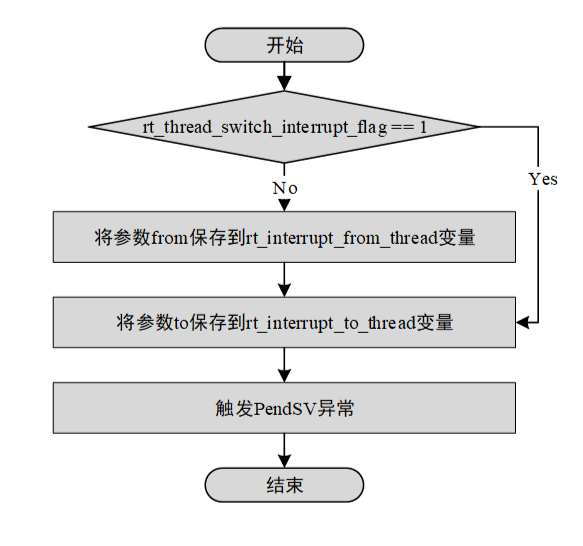
RT-Thread内核组成——内核移植
内核移植就是指将 RT-Thread 内核在不同的芯片架构、不同的板卡上运行起来,能够具备线程管理和调度,内存管理,线程间同步和通信、定时器管理等功能。移植可分为 CPU 架构移植和 BSP(Board support package,板级支持包&…...

Docker_Desktop开启k8s
Docker_Desktop开启k8s 原文地址:在 Docker Desktop 中启用 K8s 服务 - 墨墨墨墨小宇 - 博客园 开启k8s服务 打开docker的设置界面,选择Docker Engine,修改如下: {"debug": false,"experimental": false,…...

MS2691 全频段、多模导航、射频低噪声放大器芯片,应用于导航仪 双频测量仪
MS2691 全频段、多模导航、射频低噪声放大器芯片,应用于导航仪 双频测量仪 产品简述 MS2691 是一款具有 1164MHz 1615MHz 全频段、低功耗的低噪声放大器芯片。该芯片通过对外围电路的简单配置,使得频带具有宽带或窄带特性。支持不同频段的各种导…...
基于Java(SpringBoot、Mybatis、SpringMvc)+MySQL实现(Web)小二结账系统
结账系统 1.引言 1.1.编写目的 此说明书在概要设计的基础上,对小二结账系统的各个模块、程序分别进行了实现层面上的要求和说明。在以下的详细设计报告中将对在本阶段中对系统所做的所有详细设计进行说明。在本阶段中,确定应该如何具体的实现所要求的…...

Java泛型中的通配符详解
无界通配符 通配符的必要性 通过WrapperUtil类的示例可以清晰展示通配符的使用场景。假设我们需要为Wrapper类创建一个工具类WrapperUtil,其中包含一个静态方法printDetails(),该方法需要处理任意类型的Wrapper对象。最初的实现尝试如下: …...

Java方法引用深度解析:从匿名内部类到函数式编程的演进
文章目录 前言问题场景第一种:传统的匿名内部类技术解析优缺点分析 第二种:Lambda表达式的革命技术解析Lambda表达式的本质性能优势 第三种:方法引用的极致简洁技术解析 方法引用的四种类型1. 静态方法引用2. 实例方法引用3. 特定类型的任意对…...
三维GIS开发cesium智慧地铁教程(4)城市白模加载与样式控制
一、添加3D瓦片 <!-- 核心依赖引入 --> <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"><!-- 模型数据路径 --> u…...

越狱蒸馏-可再生安全基准测试
大家读完觉得有帮助记得关注!!! 摘要 大型语言模型(LLMs)正迅速部署在关键应用中,这引发了对稳健安全基准测试的迫切需求。我们提出了越狱提炼(JBDISTILL),这是一种新颖…...

64、js 中require和import有何区别?
在 JavaScript 中,require 和 import 都是用于模块导入的语法,但它们属于不同的模块系统,具有显著的区别: 1. 模块系统不同 require 属于 CommonJS 模块系统(Node.js 默认使用)。 语法:const…...

手机号段数据库与网络安全应用
手机号段数据库的构成与原理 手机号段数据库存储着海量手机号段及其关联信息,包括号段起始与结束号码、运营商归属、地区编码、卡类型等核心数据。这些数据主要来源于通信管理机构的官方分配信息、运营商的业务更新数据以及合法采集的使用数据。经过数据清洗、校验…...
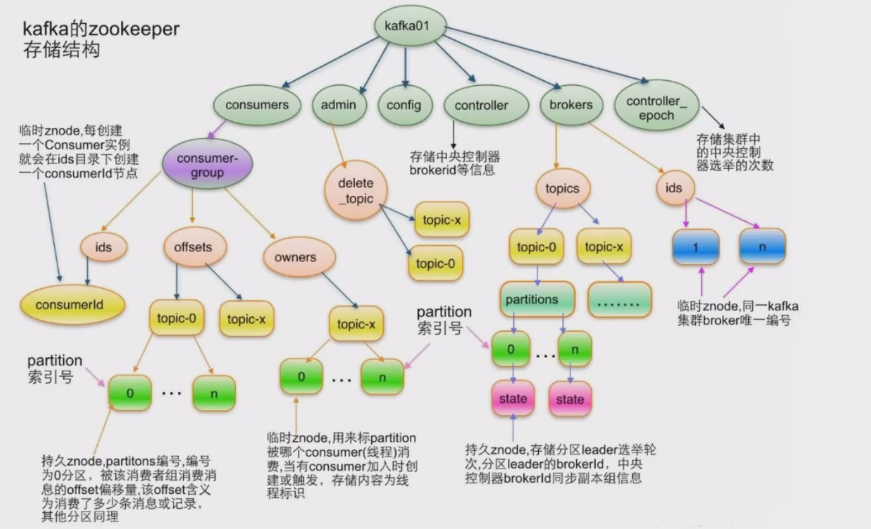
Kafka 入门指南与一键部署
Kafka 介绍 想象一下你正在运营一个大型电商平台,每秒都有成千上万的用户浏览商品、下单、支付,同时后台系统还在记录用户行为、更新库存、处理物流信息。这些海量、持续产生的数据就像奔腾不息的河流,你需要一个强大、可靠且实时的系统来接…...

MATLAB实战:视觉伺服控制实现方案
以下是一个基于MATLAB的视觉伺服控制项目实现方案,结合实时图像处理、目标跟踪和控制系统设计。我们将使用模拟环境进行演示,但代码结构可直接应用于真实硬件。 系统架构 图像采集 → 目标检测 → 误差计算 → PID控制器 → 执行器控制 完整代码实现 …...
Oracle正则表达式学习
目录 一、正则表达简介 二、REGEXP_LIKE(x,匹配项) 三、REGEXP_INSTR 四、REGEXP_SUBSTR 五、REGEXP_REPLACE 一、正则表达简介 相关网址: https://cloud.tencent.com/developer/article/1456428 https://www.cnblogs.com/lxl57610/p/8227599.html https://…...

校招 java 面试基础题目及解析
我将结合常见的校招Java面试基础题目,从概念阐述、代码示例等角度展开,为你提供一份可用于学习的技术方案及应用实例。 校招Java面试基础题目解析与学习指南 在Java校招面试中,扎实掌握基础知识是成功的关键。本文将围绕常见的Java基础面试…...

# STM32F103 SD卡读写程序
下面是一个基于STM32F103系列微控制器的SD卡读写完整程序,使用标准外设库(StdPeriph)和FatFs文件系统。 硬件准备 STM32F103C8T6开发板(或其他F103系列)SD卡模块(SPI接口)连接线缆 硬件连接 SD卡模块 STM32F103 CS -> PA4 (SPI1_NSS) SCK -> PA5 (SPI…...

Spring中循环依赖问题的解决机制总结
一、解决机制 1. 什么是循环依赖 循环依赖是指两个或多个Bean之间相互依赖对方,形成一个闭环的依赖关系。最常见的情况是当Bean A依赖Bean B,而Bean B又依赖Bean A时,就形成了循环依赖。在Spring容器初始化过程中,如果不加以特殊…...

青少年编程与数学 01-011 系统软件简介 04 Linux操作系统
青少年编程与数学 01-011 系统软件简介 04 Linux操作系统 一、Linux 的发展历程(一)起源(二)早期发展(三)成熟与普及(四)移动与嵌入式领域的拓展 二、Linux 的内核与架构(…...

微软PowerBI考试 PL300-使用适用于 Power BI 的 Copilot 创建交互式报表
微软PowerBI考试 PL300-使用适用于 Power BI 的 Copilot 创建交互式报表 Microsoft Power BI 可帮助您通过交互式报表准备数据并对数据进行可视化。 如果您是 Power BI 的新用户,可能很难知道从哪里开始,并且创建报表可能很耗时。 通过适用于 Power BI …...

损坏的RAID5 第十六次CCF-CSP计算机软件能力认证
纯大模拟 提前打好板子 我只通过4个用例点 然后就超时了。 #include<iostream> #include<cstring> #include<algorithm> #include<unordered_map> #include<bits/stdc.h> using namespace std; int n, s, l; unordered_map<int, string>…...

Android USB 通信开发
Android USB 通信开发主要涉及两种模式:主机模式(Host Mode)和配件模式(Accessory Mode)。以下是开发USB通信应用的关键知识点和步骤。 1. 基本概念 主机模式(Host Mode) Android设备作为USB主机,控制连接的USB设备 需要设备支持USB主机功能(通常需要O…...

Prompt提示工程指南#Kontext图像到图像
重要提示:单个prompt的最大token数为512 # 核心能力 Kontext图像编辑系统能够: 理解图像上下文语义实现精准的局部修改保持原始图像风格一致性支持复杂的多步迭代编辑 # 基础对象修改 示例场景:改变汽车颜色 Prompt设计: Change …...
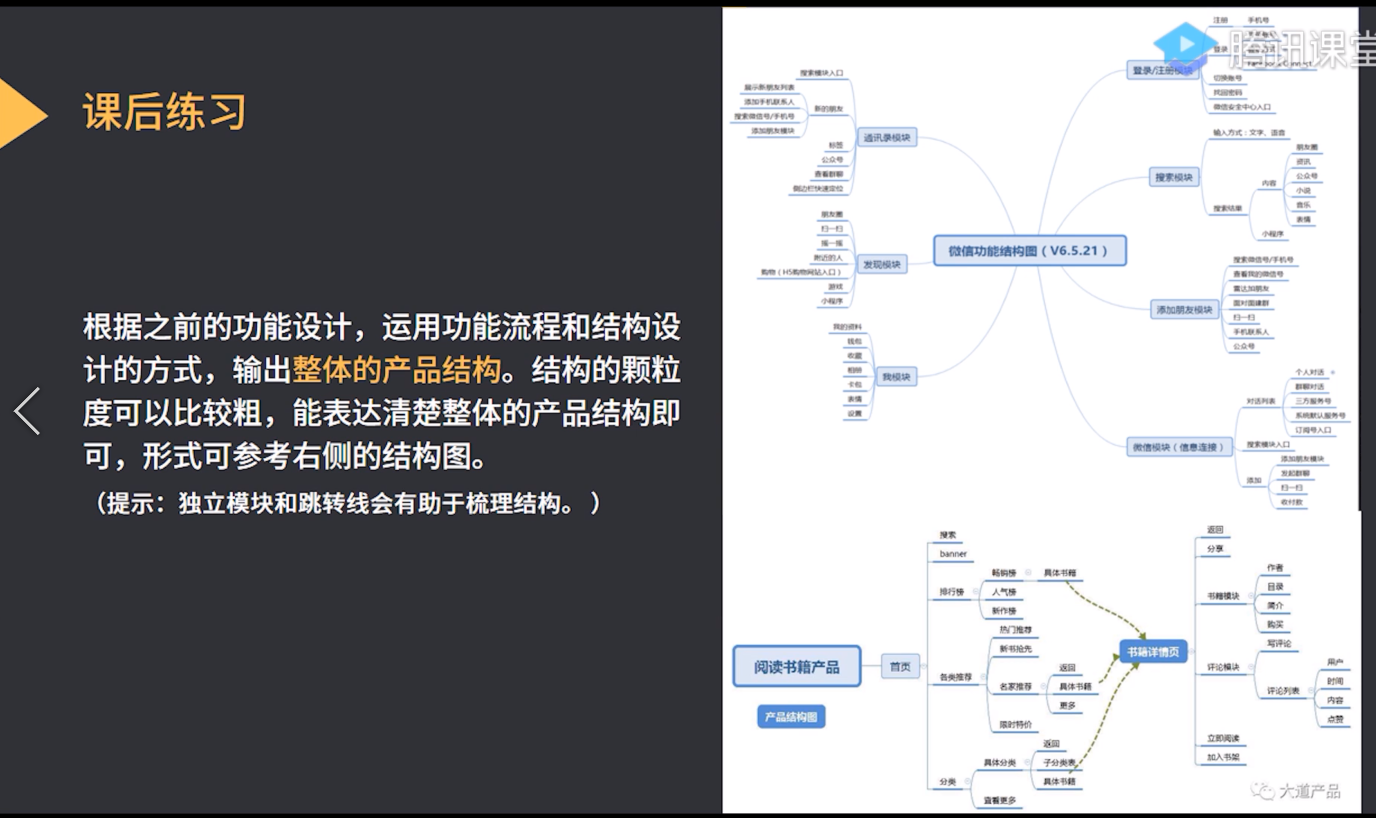
产品经理课程(十一)
(一)复习 1、用户需求不等于产品需求,挖掘用户的本质需求 2、功能设计的前提:不违背我们的产品的基础定位(用一句话阐述我们的产品:工具:产品画布) 3、判断设计好坏的标准…...