第5章:Cypher查询语言进阶
在掌握了Cypher的基础知识后,本章将深入探讨更高级的查询技术。这些进阶技能将帮助您构建更复杂、更高效的查询,解决实际业务中的复杂问题,并充分发挥Neo4j的图数据处理能力。
5.1 复杂查询构建
随着业务需求的复杂性增加,查询也需要变得更加复杂和精细。本节将介绍如何构建和组织复杂的Cypher查询。
多层关系查询
在实际应用中,我们经常需要查询跨越多个关系层级的数据。例如,查找"朋友的朋友"、"供应商的供应商"或"经理的经理"等。
固定深度的多层关系:
当我们知道确切的关系深度时,可以直接在查询中指定完整路径:
// 查找Alice的朋友的朋友
MATCH (alice:Person {name: 'Alice'})-[:KNOWS]->(friend)-[:KNOWS]->(foaf)
WHERE alice <> foaf // 排除Alice自己
RETURN DISTINCT foaf.name
这种方法直观明确,但缺乏灵活性,每增加一层关系就需要修改查询。
可变深度的多层关系:
当关系深度不确定或需要查询不同深度时,可以使用可变长度路径:
// 查找与Alice距离1到3跳的所有人
MATCH (alice:Person {name: 'Alice'})-[:KNOWS*1..3]->(person)
RETURN DISTINCT person.name, length(shortestPath((alice)-[:KNOWS*]-(person))) AS distance
语法[:KNOWS*1..3]表示"1到3跳的KNOWS关系"。如果省略下限,如[:KNOWS*..3],则表示"最多3跳";如果省略上限,如[:KNOWS*1..],则表示"至少1跳";如果两者都省略,如[:KNOWS*],则表示"任意跳数"(但要注意性能影响)。
带条件的多层关系:
可以对路径中的节点或关系添加条件:
// 查找Alice通过活跃关系连接的朋友的朋友
MATCH path = (alice:Person {name: 'Alice'})-[:KNOWS*1..2]->(person)
WHERE all(r IN relationships(path) WHERE r.active = true)
RETURN DISTINCT person.name
函数relationships(path)返回路径中的所有关系,all()函数检查是否所有关系都满足指定条件。
路径函数:
Neo4j提供了多种处理路径的函数:
| 函数/表达式 | 说明 |
|---|---|
length(path) | 返回路径中的关系数量 |
nodes(path) | 返回路径中的所有节点 |
relationships(path) | 返回路径中的所有关系 |
shortestPath((a)-[*]-(b)) | 查找两个节点之间的最短路径 |
allShortestPaths((a)-[*]-(b)) | 查找两个节点之间的所有最短路径 |
// 查找Alice和Bob之间的最短路径,并返回路径上的所有人名
MATCH path = shortestPath((alice:Person {name: 'Alice'})-[:KNOWS*]-(bob:Person {name: 'Bob'}))
RETURN [node IN nodes(path) | node.name] AS people
条件过滤与模式匹配
复杂查询通常需要精细的条件过滤和模式匹配。
复合条件过滤:
使用逻辑运算符组合多个条件:
// 查找30岁以上且住在伦敦或纽约的人
MATCH (p:Person)
WHERE p.age > 30 AND (p.city = 'London' OR p.city = 'New York')
RETURN p.name, p.age, p.city
存在性检查:
检查节点是否有特定的关系或属性:
// 查找有电子邮件但没有电话号码的人
MATCH (p:Person)
WHERE exists(p.email) AND NOT exists(p.phone)
RETURN p.name, p.email
模式存在性检查:
检查是否存在特定的图模式:
// 查找住在伦敦但不在任何公司工作的人
MATCH (p:Person)-[:LIVES_IN]->(c:City {name: 'London'})
WHERE NOT (p)-[:WORKS_FOR]->(:Company)
RETURN p.name
可选模式匹配:
使用OPTIONAL MATCH查找可能不存在的模式:
// 查找所有人及其工作的公司(如果有)
MATCH (p:Person)
OPTIONAL MATCH (p)-[:WORKS_FOR]->(c:Company)
RETURN p.name, c.name AS company
如果一个人没有工作关系,company将为null。
条件路径:
根据条件选择不同的路径:
// 根据关系类型查找Alice的直接联系人
MATCH (alice:Person {name: 'Alice'})
OPTIONAL MATCH (alice)-[:KNOWS]->(friend:Person)
OPTIONAL MATCH (alice)-[:WORKS_WITH]->(colleague:Person)
RETURN collect(DISTINCT friend.name) AS friends,collect(DISTINCT colleague.name) AS colleagues
CASE表达式:
使用CASE表达式进行条件逻辑:
// 根据年龄对人进行分类
MATCH (p:Person)
RETURN p.name, CASEWHEN p.age < 18 THEN 'Minor'WHEN p.age < 65 THEN 'Adult'ELSE 'Senior'END AS ageCategory
子查询与复合查询
对于非常复杂的查询,可以将其分解为多个部分,使用WITH子句连接。
WITH子句:
WITH子句类似于SQL中的子查询或中间结果,它将一个查询部分的结果传递给下一个部分:
// 查找朋友数量最多的5个人
MATCH (p:Person)-[:KNOWS]->(friend)
WITH p, count(friend) AS friendCount
ORDER BY friendCount DESC
LIMIT 5
RETURN p.name, friendCount
在这个例子中,第一部分计算每个人的朋友数量,第二部分对结果排序并限制数量。
多阶段查询:
使用多个WITH子句构建多阶段查询:
// 查找Alice的朋友中,拥有最多共同朋友的人
MATCH (alice:Person {name: 'Alice'})-[:KNOWS]->(friend)
WITH alice, friend
MATCH (alice)-[:KNOWS]->(commonFriend)<-[:KNOWS]-(friend)
WITH friend, count(commonFriend) AS commonFriends
ORDER BY commonFriends DESC
LIMIT 1
RETURN friend.name, commonFriends
聚合后过滤:
使用WITH对聚合结果进行过滤:
// 查找拥有超过5个朋友的人
MATCH (p:Person)-[:KNOWS]->(friend)
WITH p, count(friend) AS friendCount
WHERE friendCount > 5
RETURN p.name, friendCount
子查询结果重用:
使用WITH保存中间结果以便多次使用:
// 计算每个人的朋友数量和工作关系数量
MATCH (p:Person)
OPTIONAL MATCH (p)-[:KNOWS]->(friend)
WITH p, count(friend) AS friendCount
OPTIONAL MATCH (p)-[:WORKS_WITH]->(colleague)
RETURN p.name, friendCount, count(colleague) AS colleagueCount
UNION组合查询:
使用UNION或UNION ALL组合多个查询结果:
// 查找所有的朋友和同事关系
MATCH (p1:Person)-[:KNOWS]->(p2:Person)
RETURN p1.name AS person1, 'KNOWS' AS relationship, p2.name AS person2
UNION
MATCH (p1:Person)-[:WORKS_WITH]->(p2:Person)
RETURN p1.name AS person1, 'WORKS_WITH' AS relationship, p2.name AS person2
UNION会去除重复结果,而UNION ALL保留所有结果。注意,两个查询必须返回相同数量和类型的列。
参数化子查询:
使用WITH传递参数给子查询:
// 对每个部门,查找薪资高于部门平均值的员工
MATCH (d:Department)<-[:WORKS_IN]-(e:Employee)
WITH d, avg(e.salary) AS avgSalary
MATCH (d)<-[:WORKS_IN]-(e:Employee)
WHERE e.salary > avgSalary
RETURN d.name AS department, e.name AS employee, e.salary, avgSalary
通过掌握这些复杂查询构建技术,您可以解决各种复杂的业务问题,充分发挥Neo4j的图数据处理能力。
5.2 聚合与统计函数
聚合函数允许对数据进行汇总和统计分析,是数据分析和报告的重要工具。Neo4j提供了丰富的聚合和统计函数,可以应用于各种场景。
COUNT、SUM、AVG等聚合函数
Neo4j支持多种标准聚合函数,类似于SQL:
COUNT函数:
计算匹配结果的数量:
// 计算系统中的用户总数
MATCH (u:User)
RETURN count(u) AS totalUsers
计算非空值的数量:
// 计算有电话号码的用户数量
MATCH (u:User)
RETURN count(u.phone) AS usersWithPhone
SUM函数:
计算数值的总和:
// 计算所有订单的总金额
MATCH (o:Order)
RETURN sum(o.amount) AS totalAmount
AVG函数:
计算平均值:
// 计算用户的平均年龄
MATCH (u:User)
RETURN avg(u.age) AS averageAge
MIN和MAX函数:
查找最小值和最大值:
// 查找最年轻和最年长的用户
MATCH (u:User)
RETURN min(u.age) AS youngestAge, max(u.age) AS oldestAge
STDEV和STDEVP函数:
计算标准差(样本和总体):
// 计算用户年龄的标准差
MATCH (u:User)
RETURN stdev(u.age) AS ageStdDev, stdevp(u.age) AS ageStdDevP
PERCENTILE和PERCENTILE_DISC函数:
计算百分位数:
// 计算用户年龄的中位数和90百分位数
MATCH (u:User)
RETURN percentile(u.age, 0.5) AS medianAge,percentile(u.age, 0.9) AS age90thPercentile
分组统计与COLLECT函数
GROUP BY功能:
虽然Cypher没有显式的GROUP BY子句,但它通过WITH和聚合函数实现分组功能:
// 按城市统计用户数量
MATCH (u:User)-[:LIVES_IN]->(c:City)
RETURN c.name AS city, count(u) AS userCount
在这个例子中,结果按c.name自动分组。
多字段分组:
// 按城市和年龄段统计用户数量
MATCH (u:User)-[:LIVES_IN]->(c:City)
WITH c.name AS city, CASEWHEN u.age < 18 THEN 'Minor'WHEN u.age < 65 THEN 'Adult'ELSE 'Senior'END AS ageGroup,count(u) AS userCount
RETURN city, ageGroup, userCount
ORDER BY city, ageGroup
COLLECT函数:
COLLECT函数将多个值聚合为一个列表:
// 收集每个城市的所有用户名
MATCH (u:User)-[:LIVES_IN]->(c:City)
RETURN c.name AS city, collect(u.name) AS userNames
列表操作函数:
Neo4j提供了多种处理列表的函数:
// 计算每个城市的用户数量、用户名列表和平均年龄
MATCH (u:User)-[:LIVES_IN]->(c:City)
RETURN c.name AS city, count(u) AS userCount,collect(u.name) AS userNames,size(collect(u.name)) AS userNameCount, // 等同于count(u)[u IN collect(u) | u.age] AS ages, // 列表推导avg(u.age) AS avgAge
UNWIND操作符:
UNWIND将列表展开为单独的行,是COLLECT的逆操作:
// 将收集的用户名再次展开
MATCH (u:User)-[:LIVES_IN]->(c:City)
WITH c.name AS city, collect(u.name) AS userNames
UNWIND userNames AS userName
RETURN city, userName
统计结果的处理与展示
处理和转换聚合结果以便更好地展示和理解:
格式化和舍入:
// 格式化平均年龄,保留两位小数
MATCH (u:User)
RETURN round(avg(u.age) * 100) / 100 AS formattedAvgAge
条件聚合:
// 按性别统计平均年龄
MATCH (u:User)
RETURN count(u) AS totalUsers,sum(CASE WHEN u.gender = 'M' THEN 1 ELSE 0 END) AS maleCount,sum(CASE WHEN u.gender = 'F' THEN 1 ELSE 0 END) AS femaleCount,avg(CASE WHEN u.gender = 'M' THEN u.age END) AS maleAvgAge,avg(CASE WHEN u.gender = 'F' THEN u.age END) AS femaleAvgAge
排序聚合结果:
// 查找用户最多的前5个城市
MATCH (u:User)-[:LIVES_IN]->(c:City)
WITH c, count(u) AS userCount
ORDER BY userCount DESC
LIMIT 5
RETURN c.name AS city, userCount
百分比计算:
// 计算每个城市的用户占总用户的百分比
MATCH (u:User)
WITH count(u) AS totalUsers
MATCH (u:User)-[:LIVES_IN]->(c:City)
WITH c, count(u) AS cityUsers, totalUsers
RETURN c.name AS city, cityUsers,round(100.0 * cityUsers / totalUsers * 10) / 10 AS percentage
ORDER BY cityUsers DESC
累计统计:
// 计算用户年龄的分布
MATCH (u:User)
WITH u.age AS age
ORDER BY age
WITH collect(age) AS allAges
UNWIND range(0, 100, 10) AS ageBucket
RETURN ageBucket AS ageFrom, ageBucket + 9 AS ageTo,size([a IN allAges WHERE a >= ageBucket AND a <= ageBucket + 9]) AS userCount
嵌套聚合:
// 对每个部门,计算每个职位的平均薪资
MATCH (d:Department)<-[:WORKS_IN]-(e:Employee)
WITH d, e.position AS position, collect(e.salary) AS salaries
RETURN d.name AS department,[position, avg(salaries)] AS positionAvgSalary
通过掌握这些聚合和统计函数,您可以从图数据中提取有价值的洞察,支持业务决策和数据分析需求。
5.3 高级路径操作
图数据库的一个主要优势是能够高效地处理复杂的路径查询。本节将介绍Neo4j中的高级路径操作技术。
可变长度路径查询
可变长度路径查询允许查找节点之间的多跳关系,是图数据库的强大功能之一。
基本语法:
// 查找与Alice距离1到3跳的所有人
MATCH (alice:Person {name: 'Alice'})-[:KNOWS*1..3]->(person)
RETURN DISTINCT person.name
可变长度路径的语法说明如下:[:KNOWS*1..3]表示1到3跳的KNOWS关系;*1..表示至少1跳(无上限);*..3表示最多3跳(从0跳开始);*表示任意跳数。需要注意,使用无上限或任意跳数时,可能会带来较大的性能开销,应谨慎使用。
方向控制:
可以指定或忽略关系方向:
// 双向查找(忽略方向)
MATCH (alice:Person {name: 'Alice'})-[:KNOWS*1..3]-(person)
RETURN DISTINCT person.name// 指定方向
MATCH (alice:Person {name: 'Alice'})<-[:REPORTS_TO*1..3]-(subordinate)
RETURN DISTINCT subordinate.name
多关系类型:
可以指定多种关系类型:
// 通过"认识"或"一起工作"关系查找连接的人
MATCH (alice:Person {name: 'Alice'})-[:KNOWS|WORKS_WITH*1..3]-(person)
RETURN DISTINCT person.name
路径变量:
可以将整个路径赋值给变量,以便后续处理:
// 查找并返回完整路径
MATCH path = (alice:Person {name: 'Alice'})-[:KNOWS*1..3]->(person)
RETURN path
路径过滤:
可以对路径中的节点或关系应用条件:
// 查找只经过年龄大于30岁的人的路径
MATCH path = (alice:Person {name: 'Alice'})-[:KNOWS*1..3]->(person)
WHERE all(n IN nodes(path) WHERE n.age > 30 OR n = alice)
RETURN person.name
避免环路:
默认情况下,可变长度路径可能包含环路(同一节点多次出现)。可以使用SIMPLE路径类型或手动过滤来避免:
// 使用简单路径(无环路)
MATCH path = shortestPath((alice:Person {name: 'Alice'})-[:KNOWS*]-(bob:Person {name: 'Bob'}))
RETURN path// 手动过滤环路
MATCH path = (alice:Person {name: 'Alice'})-[:KNOWS*1..3]->(person)
WHERE size(nodes(path)) = length(path) + 1 // 确保节点数 = 关系数 + 1
RETURN person.name
最短路径算法
Neo4j提供了内置的最短路径算法,用于查找节点之间的最优连接。
shortestPath函数:
查找两个节点之间的单个最短路径:
// 查找Alice和Bob之间的最短路径
MATCH path = shortestPath((alice:Person {name: 'Alice'})-[:KNOWS*]-(bob:Person {name: 'Bob'}))
RETURN path
allShortestPaths函数:
查找两个节点之间的所有最短路径(如果有多条相同长度的路径):
// 查找Alice和Bob之间的所有最短路径
MATCH paths = allShortestPaths((alice:Person {name: 'Alice'})-[:KNOWS*]-(bob:Person {name: 'Bob'}))
RETURN paths
带权重的最短路径:
使用关系属性作为权重:
// 查找考虑距离权重的最短路径
MATCH (start:City {name: 'New York'}), (end:City {name: 'Los Angeles'})
MATCH path = shortestPath((start)-[:ROAD*]-(end))
RETURN path, reduce(distance = 0, r IN relationships(path) | distance + r.miles) AS totalDistance
最短路径与其他条件结合:
// 查找不经过特定城市的最短路径
MATCH (start:City {name: 'New York'}), (end:City {name: 'Los Angeles'})
MATCH path = shortestPath((start)-[:ROAD*]-(end))
WHERE NONE(n IN nodes(path) WHERE n.name = 'Chicago')
RETURN path
Tip:
shortestPath和allShortestPaths函数要求指定可变长度的关系模式,并在内部采用优化算法实现最短路径查找,通常比手动实现更高效。不过,在处理大型图时,建议为这些函数设置合理的搜索深度限制,以避免带来较大的性能开销。
全路径与部分路径
在某些场景中,我们需要处理完整路径或路径的特定部分。
提取路径信息:
// 提取路径中的所有节点和关系
MATCH path = (alice:Person {name: 'Alice'})-[:KNOWS*1..3]->(person)
RETURN nodes(path) AS pathNodes,relationships(path) AS pathRelationships,length(path) AS pathLength
路径切片:
// 提取路径中的第一个和最后一个节点
MATCH path = (alice:Person {name: 'Alice'})-[:KNOWS*1..3]->(person)
WITH nodes(path) AS pathNodes
RETURN pathNodes[0].name AS firstName,pathNodes[-1].name AS lastName
路径投影:
创建路径的自定义表示:
// 提取路径中的所有人名
MATCH path = (alice:Person {name: 'Alice'})-[:KNOWS*1..3]->(person)
RETURN [node IN nodes(path) | node.name] AS nameList
路径聚合:
聚合多条路径的信息:
// 查找从Alice到每个人的所有路径,并计算平均长度
MATCH path = (alice:Person {name: 'Alice'})-[:KNOWS*1..3]->(person)
RETURN person.name,count(path) AS pathCount,avg(length(path)) AS avgPathLength
路径比较:
比较不同路径的特性:
// 比较通过不同关系类型的路径长度
MATCH knowsPath = shortestPath((a:Person {name: 'Alice'})-[:KNOWS*]-(b:Person {name: 'Bob'}))
MATCH worksPath = shortestPath((a)-[:WORKS_WITH*]-(b))
RETURN length(knowsPath) AS knowsDistance,length(worksPath) AS worksDistance
路径可视化:
Neo4j Browser可以直接可视化路径结果,这是理解复杂关系的强大工具。
通过掌握这些高级路径操作技术,您可以充分利用图数据库的连接性优势,解决传统数据库难以处理的路径和连接性问题。
5.4 Cypher性能优化技巧
随着数据量和查询复杂性的增加,优化Cypher查询的性能变得越来越重要。本节将介绍一些提高查询效率的技巧和最佳实践。
查询计划与EXPLAIN
Neo4j提供了查询计划工具,帮助理解查询的执行方式并识别潜在的性能问题。
EXPLAIN命令:
EXPLAIN命令显示Neo4j将如何执行查询,但不实际运行它:
EXPLAIN MATCH (p:Person {name: 'Alice'})-[:KNOWS]->(friend)
RETURN friend.name
输出包括操作符树、预估成本和其他执行细节。
PROFILE命令:
PROFILE命令不仅显示执行计划,还实际运行查询并收集执行统计信息:
PROFILE MATCH (p:Person {name: 'Alice'})-[:KNOWS]->(friend)
RETURN friend.name
输出包括实际的数据库命中次数、处理的行数等详细信息。
解读查询计划:
分析查询计划时,应关注如 db hits(数据库操作次数,反映查询对存储层的访问频率)、rows(每个操作处理的数据行数,帮助判断数据流规模)、cache hits/misses(缓存命中与未命中次数,命中率高通常意味着更好的性能)以及 time(各操作消耗的时间,便于定位性能瓶颈)等关键指标。综合这些信息,可以有效评估查询的执行效率,并据此进行优化。
常见的性能问题指标包括:查询计划中出现全节点扫描(如NodeByLabelScan而不是NodeIndexSeek),db hits(数据库操作次数)数值过高,存在大量的过滤操作(Filter),以及出现大量的笛卡尔积(CartesianProduct)等。这些现象通常意味着查询未能有效利用索引、数据访问量过大或查询模式设计不合理,可能导致查询性能下降。
索引利用策略
索引是提高查询性能的关键工具,了解如何创建和利用索引至关重要。
创建索引:
// 为Person节点的name属性创建索引
CREATE INDEX person_name FOR (p:Person) ON (p.name)// 为多个属性创建复合索引
CREATE INDEX person_name_age FOR (p:Person) ON (p.name, p.age)
验证索引使用:
使用EXPLAIN或PROFILE验证查询是否使用了索引:
EXPLAIN MATCH (p:Person {name: 'Alice'}) RETURN p
如果看到NodeIndexSeek而非NodeByLabelScan,说明查询使用了索引。
索引使用的最佳实践:
在实际应用中,应优先为经常在WHERE子句中用于过滤的属性创建索引,这样可以显著提升查询效率。同时,对于经常用于排序的属性,也建议建立索引以加快排序操作。高选择性的属性(如ID、电子邮件等唯一性较强的字段)非常适合创建索引,因为它们能有效缩小查询范围。相反,对于低选择性的属性(如性别、状态等取值有限的字段),单独创建索引通常效果有限,建议避免。若查询中经常涉及多个属性的联合过滤,可以考虑使用复合索引,以进一步提升多条件查询的性能。
强制索引使用:
在某些情况下,可以使用查询提示强制使用特定索引:
MATCH (p:Person)
USING INDEX p:Person(name)
WHERE p.name = 'Alice'
RETURN p
查询重写与优化
通过重写查询可以显著提高性能,特别是对于复杂查询。
过滤尽早应用:
尽早应用过滤条件,减少需要处理的数据量:
// 低效查询
MATCH (p:Person)-[:KNOWS]->(friend)
WHERE p.name = 'Alice'
RETURN friend.name// 优化查询
MATCH (p:Person {name: 'Alice'})-[:KNOWS]->(friend)
RETURN friend.name
限制结果集大小:
使用LIMIT减少返回的结果数量:
// 只返回前10个结果
MATCH (p:Person)
RETURN p.name
ORDER BY p.name
LIMIT 10
避免笛卡尔积:
确保查询中的所有模式都有连接:
// 可能产生笛卡尔积的查询
MATCH (p:Person), (c:Company)
RETURN p.name, c.name// 优化查询
MATCH (p:Person)
OPTIONAL MATCH (p)-[:WORKS_FOR]->(c:Company)
RETURN p.name, c.name
使用参数化查询:
使用参数而非硬编码值,允许查询计划缓存:
// 硬编码值
MATCH (p:Person {name: 'Alice'}) RETURN p// 参数化查询
MATCH (p:Person {name: $name}) RETURN p
// 执行时提供参数 {name: 'Alice'}
优化路径查询:
-
限制可变长度路径的深度:
// 限制最大深度 MATCH (a:Person)-[:KNOWS*1..5]->(b:Person) RETURN a.name, b.name -
从两端同时开始搜索:
// 双向搜索 MATCH (a:Person {name: 'Alice'}), (b:Person {name: 'Bob'}) MATCH path = shortestPath((a)-[:KNOWS*]-(b)) RETURN path -
添加中间节点约束:
// 添加路径中节点的约束 MATCH path = (a:Person {name: 'Alice'})-[:KNOWS*1..5]->(b:Person) WHERE all(n IN nodes(path) WHERE n:Person) RETURN path
减少内存使用:
-
只返回需要的数据:
// 返回完整节点 MATCH (p:Person) RETURN p // 返回所有属性// 只返回需要的属性 MATCH (p:Person) RETURN p.name, p.age // 更高效 -
使用
DISTINCT减少重复:MATCH (p:Person)-[:KNOWS]->(friend) RETURN DISTINCT friend.name -
分批处理大结果集:
// 使用分页处理大量数据 MATCH (p:Person) RETURN p.name ORDER BY p.name SKIP $offset LIMIT $pageSize
利用缓存:
Neo4j采用多层缓存机制,包括查询计划缓存和数据缓存。为了更好地利用缓存,建议使用参数化查询,这样可以复用查询计划,提升执行效率。同时,应避免在同一会话中频繁执行大量不同的查询,以减少缓存失效的可能。此外,合理设计数据模型和访问模式,尽量让相关数据在物理存储上靠近,有助于提升数据局部性,从而提高缓存命中率和整体查询性能。
通过应用这些性能优化技巧,您可以显著提高Cypher查询的效率,特别是在处理大型图和复杂查询时。随着经验的积累,您将能够编写既功能强大又高效的Cypher查询。
5.5 小结
本章深入探讨了Cypher的高级查询技术,包括复杂查询构建、多层关系查询、条件过滤与模式匹配、聚合与统计函数、高级路径操作以及性能优化技巧。通过掌握这些技能,您可以构建更复杂、更高效的查询,解决实际业务中的复杂问题,并充分发挥Neo4j的图数据处理能力。
相关文章:

第5章:Cypher查询语言进阶
在掌握了Cypher的基础知识后,本章将深入探讨更高级的查询技术。这些进阶技能将帮助您构建更复杂、更高效的查询,解决实际业务中的复杂问题,并充分发挥Neo4j的图数据处理能力。 5.1 复杂查询构建 随着业务需求的复杂性增加,查询也…...

【Python进阶】元类编程
目录 🌟 前言🏗️ 技术背景与价值🩹 当前技术痛点🛠️ 解决方案概述👥 目标读者说明 🧠 一、技术原理剖析📊 核心概念图解💡 核心作用讲解🔧 关键技术模块说明⚖️ 技术选…...
算法(蓝桥杯学习C/C++版)
up: 溶金落梧桐 溶金落梧桐的个人空间-溶金落梧桐个人主页-哔哩哔哩视频 蓝桥杯三十天冲刺系列 BV18eQkY3EtP 网站: OI Wiki OI Wiki - OI Wiki 注意 比赛时,devc勾选c11(必看) 必须勾选c11一共有两个方法,任用…...

Docker镜像无法拉取问题解决办法
最近再学习RabbitMQ,需要从Docker镜像中拉取rabbitMQ,但是下拉失败 总的来说就是无法和docker镜像远程仓库建立连接 我又去尝试ping docker.io发现根本没有反应,还是无法连接找了许多办法还是没有办法解决,最后才发现是镜像问题&a…...
ZephyrOS 嵌入式开发Black Pill V1.2之Debug调试器
版本和环境信息如下: PC平台: Windows 11 专业版 Zephyr开发环境:v4.1.0 Windows 下搭建 Zephyr 开发环境 WeAct BlackPill V1.2开发板: WeAct STM32F411CEU6 BlackPill 核心板 Debug调试器: ST-LINK V2: ST-LINK V2 S…...
:英文越狱提示词下的表现与分析)
# 主流大语言模型安全性测试(二):英文越狱提示词下的表现与分析
主流大语言模型安全性测试(二):英文越狱提示词下的表现与分析 在上一篇文章中,我们对多个主流大语言模型(LLM)进行了中文诱导性提示词的越狱测试,评估其是否能够在面对非法、有害或危险内容请求…...

SAP 在 AI 与数据统一平台上的战略转向
在 2025 年 SAP Sapphire 大会上,SAP 展示了其最新的产品战略和技术整合方向,与以往不同的是,今年的讨论更加务实、聚焦客户实际需求。SAP 强调,ERP 的转型不再是“一刀切”或破坏性的,而是可以根据客户现状࿰…...
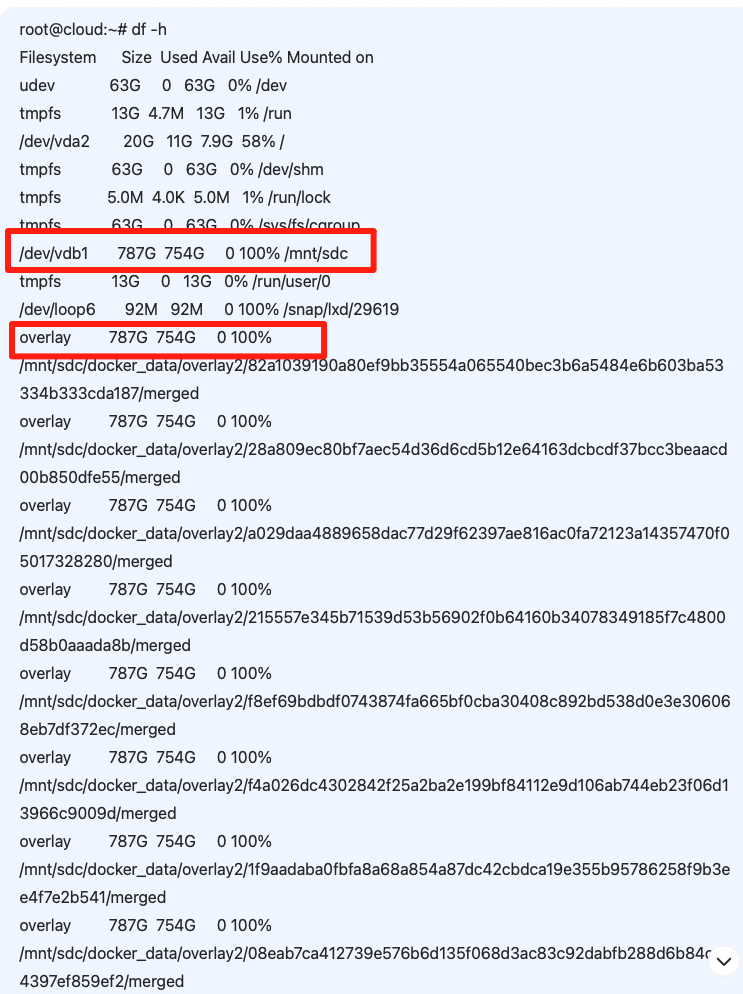
服务器磁盘空间被Docker容器日志占满处理方法
事发场景: 原本正常的服务停止运行了,查看时MQTT服务链接失败,查看对应的容器服务发现是EMQX镜像停止运行了,重启也是也报错无法正常运行,报错如下图: 报错日志中连续出现两个"no space left on devi…...
c++学习-this指针
1.基本概念 非静态成员函数都会默认传递this指针(静态成员函数属于类本身,不属于某个实例对象),方便访问对象对类成员变量和 成员函数。 2.基本使用 编译器实际处理类成员函数,this是第一个隐藏的参数,类…...
交易所系统攻坚:高并发撮合引擎与合规化金融架构设计
交易所系统攻坚:高并发撮合引擎与合规化金融架构设计 ——2025年数字资产交易平台的性能与合规双轮驱动 一、高并发撮合引擎:从微秒级延迟到百万TPS 核心架构设计 订单簿优化:数据结构创新:基于红黑树与链表混合存储,…...

OpenCV计算机视觉实战(10)——形态学操作详解
OpenCV计算机视觉实战(10)——形态学操作详解 0. 前言1. 腐蚀与膨胀1.1 为什么要做腐蚀与膨胀1.2 OpenCV 实现 2. 开运算与闭运算2.1 开运算与闭运算原理2.2 OpenCV 实现 3. 形态学梯度与骨架提取3.1 形态学梯度3.2 骨架提取 小结系列链接 0. 前言 形态…...

libiec61850 mms协议异步模式
之前项目中使用到libiec61850库,都是服务端开发。这次新的需求要接收服务端的遥测数据,这就涉及到客户端开发了。 客户端开发没搞过啊,挑战不少,但是人不就是通过战胜困难才成长的嘛。通过查看libiec61850的客户端API发现…...
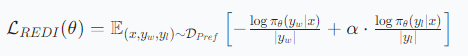
[论文阅读] 人工智能 | 利用负信号蒸馏:用REDI框架提升LLM推理能力
【论文速读】利用负信号蒸馏:用REDI框架提升LLM推理能力 论文信息 arXiv:2505.24850 cs.LG cs.AI cs.CL Harnessing Negative Signals: Reinforcement Distillation from Teacher Data for LLM Reasoning Authors: Shuyao Xu, Cheng Peng, Jiangxuan Long, Weidi…...

基于 NXP + FPGA+Debian 高可靠性工业控制器解决方案
在工业系统开发中,**“稳定”**往往比“先进”更重要。设备一旦部署,生命周期动辄 5~10 年,系统重启或异常恢复成本高昂。 这时候,一套“值得托付”的软硬件组合,就显得尤为关键。 ✅ NXP —— 提供稳定、长期供货的工…...

CSS 选择器全解析:分组选择器/嵌套选择器,从基础到高级
一、CSS 选择器基础:从单个元素到多个元素 CSS 选择器是用来定位 HTML 元素的工具,就像 “元素的地址”。最基础的选择器有: 元素选择器(按标签名定位) css p { color: red; } /* 所有<p>标签 */ div { b…...

uniapp 对接腾讯云IM群公告功能
UniApp 实战:腾讯云IM群公告功能 一、前言 在即时通讯场景中,群公告是信息同步的重要渠道。本文将基于uniapp框架,结合腾讯云IM SDK,详细讲解如何实现群公告的发布、修改、历史记录查询等核心功能。 群公告的数据结构设计权限校…...

垂起固定翼无人机应用及技术分析
一、主要应用行业 1. 能源基础设施巡检 电力巡检:适用于超高压输电线路通道的快速巡查,实时回传数据提升智能运检效率。 油田管道监测:利用长航时特性(1.5-2小时)对大范围管道进行隐患排查,减少人力巡…...

Python Robot Framework【自动化测试框架】简介
销量过万TEEIS德国护膝夏天用薄款 优惠券冠生园 百花蜂蜜428g 挤压瓶纯蜂蜜巨奇严选 鞋子除臭剂360ml 多芬身体磨砂膏280g健70%-75%酒精消毒棉片湿巾1418cm 80片/袋3袋大包清洁食品用消毒 优惠券AIMORNY52朵红玫瑰永生香皂花同城配送非鲜花七夕情人节生日礼物送女友 热卖妙洁棉…...
vite配置@别名,以及如何让IDE智能提示路经
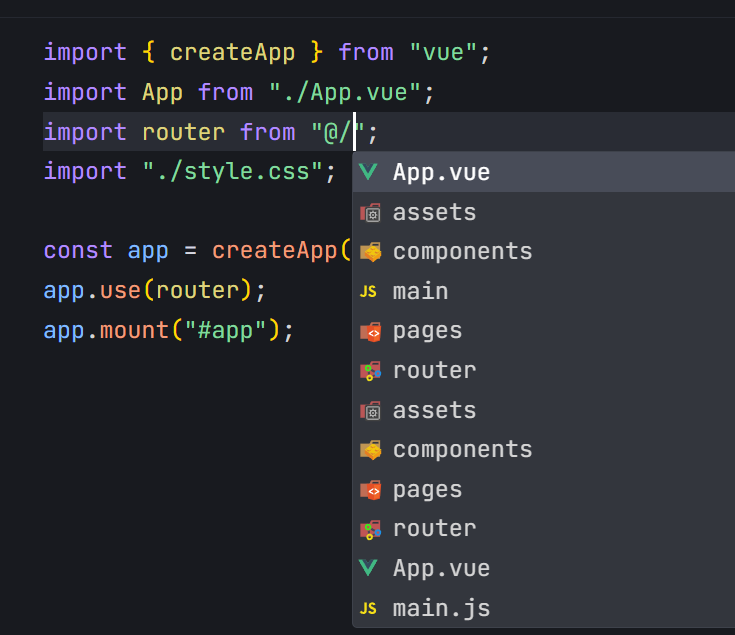
1.配置路径(vite.config.js) // vite.config.js import { defineConfig } from "vite"; import vue from "vitejs/plugin-vue"; import path from "path";// https://vite.dev/config/ export default defineConfig({server: {port: 8080,},plu…...

c#bitconverter操作,不同变量类型转byte数组
缘起:串口数据传输的基础是byte数组,write(buff,0,num)或者writeline(string),如果是字符串传输就是string变量就可以了,但是在modbus这类hex传递时,就要遇到转换了,拼凑byte数组时需要各种变量的值传递,解…...
【Linux】LInux下第一个程序:进度条
前言: 在前面的文章中我们学习了LInux的基础指令 【Linux】初见,基础指令-CSDN博客【Linux】初见,基础指令(续)-CSDN博客 学习了vim编辑器【Linux】vim编辑器_linux vim insert-CSDN博客 学习了gcc/g【Linux】编译器gc…...

RPA+AI:自动化办公机器人开发指南
RPAAI:自动化办公机器人开发指南 系统化学习人工智能网站(收藏):https://www.captainbed.cn/flu 文章目录 RPAAI:自动化办公机器人开发指南摘要引言技术融合路径1. 传感器层:多模态数据接入2. 决策层&…...
+ SSS)
daz3d + PBRSkin (MDL)+ SSS
好的,我们来解释一下 Daz3D 中的 PBRSkin (MDL) Shader。 简单来说,PBRSkin (MDL) 是 Daz Studio 中一种基于物理渲染(PBR)技术、专门用于创建高度逼真人物皮肤效果的着色器(Shader)。 它利用 NVIDIA 的材…...
计算矩阵A和B的乘积
根据矩阵乘法规则,编程计算矩阵的乘积。函数fix_prod_ele()是基本方法编写,函数fix_prod_opt()是优化方法编写。 程序代码 #define N 3 #define M 4 typedef int fix_matrix1[N][M]; typedef int fix_matrix2[M][N]; int fix_prod_ele(f…...

Houdini POP入门学习05 - 物理属性
接下来随着教程学习碰撞部分,当粒子较为复杂或者下载了一些粒子模板进行修改时,会遇到一些较奇怪问题,如粒子穿透等,这些问题实际上可以通过调节参数解决。 hip资源文件:https://download.csdn.net/download/grayrail…...

每日Prompt:双重曝光
提示词 新中式,这幅图像将人体头像轮廓与山水中式建筑融为一体,双重曝光,体现了反思、内心平静以及人与自然相互联系的主题,靛蓝,水墨画,晕染,极简...
)
sendDefaultImpl call timeout(rocketmq)
rocketmq 连接异常 senddefaultimpl call timeout-腾讯云开发者社区-腾讯云 第一种情况: 修改broker 的配置如下,注意brokerIP1 这个配置必须有,不然 rocketmq-console 显示依然是内网地址 caused by: org.apache.rocketmq.remoting.excep…...
【LLM】多智能体系统 Why Do Multi-Agent LLM Systems Fail?
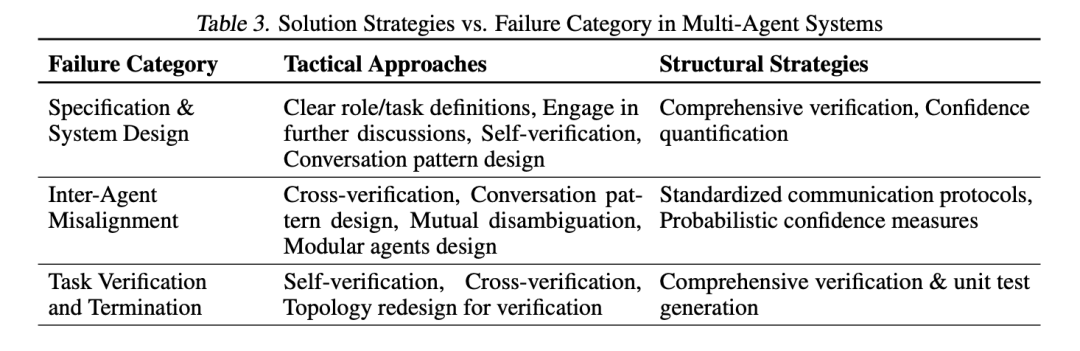
note 构建一个成功的 MAS,不仅仅是提升底层 LLM 的智能那么简单,它更像是在构建一个组织。如果组织结构、沟通协议、权责分配、质量控制流程设计不当,即使每个成员(智能体)都很“聪明”,整个系统也可能像一…...

CSS 定位:原理 + 场景 + 示例全解析
一. 什么是CSS定位? CSS中的position属性用于设置元素的定位方式,它决定了元素在页面中的"定位行为" 为什么需要定位? 常规布局(如 display: block)适用于主结构 定位适用于浮动按钮,弹出层,粘性标题等场景帮助我们精确控制元素在页面中的位置 二. 定位类型全…...

如何在没有 iTunes 的情况下备份 iPhone
我可以在没有 iTunes 的情况下将 iPhone 备份到电脑吗?虽然 iTunes 曾经是备份 iPhone 的主要方法,但它并不是 iOS 用户唯一的备份选项。您可以选择多种方便的替代方案来备份 iPhone,无需使用 iTunes。您可以在这里获得更灵活、更人性化的备份…...