数学建模期末速成 聚类分析与判别分析
聚类分析是在不知道有多少类别的前提下,建立某种规则对样本或变量进行分类。判别分析是已知类别,在已知训练样本的前提下,利用训练样本得到判别函数,然后对未知类别的测试样本判别其类别。
聚类分析
根据样本自身的属性,用数学方法按照某些相似性或差异性指标,定量地确定样本之间的亲疏关系,并按这种亲疏关系程度对样本进行分类。常见的聚类分析方法有系统聚类法、动态聚类法和模糊聚类法等。对样本进行分类称为Q型聚类分析,对指标进行分类称为R型聚类分析。
数据变换
由于样本数据矩阵由多个指标组成,不同指标一般有不同的量纲,为消除量纲的影响,通常需要进行数据变换处理。常用的数据变换方法有:
- 中心化处理:先求出每个变量的样本平均值,再从原始数据中减去该变量的均值
b i j = a i j − μ j , i = 1 , ⋯ , n ; j = 1 , ⋯ , p , 式中 : μ j = ∑ i = 1 n a i j n b_{ij}=a_{ij}-\mu_{j}\:, \quad i=1\:,\cdots,n\:;j=1\:,\cdots,p\:,\\\text{式中}:\mu_j=\frac{\sum_{i=1}^na_{ij}}n bij=aij−μj,i=1,⋯,n;j=1,⋯,p,式中:μj=n∑i=1naij - 规格化处理:每一个变量的原始数据减去该变量中的最小值,再除以极差
b i j = a i j − min 1 ≤ i ≤ n ( a i j ) max 1 ≤ i ≤ n ( a i j ) − min 1 ≤ i ≤ n ( a i j ) , i = 1 , ⋯ , n ; j = 1 , ⋯ , p . b_{ij}=\frac{a_{ij}-\min_{1\leq i\leq n}\left(\:a_{ij}\:\right)}{\max_{1\leq i\leq n}\left(\:a_{ij}\:\right)-\min_{1\leq i\leq n}\left(\:a_{ij}\right)},\quad i=1\:,\cdots,n\:;j=1\:,\cdots,p. bij=max1≤i≤n(aij)−min1≤i≤n(aij)aij−min1≤i≤n(aij),i=1,⋯,n;j=1,⋯,p. - 标准化变换:先对每个变量进行中心化变换,然后用该变量的标准差进行标准化
b i j = a i j − μ j s j , i = 1 , ⋯ , n ; j = 1 , ⋯ , p , 式中 : μ j = ∑ i = 1 n a i j n ; s j = 1 n − 1 ∑ i = 1 n ( a i j − μ j ) 2 b_{ij}=\frac{a_{ij}-\mu_{j}}{s_{j}},\quad i=1\:,\cdots,n\:;j=1\:,\cdots,p\:,\\\text{式中}:\mu_{j}=\frac{\sum_{i=1}^{n}a_{ij}}{n};s_{j}=\sqrt{\frac{1}{n-1}\sum_{i=1}^{n}\left(a_{ij}-\mu_{j}\right)^{2}} bij=sjaij−μj,i=1,⋯,n;j=1,⋯,p,式中:μj=n∑i=1naij;sj=n−11i=1∑n(aij−μj)2
样品(或指标)间亲疏程度的测度计算
研究样品或变量的亲疏程度或相似程度的数量指标通常有两种:
- 相似系数,性质越接近的变量或样品,其取值越接近于1或-1,而彼此无关的变量或样品的相似系数则越接近于0,相似的归为一类,不相似的归为不同类。
- 距离,它将每个样品看成p维空间的一个点,n个样品组成p维空间的n个点。用各点之间的距离来衡量各样品之间的相似程度(或靠近程度)。距离近的点归为一类,距离远的点属于不同的类。
对于变量之间的聚类(R型)常用相似系数来测度变量之间的亲疏程度,而对于样品之间的聚类(Q型),则常用距离来测度样品之间的亲疏程度。
相似系数的计算
- 夹角余弦
cos θ i j = ∑ k = 1 p b i k b j k ∑ k = 1 p b i k 2 ⋅ ∑ k = 1 p b j k 2 , i , j = 1 , 2 , ⋯ , n . \cos\theta_{ij}=\frac{\sum_{k=1}^pb_{ik}b_{jk}}{\sqrt{\sum_{k=1}^pb_{ik}^2}\cdot\sqrt{\sum_{k=1}^pb_{jk}^2}},\quad i,j=1,2,\cdots,n. cosθij=∑k=1pbik2⋅∑k=1pbjk2∑k=1pbikbjk,i,j=1,2,⋯,n. - 皮尔逊相关系数
r i j = ∑ k = 1 p ( b i k − μ ‾ i ) ( b j k − μ ‾ j ) ∑ k = 1 p ( b i k − μ ‾ i ) 2 ⋅ ∑ k = 1 p ( b j k − μ ‾ j ) 2 , i , j = 1 , 2 , ⋯ , n , 式中 : μ ‾ i = ∑ k = 1 p b i k p r_{ij}=\frac{\sum_{k=1}^p(\:b_{ik}\:-\:\overline{\mu}_i\:)\:(\:b_{jk}\:-\:\overline{\mu}_j\:)}{\sqrt{\sum_{k=1}^p\:(\:b_{ik}\:-\:\overline{\mu}_i\:)^2}\:\cdot\:\sqrt{\sum_{k=1}^p\:(\:b_{jk}\:-\overline{\mu}_j\:)^2}},\quad i,j=1\:,2\:,\cdots,n\:,\text{式中}:\overline{\mu}_i=\frac{\sum_{k=1}^pb_{ik}}{p} rij=∑k=1p(bik−μi)2⋅∑k=1p(bjk−μj)2∑k=1p(bik−μi)(bjk−μj),i,j=1,2,⋯,n,式中:μi=p∑k=1pbik
距离计算
- 闵式距离
. . . ... ... - 马氏距离
d ( ω i , ω j ) = ( ω i − ω j ) ∑ − 1 ( ω i − ω j ) T d\left(\:\omega_{i}\:,\omega_{j}\:\right)=\sqrt{\left(\:\omega_{i}-\omega_{j}\:\right)\sum^{-1}\left(\:\omega_{i}\:-\omega_{j}\:\right)^{\mathrm{T}}} d(ωi,ωj)=(ωi−ωj)∑−1(ωi−ωj)T
式中: ω i 表示矩阵 B 的第 i 行 ; Σ 表示观测变量之间的协方差阵 , Σ = ( σ i j ) p × p , 其中 σ i j = 1 n − 1 ∑ k = 1 n ( b k i − μ i ) ( b i j − μ j ) , i , j = 1 , 2 , ⋯ , p , 式中 : μ j = 1 n ∑ k = 1 n b k j \begin{aligned}&\text{式中:}\omega_i\text{ 表示矩阵 }B\text{ 的第 }i\text{ 行};\boldsymbol{\Sigma}\text{ 表示观测变量之间的协方差阵},\boldsymbol{\Sigma}=\left(\sigma_{ij}\right)_{p\times p},\text{其中}\\&\sigma_{ij}=\frac1{n-1}\sum_{k=1}^n\left(b_{ki}-\mu_i\right)\left(b_{ij}-\mu_j\right),\quad i,j=1,2,\cdots,p\:,\\&\text{式中}:\mu_j=\frac1n\sum_{k=1}^nb_{kj}\end{aligned} 式中:ωi 表示矩阵 B 的第 i 行;Σ 表示观测变量之间的协方差阵,Σ=(σij)p×p,其中σij=n−11k=1∑n(bki−μi)(bij−μj),i,j=1,2,⋯,p,式中:μj=n1k=1∑nbkj
基于类间距离的系统聚类
系统聚类法是聚类分析方法中使用最多的方法。其基本思想是:距离相近的样品(或变量)先聚为一类,距离远的后聚成类,此过程一直进行下去,每个样品总能聚到合适的类中。它包括如下步骤
(1)将每个样品(或变量)独自聚成一类,构造n个类。
(2)根据所确定的样品(或变量)距离公式,计算个样品(或变量)两两间的距离,构造距离矩阵,记为 D ( 0 ) D_{(0)} D(0)
(3)把距离最近的两类归为一新类,其他样品(或变量)仍各自聚为一类,共聚成n-1类。
(4)计算新类与当前各类的距离,将距离最近的两个类进一步聚成一类,共聚成-2类。以上步骤一直进行下去,最后将所有的样品(或变量)聚成一类。
(5)画聚类谱系图。
(6)决定类的个数及各类包含的样品数,并对类做出解释
类与类之间的距离
最短距离法
最长距离法
其他系统聚类方法
- 重心法
- 类平均法
- 离差平方和法
动态聚类法
…
R型聚类法
…
判别分析
距离判别法(最近邻方法)
距离判别法的基本思想:根据已知分类的数据,分别计算各类的重心即分组(类)的均值,对任意给定的一个样品,若它与第 i 类的重心距离最近,就认为它来自第 i 类。因此,距离判别法又称为最近邻方法。
Fisher判别
Fisher判别的基本思想是投影,即将表面上不易分类的数据通过投影到某个方向上,使得投影类与类之间得以分离的一种判别方法
相关文章:

数学建模期末速成 聚类分析与判别分析
聚类分析是在不知道有多少类别的前提下,建立某种规则对样本或变量进行分类。判别分析是已知类别,在已知训练样本的前提下,利用训练样本得到判别函数,然后对未知类别的测试样本判别其类别。 聚类分析 根据样本自身的属性…...
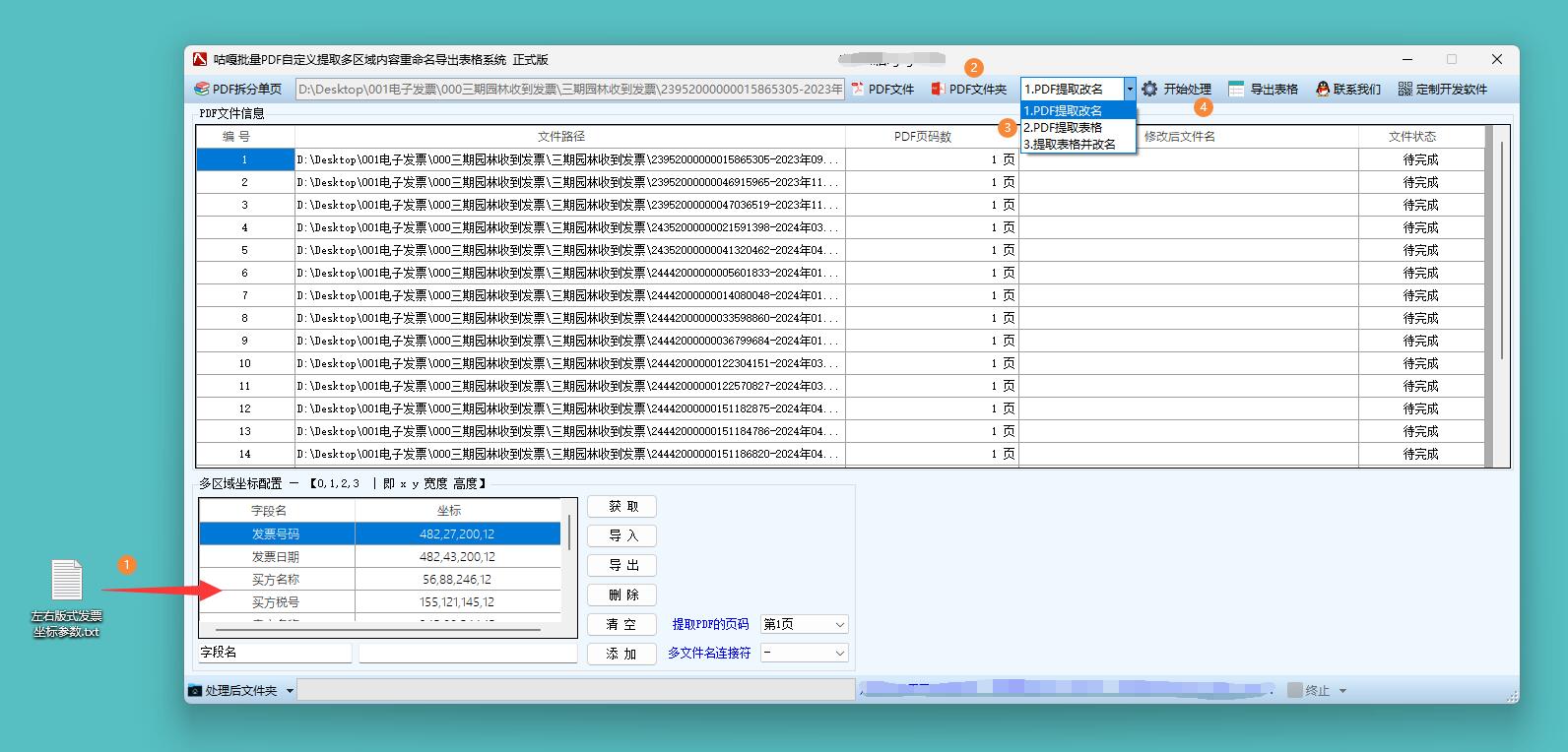
【工具教程】PDF电子发票提取明细导出Excel表格,OFD电子发票行程单提取保存表格,具体操作流程
在企业财务管理领域,电子发票提取明细导出表格是不可或缺的工具。 月末财务结算时,财务人员需处理成百上千张电子发票,将发票明细导出为表格后,通过表格强大的数据处理功能,可自动分类汇总不同项目的支出金额ÿ…...
基于STM32的DHT11温湿度远程监测LCD1602显示Proteus仿真+程序+设计报告+讲解视频
DHT11温湿度远程监测proteus仿真 1. 主要功能2.仿真3. 程序4. 设计报告5. 资料清单&下载链接 基于STM32的DHT11温湿度远程监测LCD1602显示Proteus仿真设计(仿真程序设计报告讲解视频) 仿真图proteus 8.9 程序编译器:keil 5 编程语言:C…...
分类预测 | Matlab实现CNN-BiLSTM-Attention高光谱数据分类预测
分类预测 | Matlab实现CNN-BiLSTM-Attention高光谱数据分类预测 目录 分类预测 | Matlab实现CNN-BiLSTM-Attention高光谱数据分类预测分类效果功能概述程序设计参考资料 分类效果 功能概述 该MATLAB代码实现了一个结合CNN、BiLSTM和注意力机制的高光谱数据分类预测模型&#x…...
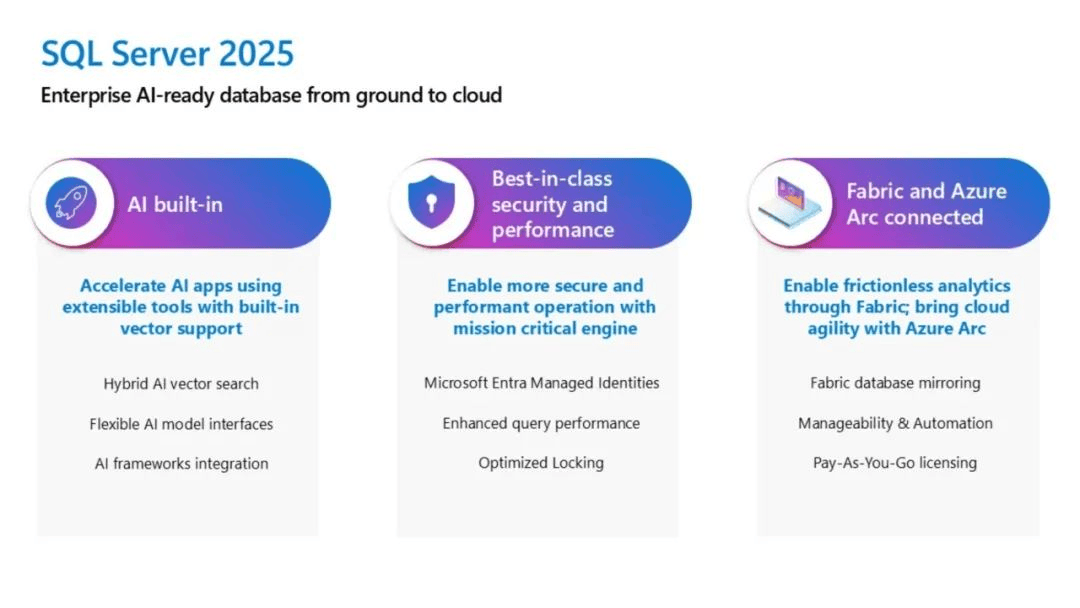
微软推出SQL Server 2025技术预览版,深化人工智能应用集成
在Build 2025 大会上,微软向开发者社区开放了SQL Server 2025的测试版本。该版本的技术改进主要涵盖人工智能功能集成、系统性能优化与开发工具链升级三个维度,展示了数据库管理系统在智能化演进方向上的重要进展。 智能数据处理功能更新 新版本的技术亮…...

.net webapi http参数自定义绑定模型
.NET Web API 中 HTTP 参数自定义绑定模型的深度解析 在 .NET Web API 开发里,常规的参数绑定往往能满足大部分需求。不过,当遇到一些特殊情况时,就需要自定义将 HTTP 参数绑定到 action 特定模型参数了。接下来,我们就深入探讨如…...

RocketMQ入门5.3.2版本(基于java、SpringBoot操作)
一、RocketMQ概述 RocketMQ是一款由阿里巴巴于2012年开源的分布式消息中间件,旨在提供高吞吐量、高可靠性的消息传递服务。主要特点有: 灵活的可扩展性 海量消息堆积能力 支持顺序消息 支持多种消息过滤方式 支持事务消息 支持回溯消费 支持延时消…...

使用osqp求解简单二次规划问题
文章目录 一、问题描述二、数学推导1. 目标函数处理2. 约束条件处理 三、代码编写 一、问题描述 已知: m i n ( x 1 − 1 ) 2 ( x 2 − 2 ) 2 s . t . 0 ⩽ x 1 ⩽ 1.5 , 1 ⩽ x 2 ⩽ 2.5 min(x_1-1)^2(x_2-2)^2 \qquad s.t. \ \ 0 \leqslant x_1 \leqslant 1.5,…...

Ubuntu创建修改 Swap 文件分区的步骤——解决嵌入式开发板编译ROS2程序卡死问题
Ubuntu创建修改 Swap 文件分区的步骤——解决嵌入式开发板编译ROS2程序卡死问题 1. 问题描述2. 创建 / 修改 Swap 分区2.1 创建 Swap 文件 (推荐)2.2 使用 Swap 分区 (如果已经存在) 3. 注意事项 同步发布在个人笔记Ubuntu创建修改 Swap 文件分区的步骤——解决嵌入式开发板编译…...

【C语言】通用统计数据结构及其更新函数(最值、变化量、总和、平均数、方差等)
【C语言】通用统计数据结构及其更新函数(最值、变化量、总和、平均数、方差等) 更新以gitee为准: gitee 文章目录 通用统计数据结构更新函数附录:压缩字符串、大小端格式转换压缩字符串浮点数压缩Packed-ASCII字符串 大小端转换什…...

Spring AI(10)——STUDIO传输的MCP服务端
Spring AI MCP(模型上下文协议)服务器Starters提供了在 Spring Boot 应用程序中设置 MCP 服务器的自动配置。它支持将 MCP 服务器功能与 Spring Boot 的自动配置系统无缝集成。 本文主要演示支持STDIO传输的MCP服务器 仅支持STDIO传输的MCP服务器 导入j…...

Sklearn 机器学习 缺失值处理 填充数据列的缺失值
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 💡使用 Scikit-learn 处理数据缺失值的完整指南 在机器学习项目中,数据缺失是不可避…...

猜字符位置游戏-position gasses
import java.util.*;public class Main {/*字符猜位置游戏;每次提交只能被告知答对几个位置;根据提示答对的位置数推测出每个字符对应的正确位置;*/public static void main(String[] args) {char startChar A;int gameLength 8;List<String> ballList new ArrayList&…...
宝塔安装配置FRP
FRP(Fast Reverse Proxy)作为一款高性能的反向代理应用,能够帮助我们轻松实现内网穿透,将内网服务暴露到公网,满足远程访问、开发调试等多种需求。宝塔面板以其简洁易用的界面和强大的功能,成为众多站长和开…...
元器件基础学习笔记——结型场效应晶体管 (JFET)
场效应晶体管(Field Effect Transistor,FET)简称场效应管,是一种三端子半导体器件,它根据施加到其其中一个端子的电场来控制电流的流动。与双极结型晶体管 (BJT) 不同,场效应晶体管 …...
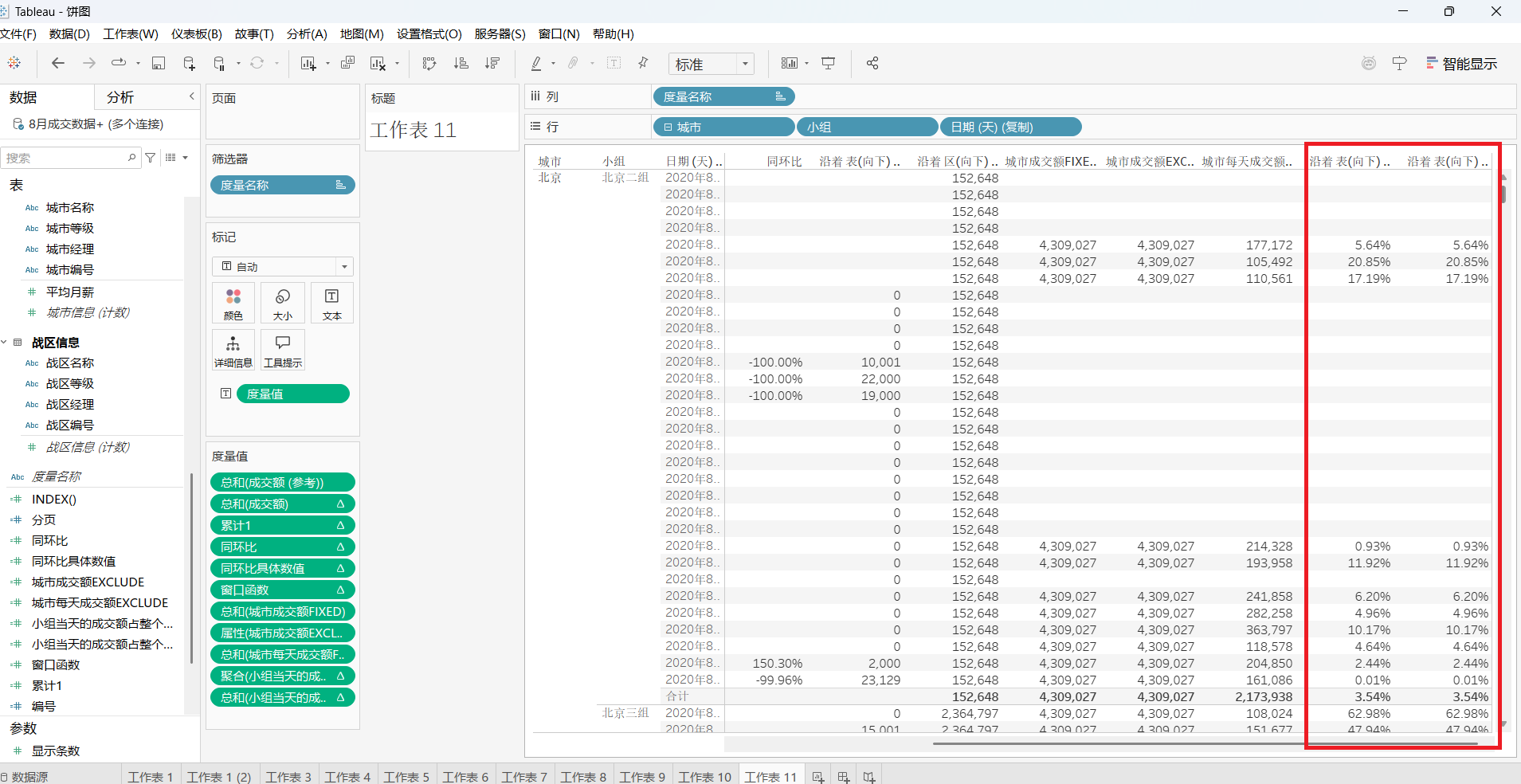
tableau 实战工作场景常用函数与LOD表达式的应用详解
这是tableau实战工作场景图表制作第七期--常用函数与LOD表达式的应用 数据资源已经与这篇博客捆绑,有需要者可以下载通过网盘分享的文件:3.2-8月成交数据.xlsx等3个文件 链接: https://pan.baidu.com/s/17WtUoZTqzoNo5kTFjua4hw?pwd0623 提取码: 06…...

智能终端与边缘计算按章复习
第1章:智能终端与边缘计算概述 简述计算机网络和Web技术发展过程中,信息和运算从用户本地向Web服务器迁移的趋势,并解释这一过程如何逐步形成了如今的云计算形态。 随着计算机网络和Web技术的不断发展,信息和运算的重心发生了显著…...

C#面试问题61-80
66. What is reflection? 反射是一种机制,它使我们能够编写可以检查应用程序中所 用类型的代码。例如,调用名称与给定字符串相等的方法,或者列出属于给定 对象的所有字段及其值。 在 Convert 方法中,我们根本不知道处理的是什么…...

分布式Session处理的五大主流方案解析
在分布式环境下,Session 处理的核心挑战是确保用户请求在不同服务器间流转时能保持会话状态一致。以下是主流解决方案及优缺点分析: 🔐 一、集中存储方案(主流推荐) Redis/Memcached 存储 原理:将 Session…...

C++ 中的 const 知识点详解,c++和c语言区别
目录 一。C 中的 const 知识点详解1. 基本用法1.1) 定义常量1.2) 指针与 const 2. 函数中的 const2.1)const 参数2.2)const 成员函数 3. 类中的 const3.1)const 成员变量3.2)const 对象 4. const 返回值5. …...

《PyTorch:开启深度学习新世界的魔法之门》
一、遇见 PyTorch:深度学习框架新星登场 在当今的技术领域中,深度学习已然成为推动人工智能发展的核心动力,而深度学习框架则是这场技术革命中的关键工具。在众多深度学习框架里,PyTorch 以其独特的魅力和强大的功能,迅速崛起并占据了重要的地位,吸引着无数开发者和研究者…...

分布式光纤传感(DAS)技术应用解析:从原理到落地场景
近年来,分布式光纤传感(Distributed Acoustic Sensing,DAS)技术正悄然改变着众多传统行业的感知方式。它将普通的通信光缆转化为一个长距离、连续分布的“听觉传感器”,对振动、声音等信号实现高精度、高灵敏度的监测。…...
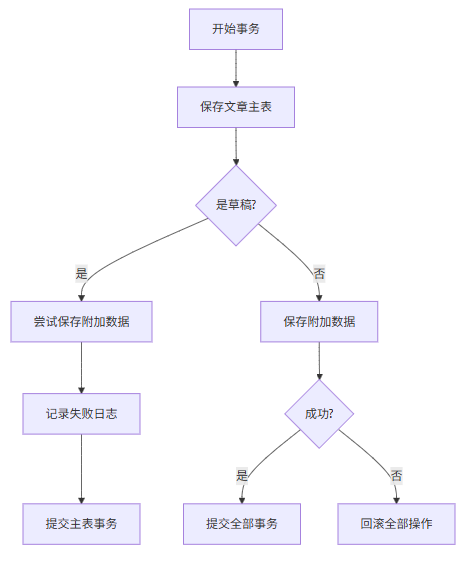
Spring事务回滚在系统中的应用
以文章发布为例,介绍Spring事务回滚在系统中的应用 事务回滚的核心概念 事务回滚是数据库管理系统中的关键机制,它确保数据库操作要么全部成功,要么全部失败。在Spring框架中,我们可以通过Transactional注解轻松实现事务管理。 …...

.Net Framework 4/C# 属性和方法
一、属性的概述 属性是对实体特征的抽象,用于提供对类或对象的访问,C# 中的属性具有访问器,这些访问器指定在它们的值被读取或写入时需要执行的语句,因此属性提供了一种机制,用于把读取和写入对象的某些特征与一些操作…...
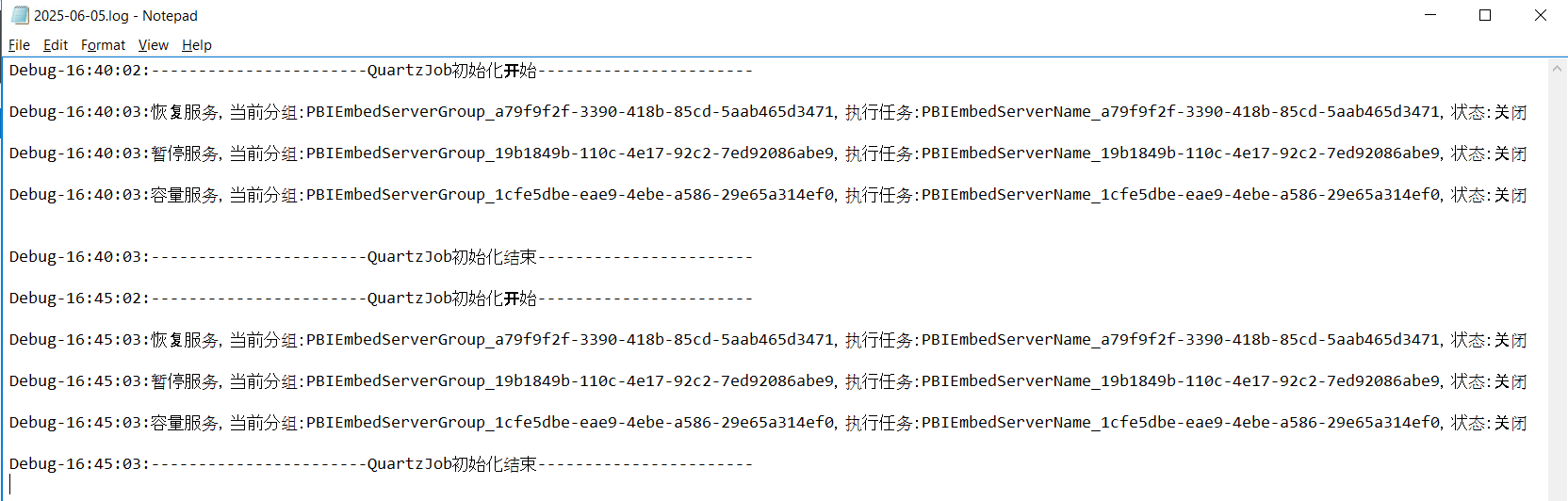
ASP.NET Core使用Quartz部署到IIS资源自动被回收解决方案
iis自动回收的原因 回收机制默认配置,间隔时间是1740分钟,意思是:默认情况下每1740分钟(29小时)回收一次,定期检查应用程序池中的工作进程,并终止那些已经存在很长时间或已经使用了太多资源的工作进程 进程模型默认配…...

Fullstack 面试复习笔记:Spring / Spring Boot / Spring Data / Security 整理
Fullstack 面试复习笔记:Spring / Spring Boot / Spring Data / Security 整理 之前的笔记: Fullstack 面试复习笔记:操作系统 / 网络 / HTTP / 设计模式梳理Fullstack 面试复习笔记:Java 基础语法 / 核心特性体系化总结Fullsta…...
调用.net DLL让CANoe自动识别串口号
1.前言 CANoe9.0用CAPL控制数控电源_canoe读取程控电源电流值-CSDN博客 之前做CAPL通过串口控制数控电源,存在一个缺点:更换电脑需要改串口号 CSDN上有类似的博客,不过要收费,本文根据VID和PID来自动获取串口号,代码…...

第5章:Cypher查询语言进阶
在掌握了Cypher的基础知识后,本章将深入探讨更高级的查询技术。这些进阶技能将帮助您构建更复杂、更高效的查询,解决实际业务中的复杂问题,并充分发挥Neo4j的图数据处理能力。 5.1 复杂查询构建 随着业务需求的复杂性增加,查询也…...

【Python进阶】元类编程
目录 🌟 前言🏗️ 技术背景与价值🩹 当前技术痛点🛠️ 解决方案概述👥 目标读者说明 🧠 一、技术原理剖析📊 核心概念图解💡 核心作用讲解🔧 关键技术模块说明⚖️ 技术选…...
算法(蓝桥杯学习C/C++版)
up: 溶金落梧桐 溶金落梧桐的个人空间-溶金落梧桐个人主页-哔哩哔哩视频 蓝桥杯三十天冲刺系列 BV18eQkY3EtP 网站: OI Wiki OI Wiki - OI Wiki 注意 比赛时,devc勾选c11(必看) 必须勾选c11一共有两个方法,任用…...