什么是预训练?深入解读大模型AI的“高考集训”
1. 预训练的通俗理解:AI的“高考集训”
我们可以将预训练(Pre-training) 形象地理解为大模型AI的“高考集训”。就像学霸在高考前需要刷五年高考三年模拟一样,大模型在正式诞生前,也要经历一场声势浩大的“题海战术”。
这个“题海战术”的核心就是将海量的文本、图片、视频等数据“喂”给AI。通过这种大规模的数据投喂,AI会进行自监督学习,疯狂地吸收知识,自主挖掘数据中的内在规律和模式。最终,通过这个过程,AI才能炼成能写诗、能看病、会作画的全能大脑。

2. 预训练的技术定义:构建基础认知能力
从技术角度来看,预训练是指在AI模型应用于特定任务之前,先利用海量无标注数据,让模型自主挖掘语言、视觉、逻辑等方面的通用规律,从而构建其基础认知能力的训练过程。
通过从大规模未标记数据中学习通用特征和先验知识,预训练能够显著减少模型对标记数据的依赖。这不仅能够加速模型在有限数据集上的训练过程,还能在很大程度上优化模型的性能,使其在后续的下游任务中表现更出色。
预训练的核心逻辑与关键操作
预训练过程并非简单的数据堆砌,其背后包含了一系列精妙的核心逻辑和技术操作。
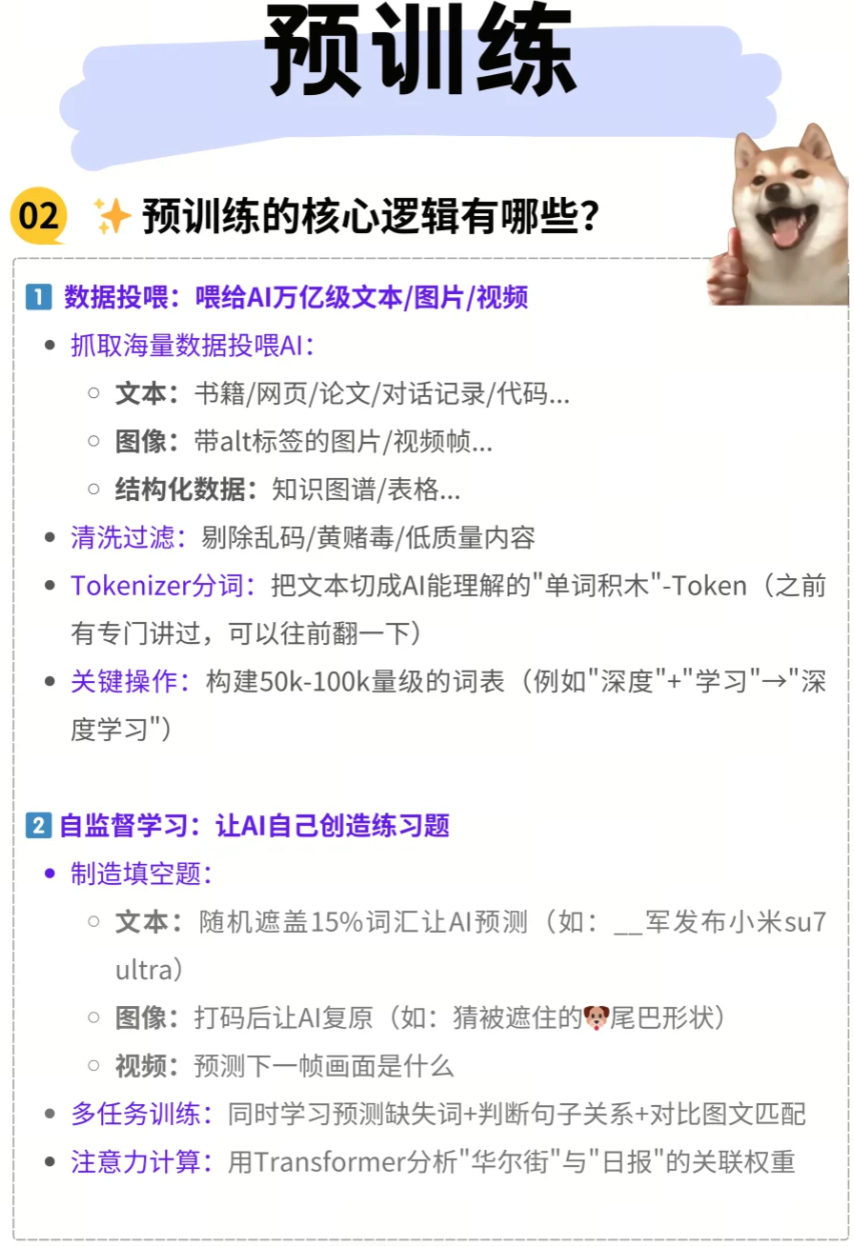
1. 数据投喂:构建AI的“知识库”
高质量、多样化、大规模的数据集是预训练的基石。
- 海量数据抓取与投喂:
- 文本数据: 包括书籍、网页、论文、对话记录、代码、新闻文章等。例如,GPT-3的训练数据包含了Common Crawl、WebText2、Books1、Books2、Wikipedia等海量语料。
- 图像数据: 带有
alt标签的图片(用于图像描述)、视频帧、图像-文本对等。例如,CLIP模型就通过大量的图像-文本对进行预训练。 - 结构化数据: 如知识图谱、表格数据等,用于增强模型的逻辑推理和事实性知识。
- 数据清洗与过滤: 在数据投喂前,必须进行严格的清洗和过滤,以确保数据质量。这包括剔除乱码、重复内容、低质量内容、以及涉及黄赌毒等不合规内容。数据质量直接影响模型的学习效果和泛化能力。
- Tokenizer分词: 对于文本数据,需要通过Tokenizer(分词器) 将原始文本切分成AI能够理解的“单词积木”,即Token。Token可以是单词、子词或字符,其目的是将连续的文本转化为离散的数值表示。
- 关键操作: 构建一个量级在50k-100k的词表(Vocabulary)。例如,像
"深度"和"学习"这样的词汇可能会被分别编码,而"深度学习"这个短语则可能被作为一个独立的Token进行编码,从而更好地捕捉语义信息。常用的分词算法包括BPE (Byte Pair Encoding)、WordPiece和SentencePiece。
- 关键操作: 构建一个量级在50k-100k的词表(Vocabulary)。例如,像
2. 自监督学习:让AI“自己创造练习题”
自监督学习(Self-supervised Learning) 是预训练的核心机制,它允许模型在没有人工标注的情况下,从大规模数据中学习有用的表示。
- 制造“填空题”: 模型通过预测数据中缺失的部分来学习。
- 文本领域(如BERT的MLM任务): 随机遮盖文本中15%的词汇(Token),然后让AI预测被遮盖的词。例如,在句子
"__军发布小米su7 ultra"中,模型需要预测出"小"字。这种机制迫使模型理解上下文语境和词汇间的关系。 - 图像领域(如MAE): 随机遮盖图像的部分区域(打码),然后让AI复原被遮盖的像素或特征。例如,
"猜被遮住的🐶尾巴形状",模型需要根据未被遮盖的部分推断出尾巴的形态。 - 视频领域: 预测视频的下一帧画面是什么,或预测被遮盖的帧内容。这有助于模型学习时序信息和运动模式。
- 文本领域(如BERT的MLM任务): 随机遮盖文本中15%的词汇(Token),然后让AI预测被遮盖的词。例如,在句子
- 多任务训练: 为了让模型学习更全面的能力,预训练通常会包含多个自监督任务。
- 文本: 除了预测缺失词,还可能包含下一句预测(NSP) 任务,即判断两个句子之间是否存在前后关系。
- 图像与文本: 学习图文匹配,让模型判断图像和文本描述是否匹配,从而理解多模态信息。
- 注意力计算(Transformer): 在预训练过程中,Transformer 架构的自注意力机制(Self-Attention) 至关重要。它允许模型在处理序列数据时,动态地计算不同部分之间的关联权重。例如,在分析
"华尔街日报"时,模型能够计算"华尔街"和"日报"这两个词之间的关联权重,从而理解其作为一个整体的特定含义。
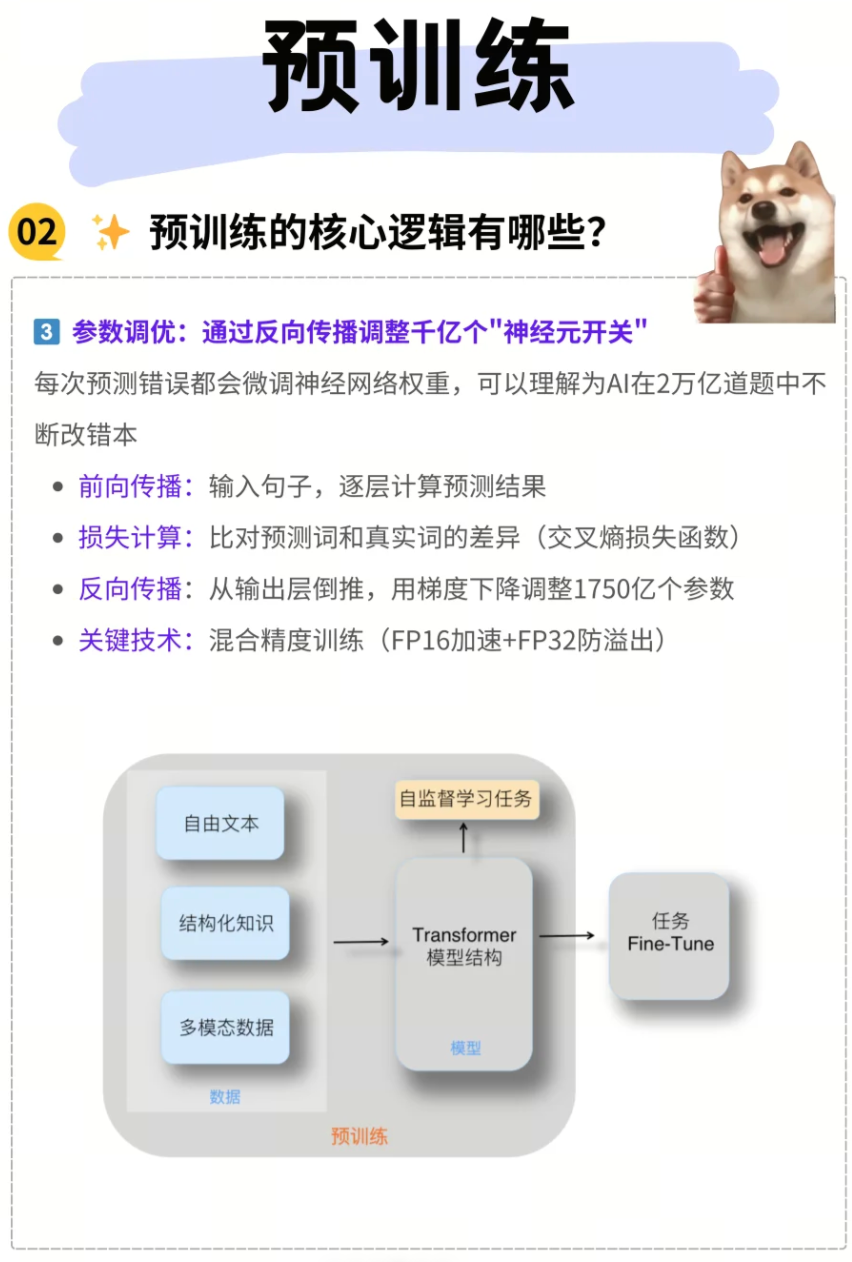
3. 参数调优:微调千亿个“神经元开关”
反向传播(Backpropagation) 和梯度下降(Gradient Descent) 是模型优化的核心算法。
- 误差纠正与权重调整: 每次模型进行预测后,都会将预测结果与真实值进行比较,计算出损失(Loss)。这个损失值通过反向传播算法,用于微调神经网络中数千亿个参数(权重)。
- AI的“改错本”: 可以把这个过程理解为AI在面对数万亿道题目时,不断地批改自己的“错题本”。每当预测错误时,模型就会根据错误程度和方向,对内部的“神经元开关”(即参数)进行细微调整,以期在下一次预测中做得更好。这个迭代优化的过程,使得模型能够逐步收敛,并学到更精确的特征表示。
相关推荐
-
2025大模型技术架构揭秘:GPT-4、Gemini、文心等九大模型核心技术对比与实战选型指南-CSDN博客
-
💡大模型中转API推荐
-
✨中转使用教程
技术交流:欢迎在评论区共同探讨!更多内容可查看本专栏文章,有用的话记得点赞收藏噜!

相关文章:
什么是预训练?深入解读大模型AI的“高考集训”
1. 预训练的通俗理解:AI的“高考集训” 我们可以将预训练(Pre-training) 形象地理解为大模型AI的“高考集训”。就像学霸在高考前需要刷五年高考三年模拟一样,大模型在正式诞生前,也要经历一场声势浩大的“题海战术”…...
鸿蒙仓颉语言开发实战教程:购物车页面
大家上午好,仓颉语言商城应用的开发进程已经过半,不知道大家通过这一系列的教程对仓颉开发是否有了进一步的了解。今天要分享的购物车页面: 看到这个页面,我们首先要对它简单的分析一下。这个页面一共分为三部分,分别是…...
OPENCV的AT函数
一.AT函数介绍 在 OpenCV 中,at() 是一个模板成员函数,用于访问和修改矩阵或图像中特定位置的元素。它提供了一种直接且类型安全的方式来操作单个像素值,但需要注意其性能和类型匹配问题 AT函数是OPENCV中重要的函数…...

【走好求职第一步】求职OMG——见面课测验4
2025最新版!!!6.8截至答题,大家注意呀!博主码字不易点个关注吧~~ 1.单选题(2分) 下列不属于简历撰写技巧原则的是( A ) A.具体性 B.相关性 C.匹配性 2.单选题(2分) 笔试的下一步一般是:( B &…...

ISO 17387——解读自动驾驶相关标准法规(LCDAS)
Intelligent transport systems — Lane change decision aid systems (LCDAS) — Performance requirements and test procedures(First edition: 2008-05-01) 原文链接:https://cdn.standards.iteh.ai/samples/43654/701fd49bde7b4d3db165444b7c6f0c53/ISO-17387…...
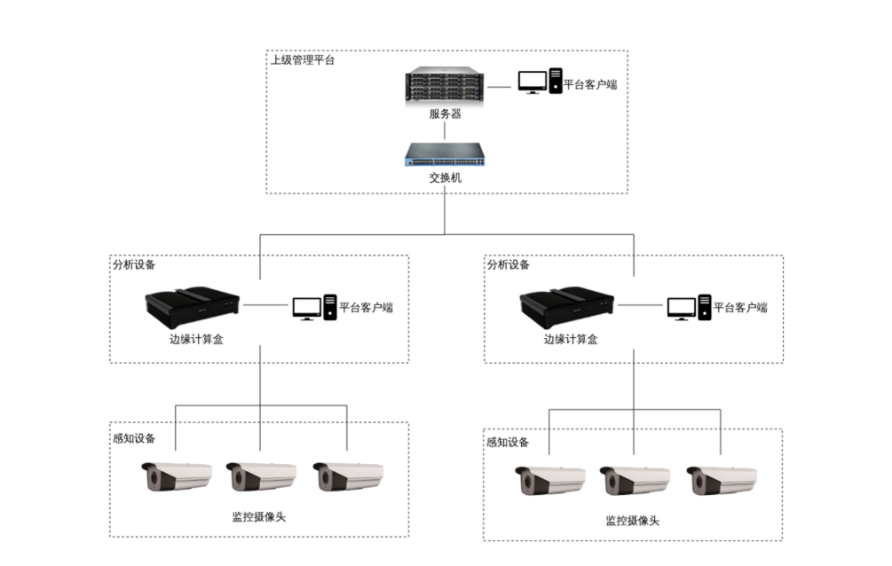
智慧零售管理中的客流统计与属性分析
智慧零售管理中的视觉分析技术应用 一、背景与需求 随着智慧零售的快速发展,传统零售门店面临管理效率低、安全风险高、客户体验差等问题。通过视觉分析技术,智慧零售管理系统可实现对门店内人员行为的实时监控与数据分析,从而提升运营效率…...

Ps:Adobe PDF 预设
Ps菜单:编辑/Adobe PDF 预设 Edit/Adobe PDF Presets 通过“Adobe PDF 预设” Adobe PDF Presets对话框,可以查看 Adobe PDF 预设,了解复杂的 PDF 设置。还可以编辑、新建、删除、载入预设,根据最终用途(如高质量打印、…...

Python Excel 文件处理:openpyxl 与 pandas 库完全指南
在数据处理和分析过程中,Excel 文件是最常见的数据存储格式之一。Python 提供了多个库来处理 Excel 文件,其中 openpyxl 和 pandas 是最常用的两个库。它们各自有独特的优势,适用于不同的需求。本文将详细介绍如何使用这两个库来处理 Excel 文…...

九、【ESP32开发全栈指南: UDP通信服务端】
一、TCP与UDP核心差异 特性TCPUDP连接方式面向连接 (需三次握手)无连接可靠性可靠传输 (重传/排序/校验)尽力交付 (不保证可靠性)实时性延迟较高低延迟,实时性强传输效率协议开销大头部开销小 (仅8字节)连接类型点对点支持广播/多播资源占用高 (需维护连接状态)极低…...
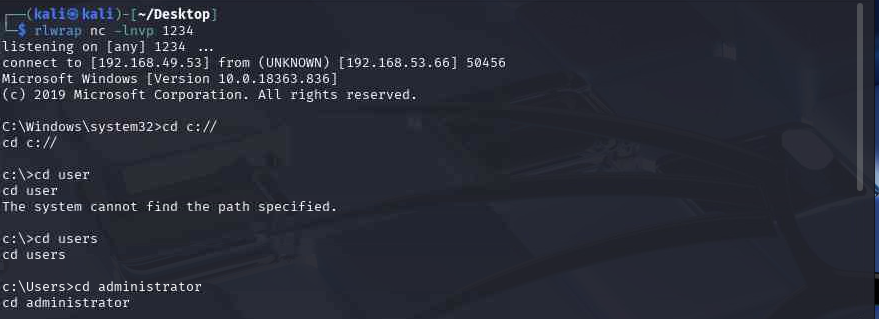
靶场(二十)---靶场体会小白心得 ---jacko
老样子开局先看端口,先看http端口 PORT STATE SERVICE VERSION 80/tcp open http Microsoft IIS httpd 10.0 |_http-title: H2 Database Engine (redirect) | http-methods: |_ Potentially risky methods: TRACE |_http-server-header:…...

【EasyExcel】导出时添加页眉页脚
一、需求 使用 EasyExcel 导出时添加页眉页脚 二、添加页眉页脚的方法 通过配置WriteSheet或WriteTable对象来添加页眉和页脚。以下是具体实现步骤: 1. 创建自定义页眉页脚实现类 public class CustomFooterHandler implements SheetWriteHandler {private final…...

高频通信与航天电子的材料革命:猎板PCB高端压合基材技术解析
—聚酰亚胺/陶瓷基板在5G与航天场景的产业化应用 一、极端环境材料体系:突破温域与频率极限 聚酰亚胺基板(PI)的航天级稳定性 猎板在卫星通信PCB中采用真空层压工艺处理聚酰亚胺基材(Dk≈10.2)&a…...

如何区分 “通信网络安全防护” 与 “信息安全” 的考核重点?
“通信网络安全防护” 与 “信息安全” 的考核重点可以从以下几个方面进行区分: 保护对象 通信网络安全防护:重点关注通信网络系统本身,包括网络基础设施,如路由器、交换机、基站等,以及网络通信链路和相关设备。同…...

Java 中 ArrayList、Vector、LinkedList 的核心区别与应用场景
Java 中 ArrayList、Vector、LinkedList 的核心区别与应用场景 引言 在 Java 集合框架体系中,ArrayList、Vector和LinkedList作为List接口的三大经典实现类,共同承载着列表数据的存储与操作功能。然而,由于底层数据结构设计、线程安全机制以…...

WPF技术体系与现代化样式
目录 1 WPF技术架构解析 1.1 技术演进与定位 1.2 核心机制对比 2 样式与资源系统 2.1 资源(Resource)定义与作用域 2.2 样式(Style)与触发器 3 开发环境配置(.NET 8) 3.1 安装流程 3.2 项目结…...

Redis 与 MySQL 数据一致性保障方案
在高并发场景下,Redis 作为缓存中间件与 MySQL 数据库配合使用时,数据一致性是一个关键挑战。本文将详细探讨如何保障 Redis 与 MySQL 的数据一致性,并结合 Java 代码实现具体方案。 数据不一致的原因分析 在分布式系统中,Redis…...

Sentry 接口返回 Status Code 429 Too Many Requests
Sentry 是一个 开源的错误追踪(Error Tracking)平台,主要用于实时捕获和监控应用程序中的异常、错误日志,并帮助开发者快速定位问题根源。 📌 Sentry 的核心功能 自动捕获异常 自动捕捉 JavaScript、Vue、React、Node.…...

数学建模期末速成 聚类分析与判别分析
聚类分析是在不知道有多少类别的前提下,建立某种规则对样本或变量进行分类。判别分析是已知类别,在已知训练样本的前提下,利用训练样本得到判别函数,然后对未知类别的测试样本判别其类别。 聚类分析 根据样本自身的属性…...
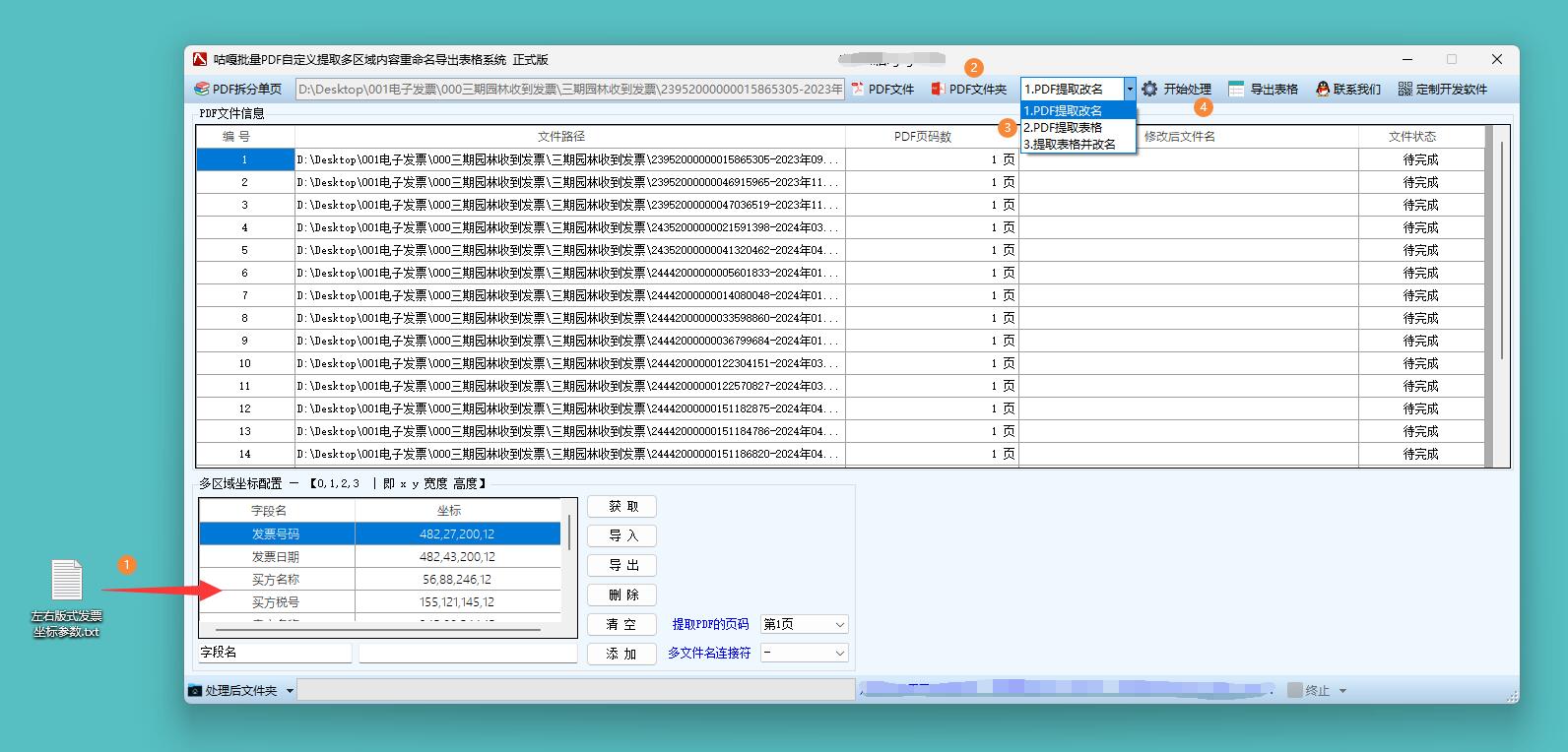
【工具教程】PDF电子发票提取明细导出Excel表格,OFD电子发票行程单提取保存表格,具体操作流程
在企业财务管理领域,电子发票提取明细导出表格是不可或缺的工具。 月末财务结算时,财务人员需处理成百上千张电子发票,将发票明细导出为表格后,通过表格强大的数据处理功能,可自动分类汇总不同项目的支出金额ÿ…...
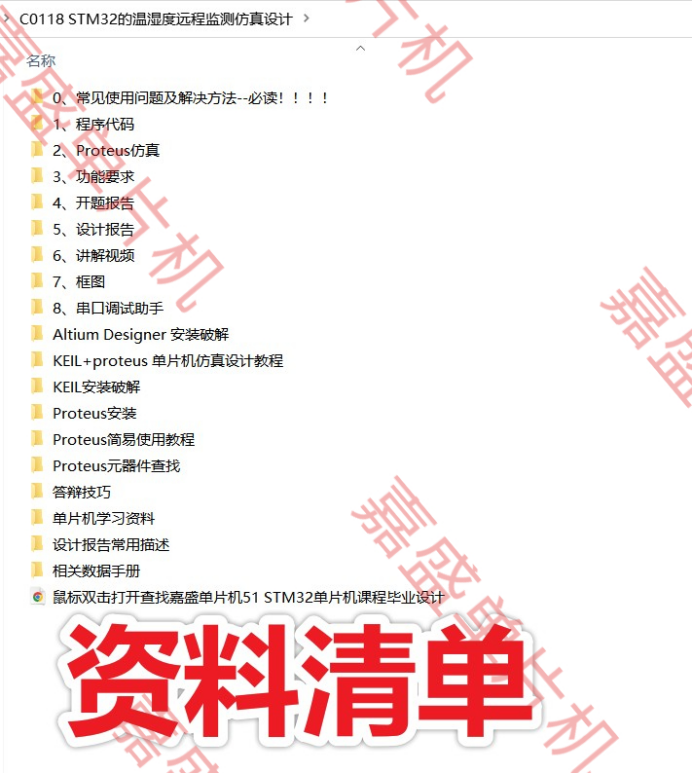
基于STM32的DHT11温湿度远程监测LCD1602显示Proteus仿真+程序+设计报告+讲解视频
DHT11温湿度远程监测proteus仿真 1. 主要功能2.仿真3. 程序4. 设计报告5. 资料清单&下载链接 基于STM32的DHT11温湿度远程监测LCD1602显示Proteus仿真设计(仿真程序设计报告讲解视频) 仿真图proteus 8.9 程序编译器:keil 5 编程语言:C…...
分类预测 | Matlab实现CNN-BiLSTM-Attention高光谱数据分类预测
分类预测 | Matlab实现CNN-BiLSTM-Attention高光谱数据分类预测 目录 分类预测 | Matlab实现CNN-BiLSTM-Attention高光谱数据分类预测分类效果功能概述程序设计参考资料 分类效果 功能概述 该MATLAB代码实现了一个结合CNN、BiLSTM和注意力机制的高光谱数据分类预测模型&#x…...
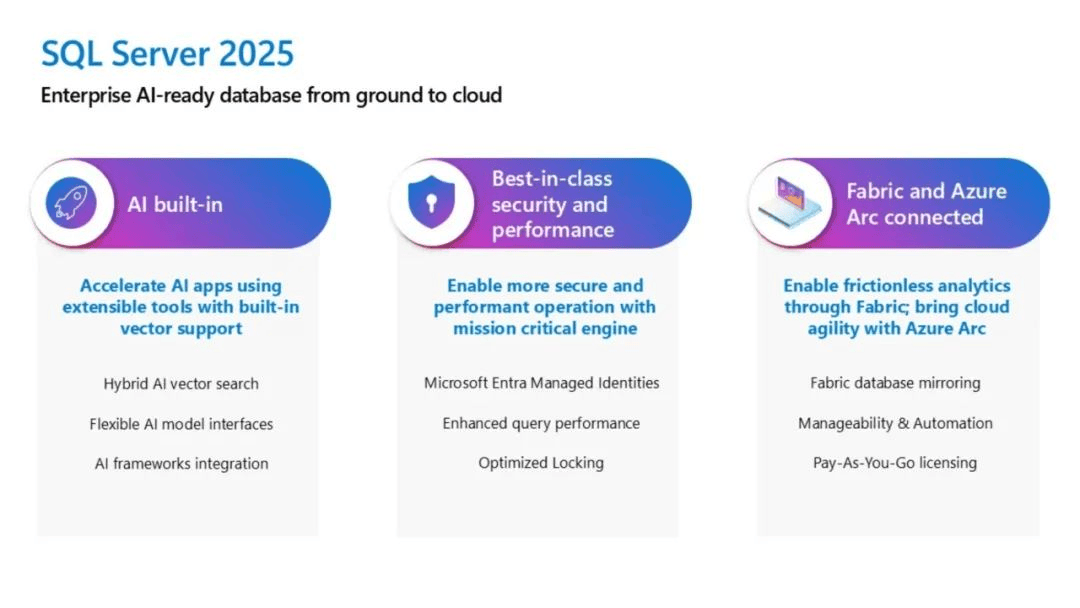
微软推出SQL Server 2025技术预览版,深化人工智能应用集成
在Build 2025 大会上,微软向开发者社区开放了SQL Server 2025的测试版本。该版本的技术改进主要涵盖人工智能功能集成、系统性能优化与开发工具链升级三个维度,展示了数据库管理系统在智能化演进方向上的重要进展。 智能数据处理功能更新 新版本的技术亮…...

.net webapi http参数自定义绑定模型
.NET Web API 中 HTTP 参数自定义绑定模型的深度解析 在 .NET Web API 开发里,常规的参数绑定往往能满足大部分需求。不过,当遇到一些特殊情况时,就需要自定义将 HTTP 参数绑定到 action 特定模型参数了。接下来,我们就深入探讨如…...

RocketMQ入门5.3.2版本(基于java、SpringBoot操作)
一、RocketMQ概述 RocketMQ是一款由阿里巴巴于2012年开源的分布式消息中间件,旨在提供高吞吐量、高可靠性的消息传递服务。主要特点有: 灵活的可扩展性 海量消息堆积能力 支持顺序消息 支持多种消息过滤方式 支持事务消息 支持回溯消费 支持延时消…...

使用osqp求解简单二次规划问题
文章目录 一、问题描述二、数学推导1. 目标函数处理2. 约束条件处理 三、代码编写 一、问题描述 已知: m i n ( x 1 − 1 ) 2 ( x 2 − 2 ) 2 s . t . 0 ⩽ x 1 ⩽ 1.5 , 1 ⩽ x 2 ⩽ 2.5 min(x_1-1)^2(x_2-2)^2 \qquad s.t. \ \ 0 \leqslant x_1 \leqslant 1.5,…...

Ubuntu创建修改 Swap 文件分区的步骤——解决嵌入式开发板编译ROS2程序卡死问题
Ubuntu创建修改 Swap 文件分区的步骤——解决嵌入式开发板编译ROS2程序卡死问题 1. 问题描述2. 创建 / 修改 Swap 分区2.1 创建 Swap 文件 (推荐)2.2 使用 Swap 分区 (如果已经存在) 3. 注意事项 同步发布在个人笔记Ubuntu创建修改 Swap 文件分区的步骤——解决嵌入式开发板编译…...

【C语言】通用统计数据结构及其更新函数(最值、变化量、总和、平均数、方差等)
【C语言】通用统计数据结构及其更新函数(最值、变化量、总和、平均数、方差等) 更新以gitee为准: gitee 文章目录 通用统计数据结构更新函数附录:压缩字符串、大小端格式转换压缩字符串浮点数压缩Packed-ASCII字符串 大小端转换什…...

Spring AI(10)——STUDIO传输的MCP服务端
Spring AI MCP(模型上下文协议)服务器Starters提供了在 Spring Boot 应用程序中设置 MCP 服务器的自动配置。它支持将 MCP 服务器功能与 Spring Boot 的自动配置系统无缝集成。 本文主要演示支持STDIO传输的MCP服务器 仅支持STDIO传输的MCP服务器 导入j…...

Sklearn 机器学习 缺失值处理 填充数据列的缺失值
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 💡使用 Scikit-learn 处理数据缺失值的完整指南 在机器学习项目中,数据缺失是不可避…...

猜字符位置游戏-position gasses
import java.util.*;public class Main {/*字符猜位置游戏;每次提交只能被告知答对几个位置;根据提示答对的位置数推测出每个字符对应的正确位置;*/public static void main(String[] args) {char startChar A;int gameLength 8;List<String> ballList new ArrayList&…...