北大开源音频编辑模型PlayDiffusion,可实现音频局部编辑,比传统 AR 模型的效率高出 50 倍!
北大开源了一个音频编辑模型PlayDiffusion,可以实现类似图片修复(inpaint)的局部编辑功能 - 只需修改音频中的特定片段,而无需重新生成整段音频。此外,它还是一个高性能的 TTS 系统,比传统 AR 模型的效率高出 50 倍。
自回归 Transformer 模型已被证明能够高效地从文本合成语音。然而,它们面临着一个显著的局限性:修改生成音频的某些部分(称为修复)或移除它们而不留下不连续的伪影,这超出了它们的标准能力。因此,需要开发更通用的语音编辑工具,并采用不同的方法。请考虑以下句子:
“The answer is out there, Neo. It's looking for you.”
现在假设你想在生成后将“Neo”更改为“Morpheus”。使用传统的 AR 模型,你的选择有限:
重新生成整个句子,这在计算上很昂贵,并且经常导致韵律或语音节奏的变化。
仅替换单词“Neo”,会导致单词边界处出现明显的伪影或不匹配。
从中间点重新生成,例如从“Morpheus。它在寻找你。”,但这可能会改变未编辑部分的韵律(“它在寻找你。”),从而产生不必要的语音节奏变化。
所有这些方法都会损害音频的连贯性和自然性。
相关链接
-
项目: https://github.com/playht/PlayDiffusion
-
试用: https://huggingface.co/spaces/PlayHT/PlayDiffusion
PlayDiffusion 简介
在 PlayAI,我们用一种新颖的基于扩散的音频语音编辑方法解决了这个问题。它的工作原理如下:
首先,我们将音频序列编码到离散空间中,将波形转换为更紧凑的表示形式。此表示中的每个单元称为一个标记 (token)。此过程适用于真实语音和文本转语音 (TTS) 模型生成的音频。
当需要修改某个片段时,我们会屏蔽该部分音频。
使用以更新后的文本为条件的扩散模型来对掩蔽区域进行去噪。
周围环境被无缝保留,确保平滑过渡和一致的扬声器特性。
然后使用我们的 BigVGAN 解码器模型将生成的输出标记序列转换回语音波形。
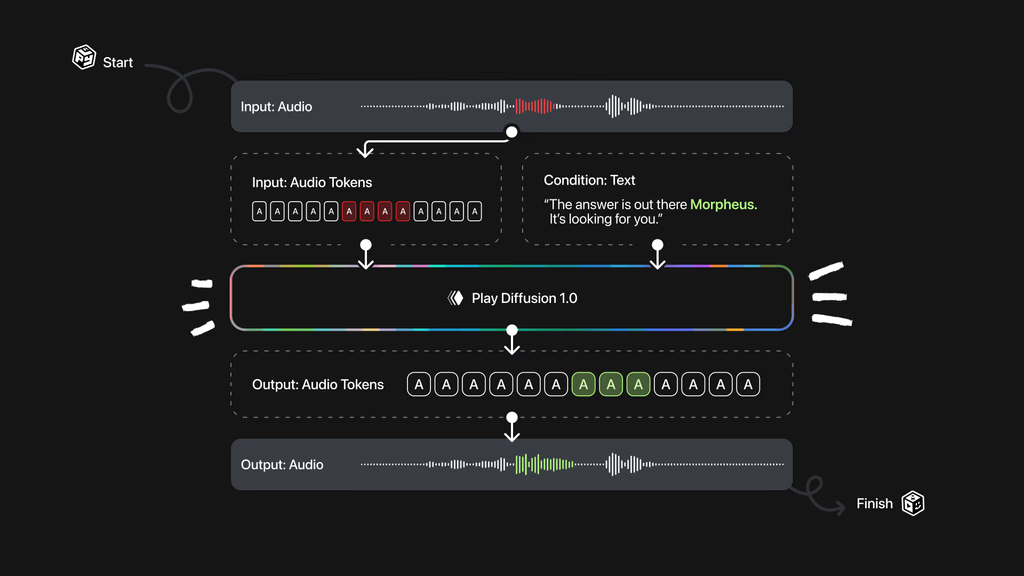
通过使用非自回归扩散模型,我们可以更好地保持编辑边界处的语境,从而实现高质量、连贯的音频编辑。这标志着音频编辑能力的重大进步,并为动态、细粒度的语音修改铺平了道路。完整流程如图 1 所示。
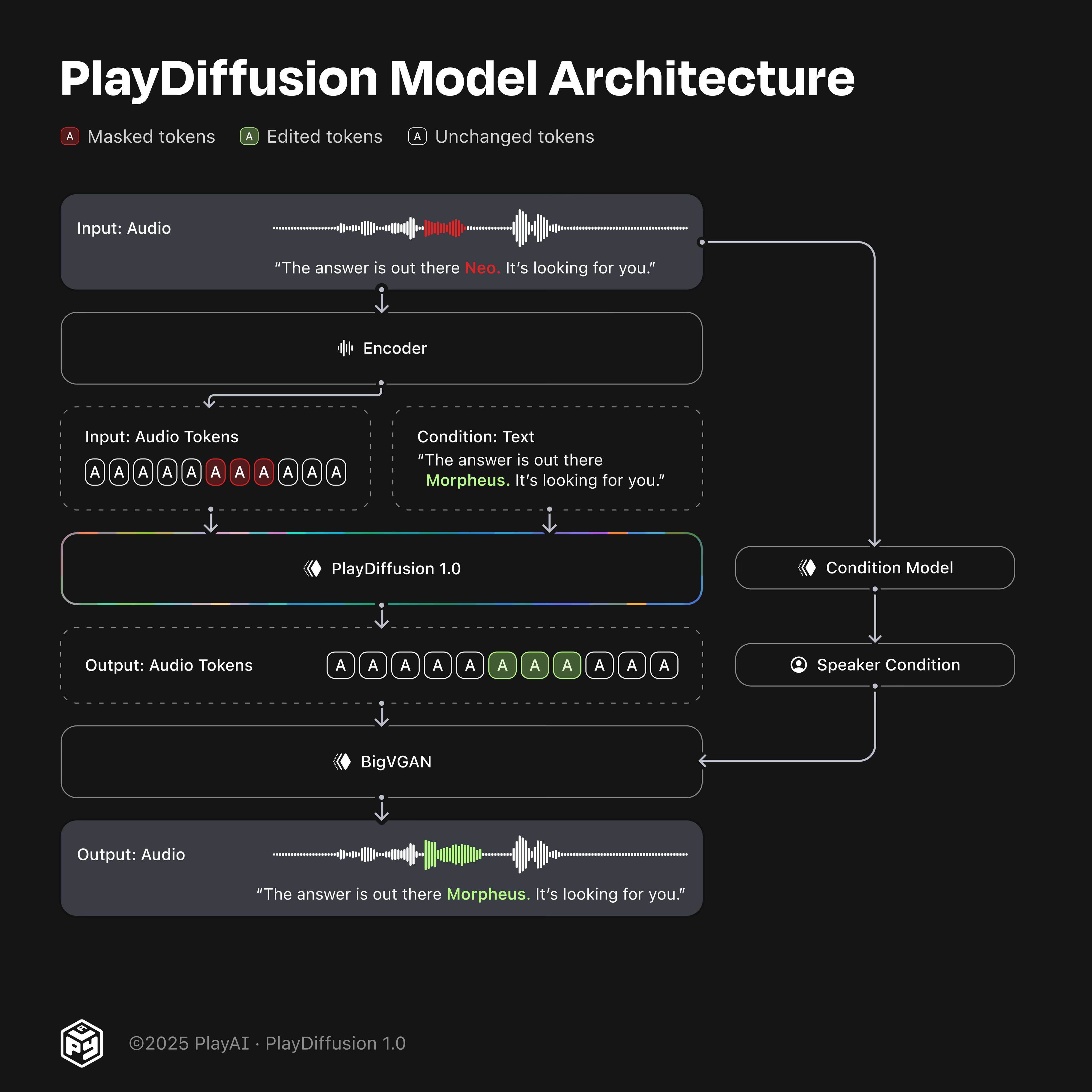
图 1. PlayDiffusion 1.0 模型。
-
包含语音“答案就在那儿,Neo。去抓住它!”的输入音频被编码为离散的音频标记。
-
与要编辑的语音对应的标记被屏蔽。这里我们屏蔽了“Neo”的标记。
-
给定更新后的文本和完整的输入标记序列(即屏蔽和未屏蔽的序列),PlayDiffusion 生成编辑后的输出序列。
-
该序列由我们的 BigVGAN 转换为波形,并以从原始片段中提取的说话人嵌入为条件。
离散扩散作为 TTS
在整个音频波形被掩盖的极端情况下,扩散模型可以作为高效的文本到语音 (TTS) 系统发挥作用。
虽然自回归 Transformer 模型在语音合成领域取得了令人瞩目的成果,但其逐个 token 的顺序生成方式本身就存在效率低下的问题。每个 token 都必须基于前一个 token 进行生成,这会导致巨大的计算开销。
相比之下,扩散模型采用非自回归方法——同时生成所有标记,并通过固定数量的去噪步骤对其进行细化。这种根本的架构差异带来了显著的性能优势。
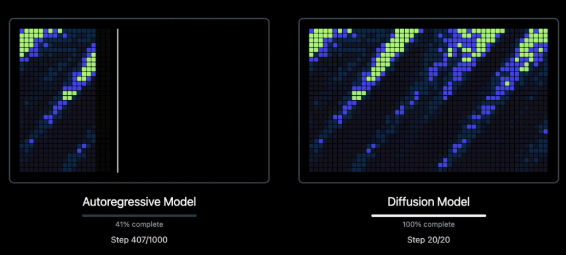
举例来说:对于运行频率为 50 Hz 的音频编解码器,在自回归模型中生成 20 秒的语音需要 1,000 个步骤。而扩散模型可以一次性生成全部 1,000 个 token,并仅需 20 个迭代步骤即可对其进行优化——这使得生成步骤的效率提高了 50 倍,同时又不影响输出的质量或清晰度。
训练
我们从预先训练的仅解码器文本转换器架构开始,并引入了专门针对音频生成定制的关键修改:
非因果掩蔽:
与 GPT 等采用因果掩蔽(允许标记仅关注先前的标记)的标准解码器专用 LLM 不同,我们改进的 LLM 实现使用非因果注意力头。这使得模型能够同时利用过去、现在和未来的标记。
自定义分词器和嵌入缩减:
为了优化效率,尤其是针对英语语音合成,我们使用了自定义字节对编码 (BPE) 分词器,该分词器仅包含 10,000 个文本分词。这大大减少了嵌入表的大小,从而显著提升了计算速度,同时又不影响音频质量。
说话人调节:
我们的模型融合了源自预训练嵌入模型 e(w): ℝᵗ → ℝᵏ 的说话人调节方法,该模型将不同长度 t 的波形映射到维度为 k 的固定大小向量。这能够捕捉说话人的基本特征,确保合成或编辑的音频片段之间语音身份的一致性。
在训练过程中,我们像 MaskGCT [1] 一样,随机屏蔽一定比例的音频 token。模型会根据说话人嵌入、文本输入以及剩余未屏蔽的音频 token 提供的上下文,学习准确预测这些被屏蔽的 token。这种方法可以有效地训练模型处理部分或完全音频屏蔽的场景。给定不同时间步长的文本样本 xₜ,文本条件 C,我们将损失建模为:

在推理过程中,解码会迭代进行,从完全掩码的 token 序列开始。解码过程包含多个步骤,记为 T:
逐步解码过程:
初步预测:在每次迭代中,模型根据当前的掩蔽音频和文本输入生成初始预测 X̂₀。
置信度评分:根据模型的预测,每个 token 都会获得一个置信度分数。新预测的(之前被屏蔽的)token 会被赋予与其预测概率相等的置信度,而之前确定的 token 则保持不变,置信度分数为 1。
自适应重掩码:我们利用一个逐步递减的方案 gamma,选择一定数量的置信度最低的 token,在后续迭代中进行重掩码。每次迭代后,需要重掩码的 token 数量都会逐渐减少,从而使模型的优化工作集中在不确定性最高的区域。更多详情,请参阅 MaskGCT [1]。
这个迭代解码过程持续进行,直到所有步骤完成,逐渐完善标记预测并产生连贯的高质量音频输出。
相关文章:
北大开源音频编辑模型PlayDiffusion,可实现音频局部编辑,比传统 AR 模型的效率高出 50 倍!
北大开源了一个音频编辑模型PlayDiffusion,可以实现类似图片修复(inpaint)的局部编辑功能 - 只需修改音频中的特定片段,而无需重新生成整段音频。此外,它还是一个高性能的 TTS 系统,比传统 AR 模型的效率高出 50 倍。 自回归 Tra…...
蒲公英盒子连接问题debug
1、 现象描述 2、问题解决 上图为整体架构图,其中左边一套硬件设备是放在机房,右边是放在办公室。左边的局域网连接了可以访问外网的路由器,利用蒲公英作为旁路路由将局域网暴露在外网环境下。 我需要通过蒲公英作为旁路路由来进行远程访问&…...

Unity | AmplifyShaderEditor插件基础(第五集:简易膨胀shader)
一、👋🏻前言 大家好,我是菌菌巧乐兹~本节内容主要讲一下,如何用shader来膨胀~ 效果预览: 二、💨膨胀的基本原理 之前的移动是所有顶点朝着一个方向走,所以是移动 如果所有顶点照着自己的方…...

Django核心知识点全景解析
引言 本文深入剖析Django核心组件,涵盖数据交换、异步交互、状态管理及安全认证,附完整代码示例和避坑指南! 目录 引言 一、JSON:轻量级数据交换标准 1. 核心特性 2. 标准格式 3. 各语言处理方法 4. 常见错误示例 二、AJA…...

生物发酵展同期举办2025中国合成生物学与生物制造创新发展论坛
一、会议介绍 2025中国合成生物学与生物制造创新发展论坛暨上海国际合成生物学与生物制造展览会于2025年8月7-9日在上海新国际博览中心(浦东新区龙阳路2345号)召开,本次论坛汇聚了国内外顶尖学者、行业领袖及政策制定者,将围绕“…...
WINUI——Magewell视频捕捉开发手记
背景 因需要融合视频,并加载患者CT中提取出的气管镜与病变,以便能实时查看气管镜是否在正确位置。 开发环境 硬件:Magewell的USB Capture HDMI Gen 2 IDE:VS2022 FrameWork: .Net6 WINUI Package: MVVMToolKit NLog Ma…...

Jetpack Compose 中,DisposableEffect、LaunchedEffect 和 sideEffect 区别和用途
在 Jetpack Compose 中,DisposableEffect、LaunchedEffect 和 sideEffect 都是用于处理副作用(Side Effects)的 API,但它们的用途和触发时机不同。以下是它们的核心概念和区别: 1. 副作用(Side Effect&…...

STM32开发,创建线程栈空间大小判断
1. 使用RTOS提供的API函数(以FreeRTOS为例) 函数原型:UBaseType_t uxTaskGetStackHighWaterMark(TaskHandle_t xTask)功能:获取指定任务堆栈中剩余的最小空间(以字为单位,非字节)。使用步骤&am…...

正则表达式检测文件类型是否为视频或图片
// 配置化文件类型检测(集中管理支持的类型) const FILE_TYPE_CONFIG {video: {extensions: [mp4, webm, ogg, quicktime], // 可扩展支持更多格式regex: /^video\/(mp4|webm|ogg|quicktime)$/i // 自动生成正则},image: {extensions: [jpeg, jpg, png,…...

Qwen大语言模型里,<CLS>属于特殊的标记:Classification Token
Qwen大语言模型里,<CLS>属于特殊的标记:Classification Token 目录 Qwen大语言模型里,<CLS>属于特殊的标记:Classification Token功能解析工作机制应用场景举例说明技术要点在自然语言处理(NLP)领域 都是<CLS> + <SEP>吗?一、CLS和SEP的作用与常见用法1. **CLS标…...

TDengine 开发指南——无模式写入
简介 在物联网应用中,为了实现自动化管理、业务分析和设备监控等多种功能,通常需要采集大量的数据项。然而,由于应用逻辑的版本升级和设备自身的硬件调整等原因,数据采集项可能会频繁发生变化。为了应对这种挑战,TDen…...

分布式互斥算法
1. 概述:什么是分布式互斥 假设有两个小孩想玩同一个玩具(临界资源),但玩具只有一个,必须保证一次只有一个人能够玩。当一个小孩在玩时,另一个小孩只能原地等待,直到玩完才能轮到自己。这就是 …...

第34次CCF-CSP认证真题解析(目标300分做法)
第34次CCF-CSP认证 矩阵重塑(其一)AC代码及解析矩阵重塑(其二)AC代码及解析货物调度AC代码及解析 矩阵重塑(其一) 输入输出及样例: AC代码及解析 1.线性化原矩阵 :由于cin的特性我们…...
video-audio-extractor:视频转换为音频
软件介绍 前几天在网上看见有人分享了一个源码,大概就是py调用的ffmpeg来制作的。 这一次我带来源码版(需要py环境才可以运行),开箱即用版本(直接即可运行) 软件特点 软件功能 视频提取音频:…...

rk3588 区分两个相同的usb相机
有时候会插入两个一模一样的usb相机,担心每次启动他们所对应的设备节点 /dev/video* 会变化,所以需要绑定usb口,区分两个相机。把两个相机都插入后,查看usb信息 rootrk3588:/# udevadm info --attribute-walk --name/dev/video0U…...
[概率论基本概念4]什么是无偏估计
关键词:Unbiased Estimation 一、说明 对于无偏和有偏估计,需要了解其叙事背景,是指整体和抽样的关系,也就是说整体的叙事是从理论角度的,而估计器原理是从实践角度说事;为了表明概率理论(不可…...

乐观锁与悲观锁的实现和应用
乐观锁与悲观锁:原理、实现与应用详解 在并发编程和数据库操作中,乐观锁和悲观锁是两种重要的并发控制策略,它们在原理、实现方式和应用场景上存在显著差异。下面我们将通过图文结合的方式,深入探讨这两种锁机制。 一、基本概念 1…...
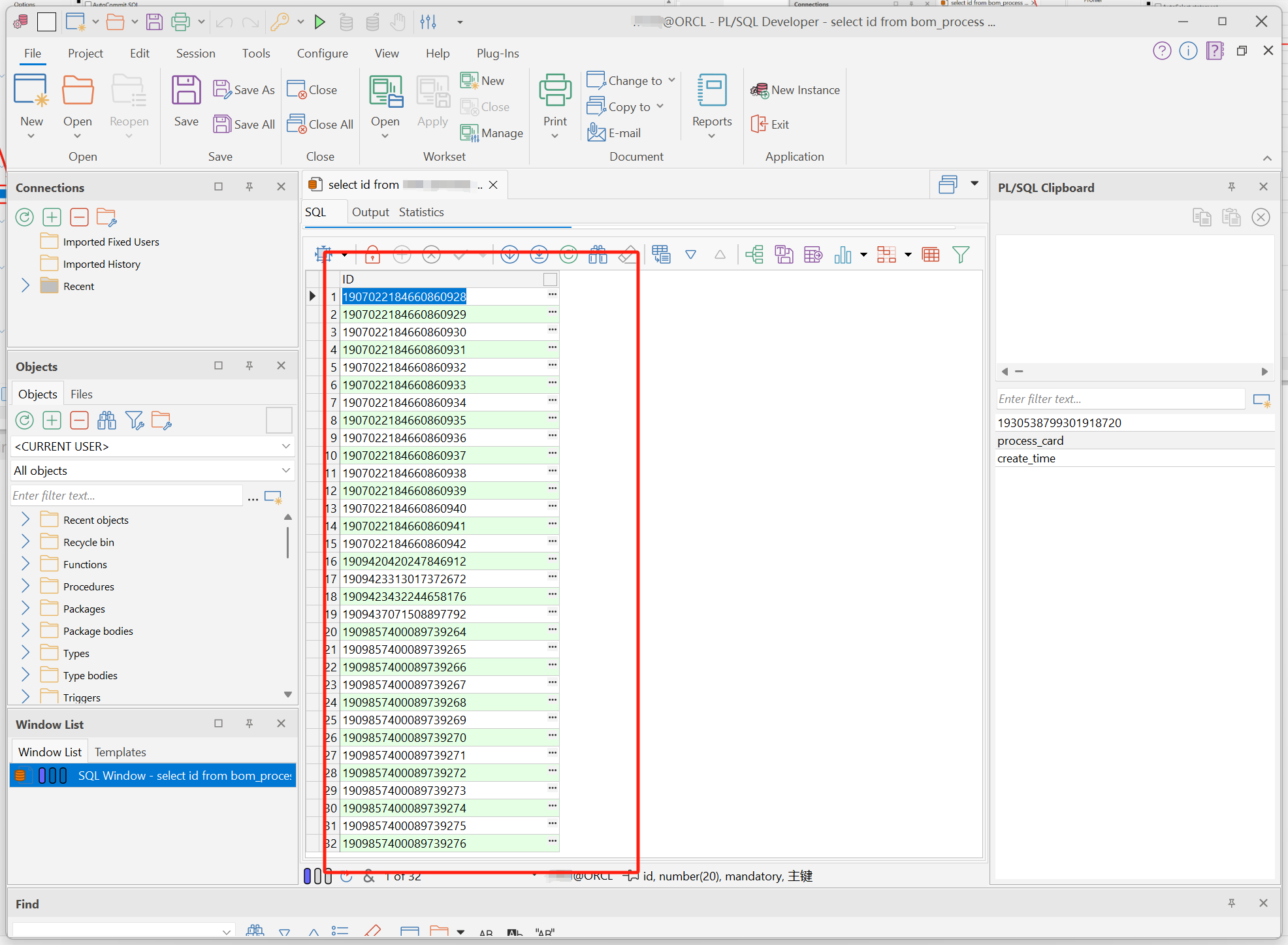
PL/SQLDeveloper中数值类型字段查询后显示为科学计数法的处理方式
PL/SQLDeveloper中数值类型字段查询后显示为科学计数法的处理方式 文章目录 PL/SQLDeveloper中数值类型字段查询后显示为科学计数法的处理方式1. 查询效果2. 处理方式3. 再次查询 1. 查询效果 2. 处理方式 3. 再次查询...

【vue】Uniapp 打包Android 文件选择上传问题详解~
需求 uniapp兼容android app,pc,h5的文件选择并上传功能。 需要支持拍照和相册选择,以及选择其他类型文件上传~ 实践过程和问题 开始使用uni-file-picker组件 以为很顺利,android模拟器测试…… 忽略了平台兼容性提示~&#…...
深度解析)
ASR技术(自动语音识别)深度解析
ASR技术(自动语音识别)深度解析 自动语音识别(Automatic Speech Recognition,ASR)是将人类语音转换为文本的核心技术,以下是其全面解析: 一、技术原理架构 #mermaid-svg-QlJOWpMtlGi9LNeF {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:1…...

图论水题2
div2 361 D. Tree Requests 题意 对于一颗 n n n节点的树,每个节点有一个字母,有 m m m次询问,每次询问求对于顶点 v v v的子树中深度为 h h h的结点能否组成一个回文串$ (1 \leq n \leq m \leq 5 \cdot 10^5) $ 思路 关于 v v v的子树结…...

Ctrl-Crash 助力交通安全:可控生成逼真车祸视频,防患于未然
视频扩散技术虽发展显著,但多数驾驶数据集事故事件少,难以生成逼真车祸图像,而提升交通安全又急需逼真可控的事故模拟。为此,论文提出可控车祸视频生成模型 Ctrl-Crash,它以边界框、碰撞类型、初始图像帧等为条件&…...
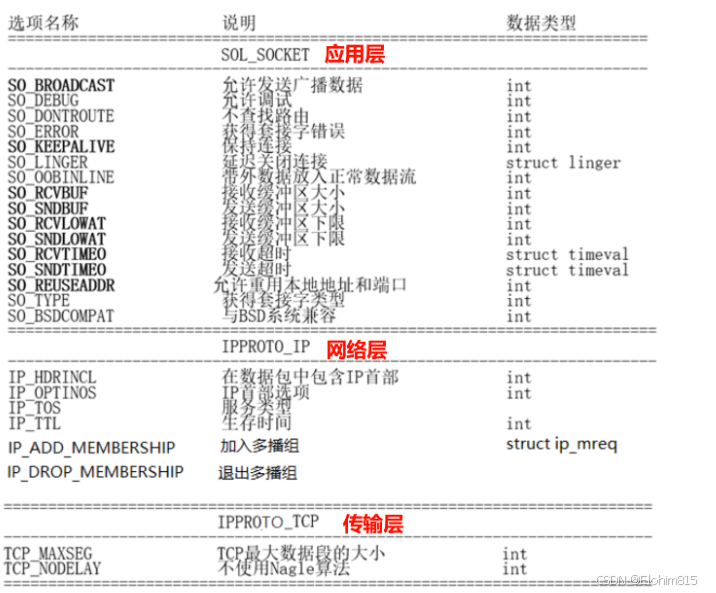
网络编程之服务器模型与UDP编程
一、服务器模型 在网络通信中,通常要求一个服务器连接多个客户端 为了处理多个客户端的请求,通常有多种表现形式 1、循环服务器模型 一个服务器可以连接多个客户端,但同一时间只能连接并处理一个客户的请求 socket() 结构体 bind() listen() …...
Transformer-BiLSTM、Transformer、CNN-BiLSTM、BiLSTM、CNN五模型时序预测
Transformer-BiLSTM、Transformer、CNN-BiLSTM、BiLSTM、CNN五模型时序预测 目录 Transformer-BiLSTM、Transformer、CNN-BiLSTM、BiLSTM、CNN五模型时序预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 Transformer-BiLSTM、Transformer、CNN-BiLSTM、BiLSTM、CNN五…...
阿里云服务器安装nginx并配置前端资源路径(前后端部署到一台服务器并成功访问)
运行以下命令,安装Nginx相关依赖。 yum install -y gcc-c yum install -y pcre pcre-devel yum install -y zlib zlib-devel yum install -y openssl openssl-devel 运行wget命令下载Nginx 1.21.6。 您可以通过Nginx开源社区直接获取对应版本的安装包URL&…...

Ubuntu 下开机自动执行命令的方法
Ubuntu 下开机自动执行命令的方法(使用 crontab) 在日常使用 Ubuntu 或其他 Linux 系统时,我们常常需要让某些程序或脚本在系统启动后自动运行。例如:启动 Clash 代理、初始化服务、定时同步数据等。 本文将介绍一种简单且常用的…...

C++11新增重要标准(下)
前言 一,forward(完美转发) 二,可变参数模板 三,emplace系列接口 四,新增类功能 五,default与delete 六,lambda表达式 七,包装器 八,bind 在C11中新增…...
【第六篇】 SpringBoot的日志基础操作
简介 日志系统在软件开发中至关重要,用于调试代码、记录运行信息及错误堆栈。本篇文章不仅详细介绍了日志对象的创建及快速使用,还说明了日志持久化的两种配置方式和滚动日志的设置。实际开发需根据场景选择合适的日志级别和存储策略。文章内容若存在错误…...
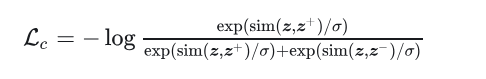
Pluto论文阅读笔记
主要还是参考了这一篇论文笔记:https://zhuanlan.zhihu.com/p/18319150220 Pluto主要有三个创新点: 横向纵向用lane的query来做将轨迹投回栅格化地图,计算碰撞loss对数据进行正增强和负增强,让正增强的结果也无增强的结果相近&a…...

ubuntu显示器未知
在Ubuntu系统中,当外接显示器被识别为“未知设备”时,可通过以下日志文件进行问题诊断,结合Xorg日志和内核日志综合分析: 🔍 一、查看Xorg显示服务日志(核心) Xorg日志记录了图形界面的详细事…...