Deepseek基座:Deepseek-v2核心内容解析
| DeepSeek原创文章 | |
| 1 | DeepSeek-v3:基于MLA的高效kv缓存压缩与位置编码优化技术 |
| 2 | Deepseek基座:DeepSeek LLM核心内容解析 |
| 3 | Deepseek基座:Deepseek MOE核心内容解析 |
| 4 | Deepseek基座:Deepseek-v2核心内容解析 |
| 5 | Deepseek基座:Deepseek-v3核心内容解析 |
| 6 | DeepSeek推理能力(Reasoning) |

DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Deepseek v2可以看作是上面那一篇paper的scale up,不过也有一些非常重要的技术。从论文名字可以看出来“A Strong, Economical, and Efficient”,他们提出了进一步降低成本的技术
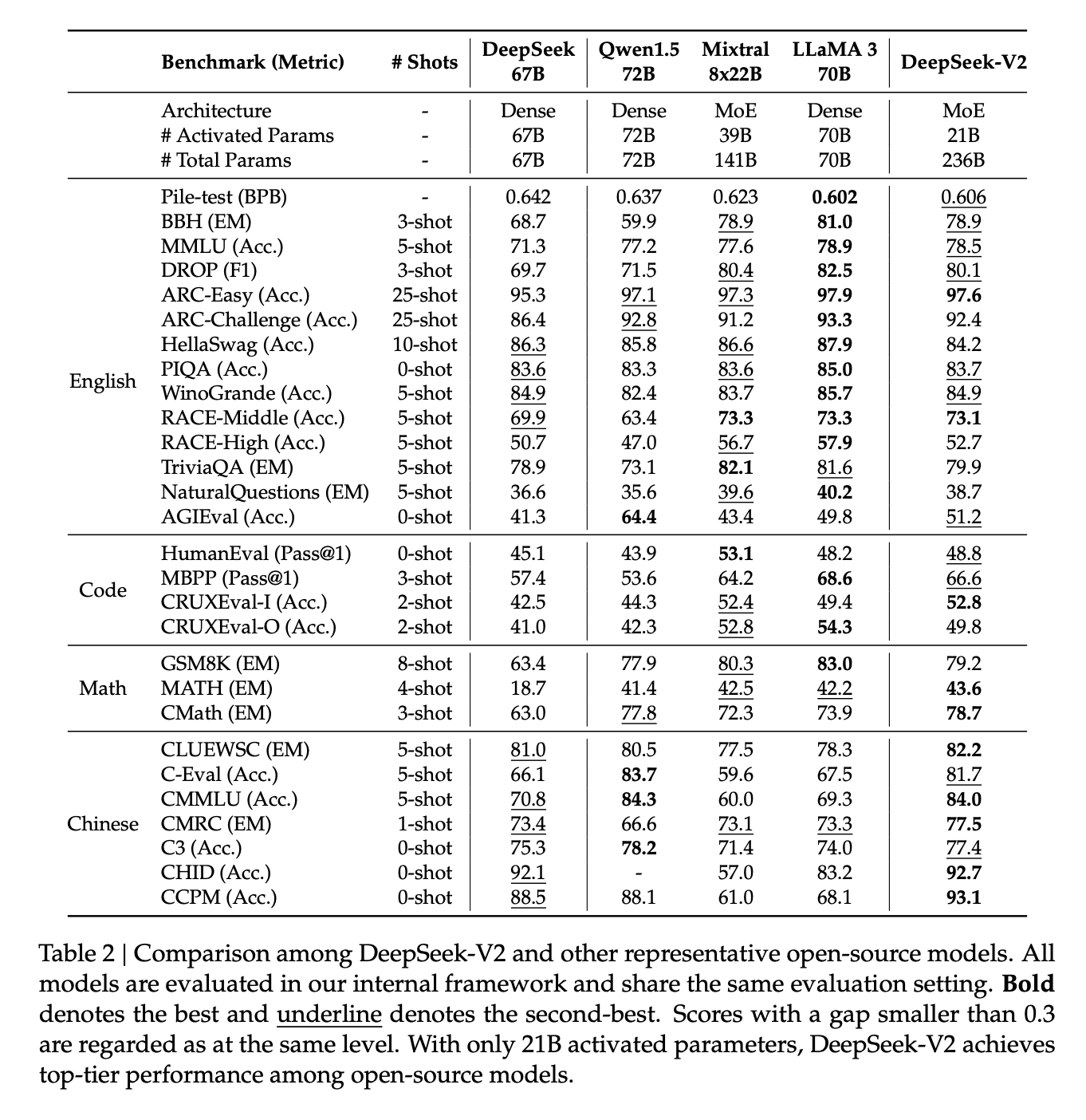
DeepSeek-V2 是236B的混合专家模型(MoE),每个 token 激活21B,极大降低了推理成本 。相比第一代的 DeepSeek 67B,虽然模型规模更大(接近其4倍),但激活参数更少,推理效率更高 。
训练与推理成本优化
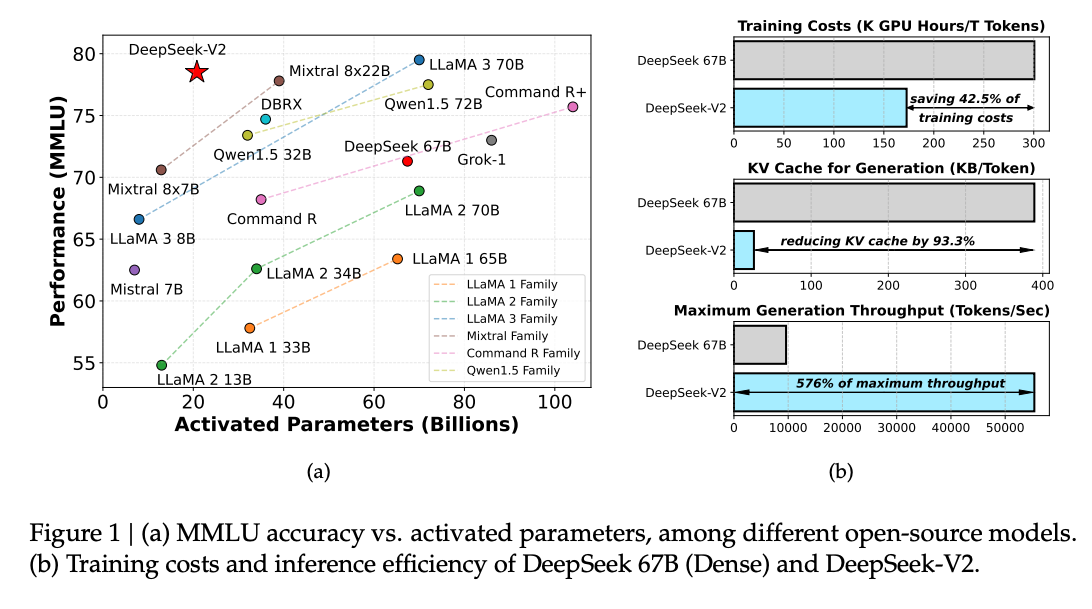
- 训练成本降低 42.5%:相比 DeepSeek 67B,DeepSeek-V2 在保持更强性能的同时,显著减少了训练所需的计算资源 。
- KV 缓存减少 93.3%:通过引入新的注意力机制 Multi-head Latent Attention(MLA),大幅压缩了 KV 缓存需求,从而降低了部署和推理成本 。
- 生成速度提升 5.76 倍:在相同硬件条件下,DeepSeek-V2 的输出速度远超前代模型,提升了实际应用中的响应效率 。
Multi-head Latent Attention(MLA)
- 这是 DeepSeek-V2 引入的一项关键技术,用于替代传统的多头注意力机制
- MLA 通过引入潜在空间(latent space)进行注意力计算,减少了计算复杂度和内存占用,进一步提升了推理效率
- 它不仅降低了 KV 缓存的需求,还使得模型能够支持更大的 batch size,从而提升整体吞吐量
DeepSeek-V2还支持 最长 128K tokens 的上下文长度
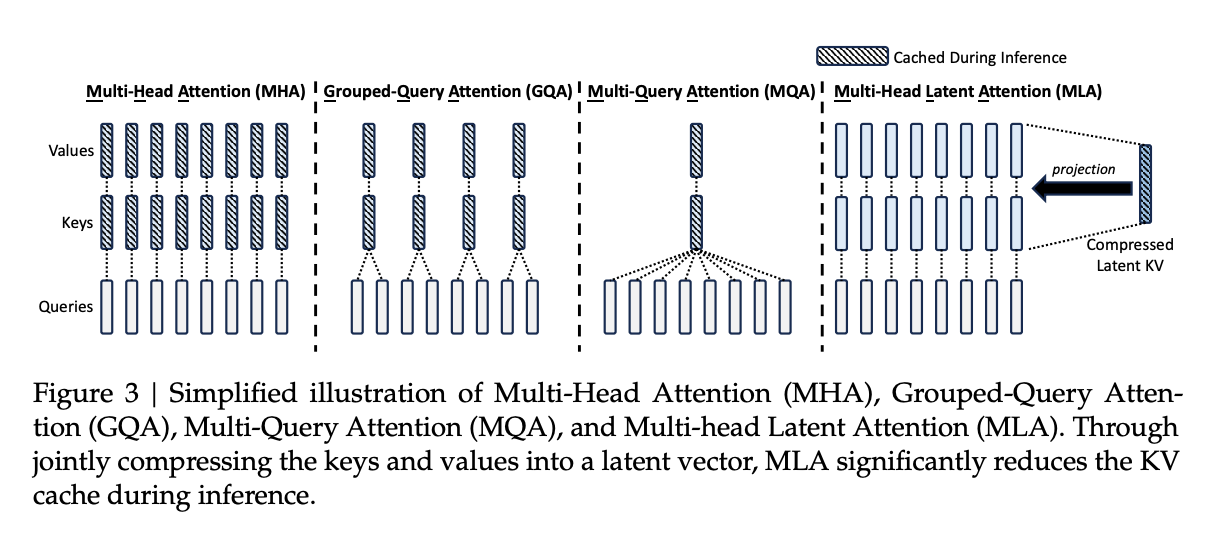
MLA
- MLA 引入了一个 潜在空间(latent space),将原始的高维 Key 和 Value 向量映射到一个低维空间中进行存储。
- 具体来说,模型先计算一个低秩的“压缩表示”
,然后在需要时通过矩阵变换恢复出 Key 和 Value:
- 这种方法被称为 Low-Rank Key-Value Compression,大幅减少了存储需求,从而降低了 KV Cache 的占用 。
MLA 与其他注意力机制的对比
| 方法 | 头数 | Key/Value 存储方式 | KV Cache 占用 | 性能影响 |
|---|---|---|---|---|
| MHA(多头注意力) | 多头 | 每个头独立存储 | 高 | 最佳 |
| GQA(Grouped Query Attention) | 多组共享 | 组内共享 Key/Value | 中等 | 稍有下降 |
| MQA(Multi-Query Attention) | 单头 | 所有头共享 Key/Value | 低 | 明显下降 |
| MLA(Multi-Head Latent Attention) | 多头 | 压缩后的潜在向量 | 极低 | 接近 MHA |
- MLA 在保持多头注意力灵活性的同时,通过低秩压缩实现了接近 MQA 的显存效率,且性能损失极小 。
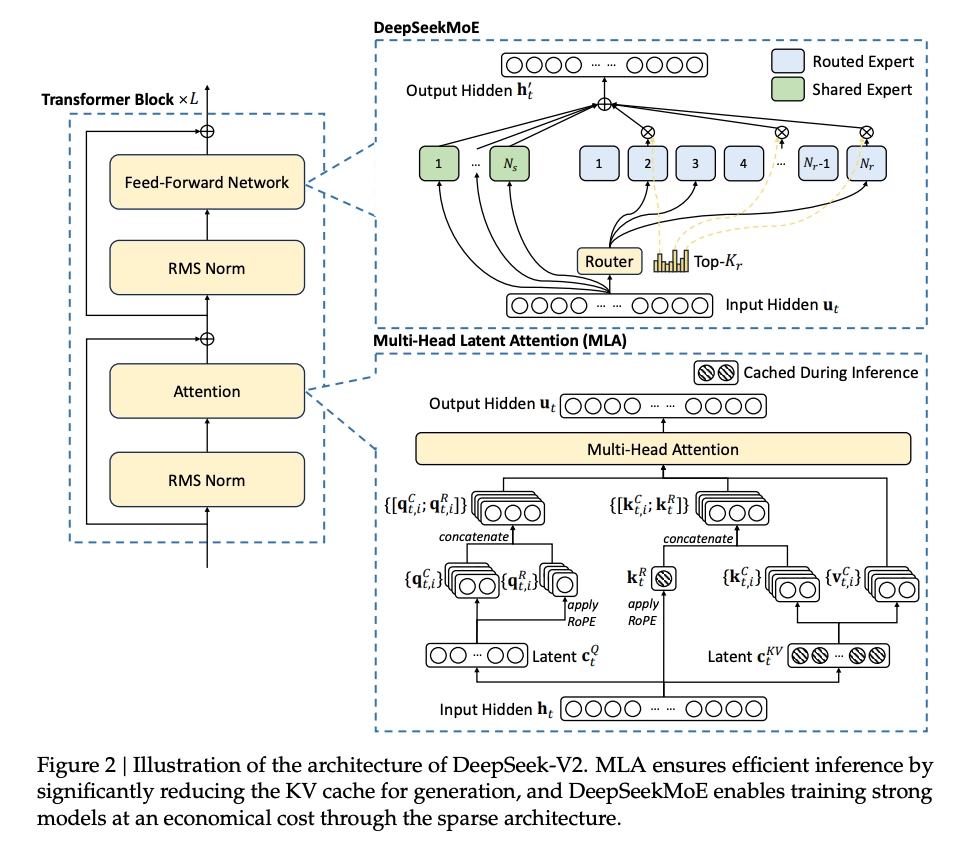
KV Cache
- 在传统的 Transformer 模型中,多头注意力机制(MHA) 需要存储大量 Key 和 Value 向量(即 KV Cache),以加速生成过程中的自回归推理。
- 这些向量的存储会占用大量 GPU 显存,尤其是在处理长上下文时,成为部署成本的主要瓶颈。
- DeepSeek-V2 提出 Multi-Head Latent Attention(MLA),旨在通过压缩 KV Cache 来显著降低推理时的显存占用和计算开销。
KV Cache 压缩效果 - 实验表明,MLA 可将 KV Cache 减少 93%,使得模型在长文本生成任务中更加高效。 - 例如,在生成 128K token 的任务中,MLA 显著降低了内存占用,提升了吞吐量和响应速度 。
说一下为什么kv cache不cache q,q不是也包含历史信息了吗,怎么不把q缓存一下?
因为transformer是自回归模型,每一次的结果都被当成新的q,所以缓存起来没意义,它只用一次,是动态变化的。而k和v则是需要经常复用,所以每次模型输出结果后,只需要把最新的token向量拿出来,进行权重矩阵计算后,直接和缓存后的k和v拼接在一起, 而不像以前需要每个token进行权重矩阵的重复计算。所以kv cache节约的是,k和v与对应权重矩阵的计算。
与 GQA 的对比
- 传统的 GQA通过共享部分head来减少 KV Cache 的大小。例如,16 个头分成 4 组,每组共享 K/V。
- MLA 相当于使用了 约 2.25 个 group 的 GQA,但性能远优于同等 group 数量的 GQA,即在更小的显存消耗下保持了更高的模型效果 。
小结
| 方面 | DeepSeek 的做法 |
|---|---|
| 注意力机制 | 提出 MLA,显著压缩 KV Cache,提升推理效率 |
| MoE 架构 | 使用大量专家(如 160 个),提升稀疏性和模型表达能力 |
| 平衡策略 | 注重专家和设备间的负载均衡,提高训练效率和资源利用率 |
| 原创文章 | |
| 1 | FFN前馈网络与激活函数技术解析:Transformer模型中的关键模块 |
| 2 | Transformer掩码技术全解析:分类、原理与应用场景 |
| 3 | 【大模型技术】Attention注意力机制详解一 |
| 4 | Transformer核心技术解析LCPO方法:精准控制推理长度的新突破 |
| 5 | Transformer模型中位置编码(Positional Embedding)技术全解析(二) |
| 6 | Transformer模型中位置编码(Positional Embedding)技术全解析(一) |
| 7 | 自然语言处理核心技术词嵌入(Word Embedding),从基础原理到大模型应用 |
| 8 | DeepSeek-v3:基于MLA的高效kv缓存压缩与位置编码优化技术 |
| 9 | 【Tokenization第二章】分词算法深度解析:BPE、WordPiece与Unigram的原理、实现与优化 |
| 10 | Tokenization自然语言处理中分词技术:从传统规则到现代子词粒度方法 |
| 11 | [预训练]Encoder-only架构的预训练任务核心机制 |
| 12 | 【第一章】大模型预训练全解析:定义、数据处理、流程及多阶段训练逻辑 |
| 13 | (第一章)深度学习标准化技术综述: 从BatchNorm到DeepNorm的演进与实战 |
| 14 | Transformer架构解析:Encoder与Decoder核心差异、生成式解码技术详解 |
相关文章:
Deepseek基座:Deepseek-v2核心内容解析
DeepSeek原创文章1 DeepSeek-v3:基于MLA的高效kv缓存压缩与位置编码优化技术 2 Deepseek基座:DeepSeek LLM核心内容解析 3 Deepseek基座:Deepseek MOE核心内容解析 4 Deepseek基座:Deepseek-v2核心内容解析 5Deepseek基座…...
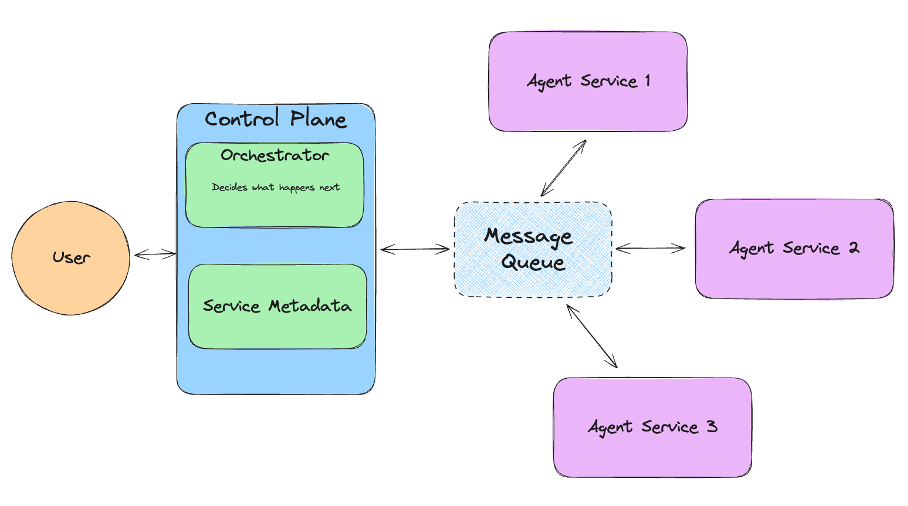
2025主流智能体Agent终极指南:Manus、OpenManus、MetaGPT、AutoGPT与CrewAI深度横评
当你的手机助手突然提醒"明天会议要带投影仪转接头",或是电商客服自动生成售后方案时,背后都是**智能体(Agent)**在悄悄打工。这个AI界的"瑞士军刀"具备三大核心特征: 自主决策能力:像老司机一样根据路况实时…...
家政小程序开发——AI+IoT技术融合,打造“智慧家政”新物种
基于用户历史订单(如“每周一次保洁”)、设备状态(如智能门锁记录的清洁频率),自动生成服务计划。 结合天气数据(如“雨天推荐玻璃清洁”),动态推送服务套餐。 IoT设备联动&#x…...

Keil开发STM32生成hex文件/bin文件
生成hex文件生成bin文件 STM32工程的hex文件和bin文件都可以通过Keil直接配置生成 生成hex文件 工程中点击魔术棒,在 Output 中勾选 Create HEX File 选项,OK保存工程配置 编译工程通过后可以看到编译输出窗口有创建hex文件的提示 默认可以在Output文…...

Windows 系统安装 Redis 详细教程
Windows 系统安装 Redis 详细教程 一、Redis 简介 Redis(Remote Dictionary Server)是一个开源的、基于内存的高性能键值存储系统,常被用作数据库、缓存和消息中间件。相比传统数据库,Redis 具有以下优势: 超高性能…...
)
“组件、路由懒加载”,在 Vue3 和 React 中分别如何实现? (copy)
Vue3 和 React 组件懒加载实现方式 React 中组件懒加载的实现方式 React 提供了 React.lazy 和 Suspense 两个 API 来实现组件的懒加载。React.lazy 用于动态导入组件,而 Suspense 则用于指定加载过程中的占位内容。例如,可以通过以下代码实现懒加载&a…...

.NET 事件模式举例介绍
.NET 事件模式:实现对象间松耦合通信 在软件开发中,对象之间的通信是一个常见且重要的问题。.NET 框架提供了一种标准化的事件模式,用于解决对象间的通信问题,实现松耦合的交互方式。今天,我们就通过一个简单的例子来…...
PDF 转 Markdown
本地可部署的模型 Marker Marker 快速准确地将文档转换为 markdown、JSON 和 HTML。 转换所有语言的 PDF、图像、PPTX、DOCX、XLSX、HTML、EPUB 文件在给定 JSON 架构 (beta) 的情况下进行结构化提取设置表格、表单、方程式、内联数学、链接、引用和代…...

北大开源音频编辑模型PlayDiffusion,可实现音频局部编辑,比传统 AR 模型的效率高出 50 倍!
北大开源了一个音频编辑模型PlayDiffusion,可以实现类似图片修复(inpaint)的局部编辑功能 - 只需修改音频中的特定片段,而无需重新生成整段音频。此外,它还是一个高性能的 TTS 系统,比传统 AR 模型的效率高出 50 倍。 自回归 Tra…...
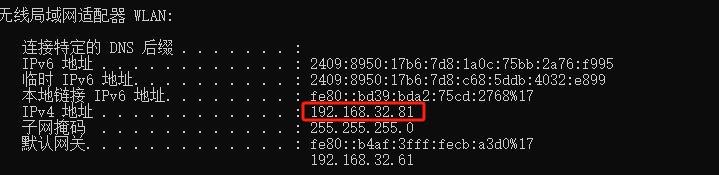
蒲公英盒子连接问题debug
1、 现象描述 2、问题解决 上图为整体架构图,其中左边一套硬件设备是放在机房,右边是放在办公室。左边的局域网连接了可以访问外网的路由器,利用蒲公英作为旁路路由将局域网暴露在外网环境下。 我需要通过蒲公英作为旁路路由来进行远程访问&…...

Unity | AmplifyShaderEditor插件基础(第五集:简易膨胀shader)
一、👋🏻前言 大家好,我是菌菌巧乐兹~本节内容主要讲一下,如何用shader来膨胀~ 效果预览: 二、💨膨胀的基本原理 之前的移动是所有顶点朝着一个方向走,所以是移动 如果所有顶点照着自己的方…...

Django核心知识点全景解析
引言 本文深入剖析Django核心组件,涵盖数据交换、异步交互、状态管理及安全认证,附完整代码示例和避坑指南! 目录 引言 一、JSON:轻量级数据交换标准 1. 核心特性 2. 标准格式 3. 各语言处理方法 4. 常见错误示例 二、AJA…...

生物发酵展同期举办2025中国合成生物学与生物制造创新发展论坛
一、会议介绍 2025中国合成生物学与生物制造创新发展论坛暨上海国际合成生物学与生物制造展览会于2025年8月7-9日在上海新国际博览中心(浦东新区龙阳路2345号)召开,本次论坛汇聚了国内外顶尖学者、行业领袖及政策制定者,将围绕“…...
WINUI——Magewell视频捕捉开发手记
背景 因需要融合视频,并加载患者CT中提取出的气管镜与病变,以便能实时查看气管镜是否在正确位置。 开发环境 硬件:Magewell的USB Capture HDMI Gen 2 IDE:VS2022 FrameWork: .Net6 WINUI Package: MVVMToolKit NLog Ma…...

Jetpack Compose 中,DisposableEffect、LaunchedEffect 和 sideEffect 区别和用途
在 Jetpack Compose 中,DisposableEffect、LaunchedEffect 和 sideEffect 都是用于处理副作用(Side Effects)的 API,但它们的用途和触发时机不同。以下是它们的核心概念和区别: 1. 副作用(Side Effect&…...

STM32开发,创建线程栈空间大小判断
1. 使用RTOS提供的API函数(以FreeRTOS为例) 函数原型:UBaseType_t uxTaskGetStackHighWaterMark(TaskHandle_t xTask)功能:获取指定任务堆栈中剩余的最小空间(以字为单位,非字节)。使用步骤&am…...

正则表达式检测文件类型是否为视频或图片
// 配置化文件类型检测(集中管理支持的类型) const FILE_TYPE_CONFIG {video: {extensions: [mp4, webm, ogg, quicktime], // 可扩展支持更多格式regex: /^video\/(mp4|webm|ogg|quicktime)$/i // 自动生成正则},image: {extensions: [jpeg, jpg, png,…...

Qwen大语言模型里,<CLS>属于特殊的标记:Classification Token
Qwen大语言模型里,<CLS>属于特殊的标记:Classification Token 目录 Qwen大语言模型里,<CLS>属于特殊的标记:Classification Token功能解析工作机制应用场景举例说明技术要点在自然语言处理(NLP)领域 都是<CLS> + <SEP>吗?一、CLS和SEP的作用与常见用法1. **CLS标…...

TDengine 开发指南——无模式写入
简介 在物联网应用中,为了实现自动化管理、业务分析和设备监控等多种功能,通常需要采集大量的数据项。然而,由于应用逻辑的版本升级和设备自身的硬件调整等原因,数据采集项可能会频繁发生变化。为了应对这种挑战,TDen…...

分布式互斥算法
1. 概述:什么是分布式互斥 假设有两个小孩想玩同一个玩具(临界资源),但玩具只有一个,必须保证一次只有一个人能够玩。当一个小孩在玩时,另一个小孩只能原地等待,直到玩完才能轮到自己。这就是 …...

第34次CCF-CSP认证真题解析(目标300分做法)
第34次CCF-CSP认证 矩阵重塑(其一)AC代码及解析矩阵重塑(其二)AC代码及解析货物调度AC代码及解析 矩阵重塑(其一) 输入输出及样例: AC代码及解析 1.线性化原矩阵 :由于cin的特性我们…...
video-audio-extractor:视频转换为音频
软件介绍 前几天在网上看见有人分享了一个源码,大概就是py调用的ffmpeg来制作的。 这一次我带来源码版(需要py环境才可以运行),开箱即用版本(直接即可运行) 软件特点 软件功能 视频提取音频:…...

rk3588 区分两个相同的usb相机
有时候会插入两个一模一样的usb相机,担心每次启动他们所对应的设备节点 /dev/video* 会变化,所以需要绑定usb口,区分两个相机。把两个相机都插入后,查看usb信息 rootrk3588:/# udevadm info --attribute-walk --name/dev/video0U…...
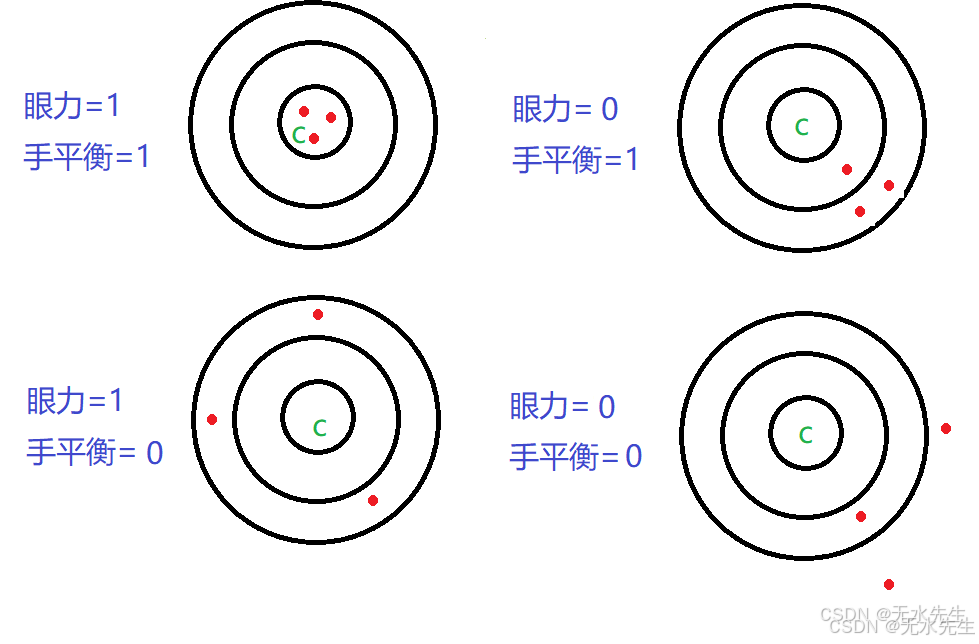
[概率论基本概念4]什么是无偏估计
关键词:Unbiased Estimation 一、说明 对于无偏和有偏估计,需要了解其叙事背景,是指整体和抽样的关系,也就是说整体的叙事是从理论角度的,而估计器原理是从实践角度说事;为了表明概率理论(不可…...

乐观锁与悲观锁的实现和应用
乐观锁与悲观锁:原理、实现与应用详解 在并发编程和数据库操作中,乐观锁和悲观锁是两种重要的并发控制策略,它们在原理、实现方式和应用场景上存在显著差异。下面我们将通过图文结合的方式,深入探讨这两种锁机制。 一、基本概念 1…...
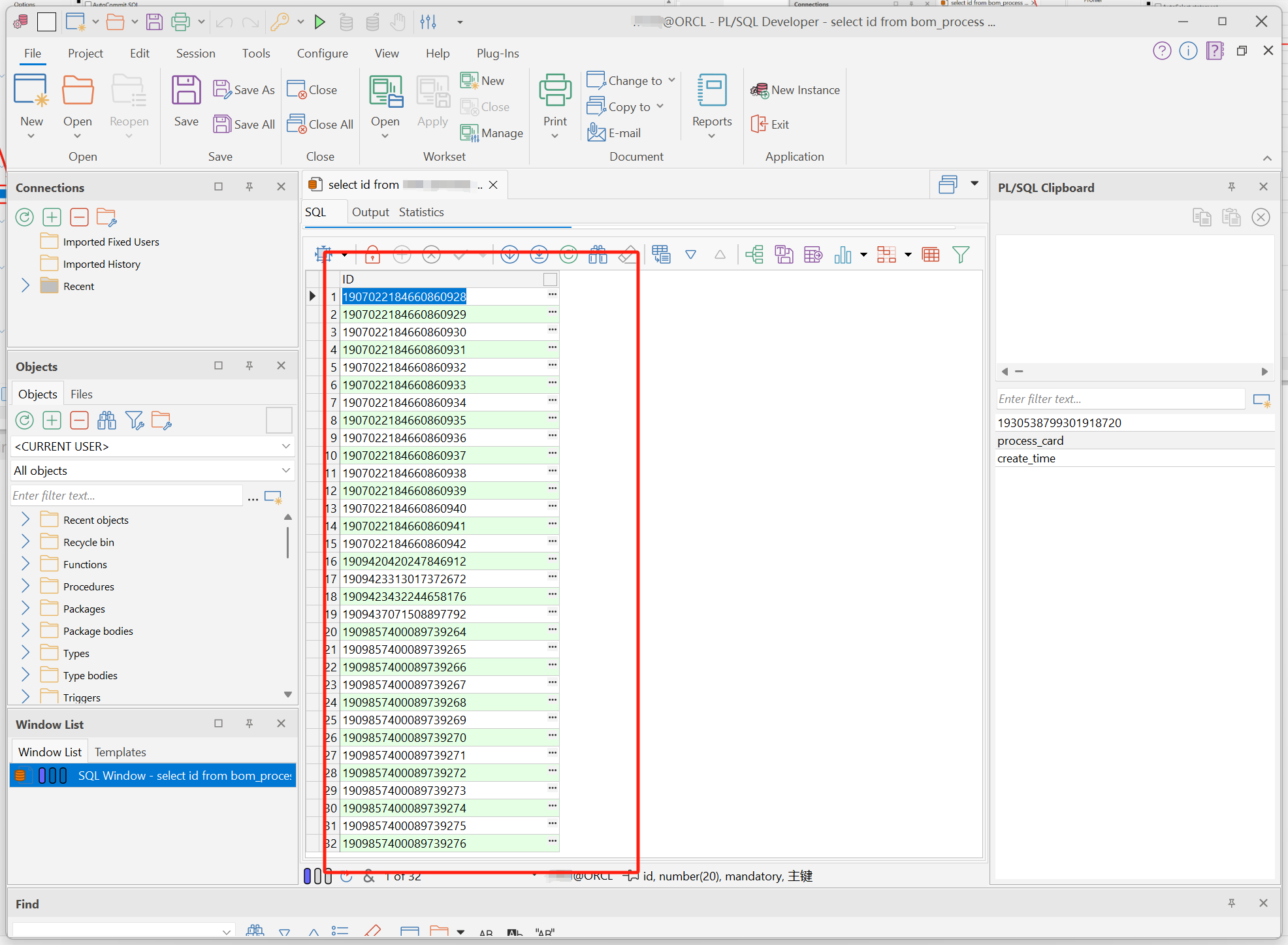
PL/SQLDeveloper中数值类型字段查询后显示为科学计数法的处理方式
PL/SQLDeveloper中数值类型字段查询后显示为科学计数法的处理方式 文章目录 PL/SQLDeveloper中数值类型字段查询后显示为科学计数法的处理方式1. 查询效果2. 处理方式3. 再次查询 1. 查询效果 2. 处理方式 3. 再次查询...

【vue】Uniapp 打包Android 文件选择上传问题详解~
需求 uniapp兼容android app,pc,h5的文件选择并上传功能。 需要支持拍照和相册选择,以及选择其他类型文件上传~ 实践过程和问题 开始使用uni-file-picker组件 以为很顺利,android模拟器测试…… 忽略了平台兼容性提示~&#…...
深度解析)
ASR技术(自动语音识别)深度解析
ASR技术(自动语音识别)深度解析 自动语音识别(Automatic Speech Recognition,ASR)是将人类语音转换为文本的核心技术,以下是其全面解析: 一、技术原理架构 #mermaid-svg-QlJOWpMtlGi9LNeF {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:1…...

图论水题2
div2 361 D. Tree Requests 题意 对于一颗 n n n节点的树,每个节点有一个字母,有 m m m次询问,每次询问求对于顶点 v v v的子树中深度为 h h h的结点能否组成一个回文串$ (1 \leq n \leq m \leq 5 \cdot 10^5) $ 思路 关于 v v v的子树结…...

Ctrl-Crash 助力交通安全:可控生成逼真车祸视频,防患于未然
视频扩散技术虽发展显著,但多数驾驶数据集事故事件少,难以生成逼真车祸图像,而提升交通安全又急需逼真可控的事故模拟。为此,论文提出可控车祸视频生成模型 Ctrl-Crash,它以边界框、碰撞类型、初始图像帧等为条件&…...