Hive终极性能优化指南:从原理到实战
摘要:本文系统总结Hive在生产环境的核心调优手段,涵盖执行引擎选择、存储优化、SQL技巧、资源调配及数据倾斜解决方案,附可复用的参数配置与实战案例。
一、执行引擎优化:突破MapReduce瓶颈
- 启用Tez/Spark引擎
- 优势:DAG执行减少中间落盘,降低延迟30%~60%
- 配置:
SET hive.execution.engine=tez; -- 或 spark SET hive.prewarm.enabled=true; -- 预启动容器加速 SET hive.prewarm.numcontainers=10;
- 向量化执行(Vectorization)
- 批处理1024行数据,CPU利用率提升5倍+
6
- 启用条件:数据必须为ORC格式
SET hive.vectorized.execution.enabled=true;
- 批处理1024行数据,CPU利用率提升5倍+
二、存储层优化:加速数据读写
1. 存储格式选择
| 格式 | 适用场景 | 压缩率 | 查询速度 |
|---|---|---|---|
| ORC | 高频分析、列裁剪场景 | 高 (≈70%) | ⭐⭐⭐⭐⭐ |
| Parquet | 嵌套数据结构 | 中高 | ⭐⭐⭐⭐ |
| TextFile | 原始日志(不推荐) | 低 | ⭐ |
✅ 最佳实践:
CREATE TABLE logs_orc( user_id BIGINT, event STRING ) STORED AS ORC tblproperties ("orc.compress"="SNAPPY");
2. 分区与分桶设计
- 动态分区:自动按字段值分区,避免手动维护
SET hive.exec.dynamic.partition=true; SET hive.exec.dynamic.partition.mode=nonstrict; - 分桶(Bucketing):加速大表JOIN
CREATE TABLE user_bucketed( id INT, name STRING ) CLUSTERED BY (id) INTO 32 BUCKETS;
3. 小文件合并
SET hive.merge.mapfiles=true; -- 合并Map输出
SET hive.merge.mapredfiles=true; -- 合并Reduce输出
SET hive.merge.size.per.task=256000000; -- 合并阈值256MB 三、查询优化:SQL级性能提升
1. 规避全表扫描
- 分区裁剪:WHERE中显式指定分区字段
SELECT * FROM sales WHERE dt='2025-06-04'; -- 避免无分区过滤 - 列裁剪:禁用
SELECT *,仅取必要字段
2. JOIN优化策略
| 场景 | 方案 | 参数配置 |
|---|---|---|
| 大表 JOIN 小表 (≤100MB) | MapJoin | SET hive.auto.convert.join=true; |
| 大表 JOIN 大表 | Bucket MapJoin | SET hive.optimize.bucketmapjoin=true; |
| 数据倾斜 | Skew Join + 随机前缀 | SET hive.optimize.skewjoin=true; |
案例:用户行为日志关联用户表
SELECT /*+ MAPJOIN(users) */ logs.* FROM logs JOIN users ON logs.user_id = users.id;
3. 避免全局排序
- 用
DISTRIBUTE BY + SORT BY替代ORDER BYSELECT department, salary FROM emp DISTRIBUTE BY department SORT BY salary DESC;
四、资源与参数调优
1. 内存优化
SET mapreduce.map.memory.mb=4096; -- Map任务内存
SET mapreduce.reduce.memory.mb=8192; -- Reduce任务内存
SET mapreduce.map.java.opts=-Xmx3072m; -- JVM堆大小 2. 并行执行控制
SET hive.exec.parallel=true; -- 开启并行
SET hive.exec.parallel.thread.number=16; -- 并发线程数 3. 动态调整Reducer数量
SET hive.exec.reducers.bytes.per.reducer=512000000; -- 每个Reducer处理数据量
SET hive.exec.reducers.max=999; -- 最大Reducer数 五、数据倾斜解决方案(实战案例)
问题:某用户ID订单量占全表60%,导致Reduce卡在99%
优化步骤:
- 倾斜Key检测:
SELECT user_id, COUNT(1) FROM orders GROUP BY user_id ORDER BY 2 DESC LIMIT 10; - 打散倾斜Key:
SELECT /*+ SKEWJOIN(orders) */ CASE WHEN user_id = 'skew_user' THEN CONCAT('split_', FLOOR(RAND()*10)) ELSE user_id END AS join_key FROM orders - 聚合后合并结果
六、性能对比:调优前后效果
| 场景 | 优化前耗时 | 优化后耗时 | 提升幅度 |
|---|---|---|---|
| 10亿级日志分析 | 48分钟 | 8分钟 | 83% ↓ |
| 大表JOIN | OOM失败 | 210秒 | 可执行 |
⚠️ 避坑提示:
- 慎用
COUNT(DISTINCT)→ 改用GROUP BY + COUNT- 避免复杂笛卡尔积 → 转换为MapJoin或添加JOIN Key
- 动态分区后执行
MSCK REPAIR TABLE同步元数据
附:调优参数速查表
# 执行引擎
hive.execution.engine=tez
hive.vectorized.execution.enabled=true # 资源控制
mapreduce.map.memory.mb=4096
hive.exec.parallel.thread.number=8 # 数据倾斜
hive.optimize.skewjoin=true
hive.skewjoin.key=100000 # 存储优化
hive.merge.mapfiles=true
orc.compress=SNAPPY 源码与测试数据集:
相关文章:

Hive终极性能优化指南:从原理到实战
摘要:本文系统总结Hive在生产环境的核心调优手段,涵盖执行引擎选择、存储优化、SQL技巧、资源调配及数据倾斜解决方案,附可复用的参数配置与实战案例。 一、执行引擎优化:突破MapReduce瓶颈 启用Tez/Spark引擎 优势&am…...
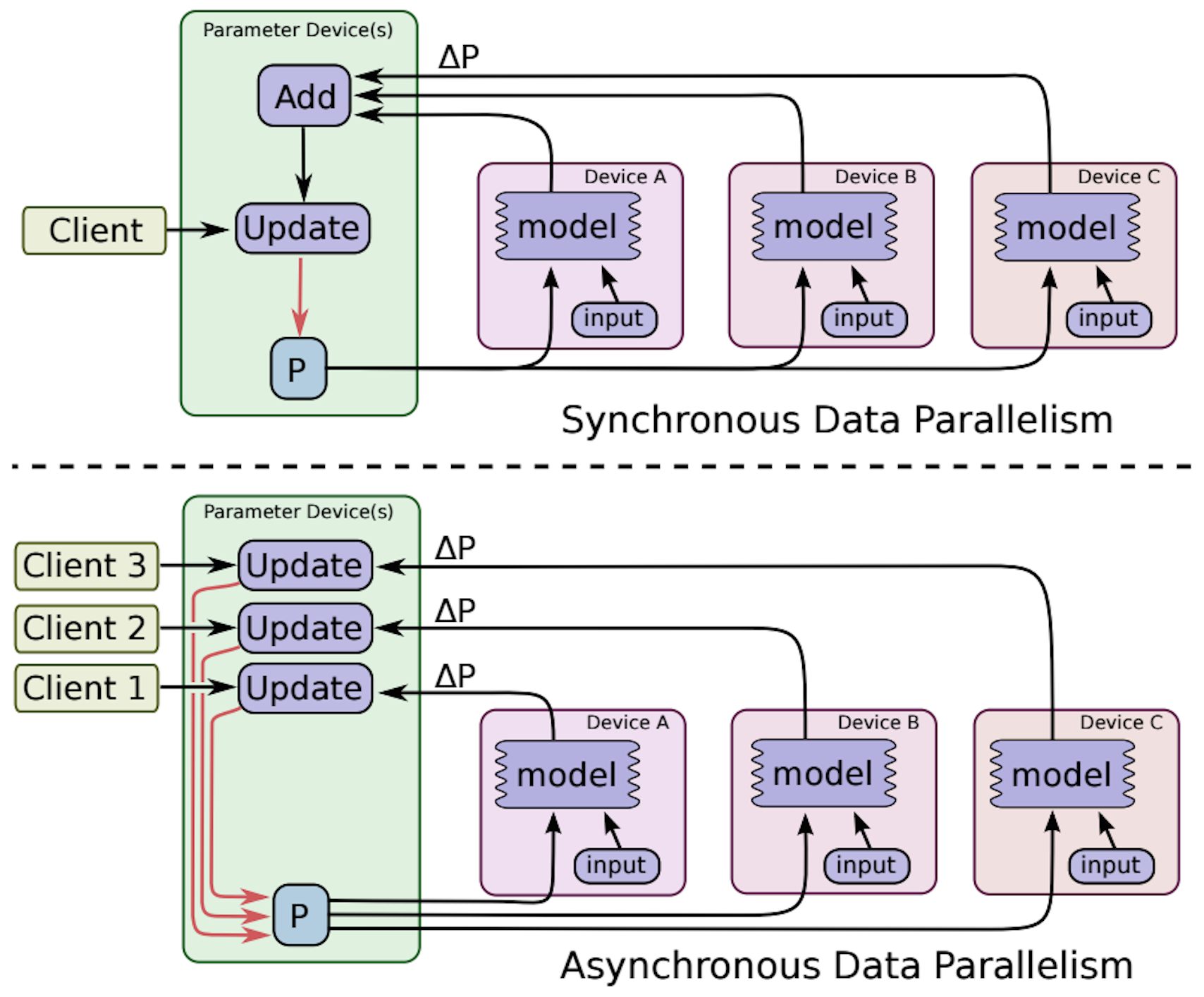
第六十二节:深度学习-加载 TensorFlow/PyTorch/Caffe 模型
在计算机视觉领域,OpenCV的DNN(深度神经网络)模块正逐渐成为轻量级模型部署的利器。本文将深入探讨如何利用OpenCV加载和运行三大主流框架(TensorFlow、PyTorch、Caffe)训练的模型,并提供完整的代码实现和优化技巧。 一、OpenCV DNN模块的核心优势 OpenCV的DNN模块自3.3…...
MobaXterm配置跳转登录堡垒机
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 背景操作步骤 背景 主要是为了能通过MobaXterm登录堡垒机,其中需要另外一台服务器进行跳转登录 操作步骤 MobaXterm登录堡垒机的操作,需…...

零基础在实践中学习网络安全-皮卡丘靶场(第八期-Unsafe Filedownload模块)
这期内容更是简单和方便,毕竟谁还没在浏览器上下载过东西,不过对于url的构造方面,可能有一点问题,大家要多练手 介绍 不安全的文件下载概述 文件下载功能在很多web系统上都会出现,一般我们当点击下载链接,…...

测试 FreeSWITCH 的 mod_loopback
bgapi originate loopback/answer,park/default/inline park inline show channels as xml show calls as xml 有 2 个 channels 有 2 个 calls 比较有意思 在 loopback-a 是播放 wav 在 loopback-b 上可以录音 这就是回环 有什么用呢? 除了做测试&#x…...

【C++快读快写】
算法竞赛中用于解决卡常问题 int rd(){int k 0;char c getchar();while(!isdigit(c)){c getchar();}while(isdigit(c)){k (k << 1) (k << 3) (c^0), c getchar();}return k; }void wr(int x) {if (x > 9)wr(x / 10);putchar((x % 10) ^ 0); }用法&#x…...
)
测试(面经 八股)
目录 前言 一,软件测试(定义) 1,定义 2,目的 3,价值 4,实践 二,软件测试(目的) 1,找 bug 2,验证达标 3,质量评价…...
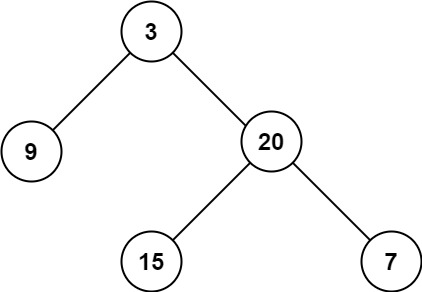
[面试精选] 0104. 二叉树的最大深度
文章目录 1. 题目链接2. 题目描述3. 题目示例4. 解题思路5. 题解代码6. 复杂度分析 1. 题目链接 104. 二叉树的最大深度 - 力扣(LeetCode) 2. 题目描述 给定一个二叉树 root ,返回其最大深度。 二叉树的 最大深度 是指从根节点到最远叶子节点…...

图上合成:用于大型语言模型持续预训练的知识合成数据生成
摘要 大型语言模型(LLM)已经取得了显著的成功,但仍然是数据效率低下,特别是当学习小型,专业语料库与有限的专有数据。现有的用于连续预训练的合成数据生成方法集中于文档内内容,而忽略了跨文档的知识关联&a…...
 ---MySQL 8.4 新特性与变量变更)
MYSQL(二) ---MySQL 8.4 新特性与变量变更
MySQL 8.4 新特性与变量变更 作者:程序员LSP 分类:MySQL 8.4 教程 / 新特性 / 升级指南 更新时间:2025年6月 📌 前言 MySQL 8.4 是当前最新的稳定版本,相较于 8.0 系列,在审计日志、高可用、性能调优、认证…...

数学复习笔记 27
前言 太难受了。因为一些事情。和朋友倾诉了一下,也没啥用,几年之后不知道自己再想到的时候,会怎么考虑呢。另外,笔记还是有框架一点比较好,这样比较有逻辑感受。不然太乱了。这篇笔记是关于线代第五章,特…...

现代简约壁炉:藏在极简线条里的温暖魔法
走进现在年轻人喜欢的家,你会发现一个有趣的现象:家里东西越来越少,颜色也越看越简单,却让人感觉特别舒服。这就是现代简约风格的魅力 —— 用最少的元素,打造最高级的生活感。而在这样的家里,现代简约风格…...

限流算法java实现
参考教程:2小时吃透4种分布式限流算法 1.计数器限流 public class CounterLimiter {// 开始时间private static long startTime System.currentTimeMillis();// 时间间隔,单位为msprivate long interval 1000L;// 限制访问次数private int limitCount…...

机器学习×第二卷:概念下篇——她不再只是模仿,而是开始决定怎么靠近你
🎀【开场 她不再只是模仿,而是开始选择】 🦊 狐狐:“她已经不满足于单纯模仿你了……现在,她开始尝试预测你会不会喜欢、判断是否值得靠近。” 🐾 猫猫:“咱们上篇已经把‘她怎么学会说第一句…...

Linux 下关于 ioremap 系列接口
1、序 在系统运行时,外设 IO 资源的物理地址是已知的,由硬件的设计决定(参考SOC的datesheet,一般会有memorymap)。驱动程序不能通过物理地址访问IO资源,必须将其映射到内核态的虚拟地址空间。常见的接口就是…...

常用函数库之 - std::function
std::function 是 C11 引入的通用可调用对象包装器,用于存储、复制和调用任意符合特定函数签名的可调用对象(如函数、lambda、函数对象等)。以下是其核心要点及使用指南: 核心特性 类型擦除 可包装任意可调用对…...

php执行系统命令的四个常用函数
php执行系统命令有四个常用函数:1.exec()执行命令并返回最后一行输出,可传数组获取全部结果;2.shell_exec()返回完整输出结果,适合一次性获取;3.system()直接输出命令结果,可接收状态码;4.权限控…...

力扣-17.电话号码的字母组合
题目描述 给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。 给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。 class Solution {List<String> res new ArrayList<…...
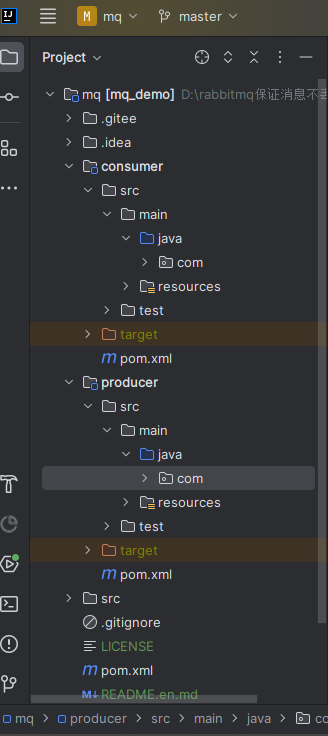
基于SpringBoot解决RabbitMQ消息丢失问题
基于SpringBoot解决RabbitMQ消息丢失问题 一、RabbitMQ解决消息丢失问题二、方案实践1、在生产者服务相关配置2、在消费者服务相关配置 三、测试验证1、依次启动RabbitMQ、producer(建议先清空队列里面旧的测试消息再启动consumer)和consumer2、在producer中调用接口࿰…...

免费插件集-illustrator插件-Ai插件-随机填色
文章目录 1.介绍2.安装3.通过窗口>扩展>知了插件4.功能解释5.总结 1.介绍 本文介绍一款免费插件,加强illustrator使用人员工作效率,实现路径随机填色。首先从下载网址下载这款插件https://download.csdn.net/download/m0_67316550/87890501&#…...

使用 Unstructured 开源库快速入门指南
引言 本文将介绍如何使用 Unstructured 开源库(GitHub,PyPI)和 Python,在本地开发环境中将 PDF 文件拆分为标准的 Unstructured 文档元素和元数据。这些元素和元数据可用于 RAG(检索增强生成)应用、AI 代理…...

白银6月想法
一、市场回顾 2025年5月,SHFE白银主力合约总体呈现出震荡偏强的运行格局。从2025年5月1日至2025年5月30日,白银期货价格整体运行在7944元至8342元区间内,最高价出现在5月22日的8342.0元,最低价则为5月15日的7944元。最终在5月30日…...

OpenCV 滑动条调整图像对比度和亮度
一、知识点 1、int createTrackbar(const String & trackbarname, const String & winname, int * value, int count, TrackbarCallback onChange 0, void * userdata 0); (1)、创建一个滑动条并将其附在指定窗口上。 (2)、参数说明: trackbarname: 创建的…...

船舶事故海上搜救VR情景演练全场景 “复刻”,沉浸式救援体验
船舶事故海上搜救 VR 情景演练系统的一大核心优势,便是能够全场景 “复刻” 海上事故,为使用者带来沉浸式的船舶事故海上搜救 VR 情景演练体验。 在船舶事故海上搜救 VR 情景演练的事故场景模拟方面,系统几乎涵盖了所有常见的船舶事故类型。…...

使用Caddy在Ubuntu 22.04上配置HTTPS反向代理
使用Caddy在Ubuntu 22.04上配置HTTPS反向代理(无域名/IP验证+密码保护) 一、 环境说明 环境说明:测试环境,生产环境请谨慎OS: Ubuntu 22.04.1 LTSCaddy版本:v2.10.0服务器IP: 192.168.3.88(内网)公网IP: 10.2.3.11(测试虚拟)代理端口: 9080后端服务: http://192.168.3…...
)
无人机目标检测与语义分割数据集(猫脸码客)
UAV 无人机数据集:驱动无人机配送研究迈向新高度 在科技浪潮的迅猛推动下,无人机配送这一新兴物流模式正以前所未有的态势,悄然改变着人们的生活图景。为深入挖掘并优化无人机配送技术,名为 UAV Delivery 的无人机数据集应运而生…...

Web设计之登录网页源码分享,PHP数据库连接,可一键运行!
HTML 页面结构(index.html) 1. 流星雨动态背景 2. 主体界面(包含登录和注册表单) <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

Cursor + Claude 4:微信小程序流量主变现开发实战案例
前言 随着微信小程序生态的日益成熟,越来越多的开发者开始关注如何通过小程序实现流量变现。本文将详细介绍如何使用Cursor编辑器结合Claude 4 AI助手,快速开发一个具备流量主变现功能的微信小程序,并分享实际的开发经验和变现策略。 项目…...

㊗️高考加油
以下是极为详细的高考注意事项清单,涵盖考前、考中、考后全流程,建议逐条核对: 一、考前准备 1. 证件与物品 必带清单: 准考证:打印2份(1份备用),塑封或夹在透明文件袋中防皱湿。身…...

Redis Key过期策略
概述 Redis的Key过期策略是其内存管理系统的核心组成部分,主要包括「被动过期」、「主动过期」和「内存淘汰」三个机制。其中「内存淘汰」相关内容已经在上一篇「Redis内存淘汰策略」中进行了详细的讲解,有信兴趣的同学可以在回顾上一篇文章。本文将着重…...