ORM框架(SQLAlchemy 与 Tortoise )
注:本文是python的学习笔记;不是教程!不是教程!内容可能有所疏漏,欢迎交流指正。
框架概述
什么是ORM?
ORM(Object-Relational Mapping,对象关系映射)是一种编程技术,用于在面向对象编程语言和关系数据库之间建立映射关系。它允许开发者使用面向对象的方式操作数据库,而不需要编写复杂的SQL语句。
ORM的核心优势:
- 代码可读性:使用Python对象而非SQL语句,代码更直观
- 数据库无关性:同一套代码可以在不同数据库间切换
- 安全性:自动防止SQL注入攻击
- 维护性:模型变更时自动处理数据库结构变化
SQLAlchemy
SQLAlchemy是Python生态系统中最成熟、功能最全面的ORM框架,自2006年发布以来一直是企业级应用的首选。它提供了完整的SQL工具包和对象关系映射系统。
核心优势:
- 成熟稳定:经过15+年生产环境验证,bug少,稳定性高
- 功能全面:支持复杂的数据库操作,包括原生SQL、存储过程、视图等
- 灵活架构:支持Core(表达式语言)和ORM两种使用模式
- 强大查询:提供类似SQL的查询构建器,支持复杂的联表查询
- 丰富生态:拥有大量第三方扩展,如Flask-SQLAlchemy、FastAPI-SQLAlchemy等
- 多数据库支持:支持PostgreSQL、MySQL、SQLite、Oracle、SQL Server等
适用场景:
- 企业级应用开发
- 复杂的数据库操作需求
- 需要高度定制化的项目
- 对稳定性要求极高的系统
Tortoise ORM
Tortoise ORM是受Django ORM启发的异步ORM框架,专为现代异步Python应用设计。它提供了简洁的API和出色的异步性能。
核心优势:
- 原生异步:所有操作都是异步的,性能优异,特别适合高并发场景
- 语法简洁:类似Django ORM的语法,学习曲线平缓
- 完美集成:与FastAPI、Starlette等异步框架无缝集成
- 自动化程度高:减少样板代码,开发效率高
- 现代化设计:基于Python 3.7+的现代特性设计
- 类型提示:完整的类型提示支持,IDE友好
适用场景:
- 现代异步Web应用(FastAPI、Starlette)
- 高并发API服务
- 微服务架构
- 对开发效率要求高的项目
核心特性对比
| 特性 | SQLAlchemy | Tortoise ORM | 详细说明 |
|---|---|---|---|
| 同步/异步 | 同步为主,2.0版本支持异步 | 原生异步 | Tortoise在异步场景下性能更优 |
| 学习曲线 | 较陡峭,概念复杂 | 平缓,类似Django ORM | 新手更容易上手Tortoise |
| 性能 | 优秀,但同步操作有限制 | 异步操作性能卓越 | 高并发场景Tortoise优势明显 |
| 生态系统 | 非常丰富,插件众多 | 相对较新,生态在快速发展 | SQLAlchemy生态更成熟 |
| 文档质量 | 详尽完整,示例丰富 | 良好,但不如SQLAlchemy全面 | SQLAlchemy文档更完善 |
| 社区支持 | 庞大活跃,问题解决快 | 快速增长,响应积极 | SQLAlchemy社区更大 |
| 企业采用 | 广泛使用,大厂首选 | 新兴选择,增长迅速 | SQLAlchemy更适合企业级 |
| 数据库支持 | 全面支持主流数据库 | 支持主要数据库 | SQLAlchemy支持更全面 |
| 查询复杂度 | 支持极复杂查询 | 支持常见复杂查询 | SQLAlchemy在复杂查询上更强 |
| 代码风格 | 显式,配置灵活 | 隐式,约定优于配置 | 看个人和团队偏好 |
SQLAlchemy 与 Tortoise ORM
一:Tortoise ORM 特性
- 异步特性:Tortoise ORM 的所有数据库操作都是异步的,这意味着它们可以在单线程中同时处理多个数据库请求,而不会阻塞彼此。这大大提高了应用的并发性和性能。
- 模型定义:在Tortoise ORM 中,开发者使用Python类来定义数据库表结构。这些类中的属性对应于数据库表中的列,这使得数据库操作更加直观和易于理解。
- 查询构建:Tortoise ORM 提供了强大的查询构建功能,允许开发者构建复杂的查询条件,以检索所需的数据。这包括使用链式调用、比较运算符、逻辑运算符等。
- 关系映射:Tortoise ORM 支持定义模型之间的关系,如一对一、一对多、多对多等。这使得开发者可以轻松地处理复杂的数据关系,并在代码中以直观的方式表示它们。
- 迁移和同步:Tortoise ORM 还提供了数据库迁移工具,用于管理数据库模式的变更。这使得在应用开发过程中,可以轻松地添加、修改或删除表结构,而无需手动编写SQL语句。
二:模型定义
1. SQLAlchemy ORM
SQLAlchemy 是 Python 中最成熟的 ORM 框架,但其语法与 Django ORM 有较大差异。在 FastAPI 中,通常使用 SQLAlchemy 的声明式方式定义模型。
SQLAlchemy使用声明式方式定义模型,需要显式定义所有关系
# models.py# 需要先导入所有需要使用的字段类型
from sqlalchemy import Column, Integer, String, ForeignKey, Numericfrom sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationshipBase = declarative_base()# 主表 (模型B)
class Category(Base):__tablename__ = "categories" # 数据库表名称id = Column(Integer, primary_key=True)name = Column(String(50))# 必须显式定义反向关系products = relationship("Product", back_populates="category")# 从表 (模型A)
class Product(Base):__tablename__ = "products"id = Column(Integer, primary_key=True)name = Column(String(100))price = Column(Numeric(10, 2))# 第一步:定义外键约束, 这是数据库级别的外键约束category_id = Column(Integer, ForeignKey("categories.id"))# 第二步:定义反向关系, 这是 Python 对象级别的关系category = relationship("Category", back_populates="products")# 在 SQLAlchemy 中,定义关系需要两步:
1. 在从表定义外键约束
2. 在两侧都定义 relationship 来创建对象间的关联# 使用方式:
通过 product.category 访问产品所属类别
通过 category.products 访问类别下所有产品
2. Tortoise ORM
Tortoise ORM 语法与 Django ORM 非常相似,更加简洁直观自动处理反向关系。
CharField 字符串类型字段
- max_length:字符串的最大长度。
- default:字段的默认值。
- null:是否允许字段为NULL。默认为False。
- unique:字段值是否必须在数据库中唯一。默认为False。
- index:是否为该字段创建索引。默认为False。
- description:字段的描述信息,主要用于文档和生成的SQL schema。
- pk:是否将此字段设置为主键。默认为False。
- generated:是否为自动生成的字段(如自增主键)。默认为False。
FloatField 浮点类型字段
- default, null, unique, index, description, pk, generated: 与CharField相同。
- gt, lt, ge, le:用于设置字段值的范围限制(大于、小于、大于等于、小于等于)。
IntegerField 整数类型字段
- default, null, unique, index, description, pk, generated:与CharField相同。
- gt, lt, ge, le:用于设置字段值的范围限制(大于、小于、大于等于、小于等于)。
BooleanField 布尔类型字段
- default, null, description:与CharField相同。
DateField 和 DateTimeField 日期时间类型字段
- auto_now:如果设置为True,则在对象保存时自动设置为当前日期/时间。默认为False。
- auto_now_add:如果设置为True,则在对象第一次保存时自动设置为当前日期/时间。默认为False。
- default, null, unique, index, description, pk:与CharField相同。
ForeignKeyField 关系型字段
- to (str or Type[Model]):指定外键关联的模型。
- related_name (str):在关联模型上创建反向关系的名称。
- on_delete (str):当关联的对象被删除时的行为(如CASCADE、SET_NULL等)。
- default, null, description, pk, index:与CharField相同。
ManyToManyField 关系型字段
- through:用于定义多对多关系的中间表。如果不指定,Tortoise ORM将自动创建一个中间表。
- related_name:与ForeignKeyField中的用法相同,用于反向查询。
- default, null, description, pk, index:与CharField相同。
TextField文本类型字段
- default, null, description:与CharField相同。通常用于存储大量文本。
JSONField序列话类型字段
- default, null, description:与CharField相同。用于存储JSON格式的数据。
# models.py
from tortoise import fields, models
from tortoise.contrib.pydantic import pydantic_model_creator# 主表 (模型B)
class Category(models.Model):id = fields.IntField(pk=True)name = fields.CharField(max_length=50)# 不需要显式定义反向关系,会自动创建 products 属性# products = fields.ReverseRelation["Product"] # 这行可以不写,会自动生成# 从表 (模型A)
class Product(models.Model):id = fields.IntField(pk=True)name = fields.CharField(max_length=100)price = fields.DecimalField(max_digits=10, decimal_places=2)# 只需在这一侧定义外键category = fields.ForeignKeyField("models.Category", related_name="products", on_delete=fields.CASCADE)# 使用方式:
通过 product.category 访问产品所属类别
通过 category.products 访问类别下所有产品 # 通过外键的related_name="products" 的名字来访问
模型定义对比总结:
| 方面 | SQLAlchemy | Tortoise ORM |
|---|---|---|
| 语法复杂度 | 较复杂,需要显式定义关系 | 简洁,自动处理反向关系 |
| 字段定义 | 需要导入具体字段类型 | 统一的fields模块 |
| 关系定义 | 双向显式定义 | 单向定义,自动生成反向 |
| 元数据配置 | 使用__tablename__ | 使用Meta类 |
字段参数详解
通用参数:
null: 是否允许为空(默认False)default: 默认值unique: 是否唯一(默认False)index: 是否创建索引(默认False)description: 字段描述
CharField特有参数:
max_length: 最大长度(必需)
数值字段特有参数:
ge: 大于等于gt: 大于le: 小于等于lt: 小于
时间字段特有参数:
auto_now: 每次保存时自动更新auto_now_add: 创建时自动设置
外键字段特有参数:
related_name: 反向关系名称on_delete: 删除策略(CASCADE、SET_NULL、RESTRICT等)
三:数据库迁移
1. SQLAlchemy ORM迁移(使用 Alembic)
SQLAlchemy 本身不提供迁移工具,通常与 Alembic 配合使用。
1:安装 Alembic 库
pip install alembic
2:初始化 Alembic
alembic init alembic# 这会创建以下文件结构:
# alembic/
# ├── versions/ # 迁移文件目录
# ├── env.py # 环境配置
# ├── script.py.mako # 迁移脚本模板
# └── alembic.ini # 配置文件
3:配置 alembic.ini 文件
sqlalchemy.url = sqlite:///./app.db
4:配置env.py文件
2. Tortoise ORM迁移(使用 aerich)
Tortoise ORM 使用 aerich 进行迁移。
1:安装 aerich 库
pip install aerich
2:在 FastAPI 应用中配置数据库
# main.py
from fastapi import FastAPI
from tortoise.contrib.fastapi import register_tortoiseapp = FastAPI()TORTOISE_ORM = {"connections": {"default": "postgresql://user:password@localhost/dbname"},"apps": {"models": {"models": ["app.models", "aerich.models"],"default_connection": "default",},},
}register_tortoise(app,config=TORTOISE_ORM,generate_schemas=False, # 不自动生成表,使用迁移add_exception_handlers=True,
)
3:初始化配置(整个项目只需执行一次)
aerich init -t app.main.TORTOISE_ORM # TORTOISE_ORM配置的位置# 初始化完成会在 当前目录下 生成一个文件(pyproject.toml) 和文件夹(migrations)
# pyproject.toml:保存配置文件路径,低版本可能是aerich.ini
# migrations:存放迁移文件的目录
4:模型迁移(在数据库创建对应模型的数据表)
aerich init-db# 此时数据库中就会有对应数据模型的数据表
# 如果TORTOISE_ORM配置文件中的models改了名字,则执行这条命令时需要增加**–app**参数,来指定修改的名称
5:更改模型字段后重新生成迁移文件
aerich migrate [--name '迁移记录'] # 标记修改操作记录(可选)
6:数据迁移(更新数据库的表字段)
aerich upgrade # 基于第五步操作
7:回滚迁移
aerich downgrade # 默认回退上一步的版本
8:查看历史迁移记录
aerich history
四:数据库操作(CURD)
1. SQLAlchemy CURD 操作
from sqlalchemy.orm import Session
from . import models, schemas# 创建 (Create)
def create_user(db: Session, user: schemas.UserCreate):"""创建用户"""# 方法1:使用构造函数db_user = models.User(username=user.username,email=user.email,hashed_password="hashed_password")db.add(db_user) # 添加到会话db.commit() # 提交事务db.refresh(db_user) # 刷新对象属性return db_user# 读取 (Read)
def get_user(db: Session, user_id: int):return db.query(models.User).filter(models.User.id == user_id).first()def get_users(db: Session, skip: int = 0, limit: int = 100):return db.query(models.User).offset(skip).limit(limit).all()def get_users_by_filter(db: Session):# 复杂查询示例return (db.query(models.User).filter(models.User.is_active == True).order_by(models.User.username).all())# 更新 (Update)
def update_user(db: Session, user_id: int, user_data: schemas.UserUpdate):db_user = db.query(models.User).filter(models.User.id == user_id).first()if db_user:# 更新模型属性for key, value in user_data.dict(exclude_unset=True).items():setattr(db_user, key, value)db.commit()db.refresh(db_user)return db_user# 删除 (Delete)
def delete_user(db: Session, user_id: int):db_user = db.query(models.User).filter(models.User.id == user_id).first()if db_user:db.delete(db_user)db.commit()return db_user# 关系查询
def get_user_posts(db: Session, user_id: int):db_user = db.query(models.User).filter(models.User.id == user_id).first()if db_user:return db_user.posts # 使用关系属性return []# 多对多关系
def add_tag_to_post(db: Session, post_id: int, tag_id: int):post = db.query(models.Post).filter(models.Post.id == post_id).first()tag = db.query(models.Tag).filter(models.Tag.id == tag_id).first()if post and tag:post.tags.append(tag)db.commit()
2. Tortoise ORM CURD 操作
from tortoise.transactions import in_transaction
from . import models, schemas# 创建 (Create)
async def create_user(user: schemas.UserCreate):return await models.User.create(username=user.username,email=user.email,hashed_password="hashed_password")# 读取 (Read)
async def get_user(user_id: int):'''get() 方法用于根据主键获取单条数据。如果数据不存在,则抛出错误get_or_none() 方法用于根据主键获取单条数据。如果数据不存在,将返回 None'''return await models.User.get(id=user_id)return await models.User.get_or_none(id=user_id)async def get_user(user_id: int):'''filter() 方法用于根据条件查询数据,返回满足条件的数据集(QuerySet对象)。使用 first() 方法获取第一个结果;使用 all() 方法获取所有的查询结果。'''return await models.User.filter(id=user_id).first()return await models.User.filter(id=user_id).all()async def get_users(skip: int = 0, limit: int = 100):'''all() 方法用于查询所有数据,返回所有数据集(QuerySet对象)。如果不加任何条件,它会返回表中的所有记录。'''return await models.User.all().offset(skip).limit(limit)async def get_users_by_filter():# 复杂查询示例return await (models.User.filter(is_active=True).order_by('username'))# 更新 (Update)
async def update_user(user_id: int, user_data: schemas.UserUpdate):# 方法 1:先查询再更新user = await models.User.filter(id=user_id).first()if user:user_data_dict = user_data.dict(exclude_unset=True)for key, value in user_data_dict.items():setattr(user, key, value)await user.save()return user# 方法 2:直接使用 updateupdated = await models.User.filter(id=user_id).update(**user_data.dict(exclude_unset=True))if updated:return await models.User.filter(id=user_id).first()return None# 删除 (Delete)
async def delete_user(user_id: int):user = await models.User.filter(id=user_id).first()if user:await user.delete()return userreturn None# 关系查询
async def get_user_posts(user_id: int):# 方法 1:通过用户查询user = await models.User.filter(id=user_id).first().prefetch_related('posts')if user:return user.posts# 方法 2:直接查询文章return await models.Post.filter(author_id=user_id)# 多对多关系
async def add_tag_to_post(post_id: int, tag_id: int):post = await models.Post.filter(id=post_id).first()tag = await models.Tag.filter(id=tag_id).first()if post and tag:await post.tags.add(tag) # 添加多对多关系return Truereturn False# 事务处理
async def create_post_with_tags(post_data, tag_ids):async with in_transaction() as conn:# 在事务中创建文章post = await models.Post.create(title=post_data.title,content=post_data.content,author_id=post_data.author_id,using_db=conn)# 添加标签for tag_id in tag_ids:tag = await models.Tag.filter(id=tag_id).using_db(conn).first()if tag:await post.tags.add(tag, using_db=conn)return post
2. 比较运算符
async def get_users():'''获取(= 等于)1的数据'''return await models.User.filter(id=1).all()async def get_users():'''获取(__not 不等于)1的数据'''return await models.User.filter(id__not=1).all()async def get_users():'''获取(__gt 大于)1的数据'''return await models.User.filter(id__gt=1).all()async def get_users():'''获取(id__gte 大于等于)1的数据'''return await models.User.filter(id__gte=1).all()async def get_users():'''获取(id__lt 小于)1的数据'''return await models.User.filter(id__lt=1).all()async def get_users():'''获取(id__lte 小于等于)1的数据'''return await models.User.filter(id__lte=1).all()
3. 成员运算符
async def get_users():'''获取(__in 在)列表中的数据'''names = ['张三', '李四', '王五']return await models.User.filter(user__in=names).all()
4. 模糊查询
# Tortoise ORM 不直接支持SQL中的LIKE模糊查询,async def get_users():'''获取(__icontains 包含)200的数据'''return await models.User.filter(num__icontains='200').all()async def get_users():'''获取(__istartswith 开头)200的数据'''return await models.User.filter(num__istartswith='200').all()async def get_users():'''获取(__iendswith 结尾)200的数据'''return await models.User.filter(num__iendswith='200').all()async def get_users():'''获取(__range 指定范围之间)的数据'''# 获取学号在[2021, 2024]之间的数据return await models.User.filter(num__range=[2021, 2024]).all()async def get_users():'''获取(__isnull 是否为空)的数据'''return await models.User.filter(num__isnull=True).all()
5. exclude():排除
用于排除满足条件的数据,返回不满足条件的数据集
async def get_users(name : str = '张三'):'''(exclude 排除)名字不是 '张三' 的所有数据'''return await models.User.exclude(user=name).all()
6. count():统计
用于统计满足条件的数据数量
async def get_users(num: int = 18):'''(count 统计)(__gt 大于)18的数据量'''return await models.User.filter(age__gt=num).count()
7. order_by():排序
用于安装指定字段排序查询结果
async def get_users():'''按id进行排序, 获取所有数据'''return await models.User.all().orderby('id') # 升序return await models.User.all().orderby('id') # 降序
原生SQL查询
SQLAlchemy 原生SQL
from sqlalchemy import textdef execute_raw_sql(db: Session):"""执行原生SQL"""result = db.execute(text("""SELECT u.username, COUNT(p.id) as post_countFROM users uLEFT JOIN posts p ON u.id = p.author_idGROUP BY u.id, u.usernameORDER BY post_count DESC"""))return result.fetchall()def execute_raw_sql_with_params(db: Session, min_posts: int):"""带参数的原生SQL"""result = db.execute(text("""SELECT u.username, COUNT(p.id) as post_countFROM users uLEFT JOIN posts p ON u.id = p.author_idGROUP BY u.id, u.usernameHAVING COUNT(p.id) >= :min_postsORDER BY post_count DESC"""), {"min_posts": min_posts})return result.fetchall()
Tortoise ORM 原生SQL
from tortoise import connectionsasync def execute_raw_sql():"""执行原生SQL"""conn = connections.get("default")result = await conn.execute_query("""SELECT u.username, COUNT(p.id) as post_countFROM users uLEFT JOIN posts p ON u.id = p.author_idGROUP BY u.id, u.usernameORDER BY post_count DESC""")return resultasync def execute_raw_sql_with_params(min_posts: int):"""带参数的原生SQL"""conn = connections.get("default")result = await conn.execute_query("""SELECT u.username, COUNT(p.id) as post_countFROM users uLEFT JOIN posts p ON u.id = p.author_idGROUP BY u.id, u.usernameHAVING COUNT(p.id) >= $1ORDER BY post_count DESC""", [min_posts])return result
选择建议
何时选择SQLAlchemy
适合场景:
- 企业级应用:需要高度稳定性和成熟的生态系统
- 复杂业务逻辑:涉及复杂的数据库操作和查询
- 团队经验:团队对SQLAlchemy有丰富经验
- 数据库多样性:需要支持多种数据库类型
- 现有项目:已有基于SQLAlchemy的项目需要维护
优势:
- 生态系统成熟,第三方工具丰富
- 文档详尽,社区支持强大
- 功能全面,支持复杂的数据库操作
- 经过长期生产环境验证
何时选择Tortoise ORM
适合场景:
- 现代异步应用:基于FastAPI、Starlette等异步框架
- 高并发需求:需要处理大量并发请求
- 快速开发:追求开发效率和代码简洁性
- 新项目:从零开始的新项目
- 微服务架构:轻量级的微服务应用
优势:
- 原生异步支持,性能优异
- 语法简洁,学习成本低
- 与现代异步框架集成度高
- 开发效率高,代码量少
相关文章:
)
ORM框架(SQLAlchemy 与 Tortoise )
注:本文是python的学习笔记;不是教程!不是教程!内容可能有所疏漏,欢迎交流指正。 框架概述 什么是ORM? ORM(Object-Relational Mapping,对象关系映射)是一种编程技术&a…...

go语言map扩容
map是什么? 在Go语言中,map是一种内置的无序key/value键值对的集合,可以根据key在O(1)的时间复杂度内取到value,有点类似于数组或者切片结构,可以把数组看作是一种特殊的map,数组的key为数组的下标&…...

安全访问家中 Linux 服务器的远程方案 —— 专为单用户场景设计
在现代远程办公与频繁差旅的背景下,许多人需要从外地访问家中的 Linux 文件服务器,以获取重要文件。在涉及敏感数据(如客户资料、财务信息)时,数据的安全性成为首要考虑因素。以下内容将聚焦于如何在仅有一台笔记本电脑…...

前端开发三剑客:HTML5+CSS3+ES6
在前端开发领域,HTML、CSS和JavaScript构成了构建网页与Web应用的核心基础。随着技术标准的不断演进,HTML5、CSS3以及ES6(ECMAScript 2015及后续版本)带来了诸多新特性与语法优化,极大地提升了开发效率和用户体验。本文…...

[Java 基础]Java 中的关键字
在 Java 编程语言中,关键字 (Keywords) 是预定义的、具有特殊含义的标识符 (identifiers)。它们是 Java 语言语法的一部分,被 Java 编译器赋予了特定的功能和用途。因此,你不能将关键字用作变量名、类名、方法名或其他用户自定义的标识符。 …...

5.3 Spring Boot整合JPA
本文详细介绍了如何在Spring Boot项目中整合Spring JPA,实现对数据库的高效操作。首先,创建Spring Boot项目并添加必要的依赖,如Druid数据源。接着,配置数据源属性,创建实体类Comment和Article,并使用JPA注…...

腾讯开源视频生成工具 HunyuanVideo-Avatar,上传一张图+一段音频,就能让图中的人物、动物甚至虚拟角色“活”过来,开口说话、唱歌、演相声!
腾讯混元团队提出的 HunyuanVideo-Avatar 是一个基于多模态扩散变换器(MM-DiT)的模型,能够生成动态、情绪可控和多角色对话视频。支持仅 10GB VRAM 的单 GPU运行,支持多种下游任务和应用。例如生成会说话的虚拟形象视频࿰…...
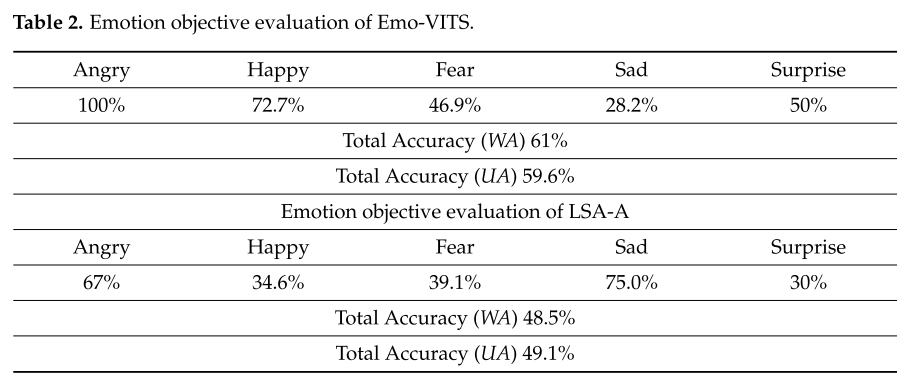
[文献阅读] Emo-VITS - An Emotion Speech Synthesis Method Based on VITS
[文献阅读]:An Emotion Speech Synthesis Method Based on VITS 在VITS基础上通过参考音频机制,获取情感信息,从而实现的情感TTS方式。 摘要 VITS是一种基于变分自编码器(VAE)和对抗神经网络(GAN…...

网络协议通俗易懂详解指南
目录 1. 什么是网络协议? 1.1 协议的本质 1.2 为什么需要协议? 1.3 协议分层的概念 2. TCP协议详解 - 可靠的信使 📦 2.1 TCP是什么? 2.2 TCP的核心特性 🔗 面向连接 🛡️ 可靠传输 📊 流量控制 2.3 TCP三次握手 - 建立连接 2.4 TCP四次挥手 - 断开连接…...
OpenCV-Python Tutorial : A Candy from Official Main Page(持续更新)
OpenCV-Python 是计算机视觉领域最流行的开源库之一,它结合了 OpenCV (Open Source Computer Vision Library) 的 C 高性能实现和 Python 的简洁易用特性,为开发者提供了强大的图像和视频处理能力。具有以下优势: 典型应用领域: …...

【Vue】指令补充+样式绑定+计算属性+侦听器
【指令补充】 【指令修饰符】 指令修饰符可以让指令的 功能更强大,书写更便捷 分类: 1.按键修饰符(侦测当前点击的是哪个按键) 2.事件修饰符(简化程序对于阻止冒泡, 一些标签的默认默认行为的操作&…...

.Net Framework 4/C# 泛型的使用、迭代器和分部类
一、泛型的使用 泛型是用于处理算法、数据结构的一种编程方法。泛型的目标是采用广泛适用和可交互性的形式来表示算法和数据结构,以便它们能够直接用于软件构造。 泛型简单理解就是,在声明时暂时不固定其类型,例如 int 类型、double 类型等,在调用泛型时,再将要用的类型补…...

LLM 笔记:Speculative Decoding 投机采样
1 基本介绍 投机采样(Speculative Sampling)是一种并行预测多个可能输出,然后快速验证并采纳正确部分的加速策略 在不牺牲输出质量的前提下,减少语言模型生成 token 所需的时间 传统的语言模型生成是 串行 的 必须生成一个&…...
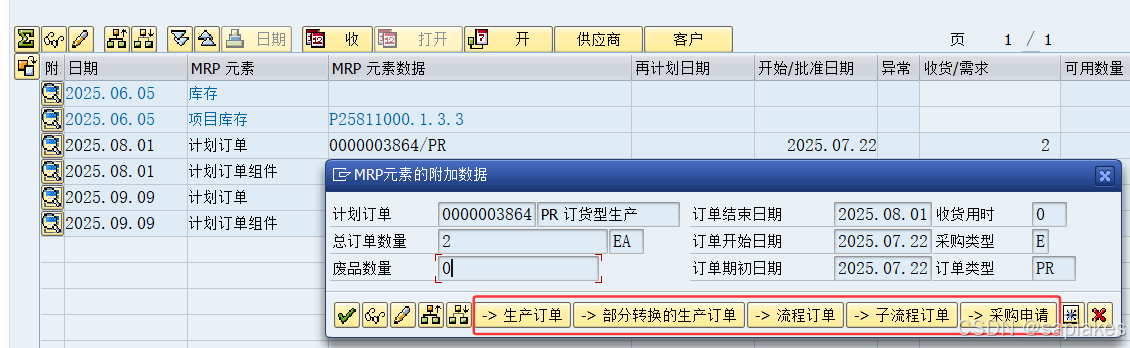
当SAP系统内计划订单转换为生产订单时发生了什么?
【SAP系统研究】 #SAP #计划订单 #生产订单 #采购申请 一、关于计划订单的一点疑惑 曾经对SAP为什么会有计划订单,是感到很疑惑的。 这个界面简单,配置点也不多,能被随意“摆布”,一旦要变形就消失得无影无踪的计划订单,why? 但是,再次重新审视过之后,才发现它其实…...

PDF转PPT转换方法总结
你是否遇到过这些场景? 收到客户发来的产品手册PDF,明天就要用它做演示; 公司历史资料只有PDF版,领导突然要求更新为幻灯片。 这时PDF转PPT工具就成了救命稻草。接下来,介绍三种PDF转PPT工具。 1. iLoveOFD在线转换…...
3D Web轻量化引擎HOOPS Communicator的定制化能力全面解析
HOOPS Communicator 是Tech Soft 3D推出的高性能Web工程图形引擎。它通过功能丰富的JavaScript API,帮助开发团队在浏览器中快速添加2D/3D CAD模型的查看与交互功能。该引擎专为工程应用优化,支持大规模模型的流畅浏览、复杂装配的智能导航、流式加载和服…...
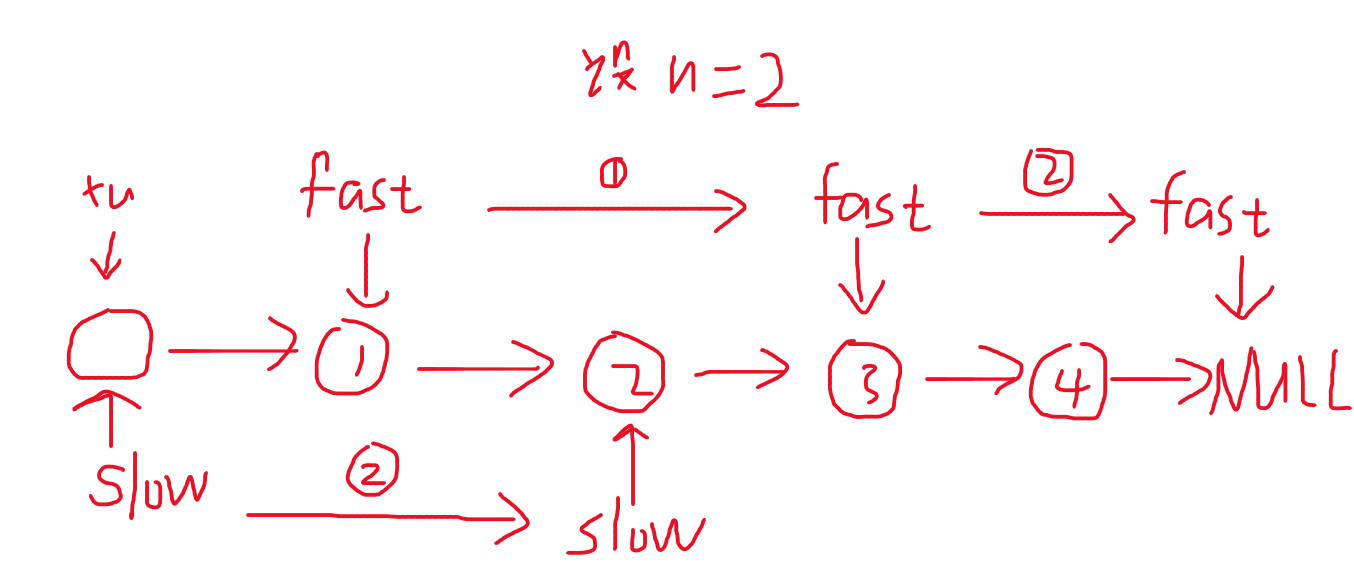
【力扣链表篇】19.删除链表的倒数第N个节点
题目: 给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。 示例 1: 输入:head [1,2,3,4,5], n 2 输出:[1,2,3,5]示例 2: 输入:head [1], n 1 输出:[]…...

.Net Framework 4/C# 集合和索引器
一、ArrayList 类(集合) ArrayList 类位于 System.Collections 命名空间下,它可以动态地添加和删除元素。 ArrayList 提供了3个构造器,通过这3个构造器可以有3种声明方式: 默认构造器,将会以默认ÿ…...

如何使用Jmeter进行压力测试?
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 一、什么是压力测试 软件测试中:压力测试(Stress Test),也称为强度测试、负载测试。压力测试是模拟实际应用的软硬…...
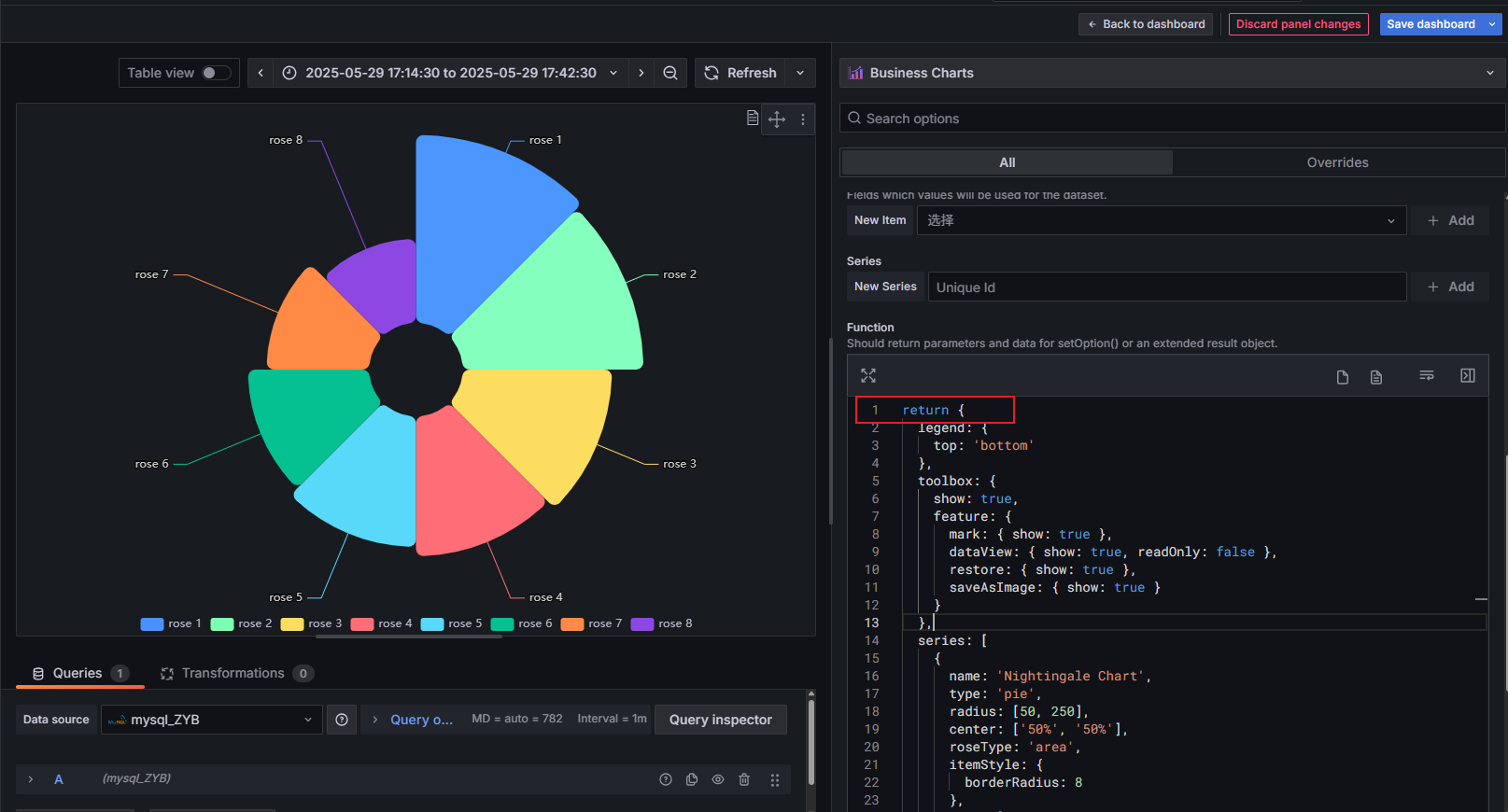
Grafana-ECharts应用讲解(玫瑰图示例)
工具: MySQL 数据库 MySQL Workbench 数据库管理工具(方便编辑数据) Grafana v11.5.2 Business Charts 6.6(原 Echarts插件) 安装 安装 MySQL社区版安装 MySQL Workbench安装 Grafana在 Grafana 插件中搜索 Business Charts 进行安装以上安装步骤网上教程很多,自行搜…...

洛谷P1591阶乘数码
P1591 阶乘数码 题目描述 求 n ! n! n! 中某个数码出现的次数。 输入格式 第一行为 t ( t ≤ 10 ) t(t \leq 10) t(t≤10),表示数据组数。接下来 t t t 行,每行一个正整数 n ( n ≤ 1000 ) n(n \leq 1000) n(n≤1000) 和数码 a a a。 输出格式…...
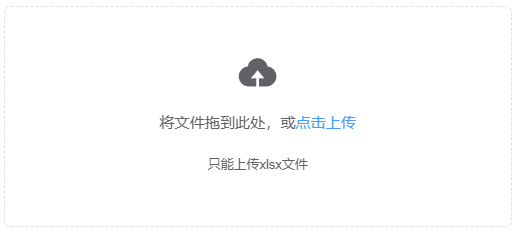
前端vue3 上传/导入文件 调用接口
点击按钮导入: <el-uploadaction"https://run.mocky.io/v3/9d059bf9-4660-45f2-925d-ce80ad6c4d15":auto-upload"false":on-change"handleFileChange":show-file-list"false"><el-button type"warning"…...

概述侧边导航的作用与价值
侧边导航的作用与价值:介绍侧边导航的核心优势和用户体验提升点。设计原则:使用表格对比说明侧边导航的三大设计准则。基础实现方法:分步骤讲解静态侧边导航的实现技术。高级交互实现:提供滑动式侧边栏的完整交互解决方案。优化技…...
Python训练营-Day22-Titanic - Machine Learning from Disaster
Description linkkeyboard_arrow_up 👋🛳️ Ahoy, welcome to Kaggle! You’re in the right place. This is the legendary Titanic ML competition – the best, first challenge for you to dive into ML competitions and familiarize yourself w…...
FreeCAD:开源世界的三维建模利器
FreeCAD 开发模式 FreeCAD的开发采用多语言协作模式,其核心框架与高性能模块主要使用C构建,而用户界面与扩展功能则通过Python脚本实现灵活定制。具体来说: C核心层:作为基础架构,C负责实现与Open CASCADE Technology…...

指针的定义与使用
1.指针的定义和使用 int point1(){//定义指针int a 10;//指针定义语法: 数据类型 * 指针变量名int * p;cout << "sizeof (int(*)) --> " << sizeof(p) << endl;//让指针记录变量a的地址 & 取址符p &a ;cout << &qu…...
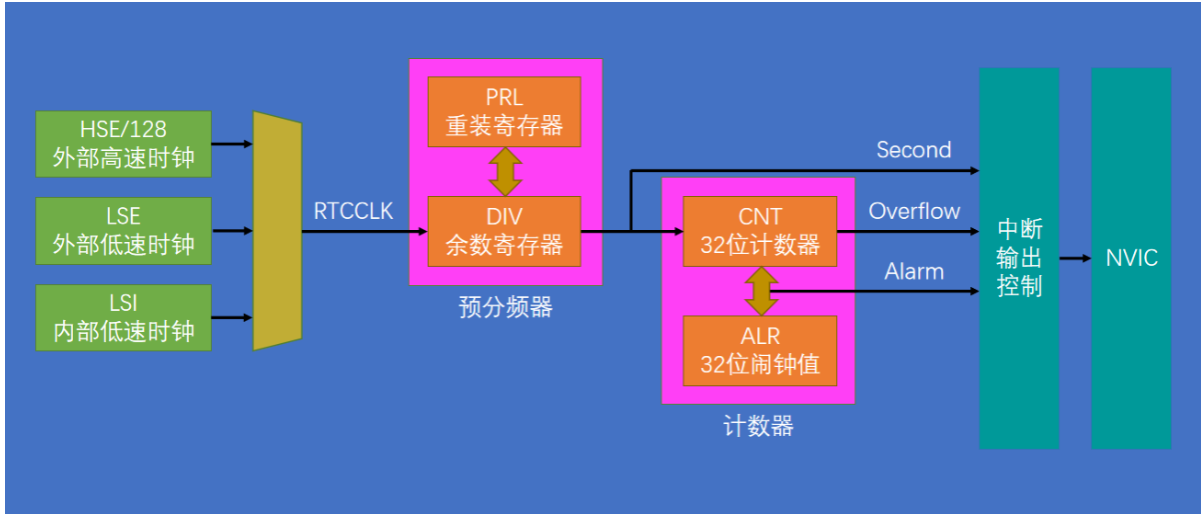
嵌入式里的时间魔法:RTC 与 BKP 深度拆解
文章目录 RTC实时时钟与BKPUnix时间戳UTC/GMT时间戳转换时间戳转换BKP简介BKP基本结构1. 电池供电模块(VBAT 输入)2. 侵入检测模块(TAMPER 输入)3. 时钟输出模块(RTC 输出)4. 内部寄存器组 RTC简介RTC时钟源…...

Java项目中常用的中间件及其高频问题避坑
Java项目中常用的中间件及其高频问题避坑如下: 一、常用中间件分类及作用 1. 消息队列中间件 作用:解耦系统、异步通信、削峰填谷。代表产品: Kafka:高吞吐量流处理,适合日志收集、实时分析。RocketMQ:金融级可靠性,支持事务消…...
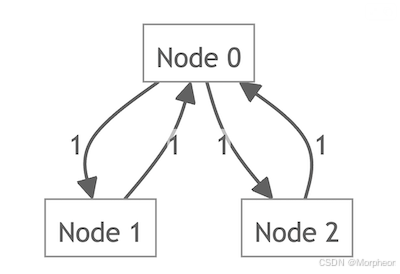
图卷积网络:从理论到实践
图卷积网络(Graph Convolutional Networks, GCNs)彻底改变了基于图的机器学习领域,使得深度学习能够应用于非欧几里得结构,如社交网络、引文网络和分子结构。本文将解释GCN的直观理解、数学原理,并提供代码片段帮助您理…...
ES 学习总结一 基础内容
ElasticSearch学习 一、 初识ES1、 认识与安装2、 倒排索引2.1 正向索引2.2 倒排索引 3、 基本概念3.1 文档和字段3.2 索引和倒排 4 、 IK分词器 二、 操作1、 mapping 映射属性2、 索引库增删改查3、 文档的增删改查3.1 新增文档3.2 查询文档3.3 删除文档3.4 修改文档3.5 批处…...