AI Agent 架构设计:ReAct 与 Self-Ask 模式对比与分析
一、引言
(一) AI Agent 技术发展背景 🚀
AI Agent 的演进是一场从“遵循指令”到“自主决策”的深刻变革。早期,以规则引擎为核心的系统(如关键词匹配的客服机器人)只能在预设的流程上运行。然而,大语言模型的崛起为 Agent 注入了“灵魂”,使其具备了前所未有的自主规划与执行能力。像 AutoGPT 和 BabyAGI 这样的项目,已经能根据用户设定的宏大目标,自主地分解任务、调用工具、并完成一系列复杂操作,这标志着认知型 Agent 时代的到来。
在现代 Agent 设计中,任务型 Agent 和 认知型 Agent 的界限愈发清晰。前者专注于高效执行封闭领域的具体流程(如处理退款申请),而后者则致力于解决开放域的复杂问题(如“分析市场趋势并撰写报告”)。架构设计是决定 Agent 智能上限的关键。ReAct 和 Self-Ask 正是当前 LLM-based Agent 架构中,分别代表“行动派”和“思考派”的两种主流范式。
(二) ReAct 与 Self-Ask 模式的技术定位
ReAct (Reasoning and Acting) 和 Self-Ask 都是驱动 LLM 进行复杂决策的核心架构,但它们的实现路径截然不同。
- ReAct:以任务执行为中心。它将 LLM 封装在一个“思考 → 行动 → 观察 → 思考…”的循环中。LLM 不直接回答最终问题,而是生成一个“想法”(Thought)和一个需要执行的“动作”(Action),通过与外部工具(如搜索引擎、API)交互来获取信息,然后根据“观察”(Observation)到的结果进行下一步推理。这种模式侧重于实时交互和动态适应。
- Self-Ask:以问题分解为核心。它通过递归地向自己提问来将一个复杂问题拆解成一系列更简单的子问题。每个子问题都通过外部工具(主要是搜索引擎)来回答,然后将这些中间答案逐步聚合,最终形成对原始问题的完整解答。这种模式侧重于深度推理和知识溯源。
| 特性 | ReAct | Self-Ask |
|---|---|---|
| 核心逻辑 | 推理-动作循环 | 递归问题分解 |
| 适用场景 | 需要与环境/工具持续交互的流程化任务 (如智能客服、个人助理) | 需要深度知识推理和证据链的复杂问答 (如研究分析、报告生成) |
| 交互模式 | 多轮、动态 | 通常为单轮、离线分析 |
| 产出特点 | 过程透明,展示行动轨迹 | 逻辑清晰,展示推理链条 |
二、ReAct 模式技术解析 ⚙️
(一) 核心技术原理
ReAct 的精髓在于将推理和行动解耦并显式化。它强迫 LLM 不仅要思考“做什么”,还要思考“为什么这么做”,并将此过程以文本形式表达出来。这极大地增强了 Agent 的可控性和可解释性。
其核心循环可以用下图表示:
这个循环的背后是精巧的提示词工程。模型被引导生成特定格式的文本,通常包含:
- Thought: 模型的内心独白,用于分析当前情况、制定下一步计划。
- Action: 决定调用的具体工具及输入参数。
- Observation: 执行 Action 后从外部环境(工具)返回的结果。
- Final Answer: 当模型认为已经收集到足够信息时,给出的最终答案。
(二) 架构组成要素
一个完备的 ReAct Agent 系统通常包含以下几个模块:
- LLM 核心 (LLM Core):负责根据上下文和历史记录生成
Thought和Action。 - 工具集 (Tool Suite):一组可供 Agent 调用的函数或 API,如搜索引擎、计算器、数据库查询接口等。
- 提示模板 (Prompt Template):定义了 Agent 思考和行动的框架,是引导 LLM 按 ReAct 范式工作的关键。
- 解析器 (Output Parser):负责解析 LLM 的输出,从中提取出
Action和Action Input,以便分发给相应的工具。 - 执行器 (Executor):协调整个 ReAct 循环,接收用户输入,调用 LLM,解析输出,执行工具,并将结果反馈给 LLM,直到任务完成。
(三) 工程实践与代码案例
原有的 LangChain 示例非常经典,但为了更深入地理解其工作原理,我们来构建一个不依赖高级抽象、能清晰展示每一步循环的 Python 案例。
场景:一个简单的研究助手,需要回答“LangChain 的作者是谁?他现在的公司是什么?” 这个问题需要两次搜索。
import os
import re
from openai import OpenAI# 假设已配置 OpenAI API Key
# os.environ["OPENAI_API_KEY"] = "YOUR_API_KEY"
client = OpenAI()# --- 1. 定义工具 ---
# 这是一个模拟的搜索工具
def search_tool(query: str) -> str:"""一个模拟的搜索引擎"""print(f" [Tool] 正在搜索: {query}")# 针对本案例的模拟数据库mock_db = {"who is the author of LangChain": "The main author of LangChain is Harrison Chase.","Harrison Chase's current company": "Harrison Chase founded a company called LangChain AI.",}return mock_db.get(query, "No information found.")tools = {"search": search_tool
}# --- 2. 定义 ReAct 提示模板 ---
react_prompt_template = """
Answer the following questions as best you can. You have access to the following tools:search: A search engine. Use this to find information about people, events, or concepts.Use the following format:Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [search]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input questionBegin!Question: {question}
Thought:
"""# --- 3. 构建 ReAct 执行循环 ---
def run_react_agent(question: str):prompt = react_prompt_template.format(question=question)max_turns = 5for i in range(max_turns):print(f"--- Turn {i+1} ---")# 调用 LLMresponse = client.chat.completions.create(model="gpt-4o",messages=[{"role": "user", "content": prompt}],temperature=0,stop=["Observation:"] # 让模型在生成 Action 后停止)generated_text = response.choices[0].message.contentprint(f"[LLM Output]\n{generated_text}")prompt += generated_text# 解析 Actionaction_match = re.search(r"Action: (.*)\nAction Input: (.*)", generated_text)if action_match:action = action_match.group(1).strip()action_input = action_match.group(2).strip()# 执行工具if action in tools:tool_output = tools[action](action_input)observation = f"Observation: {tool_output}\n"print(f"[Observation]\n{observation}")prompt += observationelse:prompt += "Observation: Invalid tool name.\n"else:# 如果没有 Action,说明可能已经得出最终答案final_answer_match = re.search(r"Final Answer: (.*)", generated_text, re.DOTALL)if final_answer_match:final_answer = final_answer_match.group(1).strip()print(f"\n✅ Final Answer Found: {final_answer}")return final_answerelse:# 无法解析,可能是逻辑卡住了print("\n❌ Agent stopped: Cannot parse action or find final answer.")return Noneprint("\n❌ Agent stopped: Reached max turns.")return None# --- 4. 执行任务 ---
question = "Who is the author of LangChain and what is his current company?"
run_react_agent(question)
代码运行输出:
--- Turn 1 ---
[LLM Output]
I need to find out who the author of LangChain is first.
Action: search
Action Input: who is the author of LangChain[Tool] 正在搜索: who is the author of LangChain
[Observation]
Observation: The main author of LangChain is Harrison Chase.--- Turn 2 ---
[LLM Output]
Thought: Now that I know the author is Harrison Chase, I need to find his current company.
Action: search
Action Input: Harrison Chase's current company[Tool] 正在搜索: Harrison Chase's current company
[Observation]
Observation: Harrison Chase founded a company called LangChain AI.--- Turn 3 ---
[LLM Output]
Thought: I have found the author of LangChain and his current company. I can now provide the final answer.
Final Answer: The author of LangChain is Harrison Chase, and his current company is LangChain AI.✅ Final Answer Found: The author of LangChain is Harrison Chase, and his current company is LangChain AI.
三、Self-Ask 模式技术解析 🧠
(一) 核心技术原理
Self-Ask 的核心思想是化繁为简。它模拟了人类解决复杂问题时的思维过程:先将大问题分解为一系列可以被直接回答的小问题,然后逐个击破。
其工作流程可以描绘成一个依赖图:
与 ReAct 不同,Self-Ask 的提示中通常包含 Are follow up questions needed here: 这样的关键词,引导模型判断当前信息是否足以回答,如果不足,则生成一个 Follow up: 问题,并通过 Intermediate answer: 记录中间结果。
(二) 架构组成要素
一个标准的 Self-Ask Agent 架构包括:
- **分解器 **:通常是 LLM,负责接收原始问题和历史对话,生成下一个需要被回答的子问题。
- **搜索引擎 **:这是 Self-Ask 的关键外部工具,用于回答分解器生成的具体子问题。
- **合成器 **:也是 LLM,负责整合所有子问题的答案,形成一个连贯、全面的最终答案。在实践中,分解器和合成器可以是同一个 LLM。
(三) 工程实践与代码案例
场景:回答与 ReAct 案例中相同的问题:“LangChain 的作者是谁?他现在的公司是什么?”
import os
from openai import OpenAI# 假设已配置 OpenAI API Key
client = OpenAI()# --- 1. 定义工具 (与 ReAct 案例相同) ---
def search_tool(query: str) -> str:"""一个模拟的搜索引擎"""print(f" [Tool] 正在搜索: {query}")mock_db = {"who is the author of LangChain": "Harrison Chase is the main author of LangChain.","Harrison Chase's current company": "Harrison Chase is the founder of LangChain AI.",}return mock_db.get(query, "No information found.")# --- 2. 定义 Self-Ask 提示模板 ---
self_ask_prompt_template = """
Question: Who is the author of LangChain and what is his current company?
Are follow up questions needed here: Yes.
Follow up: Who is the author of LangChain?
Intermediate answer: Harrison Chase is the main author of LangChain.
Are follow up questions needed here: Yes.
Follow up: What is Harrison Chase's current company?
Intermediate answer: Harrison Chase is the founder of LangChain AI.
Are follow up questions needed here: No.
So the final answer is: The author of LangChain is Harrison Chase, and his current company is LangChain AI.Question: {question}
"""# --- 3. 构建 Self-Ask 执行类 ---
class SelfAskAgent:def __init__(self, llm_client, search_tool):self.client = llm_clientself.search_tool = search_tooldef run(self, question: str, max_iters=5):prompt = self_ask_prompt_template.format(question=question)for i in range(max_iters):print(f"--- Iteration {i+1} ---")prompt += "\nAre follow up questions needed here:"# 调用 LLM 判断是否需要子问题或生成最终答案response = self.client.chat.completions.create(model="gpt-4o",messages=[{"role": "user", "content": prompt}],temperature=0,stop=["\n"] # 在换行符处停止)choice = response.choices[0].message.content.strip()prompt += choiceprint(f"[LLM Decision]: {choice}")if "Yes" in choice:# 生成并执行子问题prompt += "\nFollow up:"resp_follow_up = self.client.chat.completions.create(model="gpt-4o",messages=[{"role": "user", "content": prompt}],temperature=0,stop=["\n"]).choices[0].message.content.strip()prompt += resp_follow_upsub_question = resp_follow_upprint(f"[Sub-question]: {sub_question}")# 执行搜索answer = self.search_tool(sub_question)prompt += f"\n {answer}"print(f"[Intermediate Answer]: {answer}")elif "No" in choice:# 生成最终答案prompt += "\nSo the final answer is:"resp_final = self.client.chat.completions.create(model="gpt-4o",messages=[{"role": "user", "content": prompt}],temperature=0,).choices[0].message.content.strip()print(f"\n✅ Final Answer: {resp_final}")return resp_finalelse:print("\n❌ Agent stopped: Unexpected decision.")return Noneprint("\n❌ Agent stopped: Reached max iterations.")return None# --- 4. 执行任务 ---
agent = SelfAskAgent(client, search_tool)
agent.run("Who is the author of LangChain and what is his current company?")
代码运行输出:
--- Iteration 1 ---
[LLM Decision]: Yes.
[Sub-question]: Who is the author of LangChain?[Tool] 正在搜索: Who is the author of LangChain?
[Intermediate Answer]: Harrison Chase is the main author of LangChain.
--- Iteration 2 ---
[LLM Decision]: Yes.
[Sub-question]: What is Harrison Chase's current company?[Tool] 正在搜索: What is Harrison Chase's current company?
[Intermediate Answer]: Harrison Chase is the founder of LangChain AI.
--- Iteration 3 ---
[LLM Decision]: No.✅ Final Answer: The author of LangChain is Harrison Chase, and his current company is LangChain AI.
四、核心技术对比与选型指南
| 对比维度 | ReAct | Self-Ask |
|---|---|---|
| 决策逻辑 | 任务导向:基于环境反馈进行状态转移,遵循决策过程 。决策粒度为细粒度动作。 | 问题导向:基于问题依赖图进行推理,状态转移由子问题驱动。决策粒度为粗粒度问题分解。 |
| 任务处理能力 | 流程化任务王者。非常适合需要与多个不同工具(API、数据库)交互的场景,如智能客服、自动化运维、个人助理。 | 知识推理专家。在处理需要深度、广度信息检索和整合的开放域问题上表现出色,如学术研究、市场分析。 |
| 上下文管理 | 依赖对话历史和中间Thought来维持上下文,对长序列处理能力要求高。 | 通过Intermediate answer显式记录知识,上下文压力相对较小,但依赖于清晰的问题分解。 |
| 错误处理 | Observation中返回的错误信息可以被Thought捕获,进行重试或改变策略。对工具的健壮性要求高。 | 如果一个子问题无法回答或回答错误,可能会影响整个推理链。可以通过设计更好的回溯机制来弥补。 |
| 性能与成本 | 时间复杂度约为 O ( n ⋅ m ) O(n \cdot m) O(n⋅m),其中 n n n 是交互轮次, m m m 是每次 LLM 推理和工具调用的平均耗时。API 调用频繁。 | 时间复杂度约为 O ( k d ) O(k^d) O(kd),其中 k k k 是每个问题分解出的子问题数, d d d 是推理深度。LLM 调用次数可能较多。 |
| 可解释性 | 行动轨迹透明。用户可以看到 Agent 的每一步思考和尝试,即使失败了也能理解原因。 | 推理链条清晰。用户可以看到原始问题是如何一步步被拆解和回答的,答案的来源有据可查。 |
如何选择:一个实用的决策框架 🤔
在实际项目中,该如何选择?可以从以下四个角度考虑:
-
任务的本质是什么?
- 是“做事”还是“回答”? 如果任务是执行一个多步骤流程(预订机票、管理日历),选择 ReAct。如果任务是回答一个复杂的、需要查证和综合信息的问题,选择 Self-Ask。
-
交互性要求有多高?
- 需要实时反馈吗? 如果 Agent 需要与用户或动态环境进行多轮对话和交互,ReAct 的循环机制更具优势。如果是一次性提交问题,等待最终分析报告,Self-Ask 更合适。
-
工具的多样性如何?
- 需要调用多种工具吗? ReAct 的
Action设计天然支持调用各种不同的工具(计算器、代码解释器、搜索引擎等)。Self-Ask 则强依赖于一个核心工具——搜索引擎。
- 需要调用多种工具吗? ReAct 的
-
对过程还是结果更看重?
- 需要追溯答案来源吗? 如果最终答案的可靠性和证据链至关重要,Self-Ask 提供的
Intermediate answer提供了极佳的可追溯性。如果更关心任务是否被成功执行,ReAct 的行动日志则更为直观。
- 需要追溯答案来源吗? 如果最终答案的可靠性和证据链至关重要,Self-Ask 提供的
混合模式:未来的方向
ReAct 和 Self-Ask 并非完全互斥。先进的 Agent 架构已经开始融合两者的优点。例如,一个 ReAct Agent 在其 Thought 阶段,可能会发现需要回答一个复杂的子问题,此时它可以“启动”一个临时的 Self-Ask 流程来解决这个子问题,然后将结果作为 Observation 返回到 ReAct 的主循环中。这种分层、混合的架构将是未来 AI Agent 实现更高级智能的关键。
相关文章:

AI Agent 架构设计:ReAct 与 Self-Ask 模式对比与分析
一、引言 (一) AI Agent 技术发展背景 🚀 AI Agent 的演进是一场从“遵循指令”到“自主决策”的深刻变革。早期,以规则引擎为核心的系统(如关键词匹配的客服机器人)只能在预设的流程上运行。然而,大语言模型的崛起为…...
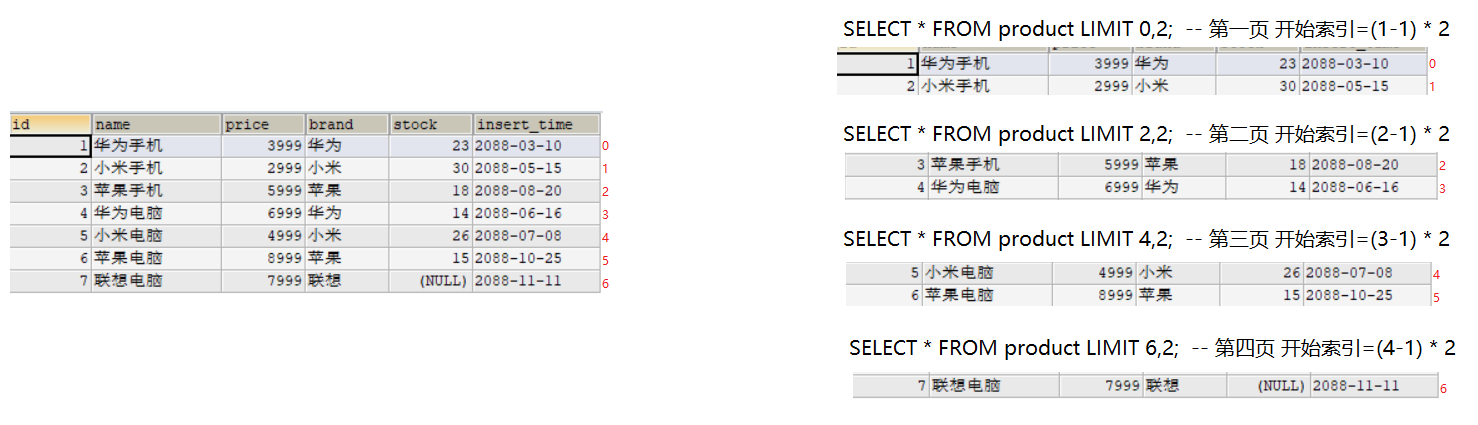
sql入门语句-案例
Sql入门 数据库、数据表、数据的关系介绍 数据库 用于存储和管理数据的仓库 一个库中可以包含多个数据表 数据表 数据库最重要的组成部分之一 它由纵向的列和横向的行组成(类似excel表格) 可以指定列名、数据类型、约束等 一个表中可以存储多条数据 数据 想要永久化存储…...
A Survey on the Memory Mechanism of Large Language Model based Agents
目录 摘要Abstract1. LLM-Based Agent的Memory1.1 基础概念1.2 用于解释Memory的例子1.3 智能体记忆的定义1.3.1 狭义定义(肯定不用这个定义)1.3.2 广义定义 1.4 记忆协助下智能体与环境的交互过程1.4.1 记忆写入1.4.2 记忆管理1.4.3 记忆读取1.4.4 总过程 2. 如何实现智能体记…...

华为OD机试 - 猴子吃桃 - 二分查找(Java 2025 B卷 200分)
public class Test14 {public static void main(String[] args) {Scanner sc = new Scanner(System.in);while (sc.hasNext()) {String[] s = sc.nextLine().split(" ");int[] arr = new int[s.length-1];int count = Integer.parseInt(s[s...

提取数据区域中表格
查看本示例演示效果本示例关键代码的编写位置,请参考“开始 - 快速上手”里您所使用的开发语言框架的最简集成代码 在实际的开发过程中,有时会遇到希望提取Word文档中表格数据保存到服务器的需求,此时可以使用PageOffice提取Word文档数据区域…...
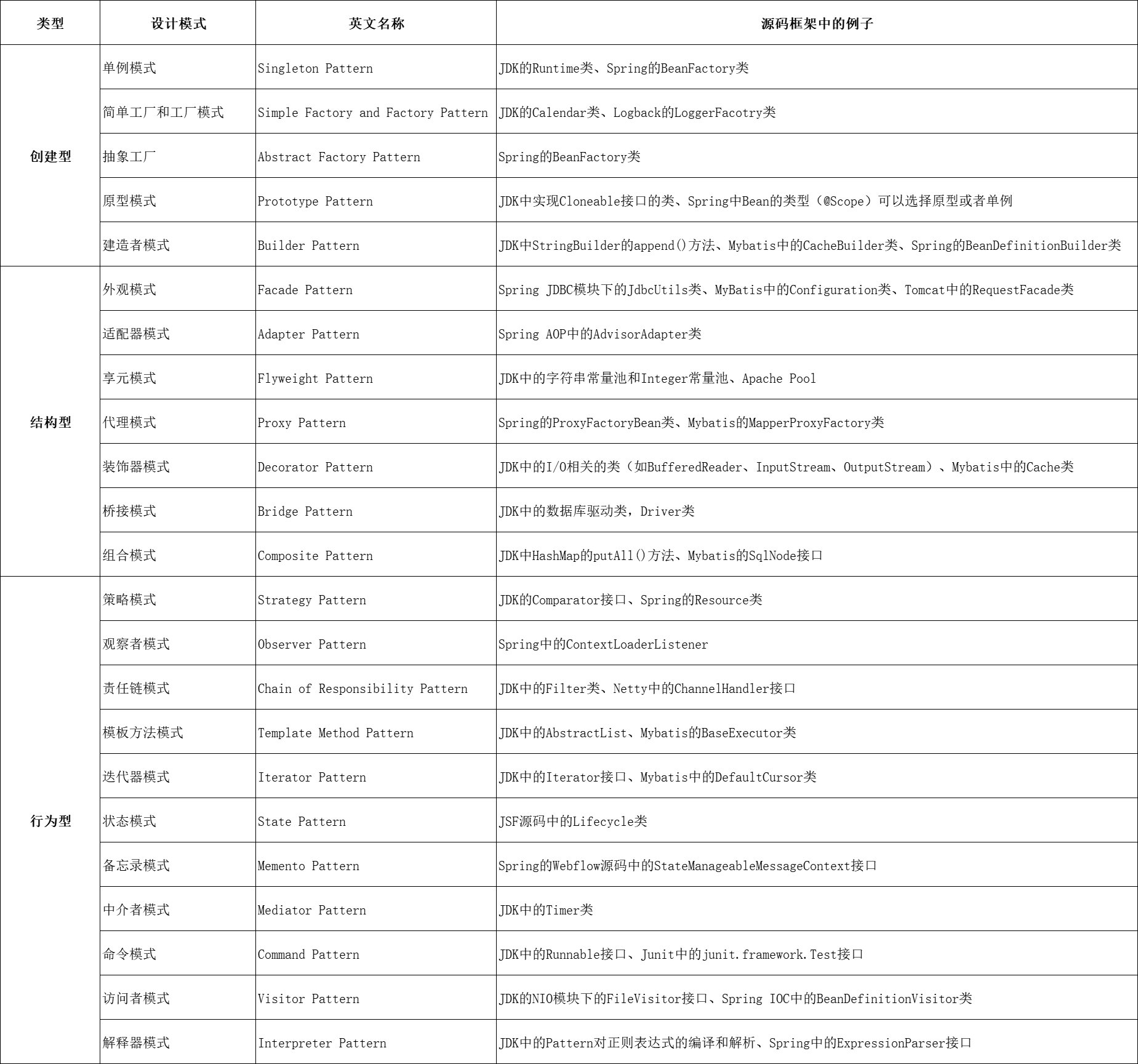
【设计模式-5】设计模式的总结
说明:介绍完所有的设计模式,本文做一下总结 设计模式介绍 博主写的设计模式博客如下: 【设计模式-1】UML和设计原则 【设计模式-2.1】创建型——单例模式 【设计模式-2.2】创建型——简单工厂和工厂模式 【设计模式-2.3】创建型——原型…...

【无人机】无人机UAV、穿越机FPV的概念介绍,机型与工具,证书与规定
【无人机】无人机UAV、穿越机FPV的概念介绍,机型与工具,证书与规定 文章目录 1、无人机的定义、概念、技术栈1.1 无人机的概念1.2 无人机技术(飞控,动力,通信) 2、无人机机型2.1 DJI无人机 (航拍…...
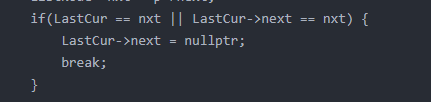
链表好题-多种实现
143. 重排链表 - 力扣(LeetCode) 这道题非常经典,很多大厂都作为面试题。 方法一:寻找中点翻转链表合并链表 class Solution { public:void reorderList(ListNode* head) {if (head nullptr) {return;}ListNode* mid middleNo…...
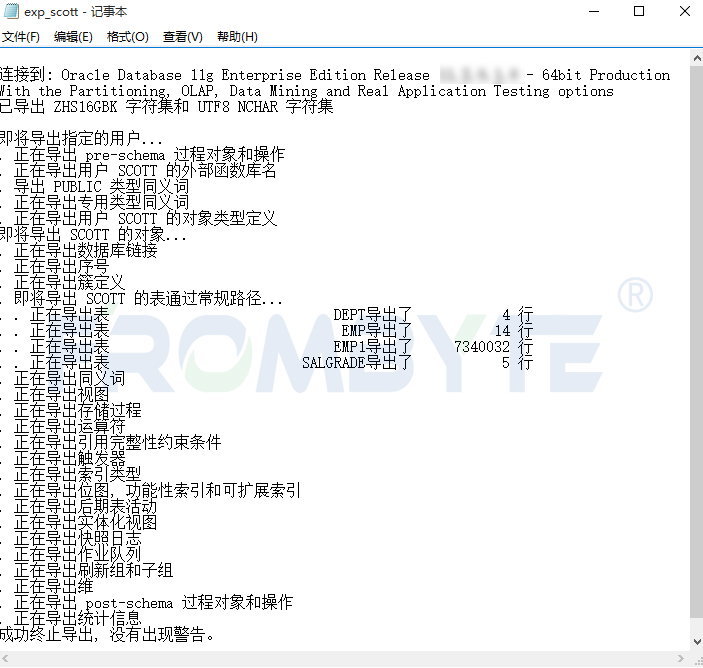
oracle数据恢复—oracle数据库执行truncate命令后的怎么恢复数据?
oracle数据库误执行truncate命令导致数据丢失是一种常见情况。通常情况下,oracle数据库误操作删除数据只需要通过备份恢复数据即可。也会碰到一些特殊情况,例如数据库备份无法使用或者还原报错等。下面和大家分享一例oracle数据库误执行truncate命令导致…...
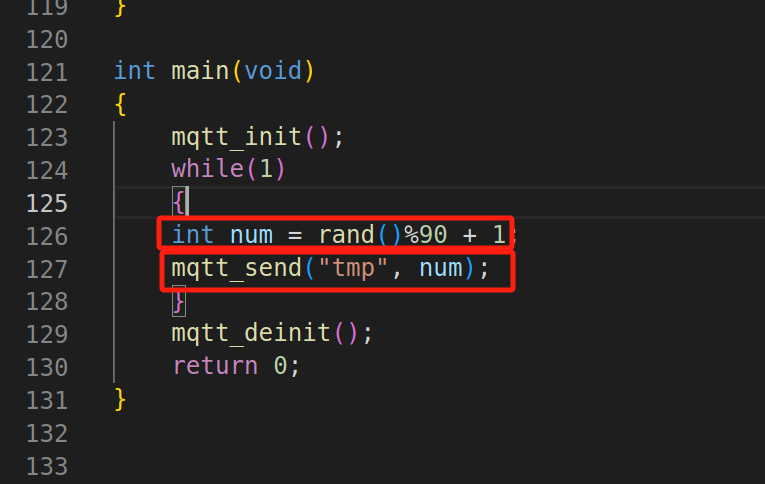
OneNet + openssl + MTLL
1.OneNet 使用的教程 1.在网络上搜索onenet,注册并且登录账号。 2.产品服务-----物联网服务平台立即体验 3.在底下找到立即体验进去 4.产品开发------创建产品 5.关键是选择MQTT,其他的内容自己填写 6.这里产品以及开发完成,接下来就是添加设…...
分享两个日常办公软件:uTools、PixPin
1. uTools 网址:https://u.tools/ 这是一个高效智能的在线工具平台。 特点: 专为提升用户的工作效率跟生活便利性设计。 优点: 1:由国内团队开发。 2:通过插件化的方式为用户提供多样化的功能支持。 3…...
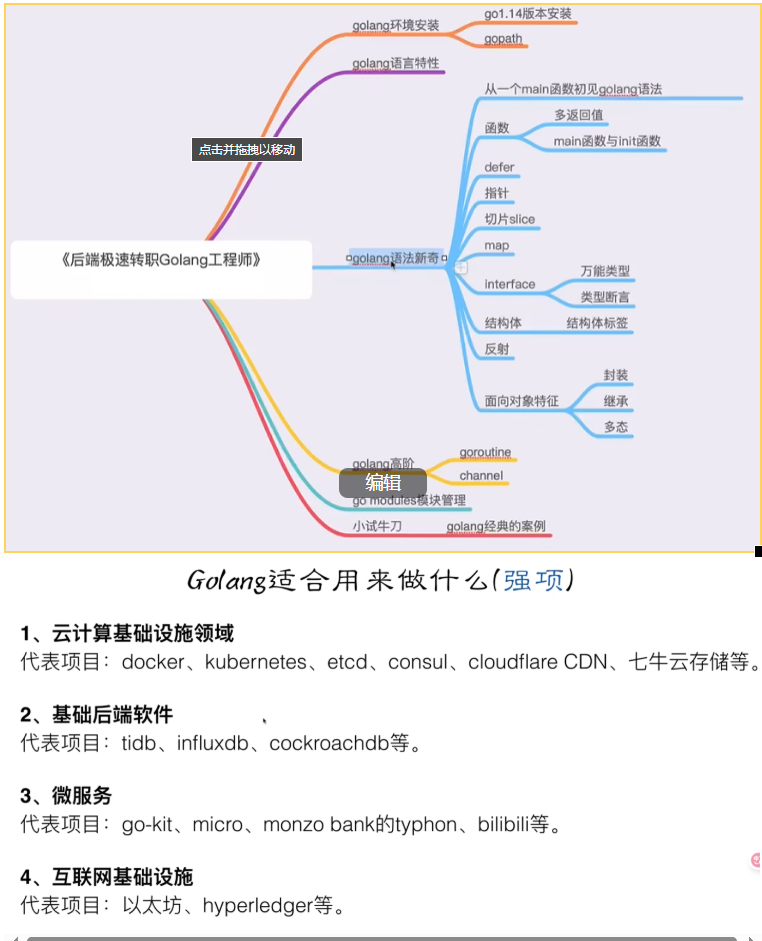
Golang基础学习
初见golang语法 go项目路径 cd $GOPATH //ls可以看到有bin,pkg,src三个文件 cd src/ mkdir GolangStudy cd GolangStudy mkdir firstGolanggo程序执行: go run hello.go//如果想分两步执行: go build hello.go ./hello导入包的方式 import "f…...
)
[学习] GNSS信号跟踪环路原理、设计与仿真(仿真代码)
GNSS信号跟踪环路原理、设计与仿真 文章目录 GNSS信号跟踪环路原理、设计与仿真一、GNSS信号跟踪环路概述二、跟踪环路基本原理1. 信号跟踪的概念与目标2. 锁相环(PLL)原理3. 锁频环(FLL)原理4. 延迟锁定环(DLL&#x…...

Python实例题:Python计算微积分
目录 Python实例题 题目 代码实现 实现原理 符号计算: 数值计算: 可视化功能: 关键代码解析 1. 导数计算 2. 积分计算 3. 微分方程求解 4. 函数图像绘制 使用说明 安装依赖: 基本用法: 示例输出&#…...

如何判断指针是否需要释放?
在 C 中判断一个指针是否需要释放可以考虑以下几个方面: 一、确定指针的来源 1. 动态分配的内存: 如果指针是通过new、new[]、malloc、calloc等动态内存分配函数获取的,那么在不再需要该内存时,必须手动释放。 例如:…...

Spark 之 AQE
个人其他链接 AQE 执行顺序https://blog.csdn.net/zhixingheyi_tian/article/details/125112793 AQE 产生 AQE 的 循环触发点 src/main/scala/org/apache/spark/sql/execution/adaptive/AdaptiveSparkPlanExec.scala override def doExecute(): RDD[InternalRow] = {withFin…...

随访系统安装的记录
安装PG17.5 安装https://www.cnblogs.com/nulixuexipython/p/18040243 1、遇到navicat链接不了PG https://blog.csdn.net/sarsscofy/article/details/84985933 2、查看有无安装mysqlhttps://blog.51cto.com/u_16175430/7261412 3、 方案一:oracle不开日志 data…...
:门控循环单元(GRU))
NLP学习路线图(二十四):门控循环单元(GRU)
一、背景:RNN的困境与门控机制的曙光 RNN的基本原理: RNN的核心思想是引入循环连接,使网络具有“记忆”功能。 在时刻 t,RNN接收当前输入 x_t 和前一个时刻的隐藏状态 h_{t-1}。 通过一个共享的权重参数(W, U, b)计算当前时刻的隐藏状态 h_t: h_t = tanh(W * x_t + U * …...

Doris查询Hive数据:实现高效跨数据源分析的实践指南
#### 1. Doris与Hive的集成背景 在大数据生态中,Hive作为基于Hadoop的数据仓库工具,广泛用于海量数据的批处理分析。而Apache Doris(原百度 Palo)是一种高性能、实时分析的MPP(大规模并行处理)数据库&…...

vsCode使用本地低版本node启动配置文件
npm run dev的配置文件 {"configurations": [{"type": "node-terminal","name": "项目运行: dev","request": "launch",//重点在这里 这行注释到时候删掉"command": "E:\\node-v14.21.…...

在Ubuntu上使用 dd 工具制作U盘启动盘
在Ubuntu上使用 dd 工具制作U盘启动盘 在Linux系统中,dd 是一个功能强大且原生支持的命令行工具,常用于复制文件和转换数据。它也可以用来将ISO镜像写入U盘,从而创建一个可启动的操作系统安装盘。虽然图形化工具(如 Startup Disk…...

el-table表格增加序号列index vue2和vue3的写法
<el-table><!--每页从1开始的序号--><el-table-column label"序号" width"60" align"center" type"index" /><!--一直递增的序号 vue2写法--><el-table-column label"序号" width"60"…...

【学习记录】如何使用 Python 提取 PDF 文件中的内容
如何使用 Python 提取 PDF 文件中的内容 在文档自动化处理、数据提取和信息分析等任务中,从 PDF 文件中提取文本是一项常见需求。PDF 文件通常分为两种类型:基于文本的 PDF 和 包含扫描图像的 PDF。 本文将介绍如何使用 Python 分别提取这两种类型的 P…...

Spark 之 DataFrame 开发
foreachPartition val data = spark.sparkContext.parallelize(1 to 100)// 使用 foreachPartition 批量处理分区 data.foreachPartition {partitionIterator =...

嵌入式学习笔记 - freeRTOS xTaskResumeAll( )函数解析
第一部分 移除挂起等待列表中的任务 while( listLIST_IS_EMPTY( &xPendingReadyList ) pdFALSE )//循环寻找直到为空,把全部任务扫描一遍 { pxTCB ( TCB_t * ) listGET_OWNER_OF_HEAD_ENTRY( ( &xPendingR…...
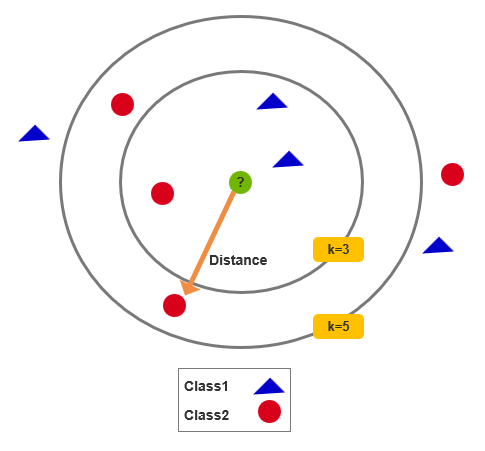
机器学习KNN算法全解析:从原理到实战
大家好!今天我们来聊聊机器学习中的"懒人算法"——KNN(K-Nearest Neighbors,K近邻)算法。这个算法就像个"墙头草",它不学习模型参数,而是直接根据邻居的"投票"来做决策&…...
【QT】自定义QWidget标题栏,可拖拽(拖拽时窗体变为normal大小),可最小/大化、关闭(图文详情)
目录 0.背景 1.详细实现 思路简介 .h文件 .cpp文件 0.背景 Qt Linux;项目遇到问题,解决后特此记录 项目需要,个性化的标题栏(是个widget),在传统的三个按钮(最大化、最小化、关闭…...
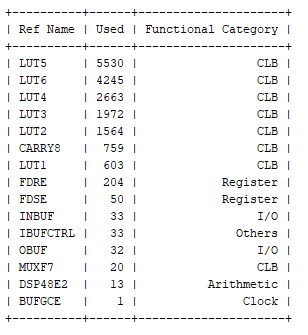
FPGA定点和浮点数学运算-实例对比
在创建 RTL 示例时,经常使用 VHDL 2008 附带的 VHDL 包。它提供了出色的功能,可以高效地处理定点数,当然,它们也是可综合的。该包的一些优点包括: 有符号和无符号(后缀和后缀)定点向量。轻松将定…...

MySQL Binlog 数据恢复全指南
MySQL Binlog 数据恢复全指南 一、Binlog 核心概念 1. 什么是 Binlog? Binlog(二进制日志)是 MySQL 记录所有修改数据的 SQL 语句的日志文件,采用二进制格式存储。它是 MySQL 最重要的日志之一,具有三大核心功能&am…...

python版若依框架开发:后端开发规范
python版若依框架开发 从0起步,扬帆起航。 python版若依部署代码生成指南,迅速落地CURD!项目结构解析前端开发规范后端开发规范文章目录 python版若依框架开发1.启动命令2.配置⽂件3.上传配置1.启动命令 本项⽬⾃定义了两个启动命令 pyhton app.py --env=devpython app.p…...