Doris查询Hive数据:实现高效跨数据源分析的实践指南
#### 1. Doris与Hive的集成背景
在大数据生态中,Hive作为基于Hadoop的数据仓库工具,广泛用于海量数据的批处理分析。而Apache Doris(原百度 Palo)是一种高性能、实时分析的MPP(大规模并行处理)数据库,擅长高并发、低延迟的查询场景。两者的结合能够实现以下目标:
- **实时分析Hive冷数据**:无需数据迁移,直接查询Hive中的历史数据。
- **统一查询入口**:通过Doris统一对接多种数据源(Hive、MySQL、HDFS等),简化分析流程。
- **资源隔离**:利用Doris的高性能引擎加速复杂查询,减少对Hive计算资源的依赖。
#### 2. 技术实现原理
Doris通过**外部表(External Table)**和**Multi-Catalog**两种机制查询Hive数据:
- **外部表**:在Doris中创建表结构映射,直接读取Hive存储在HDFS或对象存储(如S3)中的数据。
- **Multi-Catalog(1.2.0+版本)**:直接连接Hive Metastore,自动同步元数据,无需手动建表。

*(示意图:Doris通过Hive Metastore获取元数据,通过HDFS/对象存储读取数据)*
#### 3. 配置与操作步骤
##### 方式1:通过外部表查询
```sql
-- 创建Hive外部表
CREATE EXTERNAL TABLE hive_analytics (
user_id INT,
event_time DATETIME,
event_type STRING
) ENGINE=HIVE
PROPERTIES (
"hive.metastore.uris" = "thrift://hive-metastore:9083",
"database" = "default",
"table" = "user_events"
);
-- 执行查询(Doris自动将查询下推至Hive)
SELECT event_type, COUNT(*)
FROM hive_analytics
WHERE event_time >= '2023-01-01'
GROUP BY event_type;
```
##### 方式2:通过Multi-Catalog(推荐)
```sql
-- 创建Hive Catalog
CREATE CATALOG hive_catalog PROPERTIES (
"type" = "hms",
"hive.metastore.uris" = "thrift://hive-metastore:9083",
"dfs.nameservices" = "my_hdfs",
"dfs.ha.namenodes.my_hdfs" = "nn1,nn2",
"dfs.namenode.rpc-address.my_hdfs.nn1" = "namenode1:8020",
"dfs.namenode.rpc-address.my_hdfs.nn2" = "namenode2:8020",
"dfs.client.failover.proxy.provider" = "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
);
-- 查询Hive表(自动同步元数据)
SELECT * FROM hive_catalog.default.sales_data WHERE region = 'Asia';
```
#### 4. 性能优化策略
- **分区剪枝**:确保Hive表已分区,Doris自动过滤无关分区。
- **列式格式优先**:优先查询Parquet/ORC格式数据,Doris可高效读取。
- **缓存加速**:通过Doris的查询缓存(默认开启)缓存热数据。
- **资源限制**:避免大表扫描,通过`SET exec_mem_limit=8G;`限制单查询内存。
#### 5. 最佳实践与注意事项
- **数据更新延迟**:Hive数据变更后,需执行`REFRESH CATALOG hive_catalog`同步元数据。
- **安全认证**:若HDFS启用Kerberos,需在Doris BE节点配置`krb5.conf`和keytab文件。
- **数据类型映射**:注意Hive的`TIMESTAMP`类型与Doris的`DATETIME`差异。
- **混合查询**:结合Doris内部表与Hive外部表实现跨源关联查询:
```sql
SELECT d.user_name, h.order_count
FROM doris_user_profiles d
JOIN hive_catalog.default.order_stats h ON d.user_id = h.user_id;
```
#### 6. 性能对比测试
| 场景 | Hive查询耗时 | Doris查询耗时 |
|------|-------------|---------------|
| 全表扫描(1TB Parquet) | 82s | 27s |
| 分区过滤查询 | 45s | 9s |
| 聚合查询(10亿行) | 68s | 14s |
*测试环境:10节点Doris集群,16核/64GB内存/SSD;Hive on Tez*
#### 7. 典型应用场景
- **实时+历史数据分析**:将Hive作为数据湖存储历史数据,Doris处理近实时数据。
- **数据湖查询加速**:对Hive中频繁访问的表建立Doris物化视图。
- **AB测试分析**:快速查询Hive中的用户行为日志,结合Doris实时指标计算。
#### 8. 总结
Doris与Hive的深度集成,通过元数据自动同步、查询下推、列式存储优化等技术,实现了对海量Hive数据的亚秒级响应。这种架构既保留了Hive的弹性存储能力,又发挥了Doris的高性能分析优势,为企业构建湖仓一体架构提供了关键支持。未来,随着Doris对Iceberg、Hudi等格式的支持,将进一步拓展其在数据湖场景的应用边界。
(注:本文基于Doris 1.2.4版本,配置细节请参考[官方文档](https://doris.apache.org/))
相关文章:

Doris查询Hive数据:实现高效跨数据源分析的实践指南
#### 1. Doris与Hive的集成背景 在大数据生态中,Hive作为基于Hadoop的数据仓库工具,广泛用于海量数据的批处理分析。而Apache Doris(原百度 Palo)是一种高性能、实时分析的MPP(大规模并行处理)数据库&…...

vsCode使用本地低版本node启动配置文件
npm run dev的配置文件 {"configurations": [{"type": "node-terminal","name": "项目运行: dev","request": "launch",//重点在这里 这行注释到时候删掉"command": "E:\\node-v14.21.…...

在Ubuntu上使用 dd 工具制作U盘启动盘
在Ubuntu上使用 dd 工具制作U盘启动盘 在Linux系统中,dd 是一个功能强大且原生支持的命令行工具,常用于复制文件和转换数据。它也可以用来将ISO镜像写入U盘,从而创建一个可启动的操作系统安装盘。虽然图形化工具(如 Startup Disk…...

el-table表格增加序号列index vue2和vue3的写法
<el-table><!--每页从1开始的序号--><el-table-column label"序号" width"60" align"center" type"index" /><!--一直递增的序号 vue2写法--><el-table-column label"序号" width"60"…...

【学习记录】如何使用 Python 提取 PDF 文件中的内容
如何使用 Python 提取 PDF 文件中的内容 在文档自动化处理、数据提取和信息分析等任务中,从 PDF 文件中提取文本是一项常见需求。PDF 文件通常分为两种类型:基于文本的 PDF 和 包含扫描图像的 PDF。 本文将介绍如何使用 Python 分别提取这两种类型的 P…...

Spark 之 DataFrame 开发
foreachPartition val data = spark.sparkContext.parallelize(1 to 100)// 使用 foreachPartition 批量处理分区 data.foreachPartition {partitionIterator =...

嵌入式学习笔记 - freeRTOS xTaskResumeAll( )函数解析
第一部分 移除挂起等待列表中的任务 while( listLIST_IS_EMPTY( &xPendingReadyList ) pdFALSE )//循环寻找直到为空,把全部任务扫描一遍 { pxTCB ( TCB_t * ) listGET_OWNER_OF_HEAD_ENTRY( ( &xPendingR…...
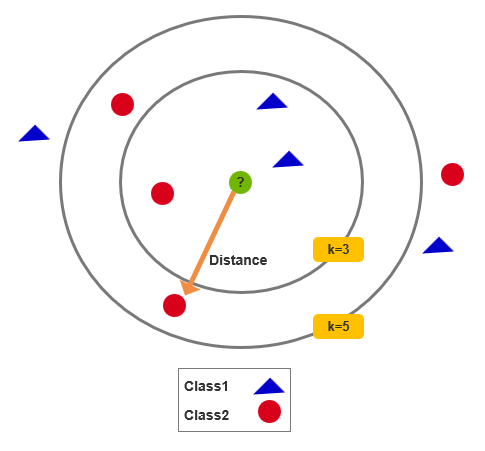
机器学习KNN算法全解析:从原理到实战
大家好!今天我们来聊聊机器学习中的"懒人算法"——KNN(K-Nearest Neighbors,K近邻)算法。这个算法就像个"墙头草",它不学习模型参数,而是直接根据邻居的"投票"来做决策&…...
【QT】自定义QWidget标题栏,可拖拽(拖拽时窗体变为normal大小),可最小/大化、关闭(图文详情)
目录 0.背景 1.详细实现 思路简介 .h文件 .cpp文件 0.背景 Qt Linux;项目遇到问题,解决后特此记录 项目需要,个性化的标题栏(是个widget),在传统的三个按钮(最大化、最小化、关闭…...
FPGA定点和浮点数学运算-实例对比
在创建 RTL 示例时,经常使用 VHDL 2008 附带的 VHDL 包。它提供了出色的功能,可以高效地处理定点数,当然,它们也是可综合的。该包的一些优点包括: 有符号和无符号(后缀和后缀)定点向量。轻松将定…...

MySQL Binlog 数据恢复全指南
MySQL Binlog 数据恢复全指南 一、Binlog 核心概念 1. 什么是 Binlog? Binlog(二进制日志)是 MySQL 记录所有修改数据的 SQL 语句的日志文件,采用二进制格式存储。它是 MySQL 最重要的日志之一,具有三大核心功能&am…...

python版若依框架开发:后端开发规范
python版若依框架开发 从0起步,扬帆起航。 python版若依部署代码生成指南,迅速落地CURD!项目结构解析前端开发规范后端开发规范文章目录 python版若依框架开发1.启动命令2.配置⽂件3.上传配置1.启动命令 本项⽬⾃定义了两个启动命令 pyhton app.py --env=devpython app.p…...
Linux编程:2、进程基础知识
一、进程基本概念 1、进程与程序的区别 程序:静态的可执行文件(如电脑中的vs2022安装程序)。进程:程序的动态执行过程(如启动后的vs2022实例),是操作系统分配资源的单位(如 CPU 时…...

时序数据库IoTDB与EdgeX Foundry集成适配服务介绍
一、背景介绍 EdgeX Foundry:由Linux基金会运维的开放源码边缘计算软件框架,自2017年开源后广泛应用于全球各行业场景。VMware自2018年起在中国社区推广EdgeX技术,拓展生态,并持续贡献代码。IoTDB:由Apache基…...

Android第十二次面试-多线程和字符串算法总结
多线程的创建与常见使用方法 一、多线程创建方式 1. 继承Thread类 class MyThread extends Thread {Overridepublic void run() {// 线程执行逻辑System.out.println(Thread.currentThread().getName() " is running");} }// 使用 MyThread thread new …...

ES6——数组扩展之Set数组
在ES6(ECMAScript 2015)中,JavaScript的Set对象提供了一种存储任何值唯一性的方式,类似于数组但又不需要索引访问。这对于需要确保元素唯一性的场景非常有用。Set对象本身并不直接提供数组那样的方法来操作数据(例如ma…...

Cursor Rules 使用
前言 最近在使用 Cursor 进行编程辅助时,发现 AI 生成的代码风格和当前的代码风格大相径庭。而且有时它会输出很奇怪的代码,总是不符合预期。 遂引出本篇,介绍一下 Rules ,它就可以做一些规范约束之类的事情。 什么是 Cursor R…...

服务器数据恢复—服务器raid5阵列崩溃如何恢复数据?
服务器数据恢复环境&故障: 某品牌型号为X3850服务器上有一组由14块数据盘和1块热备盘组建的raid5磁盘阵列。 服务器在正常使用过程中突然崩溃,管理员查看raid5阵列故障情况的时发现磁盘阵列中有2块硬盘掉线,但是热备盘没有启用。 服务器数…...

Go语言堆内存管理
Go堆内存管理 1. Go内存模型层级结构 Golang内存管理模型与TCMalloc的设计极其相似。基本轮廓和概念也几乎相同,只是一些规则和流程存在差异。 2. Go内存管理的基本概念 Go内存管理的许多概念在TCMalloc中已经有了,含义是相同的,只是名字有…...
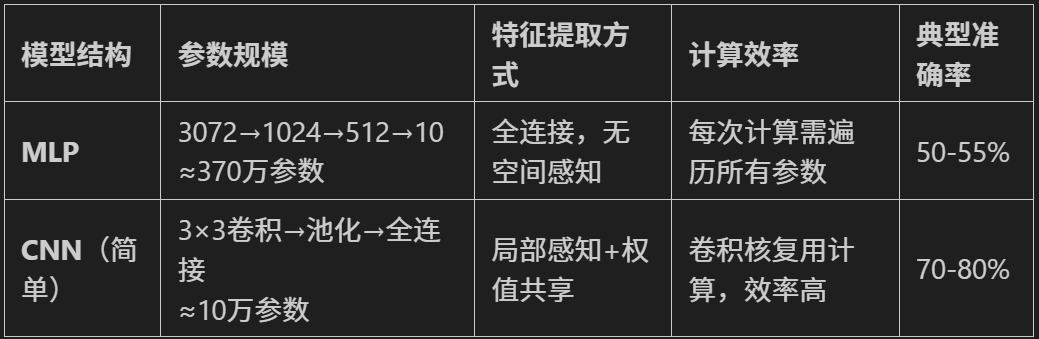
【DAY41】简单CNN
内容来自浙大疏锦行python打卡训练营 浙大疏锦行 知识点: 数据增强卷积神经网络定义的写法batch归一化:调整一个批次的分布,常用与图像数据特征图:只有卷积操作输出的才叫特征图调度器:直接修改基础学习率 卷积操作常…...

Rust 学习笔记:使用自定义命令扩展 Cargo
Rust 学习笔记:使用自定义命令扩展 Cargo Rust 学习笔记:使用自定义命令扩展 Cargo Rust 学习笔记:使用自定义命令扩展 Cargo Cargo 支持通过 $PATH 中的 cargo-something 形式的二进制文件拓展子命令,而无需修改 Cargo 本身。 …...
)
LeetCode 08.06 面试题 汉诺塔 (Java)
经典递归解决汉诺塔问题:清晰的三步移动策略 问题描述 在汉诺塔问题中,有 3 根柱子和 N 个大小不同的盘子,盘子初始按升序堆叠在第一根柱子上(最小的在顶部)。目标是将所有盘子移动到第三根柱子上,并满足…...
使用MinIO搭建自己的分布式文件存储
目录 引言: 一.什么是 MinIO ? 二.MinIO 的安装与部署: 三.Spring Cloud 集成 MinIO: 1.前提准备: (1)安装依赖: (2)配置MinIO连接: &…...

单元测试与QTestLib框架使用
一.单元测试的意义 在软件开发中,单元测试是指对软件中最小可测试单元(通常是函数、类的方法)进行隔离的、可重复的验证。进行单元测试具有以下重要意义: 1.提升代码质量与可靠性: 早期错误检测: 在开发…...

java面试场景题:QPS 短链系统怎么设计
以下是对文章的润色版本: 这道场景设计题,初看似乎业务简单,实则覆盖的知识点极为丰富: 高并发与高性能分布式 ID 生成机制;Redis Bloom Filter——高并发、低内存损耗的过滤组件知识;分库、分表海量数据存…...

java面试场景提题:
以下是润色后的文章,结构更清晰,语言更流畅,同时保留了技术细节: 应对百倍QPS增长的系统设计策略 整体架构设计思路 面对突发性百倍QPS增长,系统设计需从硬件、架构、代码、数据四个维度协同优化: 硬件层…...
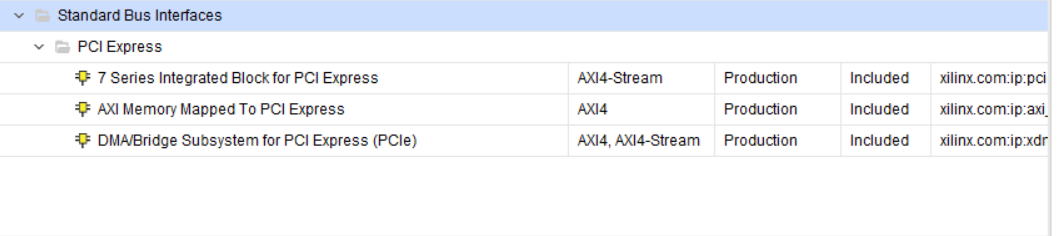
K7 系列各种PCIE IP核的对比
上面三个IP 有什么区别,什么时候用呢? 7 series Integrated Block for PCIE AXI Memory Mapped to PCI Express DMA subsystem for PCI Express 特点 这是 Kintex-7 内置的 硬核 PCIe 模块。部分事务层也集成在里面,使用标准的PCIE 基本没…...
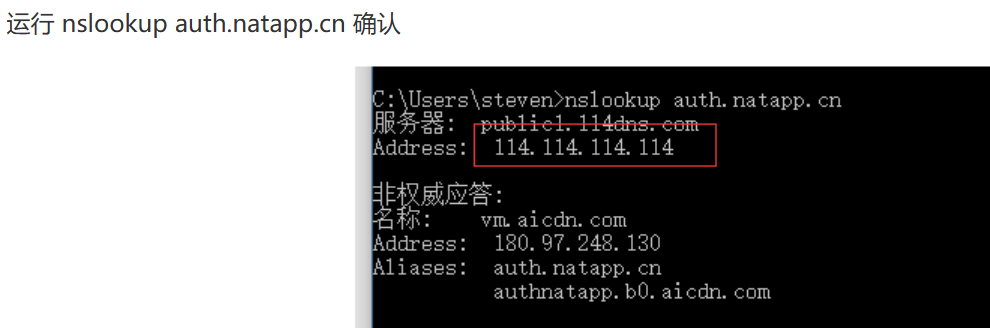
natapp 内网穿透失败
连不上网络错误调试排查详解 - NATAPP-内网穿透 基于ngrok的国内高速内网映射工具 如何将DNS服务器修改为114.114.114.114_百度知道 连不上/错误信息等问题解决汇总 - NATAPP-内网穿透 基于ngrok的国内高速内网映射工具 nslookup auth.natapp.cnping auth.natapp.cn...
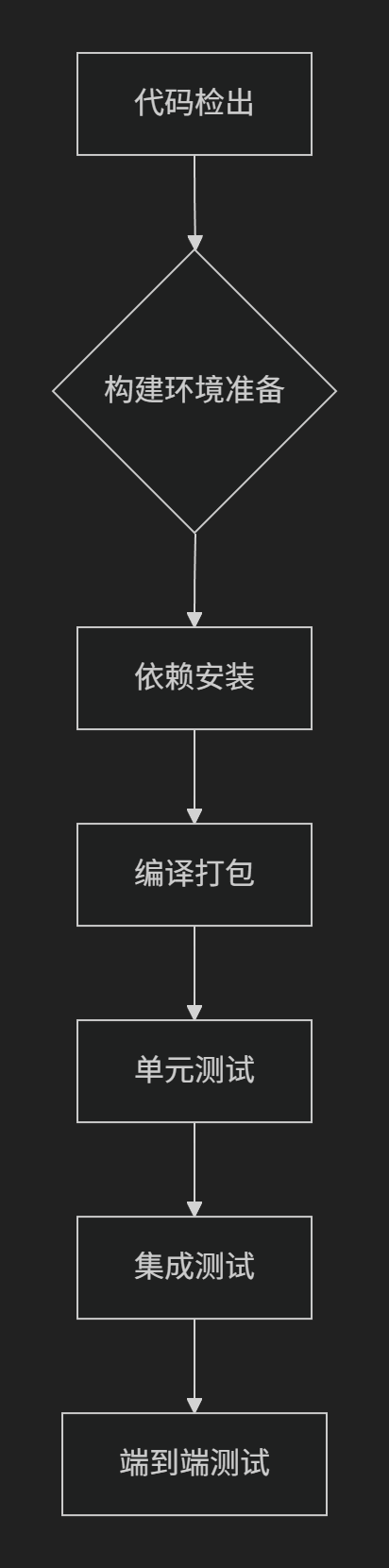
深入解析CI/CD开发流程
引言:主播最近实习的时候发现部门里面使用的是CI/CD这样的集成开发部署,但是自己不是太了解什么意思,所以就自己查了一下ci/cd相关的资料,整理分享了一下 一、CI/CD CI/CD是持续集成和持续交付部署的缩写,旨在简化并…...

Docke启动Ktransformers部署Qwen3MOE模型实战与性能测试
docker运行Ktransformers部署Qwen3MOE模型实战及 性能测试 最开始拉取ktransformers:v0.3.1-AVX512版本,发现无论如何都启动不了大模型,后来发现是cpu不支持avx512指令集。 由于本地cpu不支持amx指令集,因此下载avx2版本镜像: …...