pandas 字符串存储技术演进:从 object 到 PyArrow 的十年历程
文章目录
- 1. 引言
- 2. 阶段1:原始时代(pandas 1.0前)
- 3. 阶段2:Python-backed StringDtype(pandas 1.0 - 1.3)
- 4. 阶段3:PyArrow初次尝试(pandas 1.3 - 2.1)
- 5. 阶段4:过渡方案pyarrow_numpy(pandas 2.1 - 2.3)
- 6. 阶段5:全面转向PyArrow(pandas 2.0+及未来3.0)
- 7. 结论
在数据分析领域,字符串数据是最常见的数据类型之一。无论是处理文本文件、数据库查询结果,还是网页抓取的内容,字符串都承载着大量有价值的信息。而pandas作为Python生态中最受欢迎的数据处理库,其对字符串的存储和处理能力,直接影响着数据分析的效率和效果。在过去的十年里,pandas的字符串存储技术经历了多次重要的变革,从最初简单的object类型存储,逐步发展到基于PyArrow的高效存储方案。本文将沿着这一技术演进的脉络,深入探讨每一个阶段的特点、问题以及带来的改进。
1. 引言
字符串处理在数据分析中的核心地位不言而喻。在实际应用中,我们经常需要对字符串进行清洗、转换、匹配等操作。例如,在处理电商交易数据时,商品名称、客户地址等都是字符串类型;在自然语言处理任务中,文本内容更是以字符串的形式存在。高效的字符串存储和处理技术,能够显著提升数据分析的速度,减少内存占用,从而提高整个分析流程的效率。
随着数据规模的不断增大,pandas早期的字符串存储技术逐渐暴露出性能和内存管理上的不足。为了适应大数据时代的需求,pandas字符串存储技术的演进势在必行。这不仅是技术发展的必然要求,也是为了更好地满足用户在实际数据分析工作中的需求。
2. 阶段1:原始时代(pandas 1.0前)
在pandas 1.0版本之前,字符串数据默认使用object数据类型(dtype)进行存储。object dtype本质上是存储Python字符串对象的引用,缺失值则使用np.nan表示。这种存储方式简单直接,但也带来了一系列严重的问题。
从内存占用角度来看,object dtype的效率非常低。假设有一个包含100万个字符串的Series,每个字符串平均长度为10个字符,使用object dtype存储时,其内存占用约为80MB。这是因为每个Python字符串对象除了存储实际的字符数据外,还需要额外的内存来存储对象的元数据,如引用计数、类型信息等。
在性能方面,基于object dtype的字符串操作也十分缓慢。以将所有字符串转换为大写为例,使用str.upper()方法对100万个字符串进行操作,耗时大约需要2.1秒。这是因为object dtype下的字符串操作本质上是对Python对象进行循环操作,无法充分利用底层的向量化计算优势。
此外,object dtype还存在混合类型的隐患。由于object dtype可以存储任意Python对象,当Series中同时存在字符串、整数、浮点数等不同类型的数据时,整个Series都会被转换为object dtype。这不仅会导致性能下降,还可能引发一些难以排查的错误。
下面通过一段代码来直观感受object dtype的存储和性能问题:
import pandas as pd
import numpy as np
import time# 创建包含100万个字符串的Series
data = [f"string_{i}" for i in range(1000000)]
s = pd.Series(data)# 查看数据类型
print(s.dtype) # object# 记录开始时间
start_time = time.time()
# 将字符串转换为大写
s = s.str.upper()
# 记录结束时间
end_time = time.time()
print(f"转换为大写耗时: {end_time - start_time} 秒") # 查看内存占用
print(f"内存占用: {s.memory_usage(index=True, deep=True) / (1024 * 1024):.2f} MB")
3. 阶段2:Python-backed StringDtype(pandas 1.0 - 1.3)
为了解决object dtype在字符串存储上的一些问题,pandas 1.0版本引入了StringDtype,其中StringDtype("python")是基于Python对象的实现。这种存储方式强制将数据存储为字符串类型或者pd.NA(用于表示缺失值),明确了类型边界,统一了缺失值语义。
与object dtype相比,StringDtype("python")在类型检查和缺失值处理上更加严格和规范。例如,当尝试将非字符串类型的数据存入StringDtype的Series时,pandas会抛出类型错误,而不是像object dtype那样将数据强制转换为对象。同时,pd.NA的引入,使得缺失值的处理更加统一,避免了np.nan在不同数据类型下可能产生的歧义。
然而,StringDtype("python")本质上仍然是基于Python对象的存储,因此在内存占用和性能上与object dtype相比并没有本质的提升。它只是在类型管理和缺失值处理上进行了优化,并没有解决底层存储效率和计算性能的问题。
通过以下代码可以体验StringDtype("python")的特点:
import pandas as pd# 创建使用StringDtype("python")的Series
s = pd.Series(["apple", "banana", pd.NA], dtype="string[python]")
print(s.dtype) # string[python]# 尝试存入非字符串类型数据,会抛出类型错误
try:s[0] = 1
except TypeError as e:print(f"错误信息: {e}")
4. 阶段3:PyArrow初次尝试(pandas 1.3 - 2.1)
pandas 1.3版本开始引入StringDtype("pyarrow"),这是一个基于Apache Arrow的字符串存储方案。Apache Arrow是一个跨语言的内存数据格式,它采用列式内存布局,能够高效地存储和处理数据。基于PyArrow的字符串存储,使得pandas在字符串处理上有了质的飞跃。
在内存占用方面,使用StringDtype("pyarrow")存储100万个字符串,内存占用可以降至28MB左右。这是因为PyArrow采用了更加紧凑的内存布局,避免了Python对象额外的元数据开销。在性能上,同样是将100万个字符串转换为大写,使用StringDtype("pyarrow")的str.upper()操作耗时可以缩短至0.25秒,大幅提升了处理速度。
此外,基于PyArrow的存储方案还带来了零拷贝生态兼容的优势。它可以与其他基于Arrow的库(如Dask、Vaex等)进行无缝协作,避免了数据在不同库之间转换时的拷贝开销,进一步提高了数据处理的效率。
不过,StringDtype("pyarrow")也存在一些问题。其中最主要的是缺失值语义的冲突。StringDtype("pyarrow")使用pd.NA表示缺失值,而在pandas的传统体系中,很多操作和函数仍然依赖np.nan来表示缺失值,这就导致在一些混合场景下,缺失值的处理会出现不兼容的情况。
下面通过代码展示StringDtype("pyarrow")的性能和内存优势:
import pandas as pd
import time# 创建使用StringDtype("pyarrow")的Series
data = [f"string_{i}" for i in range(1000000)]
s = pd.Series(data, dtype="string[pyarrow]")# 记录开始时间
start_time = time.time()
# 将字符串转换为大写
s = s.str.upper()
# 记录结束时间
end_time = time.time()
print(f"转换为大写耗时: {end_time - start_time} 秒") # 查看内存占用
print(f"内存占用: {s.memory_usage(index=True, deep=True)/ (1024 * 1024):.2f} MB")
5. 阶段4:过渡方案pyarrow_numpy(pandas 2.1 - 2.3)
为了解决StringDtype("pyarrow")在缺失值语义上与传统np.nan的冲突问题,pandas 2.1版本引入了pyarrow_numpy存储方案。pyarrow_numpy采用PyArrow进行字符串存储,但使用np.nan表示缺失值,通过强制转换的方式来兼容传统的缺失值语义。
这种设计的动机是为了在保证性能提升的同时,解决混合场景下的兼容性问题。在实际应用中,很多用户的代码和工作流程已经习惯了使用np.nan来处理缺失值,如果突然完全改用pd.NA,可能会导致大量代码需要修改。pyarrow_numpy的出现,为用户提供了一个过渡方案,使得他们可以在享受PyArrow带来的性能优势的同时,继续使用熟悉的缺失值处理方式。
然而,pyarrow_numpy方案也存在一定的局限性。由于需要在PyArrow存储和np.nan缺失值之间进行额外的转换逻辑,这会导致一定的性能妥协。例如,使用pyarrow_numpy存储100万个字符串,内存占用大约为35MB,str.upper()操作耗时约为0.4秒,相比纯粹的StringDtype("pyarrow"),性能有所下降。
通过以下代码可以了解pyarrow_numpy的使用和性能情况:
import pandas as pd
import time# 创建使用pyarrow_numpy的Series
data = [f"string_{i}" for i in range(1000000)]
s = pd.Series(data, dtype="string[pyarrow_numpy]")# 记录开始时间
start_time = time.time()
# 将字符串转换为大写
s = s.str.upper()
# 记录结束时间
end_time = time.time()
print(f"转换为大写耗时: {end_time - start_time} 秒")# 查看内存占用
print(f"内存占用: {s.memory_usage(index=True, deep=True) / (1024 * 1024):.2f} MB")
6. 阶段5:全面转向PyArrow(pandas 2.0+及未来3.0)
从pandas 2.0版本开始,字符串存储逐步向PyArrow全面过渡。在pandas 2.0及以上版本中,默认会推断出string[pyarrow]类型,并且在缺失值处理上,也逐渐兼容np.nan。这意味着用户在使用pandas处理字符串数据时,无需手动指定存储类型,就能享受到PyArrow带来的性能优势,同时在缺失值处理上也更加灵活。
对于未来的pandas 3.0版本,官方计划强制使用PyArrow进行字符串存储,并移除pyarrow_numpy过渡方案。这一举措将进一步简化pandas的字符串存储体系,提高整体的性能和稳定性。同时,全面转向PyArrow也有助于更好地与其他大数据处理库(如Dask、PySpark)进行生态整合,实现数据在不同库之间的无缝流转和高效处理。
在实际应用中,用户可以通过以下代码体验pandas 2.0+版本中默认的string[pyarrow]存储:
import pandas as pd# 创建Series,pandas会自动推断为string[pyarrow]类型
s = pd.Series(["apple", "banana", None])
print(s.dtype) # string[pyarrow]
7. 结论
| 阶段 | 时间范围 | 存储方式 | 核心特点 | 解决的问题 |
|---|---|---|---|---|
| 原始时代 | pandas 1.0 前 | object dtype | Python 字符串对象存储,np.nan 缺失值 | 无专门字符串类型,混合类型问题严重 |
| Python-backed StringDtype | pandas 1.0 - 1.3 | StringDtype("python") | 强制字符串/pd.NA,但仍基于 Python 对象 | 解决混合类型问题,但性能无提升 |
| PyArrow 初次尝试 | pandas 1.3 - 2.1 | StringDtype("pyarrow") | Arrow 存储,pd.NA 缺失值 | 高性能、低内存,但与传统 np.nan 不兼容 |
| 过渡方案 pyarrow_numpy | pandas 2.1 - 2.3 | StringDtype("pyarrow_numpy") | Arrow 存储,np.nan 缺失值 | 临时解决缺失值语义冲突,但性能妥协 |
| 全面转向 PyArrow | pandas 2.0+(3.0 默认) | StringDtype("pyarrow") | Arrow 存储,兼容 np.nan 缺失值 | 统一高性能、低内存、生态兼容,替代所有旧方案 |
回顾pandas字符串存储技术的十年演进历程,我们可以清晰地看到其发展的核心驱动力:性能、兼容性和生态整合。从最初简单的object dtype,到逐步引入基于Python对象的StringDtype,再到基于PyArrow的高效存储方案,每一次技术变革都是为了更好地解决实际应用中遇到的问题。
未来,随着pandas 3.0版本全面强制使用PyArrow进行字符串存储,PyArrow将成为pandas字符串处理的事实标准。这不仅会进一步提升pandas在字符串处理上的性能和效率,还将加强其与大数据生态的融合,为用户提供更加统一、高效的数据处理体验。对于数据分析从业者来说,了解和掌握pandas字符串存储技术的演进,将有助于更好地应对日益复杂和大规模的数据处理任务。
相关文章:

pandas 字符串存储技术演进:从 object 到 PyArrow 的十年历程
文章目录 1. 引言2. 阶段1:原始时代(pandas 1.0前)3. 阶段2:Python-backed StringDtype(pandas 1.0 - 1.3)4. 阶段3:PyArrow初次尝试(pandas 1.3 - 2.1)5. 阶段4…...

LLMs 系列科普文(6)
截止到目前,我们从模型预训练阶段的数据准备讲起,谈到了 Tokenizer、模型的结构、模型的训练,基础模型、预训练阶段、后训练阶段等,这里存在大量的术语或名词,也有一些奇奇怪怪或者说是看起来乱七八糟的内容。这期间跳…...

exp1_code
#include <iostream> using namespace std; // 链栈节点结构 struct StackNode { int data; StackNode* next; StackNode(int val) : data(val), next(nullptr) {} }; // 顺序栈实现 class SeqStack { private: int* data; int top; int capac…...
serv00 ssh登录保活脚本-邮件通知版
适用于自己有服务器情况,ssh定时登录到serv00,并在登录成功后发送邮件通知 msmtp 和 mutt安装 需要安装msmtp 和 mutt这两个邮件客户端并配置,参考如下文章前几步是讲配置这俩客户端的,很简单,不再赘述 用Shell脚本实…...

意识上传伦理前夜:我们是否在创造数字奴隶?
当韩国财阀将“数字永生”标价1亿美元准入权时,联合国预警的“神经种姓制度”正从科幻步入现实。某脑机接口公司用户协议中“上传意识衍生算法归公司所有”的隐藏条款,恰似德里达预言的当代印证:“当意识沦为可交易数据流,主体性便…...

【AIGC】RAGAS评估原理及实践
【AIGC】RAGAS评估原理及实践 (1)准备评估数据集(2)开始评估2.1 加载数据集2.2 评估忠实性2.3 评估答案相关性2.4 上下文精度2.5 上下文召回率2.6 计算上下文实体召回率 RAGas(RAG Assessment)RAG 评估的缩写ÿ…...
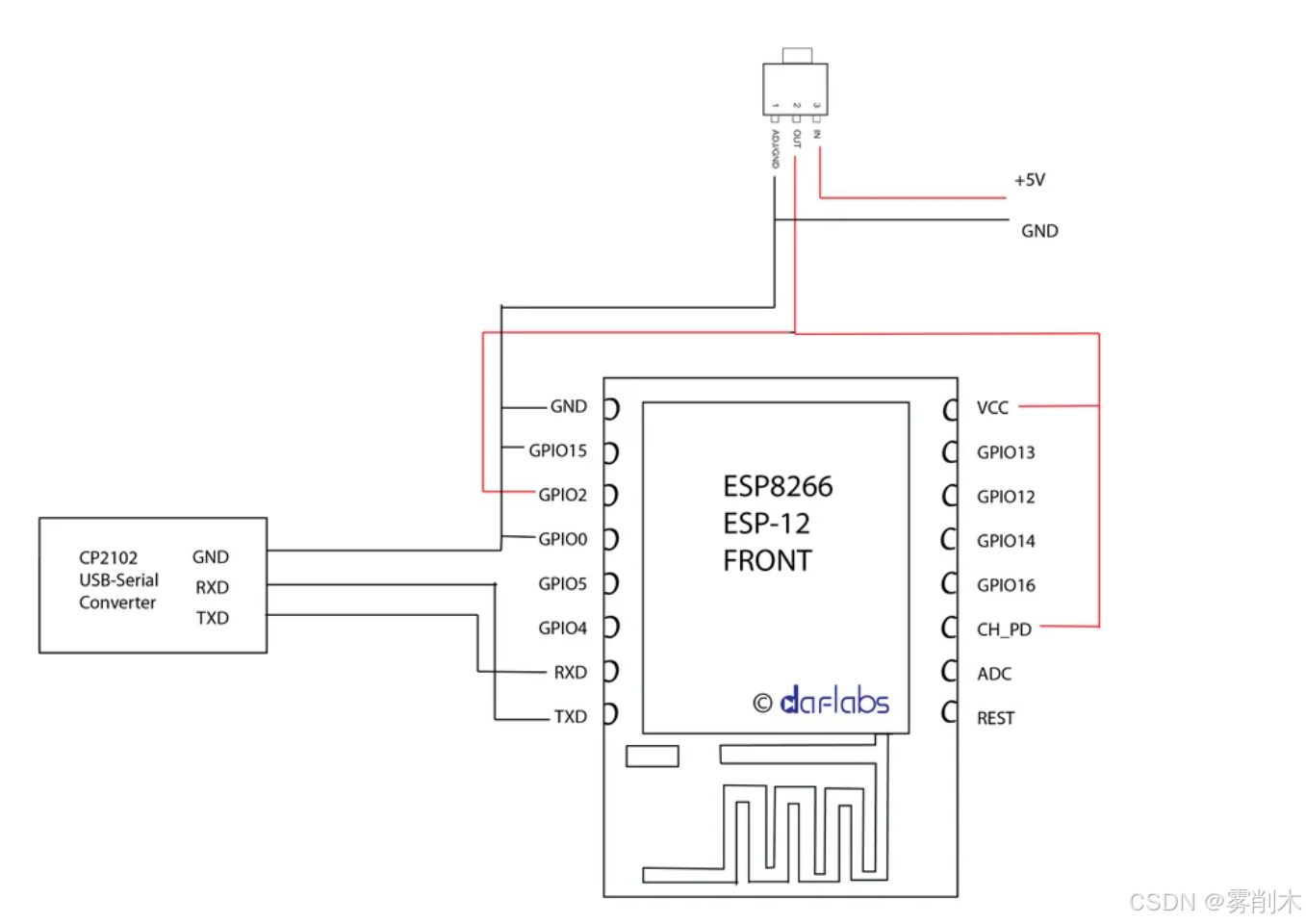
ESP12E/F 参数对比
模式GPIO0GPIO2GPIO15描述正常启动高高低从闪存运行固件闪光模式低高低启用固件刷写 PinNameFunction1RSTReset (Active Low)2ADC (A0)Analog Input (0–1V)3EN (CH_PD)Chip Enable (Pull High for Normal Operation)4GPIO16Wake from Deep Sleep, General Purpose I/O5GPIO14S…...

第二十八章 字符串与数字
第二十八章 字符串与数字 计算机程序完全就是和数据打交道。很多编程问题需要使用字符串和数字这种更小的数据来解决。 参数扩展 第七章,已经接触过参数扩展,但未进行详细说明,大多数参数扩展并不用于命令行,而是出现在脚本文件中。 如果没有什么特殊原因,把参数扩展放…...
[RDK X5] MJPG编解码开发实战:从官方API到OpenWanderary库的C++/Python实现
业余时间一直在基于RDK X5搞一些小研究,需要基于高分辨率图像检测目标。实际落地时,在图像采集上遇到了个大坑。首先,考虑到可行性,我挑选了一个性价比最高的百元内摄像头,已确定可以在X5上使用,接下来就开…...

java复习 05
我的天啊一天又要过去了,没事的还有时间!!! 不要焦虑不要焦虑,事实证明只要我认真地投入进去一切都还是来得及的,代码多实操多复盘,别叽叽喳喳胡思乱想多多思考,有迷茫前害怕后的功…...

aardio 简单网页自动化
WebView自动化,以前每次重复做网页登录、搜索这些操作时都觉得好麻烦,现在终于能让程序替我干活了,赶紧记录下这个超实用的技能! 一、初次接触WebView WebView自动化就像给程序装了个"网页浏览器",第一步得…...

打卡第39天:Dataset 和 Dataloader类
知识点回顾: 1.Dataset类的__getitem__和__len__方法(本质是python的特殊方法) 2.Dataloader类 3.minist手写数据集的了解 作业:了解下cifar数据集,尝试获取其中一张图片 import torch import torch.nn as nn import…...

【评测】Qwen3-Embedding模型初体验
每一篇文章前后都增加返回目录 回到目录 【评测】Qwen3-Embedding模型初体验 模型的介绍页面 本机配置:八代i5-8265U,16G内存,无GPU核显运行,win10操作系统 ollama可以通过下面命令拉取模型: ollama pull modelscope…...

BeanFactory 和 FactoryBean 有何区别与联系?
导语: Spring 是后端面试中的“常青树”,而 BeanFactory 与 FactoryBean 的关系更是高频卡人点。很多候选人混淆两者概念,答非所问,轻则失分,重则直接被“pass”。本文将从面试官视角,深入剖析这一经典问题…...

如何做好一份优秀的技术文档:专业指南与最佳实践
如何做好一份优秀的技术文档:专业指南与最佳实践 技术文档是产品开发、用户支持和团队协作的核心工具。高质量的技术文档能够提升开发效率、降低维护成本并改善用户体验。本文将从实践出发,详细讲解如何编写专业、清晰且实用的技术文档。 🌟…...

C语言内存管理和编译优化实战
参考: C语言内存管理“玄学”:从崩溃到精通的避坑指南C语言编译优化实战:从入门到进阶的高效代码优化技巧...

TCP相关问题 第一篇
TCP相关问题1 1.TCP主动断开连接方为什么需要等待2MSL 如上图所示:在被动链接方调用close,发送FIN时进入LAST_ACK状态,但未收到主动连接方的ack确认,需要被动连接方重新发送一个FIN,而为什么是2MSL,一般认为丢失ack在…...
6.Pandas 数据可视化图-1
第三章 数据可视化 文章目录 目录 第三章 数据可视化 文章目录 前言 一、数据可视化 二、使用步骤 1.pyplot 1.1引入库 1.2 设置汉字字体 1.3 数据准备 1.4 设置索引列 编辑 1.5 调用绘图函数 2.使用seaborn绘图 2.1 安装导入seaborn 2.2 设置背景风格 2.3 调用绘图方法 2.…...

软件功能测试报告都包含哪些内容?
软件功能测试报告是软件开发生命周期中的重要文档,主要涵盖以下关键内容: 1.测试概况:概述测试目标、范围和方法,确保读者对测试背景有清晰了解。 2.测试环境:详细描述测试所用的硬件、软件环境,确保…...

在Vue或React项目中使用Tailwind CSS实现暗黑模式切换:从系统适配到手动控制
在现代Web开发中,暗黑模式(Dark Mode)已成为提升用户体验的重要功能。本文将带你使用Tailwind CSS在React项目(Vue项目类似)中实现两种暗黑模式控制方式: 系统自动适配 - 根据用户设备偏好自动切换手动切换 - 通过按钮让用户自由选择 一、项目准备 使…...
Linux--命令行参数和环境变量
1.命令行参数 Linux 命令行参数基础 1.1参数格式 位置参数:无符号,按顺序传递(如 ls /home/user 中 /home/user 是位置参数) 选项参数: 短选项:以 - 开头,单个字母(如 -l 表示长格…...

Android 集成 Firebase 指南
Firebase 是 Google 提供的一套移动开发平台,包含分析、认证、数据库、消息推送等多种服务。以下是在 Android 应用中集成 Firebase 的详细步骤: 1. 准备工作 安装 Android Studio - 确保使用最新版本 创建或打开 Android 项目 - 项目需要配置正确的包…...

springboot线上教学平台
摘要:在社会快速发展的影响下,使线上教学平台的管理和运营比过去十年更加理性化。依照这一现实为基础,设计一个快捷而又方便的网上线上教学平台系统是一项十分重要并且有价值的事情。对于传统的线上教学平台控制模型来说,网上线上…...

阿里云 Linux 搭建邮件系统全流程及常见问题解决
阿里云 Linux 搭建 [conkl.com]邮件系统全流程及常见问题解决 目录 阿里云 Linux 搭建 [conkl.com]邮件系统全流程及常见问题解决一、前期准备(关键配置需重点检查)1.1 服务器与域名准备1.2 系统初始化(必做操作) 二、核心组件安装…...

【Elasticsearch】映射:fielddata 详解
映射:fielddata 详解 1.fielddata 是什么2.fielddata 的工作原理3.主要用法3.1 启用 fielddata(通常在 text 字段上)3.2 监控 fielddata 使用情况3.3 清除 fielddata 缓存 4.使用场景示例示例 1:对 text 字段进行聚合示例 2&#…...

用Python训练自动驾驶神经网络:从零开始驾驭未来之路
用Python训练自动驾驶神经网络:从零开始驾驭未来之路 哈喽,朋友们!我是Echo_Wish,今天咱们聊点超酷的话题——自动驾驶中的神经网络训练,用Python怎么玩转起来? 说实话,自动驾驶一直是科技圈的香饽饽,为什么?因为它承载了未来交通的无限可能:减少事故、提升效率、节…...

【电路】阻抗匹配
📝 阻抗匹配 一、什么是阻抗匹配? 阻抗匹配(Impedance Matching)是指在电子系统中,为了实现最大功率传输或最小信号反射,使信号源、传输线与负载之间的阻抗达到一种“匹配”状态的技术。 研究对象&#x…...
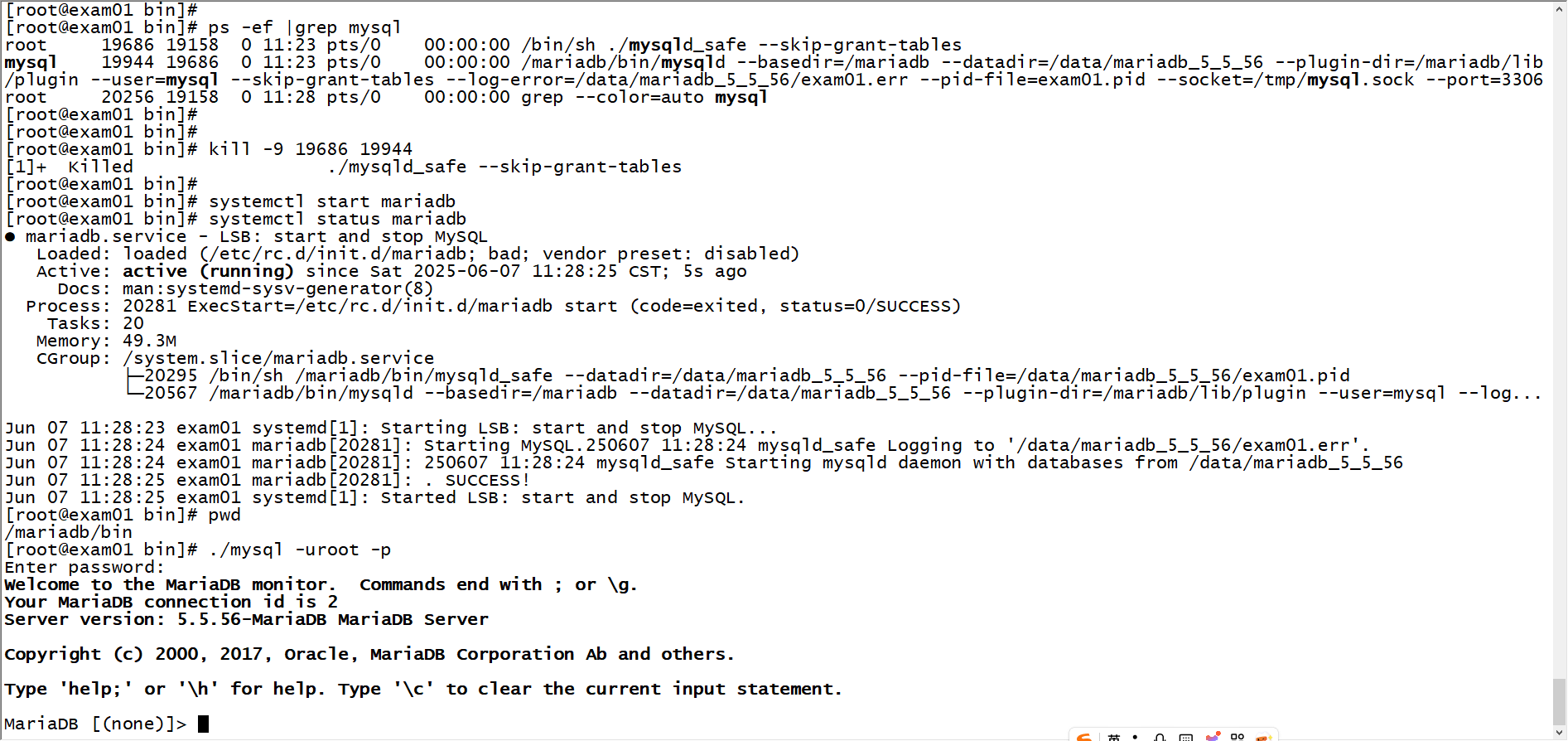
mariadb5.5.56在centos7.6环境安装
mariadb5.5.56在centos7.6环境安装 1 下载安装包 https://mariadb.org/mariadb/all-releases/#5-5 2 上传安装包的服务器 mariadb-5.5.56-linux-systemd-x86_64.tar.gz 3 解压安装包 tar -zxvf mariadb-5.5.56-linux-systemd-x86_64.tar.gz mv mariadb-5.5.56-linux-syst…...

MySQL 索引失效:六大场景与原理剖析
我们都熟知索引是优化 MySQL 查询性能的利器。但你是否遇到过这样的困境:明明在表上建立了索引,查询却依然缓慢,EXPLAIN 分析后发现索引并未被使用?这就是所谓的“索引失效”。 索引失效并非一个 Bug,而是 MySQL 查询…...

打造你的 Android 图像编辑器:深入解析 PhotoEditor 开源库
📸 什么是 PhotoEditor? PhotoEditor 是一个专为 Android 平台设计的开源图像编辑库,旨在为开发者提供简单易用的图像编辑功能。它支持绘图、添加文本、应用滤镜、插入表情符号和贴纸等功能,类似于 Instagram 的编辑体验。该库采…...