从游戏到自动驾驶:互联网时代强化学习如何让机器学会自主决策?
一、为什么机器需要“试错学习”?——强化学习的核心秘密
你有没有玩过《超级马里奥》?当你操控马里奥躲避乌龟、跳过悬崖时,其实就在用一种“试错”的方法学习最优路径。强化学习(Reinforcement Learning, RL)就是让机器像人类玩游戏一样,通过不断尝试和环境反馈来学会做决策的技术。只不过机器的“游戏”可能是开车、下棋、推荐商品等更复杂的场景。
1. 强化学习的三大角色
- 智能体(Agent):像游戏中的马里奥,是做决策的主体,比如自动驾驶汽车、下棋程序。
- 环境(Environment):智能体所处的世界,比如马路、棋盘,环境会给智能体反馈。
- 奖励(Reward):环境对智能体动作的打分,比如马里奥吃到金币+10分,碰到敌人-5分。
2. 核心公式:用数学描述“学习目标”
智能体的终极目标是最大化未来奖励的总和。用公式表示就是:
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + … G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \dots Gt=Rt+1+γRt+2+γ2Rt+3+…
- G t G_t Gt:从时刻t开始的总奖励
- R t + k R_{t+k} Rt+k:时刻t+k获得的奖励
- γ \gamma γ(伽马):折扣因子,比如明天的1分奖励可能不如今天的1分重要,通常取0.9左右
举个例子:假设你在玩一个“写作业游戏”,状态是“是否写完作业”,动作是“写作业”或“玩游戏”。奖励规则是:写完作业+100分(未来还能看动画片),没写完-50分(被妈妈批评)。你会选择先写作业,因为长远来看总奖励更高,这就是强化学习的逻辑!
二、机器如何“学会”做决策?——强化学习的实现步骤
1. 第一步:把世界“翻译”成机器能懂的语言(环境建模)
- 状态(State):环境的“快照”,比如开车时的车速、周围车辆位置,用数字或图像表示。
示例:在“红绿灯路口决策”中,状态可以是:
[红灯/绿灯状态,本车速度,前车距离,左右车道车辆速度] - 动作(Action):智能体的可选操作,比如开车时“加速”“刹车”“变道”。
表格表示:状态(红绿灯颜色) 可选动作 红灯 刹车停车 绿灯 保持速度/加速通过
2. 第二步:设计“游戏得分规则”(奖励函数)
奖励函数是强化学习的“指挥棒”,决定了智能体的行为方向。
案例:智能扫地机器人
- 碰到家具 → 奖励-10分(避免碰撞)
- 清扫完房间 → 奖励+100分(核心目标)
- 每移动1米 → 奖励+1分(鼓励高效工作)
公式化表达:
R ( s , a ) = { + 100 if 清扫完成 − 10 if 碰撞 + 1 otherwise R(s,a) = \begin{cases} +100 & \text{if 清扫完成} \\ -10 & \text{if 碰撞} \\ +1 & \text{otherwise} \end{cases} R(s,a)=⎩ ⎨ ⎧+100−10+1if 清扫完成if 碰撞otherwise
3. 第三步:选择学习策略——无模型学习 vs 有模型学习
(1)无模型学习:像玩新游戏一样瞎试
-
Q-Learning算法:用表格记录每个状态-动作的“得分”(Q值),每次选Q值最高的动作。
公式:
Q ( s , a ) ← Q ( s , a ) + α [ r + γ max a ′ Q ( s ′ , a ′ ) − Q ( s , a ) ] Q(s,a) \leftarrow Q(s,a) + \alpha \left[ r + \gamma \max_{a'} Q(s',a') - Q(s,a) \right] Q(s,a)←Q(s,a)+α[r+γa′maxQ(s′,a′)−Q(s,a)]- α \alpha α(阿尔法):学习率,比如0.1表示慢慢更新表格
- 类比:你第一次学骑自行车时,每次摔倒后调整姿势,慢慢记住“车向左歪时要向右打方向盘”。
-
深度Q网络(DQN):用神经网络代替表格,处理图像等复杂状态,比如AlphaGo用CNN识别棋盘。
(2)有模型学习:先“脑补”世界再行动
- 蒙特卡洛树搜索(MCTS):像下棋时先在脑子里模拟几步走法。
步骤:- 选分支:优先选“没试过的走法”或“看起来能赢的走法”
- 模拟:随机走完剩下的步数,看输赢
- 更新:根据模拟结果给走法打分
类比:你考试时遇到选择题,先排除明显错误的选项,再在剩下的选项里“脑补”解题过程。
三、真实世界的“强化学习玩家”——从AlphaGo到自动驾驶
1. AlphaGo:让机器学会下围棋的“超级玩家”
- 三招绝技:
- 策略网络(Policy Network):用人类棋谱训练,预测下一步可能的落子(像模仿高手下棋)。
- 价值网络(Value Network):评估当前棋局的胜率,避免无效搜索(比如一眼看出“这步棋必输”)。
- 蒙特卡洛树搜索(MCTS):结合前两者,优先探索高胜率的走法。
- 突破性成果:2016年击败人类围棋冠军李世石,靠的就是“强化学习+树搜索”的组合拳。
2. 自动驾驶:让汽车学会“看路”和“决策”
- 场景:无保护左转
- 状态:摄像头拍摄的图像(识别行人、车辆)、雷达测量的距离、交通灯状态。
- 动作:左转、等待、鸣笛。
- 奖励函数:
R = { − 1000 碰撞行人 + 50 成功左转 − 1 每等待1秒 R = \begin{cases} -1000 & \text{碰撞行人} \\ +50 & \text{成功左转} \\ -1 & \text{每等待1秒} \end{cases} R=⎩ ⎨ ⎧−1000+50−1碰撞行人成功左转每等待1秒 - 算法:DDPG(深度确定性策略梯度),处理连续动作空间(如方向盘转角)。
四、强化学习的“成长烦恼”——挑战与解决办法
1. 问题1:奖励太少,学不会(奖励稀疏性)
- 例子:机器人学开门,只有最后成功开门才有奖励,中间步骤不知道对错。
- 解决:
- 设计“中间奖励”:比如手靠近门把手时+10分,握住把手时+20分。
- 逆强化学习:观察人类怎么做,反推出奖励规则(比如通过老师批改作业的结果,反推评分标准)。
2. 问题2:不敢尝试新动作(探索-利用平衡)
- 例子:推荐系统总推荐用户看过的内容(利用),不敢推荐新内容(探索),导致用户体验变差。
- 解决:
- ϵ \epsilon ϵ-贪心策略:以10%的概率随机推荐新内容,90%的概率推荐热门内容。
- 好奇心驱动学习:机器自己给自己设置“探索奖励”,比如“没见过的商品页面+5分”。
3. 问题3:计算量太大(算力需求高)
- 例子:AlphaGo训练需要数千块GPU,普通电脑根本跑不动。
- 解决:
- 分布式训练:让多台电脑一起算,像“分工合作写作业”。
- 迁移学习:先用简单游戏(如Atari)预训练模型,再微调适应新任务(如围棋)。
五、未来展望:强化学习如何改变互联网?
1. 通用强化学习(GRL):让机器学会“学习”
未来可能出现一种算法,能像人类一样快速适应不同任务:今天学下棋,明天学开车,后天学写代码。比如DeepMind的IMPALA架构,已经能在多种Atari游戏中表现出色。
2. 神经符号强化学习:让决策“可解释”
现在的强化学习像“黑箱”,机器为什么选这个动作说不清楚。未来可能结合逻辑推理(如“如果前方有行人,必须刹车”),让决策过程像“写作文列提纲”一样清晰。
3. 自然语言控制:用说话指挥机器
你可以对智能音箱说:“帮我规划一个省油又安全的上班路线”,它会自动把语言转化为奖励函数,让汽车优化驾驶策略。这需要强化学习与自然语言处理(NLP)结合。
六、小学生也能懂的强化学习——用“学走路”打比方
假设你是一个刚学走路的小朋友(智能体),环境是客厅,目标是从沙发走到玩具堆(终点)。
- 状态:你当前的位置(离沙发多远,离玩具多远)、身体平衡度(晃不晃)。
- 动作:迈左脚、迈右脚、伸手扶墙。
- 奖励:
- 走到玩具堆 +100分(开心!)
- 摔倒 -50分(疼!)
- 每走稳1步 +10分(中间奖励)
- 学习过程:
一开始你乱走,经常摔倒(探索);慢慢发现“扶墙走更稳”(利用);后来学会先迈左脚再迈右脚,平衡感越来越好(策略优化)。这就是强化学习的核心——在试错中找规律,用奖励指导行动。
结语:从“机器”到“智能体”的进化之路
强化学习让机器不再是被动执行指令的工具,而是能主动“思考”、适应环境的智能体。从互联网推荐系统(猜你喜欢的视频)到工业机器人(智能工厂流水线),它正在悄悄改变我们的生活。虽然现在还有“黑箱”、算力等挑战,但随着技术进步,未来的机器可能像人类一样,在复杂世界中灵活决策,甚至学会“创新”和“探索”。
如果你对强化学习感兴趣,可以试着用“奖励思维”分析生活中的问题:比如如何用“中间奖励”激励自己每天坚持读书?这其实就是强化学习的入门实践哦!
相关文章:

从游戏到自动驾驶:互联网时代强化学习如何让机器学会自主决策?
一、为什么机器需要“试错学习”?——强化学习的核心秘密 你有没有玩过《超级马里奥》?当你操控马里奥躲避乌龟、跳过悬崖时,其实就在用一种“试错”的方法学习最优路径。强化学习(Reinforcement Learning, RL)就是让…...

实验四:图像灰度处理
实验四 图像处理实验报告 目录 实验目的实验内容 原理描述Verilog HDL设计源代码Testbench仿真代码及仿真结果XDC文件配置下板测试 实验体会实验照片 实验目的 在实验三的基础上,将图片显示在显示器上,并进行灰度处理。 实验内容 原理描述 1. 图片的…...

asp.net mvc如何简化控制器逻辑
在ASP.NET MVC中,可以通过以下方法简化控制器逻辑: ASP.NET——MVC编程_aspnet mvc-CSDN博客 .NET/ASP.NET MVC Controller 控制器(IController控制器的创建过程) https://cloud.tencent.com/developer/article/1015115 【转载…...

解析“与此站点的连接不安全”警告:成因与应对策略
一、技术本质:SSL/TLS协议的信任链断裂 现代浏览器通过SSL/TLS协议建立加密通信,其核心在于证书颁发机构(CA)构建的信任链。当用户访问网站时,浏览器会验证服务器证书的有效性,包括: 证书链完…...

PyCharm和VS Code哪个更适合初学者
对于 Python 初学者来说,选择 VS Code 还是 PyCharm 取决于你的具体需求和使用场景。以下是两者的详细对比和推荐建议: VS Code 优点: 轻量级:启动速度快,占用资源少,适合在低端设备上运行。高度可定制&am…...

⚡️ Linux Docker 基本命令参数详解
🐳 Linux Docker 基本命令参数详解 📘 1. Docker 简介 Docker 是一个开源的容器化平台,它通过将应用及其依赖打包到一个轻量级、可移植的容器中,从而实现跨平台运行。Docker 采用 C/S 架构,服务端称为 Docker Daemon&a…...

做题笔记(ctfshow)
一。ctfshow web13 文件扫描 存在upload.php.bak <?php header("content-type:text/html;charsetutf-8");$filename $_FILES[file][name];$temp_name $_FILES[file][tmp_name];$size $_FILES[file][size];$error $_FILES[file][error];$arr pathinfo($fi…...

Linux 用户层 和 内核层锁的实现
目录 一、系统调用futex介绍1. 核心机制2. 常见操作3. 工作流程示例(互斥锁)4. 优势5. 注意事项6. 典型应用 二、Linux中用户态的锁和内核的锁不是同一个实现吗?2.1 本质区别2.2 用户态锁如何工作(以 pthread_mutex 为例ÿ…...
)
Android第十五次面试总结(第三方组件和adb命令)
Android 第三方组件转为系统组件核心流程 这通常是在进行 Android 系统定制(如 ROM 开发、固件制作)时完成,目的是让第三方应用拥有更高的权限和系统身份。主要过程如下: 核心准备:签名!赋予系统身份 …...
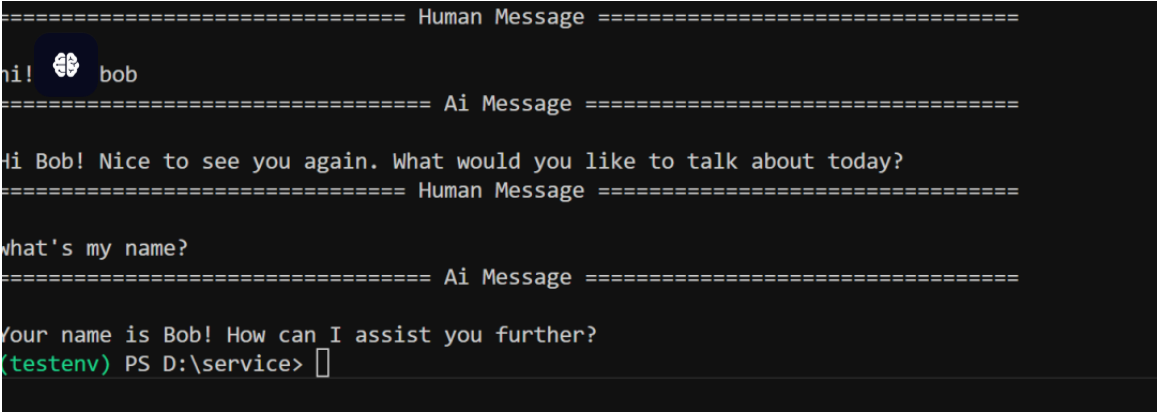
Agent短期记忆的几种持久化存储方式
今天给大家讲一下关于Agent长期对话的几种持久化存储方式,之前的文章给大家说过短期记忆和长期记忆,短期记忆基于InMemorySaver做checkpointer(检查点),短期记忆 (线程级持久性) 使代理能够跟踪…...
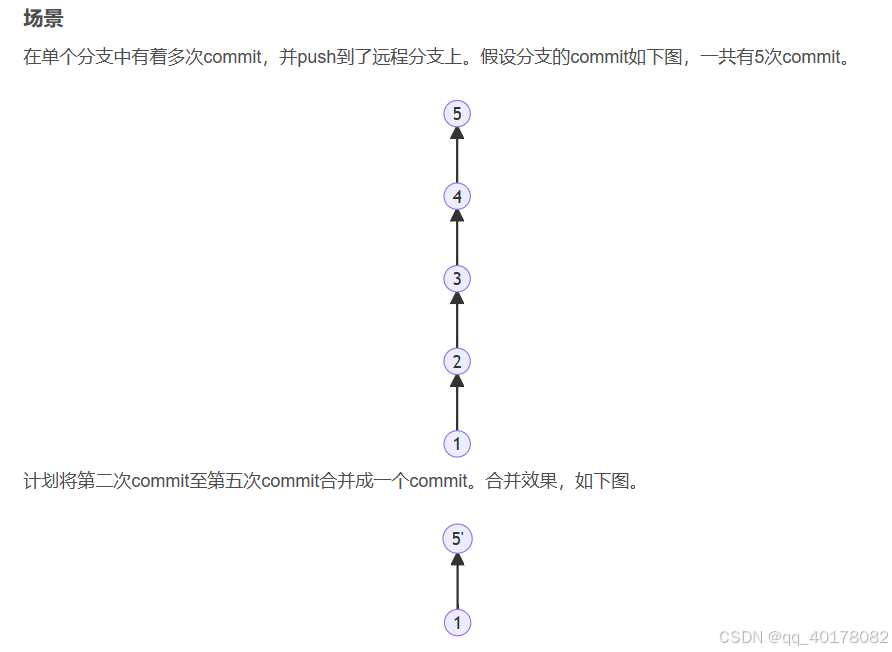
Git 常见操作
目录 1.git stash 2.合并多个commit 3. git commit -amend (后悔药) 4.版本回退 5.merge和rebase 6.cherry pick 7.分支 8.alias 1.git stash git-stash操作_git stash 怎么增加更改内容-CSDN博客 2.合并多个commit 通过git bash工具交互式操作。 1.查询commit的c…...
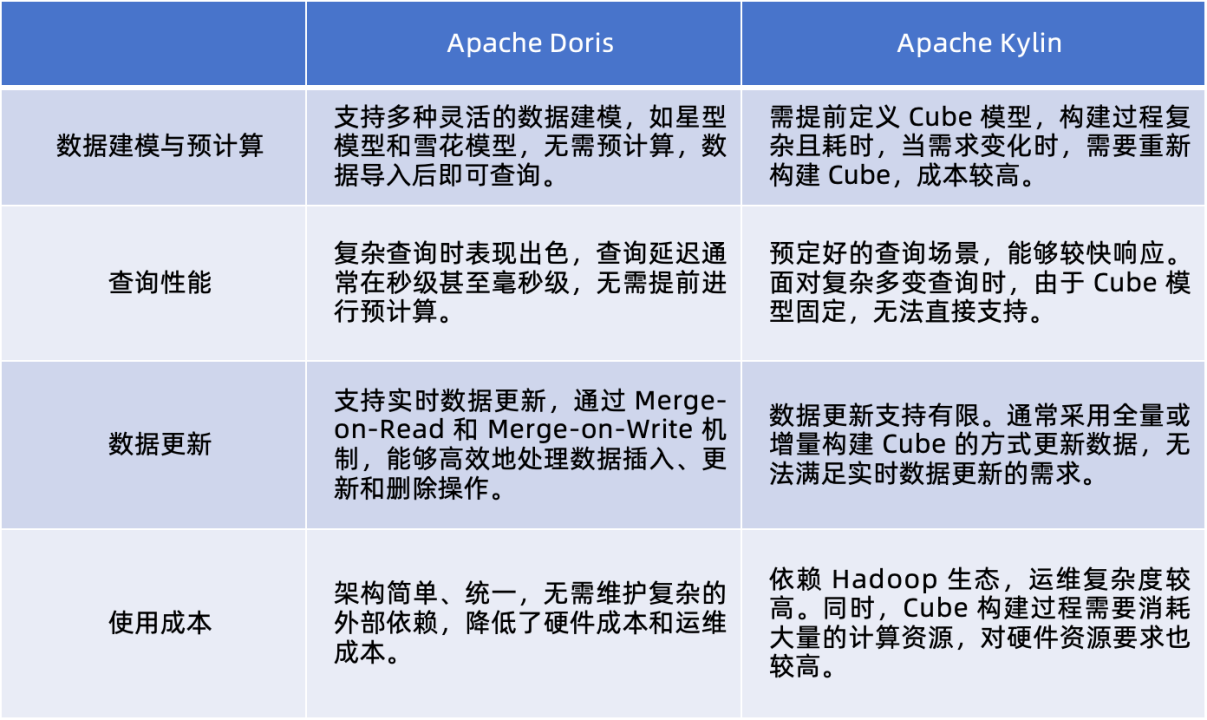
从 ClickHouse、Druid、Kylin 到 Doris:网易云音乐 PB 级实时分析平台降本增效
网易云音乐基于 Apache Doris 替换了早期架构中 Kylin、Druid、Clickhouse、Elasticsearch、HBase 等引擎,统一了实时分析架构,并广泛应用于广告实时数仓、日志平台和会员报表分析等典型场景中,带来导入性能提升 3~30 倍ÿ…...

隐函数 因变量确定标准
涉及多元隐函数求导法的逻辑本质:当我们对隐函数关系 F ( x , y , z ) 0 F(x, y, z) 0 F(x,y,z)0 使用偏导法求 ∂ z ∂ x \frac{\partial z}{\partial x} ∂x∂z时,为什么「偏导」能确定谁是因变量?为什么只有当对 z z z 的偏导 F z…...
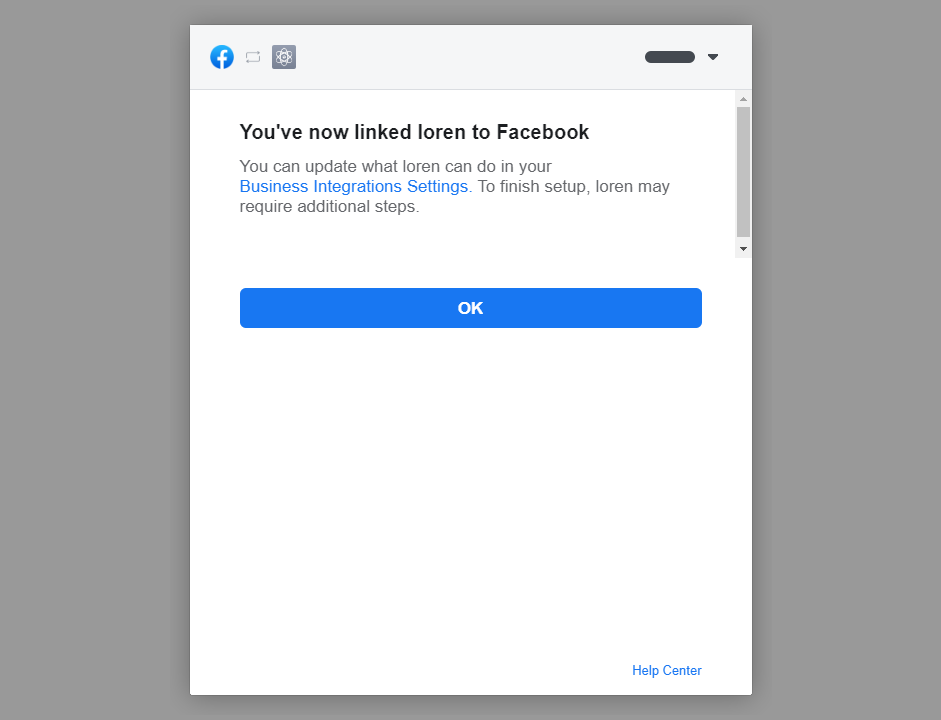
Facebook接入说明
Facebook 原生 Messenger 聊天消息接入到一洽对话中 1、创建 Facebook 主页 进入 https://www.facebook.com/pages/create 页面根据提示创建主页(如果已经有待用主页,可跳过) 2、授权对话权限 1、向您的一洽负责人获取 Facebook 授权链接 2、…...
Grafana 地图本土化方案:使用高德地图API平替GeoMap地图指南
[ 知识是人生的灯塔,只有不断学习,才能照亮前行的道路 ] 📢 大家好,我是 WeiyiGeek,一名深耕安全运维开发(SecOpsDev)领域的技术从业者,致力于探索DevOps与安全的融合(De…...

Python爬虫实战:研究demiurge框架相关技术
1. 引言 在当今数字化时代,互联网上蕴含着海量的有价值信息。爬虫技术作为获取这些信息的重要手段,被广泛应用于学术研究、商业分析、舆情监测等多个领域。然而,构建一个高效、稳定且可维护的爬虫系统面临诸多挑战,如网页结构复杂多变、反爬机制日益严格、数据处理流程繁琐…...

3 个优质的终端 GitHub 开源工具
1、Oh My Zsh Oh My Zsh 是一个帮助你管理和美化 zsh 终端的开源工具。它让你的终端更炫酷、更高效。安装后,你可以快速使用各种插件和主题,比如常见的 git 命令简化、支持多种编程语言工具等,每次打开终端都会有惊喜。无论你是开发者还是普…...
 = 0 隐函数微分 确定自变量)
F(x, y, z) = 0 隐函数微分 确定自变量
多元隐函数偏导的通用公式: 设一个隐函数由三元函数定义: F ( x , y , z ) 0 F(x, y, z) 0 F(x,y,z)0 且假设 z z ( x , y ) z z(x, y) zz(x,y),即 z z z 是 x , y x, y x,y 的函数,满足这个等式恒成立。则有以下公式&am…...
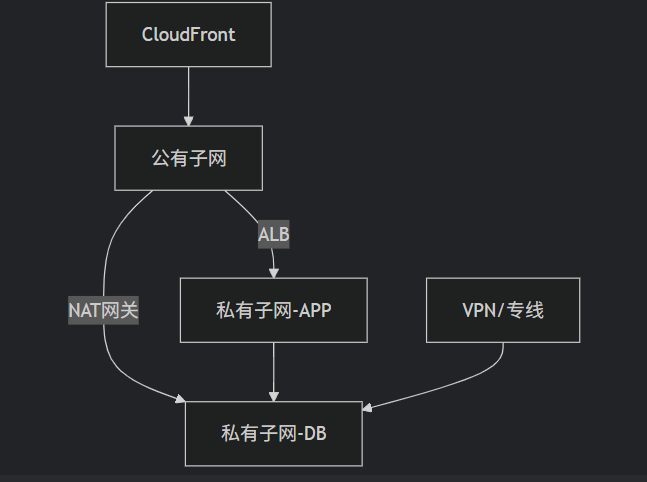
亚马逊AWS云服务器高效使用指南:最大限度降低成本的实战策略
对于初次接触云计算的企业或个人开发者而言,亚马逊云服务器(Amazon EC2)的配置与成本控制往往面临双重挑战:既要理解数百种实例规格的技术参数,又要避免因配置不当导致的资源浪费。本文将深入剖析AWS EC2的核心使用场景…...

Android设备推送traceroute命令进行网络诊断
文章目录 工作原理下载traceroute for android推送到安卓设备执行traceroutetraceroute www.baidu.com Traceroute(追踪路由) 是一个用于网络诊断的工具,主要用于追踪数据包从源主机到目标主机所经过的路由路径,以及每一跳&#x…...
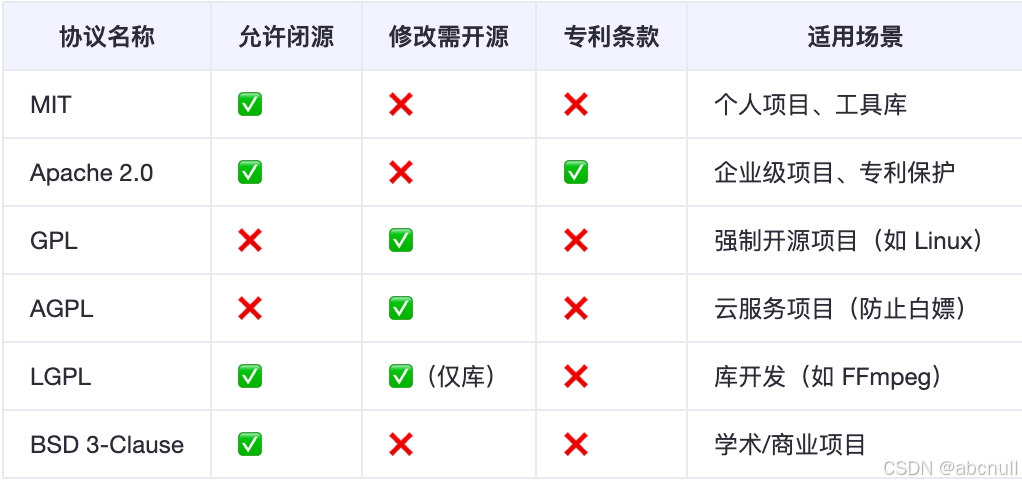
github开源协议选择
文章目录 怎么选协议宽松型协议 Permissive Licenses传染型协议 怎么选协议 希望代码被广泛使用,允许闭源 MIT、Apache 2.0、BSD需要专利保护 Apache 2.0强制开源衍生作品 GPL、AGPL开发库,允许闭源调用 LGPL云服务项目,防止白嫖 AGPL企业级…...
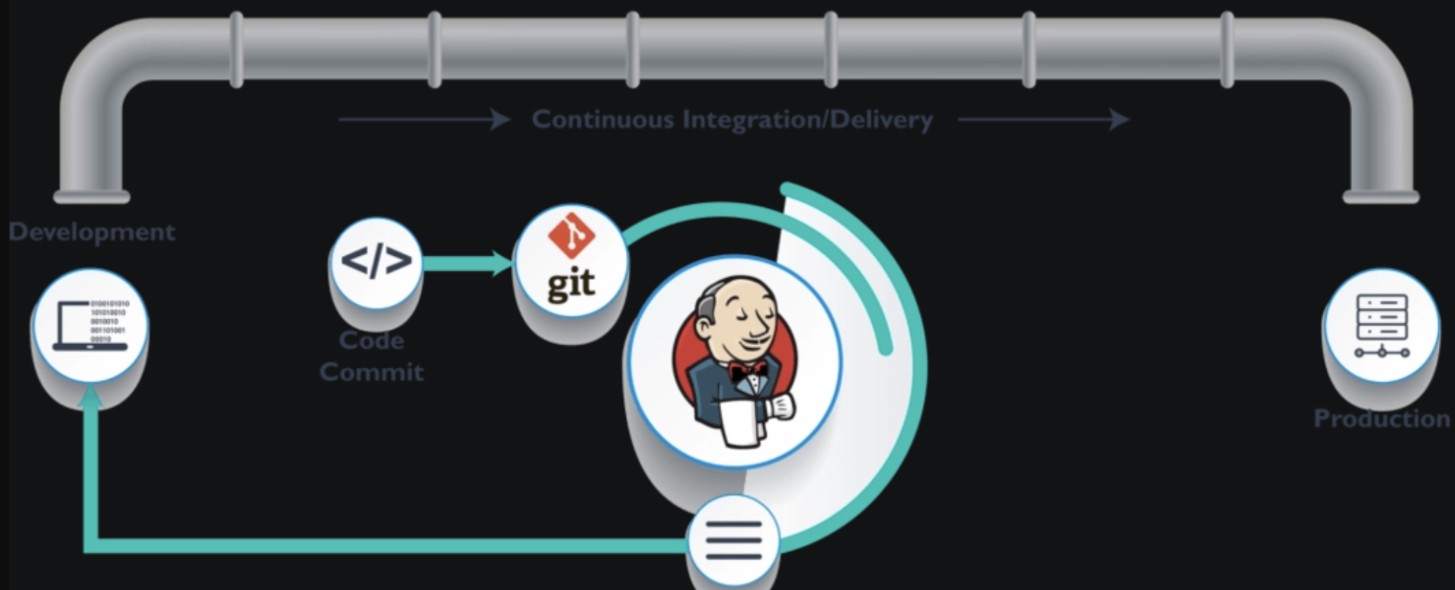
详解Jenkins Pipeline 中git 命令的使用方法
在 Jenkins Pipeline 中,git 命令是用于从版本控制系统(如 Git)拉取代码的核心步骤。其用法灵活,支持多种配置参数,但需要遵循 Jenkins 流水线语法规范。 一、基础语法 1. 声明式流水线(Declarative Pipe…...

【Mini-F5265-OB开发板试用测评】显示RTC日历时钟
一、前言 本章节承接上期的【Mini-F5265-OB开发板试用测评】硬件SPI方式驱动LCD屏帖子上。灵动微官方提供的“LibSamples_MM32F5260_V0.10.2”SDK中包含一个RTC日历的参考例程,因此将该功能移植到上期工程中,即可达成在LCD屏上显示RTC日历时钟。 官方提…...

【生活】程序员防猝si指南
note 一、定期体检二、均衡饮食,多食用对心脏有保护作用的食物三、每周运动四、减压五、保证睡眠六、戒烟限酒7、控制血压8、警惕流感攻击心脏9、关注牙齿健康10、不要抵触吃药 文章目录 note一、定期体检二、均衡饮食,多食用对心脏有保护作用的食物三、…...

CommandLineRunner详细教程
文章目录 1. CommandLineRunner基础概念和背景1.1 什么是CommandLineRunner?1.1.1 核心概念1.1.2 接口定义 1.2 为什么需要CommandLineRunner?1.3 CommandLineRunner的特点1.3.1 执行时机1.3.2 与ApplicationRunner的区别 2. 环境搭建和项目结构2.1 Mave…...

Github 2025-06-05 Go开源项目日报 Top10
根据Github Trendings的统计,今日(2025-06-05统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量Go项目10TypeScript项目1Go编程语言:构建简单、可靠和高效的软件 创建周期:3474 天开发语言:Go协议类型:BSD 3-Clause “New” or “Revise…...

C++进阶--C++11--智能指针(重点)
文章目录 C进阶--智能指针(重点)智能指针使用的场景RAII和智能指针的设计思路C标准库智能指针的使用定制删除器智能指针的原理shared_ptr和weak_ptr循环引用(容易考)weak_ptr 其他知识扩展(类型转换)总结个人学习心得结语 很高兴和…...

CSP-38th
目录 1.正态分布 2.走马 3.信息传输 4.字符串可能性个数 5.最多访问节点个数 1.正态分布 本来是很简单的一道模拟题,根据 (n-u) /a 的整数位、十分位确定是在第几行,根据百分位确定是在第几列,但是我直接将 (n-u)/a 乘以100后进行 // 和…...

企业私有化部署DeepSeek实战指南:从硬件选型到安全运维——基于国产大模型的安全可控落地实践
一、部署前的战略评估与规划 私有化部署不仅是技术工程,更是企业数据战略的核心环节。需重点评估三方面: 1、业务场景适配性 适用场景:金融风控(需实时数据处理)、医疗诊断(敏感病历保护)、政…...

【西门子杯工业嵌入式-5-串口实现数据收发】
西门子杯工业嵌入式-5-串口实现数据收发 一、通信基础1.1 什么是通信1.2 嵌入式系统中的通信 二、串行通信原理2.1 串行通信简介2.2 通信参数约定 三、GD32F470 串口资源与性能3.1 串口硬件资源 四、串口通信的实现4.1 串口初始化流程4.2 串口发送函数编写4.3 使用 printf 实现…...