Spring Cloud 多机部署与负载均衡实战详解
🧱 一、引言
为什么需要多机部署?
解决单节点性能瓶颈,提升系统可用性和吞吐量
在传统单机部署模式下,系统的所有服务或应用都运行在单一服务器上。这种模式在小型项目或低并发场景中可能足够,但随着业务规模扩大、用户量激增,单节点的性能瓶颈会逐渐显现,甚至导致系统崩溃。因此,多机部署成为现代分布式系统的核心实践之一。

🚀 1. 解决单节点性能瓶颈
单机部署的性能受限于硬件资源(CPU、内存、磁盘、网络带宽等),当请求量超过服务器承载能力时,会出现以下问题:
| 问题 | 表现 |
|---|---|
| 响应延迟增加 | 服务器处理请求的速度变慢,用户感知到“卡顿”或“超时”。 |
| 资源耗尽 | CPU、内存或网络带宽被耗尽,导致服务崩溃或重启。 |
| 无法横向扩展 | 单节点无法通过增加资源(如升级服务器)来应对高并发,成本高昂且效率低。 |
多机部署的优势:
- 负载均衡:通过反向代理(如 Nginx、HAProxy)或服务网格(如 Istio)将请求分发到多个节点,避免单点过载。
- 资源隔离:不同服务或模块部署在独立节点上,避免资源争抢(如数据库节点与应用节点分离)。
- 弹性伸缩:根据负载动态增加或减少节点数量(如云原生环境中的 Kubernetes 自动扩缩容)。
示例:
- 单节点场景:一个 Web 服务器处理 1000 QPS(每秒请求数)时,可能因 CPU 爆满而无法响应新请求。
- 多机部署场景:将服务部署在 3 台服务器上,通过负载均衡器将请求均分,每台服务器只需处理 333 QPS,系统整体吞吐量提升至 3000 QPS。
🛡️ 2. 提升系统可用性
单节点部署存在单点故障风险:若服务器宕机,整个系统将不可用。多机部署通过以下方式提升可用性:
| 机制 | 作用 |
|---|---|
| 冗余备份 | 多个节点同时运行相同服务,某节点故障时,流量自动切换到其他节点。 |
| 健康检查与自动恢复 | 通过心跳检测(如 Eureka、Zookeeper)监控节点状态,故障节点自动剔除并重启。 |
| 容灾能力 | 跨机房或跨地域部署,避免因区域性故障(如断电、网络中断)导致服务中断。 |
示例:
- 单节点场景:某电商网站的订单服务部署在单台服务器上,若服务器宕机,用户无法下单,直接损失业务。
- 多机部署场景:订单服务部署在 3 台服务器上,其中一台宕机后,流量自动切换到其他节点,用户无感知。
📈 3. 提升系统吞吐量
吞吐量(Throughput)指系统单位时间内处理的请求数。单节点的吞吐量受限于硬件性能,而多机部署通过横向扩展实现吞吐量线性增长:
| 场景 | 单节点 | 多机部署 |
|---|---|---|
| 处理能力 | 固定(如 1000 QPS) | 可扩展(如 1000 * N QPS) |
| 扩展成本 | 高(需升级硬件) | 低(新增节点即可) |
| 适用场景 | 小型应用、测试环境 | 生产环境、高并发场景 |
示例:
- 单节点场景:某视频平台的视频转码服务部署在单台服务器上,高峰期因资源不足导致转码延迟。
- 多机部署场景:将转码服务部署在 10 台服务器上,通过任务队列(如 RabbitMQ、Kafka)分发任务,吞吐量提升 10 倍。
🌐 4. 多机部署的典型应用场景
- 微服务架构:每个服务独立部署,通过服务发现(如 Eureka、Nacos)动态调用。
- 云原生应用:基于 Kubernetes 的自动扩缩容,按需分配资源。
- 高并发场景:如电商秒杀、直播平台,需应对瞬时流量峰值。
- 分布式数据库:通过分片(Sharding)或主从复制提升读写性能。
🎯 总结:多机部署的核心价值
| 维度 | 单节点 | 多机部署 |
|---|---|---|
| 性能瓶颈 | 硬件资源限制 | 横向扩展,突破性能上限 |
| 可用性 | 单点故障风险高 | 冗余设计,高可用性保障 |
| 吞吐量 | 固定,难以扩展 | 线性增长,适应高并发 |
| 成本 | 初期低,后期扩容成本高 | 初期较高,但长期更经济 |
“单机部署是起点,多机部署是必然。通过多机部署,系统能应对高并发、高可用、弹性扩展的挑战,成为现代分布式架构的基石。”
(๑•̀ㅂ•́)و✧
🧱 负载均衡在分布式系统中的核心作用
1. 流量分配:让请求均匀分布,避免单点过载
在分布式系统中,负载均衡的核心作用是将请求流量动态分配到多个服务器节点,避免单个节点因请求过多而崩溃,同时提升整体系统的稳定性。
① 常见的负载均衡算法
- 轮询(Round Robin) :按顺序将请求依次分配给每个节点,适合节点性能相近的场景。
- 加权轮询(Weighted Round Robin) :根据节点的性能(如 CPU、内存)分配权重,性能高的节点处理更多请求。
- 最少连接数(Least Connections) :将请求分配给当前连接数最少的节点,适合长连接场景(如数据库连接)。
- IP 哈希(IP Hash) :根据客户端 IP 计算哈希值,确保同一客户端的请求始终分配到同一节点,适合会话保持(Session Persistence)。
② 与服务发现的结合
负载均衡通常与 服务发现组件(如 Eureka、Nacos)结合使用,动态获取可用节点列表:
- 服务注册:服务实例启动后向注册中心注册自身信息(IP、端口、健康状态)。
- 服务发现:负载均衡器(如 Nginx、Ribbon)从注册中心获取实例列表,并根据算法分配请求。
示例:
// Feign + Ribbon 实现负载均衡
@FeignClient(name = "product-service")
public interface ProductServiceClient { @GetMapping("/api/products") List<Product> getProducts();
}
Feign 会自动调用 Ribbon 的 RoundRobinRule 策略,将请求分发到 product-service 的多个实例。
2. 资源利用率优化:动态调整请求,最大化硬件效率
负载均衡通过动态分配请求,避免部分节点空闲而其他节点过载,从而提升整体资源利用率。
① 资源利用率优化的关键机制
- 健康检查:定期检测节点状态(如
/actuator/health),剔除故障节点,避免请求发送到不可用实例。 - 动态扩缩容:根据负载自动增减节点(如 Kubernetes 的 Horizontal Pod Autoscaler),确保资源按需分配。
- 权重调整:根据节点性能动态调整权重(如 CPU 使用率、响应时间),优先将请求分配给性能更好的节点。
② 实际效果
- 避免资源浪费:闲置节点不会被请求占用,节省电力和硬件成本。
- 提升吞吐量:所有节点的资源被充分利用,系统整体处理能力提升。
示例:
- 单节点场景:某 Web 服务器处理 1000 QPS 时,CPU 使用率 100%,无法处理更多请求。
- 多机部署 + 负载均衡:将服务部署在 3 台服务器上,负载均衡器将请求均分,每台处理 333 QPS,系统总吞吐量提升至 3000 QPS。
3. 高并发场景必备:应对瞬时流量峰值,保障系统稳定性
在高并发场景(如电商秒杀、直播平台)中,负载均衡是保障系统不崩溃的关键。
① 高并发下的挑战
- 瞬时流量峰值:短时间内的大量请求可能导致服务崩溃(如 10 万 QPS 的秒杀活动)。
- 节点故障:部分节点因过载宕机,导致流量集中到其他节点,进一步加剧问题。
② 负载均衡的解决方案
- 限流降级:通过限流算法(如令牌桶、漏桶)控制请求速率,防止系统过载。
- 熔断机制:当节点故障或响应超时时,自动切换到其他节点,避免雪崩效应。
- 缓存与异步处理:结合 Redis 缓存、消息队列(如 Kafka)缓解后端压力。
示例:
- 电商秒杀场景:
- 负载均衡器将请求分发到多个商品服务实例,每个实例处理 1/10 的流量。
- 若某实例因过载宕机,负载均衡器自动将其移出列表,流量重新分配。
🎯 负载均衡的核心价值总结
| 维度 | 作用 |
|---|---|
| 流量分配 | 动态分配请求,避免单点过载(如轮询、加权轮询、IP 哈希)。 |
| 资源利用率 | 通过健康检查和动态扩缩容,最大化硬件资源利用率(如 CPU、内存)。 |
| 高并发支持 | 应对瞬时流量峰值,保障系统稳定性(如限流、熔断、缓存)。 |
“负载均衡是分布式系统的‘交通指挥官’ ,它让请求像车流一样有序流动,避免拥堵和事故,确保系统高效、稳定运行。”
(๑•̀ㅂ•́)و✧
🧱 二、负载均衡基础概念
1. 问题引入:单实例与多实例的流量分配困境
在分布式系统中,单实例部署和多实例部署的流量分配逻辑存在显著差异。当服务部署为多实例时,若未正确配置负载均衡策略,可能会导致请求集中在单一实例,造成资源浪费和性能瓶颈。
① 代码示例:默认获取第一个服务实例的局限性
在使用 DiscoveryClient 获取服务实例时,若直接通过 getInstances("service-name").get(0) 获取第一个实例,会导致所有请求始终发送到该实例:
List<ServiceInstance> instances = discoveryClient.getInstances("product-service");
ServiceInstance instance = instances.get(0);
String url = "http://" + instance.getHost() + ":" + instance.getPort() + "/api/products";
// 发送请求到固定实例
问题表现:
- 即使服务有多个实例(如
product-service-1、product-service-2),请求始终发送到product-service-1。 - 资源利用率不均:
product-service-1可能过载,而product-service-2空闲。
② 实验现象:启动多个实例后请求集中在同一节点
实验步骤:
- 启动
product-service的两个实例,分别运行在8081和8082端口。 - 在
order-service中通过DiscoveryClient获取product-service实例列表。 - 执行请求,观察日志发现所有请求均发送到
8081端口。
现象分析:
- 实例列表顺序固定:Eureka 返回的实例列表可能按注册顺序排列,
get(0)总是选择第一个实例。 - 未启用负载均衡策略:未配置
Ribbon或Spring Cloud LoadBalancer,导致请求未被分发到多个实例。
2. 根本原因:未正确配置负载均衡策略
① 单实例部署的局限性
- 单实例:请求始终指向固定地址,无需负载均衡。
- 多实例:需通过负载均衡策略(如轮询、随机)分配请求,避免单点过载。
② 多实例部署的挑战
- 实例动态变化:服务实例可能因扩容、缩容或故障而动态变化。
- 请求分配不均:若未配置负载均衡,请求可能集中在某个实例,导致性能瓶颈。
3. 解决方案:启用负载均衡策略
① 使用 Ribbon 实现客户端负载均衡
Ribbon 是 Spring Cloud 提供的客户端负载均衡器,支持多种策略(如轮询、随机)。
配置示例:
product-service: ribbon: NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RoundRobinRule # 轮询策略
代码示例:
@FeignClient(name = "product-service")
public interface ProductServiceClient { @GetMapping("/api/products") List<Product> getProducts();
}
Feign 会自动结合 Ribbon 的 RoundRobinRule 策略,将请求分发到多个 product-service 实例。
② 使用 Spring Cloud LoadBalancer(推荐)
Spring Cloud 2020.0.x 后推荐使用 Spring Cloud LoadBalancer 替代 Ribbon。
配置示例:
spring: cloud: loadbalancer: ribbon: enabled: false # 禁用 Ribbon,使用 LoadBalancer
代码示例:
@LoadBalanced
@Bean
public RestTemplate restTemplate() { return new RestTemplate();
}
@LoadBalanced 注解会自动将 RestTemplate 配置为负载均衡客户端,请求会被分发到多个实例。
4. 验证负载均衡效果
① 日志验证
在 product-service 的日志中观察请求来源:
2023-10-05 10:00:00.123 INFO 12345 --- [http-nio-8081] c.example.ProductServiceController : Request from 192.168.1.100:5000
2023-10-05 10:00:01.456 INFO 12345 --- [http-nio-8082] c.example.ProductServiceController : Request from 192.168.1.100:5000 - 预期结果:请求交替发送到
8081和8082端口。
② 压力测试工具
使用 JMeter 或 wrk 发送大量请求,观察各实例的请求量是否均衡。
🎯 总结:问题根源与解决方案
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 请求集中在单个实例 | 未配置负载均衡策略,手动选择第一个实例 | 启用 Ribbon 或 Spring Cloud LoadBalancer |
| 实例列表顺序固定 | Eureka 返回的实例顺序可能固定 | 使用负载均衡策略(轮询、随机) |
| 多实例未充分利用 | 未动态分配请求 | 配置 @LoadBalanced 或 RibbonRule |
“负载均衡是分布式系统的‘交通指挥官’ ,它让请求像车流一样有序流动,避免拥堵和事故,确保系统高效、稳定运行。”
(๑•̀ㅂ•́)و✧
🧱 负载均衡定义与核心目标
1. 负载均衡的定义
负载均衡(Load Balancing) 是指在多个服务实例(如服务器、节点、微服务)之间按规则分配请求或任务,以实现资源的高效利用和系统的高可用性。
核心思想:
- 动态分配:根据当前节点的负载情况(如 CPU、内存、网络带宽)或预设策略(如轮询、加权、最少连接数)分配请求。
- 透明性:对客户端(如用户、调用方)来说,无需关心具体哪个实例处理请求,只需通过统一入口(如负载均衡器)提交任务。
技术场景:
- Web 服务器集群:Nginx 将用户请求分发到多个后端服务器。
- 微服务架构:Feign + Ribbon 将服务调用分发到多个服务实例。
- 数据库分片:将查询请求分配到不同的数据库节点。
2. 负载均衡的核心目标
| 目标 | 说明 |
|---|---|
| 提高系统可用性 | 避免单点故障,当某个实例宕机时,流量自动切换到其他健康实例。 |
| 优化资源利用率 | 防止部分节点过载,部分节点空闲,最大化硬件资源的使用效率。 |
| 提升系统吞吐量 | 通过多实例并行处理请求,显著提高单位时间内的处理能力。 |
| 保障用户体验 | 避免因单节点性能瓶颈导致的延迟或超时,提升服务响应速度和稳定性。 |
3. 类比说明:团队任务分配与服务器流量分配的相似性
类比场景:
假设一个团队有 3 名开发人员(A、B、C),他们负责处理用户的 Bug 报告。
① 无负载均衡(手动分配)
- 问题:项目经理总是将新任务分配给 A,导致 A 超负荷,而 B 和 C 空闲。
- 对应服务器场景:
- 未配置负载均衡时,所有请求始终发送到某个特定实例(如
getInstances("service").get(0))。 - 该实例可能因过载崩溃,而其他实例闲置。
- 未配置负载均衡时,所有请求始终发送到某个特定实例(如
② 有负载均衡(动态分配)
- 规则:
- 轮询:按顺序分配任务(A → B → C → A → B → C...)。
- 最少连接数:优先分配给当前任务数最少的成员。
- 权重分配:根据成员能力分配任务(如 A 能力强,分配更多任务)。
- 效果:
- 所有成员工作量均衡,整体处理效率提升。
- 若某成员临时故障,任务会自动分配给其他成员,避免服务中断。
对应服务器场景
- 负载均衡器(如 Nginx、Ribbon)扮演“项目经理”角色,动态分配请求到多个服务器实例。
- 示例:
- 3 个
product-service实例(8081、8082、8083)。 - 负载均衡器按轮询策略将请求依次分配给每个实例,确保每个实例处理约 1/3 的流量。
- 3 个
🎯 负载均衡的核心价值总结
| 维度 | 类比说明 | 技术目标 |
|---|---|---|
| 动态分配 | 项目经理按规则分配任务 | 请求按策略分配到多个实例 |
| 资源利用率 | 所有成员工作量均衡 | 所有服务器资源被充分利用 |
| 高可用性 | 某成员故障时任务自动转移 | 某实例宕机时流量自动切换到其他实例 |
| 扩展性 | 新增成员后任务自动分配 | 新增服务器实例后自动加入负载均衡池 |
“负载均衡是分布式系统的‘任务调度员’ ,它让请求像团队协作一样高效流动,避免单点过载,确保系统稳定运行。”
(๑•̀ㅂ•́)و✧
🧱 分类:服务端 vs 客户端负载均衡
1. 服务端负载均衡
代表工具:Nginx、HAProxy、Apache LoadBalancer
核心特点:负载均衡逻辑由独立的中间件(如 Nginx)完成,客户端无需感知服务实例的分布。
原理
-
请求流程:
- 客户端请求发送到负载均衡器(如 Nginx)。
- 负载均衡器根据配置的策略(如轮询、加权轮询)将请求转发到后端服务器。
- 后端服务器处理请求并返回结果给客户端。
-
服务清单存储:
- 集中式存储:负载均衡器的配置文件中直接定义后端服务器地址(如 Nginx 的
upstream配置)。 - 动态更新:通过服务注册中心(如 Eureka、Zookeeper)动态更新后端实例列表(需额外配置)。
- 集中式存储:负载均衡器的配置文件中直接定义后端服务器地址(如 Nginx 的
优势
- 简化客户端:客户端只需知道负载均衡器的地址,无需处理服务发现和负载均衡逻辑。
- 统一管理:负载均衡策略集中配置,便于统一维护和监控。
- 高可用性:负载均衡器本身可集群部署,避免单点故障。
劣势
- 单点风险:若负载均衡器宕机,整个系统不可用。
- 扩展性限制:需手动维护后端实例列表,动态扩容时需更新配置。
- 性能瓶颈:负载均衡器可能成为性能瓶颈(尤其在高并发场景)。
典型场景
- 传统架构:如单体应用部署在多台服务器上,通过 Nginx 分发请求。
- 混合架构:微服务与传统服务共存,需统一入口。
2. 客户端负载均衡
代表工具:Ribbon(已弃用)、Spring Cloud LoadBalancer(推荐)
核心特点:负载均衡逻辑由客户端应用完成,客户端直接从注册中心获取服务实例列表并执行分配策略。
原理
-
请求流程:
- 客户端通过服务注册中心(如 Eureka、Nacos)获取服务实例列表。
- 客户端根据本地配置的负载均衡策略(如轮询、随机)选择一个实例发起请求。
- 服务实例处理请求并返回结果。
-
服务清单存储:
- 客户端本地存储:客户端缓存服务实例列表(如通过 Eureka Client 获取并缓存)。
- 动态更新:客户端定期从注册中心拉取最新实例列表,确保一致性。
优势
- 去中心化:无需依赖独立的负载均衡器,降低系统复杂性。
- 灵活性:客户端可自定义负载均衡策略(如基于响应时间的动态调整)。
- 与微服务集成:天然支持服务发现(如 Spring Cloud 生态)。
劣势
- 客户端复杂性:需在客户端实现服务发现和负载均衡逻辑,增加开发成本。
- 网络开销:客户端需频繁与注册中心通信,可能增加网络延迟。
- 配置复杂性:需在客户端配置服务发现和负载均衡策略。
典型场景
- 微服务架构:如 Spring Cloud 应用通过 Eureka + Ribbon 实现服务调用。
- 云原生环境:Kubernetes 中通过 Service 和 Endpoints 实现客户端负载均衡。
🔄 核心区别:服务清单存储位置
| 维度 | 服务端负载均衡(Nginx) | 客户端负载均衡(Ribbon/LoadBalancer) |
|---|---|---|
| 服务清单存储 | 集中式(负载均衡器配置文件或注册中心) | 客户端本地缓存(如 Eureka Client 缓存) |
| 负载均衡逻辑 | 由负载均衡器(如 Nginx)执行 | 由客户端应用(如 Feign + Ribbon)执行 |
| 服务发现 | 需额外配置服务发现(如 Nginx + Consul) | 与服务注册中心(如 Eureka)深度集成 |
| 扩展性 | 扩容需更新负载均衡器配置 | 自动感知服务实例变化(通过注册中心) |
| 适用场景 | 传统架构、混合架构 | 微服务架构、云原生环境 |
🧠 类比说明:团队任务分配 vs 个人任务分配
-
服务端负载均衡(Nginx) :
- 类比:公司有一个“项目经理”(Nginx),负责将任务(请求)分配给不同开发人员(服务器)。
- 特点:项目经理统一管理任务分配,开发人员无需关心任务来源。
-
客户端负载均衡(Ribbon) :
- 类比:开发人员(客户端)自行查看任务清单(服务实例列表),按规则(如轮询)分配任务。
- 特点:开发人员需主动获取任务清单,灵活但需自行管理分配逻辑。
🎯 选择建议
| 场景 | 推荐方案 | 原因 |
|---|---|---|
| 传统架构 | 服务端负载均衡(Nginx) | 简单易用,无需改造现有系统。 |
| 微服务架构 | 客户端负载均衡(Ribbon/LoadBalancer) | 与服务发现(如 Eureka)深度集成,支持动态扩缩容。 |
| 高可用需求 | 服务端 + 客户端混合模式 | 服务端负载均衡保障基础可用性,客户端负载均衡优化动态扩展能力。 |
| 云原生环境 | 客户端负载均衡(Spring Cloud LoadBalancer) | 与 Kubernetes、Service Mesh(如 Istio)兼容性更好。 |
🧱 三、Spring Cloud LoadBalancer 实战
1. 快速入门:3 步实现负载均衡
步骤 1:给 RestTemplate 添加 @LoadBalanced 注解
@LoadBalanced 是 Spring Cloud LoadBalancer 的核心注解,用于标记 RestTemplate 或 WebClient 为负载均衡客户端。
代码示例:
@Configuration
public class RestTemplateConfig { @Bean @LoadBalanced // 标记为负载均衡客户端 public RestTemplate restTemplate() { return new RestTemplate(); }
}
- 作用:
@LoadBalanced会将RestTemplate与Spring Cloud LoadBalancer集成,自动处理服务发现和负载均衡逻辑。- 如果未添加此注解,
RestTemplate会直接调用硬编码的 URL,无法实现负载均衡。
步骤 2:URL 中使用服务名替代 IP + 端口
在调用远程服务时,直接使用服务名(如 product-service) ,而非硬编码的 IP 和端口。
代码示例:
@RestController
public class OrderController { @Autowired private RestTemplate restTemplate; @GetMapping("/orders/{id}") public String getOrder(@PathVariable String id) { // 使用服务名调用,而非硬编码地址 String url = "http://product-service/product/{id}"; return restTemplate.getForObject(url, String.class, id); }
}
- 关键点:
product-service是服务注册中心(如 Eureka、Nacos)中注册的服务名。RestTemplate会自动从注册中心获取product-service的实例列表,并根据负载均衡策略选择目标实例。
步骤 3:启动多实例验证
启动多个 product-service 实例,分别使用不同端口(如 9090、9091、9092),并确保它们都注册到服务发现组件(如 Eureka)。
启动命令示例:
# 启动第一个实例
java -jar product-service.jar --server.port=9090 # 启动第二个实例
java -jar product-service.jar --server.port=9091 # 启动第三个实例
java -jar product-service.jar --server.port=9092 服务注册:确保每个实例的 application.yml 中配置了服务名:
spring: application: name: product-service
2. 测试结果:请求均匀分配至不同实例
验证方法:
- 日志观察:在
product-service的控制器中添加日志,记录请求的来源端口。
@RestController
public class ProductController { @GetMapping("/product/{id}") public String getProduct(@PathVariable String id) { System.out.println("Request handled by port: " + serverPort()); return "Product ID: " + id; } private int serverPort() { return Integer.parseInt(System.getProperty("server.port")); }
}
2. 发送请求:通过 order-service 发送多次请求,观察日志输出。
预期结果:
Request handled by port: 9090
Request handled by port: 9091
Request handled by port: 9092
Request handled by port: 9090
... - 现象:请求按轮询策略(默认)均匀分配到
9090、9091、9092三个实例。
3. 负载均衡策略的默认行为
Spring Cloud LoadBalancer 的默认策略是 轮询(Round Robin) ,即依次将请求分发到每个实例。
验证策略:
- 日志输出:每次请求的端口会按顺序循环。
- 自定义策略:可通过配置修改策略,例如随机选择实例:
product-service: ribbon: NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
4. 完整配置示例
依赖引入(Maven)
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency> 服务发现配置(Eureka)
eureka: client: service-url: default-zone: http://localhost:8761/eureka
启动类注解
@SpringBootApplication
@EnableEurekaClient // 注册到 Eureka
public class ProductServiceApplication { public static void main(String[] args) { SpringApplication.run(ProductServiceApplication.class, args); }
}
5. 常见问题与解决方案
| 问题 | 解决方案 |
|---|---|
| 请求未分配到多个实例 | - 确保 @LoadBalanced 注解已添加。 <br> - 检查服务是否成功注册到 Eureka。 <br> - 确认 product-service 的服务名与调用方一致。 |
| 请求始终分配到同一个实例 | - 检查是否启用了负载均衡策略(如 RandomRule)。 <br> - 确保多个实例已启动并注册。 |
| 服务发现失败 | - 检查 Eureka Server 地址是否正确。 <br> - 确保 eureka.client.service-url.default-zone 配置正确。 |
🎯 总结:3 步实现负载均衡
| 步骤 | 操作 |
|---|---|
| 1. 添加注解 | 在 RestTemplate 上添加 @LoadBalanced,启用负载均衡功能。 |
| 2. 使用服务名 | 在 URL 中使用服务名(如 http://product-service/product/{id}),而非硬编码地址。 |
| 3. 启动多实例 | 启动多个服务实例,确保它们注册到服务发现组件(如 Eureka)。 |
“Spring Cloud LoadBalancer 是微服务的‘调度器’ ,通过服务名和负载均衡策略,让请求像接力赛一样在多个实例间传递,避免单点过载。”
(๑•̀ㅂ•́)و✧
🧱 负载均衡策略详解
1. 内置策略
Spring Cloud LoadBalancer 提供了多种内置的负载均衡策略,开发者可根据业务需求选择合适的策略。
① 轮询(Round Robin):默认策略
- 核心思想:按顺序将请求轮流分配给每个服务实例。
- 适用场景:服务实例性能相近,需均匀分配请求。
- 类比场景:
- 学校值日场景:
- 3 个学生(A、B、C)轮流值日,确保每人机会均等。
- 请求依次分配给
product-service-1、product-service-2、product-service-3,循环往复。
- 学校值日场景:
代码示例:
@Configuration
public class LoadBalancerConfig { @Bean public ReactorLoadBalancer<ServiceInstance> randomLoadBalancer(Environment environment, LoadBalancerClientFactory factory) { return new RoundRobinLoadBalancer(factory, environment.getProperty("service.name")); }
}
② 随机(Random)
- 原理:随机选择一个服务实例处理请求。
- 适用场景:
- 流量分布均匀,无需特定顺序(如 API 网关、无状态服务)。
- 需要避免请求集中到某个实例。
- 类比场景:
- 抽签决定任务分配:随机抽取员工分配任务,避免人为偏袒。
配置示例:
product-service: ribbon: NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
注意:Spring Cloud LoadBalancer 已逐步替代 Ribbon,建议使用
Spring Cloud LoadBalancer的配置方式。
2. 自定义策略:以随机策略为例
若需自定义负载均衡策略(如随机策略),需通过以下步骤实现。
步骤 1:定义 RandomLoadBalancer Bean 并注入容器
创建一个自定义的负载均衡器,实现 ServiceInstanceListSupplier 接口。
代码示例:
import org.springframework.cloud.client.ServiceInstance;
import org.springframework.cloud.client.loadbalancer.ServiceInstanceListSupplier;
import org.springframework.stereotype.Component;
import reactor.core.publisher.Flux; import java.util.List;
import java.util.Random;
import java.util.stream.Collectors; @Component
public class RandomLoadBalancer implements ServiceInstanceListSupplier { private final Random random = new Random(); @Override public String getServiceId() { return "product-service"; // 服务名 } @Override public Flux<List<ServiceInstance>> get() { return Flux.defer(() -> { List<ServiceInstance> instances = getInstances(); if (instances.isEmpty()) { return Flux.empty(); } // 随机选择一个实例 int index = random.nextInt(instances.size()); return Flux.just(List.of(instances.get(index))); }); } private List<ServiceInstance> getInstances() { // 从注册中心获取实例列表(此处需结合 Eureka/Nacos 实现) // 示例中简化为硬编码 return List.of( new DefaultServiceInstance("product-service", "192.168.1.1", 9090, false), new DefaultServiceInstance("product-service", "192.168.1.2", 9091, false), new DefaultServiceInstance("product-service", "192.168.1.3", 9092, false) ); }
}
步骤 2:使用 @LoadBalancerClient 指定服务与策略配置类
通过 @LoadBalancerClient 注解,将自定义策略绑定到特定服务。
代码示例:
import org.springframework.cloud.client.loadbalancer.LoadBalancerClient;
import org.springframework.cloud.client.loadbalancer.LoadBalancerProperties;
import org.springframework.cloud.loadbalancer.annotation.LoadBalancerClient;
import org.springframework.context.annotation.Configuration; @Configuration
@LoadBalancerClient(name = "product-service", configuration = RandomLoadBalancerConfig.class)
public class RandomLoadBalancerConfig { // 配置类内容
}
关键点:
@LoadBalancerClient的name属性需与服务名一致(如product-service)。configuration属性指向自定义策略的配置类。
3. 注意事项
-
配置类不使用
@Configuration- 原因:
@LoadBalancerClient会自动扫描配置类,无需显式标注@Configuration。 - 解决方法:确保配置类位于组件扫描路径下(如
src/main/java下的包)。
- 原因:
-
服务实例获取方式
- 自定义策略中需从注册中心(如 Eureka、Nacos)动态获取实例列表,而非硬编码。
- 示例中使用
DefaultServiceInstance仅为演示,实际应通过DiscoveryClient或ServiceInstanceListSupplier获取实例。
-
策略生效验证
- 启动多个
product-service实例,发送请求观察日志,确认请求是否随机分配到不同实例。
- 启动多个
🎯 策略选择建议
| 策略 | 适用场景 | 特点 |
|---|---|---|
| 轮询 | 服务性能相近、需均匀分配流量 | 简单高效,但可能因实例性能差异导致负载不均 |
| 随机 | 流量均匀、无状态服务 | 避免请求集中,但无法感知实例负载 |
| 加权轮询 | 实例性能差异较大 | 根据权重分配流量(需自定义实现) |
| 最少连接数 | 长连接场景(如数据库连接池) | 优先分配给当前连接数最少的实例 |
🚀 实践建议
- 默认策略:优先使用轮询(
RoundRobinRule),适合大多数场景。 - 自定义策略:
- 通过
@LoadBalancerClient绑定策略类,避免直接修改全局配置。 - 使用
ServiceInstanceListSupplier动态获取实例列表,确保策略与服务发现集成。
- 通过
- 监控与调优:
- 通过
Prometheus + Grafana监控实例负载,动态调整策略。 - 在高并发场景中,结合
Health Check确保故障实例被自动剔除。
- 通过
“负载均衡策略是系统的‘调度员,选择合适的策略能显著提升系统性能和稳定性。轮询适合公平分配,随机适合无状态服务,而自定义策略则为复杂场景提供灵活性。”
(๑•̀ㅂ•́)و✧
🧱 核心原理:请求拦截与实例选择
1. 关键组件:LoadBalancerInterceptor 拦截 RestTemplate 请求
LoadBalancerInterceptor 是 Spring Cloud LoadBalancer 的核心组件,用于拦截 RestTemplate 的请求,实现服务发现和负载均衡。
作用:
- 拦截请求:在
RestTemplate发送 HTTP 请求前,拦截请求 URL,解析服务名(如product-service)。 - 动态替换地址:根据负载均衡策略,将服务名替换为实际的 IP + 端口,完成请求分发。
工作原理:
LoadBalancerInterceptor是ClientHttpRequestInterceptor的实现类,通过RestTemplate的intercept方法介入请求流程。- 在请求发送前,拦截器会解析 URL 中的服务名,并调用负载均衡器(
ReactorLoadBalancer)选择目标实例。
代码示例:
public class LoadBalancerInterceptor implements ClientHttpRequestInterceptor { private final LoadBalancerClient loadBalancerClient; public LoadBalancerInterceptor(LoadBalancerClient loadBalancerClient) { this.loadBalancerClient = loadBalancerClient; } @Override public ClientHttpResponse intercept(HttpRequest request, byte[] body, ClientHttpRequestExecution execution) throws IOException { // 解析 URL 中的服务名 URI originalUri = request.getURI(); String serviceId = extractServiceId(originalUri); // 从注册中心获取服务实例列表 List<ServiceInstance> instances = loadBalancerClient.getInstances(serviceId); // 调用负载均衡器选择实例 ServiceInstance instance = loadBalancerClient.choose(serviceId); // 替换 URL 中的服务名为真实地址 URI newUri = UriComponentsBuilder.fromUri(originalUri) .host(instance.getHost()) .port(instance.getPort()) .build() .toUri(); // 重写请求 URI 并继续执行 HttpRequest newRequest = new HttpRequestWrapper(request, newUri); return execution.execute(newRequest, body); }
}
2. 执行流程详解
① 解析 URL 中的服务名(如 product-service)
轮询实现逻辑:
- 输入示例:
String url = "http://product-service/api/products"; - 解析逻辑:
- 使用
UriComponentsBuilder提取服务名product-service。 - 确保服务名与注册中心(如 Eureka、Nacos)中注册的名称一致。
- 使用
-
② 从注册中心获取服务实例列表
- 服务发现:
- 通过
LoadBalancerClient(如EurekaLoadBalancerClient)从注册中心(如 Eureka Server)获取服务实例列表。 - 实例列表包含多个实例的 IP、端口、元数据等信息。
- 通过
-
代码示例:
List<ServiceInstance> instances = loadBalancerClient.getInstances("product-service"); // 返回类似 [192.168.1.1:9090, 192.168.1.2:9091, 192.168.1.3:9092]③ 通过负载均衡算法选择实例(如轮询、随机)
- 默认策略:轮询(Round Robin),按顺序选择实例。
- 自定义策略:通过
@LoadBalancerClient配置随机、加权轮询等策略。 - 维护一个计数器,每次请求后递增,选择对应索引的实例。
- 示例:
int index = counter.getAndIncrement() % instances.size(); ServiceInstance instance = instances.get(index);随机选择逻辑:
- 使用
Random类随机生成索引。 - 示例:
int index = new Random().nextInt(instances.size()); ServiceInstance instance = instances.get(index);④ 替换 URL 中的服务名为真实 IP + 端口
- 原始 URL:
http://product-service/api/products替换后 URL:
http://192.168.1.1:9090/api/products - 实现方式:
- 使用
UriComponentsBuilder构建新的 URI,替换主机和端口。 - 最终请求由
RestTemplate发送到实际实例。
- 使用
-
3. 核心流程图
[RestTemplate 发送请求] ↓ [LoadBalancerInterceptor 拦截请求] ↓ [解析 URL 中的服务名(如 product-service)] ↓ [从注册中心获取服务实例列表] ↓ [负载均衡器选择一个实例] ↓ [替换 URL 中的服务名为真实地址] ↓ [发送请求到目标实例]
4. 关键组件与依赖关系
| 组件 | 作用 |
|---|---|
LoadBalancerInterceptor | 拦截请求,执行服务发现和负载均衡。 |
LoadBalancerClient | 与注册中心交互,获取服务实例列表。 |
ReactorLoadBalancer | 实现负载均衡算法(轮询、随机等),选择目标实例。 |
ServiceInstanceListSupplier | 动态获取服务实例列表(如通过 Eureka、Nacos)。 |
5. 示例:轮询策略的完整流程
- 请求发送:
restTemplate.getForObject("http://product-service/api/products", String.class);
- 拦截器拦截:
- 解析服务名
product-service。
- 解析服务名
- 获取实例列表:
- 从 Eureka 获取
product-service的三个实例:
- 从 Eureka 获取
[192.168.1.1:9090, 192.168.1.2:9091, 192.168.1.3:9092] - 轮询选择实例:
- 第一次请求 → 选择
192.168.1.1:9090 - 第二次请求 → 选择
192.168.1.2:9091 - 第三次请求 → 选择
192.168.1.3:9092
- 第一次请求 → 选择
- 替换 URL 并发送请求:
restTemplate.getForObject("http://192.168.1.1:9090/api/products", String.class);
注意事项
- 服务发现的动态性:
- 实例列表会动态更新(如新增/下线实例),通过注册中心的健康检查机制(如 Eureka 的心跳检测)保持一致性。
- 负载均衡策略的灵活性:
- 可通过配置或自定义策略(如随机、加权轮询)调整请求分配逻辑。
- 健康检查与故障剔除:
- 通过
/actuator/health接口检测实例状态,自动剔除故障节点。
- 通过
🎯 总结:核心流程与组件
| 步骤 | 关键组件 | 实现方式 |
|---|---|---|
| 解析服务名 | LoadBalancerInterceptor | 通过 UriComponentsBuilder 提取服务名。 |
| 获取实例列表 | LoadBalancerClient | 与注册中心(如 Eureka)交互,获取实例列表。 |
| 选择实例 | ReactorLoadBalancer | 轮询、随机等策略选择目标实例。 |
| 替换 URL | LoadBalancerInterceptor | 使用 UriComponentsBuilder 替换服务名为真实地址。 |
“LoadBalancerInterceptor 是请求的‘导航员,它将抽象的服务名转换为具体的实例地址,让请求精准到达目标服务。”
(๑•̀ㅂ•́)و✧
🧱 四、总结与扩展
"部署不是终点,而是新旅程的起点!🚀"
🌟 核心价值:负载均衡如何提升系统可用性与稳定性
负载均衡就像系统的“交通指挥官”,通过智能分配流量,让每个节点都能高效运转。它的核心价值体现在:
- 高可用性:当某台服务器宕机时,流量自动转移到其他节点,避免服务中断 ✅
- 稳定性:分散压力,防止单点过载导致系统崩溃 🚫
- 弹性扩展:轻松添加或移除节点,应对流量波动 📈
举个栗子🌰:
假设你有3台服务器处理用户请求,负载均衡器会根据策略(如轮询)分配任务。如果其中一台服务器突然“罢工”,其他两台会自动接管,用户几乎察觉不到变化!
🚀 扩展方向:从“能用”到“好用”的进阶之路
-
更多负载均衡算法
- 权重轮询(Weighted Round Robin) :
- 场景:后端服务器性能不均时(如1台配置高,1台低)。
- 操作:给高性能服务器分配更高权重(如2:1),让它处理更多请求。
- 最少连接数(Least Connections) :
- 场景:处理长连接(如WebSocket)时,避免某台服务器连接数爆表。
- 操作:将新请求分配给当前连接数最少的节点。
- IP哈希(IP Hash) :
- 场景:需要会话保持(Session Persistence)时(如电商购物车)。
- 操作:根据客户端IP地址分配节点,确保同一用户始终访问同一服务器。
- 权重轮询(Weighted Round Robin) :
-
生产环境部署优化
- 容器化(Docker/K8s) :
- 优势:
- 快速部署:1个镜像 = 全平台兼容 📦
- 资源隔离:避免“隔壁装修,我漏水”的问题 🛡️
- 弹性伸缩:根据负载自动增减实例 🔄
- 实战建议:
- 使用
Docker Compose简化多容器编排 🧩 - 在 Kubernetes 中通过
Deployment+Service实现自动扩缩容 🌱
- 使用
- 优势:
- K8s 集成:
- Ingress 控制器:
- 通过
Nginx Ingress或Traefik实现 HTTP 路由和负载均衡 🌐
- 通过
- Service 类型:
ClusterIP(集群内访问)NodePort(暴露端口到外网)LoadBalancer(云厂商自动创建负载均衡器) 🌐
- Ingress 控制器:
- 容器化(Docker/K8s) :
📚 参考资料
-
Spring Cloud LoadBalancer 官方文档:
https://spring.io/projects/spring-cloud-loadbalancer- 核心功能:支持自定义负载均衡策略、与 Ribbon 兼容、集成 Spring Cloud Gateway
- 实战示例:
@Bean public ReactorLoadBalancer<ServiceInstance> loadBalancer() {return new RoundRobinLoadBalancer(new ArrayList<>(), "my-service"); }
-
Kubernetes 官方文档:
Service | Kubernetes- 重点学习:
Service与Ingress的关系Horizontal Pod Autoscaler(HPA)配置
- 重点学习:
🎯 小贴士
- 监控与告警:
- 使用 Prometheus + Grafana 监控负载均衡器状态 📊
- 设置阈值告警(如 CPU > 80% 时自动扩容) 🚨
- 安全加固:
- 在负载均衡层启用 HTTPS 终止(如 Nginx SSL 配置) 🔒
- 限制访问频率(Rate Limiting)防 DDoS 攻击 🛡️
🧩 五. 结语:从理论到落地,你的系统架构已进化!
通过本章的实战演练,你已经掌握了 Spring Cloud 多机部署 的完整流程,从环境搭建、数据库配置到负载均衡策略的落地,每一步都为你构建了一个 高可用、可扩展、易维护 的分布式系统基础。
现在,你不仅是技术的使用者,更是架构的设计师!
🌈 技术的价值:不止于功能,更在于韧性
- 多机部署 让你的服务不再依赖单点,即使某台机器宕机,系统依然能稳定运行。
- 负载均衡 通过智能流量分配,不仅提升了性能,更让资源利用率最大化,避免“一锅端”的尴尬。
- Spring Cloud 作为现代化微服务框架,为你提供了开箱即用的工具链(如
Ribbon、LoadBalancer、Consul),让你专注于业务逻辑,而非底层复杂性。
记住:
“真正的系统架构,不是追求完美,而是追求在不确定性中保持稳定。”
🚀 未来方向:从“能用”到“极致”
-
深入学习云原生技术
- 探索 Kubernetes 的高级特性(如
Helm、Operator、Service Mesh),让系统更智能、更自治。 - 尝试将 Spring Cloud 与云厂商(如 AWS、阿里云)深度集成,利用其弹性计算能力。
- 探索 Kubernetes 的高级特性(如
-
性能调优与监控体系
- 构建完整的监控体系(Prometheus + Grafana + ELK),实时感知系统健康状态。
- 通过压测工具(JMeter、Locust)模拟高并发场景,优化负载均衡策略。
-
安全与合规
- 在负载均衡层加入 HTTPS 终止、访问控制(如 IP 白名单)、速率限制(Rate Limiting),抵御攻击。
- 遵循 GDPR、ISO 27001 等安全规范,确保数据合规。
📚 参考资料:持续精进的指南
- Spring Cloud 官方文档:Spring Cloud
- Kubernetes 官方文档:Kubernetes Documentation | Kubernetes
- Nginx 负载均衡手册:Using nginx as HTTP load balancer
- 《Spring Cloud 微服务实战》 :深入解析 Spring Cloud 各组件原理与实战技巧。
🎯 最后的鼓励:技术是不断迭代的旅程
多机部署和负载均衡只是分布式系统的起点,未来的你可能会面对更复杂的场景(如跨数据中心容灾、服务网格、Serverless 架构)。但请记住:
“每一个伟大的系统,都是从一个小的负载均衡策略开始的。”
现在,拿起你的代码编辑器,把今天学到的知识变成实际的系统吧! 🚀
愿你的服务永不宕机,流量永不爆表,代码永无 Bug!✨
“技术的尽头是实践,而实践的终点是不断突破!”
—— 永远热爱技术的你 🌟
相关文章:
Spring Cloud 多机部署与负载均衡实战详解
🧱 一、引言 为什么需要多机部署? 解决单节点性能瓶颈,提升系统可用性和吞吐量 在传统单机部署模式下,系统的所有服务或应用都运行在单一服务器上。这种模式在小型项目或低并发场景中可能足够,但随着业务规模扩大、用…...

基于定制开发开源AI智能名片S2B2C商城小程序的首屏组件优化策略研究
摘要:在数字化转型背景下,用户对首屏交互效率的诉求日益提升。本文以"定制开发开源AI智能名片S2B2C商城小程序"为技术载体,结合用户行为数据与认知心理学原理,提出首屏组件动态布局模型。通过分析搜索栏、扫码入口、个人…...
EasyRTC嵌入式音视频通信SDK音视频功能驱动视频业务多场景应用
一、方案背景 随着互联网技术快速发展,视频应用成为主流内容消费方式。用户需求已从高清流畅升级为实时互动,EasyRTC作为高性能实时音视频框架,凭借低延迟、跨平台等特性,有效满足市场对多元化视频服务的需求。 二、EasyRTC技术…...

Flink 失败重试策略 :restart-strategy.type
在 Apache Flink 中,restart-strategy.type 用于指定作业的重启策略(Restart Strategy),它决定了作业在失败后如何恢复。 Flink 提供了 4 种内置重启策略,可以通过 flink-conf.yaml 或代码动态配置。 1. 可配置的 rest…...
linux下gpio控制
linux下gpio控制 文章目录 linux下gpio控制1.中断命令控制/sys/class/gpio/export终端命令控制led 2.应用程序控制 3.驱动代码控制 1.中断命令控制 通用GPIO主要用于产生输出信号和捕捉输入信号。每组GPIO均可以配置为输出输入以及特定的复用功能。 当作为输入时,内…...
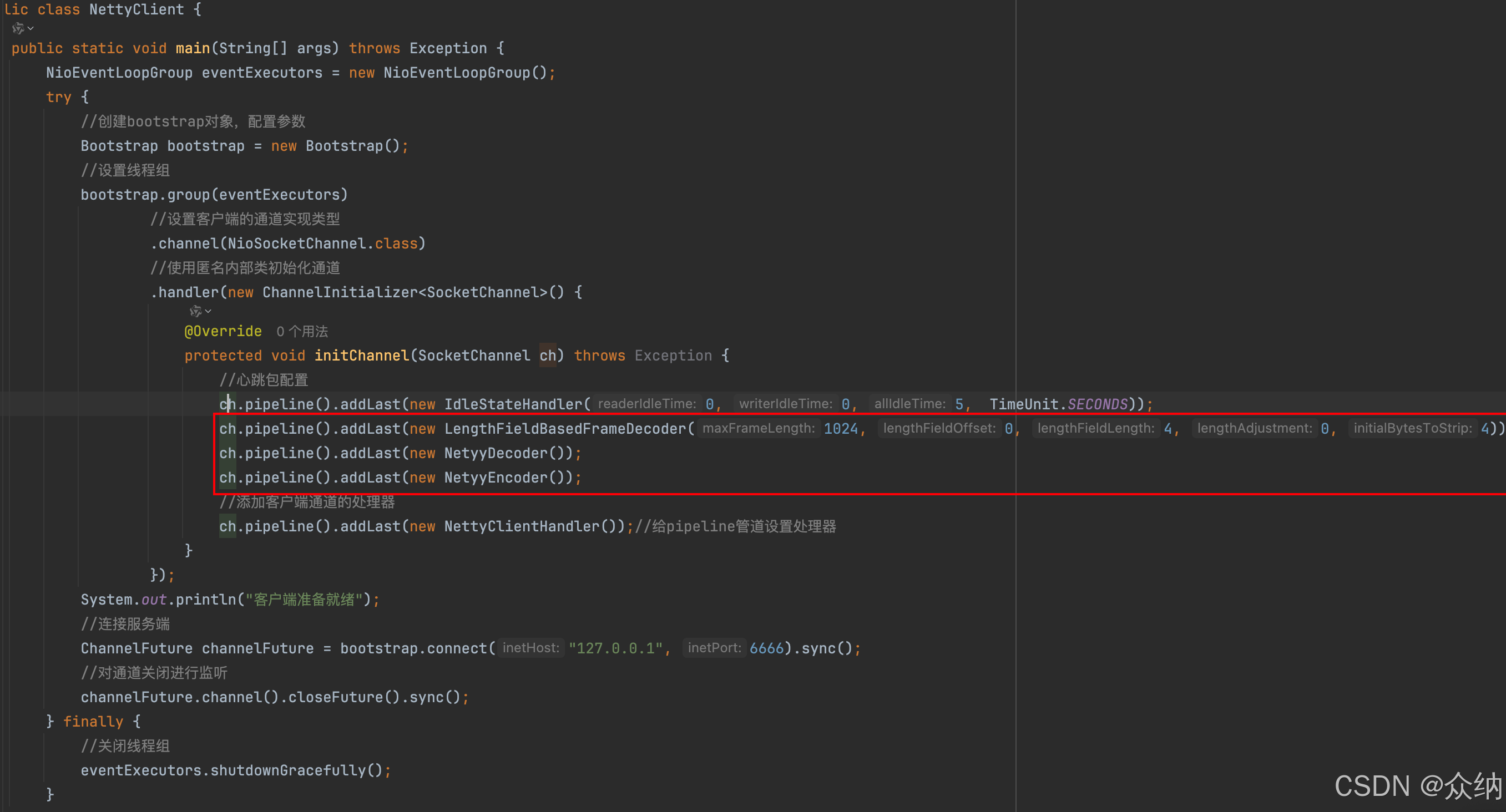
Spring Boot 从Socket 到Netty网络编程(下):Netty基本开发与改进【心跳、粘包与拆包、闲置连接】
上一篇:《Spring Boot 从Socket 到Netty网络编程(上):SOCKET 基本开发(BIO)与改进(NIO)》 前言 前文中我们简单介绍了基于Socket的BIO(阻塞式)与NIO(非阻塞式࿰…...
Orthanc:轻量级PACS服务器与DICOMweb支持的技术详解
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C++, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C++、C#等开发语言,熟悉Java常用开发技术,能熟练应用常用数据库SQL server,Oracle,mysql,postgresql等进行开发应用…...
量子计算导论课程设计 之 PennyLane环境搭建
文章目录 具体配置conda 虚拟环境配置Pennylane 正所谓,磨刀不误砍柴工,想要进行量子计算导论的课程设计,首先就是搭建好平台,推荐大家就是本地搭建,那么下面有三种选择 QiskitTensorFlow QuantumPennylane 具体配置…...

GAN优化与改进:从条件生成到训练稳定性
摘要 本文聚焦生成对抗网络(GAN)的核心优化技术与改进模型。系统解析 条件生成对抗网络(CGAN) 的可控生成机制、深度卷积GAN(DCGAN) 的架构创新,揭示GAN训练崩溃的本质原因,并介绍W…...

【Dv3Admin】系统视图下载中心API文件解析
大文件导出与批量数据下载常常成为后台系统性能瓶颈,合理管理下载任务是保障系统稳定运行的关键。任务化下载机制通过异步处理,避免前端等待阻塞,提升整体交互体验。 围绕 download_center.py 模块,剖析其在下载任务创建、查询、…...

linux库(AI回答)
STL POSIX关系 DeepSeek-R1 回答完成 搜索全网22篇资料 STL(标准模板库)和 POSIX(可移植操作系统接口)是两种不同领域的技术标准,它们在 C/C 开发中各有侧重,但可以协同使用。以下是它们的关系和区别&…...
CoordConv: CNN坐标感知特征适应
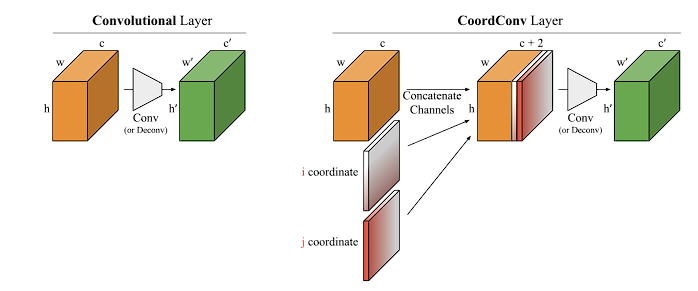
传统卷积 vs CoordConv 详细对比 传统卷积对空间位置不敏感,CoordConv通过显式添加坐标信息解决这个问题在特征图中嵌入(x, y)坐标和可选的径向距离r使模型能够感知空间位置关系 1. 传统卷积的"空间位置不敏感"问题 传统卷积的特点: 输入: …...
)
Kafka 快速上手:安装部署与 HelloWorld 实践(二)
四、Kafka 的 HelloWorld 实践 完成 Kafka 的安装部署后,我们就可以进行一些简单的操作来体验 Kafka 的功能了。下面通过一个 HelloWorld 示例,展示如何在 Kafka 中创建主题、发送消息和消费消息。 (一)创建主题(Top…...

opencv学习笔记2:卷积、均值滤波、中值滤波
目录 一、卷积概念 1.定义 2.数学原理 3.实例计算 (1) 输入与卷积核 (2)计算输出 g(2,2) 4.作用 二、针对图像噪声的滤波技术——均值滤波 1.均值滤波概念 (1)均值滤波作用 (2&#…...
在 Android Studio 中使用 GitLab 添加图片到 README.md
1. 将图片文件添加到项目中 在项目根目录下创建一个 images 或 assets 文件夹 将你的图片文件(如 screenshot.png)复制到这个文件夹中 2. 跟提交项目一样,提交图片到 GitLab 在 Android Studio 的 Git 工具窗口中: 右键点击图片…...
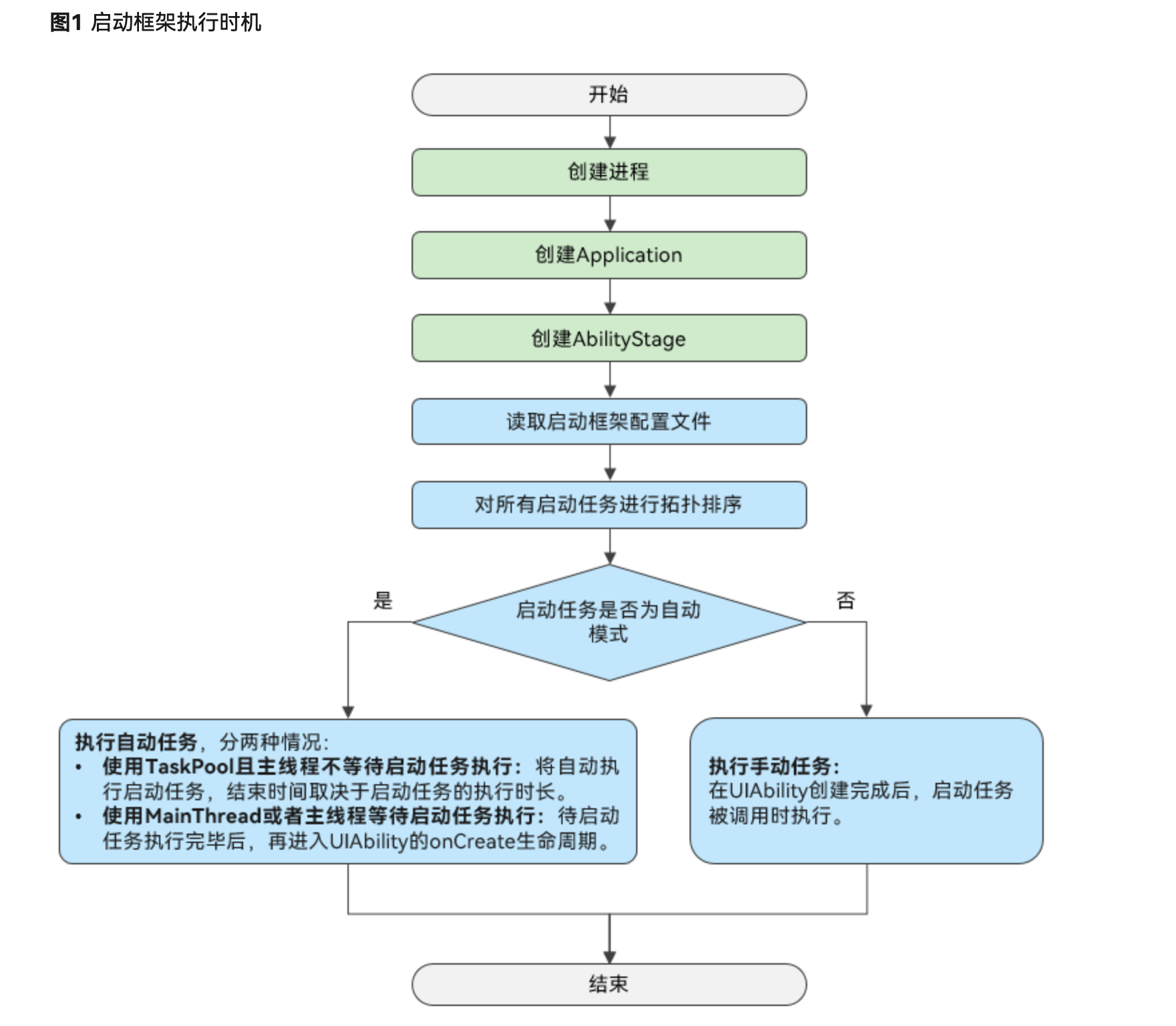
HarmonyOS:如何在启动框架中初始化HMRouter
应用启动时通常需要执行一系列初始化启动任务,如果将启动任务都放在应用主模块(即entry类型的Module)的UIAbility组件的onCreate生命周期中,那么只能在主线程中依次执行,不但影响应用的启动速度,而且当启动…...

Ubuntu下有关UDP网络通信的指令
1、查看防火墙状态: sudo ufw status # Ubuntu 2、 检查系统全局广播设置 # 查看是否忽略广播包(0表示接收,1表示忽略) sysctl net.ipv4.icmp_echo_ignore_broadcasts# 查看是否允许广播转发(1表示允许)…...
)
JavaWeb预习(jdbc)
基础 1.驱动程序接口Driver 每种数据库都提供了数据库驱动程序,并且都提供了一个实现java.sql.Driver接口的类,称为Driver 对于MySql,其Driver类为com.mysql.jdbc.Driver,加载该类的语句为: Class.forName("c…...
Web3 借贷与清算机制全解析:链上金融的运行逻辑
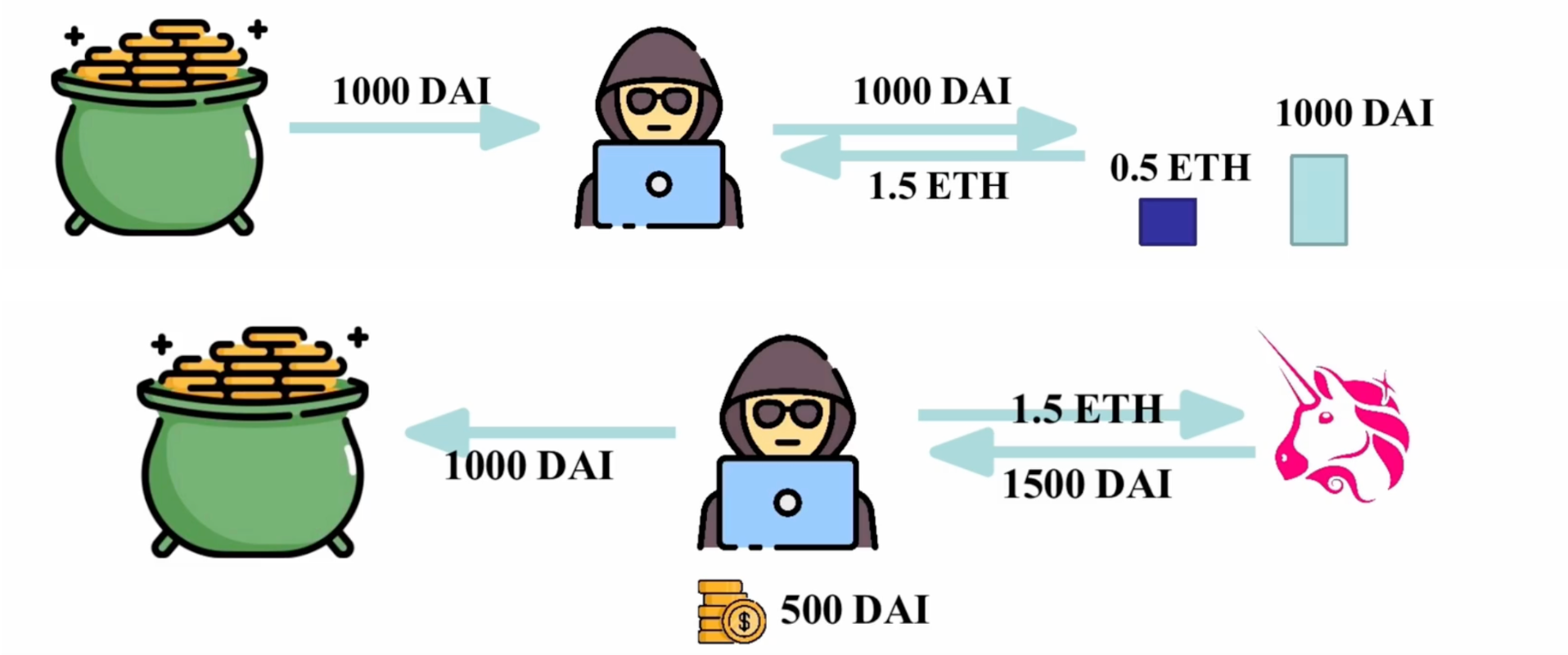
Web3 借贷与清算机制全解析:链上金融的运行逻辑 超额抵押借款 例如,借款人用ETH为抵押借入DAI;借款人的ETH的价值一定是要超过DAI的价值;借款人可以任意自由的使用自己借出的DAI 稳定币 第一步:借款人需要去提供一定…...

【Vue3】(三)vue3中的pinia状态管理、组件通信
目录 一、vue3的pinia 二、【props】传参 三、【自定义事件】传参 四、【mitt】传参 五、【v-model】传参(平常基本不写) 六、【$attrs】传参 七、【$refs和$parent】传参 八、provide和inject 一、vue3的pinia 1、什么是pinia? pinia …...

ingress-nginx 开启 Prometheus 监控 + Grafana 查看指标
环境已经部署了 ingress-nginx(DaemonSet 方式),并且 Prometheus Grafana 也已经运行。但之前 /metrics 端点没有暴露 Nginx 核心指标(如 nginx_ingress_controller_requests_total),经过调整后现在可以正…...

SQL进阶之旅 Day 21:临时表与内存表应用
【SQL进阶之旅 Day 21】临时表与内存表应用 文章简述 在SQL开发过程中,面对复杂查询、数据预处理和性能优化时,临时表和内存表是不可或缺的工具。本文深入讲解了临时表(Temporary Table)和内存表(Memory Table&#x…...

Jenkins自动化部署Maven项目
Jenkins自动化部署Maven项目 一、环境准备(Prerequisites) SpringBoot项目 确保项目根目录有标准Maven结构(pom.xml)且包含Dockerfile: # Dockerfile 示例 FROM openjdk:11-jre-slim VOLUME /tmp ARG JAR_FILE=target/*.jar COPY ${JAR_FILE} app.jar ENTRYPOINT ["j…...

LeetCode 高频 SQL 50 题(基础版)之 【高级字符串函数 / 正则表达式 / 子句】· 上
题目:1667. 修复表中的名字 题解: select user_id, concat(upper(left(name,1)),lower(right(name,length(name)-1))) name from Users order by user_id题目:1527. 患某种疾病的患者 题解: select * from Patients where con…...
Python 中 Django 中间件:原理、方法与实战应用
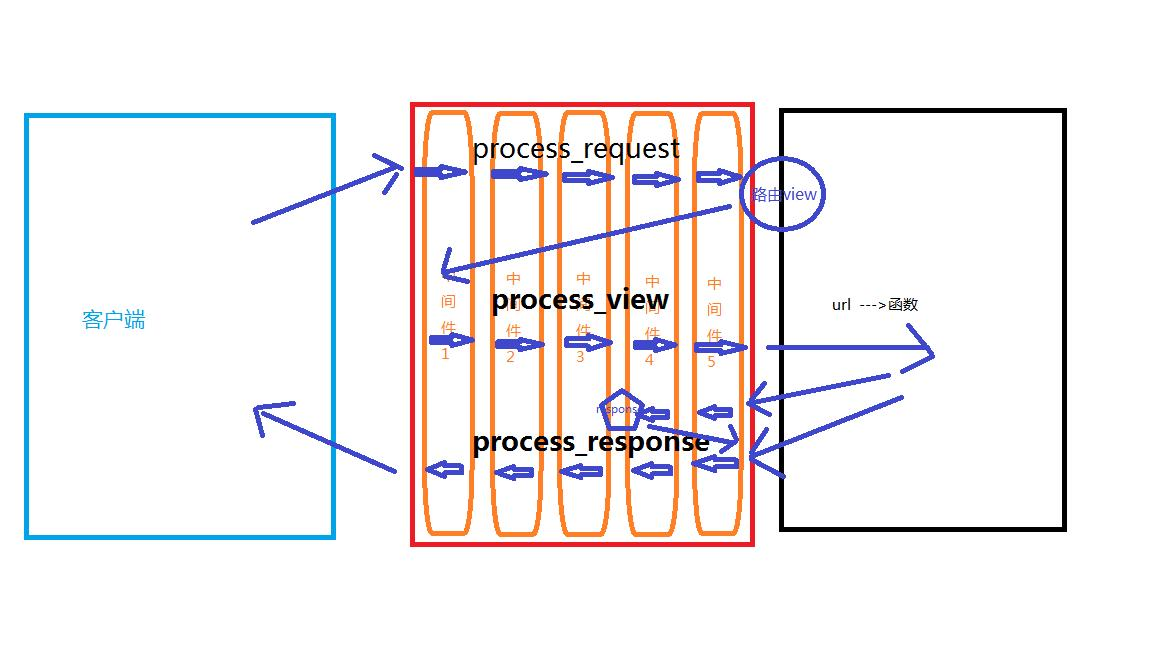
在 Python 的 Web 开发领域,Django 框架凭借其高效、便捷和功能丰富的特点备受开发者青睐。而 Django 中间件作为 Django 框架的重要组成部分,犹如 Web 应用的 “交通枢纽”,能够在请求与响应的处理流程中,实现对请求和响应的拦截…...
深入浅出玩转物联网时间同步:基于BC260Y的NTP实验与嵌入式仿真教学革命
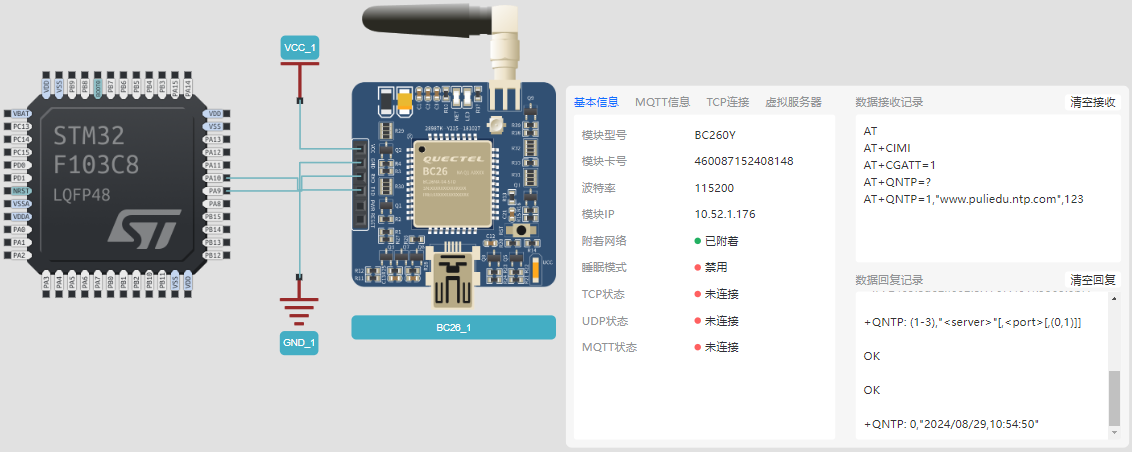
在万物互联的时代,精准的时间戳是物联网系统的神经节拍器,而NTP协议正是维持这一节律的核心技术。 一、时间同步:物联网世界的隐形基石 在智慧城市、工业4.0等场景中,分散的设备需要毫秒级的时间协同。网络时间协议(N…...

数学建模期末速成 主成分分析的基本步骤
设有 n n n个研究对象, m m m个指标变量 x 1 , x 2 , ⋯ , x m x_1,x_2,\cdots,x_m x1,x2,⋯,xm,第 i i i个对象关于第 j j j个指标取值为 a i j a_{ij} aij,构造数据矩阵 A ( a i j ) n m A\left(\begin{array}{c}a_{ij}\end{array}\right)_{…...

视频音频去掉开头结尾 视频去掉前n秒后n秒 电视剧去掉开头歌曲
视频音频去掉开头结尾 视频去掉前n秒后n秒 视频音频去掉开头结尾 视频去掉前n秒后n秒 电视剧去掉开头歌曲 如果你有一些视频或者音频,你想去掉开头或结尾的几秒钟,那么你可以尝试一下这个工具,首先,我们来看一下,我们以…...

【在线五子棋对战】二、websocket 服务器搭建
文章目录 Ⅰ. WebSocket1、简介2、特点3、原理解析4、报文格式 Ⅱ. WebSocketpp1、认识2、常用接口3、websocketpp库搭建服务器搭建流程主体框架填充回调函数细节 4、编写 makefile 文件5、websocket客户端 Ⅰ. WebSocket 1、简介 WebSocket 是从 HTML5 开始支持的一种网页端…...
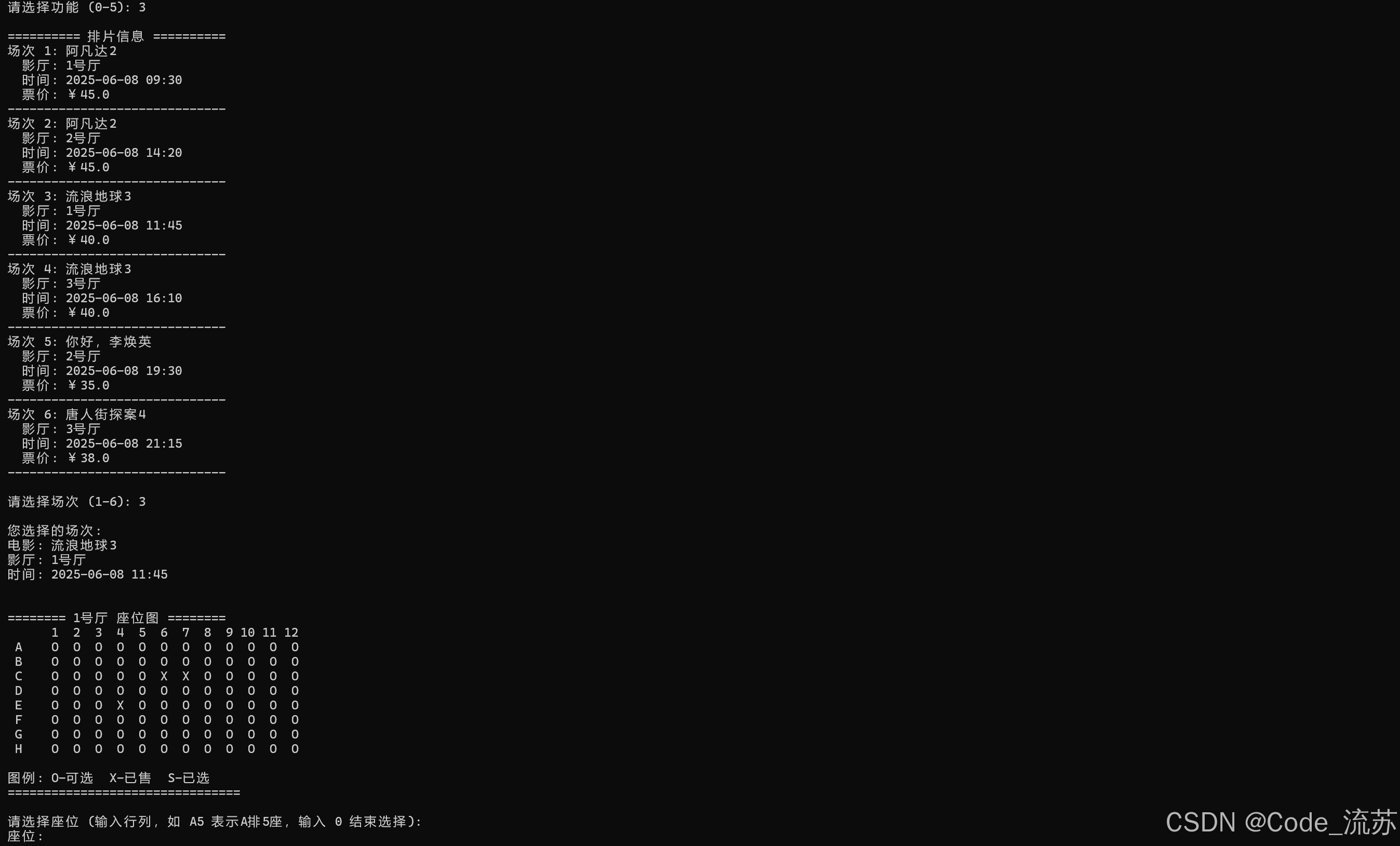
C++课设:从零开始打造影院订票系统
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏介绍:《编程项目实战》 目录 一、项目背景与需求分析二、系统架构设计…...