【CUDA 】第5章 共享内存和常量内存——5.3减少全局内存访问(2)
CUDA C编程笔记
- 第五章 共享内存和常量内存
- 5.3 减少全局内存访问
- 5.3.2 使用展开的并行规约
- 思路
- reduceSmemUnroll4(共享内存)具体代码:
- 运行结果
- 意外发现书上全局加载事务和全局存储事务和ncu中这两个值相同
- 5.3.3 动态共享内存的并行规约
- reduceSmemUnroll4Dyn(共享内存)具体代码:
- 5.3.4 有效带宽
待解决的问题:意外发现书上全局加载事务和全局存储事务和ncu中这两个值相同,是否有直接相关???
ncu中带宽的查看方式
第五章 共享内存和常量内存
5.3 减少全局内存访问
使用共享内存的主要原因之一是要缓存片上的数据,来减少核函数中全局内存访问的次数。
第三章介绍了用全局内存的并行规约核函数,并解释了下面2个问题:
①如何重新安排数据访问模式来避免线程束分化
②如何展开循环来保证有足够的操作使指令和内存带宽饱和
本节重新使用并行规约核函数,但是这里用共享内存作为缓存来减少全局内存的访问。【并行规约+共享内存】
5.3.2 使用展开的并行规约
前面的核函数用一个线程块处理一个数据块。继续优化用第三章的思想,一次运行多个IO操作,展开线程块来提高核函数性能。
这里展开了4个线程块,即每个线程处理4个数据块的数据。
这样做的优势是:
①提高全局内存的吞吐量,因为每个线程进行了更多的并行IO。
②全局内存存储事务减少了1/4
③整体内核性能提升
思路
先重新计算全局输入数据的偏移值。
//全局索引,一次处理4个输入数据块unsigned int idx = blockIdx.x * blockDim.x * 4 + threadIdx.x;//这里乘4
再一次性处理4个元素,每个线程读取4个数据,把这个4个数据的和放到局部变量tmpSum中,用tmpSum来初始化共享内存,而非从全局内存初始化共享内存。
//边界条件检查if(idx < n)//在范围内的相邻块大小的元素都加起来,最多可以一次处理4个块{int a1, a2, a3, a4;a1 = a2 = a3 = a4 = 0;a1 = g_idata[idx];if(idx + blockDim.x < n) a2 = g_idata[idx + blockDim.x];if(idx + 2 * blockDim.x < n) a3 = g_idata[idx + 2 * blockDim.x];if(idx + 3 * blockDim.x < n) a4 = g_idata[idx + 3 * blockDim.x];tmpSum = a1 + a2 + a3 + a4;}
reduceSmemUnroll4(共享内存)具体代码:
//reduceSmemUnroll4
__global__ void reduceSmemUnroll(int *g_idata, int *g_odata, unsigned int n){//静态共享数组__shared__ int smem[DIM];//设置线程IDunsigned int tid = threadIdx.x;//全局索引,一次处理4个输入数据块unsigned int idx = blockIdx.x * blockDim.x * 4 + threadIdx.x;//这里乘4//展开4个块int tmpSum = 0;//【】//边界条件检查if(idx < n)//在范围内的相邻块大小的元素都加起来,最多可以一次处理4个块{int a1, a2, a3, a4;a1 = a2 = a3 = a4 = 0;a1 = g_idata[idx];if(idx + blockDim.x < n) a2 = g_idata[idx + blockDim.x];if(idx + 2 * blockDim.x < n) a3 = g_idata[idx + 2 * blockDim.x];if(idx + 3 * blockDim.x < n) a4 = g_idata[idx + 3 * blockDim.x];tmpSum = a1 + a2 + a3 + a4;}smem[tid] = tmpSum;__syncthreads();//在共享内存中就地规约if(blockDim.x >= 1024 && tid < 512) smem[tid] += smem[tid + 512];__syncthreads();if(blockDim.x >= 512 && tid < 256) smem[tid] += smem[tid + 256];__syncthreads();if(blockDim.x >= 256 && tid < 128) smem[tid] += smem[tid + 128];__syncthreads();if(blockDim.x >= 128 && tid < 64) smem[tid] += smem[tid + 64];__syncthreads();//展开warpif(tid < 32){volatile int *vsmem = smem;vsmem[tid] += vsmem[tid + 32];vsmem[tid] += vsmem[tid + 16];vsmem[tid] += vsmem[tid + 8];vsmem[tid] += vsmem[tid + 4];vsmem[tid] += vsmem[tid + 2];vsmem[tid] += vsmem[tid + 1];}//把结果写回全局内存if(tid == 0) g_odata[blockIdx.x] = smem[0];
}
对应的主函数调用核函数也要修改,网格除4。
这里只能给grid.x/4,不能给block/4。
如果block/4,假设原来block大小为256,调用时block/4=64,blockDim.x=64,共享内存仍分配256个空间,只有前64个有值,后面的都是未定义的有问题的值。并且归约也会崩溃,索引也有问题。
//3、reduceSmemUnroll4cudaMemcpy(d_idata, h_idata, bytes, cudaMemcpyHostToDevice);reduceSmemUnroll<<<grid.x / 4, block>>>(d_idata, d_odata, size);//这里要除4,因为一个线程块处理四个数据块,需要的线程块减为原来的1/4cudaMemcpy(h_odata, d_odata, grid.x / 4 * sizeof(int), cudaMemcpyDeviceToHost);gpu_sum = 0;for(int i = 0; i < grid.x / 4; i++) gpu_sum += h_odata[i];printf("reduceSmemUnroll4: %d <<<grid %d block %d>>>\n", gpu_sum, grid.x / 4,block.x);
运行结果
[6/8] Executing 'cuda_gpu_kern_sum' stats reportTime (%) Total Time (ns) Instances Avg (ns) Med (ns) Min (ns) Max (ns) StdDev (ns) Name -------- --------------- --------- --------- --------- -------- -------- ----------- --------------------------------------------50.4 238,789 1 238,789.0 238,789.0 238,789 238,789 0.0 reduceGmem(int *, int *, unsigned int) 32.5 154,051 1 154,051.0 154,051.0 154,051 154,051 0.0 reduceSmem(int *, int *, unsigned int) 17.2 81,377 1 81,377.0 81,377.0 81,377 81,377 0.0 reduceSmemUnroll(int *, int *, unsigned int)
意外发现书上全局加载事务和全局存储事务和ncu中这两个值相同
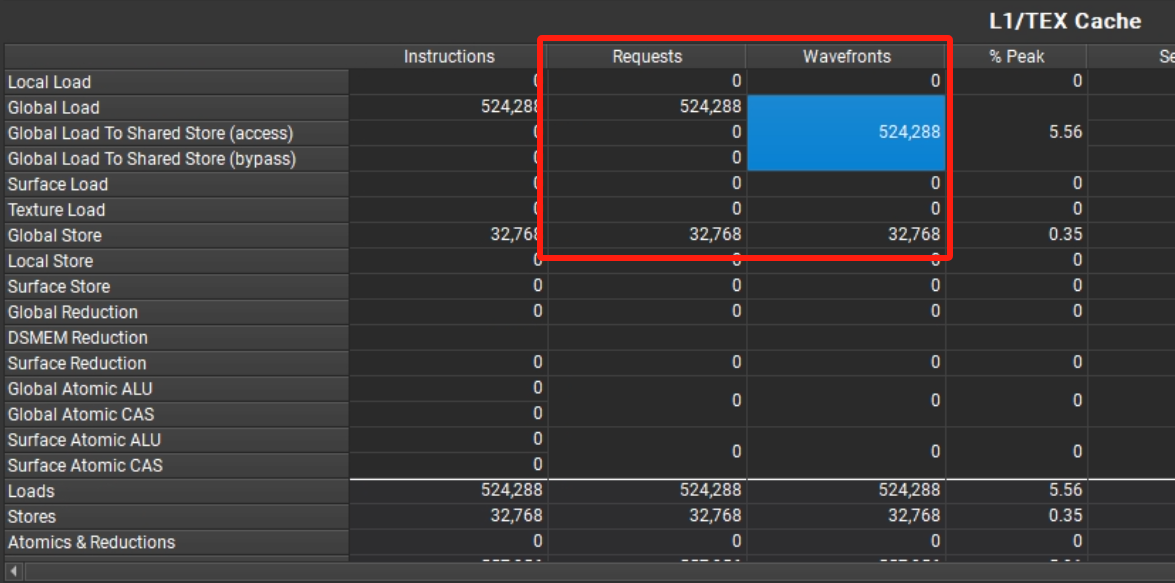
存储事务:与reduceSmem相比,reduceSmemUnroll4存储事务数量减少为1/4,加载事务数量不变。
全局内存吞吐量:
加载吞吐量增加,因为大量同时加载请求。
存储吞吐量下降,较少的存储请求让总线饱和。
5.3.3 动态共享内存的并行规约
reduceSmemUnroll4中用动态共享内存代替静态共享内存
extern __shared__ int smem[];
reduceSmemUnroll4Dyn(共享内存)具体代码:
//动态共享内存+reduceSmemUnroll4
__global__ void reduceSmemUnrollDyn(int *g_idata, int *g_odata, unsigned int n){extern __shared__ int smem[];//设置动态共享内存,其他的和reduceSmemUnroll4一样//设置线程idunsigned int tid = threadIdx.x;unsigned int idx = blockIdx.x * blockDim.x * 4 + threadIdx.x;//展开4个块int tmpSum = 0;if(idx < n){int a1, a2, a3, a4;a1 = a2 = a3 = a4 = 0;a1 = g_idata[idx];if(idx + blockDim.x < n) a2 = g_idata[idx + blockDim.x];if(idx + 2 * blockDim.x < n) a3 = g_idata[idx + blockDim.x * 2];if(idx + 3 * blockDim.x < n) a4 = g_idata[idx + blockDim.x * 3];tmpSum = a1 + a2 + a3 + a4;}smem[tid] = tmpSum;__syncthreads();//在全局内存就地规约if(blockDim.x > 1024 && tid < 512) smem[tid] += smem[tid + 512];__syncthreads();if(blockDim.x > 512 && tid < 256) smem[tid] += smem[tid + 256];__syncthreads();if(blockDim.x > 256 && tid < 128) smem[tid] += smem[tid + 128];__syncthreads();if(blockDim.x > 128 && tid < 64) smem[tid] += smem[tid + 64];__syncthreads();//展开warpif(tid < 32){volatile int *vsmem = smem;vsmem[tid] += vsmem[tid + 32];vsmem[tid] += vsmem[tid + 16];vsmem[tid] += vsmem[tid + 8];vsmem[tid] += vsmem[tid + 4];vsmem[tid] += vsmem[tid + 2];vsmem[tid] += vsmem[tid + 1];}//把这个块的结果写回全局内存if(tid == 0) g_odata[threadIdx.x] = smem[0];
}
对应main函数调用核函数的时候也要修改。
//4、reduceSmemUnroll4DyncudaMemcpy(d_idata, h_idata, bytes, cudaMemcpyHostToDevice);reduceSmemUnrollDyn<<<grid.x / 4, block, DIM * sizeof(int)>>>(d_idata, d_odata, size);//1、指定待动态分配的共享内存数量 2、除4,因为一个线程块处理四个数据块,需要的线程块减为原来的1/4cudaMemcpy(h_odata, d_odata, grid.x / 4 * sizeof(int), cudaMemcpyDeviceToHost);gpu_sum = 0;for(int i = 0; i < grid.x / 4; i++) gpu_sum += h_odata[i];printf("reduceSmemUnroll4Dyn: %d <<<grid %d block %d>>>\n", gpu_sum, grid.x / 4,block.x);
运行效果:动态共享内存和静态共享内存运行时间差不多。
[6/8] Executing 'cuda_gpu_kern_sum' stats reportTime (%) Total Time (ns) Instances Avg (ns) Med (ns) Min (ns) Max (ns) StdDev (ns) Name -------- --------------- --------- --------- --------- -------- -------- ----------- -----------------------------------------------43.7 263,970 1 263,970.0 263,970.0 263,970 263,970 0.0 reduceGmem(int *, int *, unsigned int) 27.5 166,400 1 166,400.0 166,400.0 166,400 166,400 0.0 reduceSmem(int *, int *, unsigned int) 14.4 87,169 1 87,169.0 87,169.0 87,169 87,169 0.0 reduceSmemUnrollDyn(int *, int *, unsigned int)14.4 86,720 1 86,720.0 86,720.0 86,720 86,720 0.0 reduceSmemUnroll(int *, int *, unsigned int) 5.3.4 有效带宽
规约核函数受到内存带宽的限制,因此用有效带宽来评估他们的性能指标。
有效带宽:核函数的完整执行时间内IO的数量;对于内存约束的应用程序,有效带宽是估算实际带宽利用率的好指标。
相关文章:
【CUDA 】第5章 共享内存和常量内存——5.3减少全局内存访问(2)
CUDA C编程笔记 第五章 共享内存和常量内存5.3 减少全局内存访问5.3.2 使用展开的并行规约思路reduceSmemUnroll4(共享内存)具体代码:运行结果意外发现书上全局加载事务和全局存储事务和ncu中这两个值相同 5.3.3 动态共享内存的并行规约reduc…...

Python 训练营打卡 Day 46
通道注意力 一、什么是注意力 注意力机制是一种让模型学会「选择性关注重要信息」的特征提取器,就像人类视觉会自动忽略背景,聚焦于图片中的主体(如猫、汽车)。 transformer中的叫做自注意力机制,他是一种自己学习自…...
什么是复合索引?)
MySQL(56)什么是复合索引?
复合索引(Composite Index),也称为多列索引,是在数据库表的多列上创建的索引。它可以提高涉及多个列的查询性能,通过组合多个列的值来索引数据。复合索引特别适用于需要同时过滤多列的查询。 复合索引的优点 提高多列…...

Rust学习(1)
声明:学习来源于 《Rust 圣经》 变量的绑定和解构 变量绑定 let a "hello world":这个过程称之为变量绑定。绑定就是把这个对象绑定给一个变量,让这个变量成为它的主人。 变量可变性 Rust 变量默认情况下不可变,可以通过 mut …...
鸿蒙仓颉语言开发实战教程:商城应用个人中心页面
又到了高考的日子,幽蓝君在这里祝各位考生朋友冷静答题,超常发挥。 今天要分享的内容是仓颉语言商城应用的个人中心页面,先看效果图: 下面介绍下这个页面的实现过程。 我们可以先分析下整个页面的布局结构。可以看出它是纵向的布…...

vue3 eslint ts 关闭多单词命名检查
无效做法 import { globalIgnores } from eslint/config import {defineConfigWithVueTs,vueTsConfigs, } from vue/eslint-config-typescript import pluginVue from eslint-plugin-vue import skipFormatting from vue/eslint-config-prettier/skip-formatting// To allow m…...

横向对比npm和yarn
🔧 基本概况 维度npmYarn所属Node.js 官方工具(npm, Inc.)Meta(Facebook)主导开发初始发布时间2010 年2016 年(为了解决 npm 的一些痛点而诞生)默认安装Node.js 安装后自带需要手动安装最新版本…...
智能生成完整 Java 后端架构,告别手动编写 ControllerServiceDao
在 Java 后端开发的漫长征途上,开发者们常常深陷繁琐的基础代码编写泥潭。尤其是 Controller、Service、Dao 这三层代码的手动编写,堪称开发效率的 “拦路虎”。从搭建项目骨架到填充业务逻辑,每一个环节都需要开发者投入大量精力,…...
Python----目标检测(yolov5-7.0安装及训练细胞)
一、下载项目代码 yolov5代码源 GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite yolov5-7.0代码源 Release v7.0 - YOLOv5 SOTA Realtime Instance Segmentation ultralytics/yolov5 GitHub 二、创建虚拟环境 创建一个3.8…...

MySQL EXPLAIN 命令详解
文章目录 MySQL EXPLAIN 命令详解EXPLAIN 输出的基本结构id2. select_type3. table4. partitions5. type6. possible_keys7. key8. key_len9. ref10. rows11. filtered12. Extra 使用 EXPLAIN 的注意事项示例 MySQL EXPLAIN 命令详解 EXPLAIN 是 MySQL 中一个非常有用的命令&a…...

【Linux】文件赋权(指定文件所有者、所属组)、挂载光驱(图文教程)
文章目录 文件赋权创建文件 testChmod查看文件的当前权限使用 chmod 命令修改权限验证权限关键命令总结答案汇总 光驱挂载确认文件是否存在打包压缩压缩验证创建 work 目录将压缩文件复制到 work 目录新建挂载点 /MNT/CDROM 并挂载光驱答案汇总 更多相关内容可查看 此篇用以解决…...
第22讲、Odoo18 QWeb 模板引擎详解
Odoo QWeb 模板引擎详解与实战 Odoo 的 QWeb 是其自研的模板引擎,广泛应用于 HTML、XML、PDF 等内容的生成,支撑了前端页面渲染、报表输出、门户页面、邮件模板等多种场景。本文将系统介绍 QWeb 的核心用法、工作原理,并通过实战案例演示如何…...

OpenJudge | 大整数乘法
总时间限制: 1000ms 内存限制: 65536kB 描述 求两个不超过200位的非负整数的积。 输入 有两行,每行是一个不超过200位的非负整数,没有多余的前导0。 输出 一行,即相乘后的结果。结果里不能有多余的前导0,即如果结果是342&am…...

【原理解析】为什么显示器Fliker dB值越大,闪烁程度越轻?
显示器Fliker 1 显示器闪烁现象说明2 Fliker量测方法2.1 FMA法2.2 JEITA法问题答疑:为什么显示器Fliker dB值越大,闪烁程度越轻? 3 参考文献 1 显示器闪烁现象说明 当一个光源闪烁超过每秒10次以上就可在人眼中产生视觉残留,此时…...

Bootstrap Table开源的企业级数据表格集成
Bootstrap Table 是什么 Bootstrap Table 是一个基于 Bootstrap 框架的开源插件,专为快速构建功能丰富、响应式的数据表格而设计。 它支持排序、分页、搜索、导出等核心功能,并兼容多种 CSS 框架(如 Semantic UI、Material Design 等&am…...

JDK8新特性之Steam流
这里写目录标题 一、Stream流概述1.1、传统写法1.2、Stream写法1.3、Stream流操作分类 二、Stream流获取方式2.1、根据Collection获取2.2、通过Stream的of方法 三、Stream常用方法介绍3.1、forEach3.2、count3.3、filter3.4、limit3.5、skip3.6、map3.7、sorted3.8、distinct3.…...
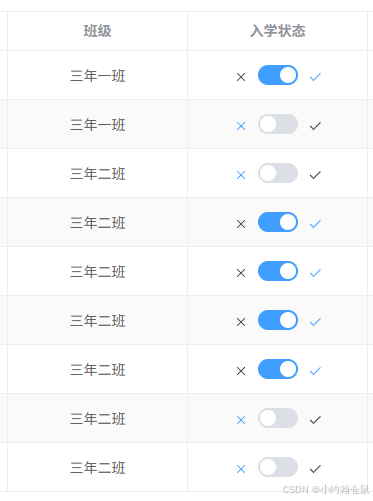
vue3表格使用Switch 开关
本示例基于vue3 element-plus 注:表格数据返回状态值为0、1。开关使用 v-model"scope.row.state 0" 会报错 故需要对写法做些修改,效果图如下 <el-table-column prop"state" label"入学状态" width"180" …...

【11408学习记录】考研写作双核引擎:感谢信+建议信复合结构高分模板(附16年真题精讲)
感谢信建议信 英语写作2016年考研英语(二)真题小作文题目分析写作思路第一段第二段锦囊妙句9:锦囊妙句12:锦囊妙句13:锦囊妙句18: 第三段 妙句成文 每日一句词汇第一步:找谓语第二步:…...

一套个人知识储备库构建方案
写文章的初心是做知识沉淀。 好记性不如烂笔头,将阶段性的经验总结成文章,下次遇到相同的问题时,查起来比再次去搜集资料快得多。 然而,当文章越来越多时,有一个问题逐渐开始变得“严峻”起来。 比如,我…...

行李箱检测数据集VOC+YOLO格式2083张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):2083 标注数量(xml文件个数):2083 标注数量(txt文件个数):2083 …...

QT进阶之路:带命名空间的自定义控件在Qt设计器与qss中的使用技巧
文章目录 0.前言1.带命名空间Qt自定义类在QT设计器中的使用技巧1.1 定义一个带命令空间QLabel自定义类1.2 在QT设计器中引入自定义控件类 2.带命名空间Qt自定义类在qss中的使用技巧2.1 命名空间在 QSS 中的特殊语法2.1 在QSS中定义带命名空间的样式 3.在项目中使用带命名空间的…...

矩阵详解:从基础概念到实际应用
矩阵详解:从基础概念到实际应用 目录 矩阵的基本概念矩阵的类型矩阵运算特殊矩阵矩阵的逆与伴随矩阵的秩与等价分块矩阵矩阵的应用 矩阵知识体系思维导图 mindmaproot((矩阵))基本概念定义mn数表元素aij矩阵记号基本术语行数和列数方阵与非方阵矩阵相等矩阵类型…...

Prompt工程学习之自我一致性
自我一致性 (Self-consistency) 概念:该技术通过对同一问题采样不同的推理路径,并通过多数投票选择最一致的答案,来解决大语言模型(LLM)输出的可变性问题。通过使用不同的温度(temp…...

实践提炼,EtherNet/IP转PROFINET网关实现乳企数字化工厂增效
乳企数字化工厂的核心技术应用 1. 智能质检:机器视觉协议网关的协同 液态奶包装线(利乐罐装)的漏码检测生产线,其高速产线(20,000包/小时)需实时识别微小缺陷,但视觉系统(康耐视Ca…...

从以物换物到DeFi:交易的演变与Arbitrum的DeFi生态
交易的本质:从以物换物到现代金融 交易是人类社会经济活动的核心,是通过交换资源(如货物、服务或货币)满足各方需求的行为。其本质是价值交换,旨在实现资源的优化配置。交易的历史可以追溯到人类文明的起源࿰…...

一文掌握 Tombola 抽象基类的自动化子类测试策略
深入解析 Python 抽象基类的自动化测试框架设计 在 Python 开发中,抽象基类(ABC)是定义接口规范的强大工具。本文将以 Tombola 抽象基类为例,详细解析其子类的自动化测试框架设计,展示如何通过 Python 的内省机制实现…...

vue.js not detected解决方法
如果你在开发环境中遇到“Vue.js not detected”的错误,这通常意味着你的项目没有正确设置或者配置以识别Vue.js。下面是一些解决这个问题的步骤: 1. 确认Vue.js已正确安装 首先,确保你的项目中已经正确安装了Vue.js。你可以通过以下命令来…...

Redis 知识点一
参考 Redis - 常见缓存问题 - 知乎 Redis的缓存更新策略 - Sherlock先生 - 博客园 三种缓存策略:Cache Aside 策略、Read/Write Through 策略、Write Back 策略-CSDN博客 1.缓存问题 1.1.缓存穿透 大量请求未命中缓存,直接访问数据库。 解决办法&…...

分类场景数据集大全「包含数据标注+训练脚本」 (持续原地更新)
一、作者介绍:六年算法开发经验、AI 算法经理、阿里云专家博主。擅长:检测、分割、理解、大模型 等算法训练与推理部署任务。 二、数据集介绍: 质量高:高质量图片、高质量标注数据,吐血标注、整理,可以作为…...
)
数据结构与算法——二叉树高频题目(1)
前言: 简单记录一下自己学习算法的历程,主要根据左老师自己的视频课进行,由于大部分课程涉及题目较多,所以分文章进行记录。 本文将简单记录一下二叉树的层序遍历和 Z 形层次遍历。 参考视频: 算法讲解036【必备】…...