在本地电脑中部署阿里 Qwen3 大模型及连接到 Elasticsearch
在今天的文章中,我将参考文章 “使用 Elastic 和 LM Studio 的 Herding Llama 3.1” 来部署 Qwen3 大模型。据测评,这是一个非常不错的大模型。我们今天尝试使用 LM Studio 来对它进行部署,并详细描述如何结合 Elasticsearch 来对它进行使用。

关于 LM Studio
LM Studio 是本地大型语言模型 (LLM) 的浏览器/IDE,专注于使本地 AI 变得有价值且易于访问,同时为开发人员提供构建平台。
用户考虑本地 LLMs 的原因有很多,但其中最主要的是能够在不放弃对你或你公司的数据主权的情况下利用 AI。其他原因包括:
- 增强数据隐私和安全性
- 减少威胁检测的延迟
- 获得运营优势
- 在现代威胁环境中保护你的组织
LM Studio 提供统一的界面,用于本地发现、下载和运行领先的开源模型,如 Llama 3.1、Phi-3 和 Gemini。使用 LM Studio 本地托管的模型允许 SecOps 团队使用 Elastic AI Assistant 来帮助提供警报分类、事件响应等方面的情境感知指导。所有这些都不需要组织连接到第三方模型托管服务。
在本地电脑中部署阿里 Qwen3 大模型及连接到 Elasticsearch
安装 Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,那么我们可以参考如下的文章来进行安装:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
特别值得注意的是,我们选择 “Elastic Stack 8.x/9.x 安装” 安装指南。在本次的练习中,我们将使用最新的 Elastic Stack 9.0.1。
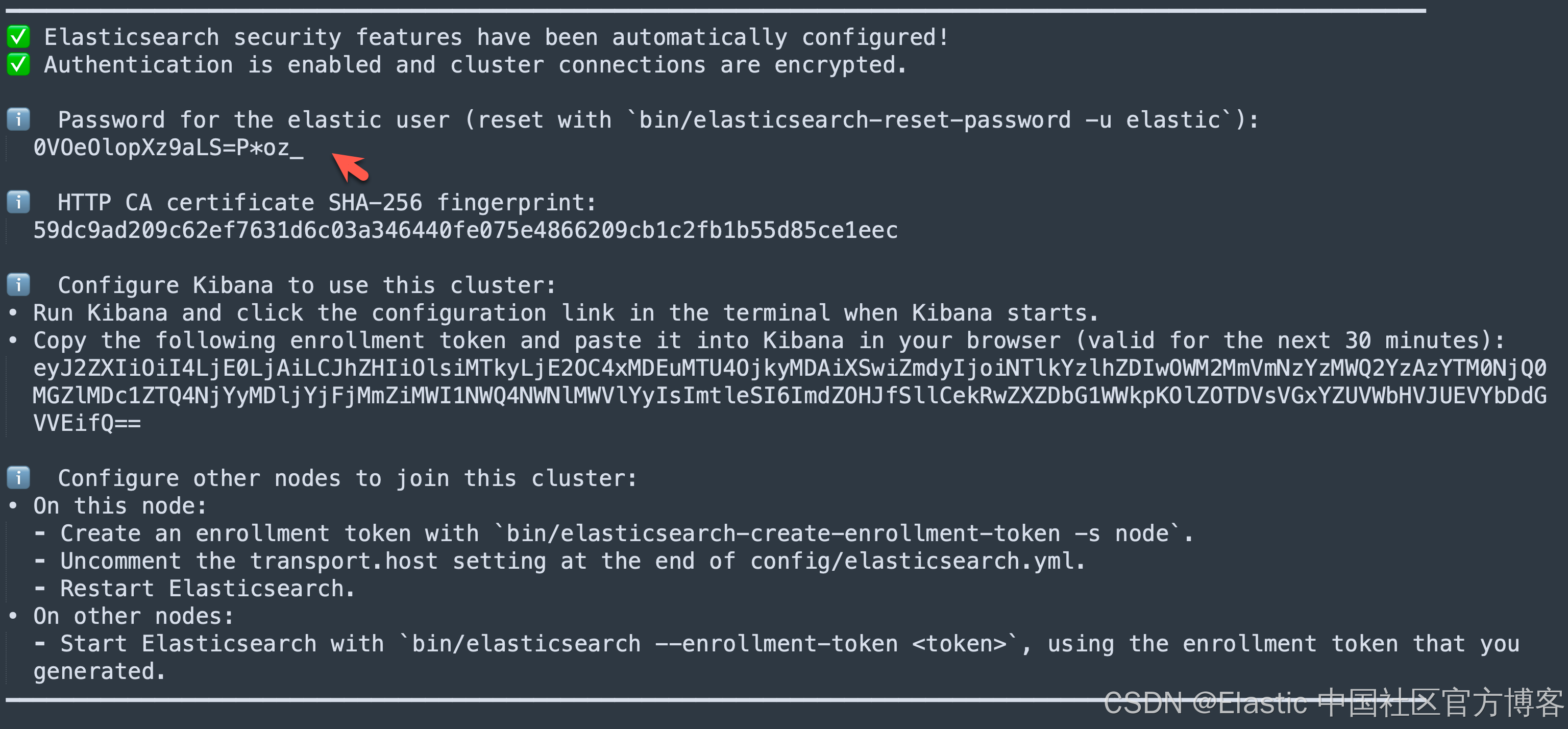
我们记下上面的密码,并在下面的代码中进行使用。
另外,为了能够使得我们避免警告,我们在 Kibana 中针对 xpack.encryptedSavedObjects.encryptionKey 进行设置。这个也是我们需要使用 Playground 所必须的。详细布置也可以参考文章 “Elasticsearch:使用 Playground 与你的 PDF 聊天”。 我们在 terminal 中打入如下的命令:
bin/kibana-encryption-keys generate$ pwd
/Users/liuxg/elastic/kibana-9.0.1
$ bin/kibana-encryption-keys generate
## Kibana Encryption Key Generation UtilityThe 'generate' command guides you through the process of setting encryption keys for:xpack.encryptedSavedObjects.encryptionKeyUsed to encrypt stored objects such as dashboards and visualizationshttps://www.elastic.co/guide/en/kibana/current/xpack-security-secure-saved-objects.html#xpack-security-secure-saved-objectsxpack.reporting.encryptionKeyUsed to encrypt saved reportshttps://www.elastic.co/guide/en/kibana/current/reporting-settings-kb.html#general-reporting-settingsxpack.security.encryptionKeyUsed to encrypt session informationhttps://www.elastic.co/guide/en/kibana/current/security-settings-kb.html#security-session-and-cookie-settingsAlready defined settings are ignored and can be regenerated using the --force flag. Check the documentation links for instructions on how to rotate encryption keys.
Definitions should be set in the kibana.yml used configure Kibana.Settings:
xpack.encryptedSavedObjects.encryptionKey: 6f1fdc6da9e4cdb8558fc8b4d3fe1048
xpack.reporting.encryptionKey: a22c866f356cda8097ad1b9befc56a25
xpack.security.encryptionKey: f4d6361ebd74b385c6ed722244985321我们必须把正在运行的 Kibana 停止再运行上面的命令。我们把上面最后面显示的设置拷贝到 config/kibana.yml 文件的最后面,并保存。然后重新启动 Kibana。
启动白金试用功能
为了能够创建 OpenAI 连接器,我们需要打开白金版试用功能:




这样我们的白金版试用功能就设置好了。有了这个我们在下面就可以创建 OpenAI 的连接器了。
安装 ES 向量模型
在我们的搜索中,我们需要使用一个嵌入向量模型来针对数据进行向量化。在本次练习中,我们使用 ES。这也是 Elasticsearch 自带的模型。我们需要对它进行配置:





从上面的显示中,我们已经成功地把 .multilingual-e5-small 模型部署到我们的 Elasticsearch 中了。
我们可以在 Kibana 中进行查看:
GET _inference
我们可以看到一个叫做 .multilingual-e5-small-elasticsearch 的 inference id 已经生成。
如何设置 LM Studio
下载并安装最新版本的 LM Studio。
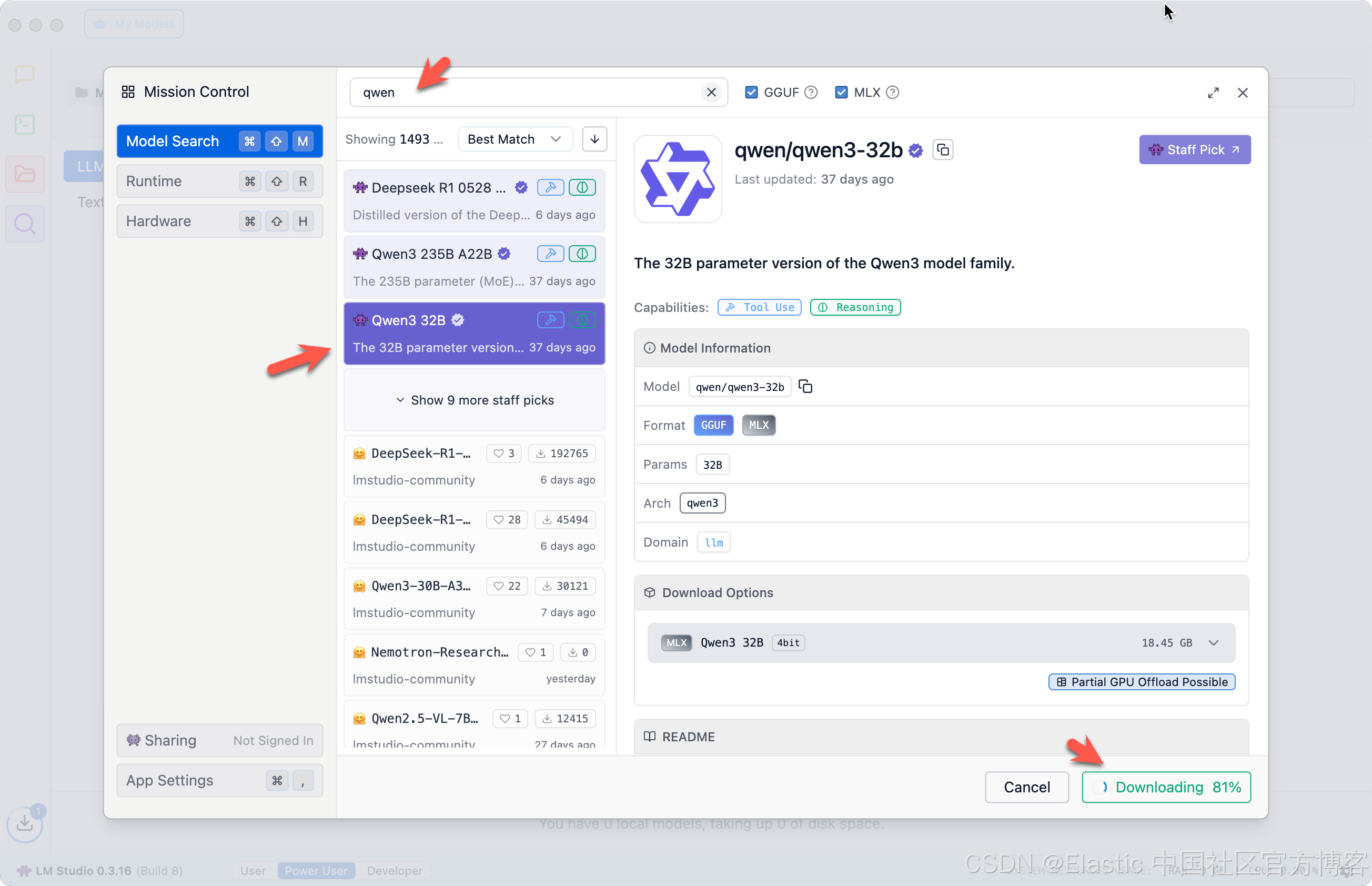
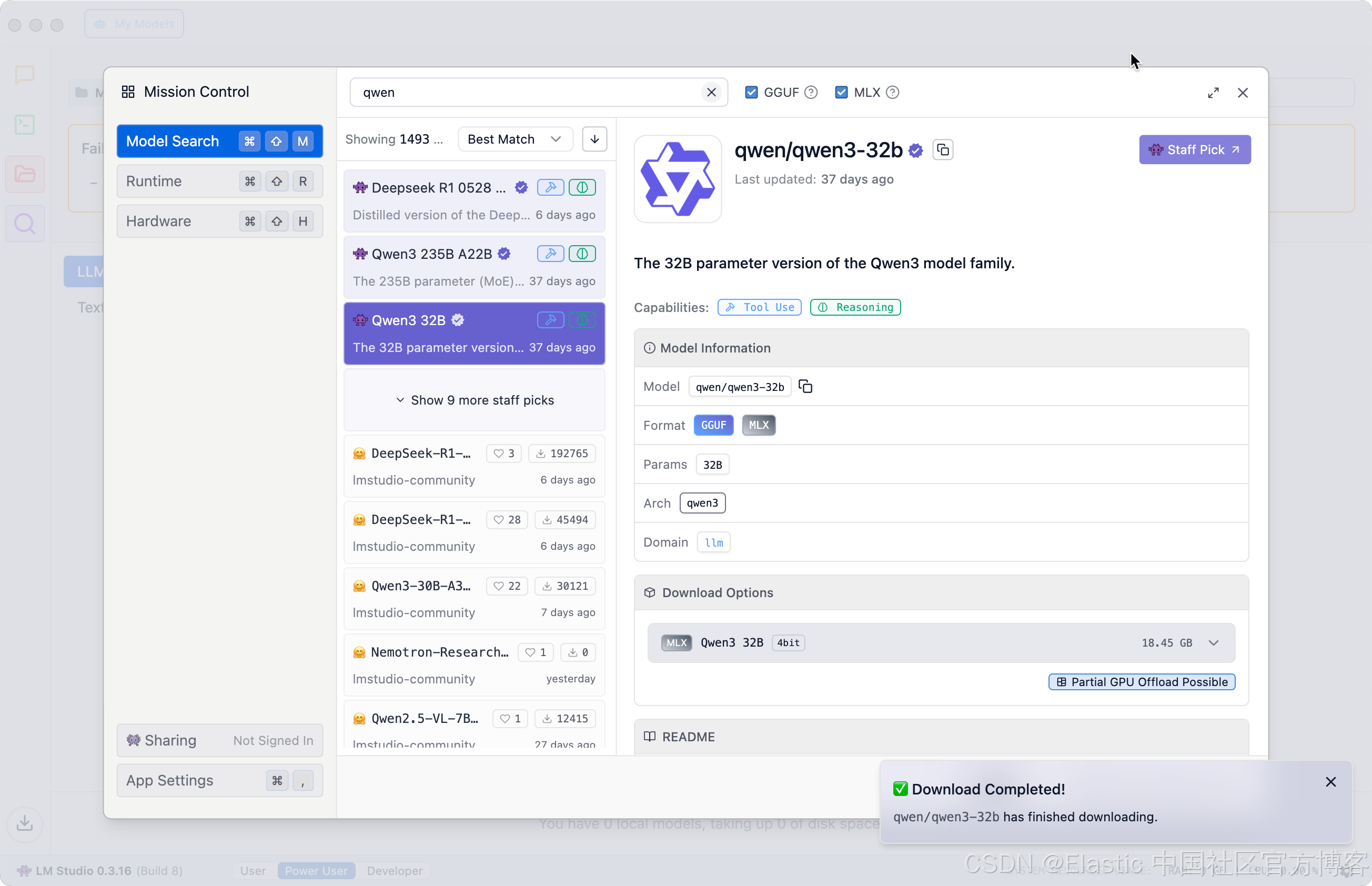
在下载完毕后,经过 checksum 验证,我们最终可以看到上面的画面。
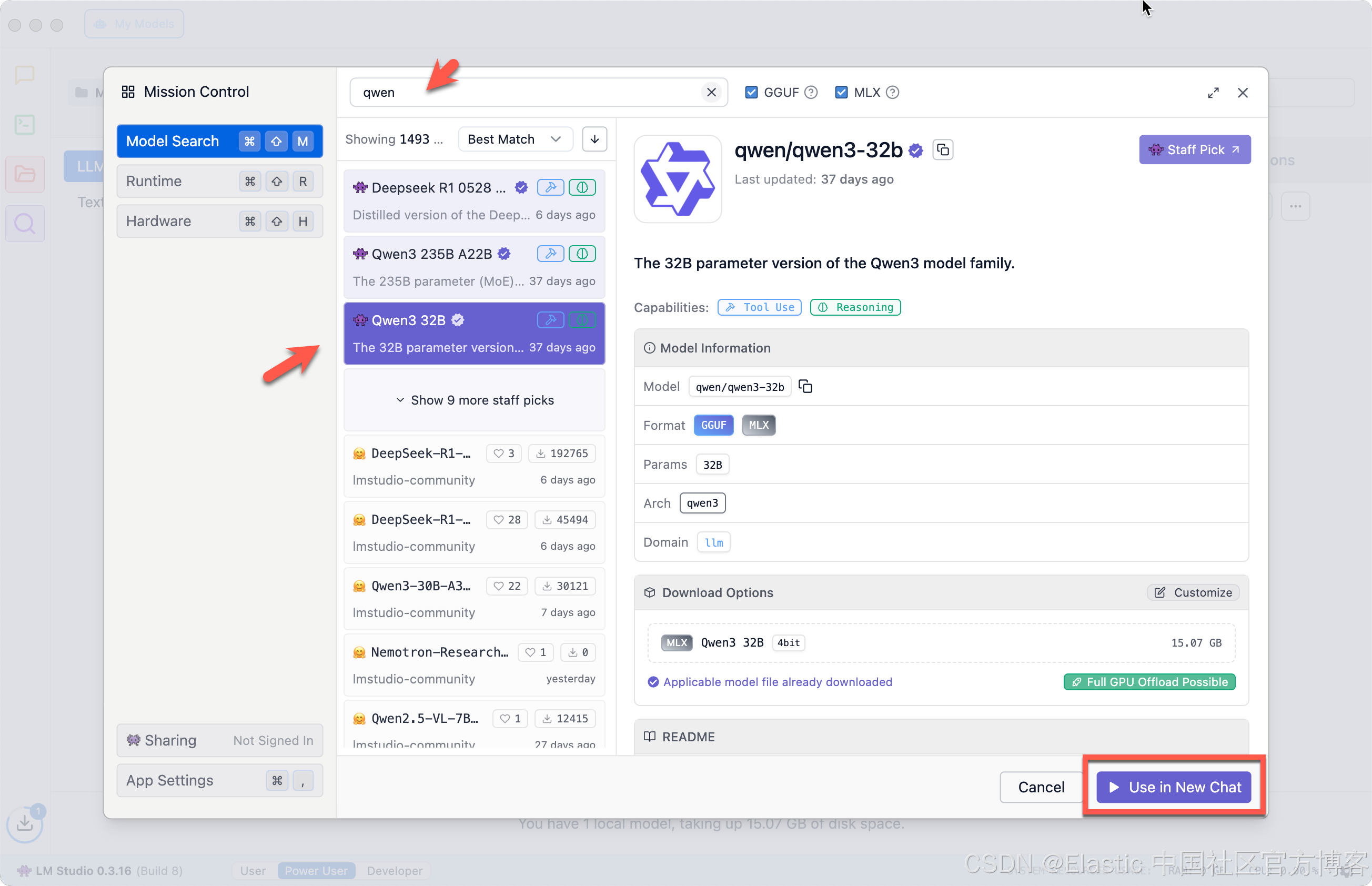
在 Discover 界面搜索 “Qwen”,并下载安装。如上所示,Qwen3 共有 18.45 GB,所以在下载之前,确保你有足够的电脑硬盘容量来对它进行安装。我们点击 “Use in New Chat”:
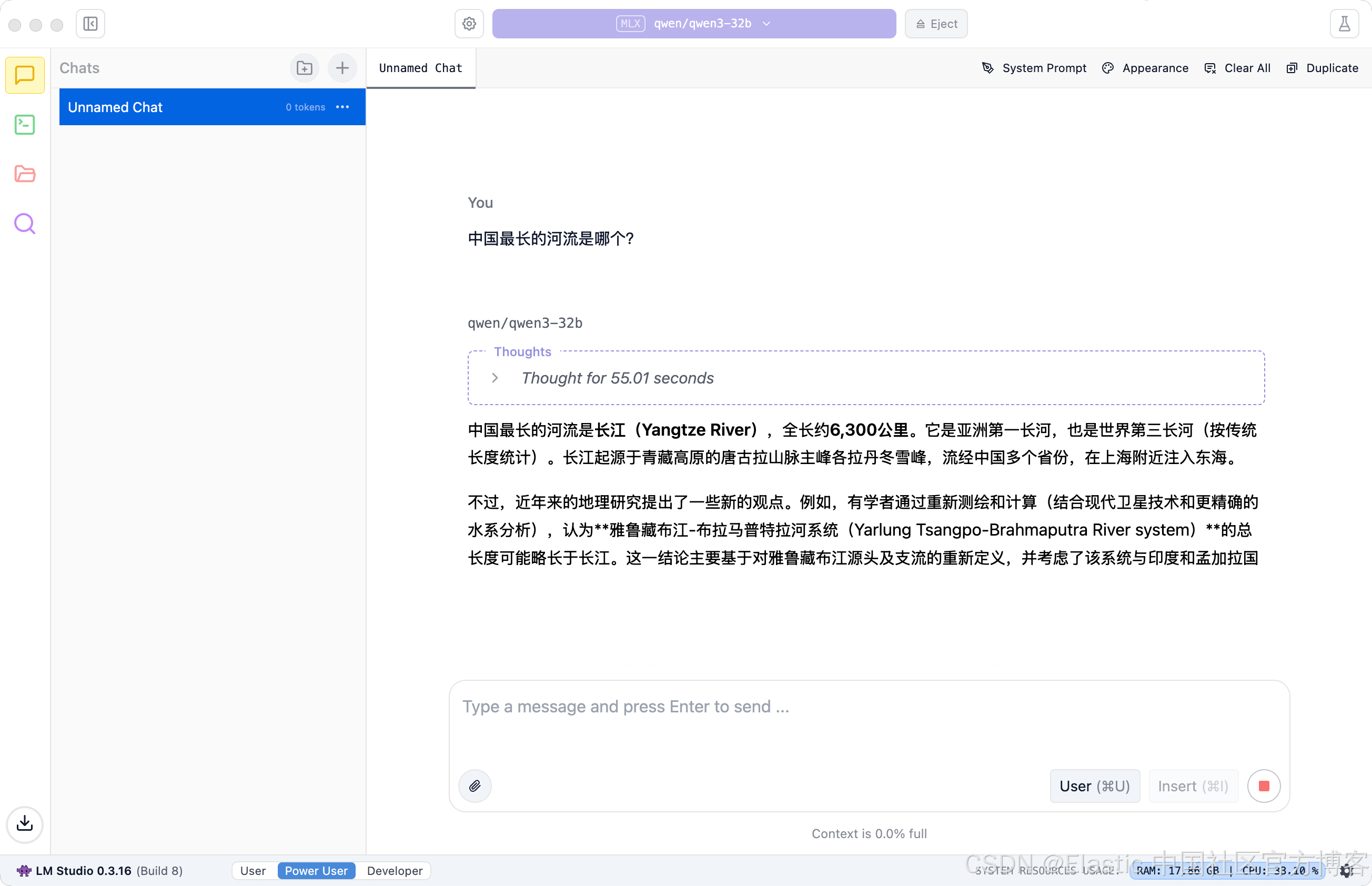
在上面,我们提出问题 “中国最长的河流是哪个?”。它最终给出了答案:
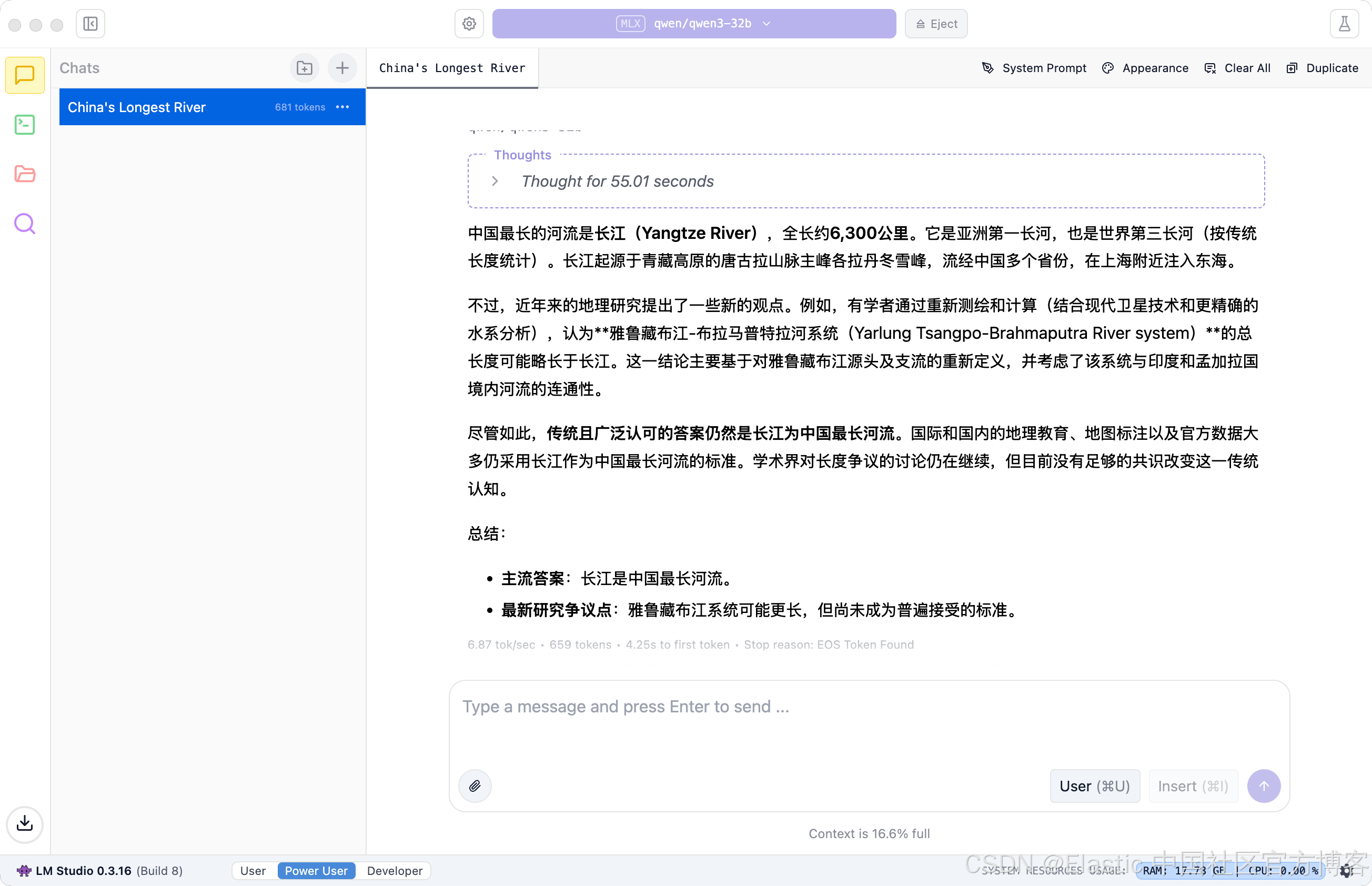
我们接下来验证一下它的英文能力:
What is the longest river in China?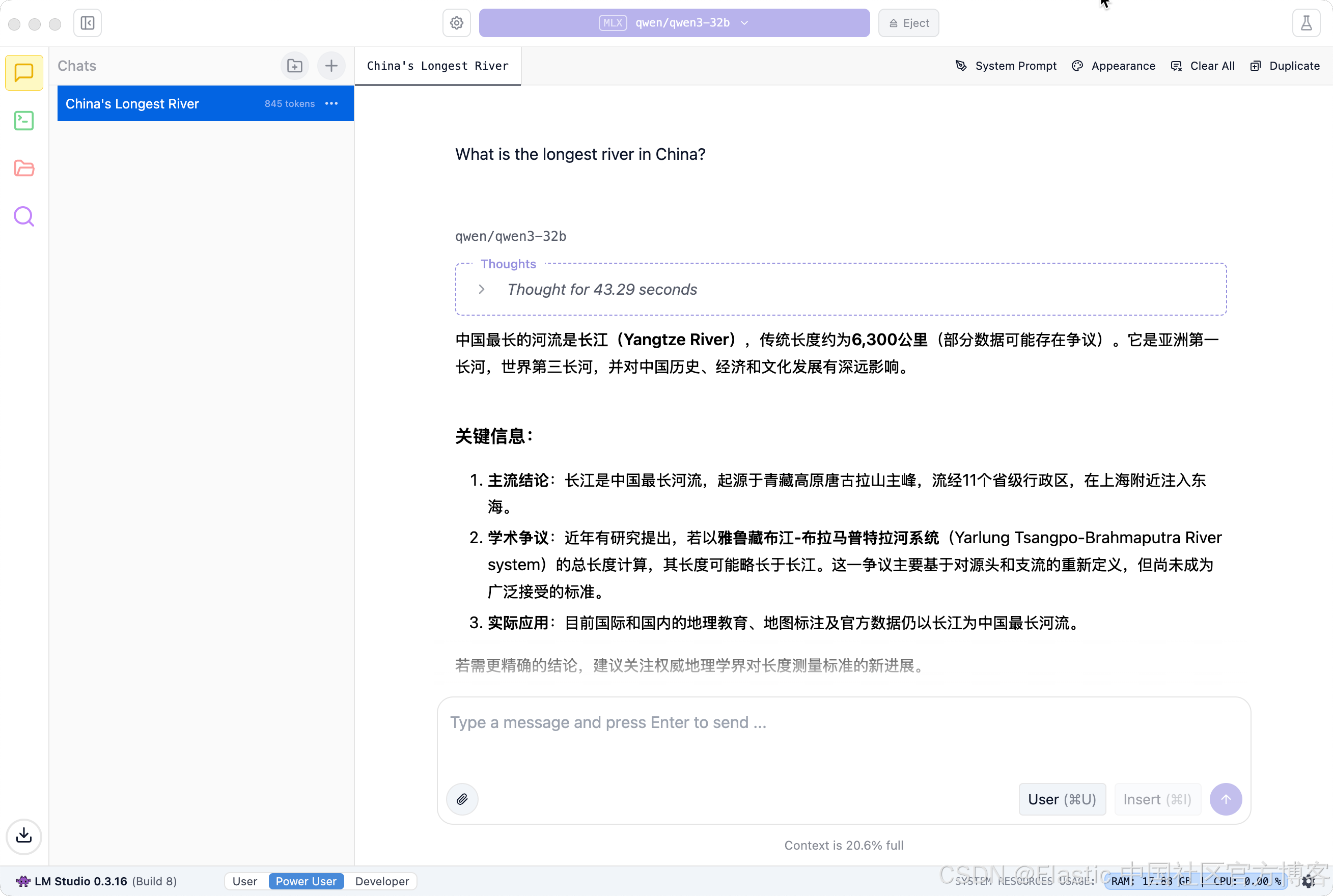
很有意思的是它给出的结果是以中文的形式。这个是和 DeepSeek 及 ChatGPT 有不同的地方。通常在 DeepSeek 中,如果我们的提问是以英文形式的,那么你得到的答案就是英文格式的。
注意:由于模型是在本地电脑部署的。这个依赖于你自己的电脑算力。有时给出的结果有点慢,但是需要大家的耐心等待!
我们接下来进入 “My Models" 来进行验证:
我们可以看到 qwen 已经被成功地安装了。
我们接下来打开 Developer 窗口,我们可以看到 qwen 的接口 API:
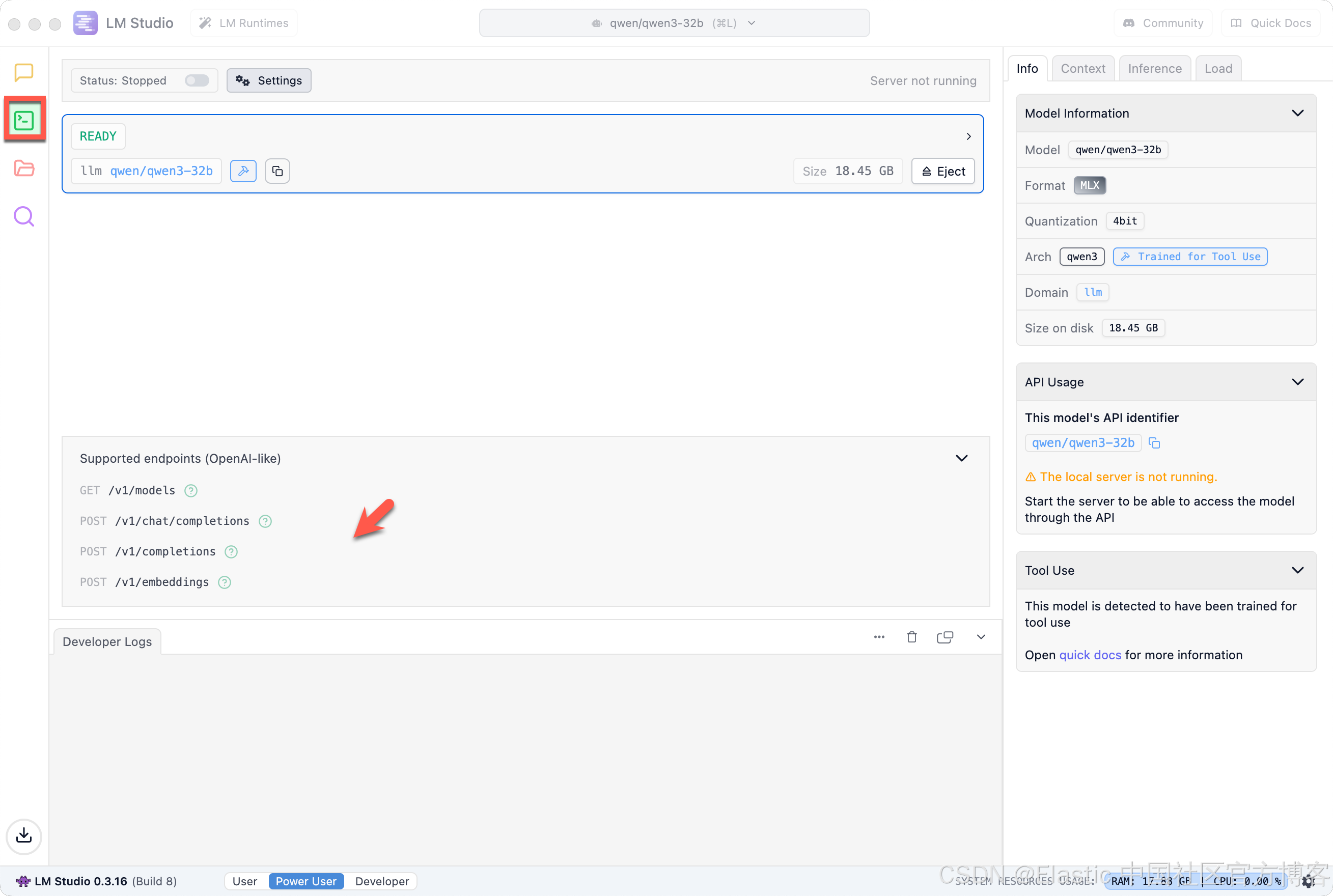
我们将在下面的练习中进行使用。同时我们注意到它的接口是以 Open AI 的格式来进行提供的。我们对本地服务器做如下的配置:
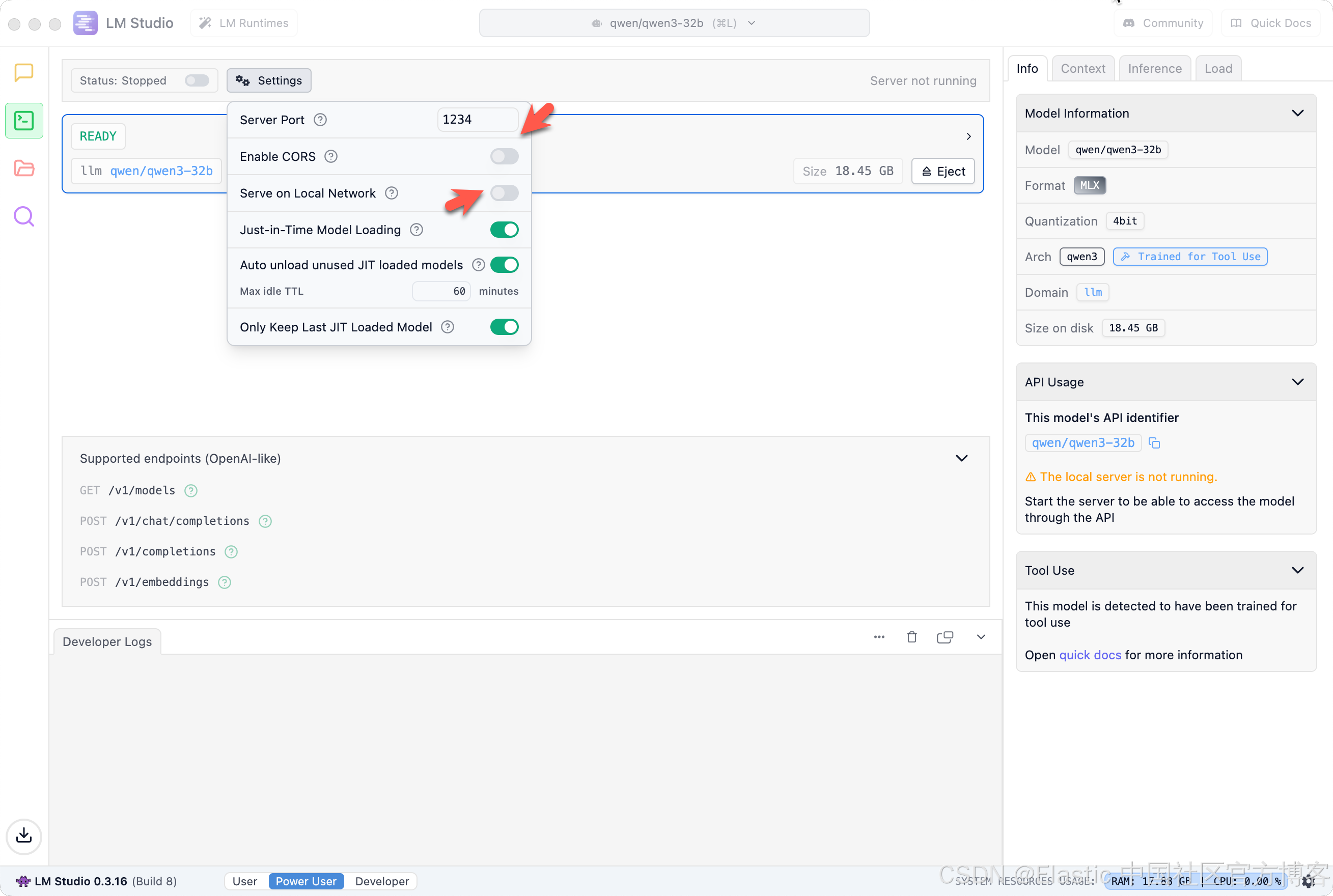
打开上面的两个配置:
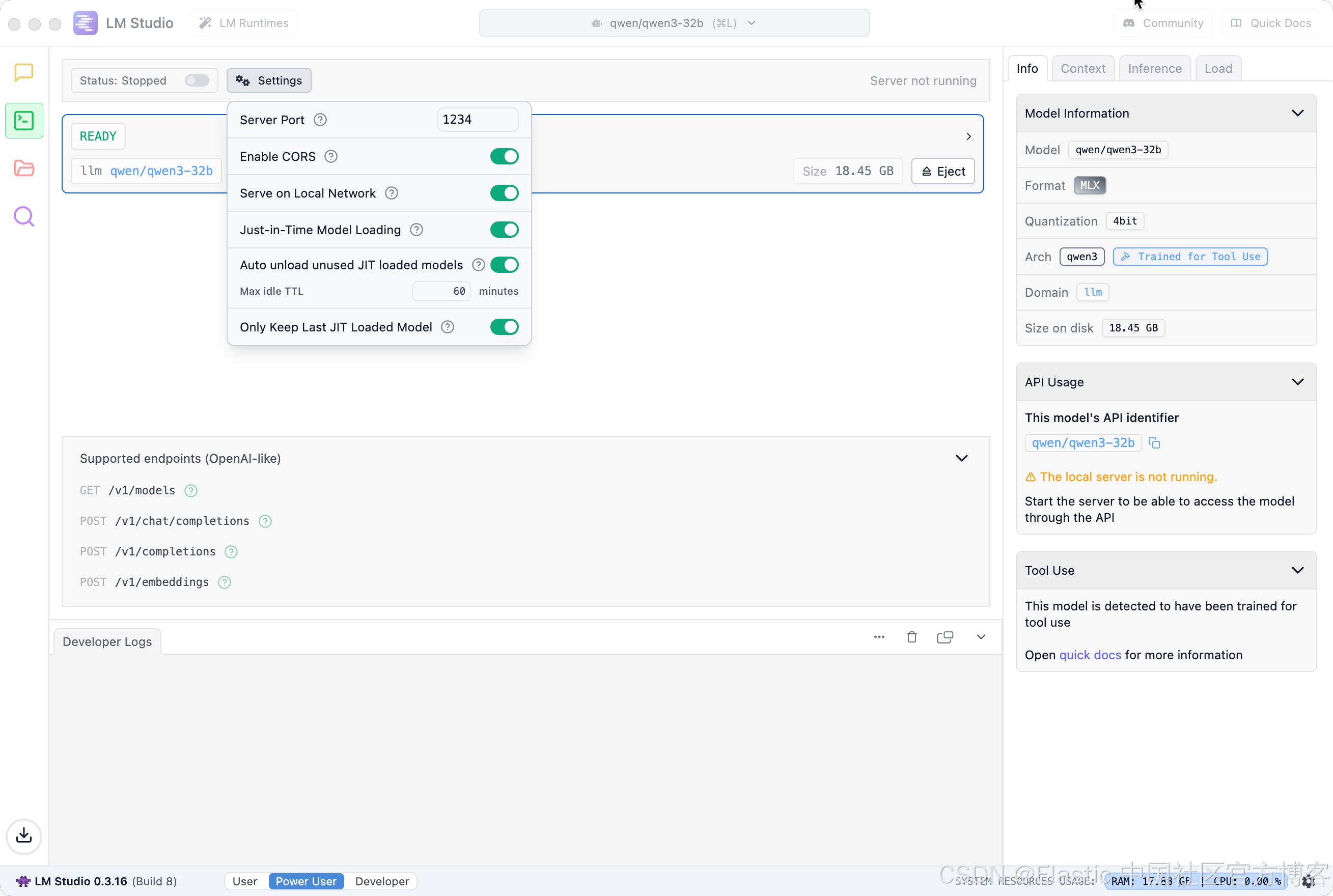
我们还需要同时打开这个本地服务器:
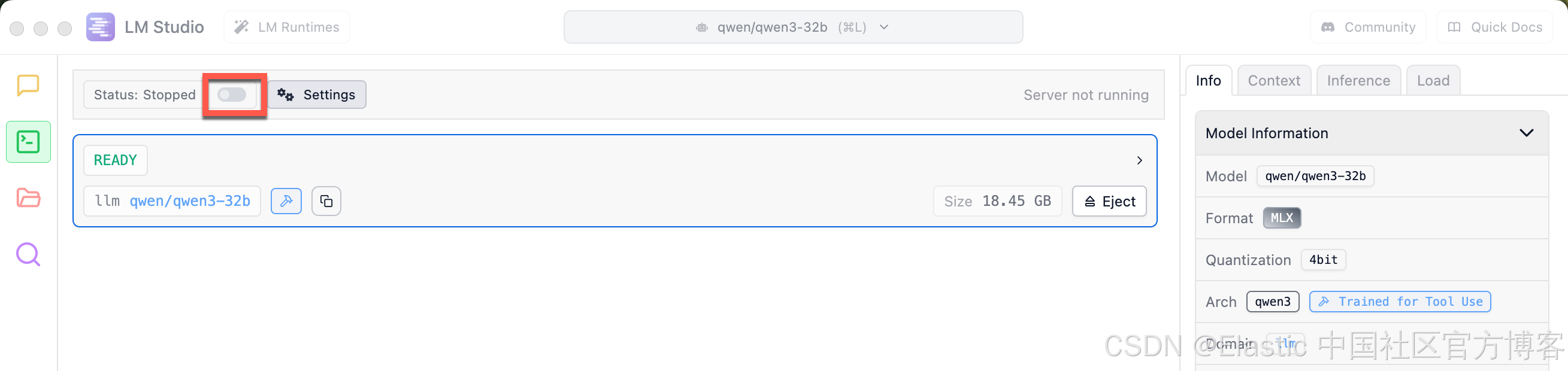
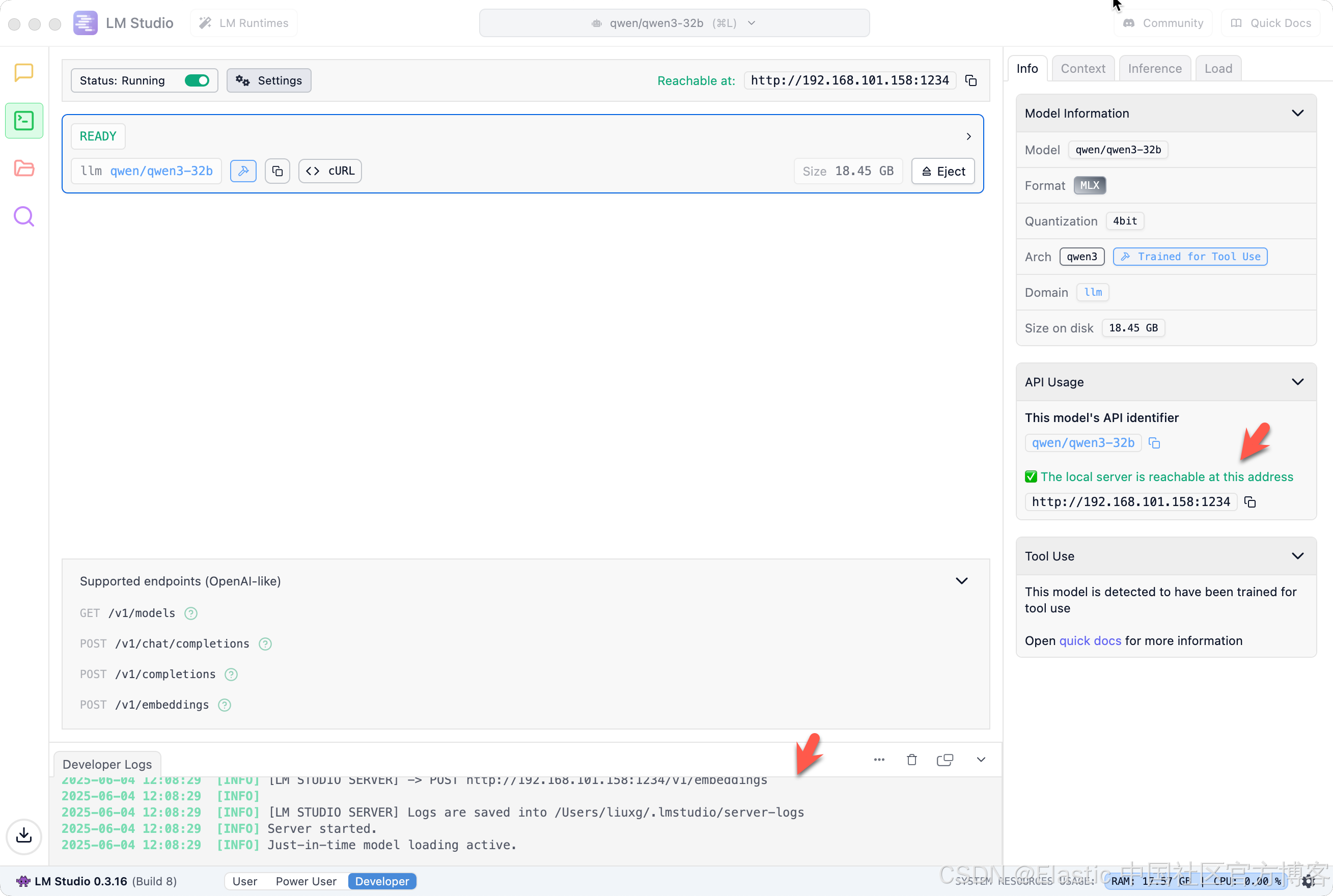
一旦打开,我们可以看到日志,并看到服务器的状态已经发生改变。
我们可以通过如下的方式来获得本地电脑的 IP 地址:
ifconfig | grep inet | grep 192$ ifconfig | grep inet | grep 192inet 192.168.101.158 netmask 0xffffff00 broadcast 192.168.101.255注:如果你的 qwen3 不是和你自己的 Elasticsearch 处于同一个机器上,那么你需要使用到上面的私有地址(在同一局域网里)
我们可以通过如下的命令来验证我们的服务器接口:
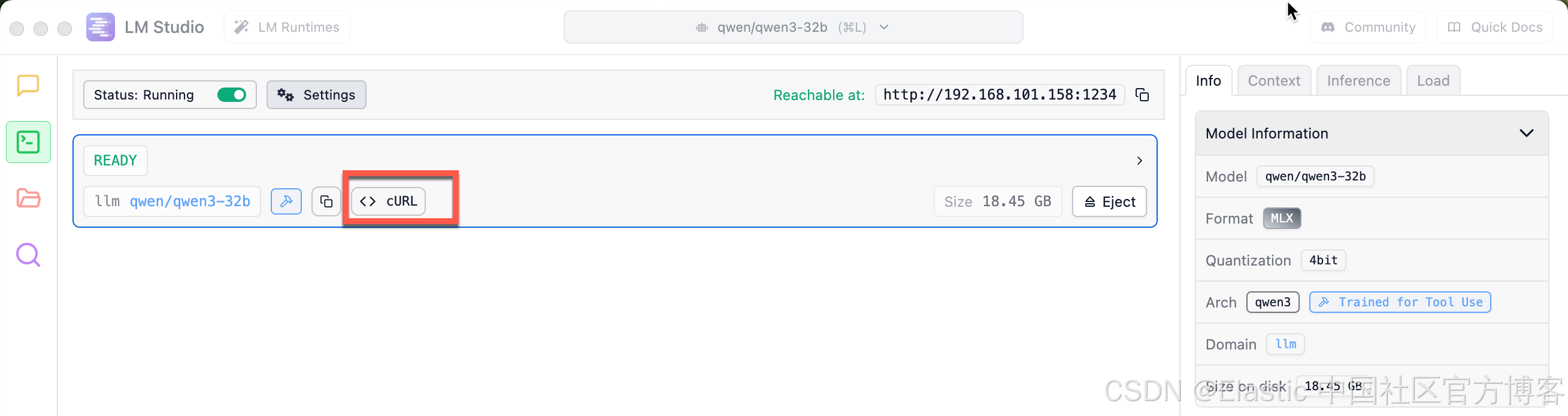
拷贝上面的 cURL 命令:
curl http://localhost:1234/v1/chat/completions \-H "Content-Type: application/json" \-d '{"model": "qwen/qwen3-32b","messages": [{ "role": "system", "content": "Always answer in rhymes. Today is Thursday" },{ "role": "user", "content": "What day is it today?" }],"temperature": 0.7,"max_tokens": -1,"stream": false
}'我们可以直接在电脑的 terminal 中打入上面的命令:
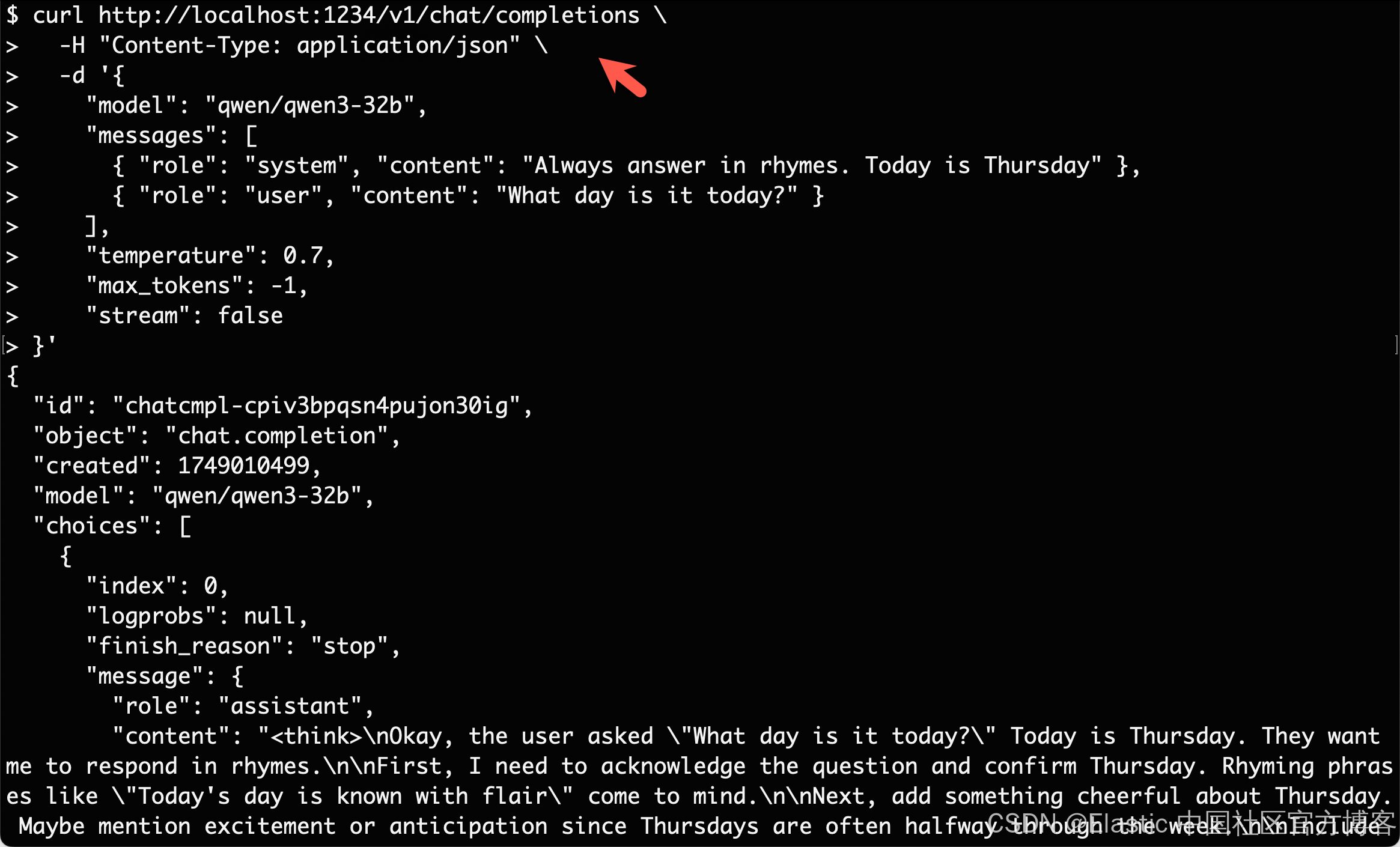
我们得到了一个相关的结果。我们接下来稍微修改一下我们的问题:
curl http://localhost:1234/v1/chat/completions \-H "Content-Type: application/json" \-d '{"model": "qwen/qwen3-32b","messages": [{ "role": "system", "content": "You are a helpful AI Assistant that uses the following context to answer questions only use the following context. \n\nContext: 小明今天早上和妈妈一起去上学"},{ "role": "user", "content": "小明今天和谁一起去上学的?" }],"temperature": 0.7,"max_tokens": -1,"stream": false
}'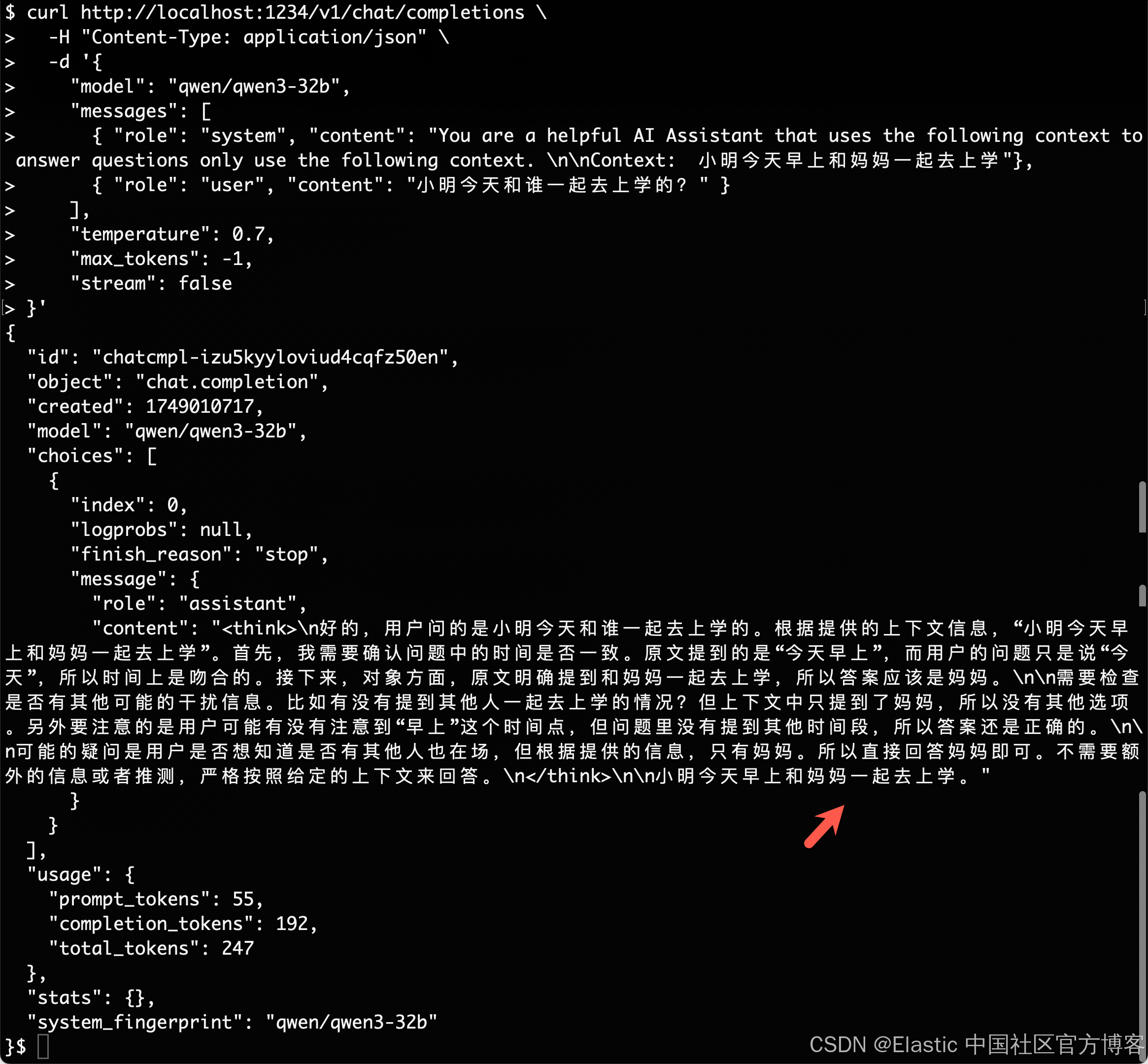
很显然,它具备一定的推理能力。我们得到了我们想要的答案。
在 Kibana 中创建连接到 Qwen 的连接器
我们按照如下的步骤来进行:
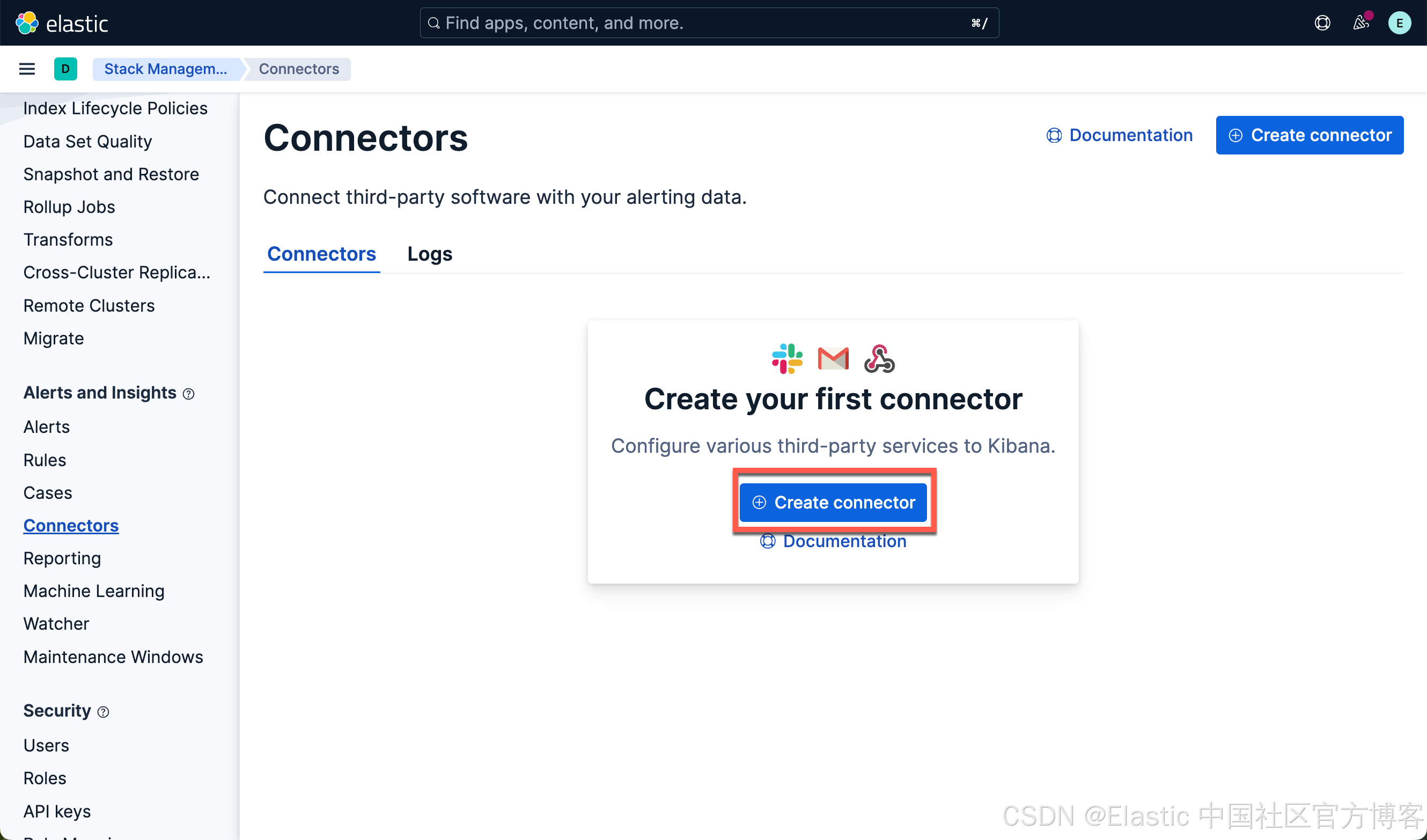
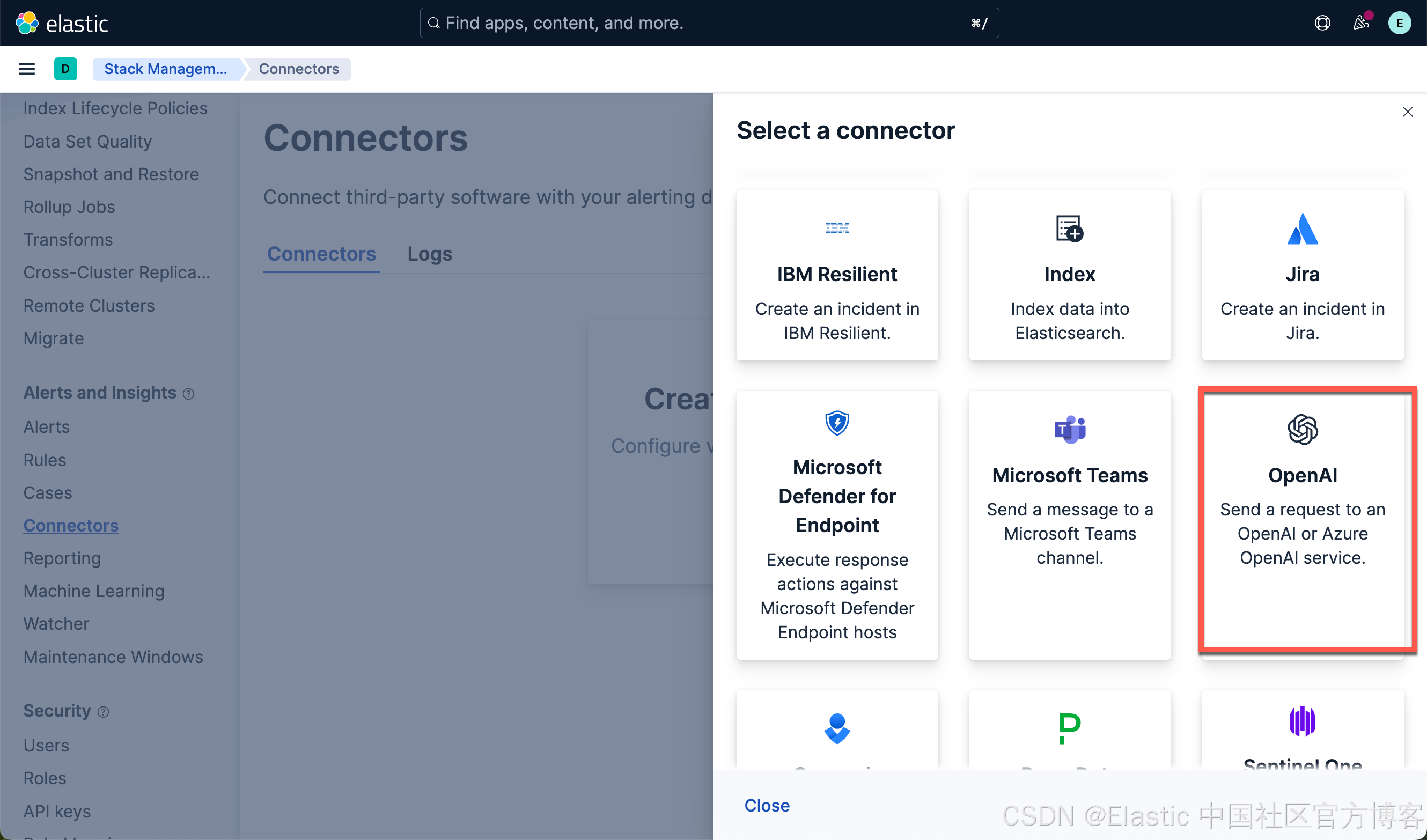
使用以下设置配置连接器:
- Connector name:qwen3
- 选择 OpenAI provider:other (OpenAI Compatible Service)
- URL:http://localhost:1234/v1/chat/completions
- 调整到你的 qwen3 的正确路径。如果你从容器内调用,请记住替换 host.docker.internal 或等效项
- 默认模型:qwen/qwen3-32b
- API 密钥:编造一个,需要输入,但值无关紧要
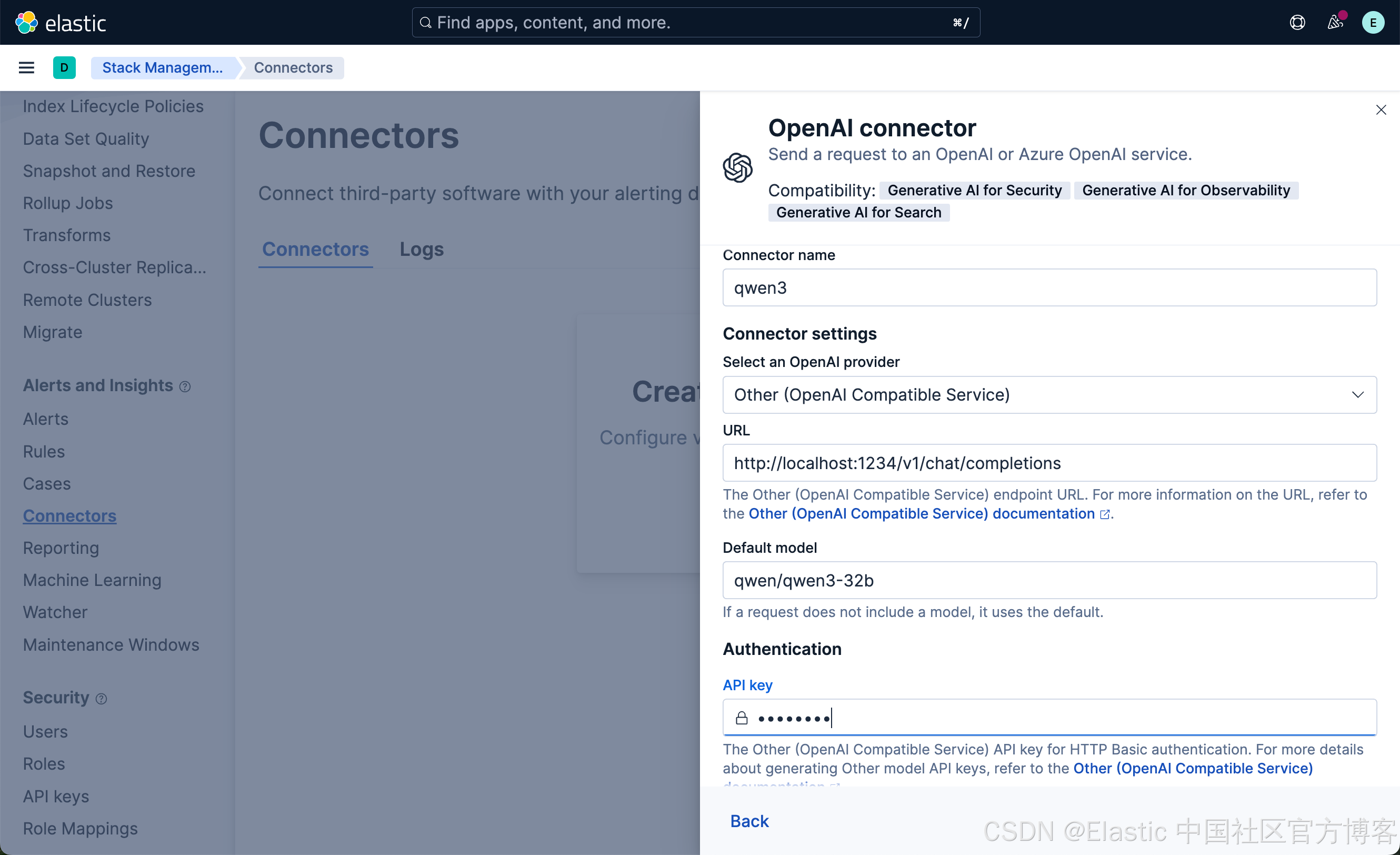
点击 Save 按钮:
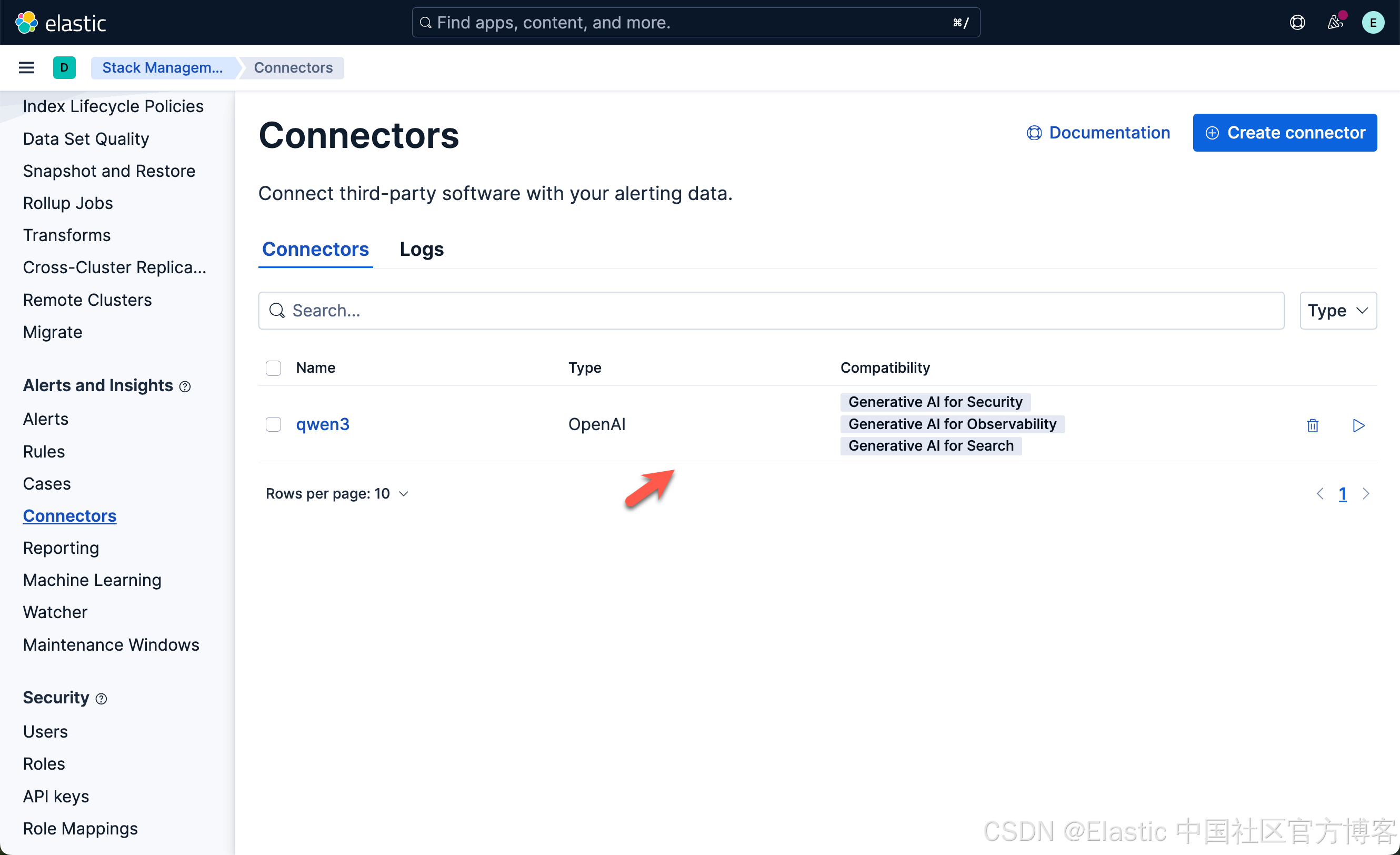
就这样,我们成功地创建了一个叫做 qwen3 的 OpenAI 连接器。
将嵌入向量的数据导入 Elasticsearch
如果你已经熟悉 Playground 并设置了数据,则可以跳至下面的 Playground 步骤,但如果你需要一些快速测试数据,我们需要确保设置了 _inference API。从 8.17 开始,机器学习分配是动态的,因此要下载并打开 e5 多语言密集向量,我们只需在 Kibana Dev 工具中运行以下命令即可。
GET /_inferencePOST /_inference/text_embedding/.multilingual-e5-small-elasticsearch
{"input": "are internet memes about deepseek sound investment advice?"
}如果你还没有这样做,这将触发从 Elastic 的模型存储库下载 e5 模型。在上面的安装部分,我们已经成功地部署了 es 模型,所以执行下面的命令时,不会触发下载模型。我们从右边的输出中可以看到文字被转换后的向量表示。
接下来,让我们加载一本公共领域的书作为我们的 RAG 上下文。这是从 Project Gutenberg 下载 “爱丽丝梦游仙境” 的地方:链接。将其保存为 .txt 文件。
$ pwd
/Users/liuxg/data/alice
$ wget https://www.gutenberg.org/cache/epub/11/pg11.txt
--2025-02-10 16:59:19-- https://www.gutenberg.org/cache/epub/11/pg11.txt
Resolving www.gutenberg.org (www.gutenberg.org)... 152.19.134.47
Connecting to www.gutenberg.org (www.gutenberg.org)|152.19.134.47|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 174357 (170K) [text/plain]
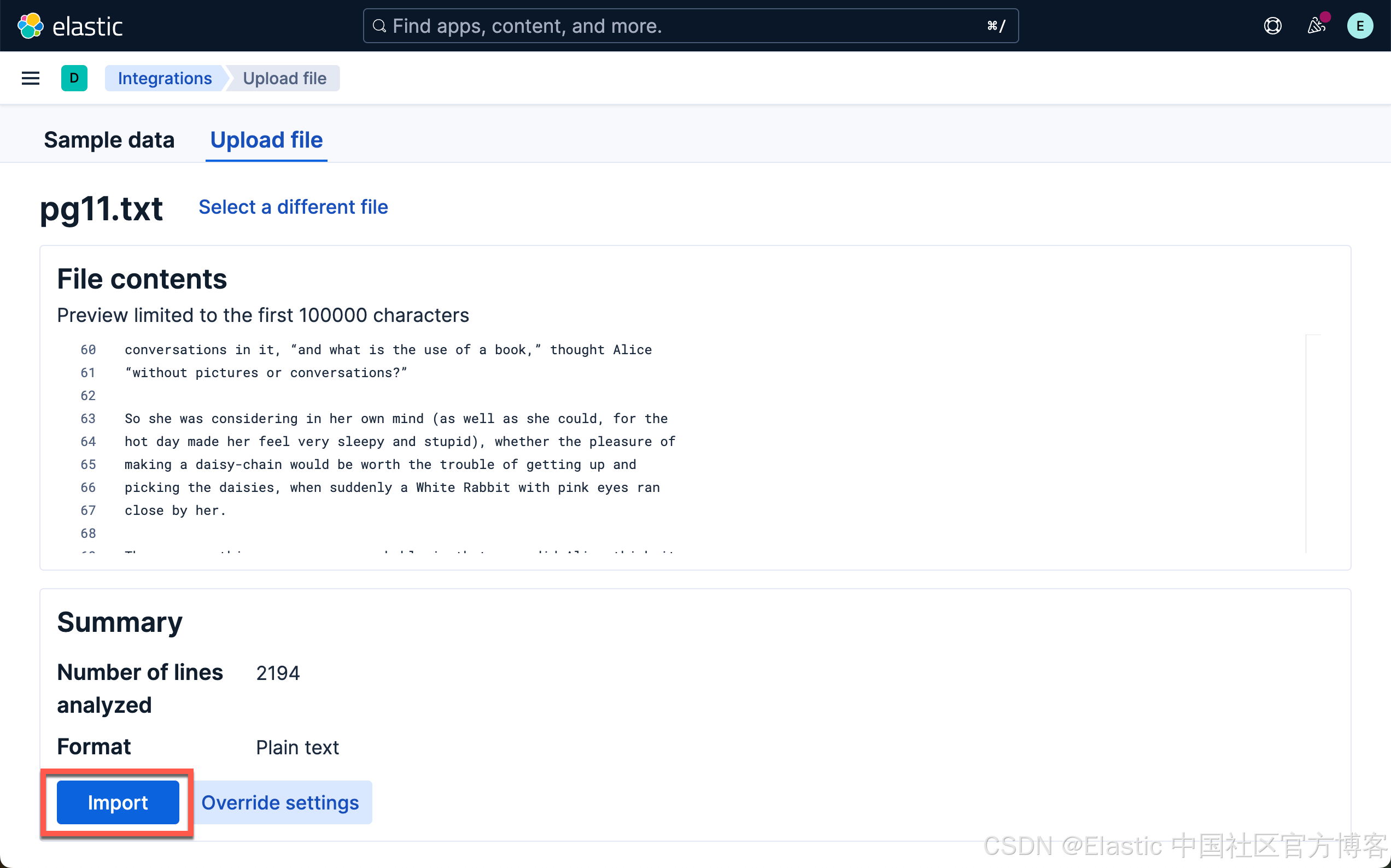
Saving to: ‘pg11.txt’pg11.txt 100%[=====================================>] 170.27K 304KB/s in 0.6s 2025-02-10 16:59:21 (304 KB/s) - ‘pg11.txt’ saved [174357/174357]等下载完文件后,我们可以使用如下的方法来上传文件到 Elasticsearch 中:
我们或者使用如下的方法:



选择刚刚下好的文件:
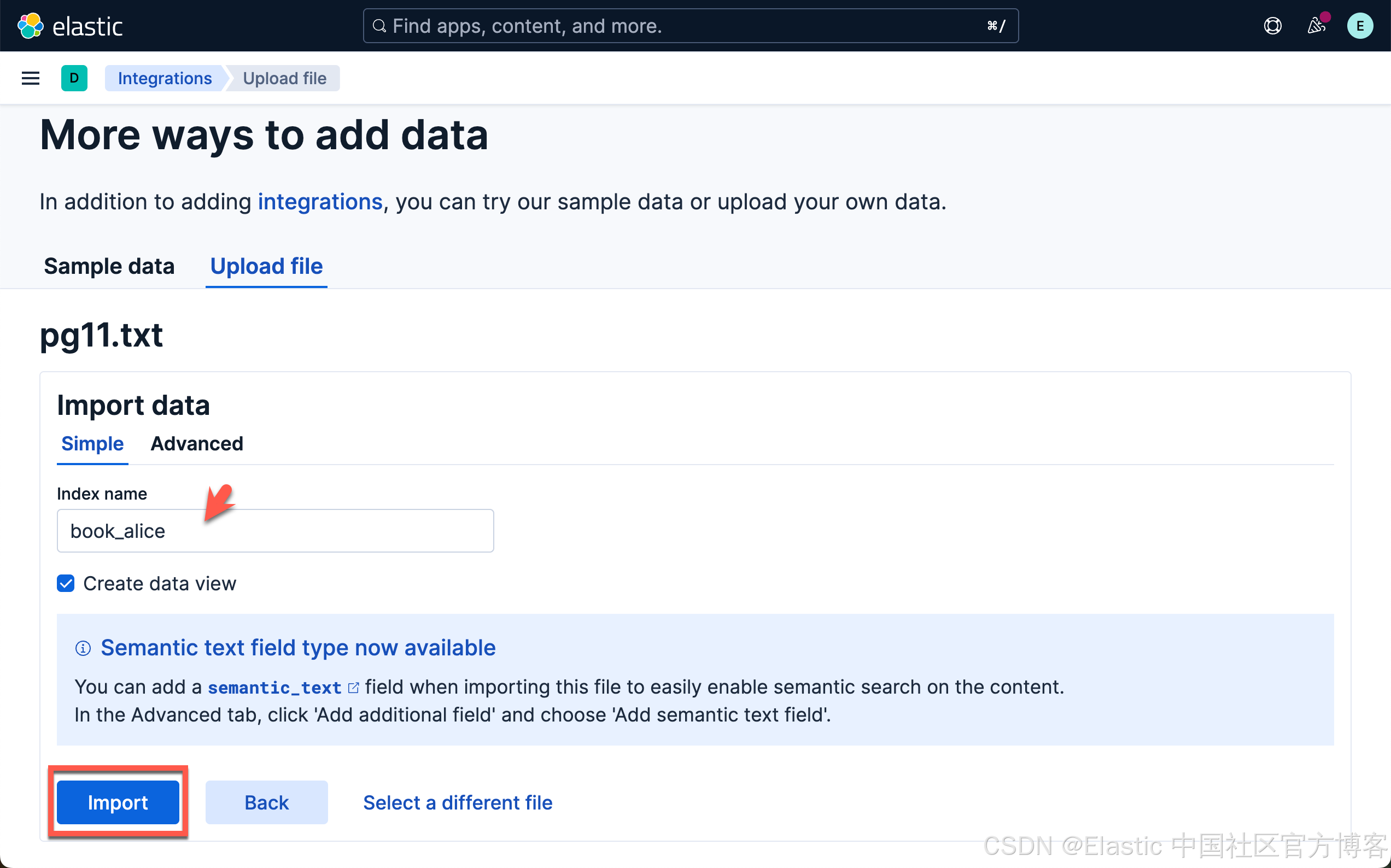
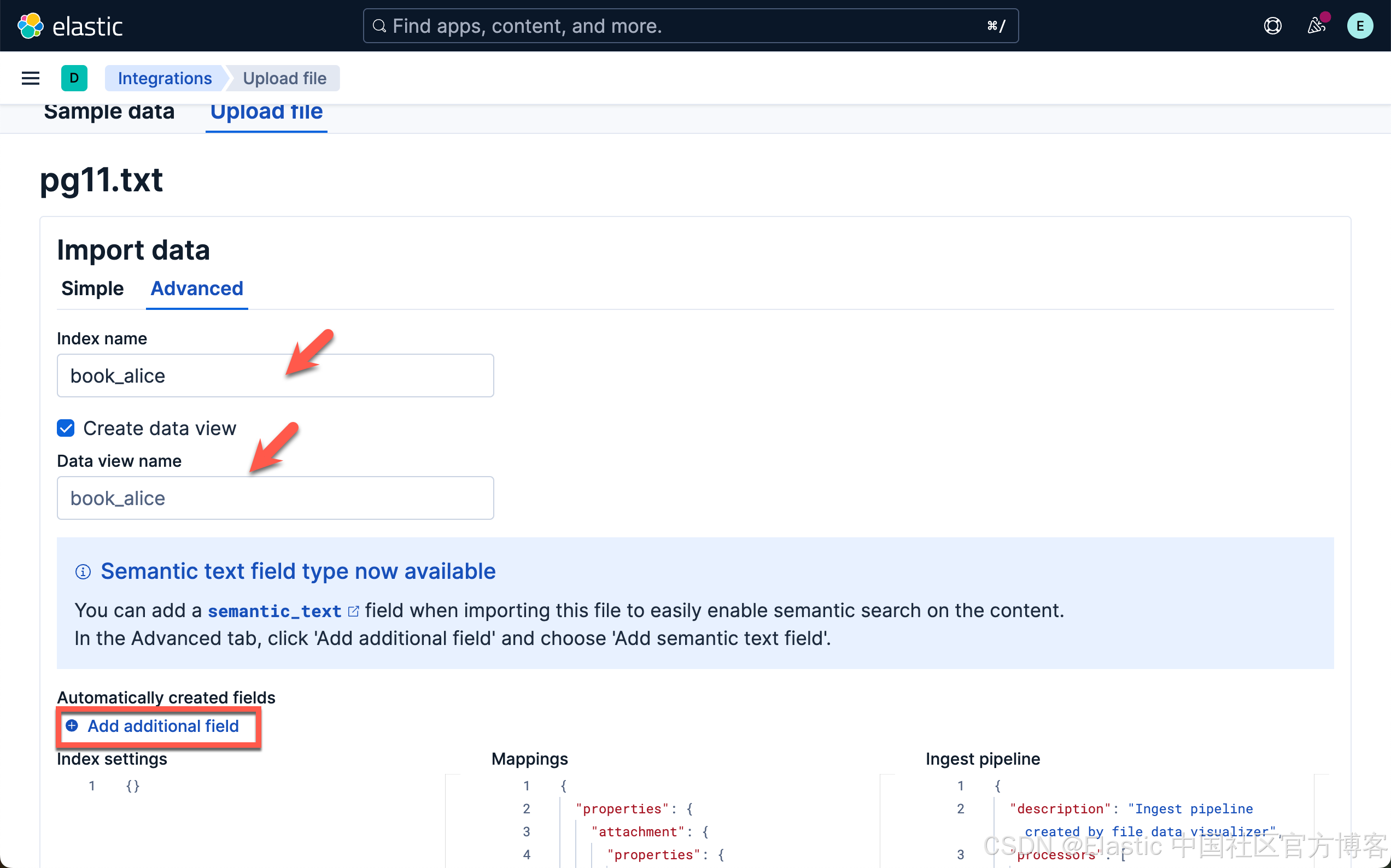
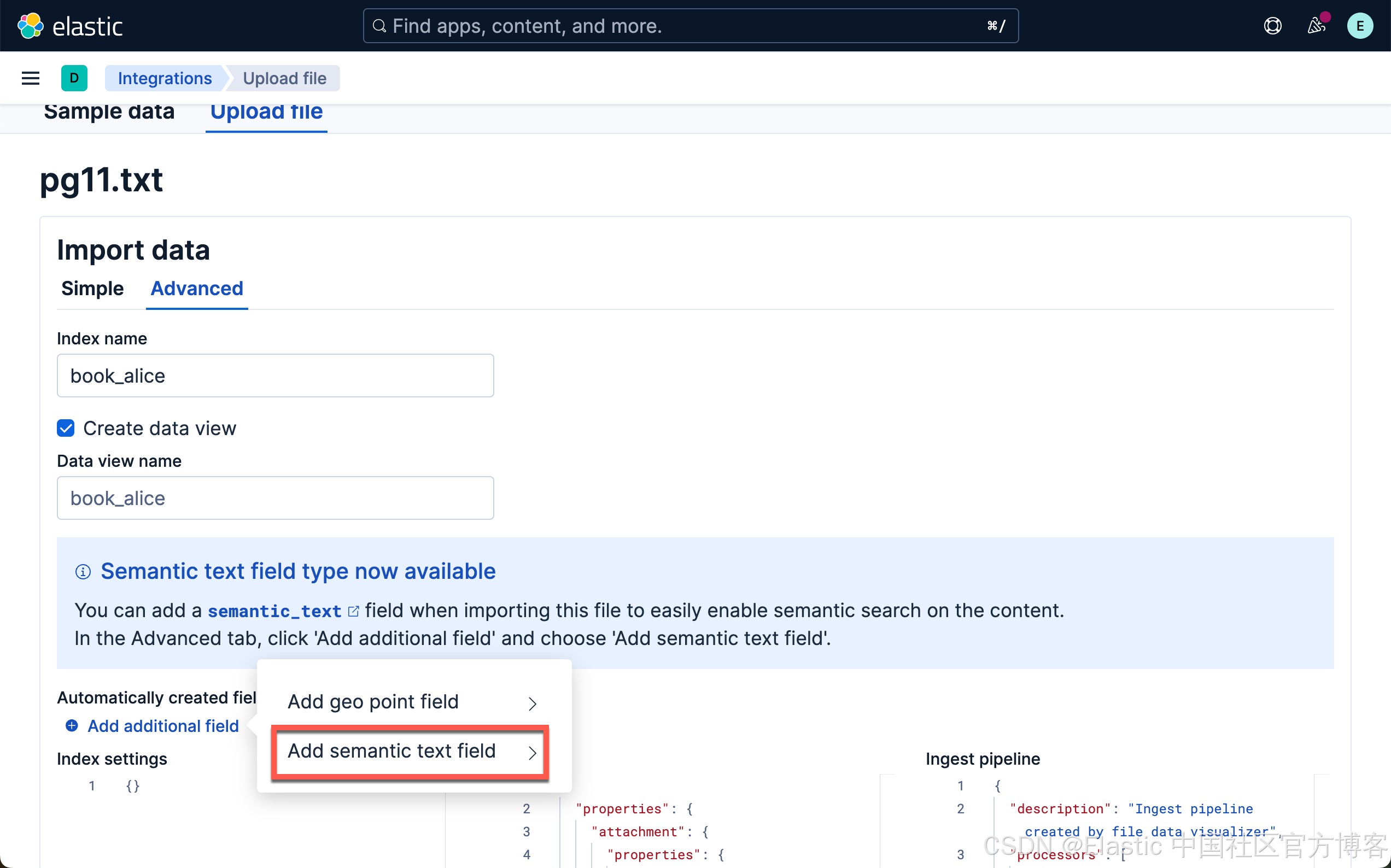
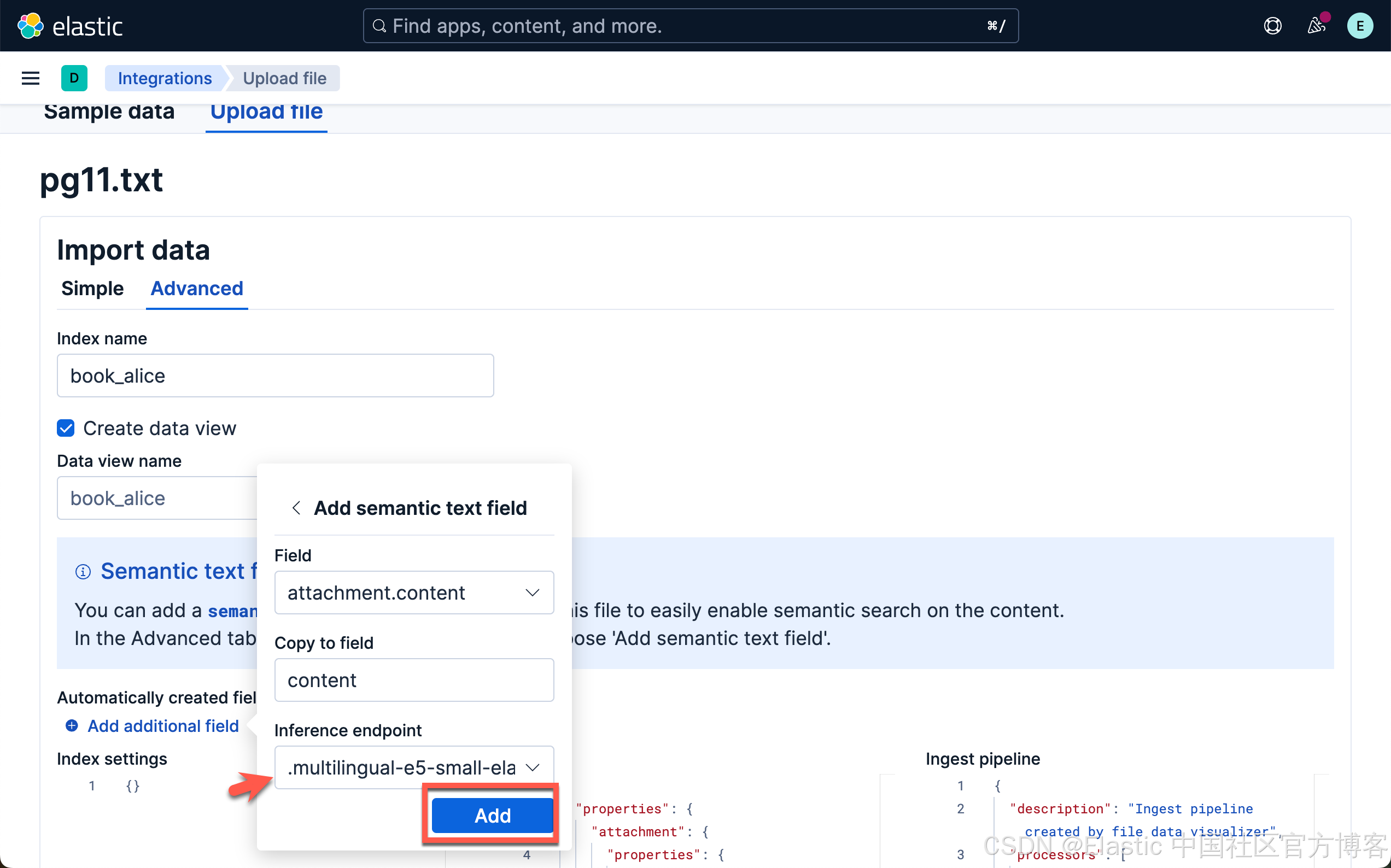
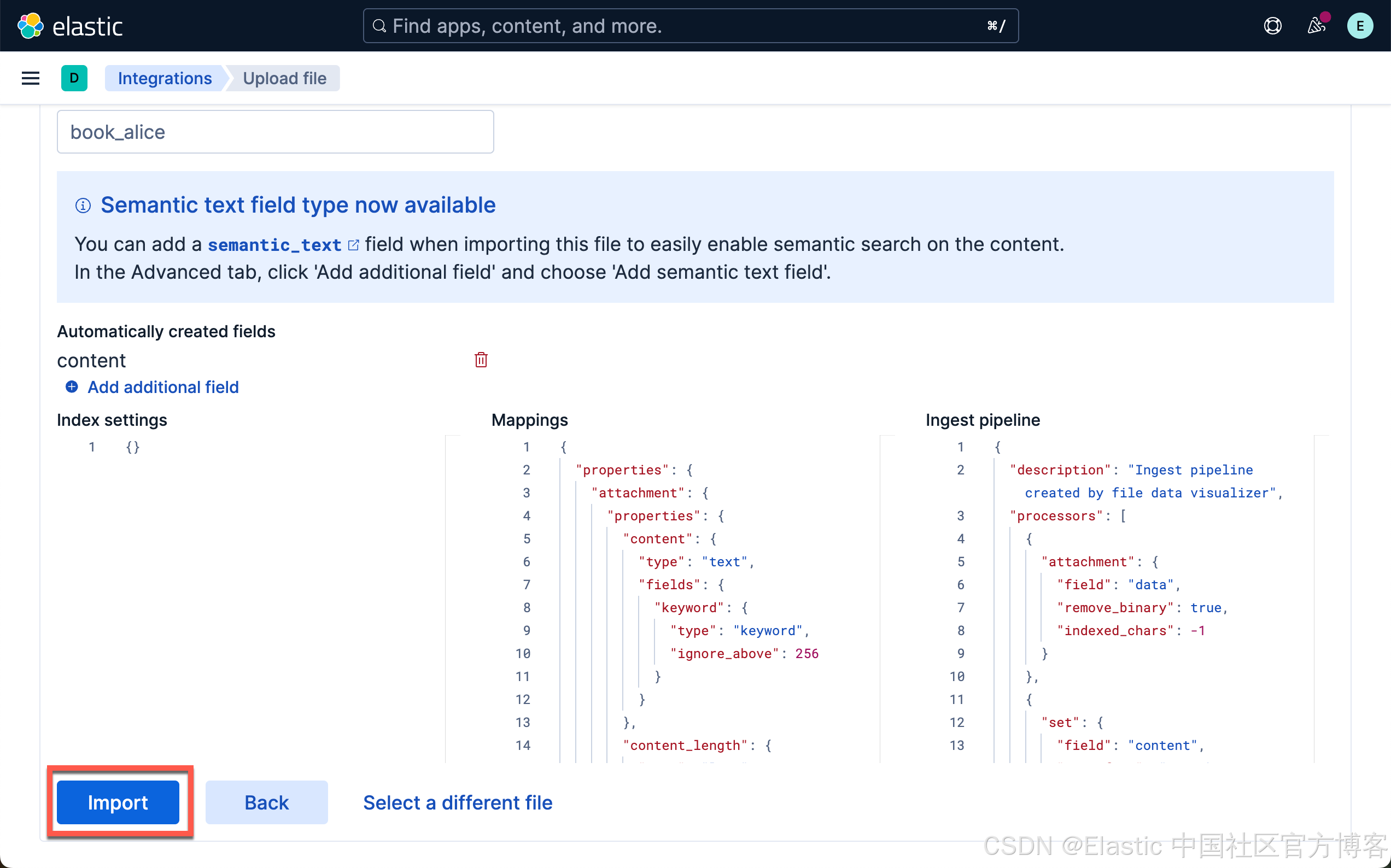
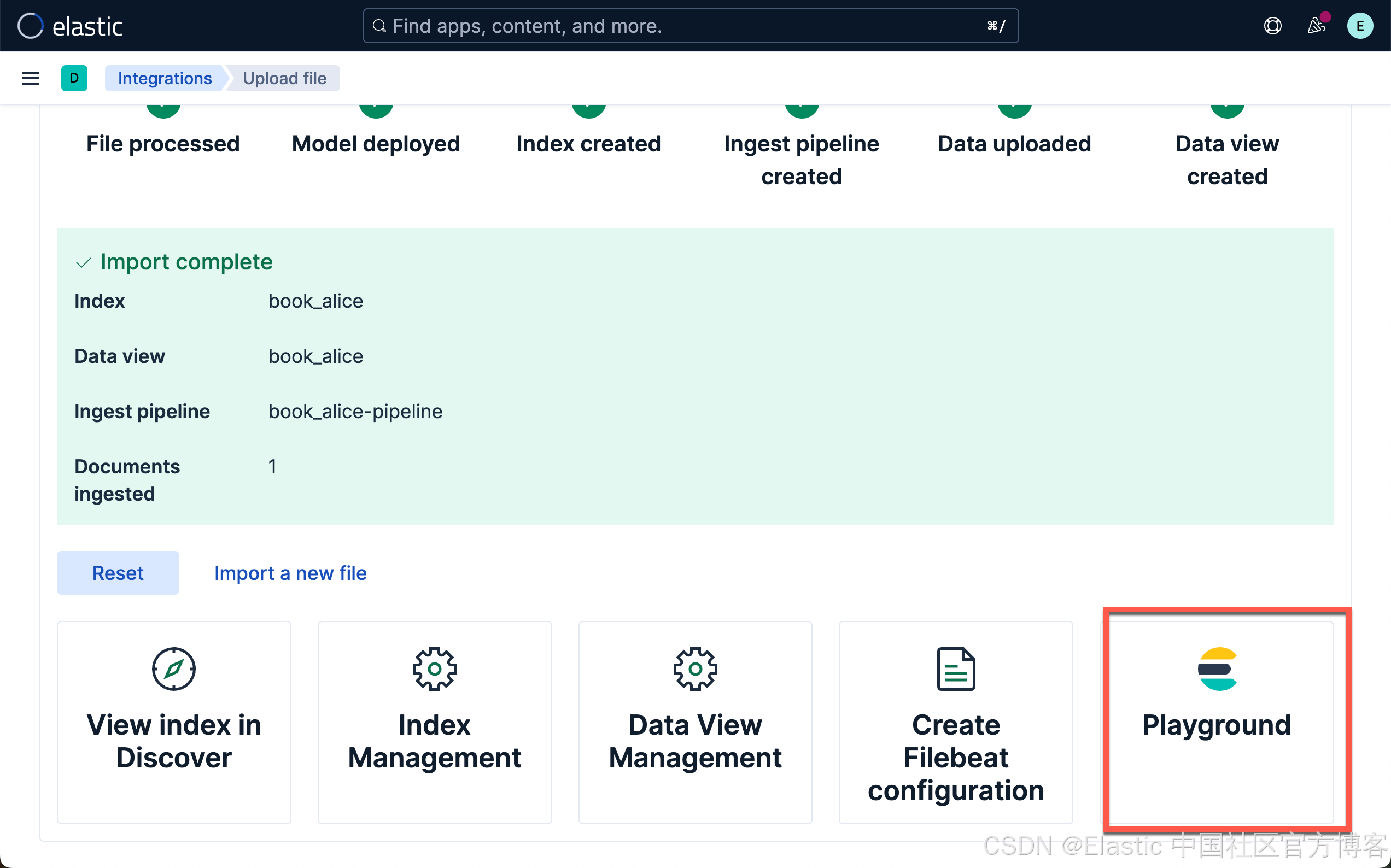
当加载和推理完成后,我们就可以前往 Playground 了。
在 Playground 中测试 RAG
在 Kibana 中导航到 Elasticsearch > Playground。可以在此处找到 Playground 的详细指南。
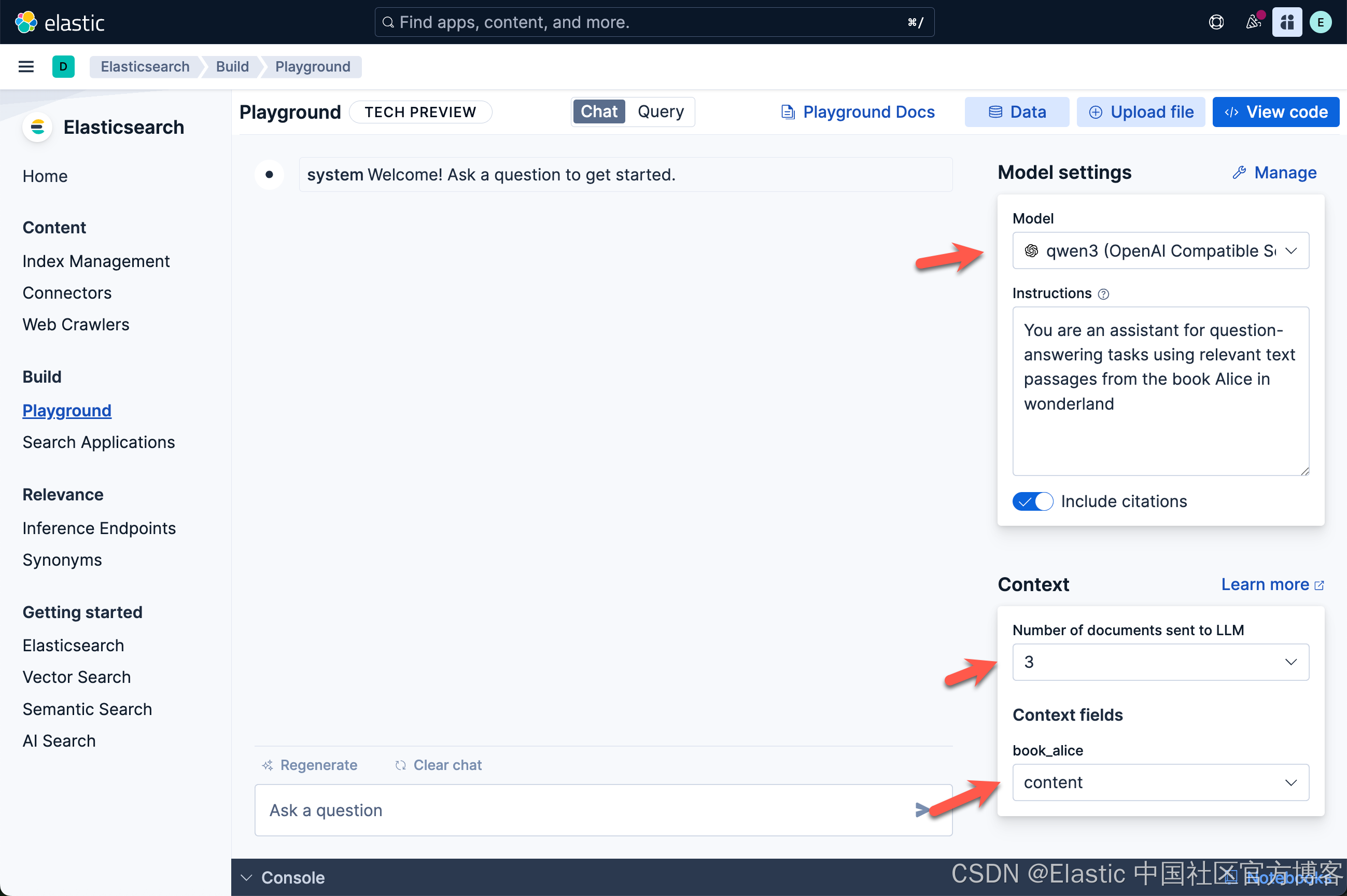
在我们的 Playground 设置中,我们输入了以下系统提示 “You are an assistant for question-answering tasks using relevant text passages from the book Alice in wonderland - 你是使用《爱丽丝梦游仙境》一书中的相关文本段落进行问答任务的助手”,并接受其他默认设置。
对于 “Who was at the tea party? - 谁参加了茶话会?”这个问题
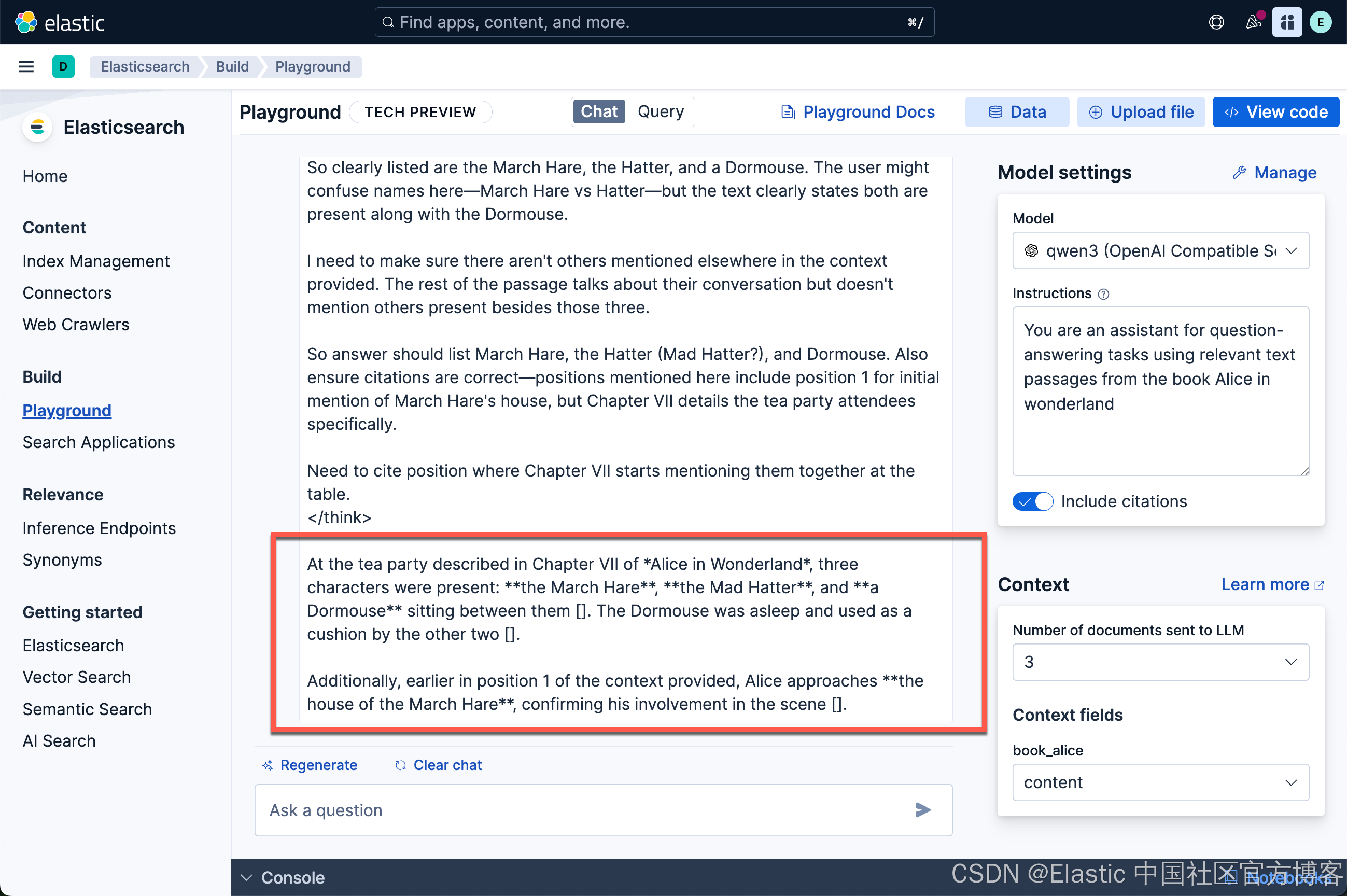
我们尝试使用中文来提问:
谁参加了茶话会?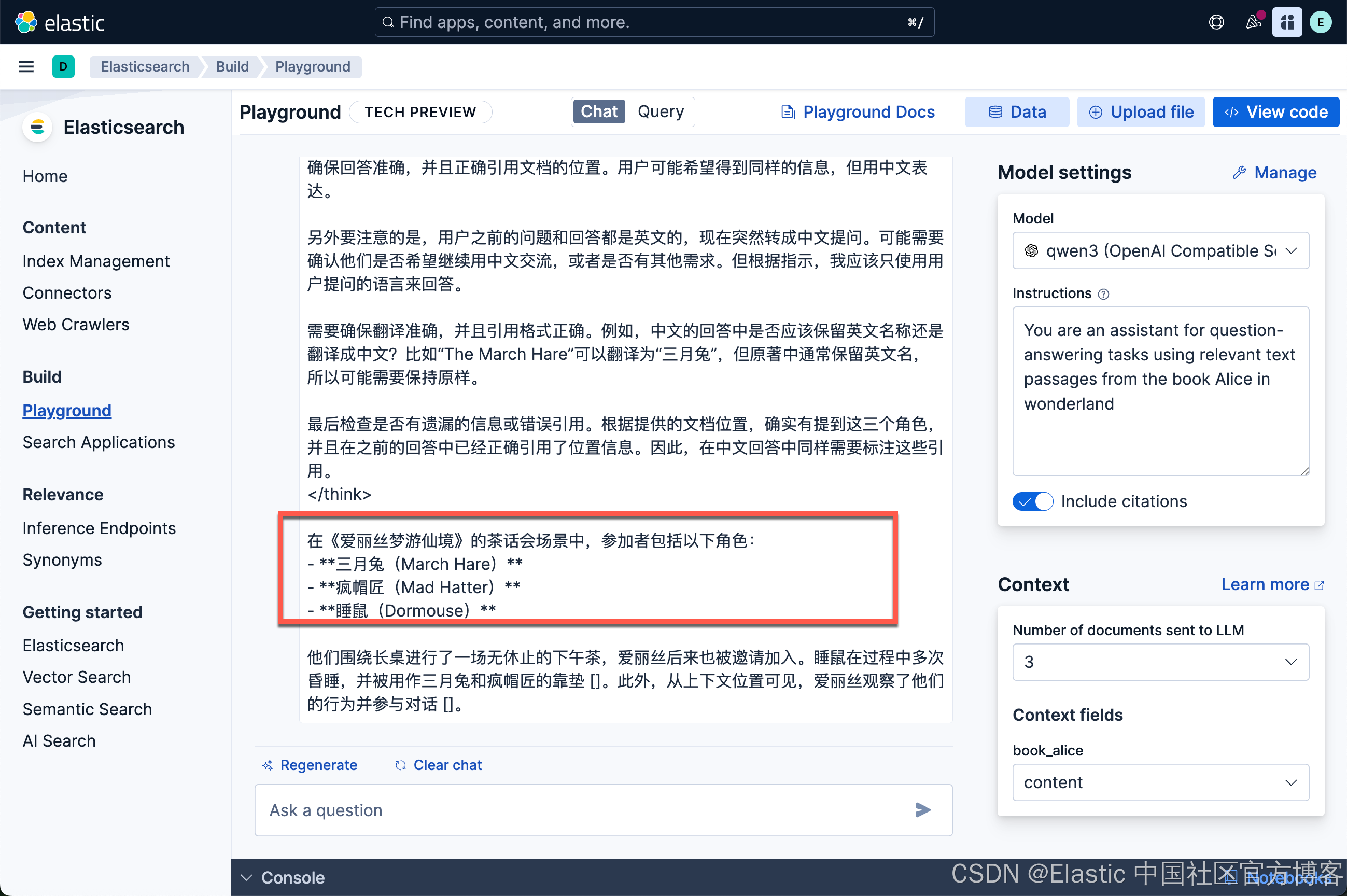
从上面的输出中我们看到了我们希望的答案。我们可以详细查看原文,在如下的位置可以看到我们想要的答案:

非常好! Qwen3 能够针对我们的英文和中文进行回答问题。 给出了我们想要的中文答案。
如果大家对如何使用代码来实现上述查询,你可以点击 Playground 的右上角的 View code 来得到一个初始的代码。然后我们可以做响应的修改。在这里我就不赘述了。对于感兴趣的开发者,可以参考我的另外一篇文章 “Elasticsearch:在 Elastic 中玩转 DeepSeek R1 来实现 RAG 应用” 来查看实现的方法。
祝大家学习 Qwen3 愉快!
相关文章:
在本地电脑中部署阿里 Qwen3 大模型及连接到 Elasticsearch
在今天的文章中,我将参考文章 “使用 Elastic 和 LM Studio 的 Herding Llama 3.1” 来部署 Qwen3 大模型。据测评,这是一个非常不错的大模型。我们今天尝试使用 LM Studio 来对它进行部署,并详细描述如何结合 Elasticsearch 来对它进行使用。…...
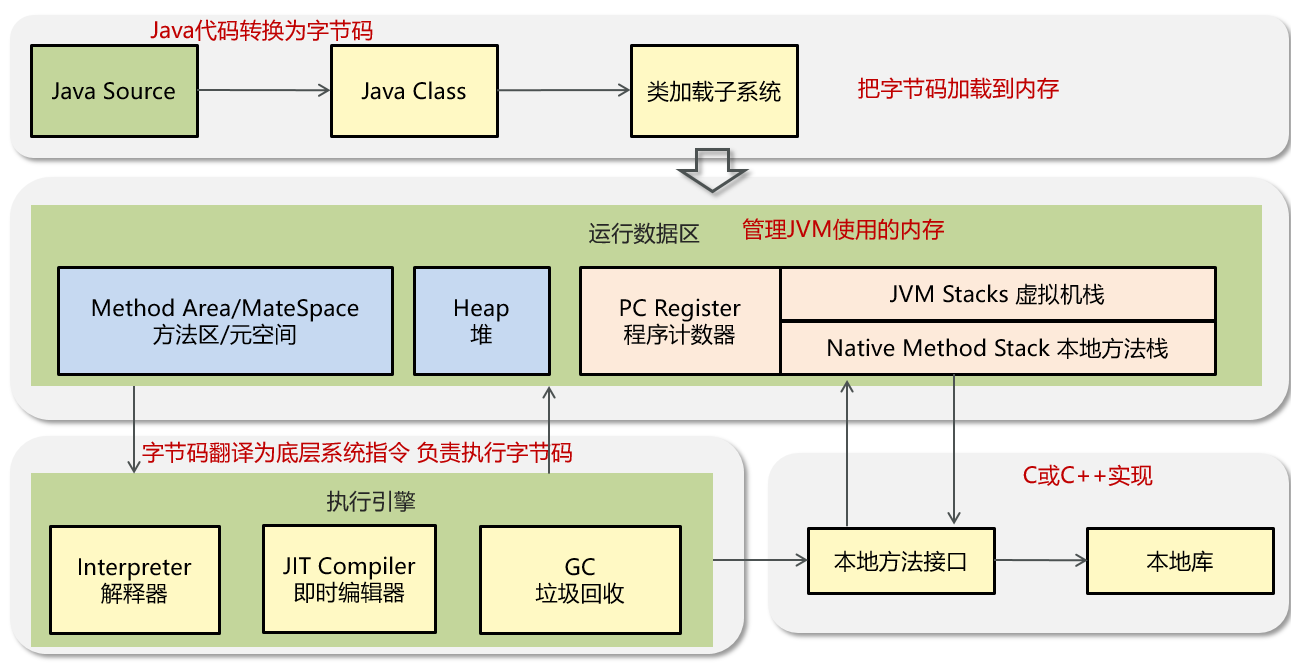
八股---7.JVM
1. JVM组成 1.1 JVM由哪些部分组成?运行流程? 难易程度:☆☆☆ 出现频率:☆☆☆☆ Java Virtual Machine:Java 虚拟机,Java程序的运行环境(java二进制字节码的运行环境)好处:一次编写,到处运行;自动内存管理,垃圾回收机制程序运行之前,需要先通过编译器将…...
C++性能优化指南
思维导图(转载) https://www.processon.com/view/5e5b3fc5e4b03627650b1f42 第 1 章 优化概述 1.1 优化是软件开发的一部分 优化更像是一门实验科学。 1.2 优化是高效的 1.3 优化是没有问题的 **90/10 规则:**程序中只有 10% 的代码…...

数据集-目标检测系列- 猴子 数据集 monkey >> DataBall
贵在坚持! * 相关项目 1)数据集可视化项目:gitcode: https://gitcode.com/DataBall/DataBall-detections-100s/overview 2)数据集训练、推理相关项目:GitHub - XIAN-HHappy/ultralytics-yolo-webui: ultralytics-yo…...

【RAG召回】bge实现向量相似度索引
sentence-transformers 是一个非常强大的 Python 框架,它可以将句子或段落转换成高质量、高信息密度的数字向量(称为“嵌入”或 Embeddings)。它厉害的地方在于,语义上相似的句子,其向量在空间中的距离也更近。 这使得…...
算法-数论
C-小红的数组查询(二)_牛客周赛 Round 95 思路:不难看出a数组是有循环的 d3,p4时,a数组:1、0、3、2、1、0、3、2....... 最小循环节为4,即最多4种不同的数 d4,p6时,a数组:1、5、3、…...
详解)
原型对象(Prototype)详解
原型对象(Prototype)详解 一、核心概念 本质:每个 JavaScript 对象(除 null 外)都有的内置属性作用:实现对象间的属性/方法继承(原型继承)存储位置:[[Prototype]] 内部属性(通过 __proto__ 或 Object.getPrototypeOf() 访问)二、关键特性图示 对象实例 (obj)│├─…...

MongoDB账号密码笔记
先连接数据库,新增用户密码 admin用户密码 use admin db.createUser({ user: "admin", pwd: "yourStrongPassword", roles: [ { role: "root", db: "admin" } ] })用户数据库用户密码 use myappdb db.createUser({ user: &…...

SQL导出Excel支持正则脱敏
SQL to Excel Exporter 源码功能特性核心功能性能优化安全特性 快速开始环境要求安装运行 API 使用说明1. 执行SQL并导出Excel2. 下载导出文件3. 获取统计信息4. 清理过期文件 数据脱敏配置支持的脱敏类型脱敏规则配置示例 配置说明应用配置数据库配置 测试运行单元测试运行集成…...

05.查询表
查询表 字段显示可以使用别名: col1 AS alias1, col2 AS alias2, … WHERE子句:指明过滤条件以实现“选择"的功能: 过滤条件: 布尔型表达式算术操作符:,-,*,/,%比较操作符:,<>(相等或都为空),<>,!(非标准SQL),>,>,<,<范围查询: BETWEEN min_num …...

基于深度强化学习的智能机器人导航系统
前言 随着人工智能技术的飞速发展,机器人在日常生活和工业生产中的应用越来越广泛。其中,机器人导航技术是实现机器人自主移动的关键。传统的导航方法依赖于预设的地图和路径规划算法,但在复杂的动态环境中,这些方法往往难以适应。…...

【第三十九周】ViLT
ViLT 摘要Abstract文章信息介绍提取视觉特征的方式的演变模态融合的两种方式四种不同的 VLP 模型Q&A 方法模型结构目标函数Whole Word Masking(WWM) 实验结果总结 摘要 本篇博客介绍了ViLT(Vision-and-Language Transformer)…...
代码随想录算法训练营第60期第六十天打卡
大家好,今天因为有数学建模比赛的校赛,今天的文章可能会简单一点,望大家原谅,我们昨天主要讲的是并查集的题目,我们复习了并查集的功能,我们昨天的题目其实难度不小,尤其是后面的有向图…...

数据结构——D/串
一、串的定义和基本操作  1. 串的定义   1)串的概念   组成结构: 串是由零个或多个字符组成的有限序列,记为 S′a1a2⋯an′Sa_1a_2\cdots a_nS′a1a2⋯an′&#x…...

瀚文机械键盘固件开发详解:HWKeyboard.cpp文件解析与应用
🔥 机械键盘固件开发从入门到精通:HWKeyboard模块全解析 作为一名嵌入式开发老司机,今天带大家拆解一个完整的机械键盘固件代码。即使你是单片机小白,看完这篇教程也能轻松理解机械键盘的工作原理,甚至自己动手复刻一…...

Nginx+Tomcat负载均衡与动静分离架构
目录 简介 一、Tomcat基础部署与配置 1.1 Tomcat应用场景与特性 1.2 环境准备与安装 1.3 Tomcat主配置文件详解 1.4 部署Java Web站点 二、NginxTomcat负载均衡群集搭建 2.1 架构设计与原理 2.2 环境准备 2.3 Tomcat2配置(与Tomcat1对称) 2.4…...
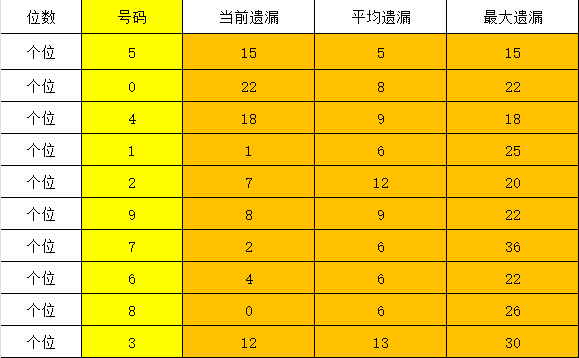
AI+预测3D新模型百十个定位预测+胆码预测+去和尾2025年6月8日第102弹
从今天开始,咱们还是暂时基于旧的模型进行预测,好了,废话不多说,按照老办法,重点8-9码定位,配合三胆下1或下2,杀1-2个和尾,再杀4-5个和值,可以做到100-300注左右。 (1)定…...

LeetCode--25.k个一组翻转链表
解题思路: 1.获取信息: (1)给定一个链表,每k个结点一组进行翻转 (2)余下不足k个结点,则不进行交换 2.分析题目: 其实就是24题的变题,24题是两两一组进行交换&…...

css | class中 ‘.‘ 和 ‘:‘ 的使用 | 如,何时用 .is-selected{ ... } 何时用 :hover{...}?
省流总结:交互时的短暂视觉反馈 → 用 :hover,状态需要记录或切换 → 用类名如 .is-selected。 🧠 本质区别: 写法触发方式用途&.is-selected依赖 class 切换需要 JavaScript 控制状态,如选中、激活&:hover鼠…...
【第九篇】 SpringBoot测试补充篇
简介 本文介绍了SpringBoot测试中的五项关键技术:测试类专用属性加载、 测试类专用Bean配置、 表现层测试方法、测试类事务回滚控制、配置文件随机数据设置)。这些技术可以有效隔离测试环境,确保测试数据不影响生产环境,同时提供了…...
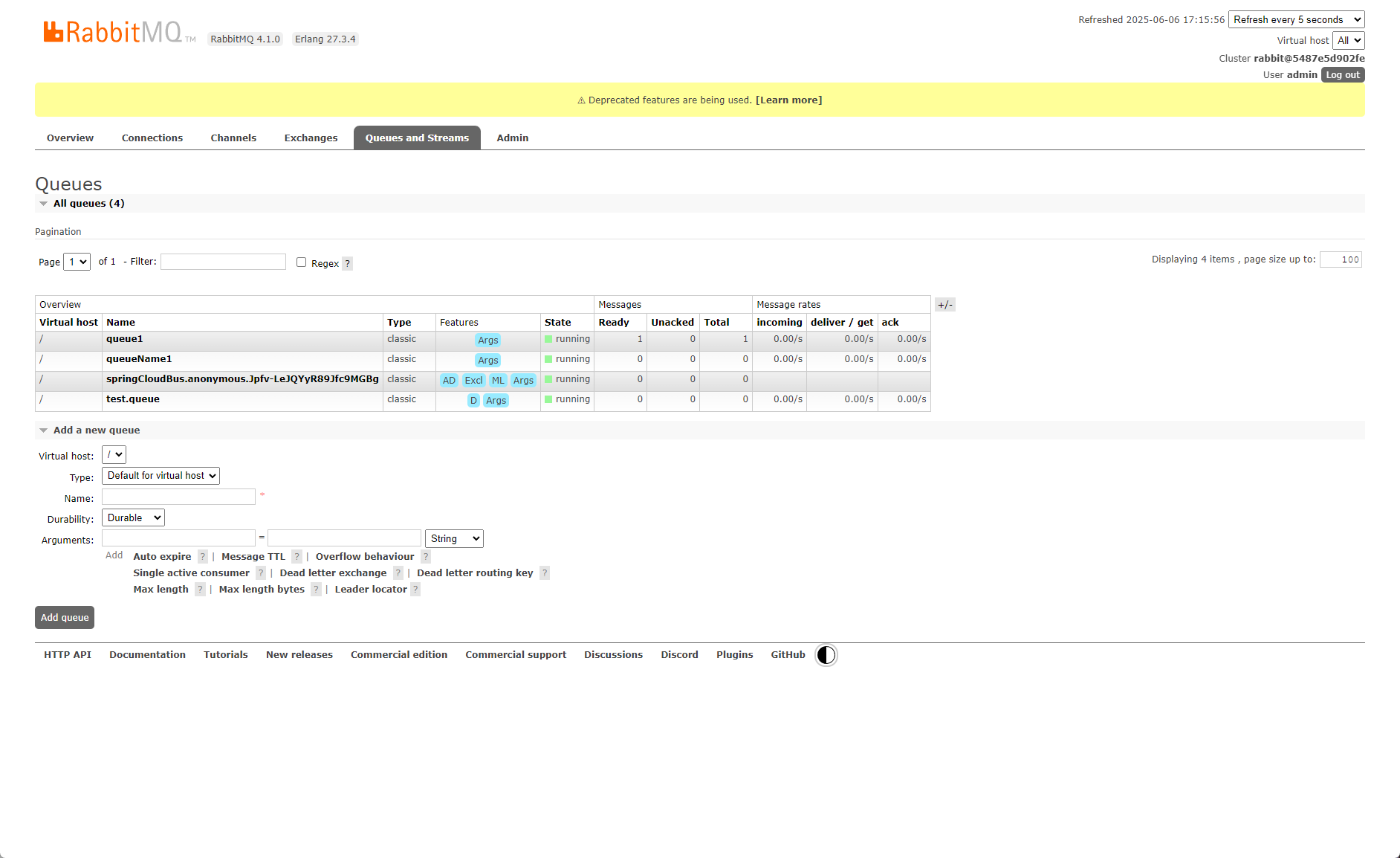
springcloud SpringAmqp消息队列 简单使用
这期只是针对springBoot/Cloud 在使用SpringAmqp消息队列的时候遇到的坑。 前提 如果没有安装RabbitMQ是无法连接成功的!所以前提是你要安装好RabbitMQ。 docker 安装命令 # 拉取docker镜像 docker pull rabbitmq:management# 创建容器 docker run -id --namera…...
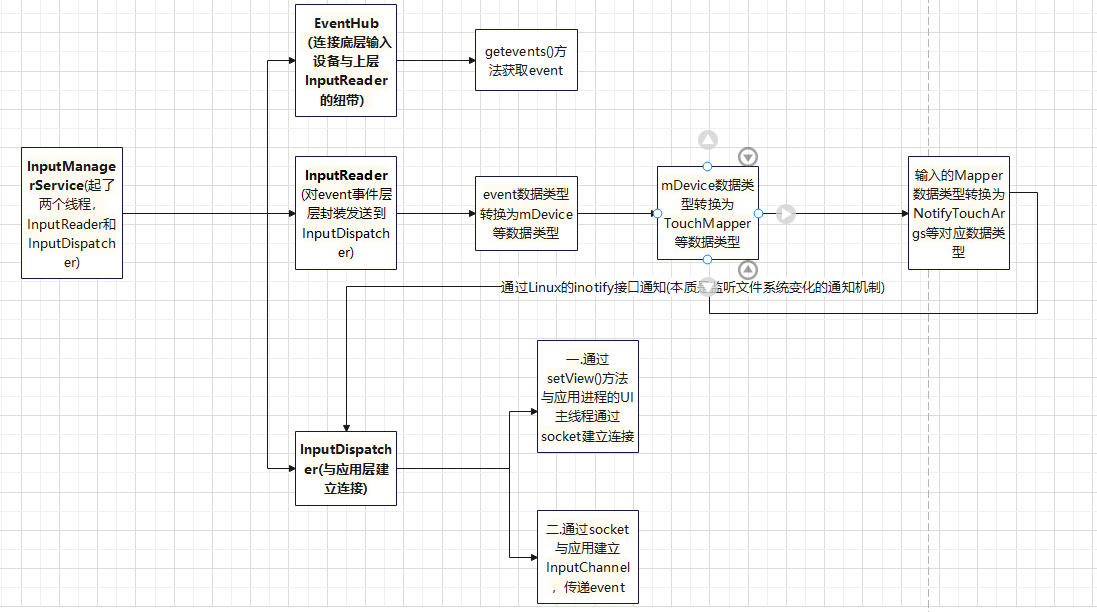
Framework开发之IMS逻辑浅析1--关键线程及作用
关键线程:EventHub,InputReader,InputDispatcher EventHub: 由于Android继承Linux,Linux的思想是一切皆文件,而输入的类型不止一种(触碰,写字笔,键盘等),每种类型都对应一种驱动设备,而每个硬件驱动设备又对应Linux的一个目录文件…...

The Quantization Model of Neural Scaling
文章目录 摘要1引言2 理论3 概念验证:一个玩具数据集3.1 “多任务稀疏奇偶校验”数据集3.2 幂律规模和新兴能力 4 拆解大型语言模型的规模定律4.1 单token损失的分布4.2 单基因(monogenic)与多基因(polygenic)的规模曲…...

数据源指的是哪里的数据,磁盘中还是内存中
在 MyDB 项目中,特别是这段缓存框架代码: T obj getForCache(key);以及它的上下文: AbstractCache 是一个抽象类,内部有两个抽象方法,留给实现类去实现具体的操作: protected abstract T getForCache(lon…...

系统思考:跳出症状看全局
明天将为华为全球采购认证管理部的伙伴们带来一场关于系统思考的深度课程!通过经典的啤酒游戏经营决策沙盘,一起沉浸式体验如何从全局视角看待问题,发现单点最优并不等于全局最优。 这不仅是一次简单的课程,更是一次洞察系统背后…...

DeepSeek R1 V2 深度探索:开源AI编码新利器,效能与创意并进
最近,AI界迎来了一位神秘的“突袭者”——DeepSeek团队悄无声息地发布了其推理模型DeepSeek R1的重磅升级版V2(具体型号R1-0528)。这款基于MIT许可的开源模型,在原版R1的基础上进行了多项令人瞩目的改进,正以其强大的潜…...
surfer15安装
安装文件 安装包和破解文件 安装 破解及汉化 打开软件...

MySQL从入门到DBA深度学习指南
目录 引言 MySQL基础入门 数据库基础概念 MySQL安装与配置 SQL语言进阶 数据库设计与规范化 数据库设计原则 表结构设计 MySQL核心管理 用户权限管理 备份与恢复 性能优化基础 高级管理与高可用 高可用与集群 故障诊断与监控 安全与审计 DBA实战与运维 性能调…...

Python训练营---DAY48
DAY 48 随机函数与广播机制 知识点回顾: 随机张量的生成:torch.randn函数卷积和池化的计算公式(可以不掌握,会自动计算的)pytorch的广播机制:加法和乘法的广播机制 ps:numpy运算也有类似的广播机…...

debian12拒绝海外ip连接
确保 nftables 已安装: Debian 12 默认使用 nftables 作为防火墙框架。检查是否安装: sudo apt update sudo apt install nftables启用并启动 nftables 服务 sudo systemctl enable nftables sudo systemctl start nftables下载maxmind数据库 将文件解…...