【RAG召回】BM25算法示例
rank-bm25 功能示例
本篇将通过多个示例,快速展示 rank-bm25 库的核心功能。不使用jieba。
准备工作
首先,确保您已经安装了 rank-bm25。
pip install rank-bm25
接下来,我们定义一个通用的中文语料库和分词函数。这里我们使用简单的单字切分作为分词方法,以避免引入第三方库。
# 1. 定义一个中文语料库
corpus = ["北京是中国的首都,也是一座历史悠久的文化名城。","上海是中国的经济中心,拥有繁忙的港口和现代化的建筑。","深圳是中国科技创新的重要城市,被誉为“中国硅谷”。","广州的美食文化闻名全国,是粤菜的发源地。","学习人工智能技术需要扎实的数学基础和编程能力。","中国的历史源远流长,有许多著名的历史人物和事件。"
]# 2. 定义分词函数 (不使用jieba,直接按字切分)
def char_tokenizer(text):"""一个简单的按字切分的函数。"""return list(text)# 3. 对语料库进行分词
tokenized_corpus = [char_tokenizer(doc) for doc in corpus]print("分词后的语料库 (部分展示):")
print(tokenized_corpus[0])
# 输出: ['北', '京', '是', '中', '国', '的', '首', '都', ',', '也', '是', '一', '座', '历', '史', '悠', '久', '的', '文', '化', '名', '城', '。']
示例 1:基础用法 - 获取最相关的 N 个文档
这是最常用、最直接的功能:输入一个查询,直接返回最相关的文档列表。
from rank_bm25 import BM25Okapi# 初始化 BM25 模型
bm25 = BM25Okapi(tokenized_corpus)查询 = "中国的历史文化"
分词后的查询 = char_tokenizer(查询)# 使用 get_top_n 获取最相关的 3 个文档
# 参数: (分词后的查询, 原始语料库, n=返回数量)
top_n_docs = bm25.get_top_n(分词后的查询, corpus, n=3)print(f"查询: '{查询}'")
print("--- 最相关的3个文档 ---")
for doc in top_n_docs:print(doc)
运行结果:
查询: '中国的历史文化'
--- 最相关的3个文档 ---
北京是中国的首都,也是一座历史悠久的文化名城。
中国的历史源远流长,有许多著名的历史人物和事件。
广州的美食文化闻名全国,是粤菜的发源地。
示例 2:获取所有文档的 BM25 分数
如果你不仅想知道谁最相关,还想知道具体的相关性分数是多少,可以使用 get_scores。
from rank_bm25 import BM25Okapi
import numpy as npbm25 = BM25Okapi(tokenized_corpus)查询 = "中国的经济与科技"
分词后的查询 = char_tokenizer(查询)# 使用 get_scores 获取每个文档的分数
doc_scores = bm25.get_scores(分词后的查询)print(f"查询: '{查询}'")
print("--- 所有文档的BM25分数 ---")
print(np.round(doc_scores, 2))# 你可以手动将分数和文档结合起来排序
带分数的文档 = list(zip(corpus, doc_scores))
排序后的文档 = sorted(带分数的文档, key=lambda item: item[1], reverse=True)print("\n--- 手动排序后的结果 ---")
for doc, score in 排序后的文档:print(f"分数: {score:.2f} | 文档: {doc}")
运行结果:
查询: '中国的经济与科技'
--- 所有文档的BM25分数 ---
[2.08 4.29 4.38 0. 2.19 2.08]--- 手动排序后的结果 ---
分数: 4.38 | 文档: 深圳是中国科技创新的重要城市,被誉为“中国硅谷”。
分数: 4.29 | 文档: 上海是中国的经济中心,拥有繁忙的港口和现代化的建筑。
分数: 2.19 | 文档: 学习人工智能技术需要扎实的数学基础和编程能力。
分数: 2.08 | 文档: 北京是中国的首都,也是一座历史悠久的文化名城。
分数: 2.08 | 文档: 中国的历史源远流长,有许多著名的历史人物和事件。
分数: 0.00 | 文档: 广州的美食文化闻名全国,是粤菜的发源地。
示例 3:批量查询 - 同时处理多个查询
当有多个查询需要执行时,使用 get_batch_scores 会比循环调用 get_scores 更高效。
from rank_bm25 import BM25Okapi
import numpy as npbm25 = BM25Okapi(tokenized_corpus)查询列表 = ["历史名城","科技创新","美食文化"
]# 批量分词
分词后的查询列表 = [char_tokenizer(q) for q in 查询列表]# 使用 get_batch_scores 进行批量计算
批量分数 = bm25.get_batch_scores(分词后的查询列表, list(range(len(corpus))))print("--- 批量查询分数矩阵 ---")
print("行代表查询 (查询列表),列代表文档 (corpus)")
print(np.round(批量分数, 2))# 为每个查询找到最相关的文档
print("\n--- 每个查询的最佳匹配 ---")
for i, query in enumerate(查询列表):best_doc_index = np.argmax(批量分数[i])print(f"查询 '{query}' 的最佳匹配: {corpus[best_doc_index]}")
运行结果:
--- 批量查询分数矩阵 ---
行代表查询 (查询列表),列代表文档 (corpus)
[[3.11 0. 0. 1.61 0. 3.11][0. 0. 3.7 0. 1.61 0. ][1.61 0. 0. 3.11 0. 0. ]]--- 每个查询的最佳匹配 ---
查询 '历史名城' 的最佳匹配: 北京是中国的首都,也是一座历史悠久的文化名城。
查询 '科技创新' 的最佳匹配: 深圳是中国科技创新的重要城市,被誉为“中国硅谷”。
查询 '美食文化' 的最佳匹配: 广州的美食文化闻名全国,是粤菜的发源地。
示例 4:自定义 BM25 参数 (k1 和 b)
BM25Okapi 模型可以接受两个重要参数 k1 和 b 来微调其行为。
k1(float, default=1.5): 控制词频(TF)的缩放。值越高,词频对分数的影响就越大。b(float, default=0.75): 控制文档长度惩罚。值在[0, 1]区间,b=1表示完全根据文档长度进行惩罚,b=0表示不进行惩罚。
from rank_bm25 import BM25Okapi# 使用默认参数的 BM25 模型
bm25_default = BM25Okapi(tokenized_corpus) # 创建一个自定义参数的 BM25 模型
# 增强词频影响 (k1=2.0), 减弱文档长度惩罚 (b=0.5)
bm25_custom = BM25Okapi(tokenized_corpus, k1=2.0, b=0.5)查询 = "中国历史"
分词后的查询 = char_tokenizer(查询)# 获取两种模型下的分数
scores_default = bm25_default.get_scores(分词后的查询)
scores_custom = bm25_custom.get_scores(分词后的查询)print(f"查询: '{查询}'")
print(f"默认参数 (k1=1.5, b=0.75) 分数: \n{np.round(scores_default, 2)}")
print(f"自定义参数 (k1=2.0, b=0.5) 分数: \n{np.round(scores_custom, 2)}")
运行结果:
查询: '中国历史'
默认参数 (k1=1.5, b=0.75) 分数:
[2.08 0. 0. 0. 0. 2.08]
自定义参数 (k1=2.0, b=0.5) 分数:
[2.35 0. 0. 0. 0. 2.35]
(注意:调整参数后,分数发生了变化)
示例 5:获取模型内部信息
有时需要查看模型内部的一些统计数据,例如词的文档频率、平均文档长度等。
from rank_bm25 import BM25Okapibm25 = BM25Okapi(tokenized_corpus)# 获取模型计算出的平均文档长度
avg_dl = bm25.avgdl
print(f"平均文档长度: {avg_dl:.2f} 个字")# 获取语料库的文档总数
doc_count = bm25.doc_count
print(f"文档总数: {doc_count}")# 获取某个词在多少个文档中出现过 (文档频率)
词 = "中"
doc_freq = bm25.doc_freqs.get(词, 0)
print(f"'{词}' 这个字在 {doc_freq} 个文档中出现过。")词 = "港"
doc_freq = bm25.doc_freqs.get(词, 0)
print(f"'{港}' 这个字在 {doc_freq} 个文档中出现过。")# 查看模型为一个词计算的 IDF (逆文档频率) 分数
idf_score = bm25.idf.get(词, 0)
print(f"'{港}' 这个字的 IDF 分数是: {idf_score:.2f}")运行结果:
平均文档长度: 28.50 个字
文档总数: 6
'中' 这个字在 4 个文档中出现过。
'港' 这个字在 1 个文档中出现过。
'港' 这个字的 IDF 分数是: 1.50
相关文章:

【RAG召回】BM25算法示例
rank-bm25 功能示例 本篇将通过多个示例,快速展示 rank-bm25 库的核心功能。不使用jieba。 准备工作 首先,确保您已经安装了 rank-bm25。 pip install rank-bm25接下来,我们定义一个通用的中文语料库和分词函数。这里我们使用简单的单字切…...

vue中Echarts的使用
文章目录 Echarts概述什么是EchartsEcharts的好处 Vue中Echarts的使用Echarts的安装Echarts的引入 Echarts概述 什么是Echarts Apache ECharts:一个基于 JavaScript 的开源可视化图表库。 其官网如下:https://echarts.apache.org/zh/index.html Echar…...
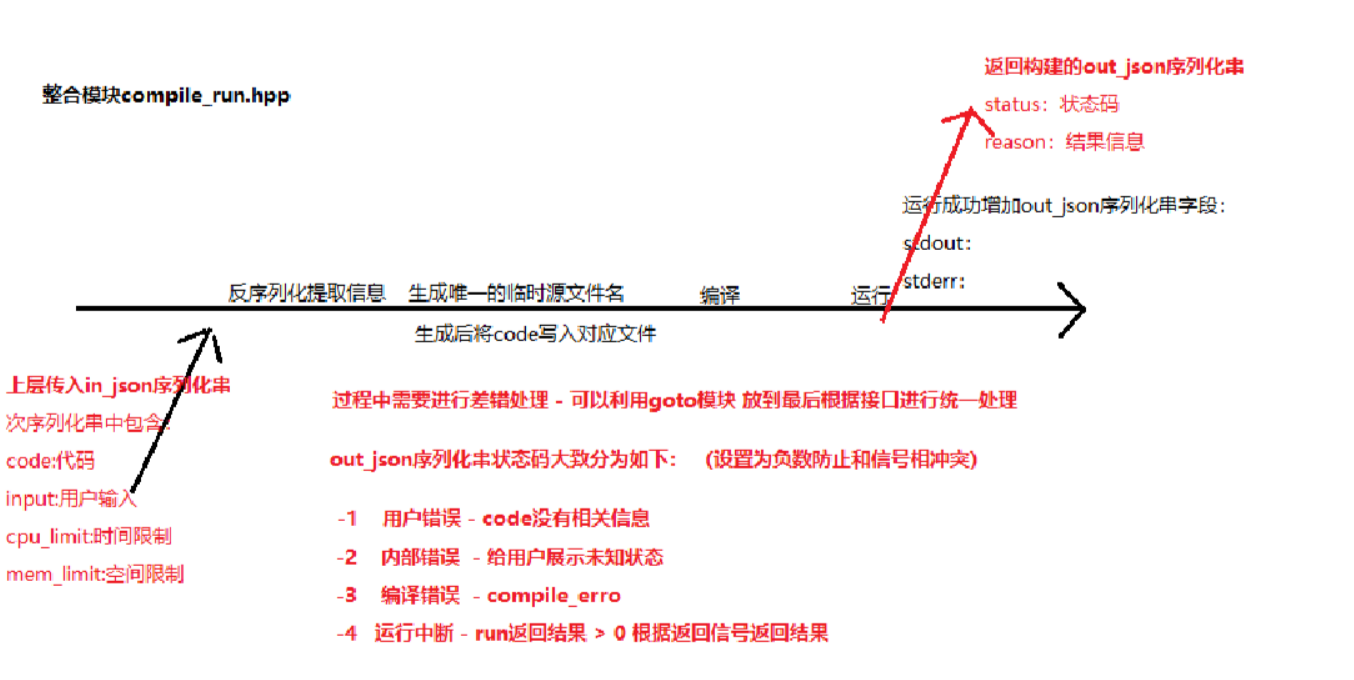
【C++项目】负载均衡在线OJ系统-1
文章目录 前言项目结果演示技术栈:结构与总体思路compiler编译功能-common/util.hpp 拼接编译临时文件-common/log.hpp 开放式日志-common/util.hpp 获取时间戳方法-秒级-common/util.hpp 文件是否存在-compile_server/compiler.hpp 编译功能编写(重要&a…...

Linux环境-通过命令查看zookeeper注册的服务
假设前置条件如下: 1.root权限用户名:zookeeper 2.zookeeper所在服务器地址:168.7.3.254(非真实ip) 3.zookeeper的bin文件路径:/opt/zookeeper/bin 4.确保zookeeper注册中心已启动 查看注册中心服务如下&a…...

Spring Boot微服务架构(十一):独立部署是否抛弃了架构优势?
Spring Boot 的独立部署(即打包为可执行 JAR/WAR 文件)本身并不会直接丧失架构优势,但其是否体现架构价值取决于具体应用场景和设计选择。以下是关键分析: 一、独立部署与架构优势的关系 内嵌容器的优势保留 Spring Boot 独立部署…...
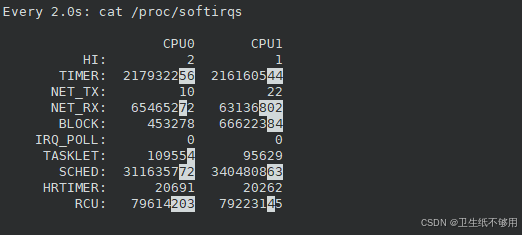
(四)Linux性能优化-CPU-软中断
软中断 中断其实是一种异步的事件处理机制,可以提高系统的并发处理能力 由于中断处理程序会打断其他进程的运行,所以,为了减少对正常进程运行调度的影响,中断处理程序就需要尽可能快地运行 Linux 将中断处理过程分成了两个阶段&a…...

SCADA|RESTful学习,Apipost通过GET获取KingSCADA实时数据
哈喽,你好啊,我是雷工! 以前记录过一篇《安装APIPost工具,了解RESTful》的笔记。 最近涉及到SCADA程序和MES对接,这种信息化的对接,常常要用到RESTful。 好像还有什么Webservices,我是听的一头雾水。 根本听不懂啊,于是加班补补课,先了解下RESTful。 01 RESTful传…...

【CSS-7】深入解析CSS伪类:从基础到高级应用
CSS伪类是前端开发中不可或缺的强大工具,它们允许我们根据文档树之外的信息或简单选择器无法表达的状态来样式化元素。本文将全面探讨CSS伪类的各种类型、使用场景和最佳实践。 1. 伪类基础概念 1.1 什么是伪类? 伪类(Pseudo-class&#x…...

QT的工程文件.pro文件
文章目录 QT的工程文件.pro文件QT5中的基本模块Qt CoreQt GUIQt WidgetsQt QMLQt QuickQt NetworkQt SQLQt MultimediaQt ConcurrentQt WebEngineQt TestLib TARGET 可选择的模版CONFIG的配置项 QT的工程文件.pro文件 每一个QT项目都至少有一个.pro文件,用来配置项目…...

用 DeepSeek 高效完成数据分析与挖掘
一、DeepSeek 是什么? DeepSeek 是由深度求索推出的智能助手(当前版本 DeepSeek-R1),具备强大的自然语言理解、代码生成与数据分析能力。它支持 128K超长上下文,可处理复杂数据文档,并直接生成可运行的 Python 数据分析代码,是数据工作者的“AI副驾驶”。 二、DeepSeek…...
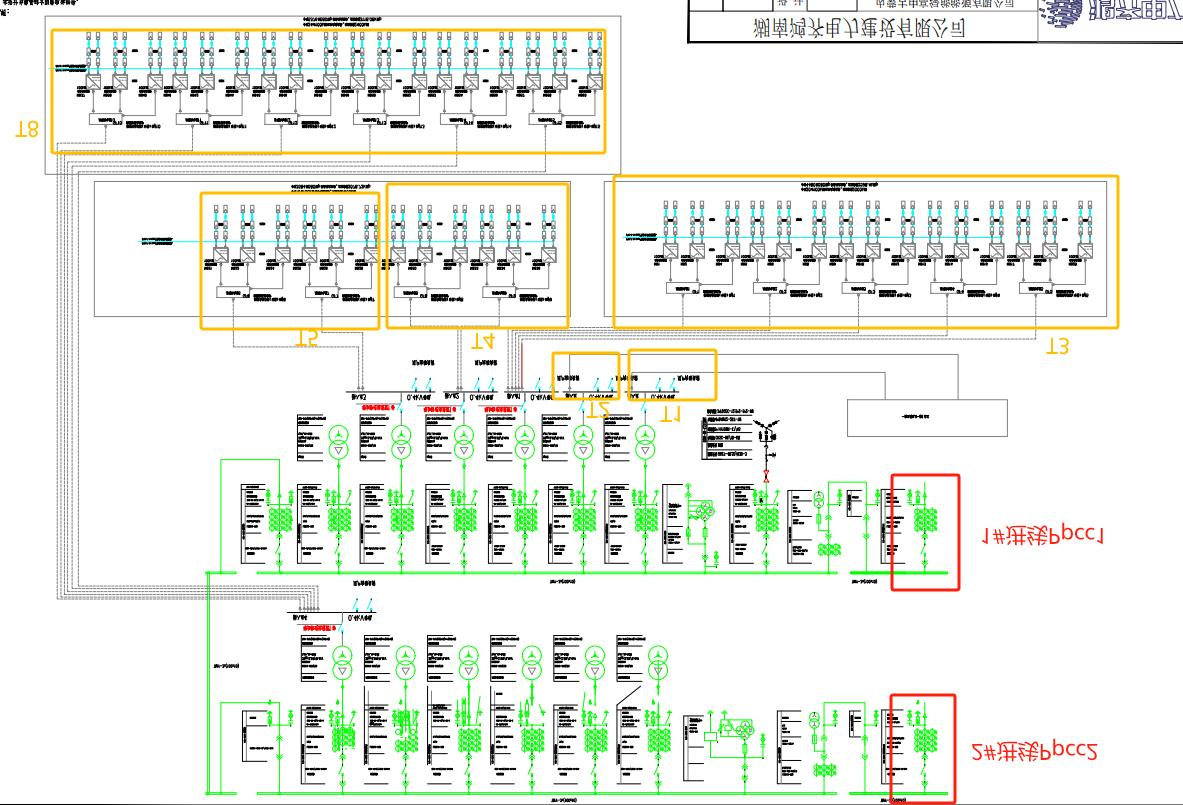
安科瑞防逆流方案落地内蒙古中高绿能光伏项目,筑牢北疆绿电安全防线
一、项目概况 内蒙古阿拉善中高绿能能源分布式光伏项目,位于内蒙古乌斯太镇,装机容量为7MW,采用自发自用、余电不上网模式。 用户配电站为35kV用户站,采用两路电源单母线分段系统。本项目共设置12台35/0.4kV变压器,在…...

stress 服务器压力测试的工具学习
一、stress 工具介绍 tress 是一种工具,可以对符合 POSIX 标准的操作系统施加可配置数量的 CPU、内存、I/O 或磁盘压力,并报告其检测到的任何错误。 stress 不是一个基准测试。它是由系统管理员用来评估其系统扩展性的工具,由内核程序员用来…...

在本地电脑中部署阿里 Qwen3 大模型及连接到 Elasticsearch
在今天的文章中,我将参考文章 “使用 Elastic 和 LM Studio 的 Herding Llama 3.1” 来部署 Qwen3 大模型。据测评,这是一个非常不错的大模型。我们今天尝试使用 LM Studio 来对它进行部署,并详细描述如何结合 Elasticsearch 来对它进行使用。…...
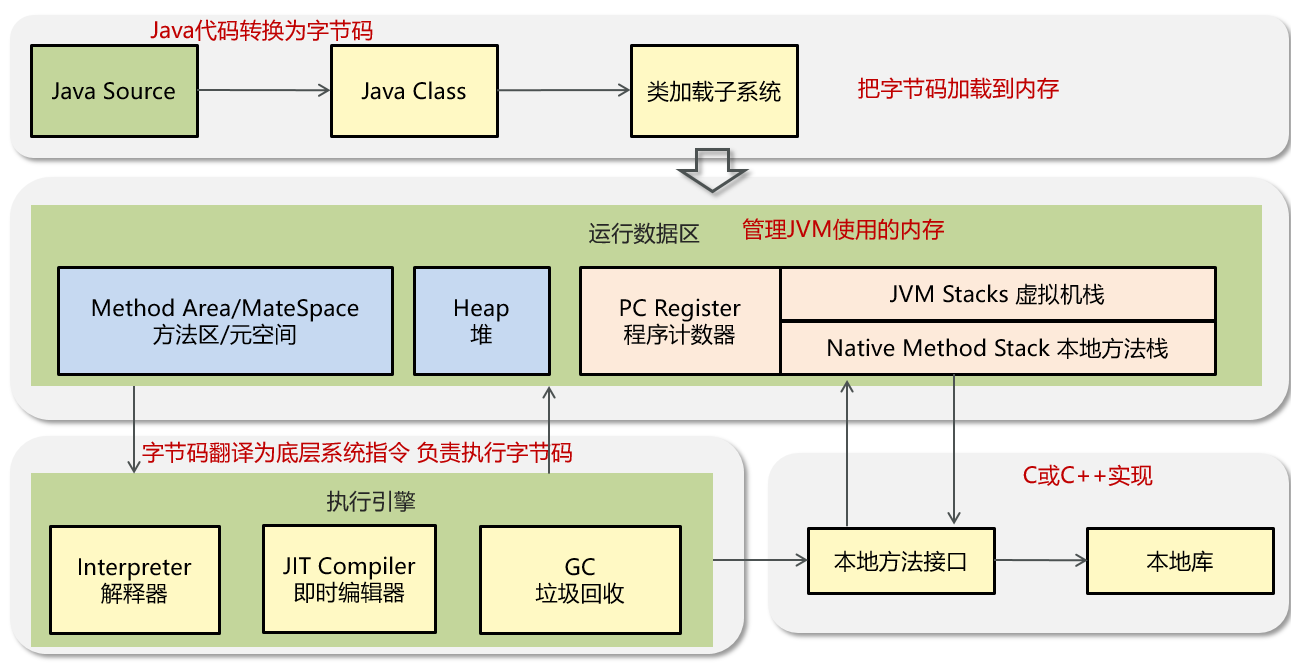
八股---7.JVM
1. JVM组成 1.1 JVM由哪些部分组成?运行流程? 难易程度:☆☆☆ 出现频率:☆☆☆☆ Java Virtual Machine:Java 虚拟机,Java程序的运行环境(java二进制字节码的运行环境)好处:一次编写,到处运行;自动内存管理,垃圾回收机制程序运行之前,需要先通过编译器将…...
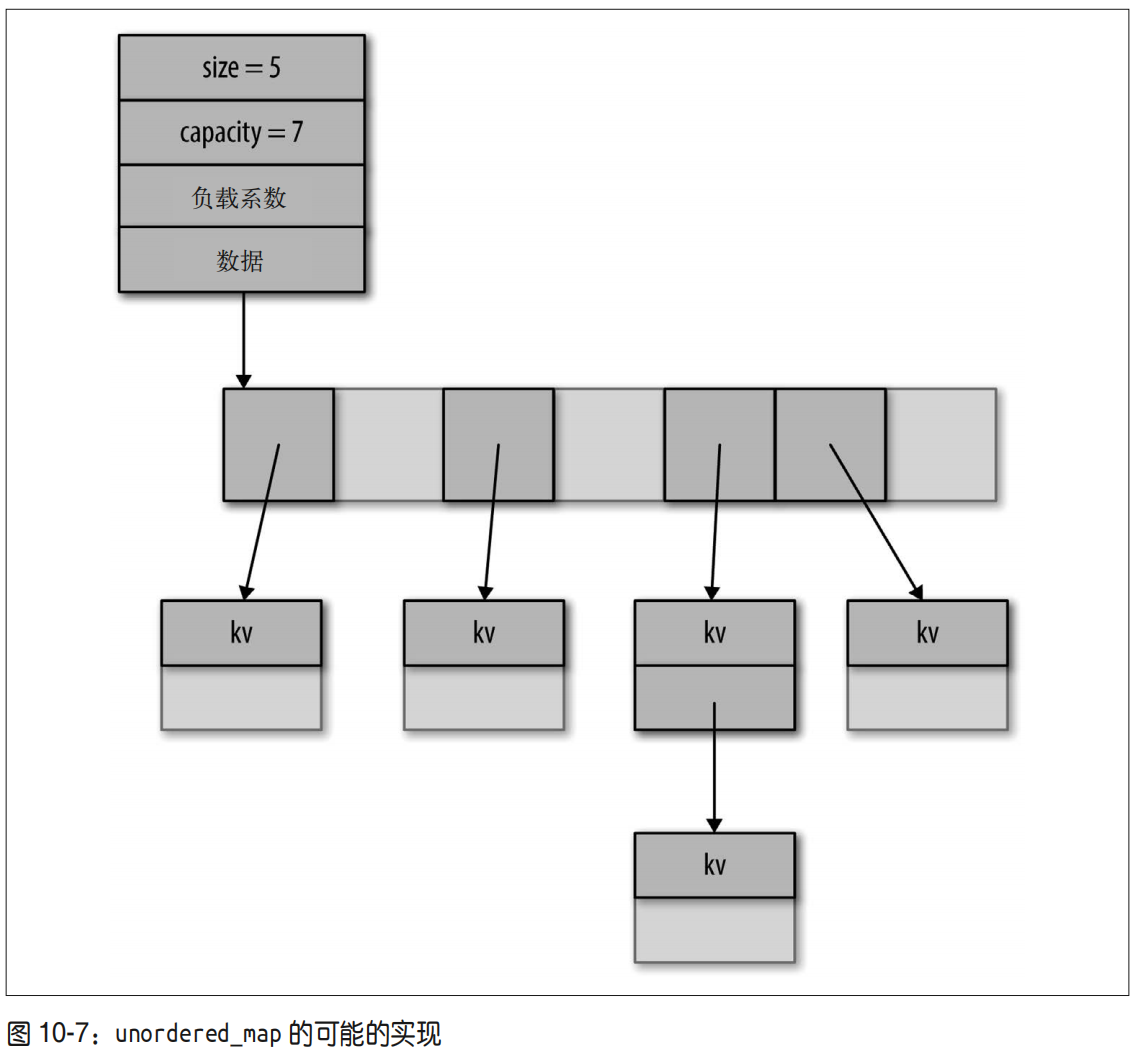
C++性能优化指南
思维导图(转载) https://www.processon.com/view/5e5b3fc5e4b03627650b1f42 第 1 章 优化概述 1.1 优化是软件开发的一部分 优化更像是一门实验科学。 1.2 优化是高效的 1.3 优化是没有问题的 **90/10 规则:**程序中只有 10% 的代码…...

数据集-目标检测系列- 猴子 数据集 monkey >> DataBall
贵在坚持! * 相关项目 1)数据集可视化项目:gitcode: https://gitcode.com/DataBall/DataBall-detections-100s/overview 2)数据集训练、推理相关项目:GitHub - XIAN-HHappy/ultralytics-yolo-webui: ultralytics-yo…...

【RAG召回】bge实现向量相似度索引
sentence-transformers 是一个非常强大的 Python 框架,它可以将句子或段落转换成高质量、高信息密度的数字向量(称为“嵌入”或 Embeddings)。它厉害的地方在于,语义上相似的句子,其向量在空间中的距离也更近。 这使得…...
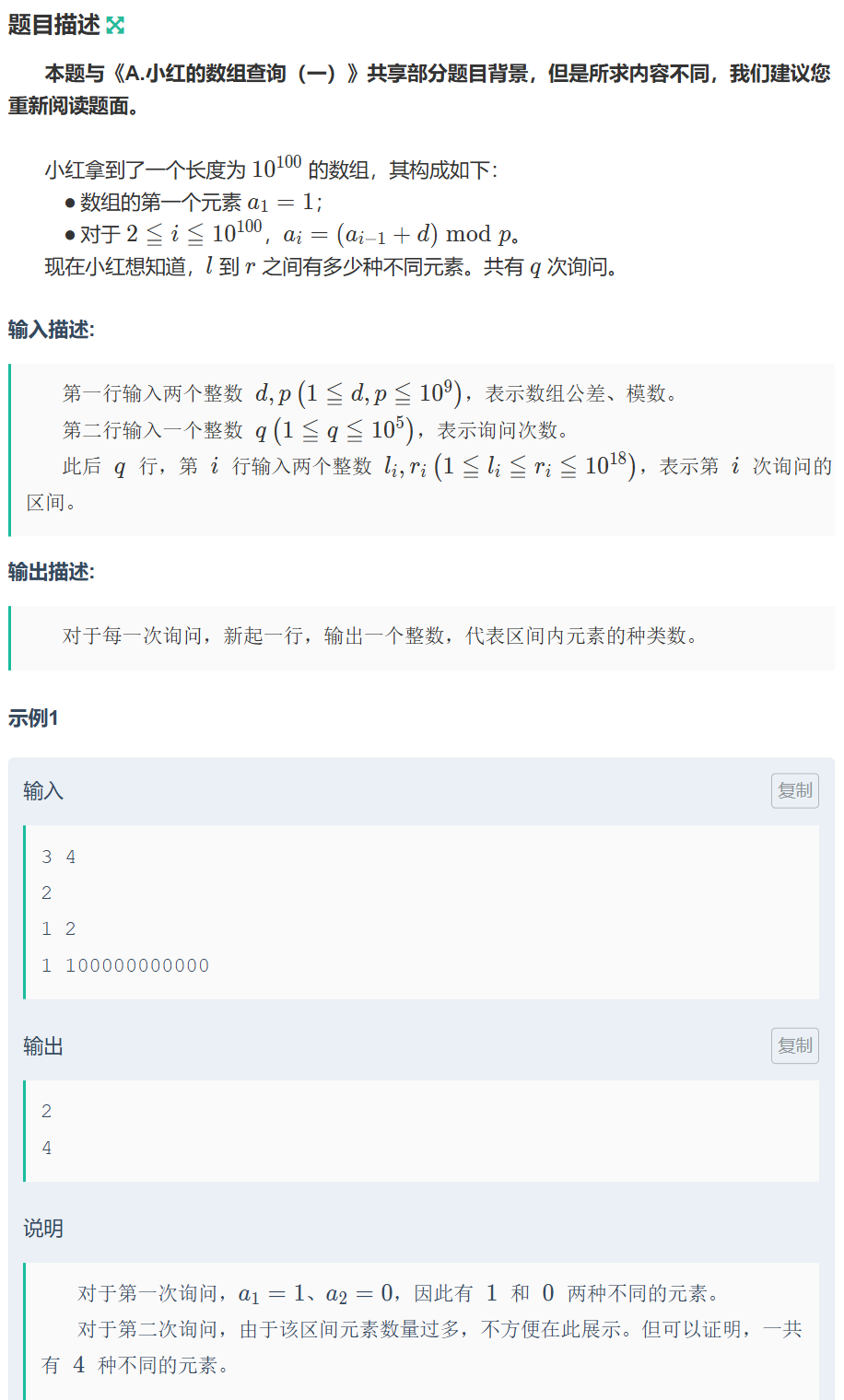
算法-数论
C-小红的数组查询(二)_牛客周赛 Round 95 思路:不难看出a数组是有循环的 d3,p4时,a数组:1、0、3、2、1、0、3、2....... 最小循环节为4,即最多4种不同的数 d4,p6时,a数组:1、5、3、…...
详解)
原型对象(Prototype)详解
原型对象(Prototype)详解 一、核心概念 本质:每个 JavaScript 对象(除 null 外)都有的内置属性作用:实现对象间的属性/方法继承(原型继承)存储位置:[[Prototype]] 内部属性(通过 __proto__ 或 Object.getPrototypeOf() 访问)二、关键特性图示 对象实例 (obj)│├─…...

MongoDB账号密码笔记
先连接数据库,新增用户密码 admin用户密码 use admin db.createUser({ user: "admin", pwd: "yourStrongPassword", roles: [ { role: "root", db: "admin" } ] })用户数据库用户密码 use myappdb db.createUser({ user: &…...

SQL导出Excel支持正则脱敏
SQL to Excel Exporter 源码功能特性核心功能性能优化安全特性 快速开始环境要求安装运行 API 使用说明1. 执行SQL并导出Excel2. 下载导出文件3. 获取统计信息4. 清理过期文件 数据脱敏配置支持的脱敏类型脱敏规则配置示例 配置说明应用配置数据库配置 测试运行单元测试运行集成…...

05.查询表
查询表 字段显示可以使用别名: col1 AS alias1, col2 AS alias2, … WHERE子句:指明过滤条件以实现“选择"的功能: 过滤条件: 布尔型表达式算术操作符:,-,*,/,%比较操作符:,<>(相等或都为空),<>,!(非标准SQL),>,>,<,<范围查询: BETWEEN min_num …...

基于深度强化学习的智能机器人导航系统
前言 随着人工智能技术的飞速发展,机器人在日常生活和工业生产中的应用越来越广泛。其中,机器人导航技术是实现机器人自主移动的关键。传统的导航方法依赖于预设的地图和路径规划算法,但在复杂的动态环境中,这些方法往往难以适应。…...

【第三十九周】ViLT
ViLT 摘要Abstract文章信息介绍提取视觉特征的方式的演变模态融合的两种方式四种不同的 VLP 模型Q&A 方法模型结构目标函数Whole Word Masking(WWM) 实验结果总结 摘要 本篇博客介绍了ViLT(Vision-and-Language Transformer)…...
代码随想录算法训练营第60期第六十天打卡
大家好,今天因为有数学建模比赛的校赛,今天的文章可能会简单一点,望大家原谅,我们昨天主要讲的是并查集的题目,我们复习了并查集的功能,我们昨天的题目其实难度不小,尤其是后面的有向图…...

数据结构——D/串
一、串的定义和基本操作  1. 串的定义   1)串的概念   组成结构: 串是由零个或多个字符组成的有限序列,记为 S′a1a2⋯an′Sa_1a_2\cdots a_nS′a1a2⋯an′&#x…...

瀚文机械键盘固件开发详解:HWKeyboard.cpp文件解析与应用
🔥 机械键盘固件开发从入门到精通:HWKeyboard模块全解析 作为一名嵌入式开发老司机,今天带大家拆解一个完整的机械键盘固件代码。即使你是单片机小白,看完这篇教程也能轻松理解机械键盘的工作原理,甚至自己动手复刻一…...

Nginx+Tomcat负载均衡与动静分离架构
目录 简介 一、Tomcat基础部署与配置 1.1 Tomcat应用场景与特性 1.2 环境准备与安装 1.3 Tomcat主配置文件详解 1.4 部署Java Web站点 二、NginxTomcat负载均衡群集搭建 2.1 架构设计与原理 2.2 环境准备 2.3 Tomcat2配置(与Tomcat1对称) 2.4…...
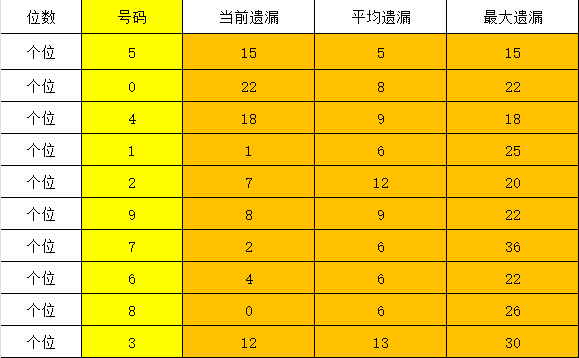
AI+预测3D新模型百十个定位预测+胆码预测+去和尾2025年6月8日第102弹
从今天开始,咱们还是暂时基于旧的模型进行预测,好了,废话不多说,按照老办法,重点8-9码定位,配合三胆下1或下2,杀1-2个和尾,再杀4-5个和值,可以做到100-300注左右。 (1)定…...

LeetCode--25.k个一组翻转链表
解题思路: 1.获取信息: (1)给定一个链表,每k个结点一组进行翻转 (2)余下不足k个结点,则不进行交换 2.分析题目: 其实就是24题的变题,24题是两两一组进行交换&…...