循环神经网络(RNN):从理论到翻译
循环神经网络(RNN)是一种专为处理序列数据设计的神经网络,如时间序列、自然语言或语音。与传统的全连接神经网络不同,RNN具有"记忆"功能,通过循环传递信息,使其特别适合需要考虑上下文或顺序的任务。它出现在Transformer之前,广泛应用于文本生成、语音识别和时间序列预测(如股价预测)等领域。
RNN的数学基础
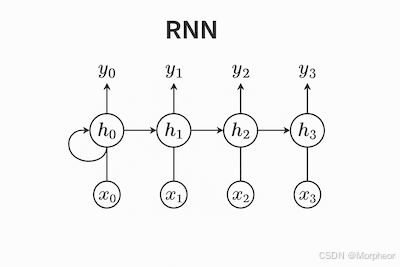
核心方程
在每个时间步 t t t,RNN执行以下操作:
-
隐藏状态更新:
h t = tanh ( W h h h t − 1 + W x h x t + b h ) h_t = \text{tanh}(W_{hh}h_{t-1} + W_{xh}x_t + b_h) ht=tanh(Whhht−1+Wxhxt+bh)- h t h_t ht: 时间 t t t的新隐藏状态(形状:
[hidden_size]) - h t − 1 h_{t-1} ht−1: 前一个隐藏状态(形状:
[hidden_size]) - x t x_t xt: 时间 t t t的输入(形状:
[input_size]) - W h h W_{hh} Whh: 隐藏到隐藏的权重矩阵(形状:
[hidden_size, hidden_size]) - W x h W_{xh} Wxh: 输入到隐藏的权重矩阵(形状:
[hidden_size, input_size]) - b h b_h bh: 隐藏层偏置项(形状:
[hidden_size]) - tanh \text{tanh} tanh: 双曲正切激活函数
- h t h_t ht: 时间 t t t的新隐藏状态(形状:
-
输出计算:
o t = W h y h t + b y o_t = W_{hy}h_t + b_y ot=Whyht+by- o t o_t ot: 时间 t t t的输出(形状:
[output_size]) - W h y W_{hy} Why: 隐藏到输出的权重矩阵(形状:
[output_size, hidden_size]) - b y b_y by: 输出偏置项(形状:
[output_size])
- o t o_t ot: 时间 t t t的输出(形状:
随时间反向传播(BPTT)
RNN使用BPTT进行训练,它通过时间展开网络并应用链式法则:
∂ L ∂ W = ∑ t = 1 T ∂ L t ∂ o t ∂ o t ∂ h t ∑ k = 1 t ( ∏ i = k + 1 t ∂ h i ∂ h i − 1 ) ∂ h k ∂ W \frac{\partial L}{\partial W} = \sum_{t=1}^T \frac{\partial L_t}{\partial o_t} \frac{\partial o_t}{\partial h_t} \sum_{k=1}^t \left( \prod_{i=k+1}^t \frac{\partial h_i}{\partial h_{i-1}} \right) \frac{\partial h_k}{\partial W} ∂W∂L=t=1∑T∂ot∂Lt∂ht∂otk=1∑t(i=k+1∏t∂hi−1∂hi)∂W∂hk
这可能导致梯度消失/爆炸问题,LSTM和GRU架构可以解决这个问题。
GRU:门控循环单元
在深入翻译示例之前,让我们先了解GRU的数学基础。GRU通过门控机制解决了标准RNN中的梯度消失问题。
GRU方程
在每个时间步 t t t,GRU计算以下内容:
-
更新门 ( z t z_t zt):
z t = σ ( W z ⋅ [ h t − 1 , x t ] + b z ) z_t = \sigma(W_z \cdot [h_{t-1}, x_t] + b_z) zt=σ(Wz⋅[ht−1,xt]+bz)- z t z_t zt: 更新门(形状:
[hidden_size]) - W z W_z Wz: 更新门的权重矩阵(形状:
[hidden_size, hidden_size + input_size]) - b z b_z bz: 更新门的偏置项(形状:
[hidden_size]) - h t − 1 h_{t-1} ht−1: 前一个隐藏状态
- x t x_t xt: 当前输入
- σ \sigma σ: Sigmoid激活函数(将值压缩到0和1之间)
更新门决定保留多少之前的隐藏状态。
- z t z_t zt: 更新门(形状:
-
重置门 ( r t r_t rt):
r t = σ ( W r ⋅ [ h t − 1 , x t ] + b r ) r_t = \sigma(W_r \cdot [h_{t-1}, x_t] + b_r) rt=σ(Wr⋅[ht−1,xt]+br)- r t r_t rt: 重置门(形状:
[hidden_size]) - W r W_r Wr: 重置门的权重矩阵(形状:
[hidden_size, hidden_size + input_size]) - b r b_r br: 重置门的偏置项(形状:
[hidden_size])
重置门决定忘记多少之前的隐藏状态。
- r t r_t rt: 重置门(形状:
-
候选隐藏状态 ( h ~ t \tilde{h}_t h~t):
h ~ t = tanh ( W ⋅ [ r t ⊙ h t − 1 , x t ] + b ) \tilde{h}_t = \text{tanh}(W \cdot [r_t \odot h_{t-1}, x_t] + b) h~t=tanh(W⋅[rt⊙ht−1,xt]+b)- h ~ t \tilde{h}_t h~t: 候选隐藏状态(形状:
[hidden_size]) - W W W: 候选状态的权重矩阵(形状:
[hidden_size, hidden_size + input_size]) - b b b: 偏置项(形状:
[hidden_size]) - ⊙ \odot ⊙: 逐元素乘法(哈达玛积)
这表示可能使用的新隐藏状态内容。
- h ~ t \tilde{h}_t h~t: 候选隐藏状态(形状:
-
最终隐藏状态 ( h t h_t ht):
h t = ( 1 − z t ) ⊙ h t − 1 + z t ⊙ h ~ t h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t ht=(1−zt)⊙ht−1+zt⊙h~t- 最终隐藏状态是前一个隐藏状态和候选状态的组合
- z t z_t zt作为新旧信息之间的插值因子
GRU在翻译中的优势
-
更新门
- 在英中翻译中,这有助于决定:
- 保留多少上下文(例如,保持句子的主语)
- 更新多少新信息(例如,遇到新词时)
- 在英中翻译中,这有助于决定:
-
重置门
- 帮助忘记不相关的信息
- 例如,在翻译新句子时,可以重置前一个句子的上下文
-
梯度流动
- 最终隐藏状态计算中的加法更新( + + +)有助于保持梯度流动
- 这对于学习翻译任务中的长程依赖关系至关重要
简单的RNN示例
这个简化示例训练一个RNN来预测单词"hello"中的下一个字符。
-
模型定义:
nn.RNN处理循环计算- 全连接层(
fc)将隐藏状态映射到输出(字符预测)
-
数据:
- 使用"hell"作为输入,期望输出为"ello"(序列移位)
- 字符转换为one-hot向量(例如,‘h’ → [1, 0, 0, 0])
-
训练:
- 通过最小化预测字符和目标字符之间的交叉熵损失来学习
-
预测:
- 训练后,模型可以预测下一个字符
import torch
import torch.nn as nnclass SimpleRNN(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(SimpleRNN, self).__init__()self.hidden_size = hidden_sizeself.rnn = nn.RNN(input_size, hidden_size, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x, hidden):out, hidden = self.rnn(x, hidden)out = self.fc(out)return out, hiddendef init_hidden(self, batch_size):return torch.zeros(1, batch_size, self.hidden_size)# 超参数
input_size = 4 # 唯一字符数 (h, e, l, o)
hidden_size = 8 # 隐藏状态大小
output_size = 4 # 与input_size相同
learning_rate = 0.01# 字符词汇表
chars = ['h', 'e', 'l', 'o']
char_to_idx = {ch: i for i, ch in enumerate(chars)}
idx_to_char = {i: ch for i, ch in enumerate(chars)}# 输入数据:"hell" 预测 "ello"
input_seq = "hell"
target_seq = "ello"# 转换为one-hot编码
def to_one_hot(seq):tensor = torch.zeros(1, len(seq), input_size) # [batch_size, seq_len, input_size]for t, char in enumerate(seq):tensor[0][t][char_to_idx[char]] = 1 # 批大小为1return tensor# 准备输入和目标张量
input_tensor = to_one_hot(input_seq) # 形状: [1, 4, 4]
print("输入张量形状:", input_tensor.shape)
target_tensor = torch.tensor([char_to_idx[ch] for ch in target_seq], dtype=torch.long) # 形状: [4]# 初始化模型、损失函数和优化器
model = SimpleRNN(input_size, hidden_size, output_size)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)# 训练循环
for epoch in range(100):hidden = model.init_hidden(1) # 批大小为1print("隐藏状态形状:", hidden.shape) # 应该是 [1, 1, 8]optimizer.zero_grad()output, hidden = model(input_tensor, hidden) # 输出: [1, 4, 4], 隐藏: [1, 1, 8]loss = criterion(output.squeeze(0), target_tensor) # output.squeeze(0): [4, 4], target: [4]loss.backward()optimizer.step()if epoch % 20 == 0:print(f'轮次 {epoch}, 损失: {loss.item():.4f}')# 测试模型
with torch.no_grad():hidden = model.init_hidden(1)
英中翻译示例
我们将使用PyTorch的GRU(门控循环单元)构建一个简单的英中翻译模型,GRU是RNN的一种变体,能更好地处理长程依赖关系。
1. 数据准备
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np# 样本平行语料(英文 -> 中文)
english_sentences = ["hello", "how are you", "i love machine learning","good morning", "artificial intelligence"
]chinese_sentences = ["你好", "你好吗", "我爱机器学习","早上好", "人工智能"
]# 创建词汇表
eng_chars = sorted(list(set(' '.join(english_sentences))))
zh_chars = sorted(list(set(''.join(chinese_sentences))))# 添加特殊标记
SOS_token = 0 # 句子开始
EOS_token = 1 # 句子结束
eng_chars = ['<SOS>', '<EOS>', '<PAD>'] + eng_chars
zh_chars = ['<SOS>', '<EOS>', '<PAD>'] + zh_chars# 创建词到索引的映射
eng_to_idx = {ch: i for i, ch in enumerate(eng_chars)}
zh_to_idx = {ch: i for i, ch in enumerate(zh_chars)}# 将句子转换为张量
def sentence_to_tensor(sentence, vocab, is_target=False):indices = [vocab[ch] for ch in (sentence if not is_target else sentence)]if is_target:indices.append(EOS_token) # 为目标添加EOS标记return torch.tensor(indices, dtype=torch.long).view(-1, 1)
2. 模型架构
class Seq2Seq(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(Seq2Seq, self).__init__()self.hidden_size = hidden_size# 编码器(英文到隐藏状态)self.embedding = nn.Embedding(input_size, hidden_size)self.gru = nn.GRU(hidden_size, hidden_size)# 解码器(隐藏状态到中文)self.out = nn.Linear(hidden_size, output_size)self.softmax = nn.LogSoftmax(dim=1)def forward(self, input_seq, hidden=None, max_length=10):# 编码器embedded = self.embedding(input_seq).view(1, 1, -1)output, hidden = self.gru(embedded, hidden)# 解码器decoder_input = torch.tensor([[SOS_token]], device=input_seq.device)decoder_hidden = hiddendecoded_words = []for _ in range(max_length):output, decoder_hidden = self.gru(self.embedding(decoder_input).view(1, 1, -1),decoder_hidden)output = self.softmax(self.out(output[0]))topv, topi = output.topk(1)if topi.item() == EOS_token:breakdecoded_words.append(zh_chars[topi.item()])decoder_input = topi.detach()return ''.join(decoded_words), decoder_hiddendef init_hidden(self):return torch.zeros(1, 1, self.hidden_size)
3. 训练模型
# 超参数
hidden_size = 256
learning_rate = 0.01
n_epochs = 1000# 初始化模型
model = Seq2Seq(len(eng_chars), hidden_size, len(zh_chars))
criterion = nn.NLLLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)# 训练循环
for epoch in range(n_epochs):total_loss = 0for eng_sent, zh_sent in zip(english_sentences, chinese_sentences):# 准备数据input_tensor = sentence_to_tensor(eng_sent, eng_to_idx)target_tensor = sentence_to_tensor(zh_sent, zh_to_idx, is_target=True)# 前向传播model.zero_grad()hidden = model.init_hidden()# 编码器前向传播embedded = model.embedding(input_tensor).view(len(input_tensor), 1, -1)_, hidden = model.gru(embedded, hidden)# 准备解码器decoder_input = torch.tensor([[SOS_token]])decoder_hidden = hiddenloss = 0# 教师强制:使用目标作为下一个输入for di in range(len(target_tensor)):output, decoder_hidden = model.gru(model.embedding(decoder_input).view(1, 1, -1),decoder_hidden)output = model.out(output[0])loss += criterion(output, target_tensor[di])decoder_input = target_tensor[di]# 反向传播和优化loss.backward()optimizer.step()total_loss += loss.item() / len(target_tensor)# 打印进度if (epoch + 1) % 100 == 0:print(f'轮次 {epoch + 1}, 平均损失: {total_loss / len(english_sentences):.4f}')# 测试翻译
def translate(sentence):with torch.no_grad():input_tensor = sentence_to_tensor(sentence.lower(), eng_to_idx)output_words, _ = model(input_tensor)return output_words# 示例翻译
print("\n翻译结果:")
print(f"'hello' -> '{translate('hello')}'")
print(f"'how are you' -> '{translate('how are you')}'")
print(f"'i love machine learning' -> '{translate('i love machine learning')}'")
4. 理解输出
训练后,模型应该能够将简单的英文短语翻译成中文。例如:
-
输入: “hello”
- 输出: “你好”
-
输入: “how are you”
- 输出: “你好吗”
-
输入: “i love machine learning”
- 输出: “我爱机器学习”
5. 关键组件解释
-
嵌入层:
- 将离散的词索引转换为连续向量
- 捕捉词与词之间的语义关系
-
GRU(门控循环单元):
- 使用更新门和重置门控制信息流
- 解决标准RNN中的梯度消失问题
-
教师强制:
- 在训练过程中使用目标输出作为下一个输入
- 帮助模型更快地学习正确的翻译
-
束搜索:
- 可以用于提高翻译质量
- 在解码过程中跟踪多个可能的翻译
6. 挑战与改进
-
处理变长序列:
- 使用填充和掩码
- 实现注意力机制以获得更好的对齐
-
词汇表大小:
- 使用子词单元(如Byte Pair Encoding, WordPiece)
- 实现指针生成网络处理稀有词
-
性能:
- 使用双向RNN增强上下文理解
- 实现Transformer架构以实现并行处理
这个示例为使用RNN进行序列到序列学习提供了基础。对于生产系统,建议使用基于Transformer的模型(如BART或T5),这些模型在机器翻译任务中表现出色。
相关文章:
循环神经网络(RNN):从理论到翻译
循环神经网络(RNN)是一种专为处理序列数据设计的神经网络,如时间序列、自然语言或语音。与传统的全连接神经网络不同,RNN具有"记忆"功能,通过循环传递信息,使其特别适合需要考虑上下文或顺序的任…...

Redis:常用数据结构 单线程模型
🌈 个人主页:Zfox_ 🔥 系列专栏:Redis 🔥 常用数据结构 🐳 Redis 当中常用的数据结构如下所示: Redis 在底层实现上述数据结构的过程中,会在源码的角度上对于上述的内容进行特定的…...

夏普比率(Sharpe ratio)
具有投资常识的人都明白,投资光看收益是不够的,还要看承受的风险,也就是收益风险比。 夏普比率描述的正是这个概念,即每承受一单位的总风险,会产生多少超额的报酬。 用数学公式描述就是: 其中࿱…...

【优选算法】模拟 问题算法
一:替换所有的问号 class Solution { public:string modifyString(string s) {int n s.size();for(int i 0; i < n; i){if(s[i] ?){for(char ch a; ch < z; ch){if((i0 && ch !s[i1]) || (in-1 && ch ! s[i-1]) || ( i>0 &&…...

Flask+LayUI开发手记(八):通用封面缩略图上传实现
前一节做了头像上传的程序,应该说,这个程序编写和操作都相当繁琐,实际上,头像这种缩略图在很多功能中都会用到,屏幕界面有限,绝不会给那么大空间摆开那么大一个界面,更可能的处理,就…...
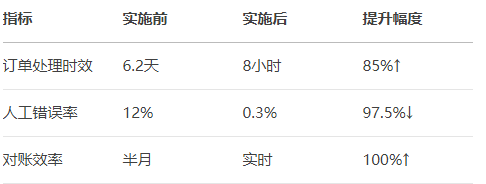
低代码采购系统搭建:鲸采云+能源行业订单管理自动化案例
在能源行业数字化转型浪潮下,某大型能源集团通过鲸采云低代码平台,仅用3周时间就完成了采购订单管理系统的定制化搭建。本文将揭秘这一成功案例的实施路径与关键成效。 项目背景与挑战 该企业面临: 供应商分散:200供应商使用不同…...

android关于pthread的使用过程
文章目录 简介代码流程pthread使用hello_test.cppAndroid.bp 编译过程报错处理验证过程 简介 android开发经常需要使用pthread来编写代码实现相关的业务需求 代码流程 pthread使用 需要查询某个linux函数的方法使用,可以使用man 函数名 // $ man pthread_crea…...

Faiss vs Milvus 深度对比:向量数据库技术选型指南
Faiss vs Milvus 深度对比:向量数据库技术选型指南 引言:向量数据库的时代抉择 在AI应用爆发的今天,企业和开发者面临着如何存储和检索海量向量数据的重大技术选择。作为当前最受关注的两大解决方案,Faiss和Milvus代表了两种不同…...
分析)
慢慢欣赏linux 之 last = switch_to(prev, next)分析
last switch_to(prev, next); 为什么需要定义last作为调用switch_to之前的prev的引用 原因如下: struct task_struct * switch_to(struct task_struct *prev,struct task_struct *next) {... ...return cpu_switch_to(prev, next);> .global cpu_switch_tocpu_…...
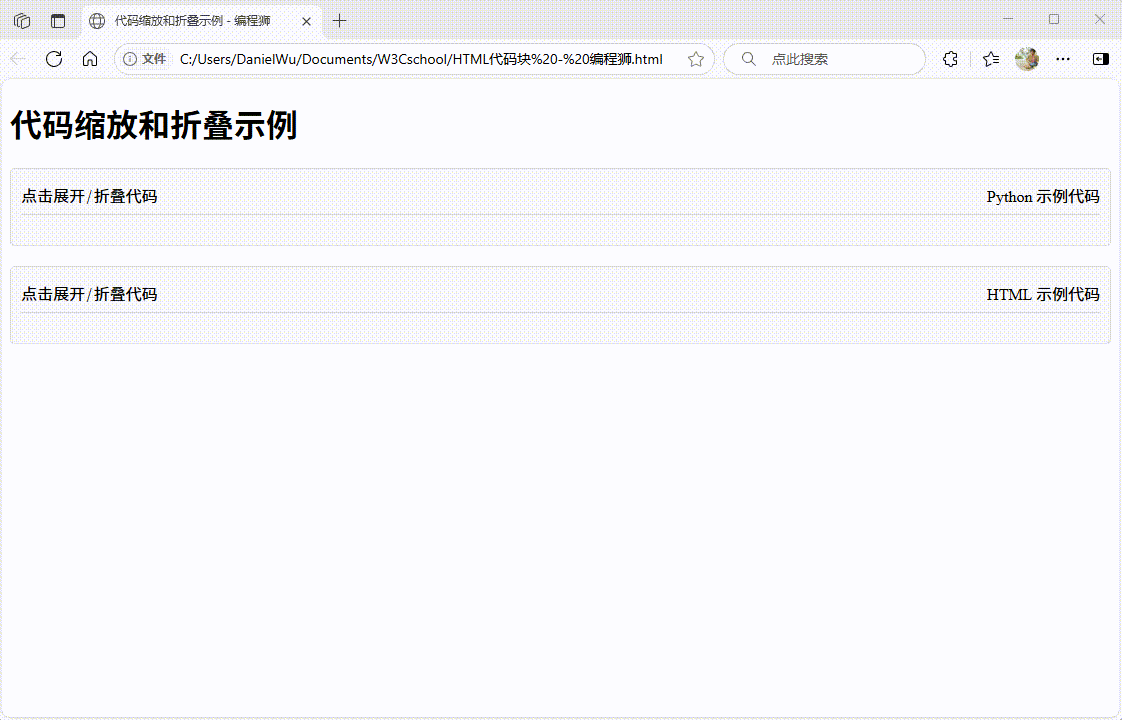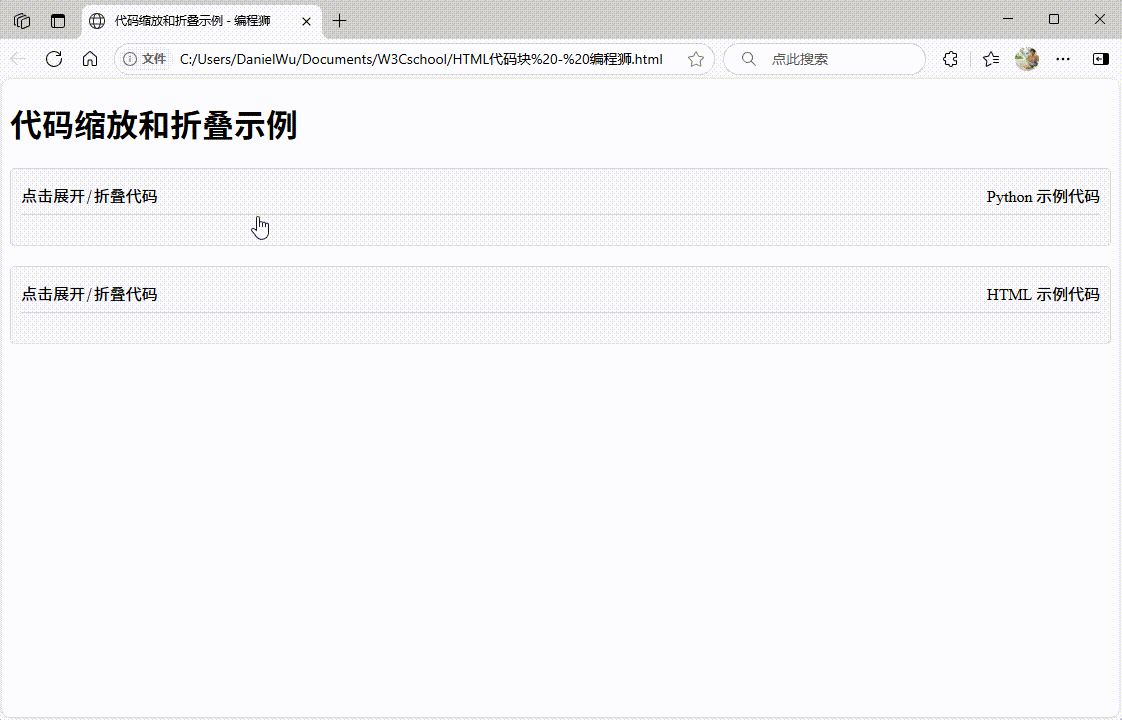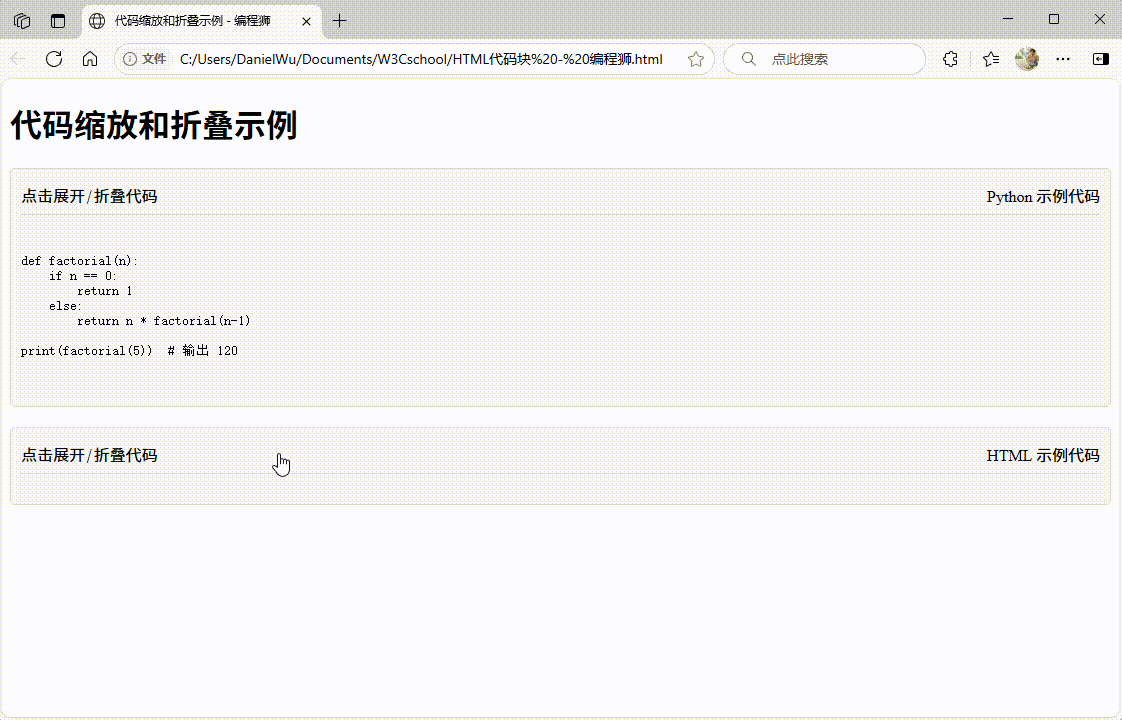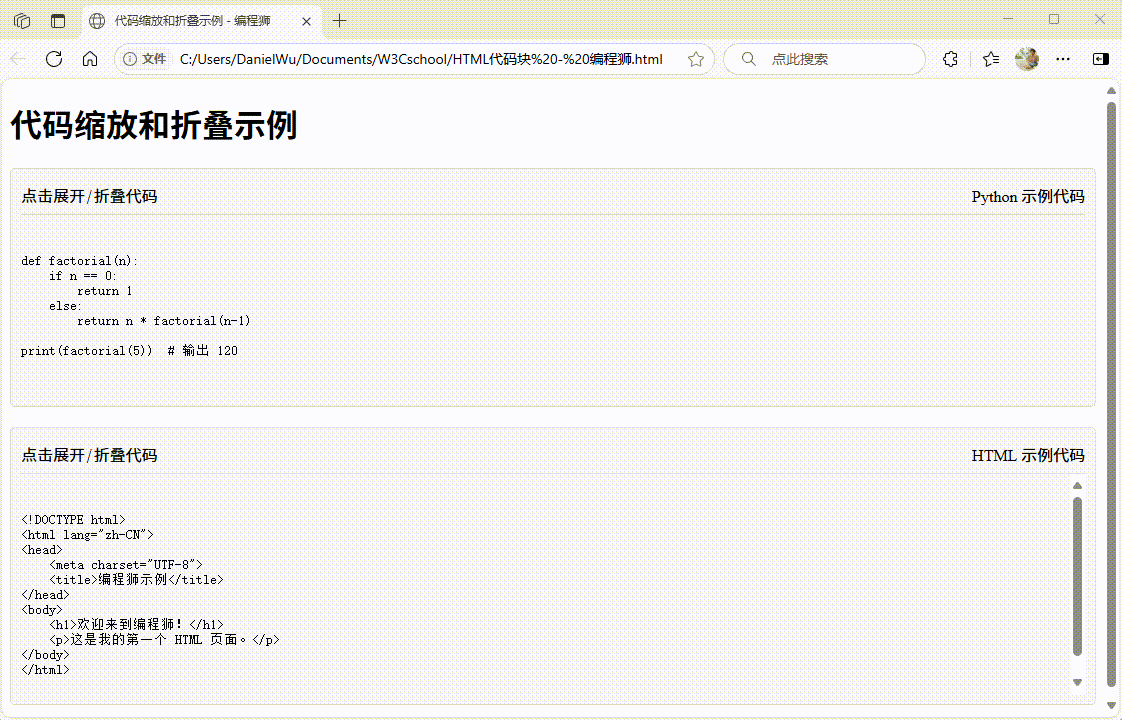
如何用 HTML 展示计算机代码
原文:如何用 HTML 展示计算机代码 | w3cschool笔记 (请勿将文章标记为付费!!!!) 在编程学习和文档编写过程中,清晰地展示代码是一项关键技能。HTML 作为网页开发的基础语言&#x…...
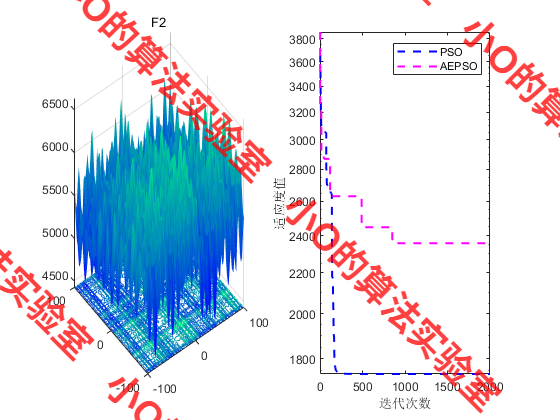
2025年ESWA SCI1区TOP,自适应学习粒子群算法AEPSO+动态周期调节灰色模型,深度解析+性能实测
目录 1.摘要2.粒子群算法PSO原理3.改进策略4.结果展示5.参考文献6.代码获取7.算法辅导应用定制读者交流 1.摘要 能源数据的科学预测对于能源行业决策和国家经济发展具有重要意义,尤其是短期能源预测,其精度直接影响经济运行效率。为了更好地提高预测模型…...
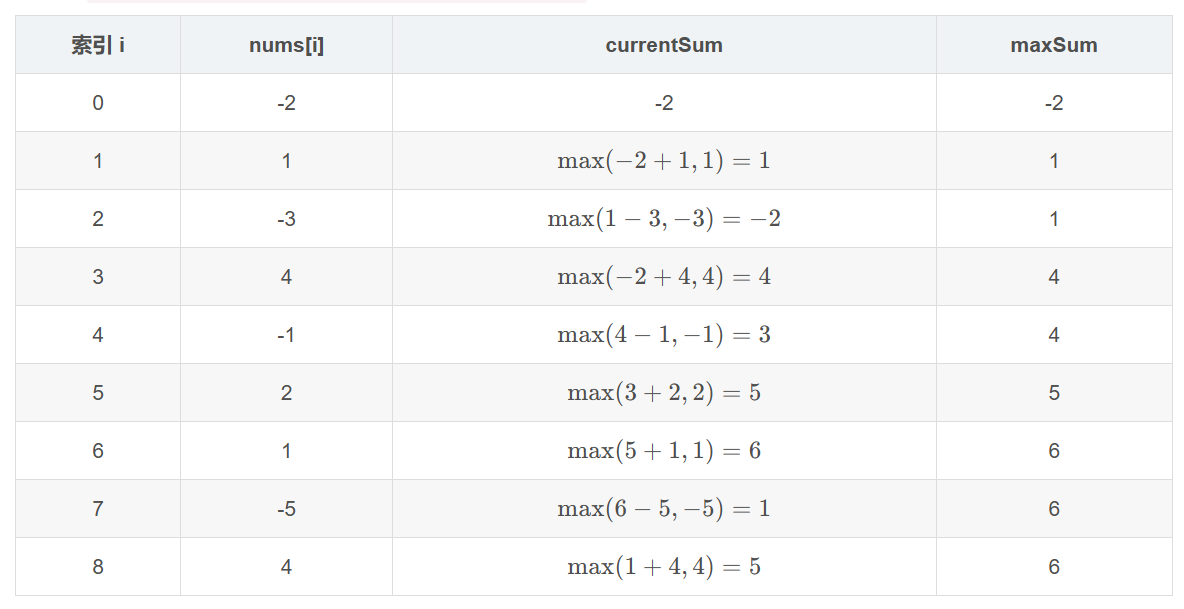
LeetCode - 53. 最大子数组和
目录 题目 Kadane 算法核心思想 Kadane 算法的步骤分析 读者可能的错误写法 正确的写法 题目 53. 最大子数组和 - 力扣(LeetCode) Kadane 算法核心思想 定义状态变量: currentSum: 表示以当前元素为结束的子数组的最大和。 maxSum: 记录全局最大…...
)
稻米分类和病害检测数据集(猫脸码客第237期)
稻米分类图像数据集:驱动农业智能化发展的核心资源 引言 在全球农业体系中,稻米作为最关键的粮食作物之一,其品种多样性为人类饮食提供了丰富选择。然而,传统稻米分类方法高度依赖人工经验,存在效率低、主观性强等缺…...
深度解析)
DOM(文档对象模型)深度解析
DOM(文档对象模型)深度解析 DOM 是 HTML/XML 文档的树形结构表示,提供了一套让 JavaScript 动态操作网页内容、结构和样式的接口。 一、DOM 核心概念 1. 节点(Node)类型 类型值说明示例ELEMENT_NODE1元素节点<div>, <p>TEXT_NODE3文本节点元素内的文字COMMEN…...

四、Sqoop 导入表数据子集
作者:IvanCodes 日期:2025年6月4日 专栏:Sqoop教程 当不需要将关系型数据库中的整个表一次性导入,而是只需要表中的一部分数据时,Sqoop 提供了多种方式来实现数据子集的导入。这通常通过过滤条件或选择特定列来完成。 …...
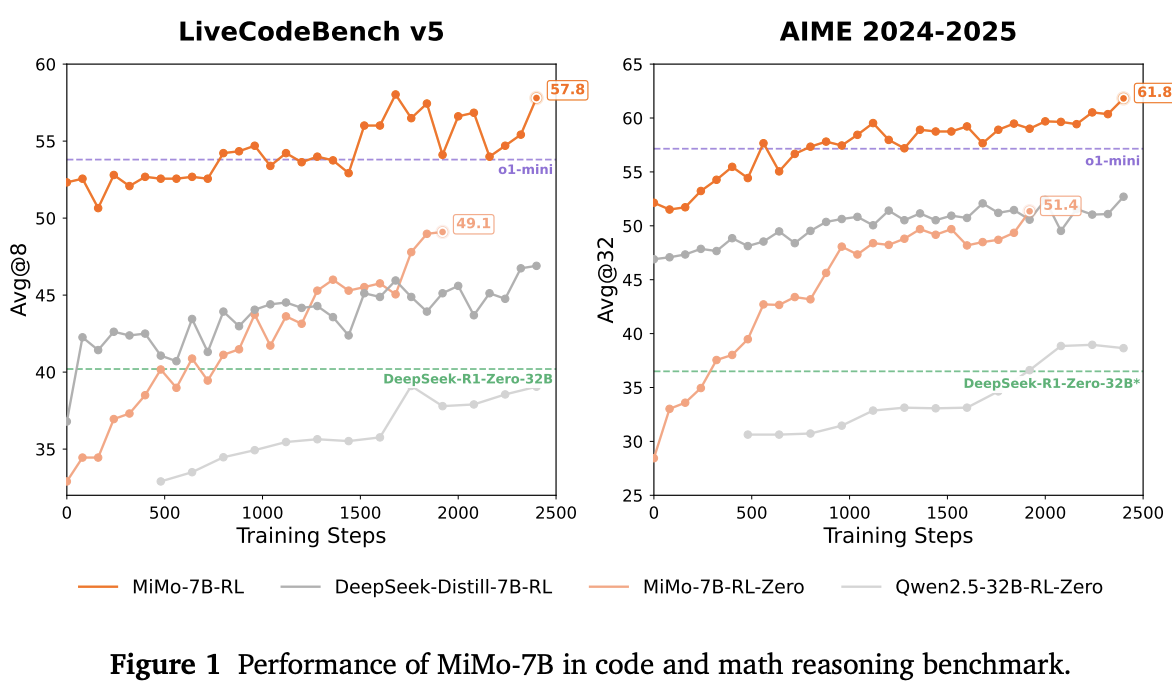
【读代码】从预训练到后训练:解锁语言模型推理潜能——Xiaomi MiMo项目深度解析
项目开源地址:https://github.com/XiaomiMiMo/MiMo 一、基本介绍 Xiaomi MiMo是小米公司开源的7B参数规模语言模型系列,专为复杂推理任务设计。项目包含基础模型(MiMo-7B-Base)、监督微调模型(MiMo-7B-SFT)和强化学习模型(MiMo-7B-RL)等多个版本。其核心创新在于通过…...
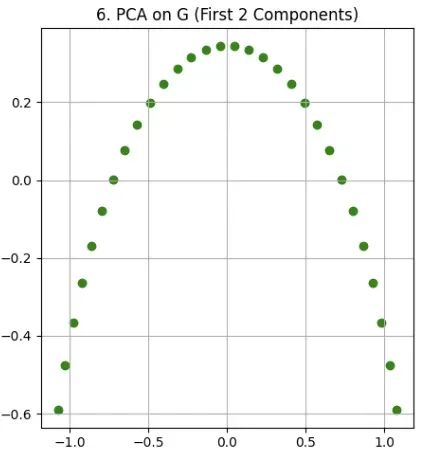
DROPP算法详解:专为时间序列和空间数据优化的PCA降维方案
DROPP (Dimensionality Reduction for Ordered Points via PCA) 是一种专门针对有序数据的降维方法。本文将详细介绍该算法的理论基础、实现步骤以及在降维任务中的具体应用。 在现代数据分析中,高维数据集普遍存在特征数量庞大的问题。这种高维特性不仅增加了计算…...

DeepSeek11-Ollama + Open WebUI 搭建本地 RAG 知识库全流程指南
🛠️ Ollama Open WebUI 搭建本地 RAG 知识库全流程指南 💻 一、环境准备 # 1. 安装 Docker 和 Docker Compose sudo apt update && sudo apt install docker.io docker-compose -y# 2. 添加用户到 docker 组(避免 sudo 权限&…...
【AI大模型】Transformer架构到底是什么?
引言 —— 想象一台能瞬间读懂整本《战争与和平》、精准翻译俳句中的禅意、甚至为你的设计草图生成前端代码的机器——这一切并非科幻,而是过去七年AI领域最震撼的技术革命:Transformer架构创造的奇迹。 当谷歌在2017年揭开Transformer的神秘面纱时&…...

code-server安装使用,并配置frp反射域名访问
为什么使用 code-server是VSCode网页版开发软件,可以在浏览器访问编程,可以使用vscode中的插件。如果有自己的服务器,使用frp透传后,域名访问在线编程,使用方便,打开的服务端口不需要单独配置,可…...
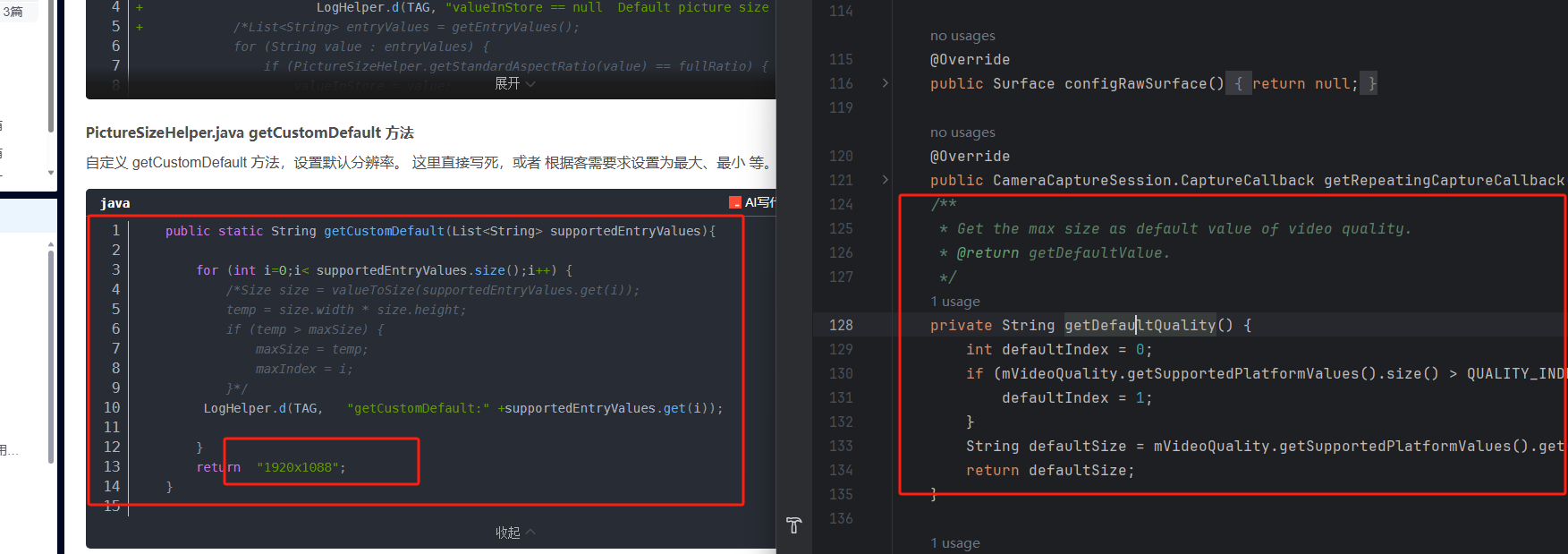
MTK-Android12-13 Camera2 设置默认视频画质功能实现
MTK-Android12-13 Camera2 设置默认视频画质功能实现 场景:部分客户使用自己的mipi相机安装到我们主板上,最大分辨率为1280720,但是视频画质默认的是640480。实际场景中,在默认视频分辨率情况下拍出来的视频比较模糊、预览也不清晰…...
)
Kafka 消息模式实战:从简单队列到流处理(一)
一、Kafka 简介 ** Kafka 是一种分布式的、基于发布 / 订阅的消息系统,由 LinkedIn 公司开发,并于 2011 年开源,后来成为 Apache 基金会的顶级项目。它最初的设计目标是处理 LinkedIn 公司的海量数据,如用户活动跟踪、消息传递和…...
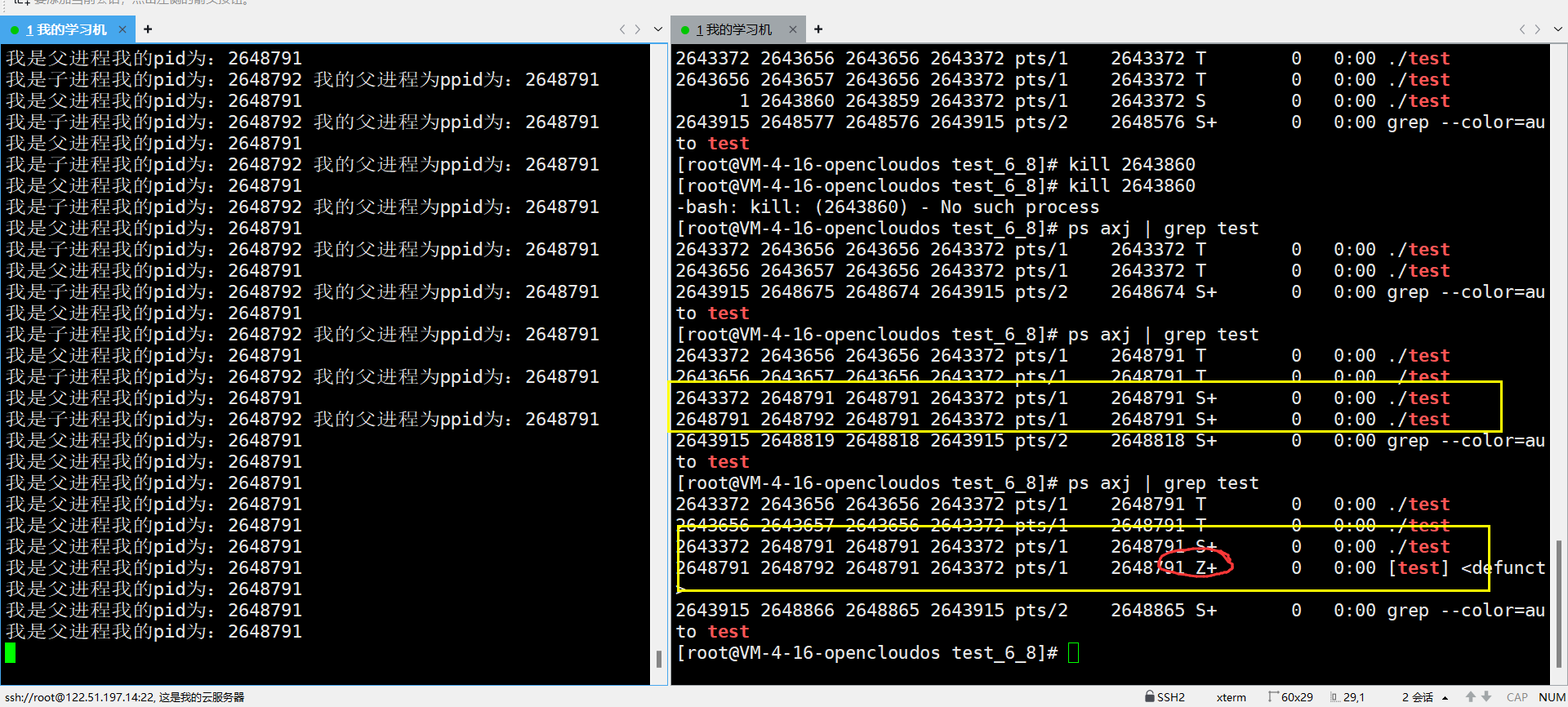
Linux知识回顾总结----进程状态
本章将会介绍进程的一些概念:冯诺伊曼体系结构、进程是什么,怎么用、怎么表现得、进程空间地址、物理地址、虚拟地址、为什么存在进程空间地址、如何感性得去理解进程空间地址、环境变量是如何使用的。 目录 1. 冯诺伊曼体系结构 1.1 是什么 1.2 结论 …...
Linux 进程管理学习指南:架构、计划与关键问题全解
Linux 进程管理学习指南:架构、计划与关键问题全解 本文面向初学者,旨在帮助你从架构视角理解 Linux 进程管理子系统,构建系统化学习路径,并通过结构化笔记方法与典型问题总结,夯实基础、明确方向,逐步掌握…...
)
【异常】极端事件的概率衰减方式(指数幂律衰减)
在日常事件中,极端事件的概率衰减方式并非单一模式,而是取决于具体情境和数据生成机制。以下是科学依据和不同衰减形式的分析: 1. 指数衰减(Exponential Decay) 典型场景:当事件服从高斯分布(正态分布)或指数分布时,极端事件的概率呈指数衰减。 数学形式:概率密度函数…...

Git 使用大全:从入门到精通
Git 是目前最流行的分布式版本控制系统,被广泛应用于软件开发中。本文将全面介绍 Git 的各种功能和使用方法,包含大量代码示例和实践建议。 文章目录 Git 基础概念版本控制系统Git 的特点Git 的三个区域Git 文件状态 Git 安装与配置安装 GitLinuxmacOSWi…...
奈飞工厂官网,国内Netflix影视在线看|中文网页电脑版入口
奈飞工厂是一个专注于提供免费Netflix影视资源的在线播放平台,致力于为国内用户提供的Netflix热门影视内容。该平台的资源与Netflix官网基本同步,涵盖电影、电视剧、动漫和综艺等多个领域。奈飞工厂的界面简洁流畅,资源分类清晰,方…...
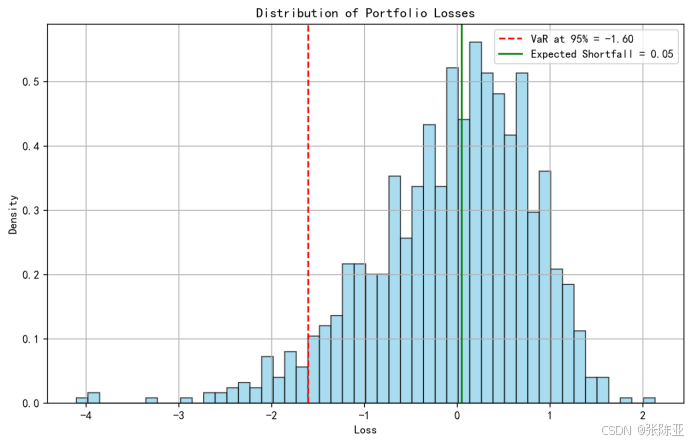
Python基于蒙特卡罗方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融投资中,风险管理是确保资产安全和实现稳健收益的关键环节。随着市场波动性的增加,传统…...

【bat win系统自动运行脚本-双击启动docker及其它】
win系统自动化运行脚本 创建一个 startup.bat右键编辑,输入以下示例 echo off start "" "C:\Program Files\Docker\Docker\Docker Desktop.exe"timeout /t 5docker start your_container_namestart cmd /k "conda activate your_conda_e…...

SpringBoot离线应用的5种实现方式
在当今高度依赖网络的环境中,离线应用的价值日益凸显。无论是在网络不稳定的区域运行的现场系统,还是需要在断网环境下使用的企业内部应用,具备离线工作能力已成为许多应用的必备特性。 本文将介绍基于SpringBoot实现离线应用的5种不同方式。…...