Spring Boot 与 Kafka 的深度集成实践(二)
3. 生产者实现
3.1 生产者配置
在 Spring Boot 项目中,配置 Kafka 生产者主要是配置生产者工厂(ProducerFactory)和 KafkaTemplate 。生产者工厂负责创建 Kafka 生产者实例,而 KafkaTemplate 则是用于发送消息的核心组件,它封装了生产者的发送逻辑,提供了简洁易用的方法来发送消息到 Kafka 集群 。
首先,创建一个配置类,用于配置生产者工厂和 KafkaTemplate。在 Spring Boot 中,可以通过@Configuration注解将一个类标记为配置类,然后使用@Bean注解来定义需要创建的 Bean。以下是配置生产者的 Java 代码示例:
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class KafkaProducerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
// Kafka服务器地址
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
// 生产者在收到服务器的确认之前需要等待的时间,0表示不等待,1表示等待leader确认,all表示等待所有副本确认
props.put(ProducerConfig.ACKS_CONFIG, "1");
// 消息发送失败时的重试次数
props.put(ProducerConfig.RETRIES_CONFIG, 0);
// 批量发送消息时,缓冲区的大小,单位是字节
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
// 生产者在发送消息之前等待更多消息进入缓冲区的时间,单位是毫秒
props.put(ProducerConfig.LINGER_MS_CONFIG, 1);
// 生产者用于缓存消息的总内存大小,单位是字节
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
// 键的序列化器
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
// 值的序列化器
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return props;
}
@Bean
public ProducerFactory<String, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
在上述代码中:
- producerConfigs方法用于配置 Kafka 生产者的属性。其中,bootstrapServers从application.properties或application.yml文件中读取 Kafka 服务器的地址;acks配置为1,表示生产者在发送消息后,只要收到 Kafka 集群中 leader 节点的确认,就认为消息发送成功;retries设置为0,表示消息发送失败时不进行重试;batchSize设置为16384字节,即当缓冲区达到这个大小后,生产者会将消息批量发送出去;lingerMs设置为1毫秒,生产者会在等待 1 毫秒后,即使缓冲区未满,也会将消息发送出去;bufferMemory设置为33554432字节,即生产者用于缓存消息的总内存大小;KEY_SERIALIZER_CLASS_CONFIG和VALUE_SERIALIZER_CLASS_CONFIG分别指定了键和值的序列化器为StringSerializer,用于将字符串类型的键和值序列化为字节数组,以便在网络中传输。
- producerFactory方法通过DefaultKafkaProducerFactory创建了一个生产者工厂,它使用producerConfigs方法返回的配置属性来创建 Kafka 生产者实例 。
- kafkaTemplate方法创建了一个 KafkaTemplate 实例,它依赖于producerFactory创建的生产者工厂,通过 KafkaTemplate,我们可以方便地发送消息到 Kafka 集群 。
3.2 发送消息
配置好生产者后,就可以使用 KafkaTemplate 来发送消息了。KafkaTemplate 提供了多种发送消息的方法,支持同步发送和异步发送,并且可以通过回调机制来处理消息发送的结果 。
同步发送消息
同步发送消息会阻塞当前线程,直到消息被成功发送或发送失败。以下是同步发送消息的代码示例:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;
@Service
public class KafkaProducerService {
private static final String TOPIC = "my-topic";
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
public void sendMessageSync(String message) {
kafkaTemplate.send(TOPIC, message).get();
}
}
在上述代码中,sendMessageSync方法使用kafkaTemplate.send(TOPIC, message)发送消息到指定的主题my-topic,然后调用get()方法阻塞当前线程,等待 Kafka 集群返回消息发送的结果。如果消息发送成功,get()方法会返回一个包含消息元数据(如分区号、偏移量等)的RecordMetadata对象;如果发送失败,get()方法会抛出异常,开发者可以通过捕获异常来处理发送失败的情况 。
异步发送消息
异步发送消息不会阻塞当前线程,生产者会立即返回,消息将在后台被发送到 Kafka 集群 。为了处理消息发送的结果,可以使用ListenableFuture和回调函数。以下是异步发送消息的代码示例:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Service;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
@Service
public class KafkaProducerService {
private static final String TOPIC = "my-topic";
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
public void sendMessageAsync(String message) {
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(TOPIC, message);
future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onSuccess(SendResult<String, String> result) {
System.out.println("消息发送成功:" + result.getRecordMetadata());
}
@Override
public void onFailure(Throwable ex) {
System.out.println("消息发送失败:" + ex.getMessage());
}
});
}
}
在上述代码中,sendMessageAsync方法使用kafkaTemplate.send(TOPIC, message)发送消息到指定主题,该方法返回一个ListenableFuture<SendResult<String, String>>对象 。通过调用future.addCallback方法,添加了一个回调函数,当消息发送成功时,会调用onSuccess方法,在方法中可以获取到消息的元数据,如分区号、偏移量等;当消息发送失败时,会调用onFailure方法,在方法中可以获取到发送失败的异常信息,以便进行相应的处理,比如记录日志、进行重试等 。
3.3 高级特性
Kafka 生产者还提供了一些高级特性,如事务管理、自定义分区、消息序列化优化等,这些特性可以满足更复杂的业务需求 。
事务管理
Kafka 的事务功能可以确保在一个事务中发送的所有消息要么全部成功,要么全部失败,从而保证数据的一致性 。在 Spring Boot 中使用 Kafka 的事务管理,需要进行以下配置:
- 在生产者配置中开启事务支持,将ProducerConfig.TRANSACTIONAL_ID_CONFIG属性设置为一个唯一的事务 ID 。
- 使用@EnableKafkaTransaction注解开启事务支持 。
- 在发送消息的方法上使用@Transactional注解来定义事务边界 。
以下是配置事务管理的代码示例:
import org.apache.kafka.clients.producer.ProducerConfig;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafkaTransaction;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import org.springframework.transaction.annotation.EnableTransactionManagement;
import java.util.HashMap;
import java.util.Map;
@Configuration
@EnableKafkaTransaction
@EnableTransactionManagement
public class KafkaTransactionConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Value("${spring.kafka.producer.transaction-id-prefix}")
private String transactionIdPrefix;
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.ACKS_CONFIG, "all");
props.put(ProducerConfig.RETRIES_CONFIG, Integer.MAX_VALUE);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
// 开启事务支持,设置事务ID前缀
props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, transactionIdPrefix + "-" + System.currentTimeMillis());
return props;
}
@Bean
public ProducerFactory<String, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
KafkaTemplate<String, String> kafkaTemplate = new KafkaTemplate<>(producerFactory());
kafkaTemplate.setTransactionIdPrefix(transactionIdPrefix);
return kafkaTemplate;
}
}
在上述代码中:
- ProducerConfig.TRANSACTIONAL_ID_CONFIG属性设置为transactionIdPrefix + "-" + System.currentTimeMillis(),其中transactionIdPrefix从配置文件中读取,用于生成唯一的事务 ID 。
- 使用@EnableKafkaTransaction和@EnableTransactionManagement注解分别开启 Kafka 事务支持和 Spring 的事务管理 。
在发送消息的服务类中,可以使用@Transactional注解来定义事务边界,如下所示:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
@Service
public class KafkaTransactionService {
private static final String TOPIC = "my-topic";
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@Transactional
public void sendTransactionalMessage(String message1, String message2) {
kafkaTemplate.send(TOPIC, message1);
// 模拟一个可能会失败的操作,比如抛出异常
if (Math.random() > 0.5) {
throw new RuntimeException("模拟发送失败");
}
kafkaTemplate.send(TOPIC, message2);
}
}
在sendTransactionalMessage方法中,使用@Transactional注解定义了事务边界。如果在事务中发送消息时发生异常,比如Math.random() > 0.5时抛出RuntimeException,则事务会回滚,之前发送的消息也会被撤销,从而保证了数据的一致性 。
自定义分区
默认情况下,Kafka 生产者会根据消息的键(Key)的哈希值来决定消息发送到哪个分区 。在某些场景下,可能需要根据业务逻辑来自定义分区策略,比如按照用户 ID、订单 ID 等进行分区 。
要实现自定义分区,需要实现org.apache.kafka.clients.producer.Partitioner接口,并在生产者配置中指定自定义的分区器 。以下是自定义分区器的代码示例:
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import java.util.List;
import java.util.Map;
public class CustomPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 根据业务逻辑自定义分区策略,这里简单示例根据key的第一个字符进行分区
if (key != null) {
String keyStr = (String) key;
int partition = Math.abs(keyStr.charAt(0)) % cluster.partitionsForTopic(topic).size();
return partition;
}
// 如果key为null,则使用默认分区策略
return 0;
}
@Override
public void close() {
// 关闭分区器时的操作,一般为空
}
@Override
public void configure(Map<String, ?> configs) {
// 配置分区器时的操作,一般为空
}
}
在上述代码中,CustomPartitioner实现了Partitioner接口,重写了partition方法。在partition方法中,根据消息的键的第一个字符的绝对值对分区数量取模,来决定消息发送到哪个分区。如果键为null,则返回默认分区0 。
然后,在生产者配置中指定自定义的分区器:
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class KafkaProducerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.ACKS_CONFIG, "1");
props.put(ProducerConfig.RETRIES_CONFIG, 0);
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
props.put(ProducerConfig.LINGER_MS_CONFIG, 1);
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
// 指定自定义分区器
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, CustomPartitioner.class);
return props;
}
@Bean
public ProducerFactory<String, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
在producerConfigs方法中,通过props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, CustomPartitioner.class)指定了自定义的分区器为CustomPartitioner 。这样,生产者在发送消息时就会使用自定义的分区策略 。
消息序列化优化
Kafka 默认提供了一些序列化器,如StringSerializer、ByteArraySerializer等,但在处理复杂对象时,可能需要自定义序列化器来提高序列化和反序列化的效率 。例如,使用 Apache Avro、Protobuf 等序列化框架,可以实现更高效的数据序列化和反序列化,同时减少数据传输的大小 。
以使用 Apache Avro 为例,首先需要定义 Avro 的 Schema 文件,例如定义一个用户信息的 Schema:
{
"namespace": "com.example",
"type": "record",
"name": "User",
"fields": [
{"name": "id", "type": "int"},
{"name": "name", "type": "string"},
{"name": "age", "type": "int"}
]
}
然后,使用 Avro 的工具生成 Java 类:
avro-tools compile schema user.avsc .
生成的 Java 类包含了用户信息的字段和对应的 getter、setter 方法 。
接下来,实现自定义的 Avro 序列化器:
import org.apache.avro.Schema;
import org.apache.avro.generic.GenericDatumWriter;
import org.apache.avro.generic.GenericRecord;
import org.apache.avro.io.DatumWriter;
import org.apache.avro.io.Encoder;
import org.apache.avro.io.EncoderFactory;
import org.apache.kafka.common.errors.SerializationException;
import org.apache.kafka.common.serialization.Serializer;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.util.Map;
public class AvroSerializer implements Serializer<GenericRecord> {
private Schema schema;
@Override
public void configure(Map<String, ?> configs, boolean isKey) {
// 从配置中获取Schema字符串,并解析为Schema对象
String schemaStr = (String) configs.get("schema");
this.schema = new Schema.Parser().parse(schemaStr);
## 4. 消费者实现
### 4.1 消费者配置
在Spring Boot中配置Kafka消费者,主要涉及配置消费者工厂(ConsumerFactory)和Kafka监听器容器工厂(KafkaListenerContainerFactory)。消费者工厂负责创建Kafka消费者实例,而监听器容器工厂则用于创建监听Kafka主题的容器 。
首先,创建一个配置类,用于配置消费者工厂和监听器容器工厂。以下是配置消费者的Java代码示例:
```java
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import java.util.HashMap;
import java.util.Map;
@Configuration
@EnableKafka
public class KafkaConsumerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Value("${spring.kafka.consumer.group-id}")
private String groupId;
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> props = new HashMap<>();
// Kafka服务器地址
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
// 消费者组ID
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
// 自动提交偏移量,true表示自动提交,false表示手动提交
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
// 自动提交偏移量的时间间隔,单位是毫秒
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 1000);
// 当消费者首次启动或找不到上次的消费偏移量时,决定从哪里开始消费消息,earliest表示从最早的消息开始消费,latest表示从最新的消息开始消费
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 消费者键的反序列化器
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
// 消费者值的反序列化器
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return props;
}
@Bean
public ConsumerFactory<String, String> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
// 设置并发消费者数量,默认为1,可以根据需要调整
factory.setConcurrency(3);
return factory;
}
}
在上述代码中:
- consumerConfigs方法用于配置 Kafka 消费者的属性。其中,bootstrapServers和groupId分别从配置文件中读取 Kafka 服务器地址和消费者组 ID;ENABLE_AUTO_COMMIT_CONFIG设置为true,表示开启自动提交偏移量功能,消费者在消费消息后会自动将偏移量提交到 Kafka 集群;AUTO_COMMIT_INTERVAL_MS_CONFIG设置为1000毫秒,即每隔 1 秒自动提交一次偏移量;AUTO_OFFSET_RESET_CONFIG设置为earliest,表示当消费者首次启动或找不到上次的消费偏移量时,从最早的消息开始消费;KEY_DESERIALIZER_CLASS_CONFIG和VALUE_DESERIALIZER_CLASS_CONFIG分别指定了键和值的反序列化器为StringDeserializer,用于将字节数组反序列化为字符串 。
- consumerFactory方法通过DefaultKafkaConsumerFactory创建了一个消费者工厂,它使用consumerConfigs方法返回的配置属性来创建 Kafka 消费者实例 。
- kafkaListenerContainerFactory方法创建了一个并发的 Kafka 监听器容器工厂,它依赖于consumerFactory创建的消费者工厂。通过setConcurrency(3)设置了并发消费者的数量为 3,这意味着可以同时有 3 个消费者线程从 Kafka 主题中拉取消息进行消费,提高消费效率 。
相关文章:
)
Spring Boot 与 Kafka 的深度集成实践(二)
3. 生产者实现 3.1 生产者配置 在 Spring Boot 项目中,配置 Kafka 生产者主要是配置生产者工厂(ProducerFactory)和 KafkaTemplate 。生产者工厂负责创建 Kafka 生产者实例,而 KafkaTemplate 则是用于发送消息的核心组件&#x…...

【学习记录】使用 Kali Linux 与 Hashcat 进行 WiFi 安全分析:合法的安全测试指南
文章目录 📌 前言🧰 一、前期准备✅ 安装 Kali Linux✅ 获取支持监听模式的无线网卡 🛠 二、使用 Kali Linux 进行 WiFi 安全测试步骤 1:插入无线网卡并确认识别步骤 2:开启监听模式步骤 3:扫描附近的 WiFi…...
)
后端下载限速(redis记录实时并发,bucket4j动态限速)
✅ 使用 Redis 记录 所有用户的实时并发下载数✅ 使用 Bucket4j 实现 全局下载速率限制(动态)✅ 支持 动态调整限速策略✅ 下载接口安全、稳定、可监控 🧩 整体架构概览 模块功能Redis存储全局并发数和带宽令牌桶状态Bucket4j Redis分布式限…...
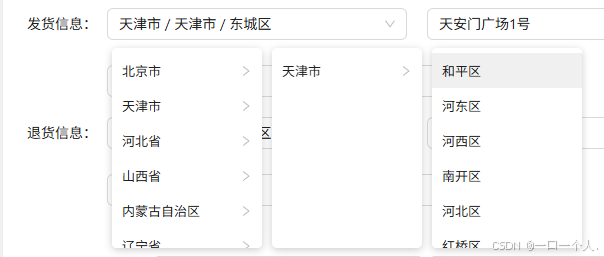
vue3 手动封装城市三级联动
要做的功能 示意图是这样的,因为后端给的数据结构 不足以使用ant-design组件 的联动查询组件 所以只能自己分装 组件 当然 这个数据后端给的不一样的情况下 可能组件内对应的 逻辑方式就不一样 毕竟是 三个 数组 省份 城市 区域 我直接粘贴组件代码了 <temp…...

Angular中Webpack与ngx-build-plus 浅学
Webpack 在 Angular 中的概念 Webpack 是一个模块打包工具,用于将多个模块和资源打包成一个或多个文件。在 Angular 项目中,Webpack 负责将 TypeScript、HTML、CSS 等文件打包成浏览器可以理解的 JavaScript 文件。Angular CLI 默认使用 Webpack 进行项目…...

大模型智能体核心技术:CoT与ReAct深度解析
**导读:**在当今AI技术快速发展的背景下,大模型的推理能力和可解释性成为业界关注的焦点。本文深入解析了两项核心技术:CoT(思维链)和ReAct(推理与行动),这两种方法正在重新定义大模…...

信息系统分析与设计复习
2024试卷 单选题(20) 1、在一个聊天系统(类似ChatGPT)中,属于控制类的是()。 A. 话语者类 B.聊天文字输入界面类 C. 聊天主题辨别类 D. 聊天历史类 解析 B-C-E备选架构中分析类分为边界类、控制类和实体类。 边界…...
Linux【5】-----编译和烧写Linux系统镜像(RK3568)
参考:讯为 1、文件系统 不同的文件系统组成了:debian、ubuntu、buildroot、qt等系统 每个文件系统的uboot和kernel是一样的 2、源码目录介绍 目录 3、正式编译 编译脚本build.sh 帮助内容如下: Available options: uboot …...

记一次spark在docker本地启动报错
1,背景 在docker中部署spark服务和调用spark服务的微服务,微服务之间通过fegin调用 2,问题,docker容器中服务器来后,注册中心都有,调用服务也正常,但是调用spark启动任务后报错,报错…...

【向量库】Weaviate 搜索与索引技术:从基础概念到性能优化
文章目录 零、概述一、搜索技术分类1. 向量搜索:捕捉语义的智能检索2. 关键字搜索:精确匹配的传统方案3. 混合搜索:语义与精确的双重保障 二、向量检索技术分类1. HNSW索引:大规模数据的高效引擎2. Flat索引:小规模数据…...

ABB馈线保护 REJ601 BD446NN1XG
配电网基本量程数字继电器 REJ601是一种专用馈线保护继电器,用于保护一次和二次配电网络中的公用事业和工业电力系统。该继电器在一个单元中提供了保护和监控功能的优化组合,具有同类产品中最佳的性能和可用性。 REJ601是一种专用馈线保护继电器…...
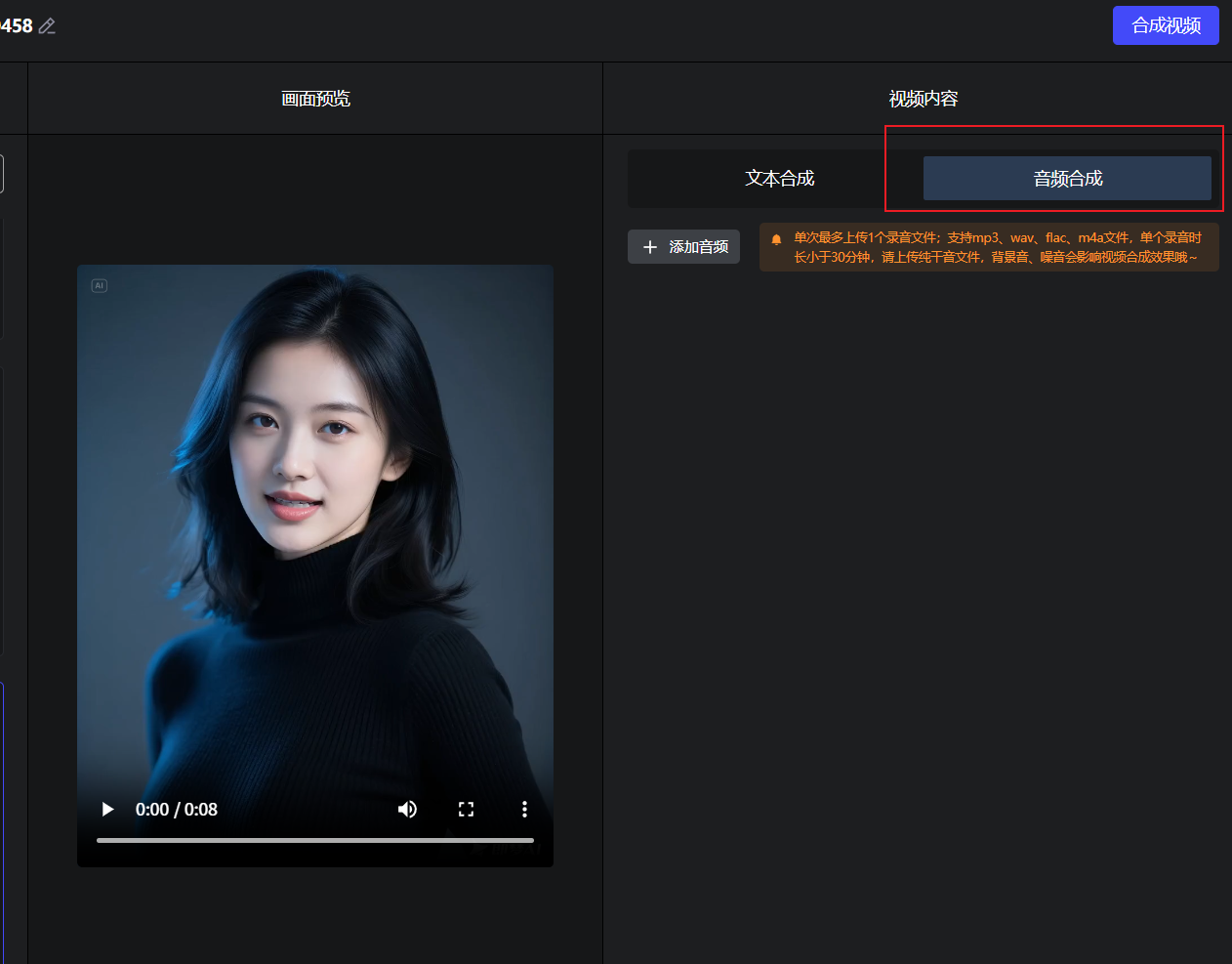
Heygem50系显卡合成的视频声音杂音模糊解决方案
如果你在使用50系显卡有杂音的情况,可能还是官方适配问题,可以使用以下方案进行解决: 方案一:剪映替换音色(简单适合普通玩家) 使用剪映换音色即可,口型还是对上的,没有剪映vip的&…...
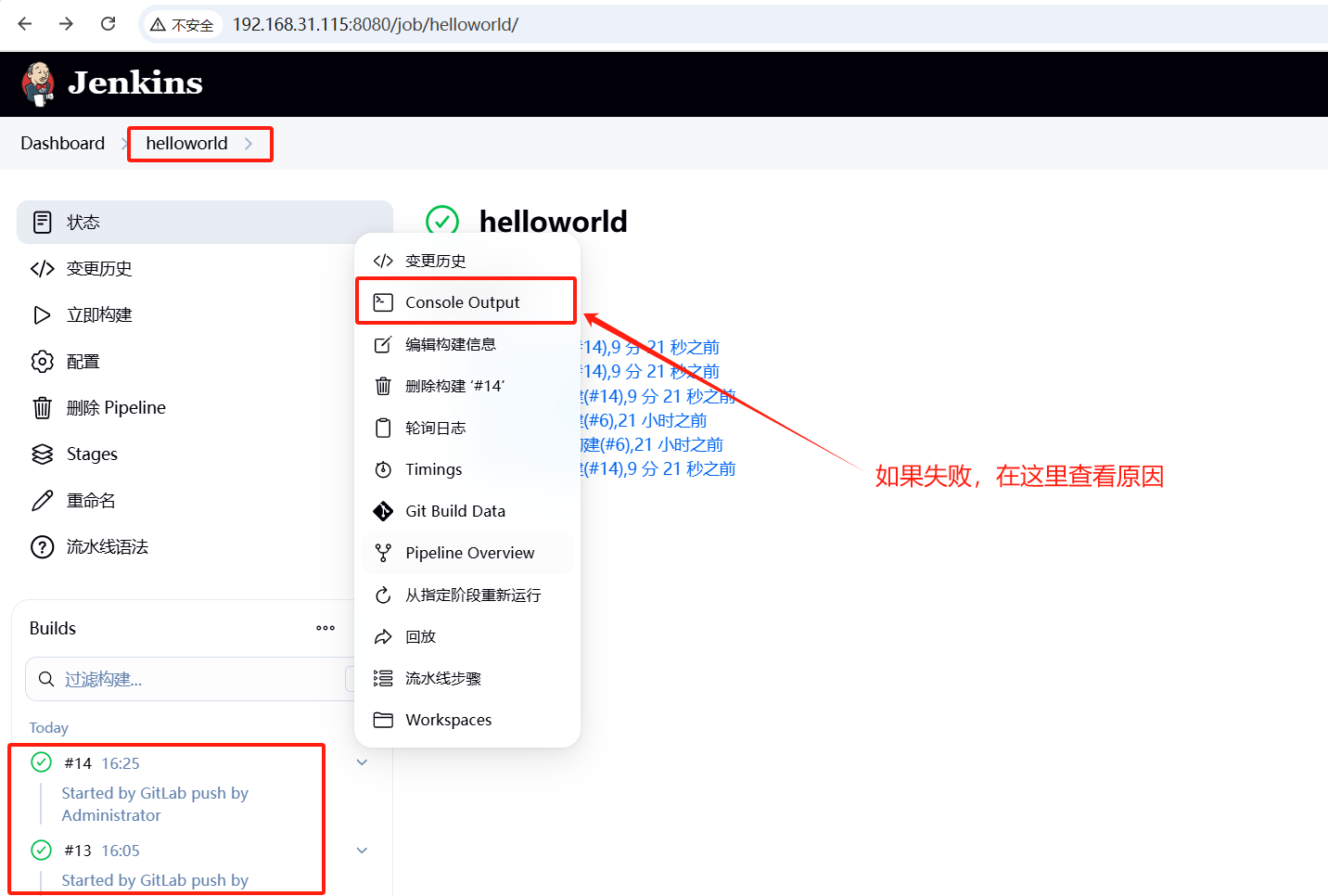
Gitlab + Jenkins 实现 CICD
CICD 是持续集成(Continuous Integration, CI)和持续交付/部署(Continuous Delivery/Deployment, CD)的缩写,是现代软件开发中的一种自动化流程实践。下面介绍 Web 项目如何在代码提交到 Gitlab 后,自动发布…...
无头浏览器技术:Python爬虫如何精准模拟搜索点击
1. 无头浏览器技术概述 1.1 什么是无头浏览器? 无头浏览器是一种没有图形用户界面(GUI)的浏览器,它通过程序控制浏览器内核(如Chromium、Firefox)执行页面加载、JavaScript渲染、表单提交等操作。由于不渲…...
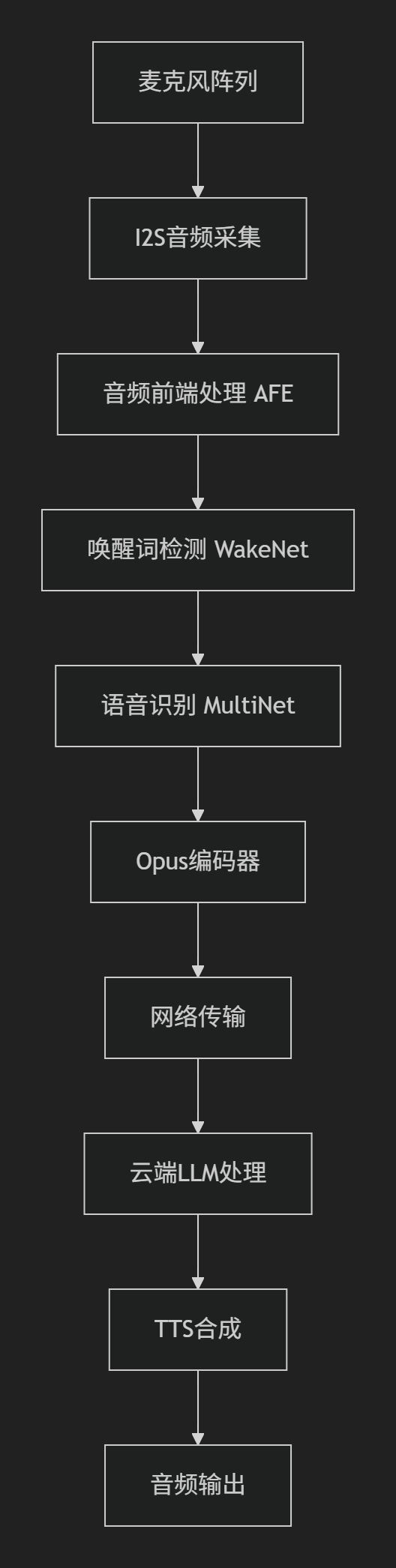
SDU棋界精灵——硬件程序ESP32实现opus编码
一、 音频处理框架 该项目基于Espressif的音频处理框架构建,核心组件包括 ESP-ADF 和 ESP-SR,以下是完整的音频处理框架实现细节: 1.核心组件 (1) 音频前端处理 (AFE - Audio Front-End) main/components/audio_pipeline/afe_processor.c功能: 声学回声…...
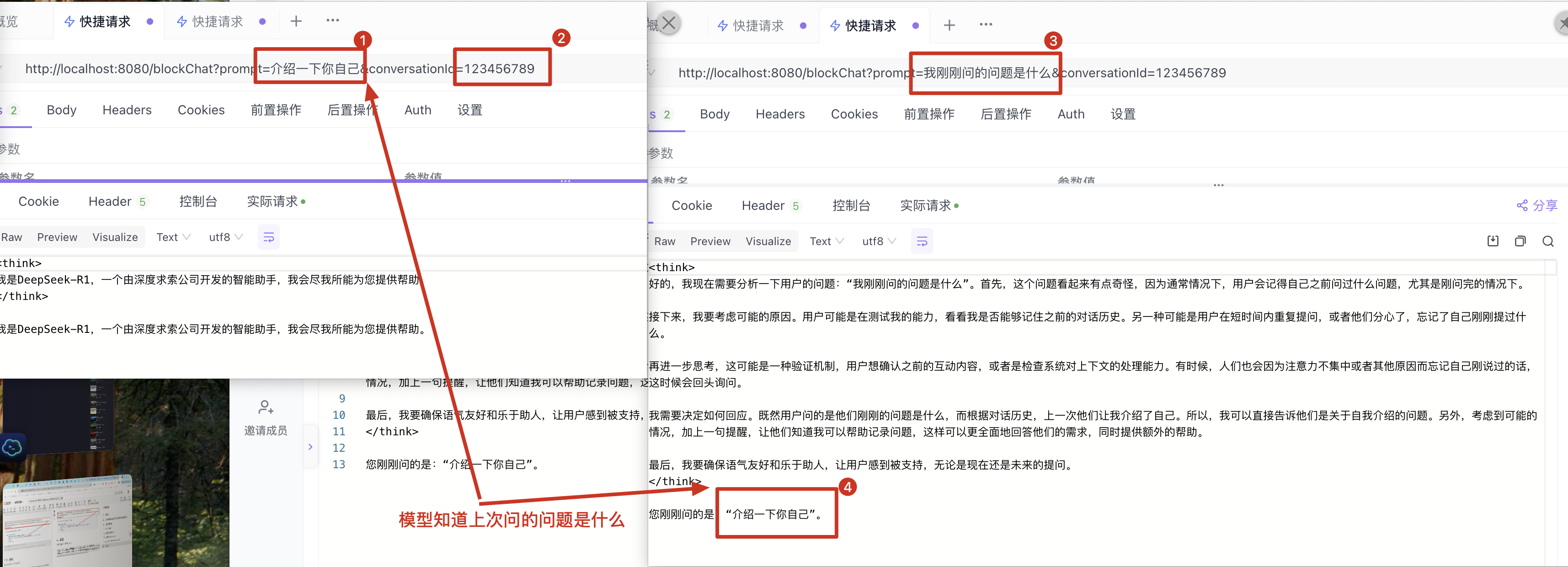
Spring AI中使用ChatMemory实现会话记忆功能
文章目录 1、需求2、ChatMemory中消息的存储位置3、实现步骤1、引入依赖2、配置Spring AI3、配置chatmemory4、java层传递conversaionId 4、验证5、完整代码6、参考文档 1、需求 我们知道大型语言模型 (LLM) 是无状态的,这就意味着他们不会保…...
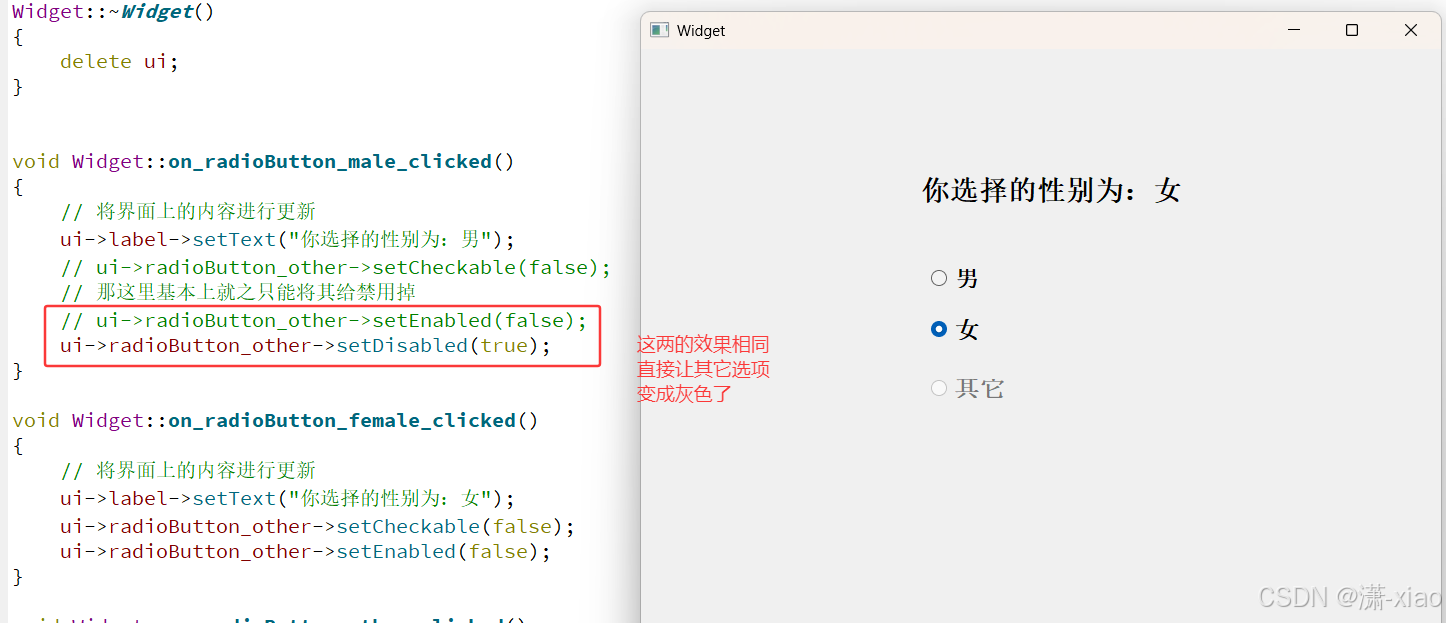
Qt 按钮类控件(Push Button 与 Radio Button)(1)
文章目录 Push Button前提概要API接口给按钮添加图标给按钮添加快捷键 Radio ButtonAPI接口性别选择 Push Button(鼠标点击不放连续移动快捷键) Radio Button Push Button 前提概要 1. 之前文章中所提到的各种跟QWidget有关的各种属性/函数/方法&#…...
生成对抗网络(GAN)损失函数解读
GAN损失函数的形式: 以下是对每个部分的解读: 1. , :这个部分表示生成器(Generator)G的目标是最小化损失函数。 :判别器(Discriminator)D的目标是最大化损失函数。 GAN的训…...
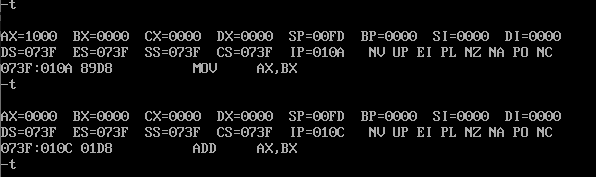
汇编语言学习(三)——DoxBox中debug的使用
目录 一、安装DoxBox,并下载汇编工具(MASM文件) 二、debug是什么 三、debug中的命令 一、安装DoxBox,并下载汇编工具(MASM文件) 链接: https://pan.baidu.com/s/1IbyJj-JIkl_oMOJmkKiaGQ?pw…...
和向下转型(Downcasting))
【Java基础】向上转型(Upcasting)和向下转型(Downcasting)
在面向对象编程中,转型(Casting) 是指改变对象的引用类型,主要涉及 继承关系 和 多态。 向上转型(Upcasting) ⬆️ 定义 将 子类对象 赋值给 父类引用(自动完成,无需强制转换&…...
)
GitHub 常见高频问题与解决方案(实用手册)
1.Push 提示权限错误(Permission denied) 问题: Bash Permission denied (publickey) fatal: Could not read from remote repository. 原因: 没有配置 SSH key 或使用了 HTTPS 而没有权限…...
数据可视化交互
目录 【实验目的】 【实验原理】 【实验环境】 【实验步骤】 一、安装 pyecharts 二、下载数据 三、实验任务 实验 1:AQI 横向对比条形图 代码说明: 运行结果: 实验 2:AQI 等级分布饼图 实验 3:多城市 AQI…...

安宝特方案丨从依赖经验到数据驱动:AR套件重构特种装备装配与质检全流程
在高压电气装备、军工装备、石油测井仪器装备、计算存储服务器和机柜、核磁医疗装备、大型发动机组等特种装备生产型企业,其产品具有“小批量、多品种、人工装配、价值高”的特点。 生产管理中存在传统SOP文件内容缺失、SOP更新不及、装配严重依赖个人经验、产品装…...
【JavaEE】万字详解HTTP协议
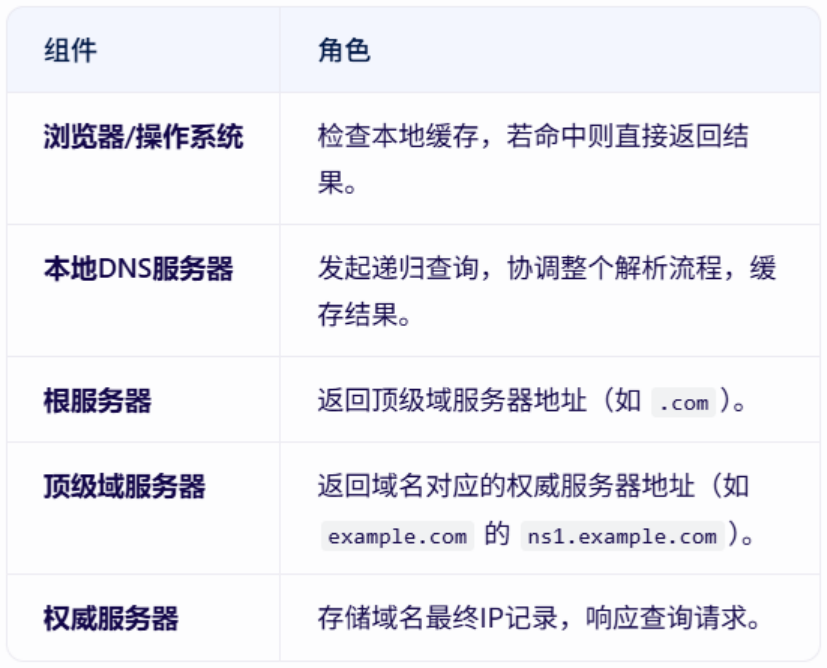
HTTP是什么?-----互联网的“快递小哥” 想象我们正在网上购物:打开淘宝APP,搜索“蓝牙耳机”,点击商品图片,然后下单付款。这一系列操作背后,其实有一个看不见的“快递小哥”在帮我们传递信息,…...
)
Vue3学习(接口,泛型,自定义类型,v-for,props)
一,前言 继续学习 二,TS接口泛型自定义类型 1.接口 TypeScript 接口(Interface)是一种定义对象形状的强大工具,它可以描述对象必须包含的属性、方法和它们的类型。接口不会被编译成 JavaScript 代码,仅…...
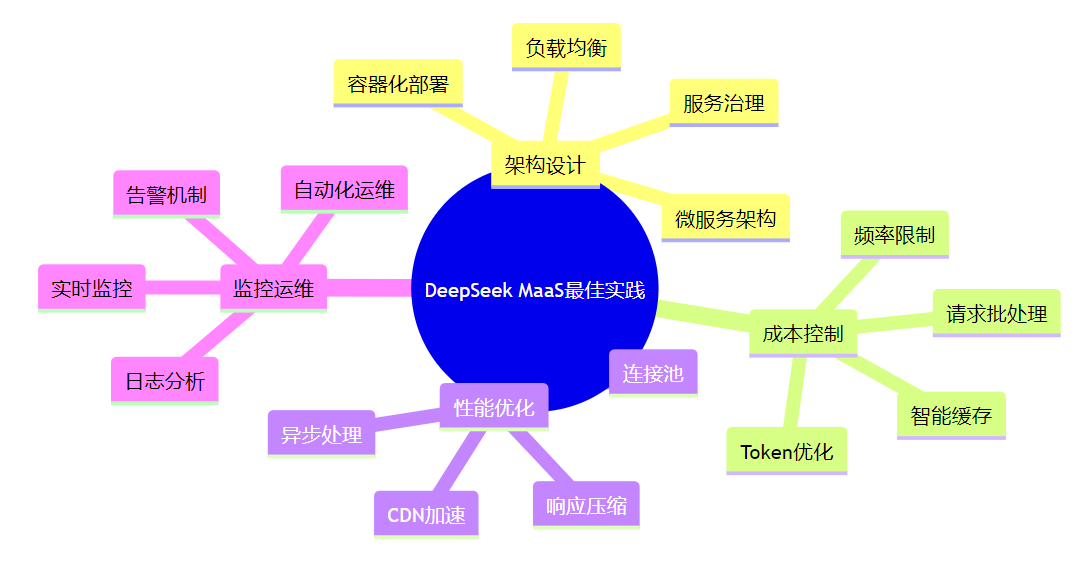
华为云Flexus+DeepSeek征文 | MaaS平台避坑指南:DeepSeek商用服务开通与成本控制
作者简介 我是摘星,一名专注于云计算和AI技术的开发者。本次通过华为云MaaS平台体验DeepSeek系列模型,将实际使用经验分享给大家,希望能帮助开发者快速掌握华为云AI服务的核心能力。 目录 作者简介 前言 一、技术架构概览 1.1 整体架构设…...

WEB3全栈开发——面试专业技能点P8DevOps / 区块链部署
一、Hardhat / Foundry 进行合约部署 概念介绍 Hardhat 和 Foundry 都是以太坊智能合约开发的工具套件,支持合约的编译、测试和部署。 它们允许开发者在本地或测试网络快速开发智能合约,并部署到链上(测试网或主网)。 部署过程…...

【动态规划】B4336 [中山市赛 2023] 永别|普及+
B4336 [中山市赛 2023] 永别 题目描述 你做了一个梦,梦里有一个字符串,这个字符串无论正着读还是倒着读都是一样的,例如: a b c b a \tt abcba abcba 就符合这个条件。 但是你醒来时不记得梦中的字符串是什么,只记得…...

可下载旧版app屏蔽更新的app市场
软件介绍 手机用久了,app越来越臃肿,老手机卡顿成常态。这里给大家推荐个改善老手机使用体验的方法,还能帮我们卸载不需要的app。 手机现状 如今的app不断更新,看似在优化,实则内存占用越来越大,对手机性…...
claude3.7高阶玩法,生成系统架构图,国内直接使用
文章目录 零、前言一、操作指南操作指导 二、提示词模板三、实战图书管理系统通过4o模型生成系统描述通过claude3.7生成系统架构图svg代码转换成图片 在线考试系统通过4o模型生成系统描述通过claude3.7生成系统架构图svg代码转换成图片 四、感受 零、前言 现在很多AI大模型可以…...