PostgreSQL 与 SQL 基础:为 Fast API 打下数据基础
在构建任何动态、数据驱动的Web API时,一个稳定高效的数据存储方案是不可或缺的。对于使用Python FastAPI的开发者来说,深入理解关系型数据库的工作原理、掌握SQL这门与数据库“对话”的语言,以及学会如何在Python中操作数据库,是构建强大应用的关键一步。
本文将带你探索关系型数据库(以PostgreSQL为例)的核心概念,精通SQL的关键操作,并学习如何使用Python的psycopg2驱动连接和操作PostgreSQL,为你的FastAPI项目打下坚实的数据基础。
1. 关系型数据库与数据库管理系统(DBMS) (以PostgreSQL为例)
关系型数据库因其清晰的结构、强大的数据一致性保障以及成熟的生态系统而备受青睐。其核心思想是将数据组织成一张张表格 (Table)。这些表格就像电子表格一样,有行有列。更重要的是,这些表格之间可以通过预定义的关系 (Relationship) 相互连接。例如,在一个博客系统中,用户 (users) 表和 帖子 (posts) 表可以通过“用户ID”建立联系,表明哪篇帖子是由哪个用户创建的。这种结构化的方式使得数据的查询、维护和管理变得高效且可靠。
我们通常不会直接去操作底层的数据库文件。取而代之的是,我们会通过一个中间件软件——数据库管理系统 (DBMS) 来与数据库交互。DBMS可以看作是数据库的“大管家”或“智能大脑”,它负责接收我们(或我们的应用程序)发出的指令(比如“帮我查一下所有价格大于100的商品”、“新建一条用户记录”),执行这些操作,并将结果返回。PostgreSQL 就是一款功能强大、开源且高度可扩展的关系型DBMS,深受开发者喜爱。
安装PostgreSQL后,你可以在一台服务器上创建多个相互独立的数据库实例 (Database Instance),每个实例都可以服务于不同的应用程序。这意味着你可以为你的FastAPI博客项目创建一个专属的数据库,而不会与其他应用(比如一个电商系统)的数据混淆。通常,PostgreSQL安装时会默认创建一个名为 postgres 的数据库,它可以作为连接到PostgreSQL服务器的初始入口点。
2. SQL:与数据库“流利对话”的语言
无论你选择哪款关系型DBMS——PostgreSQL、MySQL、Oracle还是SQL Server——它们都“听得懂”一门通用的语言:SQL (Structured Query Language)。SQL是与关系型数据库进行交互的标准语言。虽然不同DBMS在SQL的某些高级特性或方言上可能存在细微差别,但其核心语法和概念是高度一致的。
对于PostgreSQL,我们可以使用像PG Admin这样的可视化管理工具,在其查询工具中直接编写和执行SQL命令来创建表、插入数据、查询信息等。但更常见的是,我们的应用程序(比如用FastAPI构建的API)需要通过代码来执行这些SQL操作。
3. Python与PostgreSQL的桥梁:psycopg2 驱动
要在Python应用程序中与PostgreSQL数据库通信,我们需要一个数据库驱动程序 (Database Driver)。对于PostgreSQL,psycopg2 是最流行和功能最完善的Python驱动之一。它实现了Python数据库API规范v2.0 (DB-API 2.0),允许我们用Python代码连接到PostgreSQL、执行SQL语句并处理结果。
安装 psycopg2:
在你的Python虚拟环境中,可以通过pip轻松安装:
pip install psycopg2-binary
(psycopg2-binary 包包含了预编译的二进制文件,安装更便捷。)
建立连接与创建游标:
在FastAPI应用启动时(或者在需要操作数据库的模块中),你需要建立到PostgreSQL的连接。一个典型的连接过程如下:
# main.py (部分代码,展示连接逻辑)
import psycopg2
from psycopg2.extras import RealDictCursor # 让查询结果以字典形式返回,键为列名
import time# 尝试连接数据库,如果失败则重试
while True:try:conn = psycopg2.connect(host="localhost", # 数据库服务器地址database="fastapi_db", # 你创建的数据库名称user="your_postgres_user", #你的PostgreSQL用户名password="your_postgres_password", # 你的PostgreSQL密码cursor_factory=RealDictCursor # 重要!使查询结果返回字典而非元组)cur = conn.cursor() # 创建一个游标对象,用于执行SQL语句print("数据库连接成功!")break # 连接成功,跳出循环except Exception as error:print("连接数据库失败")print("错误详情: ", error)time.sleep(2) # 等待2秒后重试
psycopg2.connect(): 这是建立连接的核心函数,需要提供主机、数据库名、用户名和密码。cursor_factory=RealDictCursor: 这是一个非常有用的配置。默认情况下,psycopg2查询返回的是元组 (tuple) 列表。使用RealDictCursor,查询结果会变成字典 (dict) 列表,其中键是数据库表的列名,这使得在代码中通过列名访问数据更加直观和方便,尤其是在构建API响应时。conn.cursor(): 连接成功后,我们通过conn.cursor()方法创建一个游标 (Cursor) 对象。游标就像一个在数据库结果集上移动的指针,我们通过它来执行SQL语句和获取结果。- 错误处理与重试: 在实际应用中,数据库连接可能会因为网络问题、数据库服务未启动等原因失败。上面的代码片段包含了一个简单的循环重试机制,这在生产环境中是常见的做法(尽管更健壮的方案可能还会涉及更复杂的重试策略和日志记录)。
现在我们有了连接和游标,就可以开始学习如何用SQL结合psycopg2来操作数据了。
4. SQL核心操作:与数据互动
4.1 数据查询:SELECT语句 —— 探索你的数据宝藏
SELECT 是SQL中使用频率最高的命令,它的使命是从数据库中检索你需要的数据。
-
选择所有列 (
*):SELECT * FROM products;在Python中使用
psycopg2执行:# 【示例】在FastAPI路径操作中获取所有帖子 @app.get("/posts") def get_all_posts():cur.execute("SELECT * FROM posts;") # 执行SQL查询posts_data = cur.fetchall() # 获取所有查询结果return posts_data # FastAPI会自动将字典列表转为JSONcur.execute(sql_query)用于执行SQL语句。对于SELECT查询,执行后结果并不会立即返回到Python变量中,而是存储在游标内部。你需要使用获取方法(如fetchall(),fetchone(),fetchmany())来检索数据。cur.fetchall(): 获取查询结果集中的所有行。cur.fetchone(): 获取查询结果集中的下一行,如果结果集为空或已读取完毕,则返回None。cur.fetchmany(size): 获取指定数量的行。
-
选择特定列:
SELECT id, name, price FROM products;cur.execute("SELECT id, title, content FROM posts WHERE published = TRUE;") published_posts = cur.fetchall() -
列别名 (
AS): 在SQL中使用AS为列指定别名,可以使API响应的JSON字段名更友好。SELECT id AS product_id, name AS product_name FROM products;如果使用了
RealDictCursor,返回的字典键名会自动使用你指定的别名。
4.2 数据过滤:WHERE子句 —— 精准定位信息
WHERE子句是SELECT语句的得力助手,它允许你根据特定条件筛选数据,只返回那些你真正感兴趣的行。
-
相等条件 (
=):SELECT * FROM products WHERE id = 10; SELECT * FROM products WHERE name = '智能电视'; -- 文本值用单引号在Python中使用
psycopg2时,强烈建议使用参数化查询 (Parameterized Queries) 来防止SQL注入攻击:# 【示例】在FastAPI路径操作中获取特定ID的帖子 @app.get("/posts/{post_id}") def get_one_post(post_id: int):cur.execute("SELECT * FROM posts WHERE id = %s;", (str(post_id),)) # 使用%s占位符post = cur.fetchone()if not post:raise HTTPException(status_code=404, detail="帖子未找到")return post- 参数化查询 (
%s): 在SQL语句中使用%s作为占位符,然后将实际的值作为元组传递给cur.execute()的第二个参数。psycopg2会自动处理值的转义,从而保护你的应用免受SQL注入的威胁。切勿直接将用户输入拼接到SQL字符串中!
- 参数化查询 (
-
比较运算符 (
>,<,>=,<=,<>或!=):SELECT * FROM products WHERE price > 50.00;cur.execute("SELECT * FROM posts WHERE rating > %s;", (3,)) highly_rated_posts = cur.fetchall() -
逻辑运算符 (
AND,OR):SELECT * FROM products WHERE inventory > 0 AND price < 100.00;cur.execute("SELECT * FROM posts WHERE published = %s AND owner_id = %s;", (True, current_user_id)) -
IN运算符: 匹配列表中的任意一个值。SELECT * FROM products WHERE category_id IN (1, 5, 7);category_ids = (1, 5, 7) # 必须是元组 cur.execute("SELECT * FROM products WHERE category_id IN %s;", (category_ids,))注意:当
IN操作符与%s占位符一起使用时,值本身需要是一个元组。 -
LIKE运算符 (模式匹配): 与通配符%(匹配零或多个字符) 和_(匹配单个字符) 结合使用。SELECT * FROM products WHERE name LIKE '智能%'; -- 名称以“智能”开头search_term = "快速入门" cur.execute("SELECT * FROM posts WHERE title LIKE %s;", ('%' + search_term + '%',)) # 构造包含通配符的搜索模式 search_results = cur.fetchall()
4.3 数据排序:ORDER BY子句 —— 让结果井然有序
ORDER BY 用于指定查询结果的排序方式。
SELECT * FROM products ORDER BY price ASC; -- 按价格升序 (ASC是默认)
SELECT * FROM products ORDER BY created_at DESC; -- 按创建时间降序 (最新在前)
cur.execute("SELECT * FROM posts ORDER BY created_at DESC, title ASC;")
sorted_posts = cur.fetchall()
4.4 结果限制与偏移:LIMIT 和 OFFSET —— 高效分页的秘诀
在处理大量数据时,一次性返回所有结果是不明智的。LIMIT 和 OFFSET 是实现分页功能的关键。
SELECT * FROM products ORDER BY id LIMIT 10 OFFSET 20; -- 跳过前20条,然后取10条
page_size = 10
page_number = 3
offset_val = (page_number - 1) * page_size
cur.execute("SELECT * FROM posts ORDER BY id LIMIT %s OFFSET %s;", (page_size, offset_val))
paginated_posts = cur.fetchall()
4.5 数据修改操作:改变数据库的状态
-
插入数据:
INSERT INTO语句INSERT INTO products (name, price, inventory, category_id) VALUES ('新款耳机', 199.99, 50, 3);在Python (
psycopg2)中插入数据并获取新插入记录的ID (或其他列):# 【示例】在FastAPI路径操作中创建新帖子 @app.post("/posts", status_code=201) def create_new_post(post_payload: PostSchema): # PostSchema是Pydantic模型cur.execute("""INSERT INTO posts (title, content, published, owner_id)VALUES (%s, %s, %s, %s) RETURNING *;""", (post_payload.title, post_payload.content, post_payload.published, current_user_id))newly_created_post = cur.fetchone()conn.commit() # !!! 重要:提交事务,使更改永久生效 !!!return newly_created_postRETURNING *(或RETURNING id): 这是PostgreSQL的一个强大特性,允许你在执行INSERT(同样适用于UPDATE和DELETE) 操作后立即返回被操作行的数据(比如新生成的ID),非常适合在API响应中返回新创建或修改后的资源。conn.commit(): 对于任何修改数据库的操作(INSERT,UPDATE,DELETE),执行完cur.execute()后,更改只是暂存在当前事务中。你必须调用conn.commit()才能将这些更改永久写入数据库。否则,当连接关闭或程序结束时,这些更改会丢失(回滚)。conn.rollback(): 如果在事务过程中发生错误,你可以调用conn.rollback()来撤销当前事务中所有未提交的更改。
-
更新数据:
UPDATE语句UPDATE products SET price = 209.99, inventory = 45 WHERE id = 123;# 【示例】更新帖子 @app.put("/posts/{post_id}") def update_existing_post(post_id: int, post_payload: PostUpdateSchema):cur.execute("""UPDATE posts SET title = %s, content = %s, published = %sWHERE id = %s RETURNING *;""", (post_payload.title, post_payload.content, post_payload.published, str(post_id)))updated_post_data = cur.fetchone()if not updated_post_data:raise HTTPException(status_code=404, detail="要更新的帖子未找到")conn.commit()return updated_post_data -
删除数据:
DELETE FROM语句DELETE FROM products WHERE id = 789;# 【示例】删除帖子 @app.delete("/posts/{post_id}", status_code=204) def delete_existing_post(post_id: int):cur.execute("DELETE FROM posts WHERE id = %s RETURNING *;", (str(post_id),))deleted_post_data = cur.fetchone()if not deleted_post_data:raise HTTPException(status_code=404, detail="要删除的帖子未找到")conn.commit()# 对于204 No Content,通常不返回响应体return Response(status_code=status.HTTP_204_NO_CONTENT)务必小心使用
DELETE! 如果忘记了WHERE子句,它会删除表中的所有数据!
4.6 SQL 最佳实践回顾
- 大写SQL关键字:提高可读性 (如
SELECT,FROM,WHERE)。 - 分号结尾:
psycopg2通常不需要在execute()的字符串末尾加分号,但如果你在PG Admin或其他工具中写SQL,记得加上。 - 参数化查询:永远,永远,永远 使用参数化查询 (
%s占位符和值元组) 来防止SQL注入,尤其是在处理用户输入时。 - 事务管理 (
commit/rollback):理解何时以及为何需要提交或回滚事务。
5. 数据库设计基础:为你的数据建模
良好的数据库设计是构建健壮、可维护应用的核心。
5.1 表 (Tables)、行 (Rows) 与列 (Columns)
- 表 (Table):代表应用中的一个核心“事物”或“概念”,如
users,posts,comments。 - 列 (Column):表的属性,描述“事物”的特征,如
users表的username,email,created_at。 - 行 (Row):表中的一条记录,代表一个具体的“事物”实例,如一个特定的用户。
5.2 数据类型 (Data Types)
为列选择正确的数据类型至关重要,它确保了数据的准确性、存储效率和查询性能。PostgreSQL提供了丰富的数据类型:
- 数值类型:
INTEGER(整数),BIGINT(大整数),NUMERIC(precision, scale)(精确小数),REAL(单精度浮点),DOUBLE PRECISION(双精度浮点)。 - 文本类型:
VARCHAR(n)(可变长度字符串,最大长度n),TEXT(可变长度字符串,无显式长度限制)。 - 布尔类型:
BOOLEAN(TRUE或FALSE)。 - 日期/时间类型:
DATE(日期),TIME(时间),TIMESTAMP(时间戳,不带时区),TIMESTAMPTZ(或TIMESTAMP WITH TIME ZONE, 时间戳,带时区 - 推荐使用,以避免时区混淆)。 - 其他:
UUID(通用唯一标识符),JSON,JSONB(二进制JSON,查询性能更好),ARRAY(数组) 等。
5.3 主键 (Primary Key - PK) —— 每行的唯一“身份证”
主键是一列或多列的组合,其值能唯一标识表中的每一行。
- 唯一性 (UNIQUE):主键值在表中不能重复。
- 非空性 (NOT NULL):主键值不能为空。
- 常用选择: 通常,我们会为每个表添加一个名为
id的列,类型为SERIAL(自动递增的整数,PostgreSQL特有,相当于INTEGER NOT NULL DEFAULT nextval('sequence_name')) 或BIGSERIAL,并将其设为主键。或者使用UUID类型并生成UUID作为主键。CREATE TABLE users (id SERIAL PRIMARY KEY, -- 自动递增的整数主键username VARCHAR(50) UNIQUE NOT NULL,email VARCHAR(100) UNIQUE NOT NULL );
5.4 外键 (Foreign Key - FK) —— 表与表之间的“纽带”
外键是表中的一列(或多列),其值引用了另一张表的主键。它用于建立和强制表之间的链接或关系。
- 定义关系: 例如,
posts表可以有一个owner_id列作为外键,引用users表的id列,表明该帖子属于哪个用户。 - 数据完整性 (Referential Integrity): 外键有助于维护数据的一致性。例如,不能创建一个
owner_id指向一个不存在的用户的帖子。 ON DELETE策略: 当被引用的父表行(如users表中的某用户)被删除时,需要定义子表(如posts表中该用户的所有帖子)如何响应:CASCADE: 父行删除,所有引用它的子行也自动删除(例如,删除用户,其所有帖子也删除)。SET NULL: 父行删除,子行中的外键列被设置为NULL(前提是该外键列允许为NULL)。SET DEFAULT: 父行删除,子行中的外键列被设置为其默认值。RESTRICT/NO ACTION(通常是默认行为): 如果存在引用的子行,则阻止删除父行。
CREATE TABLE posts (id SERIAL PRIMARY KEY,title TEXT NOT NULL,content TEXT NOT NULL,owner_id INTEGER NOT NULL,CONSTRAINT fk_posts_owner_id FOREIGN KEY (owner_id) -- 定义外键约束REFERENCES users (id) ON DELETE CASCADE -- 如果用户被删除,其帖子也级联删除 );
5.5 约束 (Constraints) —— 数据的“规则守护者”
约束是施加在表或列上的规则,用于限制可以存入的数据,进一步保证数据的质量。
NOT NULL: 列值不能为空。UNIQUE: 列中的所有值必须唯一(一个表可以有多个UNIQUE约束)。PRIMARY KEY: 隐含NOT NULL和UNIQUE。FOREIGN KEY: 确保引用完整性。CHECK: 定义一个布尔表达式,插入或更新的行必须满足该表达式(例如CHECK (price > 0))。DEFAULT: 如果插入时未提供值,则使用此默认值(例如published BOOLEAN DEFAULT FALSE)。
总结:数据驱动FastAPI的坚实一步
通过本文的探索,你不仅深入了解了关系型数据库(特别是PostgreSQL)的基石,掌握了SQL这门与数据对话的通用语言的核心操作,更重要的是,你学会了如何使用Python的psycopg2驱动程序作为桥梁,在你的FastAPI应用中实际连接并操作PostgreSQL数据库。从基础的SELECT查询到复杂的数据修改,再到数据库设计的关键概念如主键、外键和约束,这些都是构建任何数据驱动型FastAPI应用不可或缺的知识。
熟练运用psycopg2执行参数化查询、管理事务,并结合良好的数据库设计原则,将使你能够高效地为你的FastAPI应用构建强大、安全且可维护的后端数据支持。
下一步建议:从原生SQL到ORM的飞跃
虽然直接使用psycopg2和原生SQL语句能让你对数据库操作有非常清晰的控制,但在大型项目中,直接编写大量SQL可能会变得繁琐且容易出错。
因此,我强烈建议你接下来深入学习对象关系映射器 (Object-Relational Mapper, ORM),特别是与FastAPI无缝集成的 SQLAlchemy ORM。ORM允许你使用Python类和对象来定义数据库表和行,用Python方法来执行数据库查询和操作,从而在很大程度上抽象掉了原生SQL的编写。这不仅能提高开发效率,还能使代码更具Pythonic风格,更易于维护和测试。
同时,不要停止实践SQL本身!继续探索更高级的SQL特性,例如:
JOIN操作: 这是关系型数据库的精髓所在,允许你根据表之间的关系,从多张表中组合和检索数据(例如,获取一篇帖子及其作者的用户名和邮箱)。- 聚合函数 (
COUNT,SUM,AVG,MAX,MIN) 与GROUP BY: 用于数据统计和分析。 - 子查询 (Subqueries): 在一个查询中嵌套另一个查询。
- 窗口函数 (Window Functions): 用于执行复杂的分析计算。
掌握这些,你的数据处理能力将更上一层楼,为构建功能更丰富的FastAPI应用奠定更坚实的基础。
相关文章:

PostgreSQL 与 SQL 基础:为 Fast API 打下数据基础
在构建任何动态、数据驱动的Web API时,一个稳定高效的数据存储方案是不可或缺的。对于使用Python FastAPI的开发者来说,深入理解关系型数据库的工作原理、掌握SQL这门与数据库“对话”的语言,以及学会如何在Python中操作数据库,是…...

Python异步编程:深入理解协程的原理与实践指南
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 持续学习,不断…...

Ray框架:分布式AI训练与调参实践
Ray框架:分布式AI训练与调参实践 系统化学习人工智能网站(收藏):https://www.captainbed.cn/flu 文章目录 Ray框架:分布式AI训练与调参实践摘要引言框架架构解析1. 核心组件设计2. 关键技术实现2.1 动态资源调度2.2 …...
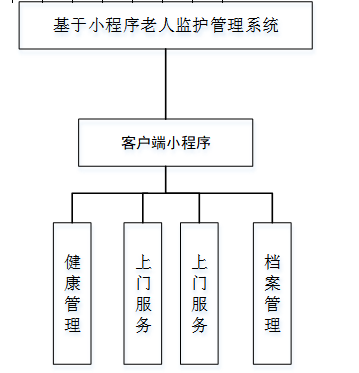
基于小程序老人监护管理系统源码数据库文档
摘 要 近年来,随着我国人口老龄化问题日益严重,独居和居住养老机构的的老年人数量越来越多。而随着老年人数量的逐步增长,随之而来的是日益突出的老年人问题,尤其是老年人的健康问题,尤其是老年人产生健康问题后&…...

el-amap-bezier-curve运用及线弧度设置
文章目录 简介示例线弧度属性主要弧度相关属性其他相关样式属性完整示例链接简介 el-amap-bezier-curve 是 Vue-Amap 组件库中的一个组件,用于在 高德地图 上绘制贝塞尔曲线。 基本用法属性path定义曲线的路径,可以是多个弧线段的组合。stroke-weight线条的宽度。stroke…...

深入浅出JavaScript中的ArrayBuffer:二进制数据的“瑞士军刀”
深入浅出JavaScript中的ArrayBuffer:二进制数据的“瑞士军刀” 在JavaScript中,我们经常需要处理文本、数组、对象等数据类型。但当我们需要处理文件上传、图像处理、网络通信等场景时,单纯依赖字符串或数组就显得力不从心了。这时ÿ…...
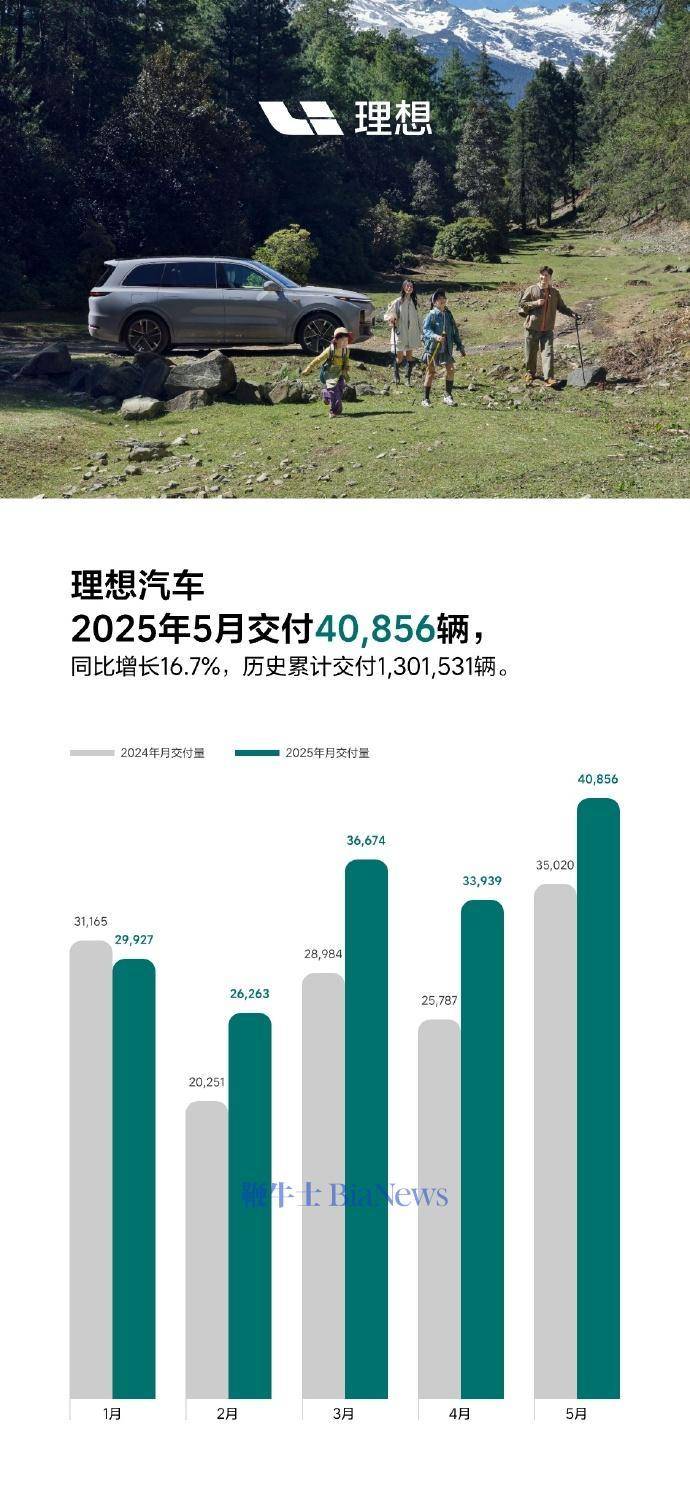
理想汽车5月交付40856辆,同比增长16.7%
6月1日,理想汽车官方宣布,5月交付新车40856辆,同比增长16.7%。截至2025年5月31日,理想汽车历史累计交付量为1301531辆。 官方表示,理想L系列智能焕新版在5月正式发布,全系产品力有显著的提升,每…...

Linux中INADDR_ANY详解
在Linux网络编程中,INADDR_ANY 是一个特殊的IPv4地址常量(定义在 <netinet/in.h> 头文件中),用于表示绑定到所有可用网络接口的地址。它是服务器程序中的常见用法,允许套接字监听所有本地IP地址上的连接请求。 关…...
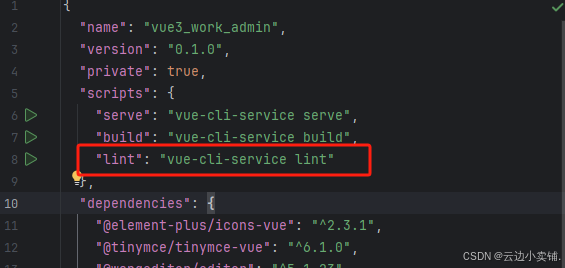
运行vue项目报错 errors and 0 warnings potentially fixable with the `--fix` option.
报错 找到package.json文件 找到这个修改成 "lint": "eslint --fix --ext .js,.vue src" 为elsint有配置结尾换行符,最后运行:npm run lint --fix...

java+webstock
maven依赖 <dependency><groupId>org.java-websocket</groupId><artifactId>Java-WebSocket</artifactId><version>1.3.5</version></dependency><dependency><groupId>org.apache.tomcat.websocket</groupId&…...

STL 2迭代器
文章目录 1.迭代器2.输入迭代器3.输出迭代器1.插入迭代器 4.前向迭代器5.双向迭代器6.随机访问迭代器7.不同容器返回的迭代器类型1.输入 / 输出迭代器2.前向迭代器3.双向迭代器4.随机访问迭代器5.特殊迭代器适配器6.为什么 unordered_set 只提供前向迭代器? 1.迭代器…...

CppCon 2015 学习:Simple, Extensible Pattern Matching in C++14
什么是 Pattern Matching(模式匹配) ❝ 模式匹配就是一种“描述式”的写法,不需要你手动判断、提取数据,而是直接描述你希望的数据结构是什么样子,系统自动判断并提取。❞ 你给的定义拆解: ✴ Instead of …...
智警杯备赛--excel模块
数据透视与图表制作 创建步骤 创建 1.在Excel的插入或者数据标签页下找到数据透视表的按钮 2.将数据放进“请选择单元格区域“中,点击确定 这是最终结果,但是由于环境启不了,这里用的是自己的excel,真实的环境中的excel根据实训…...

uniapp获取当前位置和经纬度信息
1.1. 获取当前位置和经纬度信息(需要配置高的SDK) 调用uni-app官方API中的uni.chooseLocation(),即打开地图选择位置。 <button click"getAddress">获取定位</button> const getAddress () > {uni.chooseLocatio…...

【多线程初阶】单例模式 指令重排序问题
文章目录 1.单例模式1)饿汉模式2)懒汉模式①.单线程版本②.多线程版本 2.分析单例模式里的线程安全问题1)饿汉模式2)懒汉模式懒汉模式是如何出现线程安全问题的 3.解决问题进一步优化加锁导致的执行效率优化预防内存可见性问题 4.解决指令重排序问题 1.单例模式 单例模式确保某…...

基于Python的气象数据分析及可视化研究
目录 一.🦁前言二.🦁开源代码与组件使用情况说明三.🦁核心功能1. ✅算法设计2. ✅PyEcharts库3. ✅Flask框架4. ✅爬虫5. ✅部署项目 四.🦁演示效果1. 管理员模块1.1 用户管理 2. 用户模块2.1 登录系统2.2 查看实时数据2.3 查看天…...

Pandas 可视化集成:数据科学家的高效绘图指南
为什么选择 Pandas 进行数据可视化? 在数据科学和分析领域,可视化是理解数据、发现模式和传达见解的关键步骤。Python 生态系统提供了多种可视化工具,如 Matplotlib、Seaborn、Plotly 等,但 Pandas 内置的可视化功能因其与数据结…...
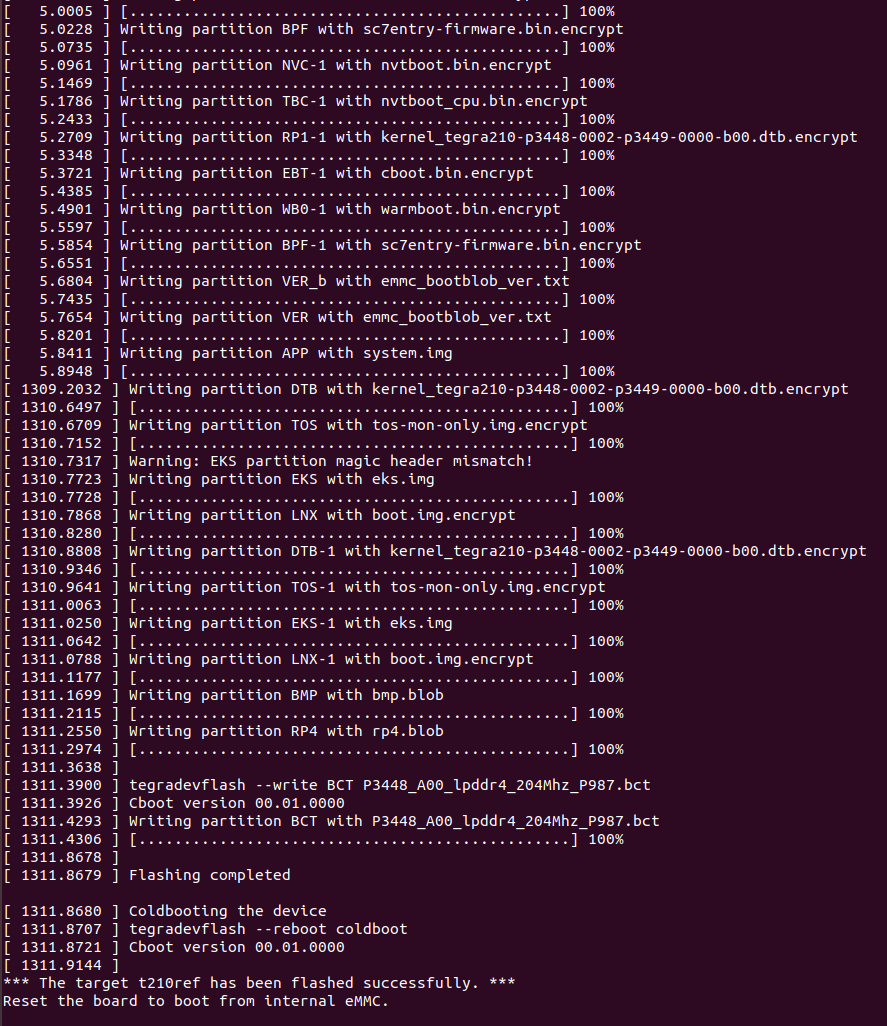
新版NANO下载烧录过程
一、序言 搭建 Jetson 系列产品烧录系统的环境需要在电脑主机上安装 Ubuntu 系统。此处使用 18.04 LTS。 二、环境搭建 1、安装库 $ sudo apt-get install qemu-user-static$ sudo apt-get install python 搭建环境的过程需要这个应用库来将某些 NVIDIA 软件组件安装到 Je…...

Vue 实例的数据对象详解
Vue 实例的数据对象详解 在 Vue 中,数据对象是响应式系统的核心,也是组件状态的载体。理解数据对象的原理和使用方式是成为 Vue 专家的关键一步。我将从多个维度深入剖析 Vue 实例的数据对象。 一、数据对象的定义方式 1. Options API 中的定义 在 Options API 中,使用 …...
Axure Rp 11 安装、汉化、授权
Axure Rp 11 安装、汉化、授权 1、前言2、汉化2.1、汉化文件下载2.2、windows汉化流程2.3、 macOs汉化流程 3、授权 1、前言 Axure Rp 11官方下载链接:https://www.axure.com/downloadthanks 2、汉化 2.1、汉化文件下载 链接: https://pan.baidu.com/s/18Clf…...
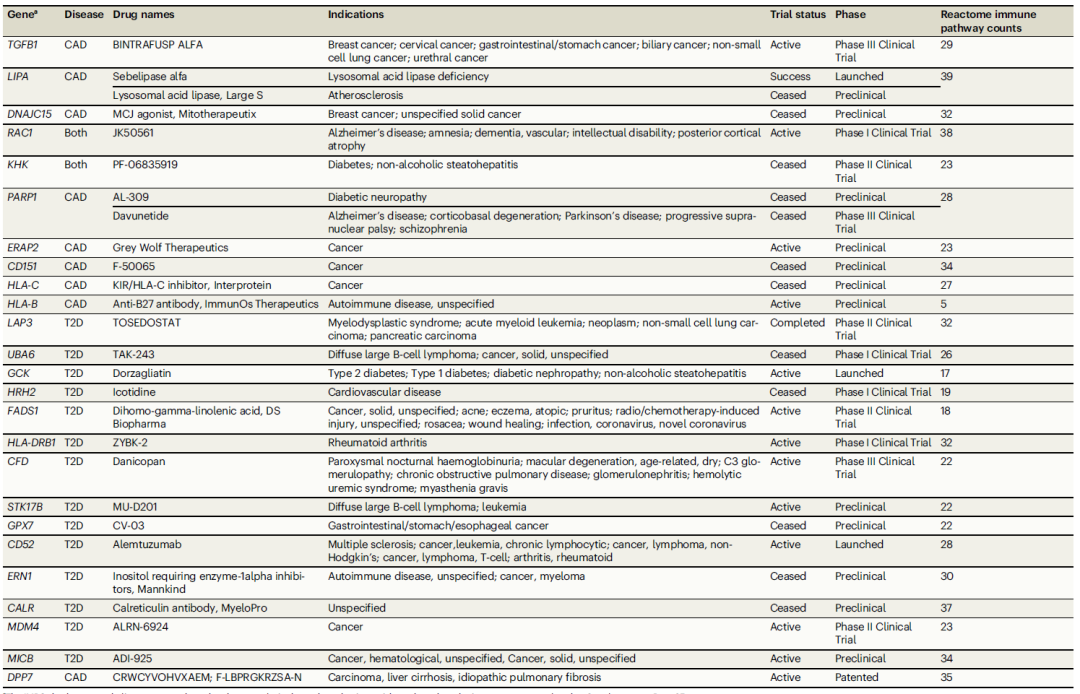
中科院1区顶刊|IF14+:多组学MR联合单细胞时空分析,锁定心血管代谢疾病的免疫治疗新靶点
中科院1区顶刊|IF14:多组学MR联合单细胞时空分析,锁定心血管代谢疾病的免疫治疗新靶点 当下,免疫与代谢性疾病的关联研究已成为生命科学领域的前沿热点。随着研究的深入,我们愈发清晰地认识到免疫系统与代谢系统之间存在着极为复…...

GB/T 43887-2024 核级柔性石墨板材检测
核级柔性石墨板材是指以可膨胀石墨为原料、未经改性和增强、用于核工业的核级柔性石墨板材。 GB/T 43887-2024核级柔性石墨板材检测检测指标: 测试项目 测试标准 外观 GB/T 43887 尺寸偏差 GB/T 43887 化学成分 GB/T 43887 密度偏差 GB/T 43887 拉伸强度…...
:处理原始数据命令)
ffmpeg(三):处理原始数据命令
FFmpeg 可以直接处理原始音频和视频数据(Raw PCM、YUV 等),常见场景包括: 将原始 YUV 图像编码为 H.264 视频将 PCM 音频编码为 AAC 或 MP3对原始音视频数据进行封装(如封装为 MP4、TS) 处理原始 YUV 视频…...

标注工具核心架构分析——主窗口的图像显示
🏗️ 标注工具核心架构分析 📋 系统概述 主要有两个核心类,采用经典的 Scene-View 架构模式: 🎯 核心类结构 1. AnnotationScene (QGraphicsScene子类) 主要负责标注场景的管理和交互 🔧 关键函数&…...

作为点的对象CenterNet论文阅读
摘要 检测器将图像中的物体表示为轴对齐的边界框。大多数成功的目标检测方法都会枚举几乎完整的潜在目标位置列表,并对每一个位置进行分类。这种做法既浪费又低效,并且需要额外的后处理。在本文中,我们采取了不同的方法。我们将物体建模为单…...

基于Java项目的Karate API测试
Karate 实现了可以只编写Feature 文件进行测试,但是对于熟悉Java语言的开发或是测试人员,可以通过编程方式集成 Karate 丰富的自动化和数据断言功能。 本篇快速介绍在Java Maven项目中编写和运行测试的示例。 创建Maven项目 最简单的创建项目的方式就是创建一个目录,里面…...

自定义线程池1.2
自定义线程池 1.2 1. 简介 上次我们实现了 1.1 版本,将线程池中的线程数量交给使用者决定,并且将线程的创建延迟到任务提交的时候,在本文中我们将对这个版本进行如下的优化: 在新建线程时交给线程一个任务。让线程在某种情况下…...

Spring事务传播机制有哪些?
导语: Spring事务传播机制是后端面试中的必考知识点,特别容易出现在“项目细节挖掘”阶段。面试官通过它来判断你是否真正理解事务控制的本质与异常传播机制。本文将从实战与源码角度出发,全面剖析Spring事务传播机制,帮助你答得有…...
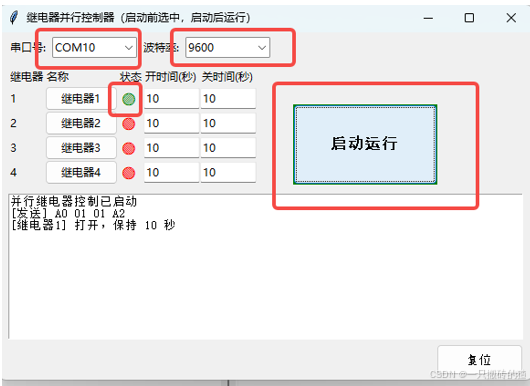
使用ch340继电器完成随机断电测试
前言 如图所示是市面上常见的OTA压测继电器,通过ch340串口模块完成对继电器的分路控制,这里我编写了一个脚本方便对4路继电器的控制,可以设置开启时间,关闭时间,复位等功能 软件界面 在设备管理器查看串口号后&…...
基于谷歌ADK的 智能产品推荐系统(2): 模块功能详解
在我的上一篇博客:基于谷歌ADK的 智能产品推荐系统(1): 功能简介-CSDN博客 中我们介绍了个性化购物 Agent 项目,该项目展示了一个强大的框架,旨在模拟和实现在线购物环境中的智能导购。它不仅仅是一个简单的聊天机器人,更是一个集…...