深入理解linux内核--内存管理
RAM的某些部分永久分配给内核,
来存放内核代码及静态内核数据结构。
RAM的其余部分称为动态内存,
这不仅是进程所需的宝贵资源,
也是内核本身所需的宝贵资源。
页框管理
Intel的Pentinum处理器可采用两种不同的页框大小:
4KB,4MB(如PAE被激活,则为2MB)。
Linux采用4KB页框大小作为标准的内存分配单元。
1.由分页单元引发的缺页异常很容易得到解释,
或由于请求的页存在但不允许进程对其访问,
或由于请求的页不存在。
第二种情况下,
内存分配器必须找到一个4KB的空闲页框,
并将其分配给进程。
2.虽然4KB,4MB都是磁盘块大小的倍数,
但绝大多数情况下,
当主存和磁盘之间传输小块数据时更高效。
页描述符
内核必须记录每个页框当前的状态。
如,内核必须能区分哪些页框包含的是属于进程的页,
哪些页框包含的是内核代码或内核数据。
类似地,内核还必须能确定动态内存中的页框是否空闲。
页框的状态信息保存在一个类型为page的页描述符中,
其中的字段如表所示:
| 类型 | 名字 | 说明 |
|---|---|---|
| unsigned long | flags | 一组标志。对页框所在的管理区进行编号。 |
| atomic_t | _count | 页框的引用计数器 |
| atomic_t | _mapcount | 页框中的页表项数量(没有则为-1) |
| unsigned long | private | 可用于正使用页的内核成分 |
| struct address_space* | mapping | 当页被插入页高速缓存时使用。或当页属于匿名区时使用。 |
| unsigned long | index | 作为不同的含义被几种内核成分使用。 |
| struct list_head | lru | 包含页的最近最少使用双向链表的指针 |
所有的页描述符存放在mem_map数组中。
每个描述符长度为32字节,
所以mem_map所需要的空间略小于整个RAM的1%。
virt_to_page(addr)宏产生线性地址addr对应的页描述符地址。
pfn_to_page(pfn)宏产生与页框号pfn对应的页描述符地址。
让我们较详细地描述以下两个字段:
_count页的引用计数器。如字段为-1,则相应页框空闲,并可被分配给任一进程或内核本身。如该字段值大于或等于0,则说明页框被分配给了一个或多个进程,或用于存放一些内核数据结构。page_count返回__count加1后的值,即该页的使用者的数目。
flags包含多达32个用来描述页框状态的标志。对每个PG_xyz标志,内核都定义了操纵其值的一些宏。通常,PageXyz宏返回标志的值,SetPageXyz和ClearPageXyz宏分别设置和清除相应的位。
| 标志名 | 含义 |
|---|---|
| PG_locked | 页被锁住。如,在磁盘I/O操作中涉及的页 |
| PG_error | 在传输页时发生I/O错误 |
| PG_referenced | 刚刚访问过的页 |
| PG_uptodate | 在完成读操作后置位,除非发生磁盘I/O错误 |
| PG_dirty | 页已经被修改 |
| PG_lru | 页在活动或非活动页链表中 |
| PG_active | 页在活动页链表中 |
| PG_highmem | 页框属于ZONE_HIGHMEM管理区 |
| PG_checked | 由一些文件系统使用的标志 |
| PG_arch_1 | 在80x86体系结构上没有使用 |
| PG_reserved | 页框留给内核代码或没有使用 |
| PG_private | 页描述符的private字段存放了有意义的数据 |
| PG_writeback | 正使用writeback方法将页写到磁盘上 |
| PG_nosave | 系统挂起、唤醒时使用 |
| PG_compound | 通过扩展分页机制处理页框 |
| PG_swapcache | 页属于对换高速缓存 |
| PG_mappedtodisk | 页框中的所有数据对应于磁盘上分配的块 |
| PG_reclaim | 为回收内存对页已经做了写入磁盘的标记 |
| PG_nosave_free | 系统挂起、恢复时使用 |
非一致内存访问(NUMA)
习惯上,认为计算机内存是一种均匀,共享的资源。
在忽略硬件高速缓存作用的情况下,
期望不管内存单元处于何处,CPU处于何处,
CPU对内存单元的访问都需相同的时间。
可惜,
这些假设在某些体系结构上并不总是成立。
如,对某些多处理器Alpha或MIPS计算机,就不成立。Linux2.6支持非一致内存访问模型,
在这种模型中,
给定CPU对不同内存单元的访问时间可能不一样。
系统的物理内存被划分为几个节点(node)。
在一个单独的节点内,
任一给定CPU访问页面所需的时间都是相同的。
然而,
对不同CPU,这个时间可能就不同。对每个CPU而言,
内核都试图把耗时节点的访问次数减到最少,
这就要小心地选择CPU最常引用的内核数据结构的存放位置。每个节点中的物理内存又可分为几个管理区。
每个节点都有一个类型为pg_data_t的描述符。
| 类型 | 名字 | 说明 |
|---|---|---|
| struct zone[] | node_zones | 节点中管理区描述符的数组 |
| struct zonelist[] | node_zonelists | 页分配器使用的zonelist数据结构的数组 |
| int | nr_zones | 节点中管理区的个数 |
| struct page* | node_mem_map | 节点中页描述符的数组 |
| struct bootmem_data* | bdata | 用在内核初始化阶段 |
| unsigned long | node_start_pfn | 节点中第一个页框的下标 |
| unsigned long | node_present_pages | 内存节点的大小,不包含洞(以页框为单位) |
| unsigned long | node_spanned_pages | 节点的大小,包括洞(以页框为单位) |
| int | node_id | 节点标识符 |
| pg_data_t* | pgdat_next | 节点内存链表中的下一项 |
| wait_queue_head_t | kswapd_wait | kswapd页换出守护进程使用的等待队列 |
| struct task_struct* | kswapd | 指针指向kswapd内核线程的进程描述符 |
| int | kswapd_max_order | kswapd将要创建的空闲块大小取对数的值 |
同样,我们只关注80x86。
IBM兼容PC使用一致内存访问模型,
因此,
并不真正需要NUMA的支持。
然而,
即使NUMA的支持没有编译进内核,
Linux还是使用节点。
不过,
这是一个单独的节点,
它包含了系统中所有的物理内存。
故,pgdat_list指向一个链表,
此链表是由一个元素组成的。
这个元素就是节点0描述符,它被存放在config_page_data。在80x86结构中,
把物理内存分组在一个单独的节点中可能显得没用处;
但,这种方式有助于内核代码的处理具有可移植性。
内存管理区
在一个理想的计算机体系结构中,
一个页框就是一个内存存储单元,
可用于任何事情:
存放内核数据和用户数据,缓冲磁盘数据等等。
任何种类的数据页都可存放在任何页框中。但实际的计算机体系结构有硬件的制约,
这限制了页框可使用的方式。
尤其是,Linux内核必须处理80x86体系结构的两种硬件约束:
1.ISA总线的直接内存存取(DMA)处理器有一个严格的限制:
它们只能对RAM的前16MB寻址、
2.在具有大容量RAM的现代32位计算机中,
CPU不能直接访问所有的物理内存,
因此线性地址空间太小。为应对这两种限制,
Linux2.6把每个内存节点的物理内存划分为三个管理区。
在80x86UMA体系结构中的管理区为:
ZONE_DMA包含低于16MB的内存页框
ZONE_NORMAL包含高于16MB且低于896MB的内存页框
ZONE_HIGHMEM包含从896MB开始高于896MB的内存页框
ZONE_DMA区包含的页框可由老式基于ISA的设备通过DMA使用。ZONE_DMA和ZONE_NORMAL区包含内存的"常规"页框,
通过把它们线性地址映射到线性地址空间的第4个GB,
内核就可直接进行访问。
相反,
ZONE_HIGHMEM区包含的内存页不能由内核直接访问,
尽管它们页线性地映射到了线性地址空间的第4个GB。
在64位体系结构上,
ZONE_HIGHMEM区总是空的。每个内存管理区都有自己的描述符。
| 类型 | 名称 | 说明 |
|---|---|---|
| unsigned long | free_pages | 管理区中空闲页的数目 |
| unsigned long | pages_min | 管理区中保留页的数目 |
| unsigned long | pages_low | 回收页框使用的下界;同时也被管理区分配器作为阀值使用 |
| unsigned long | pages_high | 回收页框使用的上届;同时也被管理区分配器作为阀值使用 |
| unsigned long[] | lowmem_reserve | 指明在处理内存不足的临界情况下每个管理区必须保留的页框数目 |
| struct per_cpu_pageset[] | pageset | 用于实现单一页框的特殊高速缓存 |
| spinlock_t | lock | 保护该描述符的自旋锁 |
| struct free_area[] | free_area | 标识出管理区的空闲页框块 |
| spinlock_t | lru_lock | 活动以及非活动链表使用的自旋锁 |
| struct list_head | active_list | 管理区中的活动页链表 |
| struct list_head | inactive_list | 管理区中的非活动页链表 |
| unsigned long | nr_scan_active | 回收内存时需扫描的活动页数目 |
| unsigned long | nr_scan_inactive | 回收内存时需扫描的非活动页数目 |
| unsigned long | nr_active | 管理区的活动链表上的页数目 |
| unsigned long | nr_inactive | 管理区的非活动链表上的页数目 |
| unsigned long | pages_scanned | 管理区内回收页框时使用的计数器 |
| int | all_unreclaimable | 在管理区中填满不可回收页时此标志被置位 |
| int | temp_priority | 临时管理区的优先级 |
| int | prev_priority | 管理区优先级,范围在12和0之间 |
| wait_queue_head_t* | wait_table | 进等待队列的散列表,这些进程正在等待管理区中的某页 |
| unsigned long | wait_table_size | 等待队列散列表的大小 |
| unsigned long | wait_table_bits | 等待队列散列表数组大小,值为2^order |
| struct pglist_data* | zone_pgdat | 内存节点 |
| struct page* | zone_mem_map | 指向管理区的第一个页描述符的指针 |
| unsigned long | zone_start_pfn | 管理区第一个页框的下标 |
| unsigned long | spanned_pages | 以页为单位的管理区的总大小,包括洞 |
| unsigned long | present_pages | 以页为单位的管理区的总大小,不包括洞 |
| char* | name | 指针指向管理区的传统名称:“DMA”,“NORMAL”,“HighMem” |
每个页描述符都有到内存节点和节点内管理区的链接。
为节省空间,这些链接被编码成索引存放在flags字段的高位。
实际上,
刻画页框的标志的数目是有限的。
保留flags字段的最高位来编码特定内存节点和管理区号总是可能的。
page_zone接收一个页描述符的地址作为它的参数;
它读取页描述符中flags字段的最高位,
然后通过查看zone_table数组来确定相应管理区描述符的地址。
在启动时用所有内存节点的所有管理区描述符的地址初始化这个数组。当内核调一个内存分配函数时,
必须指明请求页框所在的管理区。
内核通常指明它愿意使用哪个管理区。为了在内存分配请求中指定首选管理区,
内核使用zonelist数据结构,
这就是管理区描述符指针数组。
保留的页框池
可用两种不同的方法来满足内存分配请求。
如有足够的空闲内存可用,
请求就会被立刻满足。
否则,必须回收一些内存,且将发出请求的内核控制路径阻塞,直到内存被释放。当请求内存时,
一些内核控制路径不能被阻塞--如,这种情况发生在处理中断或执行临界区内的代码时。
此时,
一条内核控制路径应产生原子内存分配请求。
原子请求从不被阻塞:
如没有足够的空闲页,则仅仅是分配失败而已。尽管无法保证一个原子内存分配请求决不失败,
但内核会设法尽量减少这种不幸事件发生的可能性。
为做到这一点,
内核为原子内存分配请求保留了一个页框池,
只有在内存不足时才使用。保留内存的数量(以KB为单位)存放在min_free_kbytes中。
它的初始值在内核初始化时设置,
并取决于直接映射到内核线性地址空间的第4个GB的物理内存的数量
--即,取决于包含在ZONE_DMA和ZONE_NORMAL内存管理区内的页框数目。
保留池的大小=sqrt(16*直接映射内存)(KB)
但,min_free_kbytes的初始值不能小于128也不能大于65536。
ZONE_DMA和ZONE_NORMAL内存管理区将一定数量的页框贡献给保留内存,
这个数目与两个管理区的相对大小成比例。
例,如ZONE_NORMAL管理区比ZONE_DMA大8倍,
则页框的7/8从ZONE_NORMAL获得。
1/8从ZONE_DMA获得。管理区描述符的pages_min存储了管理区内保留页框的数目。
这个字段和pages_low,pages_high一起还在页框回收算法中起作用。
pages_low总是设为pages_min的值的5/4,
pages_high总是被设为pages_min的3/2。
分区页框分配器
相关文章:

深入理解linux内核--内存管理
RAM的某些部分永久分配给内核, 来存放内核代码及静态内核数据结构。 RAM的其余部分称为动态内存, 这不仅是进程所需的宝贵资源, 也是内核本身所需的宝贵资源。页框管理 Intel的Pentinum处理器可采用两种不同的页框大小: 4KB&…...
SpringBoot热部署的开启与关闭
1、 开启热部署 (1)导入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId> </dependency>(2)设置 此时就搞定了。。。 2、…...
)
k8s集群部署(使用kubeadm部署工具进行快速部署,相关对应版本为docker20.10.0+k8s1.23.0+flannel)
1. 安装要求 在开始之前,部署Kubernetes集群机器需要满足以下几个条件: 一台或多台机器,操作系统 CentOS7.x-86_x64硬件配置:2GB或更多RAM,2个CPU或更多CPU,硬盘20GB或更多可以访问外网,需要拉…...

20230729 git github gitee
1.gitee与gitHub概念? Gitee(码云)是开源中国社区推出的代码托管协作开发平台,支持Git和SVN,提供免费的私有仓库托管。Gitee专为开发者提供稳定、高效、安全的云端软件开发协作平台,无论是个人、团队、或是…...

php建造者模式
一,建造者模式,也叫做生成器模式,是创建设计模式的一种,它能将一个复杂的对象的创建过程分离开来,使你能够分步骤的创建对象。建造者模式也允许你使用相同的建造代码创造出不同类型和形式的对象。 建造者模式一般包括四…...

linux---》用户操作/su和sudo/普通权限/特殊权限/解压压缩/软件管理,rpm和yum/源码安装nginx
用户操作 ####创建用户####1 创建sa和sutdents组 groupadd sa groupadd students # 2 用户可以属于多个组,只能属于一个主组,附加组可以有多个 G useradd -u 5001 -g students -G sa -c "注释" -s /bin/bash lqz666 # 3 设置密码 passwd lqz6…...

tinkerCAD案例:20. Simple Button 简单按钮和骰子
文章目录 tinkerCAD案例:20. Simple Button 简单按钮Make a Trick Die tinkerCAD案例:20. Simple Button 简单按钮 Project Overview: 项目概况: This is a series of fun beginner level lessons to hone your awesome Tinkercad skills a…...

Java - 为什么要用BigDecimal?
🤔️为什么要用BigDecimal? 当然是因为使用Double计算,在某些对精度要求很高的场景下会出现问题💀不信你看⤵️ Test void test12() {// 丢失精度double result 0.2 0.1;System.out.println(result); // 输出结果为 0.300000000…...
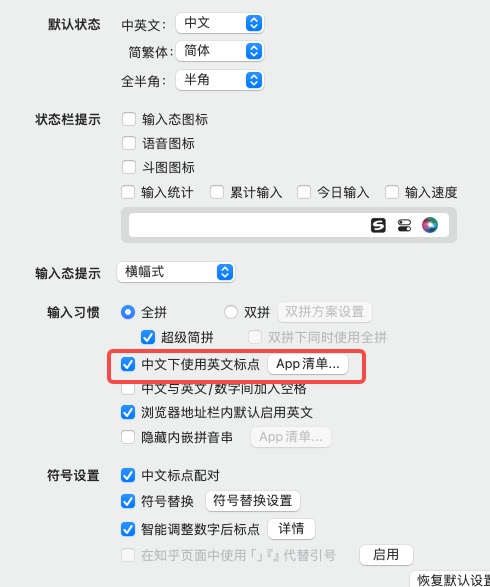
mac 删除自带的ABC输入法保留一个搜狗输入法,搜狗配置一下可以减少很多的敲击键盘和鼠标点击次数
0. 背景 对于开发者来说,经常被中英文切换输入法所困扰,我这边有一个方法,删除mac默认的ABC输入法 仅仅保留搜狗一个输入法,配置一下搜狗输入:哪些指定为英文输入,哪些指定为中文输入(符号也可…...

JiaYu说:如何做好IT类的技术面试?
IT类的技术面试 面试IT公司的小技巧IT技术面试常见的问题嵌入式技术面试嵌入式技术面试常见的问题嵌入式软件/硬件面试题 JiaYu归属嵌入式行业,所以这里只是以普通程序员的角度去分析技术面试的技巧 当然,也对嵌入式技术面试做了小总结,友友们…...

RL 实践(6)—— CartPole【REINFORCE with baseline A2C】
本文介绍 REINFORCE with baseline 和 A2C 这两个带 baseline 的策略梯度方法,并在 CartPole-V0 上验证它们和无 baseline 的原始方法 REINFORCE & Actor-Critic 的优势参考:《动手学强化学习》完整代码下载:7_[Gym] CartPole-V0 (REINFO…...
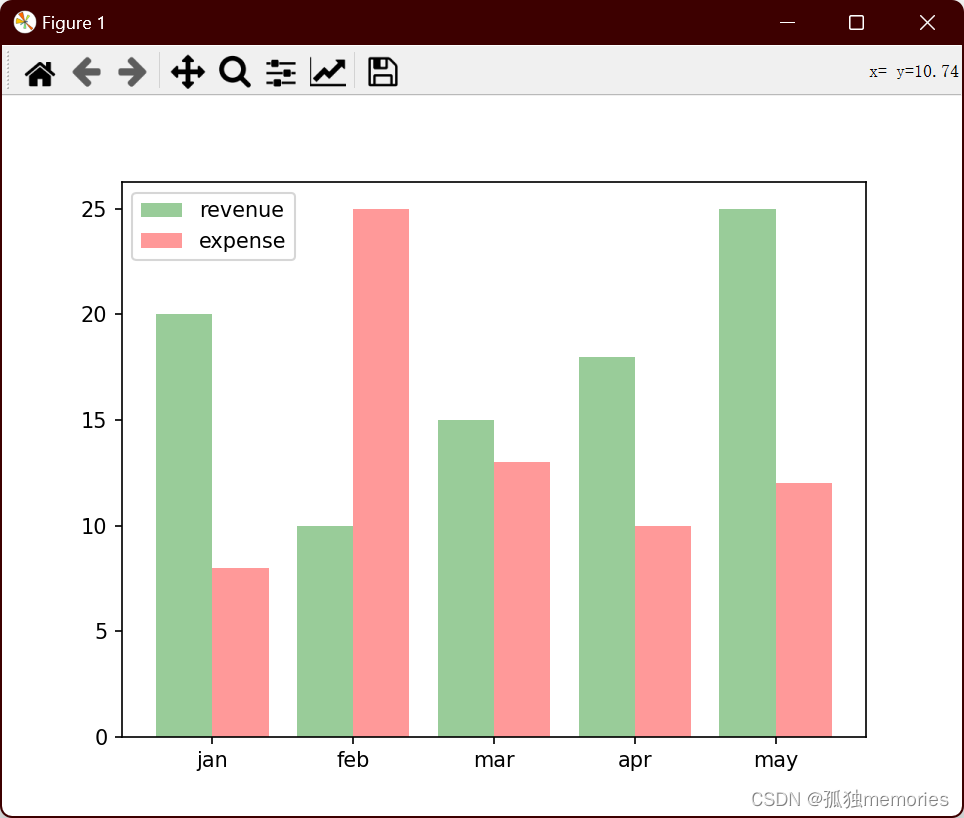
Python numpy库的应用、matplotlib绘图、opencv的应用
numpy import numpy as npl1 [1, 2, 3, 4, 5]# array():将列表同构成一个numpy的数组 l2 np.array(l1) print(type(l2)) print(l2) # ndim : 返回数组的轴数(维度数) # shape:返回数组的形状,用元组表示;元组的元素…...

SpringBoot 如何进行 统一异常处理
在Spring Boot中,可以通过自定义异常处理器来实现统一异常处理。异常处理器能够捕获应用程序中抛出的各种异常,并提供相应的错误处理和响应。 Spring Boot提供了ControllerAdvice注解,它可以将一个类标记为全局异常处理器。全局异常处理器能…...

数据库索引优化与查询优化——醍醐灌顶
索引优化与查询优化 哪些维度可以进行数据库调优 索引失效、没有充分利用到索引-一索引建立关联查询太多JOIN (设计缺陷或不得已的需求) --SQL优化服务器调优及各个参数设置 (缓冲、线程数等)–调整my.cnf数据过多–分库分表 关于数据库调优的知识点非常分散。不同的 DBMS&a…...
与知识蒸馏)
Student and Teacher network(学生—教师网络)与知识蒸馏
Student and Teacher network指一个较小且较简单的模型(学生)被训练来模仿一个较大且较复杂的模型(教师)的行为或预测。教师网络通常是一个经过训练在大型数据集上并在特定任务上表现良好的模型。而学生网络被设计成计算效率高且参…...

FPGA——PLD的区别以及各自的特点
目录 一、概述二、PLD的优点三、PLD的分类1、PROM(可编程只读存储器):2、PAL(可编程阵列逻辑)3、GAL(通用阵列逻辑)4、CPLD (复杂PLD)5、FPGA(现场可编程门阵…...
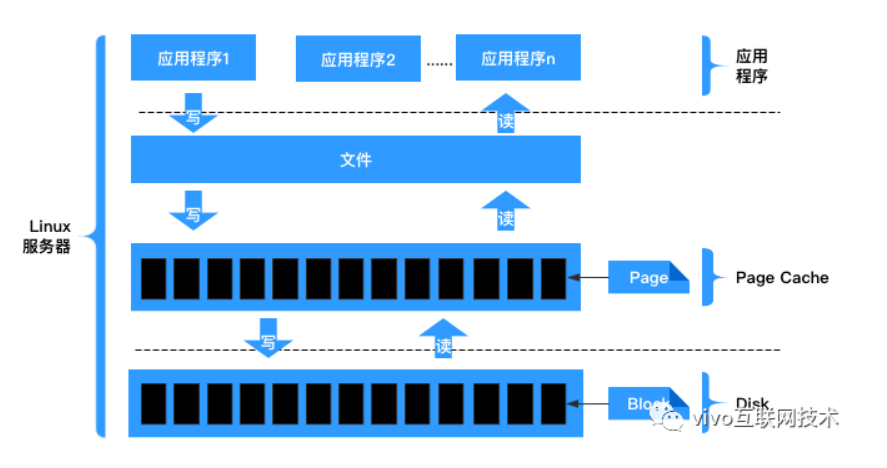
八、Kafka时间轮与常见问题
Kafka与时间轮 Kafka中存在大量的延时操作。 1、发送消息-超时重试机制 2、ACKS 用于指定分区中必须要有多少副本收到这条消息,生产者才认为写入成功(延时 等) Kafka并没有使用JDK自带的Timer或者DelayQueue来实现延迟的功能,而…...
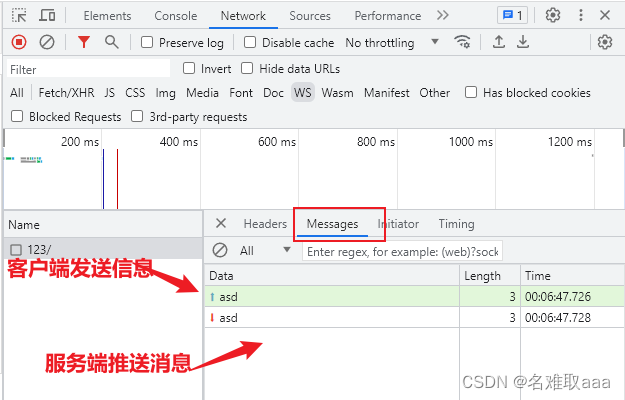
Web端即时通讯技术(SEE,webSocket)
目录 背景简介个人见解被动推送轮询简介实现 长轮询(comet)简介实现 比较 主动推送长连接(SSE)简介实现GETPOST 效果 webSocket简介WebSocket的工作原理:WebSocket的主要优点:WebSocket的主要缺点: 实现用法一用法二 **效果** 比较…...
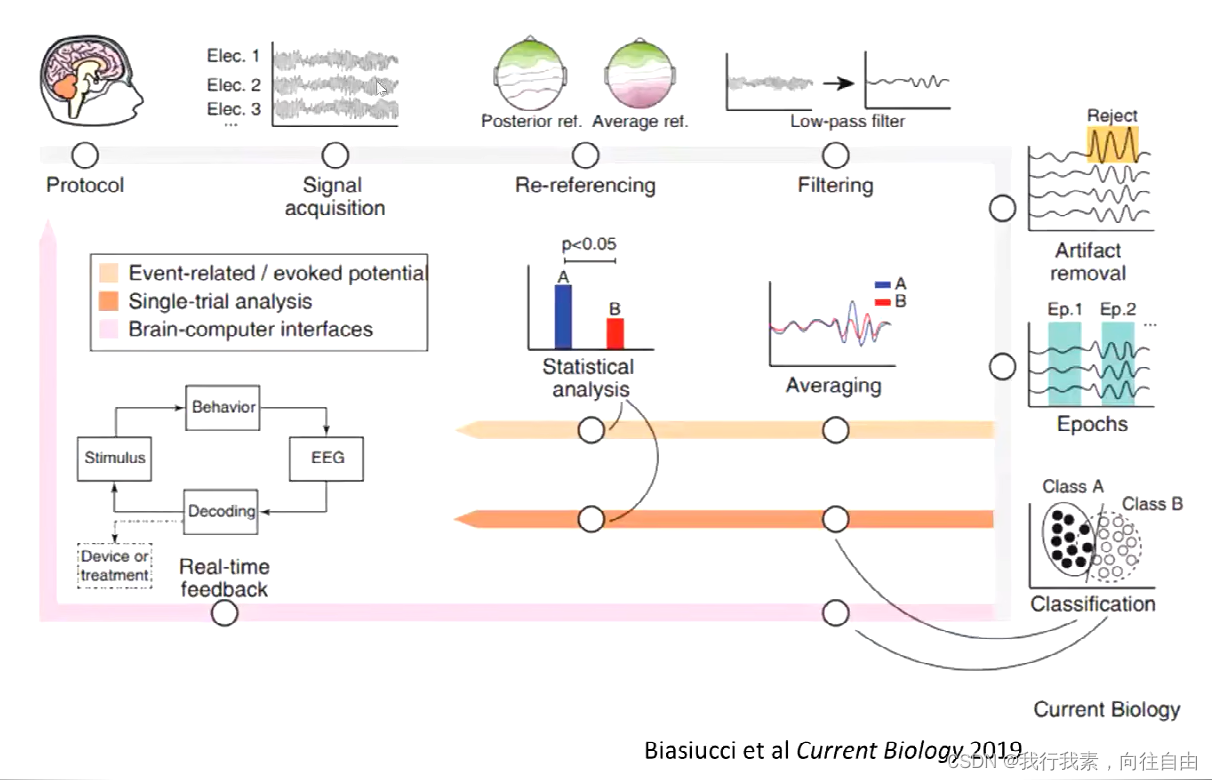
脑电信号处理与特征提取——4.脑电信号的预处理及数据分析要点(彭微微)
目录 四、脑电信号的预处理及数据分析要点 4.1 脑电基础知识回顾 4.2 伪迹 4.3 EEG预处理 4.3.1 滤波 4.3.2 重参考 4.3.3 分段和基线校正 4.3.4 坏段剔除 4.3.5 坏导剔除/插值 4.3.6 独立成分分析ICA 4.4 事件相关电位(ERPs) 4.4.1 如何获…...
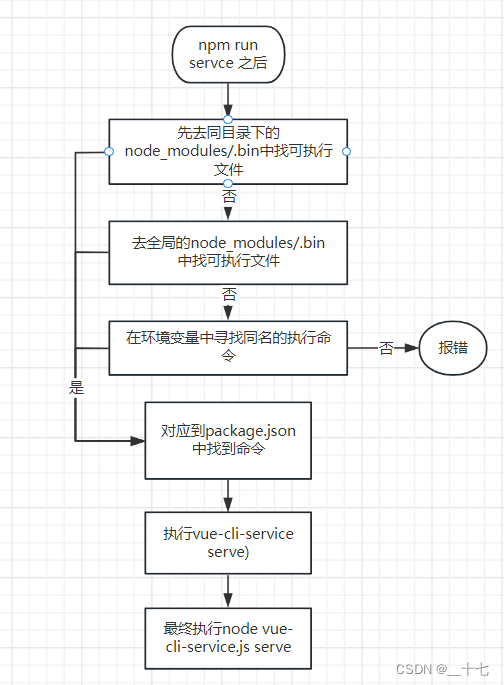
分析npm run serve之后发生了什么?
首先需要明白的是,当你在终端去运行 npm run ****,会是什么过程。 根据上图的一个流程,就可以衍生出很多问题。 1,为什么不直接运行vue-cli-service serve? 因为直接运行 vue-cli-service serve,会报错,…...

AI Agent在智能风控中的实战:多智能体欺诈检测与预警
AI Agent在智能风控中的实战:多智能体欺诈检测与预警 你有没有过明明是正常交易却被银行冻结账户的糟糕体验?或是听说过某电商平台上线新活动首日就被黑产团伙薅走数千万补贴的新闻?随着黑产欺诈向团伙化、专业化、动态化演进,传统依赖规则引擎、单模型机器学习的风控体系已…...

CentOS 7下‘Development Tools’和‘开发工具’组有区别吗?实测告诉你答案
CentOS 7下‘Development Tools’与‘开发工具’的隐藏关联:技术细节全解析在Linux系统管理中,yum的软件包组功能一直是个既实用又充满谜团的领域。特别是当系统语言环境与软件包元数据语言不一致时,开发者们常常会遇到一个有趣的现象&#x…...

Java数组工具类实战:设计不可实例化的静态工具类
实现一个工具类 MathUtils,满足以下要求: 1. 所有方法均为静态,且该类不能从外部实例化(提示:使用私有构造器)。 2. 提供三个静态方法:- maxArray(int[] arr):返回较大值;…...

ARM PMU性能监控单元原理与实践指南
1. ARM PMU性能监控单元概述性能监控单元(PMU)是现代ARM处理器中用于硬件级性能分析的核心组件。它通过一组可编程的硬件计数器,实现对处理器内部各种关键事件的精确测量。这些事件涵盖了从指令执行、缓存访问到内存子系统行为等处理器活动的…...

华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate
华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zen…...

终极免费方案:WandEnhancer完整解锁WeMod Pro功能快速指南
终极免费方案:WandEnhancer完整解锁WeMod Pro功能快速指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否渴望享受WeMod Pro会员的所…...

SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能
SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...

Performance-Fish:让你的《环世界》后期游戏帧率提升400%的终极优化方案
Performance-Fish:让你的《环世界》后期游戏帧率提升400%的终极优化方案 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish 你是否曾在《环世界》游戏后期,面对庞大…...

终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词
终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词 【免费下载链接】lrcget Utility for mass-downloading LRC synced lyrics for your offline music library. 项目地址: https://gitcode.com/gh_mirrors/lr/lrcget 你是否厌倦了在听歌时手动搜索歌词…...

XZ1018,100V,40A,NMOS 封装:TO252
封装:TO252类型:NVDS:100V VGS: 20V ID:40ARDS(ON):10V <14mΩRDS(ON):4.5V <19mΩ型号: XZ1018 封装:TO252类型…...