Training-Time-Friendly Network for Real-Time Object Detection 论文学习
1. 解决了什么问题?
目前的目标检测器很少能做到快速训练、快速推理,并同时保持准确率。直觉上,推理越快的检测器应该训练也很快,但大多数的实时检测器反而需要更长的训练时间。准确率高的检测器大致可分为两类:推理时间久的的训练时间久的。
推理时间久的检测器一般依赖于复杂的后处理逻辑或沉重的检测 head。尽管这些设计能提升准确率和收敛速度,但是推理速度很慢,不适合实时应用。
为了降低推理速度,人们尝试去简化检测 head 与后处理,同时能维持准确率。CenterNet 的推理速度快,但是需要很长的训练时间,这是因为简化后的网络很难训练,过度依赖于数据增强和长训练周期。比如,CenterNet 在 MS COCO 数据集上需要训练 140 140 140个 epochs,而第一类方法只要训练 12 12 12epochs。
研究发现,如果 batch size 越大,可采取较大的学习率,二者之间服从某种线性关系。作者发现,从标注框编码更多的训练样本,与增大 batch size 的作用相似。与特征提取相比,编码特征、计算损失的时间微乎其微。这样我们就可以很低的代价来加快收敛。CenterNet 在回归目标的尺寸时,只关注目标的中心点,无法利用目标中心点附近的信息,造成收敛速度很慢。
2. 提出了什么方法?
为了平衡速度和准确率,作者提出了 TTFNet,它具有 light-head、单阶段和 anchor-free 的特点,推理速度很快。为了降低训练时间,作者发现从标注框中编码更多的训练样本,与增大 batch size 作用相似,从而可以增大学习率、加快训练过程。最后,在进行定位和回归时,提出利用高斯核来编码训练样本的方法。于是网络可以更好地利用标注框,产生更多的监督信号,实现快速收敛。通过高斯核构建出目标中心的附近区域,从该区域内提取训练样本。将高斯概率作为回归样本的权重使用,这样能更加关注于中心附近的样本。该方法能减少模糊的、低质量样本,无需 FPN 结构。此外,也无需预测偏移量来修正预测结果。
Motivation
编码更多的训练样本与增大 batch size 是相似的,都可以提供更多的监督信号。这里的“训练样本”是指标注框内编码的特征。在随机梯度下降(SGD)中,权重更新表示为:
w t + 1 = w t − η 1 n ∑ x ∈ B Δ l ( x , w t ) w_{t+1}=w_t - \eta\frac{1}{n}\sum_{x\in B}\Delta l(x,w_t) wt+1=wt−ηn1x∈B∑Δl(x,wt)
w w w是网络权重, B B B是训练集里的 mini-batch, n = ∣ B ∣ n=|B| n=∣B∣是 mini-batch size, η \eta η是学习率, l ( x , w ) l(x,w) l(x,w)是图像 x x x的损失计算。
对于目标检测任务,图像 x x x包含多个标注边框,这些边框会被编码为训练样本 s ∈ S x s\in S_x s∈Sx。 m x = ∣ S x ∣ m_x=|S_x| mx=∣Sx∣是图像 x x x中所有边框产生的样本个数。因此上式可写为:
w t + 1 = w t − η 1 n ∑ x ∈ B 1 m x ∑ s ∈ S x Δ l ( s , w t ) w_{t+1}=w_t - \eta \frac{1}{n}\sum_{x\in B} \frac{1}{m_x} \sum_{s\in S_x} \Delta l(s, w_t) wt+1=wt−ηn1x∈B∑mx1s∈Sx∑Δl(s,wt)
为了更简洁,我们假设 mini-batch B B B里的每张图像 x x x的 m x m_x mx都相等。对于每个训练样本 s s s,上式写为:
w t + 1 = w t − η 1 n m ∑ s ∈ B Δ l ( s , w t ) w_{t+1}=w_t - \eta \frac{1}{nm}\sum_{s\in B}\Delta l(s,w_t) wt+1=wt−ηnm1s∈B∑Δl(s,wt)
根据线性缩放规则,如果 batch size 乘以 k k k,则学习率也要乘以 k k k,除非网络变动很大,或使用了非常大的 mini-batch。只有当我们能假设 Δ l ( x , w t ) ≈ Δ l ( x , w t + j ) , j < k \Delta l(x,w_t)\approx \Delta l(x, w_{t+j}),j<k Δl(x,wt)≈Δl(x,wt+j),j<k时,用小 mini-batch B j B_j Bj跑 k k k次、学习率为 η \eta η,与用较大的 mini-batch ∪ j ∈ [ 0 , k ) B j \cup_{j\in [0,k)}B_j ∪j∈[0,k)Bj、学习率为 k η k\eta kη跑 1 1 1次是等价的。这里,我们只关注训练样本 s s s,mini-batch size ∣ B ∣ = n m |B|=nm ∣B∣=nm。作者提出了一个相似的结论:每个 mini-batch 内的训练样本个数乘以 k k k,则学习率乘以 l l l, 1 ≤ l ≤ k 1\leq l\leq k 1≤l≤k。
CenterNet 的推理速度很快,但训练时间很长。它在训练过程中使用了复杂的数据增强方法。尽管这些增强能提升训练准确率,但是收敛很慢。为了排除它们对收敛速度的影响,实验时不使用数据增强,而且加大学习率。如下图,较大的学习率能加快收敛,但是准确率下降,会造成过拟合。这是因为 CenterNet 在训练时只会在目标中心位置编码一个回归样本,这使得 CenterNet 必须依赖于数据增强和长训练周期。

Approach
Background
CenterNet 将目标检测任务分为两个部分:中心定位和尺寸回归。在定位任务,它采取高斯核输出热力图,网络在目标中心附近产生高激活值。在回归任务,将目标中心点的像素定义为训练样本,直接预测目标的宽度和高度。此外,它会预测目标因输出步长而造成的偏移。网络在推理时,目标中心点附近的激活值较高,NMS 可被替换为其它操作。为了去除 NMS,作者采取了与中心定位相似的策略,在高斯核中加入了边框的宽高比。CenterNet 没有考虑到这一点,不是最优的。
对于尺寸回归,作者将高斯区域内所有的像素点都当作训练样本。此外,使用目标大小和高斯概率计算出样本的权重,更好地利用信息。该方法无需预测偏移量来修正下采样造成的误差,因此更加简洁、高效。下图中,主干网络提取特征,然后上采样到原图 1 / 4 1/4 1/4分辨率。然后这些特征用于定位和回归任务。定位时,网络在目标中心输出高激活值。回归时,边框的高斯区域内的所有样本都能直接预测它到四条边的距离。
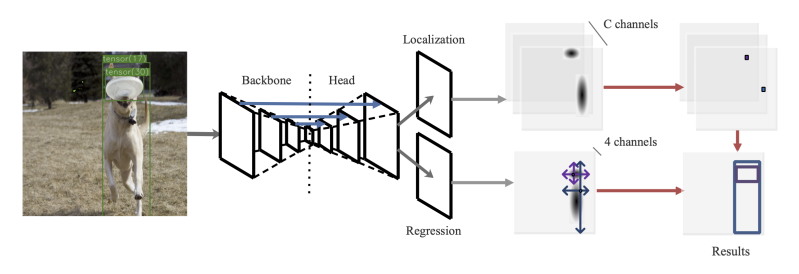
Gaussian Kernels for Training
给定一张图片,网络分别预测特征 H ^ ∈ R N × C × H r × W r \hat{H}\in \mathcal{R}^{N\times C\times \frac{H}{r}\times \frac{W}{r}} H^∈RN×C×rH×rW和 S ^ ∈ R N × 4 × H r × W r \hat{S}\in \mathcal{R}^{N\times 4\times \frac{H}{r}\times \frac{W}{r}} S^∈RN×4×rH×rW。前者表示目标中心点在哪,后者获取目标尺寸的信息。 N , C , H , W , r N,C,H,W,r N,C,H,W,r分别是 batch size、类别数、输入图像的高度和宽度、输出步长。实验中, C = 80 , r = 4 C=80,r=4 C=80,r=4。在定位和回归任务,都使用了高斯核,使用标量 α , β \alpha,\beta α,β来控制高斯核大小。
Object Localization
假设第 m m m个标注框属于第 c m c_m cm个类别,首先将它线性映射到特征图尺度。然后 2D 高斯核 K m ( x , y ) = exp ( − ( x − x 0 ) 2 2 σ x 2 − ( y − y 0 ) 2 2 σ y 2 ) \mathbf{K}_m(x,y)=\exp({-\frac{(x-x_0)^2}{2\sigma_x^2}}-\frac{(y-y_0)^2}{2\sigma_y^2}) Km(x,y)=exp(−2σx2(x−x0)2−2σy2(y−y0)2)用于输出 H m ∈ R 1 × H r × W r H_m\in \mathcal{R}^{1\times \frac{H}{r}\times \frac{W}{r}} Hm∈R1×rH×rW,其中 σ x = α ⋅ w 6 , σ y = α ⋅ h 6 \sigma_x=\frac{\alpha\cdot w}{6},\sigma_y=\frac{\alpha\cdot h}{6} σx=6α⋅w,σy=6α⋅h。最后,对 H m H_m Hm使用 element-wise max 操作,更新 H H H的第 c m c_m cm个通道。 H m H_m Hm由参数 α \alpha α、中心位置 ( x 0 , y 0 ) m (x_0,y_0)_m (x0,y0)m和边框大小 ( h , w ) m (h,w)_m (h,w)m决定。使用 ( ⌊ x r ⌋ , ⌊ y r ⌋ ) (\lfloor\frac{x}{r}\rfloor, \lfloor\frac{y}{r}\rfloor) (⌊rx⌋,⌊ry⌋)使中心点落在某像素点上。网络中,设定 α = 0.54 \alpha=0.54 α=0.54。
将高斯分布的峰值点(边框中心像素点)当作正样本,其它像素点当作负样本。
给定预测 H ^ \hat{H} H^和定位目标 H H H:
L l o c = − 1 M { ( 1 − H ^ i j c ) α f log ( H ^ i j c ) if H i j c = 1 ( 1 − H i j c ) β f H ^ i j c α f log ( 1 − H ^ i j c ) , otherwise L_{loc} = -\frac{1}{M}\left\{ \begin{array}{ll} (1-\hat{H}_{ijc})^{\alpha_f}\log(\hat{H}_{ijc})\quad\quad\quad\quad\quad\quad\quad\text{if}\quad H_{ijc}=1 \\ (1-H_{ijc})^{\beta_f}\hat{H}^{\alpha_f}_{ijc}\log (1-\hat{H}_{ijc}),\quad\quad\quad \text{otherwise} \end{array} \right. Lloc=−M1{(1−H^ijc)αflog(H^ijc)ifHijc=1(1−Hijc)βfH^ijcαflog(1−H^ijc),otherwise
其中 α f , β f \alpha_f,\beta_f αf,βf是 focal loss 的超参。 M M M表示标注框的个数。 α f = 0.2 , β f = 4 \alpha_f=0.2,\beta_f=4 αf=0.2,βf=4。
Size Regression
给定特征图尺度上的第 m m m个标注框,用高斯核输出 S m ∈ R 1 × H r × W r S_m\in \mathcal{R}^{1\times \frac{H}{r}\times \frac{W}{r}} Sm∈R1×rH×rW, β \beta β控制高斯核大小。 S m S_m Sm中的非零区域叫做高斯区域 A m A_m Am。 A m A_m Am总是存在于第 m m m个边框内,因此被叫做 sub-area。
Sub-area 内每个像素都是一个回归样本。给定 A m A_m Am内的像素 ( i , j ) (i,j) (i,j)及输出步长 r r r,回归目标定义为 ( i r , j r ) (ir,jr) (ir,jr)到第 m m m边框四条边的距离,记做一个四维向量 ( w l , h t , w r , h b ) i j m (w_l,h_t,w_r,h_b)^m_{ij} (wl,ht,wr,hb)ijm。 ( i , j ) (i,j) (i,j)位置的预测框表示为:
x ^ 1 = i r − w ^ l s , y ^ 1 = j r − h ^ t s \hat{x}_1=ir-\hat{w}_ls, \quad\quad \hat{y}_1=jr-\hat{h}_ts x^1=ir−w^ls,y^1=jr−h^ts
x ^ 2 = i r + w ^ r s , y ^ 2 = j r + h ^ b s \hat{x}_2=ir+\hat{w}_rs, \quad\quad \hat{y}_2=jr+\hat{h}_bs x^2=ir+w^rs,y^2=jr+h^bs
s s s是个固定标量,扩大预测结果,从而降低优化难度。实验中 s = 16 s=16 s=16。预测框 ( x ^ 1 , y ^ 1 , x ^ 2 , y ^ 2 ) (\hat{x}_1,\hat{y}_1,\hat{x}_2,\hat{y}_2) (x^1,y^1,x^2,y^2)位于图像尺度,而非特征图尺度。
不存在于任何 sub-area 内的像素,在训练时会被忽略。如果一个像素同时存在于多个 sub-area(模糊样本),则训练 target 设为面积较小的目标。
给定预测结果 S ^ \hat{S} S^和回归目标 S S S,从 S S S中汇集训练目标 S ′ ∈ R N r e g × 4 S'\in \mathcal{R}^{N_{reg}\times 4} S′∈RNreg×4,及其对应的预测结果 S ′ ^ ∈ R N r e g × 4 \hat{S'}\in \mathcal{R}^{N_{reg}\times 4} S′^∈RNreg×4, N r e g N_{reg} Nreg表示回归样本数。如上式所做的,对于这些样本,解码出预测边框,及其对应的标注框。使用 GIoU 计算损失:
L r e g = 1 N r e g ∑ ( i , j ) ∈ A m GIoU ( B ^ i j , B m ) × W i j L_{reg}=\frac{1}{N_{reg}}\sum_{(i,j)\in A_m} \text{GIoU}(\hat{B}_{ij},B_m)\times W_{ij} Lreg=Nreg1(i,j)∈Am∑GIoU(B^ij,Bm)×Wij
B ^ i j \hat{B}_{ij} B^ij表示解码后的边框 ( x ^ 1 , y ^ 1 , x ^ 2 , y ^ 2 ) i j (\hat{x}_1,\hat{y}_1,\hat{x}_2,\hat{y}_2)_{ij} (x^1,y^1,x^2,y^2)ij, B m = ( x 1 , y 1 , x 2 , y 2 ) m B_m=({x}_1,{y}_1,{x}_2,{y}_2)_m Bm=(x1,y1,x2,y2)m表示图像尺度的第 m m m个标注框。 W i j W_{ij} Wij是样本权重,平衡各样本的损失。
因为目标尺度都不一样,大目标可能产生几千个样本,而小目标只能产生很少。损失归一化后,小目标的损失几乎都没了,这不利于检测小目标。因此,样本权重 W i j W_{ij} Wij发挥着重要作用,平衡损失。假定 ( i , j ) (i,j) (i,j)位于第 m m m个标注框的子区域 A m A_m Am内,
W i j = { log ( a m ) × G m ( i , j ) ∑ ( x , y ) ∈ A m G m ( x , y ) if ( i , j ) ∈ A m 0 if ( i , j ) ∉ A m W_{ij} = \left\{ \begin{array}{ll} \log(a_m)\times \frac{G_m(i,j)}{\sum_{(x,y)\in A_m} G_m(x,y)} \quad\quad\quad\quad\text{if}\quad (i,j)\in A_m \\ 0\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\text{if}\quad (i,j)\notin A_m \end{array} \right. Wij={log(am)×∑(x,y)∈AmGm(x,y)Gm(i,j)if(i,j)∈Am0if(i,j)∈/Am
其中 G m ( i , j ) G_m(i,j) Gm(i,j)是 ( i , j ) (i,j) (i,j)位置的高斯概率。 a m a_m am是第 m m m个边框的面积。该机制能更好地利用大目标的标注信息,保留小目标的信息。它也能突出目标中心附近的样本,减少模糊和低质量样本。
Total Loss
总损失 L L L包括了定位损失 L l o s L_{los} Llos和回归损失 L r e g L_{reg} Lreg,用两个标量加权。 L = w l o g L l o c + w r e g L r e g L=w_{log}L_{loc}+w_{reg}L_{reg} L=wlogLloc+wregLreg,本文设定 w l o c = 1.0 , w r e g = 5.0 w_{loc}=1.0, w_{reg}=5.0 wloc=1.0,wreg=5.0。
Overall Design
TTFNet 的结构如上图所示。主干使用 ResNet 和 DarkNet。主干提取特征后,上采样到原图的 1 / 4 1/4 1/4分辨率,用 Modulated Deform Conv 和上采样层实现,后面跟着 BN 层和 ReLU 层。
然后,上采样特征分别输入进两个 heads。定位 head 对目标中心附近的位置输出高激活值,而回归 head 直接预测这些位置到边框四条边的距离。因为目标中心对应特征图的局部极大值,用 2D 最大池化来抑制非极大值。然后用局部极大值来汇总回归结果。最后得到检测结果。
该方法充分利用了大中目标的标注信息,而小目标的提升有限。为了提升短训练周期中小目标的表现,通过短路连接来引入高分辨率、低层级特征。短路连接引入了主干网络第2、3、4阶段的特征,每个连接用 3 × 3 3\times 3 3×3卷积实现。短路连接的第2、3、4阶段的层数分别设为3、2、1,每层后跟着一个 ReLU,除了最后一个。
相关文章:
Training-Time-Friendly Network for Real-Time Object Detection 论文学习
1. 解决了什么问题? 目前的目标检测器很少能做到快速训练、快速推理,并同时保持准确率。直觉上,推理越快的检测器应该训练也很快,但大多数的实时检测器反而需要更长的训练时间。准确率高的检测器大致可分为两类:推理时…...

HTTP改HTTPS
tomcat中http协议改https 第一步,配置server.xml <?xml version"1.0" encoding"UTF-8"?> <Server port"8005" shutdown"SHUTDOWN"><Listener className"org.apache.catalina.startup.VersionLogger…...
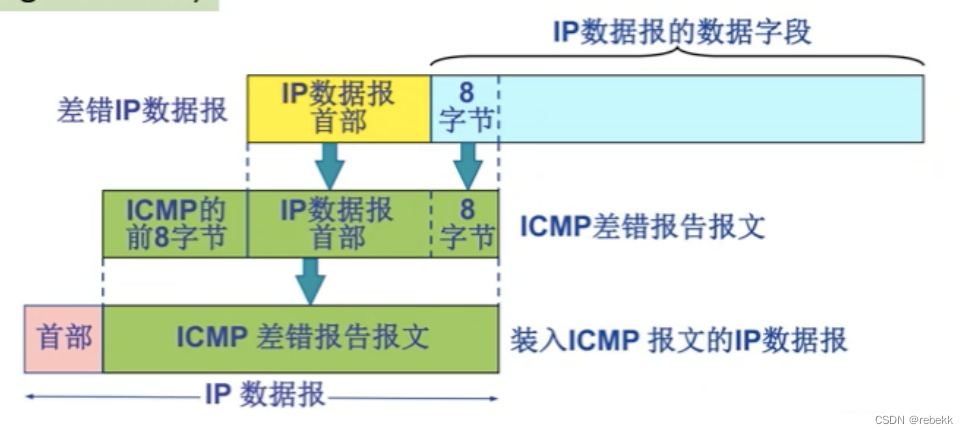
网络层中一些零碎且易忘的知识点
异构网络:指传输介质、数据编码方式、链路控制协议以及数据单元格式和转发机制不同,异构即物理层和数据链路层均不同RIP、OSPF、BGP分别是哪一层的协议: -RIPOSPFBGP所属层次应用层网络层应用层封装在什么协议中UDPIPTCP 一个主机可以有多个I…...
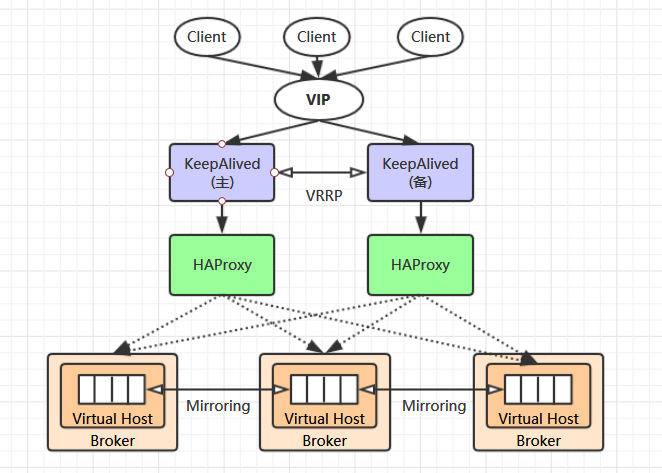
【RabbitMQ】之高可用集群搭建
目录 一、RabbitMQ 集群原理 1、默认集群原理2、镜像集群原理3、负载均衡方案 二、RabbitMQ 高可用集群搭建 1、RabbitMQ 集群搭建2、配置镜像队列3、HAProxy 环境搭建4、Keepalived 环境搭建 一、RabbitMQ 集群简介 1、默认集群原理 3-1、RabbitMQ 集群简介 单台 RabbitM…...
【node.js】01-fs读写文件内容
目录 一、fs.readFile() 读取文件内容 二、fs.writeFile() 向指定的文件中写入内容 案例:整理txt 需求: 代码: 一、fs.readFile() 读取文件内容 代码: //导入fs模块,从来操作文件 const fs require(fs)// 2.调…...

GitHub仓库如何使用
核心:GitHub仓库如何使用 目录 1.创建仓库: 2.克隆仓库到本地: 3.添加、提交和推送更改: 4.分支管理: 5.拉取请求(Pull Requests): 6.合并代码: 7.其他功能&…...

雪花算法,在分布式环境下实现高效的ID生成
其实雪花算法比较简单,可能称不上什么算法就是一种构造UID的方法。 点1:UID是一个long类型的41位时间戳,10位存储机器码,12位存储序列号。 点2:时间戳的单位是毫秒,可以同时链接1024台机器,每台…...

使用css 动画实现,水波纹的效果
每日鸡汤:每个你想要学习的瞬间都是未来的你向自己求救 需求,实现水波纹动画效果,要求中心一个圆点,然后有3个圈,一圈一圈的向里面缩小。 说实话我第一个想到了给3个圈设置不同的宽高,然后设置动画0-100%&a…...
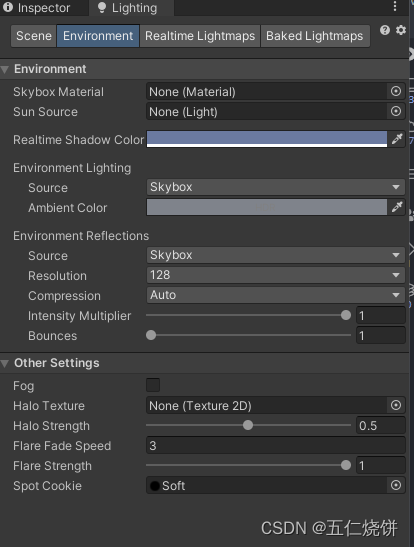
Unity光照相关知识和实践 (烘焙光照,环境光设置,全局光照)
简介 本文将会通过一个简单的场景搭建,介绍如何使用烘焙光照以及相关的注意事项。另外还介绍了Unity内全局光照(GI)的知识和GI实际在游戏内的表现效果。 Unity关于光照相关的参考文档地址:https://docs.unity.cn/cn/current/Man…...

【设计模式——学习笔记】23种设计模式——适配器模式Adapter(原理讲解+应用场景介绍+案例介绍+Java代码实现)
文章目录 介绍生活中的案例基础介绍工作原理分类应用场景 案例类适配器模式例1介绍类图代码实现优缺点分析 例2类图代码实现 对象适配器模式(常用方式)例1介绍类图代码实现优缺点分析 例2代码实现 接口适配器模式介绍类图代码实现 登场角色类图类适配器模…...
Android Unit Test
一、测试基础知识 1.1 测试级别 测试金字塔(如图 2 所示)说明了应用应如何包含三类测试(即小型、中型和大型测试): 小型测试是指单元测试,用于验证应用的行为,一次验证一个类。 中型测试是指…...

docker更新jenkins
下载文件 1、jenkins提示下载 2、官网下载jenkins官网 文件放服务器内 通过工具把jenkins.war放进服务器例如tmp 文件复制到docker的jenkins容器 docker cp 路径文件 容器id:/{后面不接内容为根路径} docker cp /tmp/jenkins.war 53dc1c71058a:/进入容器内 docker exec …...

一种新的基于区域的在线活动轮廓模型研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

【Docker】基于Dockerfile搭建LNMP架构
一、项目环境 公司在实际的生产环境中,需要使用Docker 技术在一台主机上创建LNMP服务并运行Wordpress网站平台。然后对此服务进行相关的性能调优和管理工作。 1. 环境配置 主机操作系统IP地址主要软件DockerCentOS 7.3 x86_64192.168.145.15Docker 19.03容器ip地址规划 ngin…...
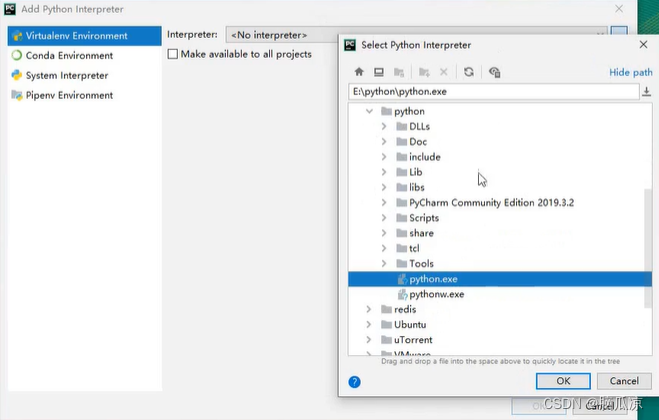
爬虫003_pycharm的安装以及使用_以及python脚本模版设置---python工作笔记021
这里我们用ide,pycharm来编码,看一看如何下载 这里我们下载这个社区办,这个是免费的,个人版是收费的 然后勾选以后 安装以后我们来创建一个项目 这里可以选择python的解释器,选择右边的... 这里我们找到我们自己安装的python解释器...

远程xml读取解析,将image url下载到本地,延时队列定时删除文件,图片访问路径保存在数据库中
远程xml部分内容 <imagelist name"FY4A AGRI IMG REGI MTCC GLL" tag"FY4A AGRI IMG REGI MTCC GLL"><image time"2023-07-25 22:30 (UTC)" desc"FY4A AGRI IMG REGI MTCC GLL" url"http://img.nsmc.org.cn/PORTAL/FY4…...
firefox笔记-Centos7离线安装firefox
目前(2023-03-22 16:41:35)Centos7自带的firefox已经很新了是2020年的。主要原因是有个web项目,用2020年的firefox打不开。 发到互联网上是2023-07-24。 报错是js有问题,估计是搞前端的只做了chrome适应,没做firefox…...

Flutter:滑动面板
前言 无意中发现了这个库,发现现在很多app中都有类似的功能。以手机b站为例,当你在看视频时,点击评论,视频会向上偏移,下方划出评论界面。 sliding_up_panel SlidingUpPanel是一个Flutter插件,用于创建滑…...
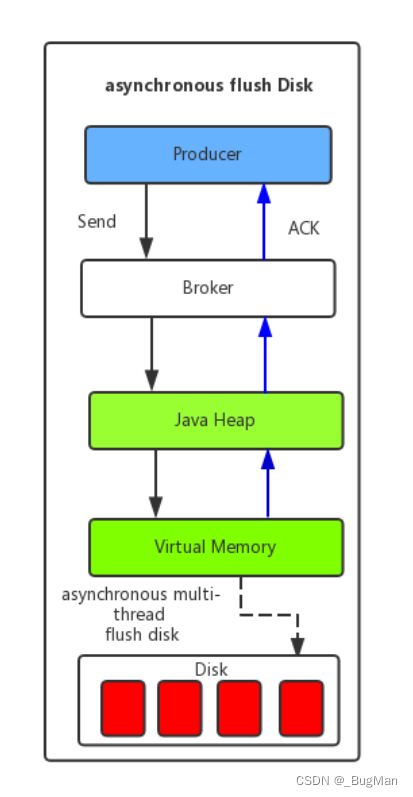
RocketMQ概论
目录 前言: 1.概述 2.下载安装、集群搭建 3.消息模型 4.如何保证吞吐量 4.1.消息存储 4.1.1顺序读写 4.1.2.异步刷盘 4.1.3.零拷贝 4.2.网络传输 前言: RocketMQ的代码示例在安装目录下有全套详细demo,所以本文不侧重于讲API这种死…...

任务的创建与删除
Q: 什么是任务? A: 任务可以理解为进程/线程,创建一个任务,就会在内存开辟一个空间。 比如: 玩游戏,打篮球,开车,都可以视为任务。 Windows 系统中的 MarkText 、谷歌浏览器、记事本࿰…...

除了排错,你可能不知道OPC Expert v8.1还能做这些:数据归档、计算与冗余实战
解锁OPC Expert v8.1的隐藏潜力:数据归档、实时计算与冗余架构实战指南在工业自动化领域,OPC Expert常被视为故障排查的"急救箱",但它的能力远不止于此。当大多数工程师还在用它解决DCOM配置问题时,少数先行者已经用它重…...

从分立逻辑到单片机:基于ATmega8的MIDI通道分析仪设计与实现
1. 项目概述:从分立逻辑到单片机的MIDI通道分析仪进化史二十年前,当我在《Elektor》杂志上发表第一版MIDI通道分析仪时,整个数字音乐世界还处于一个相当“硬核”的阶段。那个版本的设计,用今天的话来说,简直就是一场“…...

苏州创新药20年,站上全球产业洗牌暴风眼
一个城市的创新药产业集群如何从无到有,又如何在全球化临界点寻找自己的位置。文|徐鑫编|任晓渔过去一年多,苏州是全球创新药产业版图中一个绕不过去的城市。大额海外授权交易频繁传出,在中国高端制造走出去的背景下&a…...

适合地产人用的中介房源管理系统
在房产经纪行业,房源管理与客源管理是经纪人日常工作的核心,直接影响业务效率与成交转化。选择一套适配行业需求的中介房源管理系统,能帮助中介团队规范流程、降低运营成本、大幅提升业绩。今天我们以客观视角,详细解析全房源系统…...

解决Claude Code访问不稳定与Token不足的痛点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code访问不稳定与Token不足的痛点 许多开发者将Claude Code作为日常编程的得力助手,用于代码生成、问题调试…...

户外实用|艾迪欧 R6000 测评 —— 户外 / 自驾 / 露营的通讯好搭档
户外出行,通讯工具的核心是稳定、清晰、耐用、续航久、功能全。艾迪欧 R6000 作为一款兼顾专业与户外的 DMR 对讲机,全频段覆盖、双模通讯、自定义功能、长续航,完美适配自驾、露营、登山、越野等户外场景,是户外爱好者的靠谱通讯…...

6款高效降AI率工具 改写实力出众
写论文时反复检测出的AI痕迹总让你提心吊胆?别担心,这里整理了6款真正好用的论文降AI率工具,堪称应对AI生成特征的“得力助手”。它们能有效识别并消除AI生成的痕迹,改写能力出众,帮你快速降低查重率,顺利通…...

告别元素变动导致的报错:探索自动化测试脚本的 AI“自愈”能力
前言:一个所有测试人都经历过的噩梦 周三晚上十一点,CI/CD流水线再次亮起红灯。 你打开日志,满屏的NoSuchElementException扑面而来。仔细一看——前端团队在昨天的版本中重构了登录页面的DOM结构,原本的#login-btn变成了#signin-button-v2,30个测试用例因此全军覆没。 …...
)
别再手动编译了!Matlab一键调用CEC2017测试函数的完整配置指南(附30个函数调用示例)
别再手动编译了!Matlab一键调用CEC2017测试函数的完整配置指南(附30个函数调用示例) 算法研究者们常常需要借助标准测试函数来验证优化算法的性能,而CEC2017测试函数集因其复杂性和多维度的挑战性,成为评估算法鲁棒性的…...

不止于绘图:用GMT 6.4的`grdtrack`和`project`命令玩转地形剖面分析与可视化
不止于绘图:用GMT 6.4的grdtrack和project命令玩转地形剖面分析与可视化 当我们谈论地理空间分析时,很多人首先想到的是绘制精美的地图。但GMT(Generic Mapping Tools)的真正魅力在于它强大的地理计算能力。本文将带你超越基础绘图…...