基于飞桨paddle波士顿房价预测练习模型测试代码
基于飞桨paddle波士顿房价预测练习模型测试代码
导入基础库
#paddle:飞桨的主库,paddle 根目录下保留了常用API的别名,当前包括:paddle.tensor、paddle.framework、paddle.device目录下的所有API;
import paddle
#Linear:神经网络的全连接层函数,包含所有输入权重相加的基本神经元结构。在房价预测任务中,使用只有一层的神经网络(全连接层)实现线性回归模型。
from paddle.nn import Linear
#paddle.nn:组网相关的API,包括 Linear、卷积 Conv2D、循环神经网络LSTM、损失函数CrossEntropyLoss、激活函数ReLU等;
#paddle.nn.functional:与paddle.nn一样,包含组网相关的API,如:Linear、激活函数ReLU等,二者包含的同名模块功能相同,运行性能也基本一致。
#差别在于paddle.nn目录下的模块均是类,每个类自带模块参数;paddle.nn.functional目录下的模块均是函数,需要手动传入函数计算所需要的参数。
#在实际使用时,卷积、全连接层等本身具有可学习的参数,建议使用paddle.nn;而激活函数、池化等操作没有可学习参数,可以考虑使用paddle.nn.functional。
import paddle.nn.functional as F
#NumPy(Numerical Python的简称)是高性能科学计算和数据分析的基础包
import numpy as np
#os 操作系统库
import os
#random 椭机数库
import random
#数据处理
#数据处理
#====================================================
def load_data():# 从文件导入数据datafile = 'housing.data'data = np.fromfile(datafile, sep=' ', dtype=np.float32)# 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]feature_num = len(feature_names)# 将原始数据进行Reshape,变成[N, 14]这样的形状data = data.reshape([data.shape[0] // feature_num, feature_num])# 将原数据集拆分成训练集和测试集# 这里使用80%的数据做训练,20%的数据做测试# 测试集和训练集必须是没有交集的ratio = 0.8offset = int(data.shape[0] * ratio) #404*0.8=323=offsettraining_data = data[:offset] #获取-训练集# 计算train数据集的最大值,最小值maximums, minimums = training_data.max(axis=0), training_data.min(axis=0)# 记录数据的归一化参数,在预测时对数据做归一化global max_valuesglobal min_valuesmax_values = maximumsmin_values = minimums# 对数据进行归一化处理for i in range(feature_num):data[:, i] = (data[:, i] - min_values[i]) / (maximums[i] - minimums[i])# 训练集和测试集的划分比例training_data = data[:offset]test_data = data[offset:]return training_data, test_data
#====================================================
# 验证数据集读取程序的正确性
training_data, test_data = load_data()
print(training_data.shape) #=(404, 14)
print(training_data[1,:]) #模型设计
#模型设计
#====================================================
class Regressor(paddle.nn.Layer):# self代表类的实例自身def __init__(self):# 初始化父类中的一些参数super(Regressor, self).__init__()# 定义一层全连接层,输入维度是13,输出维度是1self.fc = Linear(in_features=13, out_features=1)# 网络的前向计算def forward(self, inputs):x = self.fc(inputs)return x
#====================================================
#训练配置
#训练配置
# 声明定义好的线性回归模型
model = Regressor()
# 开启模型训练模式
model.train()
# 加载数据
training_data, test_data = load_data()
# 定义优化算法,使用随机梯度下降SGD
# 学习率设置为0.01
opt = paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters())
#模型实例有两种状态:训练状态.train()和预测状态.eval()。
# 训练时要执行正向计算和反向传播梯度两个过程,而预测时只需要执行正向计算,
# 为模型指定运行状态, **# 训练过程**
#训练过程采用二层循环嵌套方式:
#内层循环: 负责整个数据集的一次遍历,采用分批次方式(batch)。
#外层循环: 定义遍历数据集的次数,通过参数EPOCH_NUM设置。
#====================================================
EPOCH_NUM = 10 # 设置外层循环次数
BATCH_SIZE = 10 # 设置batch大小# 定义外层循环
for epoch_id in range(EPOCH_NUM):# 在每轮迭代开始之前,将训练数据的顺序随机的打乱np.random.shuffle(training_data)# 将训练数据进行拆分,每个batch包含10条数据mini_batches = [training_data[k:k+BATCH_SIZE] for k in range(0, len(training_data), BATCH_SIZE)]# 定义内层循环for iter_id, mini_batch in enumerate(mini_batches):x = np.array(mini_batch[:, :-1]) # 获得当前批次训练数据y = np.array(mini_batch[:, -1:]) # 获得当前批次训练标签(真实房价)# 将numpy数据转为飞桨动态图tensor的格式house_features = paddle.to_tensor(x)prices = paddle.to_tensor(y)# 前向计算predicts = model(house_features)# 计算损失loss = F.square_error_cost(predicts, label=prices)avg_loss = paddle.mean(loss)if iter_id%20==0:print("epoch: {}, iter: {}, loss is: {}".format(epoch_id, iter_id, avg_loss.numpy()))# 反向传播,计算每层参数的梯度值avg_loss.backward()# 更新参数,根据设置好的学习率迭代一步opt.step()# 清空梯度变量,以备下一轮计算opt.clear_grad()
#====================================================
# 保存并测试模型
# 保存模型
# 保存模型
# 使用paddle.save API将模型当前的参数数据 model.state_dict() 保存到文件中,
# 用于模型预测或校验的程序调用。
# 保存模型参数,文件名为LR_model.pdparams
paddle.save(model.state_dict(), 'LR_model.pdparams')
print("模型保存成功,模型参数保存在LR_model.pdparams中")
#测试模型
#测试模型
#====================================================
def load_one_example():# 从上边已加载的测试集中,随机选择一条作为测试数据idx = np.random.randint(0, test_data.shape[0])idx = -10one_data, label = test_data[idx, :-1], test_data[idx, -1]# 修改该条数据shape为[1,13]one_data = one_data.reshape([1,-1])return one_data, label
#====================================================
# 参数为保存模型参数的文件地址
model_dict = paddle.load('LR_model.pdparams')
model.load_dict(model_dict)
model.eval()# 参数为数据集的文件地址
one_data, label = load_one_example()
# 将数据转为动态图的variable格式
one_data = paddle.to_tensor(one_data)
predict = model(one_data)# 对结果做反归一化处理
predict = predict * (max_values[-1] - min_values[-1]) + min_values[-1]
# 对label数据做反归一化处理
label = label * (max_values[-1] - min_values[-1]) + min_values[-1]print("预测结果Inference result is {}, 原相应值the corresponding label is {}".format(predict.numpy(), label))
#====================================================
执行结果如下所示:
PS E:\project\python> & D:/Python39/python.exe e:/project/python/BSD_House.py
(404, 14)
[2.35922547e-04 0.00000000e+00 2.62405723e-01 0.00000000e+001.72839552e-01 5.47997713e-01 7.82698274e-01 3.48961979e-014.34782617e-02 1.14822544e-01 5.53191364e-01 1.00000000e+002.04470202e-01 3.68888885e-01]
epoch: 0, iter: 0, loss is: [1.0095187]
epoch: 0, iter: 20, loss is: [0.05577583]
epoch: 0, iter: 40, loss is: [0.10179052]
epoch: 1, iter: 0, loss is: [0.05334579]
epoch: 1, iter: 20, loss is: [0.05690664]
epoch: 1, iter: 40, loss is: [0.00672564]
epoch: 2, iter: 0, loss is: [0.07125398]
epoch: 2, iter: 20, loss is: [0.07457525]
epoch: 2, iter: 40, loss is: [0.06540678]
epoch: 3, iter: 0, loss is: [0.06383592]
epoch: 8, iter: 40, loss is: [0.02903528]
epoch: 9, iter: 0, loss is: [0.05061438]
epoch: 9, iter: 20, loss is: [0.03942648]
epoch: 9, iter: 40, loss is: [0.02119895]
模型保存成功,模型参数保存在LR_model.pdparams中
预测结果Inference result is [[18.37352]], 原相应值the corresponding label is 19.700000762939453
PS E:\project\python>
模型保存成功,模型参数保存在LR_model.pdparams中
预测结果
预测结果Inference result is [[18.37352]], 原相应值the corresponding label is 19.700000762939453
相关文章:

基于飞桨paddle波士顿房价预测练习模型测试代码
基于飞桨paddle波士顿房价预测练习模型测试代码 导入基础库 #paddle:飞桨的主库,paddle 根目录下保留了常用API的别名,当前包括:paddle.tensor、paddle.framework、paddle.device目录下的所有API; import paddle #Lin…...
只会“点点点”,凭什么让开发看的起你?
众所周知,如今无论是大厂还是中小厂,自动化测试基本是标配了,毕竟像双 11、618 这种活动中庞大繁杂的系统,以及多端发布、多版本、机型发布等需求,但只会“写一些自动化脚本”很难胜任。这一点在招聘要求中就能看出来。…...

35.图片幻灯片
图片幻灯片 html部分 <div class"carousel"><div class"image-container"><img src"./static/20180529205331_yhGyf.jpeg" alt"" srcset""><img src"./static/20190214214253_hsjqw.webp"…...
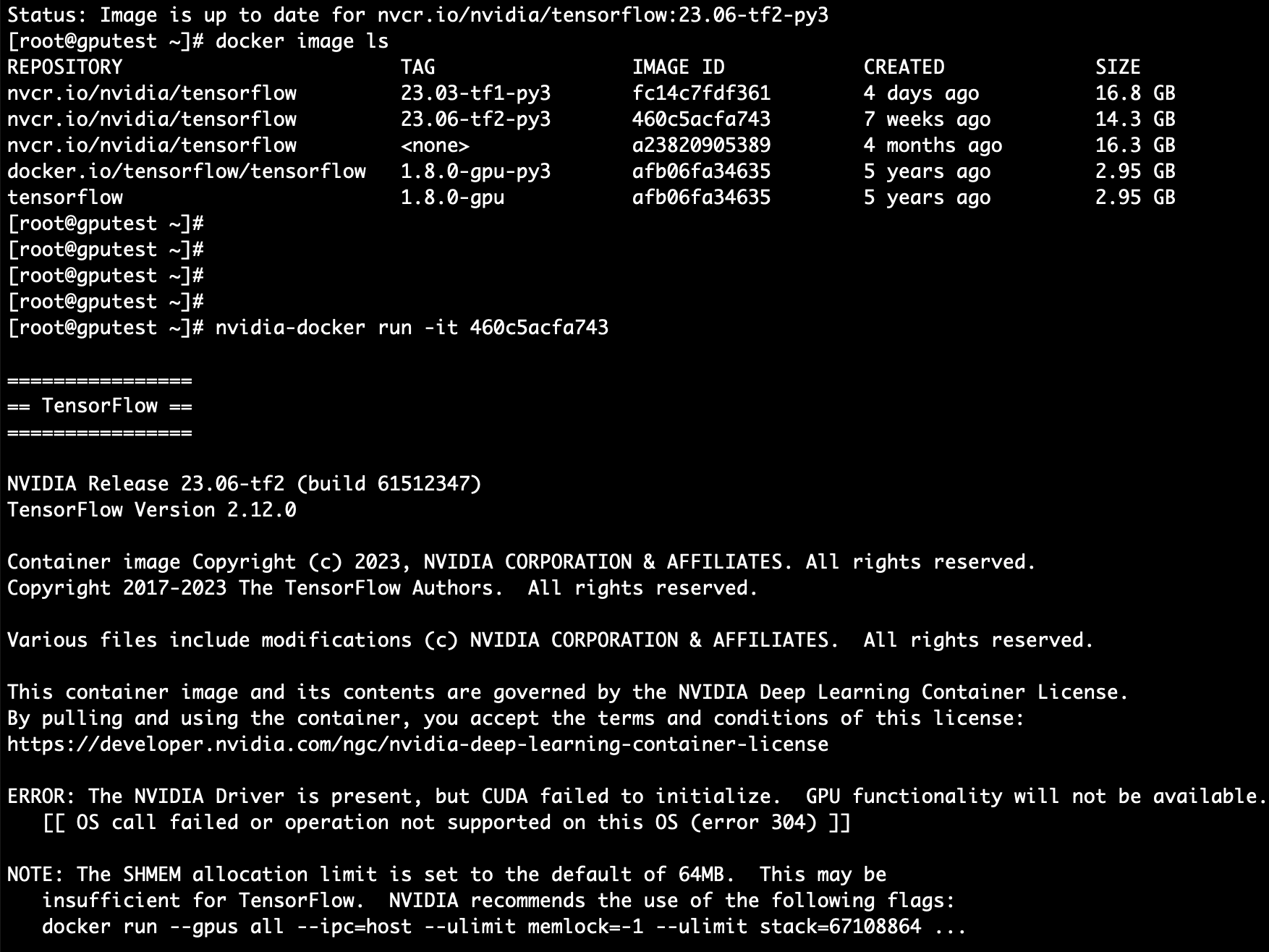
CentOS7系统Nvidia Docker容器基于TensorFlow2.12测试GPU
CentOS7系统Nvidia Docker容器基于TensorFlow1.15测试GPU 参考我的另一篇博客 1. 安装NVIDIA-Docker的Tensorflow2.12.0版本 1. 版本依赖对应关系:从源代码构建 | TensorFlow GPU 版本Python 版本编译器构建工具cuDNNCUDAtensorflow-2.6.03.6-3.9GCC 7.3.1Ba…...
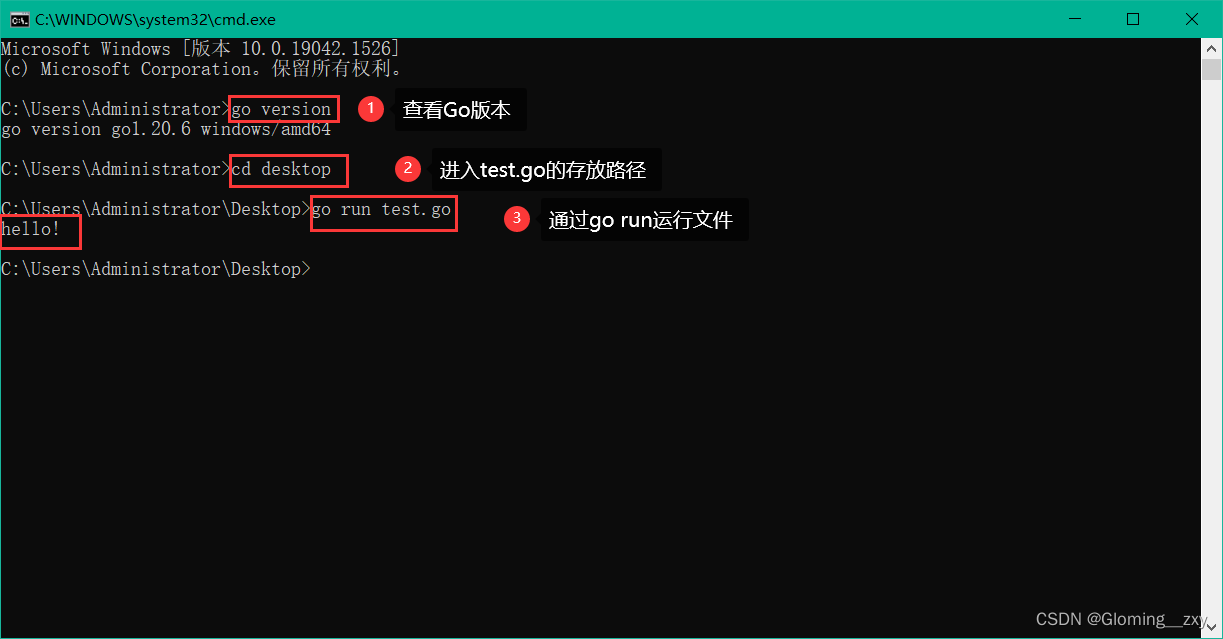
Go 下载安装教程
1. 下载地址:The Go Programming Language (google.cn) 2. 下载安装包 3. 安装 (1)下一步 (2)同意 (3)修改安装路径,如果不修改,直接下一步 更改后,点击下一…...
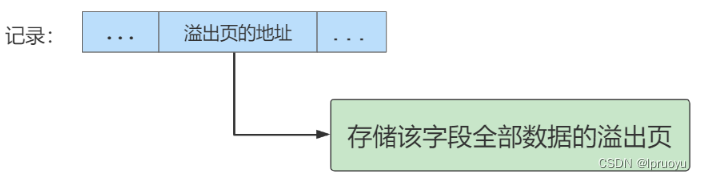
InnoDB数据存储结构
一. InnoDB的数据存储结构:页 索引是在存储引擎中实现的,MySQL服务器上的存储引擎负责对表中数据的读取和写入工作。不同存储引擎中存放的格式一般不同的,甚至有的存储引擎比如Memory都不用磁盘来存储数据,这里讲讲InooDB存储引擎…...
)
基于ts的浏览器缓存工具封装(含源码)
cache.ts缓存工具 浏览器缓存工具封装实现使用方法示例代码 浏览器缓存工具封装 在前端开发中,经常会遇到需要缓存数据的情况,例如保存用户的登录状态、缓存部分页面数据等 但有时候需要缓存一些复杂的对象,例如用户信息对象、设置配置等。…...

GIT涵盖工作中用的相关指令
git安装一直默认点击下去,安装完成,右键会看见gitBash git --version 查看git安装的版本 使用git前配置git git config --global user.name 提交人姓名 git config --global user.email 提交人邮箱 git config --list 查看git配置信息 使用git中配置…...
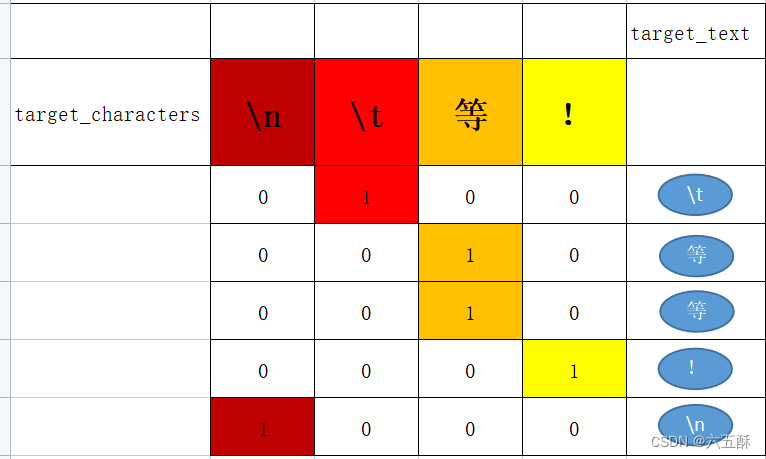
【如何训练一个中英翻译模型】LSTM机器翻译seq2seq字符编码(一)
系列文章 【如何训练一个中英翻译模型】LSTM机器翻译seq2seq字符编码(一) 【如何训练一个中英翻译模型】LSTM机器翻译模型训练与保存(二) 【如何训练一个中英翻译模型】LSTM机器翻译模型部署(三) 【如何训…...
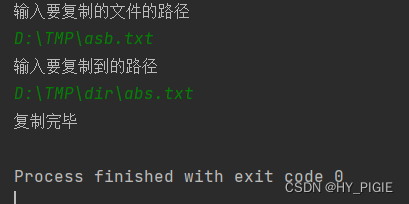
[JAVAee]文件操作-IO
本文章讲述了通过java对文件进行IO操作 IO:input/output,输入/输出. 建议配合文章末尾实例食用 目录 文件 文件的管理 文件的路径 文件的分类 文件系统的操作 File类的构造方法 File的常用方法 文件内容的读写 FileInputStream读取文件 构造方法 常用方法 Scan…...
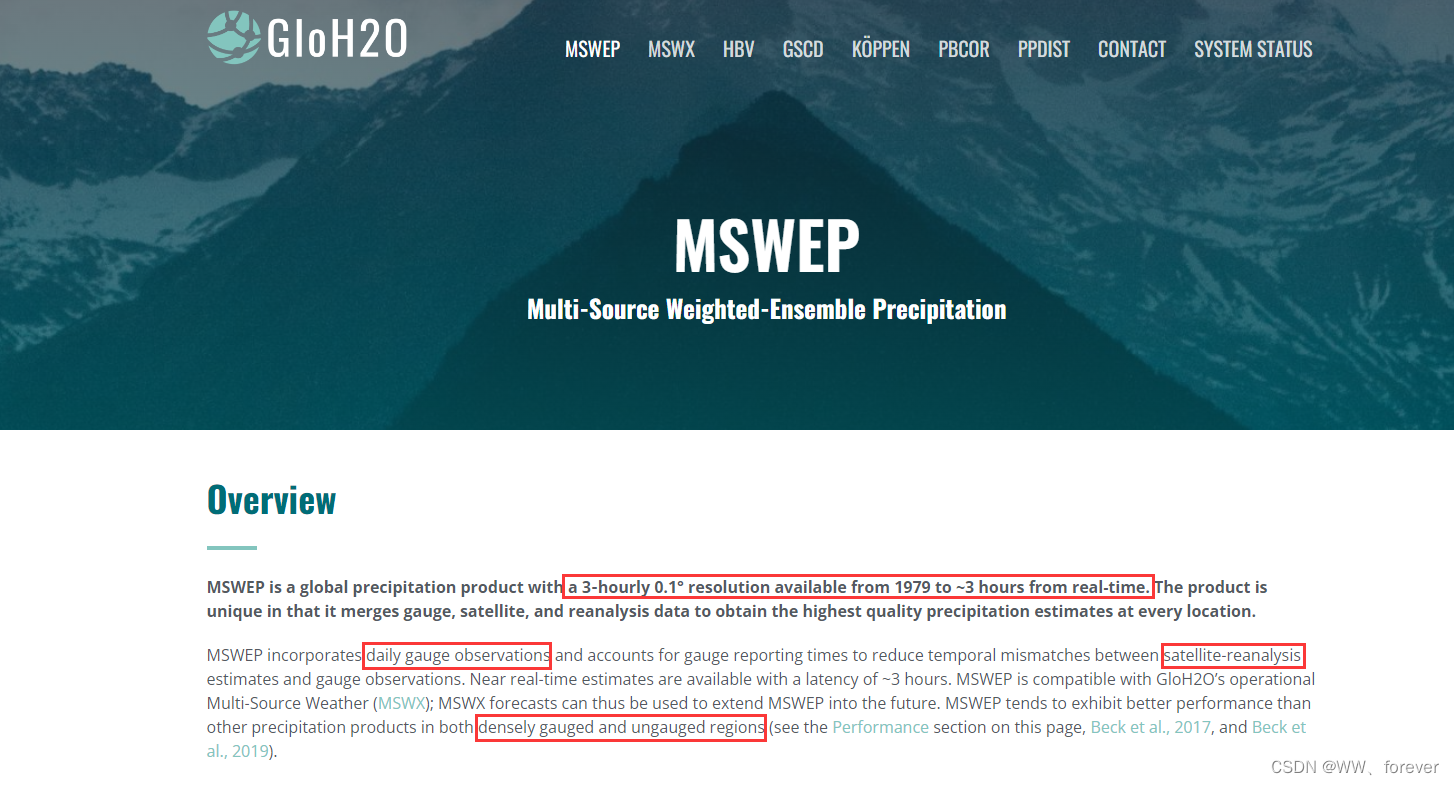
【数据集】3小时尺度降水数据集-MSWEPV2
1 MSWEP V2 precipitation product 官网-MSWEP V2降水产品 参考...
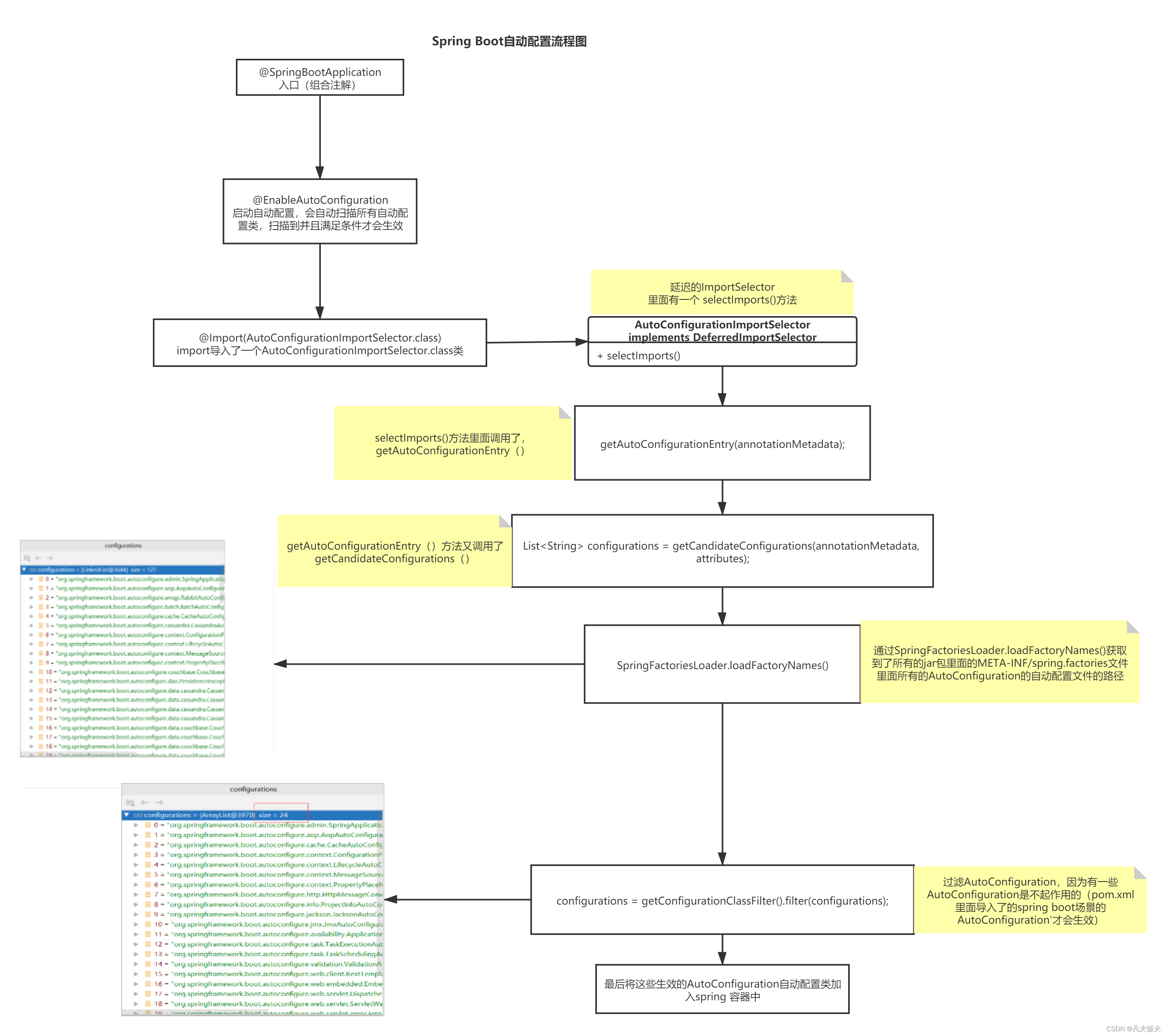
Springboot之把外部依赖包纳入Spring容器管理的两种方式
前言 在Spring boot项目中,凡是标记有Component、Controller、Service、Configuration、Bean等注解的类,Spring boot都会在容器启动的时候,自动创建bean并纳入到Spring容器中进行管理,这样就可以使用Autowired等注解,…...

更安全,更省心丨DolphinDB 数据库权限管理系统使用指南
在数据库产品使用过程中,为保证数据不被窃取、不遭破坏,我们需要通过用户权限来限制用户对数据库、数据表、视图等功能的操作范围,以保证数据库安全性。为此,DolphinDB 提供了具备以下主要功能的权限管理系统: 提供用户…...
WPS本地镜像化在线文档操作以及样例
一个客户项目有引进在线文档操作需求,让我这边做一个demo调研下,给我的对接文档里有相关方法的说明,照着对接即可。但在真正对接过程中还是踩过不少坑,这儿对之前的对接工作做个记录。 按照习惯先来一个效果: Demo下载…...
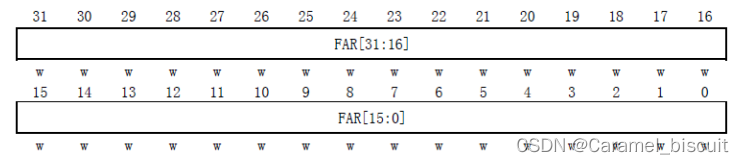
STM32 Flash学习(一)
STM32 FLASH简介 不同型号的STM32,其Flash容量也不同。 MiniSTM32开发板选择的STM32F103RCT6的FLASH容量为256K字节,属于大容量产品。 STM32的闪存模块由:主存储器、信息块和闪存存储器接口寄存器等3部分组成。 主存储器,该部分…...
Spring中IOC容器常用的接口和具体的实现类
在Spring框架没有出现之前,在Java语言中,程序员们创建对象一般都是通过关键字new来完成,那时流行一句话“万物即可new,包括女朋友”。但是这种创建对象的方式维护成本很高,而且对于类之间的相互关联关系很不友好。鉴于…...

【MySQL】索引特性
🌠 作者:阿亮joy. 🎆专栏:《零基础入门MySQL》 🎇 座右铭:每个优秀的人都有一段沉默的时光,那段时光是付出了很多努力却得不到结果的日子,我们把它叫做扎根 目录 👉没…...

【深度学习笔记】动量梯度下降法
本专栏是网易云课堂人工智能课程《神经网络与深度学习》的学习笔记,视频由网易云课堂与 deeplearning.ai 联合出品,主讲人是吴恩达 Andrew Ng 教授。感兴趣的网友可以观看网易云课堂的视频进行深入学习,视频的链接如下: 神经网络和…...
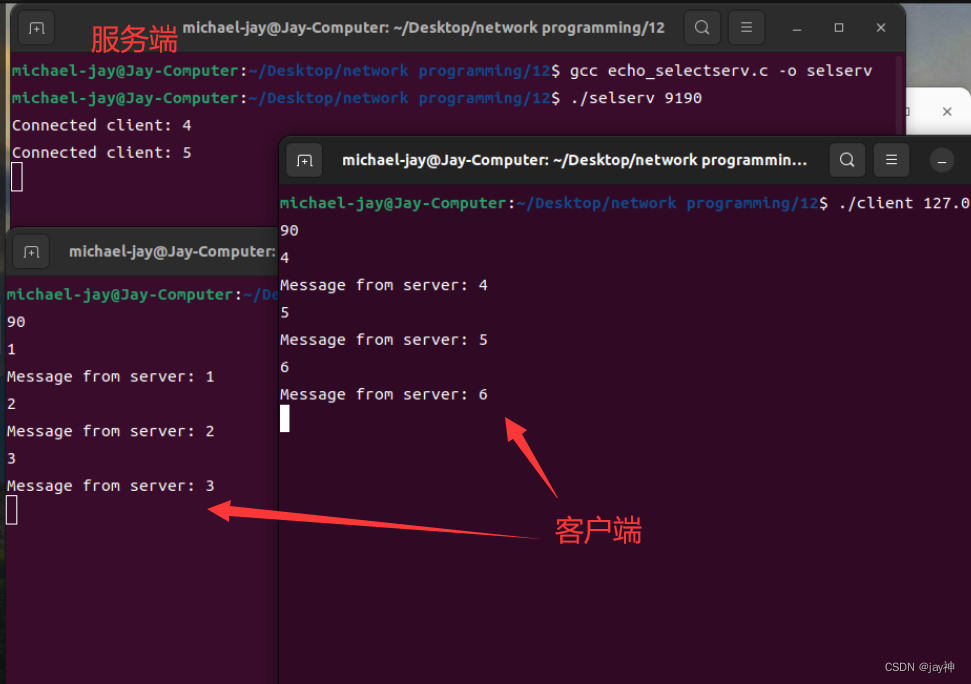
《TCP IP网络编程》第十二章
第 12 章 I/O 复用 12.1 基于 I/O 复用的服务器端 多进程服务端的缺点和解决方法: 为了构建并发服务器,只要有客户端连接请求就会创建新进程。这的确是实际操作中采用的一种方案,但并非十全十美,因为创建进程要付出很大的代价。…...

基于CNN卷积神经网络的调制信号识别算法matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 1. 卷积神经网络(CNN) 2. 调制信号识别 3.实现过程 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 MATLAB2022A 3.部分核心程序 % 构建调制类型…...

Yokogawa AAI835-H50/K4A00模拟输入/输出模块
Yokogawa AAI835-H50/K4A00 模拟输入/输出模块产品特点:通道配置:共8个通道,含4路模拟输入和4路模拟输出。信号类型:所有通道均支持4-20mA标准电流信号。HART通信:支持HART协议,可与智能现场设备双向数字通…...

开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南
开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南 【免费下载链接】Tkinter-Designer An easy and fast way to create a Python GUI 🐍 项目地址: https://gitcode.com/gh_mirrors/tk/Tkinter-Designer 在Python GUI开发…...

AI学习 - 大模型基础入门
AI学习 - 大模型基础入门 从零开始:Ollama 安装 → 本地模型运行 → Python 代码接入 → 理解核心概念 摘要 本文记录了在 Windows 上使用 Ollama 部署本地大模型、并通过 Python 代码接入调用的完整过程。内容涵盖:Ollama 安装与模型拉取、大模型基础概…...

ShrinkBox后门攻击:如何让自动驾驶模型“看错”距离,威胁ML-ADAS安全
1. 项目概述在自动驾驶和高级驾驶辅助系统(ADAS)领域,基于机器学习的目标检测模型,如YOLO系列,已成为感知环境、实现碰撞预警的核心组件。这些模型通过实时识别和定位道路上的车辆、行人等目标,为后续的距离…...

保姆级教程:在Windows 10上用QEMU+Kylin搭建可内外网访问的完整开发环境
在Windows 10上构建QEMUKylin全功能开发环境的终极指南当开发者需要在本地快速搭建一个隔离的国产操作系统开发环境时,QEMU虚拟化方案配合银河麒麟系统能提供高度灵活的沙箱体验。本文将手把手带你完成从零配置到内外网联通的完整工作流,涵盖虚拟化环境部…...

【C语言】C 语言为什么叫 C 语言呢?
【C语言】C 语言为什么叫 C 语言呢?笔记改自于王道训练营资料 其实是因为先有高级语言ALGOL 60,简称 A 语言,后来经过简化,变为 BCPL 语言,简称 B 语言,而 C 语言是在 B 语言的基础之上发展而来的ÿ…...

多模型聚合平台如何助力网站AIB测试与选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 多模型聚合平台如何助力网站AIB测试与选型 对于网站产品经理而言,首页文案的生成质量直接影响用户的第一印象和转化率。…...

猫抓浏览器扩展终极指南:5分钟掌握全网视频资源下载技巧
猫抓浏览器扩展终极指南:5分钟掌握全网视频资源下载技巧 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否经常遇到心仪的视频无法…...

ncmdumpGUI终极指南:深度解析网易云音乐NCM加密文件转换技术
ncmdumpGUI终极指南:深度解析网易云音乐NCM加密文件转换技术 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI ncmdumpGUI是一款专为Windows平台设计…...

修复 PowerShell 7 下 conda activate 报错的指南
修复 PowerShell 7 下 conda activate 报错的指南 适用场景:升级到 PowerShell 7.x 后,conda activate 突然报错,但 Windows PowerShell 5.1 正常。 发布日期:2026-05-24 适用版本:conda 23.x PowerShell 7.x 一、问题…...