数据结构—链表
链表
- 前言
- 链表
- 链表的概念及结构
- 链表的分类
- 无头单向非循环链表的相关实现
- 带头双向循环链表的相关实现
- 顺序表和链表(带头双向循环链表)的区别
前言
顺序表是存在一些固有的缺陷的:
- 中间/头部的插入删除,时间复杂度为O(N),效率比较低(因为需要挪动数据)
- 增容(需要开辟新空间释放旧空间)需要申请新空间,拷贝数据,释放旧空间。会有不小的消耗。
- 增容一般是呈2倍的增长,势必会有一定的空间浪费。例如当前容量为100,满了以后增容到200,再继续插入了5个数据,后面没有数据插入了,那么就浪费了95个数据空间。
其中链表就可以很好的解决上面的问题。
链表
链表的概念及结构
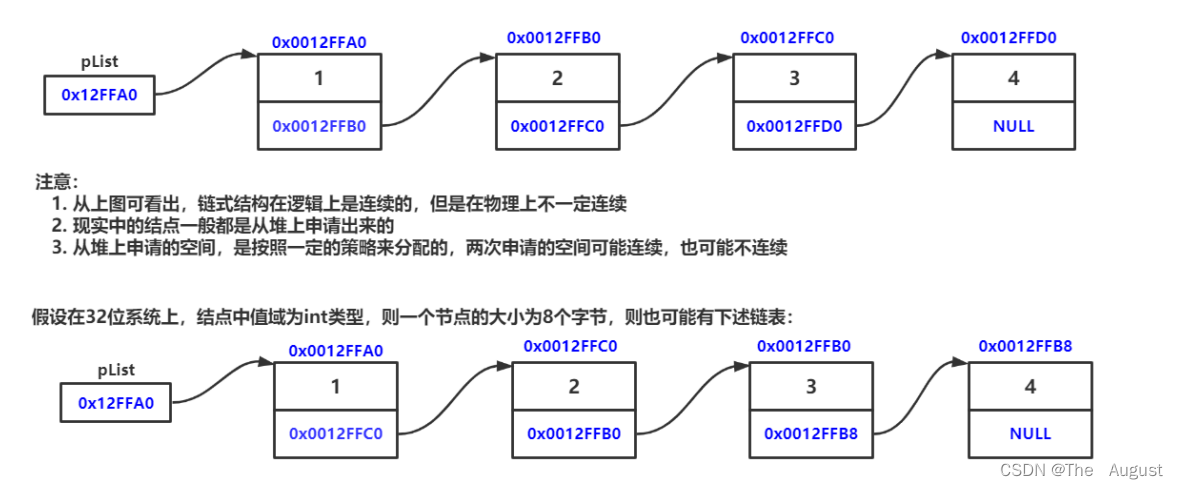
链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。
数据结构中:
注:
- 链表在逻辑上是线性,物理上不一定是线性的
- phead一般是指向第一个节点的指针(头指针)
链表的分类
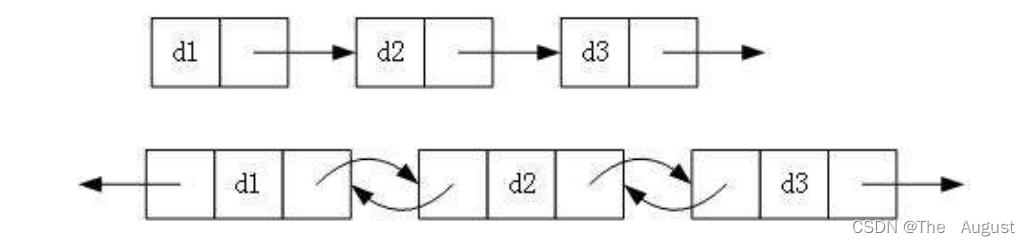
实际中链表的结构非常多样,以下情况组合起来就有8种链表结构:
- 单向或者双向
2. 带头或者不带头
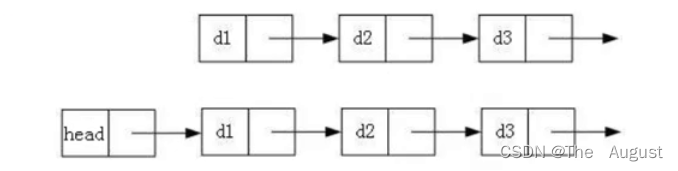
注:
- d1-头节点,head-哨兵位的头节点,这个节点不存储有效数据
- 带哨兵位头节点的好处是如果头指针指向的是不带哨兵位的头节点时再做头插尾插等操作就得传二级指针,因为头插尾插等操作只要动到头节点就需要改变头指针。如果是带哨兵位的头节点就不用传二级指针,因为头指针永远都不会变一直指向带哨兵位的头节点,头插是在带哨兵位的头节点之后插入,尾插也一样。永远不会动到头指针因为带哨兵位的头节点没有存储有效数据。
- 这里的带头指的是哨兵位的头节点,不存储有效数据
- 循环或者非循环
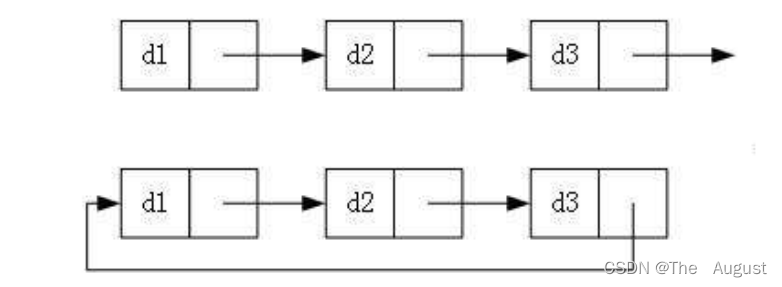
虽然有这么多的链表的结构,但是实际中最常用还是两种结构:无头单项非循环链表、带头双向循环链表
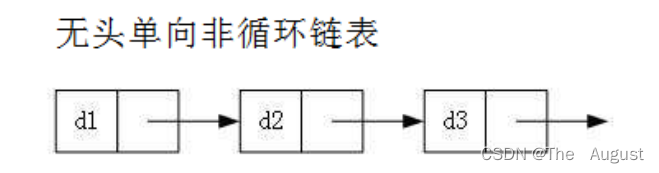

- 无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
- 带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了。
无头单向非循环链表的相关实现
链表的定义
typedef int SLTDataType;typedef struct SListNode
{SLTDataType data; // int val;struct SListNode* next; //注意这个地方不能使用SLTNode* next;这个地方还没有typedef出来就开始使用SLTNode,编译器找定义时只会向上找,然而上面并没有SLTNode。
}SLTNode;链表的打印
链表的打印需要将头节点的地址进行传参,从指向头节点位置的指针开始依次循环遍历直到遇到NULL为止停止打印节点的数据
void SListPrint(SLTNode* phead)
{SLTNode* cur = phead;while (cur != NULL){printf("%d->", cur->data);cur = cur->next;}printf("NULL\n");
}链表的尾插
链表的尾插首先通过循环的方式找到链表中的最后一个节点,接着要创建一个新节点,节点里面存放尾插的数据,最后将新节点的地址存放到最后一个节点中从而完成连接的过程。这时是最常见的一种情况,还有一种是当链表为空时(没有一个节点,头指针存放NULL),需要创建一个新节点并把新节点的地址存放到头指针中即可。
SLTNode* BuySListNode(SLTDataType x)
{SLTNode* node = (SLTNode*)malloc(sizeof(SLTNode));if (node == NULL){printf("malloc fail\n");exit(-1);}node->data = x;node->next = NULL;return node;
}void SListPushBack(SLTNode** pphead, SLTDataType x)
{assert(pphead);//头指针可能为空,但是头指针的地址是不可能为空的if (*pphead == NULL){SLTNode* newnode = BuySListNode(x);*pphead = newnode;}else{SLTNode* tail = *pphead;while (tail->next != NULL){tail = tail->next;}SLTNode* newnode = BuySListNode(x);tail->next = newnode;}
}
注意:
- 这里不要使用一级指针进行传参,因为指针传值,相当于把plist指针变量得值拷贝给phead,phead里面赋值newnode,而phead的改变不会影响plist。因此想在函数内部修改外面plist的值就得使用二级指针进行传参。
- 要改变传过来的指向第一个节点的指针就传二级;不改变传过来的指向第一个节点的指针就传一级
链表的头插
链表的头插只需要创建一个新节点,将头指针内存放的第一个节点的地址存储到新结点中,再将新节点的地址存放到头指针中(其中这两步顺序不能颠倒),从而完成头插的连接。注意当链表为空时这个头插不会出现问题。
void SListPushFront(SLTNode** pphead, SLTDataType x)
{assert(pphead);SLTNode* newnode = BuySListNode(x);newnode->next = *pphead;*pphead = newnode;
}
链表的尾删
链表尾删的方式有两种:
- 一种是定义两个指针(prev、tail),当tail指向下一个节点之前先将tail赋给prev,然后tail在指向下一个节点。这样以此往复直到tail指向最后一个节点停止,此时prev指向tail所指向节点的前一个节点。最后将tail所指向的节点释放掉,再将prev所指向节点的next置成NULL。
- 另一种是定义一个指针(tail)利用单链表的特点完成链表的尾删,单链表的特点是只能向一个方向走,只要走完就回不去了。因此tail指针找得到下一个节点但是找不到当前节点的前一个节点。 那直接找前一个从而也就能找到它的下一个,单链表是在当前位置找不到前一个但是在前一个位置是可以找到后一个的。此时就需要看tail所指向当前节点的下一个节点的下一个节点是否为NULL,如此往复直到它为NULL停止就说明tail所指向当前节点的下一个节点就是单链表的最后一个节点,那tail所指向当前节点就是最后一个节点的前一个节点。最后将tail所指向当前节点的下一个节点释放掉,并将tail所指向当前节点的next置成NULL即可。
注:
- 当链表尾删删除的是最后一个节点时需要注意头指针的指向问题(eg:phead)以及节点指针的野指针问题(eg:prev、tail->next)
- 链表尾删时需要分三种情况:无节点、一个节点、多个节点。当链表为空时进行尾删此时需要对头指针进行判断(eg:assert、if)。当链表有一个节点时(即头节点的next存储的是NULL)直接对该节点进行释放并把头指针指向空。当链表有多个节点时按照上述方式处理即可。
//第一种:void SListPopBack(SLTNode** pphead)
{// 检查参数是否传错assert(pphead);// 没有节点断言报错 -- 处理比较激进// 无节点assert(*pphead);// 一个节点if ((*pphead)->next == NULL){free(*pphead);*pphead = NULL;}// 多个节点else{SLTNode* tail = *pphead;while (tail->next->next != NULL){tail = tail->next;}free(tail);tail->next = NULL;}
}//第二种:
void SListPopBack(SLTNode** pphead)
{// 参数传错assert(pphead);// 无节点// 温和处理if (*pphead == NULL){return;}// 一个节点if ((*pphead)->next == NULL){free(*pphead);*pphead = NULL;}// 多个节点else{SLTNode* prev = NULL;SLTNode* tail = *pphead;while (tail->next != NULL){prev = tail;tail = tail->next;}free(tail);prev->next = NULL;}
}//第三种:
void SListPopBack(SLTNode** pphead)
{// 参数传错assert(pphead);// 无个节点// 链表为空了,还在调用尾删assert(*pphead);// 一个节点if ((*pphead)->next == NULL){free(*pphead);*pphead = NULL;}// 多个节点else{SLTNode* prev = NULL;SLTNode* tail = *pphead;while (tail->next != NULL){prev = tail;tail = tail->next;}free(tail);prev->next = NULL;}
}//第四种:
void SListPopBack(SLTNode** pphead)
{// 参数传错assert(pphead);// 无节点// 温和处理if (*pphead == NULL){return;}// 一个节点if ((*pphead)->next == NULL){free(*pphead);*pphead = NULL;}// 多个节点else{SLTNode* prev = NULL;SLTNode* tail = *pphead;while (tail->next != NULL){prev = tail;tail = tail->next;}free(tail);prev->next = NULL;}
}
注:pphead的意义是能够在增删的函数中改变外面的plist
链表的头删
链表的头删首先判断头指针的地址是否为空,其次再处理链表中无节点、一个节点、多个节点的情况即可。
注:
- 链表头删处理多个节点(一个节点)时需要先对头节点的下一个节点进行保存,再对头节点进行删除,最后再将头节点的下一个节点的地址存放到头指针里即可。
- 链表头删中的处理多个节点的情况也包含了一个节点的情况。
//第一种:void SListPopFront(SLTNode** pphead)
{// plist一定有地址,所以pphead不为空assert(pphead);// 链表为空assert(*pphead);// 只有一个节点if ((*pphead)->next == NULL){free(*pphead);*pphead = NULL;}// 多个节点else{SLTNode* next = (*pphead)->next;free(*pphead);(*pphead) = next;}
}//第二种:void SListPopFront(SLTNode** pphead)
{// plist一定有地址,所以pphead不为空assert(pphead);//链表为空assert(*pphead);//只有一个节点//多个节点SLTNode* next = (*pphead)->next;free(*pphead);(*pphead) = next;
}
链表中节点的个数
可以通过循环的方式(终止条件是当前节点的地址是否为空)求链表中节点的个数。
注:phead不需要进行断言,因为phead有可能为空(链表为空)空链表可以求节点个数
int SListSize(SLTNode* phead)
{int size = 0;SLTNode* cur = phead;while (cur){size++;cur = cur->next;}return size;
}
链表判空
链表的判空只需对头指针进行判空即可,如果头指针为空返回true,否则返回false。
注:C语言中用bool类型需要引头文件stdbool.h
//第一种:bool SListEmpty(SLTNode* phead)
{return phead == NULL;
}//第二种:bool SListEmpty(SLTNode* phead)
{if (phead == NULL){return true;}else{return false;}
}//第三种:bool SListEmpty(SLTNode* phead)
{return phead == NULL ? true : false;
}
链表的查找
链表的查找是通过循环遍历的方式进行查找,如果找到了返回该节点的地址,否则返回NULL。
SLTNode* SListFind(SLTNode* phead, SLTDataType x)
{SLTNode* cur = phead;while (cur){if (cur->data == x){return cur;}else{cur = cur->next;}}return NULL;
}
链表的插入
链表的前插入分两种情况处理:头插、后面插入。这里注意后面插入时首先需要找到pos位置之前的节点的位置(通过循环的方式找到pos位置之前的节点的位置),其次创建要插入的新节点,最后进行插入使其新节点的next指向pos位置的节点(next存储pos的值)并使前一个节点的next指向新节点(next存储新节点的地址)即可。
// 在pos位置之前去插入x
void SListInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{assert(pphead);assert(pos);// 头插if (*pphead == pos){SListPushFront(pphead, x);}// 后面插入else{// 找到pos位置的前一个节点SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}SLTNode* newnode = BuySListNode(x);newnode->next = pos;prev->next = newnode;}
}
链表的后插入首先要创建一个新节点,其次使其新节点的next指向pos位置上的节点的下一个节点,最后将pos位置上节点的next指向新节点。
// 在pos位置后面去插入x
void SListInsertAfter(SLTNode* pos, SLTDataType x)
{assert(pos);//注意插入顺序,不可颠倒SLTNode* newnode = BuySListNode(x);newnode->next = pos->next;pos->next = newnode;
}
注:单链表不适合在某个位置之前插入,因为需要找前一个位置。单链表适合在某个位置之后插入。
链表的删除
链表删除当前位置的节点分两种情况:头删、后面删除。这里注意后面删除首先需要找当前位置节点的前一个节点,其次使其前一个节点的next指向当前位置节点的后一个节点,最后再将pos位置上的节点释放掉。
// 删除pos位置的值
void SListErase(SLTNode** pphead, SLTNode* pos)
{assert(pphead);assert(pos);// 头删if (pos == *pphead){SListPopFront(pphead);}// 后面节点删除else{// 找到pos位置的前一个节点SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}prev->next = pos->next;free(pos);pos = NULL;}
}
链表删除当前位置的之后的节点,只需将当前位置的节点的next指向当前位置的节点的下一个节点的下一个节点即可,不过在此之前需要对当前位置的节点的下一个节点进行保存避免找不到该节点。最后再将该节点释放掉即可。
void SListEraseAfter(SLTNode* pos)
{assert(pos);assert(pos->next);SLTNode* next = pos->next;pos->next = next->next;free(next);next = NULL;
}链表的销毁
链表的销毁是将所有节点释放掉,通过循环的方式对链表进行销毁。这里注意释放节点时需要对下一个节点的地址进行保存避免找不到下一个节点的地址,最后需要将头指针置空即可。
注:节点的释放会引发一些问题会把这块节点的使用权还给操作系统并且指向这块空间上的值会被置成随机值
void SListDestory(SLTNode** pphead)
{assert(pphead);SLTNode* cur = *pphead;while (cur){SLTNode* next = cur->next;free(cur);cur = next;}*pphead = NULL;
}
带头双向循环链表的相关实现
链表的定义
typedef int LTDataType;typedef struct ListNode
{struct ListNode* next;struct ListNode* prev;LTDataType data;
}LTNode;链表的初始化
链表初始化首先要创建一个哨兵位的头节点,其次将哨兵位的头节点的前驱和后继都指向该头节点即可
LTNode* BuyListNode(LTDataType x)
{LTNode* node = (LTNode*)malloc(sizeof(LTNode));if (node == NULL){printf("malloc fail\n");exit(-1);}node->next = NULL;node->prev = NULL;node->data = x;return node;
}//第一种:void ListInit(LTNode** pphead)
{*pphead = BuyListNode(-1);(*pphead)->next = *pphead;(*pphead)->prev = *pphead;
}//第二种:LTNode* ListInit()
{LTNode* phead = BuyListNode(0);phead->next = phead;phead->prev = phead;return phead;
}
链表的打印
链表打印通过循环的方式从头节点的下一个节点开始进行打印节点(带有哨兵位的头节点是无效节点,不存储有效数据),注意当循环遍历到头节点时结束循环。
void ListPrint(LTNode* phead)
{assert(phead);LTNode* cur = phead->next;while (cur != phead){printf("%d ", cur->data);cur = cur->next;}printf("\n");
}
链表的尾插
链表尾插首先通过头节点的前驱找到尾节点的地址,其次创建新节点,然后修改头节点、新节点、尾节点三者的连接关系即可
注:链表尾插的过程中没有修改头指针
//第一种:void ListPushBack(LTNode* phead, LTDataType x)
{assert(phead);LTNode* tail = phead->prev;LTNode* newnode = BuyListNode(x);tail->next = newnode;newnode->prev = tail;newnode->next = phead;phead->prev = newnode;
}//第二种://利用函数复用只需将头节点的指针传给链表的插入函数(相当于在头节点之前插入(链表的尾插))即可。
void ListPushBack(LTNode* phead, LTDataType x)
{assert(phead);ListInsert(phead, x);
}
注:时间复杂度为O(1)
链表的头插
利用函数复用只需将头节点的后继传给链表的插入函数(相当于在头节点的后继所指向的节点之前插入(链表的头插))即可。
void ListPushFront(LTNode* phead, LTDataType x)
{assert(phead);ListInsert(phead->next, x);
}
补充:C语言中复用函数是指在编程过程中重复使用代码段的一种方法。每个程序中都存在很多相似的或者相同的代码段,把这些相同的代码段抽取出来,形成一个独立的函数就叫做复用函数。复用函数的好处在于可以有效提高程序的可维护性、可读性,提高代码的可复用性,还可以明显减少程序的开发时间,简化程序的结构。
链表的尾删
链表尾删通过头节点的前驱找到尾节点的地址,再通过尾节点的前驱找到尾节点的前一个节点的地址,然后删除尾节点,最后完成头节点和尾节点的前一个节点的连接关系即可。
//第一种:void ListPopBack(LTNode* phead)
{assert(phead);assert(!ListEmpty(phead));LTNode* tail = phead->prev;LTNode* tailPrev = tail->prev;free(tail);tailPrev->next = phead;phead->prev = tailPrev;
}//第二种://利用函数复用只需将头节点的前驱传给链表的删除函数(相当于在头节点的前驱所指向的节点进行删除(链表的尾删))即可。
void ListPopBack(LTNode* phead)
{assert(phead);assert(!ListEmpty(phead));ListErase(phead->prev);
}
链表的判空
链表的判空通过判断头节点的后继是否是本身如果是返回真否则返回假。
bool ListEmpty(LTNode* phead)
{assert(phead);return phead->next == phead;
}
链表中有效节点的个数
求链表中有效节点的个数通过循环遍历的方式实现即可。
size_t ListSize(LTNode* phead)
{assert(phead);size_t n = 0;LTNode* cur = phead->next;while (cur != phead){++n;cur = cur->next;}return n;
}
链表的头删
利用函数复用只需将头节点的后继传给链表的删除函数(相当于在头节点的后继所指向的节点进行删除(链表的头删))即可。
void ListPopFront(LTNode* phead)
{assert(phead);assert(!ListEmpty(phead));ListErase(phead->next);
}
链表的插入(在某个位置之前插入节点)
链表的插入首先通过pos位置上节点的前驱找到前一个节点,再创建一个新节点,最后将pos位置上的节点、新节点、pos位置的节点的前一个节点三个节点完成连接即可。
void ListInsert(LTNode* pos, LTDataType x)
{assert(pos);LTNode* newnode = BuyListNode(x);LTNode* prev = pos->prev;// prev newnode posprev->next = newnode;newnode->prev = prev;newnode->next = pos;pos->prev = newnode;
}
链表的删除(删除某个位置的节点)
链表的删除首先找到pos位置上的节点的前一个节点,其次再找到pos位置上的节点的后一个节点,然后释放pos位置上的节点,最后将pos位置上的节点的前一个节点和pos位置上的节点的后一个节点进行连接即可。
// 删除pos位置
void ListErase(LTNode* pos)
{assert(pos);LTNode* prev = pos->prev;LTNode* next = pos->next;free(pos);pos = NULL;prev->next = next;next->prev = prev;
}
链表的查找
链表的查找是通过循环遍历的方式进行查找,如果找到了返回该节点的地址,否则返回NULL。
LTNode* ListFind(LTNode* phead, LTDataType x)
{LTNode* cur = phead->next;while (cur != phead){if (cur->data == x){return cur;}cur = cur->next;}return NULL;
}
链表的销毁
链表的销毁是将所有节点释放掉(包括带哨兵位的头节点),通过循环的方式对链表进行销毁。这里注意释放节点时需要对下一个节点的地址进行保存避免找不到下一个节点的地址(最后需要将头指针置空)即可。
注:节点的释放会引发一些问题会把这块节点的使用权还给操作系统并且指向这块空间上的值会被置成随机值
//第一种:void ListDestroy(LTNode* phead)
{LTNode* cur = phead->next;while (cur != phead){LTNode* next = cur->next;free(cur);//cur = NULL;cur = next;}free(phead);//phead = NULL; // 这里其实置空不置空都可以的,因为出了函数作用域,没人能访问phead// 其次就是phead形参的置空,也不会影响外面的实参
}//第二种:void ListDestroy(LTNode** pphead)
{LTNode* cur = (*pphead)->next;while (cur != *pphead){LTNode* next = cur->next;free(cur);cur = next;}free(*pphead);*pphead = NULL;
}
注:链表销毁函数的参数可以用一级指针也可以用二级指针。参数用一级指针,外面用了以后实参存在野指针的问题。但是这个函数保持了接口的一致性。参数用二级指针,虽然解决了野指针问题但是从接口设计的角度有点混乱。
顺序表和链表(带头双向循环链表)的区别
| 不同点 | 顺序表 | 链表 |
|---|---|---|
| 存储空间上 | 物理上一定连续 | 逻辑上连续,但物理上不一定连续 |
| 随机访问(用下标访问) | 支持O(1) | 不支持:O(N) |
| 任意位置插入或者删除元素 | 可能需要搬移元素,效率低O(N) | 只需修改指针指向,效率O(1) |
| 插入 | 动态顺序表,空间不够时需要扩容 | 没有容量的概念(按需申请空间) |
| 应用场景 | 元素高效存储+频繁访问 | 任意位置插入和删除频繁 |
| 缓存利用率(缓存命中率) | 高 | 低 |
注:
- 链表和顺序表它们是不能比较出谁更优的,它们各有优缺点,相辅相成。
- 扩容有一定的消耗(拷贝数据释放空间),以及扩容后可能存在一定的空间浪费。
- 尾插尾删多并且经常随机访问用顺序表合适。随时需要任意位置插入删除用链表合适。
存储体系结构以及局部原理性。
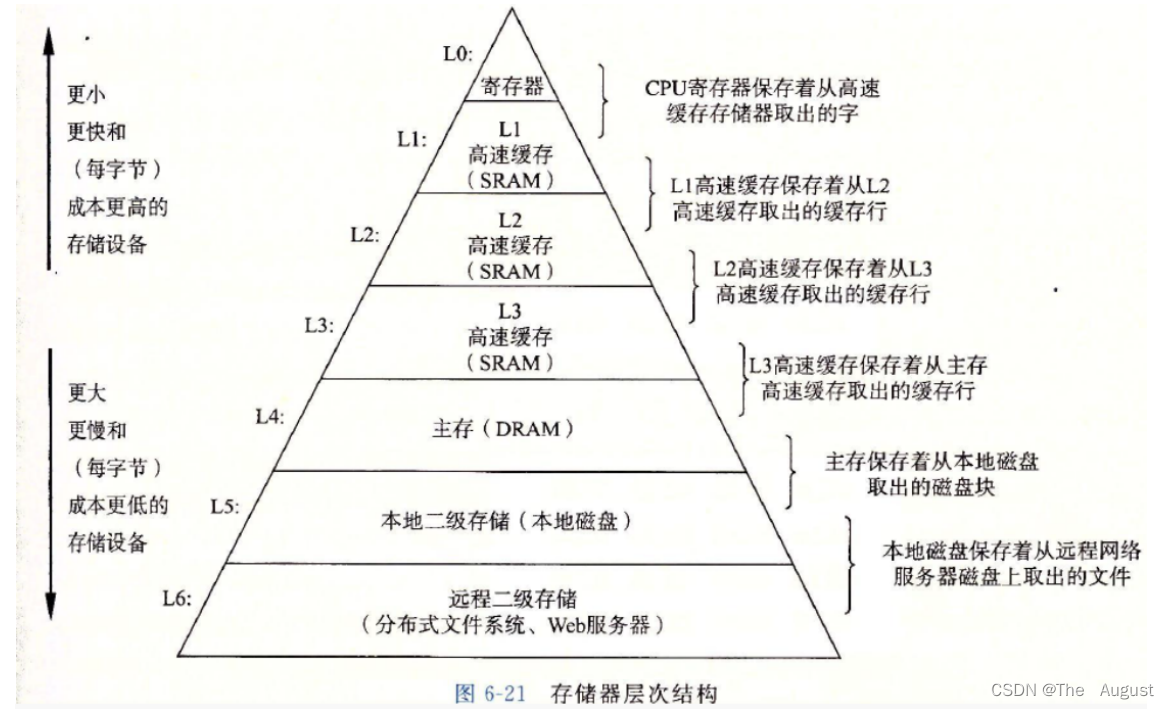
- 寄存器和三级缓存是围绕在CPU附近的
- 主存(运行内存)是带电存储的,磁盘是不带电存储
- CPU运算速度快,取内存速度跟不上。CPU一般就不会直接访问内存,而是把要访问的数据先加载的到缓存体系。如果是小于等于8字节的数据会直接到寄存器,而大数据就会到三级缓存。CPU直接跟缓存交互。
- CPU要访问内存中某个地址的数据首先要去缓存中去找,如果发现找不到(没有命中),此时就会把主存中这个地址开始的一段空间都读进来缓存(缓存预加载某个部分的空间和一段空间的成本(时间成本)是一样的),便于下一次访问。
- 缓存利用率(缓存命中率)低会造成一定的缓存污染。
相关文章:
数据结构—链表
链表 前言链表链表的概念及结构链表的分类 无头单向非循环链表的相关实现带头双向循环链表的相关实现顺序表和链表(带头双向循环链表)的区别 前言 顺序表是存在一些固有的缺陷的: 中间/头部的插入删除,时间复杂度为O(N)…...
windows 10/11 修改右键新建菜单
问题:修改右键新建菜单内容 解决方法:使用软件ShellNew Settings 1.打开软件 2.根据需要取消勾选项 3.最终效果...

6.修饰符
文章目录 6.1 在一个静态方法内调用一个非静态成员为什么是非法的?6.2 静态方法和实例方法有何不同 6.1 在一个静态方法内调用一个非静态成员为什么是非法的? 由于静态方法可以不通过对象进行调用,因此在静态方法里,不能调用其他非静态变量࿰…...

【leetcode难题】2569. 更新数组后处理求和查询【线段树实现01翻转和区间求和模版】
题目截图 题目分析 关键就是记录每次操作2时,nums1中的1的个数这就需要实现线段树进行区间反转以及区间求和 ac code class Solution:def handleQuery(self, nums1: List[int], nums2: List[int], queries: List[List[int]]) -> List[int]:n len(nums1)m le…...
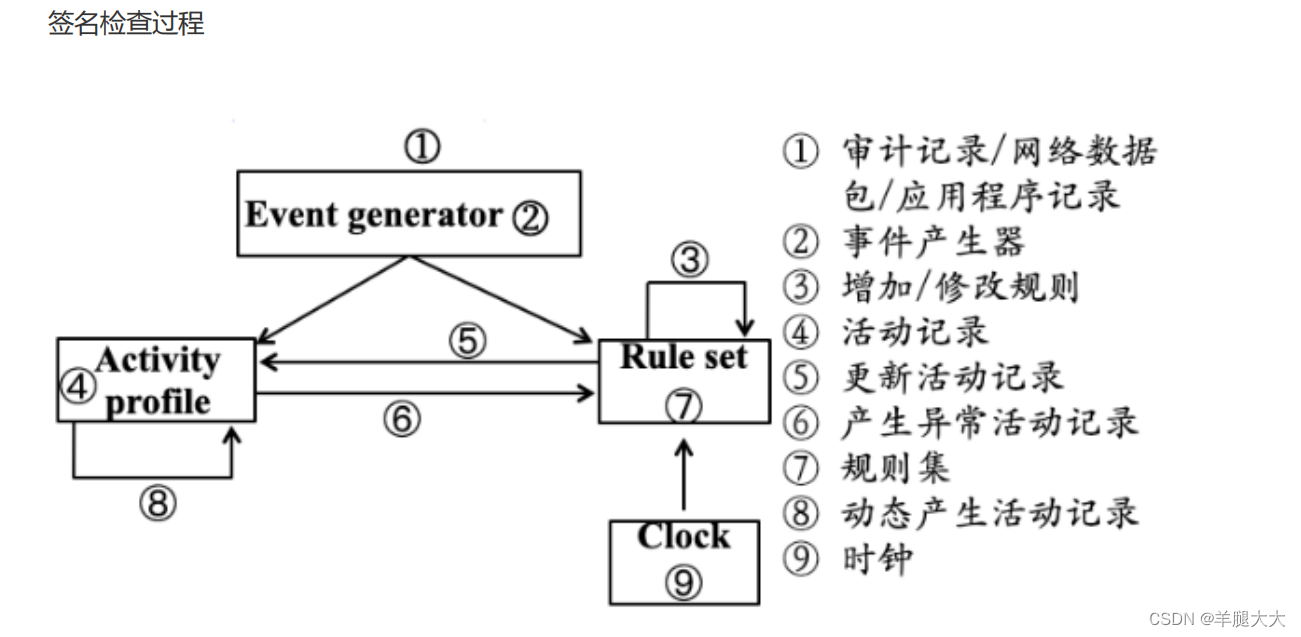
练习时长两年半的入侵检测
计算机安全的三大中心目标是:保密性 (Conf idential ity) 、完整性 (Integrity) 、可用性 (Availability) 。 身份认证与识别、访问控制机制、加密技术、防火墙技术等技术共同特征就是集中在系统的自身加固和防护上,属于静态的安全防御技术,…...

【弹力设计篇】聊聊隔离设计
为什么需要隔离设计 隔离其实就是Bulkheads,隔板。在生活中隔板的应用主要在船舱中进行设计,目的是为了避免因一处漏水导致整个船都沉下去。可以将故障减少在一定的范围内,而不是整个船体。 从架构演变来说的话,大多数系统都是从…...

MFC 透明窗体
如何制作透明窗体 ????? 使用SetLayeredWindowAttributes可以方便的制作透明窗体,此函数在w2k以上才支持,而且如果希望直接使用的话,可能需要下载最新的SDK。不过此函数在w2k的user32.dll里有实…...

C++笔记之vector的resize()和clear()用法
C笔记之vector的resize()和clear()用法 code review! 文章目录 C笔记之vector的resize()和clear()用法1.resize()2.clear() 1.resize() 运行 2.clear() 运行...

Vue2基础九、路由
零、文章目录 Vue2基础九、路由 1、单页应用 (1)单页应用是什么 单页面应用(SPA:Single Page Application): 所有功能在 一个html页面 上实现具体示例: 网易云音乐 https://music.163.com/ (2)单页面应用VS多页面…...

移动零——力扣283
题目描述 双指针 class Solution{ public:void moveZeroes(vector<int>& nums){int n nums.size(), left0, right0;while(right<n){if(nums[right]){swap(nums[right], nums[left]);left;}right;}} };...
Transformer+MIA Future Work
TransformerMIA Future Work 主要的挑战和未来发展分为三个部分,即 1、特征集成和计算成本降低、 2、数据增强和数据集收集、 3、学习方式和模态-对象分布 1、特征集成和计算成本降低 为了同时捕获局部和全局特征来提高模型性能,目前大多数工作只是…...

深度学习入门(二):神经网络整体架构
一、前向传播 作用于每一层的输入,通过逐层计算得到输出结果 二、反向传播 作用于网络输出,通过计算梯度由深到浅更新网络参数 三、整体架构 层次结构:逐层变换数据 神经元:数据量、矩阵大小(代表输入特征的数量…...

rust 配置
rustup 镜像 在 cmd 中输入以下代码,设置环境变量 setx RUSTUP_UPDATE_ROOT https://mirrors.tuna.tsinghua.edu.cn/rustup/rustup setx RUSTUP_DIST_SERVER https://mirrors.tuna.tsinghua.edu.cn/rustupcrates.io 索引镜像 在 C:\Users\用户名\.cargo\config 文…...
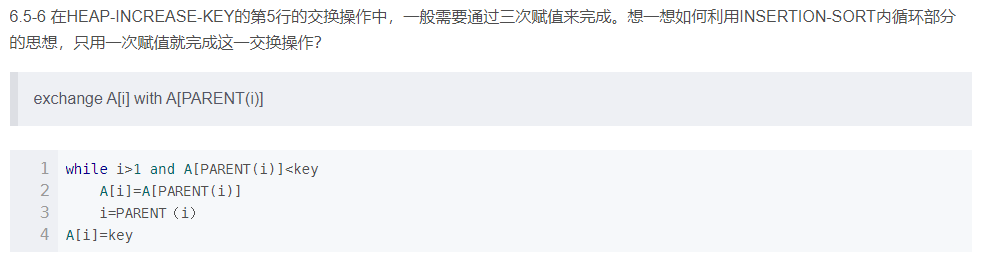
文心一言 VS 讯飞星火 VS chatgpt (67)-- 算法导论6.5 6题
文心一言 VS 讯飞星火 VS chatgpt (67)-- 算法导论6.5 6题 六、在 HEAP-INCREASE-KEY 的第 5 行的交换操作中,一般需要通过三次赋值来完成。想一想如何利用INSERTION-SORT 内循环部分的思想,只用一次赋值就完成这一交换操作? 文…...
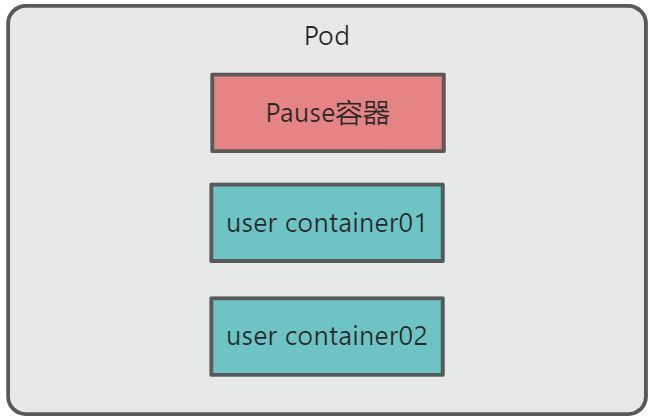
6、Kubernetes核心技术 - Pod
目录 一、概述 二、Pod机制 2.1、共享网络 2.2、共享存储 三、Pod资源清单 四、 Pod 的分类 五、Pod阶段 六、Pod 镜像拉取策略 ImagePullBackOff 七、Pod 资源限制 八、容器重启策略 一、概述 Pod 是可以在 Kubernetes 中创建和管理的、最小的可部署的计算单元。P…...
)
VlanIf虚拟接口 通信技术(二十三课)
一 Vlan技术之间的通信 单臂路由(One-Arm Routing)是一种网络架构设计方式,通常用于部署网络设备(如防火墙、负载均衡器等)实现网络流量控制和安全策略。在单臂路由中,网络设备只有一个物理接口与局域网(LAN)或广域网(WAN)相连。 1.2 交换机 数据链路层 (第二层)…...
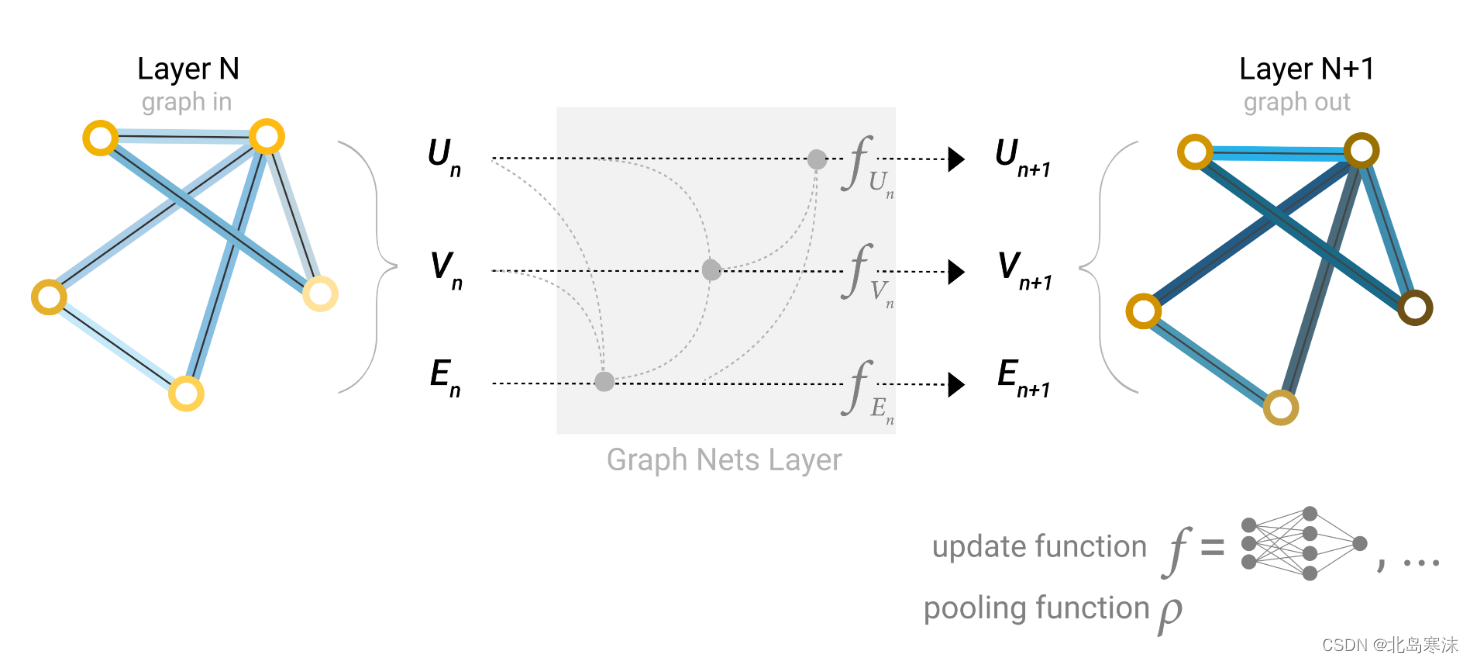
图神经网络(GNN)入门学习笔记(直观且简单)
文章目录 图的定义和表示可以使用图数据结构的问题将图结构用于机器学习的挑战最基本的图神经网络概述汇聚操作基于信息传递的改进图神经网络全局向量信息的利用 本篇文章参考发表于Distill上的图神经网络入门博客: A Gentle Introduction to Graph Neural Network…...
【Java开发】 Mybatis-Flex 01:快速入门
Mybatis 作为头部的 ORM 框架,他的增强工具可谓层出不穷,比如出名的 Mybatis-Plus 和 阿里云开源的 Fluent-MyBatis,如今出了一款 Mybatis-Flex ,相比前两款功能更为强大、性能更为强悍,不妨来了解一下。 目录 1 Myba…...

企业级业务架构学习笔记<二>
一.业务架构基础 业务架构的定义 以实现企业战略为目标,构建企业整体业务能力规划并将其传导给技术实现端的结构化企业能力分析方法 (业务架构可以从企业战略触发,按照企业战略设计业务及业务过程,业务过程时需要业务能力支撑的࿰…...
Minio在windows环境配置https访问
minio启动后,默认访问方式为http,但是有的时候我们的访问场景必须是https,浏览器有的会默认以https进行访问,这个时候就需要我们进行配置上的调整,将minio从http访问升级到https。而查看minio的官方文档,并…...

保姆级教程:用iSYSTEM winIDEA和iC5000给S32K148烧录程序,附完整配置流程
从零掌握iSYSTEM工具链:S32K148开发板烧录与调试全流程实战第一次接触iSYSTEM的winIDEA和iC5000仿真器时,很多嵌入式开发者都会感到无从下手。不同于常见的开源工具链,这套专业级开发环境在汽车电子和工业控制领域有着广泛应用,尤…...

三步实现跨架构程序兼容:Box64高效架构转换指南
三步实现跨架构程序兼容:Box64高效架构转换指南 【免费下载链接】box64 Box64 - Linux Userspace x86_64 Emulator with a twist, targeted at ARM64, RV64 and LoongArch Linux devices 项目地址: https://gitcode.com/gh_mirrors/bo/box64 你是否曾在ARM64…...

3大实战秘籍:揭秘raylib如何让游戏开发像搭积木一样简单
3大实战秘籍:揭秘raylib如何让游戏开发像搭积木一样简单 【免费下载链接】raylib A simple and easy-to-use library to enjoy videogames programming 项目地址: https://gitcode.com/GitHub_Trending/ra/raylib 你是否曾经被复杂的游戏引擎配置搞得焦头烂额…...

Veo 2提示词性能瓶颈诊断:基于1726组AB测试的token敏感度热力图与阈值红线预警
更多请点击: https://kaifayun.com 第一章:Veo 2提示词编写最佳实践总览 Veo 2 是 Google 推出的高性能视频生成模型,其对提示词(prompt)的语义精度、结构清晰度和上下文控制能力高度敏感。高质量提示词并非简单堆砌关…...

Java项目中如何提升整体系统性能?
性能优化可以说是我们程序员的必修课,如果你想要跳出CRUD的苦海,成为一个更“高级”的程序员的话,性能优化这一关你是无论无何都要去面对的。为了提升系统性能,开发人员可以从系统的各个角度和层次对系统进行优化。除了最常见的代…...

基于KS距离度量交通流分布偏移:提升DRL交通信号控制鲁棒性的工程实践
1. 项目概述与核心挑战在智能交通系统(ITS)领域,基于深度强化学习(DRL)的交通信号控制(Traffic Signal Control)正从研究走向实际部署。作为一名长期关注AI落地应用的从业者,我见过太…...

昇腾CANN elec-ops-simulation 实战:电力系统仿真——潮流计算与暂态稳定分析在 NPU 上的加速
电力系统仿真:500 节点电网的牛顿-拉夫逊潮流计算 → 解 10001000 稀疏雅可比矩阵(每迭代 1 次矩阵求逆)→ CPU 迭代 15 次 2.4s。实时调度要求 < 100ms → NPU 加速:雅可比矩阵求解用 Cube 单元做批量小矩阵 LU 分解 → 每迭…...

基于ISDN信令的来电语音播报系统:从原理到树莓派实现
1. 项目概述:一个基于ISDN的来电语音播报系统如果你家里或办公室里还有一台老式的ISDN路由器,别急着把它当电子垃圾处理掉。我最近就利用手头一台闲置的ISDN路由器,折腾出了一个挺有意思的小玩意儿:一个能自动识别来电号码&#x…...

机器学习力场攻克Peierls相变动力学:从对称性描述符到畴生长标度律
1. 项目概述:当机器学习遇见Peierls相变在凝聚态物理和材料科学的前沿,我们常常被一个核心问题所困扰:如何精确地模拟那些由电子和晶格(原子)强烈耦合所驱动的复杂动力学过程?这类系统,比如电荷…...

DeTikZify:基于AI的TikZ图形程序自动生成技术深度解析
DeTikZify:基于AI的TikZ图形程序自动生成技术深度解析 【免费下载链接】DeTikZify Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ. 项目地址: https://gitcode.com/gh_mirrors/de/DeTikZify DeTikZify是一款革命性的多模态…...