【Kafka】常用操作
1、基本概念
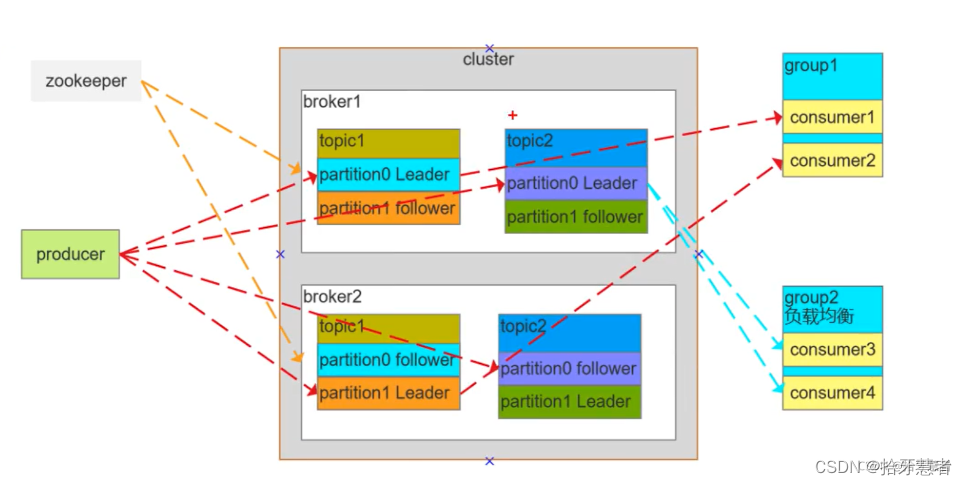
1. 消息: Kafka是一个分布式流处理平台,它通过消息进行数据的传输和存储。消息是Kafka中的基本单元,可以包含任意类型的数据。
2. 生产者(Producer): 生产者负责向Kafka主题发送消息。它将消息发布到指定的主题,可以按照自定义的逻辑生成消息,并决定消息发送的频率和顺序。
3. 消费者(Consumer): 消费者从Kafka主题订阅并接收消息。它可以以不同的方式消费消息,如批量拉取、实时流式处理或订阅特定的消息主题。
4. 主题(Topic): 主题是Kafka中消息的分类标签,用于组织消息。每个主题可以有多个生产者和多个消费者。主题通常与特定的业务领域或数据类型相关联。
5. 分区(Partition): 主题可以被分割成多个分区,每个分区都是一个有序且持久化的消息队列。分区允许Kafka对消息进行水平扩展,并提供了并行处理和负载均衡的能力。
6. 偏移量(Offset): 偏移量是消息在分区中的唯一标识符,用于表示消息在分区内的顺序位置。消费者可以跟踪偏移量来记录已经读取的消息,以便实现精确的消费位置控制。
7. 消费者组(Consumer Group): 消费者组是一组具有相同逻辑的消费者,它们共同消费一个或多个主题中的消息。消费者组允许Kafka进行水平扩展和负载均衡,在该组内的每个消费者负责处理不同的分区。
8. 副本(Replication): Kafka使用副本机制来提供数据冗余和高可用性。每个分区都可以配置多个副本,这些副本保持分区数据的一致性,并可以替代主副本以提供故障恢复功能。
2、安装部署
参考:
https://juejin.cn/post/7158663198411849741
https://www.cnblogs.com/linjiqin/p/13196347.html
3、常用命令
配置文件解析:cat server.properties
#broker 的全局唯一编号,不能重复
broker.id=0
#删除 topic 功能使能
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘 IO 的现成数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600 #kafka 运行日志存放的路径
log.dirs=/opt/module/kafka/logs
#topic 在当前 broker 上的分区个数
num.partitions=1
#用来恢复和清理 data 下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment 文件保留的最长时间,超时将被删除
log.retention.hours=168
#配置连接 Zookeeper 集群地址
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181启动/关闭 kafka:
cd /usr/local/kafka/kafka_2.12-3.5.0/bin/bin/kafka-server-start.sh config/server.properties
bin/kafka-server-stop.sh stop
验证kafka是否可以使用,仍在bin目录下
运行kafka生产者发送消息
./kafka-console-producer.sh --broker-list localhost:9092 --topic sun
运行kafka消费者接收消息
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic sun --from-beginning
4、常用操作API
创建生产者并发送消息
from kafka import KafkaProducer
import time
# 创建生产者
producer = KafkaProducer(bootstrap_servers='localhost:9092')# 发送单条消息
producer.send('my_topic', b'Hello, Kafka!')# Kafka的发送实际上是异步的
# 生产者在发送消息之后并不会等待确认消息是否已经成功到达Kafka broker
# 而是立即继续执行下一行代码或退出程序
# 在生产者发送完消息后,给消费者足够的时间来连接到Kafka broker并订阅主题# 等待消费者订阅主题
time.sleep(2) # 延迟2秒钟,给消费者足够的时间连接到Kafka并订阅主题# 发送多条消息
messages = [b'Message 1', b'Message 2', b'Message 3']
for message in messages:producer.send('my_topic', message)
time.sleep(2) # 延迟2秒钟,给消费者足够的时间连接到Kafka并订阅主题创建消费者并订阅主题并消费消息
from kafka import KafkaConsumer# 创建消费者
consumer = KafkaConsumer('my_topic', bootstrap_servers='localhost:9092')# 消费消息
for message in consumer:print(message.value.decode())指定消费者组和自动提交偏移量
from kafka import KafkaConsumer# 创建消费者,并指定消费者组和自动提交偏移量
consumer = KafkaConsumer('my_topic', group_id='my_consumer_group',bootstrap_servers='localhost:9092',enable_auto_commit=True)# 消费消息
for message in consumer:print(message.value.decode())指定消费者组和自动提交偏移量
为什么需要指定消费者组呢?
在Kafka中,消费者组是一组消费者的逻辑名称,它们共同协作来消费一个或多个主题中的消息。通过将消费者组绑定到特定主题上,Kafka能够提供高可用性、负载均衡和容错能力。
指定消费者组有以下几个原因:
- 负载均衡: 当多个消费者以相同的消费者组订阅同一个主题时,Kafka会自动分配分区给每个消费者,从而实现负载均衡。每个消费者只处理被分配的分区,这样可以确保所有分区被均匀地消费。
- 容错能力: 如果有消费者发生故障或离线,指定消费者组可以确保其他消费者接管该消费者组失去的分区,从而实现容错能力。这意味着即使某些消费者不可用,消息仍然可以被处理。
- 消费者协作: 消费者组允许多个消费者协同工作,以实现更高的消费并行度。每个消费者可以独立地处理其分配的分区,并且可以扩展系统的整体处理能力。
需要注意的是,如果您没有为消费者指定消费者组,则它将成为一个独立的消费者。这种情况下,每个消费者将独立地消费所有分区中的消息,而不会共享负载或具备容错能力。
因此,在大多数情况下,为了实现负载均衡、容错和提高处理能力,您应该指定消费者组,尤其是在需要同时处理大量消息或要求高可用性的场景中。如果您只需要简单地消费主题中的消息,而不关注这些特性,那么可以选择不指定消费者组。
手动提交偏移量
from kafka import KafkaConsumer# 创建消费者,并禁用自动提交偏移量
consumer = KafkaConsumer('my_topic', group_id='my_consumer_group',bootstrap_servers='localhost:9092',enable_auto_commit=False)# 消费消息并手动提交偏移量
for message in consumer:print(message.value.decode())consumer.commit()自动提交偏移量和手动提交偏移量有什么区别呢?
自动提交偏移量(Auto Commit Offset)和手动提交偏移量(Manual Commit Offset)是两种不同的消费者偏移量管理方式。
自动提交偏移量:
- 在自动提交模式下,消费者会定期自动将已消费的消息偏移量提交给Kafka。
- 消费者无需显式调用提交偏移量的方法,Kafka会在后台自动处理。
- 自动提交偏移量可以简化代码,减少了手动提交的复杂性。
- 然而,自动提交偏移量可能会导致一些问题。例如,如果消费者在处理消息之前发生故障,那么已经消费但尚未提交的偏移量将丢失,造成消息重复或丢失。
手动提交偏移量:
- 在手动提交模式下,消费者需要显式地调用提交偏移量的方法,将已消费的消息偏移量提交给Kafka。
- 手动提交偏移量提供了更好的控制能力,可以确保消息的准确处理和可靠提交。
- 消费者可以在适当的时机调用
commit()方法来提交偏移量。通常,在成功处理消息后再进行提交是一个常见的模式。 - 手动提交偏移量需要额外的代码来管理和处理偏移量的提交,但它提供了更高的灵活性和可靠性。
选择使用自动提交偏移量还是手动提交偏移量取决于具体的使用场景和需求。如果您的应用程序对消息处理的准确性和可靠性要求较高,或者需要更精细的控制以避免重复消费或消息丢失,那么手动提交偏移量可能更适合。否则,自动提交偏移量可以提供一种简化的方式来管理偏移量,尤其在简单的消费者应用中很常见。
手动提交偏移量与自动提交偏移量在性能方面可能存在一些差异,但这取决于具体的使用情况和配置。
性能方面的考虑:
- 提交频率: 自动提交偏移量会定期提交偏移量到Kafka服务器,默认情况下是每隔一段时间提交一次。相比之下,手动提交偏移量可以根据应用程序的需求选择何时提交,可以控制提交的频率。如果手动提交偏移量过于频繁,可能会影响性能。
- 网络延迟: 手动提交偏移量需要与Kafka服务器进行通信来提交偏移量。如果手动提交偏移量的操作导致频繁的网络调用,而且网络延迟较高,可能会对性能产生一定的影响。
- 消息处理时间: 如果消息处理时间很长,手动提交偏移量可能会在处理消息之前进行提交,以保证消息处理的可靠性。然而,这样也会增加提交偏移量的开销,可能降低整体性能。
需要注意的是,性能差异通常是微小的,并且在大多数情况下不会成为主要限制因素。如果性能是一个关键问题,可以根据实际情况进行测试和优化。
此外,可以通过调整参数来改善性能,例如增加自动提交的间隔时间、批量提交偏移量等。使用合适的配置和优化技术可以平衡性能和可靠性之间的权衡。
总而言之,手动提交偏移量可能会稍微影响性能,但仍然取决于具体的使用情况和配置。对于大多数应用程序而言,差异通常是可以接受的,并且可以根据实际需求进行调整和优化。
查看当前有哪些topic
from kafka import KafkaAdminClient# 创建AdminClient连接到Kafka集群
admin_client = KafkaAdminClient(bootstrap_servers='localhost:9092')# 获取主题列表
topic_list = admin_client.list_topics()# 打印主题列表
print(topic_list)# ['my_topic', 'sun', '__consumer_offsets']
# __consumer_offsets是Kafka中的一个系统内置主题
# 这个特殊的主题用于存储消费者组的偏移量(offsets)
# 以跟踪消费者在每个分区中读取消息的位置
# __consumer_offsets主题的目的是为了支持Kafka的消费者组功能
# 当消费者组启用自动提交偏移量时,Kafka会将消费者组的偏移量信息存储在__consumer_offsets主题中
# 以便能够在重平衡、故障恢复等情况下为消费者提供正确的偏移量。相关文章:
【Kafka】常用操作
1、基本概念 1. 消息: Kafka是一个分布式流处理平台,它通过消息进行数据的传输和存储。消息是Kafka中的基本单元,可以包含任意类型的数据。 2. 生产者(Producer): 生产者负责向Kafka主题发送消息。它将消息…...
【Spring框架】SpringBoot配置文件
目录 配置文件作用application.properties中午乱码问题:配置文件里面的配置类型分类SpringBoot热部署properties基本语法properties配置文件的优缺点:yml配置文件说明yml基本语法配置对象properties VS yml 配置文件作用 整个项⽬中所有重要的数据都是在…...
部署问题集合(十八)Windows环境下使用两个Tomcat
下载Tomcat Tomcat镜像下载地址:https://mirrors.cnnic.cn/apache/tomcat/进入如下地址:zip的是压缩版,exe是安装版 修改第二个Tomcat配置文件 第一步:编辑conf/server.xml文件,修改三个端口,有些版本改…...

数据结构问答8
查找 1. 一些基本概念 关键字:能唯一标识该元素 查找:给定值k,在含n个元素的表中找出关键字==k的元素。找到返回其位置信息,否则返回-1。 动、静态查找表:查找同时对表进行修改(插入、删除等),相应的表为动态,否则为静态。 内、外查找:整个查找过程在内存中进行…...

行为型设计模式之观察者模式【设计模式系列】
系列文章目录 C技能系列 Linux通信架构系列 C高性能优化编程系列 深入理解软件架构设计系列 高级C并发线程编程 设计模式系列 期待你的关注哦!!! 现在的一切都是为将来的梦想编织翅膀,让梦想在现实中展翅高飞。 Now everythi…...
)
vue2企业级项目(四)
vue2企业级项目(四) 路由设计,过场动画设计 1、router 项目下载依赖 npm install --save vue-router3.5.3src目录下创建router/index.js import Vue from "vue"; import Router from "vue-router";Vue.use(Router);con…...

(树) 剑指 Offer 26. 树的子结构 ——【Leetcode每日一题】
❓剑指 Offer 26. 树的子结构 难度:中等 输入两棵二叉树 A 和 B,判断 B 是不是 A 的子结构。(约定空树不是任意一个树的子结构) B 是 A 的子结构, 即 A 中有出现和B相同的结构和节点值。 例如: 给定的树 A: 3/ \4 5/ \1 2给定的树 B&…...
Linuxcnc-ethercat从入门到放弃(1)、环境搭建
项目开源网站 LinuxCNChttps://www.linuxcnc.org/当前release版本2.8.4 Downloads (linuxcnc.org)https://www.linuxcnc.org/downloads/可以直接下载安装好linuxcnc的实时debian系统,直接刻盘安装就可以了 安装IgH主站,网上有很多教程可供参考 git clo…...

14.Netty源码之模拟简单的HTTP服务器
highlight: arduino-light 简单的 HTTP 服务器 HTTP 服务器是我们平时最常用的工具之一。同传统 Web 容器 Tomcat、Jetty 一样,Netty 也可以方便地开发一个 HTTP 服务器。我从一个简单的 HTTP 服务器开始,通过程序示例为你展现 Netty 程序如何配置启动&a…...
万年历【小游戏】(Java课设)
系统类型 Java实现的小游戏 使用范围 适合作为Java课设!!! 部署环境 jdk1.8Idea或eclipse 运行效果 更多Java课设系统源码地址:更多Java课设系统源码地址 更多Java小游戏运行效果展示:更多Java小游戏运行效果展…...
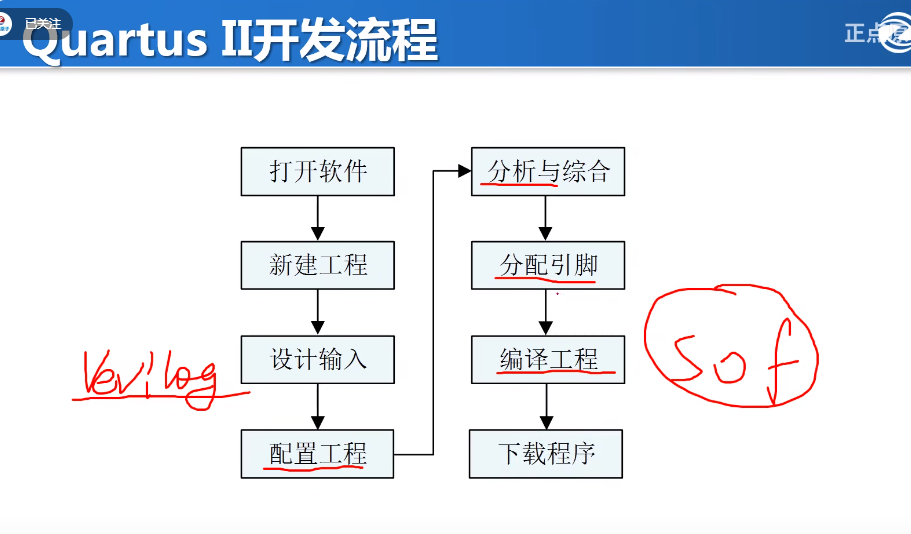
ad+硬件每日学习十个知识点(9)23.7.20
文章目录 1.正点原子fpga开拓者无gui检查项目2.排针连接器A2541WR-XP-2P3.肖特基二极管反接在LDO的输出端,是什么用?4.在AD中如何实现批量元器件的移动?5.在PCB中,如何让元器件以任意角度旋转?6.接口设计都要做静电防护…...

ipmitool 配置BMC的ip
要使用ipmitool配置BMC的IP地址,可以按照以下步骤进行操作: 确保已安装ipmitool工具。如果尚未安装,可以使用以下命令进行安装: |复制代码 sudo yum install ipmitool连接到BMC:使用IPMI-over-LAN(通过网…...
)
C++设计模式::小结(creation)
creation:隐藏创建逻辑. 1) 抽象工厂模式(Abstract Factory Pattern):多层次"任选"创建对象; 实现: 1) cShape:抽象对象; cShape*:具体对象; 2) cColor:抽象对象; cColor*:具体对象; 3) cFacto…...

运维工程师第一阶段windows的学习
文章目录 计算机硬件组成计算机历史计算机硬件组成最重要的三个硬件冯诺依曼体系:组装一台电脑:虚拟机和装系统虚拟机VMware安装系统搭建局域网本地安全策略用户本地安全策略共享文件删除操作系统操作系统分类系统优化常用命令系统的启动和密码破解winodws启动过程windows系统…...
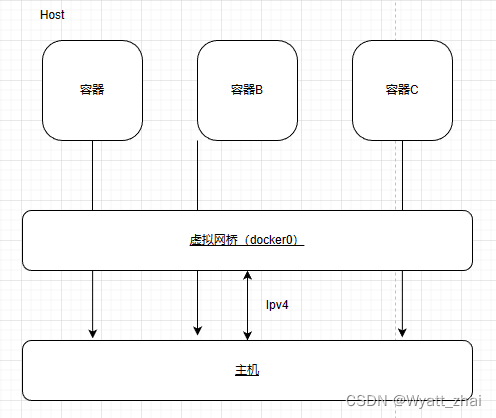
Docker复习
目录 1. Docker的理解1.1 Docker三要素 2 安装Docker2.1 安装命令2.2 配置阿里云加速器 3 Docker命令3.1 启动类命令3.2 镜像类命令 4 实战4.1 启动容器,自动创建实例4.2 查看Docker内启动的容器4.3 退出容器4.4 其他4.5 导入导出文件4.6 commit 5 Dockerfile5.1 理…...

华为OD机考--食堂供餐--带答案
题目描述: 某公司员工食堂以盒饭方式供餐。为将员工取餐排队时间降低为0,食堂的供餐速度必须要足够快。现在需要根据以往员工取餐的统计信息,计算出一个刚好能达成排队时间为0的最低供餐速度。即,食堂在每个单位时间内必须至少做出…...
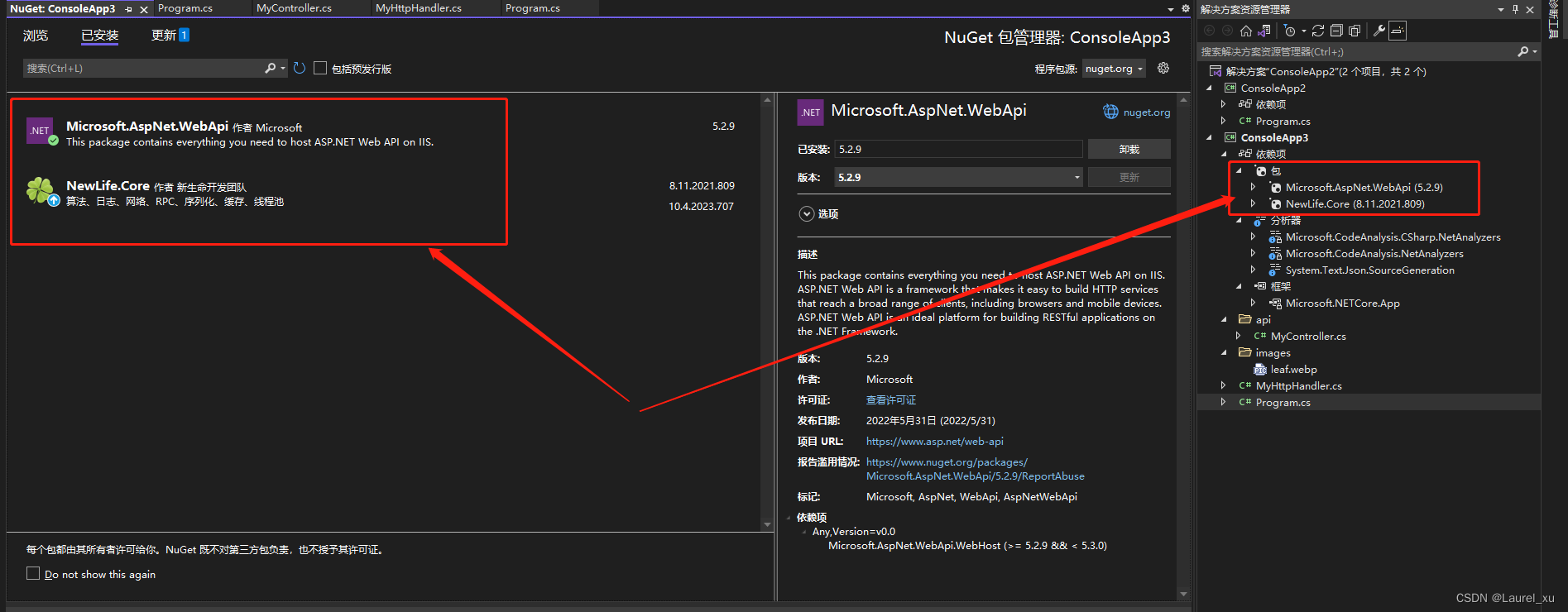
C# 关于使用newlife包将webapi接口寄宿于一个控制台程序、winform程序、wpf程序运行
C# 关于使用newlife包将webapi接口寄宿于一个控制台程序、winform程序、wpf程序运行 安装newlife包 Program的Main()函数源码 using ConsoleApp3; using NewLife.Log;var server new NewLife.Http.HttpServer {Port 8080,Log XTrace.Log,SessionLog XTrace.Log }; serv…...
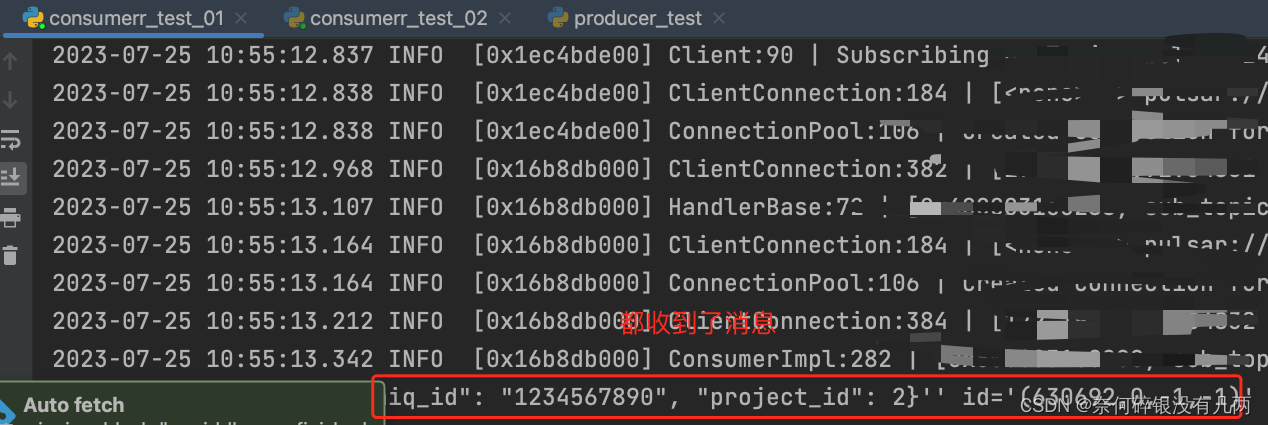
初识TDMQ
目录 一:需求背景二:相关文档三:验证TDMQ广播消息 一:需求背景 目前公司需要将决策引擎处理的结果, 一部分数据交给下游分析/入黑/通知等功能。因此就需要决策引擎生产结果让多方下游去消费。 而我需要实现下游的一部…...
UEditor 百度富文本编辑器使用 遇到问题
小小吐槽 碰到前后不分离项目,富文本使用的UEdtior UEditor 点击上传图片转base64 在ueditor.all.js文件中找到这个 callback()函数 这里使用根据图片的url转成base64 UEditore 粘贴图片转base64 UEditor回显图片(base64) 把ueditor.all…...
 单机部署以及(400)报错)
jaeger+elasticsearch(cassandra ) 单机部署以及(400)报错
Jaeger 快速体验 官网下载地址 https://www.jaegertracing.io/download/ GitHub 下载地址 https://github.com/jaegertracing/jaeger/releases 下载二进制文件压缩包后,运行解压后的 all-in-one 文件即可。 jaeger-all-in-one 采用内存存储数据,专为…...

从游戏引擎到仿真平台:手把手教你用AirSim+UE4搭建你的第一个无人机/自动驾驶仿真环境
从游戏引擎到仿真平台:构建AirSimUE4无人机与自动驾驶仿真环境实战指南当游戏引擎遇上机器人算法测试,会碰撞出怎样的火花?微软开源的AirSim项目将虚幻引擎(Unreal Engine)从游戏开发领域引入到自动驾驶和无人机研究的…...

1688运营培训/询盘成本从500元降到63.9!1688运营培训还原1688真实玩法
1688运营培训/询盘成本从500元降到63.9!1688运营培训还原1688真实玩法500块钱一个询盘,你敢信?做1688运营培训这么多年,这个数字我都觉得离谱。前阵子遇到一个老板,一上来就开始吐槽1688,说1688就是个垃圾平…...
)
Unity3D深度纹理实战:手把手教你实现可交互的激光雷达扫描特效(附完整C#/Shader代码)
Unity3D深度纹理实战:手把手教你实现可交互的激光雷达扫描特效(附完整C#/Shader代码)在科幻题材的游戏开发中,激光雷达扫描特效是营造科技感的经典元素。从《赛博朋克2077》的战术目镜到《看门狗》的环境扫描,这种动态…...

3大技术突破:重新定义Switch游戏安装性能极限
3大技术突破:重新定义Switch游戏安装性能极限 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer Awoo Installer是一款专为破解版Nintendo…...

自动加字幕软件推荐:口播视频如何批量加字幕过
口播视频加字幕,为什么越做越累?一位知识类博主连续两周日更3条口播视频,每条12–18分钟,需手动校对字幕、拆分金句切片、补气口停顿、匹配背景音乐——最后一条视频发布时,字幕错漏率达17%,平台审核未过。…...

5大核心功能掌握HandheldCompanion:Windows掌机终极控制伴侣
5大核心功能掌握HandheldCompanion:Windows掌机终极控制伴侣 【免费下载链接】HandheldCompanion ControllerService 项目地址: https://gitcode.com/gh_mirrors/ha/HandheldCompanion 你是否正在寻找一款能够彻底改变Windows掌机游戏体验的控制软件…...

LaMa图像修复:用AI魔法轻松移除照片中的不想要元素
LaMa图像修复:用AI魔法轻松移除照片中的不想要元素 【免费下载链接】lama 🦙 LaMa Image Inpainting, Resolution-robust Large Mask Inpainting with Fourier Convolutions, WACV 2022 项目地址: https://gitcode.com/GitHub_Trending/la/lama 你…...

温差发电驱动轻型电动车:热电模块与催化燃烧器的系统集成实践
1. 项目概述:用温差发电驱动轻型电动车最近在琢磨一个挺有意思的玩意儿:能不能给那些轻型的电动车,比如高尔夫球车、园区巡逻车或者小型载货三轮,换上一套不一样的“心脏”?传统的方案,要么背着一大块死沉死…...

游戏开发/机器人导航必看:极坐标到底比XY坐标强在哪?Unity/ROS中的实战案例
你的输出 (必须严格遵循以下YAML格式,无需任何分析过程)相关性: ... 改写后查询: ... 企业名称: ... 基础信息: ... 职位: ... json {"business_segment": "礼品","main_product": "百度电商","reason": "用…...

JMeter中稳定获取与传递Token的三种实战方案
1. 为什么token获取总在JMeter脚本里“掉链子”做接口测试的同行应该都踩过这个坑:明明API文档写得清清楚楚,Postman里一调一个准,可一到JMeter里,登录接口返回了token,后续请求却始终401——Header里token字段空着、变…...