libuv库学习笔记-filesystem
Filesystem
简单的文件读写是通过uv_fs_*函数族和与之相关的uv_fs_t结构体完成的。
note
libuv 提供的文件操作和 socket operations 并不相同。套接字操作使用了操作系统本身提供了非阻塞操作,而文件操作内部使用了阻塞函数,但是 libuv 是在线程池中调用这些函数,并在应用程序需要交互时通知在事件循环中注册的监视器。
所有的文件操作函数都有两种形式 - 同步**(synchronous)** 和 异步**( asynchronous)**。
同步方式如果没有指定回调函数则会被自动调用( 并阻塞),函数的返回值是libuv error code 。但以上通常只对同步调用有意义。而异步方式则会在传入回调函数时被调用, 并且返回 0。
Reading/Writing files
文件描述符可以采用如下方式获得:
int uv_fs_open(uv_loop_t* loop, uv_fs_t* req, const char* path, int flags, int mode, uv_fs_cb cb)
参数flags与mode和标准的 Unix flags 相同。libuv 会小心地处理 Windows 环境下的相关标志位(flags)的转换, 所以编写跨平台程序时你不用担心不同平台上文件打开的标志位不同。
关闭文件描述符可以使用:
int uv_fs_close(uv_loop_t* loop, uv_fs_t* req, uv_file file, uv_fs_cb cb)
文件系统的回调函数有如下的形式:
void callback(uv_fs_t* req);
让我们看一下一个简单的cat命令的实现。我们通过当文件被打开时注册一个回调函数来开始:
uvcat/main.c - opening a file
void on_open(uv_fs_t *req) {// The request passed to the callback is the same as the one the call setup// function was passed.assert(req == &open_req);if (req->result >= 0) {iov = uv_buf_init(buffer, sizeof(buffer));uv_fs_read(uv_default_loop(), &read_req, req->result,&iov, 1, -1, on_read);}else {fprintf(stderr, "error opening file: %s\n", uv_strerror((int)req->result));}
}
uv_fs_t的result域保存了uv_fs_open回调函数打开的文件描述符。如果文件被正确地打开,我们可以开始读取了。
uvcat/main.c - read callback
void on_read(uv_fs_t *req) {if (req->result < 0) {fprintf(stderr, "Read error: %s\n", uv_strerror(req->result));}else if (req->result == 0) {uv_fs_t close_req;// synchronousuv_fs_close(uv_default_loop(), &close_req, open_req.result, NULL);}else if (req->result > 0) {iov.len = req->result;uv_fs_write(uv_default_loop(), &write_req, 1, &iov, 1, -1, on_write);}
}
在调用读取函数的时候,你必须传递一个已经初始化的缓冲区,在on_read()被触发后,缓冲区被写入数据。uv_fs_*系列的函数是和POSIX的函数对应的,所以当读到文件的末尾时(EOF),result返回0。在使用streams或者pipe的情况下,使用的是libuv自定义的UV_EOF。
现在你看到类似的异步编程的模式。但是uv_fs_close()是同步的。一般来说,一次性的,开始的或者关闭的部分,都是同步的,因为我们一般关心的主要是任务和多路I/O的快速I/O。所以在这些对性能微不足道的地方,都是使用同步的,这样代码还会简单一些。
文件系统的写入使用 uv_fs_write(),当写入完成时会触发回调函数,在这个例子中回调函数会触发下一次的读取。
uvcat/main.c - write callback
void on_write(uv_fs_t *req) {if (req->result < 0) {fprintf(stderr, "Write error: %s\n", uv_strerror((int)req->result));}else {uv_fs_read(uv_default_loop(), &read_req, open_req.result, &iov, 1, -1, on_read);}
}
Warning
由于文件系统和磁盘的调度策略,写入成功的数据不一定就存在磁盘上。
我们开始在main中推动多米诺骨牌:
uvcat/main.c
int main(int argc, char **argv) {uv_fs_open(uv_default_loop(), &open_req, argv[1], O_RDONLY, 0, on_open);uv_run(uv_default_loop(), UV_RUN_DEFAULT);uv_fs_req_cleanup(&open_req);uv_fs_req_cleanup(&read_req);uv_fs_req_cleanup(&write_req);return 0;
}
Warning
函数uv_fs_req_cleanup()在文件系统操作结束后必须要被调用,用来回收在读写中分配的内存。
##Filesystem operations
所有像 unlink, rmdir, stat 这样的标准文件操作都是支持异步的,并且使用方法和上述类似。下面的各个函数的使用方法和read/write/open类似,在uv_fs_t.result中保存返回值。所有的函数如下所示:
(译者注:返回的result值,<0表示出错,其他值表示成功。但>=0的值在不同的函数中表示的意义不一样,比如在uv_fs_read或者uv_fs_write中,它代表读取或写入的数据总量,但在uv_fs_open中表示打开的文件描述符。)
UV_EXTERN int uv_fs_close(uv_loop_t* loop,uv_fs_t* req,uv_file file,uv_fs_cb cb);
UV_EXTERN int uv_fs_open(uv_loop_t* loop,uv_fs_t* req,const char* path,int flags,int mode,uv_fs_cb cb);
UV_EXTERN int uv_fs_read(uv_loop_t* loop,uv_fs_t* req,uv_file file,const uv_buf_t bufs[],unsigned int nbufs,int64_t offset,uv_fs_cb cb);
UV_EXTERN int uv_fs_unlink(uv_loop_t* loop,uv_fs_t* req,const char* path,uv_fs_cb cb);
UV_EXTERN int uv_fs_write(uv_loop_t* loop,uv_fs_t* req,uv_file file,const uv_buf_t bufs[],unsigned int nbufs,int64_t offset,uv_fs_cb cb);
UV_EXTERN int uv_fs_mkdir(uv_loop_t* loop,uv_fs_t* req,const char* path,int mode,uv_fs_cb cb);
UV_EXTERN int uv_fs_mkdtemp(uv_loop_t* loop,uv_fs_t* req,const char* tpl,uv_fs_cb cb);
UV_EXTERN int uv_fs_rmdir(uv_loop_t* loop,uv_fs_t* req,const char* path,uv_fs_cb cb);
UV_EXTERN int uv_fs_scandir(uv_loop_t* loop,uv_fs_t* req,const char* path,int flags,uv_fs_cb cb);
UV_EXTERN int uv_fs_scandir_next(uv_fs_t* req,uv_dirent_t* ent);
UV_EXTERN int uv_fs_stat(uv_loop_t* loop,uv_fs_t* req,const char* path,uv_fs_cb cb);
UV_EXTERN int uv_fs_fstat(uv_loop_t* loop,uv_fs_t* req,uv_file file,uv_fs_cb cb);
UV_EXTERN int uv_fs_rename(uv_loop_t* loop,uv_fs_t* req,const char* path,const char* new_path,uv_fs_cb cb);
UV_EXTERN int uv_fs_fsync(uv_loop_t* loop,uv_fs_t* req,uv_file file,uv_fs_cb cb);
UV_EXTERN int uv_fs_fdatasync(uv_loop_t* loop,uv_fs_t* req,uv_file file,uv_fs_cb cb);
UV_EXTERN int uv_fs_ftruncate(uv_loop_t* loop,uv_fs_t* req,uv_file file,int64_t offset,uv_fs_cb cb);
UV_EXTERN int uv_fs_sendfile(uv_loop_t* loop,uv_fs_t* req,uv_file out_fd,uv_file in_fd,int64_t in_offset,size_t length,uv_fs_cb cb);
UV_EXTERN int uv_fs_access(uv_loop_t* loop,uv_fs_t* req,const char* path,int mode,uv_fs_cb cb);
UV_EXTERN int uv_fs_chmod(uv_loop_t* loop,uv_fs_t* req,const char* path,int mode,uv_fs_cb cb);
UV_EXTERN int uv_fs_utime(uv_loop_t* loop,uv_fs_t* req,const char* path,double atime,double mtime,uv_fs_cb cb);
UV_EXTERN int uv_fs_futime(uv_loop_t* loop,uv_fs_t* req,uv_file file,double atime,double mtime,uv_fs_cb cb);
UV_EXTERN int uv_fs_lstat(uv_loop_t* loop,uv_fs_t* req,const char* path,uv_fs_cb cb);
UV_EXTERN int uv_fs_link(uv_loop_t* loop,uv_fs_t* req,const char* path,const char* new_path,uv_fs_cb cb);
Buffers and Streams
在libuv中,最基础的I/O操作是流stream(uv_stream_t)。TCP套接字,UDP套接字,管道对于文件I/O和IPC来说,都可以看成是流stream(uv_stream_t)的子类。
上面提到的各个流的子类都有各自的初始化函数,然后可以使用下面的函数操作:
int uv_read_start(uv_stream_t*, uv_alloc_cb alloc_cb, uv_read_cb read_cb);
int uv_read_stop(uv_stream_t*);
int uv_write(uv_write_t* req, uv_stream_t* handle,const uv_buf_t bufs[], unsigned int nbufs, uv_write_cb cb);
可以看出,流操作要比上述的文件操作要简单一些,而且当uv_read_start()一旦被调用,libuv会保持从流中持续地读取数据,直到uv_read_stop()被调用。
数据的离散单元是buffer-uv_buffer_t。它包含了指向数据的开始地址的指针(uv_buf_t.base)和buffer的长度(uv_buf_t.len)这两个信息。uv_buf_t很轻量级,使用值传递。我们需要管理的只是实际的数据,即程序必须自己分配和回收内存。
ERROR:
THIS PROGRAM DOES NOT ALWAYS WORK, NEED SOMETHING BETTER
为了更好地演示流stream,我们将会使用uv_pipe_t。它可以将本地文件转换为流(stream)的形态。接下来的这个是使用libuv实现的,一个简单的tee工具(如果不是很了解,请看维基百科)。所有的操作都是异步的,这也正是事件驱动I/O的威力所在。两个输出操作不会相互阻塞,但是我们也必须要注意,确保一块缓冲区不会在还没有写入之前,就提前被回收了。
这个程序执行命令如下
./uvtee <output_file>
在使用pipe打开文件时,libuv会默认地以可读和可写的方式打开文件。
uvtee/main.c - read on pipes
int main(int argc, char **argv) {loop = uv_default_loop();uv_pipe_init(loop, &stdin_pipe, 0);uv_pipe_open(&stdin_pipe, 0);uv_pipe_init(loop, &stdout_pipe, 0);uv_pipe_open(&stdout_pipe, 1);uv_fs_t file_req;int fd = uv_fs_open(loop, &file_req, argv[1], O_CREAT | O_RDWR, 0644, NULL);uv_pipe_init(loop, &file_pipe, 0);uv_pipe_open(&file_pipe, fd);uv_read_start((uv_stream_t*)&stdin_pipe, alloc_buffer, read_stdin);uv_run(loop, UV_RUN_DEFAULT);return 0;
}
当需要使用具名管道的时候(译注:匿名管道 是Unix最初的IPC形式,但是由于匿名管道的局限性,后来出现了具名管道 FIFO,这种管道由于可以在文件系统中创建一个名字,所以可以被没有亲缘关系的进程访问),uv_pipe_init()的第三个参数应该被设置为1。这部分会在Process进程的这一章节说明。uv_pipe_open()函数把管道和文件描述符关联起来,在上面的代码中表示把管道stdin_pipe和标准输入关联起来(译者注:0代表标准输入,1代表标准输出,2代表标准错误输出)。
当调用uv_read_start()后,我们开始监听stdin,当需要新的缓冲区来存储数据时,调用alloc_buffer,在函数read_stdin()中可以定义缓冲区中的数据处理操作。
uvtee/main.c - reading buffers
void alloc_buffer(uv_handle_t *handle, size_t suggested_size, uv_buf_t *buf) {*buf = uv_buf_init((char*) malloc(suggested_size), suggested_size);
}void read_stdin(uv_stream_t *stream, ssize_t nread, const uv_buf_t *buf) {if (nread < 0){if (nread == UV_EOF){// end of fileuv_close((uv_handle_t *)&stdin_pipe, NULL);uv_close((uv_handle_t *)&stdout_pipe, NULL);uv_close((uv_handle_t *)&file_pipe, NULL);}} else if (nread > 0) {write_data((uv_stream_t *)&stdout_pipe, nread, *buf, on_stdout_write);write_data((uv_stream_t *)&file_pipe, nread, *buf, on_file_write);}if (buf->base)free(buf->base);
}
标准的malloc是非常高效的方法,但是你依然可以使用其它的内存分配的策略。比如,nodejs使用自己的内存分配方法(Smalloc),它将buffer用v8的对象关联起来,具体的可以查看nodejs的官方文档。
当回调函数read_stdin()的nread参数小于0时,表示错误发生了。其中一种可能的错误是EOF(读到文件的尾部),这时我们可以使用函数uv_close()关闭流了。除此之外,当nread大于0时,nread代表我们可以向输出流中写入的字节数目。最后注意,缓冲区要由我们手动回收。
当分配函数alloc_buf()返回一个长度为0的缓冲区时,代表它分配内存失败。在这种情况下,读取的回调函数会被错误UV_ENOBUFS唤醒。libuv同时也会继续尝试从流中读取数据,所以如果你想要停止的话,必须明确地调用uv_close().
当nread为0时,代表已经没有可读的了,大多数的程序会自动忽略这个。
uvtee/main.c - Write to pipe
typedef struct {uv_write_t req;uv_buf_t buf;
} write_req_t;void free_write_req(uv_write_t *req) {write_req_t *wr = (write_req_t*) req;free(wr->buf.base);free(wr);
}void on_stdout_write(uv_write_t *req, int status) {free_write_req(req);
}void on_file_write(uv_write_t *req, int status) {free_write_req(req);
}void write_data(uv_stream_t *dest, size_t size, uv_buf_t buf, uv_write_cb cb) {write_req_t *req = (write_req_t*) malloc(sizeof(write_req_t));req->buf = uv_buf_init((char*) malloc(size), size);memcpy(req->buf.base, buf.base, size);uv_write((uv_write_t*) req, (uv_stream_t*)dest, &req->buf, 1, cb);
}
write_data()开辟了一块地址空间存储从缓冲区读取出来的数据。这块缓存不会被释放,直到与uv_write()绑定的回调函数执行。为了实现它,我们用结构体write_req_t包裹一个write request和一个buffer,然后在回调函数中展开它。因为我们复制了一份缓存,所以我们可以在两个write_data()中独立释放两个缓存。 我们之所以这样做是因为,两个调用write_data()是相互独立的。为了保证它们不会因为读取速度的原因,由于共享一片缓冲区而损失掉独立性,所以才开辟了新的两块区域。当然这只是一个简单的例子,你可以使用更聪明的内存管理方法来实现它,比如引用计数或者缓冲区池等。
WARNING
你的程序在被其他的程序调用的过程中,有意无意地会向pipe写入数据,这样的话它会很容易被信号SIGPIPE终止掉,你最好在初始化程序的时候加入这句:
signal(SIGPIPE, SIG_IGN)。
File change events
所有的现代操作系统都会提供相应的API来监视文件和文件夹的变化(如Linux的inotify,Darwin的FSEvents,BSD的kqueue,Windows的ReadDirectoryChangesW, Solaris的event ports)。libuv同样包括了这样的文件监视库。这是libuv中很不协调的部分,因为在跨平台的前提上,实现这个功能很难。为了更好地说明,我们现在来写一个监视文件变化的命令:
./onchange <command> <file1> [file2] ...
实现这个监视器,要从uv_fs_event_init()开始:
onchange/main.c - The setup
int main(int argc, char **argv) {if (argc <= 2) {fprintf(stderr, "Usage: %s <command> <file1> [file2 ...]\n", argv[0]);return 1;}loop = uv_default_loop();command = argv[1];while (argc-- > 2) {fprintf(stderr, "Adding watch on %s\n", argv[argc]);uv_fs_event_t *fs_event_req = malloc(sizeof(uv_fs_event_t));uv_fs_event_init(loop, fs_event_req);// The recursive flag watches subdirectories too.uv_fs_event_start(fs_event_req, run_command, argv[argc], UV_FS_EVENT_RECURSIVE);}return uv_run(loop, UV_RUN_DEFAULT);
}
函数uv_fs_event_start()的第三个参数是要监视的文件或文件夹。最后一个参数,flags,可以是:
UV_FS_EVENT_WATCH_ENTRY = 1,UV_FS_EVENT_STAT = 2,UV_FS_EVENT_RECURSIVE = 4
UV_FS_EVENT_WATCH_ENTRY和UV_FS_EVENT_STAT不做任何事情(至少目前是这样),UV_FS_EVENT_RECURSIVE可以在支持的系统平台上递归地监视子文件夹。
在回调函数run_command()中,接收的参数如下:
1.
uv_fs_event_t *handle-句柄。里面的path保存了发生改变的文件的地址。
2.const char *filename-如果目录被监视,它代表发生改变的文件名。只在Linux和Windows上不为null,在其他平台上可能为null。
3.int flags-UV_RENAME名字改变,UV_CHANGE内容改变之一,或者他们两者的按位或的结果(|)。
4.int status-当前为0。
在我们的例子中,只是简单地打印参数和调用system()运行command.
onchange/main.c - file change notification callback
void run_command(uv_fs_event_t *handle, const char *filename, int events, int status) {char path[1024];size_t size = 1023;// Does not handle error if path is longer than 1023.uv_fs_event_getpath(handle, path, &size);path[size] = '\0';fprintf(stderr, "Change detected in %s: ", path);if (events & UV_RENAME)fprintf(stderr, "renamed");if (events & UV_CHANGE)fprintf(stderr, "changed");fprintf(stderr, " %s\n", filename ? filename : "");system(command);
}
相关文章:

libuv库学习笔记-filesystem
Filesystem 简单的文件读写是通过uv_fs_*函数族和与之相关的uv_fs_t结构体完成的。 note libuv 提供的文件操作和 socket operations 并不相同。套接字操作使用了操作系统本身提供了非阻塞操作,而文件操作内部使用了阻塞函数,但是 libuv 是在线程池中调…...
记录vue的一些踩坑日记
记录vue的一些踩坑日记 安装Jq npm install jquery --save vue列表跳转到详情页,再返回列表的时候不刷新页面并且保持原位置不变; 解决:使用keepAlive 在需要被缓存的页面的路由中添加:keepAlive: true, {path: /viewExamine,nam…...
Mybatis学习笔记
Mybatis 文章目录 Mybatis搭建环境创建Maven工程将数据库中的表转换为对应的实体类配置文件核心配置文件mybatis-config.xml创建Mapper接口映射文件xxxMapper.xmllog4j日志功能 Mybatis操纵数据库示例及要点说明获取参数的两种方式${}#{} 各种类型的参数处理单个字面量参数多个…...
:三次握手和四次挥手部分细节(后续补充))
网络编程(11):三次握手和四次挥手部分细节(后续补充)
关于listen 服务器如果不listen,TCP协议栈就无法从CLOSED状态变成LISTEN状态,客户端发起连接,TCP协议栈会直接返回RST报文,从而导致客户端连接失败 关于accept accept发送在三次握手完成之后,从全连接队列中取出一个节…...

MySQL学习笔记 ------ 子查询
#进阶7:子查询 /* 含义: 出现在其他语句中的select语句,称为子查询或内查询 外部的查询语句,称为主查询或外查询 分类: 按子查询出现的位置: select后面: 仅仅支持标量子查询 …...

自然语言处理应用程序设计
原文地址:https://zhanghan.xyz/posts/22426/ 文章目录 一、摘要二、数据集三、相关环境四、功能展示1.系统主界面2.中文分词3.命名实体识别4.文本分类5.文本聚类6.其他界面 五、源码链接 一、摘要 将自然语言处理课程设计中实现的模型集成到自然语言处理应用程序…...

LeetCode 436. Find Right Interval【排序,二分;双指针,莫队】中等
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...

正则表达式 —— Sed
Sed Sed 类似于vim就是一个文本编辑器,按行来进行编辑和排序 Sed的原理:读取,执行,显示 读取:读取文本内容之后,读取到的内容存放到临时的缓冲区—模式空间 执行:在模式空间,根据…...

TypeScript中数组,元组 和 枚举类型
数组 方式一 let arr: number[] [1, 2, 3, 4]方式二,使用泛型定义 let arr: Array<number> [1, 2, 3, 4]方式三,使用any let arr: any[] [12, string, true] console.log(arr[1]) // string元组 可以定义不同类型定义类型顺序需保持一直 …...

MyBatis-Plus-Join 多表查询的扩展
文章目录 网站使用方法安装使用Lambda形式用法(MPJLambdaWrapper)简单的连表查询一对多查询 网站 官方网站:https://mybatisplusjoin.com/Github地址:https://github.com/yulichang/mybatis-plus-joinGitee地址:https…...

认清现实重新理解游戏的本质
认清现实重新理解游戏的本质 OVERVIEW 认清现实重新理解游戏的本质现实两条小路的启发四个动机1.当前的学习任务或工作任务太艰巨2.完美主义3.对未来太过于自信/无知4.大脑小看未来的收益 四个方法1.让未来的收益足够巨大2.让未来的收益感觉就在眼前3.玩游戏有恶劣的结果4.玩游…...
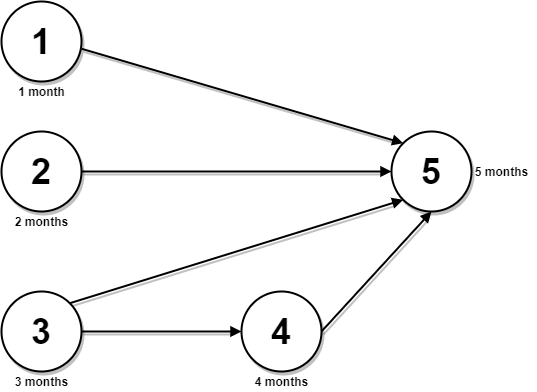
LeetCode 2050. Parallel Courses III【记忆化搜索,动态规划,拓扑排序】困难
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...
ETHERNET/IP转RS485/RS232网关什么是EtherNet/IP?
网络数据传输遇到的协议不同、数据互通麻烦等问题,一直困扰着大家。然而,现在有一种神器——捷米JM-EIP-RS485/232,它将ETHERNET/IP网络和RS485/RS232总线连接在一起,让数据传输更加便捷高效。 那么,它是如何实现这一功…...

使用node内置test runner,和 Jest say 拜拜
参考 https://nodejs.org/dist/latest-v20.x/docs/api/test.html#test-runner 在之前,我们写单元测试,必须安装第三方依赖包,而从node 20.0.0 版本之后,可以告别繁琐的第三方依赖包啦,可直接使用node的内置test runner…...

《面试1v1》Kafka的架构设计是什么样子
🍅 作者简介:王哥,CSDN2022博客总榜Top100🏆、博客专家💪 🍅 技术交流:定期更新Java硬核干货,不定期送书活动 🍅 王哥多年工作总结:Java学习路线总结…...

比较常见CPU的区别:Intel、ARM、AMD
一、开发公司不同 1、Intel:是英特尔公司开发的中央处理器,有移动、台式、服务器三个系列。 2、ARM:是英国Acorn有限公司设计的低功耗成本的第一款RISC微处理器。 3、AMD:由AMD公司生产的处理器。 二、技术不同 1、Intel&…...
CAN转EtherNet/IP网关can协议是什么意思
你是否曾经遇到过不同的总线协议难以互相通信的问题?远创智控的YC-EIP-CAN网关为你解决了这个烦恼! 远创智控YC-EIP-CAN通讯网关是一款自主研发的设备,它能够将各种CAN总线和ETHERNET/IP网络连接起来,解决不同总线协议之间的通信…...
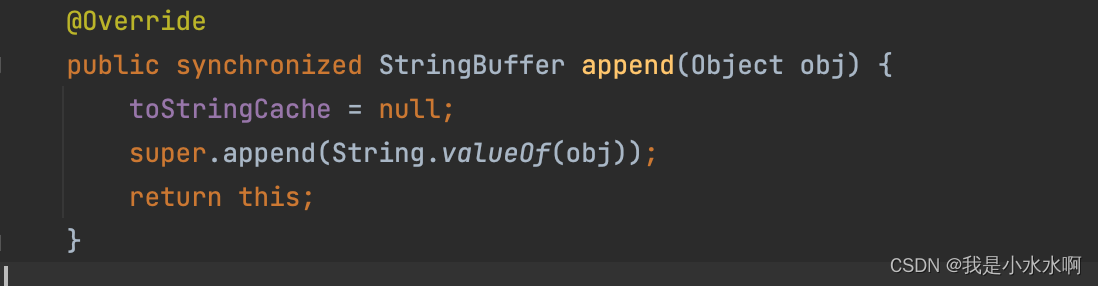
java可变字符序列:StringBuffer、StringBuilder
文章目录 StringBuffer与StringBuilder的理解StringBuilder、StringBuffer的API StringBuffer与StringBuilder的理解 因为String对象是不可变对象,虽然可以共享常量对象,但是对于频繁字符串的修改和拼接操作,效率极低,空间消耗也…...
Mac/win开发快捷键、vs插件、库源码、开发中的专业名词
目录 触控板手势(2/3指) 鼠标右键 快捷键 鼠标选择后shift⬅️→改变选择 mac command⬅️:删除←边的全部内容 commadtab显示下栏 commandshiftz向后撤回 commandc/v复制粘贴 command ⬅️→回到行首/末 commandshift3/4截图 飞…...

linux 系统编程
C标准函数与系统函数的区别 什么是系统调用 由操作系统实现并提供给外部应用程序的编程接口。(Application Programming Interface,API)。是应用程序同系统之间数据交互的桥梁。 一个helloworld如何打印到屏幕。 每一个FILE文件流(标准C库函数ÿ…...

JS中forEach与普通for
for就不用说了,最普通的循环函数forEach1. 只写 1 个参数只接收当前遍历元素let arr [10,20,30] arr.forEach(item > {console.log(item) // 依次 10、20、30 })2. 写 2 个参数依次接收元素值、下标索引let arr [10,20,30] arr.forEach((item, index) > {co…...

PostgreSQL Merge Join 大白话详解
用生活中最直观的例子,彻底搞懂 Merge Join 是什么、为什么快、什么时候用。一、先从生活场景开始 场景一:两摞乱序试卷找同学 期末考试,老师手里有两摞试卷: A 摞:数学试卷,500 份,乱序堆放B 摞…...

如何用Untrunc拯救损坏视频?2025年终极MP4修复工具完全指南
如何用Untrunc拯救损坏视频?2025年终极MP4修复工具完全指南 【免费下载链接】untrunc Restore a damaged (truncated) mp4, m4v, mov, 3gp video. Provided you have a similar not broken video. 项目地址: https://gitcode.com/gh_mirrors/unt/untrunc 当你…...

如何高效实现Windows自动化鼠标点击:AutoClicker完整实战指南
如何高效实现Windows自动化鼠标点击:AutoClicker完整实战指南 【免费下载链接】AutoClicker AutoClicker is a useful simple tool for automating mouse clicks. 项目地址: https://gitcode.com/gh_mirrors/au/AutoClicker AutoClicker是一款专业的Windows桌…...

如何快速配置虚拟显示器:面向初学者的完整指南
如何快速配置虚拟显示器:面向初学者的完整指南 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd 你是否在为游戏串流画质不佳而烦恼?或者需要为无显示器主机…...

终极指南:5分钟搞定淘宝淘金币全任务自动化脚本
终极指南:5分钟搞定淘宝淘金币全任务自动化脚本 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinbi 你是否厌倦…...

5大核心功能掌握HandheldCompanion:Windows掌机终极控制伴侣
5大核心功能掌握HandheldCompanion:Windows掌机终极控制伴侣 【免费下载链接】HandheldCompanion ControllerService 项目地址: https://gitcode.com/gh_mirrors/ha/HandheldCompanion 你是否正在寻找一款能够彻底改变Windows掌机游戏体验的控制软件…...
)
BGP选路原则--本地优先级(LocPrf)
如果BGP收到相同的路由,首选值PrefVal如果也相同的话,那么就会继续比较下一条原则:本地优先级Local_Pref 一、拓扑图 二、配置BGP路由协议: R1 bgp 100 peer 12.1.1.2 as-number 200 peer 13.1.1.3 as-number 200 R2 bgp 200 peer 4.4.4.4 as-number 200 peer 4.4.4…...

代码质量保卫战,从人工Review到DeepSeek自动审查的7天转型全记录
更多请点击: https://kaifayun.com 第一章:代码质量保卫战的范式转移 过去十年,代码质量保障已从“事后拦截”转向“全程共生”。单元测试覆盖率不再是KPI终点,而是开发流程的呼吸节律;静态分析不再停留于CI流水线末尾…...

MPC Video Renderer技术解析:DirectShow硬件加速渲染器的实现原理与深度剖析
MPC Video Renderer技术解析:DirectShow硬件加速渲染器的实现原理与深度剖析 【免费下载链接】VideoRenderer Внешний видео-рендерер 项目地址: https://gitcode.com/gh_mirrors/vi/VideoRenderer MPC Video Renderer是一款基于GPL v3协…...