理解构建LLM驱动的聊天机器人时的向量数据库检索的局限性 - (第1/3部分)
本博客是一系列文章中的第一篇,解释了为什么使用大型语言模型(LLM)部署专用领域聊天机器人的主流管道成本太高且效率低下。在第一篇文章中,我们将讨论为什么矢量数据库尽管最近流行起来,但在实际生产管道中部署时从根本上受到限制。在下面的文章中,我们说明了我们在ThirdAI上发布的最新产品如何解决这些缺点,并实现以低成本在生产中部署LLM驱动的检索的愿景。
动机
专用领域聊天机器人是 ChatGPT 最受欢迎的企业应用程序。具有特定知识库的自动问答功能可以使任何雇主的员工提高工作效率,同时节省员工宝贵的时间。举例来说,如果员工与客户互动,那么触手可及的与客户的所有历史互动将非常方便。如果你想为一个大型代码库做出贡献,如果你能在细粒度级别快速掌握任何现有功能,它可以让你非常高效。这样的例子不胜枚举。
ChatGPT 是一个很棒的对话工具,它根据互联网上发现的大量文本信息进行了训练。如果你问ChatGPT关于互联网的一般知识,它可以很好地回答。但是,它有一些明显的局限性。ChatGPT 无法回答那些答案不属于其训练数据中的问题。因此,如果您问 ChatGPT,“谁赢得了 2022 年足球世界杯? 它将无法回答,因为它在 2021 年 9 月之后没有接受过任何信息的训练。企业坐拥一堆非常专业、特有且不断更新的信息语料库,而开箱即用的 ChatGPT 不会成为该知识库的查询助手。更糟糕的是,众所周知,在没有适当保护机制的情况下,对 ChatGPT 的查询可能会导致虚构的答案。
幸运的是,有着大量措施正围绕使用提示解决上述两个缺陷。
什么是提示?
提示是一种新术语,用于告诉会话代理回答问题所需的所有特定信息。然后,它依靠座席的对话能力来生成精美的答案。如果你想让 ChatGPT 回答一个不属于其训练集的特定问题,你必须基本上让 ChatGPT 知道它需要知道的所有信息,少于 4096 个令牌(或大约 3200 个单词,GPT-4的单词上限达到了25000个),然后用给定的“上下文”问它同样的问题。
无论这听起来多么愚蠢,提示仍然是一种有价值的功能。像人类那样进行自动化的对话是我们最近在生成式人工智能方面取得显著进步的罕见壮举。实际上,构建查询助手可以归结为经典问题,即“检索与查询相关的信息”,然后使用 ChatGPT 的功能生成基于检索到的信息的对话答案。我们可以看到,这会自动在幻觉周围设置护栏,因为会话代理被迫将答案接地到检索到的文本中,而这是知识库的子集。
最难的部分是总是大海捞针!
嵌入和向量数据库生态系统:在任何给定的语料库上使用 ChatGPT 构建接地气的查询助手。
使用Langchain构建了一系列聊天机器人应用程序,您可以在其中引入任何文本语料库并使用ChatGPT与之交互。所有这些应用程序都建立在基于嵌入的标准信息检索过程之上。
该过程分为两个主要阶段。第一阶段是预处理步骤,用于生成嵌入向量并构建用于近邻搜索的向量索引。生成索引后,下一阶段是查询。我们简要介绍一下这两个阶段。
预处理步骤:此步骤获取所有原始文本并构建可以有效搜索的索引。下图描述了该过程。

预处理步骤概述:您需要同时将文本和向量嵌入存储在数据库中,并以向量作为 KEY。该过程需要LLM将文本块转换为向量。LLM 在查询时候的逻辑应该是相同的。
注意: 对LLM的任何更改或更新都需要重新索引Vector DB中的所有内容。您需要完全相同的LLM进行查询。 不允许更改尺寸。
隐私风险:所有文本都需要转到嵌入模型和向量数据库。
昂贵: 完整文本语料库中的每个标记都转到LLM和Vector DB。
假设我们有一个文本文档语料库来准备问答。第一步是将语料库(或文本文档)分解成小块文本,我们称之为块(该过程也称为分块)。然后将每个块馈送到经过训练的语言模型(如 BERT 或 GPT)以生成向量表示,也称为嵌入。然后将文本嵌入对存储在矢量数据库或 <KEY, VALUE> 存储中,其中 KEY 是矢量嵌入,VALUE 是文本块。矢量数据库的独特之处在于能够有效地对矢量执行近似近邻 (ANN) 搜索以进行 KEY 匹配,而不是在传统数据库中执行精确的 KEY 匹配。
- 注意: 对LLM的任何更改或更新都需要重新索引Vector DB中的所有内容。您需要完全相同的LLM进行查询。 不允许更改尺寸。
- 隐私风险:所有文本都必须转到嵌入模型和矢量数据库。如果两者都是不同的托管服务,则可以在两个不同的位置创建 COMPLETE 数据的两个副本。
- 注意成本: 完整文本语料库中的每个标记都转到LLM和Vector DB。将来,如果您通过微调,升级模型甚至增加维度来更新LLM,则需要重新索引并再次支付全部费用。
- 使用托管服务进行成本估算:让我们适度估计一下使用所有Pubmed摘要的知识库来构建聊天机器人,以构建医疗保健问答应用程序。Pubmed有大约35万个摘要,大约需要100M个嵌入的块。假设每块 100 个代币,我们将有大约 25B 个代币。即使我们使用Pinecone的适度矢量数据库计划(性能)和OpenAI的更便宜的嵌入模型价格(Babbage V1),我们也在考虑向量数据库每月大约7000-8000美元的成本。此费用不包括任何仓储费。此外,根据代币数量生成嵌入的一次性成本为 12500 美元。每次更改嵌入模型时,我们也需要支付12500美元。如果我们每月进行 10亿次查询,那么我们每月至少支付 25000 美元的额外经常性费用,用于使用 OpenAI 进行查询嵌入服务和响应生成。值得注意的是,PubMed是较小的公共检索数据集之一。企业可能使用在10-100倍大的语料库之上进行上述工作。
查询阶段:嵌入和使用ANN搜索,然后通过提示生成
此步骤采用用户键入的问题,在矢量数据库中搜索与问题“最相关”的文本内容,然后根据该信息征求GenAI的响应。下图总结了这些步骤。
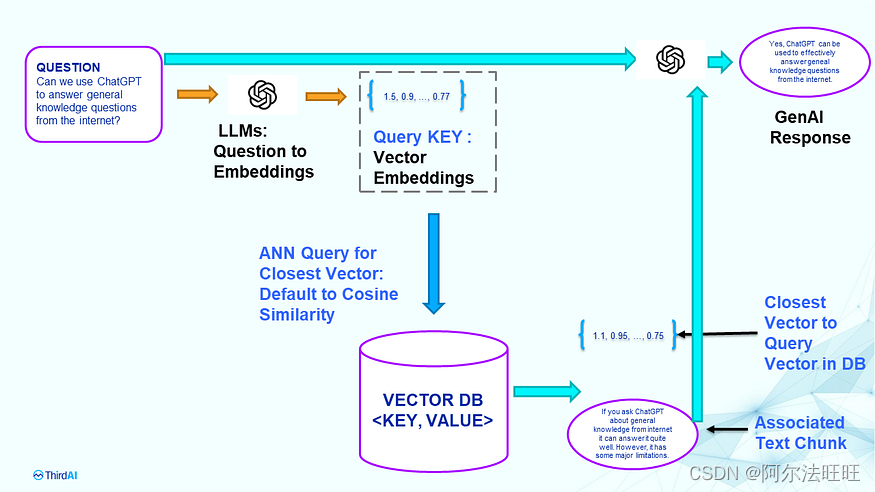
问答阶段: 对于索引文本块时使用的问题嵌入,您需要完全相同的 LLM。索引后无法修改 LLM。任何训练、调优都将使搜索过程无法使用,因为 ANN over KEY 可能不一致。如果要更新或更改LLM,则需要重新索引。注意:查询延迟是嵌入延迟 + 矢量数据库查询延迟 + GenAI 的文本生成延迟之和。
对于问答阶段,这个过程很简单。我们首先使用用于索引向量数据库的相同 LLM 生成查询的向量嵌入。此嵌入用作查询 KEY,并执行近似近邻搜索 (ANN) 以查找数据库中最接近查询嵌入的几个向量。接近度的度量是预定义和固定的,通常是余弦相似性。识别最接近的向量后,其相应的文本块用作与问题相关的信息。然后,相关信息和问题通过提示提供给生成AI,如ChatGPT,以生成响应。
- 注意:查询延迟是三个延迟的总和:嵌入问题文本延迟 + 向量数据库检索延迟 + GenAI 的文本响应生成延迟。如果您使用多个托管服务和不同的微服务,请准备好等待至少数百毫秒才能获得答案。显然,对于搜索引擎、电子商务和其他延迟关键型应用程序来说,这太慢了,其中超过 100 毫秒的延迟会导致糟糕的用户体验。这是一篇亚马逊博客,介绍了每 100 毫秒延迟如何花费 1% 的销售额。
- 成本:如上一节所述,一旦数据位于外部托管服务上,查询成本可能会很高并被锁定。
已知嵌入和矢量搜索的基本限制:为什么现代信息检索智慧提倡学习索引?
除了上面提到的延迟、成本、更新模型的不灵活性和隐私等问题外,还有一个根本的缺点,即使用基于余弦相似性的ANN(文本检索)断开了嵌入过程(KEY生成)的连接。
一个假设和Andrej Karpathy最近的实验比较接近:整个生态系统背后的隐含假设是向量嵌入之间的余弦相似性在检索相关文本。 众所周知,可能有更好的选择。这些LLM没有针对余弦相似性检索进行微调,其他相似性函数可能工作得更好。这是Andrej Karpathy的帖子和他的笔记本,以及关于他如何发现基于SVM的相似性更好。
深度学习革命告诉我们,联合优化的检索系统总是比嵌入然后ANN的断开连接的过程更好,在ANN过程中,ANN过程完全忽略了嵌入部分,反之亦然。
因此,如果矢量搜索生态系统的最终目标是为所提出的问题检索“相关文本”,为什么有两个互不关联的过程?为什么不有一个统一的学习系统,在给定问题文本时返回“最相关”的文本?难怪Andrej发现学习的SVM比简单的点积检索更好。近五年来,信息检索社区一直在构建这种联合优化的嵌入和检索系统。
神经信息检索系统最有效的形式是学习索引。在本博客的第 2/3 部分中,我们将回顾学习索引并讨论行业中以前部署的学习系统。我们将介绍神经数据库,这是一个端到端的学习索引系统,它完全绕过了昂贵而繁琐的高维近邻搜索向量。
在最后一部分(第 3/3 部分),我们将讨论 ThirdAI 的生产上使用的神经数据库 API 及其与 Langchain 和 ChatGPT 的集成。我们的解决方案完美避开了嵌入过程以及矢量数据库检索的昂贵、缓慢和严格的限制!
相关文章:
理解构建LLM驱动的聊天机器人时的向量数据库检索的局限性 - (第1/3部分)
本博客是一系列文章中的第一篇,解释了为什么使用大型语言模型(LLM)部署专用领域聊天机器人的主流管道成本太高且效率低下。在第一篇文章中,我们将讨论为什么矢量数据库尽管最近流行起来,但在实际生产管道中部署时从根本…...

IntersectionObserver实现小程序长列表优化
IntersectionObserver实现小程序长列表优化 关于 IntersectionObserver 思路 这里以一屏数据为单位【一个分页的10条数据,最好大于视口高度】, 监听每一屏数据和视口的相交比例,即用户能不能看到它 只将可视范围的数据渲染到页面上&#x…...
Nginx动静分离、资源压缩、负载均衡、黑白名单、防盗链等实战
一、前言 Nginx是目前负载均衡技术中的主流方案,几乎绝大部分项目都会使用它,Nginx是一个轻量级的高性能HTTP反向代理服务器,同时它也是一个通用类型的代理服务器,支持绝大部分协议,如TCP、UDP、SMTP、HTTPS等。 二、…...

Rust之枚举与模式匹配
枚举类型,简称枚举,允许列举所有可能的值来定义一个类型。 1、定义枚举: 枚举类型:已知所有可能的值,并且所有值的出现是互斥的,即每次只能取一种可能的值,才使用枚举类型。 示例:…...

nfs服务器的描述,搭建和使用
前言 这是我在这个网站整理的笔记,关注我,接下来还会持续更新。 作者:RodmaChen nfs服务器的描述,搭建和使用 NFS概述工作原理优缺点 nfs服务器搭建服务端客户端 NFS概述 NFS(Network File System)是一种基…...

libuv库学习笔记-filesystem
Filesystem 简单的文件读写是通过uv_fs_*函数族和与之相关的uv_fs_t结构体完成的。 note libuv 提供的文件操作和 socket operations 并不相同。套接字操作使用了操作系统本身提供了非阻塞操作,而文件操作内部使用了阻塞函数,但是 libuv 是在线程池中调…...
记录vue的一些踩坑日记
记录vue的一些踩坑日记 安装Jq npm install jquery --save vue列表跳转到详情页,再返回列表的时候不刷新页面并且保持原位置不变; 解决:使用keepAlive 在需要被缓存的页面的路由中添加:keepAlive: true, {path: /viewExamine,nam…...
Mybatis学习笔记
Mybatis 文章目录 Mybatis搭建环境创建Maven工程将数据库中的表转换为对应的实体类配置文件核心配置文件mybatis-config.xml创建Mapper接口映射文件xxxMapper.xmllog4j日志功能 Mybatis操纵数据库示例及要点说明获取参数的两种方式${}#{} 各种类型的参数处理单个字面量参数多个…...
:三次握手和四次挥手部分细节(后续补充))
网络编程(11):三次握手和四次挥手部分细节(后续补充)
关于listen 服务器如果不listen,TCP协议栈就无法从CLOSED状态变成LISTEN状态,客户端发起连接,TCP协议栈会直接返回RST报文,从而导致客户端连接失败 关于accept accept发送在三次握手完成之后,从全连接队列中取出一个节…...

MySQL学习笔记 ------ 子查询
#进阶7:子查询 /* 含义: 出现在其他语句中的select语句,称为子查询或内查询 外部的查询语句,称为主查询或外查询 分类: 按子查询出现的位置: select后面: 仅仅支持标量子查询 …...

自然语言处理应用程序设计
原文地址:https://zhanghan.xyz/posts/22426/ 文章目录 一、摘要二、数据集三、相关环境四、功能展示1.系统主界面2.中文分词3.命名实体识别4.文本分类5.文本聚类6.其他界面 五、源码链接 一、摘要 将自然语言处理课程设计中实现的模型集成到自然语言处理应用程序…...

LeetCode 436. Find Right Interval【排序,二分;双指针,莫队】中等
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...

正则表达式 —— Sed
Sed Sed 类似于vim就是一个文本编辑器,按行来进行编辑和排序 Sed的原理:读取,执行,显示 读取:读取文本内容之后,读取到的内容存放到临时的缓冲区—模式空间 执行:在模式空间,根据…...

TypeScript中数组,元组 和 枚举类型
数组 方式一 let arr: number[] [1, 2, 3, 4]方式二,使用泛型定义 let arr: Array<number> [1, 2, 3, 4]方式三,使用any let arr: any[] [12, string, true] console.log(arr[1]) // string元组 可以定义不同类型定义类型顺序需保持一直 …...

MyBatis-Plus-Join 多表查询的扩展
文章目录 网站使用方法安装使用Lambda形式用法(MPJLambdaWrapper)简单的连表查询一对多查询 网站 官方网站:https://mybatisplusjoin.com/Github地址:https://github.com/yulichang/mybatis-plus-joinGitee地址:https…...

认清现实重新理解游戏的本质
认清现实重新理解游戏的本质 OVERVIEW 认清现实重新理解游戏的本质现实两条小路的启发四个动机1.当前的学习任务或工作任务太艰巨2.完美主义3.对未来太过于自信/无知4.大脑小看未来的收益 四个方法1.让未来的收益足够巨大2.让未来的收益感觉就在眼前3.玩游戏有恶劣的结果4.玩游…...
LeetCode 2050. Parallel Courses III【记忆化搜索,动态规划,拓扑排序】困难
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...
ETHERNET/IP转RS485/RS232网关什么是EtherNet/IP?
网络数据传输遇到的协议不同、数据互通麻烦等问题,一直困扰着大家。然而,现在有一种神器——捷米JM-EIP-RS485/232,它将ETHERNET/IP网络和RS485/RS232总线连接在一起,让数据传输更加便捷高效。 那么,它是如何实现这一功…...

使用node内置test runner,和 Jest say 拜拜
参考 https://nodejs.org/dist/latest-v20.x/docs/api/test.html#test-runner 在之前,我们写单元测试,必须安装第三方依赖包,而从node 20.0.0 版本之后,可以告别繁琐的第三方依赖包啦,可直接使用node的内置test runner…...

《面试1v1》Kafka的架构设计是什么样子
🍅 作者简介:王哥,CSDN2022博客总榜Top100🏆、博客专家💪 🍅 技术交流:定期更新Java硬核干货,不定期送书活动 🍅 王哥多年工作总结:Java学习路线总结…...

Arduino ADC自检:用RC电路诊断模数转换器故障
1. 项目概述:当你的体重秤开始“说谎”你有没有遇到过这样的情况:站上家里的电子体重秤,屏幕上跳出来的数字让你瞬间怀疑人生?要么是轻得离谱,要么是重得吓人,更诡异的是,它可能只在两个固定的、…...

ModernWMS核心功能详解:从ASN入库到Dispatch出库的完整工作流
ModernWMS核心功能详解:从ASN入库到Dispatch出库的完整工作流 【免费下载链接】ModernWMS The open source simple and complete warehouse management system is derived from our many years of experience in implementing erp projects. We stripped the origin…...

京东自动购物终极指南:告别缺货烦恼,智能抢购神器
京东自动购物终极指南:告别缺货烦恼,智能抢购神器 【免费下载链接】Jd-Auto-Shopping 京东商品补货监控及自动下单 项目地址: https://gitcode.com/gh_mirrors/jd/Jd-Auto-Shopping 还在为心仪商品瞬间售罄而苦恼吗?还在熬夜等待补货却…...

为什么你明明很努力,领导却总看不到?问题出在这
许多测试同行在深夜加班排查Bug时,在凌晨赶写自动化脚本时,在对着海量数据做性能分析时,内心都会浮现一个共同的困惑:我明明已经这么拼了,为什么在领导眼里,我依然是个“找茬的”,而不是“创造价…...

为开源项目OpenClaw配置Taotoken作为其大模型服务后端
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为开源项目OpenClaw配置Taotoken作为其大模型服务后端 OpenClaw 是一个功能强大的开源工具,它允许开发者便捷地调用各类…...

智能知识学习平台
智能知识学习平台项目简介技术架构:问答驱动的开发模式前端架构后端架构核心功能:问答式交互贯穿始终1. 自定义构建知识库2.文档查看3.智能问答:知识触手可及4. 智能题目生成:严格遵循文档内容项目亮点用问答驱动的方式构建智慧学…...

终极指南:如何用ESP32打造专业级蓝牙游戏手柄
终极指南:如何用ESP32打造专业级蓝牙游戏手柄 【免费下载链接】ESP32-BLE-Gamepad Bluetooth LE Gamepad library for the ESP32 项目地址: https://gitcode.com/gh_mirrors/es/ESP32-BLE-Gamepad 你是否曾经想过用ESP32开发板制作一个自定义的游戏控制器&am…...

3步掌握ROS虚拟机器人:零硬件算法验证全攻略
3步掌握ROS虚拟机器人:零硬件算法验证全攻略 【免费下载链接】wpr_simulation 项目地址: https://gitcode.com/gh_mirrors/wp/wpr_simulation 想象一下这个场景:深夜两点,你终于调试完了最新的SLAM算法,准备在真实机器人上…...

You-Get下载视频音画不同步?可能是FFmpeg路径没配对!附Mac/Linux/Windows三平台配置指南
You-Get跨平台音视频同步解决方案:FFmpeg环境配置全指南 当你在Mac上流畅使用you-get下载合并好的视频,切换到Windows却遭遇音画分离的尴尬时,问题往往出在FFmpeg的环境配置上。本文将带你深入理解多平台下FFmpeg的配置差异,并提…...

洛谷-【动态规划1】动态规划的引入4
P1077 [NOIP 2012 普及组] 摆花题目描述小明的花店新开张,为了吸引顾客,他想在花店的门口摆上一排花,共 m 盆。通过调查顾客的喜好,小明列出了顾客最喜欢的 n 种花,从 1 到 n 标号。为了在门口展出更多种花,…...