树、二叉树(C语言版)详解
🍕博客主页:️自信不孤单
🍬文章专栏:数据结构与算法
🍚代码仓库:破浪晓梦
🍭欢迎关注:欢迎大家点赞收藏+关注
文章目录
- 🍊树的概念及结构
- 1. 树的概念
- 2. 树的相关概念
- 3.树的性质
- 4. 树的存储结构
- 4.1 双亲表示法
- 4.2 孩子表示法
- 4.3 孩子兄弟表示法
- 5. 树在实际中的应用
- 🍓二叉树概念及结构
- 1. 二叉树的概念
- 2. 特殊的二叉树
- 2.1 斜树
- 2.2 满二叉树
- 2.3 完全二叉树
- 3. 二叉树的性质
- 4. 二叉树的存储结构
- 1. 二叉树的顺序结构
- 2. 二叉树的链式结构
- 🍒二叉树的顺序结构实现
- 1. 堆的概念及结构
- 2. 堆的性质
- 3. 堆的实现
- 3.1 初始化堆
- 3.2 🍚堆的向上调整算法
- 3.3 🍚堆的向下调整算法
- 3.4 堆的插入
- 3.5 堆的删除
- 3.6 获取堆顶数据
- 3.7 获取堆中数据个数
- 3.8 堆的判空
- 3.9 堆的销毁
- 4. 堆的应用
- 4.1 堆排序
- 4.2 Top-K问题
- 🍥二叉树的链式结构实现
- 1. 遍历二叉树
- 1.1 前序遍历二叉树
- 1.2 中序遍历二叉树
- 1.3 后序遍历二叉树
- 1.4 层序遍历二叉树
- 2. 通过前序遍历的数组构建二叉树
- 3. 二叉树结点个数
- 4. 二叉树叶子结点个数
- 5. 二叉树第k层结点个数
- 6. 二叉树查找值为x的结点
- 7. 二叉树的深度
- 8. 判断二叉树是否是完全二叉树
- 9. 二叉树的销毁
🍊树的概念及结构
1. 树的概念
树是n(n>=0)个结点的有限集。当n = 0时,称为空树。在任意一棵非空树中应满足:
- 有且仅有一个特定的称为根的结点。
- 当n>1时,其余节点可分为m(m>0)个互不相交的有限集T1,T2,…,Tm,其中每个集合本身又是一棵树,并且称为根的子树。
因此,树是递归定义的。树作为一种逻辑结构,同时也是一种分层结构,具有以下两个特点:
- 树的根结点没有前驱,除根结点外的所有结点有且只有一个前驱。
- 树中所有结点可以有零个或多个后继。
注意:树形结构中,子树之间不能有交集,否则就不是树形结构了,因此n个结点的树中有n-1条边。

2. 树的相关概念
- 节点的度:一个节点含有的子树的个数称为该节点的度; 如上图:A的为6。
- 叶节点或终端节点:度为0的节点称为叶节点; 如上图:B、C、H、I…等节点为叶节点。
- 非终端节点或分支节点:度不为0的节点; 如上图:D、E、F、G…等节点为分支节点。
- 双亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点; 如上图:A是B的父节点。
- 孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点; 如上图:B是A的孩子节点。
- 兄弟节点:具有相同父节点的节点互称为兄弟节点; 如上图:B、C是兄弟节点。
- 树的度:一棵树中,最大的节点的度称为树的度; 如上图:树的度为6。
- 节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
- 树的高度或深度:树中节点的最大层次; 如上图:树的高度为4。
- 堂兄弟节点:双亲在同一层的节点互为堂兄弟;如上图:H、I互为兄弟节点。
- 节点的祖先:从根到该节点所经分支上的所有节点;如上图:A是所有节点的祖先。
- 子孙:以某节点为根的子树中任一节点都称为该节点的子孙。如上图:所有节点都是A的子孙。
- 森林:由m(m>0)棵互不相交的树的集合称为森林;

3.树的性质
树中的结点数等于所有结点的度数加 1 1 1。
度为 m m m的树中第 i i i层上至多有 m ( n − 1 ) m^{(n-1)} m(n−1)个结点( i ⩾ 1 i \geqslant 1 i⩾1 )。
高度为 h h h的 m m m叉树至多有 ( m h − 1 ) / ( m − 1 ) (m^h - 1)/(m - 1) (mh−1)/(m−1)个结点。
具有 n n n个结点的 m m m叉树的最小高度为 [ log 2 ( n ( m − 1 ) + 1 ) ] [\log_2 (n(m - 1) + 1)] [log2(n(m−1)+1)]。
4. 树的存储结构
树结构相对线性表就比较复杂了,要存储表示起来就比较麻烦了,既要保存值域,也要保存结点和结点之间的关系,实际中树有很多种表示方式如:双亲表示法,孩子表示法、孩子双亲表示法以及孩子兄弟表示法等。这里我们来介绍几种表示方法:
4.1 双亲表示法
这里以数组的方式为例,在每个结点中,存储该结点的数据信息 data 以及双亲的位置 parent。
以下是双亲表示法的结点结构定义代码:
/*树的双亲表示法结点结构定义*/
#define MAX_TREE_SIZE 10
typedef int TElemType; // 树结点的数据类型
/*结点结构*/
typedef struct PTNode
{TElemType data; // 结点数据int parent; // 双亲位置
}PTNode;
/*树结构*/
typedef struct
{PTNode nodes[MAX_TREE_SIZE]; // 结点数组int r, n; // 根的位置和结点数
}PTree;
这样的存储结构可以根据结点的 parent 的值很容易找到它的双亲结点,直到 parent 为 -1 时,表示找到了树结点的根。可如果我们要想知道,某结点的孩子是什么,需要遍历整个结构。
4.2 孩子表示法
把每个结点的孩子结点排列起来,以单链表作存储结构,则 n 个结点有 n 个孩子链表,如果是叶子结点则此单链表为空。然后 n 个头指针又组成一个线性表,采用顺序存储结构,存放进一个一维数组中。如下图:
设计两个结点,一个孩子结点,一个表头结点。孩子结点中 child 是数据域,用来存储某个结点在表头数组中的下标。next 是指针域,用来存储指向某结点的下一个孩子结点的指针。表头结点中 data 是数据域,存储某结点的数据信息。firstchild 是头指针域,存储该结点的孩子链表的头指针。
以下是孩子表示法的结点结构定义代码:

/*树的孩子表示法结构定义*/
#define MAX_TREE_SIZE 10
typedef int TElemType; // 树结点的数据类型
/*孩子结点*/
typedef struct CTNode
{int child;struct CTNode* next;
}*ChildPtr;
/*表头结点*/
typedef struct
{TElemType data;ChildPtr firstchild;
}CTBox;
/*树结构*/
typedef struct
{CTBox nodes[MAX_TREE_SIZE]; // 结点数组int r, n; // 根的位置和结点数
}
这样的存储结构对于我们要查找某个结点的某个孩子,只需要查找这个结点的孩子单链表即可。对于遍历整棵树也是很方便的,对头结点的数组循环即可。但是我们要想找到某个结点的双亲,还需要遍历整个结构。
4.3 孩子兄弟表示法
任意一棵树, 它的结点的第一个孩子如果存在就是唯一的,它的右兄弟如果存在也是唯一的。 因此,我们设置两个指针,分别指向该结点的第一个孩子和该结点的右兄弟。如下图:
以下是孩子表示法的结点结构定义代码:

/*树的孩子兄弟表示法结构定义*/
typedef int TElemType; //树结点的数据类型
typedef struct CSNode
{TElemtype data;struct CSNode* firstchild, * rightsib;
} CSNode, * CSTree;
5. 树在实际中的应用

🍓二叉树概念及结构
1. 二叉树的概念
二叉树是一种树形结构,其特点是每个结点至多只有两棵子树(即二叉树中不存在度大于2的结点),并且二叉树的子树有左右之分,其次序不能任意颠倒。
二叉树是 n (n≥0) 个结点的有限集合:
- 或者为空二叉树,即n=0。
- 或者由一个根结点和两个互不相交的被称为根的左子树和右子树组成。左子树和右子树又分别是一棵二叉树。
二叉树的5种基本形态如图所示:

2. 特殊的二叉树
2.1 斜树
所有的结点都只有左子树的二叉树叫左斜树。所有结点都是只有右子树的二叉树叫右斜树。这两者统称为斜树。
2.2 满二叉树

一棵高度为 h h h,且含有个 2 h − 1 2^h-1 2h−1结点的二叉树称为满二叉树,即树中的每层都含有最多的结点。满二叉树的叶子结点都集中在二叉树的最下一层,并且除叶子结点之外的每个结点度数均为 2 2 2。可以对满二叉树按层序编号:约定编号从根结点(根结点编号为 1 1 1)起,自上而下,自左向右。这样,每个结点对应一个编号,对于编号为 i 的结点,若有双亲,则其双亲为 i / 2 i/2 i/2,若有左孩子,则左孩子为 2 i 2i 2i;若有右孩子,则右孩子为 2 i + 1 2i+1 2i+1。
2.3 完全二叉树

完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树引出来的。对于高度为 h h h的,有 n n n个结点的二叉树,当且仅当其每一个结点都与高度为 h h h的满二叉树中编号从 1 1 1至 n n n的结点一一对应时称之为完全二叉树。满二叉树就是一种特殊的完全二叉树。
若 i ⩽ n / 2 i \leqslant n/2 i⩽n/2,则结点 i i i为分支结点,否则为叶子结点。
叶子结点只可能在层次最大的两层上出现。对于最大层次中的叶子结点,都依次排列在该层最左边的位置上。
若有度为 1 1 1的结点,则只可能有一个,且该结点只有左孩子而无右孩子(重要特征)。
按层序编号后,一旦出现某结点(编号为 i i i)为叶子结点或只有左孩子,则编号大于 i i i的结点均为叶子结点。
若 n n n为奇数,则每个分支结点都有左孩子和右孩子;若为偶数,则编号最大的分支结点(编号为 n / 2 n/2 n/2)只有左孩子,没有右孩子,其余分支结点左、右孩子都有。
3. 二叉树的性质
- 任意一棵树,若结点数量为 n n n,则边的数量为 n − 1 n-1 n−1。
- 非空二叉树上的叶子结点数等于度为 2 2 2的结点数加 1 1 1,即 n 0 = n 2 + 1 n_0=n_2+1 n0=n2+1。
- 非空二叉树上第 k k k层上至多有 2 k − 1 2^{k-1} 2k−1个结点( k ⩾ 1 k \geqslant 1 k⩾1)。
- 高度为 h h h的二叉树至多有 2 h − 1 2^h-1 2h−1个结点( h ⩾ 1 h \geqslant 1 h⩾1)。
- 对完全二叉树按从上到下、从左到右的顺序依次编号 0 , 1 , … , n 0,1,…,n 0,1,…,n,则有以下关系:
- i > 0 i>0 i>0时,结点 i i i的双亲的编号为 ( i − 1 ) / 2 (i-1)/2 (i−1)/2,即当 i i i为奇数时, 它是双亲的左孩子;当 i i i为偶数时,它是双亲的右孩子。
- 当 2 i + 1 < n 2i+1<n 2i+1<n时,结点的左孩子编号为 2 i + 1 2i+1 2i+1,否则无左孩子。
- 当 2 i + 2 < n 2i+2<n 2i+2<n时,结点 i i i的右孩子编号为 2 i + 2 2i+2 2i+2,否则无右孩子。
- 结点 i i i所在层次(深度)为 [ log 2 ( i + 1 ) ] + 1 [\log_2 (i+1)]+1 [log2(i+1)]+1。(方括号表示向下取整)
- 具有 n n n( n > 0 n>0 n>0)个结点的完全二叉树的高度为 [ log 2 n ] + 1 [\log_2 n]+1 [log2n]+1。(方括号表示向下取整)
- 具有 n n n( n > 0 n>0 n>0)个结点的满二叉树的高度为 log 2 ( n + 1 ) \log_2 (n+1) log2(n+1)。
4. 二叉树的存储结构
1. 二叉树的顺序结构
二叉树的顺序存储是指用一组地址连续的存储单元依次自上而下、自左至右存储完全二叉树上的结点元素,即将完全二叉树上编号为 i i i的结点元素存储在一维数组下标为 i − 1 i-1 i−1的分量中。
依据二叉树的性质,使用顺序结构数组只适合表示完全二叉树和满二叉树,树中结点的序号可以唯一地反映结点之间的逻辑关系,这样既能最大可能地节省存储空间,又能利用数组元素的下标值确定结点在二叉树中的位置,以及结点之间的关系。在实际应用中,堆的实现就很好的体现了这一结构。二叉树的顺序存储在物理上是一个数组,在逻辑上是一颗二叉树。

2. 二叉树的链式结构
二叉树的链式存储结构是指用链表来表示一棵二叉树,即用链来指示元素的逻辑关系。 通常的方法是链表中每个结点由三个域组成,数据域和左右指针域,左右指针分别用来给出该结点左孩子和右孩子所在的链结点的存储地址 。我们称这样的链表叫做二叉链表。
在含有 n n n个结点的二叉链表中,含有 n + 1 n+1 n+1个空链域。

/*二叉树的二叉链表结点构造定义*/
/*结点结构*/
typedef int TElemType;
typedef struct BTNode {TElemType data; // 结点数据struct BTNode* lchild, * rchild; // 左右孩子指针
} BTNode, * BTree;
🍒二叉树的顺序结构实现
1. 堆的概念及结构
如果有一个关键码的集合 K = { k 0 , k 1 , k 2 , … , k n − 1 } K=\{k_0,k_1, k_2,…,k_{n-1}\} K={k0,k1,k2,…,kn−1},把它的所有元素按完全二叉树的顺序存储方式存储在一个一维数组中,并满足: K i ⩽ K 2 ∗ i + 1 Ki \leqslant K_{2*i+1} Ki⩽K2∗i+1且 K i ⩽ K 2 ∗ i + 2 Ki \leqslant K_{2*i+2} Ki⩽K2∗i+2( K i ⩾ K 2 ∗ i + 1 Ki \geqslant K_{2*i+1} Ki⩾K2∗i+1且 K i ⩾ K 2 ∗ i + 2 Ki \geqslant K_{2*i+2} Ki⩾K2∗i+2)(其中 i = 0 , 1 , 2 , … i = 0,1,2,… i=0,1,2,…),则称为小堆(或大堆)。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。

2. 堆的性质
堆中某个节点的值总是不大于或不小于其父节点的值;
堆总是一棵完全二叉树。
3. 堆的实现
首先创建两个文件来实现堆:
- Heap.h(节点的声明、接口函数声明、头文件的包含)
- Heap.c(堆接口函数的实现)
如图:

Heap.h 文件内容如下:
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>typedef int HPDataType;
typedef struct Heap
{HPDataType* a;int size;int capacity;
}Heap;// 堆的初始化
void HeapInit(Heap* php);
// 堆的向上调整
void AdjustUp(HPDataType* a, int child);
// 堆的向下调整
void AdjustDown(HPDataType* a, int n, int parent);
// 堆的插入
void HeapPush(Heap* php, HPDataType x);
// 堆的删除
void HeapPop(Heap* php);
// 获取堆顶数据
HPDataType HeapTop(Heap* php);
// 获取堆中数据个数
int HeapSize(Heap* php);
// 堆的判空
int HeapEmpty(Heap* php);
// 堆的销毁
void HeapDestory(Heap* php);
接下来我们在 Heap.c 文件中实现各个接口函数。
3.1 初始化堆
对堆进行置空。
void HeapInit(Heap* php)
{assert(php);php->a = NULL;php->capacity = php->size = 0;
}
3.2 🍚堆的向上调整算法
当我们在堆尾插入数据时,需要进行调整使其仍然是堆,就要用到堆的向上调整算法。
以向上调整算法的基本思想(以建小堆为例):
将目标结点与其父结点比较。
若目标结点的值比其父结点的值小,则交换目标结点与其父结点的位置,并将原目标结点的父结点当作新的目标结点继续进行向上调整。若目标结点的值比其父结点的值大,则停止向上调整,此时该树已经是小堆了。
图解:

代码实现:
// 交换数据
void Swap(HPDataType* p1, HPDataType* p2)
{assert(p1);assert(p2);HPDataType tmp = *p1;*p1 = *p2;*p2 = tmp;
}void AdjustUp(HPDataType* a, int child)
{while (child > 0){int parent = (child - 1) / 2;if (a[parent] > a[child]){Swap(&a[parent], &a[child]);child = parent;}else{break;}}
}
拓展:
向上调整一次的时间复杂度为 O ( log N ) O(\log N) O(logN)。
向上调整建堆的思路:
- 从第一个结点开始,依次向上调整即可。
向上调整建堆的时间复杂度为 O ( N ∗ log N ) O(N*\log N) O(N∗logN)。
向上调整建堆的代码实现:
for (int i = 0; i < n; i++)
{AdjustUp(a, i);
}
3.3 🍚堆的向下调整算法
现在我们给出一个数组,逻辑上看作一棵完全二叉树。我们通过从根节点开始的向下调整算法可以把它调整成一个小堆。
使用向下调整算法需要满足一个前提:
若想将其调整为小堆,那么根结点的左右子树必须都为小堆。
若想将其调整为大堆,那么根结点的左右子树必须都为大堆。
向下调整算法的基本思想(以建小堆为例):
- 从根结点处开始,选出左右孩子中值较小的孩子。
- 让小的孩子与其父亲进行比较。若小的孩子比父亲还小,则该孩子与其父亲的位置进行交换。并将原来小的孩子的位置当成父亲继续向下进行调整,直到调整到叶子结点为止。若小的孩子比父亲大,则不需处理了,调整完成,整个树已经是小堆了。
图解:

代码实现:
// 交换数据
void Swap(HPDataType* p1, HPDataType* p2)
{assert(p1);assert(p2);HPDataType tmp = *p1;*p1 = *p2;*p2 = tmp;
}void AdjustDown(HPDataType* a, int n, int parent)
{int child = parent * 2 + 1;while (child < n){if (child + 1 < n && a[child] > a[child + 1]) //右孩子存在且比左孩子小{child++;}if (a[parent] > a[child]){Swap(&a[parent], &a[child]);parent = child;child = parent * 2 + 1;}else{break;}}
}
拓展:
向下调整一次的时间复杂度为 O ( log N ) O(\log N) O(logN)。
使用堆的向下调整算法需要满足其根结点的左右子树均为大堆或是小堆才行,那么如何才能将一个任意完全二叉树调整为堆呢?
答案很简单,我们只需要从倒数第一个非叶子结点开始,从后往前,按下标,依次作为根去向下调整即可。
向下调整建堆的代码实现:
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{AdjustDown(a, n, i);
}
那么向下调整建堆的时间复杂度为多少呢?
当结点数无穷大时,完全二叉树与其层数相同的满二叉树相比较来说,它们相差的结点数可以忽略不计,所以计算时间复杂度的时候我们可以将完全二叉树看作与其层数相同的满二叉树来进行计算。
建堆过程中最坏情况交换的次数:
T ( n ) = 1 × ( h − 1 ) + 2 × ( h − 2 ) + 2 h − 2 × 1 T(n) = 1 \times (h-1)+2 \times (h-2)+2^{h-2} \times 1 T(n)=1×(h−1)+2×(h−2)+2h−2×1
通过求和我们得出
T ( n ) = 2 h − h − 1 T(n)=2^h-h-1 T(n)=2h−h−1
由二叉树的性质得 N = 2 h − 1 N=2^h-1 N=2h−1
则 h = log 2 ( N + 1 ) h=\log_2(N+1) h=log2(N+1)
所以 T ( n ) = N − log 2 ( N + 1 ) T(n)=N-\log_2(N+1) T(n)=N−log2(N+1)
用大O的渐近表示法:
T ( N ) = O ( N ) T(N)=O(N) T(N)=O(N)
最终推出向下调整建堆的时间复杂度为 O ( N ) O(N) O(N)。
3.4 堆的插入
先判断扩容, 然后将结点插到堆数组的最后,再进行向上调整操作。
void HeapPush(Heap* php, HPDataType x)
{assert(php);if (php->capacity == php->size){int NewCapacity = php->capacity == 0 ? 5 : php->capacity * 2;HPDataType* tmp = (HPDataType*)realloc(php->a, NewCapacity * sizeof(HPDataType));if (tmp == NULL){perror("realloc fail");return;}php->a = tmp;php->capacity = NewCapacity;}php->size++;php->a[php->size - 1] = x;AdjustUp(php->a, php->size - 1);
}
3.5 堆的删除
堆的删除是指删除堆顶元素。
实现思路:
如果非空就将堆顶结点与最后一个结点交换,然后去掉最后一个结点,将堆顶结点进行向下调整操作。
void HeapPop(Heap* php)
{assert(php);assert(!HeapEmpty(php));Swap(&php->a[0], &php->a[php->size - 1]);php->size--;AdjustDown(php->a, php->size, 0);
}
3.6 获取堆顶数据
断言判空,返回堆顶元素的值。
HPDataType HeapTop(Heap* php)
{assert(php);assert(!HeapEmpty(php));return php->a[0];
}
3.7 获取堆中数据个数
返回堆中数据个数。
int HeapSize(Heap* php)
{assert(php);return php->size;
}
3.8 堆的判空
堆非空返回ture,否则返回false。
int HeapEmpty(Heap* php)
{assert(php);return php->size == 0;
}
3.9 堆的销毁
释放动态开辟好的内存,并对数据进行置空。
void HeapDestory(Heap* php)
{assert(php);free(php->a);php->a = NULL;php->capacity = php->size = 0;
}
4. 堆的应用
堆的应用相对广泛,我们在此仅介绍堆排序和Top-K问题。
4.1 堆排序
堆排序是利用堆的思想进行的排序,是一种选择排序。时间复杂度为 O ( N ∗ log N ) O(N*\log N) O(N∗logN),它也是一种不稳定排序。
实现分为两步:
- 建堆。
- 升序:建大堆
- 降序:建小堆
- 利用堆删除思想进行排序。
建堆和堆删除中都用到了向下调整,因此掌握了向下调整,就可以完成堆排序。
实现具体思路(以升序为例):
- 将待排序的 n n n个元素构建成一个大堆。此时,整个序列的最大值就是堆顶的根节点。
- 将其与末尾元素进行交换,此时末尾元素为最大值。
- 然后将剩余 n − 1 n-1 n−1个元素通过向下调整的重新建成大堆,这样会得到 n n n个元素的次大值。如此反复执行,便能得到一个有序序列了。
堆排序动图演示网站
代码实现:
void HeapSort(HPDataType* a, int n)
{// 向下调整建堆for (int i = (n - 1 - 1) / 2; i >= 0; i--){AdjustDown(a, n, i);}for (int i = n - 1; i >= 0; i--){Swap(&a[0], &a[i]);AdjustDown(a, i, 0);}
}
4.2 Top-K问题
求数据集合中前K个最大元素或最小元素,一般情况下数据量都比较大。
基本思路:
用数据集合中前 K K K个元素来建堆。
求前 k k k个最大的元素,则建小堆。
求前 k k k个最小的元素,则建大堆。用剩余的 N − K N-K N−K个元素依次与堆顶元素来比较,不满足则替换堆顶元素。
剩余 N − K N-K N−K个元素依次与堆顶元素比完之后,堆中剩余的 K K K个元素就是所求的前 K K K个最小或者最大的元素。
接下来,我们通过文件操作的方式来实现。首先在文件中造10000个随机数据,然后再执行以上思路。
代码实现:
// 造数据
void CreateNDate()
{int n = 10000;srand((unsigned int)time(0));const char* file = "data.txt";FILE* fin = fopen(file, "w");if (fin == NULL){perror("fopen error");return;}for (size_t i = 0; i < n; ++i){int x = rand() % 1000000;fprintf(fin, "%d\n", x);}fclose(fin);
}//打印最大的前K个数据
void PrintTopK(int k)
{const char* file = "data.txt";FILE* fout = fopen(file, "r");if (fout == NULL){perror("fopen error");return;}int* kminheap = (int*)malloc(sizeof(int) * k);if (kminheap == NULL){perror("malloc error");return;}// 存入前k个数据for (int i = 0; i < k; i++){fscanf(fout, "%d", &kminheap[i]);}// 建小堆for (int i = (k-1-1)/2; i >= 0; i--){AdjustDown(kminheap, k, i);}// 比较int val = 0;while (!feof(fout)){fscanf(fout, "%d", &val);if (val > kminheap[0]){kminheap[0] = val;AdjustDown(kminheap, k, 0);}}// 打印for (int i = 0; i < k; i++){printf("%d ", kminheap[i]);}printf("\n");
}
🍥二叉树的链式结构实现
根据二叉树的概念,我们发现链式结构能更清晰地表示二叉树。二叉树每个结点最多有两个孩子,所以我们设计一个数据域和两个指针域,数据域存放该节点的数据,指针域存放左右孩子指针。
二叉树链式结构的结点定义代码:
/*二叉树的二叉链表结点构造定义*/
/*结点结构*/
typedef char TElemType;
typedef struct BTNode {TElemType data; // 结点数据struct BTNode* lchild, * rchild; // 左右孩子指针
} BTNode;
1. 遍历二叉树
动图演示点这里!!!
1.1 前序遍历二叉树
前序遍历:先根 再左 再右
void BinaryTreePrevOrder(BTNode* root)
{if (root == NULL){printf("N ");return;}printf("%c ", root->data);BinaryTreePrevOrder(root->lchild);BinaryTreePrevOrder(root->rchild);
}
1.2 中序遍历二叉树
中序遍历:先左 再根 再右
void BinaryTreeInOrder(BTNode* root)
{if (root == NULL){printf("N ");return;}BinaryTreeInOrder(root->lchild);printf("%c ", root->data);BinaryTreeInOrder(root->rchild);
}
1.3 后序遍历二叉树
后序遍历:先左 再右 再根
void BinaryTreePostOrder(BTNode* root)
{if (root == NULL){printf("N ");return;}BinaryTreePostOrder(root->lchild);BinaryTreePostOrder(root->rchild);printf("%c ", root->data);
}
1.4 层序遍历二叉树
从上到下从左往右依次遍历
我们发现层序遍历的特点是根据根、左、右的顺序遍历每个结点。于是我们想到让根结点入队列,出队列时再将该节点的左右孩子依次入队列,直到队列为空则层序遍历结束。
队列结点及各接口函数定义
void BinaryTreeLevelOrder(BTNode* root)
{if (root == NULL){printf("N ");return;}Queue* qu = (Queue*)malloc(sizeof(Queue));QueueInit(qu);QueuePush(qu, root);while (!QueueEmpty(qu)){BTNode* ret = QueueFront(qu);if (ret){printf("%c ", ret->data);QueuePush(qu, ret->lchild);QueuePush(qu, ret->rchild);}elseprintf("N ");QueuePop(qu);}QueueDestroy(qu);free(qu);printf("\n");
}
2. 通过前序遍历的数组构建二叉树
给定前序数组(其中空节点用
#表示),通过前序递归开辟并连接结点。
BTNode* BTBuyNode(TElemType x)
{BTNode* ret = (BTNode*)malloc(sizeof(BTNode));if (!ret){perror("malloc fail");return NULL;}ret->lchild = NULL;ret->rchild = NULL;ret->data = x;return ret;
}BTNode* BinaryTreeCreate(TElemType* a, int n, int* pi)
{if (*pi == n){return NULL;}if (a[*pi] == '#'){(*pi)++;return NULL;}BTNode* root = BTBuyNode(a[*pi]);(*pi)++;root->lchild = BinaryTreeCreate(a, n, pi);root->rchild = BinaryTreeCreate(a, n, pi);return root;
}
3. 二叉树结点个数
int BinaryTreeSize(BTNode* root)
{return root == NULL ? 0 : BinaryTreeSize(root->lchild) +BinaryTreeSize(root->rchild) + 1;
}
4. 二叉树叶子结点个数
int BinaryTreeLeafSize(BTNode* root)
{if (root == NULL){return 0;}if (root->lchild == NULL && root->rchild == NULL){return 1;}return BinaryTreeLeafSize(root->lchild) +BinaryTreeLeafSize(root->rchild);
}
5. 二叉树第k层结点个数
int BinaryTreeLevelKSize(BTNode* root, int k)
{if (root == NULL){return 0;}if (k == 1){return 1;}return BinaryTreeLevelKSize(root->lchild, k - 1) +BinaryTreeLevelKSize(root->rchild, k - 1);
}
6. 二叉树查找值为x的结点
BTNode* BinaryTreeFind(BTNode* root, TElemType x)
{if (root == NULL){return NULL;}if (root->data == x){return root;}BTNode* l = BinaryTreeFind(root->lchild, x);if (l){return l;}BTNode* r = BinaryTreeFind(root->rchild, x);if (r){return r;}return NULL;
}7. 二叉树的深度
int BinaryTreeMaxDepth(BTNode* root) {if (root == NULL)return 0;int l = BinaryTreeMaxDepth(root->lchild);int r = BinaryTreeMaxDepth(root->rchild);return l > r ? l + 1 : r + 1;
}
8. 判断二叉树是否是完全二叉树
通过层序遍历的方式找到第一个空节点,如果后面还有非空结点就不是完全二叉树,否则为完全二叉树。
bool BinaryTreeComplete(BTNode* root)
{if (root == NULL)return true;Queue* qu = (Queue*)malloc(sizeof(Queue));QueueInit(qu);QueuePush(qu, root);while (!QueueEmpty(qu)){BTNode* ret = QueueFront(qu);QueuePop(qu);if (ret){QueuePush(qu, ret->lchild);QueuePush(qu, ret->rchild);}elsebreak;}int result = true;while (!QueueEmpty(qu)){BTNode* ret = QueueFront(qu);if (ret){result = false;break;}QueuePop(qu);}QueueDestroy(qu);free(qu);return result;
}
9. 二叉树的销毁
void BinaryTreeDestory(BTNode* root)
{if (root == NULL){return;}BinaryTreeDestory(root->lchild);BinaryTreeDestory(root->rchild);free(root);
}
相关文章:

树、二叉树(C语言版)详解
🍕博客主页:️自信不孤单 🍬文章专栏:数据结构与算法 🍚代码仓库:破浪晓梦 🍭欢迎关注:欢迎大家点赞收藏关注 文章目录 🍊树的概念及结构1. 树的概念2. 树的相关概念3.树…...
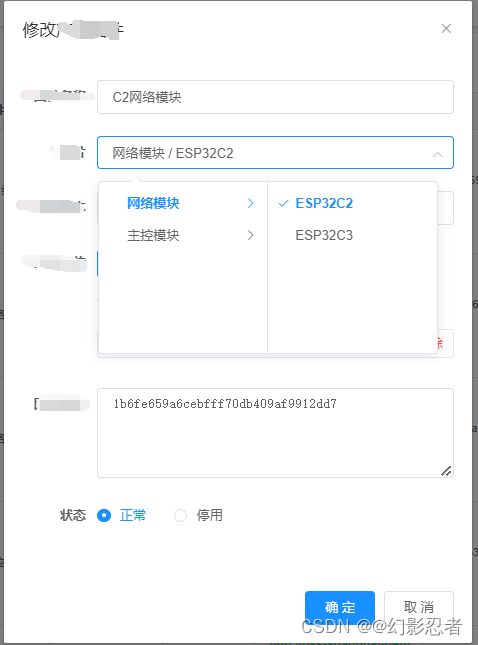
vue中Cascader 级联选择器实现-修改实现
vue 的cascader研究了好长时间,看了官网给的示例,上网查找了好多信息,才解决修改时回显的问题,现将方法总结如下: vue代码: <el-form-item label"芯片" prop"firmware"> <…...

C语言实现三子棋游戏
test.c源文件 - 三子棋游戏测试 game.h头文件 - 三子棋游戏函数的声明 game.c源文件 - 三子棋游戏函数的实现 主函数源文件: #define _CRT_SECURE_NO_WARNINGS 1#include"game.h" //自己定义的用"" void menu() {printf("*************…...
机器学习深度学习——softmax回归从零开始实现
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——向量求导问题 📚订阅专栏:机器学习&&深度学习 希望文章对你们有所帮助 …...

Windows如何安装Django及如何创建项目
目录 1、Windows安装Django--pip命令行 2、创建项目 2.1、终端创建项目 2.2、在Pycharm中创建项目 2.3、二者创建的项目有何不同 2.4、项目目录说明 1、Windows安装Django--pip命令行 安装Django有两种方式: pip命令行【推荐--简单】手动安装【稍微复杂一丢丢…...
)
在CSDN学Golang云原生(监控解决方案Prometheus)
一,记录规则配置 在golang云原生中,通常使用日志库记录应用程序的日志。其中比较常见的有logrus、zap等日志库。这些库一般支持自定义的输出格式和级别,可以根据需要进行配置。 对于云原生应用程序,我们通常会采用容器化技术将其…...
双重for循环优化
项目中有段代码逻辑是个双重for循环,发现数据量大的时候,直接导致数据接口响应超时,这里记录下不断优化的过程,算是抛砖引玉吧~ Talk is cheap,show me your code! 双重for循环优化 1、数据准备2、原始双重for循环3、…...
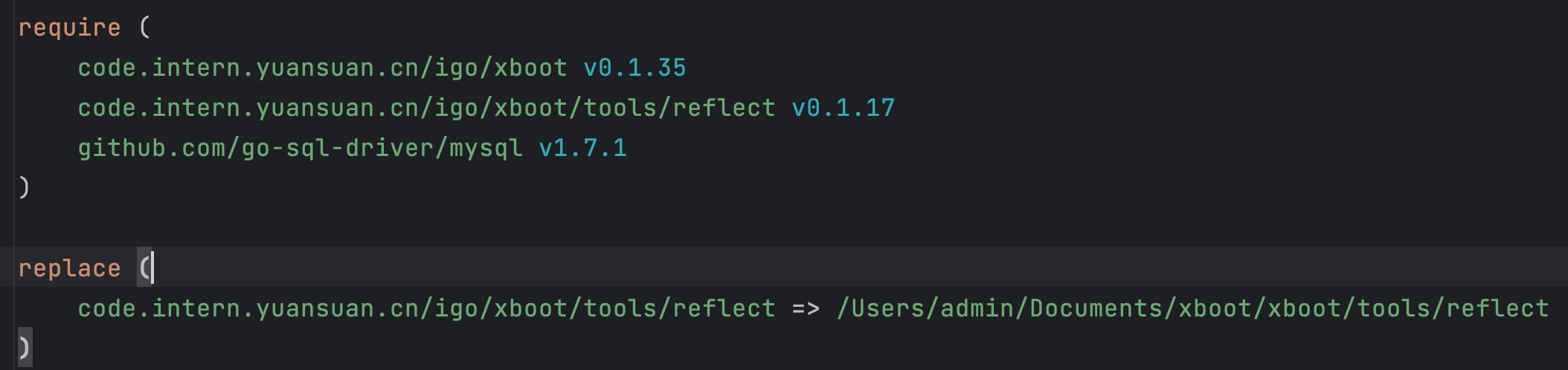
golang利用go mod巧妙替换使用本地项目的包
问题 拉了两个项目下来,其中一个项目依赖另一个项目,因为改动了被依赖的项目,想重新导入测试一下。 解决办法 go.mod文件的require中想要被代替的包名在replace中进行一个替换,注意:用来替换的需要用绝对路径…...

使用 docker 一键部署 MySQL
目录 1. 前期准备 2. 导入镜像 3. 创建部署脚本文件 4. MySQL 服务器配置文件模板 5. 执行脚本创建容器 6. 后续工作 7. 基本维护 1. 前期准备 新部署前可以从仓库(repository)下载 MySQL 镜像,或者从已有部署中的镜像生成文件&#x…...

MyBatis-Plus 查询PostgreSQL数据库jsonb类型保持原格式
文章目录 前言数据库问题背景后端返回实体对象前端 实现后端返回List<Map<String, Object>>前端 前言 在这篇文章,我们保存了数据库的jsonb类型:MyBatis-Plus 实现PostgreSQL数据库jsonb类型的保存与查询 这篇文章介绍了模糊查询json/json…...

Linux操作系统1-命令篇
不同领域的主流操作系统 桌面操作系统 Windos Mac os Linux服务器操作系统 Unix Linux(免费、稳定、占有率高) Windows Server移动设备操作系统 Android(基于Linux,开源) ios嵌入式操作系统 Linux(机顶盒、路由器、交换机) Linux 特点:免费、开源、多用户、多任务…...
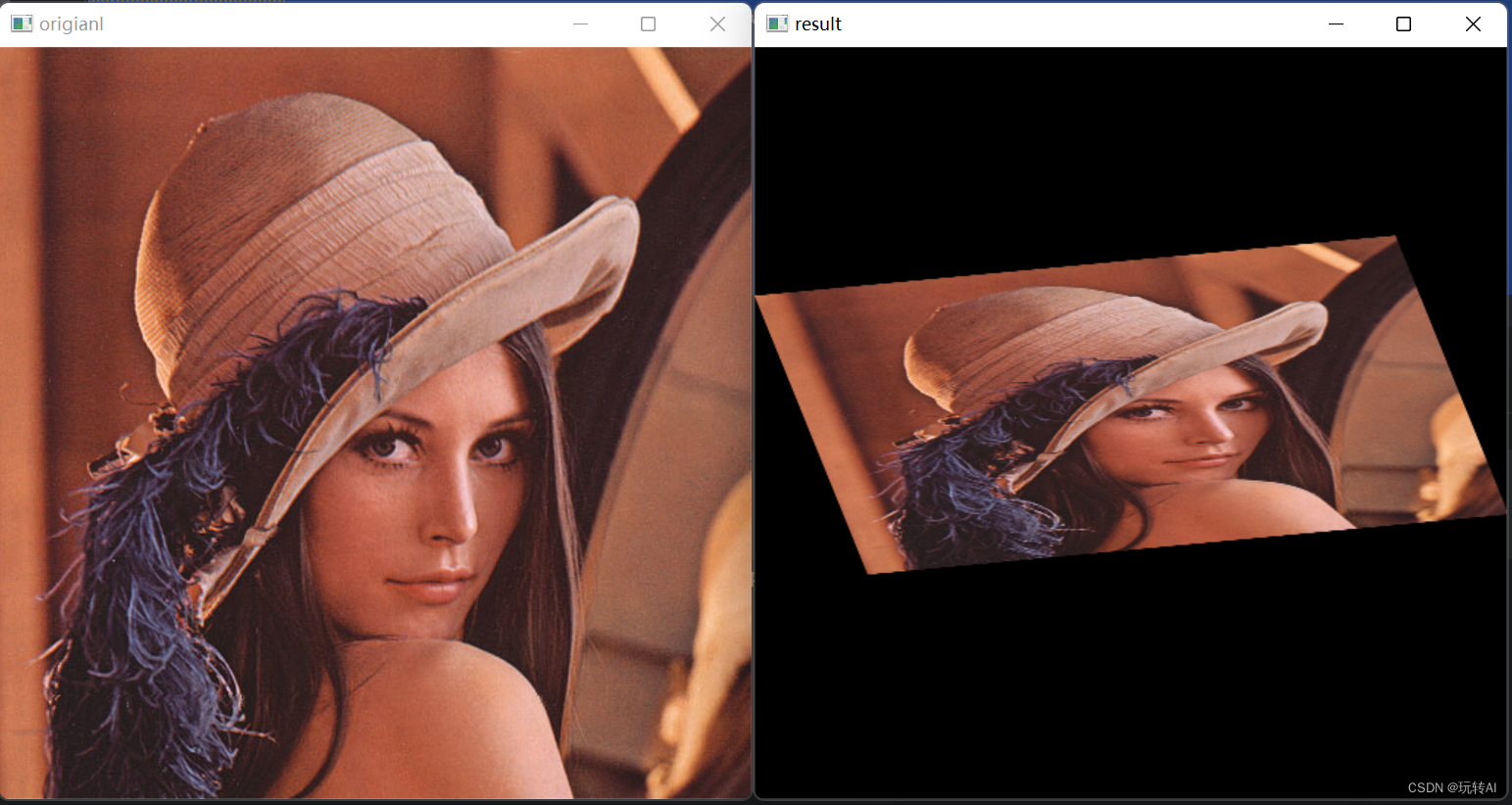
opencv-24 图像几何变换03-仿射-cv2.warpAffine()
什么是仿射? 仿射变换是指图像可以通过一系列的几何变换来实现平移、旋转等多种操作。该变换能够 保持图像的平直性和平行性。平直性是指图像经过仿射变换后,直线仍然是直线;平行性是指 图像在完成仿射变换后,平行线仍然是平行线。…...

前端常用的条件限制方法小笔记
手机号的正则表达式(以1开头的11位数字) function checkPhone(){ var phone document.getElementById(phone).value;if(!(/^1[3456789]\d{9}$/.test(phone))){ alert("手机号码有误,请重填"); return false; } }限制输入大于0且最小值要小于最大值 c…...

【LeetCode 算法】Minimum Operations to Halve Array Sum 将数组和减半的最少操作次数-Greedy
文章目录 Minimum Operations to Halve Array Sum 将数组和减半的最少操作次数问题描述:分析代码TLE优先队列 Tag Minimum Operations to Halve Array Sum 将数组和减半的最少操作次数 问题描述: 给你一个正整数数组 nums 。每一次操作中,你…...

Doc as Code (3):业内人士的观点
作者 | Anne-Sophie Lardet 在技术传播国际会议十周年之际,Fluid Topics 的认证技术传播者和功能顾问 Gaspard上台探讨了“docOps 作为实现Doc as Code的中间结构”的概念。在他的演讲中,观众提出了几个问题,我们想分享Gaspard的见解&#x…...
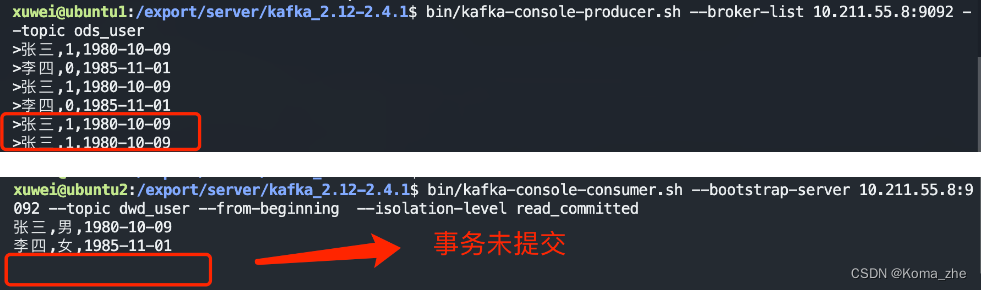
【Kafka】消息队列Kafka基础
目录 消息队列简介消息队列的应用场景异步处理系统解耦流量削峰日志处理 消息队列的两种模式点对点模式发布订阅模式 Kafka简介及应用场景Kafka比较其他MQ的优势Kafka目录结构搭建Kafka集群编写Kafka一键启动/关闭脚本 Kafka基础操作创建topic生产消息到Kafka从Kafka消费消息使…...
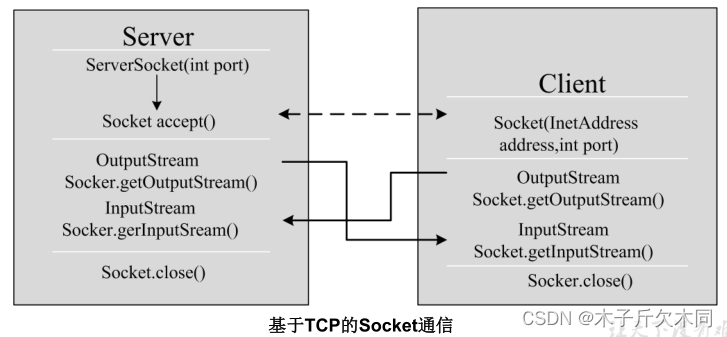
Java的第十五篇文章——网络编程(后期再学一遍)
目录 学习目的 1. 对象的序列化 1.1 ObjectOutputStream 对象的序列化 1.2 ObjectInputStream 对象的反序列化 2. 软件结构 2.1 网络通信协议 2.1.1 TCP/IP协议参考模型 2.1.2 TCP与UDP协议 2.2 网络编程三要素 2.3 端口号 3. InetAddress类 4. Socket 5. TCP网络…...

【深度学习】High-Resolution Image Synthesis with Latent Diffusion Models,论文
13 Apr 2022 论文:https://arxiv.org/abs/2112.10752 代码:https://github.com/CompVis/latent-diffusion 文章目录 PS基本概念运作原理 AbstractIntroductionRelated WorkMethodPerceptual Image CompressionLatent Diffusion Models Conditioning Mec…...

前端学习——Vue (Day6)
路由进阶 路由的封装抽离 //main.jsimport Vue from vue import App from ./App.vue import router from ./router/index// 路由的使用步骤 5 2 // 5个基础步骤 // 1. 下载 v3.6.5 // 2. 引入 // 3. 安装注册 Vue.use(Vue插件) // 4. 创建路由对象 // 5. 注入到new Vue中&…...
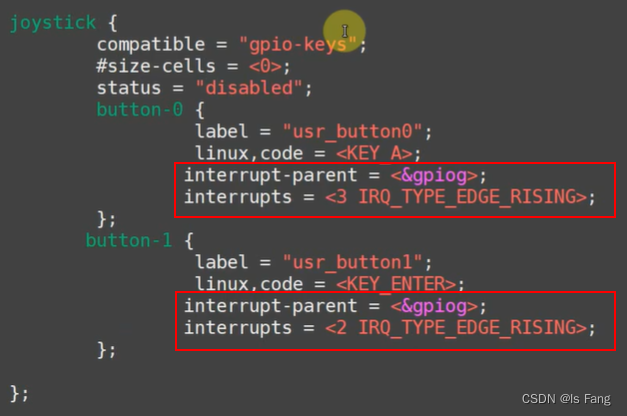
STM32MP157驱动开发——按键驱动(tasklet)
文章目录 “tasklet”机制:内核函数定义 tasklet使能/ 禁止 tasklet调度 tasklet删除 tasklet tasklet软中断方式的按键驱动程序(stm32mp157)tasklet使用方法:button_test.cgpio_key_drv.cMakefile修改设备树文件编译测试 “tasklet”机制: …...

如何在3分钟内精准定位Windows热键冲突:Hotkey Detective终极指南
如何在3分钟内精准定位Windows热键冲突:Hotkey Detective终极指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective …...
:输入你的GPU型号/任务类型/预算,3步锁定最优解)
DeepSeek模型版本选择终极决策树(2024Q3权威更新):输入你的GPU型号/任务类型/预算,3步锁定最优解
更多请点击: https://codechina.net 第一章:DeepSeek模型版本选择终极决策树(2024Q3权威更新):输入你的GPU型号/任务类型/预算,3步锁定最优解 选择适配的 DeepSeek 模型版本是高效落地大模型应用的关键前提…...

SVM与逻辑回归:从线性分类到核方法的原理、对比与实践指南
1. 项目概述:从线性分类到非线性世界的两把钥匙在机器学习的工具箱里,支持向量机(SVM)和逻辑回归(LR)是两把经久不衰的“瑞士军刀”。它们都源于线性模型,却通过不同的哲学路径,解决…...

Kubernetes多集群管理策略:统一管理多个K8s集群
Kubernetes多集群管理策略:统一管理多个K8s集群 一、多集群管理概述 Kubernetes多集群管理是指在企业环境中管理多个独立的Kubernetes集群,实现统一的部署、监控和运维。 1.1 多集群场景 场景说明示例地域隔离不同区域部署独立集群北京、上海、广州各…...

开源AI工具真能替代商业方案?2024最新Benchmark数据揭示92%团队忽略的关键短板
更多请点击: https://codechina.net 第一章:开源AI工具真能替代商业方案?2024最新Benchmark数据揭示92%团队忽略的关键短板 2024年Q2由MLPerf与OpenLLM-Bench联合发布的跨模态AI工具基准报告覆盖全球147个生产级AI部署团队,结果显…...

终极指南:如何用roop-unleashed三分钟制作专业AI换脸视频
终极指南:如何用roop-unleashed三分钟制作专业AI换脸视频 【免费下载链接】roop-unleashed Evolved Fork of roop with Web Server and lots of additions 项目地址: https://gitcode.com/gh_mirrors/ro/roop-unleashed 你是否曾梦想过轻松制作专业级的AI换脸…...

毫米波雷达非接触生命体征监测技术解密:从8.6米远距探测到医疗级精准分析
毫米波雷达非接触生命体征监测技术解密:从8.6米远距探测到医疗级精准分析 【免费下载链接】mmVital-Signs mmVital-Signs project aims at vital signs detection and provide standard python API from Texas Instrument (TI) mmWave hardware, such as xWR14xx, x…...

3大技术突破:html-to-docx如何解决HTML转Word格式失真难题
3大技术突破:html-to-docx如何解决HTML转Word格式失真难题 【免费下载链接】html-to-docx HTML to DOCX converter 项目地址: https://gitcode.com/gh_mirrors/ht/html-to-docx html-to-docx是一款专为解决HTML到Word文档转换领域格式失真问题而设计的开源工…...

惠普OMEN游戏本性能控制终极指南:5分钟解锁风扇调速与功耗限制
惠普OMEN游戏本性能控制终极指南:5分钟解锁风扇调速与功耗限制 【免费下载链接】OmenSuperHub Control Omen laptop performance, fan speeds, and keyboard lighting, and unlock power limits. 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub …...
)
Sora 2视频音频不同步?深度解析OpenAI未公开的时间戳嵌入机制,3分钟强制同步方案(含Python自动校准工具)
更多请点击: https://codechina.net 第一章:Sora 2视频音频不同步现象的系统性归因 视频与音频流在 Sora 2 模型推理及播放阶段出现时间偏移,是影响用户体验的关键缺陷。该现象并非单一环节导致,而是由多层级时序建模、硬件调度、…...