mysql常用操作命令
mysql常用操作命令
mysql:单进程多线程模型,一个SQL语句无法利用多个cpu core
一:基本命令
0.查看当前连接数
show global status like 'Thread$';
show variables like "%timeout%";
show variables like "log_%";
1.查看当前连接状态
show processlist;
2.数据库连接
mysql -h 主机名 -u root -ppassword
3.添加用户
insert into user (host,user,password,select_priv,insert_priv,update_priv) values ('localhost','guest',password('guest123'),'Y','Y','Y');
4.创建用户
create user 'username'@'host' identified by 'password';
create user 'username'@'%' identified by 'password';
#新创建用户无法登陆问题?
use mysql;
delete from user where user='';
flush privileges;# 对db_name下所有表都有查询(SELECT)权限
grant select on db_name.* to 'username'@'%';# 对所有表有全部权限
grant all on *.* to 'username'@'%';
5.删除用户
drop user 'username'@'host';
6.修改用户密码
set password for 'username'@'host' = password('123password');
update user set password=password("你的新密码") where user="root";
7.创建数据库病设置字符集和排序规则
create database data_name;
create database data_name character set utf8 collate utf8_general_ci;
8.删除数据库
drop database data_name;
二:操作命令
1.删除表
SELECT concat('DROP TABLE IF EXISTS ', table_name, ';')FROM information_schema.tablesWHERE table_schema = 'mydb';
# 或者
drop table table_name;
2.显示表属性
desc user_table;
show columns from user_table;
3.显示数据表的索引信息
show index from user_table;
4.显示数据库所有以run开头的表信息
show table status like'run%';
5.创建表,engine=指定存储引擎,每张表都可以指定存储引擎
# CREATE TABLE IF NOT EXISTS `table_test`(
CREATE TABLE `table_test`(`t_id` INT UNSIGNED AUTO_INCREMENT,`t_title` VARCHAR(100) NOT NULL,`t_author` VARCHAR(40) NOT NULL,`sub_date` DATE,PRIMARY KEY(`t_id`)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
6.插入数据
insert into table_name(field1,field2,field3,field4) values(value1,value2,value3,value4);
7.更改字段类型
alter table system_info modify column ip varchar(100) ;
8.更改字段为非空
alter table system_info alter column ip set not null;
9.添加字段
alter table system_info add email varchar(30);
10.删除字段
alter table system_info drop column email;
11.字段改名
alter table system_info rename email to new_email;
12.清空表或删除记录
/* 清空表记录三种方式 */
# 1. delete
delete from table_name; 或 delete from table_name where id=1;
# 删除select记录报错:mysql不允许对同一个表同时进行查询和更新
# 解决方案:对查询结果生产一个派生表,对派生表查询
delete from table_user where id in (select id from (select id from table_user where sex is null) as tmp);# 2.truncate
truncate table_name # 3.use information_schema 清空所有表记录
select table_name,table_schema from information_schema.tables where table_schema='alphacapture_bigai'
select table_name,table_schema from information_schema.tables where table_schema like '%alphacapture_bigai%'
select concat('truncate table',table_schema,'.',table_name,';') from information_schema.tables where table_schema in ('数据库1','数据库2')
13.插入记录
insert into table_name(field1,field2,field3) values(value1,value2,value3);
1.更新记录
update table_name set field2="张三" where id =3;``
15.修改表名
alter table table_name rename to new_table_name;
16.模糊查询,%表示任意字符
select * from Student where name like "%三%"
17.多条件查询and,or
select * from Sudent where age between 18 and 50;
select * from Student where age >18 and age <60 and address='上海'
18.去重
select distinct address from Student;
19.排序:asc升序,desc倒序
select * from Student order by age desc;
20.查询上做计算
select age*3 name from Student;
21.最大max,最小min,平均avg,求和sum,个数count
select count(id) from Student;
22.分组查询 group by 将某一列相同数据视为一组
#使用了group by,select后只能跟分组列和聚合函数
#查询人数大于3的地区的最大年龄
select address,max(age) from Student group by address having count(*)>3;
23.分页
select * from Student limit 3,5; # 从第三条记录,查询五条
select * from Student limit (n-1)*m,m; # 第n也查询m条记录
24.join连表查询 on 条件
select Sites.id,Sites.name,Log.count,Log.date from Sites inner join Log on Sites.id=Log.site_id;
24.查看表占用磁盘空间大小,M单位
# 查看单个表
select concat(round(sum(DATA_LENGTH/1024/1024),2),'M') as table_size from information_schema.tables where table_schema='csjdemo' AND table_name='demo2';
SELECT (`DATA_LENGTH`+ `INDEX_LENGTH`)/1024/1024 as `table_data_size` from `TABLES` WHERE TABLE_NAME ='tableName' and TABLE_SCHEMA='dbName';
#查看数据库
SELECT (sum(`DATA_LENGTH`) +sum(`INDEX_LENGTH`))/1024/1024 as `db_data_size` from `TABLES` where `TABLE_SCHEMA`='dbName';
25.创建主键primary三种方式
create table table_name(uid INT PRIMARY KEY,uname VARCHAR(10),
)
create table table_name(uid INT,uname VARCHAR(10),PRIMARY KEY(uid), # 或者PRIMARY KEY(uid,uname)联合主键
)
alter table table_name add PRIAMRY KEY(udi); # 添加主键约束
alter table table_name drop PRIMARY KEY; # 删除主键约束
26.创建唯一索引三种方式
create table table_name(uid INT,uname VARCHAR(10),UNIQUE []
)
alter table table_name unique index(filed_name,filed_name)
create UNIQUE INDEX indexName on table_name(filed_name,filed_name)
三: 复制,导入导出数据
1.复制n条记录并创建
INSERT into reyo (num,overtime) SELECT num,overtime from reyo where id IN(1,3,5,6,7,9);
INSERT into reyo (`num`,`overtime`) SELECT `num`,`overtime` from reyo where id IN(1,3,5,6,7,9);
2.导出整个数据库
mysqldump -u root -p dbname>dbname.sql
3.导出表 show variables like '%secure%'查看安全目录
mysqldump -u root -p dbname users>dbname_users.sql
SELECT * FROM runoob_tbl INTO OUTFILE '/var/lib/mysql-files/Dbug_manangement.txt';
SELECT * FROM users INTO OUTFILE '/var/lib/mysql-files/users.sql';
4.导入备份的整个数据库
mysql -u root -p < Detector.sql # 需要再sql文件创建或指定数据库
mysql>source /home/abc/abc.sql # 进入数据库下use Detector
5.插入数据到某个表
load data local infile "/var/lib/mysql-files/CaseUrl.sql" into table CaseUrl;
load data local infile "/var/lib/mysql-files/CaseUrl.sql" into table CaseUrl
(id,name, url, status_code, result, processresult, proposal,@create_time,test_time,case_id) FIELDS TERMINATED BY ', '
set create_time=DATE_FORMAT(@create_time,"%Y-%m-%d %H:%i:%s")
四:mysql性能优化(四个维度:1.架构,2.硬件,3.DB优化,4.sql优化)
-
架构:集群读写分离,数据库切分
-
硬件:高效的磁盘读写性能
-
DB:参数优化(日志不能笑,缓存足够大,连接够用)
-
my.ini或my.cnf配置文件:
- sort/join/read/rnd buffer:4M或8M或16M
- tmp/heap table:96M或128M
- innodb_flush_log_at_trx_commit:对redo日志刷盘频率的设定
0:缓冲区的redo log会每秒写入到磁盘的日志文件。但每次事务提交不会有任何影响,也就是 log buffer 的刷写操作和事务提交操作没有关系。在这种情况下,MySQL性能最好,但如果 mysqld 进程崩溃,通常会导致最后 1s 的日志丢失。
1:每次事务提交时,缓冲区redo log保证一定会被写入到磁盘的日志文件。这也是默认值。这是最安全的配置,但由于每次事务都需要进行磁盘I/O,所以也最慢。
2:每次事务提交时,缓冲区redo log异步写入(不保证)到磁盘的日志文件。这时如果 mysqld 进程崩溃,由于日志已经写入到系统缓存,所以并不会丢失数据;在操作系统崩溃的情况下,通常会导致最后 1s 的日志丢失。
sync_binlog:binlog刷盘的频率 - (保证主库和主从库的一致性:innodb_flush_log_at_trx_commit和sync_binlog都设置为1)
- interactive_timeout:交互模式下超时时间,五分钟或十分钟
- lock_wait_timeout:表锁锁定时间
- time_zone:使用datetime减少性能消耗
- wait_timeout:程序连接mysql超时时间,五分钟或十分钟
- innodb_buffer_pool_size:缓冲池大小(越大,磁盘I/O减少)2个G左右
- innodb_buffer_pool_instances:配置多个缓冲池实例
- tmp_table_size:临时表的最大大小
-
-
sql优化
https://www.zhihu.com/question/486105337/answer/2538190061
explain检查sql语句定位优化点或开启慢查询定位优化点
优化方向:(避免不要的列|分页优化|索引优化|JOIN优化|排序优化|union优化)1. 避免不要的列- 避免使用select *- 多用limit- 选择合理的字段类型2. 分页优化(数据量较大)- 延迟关联- 书签方式3. 索引优化- 合理使用索引(一个表索引不超过5个),避免索引失效- 利用覆盖索引- 正确使用联合索引- 避免索引失效情况4. JOIN优化- join表不宜过多(不超过5个)- 小表驱动大表- 用连接查询代替子查询5. 排序优化- 利用索引排序6. union优化- 使用UNION ALL(不去重,所有数据)替代UNION(去重)
索引失效情况:
(1)联合索引不满足最左匹配原则,联合索引最左边字段必须出现在查询条件中
(2)错误使用like,以%开头如 like ‘%abc’,(当like以%结尾索引有效)
(3)错误使用or,or两边字段有一个没有创建索引(where id=2 or name=“Tom”)或两边为范围查询(where id>10 or id<20),导致失效
(4)索引列参与运算, 如where id-1=10 或使用了函数 where SUBSTR(id_no,1,3)=100
(5)类型隐式转换,where条件上进行了类型转换,比如字段是字符串类型,却填上了数字
(6)两列做比较,即使两列都有索引,也会失效 where id>age
(7)不等于比较,where name!=“Tom” 或 where id<>“11” 有可能不走索引,查询结果集较小货走索引否则不走索引
(8)非空判断(is not null / is null / not in / in / exists / not exists/ )
使用where id_no is not null不走索引,is null走索引
使用not exists 不走索引
使用where id not in (2,3)普通索引则失效,主键走索引
(9)当mysql估计全表扫描速度比索引速度快的时候不会使用索引(order by就是如果是select *则有大量回表,索引不走索引,走全表扫描到内存去排序)
五:索引详解
操作系统和内存:最小单位是页page
操作系统和磁盘:最小单位是块block
磁盘I/O:文件系统每次读取一块(默认4K)单位大小到内存
mysql:存储数据以页(page默认16k)为单位,mysql读取一页页读取
1.索引演化史?
二叉查找树->AVL平衡二叉树->B-Tree(多路平衡查找树)->B+Tree:
B-Tree:多路平衡查找树,每个节点包含多对(父节点指针,子节点指针,键key,值data),相比于AVL缩减了节点数,减少了树的高度
B+Tree:1.非叶子节点(双向链表)只存储键值+叶子节点指针,2.值data顺序存在同一层的叶子节点上,相比于B-Tree每个节点能存储更多的key减少了树的高度和磁盘I/O次数,3.叶子节点之间有指针,链表支持范围查找
通过非叶子节点的二分查找以及指针确定数据在哪个页中,进而去数据页查找数据
一般高度为1-3:叶子节点16k(一条数据一般1k)存16条数据,非叶子节点存1170个指针=1170117016=21902400**
2.什么是索引?
对一列或多列值进行排序的数据结构(类似目录排序好了的,在小文件查找)
3.mysql有哪些索引?那些字段可以建立对应索引?
普通索引
主键索引(聚簇索引,唯一索引unique唯一且不为NULL),
复合索引(最多包含16列:where多条件最左原则):可用于包含所有列或第一列,前两列,前三列…等,blob和text也能创建索引, 但是必须指定前面多少位
全文索引(char、varchar,text 列上可以创建全文索引,一般不使用,不是mysql专长)
唯一索引(innodb不是聚簇索引),
空间索引(对空间数据类型字段建立索引,mysql有四种:GEOMETRY,POINT,LINESTRING,POLYGON)
4.聚集索引和非聚集索引区别?
都是B+Tree数据结构
聚簇索引:叶子节点存储索引和数据,找到索引就找到数据(其他为辅助索引,存储索引id,没有去覆盖索引的话要回表查找主键索引找到数据)。
非聚簇索引:叶子节点存储索引和数据行的地址,根据索引找到数据行的位置在去磁盘取出数据。
5.什么是回表?
通过非主键索引查询,select所获取的字段不能通过非主键索引获取到,需要回表查询主键索引。
6.覆盖索引,非覆盖索引?
覆盖索引:所查的字段在当前索引叶子节点上存在,不用回表,直接作为结果返回
7.什么是索引下推?
where多条件判断,对索引中包含的字段先做判断,再去回表没有索引的字段(减少回表次数)
8.什么情况下不推荐使用索引?
目的是:索引是为了查询更快,占用空间更小
1.数据唯一性差(比如性别只有两种数据)
2.频繁更新的字段不用索引
3.不用无序的的值如身份证,uuid无序不能作为索引
4.字段不在where语句后出现(where含IS NULL/IS NULL/IS NOT NULL/like "%"等,不用索引)
5.过长的字段使用前缀索引
6.参与计算的字段不适合建立索引那些情况适合建立索引?
- 频繁作为where条件语句查询的字段
- 关联字段需要建立索引,例如外键字段,student表中的classid, classes表中的schoolid 等
- 排序字段可以建立索引
六:InnoDB和MyISAM区别
MyISAM:不支持事务,支持表级别锁(限制了读/写的性能),拥有较高的插入和查询速度,B+的非聚簇索引,通常用于只读或以读为主的场景.
怎么快速向数据库插入100万条数据?先用MyISAM插入数据,然后修改存储引擎为InnoDB
InnoDB:支持事务,支持行/表级别锁,/外键(数据的完整性和一致性更高),采用B+的聚簇索引,通常用于经常更新的场景.
1.InnoDB和MyISAM索引区别
InnoBD主键索引采用B+的聚簇索引:
每个InnoDB表都有且只有一个特殊的索引,称为聚簇索引 ,用于存储行数据。通常,聚簇索引与主键同义 。
1. 表定义了主键,则pk就是聚集索引2. 没有定义主键,第一个非空唯一索引列就是聚集索引3. 否则,InnoDB会创建一个隐藏的row-id作为聚集索引MyISAM索引采用B+的非聚簇索引:
不存储全部数据,只存储数据行的地址
七:mysql预编译(sql执行前会进行解析和校验),参数带入
益处:加快执行速度,防止sql注入
场景:SQL语句一样,参数不一样,可以对SQL语句预编译
sql语句执行流程:
连接层(处理连接/鉴权/安全管理)->服务层(系统管理/sql接口/缓存/解析/预处理/优化)->引擎层(具体与文件系统打交道)->存储层
sql语句->查询缓存(默认关闭不推荐使用,sql语句必须相同,且表数据表动大)->语法解析预处理器(检查是否有语法错误)->优化器->执行器
语法:prepare name from statement;
- 定义:prepare statement_1 from ‘select * from user where id=?’; # 通过?进行占位
- 参数:set @id=2;
- 执行.execute statement_1 using @id;
怎么预防sql注入?
- 不信任用户提交的数据(参数过滤,严格检查参数类型,转义,限制长度)
- .mysql预编译(参数化查询,变量绑定)
八:mysql 事务(不在分割的操作集合)acid实现原理
1.ACID?:
原子性(Atomicity):(undo log回滚日志实现)指一个事务不可分割,是一个最小的操作单元(包含若干个操作),要么全部成功,要么全部失败
隔离性(Isolation):(锁和mvcc实现)多个事务并发执行,事务之间相互隔离
持久性(Durability):(redo log实现)InnoDB提供了一个缓存Buffer,读取和写入都先在Buffer中(并同时把操作记录到redo log,防止数据丢失)
一致性(Consistency):数据处于合法状态(满足预定约束就是合法)
从数据库层面,数据库通过原子性、隔离性、持久性来保证一致性。也就是说ACID四大特性之中,C(一致性)是目的,A(原子性)、I(隔离性)、D(持久性)是手段,是为了保证一致性,数据库提供的手段。数据库必须要实现AID三大特性,才有可能实现一致性。
从应用层面,通过代码判断数据库数据是否有效,然后决定回滚还是提交数据。Innodb如何实现事务的?
以update为例
(1).开启事务,Innodb根据接受的update语句,找到数据所在页,并加该页缓存在Buffer pool(change buffer)中
(2).执行update,修改Buffer pool中数据
(3).记录 undo log日志(便于事务回滚和mvcc)并写入Log Buffer中并关联redo log(可刷盘)
(4).记录 redo log(prepare状态)日志(便于断电恢复数据)并写入Log Buffer中(可刷盘)
(5).记录bin log(数据表结构变更日志:用于主从复制和数据库恢复)
(6-1).事务提交,redo log(改为commit状态),可触发redo log刷盘机制
(6-2).事务回滚,则利用undo log日志进行回滚
3.mysql有几种日志?
bin log(记录sql),redo log(),undo log,slog log,一般日志
4.mysql日志是否实时写入磁盘?(log buffer)
bin log:
sync_binlog=0:每次提交事务后不会马上写入到磁盘,先写到page cache,由操作系统决定写入什么时候写入磁盘(有丢失事务日志的风险)
sync_binlog=1:每次提交事务都会执行fsync写入磁盘(强一致性,性能较低)
sync_binlog=n:每次提交事务,先写到page cache,积累n个事务才fsync到磁盘(有丢失n个事务日志的风险)
redo log()和undo log:
innodb_flush_log_at_trx_commit=0:每秒(log buffer中提交的事务)写入磁盘,系统并调用fsync写入磁盘(可能丢失一秒的数据)
innodb_flush_log_at_trx_commit=1:有事务提交立即调用fsync写入磁盘(不会丢失,性能差)
innodb_flush_log_at_trx_commit=2:有事务提交都写给操作系统的page cache,由操作系统决定什么时候调用fsync写入磁盘(一系列丢失)
5.binlog有几种录入格式?
STATEMENT:默认方式,基于SQL语句的复制记录sql语句,文件较小
ROW:基于行的复制,文件较大
MIXED:前两种混合
6.为什么将redo log的数据写到磁盘比将Buffer数据持久化到磁盘要快?
1.Buffer数据持久化是随机写I/O,redo log是追加,顺序IO
2.Buffer数据持久化是以页page为单位,redo log只需要写入的真正部分(减少了无效I/O)
7.bin log和redo log(两段提交)区别?
1.写入redo log(prepare状态)
2.写入bing log
3.提交事务,redo log(改为commit)
九:主从同步
Mysql主从复制中有三个线程:Master(binlog dump thread) Slave(I/O thread,SQL thread)
使用binlog+position偏移量进行增量同步
1.同步过程
1. Master所有变更都记录到binlog中去(MySQL Server层的实现)
1. 主节点binlog dump线程,当binlog有变动时,binlog dump线程读取内容并发送给从节点
1. 从节点I/O线程接收binlog,并写入到relay log(中继日志)中
1. 从节点SQL线程读取relay log并对数据进行重放
2.同步策略
- 同步策略:Master会等待所有的Slave回应后才提交(这个策略严重影响性能)
- 半同步策略:Master至少等待一个Slave回应后才提交
- 异步策略:Master不会等待Slave回应就可以提交(默认)
- 延迟策略:Slave落后Master指定的时间
十:mysql主从方案
mysql如何保证主从数据的一致性的?
分片中间件:myCat/shardingSphere
一主多从:缓解读压力
-
主服务配置mysql.cnf:
#主服务还需要创建对应权限的用户用于数据同步
log-bin=mysql-bin # 表示启用二进制文件-文件名称
server-id=3307 # 表示server编号 -
从服务执行sql命令
# 1.配置主服务
change master to master_host=“192.168.1.2”,master_port=3306,master_user=“copy”,master_password=“123456”,master_log_file=“mysql-bin.00001”,master_log_pos=154;
# 2.开启主从同步
start slave
# 3.查看是否成功
show slave status \G;
双主双从:缓解写压力
-
主1配置
log-bin=mysql-bin
server-id=3301
auto_increment_increment=2 # 主键递增步长
auto_increment_offset=1 # 从1开始
log-slave-updates # 是否记录binglog
sync-binlog=1 # 几次事务记录binlog
-
主2配置
log-bin=mysql-bin
server-id=3302
auto_increment_increment=2 # 主键递增步长
auto_increment_offset=2 # 从1开始
log-slave-updates # 是否记录binglog
sync-binlog=1 # 几次事务记录binlog
十一:主键方案(自增id/uuid/雪花算法)
https://www.zhihu.com/question/397289720
https://juejin.cn/post/7153273187366043661
三种方案:
1. 自增id
2. uuid: uuid导致页分裂,性能问题,存储空间较大
3. 雪花算法及其改进算法
分布式id实现方式:
uuid/单机数据库自增ID+步长/Redis自增ID/跳跃式自增ID/Snowflake及其改进算法
雪花算法(保证递增性):64位
1位:符号位
43位:时间戳
10位:机器id
12位:一个节点一毫秒产生ID的数量(4096)
十二:性能极限
mysql性能极限
mysql单表字段数:建议20-50
mysql默认单字段大小:
存储最大空间为1M,可以修改max_allowed_packet=16
mysql单表:
老版mysql3.22中,还是ISAM存储引擎,单表限制为4GB
之后为INNODB 单表限制64TB
数据库:
Cmshelp 团队做CMS 系统评测时的结果来看,
MySQL单表大约在2千万条记录(4G)下能够良好运行,
经过数据库的优化后5千万条记录(10G)下运行良好。
阿里巴巴《Java 开发手册》提出单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。
PostgreSQL性能极限
最大单个数据库大小:不限
最大数据单表大小:32TB
单条记录大小:1.6TB
单字段最大允许:1GB
单表允许最大记录数:不限
单表最大字段数:250-1600取决于字段类型
单表最大索引数:不限
十三 额外问题及思路
“Lost connection to MySQL server during query” ?
1网络延迟高
2.读/写:导致数据传输超时,net_read_timeout/net_write_timeout
3.连接初始化超时,connect_timeout 默认30s
4.传输中使用了较大的string field或blob field 导致超过了max_allowed_packet
https://blog.csdn.net/zyself/article/details/91376690
数据库的三大范?
为设计冗余小,结构合理的数据库,设计数据库时必须满足一定范式(规则)
一般设计都是反范式,通过冗余的数据避免跨表垮库查询,利用空间换时间,提高性能
第一范式:表中所有字段是不可分解的原子值
第二范式:表中每一列都和主键相关,而不能只与主键一部分相关(针对联合主键)(表中只保存一种数据,不可以把多种数据保存在同一个表中)
第三范式:确保每列都和主键直接相关而不是间接相关
varcahr和char区别?
char(最多存放255个字节)适用数据大小固定/较小/经常更新/不容易产生内存碎片:
1.长度固定,插入数据小于固定长度则用空格填充
2.存取速度比varchar快很多(甚至50%),空间换时间
varchar(最多存放65532个字节,等价于21845字符):
1.varchar=长度+N(实际长度n>255,用两个字节存放长度.小于255,用一个字节存放长度)
2.长度可变,按实际插入数据来存储()
3.填写2的n次方,varchar(8),varchar(64)
InnoDB表索引前缀长度为767字节,utf-8编码为255(255*3=765)
对text,只能添加前缀索引,前缀索引最大能达到1000字节
当varchar大于某些值:
varchar大于255自动变为tinytext
varchar大于500自动变为tinytext
varchar大于20000自动变为tinytext
当varchar>255,使用varchar或text没有区别
blob和text区别?
blob:二进制大对象(存储二进制数据,没有字符集)最大长度16k
text:大对象,存储大字符串,有字符集(根据字符集的校对规则对值进行排序比较)最大长度16k
DATETIME和TIMESTAMP区别?
都表示日期和时间,格式一致,存储秒后6位小数
区别
日期范围:DATETIME(1000-01-01到9999-12-31),TIMESTAMP(1970-01-01到2038-01-09)
存储空间:DATETIM为8字节,TIMESTAMP为4字节
时区:DATETIME与时区无关,TIMESTAMP与时区有关
默认值:DATETIME默认为null,TIMESTAMP默认为当前时间,不为空(not null)
in和exists的区别?
https://blog.csdn.net/jinjiniao1/article/details/92666614
DECIMAL记录货币?
float和double是二进制存储,有误差
decimal是字符串存储
怎么存储表情包emoji?
字符串存储utf-8+mb4编码
大量外键问题?
不影响select,影响update/insert/delete(当对子表进行写入操作,父表会被加上共享锁,对子表进行高并发时,父表的共享锁长时间不能释放,就不能对父表进行写入而只能读)
WAL技术(Write-Ahead Logging)RedoLog(对所有页面的操作写入日志文件,实现事务的持久性)
delete删除记录使用binlog回滚?
恢复数据时可以先备份,在停止所有写入操作:flush tables with read lock或 set global read_only=1同时配置文件里设置read_only防止重启失效
查看binglog是否开启
show variables like '%log_bin%';查看数据文件存放路径
show variables like '%datadir%'; show master status; # 查看当前正在写入的binlog show master logs; # 查看所有binlog show binary logs;查看binlog日志内容
show binlog events in 'mysql-bin.000001'\G; # 确定需要回滚的事务的position将需要恢复的事务里的操作转为sql
/opt/bitnami/mysql/bin/mysqlbinlog --no-defaults -v --database=database_name --start-position="966048" --stop-position="981142" /bitnami/mysql/data/mysql-bin.000007 > /tmp/mysqllog.sql将导出导出sql的delete转换为insert
```shellcat srliao.sql.bak| sed -n '/###/p' | sed 's/### //g;s/\/\*.*/,/g;s/DELETE FROM/;INSERT INTO/g;s/WHERE/SELECT/g;' |sed -r 's/(@17.*),/\1;/g' | sed 's/@1=//g'| sed 's/@[1-9]=/,/g' | sed 's/@[1-9][0-9]=/,/g' > mysqllogOK.sql```
执行insert sql
source /tmp/mysqllogOK.sql
大公司为什么不使用外键强关联问题?
主要存在以下问题
1.在该表进行增删改查会触发查询关联表的记录是否存在,该性能消耗系统是允许的
2.数据一致性全部交给数据库,数据库是否能承受
3.查询关联表上会做一个内部锁,是否存在高并发死锁情况
4.后期的分库分表,外键约束格外离谱
这些问题在互联网公司显得很严重,访问量大的时候,mysql系统上无法得到解决的
https://www.cnblogs.com/JethroYu/p/13570630.html
delete,truncate,drop有什么区别?
执行速度:drop>truncate>delete
1.delete
1.属于数据库DML操作语言,只删数据不删表结构,会走事务,执行时触发trigger
2.delete执行时,会将删除数据缓存到rollback segement中,事务commit之后生效
3.delete删除全部数据,MyISAM会立刻释放磁盘空间,InnoDB不会释放
4.delete from table_name where 带条件的MyISAM和InnoDB都不会释放磁盘空间
5.delete之后optimize table table_name会立刻释放磁盘空间,不管MyISAM或InnoDB
6.delete操作是一行一行删除,且产生删除操作日志,并记录到redo和undo
7.delete删除后id会继续递增
ALTER TABLE TableName AUTO_INCREMENT=1; # 将auto_increment重置
2.truncate
1.属于DDL定义语言,不走事务,原数据不放到rollback segement中,执行不触发trigger
2.truncate table table_name会立刻释放磁盘空间不论MyISAM或InnoDB,类似drop table然后create table,做了优化
3.快速清空表,并重置auto_increment的值
MyISAM:truncate会重置auto_increment为1,delete后不变
InnoDB: truncate会重置auto_incrment为1,delete后不变(delete之后重启则auto_increment为1)
也就是说,InnoDB的表本身是无法持久保存auto_increment。delete表之后auto_increment仍然保存在内存,但是重启后就丢失了,只能从1开始。实质上重启后的auto_increment会从 SELECT 1+MAX(ai_col) FROM t 开始。
SET FOREIGN_KEY_CHECKS=0; #取消外键约束
TRUNCATE TABLE table_name;
SET FOREIGN_KEY_CHECKS=1; #设置外键约束:
3.drop
1.属于DDL定义的语言
2.drop之后立刻释放磁盘空间,不管是MyISAM或InnoDB
3.drop且删除表结构,被依赖的约束(constrain),触发器(trigger),索引(index)
4.依赖该表的存储过程/函数将保留,状态为invalid
delete是把目录撕了,truncate是把书的内容撕下来烧了,drop是把书烧了
_INCREMENT=1; # 将auto_increment重置
2.truncate
1.属于DDL定义语言,不走事务,原数据不放到rollback segement中,执行不触发trigger
2.truncate table table_name会立刻释放磁盘空间不论MyISAM或InnoDB,类似drop table然后create table,做了优化
3.快速清空表,并重置auto_increment的值
MyISAM:truncate会重置auto_increment为1,delete后不变
InnoDB: truncate会重置auto_incrment为1,delete后不变(delete之后重启则auto_increment为1)
也就是说,InnoDB的表本身是无法持久保存auto_increment。delete表之后auto_increment仍然保存在内存,但是重启后就丢失了,只能从1开始。实质上重启后的auto_increment会从 SELECT 1+MAX(ai_col) FROM t 开始。
SET FOREIGN_KEY_CHECKS=0; #取消外键约束
TRUNCATE TABLE table_name;
SET FOREIGN_KEY_CHECKS=1; #设置外键约束:
3.drop
1.属于DDL定义的语言
2.drop之后立刻释放磁盘空间,不管是MyISAM或InnoDB
3.drop且删除表结构,被依赖的约束(constrain),触发器(trigger),索引(index)
4.依赖该表的存储过程/函数将保留,状态为invalid
delete是把目录撕了,truncate是把书的内容撕下来烧了,drop是把书烧了
相关文章:

mysql常用操作命令
mysql常用操作命令 mysql:单进程多线程模型,一个SQL语句无法利用多个cpu core 一:基本命令 0.查看当前连接数 show global status like Thread$; show variables like "%timeout%"; show variables like "log_%";1.查看当前连接状态 show processlist…...

数学建模常见模型汇总
优化问题 线性规划、半定规划、几何规划、非线性规划、整数规划、多目标规划(分层序列法)、动态规划、存贮论、代理模型、响应面分析法、列生成算法 预测模型 微分方程、小波分析、回归分析、灰色预测、马尔可夫预测、时间序列分析(AR MAMA.RMA ARTMA LSTM神经网络)、混沌模…...
)
C#使用LINQ查询操作符实例代码(二)
目录 六、连表操作符 1、内连接2、左外连接(DefaultIfEmpty)3、组连接七、集合操作 八、分区操作符 1、Take():2、TakeWhile():3、Skip():4、SkipWhile():九、聚合操作符 1、Count: 返回集合项数。 2、LongCount&…...

jenkinsfile小试牛刀
序 本文主要演示一下如何用jenkinsfile来编译java服务 安装jenkins 这里使用docker来安装jenkins docker run --name jenkins-docker \ --volume $HOME/jenkins_home:/var/jenkins_home \ -p 8080:8080 jenkins/jenkins:2.416之后访问http://${yourip}:8080,然后…...

C++ xmake构建
文章目录 一、xmake.lua二、xmake常用语句 一、xmake.lua --xmake.luaset_project("XXX")add_rules("mode.debug", "mode.release") set_config("arch", "x64")if is_plat("windows") then -- the release modei…...
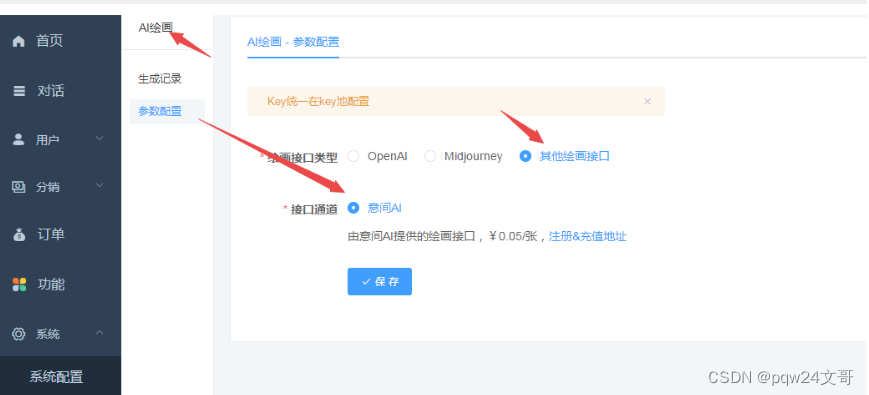
推荐带500创作模型的付费创作V2.1.0独立版系统源码
ChatGPT 付费创作系统 V2.1.0 提供最新的对应版本小程序端,上一版本增加了 PC 端绘画功能, 绘画功能采用其他绘画接口 – 意间 AI,本版新增了百度文心一言接口。 后台一些小细节的优化及一些小 BUG 的处理,前端进行了些小细节优…...
wps图表怎么改横纵坐标,MLP 多层感知器和CNN卷积神经网络区别
目录 wps表格横纵坐标轴怎么设置? MLP (Multilayer Perceptron) 多层感知器 CNN (Convolutional Neural Network) 卷积神经网络 多层感知器MLP,全连接网络,DNN三者的关系 wps表格横纵坐标轴怎么设置? 1、打开表格点击图的右侧…...

rdb和aof
RDB持久化:原理是将Redis在内存中的数据库记录定时dump到磁盘上的RDB持久化AOF持久化:原理是将Redis的操作日志以追加的方式写入文件 rdb: 开启方式:客户端可以通过向Redis服务器发送save或bgsave命令让服务器生成rdb文件&#…...
TCP网络通信编程之网络上传文件
【图片】 【思路解析】 【客户端代码】 import java.io.*; import java.net.InetAddress; import java.net.Socket; import java.net.UnknownHostException;/*** ProjectName: Study* FileName: TCPFileUploadClient* author:HWJ* Data: 2023/7/29 18:44*/ public class TCPFil…...

Java中对Redis的常用操作
目录 数据类型五种常用数据类型介绍各种数据类型特点 常用命令字符串操作命令哈希操作命令列表操作命令集合操作命令有序集合操作命令通用命令 在Java中操作RedisRedis的Java客户端Spring Data Redis使用方式介绍环境搭建配置Redis数据源编写配置类,创建RedisTempla…...

链路追踪设计
...

Golang之路---02 基础语法——常量 (包括特殊常量iota)
常量 //显式类型定义const a string "test" //隐式类型定义const b 20 //多个常量定义 const(c "test2"d 2.3e 27)iota iota是Golang语言的常量计数器,只能在常量表达式中使用 iota在const关键字出现时将被重置为0,const中每新…...

Pytest学习教程_装饰器(二)
前言 pytest装饰器是在使用 pytest 测试框架时用于扩展测试功能的特殊注解或修饰符。使用装饰器可以为测试函数提供额外的功能或行为。 以下是 pytest 装饰器的一些常见用法和用途: 装饰器作用pytest.fixture用于定义测试用例的前置条件和后置操作。可以创建可重…...
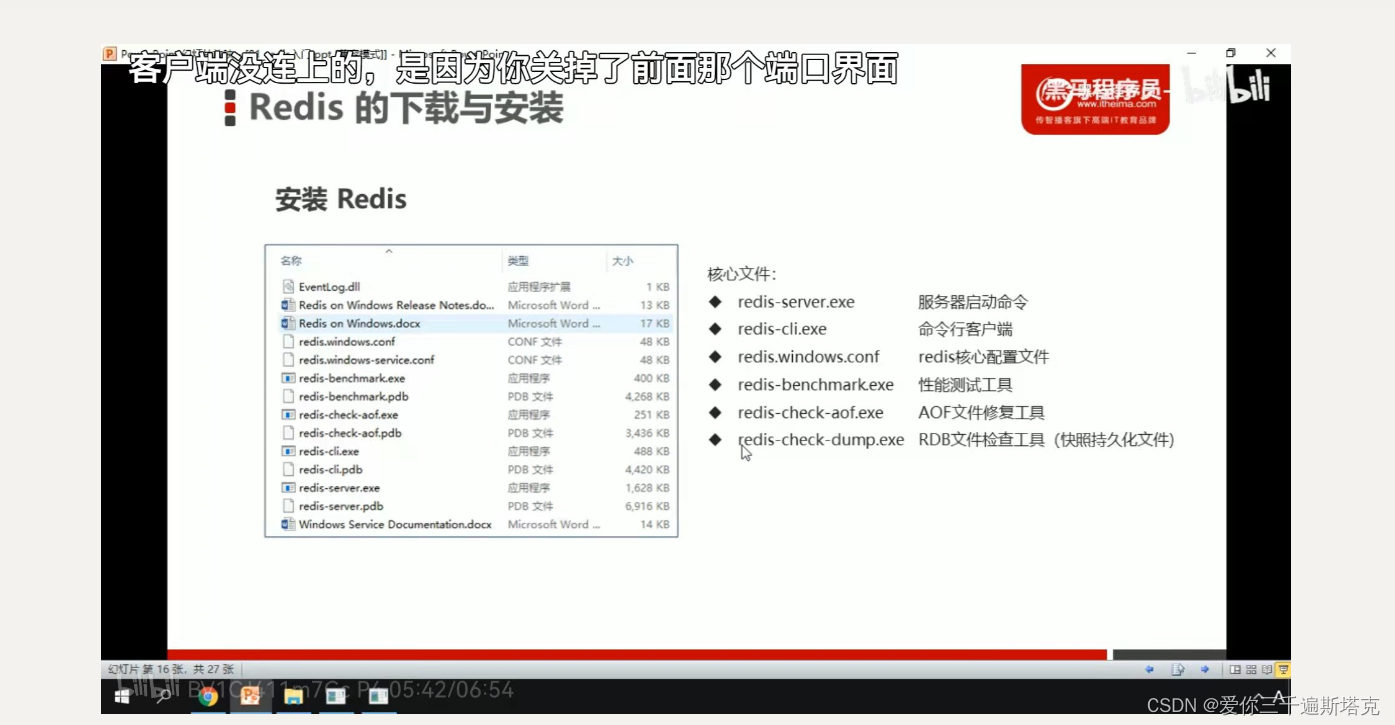
redis的如何使用
1、redis的使用 1.1windows安装 安装包下载地址:Releases dmajkic/redis GitHub 1.2 redis中常使用的几个文件 1.3 redis中运行 双击redis-server,既可以运行。 1.4使用redis客户单来连接redis 1.5redis的常用指标 redis-serve 服务端,端口号&am…...

MyBatis(二)
文章目录 一.MyBatis的模式开发1.1 定义数据表和实体类1.2 配置数据源和MyBatis1.3 编写Mapper接口和增加xxxMapper.xml1.4 测试我们功能的是否实现. 二. Mybatis的增删查改操作2.1 单表查询2.2 多表查询三.动态SQL的实现3.1 什么是动态SQL3.2 动态SQL的使用if标签的使用trim标…...
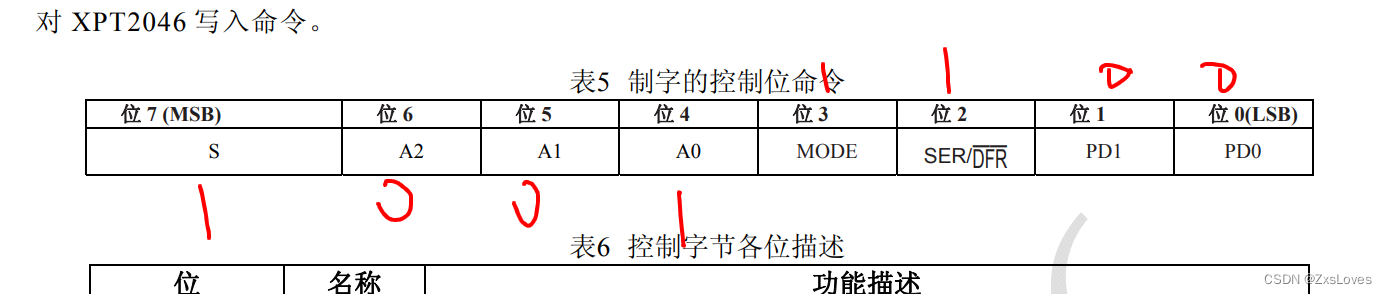
【【51单片机AD转换模块】】
代码是简单的,板子是坏的,电阻是识别不出来的 main.c #include <REGX52.H> #include "delay.h" #include "LCD1602.h" #include "XPT2046.h"unsigned int ADValue;void main(void) {LCD_Init();LCD_ShowString(1,1…...
)
Longest Divisors Interval(cf)
题意:给定一个正整数n,求正整数的区间[l,r]的最大大小,使得对于区间中的每个i(即l≤i≤r),n是i的倍数。给定两个整数l≤r,区间[l,r]的大小为r−l1(即…...

配置文件、request对象请求方法、Django连接MySQL、Django中的ORM、ORM增删改查字段、ORM增删改查数据
一、配置文件的介绍 1.注册应用的 INSTALLED_APPS [django.contrib.admin,django.contrib.auth,django.contrib.contenttypes,django.contrib.sessions,django.contrib.messages,django.contrib.staticfiles,app01.apps.App01Config, ]################中间件###############…...
CTF学习路线指南(附刷题练习网址)
前言: PWN,Reverse:偏重对汇编,逆向的理解; Gypto:偏重对数学,算法的深入学习; Web:偏重对技巧沉淀,快速搜索能力的挑战; Mic:则更为复杂&…...

【Rust 基础篇】Rust默认泛型参数:简化泛型使用
导言 Rust是一种以安全性和高效性著称的系统级编程语言,其设计哲学是在不损失性能的前提下,保障代码的内存安全和线程安全。在Rust中,泛型是一种非常重要的特性,它允许我们编写一种可以在多种数据类型上进行抽象的代码。然而&…...

自己用 ai 写了个链接 mysql 数据库的 mcp 工具
概要背景是这样的,之前用 ai 帮我生成 entity 都要我自己导出表结构,然后粘贴给它分析生成对应的 entity ,感觉好麻烦,而且还不能实时查看我的表和 entity 字段是否对应了, 问了 ai 建议我写个本地针对性的脚本或者用 …...

二维码修复工具QrazyBox:如何拯救你无法扫描的损坏二维码?
二维码修复工具QrazyBox:如何拯救你无法扫描的损坏二维码? 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 你是否曾遇到过这种情况:一个重要的二维码因为打…...

TimesFM终极指南:5大核心技术解密与实战性能优化
TimesFM终极指南:5大核心技术解密与实战性能优化 【免费下载链接】timesfm TimesFM (Time Series Foundation Model) is a pretrained time-series foundation model developed by Google Research for time-series forecasting. 项目地址: https://gitcode.com/G…...

ScienceDecrypting:三步永久解锁加密PDF,让学术文献重获自由
ScienceDecrypting:三步永久解锁加密PDF,让学术文献重获自由 【免费下载链接】ScienceDecrypting 破解CAJViewer带有效期的文档,支持破解科学文库、标准全文数据库下载的文档。无损破解,保留文字和目录,解除有效期限制…...

如何快速掌握Poppins字体:免费开源的多语言设计终极指南
如何快速掌握Poppins字体:免费开源的多语言设计终极指南 【免费下载链接】Poppins Poppins, a Devanagari Latin family for Google Fonts. 项目地址: https://gitcode.com/gh_mirrors/po/Poppins 还在为多语言项目寻找完美的字体解决方案而烦恼吗ÿ…...

HuMAL:利用人类注意力对齐提升小样本NLP任务性能的实践指南
1. 项目概述与核心思路在自然语言处理领域,Transformer架构及其核心的注意力机制已经彻底改变了游戏规则。作为一名长期在NLP一线摸爬滚打的从业者,我见过太多项目因为数据量不足而折戟沉沙。无论是初创公司的新业务,还是特定垂直领域的文本分…...

终极指南:如何构建企业级茅台自动预约系统
终极指南:如何构建企业级茅台自动预约系统 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://gitcode.com…...

qmc-decoder深度解析:高效解密QQ音乐加密格式的技术架构与实践
qmc-decoder深度解析:高效解密QQ音乐加密格式的技术架构与实践 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 在数字音乐版权保护的背景下,QQ音乐采…...

图像做 DCT:揭秘那个让像素“开口说话“的数学魔法
一、一个让我"开窍"的乐谱解读故事 我有一个学钢琴的表妹,从小就有一种让我惊叹的能力——她听任何一段陌生的旋律,都能立刻在钢琴上准确弹出来。我一直觉得她有"绝对音感"这种天赋。有一次我好奇地问她:“你怎么做到的&…...

Thorium浏览器:面向企业级部署的技术选型与架构决策指南
Thorium浏览器:面向企业级部署的技术选型与架构决策指南 【免费下载链接】thorium Chromium fork named after radioactive element No. 90. Source code and Linux releases. Windows/MacOS/ARM builds served in different repos, links are towards the top of t…...