python-pytorch基础之神经网络分类
这里写目录标题
- 生成数据函数
- 定义数据集
- 定义loader加载数据
- 定义神经网络模型
- 测试输出是否为2个
- 输入数据,输出结果
- 训练模型函数
- 计算正确率
- 训练数据并保存模型
- 测试模型
- 准备数据
- 加载模型预测
- 对比结果
生成数据函数
import random
def get_rectangle():width=random.random()height=random.random()# 如果width大于height就是1,否则就是0fat=int(width>=height)return width,height,fatget_rectangle()(0.19267437580138802, 0.645061020860627, 0)
fat=int(0.8>=0.9)
fat
0
定义数据集
import torch
class Dataset(torch.utils.data.Dataset):def __init__(self):passdef __len__(self):return 1000def __getitem__(self,i):width,height,fat=get_rectangle()# 这里注意width和height列表形式再转为tensor,另外是floattensorx=torch.FloatTensor([width,height])y=fatreturn x,y
dataset=Dataset()
# 这里没执行一次都要变,有什么意义?
len(dataset),dataset[999]
(1000, (tensor([0.4756, 0.1713]), 1))
定义loader加载数据
# 定义了数据集,然后使用loader去加载,需要记住batch_size,shuffle,drop_last这个三个常用的
loader=torch.utils.data.DataLoader(dataset=dataset,batch_size=9,shuffle=True,drop_last=True)# 加载完了以后,就可以使用next去遍历了
len(loader),next(iter(loader))
(111,[tensor([[0.1897, 0.6766],[0.2460, 0.2725],[0.5871, 0.7739],[0.3035, 0.9607],[0.7006, 0.7421],[0.4279, 0.9501],[0.6750, 0.1704],[0.5777, 0.1154],[0.5512, 0.3933]]),tensor([0, 0, 0, 0, 0, 0, 1, 1, 1])])
# 输出结果:
# (111,
# [tensor([[0.3577, 0.3401],
# [0.0156, 0.7550],
# [0.0435, 0.4984],
# [0.1329, 0.5488],
# [0.4330, 0.5362],
# [0.1070, 0.8500],
# [0.1073, 0.2496],
# [0.1733, 0.0226],
# [0.6790, 0.2119]]),
# tensor([1, 0, 0, 0, 0, 0, 0, 1, 1])]) 这里是torch自动将y组合成了一个tensor
定义神经网络模型
class Model(torch.nn.Module):def __init__(self):super().__init__()# 定义神经网络结构self.fb=torch.nn.Sequential(# 第一层输入两个,输出32个torch.nn.Linear(in_features=2,out_features=32),# 激活层的意思是小于0的数字变为0,即负数归零操作torch.nn.ReLU(),# 第二层,输入是32个,输出也是32个torch.nn.Linear(in_features=32,out_features=32),# 激活torch.nn.ReLU(),# 第三次,输入32个,输出2个torch.nn.Linear(in_features=32,out_features=2),# 激活,生成的两个数字相加等于1torch.nn.Softmax(dim=1))# 定义网络计算过程def forward(self,x):return self.fb(x)model=Model()
测试输出是否为2个
# 测试 8行2列的数据,让模型测试,看是否最后输出是否也是8行一列?model(torch.rand(8,2)).shape
torch.Size([8, 2])
输入数据,输出结果
model(torch.tensor([[0.3577, 0.3401]]))
tensor([[0.5228, 0.4772]], grad_fn=<SoftmaxBackward>)
训练模型函数
def train():#定义优化器,le-4表示0.0004,10的负四次方opitimizer=torch.optim.Adam(model.parameters(),lr=1e-4)#定义损失函数 ,一般回归使用mseloss,分类使用celossloss_fn=torch.nn.CrossEntropyLoss()#然后trainmodel.train()# 全量数据遍历100轮for epoch in range(100):# 遍历loader的数据,循环一次取9条数据,这里注意unpack时,x就是【width,height】for i,(x,y) in enumerate(loader):out=model(x)# 计算损失loss=loss_fn(out,y)# 计算损失的梯度loss.backward()# 优化参数opitimizer.step()# 梯度清零opitimizer.zero_grad()# 第二十轮的时候打印一下数据if epoch % 20 ==0:# 正确率# out.argmax(dim=1) 表示哪个值大就说明偏移哪一类,dim=1暂时可以看做是固定的# (out.argmax(dim=1)==y).sum() 表示的true的个数acc=(out.argmax(dim=1)==y).sum().item()/len(y)print(epoch,loss.item(),acc)torch.save(model,"4.model")计算正确率
执行的命令:
print(out,“======”,y,“+++++”,(out.argmax(dim=1)==y).sum().item())
print(out.argmax(dim=1),“------------”,(out.argmax(dim=1)==y),“~~~~~~~~~~~”,(out.argmax(dim=1)==y).sum())
输出的结果:
tensor([[9.9999e-01, 1.4671e-05],
[4.6179e-14, 1.0000e+00], [3.2289e-02, 9.6771e-01], [1.1237e-22, 1.0000e+00],[9.9993e-01, 7.0015e-05],[8.6740e-02, 9.1326e-01],[1.1458e-18, 1.0000e+00],[5.2558e-01, 4.7442e-01],[9.7923e-01, 2.0772e-02]], grad_fn=<SoftmaxBackward>) ====== tensor([0, 1, 1, 1, 0, 1, 1, 1, 0]) +++++ 8
tensor([0, 1, 1, 1, 0, 1, 1, 0, 0]) ------------ tensor([ True, True, True, True, True, True, True, False, True]) ~~~~~~~~~~~ tensor(8)
解释:
out.argmax(dim=1) 表示哪个值大就说明偏移哪一类,dim=1暂时可以看做是固定的
(out.argmax(dim=1)==y).sum() 表示的true的个数
a = torch.tensor([[1,2,3],[4,7,6]])d = a.argmax(dim=1)
print(d)
tensor([2, 1])
训练数据并保存模型
train()
80 0.3329530954360962 1.0
80 0.31511250138282776 1.0
80 0.33394935727119446 1.0
80 0.3242819309234619 1.0
80 0.3188716471195221 1.0
80 0.3405844569206238 1.0
80 0.32696405053138733 1.0
80 0.3540787696838379 1.0
80 0.3390745222568512 1.0
80 0.3645476996898651 0.8888888888888888
80 0.3371085822582245 1.0
80 0.31789034605026245 1.0
80 0.31553390622138977 1.0
80 0.3162603974342346 1.0
80 0.35249051451683044 1.0
80 0.3582523465156555 1.0
80 0.3162645995616913 1.0
80 0.37988030910491943 1.0
80 0.34384390711784363 1.0
80 0.31773826479911804 1.0
80 0.3145104646682739 1.0
80 0.31753242015838623 1.0
80 0.3222736120223999 1.0
80 0.38612237572669983 1.0
80 0.35490038990974426 1.0
80 0.34469687938690186 1.0
80 0.34534531831741333 1.0
80 0.31800928711891174 1.0
80 0.34892910718917847 1.0
80 0.33424195647239685 1.0
80 0.37350085377693176 1.0
80 0.3298128843307495 1.0
80 0.3715909719467163 1.0
80 0.3507140874862671 1.0
80 0.33337005972862244 1.0
80 0.3134789764881134 1.0
80 0.35244104266166687 1.0
80 0.3148314654827118 1.0
80 0.3376845419406891 1.0
80 0.3315282464027405 1.0
80 0.3450225591659546 1.0
80 0.3139556646347046 1.0
80 0.34932857751846313 1.0
80 0.3512738049030304 1.0
80 0.3258627951145172 1.0
80 0.3197799324989319 1.0
80 0.358166366815567 0.8888888888888888
80 0.3716268837451935 1.0
80 0.31426626443862915 1.0
80 0.32130196690559387 1.0
80 0.3207002282142639 1.0
80 0.3891155421733856 1.0
80 0.35045987367630005 1.0
80 0.32332736253738403 1.0
80 0.31951677799224854 1.0
80 0.3184094727039337 1.0
80 0.3341224491596222 1.0
80 0.3408585786819458 1.0
80 0.3139263093471527 1.0
80 0.33058592677116394 1.0
80 0.3134475648403168 1.0
80 0.3281571567058563 1.0
80 0.33370518684387207 1.0
80 0.33172252774238586 1.0
80 0.32849007844924927 1.0
80 0.3604048788547516 1.0
80 0.3651810884475708 1.0
测试模型
准备数据
# 准备数据
x,fat=next(iter(loader))
x,fat
(tensor([[0.6733, 0.4044],[0.6503, 0.0303],[0.9353, 0.9518],[0.4145, 0.6948],[0.9560, 0.8009],[0.6331, 0.0852],[0.5510, 0.8283],[0.1402, 0.2726],[0.3257, 0.8351]]),tensor([1, 1, 0, 0, 1, 1, 0, 0, 0]))
加载模型预测
# 加载模型
modell=torch.load("4.model")
# 使用模型
out=modell(x)
out
tensor([[1.5850e-04, 9.9984e-01],[1.4121e-06, 1.0000e+00],[7.1068e-01, 2.8932e-01],[9.9994e-01, 5.5789e-05],[4.1401e-03, 9.9586e-01],[3.3441e-06, 1.0000e+00],[9.9995e-01, 4.7039e-05],[9.9111e-01, 8.8864e-03],[1.0000e+00, 1.5224e-06]], grad_fn=<SoftmaxBackward>)
out.argmax(dim=1)
tensor([1, 1, 0, 0, 1, 1, 0, 0, 0])
对比结果
fat
tensor([1, 1, 0, 0, 1, 1, 0, 0, 0])
查看上面out的结果和fat的结论一致,不错
相关文章:

python-pytorch基础之神经网络分类
这里写目录标题 生成数据函数定义数据集定义loader加载数据定义神经网络模型测试输出是否为2个输入数据,输出结果 训练模型函数计算正确率 训练数据并保存模型测试模型准备数据加载模型预测对比结果 生成数据函数 import randomdef get_rectangle():widthrandom.ra…...
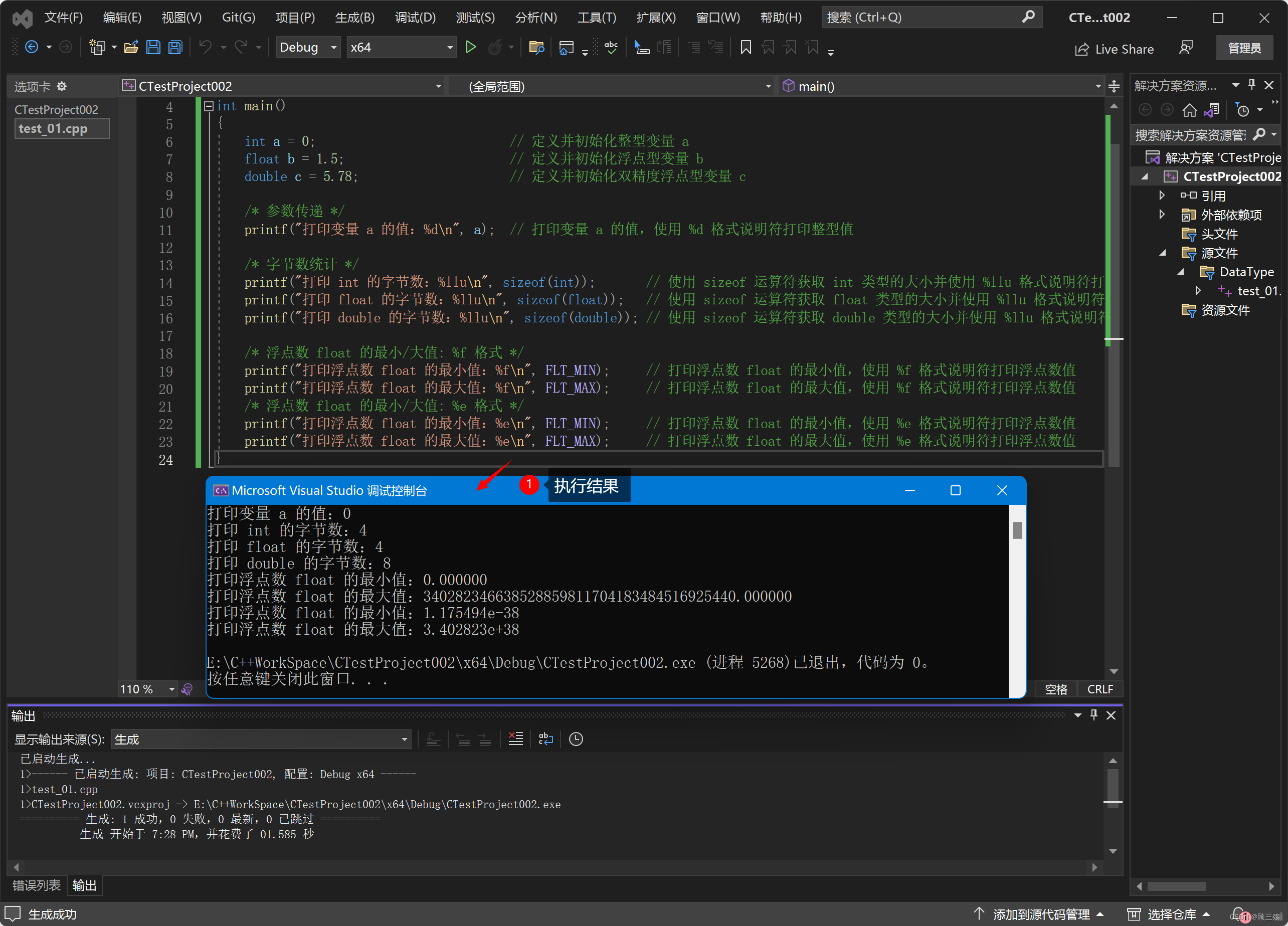
【C++ 程序设计】实战:C++ 变量实践练习题
目录 01. 变量:定义 02. 变量:初始化 03. 变量:参数传递 04. 变量:格式说明符 ① 占位符 “%d” 改为格式说明符 “%llu” ② 占位符 “%d” 改为格式说明符 “%f” 或 “%e” 05. 变量:字节数统计 06. 变量&a…...
微软对Visual Studio 17.7 Preview 4进行版本更新,新插件管理器亮相
近期微软发布了Visual Studio 17.7 Preview 4版本,而在这个版本当中,全新设计的扩展插件管理器将亮相,并且可以让用户可更简单地安装和管理扩展插件。 据了解,目前用户可以从 Visual Studio Marketplace 下载各式各样的 VS 扩展插…...
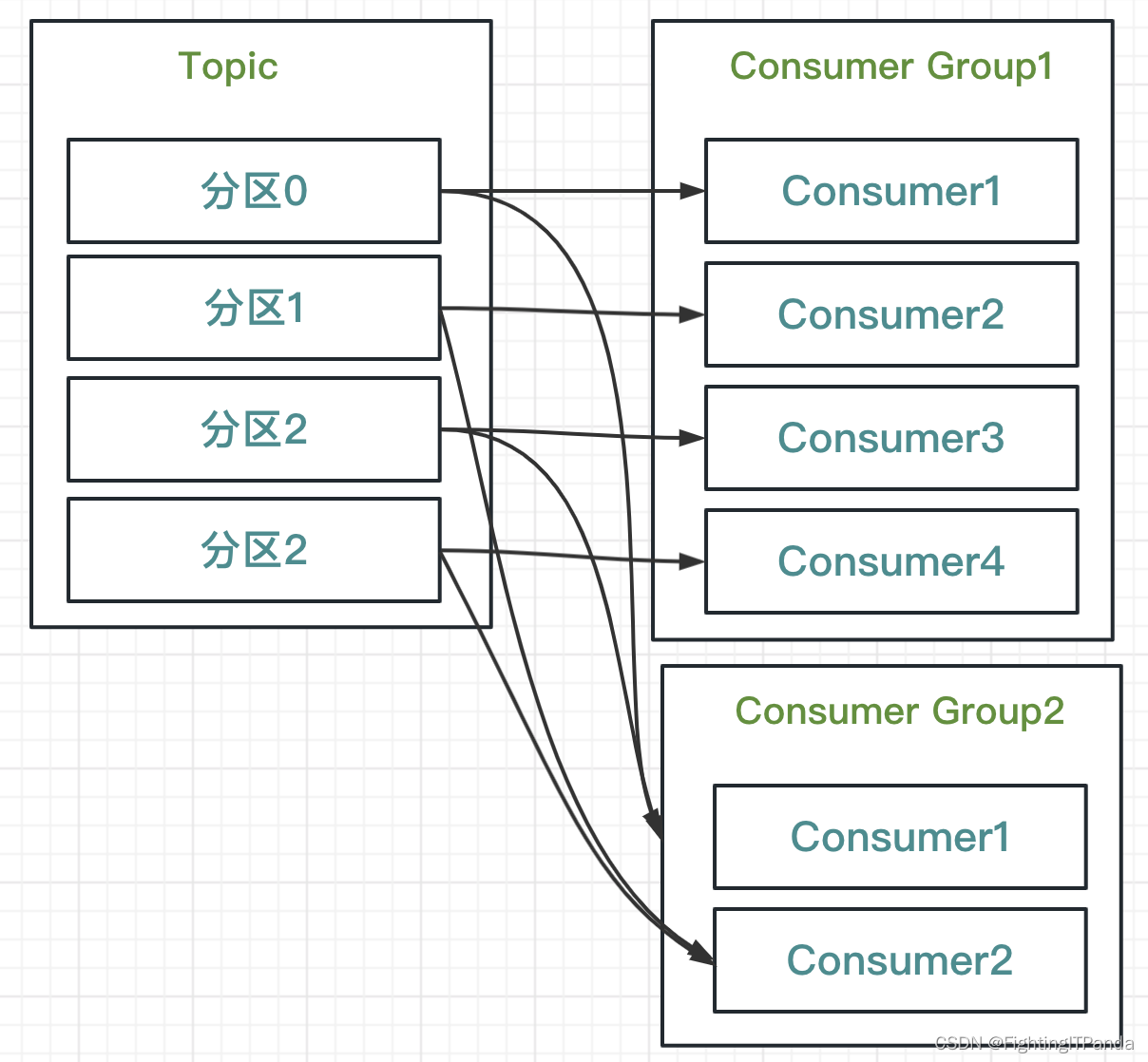
Kafka 入门到起飞 - Kafka怎么做到保障消息不会重复消费的? 消费者组是什么?
Kafka怎么做到避免消息重复消费的? 消费者组是什么? 消费者: 1、订阅Topic(主题) 2、从订阅的Topic消费(pull)消息, 3、将消费消息的offset(偏移量)保存在K…...

MongoDB 的增、查、改、删
Monogo使用 增 单条增加 db.member.insertOne({"name":"张三","age":18,"create":new Date()}) db.member.insert({"name":"李四1","age":18,"create":new Date()}) db.member.insertOne(…...

mysql常用操作命令
mysql常用操作命令 mysql:单进程多线程模型,一个SQL语句无法利用多个cpu core 一:基本命令 0.查看当前连接数 show global status like Thread$; show variables like "%timeout%"; show variables like "log_%";1.查看当前连接状态 show processlist…...

数学建模常见模型汇总
优化问题 线性规划、半定规划、几何规划、非线性规划、整数规划、多目标规划(分层序列法)、动态规划、存贮论、代理模型、响应面分析法、列生成算法 预测模型 微分方程、小波分析、回归分析、灰色预测、马尔可夫预测、时间序列分析(AR MAMA.RMA ARTMA LSTM神经网络)、混沌模…...
)
C#使用LINQ查询操作符实例代码(二)
目录 六、连表操作符 1、内连接2、左外连接(DefaultIfEmpty)3、组连接七、集合操作 八、分区操作符 1、Take():2、TakeWhile():3、Skip():4、SkipWhile():九、聚合操作符 1、Count: 返回集合项数。 2、LongCount&…...

jenkinsfile小试牛刀
序 本文主要演示一下如何用jenkinsfile来编译java服务 安装jenkins 这里使用docker来安装jenkins docker run --name jenkins-docker \ --volume $HOME/jenkins_home:/var/jenkins_home \ -p 8080:8080 jenkins/jenkins:2.416之后访问http://${yourip}:8080,然后…...

C++ xmake构建
文章目录 一、xmake.lua二、xmake常用语句 一、xmake.lua --xmake.luaset_project("XXX")add_rules("mode.debug", "mode.release") set_config("arch", "x64")if is_plat("windows") then -- the release modei…...
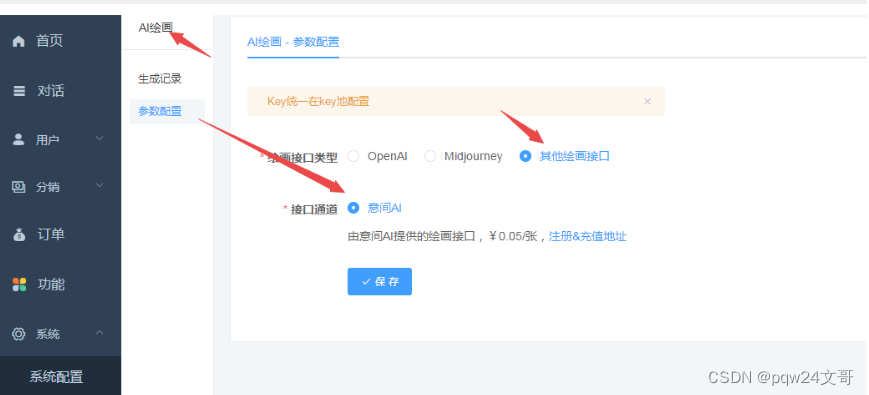
推荐带500创作模型的付费创作V2.1.0独立版系统源码
ChatGPT 付费创作系统 V2.1.0 提供最新的对应版本小程序端,上一版本增加了 PC 端绘画功能, 绘画功能采用其他绘画接口 – 意间 AI,本版新增了百度文心一言接口。 后台一些小细节的优化及一些小 BUG 的处理,前端进行了些小细节优…...
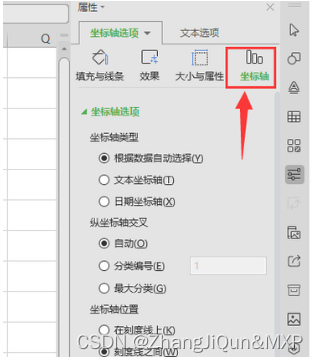
wps图表怎么改横纵坐标,MLP 多层感知器和CNN卷积神经网络区别
目录 wps表格横纵坐标轴怎么设置? MLP (Multilayer Perceptron) 多层感知器 CNN (Convolutional Neural Network) 卷积神经网络 多层感知器MLP,全连接网络,DNN三者的关系 wps表格横纵坐标轴怎么设置? 1、打开表格点击图的右侧…...

rdb和aof
RDB持久化:原理是将Redis在内存中的数据库记录定时dump到磁盘上的RDB持久化AOF持久化:原理是将Redis的操作日志以追加的方式写入文件 rdb: 开启方式:客户端可以通过向Redis服务器发送save或bgsave命令让服务器生成rdb文件&#…...
TCP网络通信编程之网络上传文件
【图片】 【思路解析】 【客户端代码】 import java.io.*; import java.net.InetAddress; import java.net.Socket; import java.net.UnknownHostException;/*** ProjectName: Study* FileName: TCPFileUploadClient* author:HWJ* Data: 2023/7/29 18:44*/ public class TCPFil…...

Java中对Redis的常用操作
目录 数据类型五种常用数据类型介绍各种数据类型特点 常用命令字符串操作命令哈希操作命令列表操作命令集合操作命令有序集合操作命令通用命令 在Java中操作RedisRedis的Java客户端Spring Data Redis使用方式介绍环境搭建配置Redis数据源编写配置类,创建RedisTempla…...

链路追踪设计
...

Golang之路---02 基础语法——常量 (包括特殊常量iota)
常量 //显式类型定义const a string "test" //隐式类型定义const b 20 //多个常量定义 const(c "test2"d 2.3e 27)iota iota是Golang语言的常量计数器,只能在常量表达式中使用 iota在const关键字出现时将被重置为0,const中每新…...

Pytest学习教程_装饰器(二)
前言 pytest装饰器是在使用 pytest 测试框架时用于扩展测试功能的特殊注解或修饰符。使用装饰器可以为测试函数提供额外的功能或行为。 以下是 pytest 装饰器的一些常见用法和用途: 装饰器作用pytest.fixture用于定义测试用例的前置条件和后置操作。可以创建可重…...
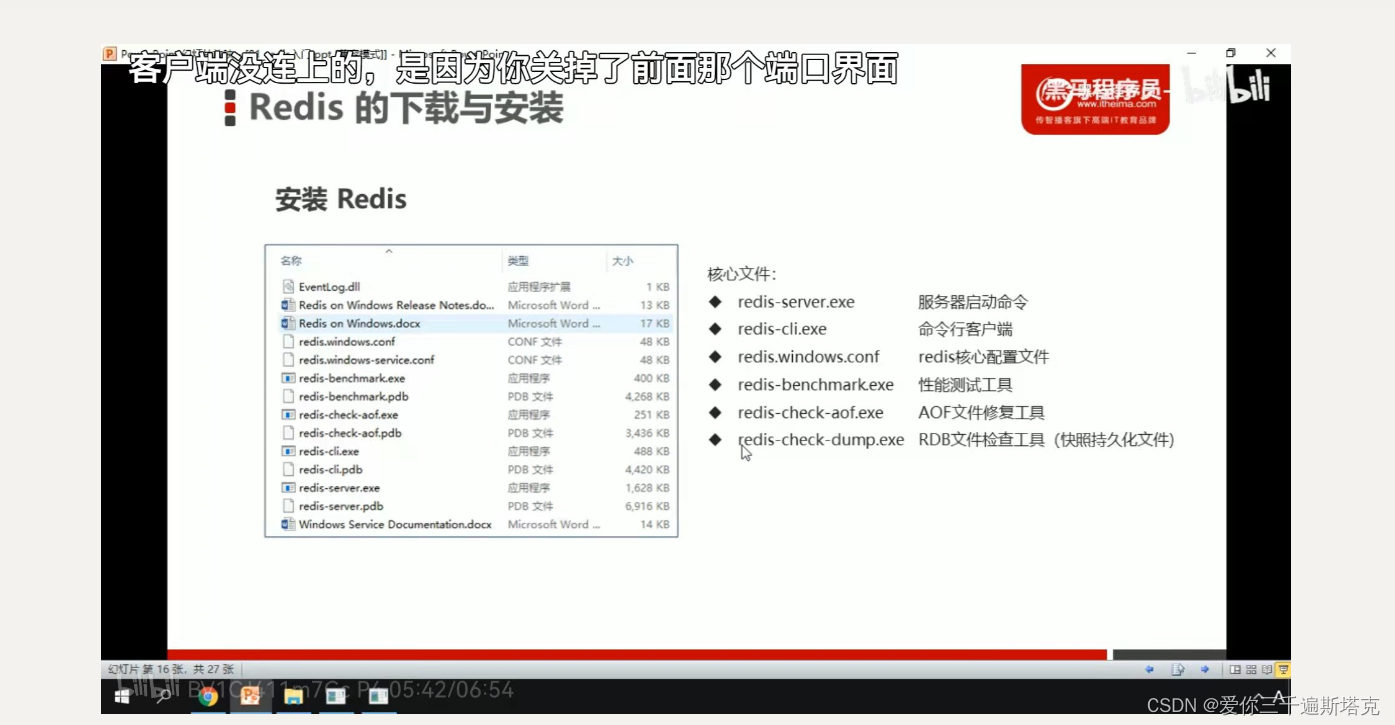
redis的如何使用
1、redis的使用 1.1windows安装 安装包下载地址:Releases dmajkic/redis GitHub 1.2 redis中常使用的几个文件 1.3 redis中运行 双击redis-server,既可以运行。 1.4使用redis客户单来连接redis 1.5redis的常用指标 redis-serve 服务端,端口号&am…...

MyBatis(二)
文章目录 一.MyBatis的模式开发1.1 定义数据表和实体类1.2 配置数据源和MyBatis1.3 编写Mapper接口和增加xxxMapper.xml1.4 测试我们功能的是否实现. 二. Mybatis的增删查改操作2.1 单表查询2.2 多表查询三.动态SQL的实现3.1 什么是动态SQL3.2 动态SQL的使用if标签的使用trim标…...
)
【实时更新 | 2026 年】国内可用的 npm 镜像源/加速器配置大全(附测速方法)
【实时更新 | 2026 年】国内可用的 npm 镜像源/加速器配置大全(附测速方法)导语:在国内用 npm 安装依赖,直连官方源的速度经常只有几十 KB/s,一个 npm install 动辄等上十几分钟。配置国内镜像源后,下载速度…...
20岁写出Transformer的人,真开源了2180亿大模型
点击下方卡片,关注“CVer”公众号AI/CV重磅干货,第一时间送达点击进入—>【顶会/顶刊】投稿交流群添加微信号:CVer2233,小助手拉你进群!扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶…...

BilibiliDown深度评测:5大实用技巧让你轻松收藏B站优质内容
BilibiliDown深度评测:5大实用技巧让你轻松收藏B站优质内容 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirr…...

FanControl终极指南:5分钟实现Windows风扇智能控制,告别散热噪音烦恼
FanControl终极指南:5分钟实现Windows风扇智能控制,告别散热噪音烦恼 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitco…...

SVM调参实战:如何用Python的sklearn找到鸢尾花分类的最佳C值和核函数?
SVM超参数优化实战:从网格搜索到贝叶斯优化的鸢尾花分类调参指南当你在sklearn中第一次使用SVC分类器时,是否曾被默认参数C1.0和kernellinear的表现所困惑?为什么同样的算法在不同数据集上表现差异巨大?本文将带你深入SVM调参的核…...

别再瞎调参了!用Python实战Sensitivity Analysis,5分钟找出模型最怕哪个变量
用Python实战全局敏感性分析:5步锁定模型关键变量 当你的机器学习模型表现不如预期时,第一反应是什么?大多数数据科学家的选择是:调参。但随机调整超参数就像在黑暗房间里找开关——效率低下且充满挫败感。本文将带你用Python实施…...

生产级MLOps鲁棒性实战:从数据漂移到模型监控的五大平台对比
1. 项目概述:为什么生产级机器学习系统必须关注鲁棒性? 在机器学习项目从实验室走向生产环境的漫长旅途中,我们常常会经历一个“高开低走”的尴尬局面:在精心准备的测试集上表现优异的模型,一旦部署上线,性…...

在多轮对话应用中感受Taotoken提供的高稳定性与低延迟
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多轮对话应用中感受Taotoken提供的高稳定性与低延迟 开发一个需要维持上下文的多轮对话应用,对后端服务的稳定性和响…...

WeChatExporter:告别数据焦虑,轻松备份你的微信聊天记忆
WeChatExporter:告别数据焦虑,轻松备份你的微信聊天记忆 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 在数字时代,微信聊天记录承载…...

信用评分中的算法公平性:从理论到实践的全面解析
1. 项目概述:当信用评分遇上算法公平性在金融科技领域,信用评分模型早已不是新鲜事物。从传统的逻辑回归到如今复杂的梯度提升树和神经网络,机器学习模型凭借其强大的预测能力,已经成为银行和金融机构进行信贷决策、管理风险的核心…...