【LLM】大语言模型学习之LLAMA 2:Open Foundation and Fine-Tuned Chat Model
大语言模型学习之LLAMA 2:Open Foundation and Fine-Tuned Chat Model
- 快速了解
- 预训练
- 预训练模型评估
- 微调
- 有监督微调(SFT)
- 人类反馈的强化学习(RLHF)
- RLHF结果
- 局限性
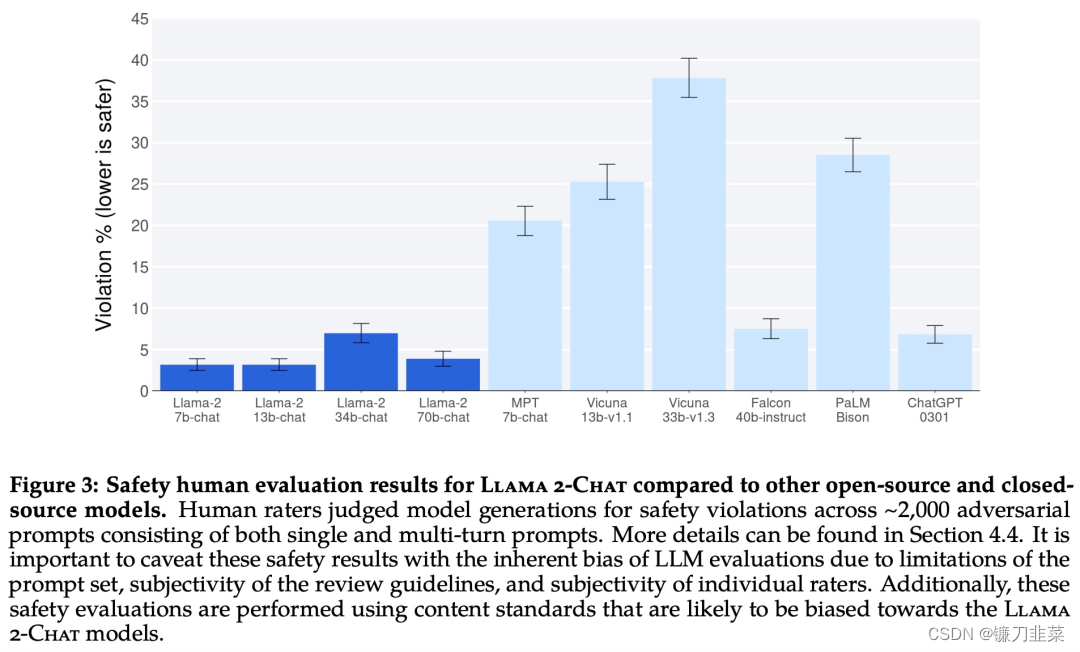
- 安全性
- 预训练的安全性
- 安全微调
- 上手就干
- 使用登记
- 代码下载
- 获取模型
- 转换模型
- 搭建Text-Generation-WebUI
- 分发模型
- 参考资料
自从开源以来,LLAMA可以说是 AI 社区内最强大的开源大模型。但因为开源协议问题,一直不可免费商用。近日,Meta发布了期待已久的免费可商用版本LLAMA 2。

在这项工作中,我们开发并发布了LLAMA 2,这是一系列预训练和微调的大型语言模型(LLMs),规模从70亿到700亿个参数不等。我们的微调LLMs,称为Llama 2-Chat,专为对话场景进行了优化。我们的模型在大多数我们测试的基准中表现优于开源对话模型,并且根据我们的人工评估,其有益性和安全性使其成为闭源模型的合适替代品。我们详细描述了我们对Llama 2-Chat的微调和安全性改进方法,旨在让社区能够在我们的工作基础上发展并为负责任的LLM发展做出贡献。
项目地址:https://github.com/facebookresearch/llama
论文地址:https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
快速了解
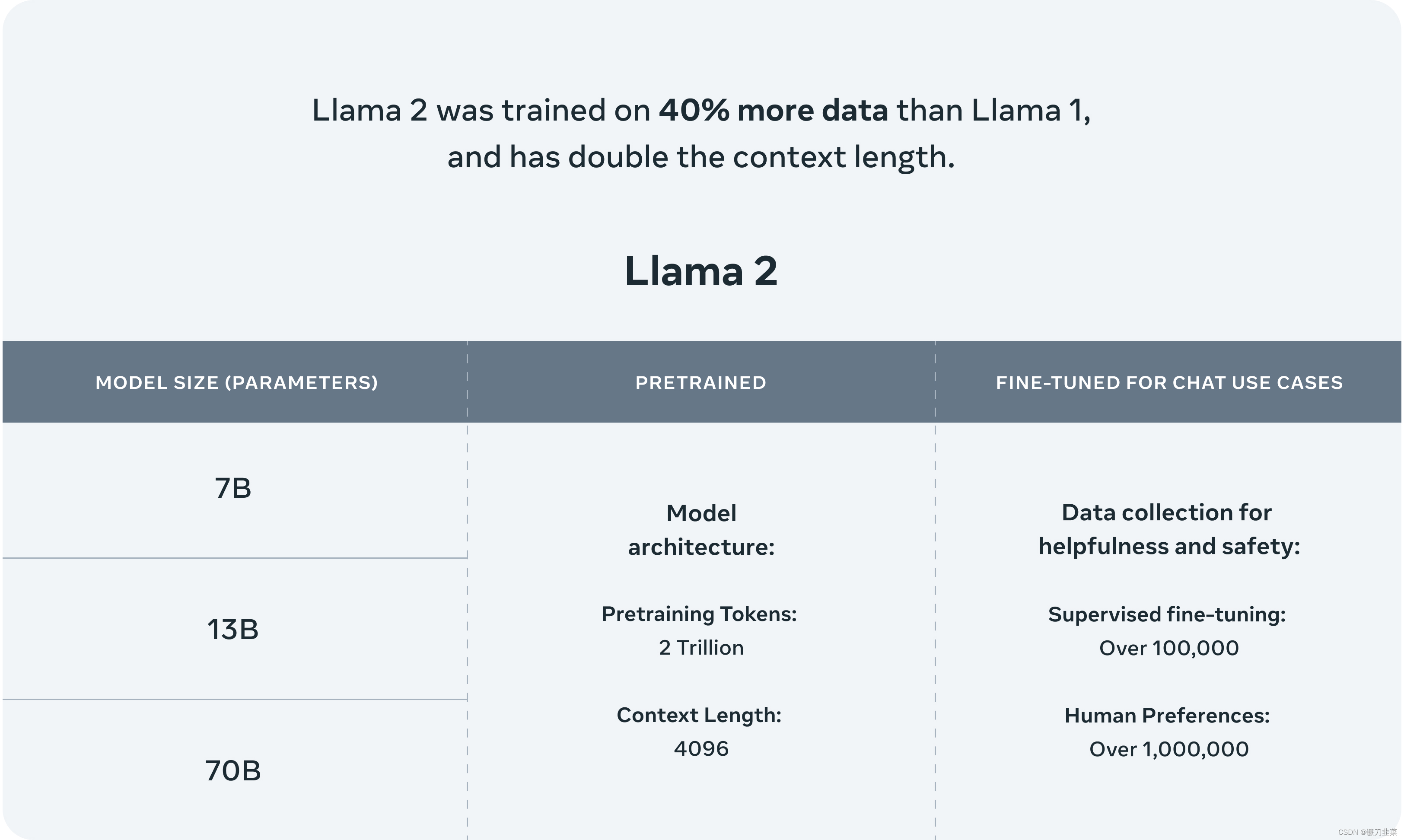
简单来说,LLaMa 2 是 LLaMA 的下一代版本,具有商业友好的许可证。它有 3种不同的尺寸:7B、13B 和 70B。预训练阶段使用了2万亿Token,SFT阶段使用了超过10w数据,人类偏好数据超过100w。7B & 13B 使用与 LLaMA 1 相同的架构,并且是商业用途的 1 对 1 替代。
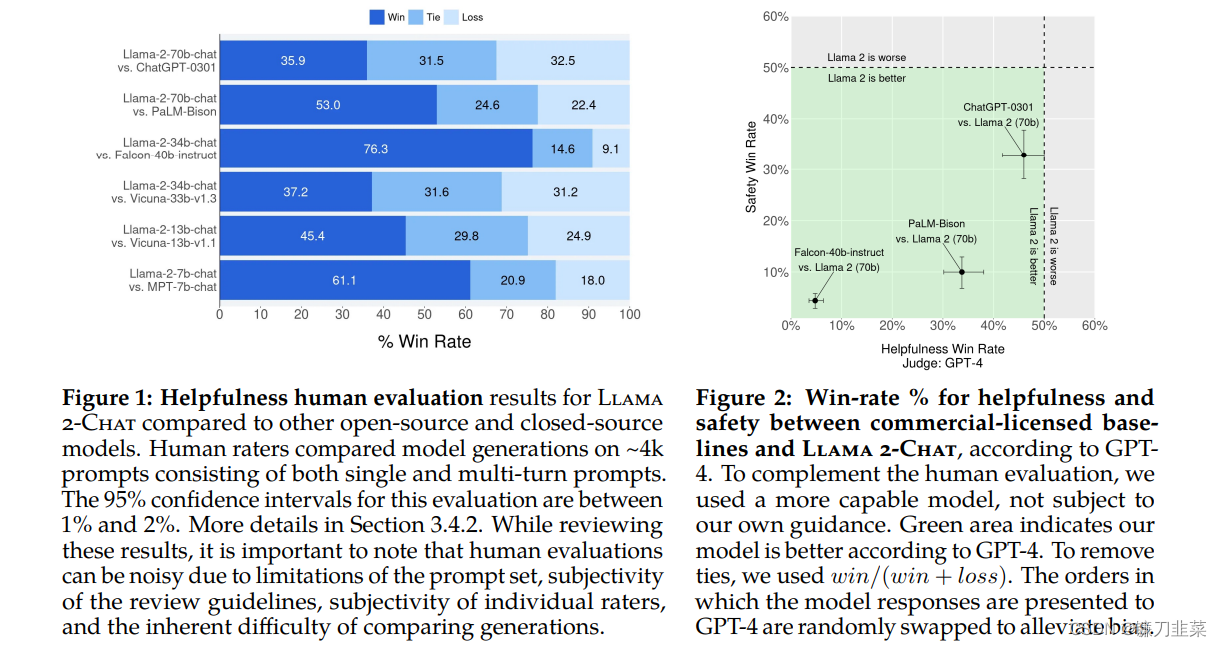
另外大家最关心的Llama2和ChatGPT模型的效果对比,在论文里也有提到,对比GPT-4,Llama2评估结果更优,绿色部分表示Llama2优于GPT4的比例,据介绍,相比于 Llama 1,Llama 2 的训练数据多了 40%,上下文长度也翻倍,并采用了分组查询注意力机制,可以理解和生成更长的文本。。
LLAMA 2体验链接:
- https://www.llama2.ai/
- https://replicate.com/a16z-infra/llama13b-v2-chat
- https://huggingface.co/meta-llama
总的来说,作为一组经过预训练和微调的大语言模型(LLM),Llama 2 模型系列的参数规模从 70 亿到 700 亿不等。其中的 Llama 2-Chat 针对对话用例进行了专门优化,使用来自人类反馈的强化学习来确保安全性和帮助性。
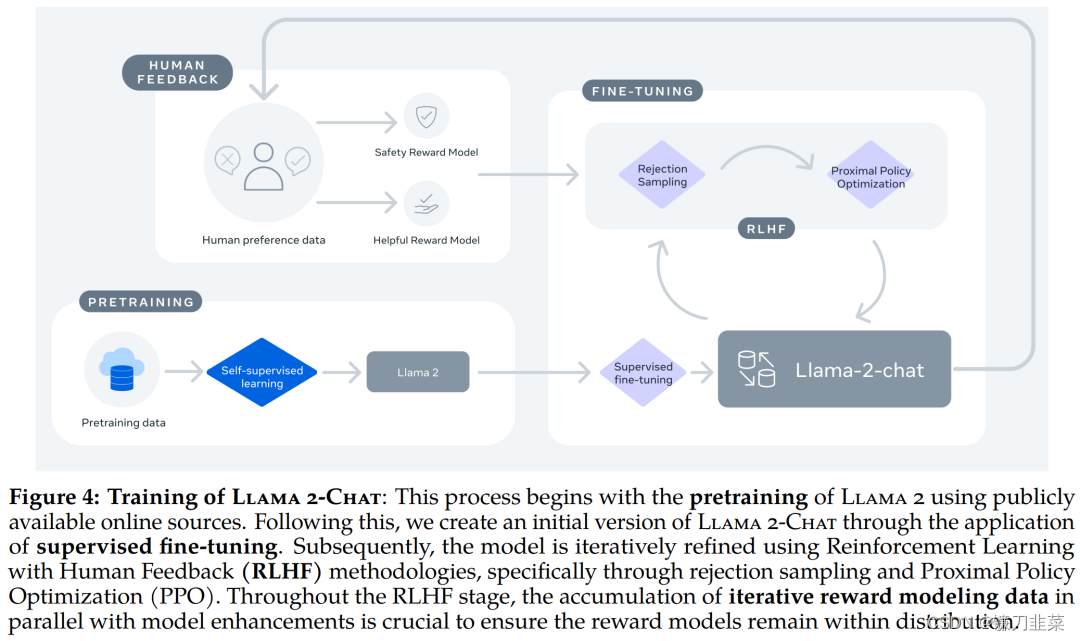
训练 Llama-2-chat:Llama 2 使用公开的在线数据进行预训练。然后通过使用监督微调创建 Llama-2-chat 的初始版本。接下来,Llama-2-chat 使用人类反馈强化学习 (RLHF) 进行迭代细化,其中包括拒绝采样和近端策略优化 (PPO)。
Llama 2 模型系列除了在大多数基准测试中优于开源模型之外,根据 Meta 对有用性和安全性的人工评估,它或许也是闭源模型的合适替代品。
预训练
为了创建全新的 Llama 2 模型系列,Meta 以 Llama 1 论文中描述的预训练方法为基础,使用了优化的自回归 transformer,并做了一些改变以提升性能。
(1)数据方面
具体而言,Meta 执行了更稳健的数据清理,更新了混合数据,训练 token 总数增加了 40%,上下文长度翻倍。下表 1 比较了 Llama 2 与 Llama 1 的详细数据。
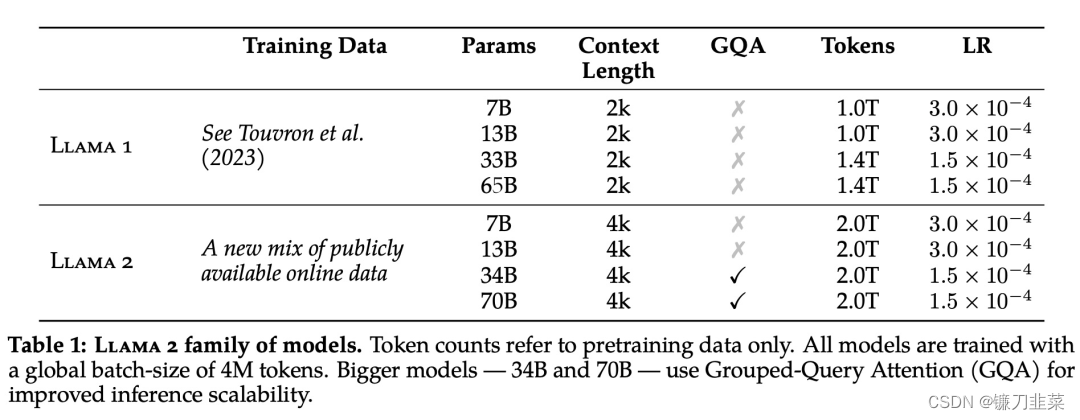
Llama 2 的训练语料库包含了来自公开可用资源的混合数据,不包括 Meta 产品或服务相关的数据。而且努力从某些已知包含大量个人信息的网站中删除数据,注重隐私。对 2 万亿个token的数据进行了训练,因为这提供了良好的性能与成本权衡,对最真实的来源进行上采样,以增加知识并抑制幻觉,保持真实。同时进行了各种预训练数据调查,以便用户更好地了解模型的潜在能力和局限性,保证安全。
(2)模型结构
Llama 2 采用了 Llama 1 中的大部分预训练设置和模型架构,包括标准 Transformer 架构、使用 RMSNorm 的预归一化、SwiGLU 激活函数和旋转位置嵌入RoPE。与 Llama 1 的主要架构差异包括增加了上下文长度和分组查询注意力(GQA)。
- 上下文长度
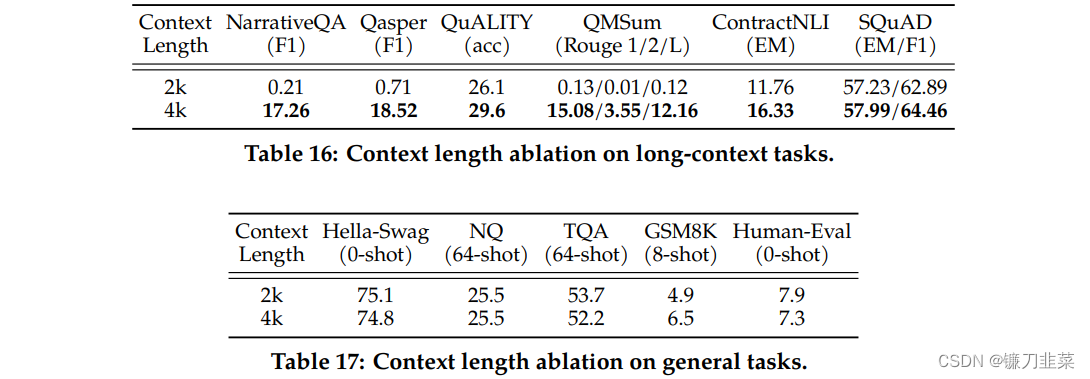
Llama 2 的上下文窗口从 2048 个标记扩展到 4096 个字符。越长上下文窗口使模型能够处理更多信息,这对于支持聊天应用程序中较长的历史记录、各种摘要任务以及理解较长的文档。多个评测结果表示较长的上下文模型在各种通用任务上保持了强大的性能。
表 16 比较了 2k 和 4k 上下文预训练在长上下文基准上的性能。 两个模型都针对 150B 令牌进行训练,保持相同的架构和超参数作为基线,仅改变上下文长度。 观察到 SCROLLS 的改进,其中平均输入长度为 3.5k,并且 SQUAD 的性能没有下降。 表 17 显示较长的上下文模型在各种通用任务上保持了强大的性能。
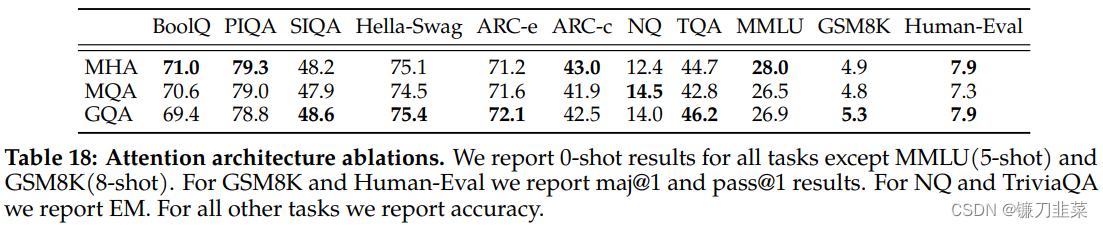
- Grouped-Query Attention 分组查询注意力
- 自回归解码的标准做法是缓存序列中先前标记的键 (K) 和值 (V) 对,从而加快注意力计算速度。然而,随着上下文窗口或批量大小的增加,多头注意力 (MHA) 模型中与 KV 缓存大小相关的内存成本显着增长。对于较大的模型,KV 缓存大小成为瓶颈,键和值投影可以在多个头之间共享,而不会大幅降低性能。可以使用具有单个 KV 投影的原始多查询格式(MQA)或具有 8 KV 投影的分组查询注意力变体(GQA)。
- Meta 将 MQA 和 GQA 变体与 MHA 基线进行了比较,使用 150B 字符训练所有模型,同时保持固定的 30B 模型大小。为了在 GQA 和 MQA 中保持相似的总体参数计数,增加前馈层的维度以补偿注意力层的减少。对于 MQA 变体,Meta 将 FFN 维度增加 1.33 倍,对于 GQA 变体,Llama将其增加 1.3 倍。从结果中观察到 GQA 变体在大多数评估任务上的表现与 MHA 基线相当,并且平均优于 MQA 变体。
(3)参数方面
在超参数方面,Meta 使用 AdamW 优化器进行训练,其中 β 1 = 0.9 β_1 = 0.9 β1=0.9, β 2 = 0.95 β_2 = 0.95 β
相关文章:
【LLM】大语言模型学习之LLAMA 2:Open Foundation and Fine-Tuned Chat Model
大语言模型学习之LLAMA 2:Open Foundation and Fine-Tuned Chat Model 快速了解预训练预训练模型评估微调有监督微调(SFT)人类反馈的强化学习(RLHF)RLHF结果局限性安全性预训练的安全性安全微调上手就干使用登记代码下载获取模型转换模型搭建Text-Generation-WebUI分发模型…...

Android是如何识别USB信号的
Android设备通过USB接口与外部设备通信时,会通过USB控制器(USB Controller)与USB设备进行通信。USB控制器是Android设备的一个硬件组件,它负责管理USB总线并控制所有USB设备的连接和通信。 当一个USB设备被插入Android设备的USB接…...

机器学习前言
1.机器学习和统计学关系 2.机器学习的发展 3.机器学习与深度学习的相同点与不同点 4.机器学习和深度学习优缺点 一、机器学习和统计学关系 机器学习和统计学密切相关,可以说机器学习是统计学在计算机科学和人工智能领域的应用。机器学习和统计学在方法论和技术上有…...
Java另一种debug方法(not remote jmv debug),类似python远程debug方式
这种Debug类似python的debug方式,是运行时将业务代码及依赖推送到Linux并使用Linux的java运行运行程。只要本地能运行,就能自动将代码推送到Linux运行,不需打包及设置远程debug jvm参数,适合一些项目Debug调试 运行时会推送一些依…...
【QT】Day4
1> 思维导图 2> 手动完成服务器的实现,并具体程序要注释清楚 widget.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QTcpServer> //服务器类 #include <QTcpSocket> //客户端类 #include <QMessageBox> //…...
)
在CSDN学Golang云原生(Kubernetes Pod 有状态部署)
一,StatefulSet部署MongoDB集群 Kubernetes StatefulSet 是 Kubernetes 中的一种资源类型,它能够保证有状态服务(Stateful Service)的唯一性和顺序部署,适用于需要持久化存储、网络标识、状态管理等场景。MongoDB 是一…...

sql-从一个或多个表中向一个表中插入 多行
INSERT还可以将SELECT语句查询的结果插入到表中,此时不需要把每一条记录的值一个一个输入,只需 要使用一条INSERT语句和一条SELECT语句组成的组合语句即可快速地从一个或多个表中向一个表中插入 多行。 基本语法格式如下: INSERT INTO 目标表…...

ElementUI 实现动态表单数据校验(已解决)
文章目录 🍋前言:🍍正文1、探讨需求2、查阅相关文档([element官网](https://element.eleme.cn/#/zh-CN/component/form))官方动态增减表单项示例3、需求完美解决4、注意事项 🎃专栏分享: &#…...
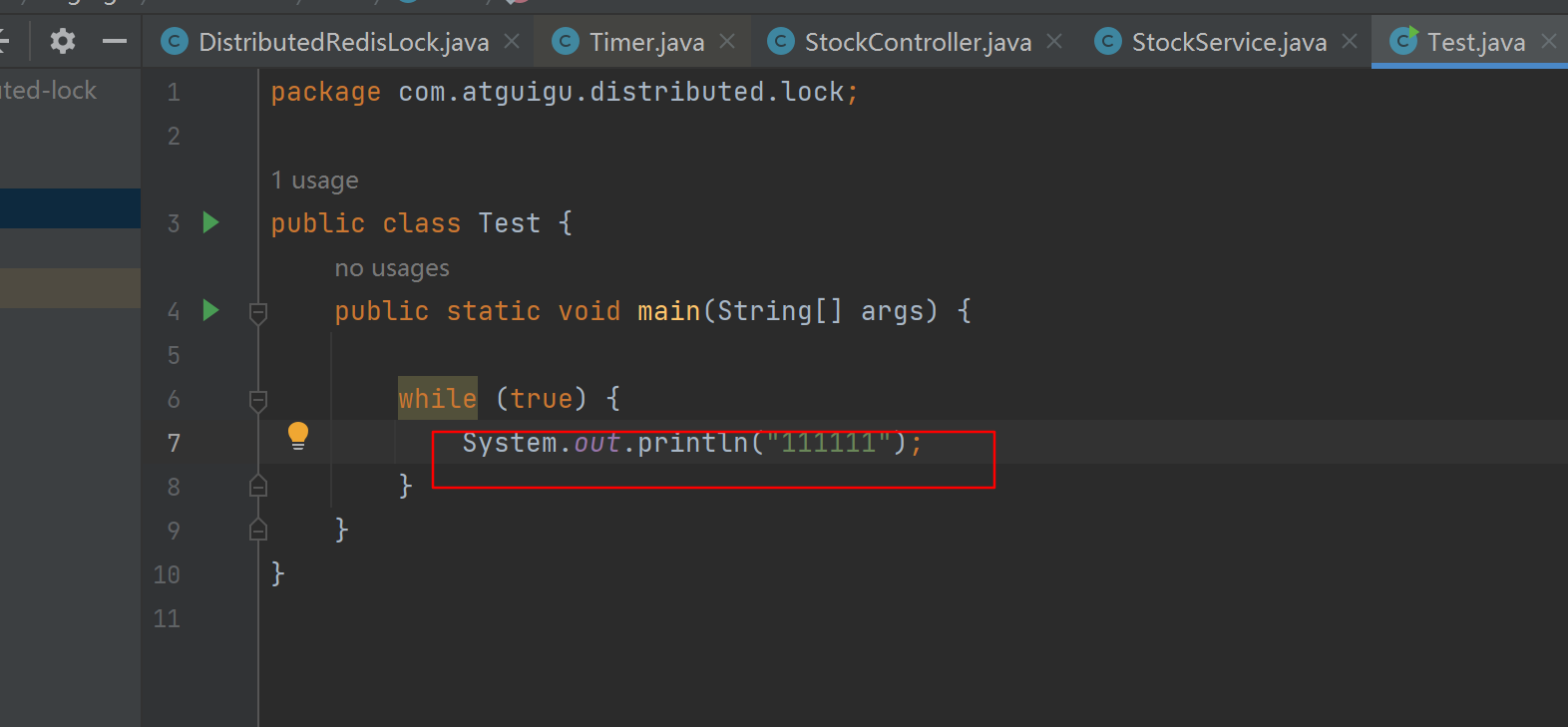
Linux上定位线上CPU飙高
【模拟场景】 写一个java main函数,死循环打印 System.out.println(“111111”) , 将其打成jar包放在linux中执行 1、通过TOP命令找到CPU耗用最厉害的那个进程的PID 2、top -H -p 进程PID 找到进程下的所有线程 可以看到 pid 为 94384的线程耗用cpu …...

06-行向量列向量_向量的运算 加法,数乘,减法,转置
行向量和列向量 行向量是按行把向量排开(横着来写), 列向量是按列把向量排开(竖着来写) 在数学中我们更多的把数据写成列向量,在编程语言中更多的把数据存成行向量! 如果想在编程语言中把行向量转化成列…...
)
基于Matlab实现最大类间方差阈值与遗传算法的道路分割(附上完整源码+图像+程序运行说明)
道路分割是计算机视觉和图像处理中的一个重要任务,它在交通监控、自动驾驶和地图制作等领域具有广泛的应用。其中,最大类间方差阈值和遗传算法是道路分割中常用的方法之一。本文将介绍如何使用Matlab实现最大类间方差阈值与遗传算法进行道路分割。 文章目…...

13.4.2 【Linux】sudo
相对于 su 需要了解新切换的使用者密码 (常常是需要 root 的密码), sudo 的执行则仅需要自己的密码即可。sudo 可以让你以其他用户的身份执行指令 (通常是使用 root 的身份来执行指令),因此并非所有人都能够…...

电脑软件:键盘按键修改器——keytweak使用介绍
对你的电脑键盘的布局不满意、键盘上的某个按键坏掉了等等键盘问题如何解决?有了KeyTweak这一切就可以轻松解决了,KeyTweak是一个免费软件程序,使用它可让你重新映射键盘键。如果您改变主意并想将其改回原样,只需点击一下即可容易…...

软件工程学术顶会——ICSE 2023 议题(网络安全方向)清单与摘要
按语:IEEE/ACM ICSE全称International Conference on Software Engineering,是软件工程领域公认的旗舰学术会议,中国计算机学会推荐的A类国际学术会议,Core Conference Ranking A*类会议,H5指数74,Impact s…...

【Python】jupyter Linux服务器使用
文章目录 环境使用访问 环境 pip install jupyter 使用 在你想访问的目录下执行: jupyter notebook --ip0.0.0.0jupyter 给出提示: [I 2023-07-28 14:32:43.589 ServerApp] Package notebook took 0.0000s to import [I 2023-07-28 14:32:43.597 Ser…...
element 级联 父传子
html代码例子 父组件 <el-cascaderstyle"width: 100%"change"unitIdChange":options"unitOptions"filterablev-model"formInline.unitId":props"unitProps"/></el-form-item>//改变级联传值到这个组件里面<r…...

【MTI 6.S081 Lab】Copy-on-write
【MTI 6.S081 Lab】Copy-on-write The problemThe solutionImplement copy-on-write fork (hard)实验任务Hints解决方案问题解决思考uvmcopykfreekallockpagerefcow_handlertrap 虚拟内存提供了一定程度的间接性:内核可以通过将PTE标记为无效或只读来拦截内存引用&a…...
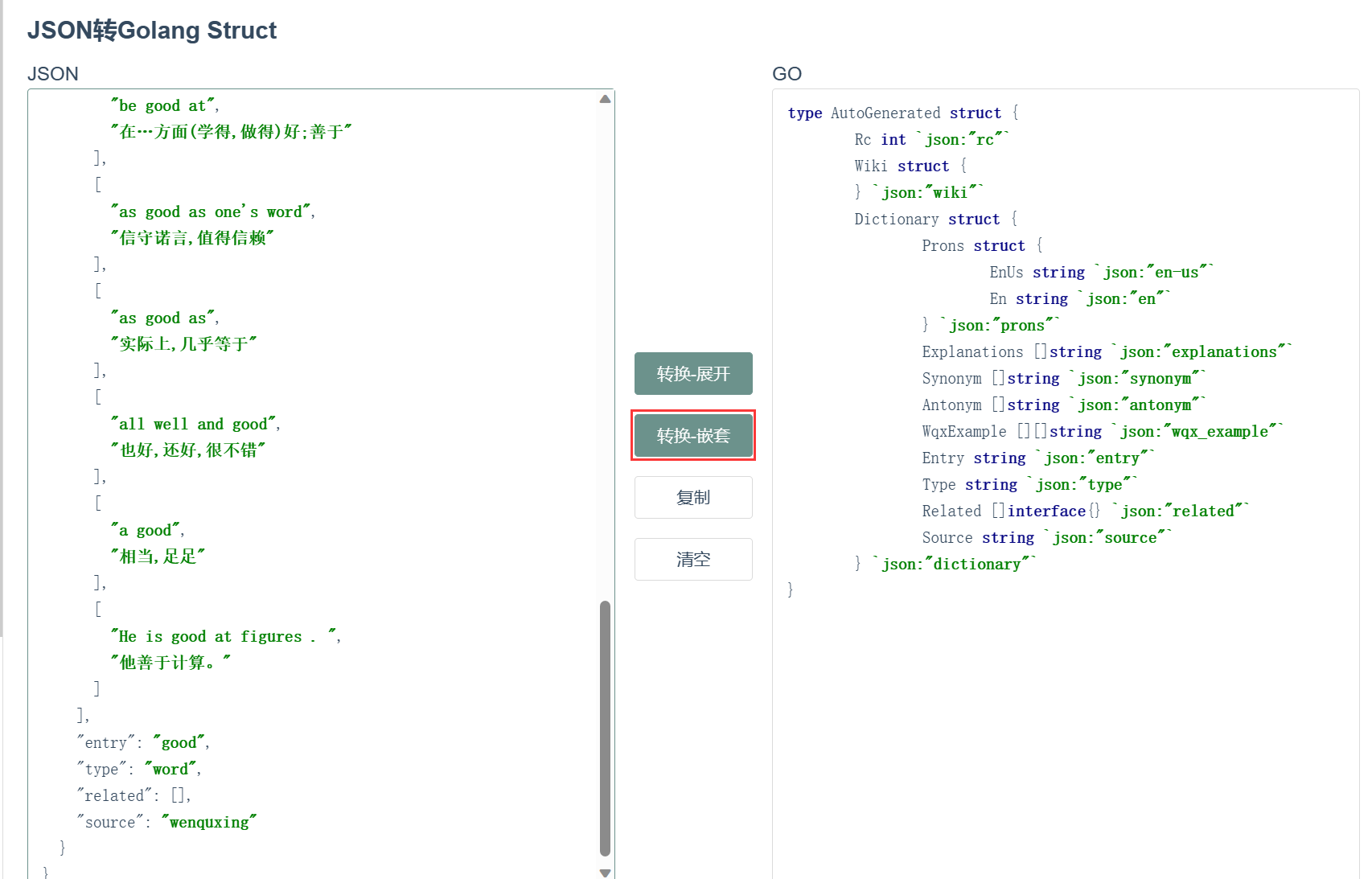
【GO】go语言入门实战 —— 命令行在线词典
文章目录 程序介绍抓包代码生成生成request body解析respond body完整代码 字节青训营基础班学习记录。 程序介绍 在运行程序的时候以命令行的形式输入要查询的单词,然后程序返回单词的音标、释义等信息。 示例如下: 抓包 我们选择与网站https://fany…...
模电模电基础知识学习笔记汇总
来源:一周搞(不)定数电模电全集,电子基础知识 11小时 一:模电学习笔记 模电主要讲述:对模拟信号进行产生、放大和处理的模拟集成电路重点知识:常用电子元器件:电阻、电容、电感、保…...
招商银行秋招攻略和考试内容详解
招商银行秋招简介 招商银行是一家股份制商业银行,银行的服务理念已经深入人心,在社会竞争愈来愈烈的今天,招商银行的招牌无疑是个香饽饽,很多人也慕名而至,纷纷向招商银行投出了简历。那么秋招银行的秋招开始时间是多…...

机器学习项目开发模式解析:从提交历史看规模、协作与演化规律
1. 项目概述:从代码提交中解码机器学习项目的真实工作流在机器学习项目的日常开发中,我们每天都在与Git打交道,提交代码、更新模型、调整参数。但你是否想过,这些看似随意的提交背后,是否隐藏着某种规律?一…...

如何免费实现NVIDIA显卡专业级色彩校准:novideo_srgb终极指南
如何免费实现NVIDIA显卡专业级色彩校准:novideo_srgb终极指南 【免费下载链接】novideo_srgb Calibrate monitors to sRGB or other color spaces on NVIDIA GPUs, based on EDID data or ICC profiles 项目地址: https://gitcode.com/gh_mirrors/no/novideo_srgb…...

BooruDatasetTagManager:重构AI训练数据标注的范式革命
BooruDatasetTagManager:重构AI训练数据标注的范式革命 【免费下载链接】BooruDatasetTagManager 项目地址: https://gitcode.com/gh_mirrors/bo/BooruDatasetTagManager 在AI模型训练领域,数据标注的质量直接影响着最终模型的性能表现。传统的标…...

UnrealPakViewer:深度剖析虚幻引擎资源包的5大可视化分析能力
UnrealPakViewer:深度剖析虚幻引擎资源包的5大可视化分析能力 【免费下载链接】UnrealPakViewer 查看 UE4 Pak 文件的图形化工具,支持 UE4 pak/ucas 文件 项目地址: https://gitcode.com/gh_mirrors/un/UnrealPakViewer UnrealPakViewer是一款专门…...

如何快速配置Atmosphere破解系统:Switch游戏体验全面升级指南
如何快速配置Atmosphere破解系统:Switch游戏体验全面升级指南 【免费下载链接】Atmosphere-stable 大气层整合包系统稳定版 项目地址: https://gitcode.com/gh_mirrors/at/Atmosphere-stable 想要让你的Nintendo Switch游戏加载速度提升65%,帧率翻…...

终极指南:如何用Sketch MeaXure插件实现高效设计标注
终极指南:如何用Sketch MeaXure插件实现高效设计标注 【免费下载链接】sketch-meaxure 项目地址: https://gitcode.com/gh_mirrors/sk/sketch-meaxure 在UI/UX设计工作流中,设计标注是连接设计与开发的关键桥梁。Sketch MeaXure作为一款基于Type…...

机器学习预测因果边界:从数据稀缺子群体到精准决策
1. 项目概述与核心挑战在医疗、经济、政策评估等关键决策领域,我们常常需要回答一个核心问题:“如果我采取了某项干预措施,结果会有什么不同?”这本质上是一个因果推断问题,它超越了简单的相关性分析,旨在揭…...

AQMLator:AutoML与量子计算融合,自动化量子机器学习模型搜索平台
1. 项目概述:当AutoML遇见量子计算如果你是一名数据科学家或机器学习工程师,最近几年肯定没少和AutoML打交道。从谷歌的AutoML Tables到开源的Auto-Sklearn、TPOT,这些工具让我们从繁琐的调参和模型选择中解放出来,把更多精力放在…...

随机森林回归与PISO算法融合:实现CFD在线模型修正与状态估计
1. 项目概述:当随机森林“遇见”PISO算法在计算流体动力学(CFD)的日常工作中,我们常常面临一个核心矛盾:物理模型的普适性与特定场景的精确性难以兼得。传统的湍流模型,无论是雷诺平均纳维-斯托克斯&#x…...

基于拓扑数据分析的脑电信号特征提取与癫痫样放电检测
1. 项目概述:从高维脑电信号到可解释的拓扑特征在神经科学和临床神经病学领域,脑电图(EEG)分析一直是诊断癫痫等神经系统疾病的核心手段。其中,发作间期癫痫样放电(Interictal Epileptic Discharges, IEDs&…...