redis高可用之主从复制,哨兵,集群
目录
前言
一、主从复制
1、主从复制的作用
2、主从复制流程
3、部署Redis 主从复制步骤
3.1 环境准备
3.3 修改Redis 配置文件(Master节点操作)
3.4 修改Redis 配置文件(Slave节点操作)
3.5 验证主从效果
二、哨兵
1、哨兵模式原理
2、哨兵模式的作用
3、哨兵结构
4、故障转移机制
4.1 由哨兵节点定期监控发现主节点是否出现了故障
4.2 当主节点出现故障
4.3 由leader哨兵节点执行故障转移,过程如下:
5、主节点的选举
6、哨兵模式的部署操作
6.1 环境准备
6.2 修改Redis哨兵模式的配置文件(所有节点操作)
6.3 启动哨兵模式
6.4 查看哨兵信息
6.5 故障模拟
三、集群
1、集群的作用,可以归纳为两点
2、Redis集群的数据分片
3、以3个节点组成的集群为例
4、Redis集群的主从复制模型
5、Redis 集群部署步骤
5.1 环境准备
5.2 创建目录复制配置文件到对应的节点上
5.3 修改主配置文件,设置开启群集功能
5.4 启动redis节点
5.5 启动集群
5.6 测试群集
前言
redis群集有三种模式,分别是主从同步/复制、哨兵模式、Cluster,下面会讲解一下三种模式的工作方式,以及如何搭建cluster群集
一、主从复制
主从复制是高可用Redis的基础,哨兵和集群都是在主从复制基础上实现高可用的。主从复制主要实现了数据的多机备份,以及对于读操作的货载均衡和简单的故障恢复。缺陷: 故障恢复无法自动化; 写操作无法负载均衡;存储能力受到单机的限制
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(Master),后者称为从节点(Slave); 数据的复制是单向的,只能由主节点到从节点。
默认情况下,每台Redis服务器都是主节点:且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
1、主从复制的作用
数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式
故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务.由从节点提供读服务 (即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载:尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制制是Redis高可用的基础。
2、主从复制流程

若启动一个slave机器进程,则它会向Master机器发送一个“synccommand"命令,请求同步连接。
无论是第一次连接还是重新连接,Master机器都会启动一个后台进程,将数据快照保存到数据文件中(执行rdb操作) ,同时Master还会记录修改数据的所有命令并缓存在数据文件中。
后台进程完成缓存操作之后,Master机器就会向slave机器发送数据文件slave端机器将数据文件保存到硬盘上,然后将其加载到内存中,接着Maste机器就会将修改数据的所有操作一并发送给slave端机器。若slave出现故障导致宕机,则恢复正常后会自动重新连接。
Master机器收到slave端机器的连接后,将其完整的数据文件发送给slave端机器,如果Mater同时收到多个slave发来的同步请求,则Master会在后台启动一个进程以保存数据文件,然后将其发送给所有的slave端机器,确保所有的slave端机器都正常。

3、部署Redis 主从复制步骤
3.1 环境准备
- master节点: 192.168.157.45 Redis
- slave1节点: 192.168.157.55 Redis
- slave2节点: 192.168.157.65 Redis
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
yum install -y gcc gcc-c++ make
#将redis-5.0.7.tar.gz的压缩包上传到/opt中
tar zxvf redis-5.0.7.tar.gz -C /opt/
cd /opt/redis-5.0.7/
make
make PREFIX=/usr/local/redis install
cd /opt/redis-5.0.7/utils
./install_server.sh
......
Please select the redis executable path [] /usr/local/redis/bin/redis-server
ln -s /usr/local/redis/bin/* /usr/local/bin/






3.3 修改Redis 配置文件(Master节点操作)
vim /etc/redis/6379.conf
bind 0.0.0.0 #70行,注释掉bind项,或修改为0.0.0.0,默认监听所有网卡
daemonize yes #137行,开启守护进程
logfile /var/log/redis_6379.log #172行,指定日志文件目录
dir /var/lib/redis/6379 #264行,指定工作目录
appendonly yes #700行,开启AOF持久化功能
/etc/init.d/redis_6379 restart


3.4 修改Redis 配置文件(Slave节点操作)
vim /etc/redis/6379.conf
bind 0.0.0.0 #70行,修改监听地址为0.0.0.0
daemonize yes #137行,开启守护进程
logfile /var/log/redis_6379.log #172行,指定日志文件目录
dir /var/lib/redis/6379 #264行,指定工作目录
replicaof 192.168.157.45 6379 #287行,取消注释并指定要同步的Master节点IP和端口
appendonly yes #700行,开启AOF持久化功能
/etc/init.d/redis_6379 restart



3.5 验证主从效果
在Master节点上看日志:
tail -f /var/log/redis_6379.log
在Master节点上验证从节点:
redis-cli
127.0.0.1:6379> info replication
二、哨兵
在主从复制的基础上,哨兵实现了自动化的故障恢复。缺陷:写操作无法负载均衡:存储能力受到单机的限制;哨兵无法对从节点进行自动故障转移,在读写分离场景下,从节点故障会导致读服务不可用,需要对从节点做额外的监控、切换操作。
主从切换技术的方法是:当服务器宕机后,需要手动一台从机切换为主机,这需要人工干预,不仅费时费力而且还会造成一段时间内服务不可用。为了解决主从复制的缺点,就有了哨兵机制制。
消兵的核心功能: 在主从复制的基础上,哨兵引入了主节点的自动故障转移
1、哨兵模式原理
哨兵(sentinel):是一个分布式系统,用于对主从结构中的每台服务器进行监控,当出现故障时通过投票机制选择新的 Master并将所有slave连接到新的Master。所以整个运行哨兵的集群的数量不得小于3个节点。
2、哨兵模式的作用
监控: 哨兵会不断地检查主节点和从节点是否运作正常。
自动故障转移:当主节点不能正常工作时,哨兵会开始自动故障转移操作,它会将失效主节点的其中一个从节点升级为新的主节点,并让其它从节点改为复制新的主节点。
通知(提醒) : 哨兵可以将故障转移的结果发送给客户端。
3、哨兵结构
哨兵结构由两部分组成,哨兵节点和数据节点:
哨兵节点: 哨兵系统由一个或多个哨兵节点组成,哨兵节点是特殊的redis节点,不存储数据。
数据节点:主节点和从节点都是数据节点。
4、故障转移机制
4.1 由哨兵节点定期监控发现主节点是否出现了故障
每个哨兵节点每隔1秒会向主节点、从节点及其它哨兵节点发送一次ping命令做一次心跳检测。如果主节点在一定时间范围内不回复或者是回复一个错误消息,那么这个哨兵就会认为这个主节点主观下线了 (单方面的) 。当超过半数哨兵节点认为该主节点主观下线了,这样就客观下线了。
4.2 当主节点出现故障
此时哨兵节点会通过Raft算法(选举算法)实现选举机制共同选举出一个哨兵节点为leader,来负责处理主节点的故障转移和通知。所以整个运行哨兵的集群的数量不得少于3个节点。
4.3 由leader哨兵节点执行故障转移,过程如下:
将某一个从节点升级为新的主节点,让其它从节点指向新的主节点;
若原主节点恢复也变成从节点,并指向新的主节点:。
通知客户端主节点已经更换。
需要特别注意的是:客观下线是主节点才有的概念;如果从节点和哨兵节点发生故障,被哨兵主观下线后,不会再有后续的客观下线和故障转移操作。
5、主节点的选举
过滤掉不健康的(已下线的),没有回复哨兵 ping 响应的从节点。
选择配置文件中从节点优先级配置最高的。 (replica-priority,默认值为100)
选择复制偏移量最大,也就是复制最完整的从节点。
6、哨兵模式的部署操作
6.1 环境准备
master节点: 192.168.229.66 Redis
slave1节点: 192.168.229.22 Redis
slave2节点: 192.168.229.200 Redis
6.2 修改Redis哨兵模式的配置文件(所有节点操作)
vim /opt/redis-5.0.7/sentinel.conf
protected-mode no #17行,关闭保护模式
port 26379 #21行,Redis哨兵默认的监听端口
daemonize yes #26行,指定sentinel为后台启动
logfile "/var/log/sentinel.log" #36行,指定日志存放路径
dir "/var/lib/redis/6379" #65行,指定数据库存放路径
sentinel monitor mymaster 192.168.2.66 6379 2 #84行, 修改
指定该哨兵节点监控192.168.2.66:6379这个主节点,该主节点的名称是mymaster,最后的2的含义与主节点的故障判定有关:至少需要2个哨兵节点同意,才能判定主节点故障并进行故障转移
sentinel down-after-milliseconds mymaster 30000 #113行,判定服务器down掉的时间周期,默认30000毫秒(30秒)
sentinel failover-timeout mymaster 180000 #146行,故障节点的最大超时时间为180000 (180秒 )
6.3 启动哨兵模式
注意:先启master,再启slave
cd /opt/redis-5.0.7/
redis-sentinel sentinel.conf &
6.4 查看哨兵信息
redis-cli -p 26379 info Sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=192.168.200.10:6379,slaves=2,sentinels=3
6.5 故障模拟
#查看redis-server进程号(在Master 上进行):
ps -ef | grep redis
5 S root 57521 1 0 80 0 - 39869 ep_pol 15:31 ? 00:00:02 /usr/local/redis/bin/redis-server 0.0.0.0:6379
5 S root 57951 1 0 80 0 - 38461 ep_pol 16:00 ? 00:00:01 redis-sentinel *:26379 [sentinel]
0 R root 58035 15559 0 80 0 - 28169 - 16:08 pts/2 00:00:00 grep --color=auto redis
#杀死 Master 节点上redis-server的进程号
kill -9 57521 #Master节点上redis-server的进程号
#验证结果,查看master是转换至从服务器
tail -f /var/log/sentinel.log
#在Slave1上查看是否转换成功
redis-cli -p 26379 INFO Sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=192.168.200.20:6379,slaves=2,sentinels=3
三、集群
通过集群,Redis解决了写操作无法负载均衡,以及存储能力受到单机限制的问题,实现了较为完善的高可用方案。
• 集群,即 Redis Cluster, 是Redis 3. 0开始引入的分布式存储方案
• 集群由多个节点(Node) 组成,Redis 的数据分布在这些节点中。集群中的节点分为主节点和从节点;只有主节点负责读写请求和集群信息的维护;从节点只进行主节点数据和状态信息的复制
• 集群中的节点分为主节点和从节点
主节点负责读写请求和集群信息的维护;
从节点只进行主节点数据和状态信息的复制
1、集群的作用,可以归纳为两点
① 数据分区:数据分区(或称数据分片) 是集群最核心的功能
集群将数据分散到多个节点,一方面突破了 Redis 单机内存大小的限制,存储容量大大增加;另一方面每个主节点都可以对外提供读服务和写服务,大大提高了集群的响应能力。
Redis 单机内存大小受限问题,在介绍持久化和主从复制时都有提及;例如,如果单机内存太大,bgsave 和 bgrewriteaof的 fork 操作可能导致主进程阻塞,主从环境下主机切换时可能导致从节点长时间无法提供服务,全量复制阶段主节点的复制缓冲区可能溢出
② 高可用:集群支持主从复制和主节点的自动故障转移(与哨兵类似) ;当任一节点发生故障时,集群仍然可以对外提供服务
2、Redis集群的数据分片
Redis集群引入了哈希槽的概念
• Redis集群有 16384 个哈希槽( 编号0-16383)
• 集群的每个节点负责一部分哈希槽
• 每个Key 通过 CRC16 校验后对16384取余来决定放置哪个哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作
3、以3个节点组成的集群为例
节点A 包含0到5460号哈希槽
节点B 包含5461到10922号哈希槽
节点C 包含10923到16383号哈希槽
4、Redis集群的主从复制模型
集群中具有A、B、C三个节点,如果节点B失败了,整个集群就会因缺少5461-10922这个范围的槽而不可以用。
为每个节点添加一个从节点A1、B1、C1整个集群便有三个Master节点和三个slave节点组成,在节点B失败后,集群选举B1位为主节点继续服务。当B和B1都失败后,集群将不可用
5、Redis 集群部署步骤
5.1 环境准备
redis的集群一般需要6个节点, 3主3从。
方便起见,这里所有节点在同一台服务器上模拟: 以端口号进行区分: 3个主节点端口号: 6001/6002/6003, 对应的从节点端口号: 6004/6005/6006
5.2 创建目录复制配置文件到对应的节点上
cd /etc/redis/
mkdir -p redis-cluster/redis600{1..6}
for i in {1. .6}
do
cp /opt/redis-5.0.7/redis.conf /etc/redis/redis-cluster/redis600$i
cp /opt/redis-5.0.7/src/redis-cli /opt/redis-5.0.7/src/redis-server /etc/redis/redis-cluster/redis600$i
done
5.3 修改主配置文件,设置开启群集功能
其他5个文件夹的配置文件以此类推修改,注意6个端口都要不一样
cd /etc/redis/redis-cluster/redis6001
vim redis.conf
#bind 127.0.0.1 #69行,注释掉bind项,默认监听所有网卡
protected-mode no #88行,修改,关闭保护模式
port 6001 #92行,修改,redis监听端口
daemonize yes #136行,开启守护进程,以独立进程启动
appendonly yes #699行,修改,开启AOF持久化
cluster-enabled yes #832行,取消注释,开启群集功能
cluster-config-file nodes-6001.conf #840行,取消注释,群集名称文件设置
cluster-node-timeout 15000 #846行,取消注释群集超时时间设置
#可以写一个for循环将6001的文件复制给6002~6006,这样就不需要全部一个一个文件进行修改了
for i in {2..6}
do
/usr/bin/cp -f /etc/redis/redis-cluster/redis6001/redis.conf /etc/redis/redis-cluster/redis600$i/redis.conf
done
#之后稍微修改文件即可
5.4 启动redis节点
方法一:<br>分别进入那六个文件夹,执行命令: redis-server redis.conf,来启动redis节点
cd /etc/redis/redis-cluster/redis6001
redis-server redis.conf
<br>方法二:使用for循环
for d in {1..6}
do
cd /etc/redis/redis-cluster/redis600$d
redis-server redis.conf
done
ps -ef | grep redis
5.5 启动集群
redis-cli --cluster create 127.0.0.1:6001 127.0.0.1:6002 127.0.0.1:6003 127.0.0.1:6004 127.0.0.1:6005 127.0.0.1:6006 --cluster-replicas 1
#六个实例分为三组,每组一主一从,前面的做主节点,后面的做从节点。下面交互的时候需要输入yes 才可以创建。
-replicas 1 #表示每个主节点有1个从节点。
5.6 测试群集
redis-cli -p 6001 -c #加-c参数,节点之间就可以互相跳转
127.0.0.1:6001> cluster slots #查看节点的哈希槽编号范围
1) 1) (integer) 5461
2) (integer) 10922 #哈希槽编号范围
3) 1) "127.0.0.1" .
2) (integer) 6003 #主节点IP和端口号
3) " fdca661922216dd69a 63a7c9d3c4540cd6baef44"
4) 1) "127.0.0.1"
2) (integer) 6004 #从节点IP和端口号
3) "a2c0c32aff0f38980accd2b63d6d952812e44740"
2) 1) (integer) 0
2) (integer) 5460
3) 1) "127.0.0.1"
2) (integer) 6001
3) "0e5873747a2e2 6bdc935bc76c2ba fb19d0a54b11"
4) 1) "127.0.0.1"
2) (integer) 6006
3) "8842ef5584a85005e135fd0ee59e5a0d67b0cf8e"
3) 1) (integer) 10923
2) (integer) 16383
3) 1) "127.0.0.1"
2) (integer) 6002
3) "81 6ddaa3d14 69540b2f fbcaaf9aa867646846b30"
4) 1) "127.0.0.1"
2) (integer) 6005
3) "f847077bfe6722466e96178ae8cbb09dc8b4d5eb"
127.0.0.1:6001> set name zhangsan
-> Redirected to slot [5798] located at 127.0.0.1: 6003
OK
127.0.0.1:6001> cluster keyslot name #查看name键的槽编号
(integer) 5798
相关文章:
redis高可用之主从复制,哨兵,集群
目录 前言 一、主从复制 1、主从复制的作用 2、主从复制流程 3、部署Redis 主从复制步骤 3.1 环境准备 3.3 修改Redis 配置文件(Master节点操作) 3.4 修改Redis 配置文件(Slave节点操作) 3.5 验证主从效果 二、哨兵 1、哨兵模式原理 2、哨兵模式…...
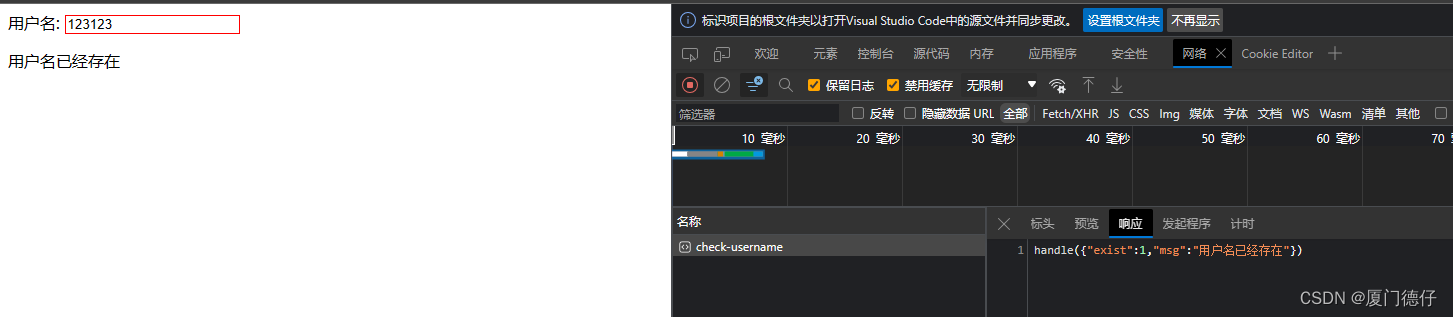
【Ajax】笔记-原生jsonp跨域请求案例
原生jsonp跨域请求 输入框:输入后,鼠标移开向服务端发送请求,返回用户不存在(直接返回不存在,不做判断) JS <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><me…...
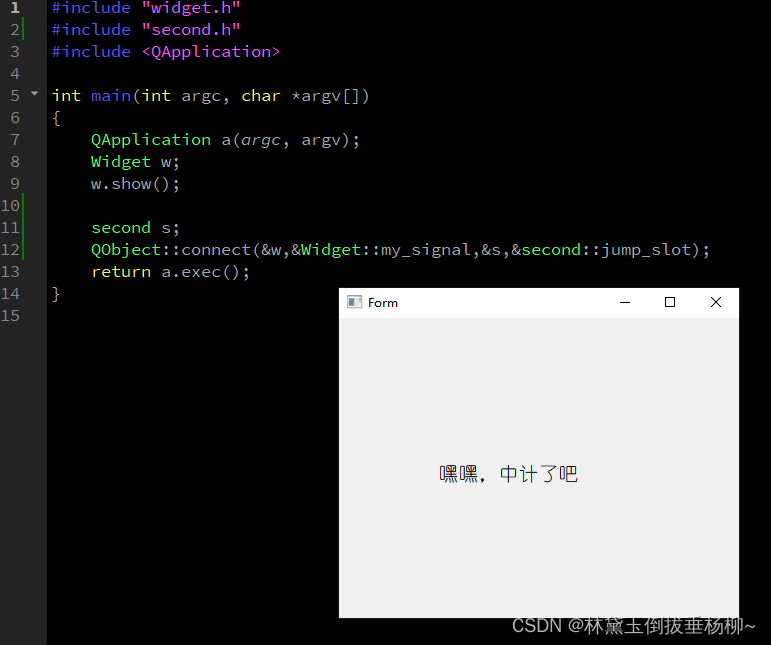
QT--day2(信号与槽,多界面跳转)
第一个界面头文件: #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QIcon> //图标头文件 #include <QPushButton> //按钮类头文件QT_BEGIN_NAMESPACE namespace Ui { class Widget; } QT_END_NAMESPACEclass Widget : public…...

热备份路由协议原理
热备份路由协议原理 HSRP协议/VRRP协议热备份协议 热备份协议(Hot Standby Protocol) 是一种基于冗余设计的协议,用于提高网络的可靠性和冗余性。它允许多个设备共享同一个IP地址,其中一个设备被选为主设备,其他设备…...

模拟实现定时器
关于java标准库中的定时器的使用可以看定时器Timer的使用 大致思路 定义一个MyTimeTask类,该类用于组织要执行任务的内容以及执行任务的时间戳,后面要根据当前系统时间以及执行任务的时间戳进行比较,来判断是否要执行任务或是要等待任务 用一…...

TCP/IP的分包粘包
TCP/IP的分包粘包 分包粘包介绍导致分包粘包的原因导致TCP粘包的原因:导致TCP分包的原因:避免分包粘包的措施 分包粘包介绍 因为TCP为了减少额外开销,采取的是流式传输,所以接收端在一次接收的时候有可能一次接收多个包。而TCP粘…...

盘点:查快递教程
在“寄快递”成为常态的当下,如何快速进行物流信息查询,是收寄人所关心的问题。在回答这个问题之前,首先我们要知道,物流信息查询,有哪些方法? 1、官网单号查询 知道物流公司和单号的情况下,直…...
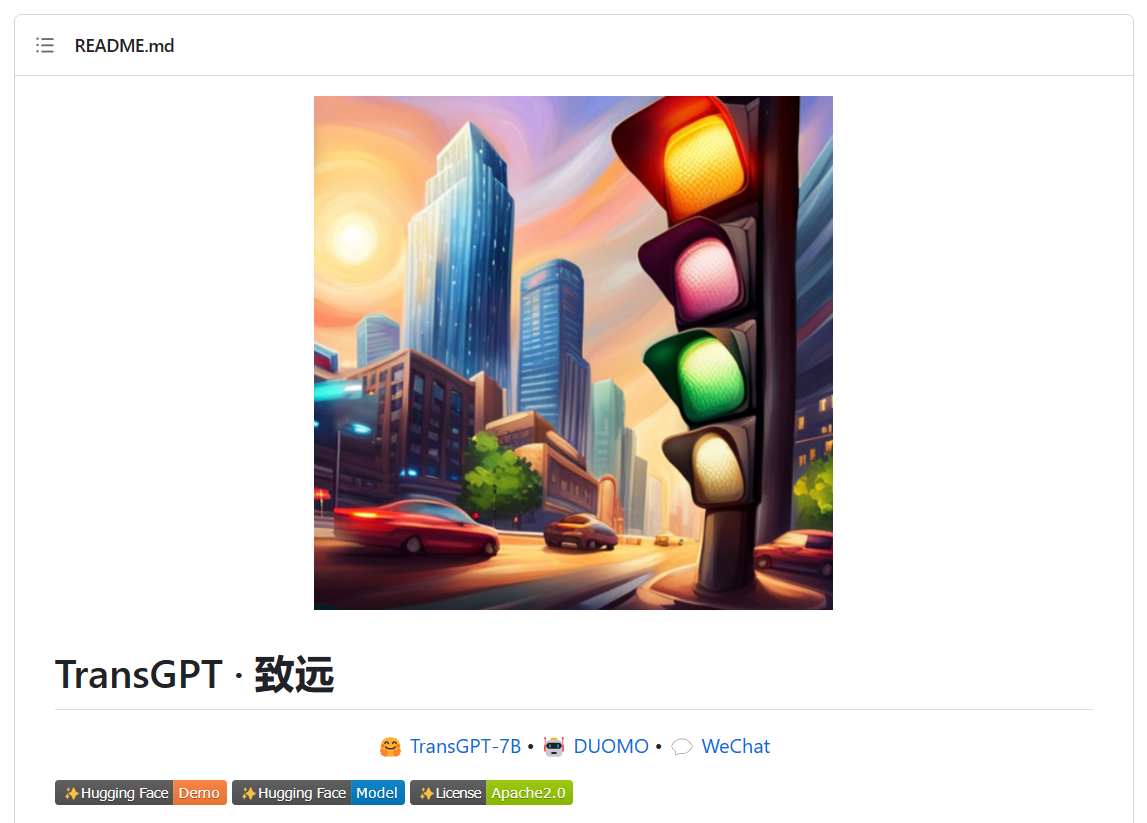
TransGPT 开源交通大模型开源
TransGPT 是开源交通大模型,主要致力于在真实交通行业中发挥实际价值。 它能够实现交通情况预测、智能咨询助手、公共交通服务、交通规划设计、交通安全教育、协助管理、交通事故报告和分析、自动驾驶辅助系统等功能。 TransGPT 作为一个通用常识交通大模型&#…...
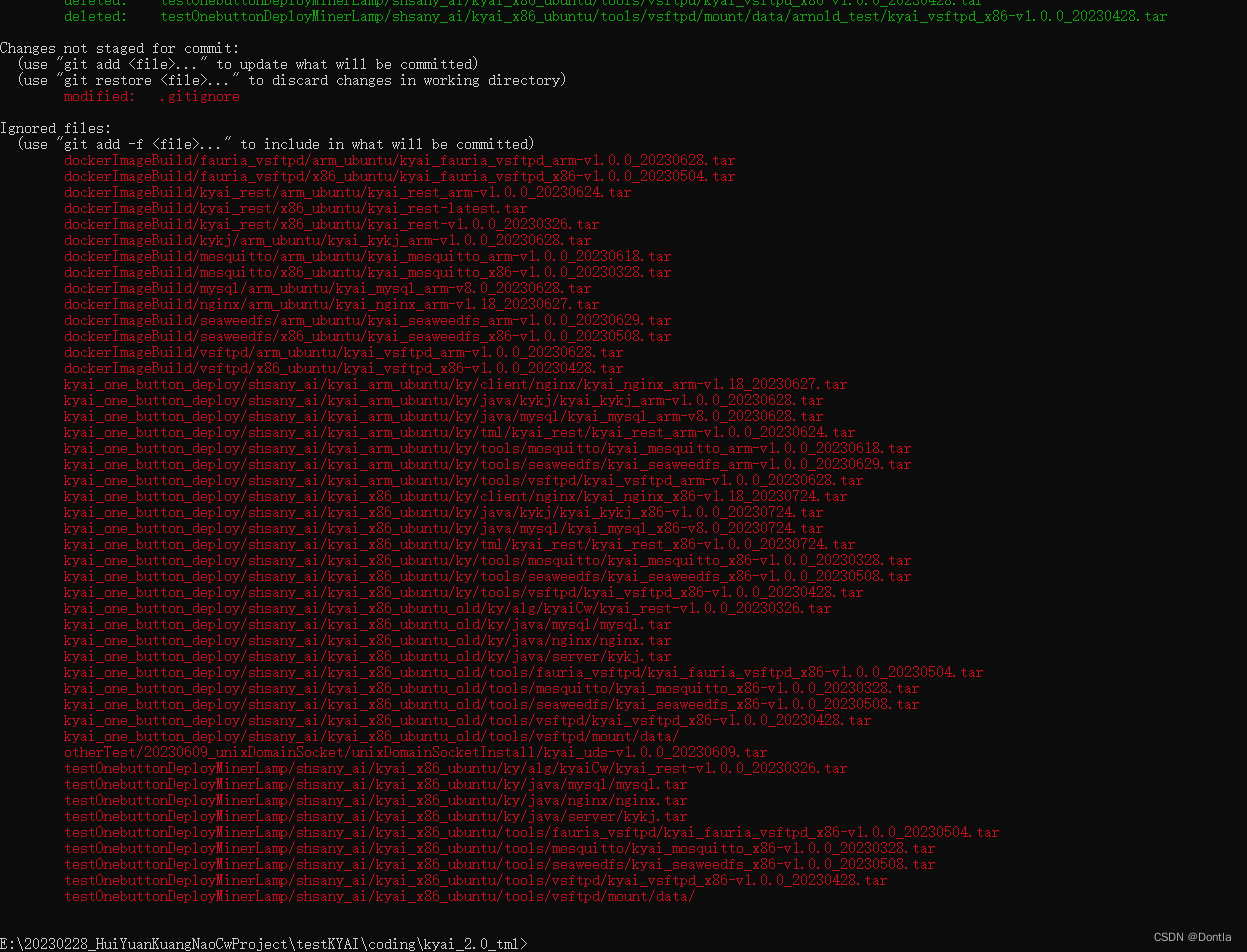
gitignore文件使用方法(gitignore教程)(git status --ignored)(git check-ignore -v <file>)
文章目录 Gitignore文件使用描述Gitignore基本语法1. 基本语法★★★★★2. 配置方法 匹配示例示例1示例2示例3 其他命令git status --ignored(用于显示被Git忽略的文件和文件夹的状态)git check-ignore -v <file>(用于检查指定文件是否…...

mybatis拼接sql导致的oom报错 GC报错
报错1:mybatis拼接过多 java.lang.OutOfMemoryError: GC overhead limit exceeded 具体报错: nested exception is org.apache.ibatis.builder.BuilderException: Error evaluating expression ew.sqlSegment ! null and ew.sqlSegment ! and ew.non…...

如何通俗理解扩散模型?
扩散模型(Diffusion Model)是一类十分先进的基于扩散思想的深度学习生 成模型。生成模型除了扩散模型之外,还有出现较早的 VAE ( Variational Auto- Encoder,变分自编码器) 和 GAN ( Generative Adversarial Net ,生成对抗网络) 等。 虽然它们…...
【C#】并行编程实战:并行编程中的模式
本章将介绍并行编程模式,重点是理解并行代码问题场景并使用并行编程/异步技术解决他们。本章会介绍几种最重要的编程模式。 本教程学习工程:魔术师Dix / HandsOnParallelProgramming GitCode 1、MapReduce 模式 引入 MapReduce 是为了解决处理大数据的问…...

Apache Kafka 入门教程
Apache Kafka 入门教程 一、简介简介架构 二、Kafka 安装和配置JDK安装 Kafka配置文件详解 三、Kafka 的基本操作启动和关闭Topic 创建和删除Partitions 和 Replication 配置Producer 和 Consumer 使用方法ProducerConsumer 四、Kafka 高级应用消息的可靠性保证Kafka StreamKaf…...
python皮卡丘编程代码教程,用python打印皮卡丘
大家好,小编来为大家解答以下问题,如何用print函数打印一只皮卡丘,用python如何打印丘比特之心,现在让我们一起来看看吧!...
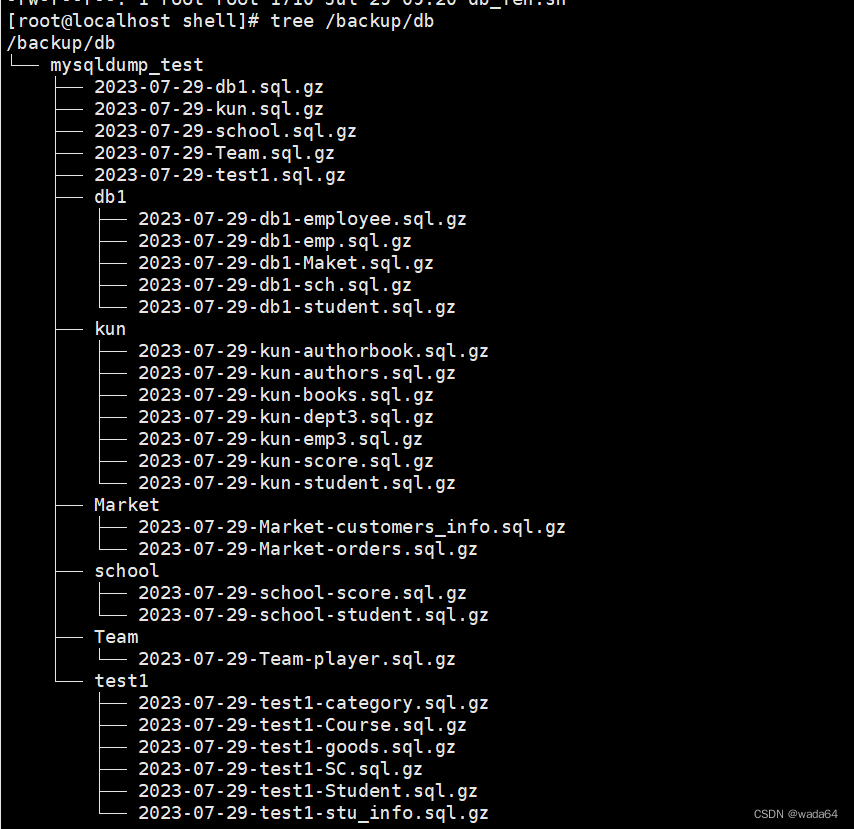
shell脚本:数据库的分库分表
#!/bin/bash ######################### #File name:db_fen.sh #Version:v1.0 #Email:admintest.com #Created time:2023-07-29 09:18:52 #Description: ########################## MySQL连接信息 db_user"root" db_password"RedHat123" db_cmd"-u${…...
)
AtCoder Beginner Contest 312(A~D)
A //语法题也要更仔细嘞,要不然也会wa #include <bits/stdc.h> // #pragma GCC optimize(3,"Ofast","inline") // #pragma GCC optimize(2) using namespace std; typedef long long LL; #define int LL typedef pair<int, int> …...

SQL中Partition的相关用法
使用Partition可以根据指定的列或表达式将数据分成多个分区。每个分区都是逻辑上独立的,可以单独进行查询、插入、更新和删除操作。Partition可以提高查询性能,因为它可以限制在特定分区上执行查询,而不是在整个表上执行。 在SQL中ÿ…...
微服务——Docker
docker与虚拟机的区别 首先要知道三个层次 硬件层:计算机硬件 内核层:与硬件交互,提供操作硬件的指令 应用层: 系统应用封装内核指令为函数,便于程序员调用。用户程序基于系统函数库实现功能。 docker在打包的时候直接把应用层的函数库也进行打包&a…...

测试|测试用例方法篇
测试|测试用例方法篇 文章目录 测试|测试用例方法篇1.测试用例的基本要素:测试环境,操作步骤,测试数据,预期结果…2.测试用例带来的好处3.测试用例的设计思路,设计方法,具体设计方法之间的关系**设计测试用…...

负载均衡的策略有哪些? 负载均衡的三种方式?
负载均衡的策略有哪些? 负载均衡的策略有如下: 1. 轮询(Round Robin):按照请求的顺序轮流分配到不同的服务器。 2. 权重(Weighted):给不同的服务器分配不同的权重,根据权重比例来…...

五八同城登录接口逆向:RSA加密、动态salt与sign验签实战
1. 这不是“爬个登录”那么简单:五八同城登录接口逆向的真实战场你点开浏览器开发者工具,F12,Network 面板里筛选 XHR,找到那个/login请求,点开看 Headers 和 Payload —— 然后傻眼了:password字段是一串 …...

Android系统级证书注入:突破HTTPS抓包限制的完整方案
1. 这不是“换个证书”那么简单:为什么系统级证书安装成了Android抓包真正的分水岭你肯定试过在Android手机上用Charles抓包——App打开,Charles配好代理,手机Wi-Fi设好代理地址,点开浏览器,流量哗哗进来了。但一打开微…...

The Front 末日生存战争游戏专属服务器搭建教程
The Front 末日生存战争游戏专属服务器搭建教程 《The Front》(前线)是一款以末日废土为背景的多人生存建造游戏,玩家在充满战争气息的废土世界中采集资源、建造据点、研发科技、与其他玩家或 NPC 势力展开激烈对抗。自建专属服务器可以让你…...

告别调参噩梦!用Ball k-means在Python里5分钟搞定百万级数据聚类
百万级数据聚类的革命:用Ball k-means实现Python高效实战 当你的数据集膨胀到百万级别时,传统k-means算法突然变得像老牛拉车——迭代缓慢、调参困难、内存告急。我曾在一个电商用户分群项目中,面对120万条用户行为数据,sklearn的…...

实测天下工厂:用它找工厂客户,数据准不准、覆盖全不全?
做 B2B 销售的人都知道,找到一份"高质量工厂名单"有多难。 不是因为工厂数量少,而是因为现有渠道普遍存在一个结构性问题:工厂和非工厂混在一起,分不清楚。用通用企业查询工具检索某个行业,跑出来的结果里&a…...
)
从纸质报表到Excel:PaddleOCR+Python自动化识别复杂表格(附完整代码)
金融表格自动化革命:用PaddleOCRPython实现纸质报表秒转Excel每次月末结算时,财务部的张经理总要面对堆积如山的纸质报表——供应商对账单、银行流水单、税务申报表,这些表格往往带有手写注释、合并单元格和模糊印章。传统的人工录入不仅耗时…...

五轴联动机床:什么叫真正做出来了,什么叫组装贴牌
机床厂的数量从来不是问题。打开任何一份机床企业名录,数以千计的厂商密密麻麻排在那里,官网上都写着"五轴联动"“高精度数控”“航空级加工”。但做五轴联动整机与自主数控系统的工厂,放到整个行业里只是极小的一部分;…...

【应用实战】基于Dify与多Agent的凭证与档案管理
一、智能文档处理:基于Dify与多Agent的凭证与档案管理革新 在金融行业,文档处理贯穿业务始终。传统的纯人工方式不仅耗时费力,而且极易出错。智能文档处理(Intelligent Document Processing, IDP)融合了OCR、自然语言处…...

洛雪音乐音源:打破音乐平台壁垒的聚合解决方案
洛雪音乐音源:打破音乐平台壁垒的聚合解决方案 【免费下载链接】lxmusic- lxmusic(洛雪音乐)全网最新最全音源 项目地址: https://gitcode.com/gh_mirrors/lx/lxmusic- 你是否曾经为了听一首歌而在多个音乐平台之间来回切换?或者因为某个平台没有…...

联发科MT6833与MT6853 5G核心板:规格对比与产品选型实战指南
1. 项目概述:两款5G安卓核心板的定位与价值在当前的移动设备开发领域,尤其是面向中高端市场的智能手机、平板电脑以及各类智能终端,选择一颗性能强劲、功能集成度高且成本可控的核心处理器平台,是决定产品成败的关键。联发科&…...