【C#】并行编程实战:并行编程中的模式
本章将介绍并行编程模式,重点是理解并行代码问题场景并使用并行编程/异步技术解决他们。本章会介绍几种最重要的编程模式。
本教程学习工程:魔术师Dix / HandsOnParallelProgramming · GitCode
1、MapReduce 模式
引入 MapReduce 是为了解决处理大数据的问题,例如跨服务器的大规模计算需求。该模式可以在单核计算机上使用。
1.1、映射和归约
MapReduce 程序顾名思义,即 Map(映射) + Reduce(归约)。MapReduce 程序的输入作为键值对被传递,输出也是同样形式。
书上讲的听起来很抽象,画张图来辅助理解:
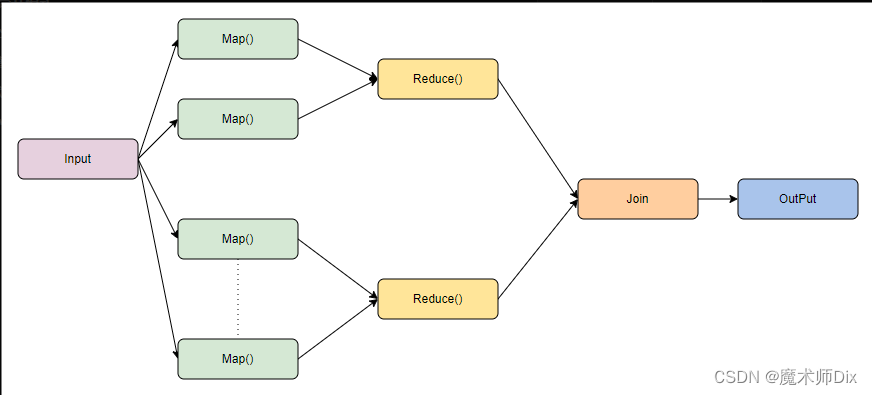
输入一个列表,然后通过某种方式先进行筛选(返回列表),然后进行分组(返回键值),最后返回各个分组的键值对作为结果:
1.2、使用 LINQ 实现 MapReduce
其示例中,扩展方法如下:
public static ParallelQuery<TResult> MapReduce<TSource, TMapped, TKey, TResult>(this ParallelQuery<TSource> source,Func<TSource, IEnumerable<TMapped>> map,Func<TMapped, TKey> keySelector,Func<IGrouping<TKey, TMapped>, IEnumerable<TResult>> reduce){return source.SelectMany(map).GroupBy(keySelector).SelectMany(reduce);}我们用一个需求来理解这段函数:
-
源数据为 1000 个 -100~100 的随机数;
-
筛选出其中的正数;
-
将其按照10位进行分组(0~9一组、10~19一组,以此类推);
-
统计每个分组的个数。
那么,使用上述 MapReduce 模板进行处理,示例代码如下:
private void RunMapReduce(){//初始化原始数据int length = 1000;List<int> L = new List<int>(length);for (int i = 0; i < length; i++){L.Add(Random.Range(-100, 100));}var ret = L.AsParallel().MapReduce(mapPositiveNumbers,//筛选正数groupNumbers,//映射分组reduceNumbers);//归约合并结果foreach (var item in ret){Debug.Log($"{item.Key * 10} ~ {(item.Key + 1) * 10} 出现了:{item.Value} 次 !");}}public static IEnumerable<int> mapPositiveNumbers(int number){IList<int> PositiveNumbers = new List<int>();if (number > 0)PositiveNumbers.Add(number);return PositiveNumbers;}public static int groupNumbers(int number){return number / 10;}public static IEnumerable<KeyValuePair<int, int>> reduceNumbers(IGrouping<int, int> grouping){return new[]{new KeyValuePair<int, int>(grouping.Key,grouping.Count())};}运行结果如下所示:
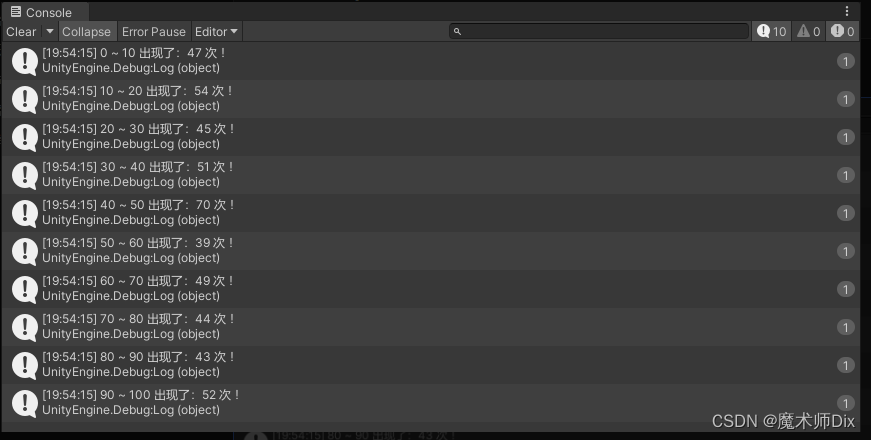
通过上述示例,这个映射与归约就容易理解多了:实际上就是某一种特定的业务模板写法:筛选 → 分组 → 合并。在并行编程中,类似这样的写法都可以通过同样的模板代码实现。
2、聚合
聚合(Aggregation)是并行应用程序中使用的另一种常见的设计模式。在并行程序中,数据被划分为多个单元,以便可以通过多个线程在内核之间进行处理。在某个时候,需要将所有相关来源数据组合起来,然后才能呈现给用户。
书上的例子只讨论了使用 PLINQ 代码的示例,我们也照着写一个:
private void RunAggregation(){var L = Utils.GetOrderList(10);var L2 = L.AsParallel().Select(TestFunction.IntToString)//并行处理.ToList();//合并foreach (var item in L2)Debug.Log(item);}public static string IntToString(int x){return $"ToString_{x}";}上述代码运行结果如下:
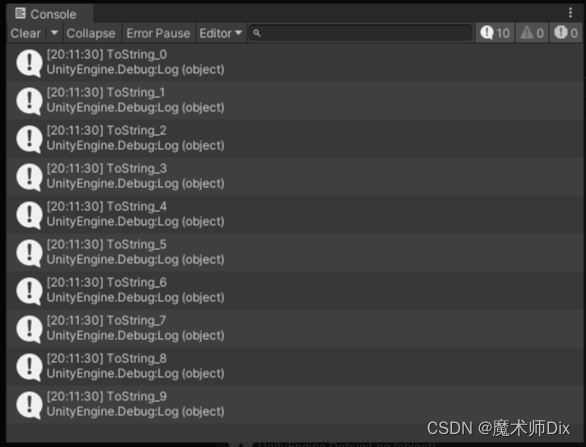
可以看到,这个运行模式是保证顺序的(源数据是List)。
一般来讲,我们为了避免锁、同步等额外处理,要么使用 PLINQ 这样的语法,要么使用并发集合。这样可以减少我们需要手动处理锁、同步等工作。
3、分叉/合并模式
在分叉/合并(Fork/Join)模式中,工作被分叉(拆分)为一组可以异步执行的任务,然后根据并行化的要求和范围,以相同(或不同)的顺序合并分叉的任务。
分叉/合并模式常见的一些实现如下:
-
Parallel.For
-
Parallel.ForEach
-
Paralle.Invoke
-
System.Threading.CountdownEvent
利用这些同步框架开发人员能快速实现开发,而不必担心同步开销(系统已经内部处理同步了,实际上如如果额外开销不可接受,用这些 API 也没办法优化)。
我们将之前的代码通过 分叉/合并模式 再改一版:
private void RunForkJoin(){var L = Utils.GetOrderList(10);ConcurrentQueue<string> queue = new ConcurrentQueue<string>();Parallel.For(0, L.Count, x =>{var ret = IntToString(x);queue.Enqueue(ret);});while (queue.Count > 0){string str;if (queue.TryDequeue(out str))Debug.Log(str);}}这次我们看运行结果:
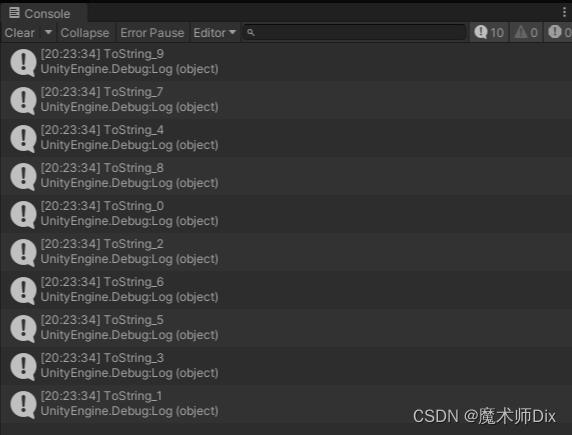
很显然,已经乱序了,这种模式就没有按照原来数据顺序进行数据处理。这也是这个模式的特点之一,我们可以选择是否要按照顺序进行合并。
4、推测处理模式
推测处理模式(Speculative Processing Pattern)是依赖高吞吐量以减少等待时间的另一种并行编程模式。
推测处理模式(Speculative Processing Pattern):
如果同时存在多种处理任务,但并不知道哪一种方式速度最快。因此第一个执行的完成的任务将被输出,其他任务处理结果将会忽略。
以下是一种推测处理模式的常见写法:
//选择一个最快执行方法的结果并返回public static TResut SpeculativeForEach<TSource, TResut>(TSource source, IEnumerable<Func<TSource, TResut>> funcs){TResut result = default;Parallel.ForEach(funcs, (func, loopState) =>{result = func(source);loopState.Stop();});return result;}//返回特定方法的最快执行结果并返回public static TResut SpeculativeForEach<TSource, TResut>(IEnumerable<TSource> source, Func<TSource, TResut> func){TResut result = default;Parallel.ForEach(source, (item, loopState) =>{result = func(item);loopState.Stop();});return result;}这种写法只会返回一个结果,首先完成的任务将被返回。但是其他任务仍然有可能执行完成,只是结果将不会被返回。
这里我们选择方法一进行示例,调用代码如下:
private void RunSpeculativeMethod_1(){Debug.Log($">===== RunSpeculativeMethod_1 开始 =====<");var L1 = new List<Func<int, string>>{IntToString,IntToString2};string result = SpeculativeForEach(4, L1);Debug.Log($"运行结果:{result}");}连续运行2次,其结果如下:
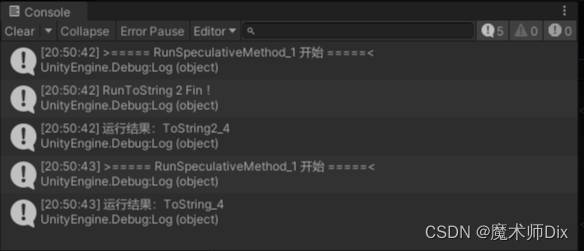
第一次是使用了 IntToString2 的结果,而第二次使用的 IntToString 的结果。
5、延迟模式
也就是在使用时才创建,也就是懒加载。这个在之前的章节中已经有详细介绍了,这里就不重复了。
详见:使用延迟初始化提高性能
【C#】并行编程实战:使用延迟初始化提高性能_魔术师Dix的博客-CSDN博客在前面的章节中讨论了 C# 中线程安全并发集合,有助于提高代码性能、降低同步开销。本章将讨论更多有助于提高性能的概念,包括使用自定义实现的内置构造。本章主要内容为通过延迟初始化提高性能,相对比较简单。https://blog.csdn.net/cyf649669121/article/details/131780600
6、共享状态模式
这个主要在 【C#】并行编程实战:同步原语(1)_魔术师Dix的博客-CSDN博客 中已经介绍过共享状态(Shared State Pattern)的实现(其实就是各种加锁,搞的好像很高级)。
不过上锁不能上太多,不然性能很差;而且我们也应该尽可能实现无锁代码。
7、本章小结
本章介绍了各种并行编程模式,其实就是各种模板的示例。当然,这里讲的不可能包罗所有,只是给大家提供一些参考。至此,多线程编程的学习告一段落,书上的内容已经讲完了。后续如果有补充会加到这个系列里。
多线程的实践还是需要在项目中多多练习。
本教程学习工程:魔术师Dix / HandsOnParallelProgramming · GitCode
相关文章:
【C#】并行编程实战:并行编程中的模式
本章将介绍并行编程模式,重点是理解并行代码问题场景并使用并行编程/异步技术解决他们。本章会介绍几种最重要的编程模式。 本教程学习工程:魔术师Dix / HandsOnParallelProgramming GitCode 1、MapReduce 模式 引入 MapReduce 是为了解决处理大数据的问…...

Apache Kafka 入门教程
Apache Kafka 入门教程 一、简介简介架构 二、Kafka 安装和配置JDK安装 Kafka配置文件详解 三、Kafka 的基本操作启动和关闭Topic 创建和删除Partitions 和 Replication 配置Producer 和 Consumer 使用方法ProducerConsumer 四、Kafka 高级应用消息的可靠性保证Kafka StreamKaf…...
python皮卡丘编程代码教程,用python打印皮卡丘
大家好,小编来为大家解答以下问题,如何用print函数打印一只皮卡丘,用python如何打印丘比特之心,现在让我们一起来看看吧!...
shell脚本:数据库的分库分表
#!/bin/bash ######################### #File name:db_fen.sh #Version:v1.0 #Email:admintest.com #Created time:2023-07-29 09:18:52 #Description: ########################## MySQL连接信息 db_user"root" db_password"RedHat123" db_cmd"-u${…...
)
AtCoder Beginner Contest 312(A~D)
A //语法题也要更仔细嘞,要不然也会wa #include <bits/stdc.h> // #pragma GCC optimize(3,"Ofast","inline") // #pragma GCC optimize(2) using namespace std; typedef long long LL; #define int LL typedef pair<int, int> …...

SQL中Partition的相关用法
使用Partition可以根据指定的列或表达式将数据分成多个分区。每个分区都是逻辑上独立的,可以单独进行查询、插入、更新和删除操作。Partition可以提高查询性能,因为它可以限制在特定分区上执行查询,而不是在整个表上执行。 在SQL中ÿ…...
微服务——Docker
docker与虚拟机的区别 首先要知道三个层次 硬件层:计算机硬件 内核层:与硬件交互,提供操作硬件的指令 应用层: 系统应用封装内核指令为函数,便于程序员调用。用户程序基于系统函数库实现功能。 docker在打包的时候直接把应用层的函数库也进行打包&a…...

测试|测试用例方法篇
测试|测试用例方法篇 文章目录 测试|测试用例方法篇1.测试用例的基本要素:测试环境,操作步骤,测试数据,预期结果…2.测试用例带来的好处3.测试用例的设计思路,设计方法,具体设计方法之间的关系**设计测试用…...

负载均衡的策略有哪些? 负载均衡的三种方式?
负载均衡的策略有哪些? 负载均衡的策略有如下: 1. 轮询(Round Robin):按照请求的顺序轮流分配到不同的服务器。 2. 权重(Weighted):给不同的服务器分配不同的权重,根据权重比例来…...
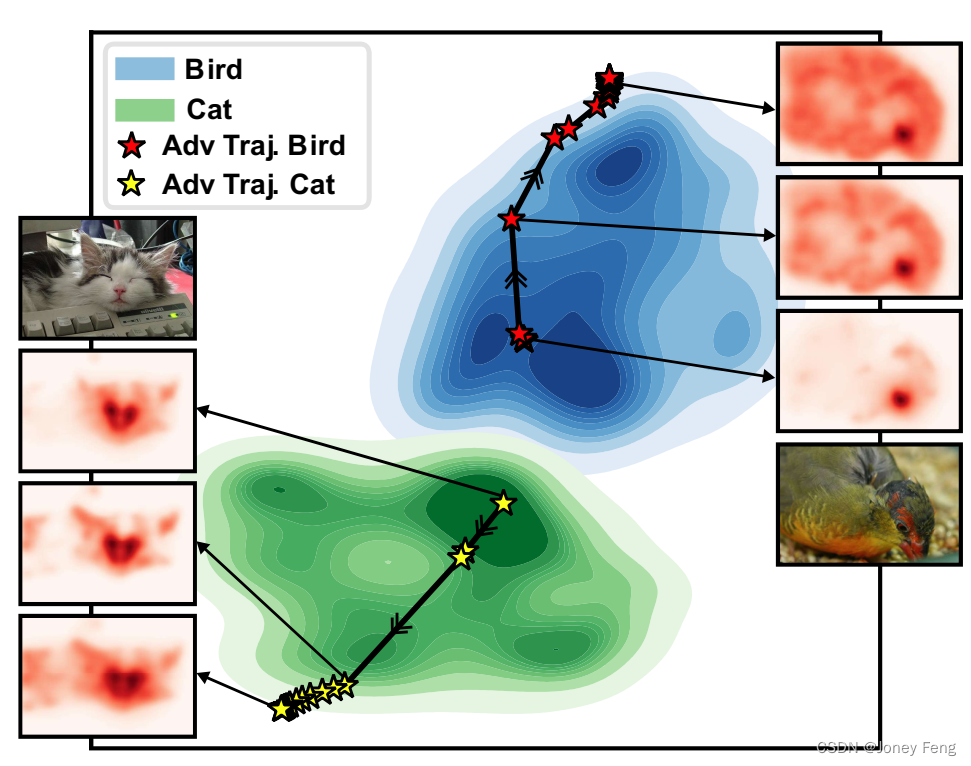
二十三章:抗对抗性操纵的弱监督和半监督语义分割的属性解释
0.摘要 弱监督语义分割从分类器中生成像素级定位,但往往会限制其关注目标对象的一个小的区域。AdvCAM是一种图像的属性图,通过增加分类分数来进行操作。这种操作以反对抗的方式实现,沿着像素梯度的相反方向扰动图像。它迫使最初被认为不具有区…...

curator实现的zookeeper可重入锁
Curator是一个Apache开源的ZooKeeper客户端库,它提供了许多高级特性和工具类,用于简化在分布式环境中使用ZooKeeper的开发。其中之一就是可重入锁。 Curator提供了InterProcessMutex类来实现可重入锁。以下是使用Curator实现ZooKeeper可重入锁的示例&am…...
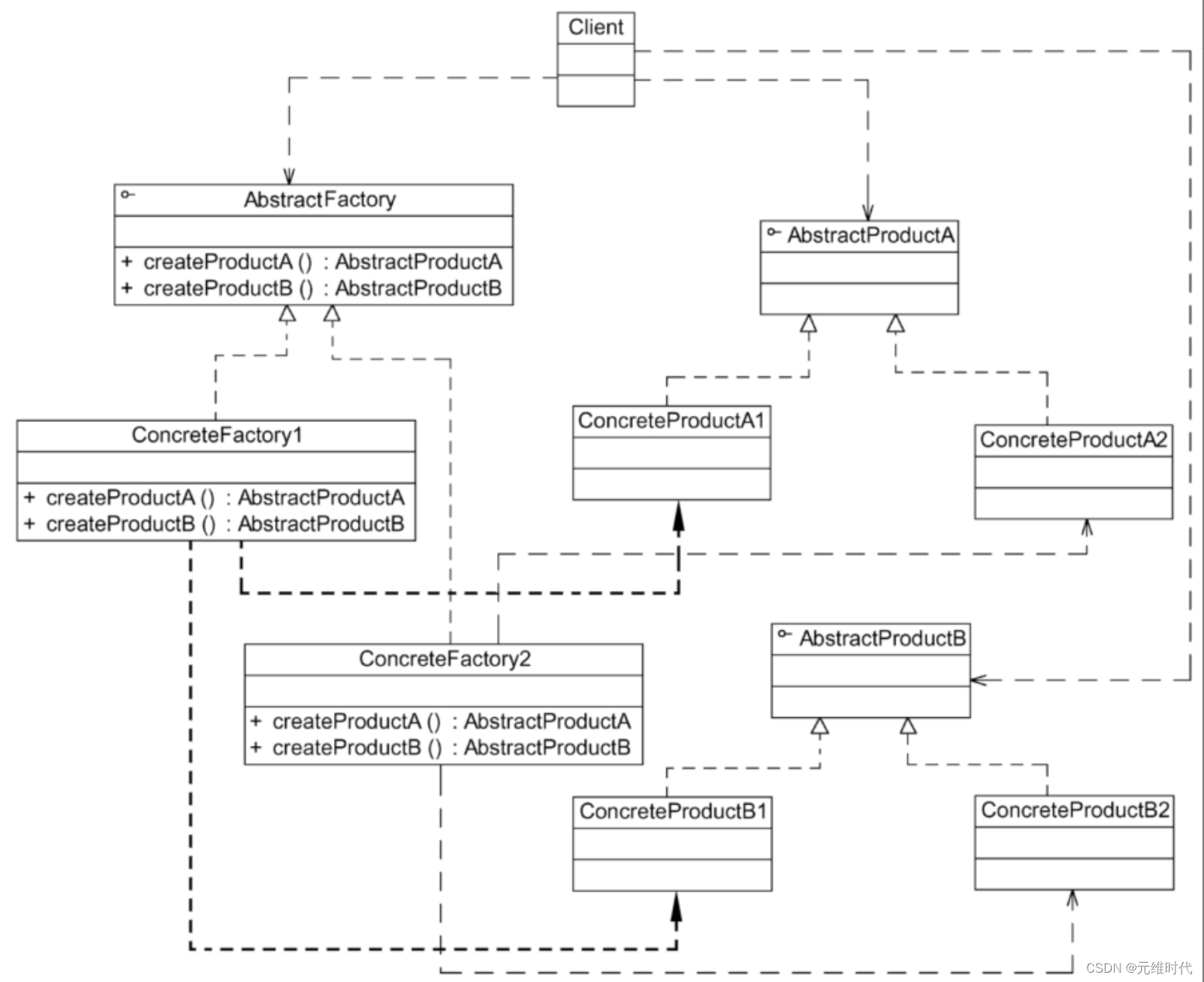
抽象工厂模式——产品族的创建
1、简介 1.1、简介 抽象工厂模式为创建一组对象提供了一种解决方案。与工厂方法模式相比,抽象工厂模式中的具体工厂不只是创建一种产品,它负责创建一族产品 1.2、定义 抽象工厂模式(Abstract Factory Pattern):提供…...

【C语言初阶篇】自定义类型结构体我不允许还有人不会!
🎬 鸽芷咕:个人主页 🔥 个人专栏:《C语言初阶篇》 《C语言进阶篇》 ⛺️生活的理想,就是为了理想的生活! 文章目录 📋 前言1 . 什么是结构体1.1 结构的定义1.2 结构的声明 2.结构体初始化2.1 用标签名定义和初始化2.2…...

重大更新|Sui主网即将上线流动性质押,助力资产再流通
Sui社区一直提议官方上线流动质押功能,现在通过SIP过程,已经升级该协议以实现这一功能。 Sui使用委托权益证明机制(DPoS)来选择和奖励负责运营网络的验证节点。为了保障网络安全,验证节点通过质押SUI token获得质押奖…...

day3 驱动开发 c语言编程
通过ioctl(内核应用层) 控制led灯三盏,风扇,蜂鸣器,小马达 头文件head.h #ifndef __LED_H__ #define __LED_H__typedef struct {volatile unsigned int TZCR; // 0x000volatile unsigned int res1[2]; // 0x…...
【字节跳动青训营】后端笔记整理-3 | Go语言工程实践之测试
**本文由博主本人整理自第六届字节跳动青训营(后端组),首发于稀土掘金:🔗Go语言工程实践之测试 | 青训营 目录 一、概述 1、回归测试 2、集成测试 3、单元测试 二、单元测试 1、流程 2、规则 3、单元测试的例…...

【Android】Recyclerview的缓存复用
介绍 RecyclerView是Android开发中常用的一个高度可定制的列表视图组件。它是在ListView和GridView的基础上进行了改进和增强,旨在提供更好的性能和更灵活的布局管理。 RecyclerView的主要特点如下: 灵活的布局管理器(LayoutManager&#…...
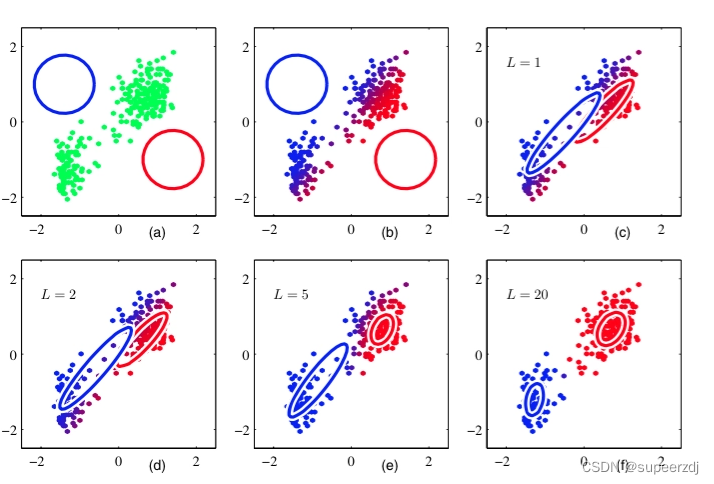
机器学习:混合高斯聚类GMM(求聚类标签)+PCA降维(3维降2维)习题
使用混合高斯模型 GMM,计算如下数据点的聚类过程: Datanp.array([1,2,6,7]) 均值初值为: μ1,μ21,5 权重初值为: w1,w20.5,0.5 方差: std1,std21,1 K2 10 次迭代后数据的聚类标签是多少? 采用python代码实现: from scipy import…...

libuv库学习笔记-processes
Processes libuv提供了相当多的子进程管理函数,并且是跨平台的,还允许使用stream,或者说pipe完成进程间通信。 在UNIX中有一个共识,就是进程只做一件事,并把它做好。因此,进程通常通过创建子进程来完成不…...

c++ 给无名形参提供默认值
如上图,若函数的形参不在函数体里使用,可以不提供形参名,而且可以给此形参提供默认值。也能编译通过。 在看vs2019上的源码时,也出现了这种写法。应用SFINAE(substitute false is not an error)原则&#x…...
)
Windows电脑C盘告急?手把手教你将Ollama模型库搬家到D盘(附环境变量配置详解)
Windows电脑C盘告急?手把手教你将Ollama模型库搬家到D盘(附环境变量配置详解)当你在Windows上玩转Ollama大模型时,C盘空间像被黑洞吞噬般迅速告急?别急着删文件或重装系统,今天带你用5分钟完成模型库的无痛…...

8051开发中禁用自动代码分区的实践指南
1. 禁用自动代码分区的技术背景在8051架构的嵌入式开发中,代码分区(Bank Switching)是一种扩展程序存储器空间的常用技术。传统8051芯片的寻址空间有限,通过分区切换机制可以将代码分布到不同的物理存储区域。Keil C51开发工具链默…...

如何用OpenSpeedy实现单机游戏5倍速运行:完整免费加速教程
如何用OpenSpeedy实现单机游戏5倍速运行:完整免费加速教程 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy 还在为游戏卡顿和漫长的等待时间烦恼吗?Ope…...

Unity实现CS级FPS手感的四大底层契约与枪械物理精调
1. 这不是又一个“FPS入门教程”,而是一份被反复验证过的实战路线图很多人点开“Unity FPS教程”时,心里想的是:抄几段代码、拖几个预制体、跑通一个能走能跳的场景,就算交差了。我试过不下二十个标着“完整”“从零开始”的FPS项…...

LLM可观测性实战:生产环境AI应用的监控体系建设
为什么LLM应用的监控与传统软件完全不同 传统软件监控关注的核心指标很清晰:响应时间、错误率、吞吐量、CPU/内存使用率。这些指标背后的系统行为是确定性的——同样的输入,永远产生同样的输出。LLM应用打破了这个假设。面对同样的用户输入:-…...
)
CentOS 7上解决soffice转换doc到docx报错‘no export filter‘的完整指南(附字体安装)
CentOS 7服务器深度修复:soffice文档转换no export filter全链路解决方案当你在CentOS 7服务器上执行soffice --convert-to docx命令时,终端突然抛出Error: no export filter的红色警告——这不是简单的命令错误,而是典型的环境依赖链断裂。作…...

SRC 漏洞挖掘实战|反射型 XSS 漏洞详解、复现全流程与 SRC 报告模板
反射型 XSS 是 Web 安全领域入门级高频漏洞,也是 SRC 漏洞提交中最易上手的类型之一。它无数据持久化存储、触发方式简单、测试门槛极低,是零基础网安爱好者入门漏洞挖掘的首选突破口。本文从核心原理、危害、挖掘思路、实战复现到标准报告模板全流程拆解…...

双系统硬盘告急?手把手教你用Ubuntu Live U盘和gparted无损调整/home分区大小
双系统用户必看:Ubuntu分区扩容实战指南你是否也遇到过这样的尴尬——当初安装双系统时随手给Ubuntu的分区分配空间,结果用着用着发现/home目录快被塞爆了,而根目录/却还有大量闲置空间?这种"旱的旱死,涝的涝死&q…...

通过curl命令调试Taotoken大模型API,快速排查接入问题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令调试Taotoken大模型API,快速排查接入问题 在接入大模型服务时,直接使用HTTP请求进行调试是一种…...

85%企业将淘汰纯业务程序员!2026年前,大模型才是你的职业救命稻草!
文章指出传统技术岗面临淘汰风险,85%企业计划在2026年前淘汰纯业务型程序员。未来职场核心竞争力在于掌握大模型技术。文章强调大模型技术是技术人的时代红利,提供从入门到精通的全套视频教程,涵盖提示词工程、RAG、Agent等技术点。文章还分析…...