【Kaggle】Kaggle数据集如何使用命令语句下载?
一、Kaggle数据集如何下载
1.1 问题的起因
最近看到了 Google 组织的 Kaggle 比赛,想自己试一下,但是数据集太大了,将近有370G的数据。直接下载的话,网速太慢,可能要下载3-4天,所以萌生了用命令语句下载的想法。
1.2 解决方法
一开始的想法简单粗暴,直接 wget 浏览器获取到的链接,然后在服务器上直接 wget,结果一试,果然不行。
然后就搜索了下,发现官方提供了下载的命令行工具,直接pip安装之后就可用。
https://github.com/Kaggle/kaggle-api
下面就写一下自己总结的关键步骤。
1.2.1 安装 Kaggle API
确保您已安装 Python 和包管理器 pip。 运行以下命令以使用命令行访问 Kaggle API:
pip install kaggle
可能需要在 Mac/Linux 上执行:
pip install --user kaggle
如果在安装过程中出现问题,建议执行此操作。
通过 root 用户完成的安装(即 sudo pip install kaggle)将无法正常工作除非你明白你在做什么。 即使这样,它们仍然可能无法工作。
如果出现权限错误,强烈建议用户安装。
如果您遇到 kaggle: command not found 错误,请确保您的 Python 二进制文件位于您的路径上。
您可以通过执行 pip uninstall kaggle 并查看二进制文件的位置来查看 kaggle 的安装位置。
-
对于 Linux 上的本地用户安装,默认位置是 ~/.local/bin;
-
在 Windows 上,默认位置是 $PYTHON_HOME/Scripts。
我是在 Windows 上运行的:
pip install kaggle
我们的输出为:
(PyTorch) F:\kaggle>pip install kaggle
Collecting kaggleDownloading kaggle-1.5.16.tar.gz (83 kB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 83.6/83.6 kB 130.5 kB/s eta 0:00:00Preparing metadata (setup.py) ... done
Requirement already satisfied: six>=1.10 in d:\anaconda\envs\pytorch\lib\site-packages (from kaggle) (1.16.0)
Requirement already satisfied: certifi in d:\anaconda\envs\pytorch\lib\site-packages (from kaggle) (2022.12.7)
Requirement already satisfied: python-dateutil in d:\anaconda\envs\pytorch\lib\site-packages (from kaggle) (2.8.2)
Requirement already satisfied: requests in d:\anaconda\envs\pytorch\lib\site-packages (from kaggle) (2.31.0)
Requirement already satisfied: tqdm in d:\anaconda\envs\pytorch\lib\site-packages (from kaggle) (4.65.0)
Collecting python-slugifyDownloading python_slugify-8.0.1-py2.py3-none-any.whl (9.7 kB)
Requirement already satisfied: urllib3 in d:\anaconda\envs\pytorch\lib\site-packages (from kaggle) (1.26.12)
Requirement already satisfied: bleach in d:\anaconda\envs\pytorch\lib\site-packages (from kaggle) (5.0.1)
Requirement already satisfied: webencodings in d:\anaconda\envs\pytorch\lib\site-packages (from bleach->kaggle) (0.5.1)
Collecting text-unidecode>=1.3Downloading text_unidecode-1.3-py2.py3-none-any.whl (78 kB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 78.2/78.2 kB 543.3 kB/s eta 0:00:00
Requirement already satisfied: charset-normalizer<4,>=2 in d:\anaconda\envs\pytorch\lib\site-packages (from requests->kaggle) (3.1.0)
Requirement already satisfied: idna<4,>=2.5 in d:\anaconda\envs\pytorch\lib\site-packages (from requests->kaggle) (3.4)
Requirement already satisfied: colorama in d:\anaconda\envs\pytorch\lib\site-packages (from tqdm->kaggle) (0.4.6)
Building wheels for collected packages: kaggleBuilding wheel for kaggle (setup.py) ... doneCreated wheel for kaggle: filename=kaggle-1.5.16-py3-none-any.whl size=110697 sha256=b988a133c1466dda33402c76755602048d45d3e79d6600b04c67842c464b53ecStored in directory: c:\users\xiaowang\appdata\local\pip\cache\wheels\43\4b\fb\736478af5e8004810081a06259f9aa2f7c3329fc5d03c2c412
Successfully built kaggle
Installing collected packages: text-unidecode, python-slugify, kaggle
Successfully installed kaggle-1.5.16 python-slugify-8.0.1 text-unidecode-1.3
1.2.2 创建token
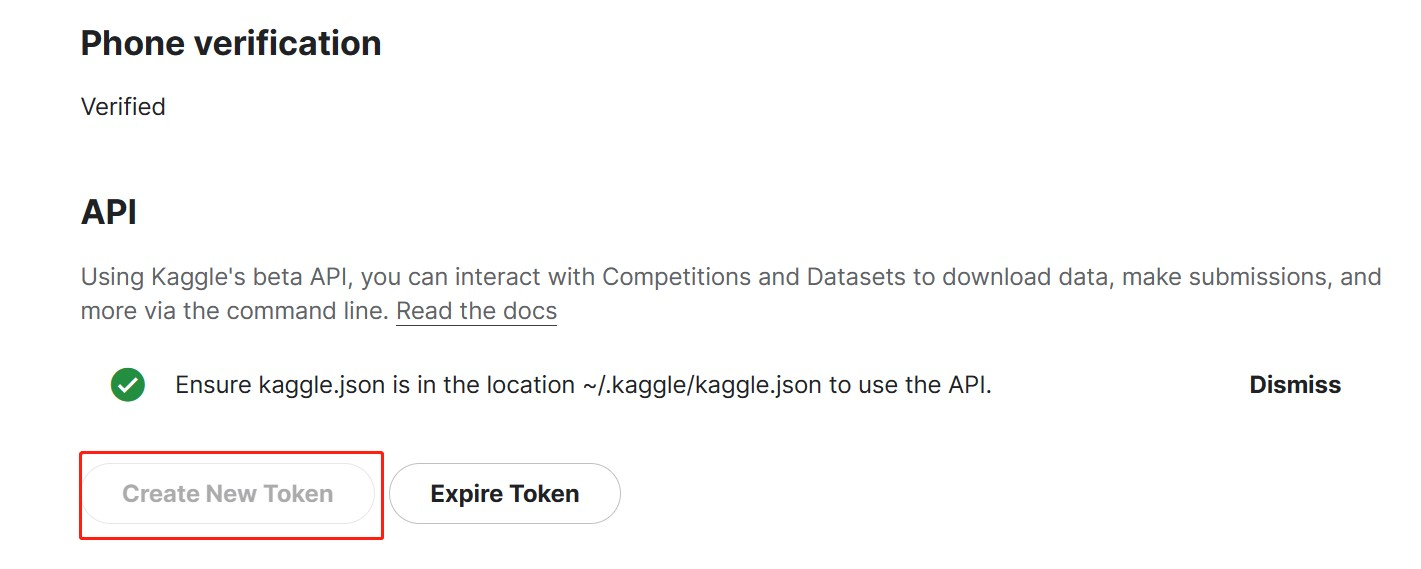
登录 kaggle 自己的主页(https://www.kaggle.com/<USER_NAME>/account),找到 API,点击 create api token 按钮,生成 kaggle.json 配置文件,文件中便包含了用户名和 token 串。
将该文件移动至 kaggle 默认的路径下(~/.kaggle/kaggle.json),我的放置路径为:
C:\Users\XiaoWang\.kaggle
如果在用户路径下没有找到 .kaggle 的文件夹,自己新建一个!
这里需要注意,kaggle.json 文件除了可以配置用户名和 token 外,还可以配置 proxy 等内容,具体参考如下:
usage: kaggle config set [-h] -n NAME -v VALUErequired arguments:-n NAME, --name NAME Name of the configuration parameter(one of competition, path, proxy)-v VALUE, --value VALUEValue of the configuration parameter, valid values depending on name- competition: Competition URL suffix (use "kaggle competitions list" to show options)- path: Folder where file(s) will be downloaded, defaults to current working directory- proxy: Proxy for HTTP requests
当然,也可以直接编辑 kaggle.json 文件。编辑好后,执行 kaggle config view,查看当前配置。
(PyTorch) F:\kaggle>kaggle config view
Configuration values from C:\Users\XiaoWang\.kaggle
- username: *****
- path: F:/kaggle
- proxy: None
- competition: None
1.2.3 下载数据
上面都准备好之后,找到要下载数据的页面,就可以进行数据下载了。这里以我要下载数据的地址为例:
https://www.kaggle.com/competitions/google-research-identify-contrails-reduce-global-warming
我们找到下面的数据集下载的 API 命令!
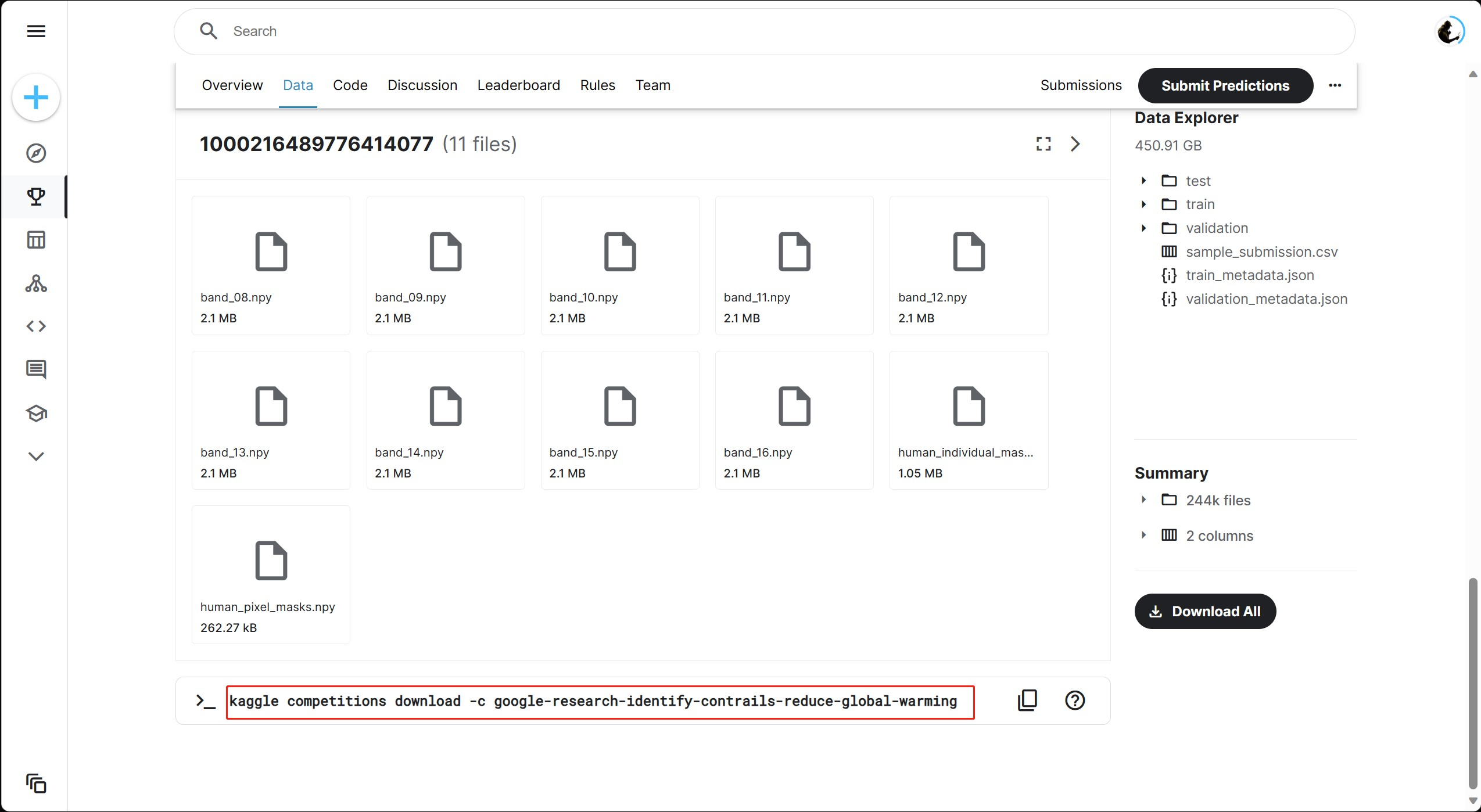
kaggle competitions download -c google-research-identify-contrails-reduce-global-warming
即可看到如下命令提示:
(PyTorch) F:\kaggle>kaggle competitions download -c google-research-identify-contrails-reduce-global-warming
Downloading google-research-identify-contrails-reduce-global-warming.zip to F:/kaggle\competitions\google-research-identify-contrails-reduce-global-warming16%|███████████████▋ | 47.4G/302G [1:21:35<6:24:02, 11.9MB/s]
更多的数据下载方式如下:
usage: kaggle datasets download [-h] [-f FILE_NAME] [-p PATH] [-w] [--unzip][-o] [-q][dataset]optional arguments:-h, --help show this help message and exitdataset Dataset URL suffix in format <owner>/<dataset-name> (use "kaggle datasets list" to show options)-f FILE_NAME, --file FILE_NAMEFile name, all files downloaded if not provided(use "kaggle datasets files -d <dataset>" to show options)-p PATH, --path PATH Folder where file(s) will be downloaded, defaults to current working directory-w, --wp Download files to current working path--unzip Unzip the downloaded file. Will delete the zip file when completed.-o, --force Skip check whether local version of file is up to date, force file download-q, --quiet Suppress printing information about the upload/download progress
相关文章:
【Kaggle】Kaggle数据集如何使用命令语句下载?
一、Kaggle数据集如何下载 1.1 问题的起因 最近看到了 Google 组织的 Kaggle 比赛,想自己试一下,但是数据集太大了,将近有370G的数据。直接下载的话,网速太慢,可能要下载3-4天,所以萌生了用命令语句下载的…...

android pdf框架,编译mupdf
因为mupdf编译的体积不小,之前也发过编译的文章,现在更新一下. 建一个mupdf_c目录,名字自己取,在里面git下载mupdf源码,把目录修改为libmupdf mupdf_c目录下建build.gradle文件,内容如下 apply plugin: com.android.library apply plugin: maven-publishgroup com.artifex.…...
线性表详细讲解
2.1 线性表的定义和特点2.2 案例引入2.3 线程表的类型定义2.4 线性表的顺序表示和实现2.4.1 线性表的顺序存储表示2.4.2 线性表的结构类型定义2.4.3 顺序表基本操作的实现2.4.4 顺序表总结 2.5 线性表的链式表示和实现2.5.1 线性表的链式存储表示2.5.2 单链表的实现(…...

代码随想录算法训练营day45
文章目录 Day45爬楼梯题目思路代码 零钱兑换题目思路代码 完全平方数题目思路代码 Day45 爬楼梯 70. 爬楼梯 - 力扣(LeetCode) 题目 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢…...
机器学习深度学习——softmax回归(上)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——线性回归的简洁实现 📚订阅专栏:机器学习&&深度学习 希望文章对你们有所…...

基于express调用chatgpt文字流输出和有道智云语音合成
express是基于node.js的一个web框架,可以更加简洁的去创建一个后台服务,由于项目的需要,引入和typescript,经过几天的努力实现了chatgpt文字流输出有道智云语音合成的结合(略有遗憾),下面我记载…...
(学习笔记-内存管理)内存分段、分页、管理与布局
内存分段 程序是由若干个逻辑分段组成的,比如可由代码分段、数据分段、栈段、堆段组成。不同的段是有不同的属性的,所以就用分段的形式把这些分段分离出来。 分段机制下,虚拟地址和物理地址是如何映射的? 分段机制下的虚拟地址由…...
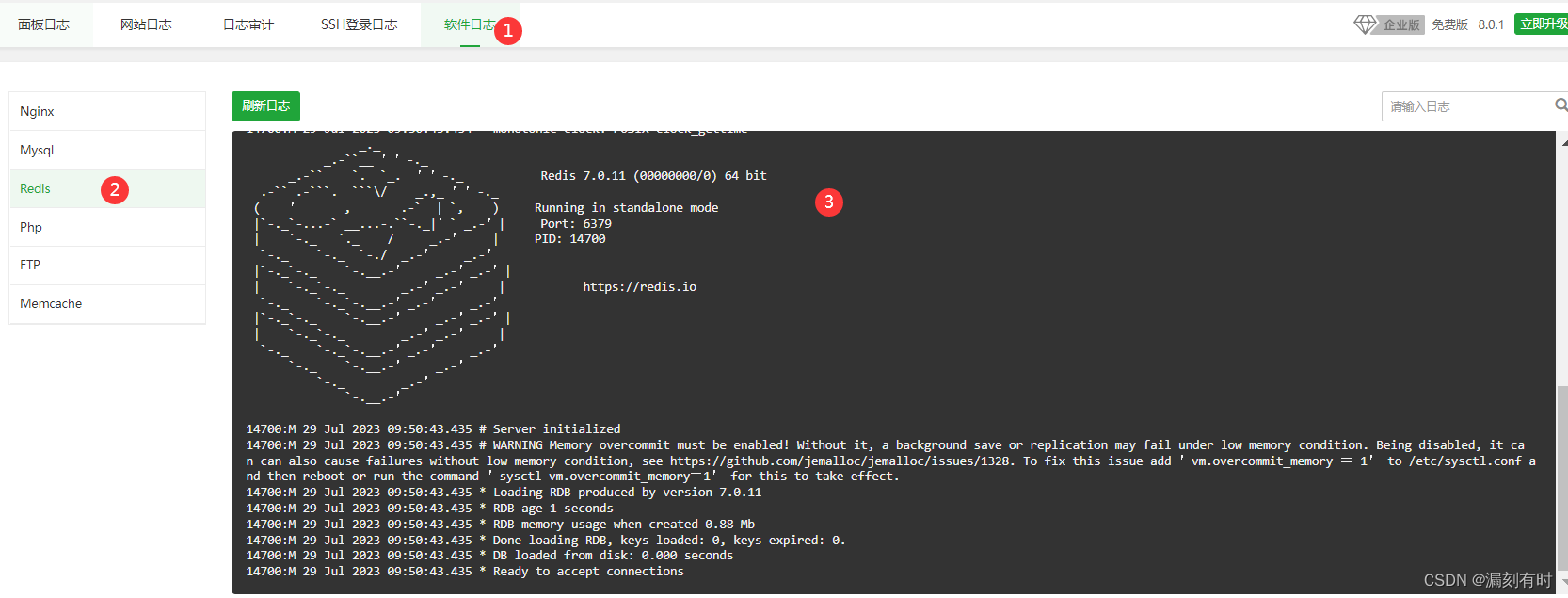
PHP使用Redis实战实录1:宝塔环境搭建、6379端口配置、Redis服务启动失败解决方案
宝塔环境搭建、6379端口配置、Redis服务启动失败解决方案 前言一、Redis安装部署1.安装Redis2.php安装Redis扩展3.启动Redis 二、避坑指南1.6379端口配置2.Redis服务启动(1)Redis服务启动失败(2)Redis启动日志排查(3&a…...
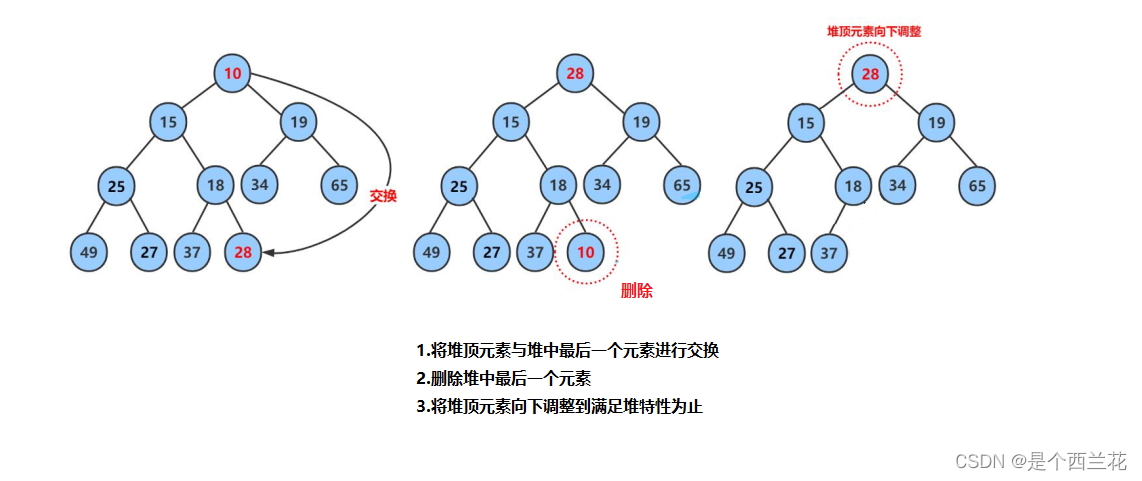
【数据结构】这堆是什么
目录 1.二叉树的顺序结构 2.堆的概念及结构 3.堆的实现 3.1 向上调整算法与向下调整算法 3.2 堆的创建 3.3 建堆的空间复杂度 3.4 堆的插入 3.5 堆的删除 3.6 堆的代码的实现 4.堆的应用 4.1 堆排序 4.2 TOP-K问题 首先,堆是一种数据结构,一种特…...
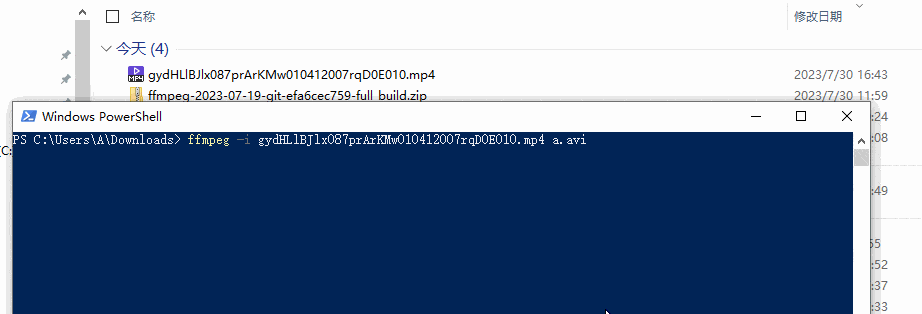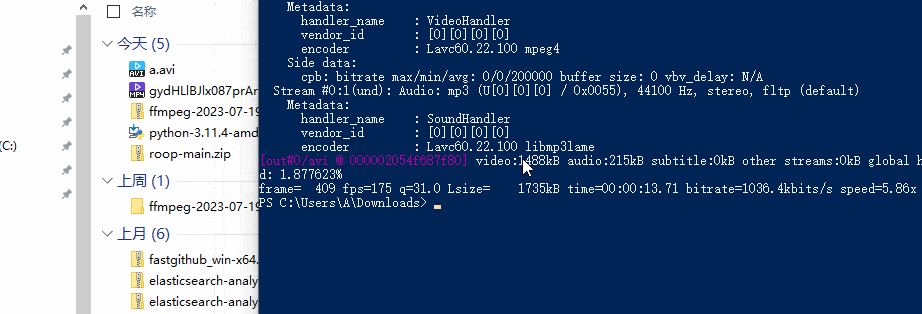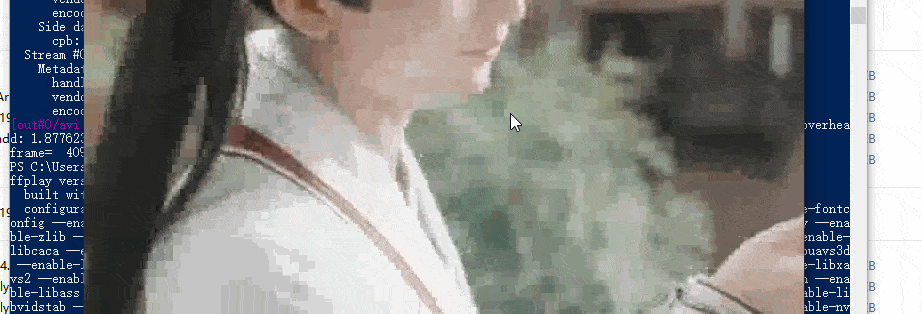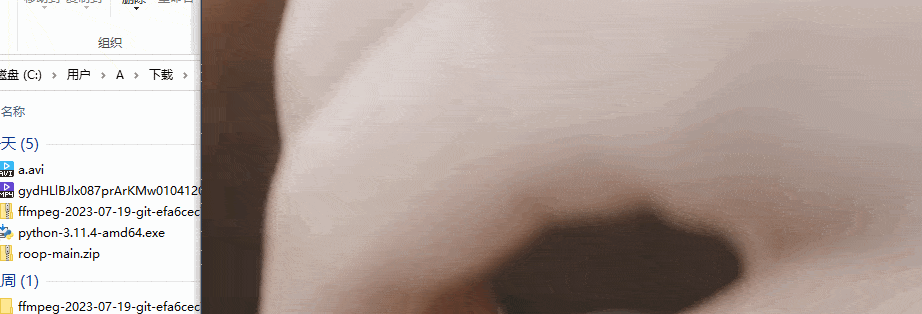
FFmpeg 音视频开发工具
目录 FFmpeg 下载与安装 ffmpeg 使用快速入门 ffplay 使用快速入门 FFmpeg 全套下载与安装 1、FFmpeg 是处理音频、视频、字幕和相关元数据等多媒体内容的库和工具的集合。一个完整的跨平台解决方案,用于录制、转换和流式传输音频和视频。 官网:http…...

Go 语言 select 都能做什么?
原文链接: Go 语言 select 都能做什么? 在 Go 语言中,select 是一个关键字,用于监听和 channel 有关的 IO 操作。 通过 select 语句,我们可以同时监听多个 channel,并在其中任意一个 channel 就绪时进行相…...
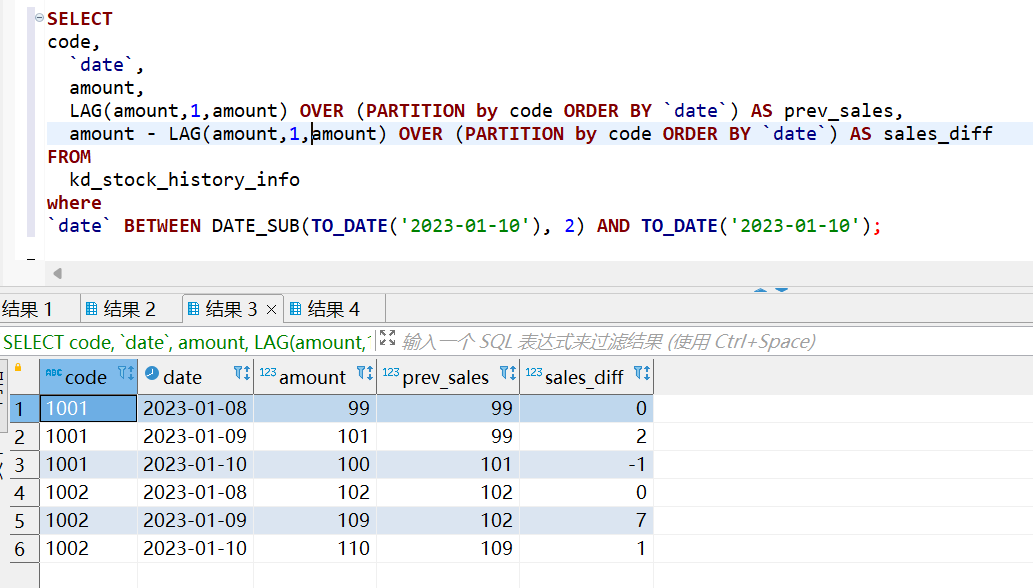
Hive之窗口函数lag()/lead()
一、函数介绍 lag()与lead函数是跟偏移量相关的两个分析函数 通过这两个函数可以在一次查询中取出同一字段的前N行的数据(lag)和后N行的数据(lead)作为独立的列,从而更方便地进行进行数据过滤,该操作可代替表的自联接,且效率更高 lag()/lead() lag(c…...

Vite+Typescript+Vue3学习笔记
ViteTypescriptVue3学习笔记 1、项目搭建 1.1、创建项目(yarn) D:\WebstromProject>yarn create vite yarn create v1.22.19 [1/4] Resolving packages... [2/4] Fetching packages... [3/4] Linking dependencies... [4/4] Building fresh packages...success Installed…...
二、SQL-6.DCL-2).权限控制
*是数据库和表的通配符,出现在数据库位置上表示所有数据库,出现在表名位置上,表示所有表 %是主机名的通配符,表示所有主机。 e.g.所有数据库(*)的所有表(*)的所有权限(a…...

[OpenStack] GPU透传
GPU透传本质就是PCI设备透传,不算是什么新技术。之前按照网上方法都没啥问题,但是这次测试NVIDIA A100遇到坑了。 首先是禁用nouveau 把intel_iommuon rdblacklistnouveau写入/etc/default/grub的cmdline,然后grub2-mkconfig -o /etc/grub2.c…...

无涯教程-jQuery - Progressbar组件函数
小部件进度条功能可与JqueryUI中的小部件一起使用。一个简单的进度条显示有关进度的信息。一个简单的进度条如下所示。 Progressbar - 语法 $( "#progressbar" ).progressbar({value: 37 }); Progressbar - 示例 以下是显示进度条用法的简单示例- <!doctype …...

[SQL挖掘机] - 窗口函数 - rank
介绍: rank() 是一种常用的窗口函数,它为结果集中的每一行分配一个排名(rank)。这个排名基于指定的排序顺序,并且在遇到相同的值时,会跳过相同的排名。 用法: rank() 函数的语法如下: rank() over ([pa…...

VBAC多层防火墙技术的研究-状态检测
黑客技术的提升和黑客工具的泛滥,造成大量的企业、机构和个人的电脑系统遭受程度不同的入侵和攻击,或面临随时被攻击的危险。迫使大家不得不加强对自身电脑网络系统的安全防护,根据系统管理者设定的安全规则把守企业网络,提供强大的、应用选通、信息过滤、流量控制、网络侦…...
PHP8的数据类型-PHP8知识详解
在PHP8中,变量不需要事先声明,赋值即声明。 不同的数据类型其实就是所储存数据的不同种类。在PHP8.0、8.1中都有所增加。以下是PHP8的15种数据类型: 1、字符串(String):用于存储文本数据,可以使…...

明晚直播:可重构计算芯片的AI创新应用分享!
大模型技术的不断升级及应用落地,正在推动人工智能技术发展进入新的阶段,而智能化快速增长和发展的市场对芯片提出了更高的要求:高算力、高性能、灵活性、安全性。可重构计算区别于传统CPU、GPU,以指令驱动的串行执行方式…...

3步解锁Windows远程桌面多人连接:RDP Wrapper Library完整指南
3步解锁Windows远程桌面多人连接:RDP Wrapper Library完整指南 【免费下载链接】rdpwrap RDP Wrapper Library 项目地址: https://gitcode.com/gh_mirrors/rd/rdpwrap 你是否曾因Windows家庭版无法支持多人远程桌面连接而感到困扰?当团队成员需要…...

Seraphine:你的英雄联盟智能助手,3大核心功能提升游戏决策力
Seraphine:你的英雄联盟智能助手,3大核心功能提升游戏决策力 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 想象一下这样的场景:你刚刚进入英雄联盟的排位赛BP阶段&#x…...

大模型落地应用全景解析:出海企业如何抓住价值变现新风口?
本文深度剖析了中国大模型在金融、零售、汽车、教育等领域的落地应用现状,指出市场重心已从技术基建转向场景变现,企业从免费试用转向为实际效果付费。文章强调智能体(Agent)成核心趋势,AI原生产品将重塑用户体验。同时…...

2026年,探寻靠谱体育器材的终极指南
在追求健康与活力的时代,体育器材成为了我们运动生活中的重要伙伴。但面对市场上琳琅满目的品牌和产品,如何选择靠谱的体育器材成为了许多人的难题。今天,让我们一同探寻 2026 年靠谱体育器材的终极指南。一、品质与口碑沧州九牌体育用品制造…...

【流体】二维稳态不可压缩层流通道流利用FVM和SIMPLE 解平行板间层流的速度、压力和温度【含Matlab源码 15558期】
💥💥💥💥💥💥💥💥💞💞💞💞💞💞💞💞💞Matlab武动乾坤博客之家💞…...

【限时解密】Lindy自动化方案未公开的4层权限熔断机制:为什么92%的企业跳过这步就触发合规雷区?
更多请点击: https://kaifayun.com 第一章:Lindy人力资源自动化方案的合规性底层逻辑 Lindy人力资源自动化方案并非简单地将流程数字化,而是以全球主流劳动法规为约束边界,将合规性内化为系统架构的刚性层。其底层逻辑建立在“规…...

不会 CSS 也能做出惊艳 PPT!Frontend Slides这个开源 Claude Code 技能让 AI 帮你生成 12 种风格演示文稿,告别千篇一律的紫渐变
不会 CSS 也能做出惊艳 PPT!Frontend Slides这个开源 Claude Code 技能让 AI 帮你生成 12 种风格演示文稿,告别千篇一律的紫渐变 💡 每次做 PPT 都在 Powerpoint 里拖来拖去,最后做出来还是那个味儿?Frontend Slides 让…...

2025年AI数字人行业现状:全国超99万家企业涌入,真正能落地的不到一成
当生成式AI的浪潮席卷各行各业,AI数字人成为最先跑出商业化落地速度的细分赛道。然而,在全国超99万家相关企业蜂拥而入的热闹背后,一个残酷的现实正在显现:绝大多数所谓的"AI数字人"不过是披着科技外衣的"会动的照…...

无人机地面站软件完全指南:Mission Planner 新手快速上手教程
无人机地面站软件完全指南:Mission Planner 新手快速上手教程 【免费下载链接】MissionPlanner Mission Planner Ground Control Station for ArduPilot (c# .net) 项目地址: https://gitcode.com/gh_mirrors/mi/MissionPlanner Mission Planner 是一款功能强…...

别再复制粘贴了!手把手带你用DEFINE_PROFILE宏实现一个正弦变化入口速度
从零实现Fluent正弦速度入口:DEFINE_PROFILE宏实战指南 在计算流体力学(CFD)仿真中,标准边界条件设置往往无法满足复杂工况需求。想象这样一个场景:你需要模拟风力发电机叶片在阵风条件下的受力情况,入口风速并非恒定值࿰…...