Informer 论文学习笔记
论文:《Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting》
代码:https://github.com/zhouhaoyi/Informer2020
地址:https://arxiv.org/abs/2012.07436v3
特点:
- 实现时间与空间复杂度为 O ( L ln L ) \mathcal{O}(L\ln L) O(LlnL) 的自注意力;
- 使用自注意力提纯(Distilling)的方法,降低了特征的冗余;
- 以生成式的风格一次性输出长序列预测结果,杜绝了 One-by-One 方式中存在的误差积累;
- 基于上面的内容,创建新的 LSTF 模型 Informer。
核心贡献:
- 用新的自注意力模块 ProbSparse Self-Attention 降低了原始 Self-Attention 的时间与空间复杂度;
- 提出 Self-Attention 净化(Distilling) 方法,进一步降低模型整体的复杂度;
Informer 模型的整体结构
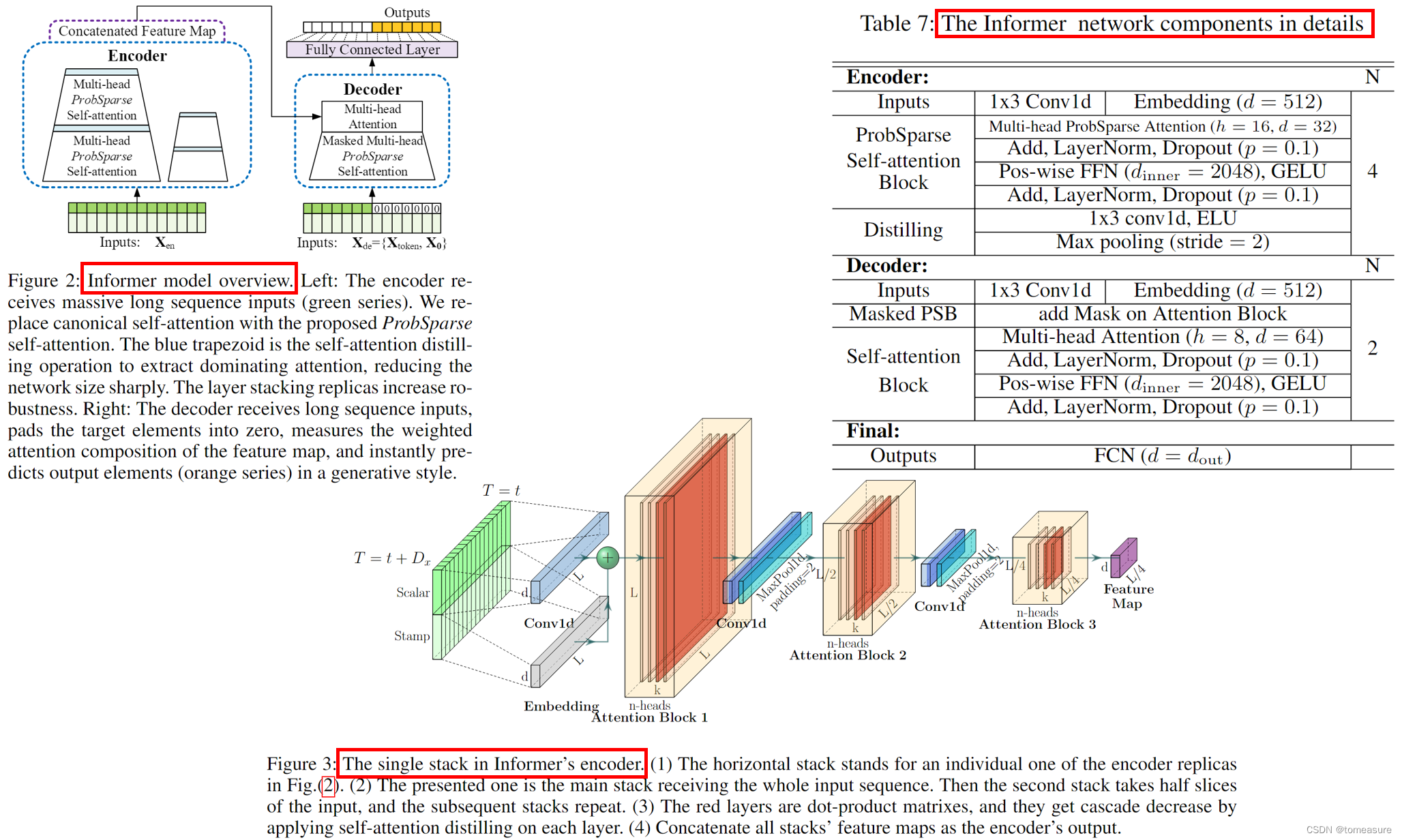
ProbSparse Self-Attention
先介绍一下算法的整体流程,后面再介绍具体含义和原因。
Require:Tensor Q ∈ R m × d , K ∈ R n × d , V ∈ R n × d \pmb{Q}\in\mathbb{R}^{m\times d},\pmb{K}\in\mathbb{R}^{n\times d},\pmb{V}\in\mathbb{R}^{n\times d} Q∈Rm×d,K∈Rn×d,V∈Rn×d
- print set hyperparameter c c c, u = c ln m u=c\ln m u=clnm and U = m ln n U=m\ln n U=mlnn
- randomly select U U U dot-product pairs from K \pmb{K} K to K ˉ \bar{\pmb{K}} Kˉ
- set the sample score S ˉ = Q K ˉ T \bar{\pmb{S}}=\pmb{Q}\bar{\pmb{K}}^T Sˉ=QKˉT
- compute the measurement M = max ( S ˉ ) − mean ( S ˉ ) M=\max(\bar{\pmb{S}})-\text{mean}(\bar{\pmb{S}}) M=max(Sˉ)−mean(Sˉ) by row
- set Top- u \text{Top-}u Top-u queries under M M M as Q ˉ \bar{\pmb{Q}} Qˉ
- set S 1 = softmax ( Q ˉ K T / d ) ⋅ V \pmb{S}_1=\text{softmax}(\bar{\pmb{Q}}\pmb{K}^T/\sqrt{d})\cdot \pmb{V} S1=softmax(QˉKT/d)⋅V
- set S 0 = mean ( V ) \pmb{S}_0=\text{mean}(\pmb{V}) S0=mean(V)
- set S = { S 1 , S 0 } \pmb{S}=\{\pmb{S}_1,\pmb{S}_0\} S={S1,S0} by their original rows accordingly
Ensure:self-attention feature map S \pmb{S} S
ProbSparse Self-Attention 的基本思想
利用原始 Self-Attention 中的稀疏性,降低算法的时间与空间复杂度。
核心方法:利用下式选出对 value 更有价值的 query
M ˉ ( q i , K ) = max j { q i k j T d } − 1 L K Σ j = 1 L K q i k j T d \bar{M}(\pmb{q}_i,\pmb{K})=\max_{j}\{\frac{\pmb{q}_i\pmb{k}_j^T}{\sqrt{d}}\}-\frac{1}{L_K}\Sigma^{L_K}_{j=1}\frac{\pmb{q}_i\pmb{k}_j^T}{\sqrt{d}} Mˉ(qi,K)=jmax{dqikjT}−LK1Σj=1LKdqikjT
即算法中的 3 与 4。
为什么用这种方法?:
原始 Self-Attention softmax ( Q K T / d ) ⋅ V \text{softmax}(\pmb{Q}\pmb{K}^T/\sqrt{d})\cdot \pmb{V} softmax(QKT/d)⋅V 可改写为下面的概率形式:
A ( q i , K , V ) = Σ j k ( q i , k j ) Σ l k ( q i , k l ) v j = E p ( k j ∣ q i ) [ v j ] \mathcal{A}(\pmb{q}_i,\pmb{K},\pmb{V})=\Sigma_j\frac{k(\pmb{q}_i,\pmb{k}_j)}{\Sigma_l k(\pmb{q}_i,\pmb{k}_l)}\pmb{v}_j=\mathbb{E}_{p(\pmb{k}_j|\pmb{q}_i)}[\pmb{v}_j] A(qi,K,V)=ΣjΣlk(qi,kl)k(qi,kj)vj=Ep(kj∣qi)[vj]
k ( ⋅ , ⋅ ) k(\cdot,\cdot) k(⋅,⋅) 的含义不再赘述。
为度量 query 的稀疏性,可以考虑 p ( k j ∣ q i ) p(\pmb{k}_j|\pmb{q}_i) p(kj∣qi) 与均匀分布 q ( k j ∣ q i ) = 1 / L K q(\pmb{k}_j|\pmb{q}_i)=1/L_K q(kj∣qi)=1/LK`之间的 KL 散度 K L ( q ∣ ∣ p ) = − Σ 1 L K ln ( k ( q i , k j ) Σ l k ( q i , k l ) L K ) KL(q||p)=-\Sigma\frac{1}{L_K}\ln(\frac{k(\pmb{q}_i,\pmb{k}_j)}{\Sigma_l k(\pmb{q}_i,\pmb{k}_l)}L_K) KL(q∣∣p)=−ΣLK1ln(Σlk(qi,kl)k(qi,kj)LK),展开并舍弃常数项之后可得第 i 个 query 的稀疏性度量为:
M ( q i , K ) = ln Σ j = 1 L K e q i k j T d − 1 L K Σ j = 1 L K q i k j T d M(\pmb{q}_i,\pmb{K})=\ln\Sigma^{L_K}_{j=1}e^{\frac{\pmb{q}_i\pmb{k}^T_j}{\sqrt{d}}}-\frac{1}{L_K}\Sigma^{L_K}_{j=1}\frac{\pmb{q}_i\pmb{k}^T_j}{\sqrt{d}} M(qi,K)=lnΣj=1LKedqikjT−LK1Σj=1LKdqikjT
基于 M,可以选用 Top-u 的 queries 构成的 Q ˉ \bar{\pmb{Q}} Qˉ 代替 Q 计算自注意力(文中设置 u = c ln L Q u=c\ln L_Q u=clnLQ,其中 c 是超参数)。
为什么要使用这两个分布的 KL 散度?为什么M可以度量注意力的稀疏性?:Self-Attention 涉及到了点积运算,该运算表明 p ( k j ∣ q i ) p(\pmb{k}_j|\pmb{q}_i) p(kj∣qi) 与均匀分布 q ( k j ∣ q i ) = 1 / L K q(\pmb{k}_j|\pmb{q}_i)=1/L_K q(kj∣qi)=1/LK 之间的差别越大越好,这启发我们使用 M 作为稀疏性的度量。
新问题:M 中的第一项实际计算时的复杂度仍旧是 O ( L 2 ) \mathcal{O}(L^2) O(L2) 的。
解决方式:基于 Lemma 1 与 Proposition 1,先随机采样 U = L K ln L Q U=L_K\ln L_Q U=LKlnLQ 个 k-q 对,然后在这 U 个 k-q 对上计算 M ˉ = max j { q i k j T d } − mean j { q i k j T d } \bar{M}=\max_{j}\{\frac{\pmb{q}_i\pmb{k}^T_j}{\sqrt{d}}\}-\text{mean}_{j}\{\frac{\pmb{q}_i\pmb{k}^T_j}{\sqrt{d}}\} Mˉ=maxj{dqikjT}−meanj{dqikjT} 作为 M 的近似值,最后选定 top-u 个 query 用作 Self-Attention 计算。(即算法中的 1、2、5 和 6,这里两次降低计算量)补充:
- Lemma 1:For each query q i ∈ R d \pmb{q}_i\in\mathbb{R}^d qi∈Rd and k j ∈ R d \pmb{k}_j\in\mathbb{R}^d kj∈Rd in the keys set K \pmb{K} K, we have the bound as ln L K ≤ M ( q i , K ) ≤ ln L K + M ˉ ( q i , K ) \ln L_K\leq M(\pmb{q}_i,\pmb{K})\leq\ln L_K +\bar{M}(\pmb{q}_i,\pmb{K}) lnLK≤M(qi,K)≤lnLK+Mˉ(qi,K). When q i ∈ K \pmb{q}_i\in\pmb{K} qi∈K, it also holds.(它说明可以用 M ˉ \bar{M} Mˉ 做近似计算。利用凸函数证明)
- Proposition 1: Assuming k j ∼ N ( μ , Σ ) \pmb{k}_j\sim\mathcal{N}(\mu,\Sigma) kj∼N(μ,Σ) and we let q k i \pmb{q}\pmb{k}_i qki denote set { ( q i k j T ) / d ∣ j = 1 , ⋯ , L K } \{(\pmb{q}_i\pmb{k}_j^T)/\sqrt{d}|j=1,\cdots,L_K\} {(qikjT)/d∣j=1,⋯,LK}, then ∀ M m = max i M ( q i , K ) \forall M_m=\max_i M(\pmb{q}_i,\pmb{K}) ∀Mm=maxiM(qi,K) there exist κ > 0 \kappa>0 κ>0 such that: in the interval ∀ q 1 , q 2 ∈ { q ∣ M ( q , K ) ∈ [ M m , M m − κ ) } \forall\pmb{q}_1,\pmb{q}_2\in\{\pmb{q}|M(\pmb{q},\pmb{K})\in[M_m,M_m-\kappa)\} ∀q1,q2∈{q∣M(q,K)∈[Mm,Mm−κ)}, if M ˉ ( q 1 , K ) > M ˉ ( q 2 , K ) \bar{M}(\pmb{q}_1,\pmb{K})>\bar{M}(\pmb{q}_2,\pmb{K}) Mˉ(q1,K)>Mˉ(q2,K) and Var ( q k 1 ) > Var ( q k 2 ) \text{Var}(\pmb{q}\pmb{k}_1)>\text{Var}(\pmb{q}\pmb{k}_2) Var(qk1)>Var(qk2), we have high probability that M ( q 1 , K ) > M ( q 2 , K ) M(\pmb{q}_1,\pmb{K})>M(\pmb{q}_2,\pmb{K}) M(q1,K)>M(q2,K).(采样后不影响排序,这说明采样之后仍旧可以保证 Top-u 的可靠性。利用对数正态分布及数值化样例定性式证明)
Self-Attention Distilling
目的:在自注意力模块之后,过滤掉 value 中的冗余信息。
方式:使用 CNN、MaxPooling 进行下采样:
\pmb{X}^t_{j+1}=\text{MaxPool}(\text{ELU}(\text{Conv1d}([\pmb{X}^t_j]_{AB})))
其中,CNN 的 kernel-size=3,pooling 的 stride=2,整体的空间复杂度为: O ( ( 2 − ϵ ) L log L ) \mathcal{O}((2-\epsilon)L\log L) O((2−ϵ)LlogL), ϵ \epsilon ϵ 是一个小量(原因是: 1 + 1 2 + 1 4 + 1 8 + ⋯ 1+\frac{1}{2}+\frac{1}{4}+\frac{1}{8}+\cdots 1+21+41+81+⋯)。
其他
- Decoder:与原始 Transformer 的一致;
- 生成式推断(Generative Inference):一次性输出长序列预测结果,而非迭代地逐个输出结果。
- Loss Function:MSE
- 位置嵌入(Position Embedding):局部时间戳的位置嵌入(PE,使用sin函数)、全局时间戳的位置嵌入(SE,用于日月周节日等特殊时间点) PE ( L x × ( t − 1 ) + i , ) + Σ [ SE ( L x × ( t − 1 ) + i ) ] p \text{PE}_{(L_x\times(t-1)+i,)}+\Sigma[\text{SE}_{(L_x\times(t-1)+i)}]_p PE(Lx×(t−1)+i,)+Σ[SE(Lx×(t−1)+i)]p
# PE pe[:, 0::2] = torch.sin(position * div_term) pe[:, 1::2] = torch.cos(position * div_term) # SE minute_x = nn.Embedding( 4, d_model)(x[:,:,4]) hour_x = nn.Embedding(24, d_model)(x[:,:,3]) weekday_x = nn.Embedding( 7, d_model)(x[:,:,2]) day_x = nn.Embedding(32, d_model)(x[:,:,1]) month_x = nn.Embedding(13, d_model)(x[:,:,0]) se = hour_x + weekday_x + day_x + month_x + minute_x
相关文章:
Informer 论文学习笔记
论文:《Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting》 代码:https://github.com/zhouhaoyi/Informer2020 地址:https://arxiv.org/abs/2012.07436v3 特点: 实现时间与空间复杂度为 O ( …...

c语言位段知识详解
本篇文章带来位段相关知识详细讲解! 如果您觉得文章不错,期待你的一键三连哦,你的鼓励是我创作的动力之源,让我们一起加油,一起奔跑,让我们顶峰相见!!! 目录 一.什么是…...
FFmpeg aresample_swr_opts的解析
ffmpeg option的解析 aresample_swr_opts是AVFilterGraph中的option。 static const AVOption filtergraph_options[] {{ "thread_type", "Allowed thread types", OFFSET(thread_type), AV_OPT_TYPE_FLAGS,{ .i64 AVFILTER_THREAD_SLICE }, 0, INT_MA…...

CAN学习笔记3:STM32 CAN控制器介绍
STM32 CAN控制器 1 概述 STM32 CAN控制器(bxCAN),支持CAN 2.0A 和 CAN 2.0B Active版本协议。CAN 2.0A 只能处理标准数据帧且扩展帧的内容会识别错误,而CAN 2.0B Active 可以处理标准数据帧和扩展数据帧。 2 bxCAN 特性 波特率…...

软工导论知识框架(二)结构化的需求分析
本章节涉及很多重要图表的制作,如ER图、数据流图、状态转换图、数据字典的书写等,对初学者来说比较生僻,本贴只介绍基础的轮廓,后面会有单独的帖子详解各图表如何绘制。 一.结构化的软件开发方法:结构化的分析、设计、…...

[SQL挖掘机] - 算术函数 - abs
介绍: 当谈到 SQL 中的 abs 函数时,它是一个用于计算数值的绝对值的函数。“abs” 代表 “absolute”(绝对),因此 abs 函数的作用是返回一个给定数值的非负值(即该数值的绝对值)。 abs 函数接受一个参数&a…...

vue拼接html点击事件不生效
vue使用ts,拼接html,点击事件不生效或者报 is not defined 点击事件要用onclick 不是click let data{name:测,id:123} let conHtml <div> "名称:" data.name "<br>" <p class"cursor blue&quo…...

【Spring】Spring之依赖注入源码解析
1 Spring注入方式 1.1 手动注入 xml中定义Bean,程序员手动给某个属性赋值。 set方式注入 <bean name"userService" class"com.firechou.service.UserService"><property name"orderService" ref"orderService"…...

【微软知识】微软相关技术知识分享
微软技术领域 一、微软操作系统: 微软的操作系统主要是 Windows 系列,包括 Windows 10、Windows Server 等。了解 Windows 操作系统的基本使用、配置和故障排除是非常重要的。微软操作系统(Microsoft System)是美国微软开发的Wi…...

12.python设计模式【观察者模式】
内容:定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变的时候,所有依赖于它的对象得到通知并被自动更新。观者者模式又称为“发布-订阅”模式。比如天气预报,气象局分发气象数据。 角色: 抽象主题…...
重生之我要学C++第五天
这篇文章主要内容是构造函数的初始化列表以及运算符重载在顺序表中的简单应用,运算符重载实现自定义类型的流插入流提取。希望对大家有所帮助,点赞收藏评论,支持一下吧! 目录 构造函数进阶理解 1.内置类型成员在参数列表中的定义 …...

复习之linux高级存储管理
一、lvm----逻辑卷管理 1.lvm定义 LVM是 Logical Volume Manager(逻辑卷管理)的简写,它是Linux环境下对磁盘分区进行管理的一种机制。 逻辑卷管理器(LogicalVolumeManager)本质上是一个虚拟设备驱动,是在内核中块设备和物理设备…...
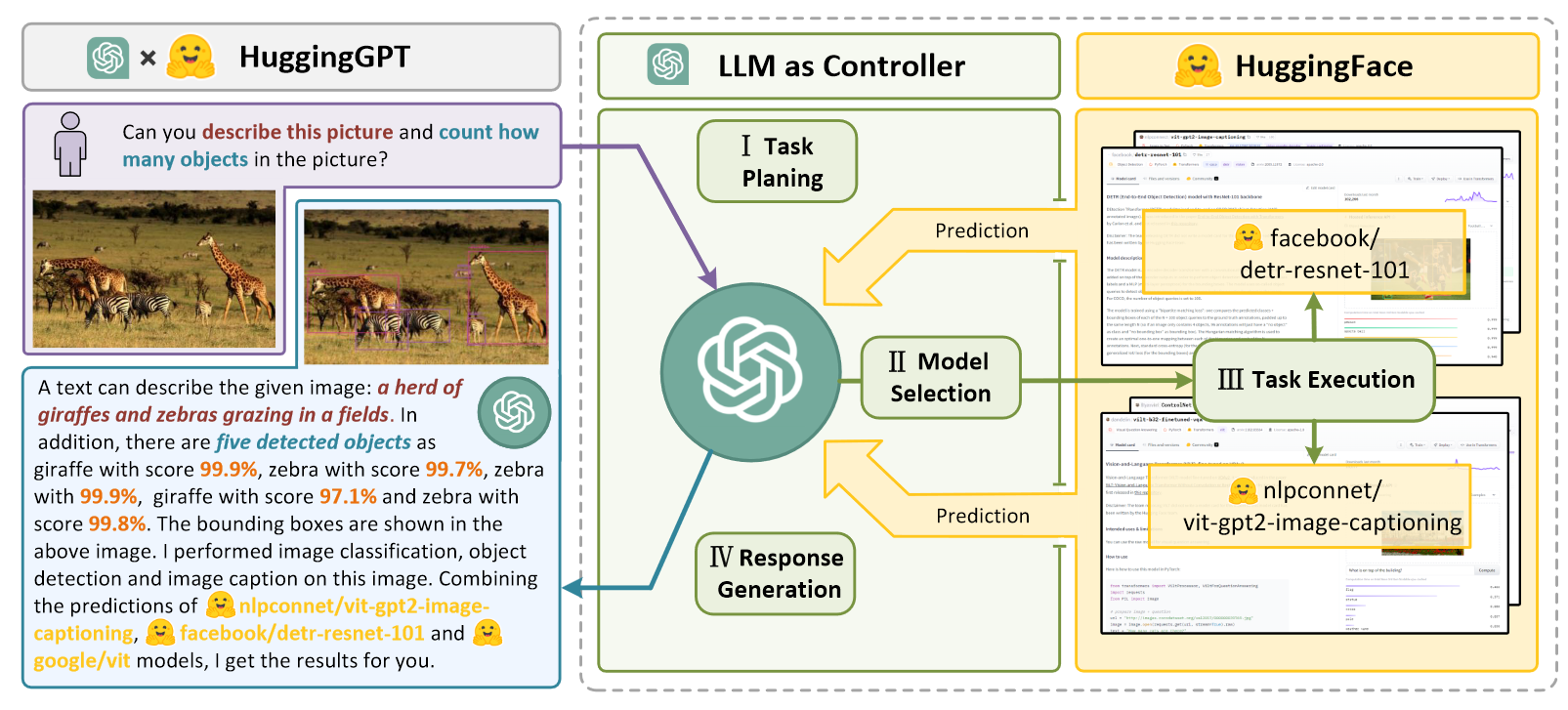
HuggingGPT Solving AI Tasks with ChatGPT and its Friends in Hugging Face
总述 HuggingGPT 让LLM发挥向路由器一样的作用,让LLM来选择调用那个专业的模型来执行任务。HuggingGPT搭建LLM和专业AI模型的桥梁。Language is a generic interface for LLMs to connect AI models 四个阶段 Task Planning: 将复杂的任务分解。但是这里…...

java工程重写jar包中class类覆盖问题
结论:直接在程序中复写jar中的类即可 原因:一般我java工程是运行在tomcat容器中,tomcat容易在加载我们工程类和jar包是的优先级为: 我们工程的class 先于 我们工程lib下的jar 重复的类只加载一次,加载我们复写后的类后…...

Mybatis基于注解与XML开发
文章目录 1 关于SpringBoot2 关于MyBatis2.1 MyBatis概述2.2 MyBatis核心思想2.3 MyBatis使用流程3 MyBatis配置SQL方式3.1 基于注解方式3.1.1 说明3.1.2 使用流程3.1.3 常用注解 3.2 基于XML方式3.2.1 相比注解优势3.2.2 使用流程3.2.3 常用标签 1 关于SpringBoot SpringBoot…...

数字化转型导师坚鹏:数字化时代扩大内需的8大具体建议
在日新月异的数字化时代、复杂多变的国际化环境下,扩大内需成为推动经济发展的国家战略,如何真正地扩大内需?结合本人15年的管理咨询经验及目前实际情况的深入研究,提出以下8大具体建议: 1、制定国民收入倍增计划。结…...
M1/M2 通过VM Fusion安装Win11 ARM,解决联网和文件传输
前言 最近新入了Macmini M2,但是以前的老电脑的虚拟机运行不起来了。😅,实际上用过K8S的时候,会发现部分镜像也跑不起来,X86的架构和ARM实际上还是有很多隐形兼容问题。所以只能重新安装ARM Win11,幸好微软…...

Linux中显示系统正在运行的进程的命令
2023年7月29日,周六上午 在Linux中,ps命令用于显示当前系统中正在运行的进程, ps应该是processes snapshot(进程快照)的缩写。 以下是ps命令的常见用法和示例: 显示当前用户的所有进程:ps 显示…...
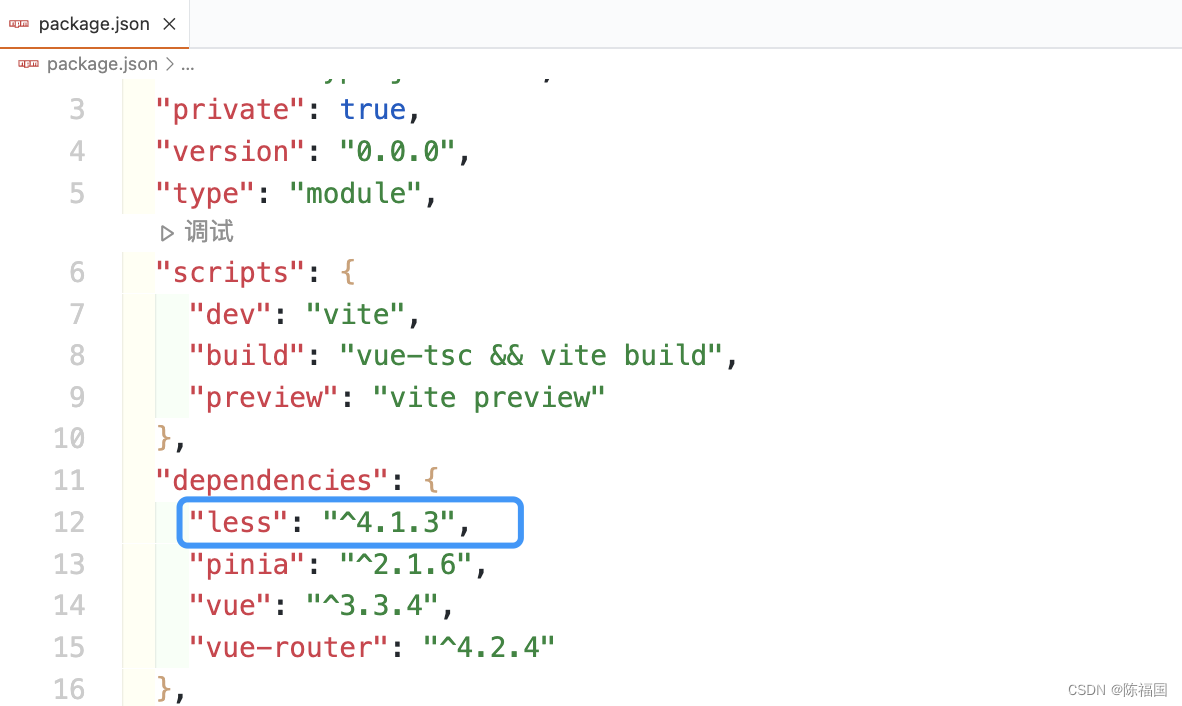
vite中安装less
使用vite创建的项目,默认是没有安装less的 如果直接在style中书写less 会报下图错误: 解决方案: npm install --save less 在package.json中查看是否安装成功 安装完成刷新页面,问题解决...
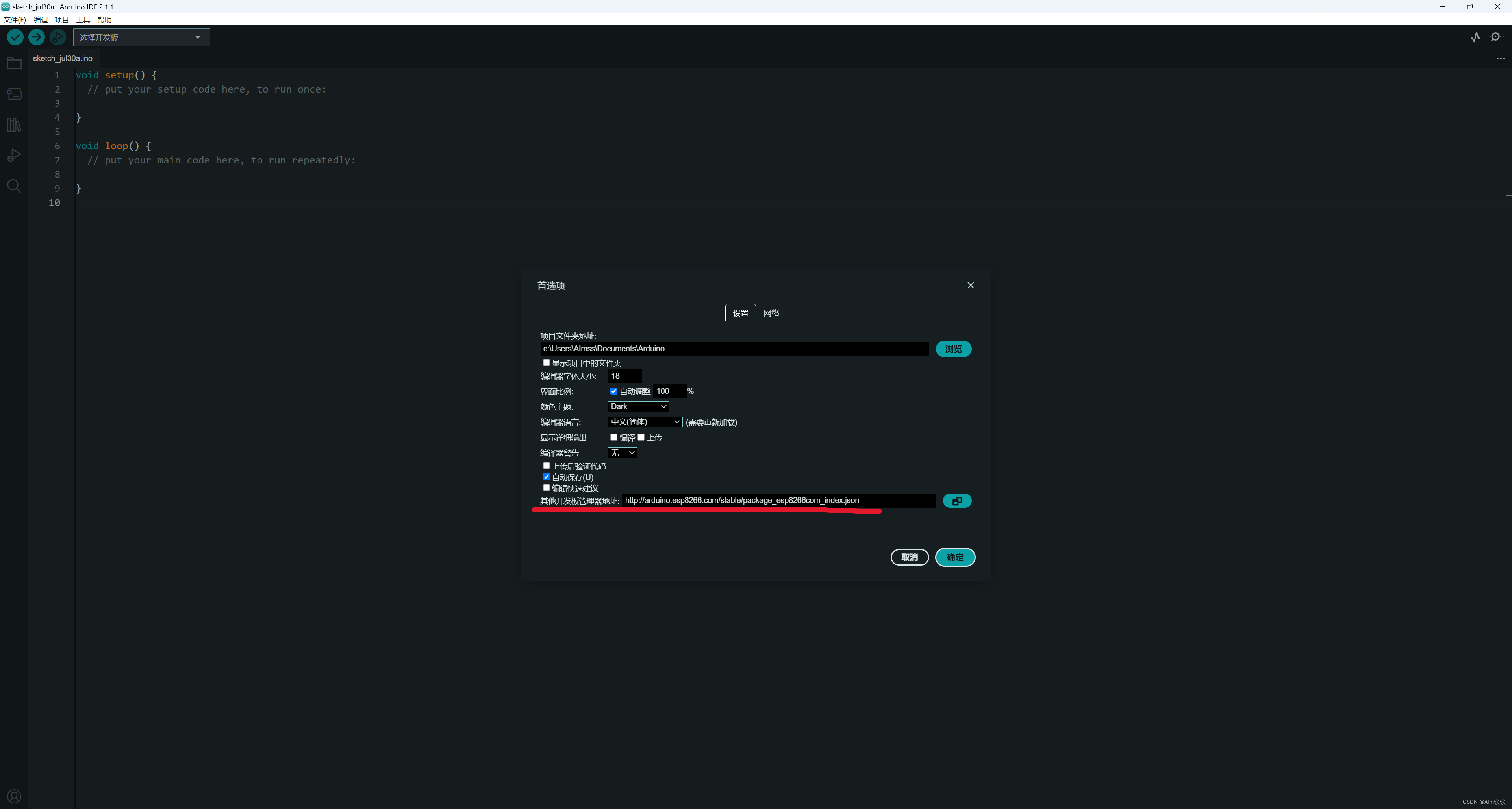
Aduino中eps环境搭建
这里只记录Arduino2.0以后版本:如果有外网环境,那么可以轻松搜到ESP32开发板环境并安装,如果没有,那就见下面操作: 进入首选项,将esp8266的国内镜像地址填入,然后保存,在开发板中查…...

企业部署 AI Agent Harness Engineering 的第一道坎不是技术,是信任
企业部署 AI Agent Harness Engineering 的第一道坎不是技术,是信任 引言 各位正在关注 AI Agent 落地企业生产环境的技术负责人、CTO、架构师、开发者们: 去年我在国内某头部 SaaS 公司做内部 Hackathon 的评委时,看到了一支由 3 个应届毕业的计算机科学博士和 2 个资深后…...

Lindy自动化不是IT部门的事!CIO亲述:如何用“业务-技术-合规”三权制衡模型锁定首期300万降本收益
更多请点击: https://intelliparadigm.com 第一章:Lindy自动化不是IT部门的事!CIO亲述:如何用“业务-技术-合规”三权制衡模型锁定首期300万降本收益 Lindy自动化(Lindy Effect-driven Automation)的本质&…...
与KAZE特征匹配技术,通过摄像头和IMU数据来估计无人机的位置附Matlab代码)
【滤波跟踪】基于EKF的视觉-惯性里程计(VIO)与KAZE特征匹配技术,通过摄像头和IMU数据来估计无人机的位置附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...

STM32H743音频实战:用CubeMX和I2S驱动WM8978,从寄存器配置到代码移植避坑
STM32H743音频实战:CubeMX与I2S驱动WM8978的深度避坑指南 第一次在STM32H743上调试WM8978音频编解码器时,我盯着示波器上杂乱无章的I2S信号波形发呆了半小时。耳机里偶尔传来的爆裂声仿佛在嘲笑我的无知——这场景想必很多嵌入式音频开发者都不陌生。本文…...

Node.js后端服务如何集成多模型能力并管理API成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Node.js后端服务如何集成多模型能力并管理API成本 1. 场景与需求 在Node.js后端服务中集成AI对话功能,开发者通常面临…...
)
当大模型遇见嵌入式MCU:RISC-V+TinyML+Agent状态机的超低功耗智能体设计(STM32H7实测待机功耗仅2.1mW)
更多请点击: https://codechina.net 第一章:AI Agent边缘计算应用 AI Agent在边缘计算场景中正从“云端智能”转向“端侧自治”,通过轻量化模型、实时推理与本地决策能力,显著降低延迟、带宽依赖与数据隐私风险。典型应用包括工业…...

保姆级教程:用闲置旧电脑和U盘,5分钟搞定OpenWrt软路由安装与基础网络配置
零成本打造高性能软路由:闲置电脑变身网络控制中心 从电子垃圾到网络枢纽的华丽转身 每个科技爱好者家里都有一台被时代淘汰的旧电脑——它们运行缓慢、硬盘老化,却依然能点亮开机。与其让这些设备在角落积灰,不如赋予它们第二次生命&#…...

MPC5604B/C 信号与引脚全解|硬件 / 底层必看
一、前言 本章主要说明每个引脚叫什么、干什么、上电默认状态、是什么电气类型、复用哪些功能。包含 封装引脚分布(64/100/144LQFP、208MAPBGA) 电源 / 地 / 复位 / 晶振 / JTAG 引脚 引脚电气类型(S/M/F/I/J/X) 复位期间引脚状态 所有 GPIO 的复用功能 AF0~AF3 引脚与外设…...

基于Java的外卖点餐配送系统_43lq510m
目录 同行可拿货,招校园代理 ,本人源头供货商项目概述技术栈核心功能模块项目亮点部署方式学习价值 项目技术支持获取博主联系方式 源码获取详细视频演示 :同行可合作点击我获取源码->获取博主联系方式->进我个人主页--> 同行可拿货,招校园代理 ,本人源头供…...

C++超详细讲解析构函数
析构函数是特殊的成员函数特征如下:析构函数名是~类名;无参数无返回值;一个类有且只有一个析构函数;对象声明周期结束,编译器自动调用析构函数;12345678910111213141516171819202122232425262728293031clas…...