【多模态】20、OVR-CNN | 使用 caption 来实现开放词汇目标检测

文章目录
- 一、背景
- 二、方法
- 2.1 学习 视觉-语义 空间
- 2.2 学习开放词汇目标检测
- 三、效果
论文:Open-Vocabulary Object Detection Using Captions
代码:https://github.com/alirezazareian/ovr-cnn
出处:CVPR2021 Oral
一、背景
目标检测数据标注很耗费人力,现有的开集大型数据,如 Open Images 和 MSCOCO 数据集大约包含 600 个数据类别
如果想要识别现实世界中的任何物体,则需要更多的人工数据标注
但人类学习显示视觉世界中的物体很大程度上是基于语言的监督信号,也可以使用几个简单的例子来泛化到其他目标上,而不需要所有的目标实例。
所以在本文中,作者模仿人类的能力,设计了一个双阶段开集目标检测 Open-Vocabulary object Detection(OVD)
- 首次提出了使用 image-caption pairs 来获得无限的词汇,类似于人类从自然语言中学习一样,然后使用部分标注实例来学习目标检测
- 这样就能够仅仅使用有限类别的标注样本就可以了,其他的就从 caption 中来学习
- 这些样本对儿获得起来更加方便,而且网络上就有很多现成的
图 2 展示了几种非常相近的任务的差别:
- Open-vocabulary:通过语言词汇来将目标类和基础类进行关联
- Zero-Shot:主要目标是实现从见过的类上扩展到没见过的类上
- Weaky Supervised:

二、方法
大体框架结构如图 1 所示:
- 要训练能检测任何目标( target vocabulary: V T V_T VT)的模型需要下面的几种信息
- 大量的 image-caption 数据集(包含大量的多样的单词): V C V_C VC
- 较少数据量的检测数据集(有基础类别框标注信息): V B V_B VB
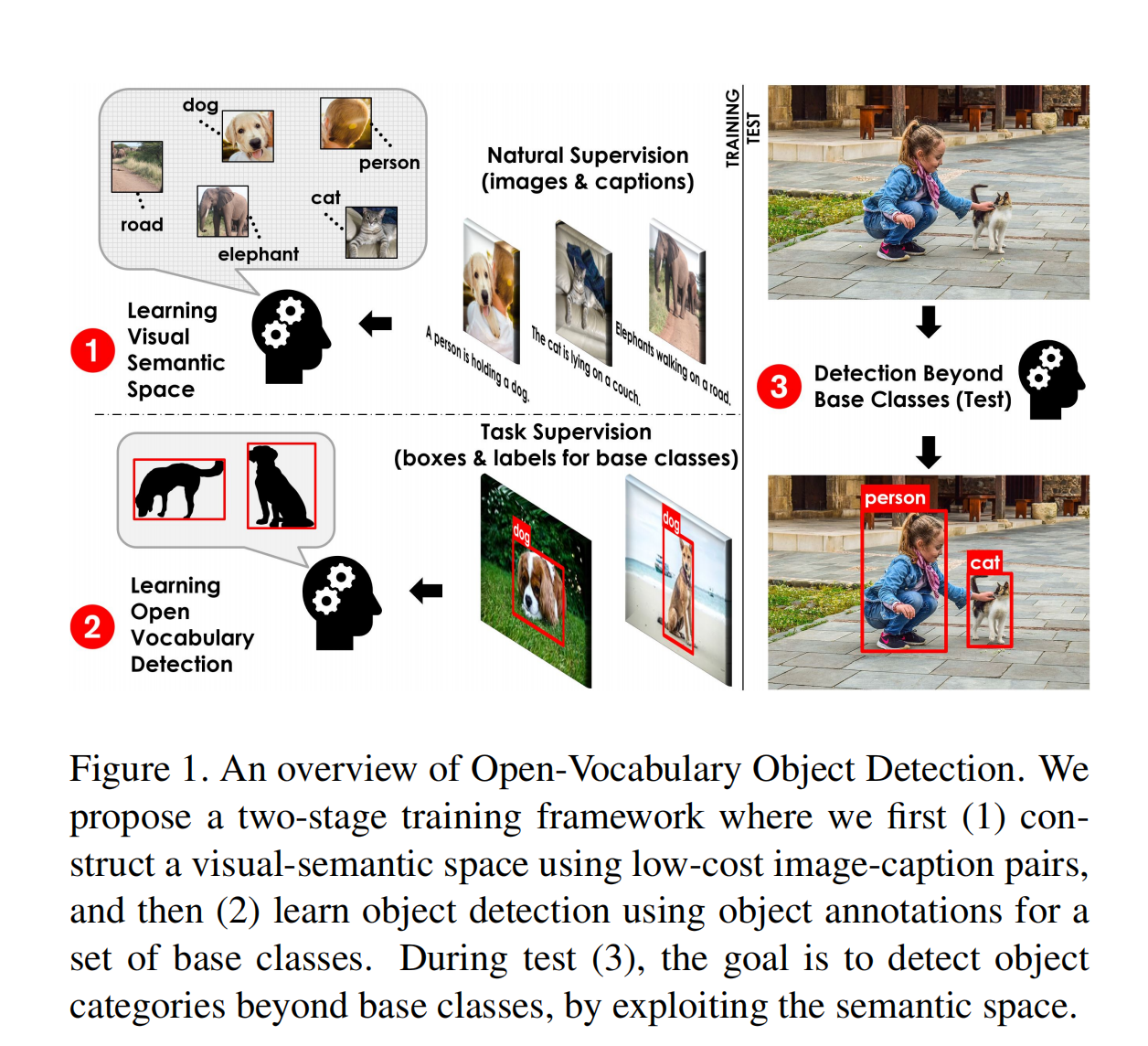
图 3 展示了详细的结构:
-
本文方法基于 Faster R-CNN,在基础类别上进行训练,在目标类别上进行测试
-
预训练:为了避免在基础类别上过拟合,作者在大量词汇量 V C V_C VC 下进行了预训练(上半部分),让模型能够学习到更全面的语义信息,而不是只有基础类别的语义信息。即在 image-caption pairs 上通过 grounding、masked language modeling (MLM) 、 image-text matching 来训练 ResNet 和 V2L layer,V2L layer 是 vision2language 模块,负责将视觉特征变换到文本空间,好让两个不同模态的特征能在同一空间来衡量相似性。
-
训练:预训练后使用得到的 ResNet 和 V2L layer 来初始化 Faster R-CNN ,以此来实现开放词汇目标检测,ResNet 50 用于 backbone,V2L layer 是会用于对每个 proposal 特征进行变换的,变换之后会与类别标签的文本特征计算相似度来进行分类的,训练的时候会固定 V2L layer 的,使其学习到的广泛的信息能够泛化到新类
-
整个模型框架和 Faster RCNN 一样,只是将最后的 cls head 替换成了 V2L,也就是换成了一个将 visual feature 投影到 text embedding space 的投影矩阵
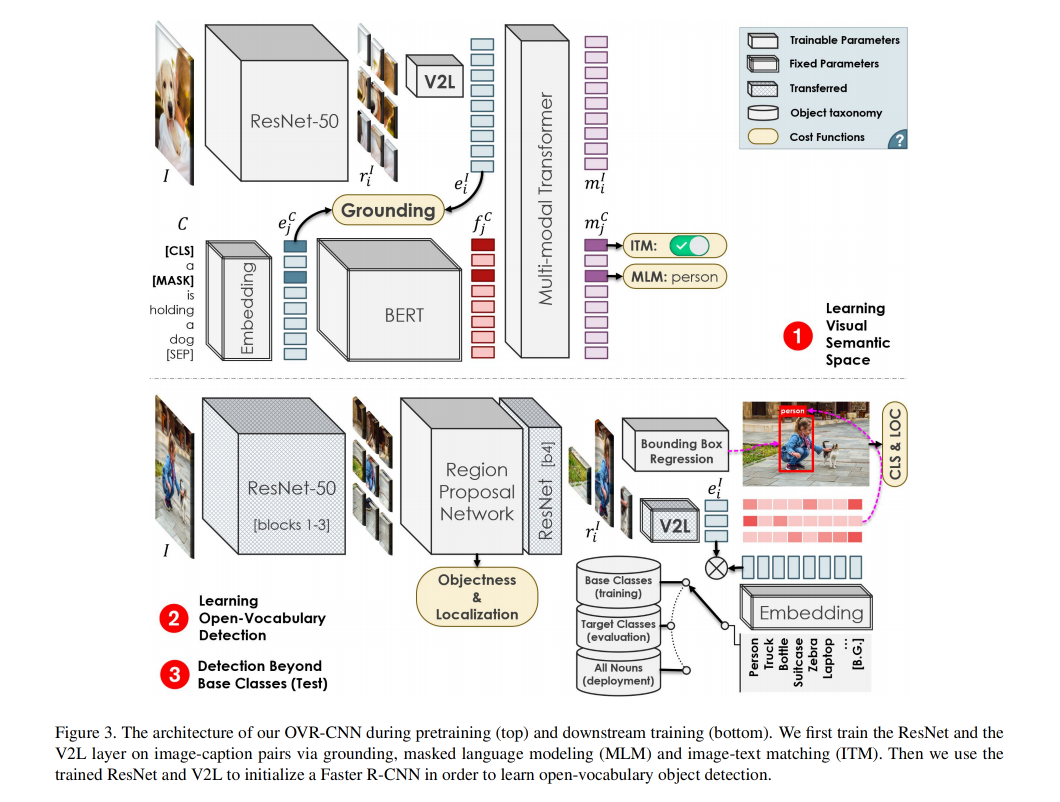
2.1 学习 视觉-语义 空间
本文提出了一个 Vision to Language(V2L)映射层,和 CNN 一起在预训练中进行学习,使用 grounding 任务和和一些辅助自监督任务来训练 CNN 和 V2L layer。
-
输入:image-caption pairs
-
特征提取:image 输入 visual backbone(ResNet50),caption 输入 language backbone(BERT),分别提取对应的特征
-
特征融合:将两种特征输入多模态特征融合器中,来抽取多模态的 embedding
-
目标:让每个 caption 的 word embedding 和其对应的图像区域更加接近,且作者设定了一个 global grounding score 来度量其关系,成对儿的 image-caption 得分要最大,不成对儿的 image-caption 得分要小

-
负样本对儿:作者使用同一个 batch 中的其他图像作为每个 caption 的negative examples,也使用同一 batch 中的其他 caption 作为每个 image 的 negative examples
-
grounding objective functions 如下:
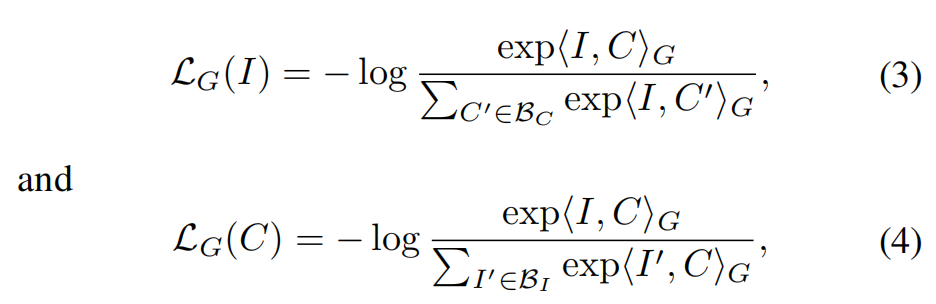
-
最终的 loss:
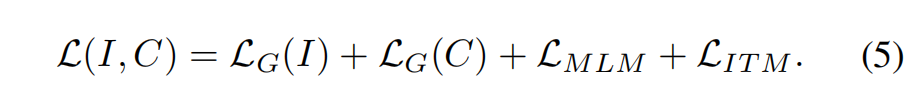
2.2 学习开放词汇目标检测
在完成 ResNet 和 V2L 的预训练后,作者要把其学习到的东西迁移到 object detection 上,方式就是用训练后的特征来初始化 Faster R-CNN
- 首先,使用经过预训练的 ResNet50 的 stem 和前 3 个 block 来抽取图像特征
- 然后,使用 region proposal network 来预测目标可能出现的位置和 objectness score,并且使用 NMS 和 RoI pooling 来得到每个目标框
- 之后,给每个 proposal 使用 ResNet50 的第 4 个 block (和一个 pooling)来提取每个 proposal 的最终特征
- 最终,对比每个 proposal 被编码到 word space 中的特征和基础类别 k 的得分
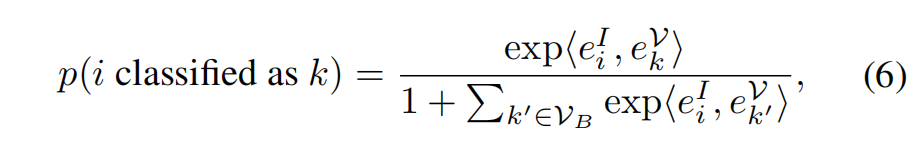
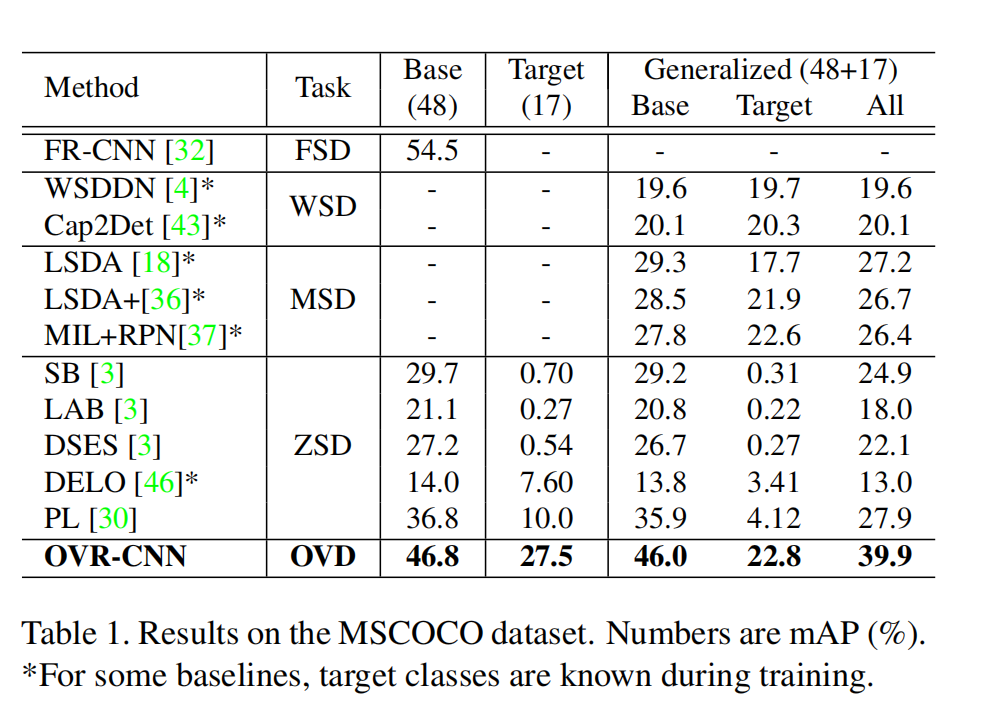
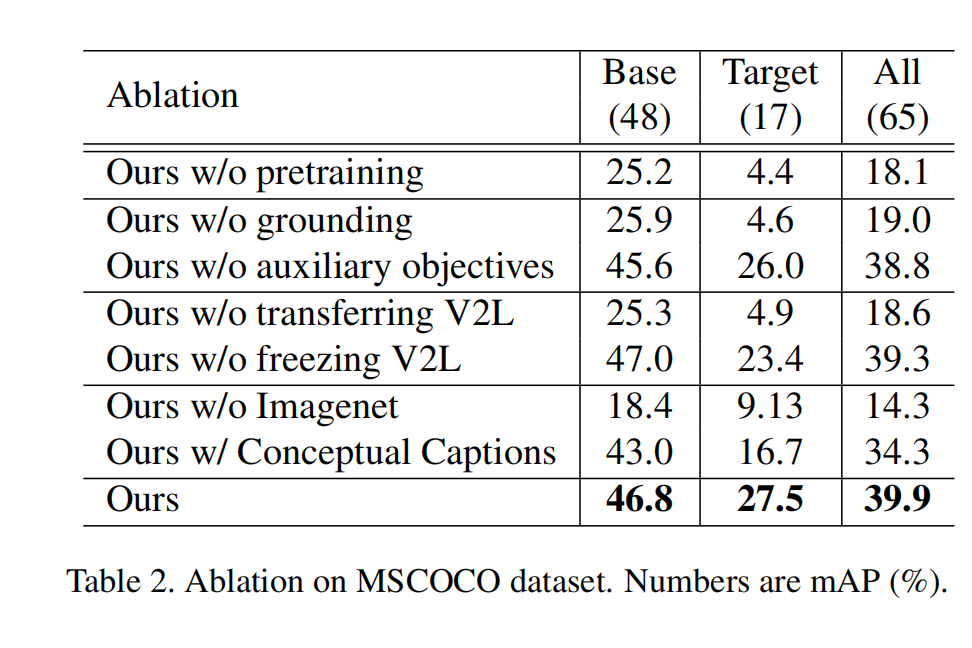
三、效果


相关文章:
【多模态】20、OVR-CNN | 使用 caption 来实现开放词汇目标检测
文章目录 一、背景二、方法2.1 学习 视觉-语义 空间2.2 学习开放词汇目标检测 三、效果 论文:Open-Vocabulary Object Detection Using Captions 代码:https://github.com/alirezazareian/ovr-cnn 出处:CVPR2021 Oral 一、背景 目标检测数…...
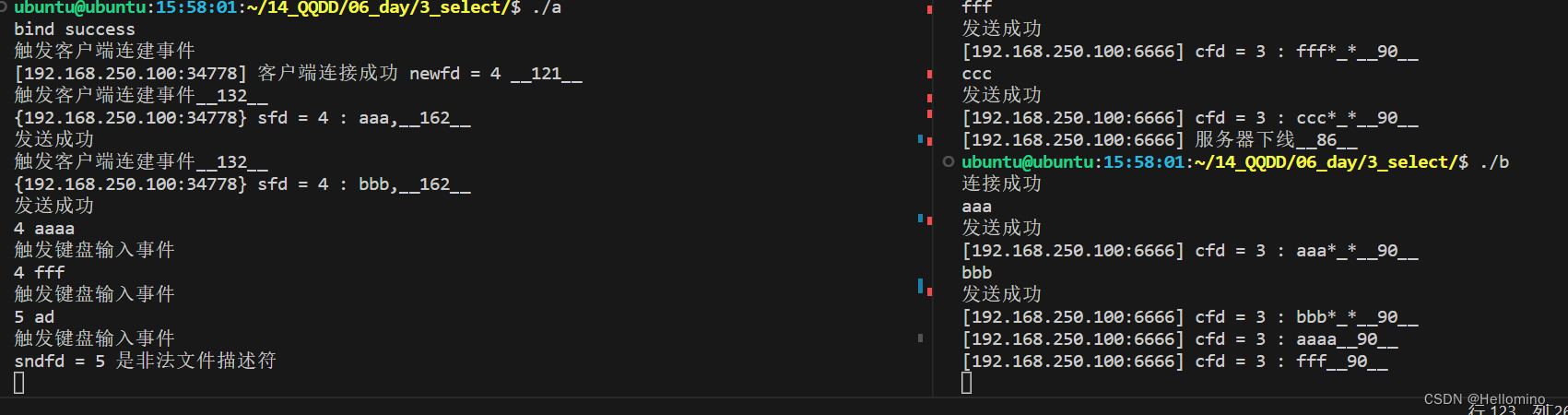
网络编程 IO多路复用 [select版] (TCP网络聊天室)
//head.h 头文件 //TcpGrpSer.c 服务器端 //TcpGrpUsr.c 客户端 select函数 功能:阻塞函数,让内核去监测集合中的文件描述符是否准备就绪,若准备就绪则解除阻塞。 原型: #include <sys/select.…...

数学建模学习(7):单目标和多目标规划
优化问题描述 优化 优化算法是指在满足一定条件下,在众多方案中或者参数中最优方案,或者参数值,以使得某个或者多个功能指标达到最优,或使得系统的某些性能指标达到最大值或者最小值 线性规划 线性规划是指目标函数和约束都是线性的情况 [x,fval]linprog(f,A,b,Aeq,Beq,LB,U…...

Element UI如何自定义样式
简介 Element UI是一套非常完善的前端组件库,但是如何个性化定制其中的组件样式呢?今天我们就来聊一聊这个 举例 就拿最常见的按钮el-button来举例,一般来说默认是蓝底白字。效果图如下 可是我们想个性化定制,让他成为粉底红字应…...

protobuf入门实践2
如何在proto中定义一个rpc服务? syntax "proto3"; //声明protobuf的版本package fixbug; //声明了代码所在的包 (对于C来说就是namespace)//下面的选项,表示生成service服务类和rpc方法描述, 默认是不生成的 option cc_generi…...

adb shell使用总结
文章目录 日志记录系统概览adb 使用方式 adb命令日志过滤按照告警等级进行过滤按照tag进行过滤根据告警等级和tag进行联合过滤屏蔽系统和其他App干扰,仅仅关注App自身日志 查看“当前页面”Activity文件传输截屏和录屏安装、卸载App启动activity其他 日志记录系统概…...
-Tag的含义、Tag类型与其他的转换)
UG NX二次开发(C++)-Tag的含义、Tag类型与其他的转换
文章目录 1、前言2、Tag号的含义3、tag_t转换为int3、TaggedObject与Tag转换3.1 TaggedObject定义3.2 TaggedObject获取Tag3.3 根据Tag获取TaggedObject4.Tag与double类型的转换1、前言 在UG NX中,每个对象对应一个tag号,C++中,其类型是tag_t,一般是5位或者6位的int数字,…...
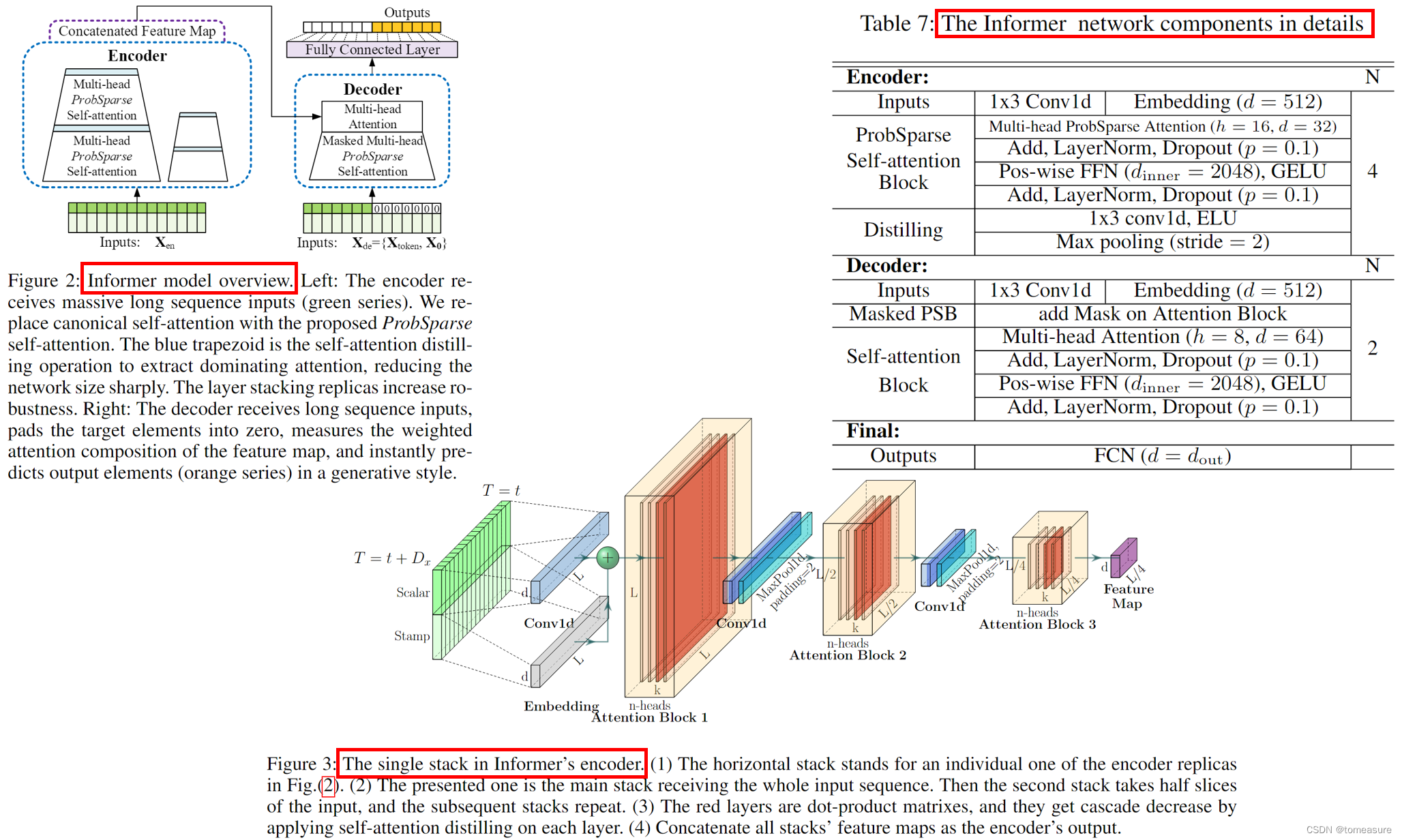
Informer 论文学习笔记
论文:《Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting》 代码:https://github.com/zhouhaoyi/Informer2020 地址:https://arxiv.org/abs/2012.07436v3 特点: 实现时间与空间复杂度为 O ( …...

c语言位段知识详解
本篇文章带来位段相关知识详细讲解! 如果您觉得文章不错,期待你的一键三连哦,你的鼓励是我创作的动力之源,让我们一起加油,一起奔跑,让我们顶峰相见!!! 目录 一.什么是…...
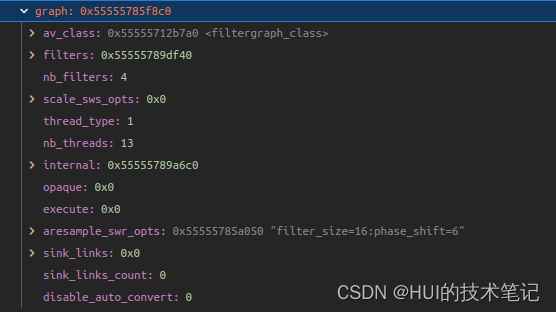
FFmpeg aresample_swr_opts的解析
ffmpeg option的解析 aresample_swr_opts是AVFilterGraph中的option。 static const AVOption filtergraph_options[] {{ "thread_type", "Allowed thread types", OFFSET(thread_type), AV_OPT_TYPE_FLAGS,{ .i64 AVFILTER_THREAD_SLICE }, 0, INT_MA…...

CAN学习笔记3:STM32 CAN控制器介绍
STM32 CAN控制器 1 概述 STM32 CAN控制器(bxCAN),支持CAN 2.0A 和 CAN 2.0B Active版本协议。CAN 2.0A 只能处理标准数据帧且扩展帧的内容会识别错误,而CAN 2.0B Active 可以处理标准数据帧和扩展数据帧。 2 bxCAN 特性 波特率…...

软工导论知识框架(二)结构化的需求分析
本章节涉及很多重要图表的制作,如ER图、数据流图、状态转换图、数据字典的书写等,对初学者来说比较生僻,本贴只介绍基础的轮廓,后面会有单独的帖子详解各图表如何绘制。 一.结构化的软件开发方法:结构化的分析、设计、…...

[SQL挖掘机] - 算术函数 - abs
介绍: 当谈到 SQL 中的 abs 函数时,它是一个用于计算数值的绝对值的函数。“abs” 代表 “absolute”(绝对),因此 abs 函数的作用是返回一个给定数值的非负值(即该数值的绝对值)。 abs 函数接受一个参数&a…...

vue拼接html点击事件不生效
vue使用ts,拼接html,点击事件不生效或者报 is not defined 点击事件要用onclick 不是click let data{name:测,id:123} let conHtml <div> "名称:" data.name "<br>" <p class"cursor blue&quo…...

【Spring】Spring之依赖注入源码解析
1 Spring注入方式 1.1 手动注入 xml中定义Bean,程序员手动给某个属性赋值。 set方式注入 <bean name"userService" class"com.firechou.service.UserService"><property name"orderService" ref"orderService"…...

【微软知识】微软相关技术知识分享
微软技术领域 一、微软操作系统: 微软的操作系统主要是 Windows 系列,包括 Windows 10、Windows Server 等。了解 Windows 操作系统的基本使用、配置和故障排除是非常重要的。微软操作系统(Microsoft System)是美国微软开发的Wi…...

12.python设计模式【观察者模式】
内容:定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变的时候,所有依赖于它的对象得到通知并被自动更新。观者者模式又称为“发布-订阅”模式。比如天气预报,气象局分发气象数据。 角色: 抽象主题…...
重生之我要学C++第五天
这篇文章主要内容是构造函数的初始化列表以及运算符重载在顺序表中的简单应用,运算符重载实现自定义类型的流插入流提取。希望对大家有所帮助,点赞收藏评论,支持一下吧! 目录 构造函数进阶理解 1.内置类型成员在参数列表中的定义 …...

复习之linux高级存储管理
一、lvm----逻辑卷管理 1.lvm定义 LVM是 Logical Volume Manager(逻辑卷管理)的简写,它是Linux环境下对磁盘分区进行管理的一种机制。 逻辑卷管理器(LogicalVolumeManager)本质上是一个虚拟设备驱动,是在内核中块设备和物理设备…...
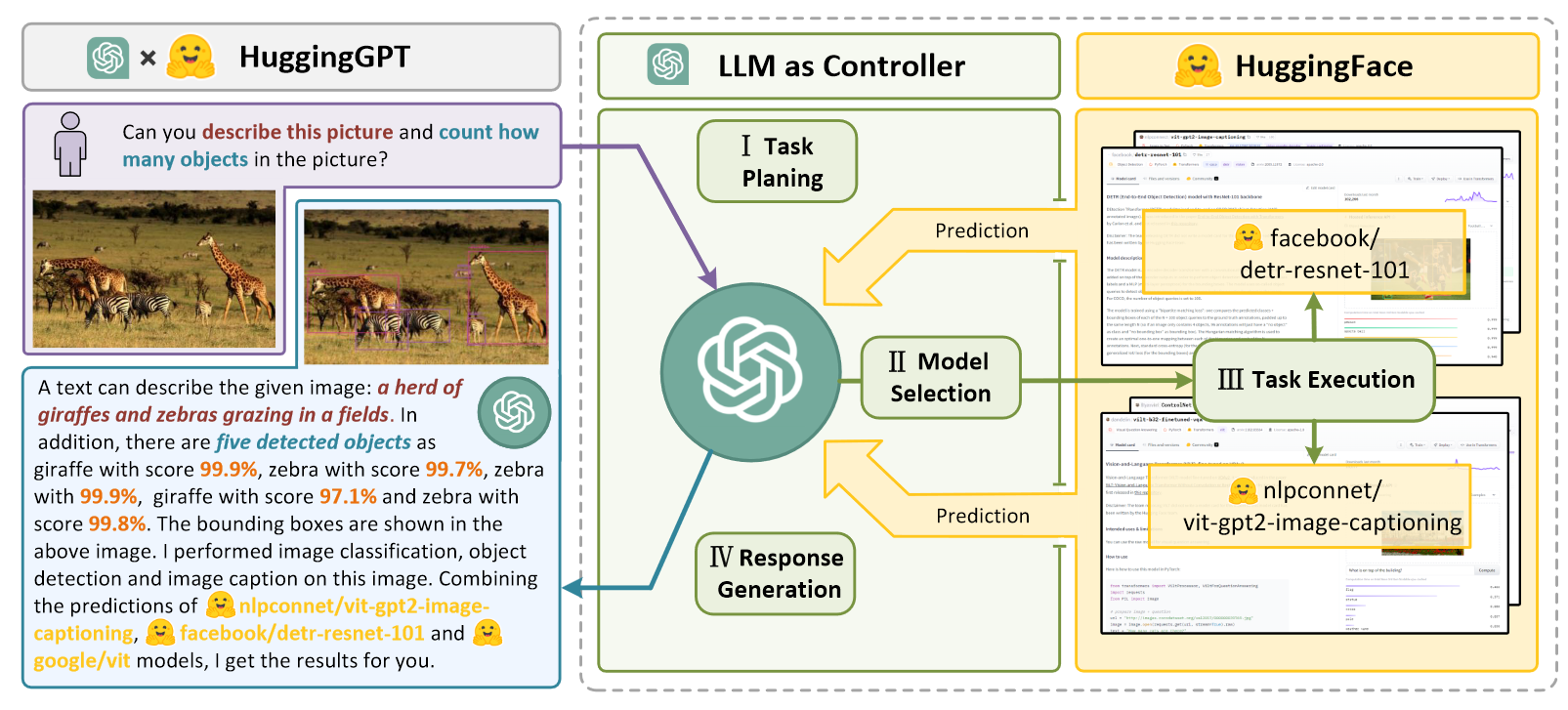
HuggingGPT Solving AI Tasks with ChatGPT and its Friends in Hugging Face
总述 HuggingGPT 让LLM发挥向路由器一样的作用,让LLM来选择调用那个专业的模型来执行任务。HuggingGPT搭建LLM和专业AI模型的桥梁。Language is a generic interface for LLMs to connect AI models 四个阶段 Task Planning: 将复杂的任务分解。但是这里…...

Linux-安装cmatrix
linux-安装cmatrix (黑客帝国矩阵效果) su root #切换身份到root不受权限控制 cd /usr/src #进入源码下载位置,准备下载安装包利用xftp 共享传送文件进入home找到文件,cp 文件 /usr/src解压,进…...

Invoke-Obfuscation深度解析:PowerShell混淆技术的实战指南与防御策略
Invoke-Obfuscation深度解析:PowerShell混淆技术的实战指南与防御策略 【免费下载链接】Invoke-Obfuscation PowerShell Obfuscator 项目地址: https://gitcode.com/gh_mirrors/in/Invoke-Obfuscation Invoke-Obfuscation是一款专业的PowerShell脚本混淆框架…...

独立开发者如何利用 Taotoken 的 Token Plan 套餐以更优成本启动 AI 项目
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用 Taotoken 的 Token Plan 套餐以更优成本启动 AI 项目 对于独立开发者或小型工作室而言,在项目启动…...

从Java全栈开发到云原生:一次真实的面试对话与技术剖析
从Java全栈开发到云原生:一次真实的面试对话与技术剖析 面试场景回顾 在一次真实的互联网大厂Java全栈开发岗位的面试中,面试官和应聘者展开了一场围绕技术栈、项目经验和系统设计的深入交流。面试官以专业严谨的态度,逐步引导应聘者展示其技…...

科研节奏管理法:4篇论文驱动的工程化落地实践
1. 项目概述:这不是一份文献综述,而是一份“科研呼吸节奏”训练手册“Month in 4 Papers (December 2024)”——这个标题乍看像一份学术月报,但如果你真把它当成四篇论文的摘要合集,就完全错过了它最核心的价值。我做了十年科研内…...

揭秘当下匹克球鞋销售厂家,背后隐藏着怎样的行业秘密?
在运动市场中,匹克球运动正逐渐兴起,匹克球鞋销售厂家也受到了更多关注。下面,让我们深入探究其中的行业秘密。市场现状与痛点行业报告显示,随着匹克球运动的普及,匹克球鞋市场规模不断扩大,但也存在诸多痛…...
vue3 大屏列表轮播,使用transition-group
一、transition-group介绍transition-group 是 Vue 框架中专门用来给列表添加动画效果的内置组件,它能让你在做添加、删除或排序列表项时,看到平滑的过渡动画 。对应的css:例如:transition-group的类名为 list动画类名就为…...

REFramework技术深度解析:企业级游戏引擎扩展框架的架构演进与设计哲学
REFramework技术深度解析:企业级游戏引擎扩展框架的架构演进与设计哲学 【免费下载链接】REFramework Mod loader, scripting platform, and VR support for all RE Engine games 项目地址: https://gitcode.com/GitHub_Trending/re/REFramework 在游戏开发领…...

不止于看见,更在于改变——双碳传媒的全球工业服务生态
在数字化与智能化重塑世界的今天,传统的工业传播边界正在被打破。双碳传媒(秦皇岛)有限公司,正以AI技术为核心驱动,重新定义全球工业服务的生态格局。我们深知,服务国家战略与顶级企业,需要的是…...

联发科MT6833与MT6853 5G核心板:规格对比与产品选型实战指南
1. 项目概述:两款5G安卓核心板的定位与价值在当前的移动设备开发领域,尤其是面向中高端市场的智能手机、平板电脑以及各类智能终端,选择一颗性能强劲、功能集成度高且成本可控的核心处理器平台,是决定产品成败的关键。联发科&…...