【语音识别】- 声学,词汇和语言模型
一、说明
语音识别是指计算机通过处理人类语言的音频信号,将其转换为可理解的文本形式的技术。也就是说,它可以将人类的口语语音转换为文本,以便计算机能够进一步处理和理解。它是自然语言处理技术的一部分,被广泛应用于语音识别助手,语音交互系统,语音搜索等领域。
二、语音识别的意图和实现
语音识别可以被视为根据声学、发音词典和语言模型找到最佳单词序列 (W)。
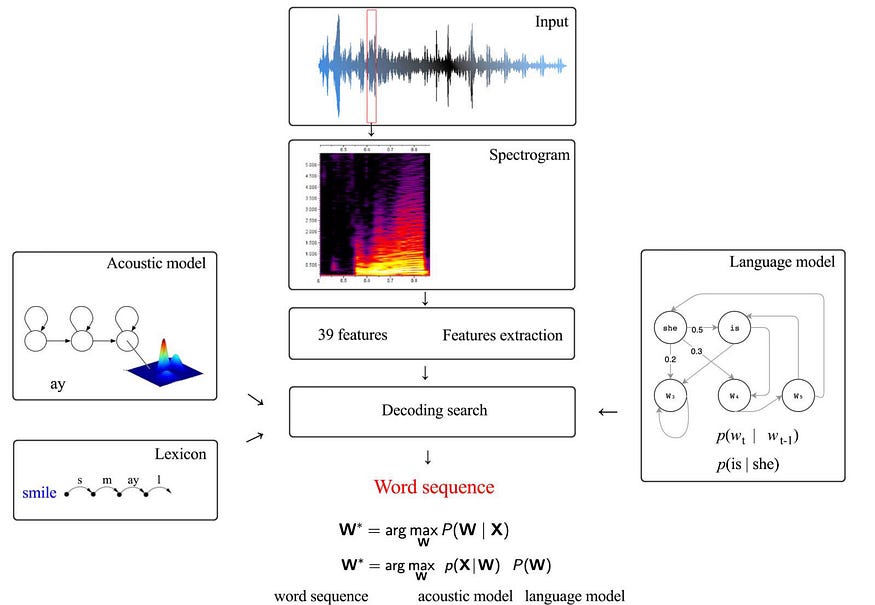
在上一篇文章中,我们学习了HMM和GMM的基础知识。现在是时候将它们放在一起来构建这些模型了。
词汇
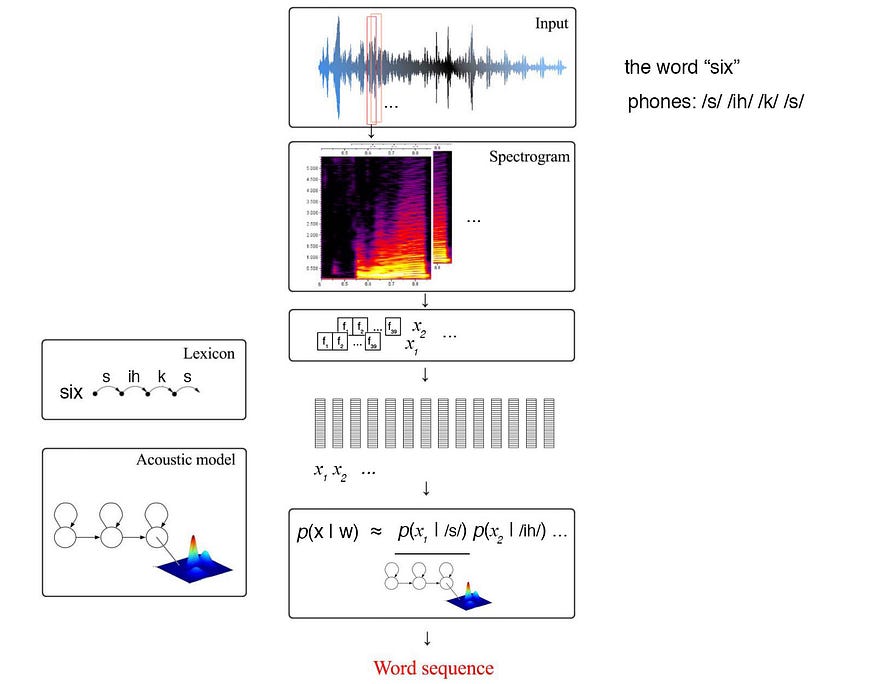
发音词典对单词的电话序列进行建模。通过使用滑动窗口分割音频剪辑,我们生成一系列音频帧。对于每一帧,我们提取了 39 个 MFCC 特征。即,我们生成一系列特征向量 X(x₁, x₂, ..., xi, ...),其中 xi 包含 39 个特征。似然 p(X|W) 可以根据词典和声学模型近似。
发音词典是用马尔可夫链建模的。

HMM 模型中的自循环将电话与观察到的音频帧对齐。
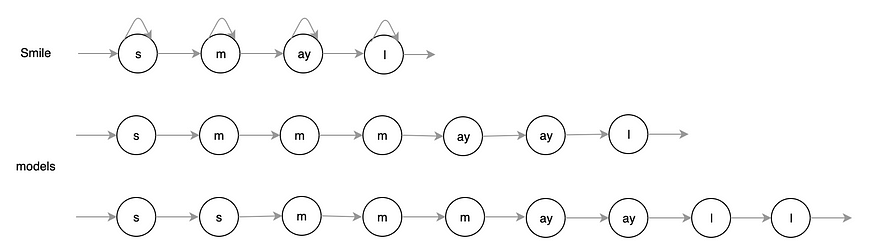
这为处理发音的时间变化提供了灵活性。

源
给定一个经过训练的HMM模型,我们对观察结果进行解码以找到内部状态序列。这可以通过下面的格子可视化。下面的箭头演示了可能的状态转换。给定一系列观察值X,我们可以使用维特比算法来解码最佳电话序列(比如下面的红线)。
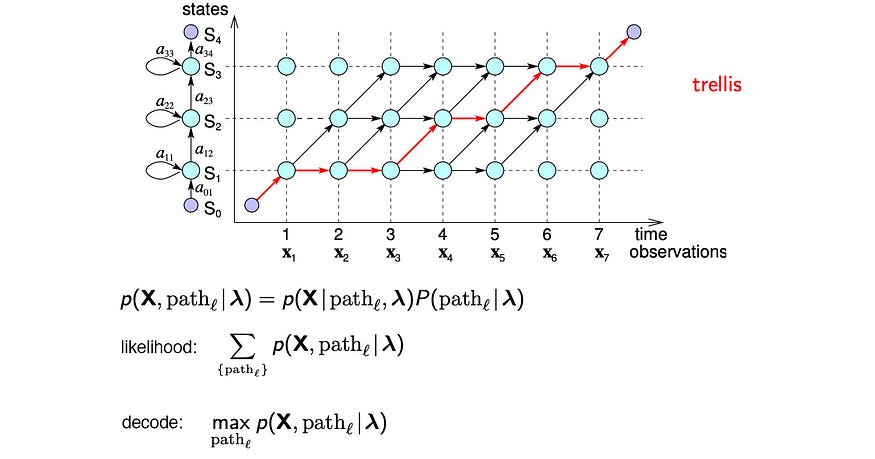
从源代码修改
在本文中,我们不会重复有关HMM和GMM的背景信息。如果您需要,这是关于这两个主题的上一篇文章。它包括维特比算法,用于寻找最佳状态序列。
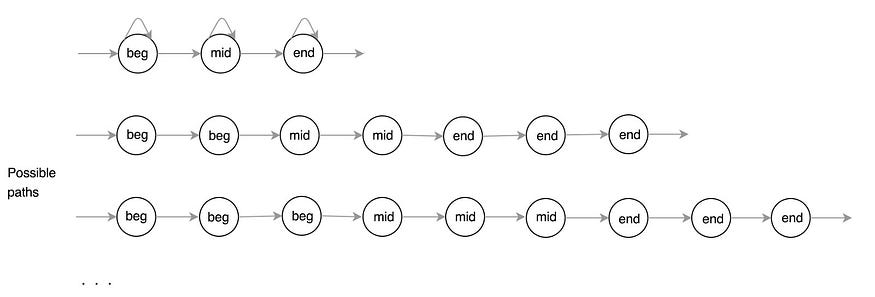
但是,手机不是同质的。频率的幅度从开始到结束都在变化。为了反映这一点,我们进一步将手机细分为三种状态:手机的开头、中间和结束部分。

从源代码修改
这是我们从每部手机的一个状态更改为三个状态的HMM。
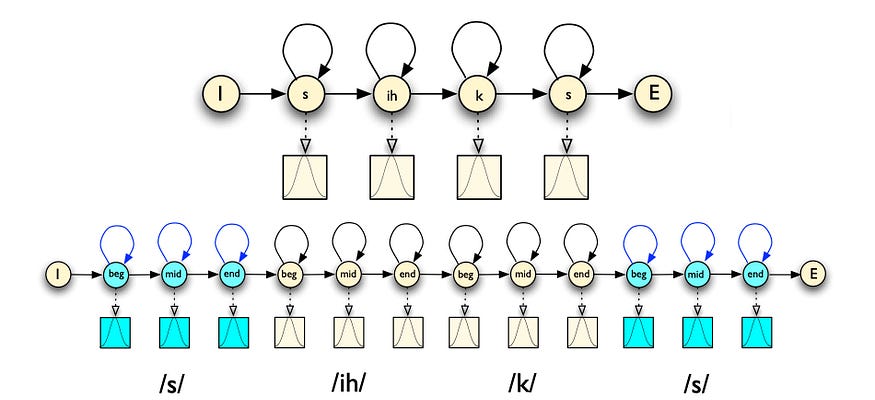
来源(“六”字)
每个内部状态的可观察量将由GMM建模。

我们可以通过在弧中写入输出分布来简化 HMM 拓扑的绘制方式。因此,弧上的标签表示输出分布(观测值),而不是将观测值绘制为节点(状态)。以下是单词“two”的 HMM 拓扑,其中包含 2 部电话,每部电话具有三种状态。弧的标签表示声学模型 (GMM)。

给定电话 W 的观测值 X 的可能性是根据所有可能路径的总和计算得出的。
对于每个路径,概率等于路径的概率乘以给定内部状态的观测值的概率。第二种概率将由 m 分量 GMM 建模。所以所有路径的总概率相等

在实践中,我们使用对数似然(log(P(x|w)))来避免下溢问题。这是HMM模型,每个电话使用三种状态来识别数字。
为了处理演讲中的沉默、噪音和填充的停顿,我们可以将它们建模为 SIL,并将其视为另一部手机。

然而,这些静音声音更难捕捉。我们可以用 5 个内部状态而不是 <> 个来建模它。对于某些 ASR,我们还可能使用不同的手机进行不同类型的静音和填充暂停。
我们还可以引入跳过弧,即具有空输入 (ε) 的弧,以对话语中的跳过声音进行建模。

三、上下文相关电话
关节取决于之前和之后的电话(共关节)。声音根据单词内或单词之间的周围上下文而变化。例如,同位素(音素的声学实现)可能是跨词边界共发音的结果。相邻电话对语音变化的影响很大。例如,如果我们把手放在嘴前,当我们发音 /p/ 代表“旋转”和 /p/ 代表“pin”时,我们会感觉到气流的差异。
在构建复杂的声学模型时,我们不应该独立于其上下文来处理手机。音频帧的标签应包括电话及其上下文。如下图所示,对于音素 /eh/,频谱图在不同的上下文下是不同的。

因此,给定下面的音频帧,我们应该将它们分别标记为 /eh/,上下文 (/w/, /d/)、(/y/, /l/) 和 (/eh/, /n/)。

这称为三音器。
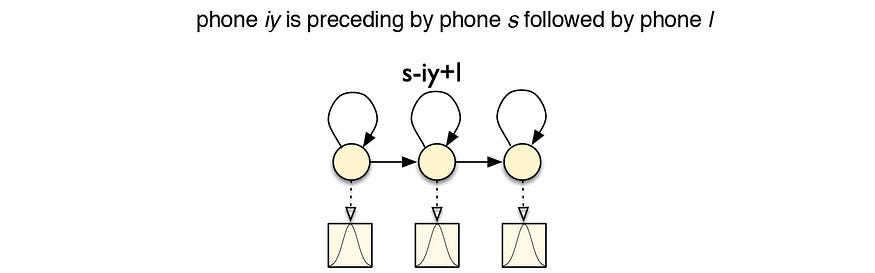
从源代码修改
三音 s-iy+l 表示电话 /iy/ 前面是 /s/,后跟 /l/。如果忽略上下文,则前面的所有三个音频帧都引用 /iy/。但在上下文相关的方案中,这三个帧将被归类为三个不同的 CD 电话。但请注意,三音符有很多符号。即使对于这个系列,也使用了几种不同的符号。
以下是分别使用电话和三音器表示“杯子”一词的示例。手机或三部电话都将由三种内部状态建模。我们不会增加表示“电话”的状态数量。我们只是扩展标签,以便我们可以以更高的粒度对它们进行分类。
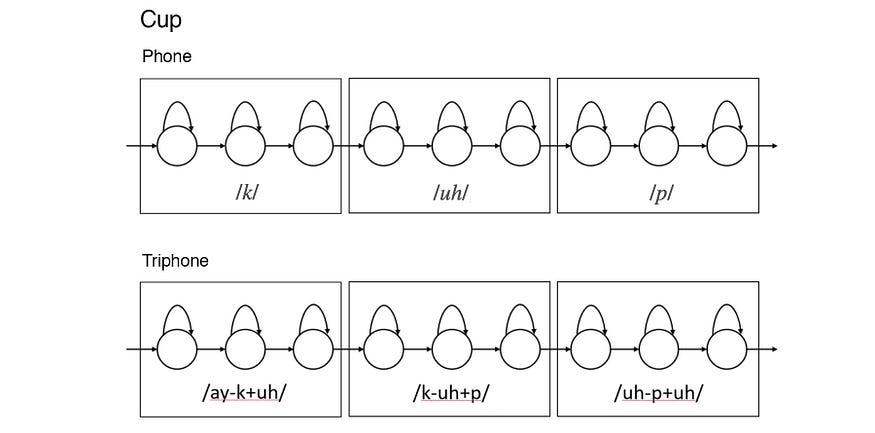
从源代码修改
然而,这有一个主要缺点。比如说,我们最初有 50 部手机。HMM 模型将有 50 × 3 个内部状态(每部手机的开始、中间和结束状态)。对于三音器,我们有 50³ × 3 个三音器状态,即每部电话 50² 个三音器。状态的分解数变得无法管理。
国家捆绑
幸运的是,三音器的某些组合很难与频谱图区分开来。实际上,可能的三音位数大于观察到的三音位数。

因此,某些州可以共享相同的GMM模型。这称为状态绑定。

源
要找到这样的聚类,我们可以参考电话的表达方式:停止、鼻音、咝咝声、元音、侧音等......我们创建了一个决策树来探索对可以共享相同GMM模型的三音器进行聚类的可能方法。

源
通常,我们使用训练数据构建此语音决策树。让我们探索构建树的另一种可能性。以下是在不同语境下说 /p/ 的不同方式。

源
对于每部手机,我们创建一个决策树,其中包含基于左右上下文的决策树桩。树的叶子聚集了可以用相同的GMM模型建模的三音器。

源
我们可以应用决策树技术来避免过度拟合。例如,我们可以限制叶节点的数量和/或树的深度。我们的训练目标是最大限度地提高最终GMM模型训练数据的可能性。以下是我们如何使用状态绑定从手机演变为三音机。对于每部手机,我们现在有更多的子类别(三音器)。我们使用GMM而不是简单的高斯来建模它们。

源
四、连续语音识别
单字语音识别的概念可以通过HMM模型扩展到连续语音。我们在HMM中添加弧线以将单词连接在一起。
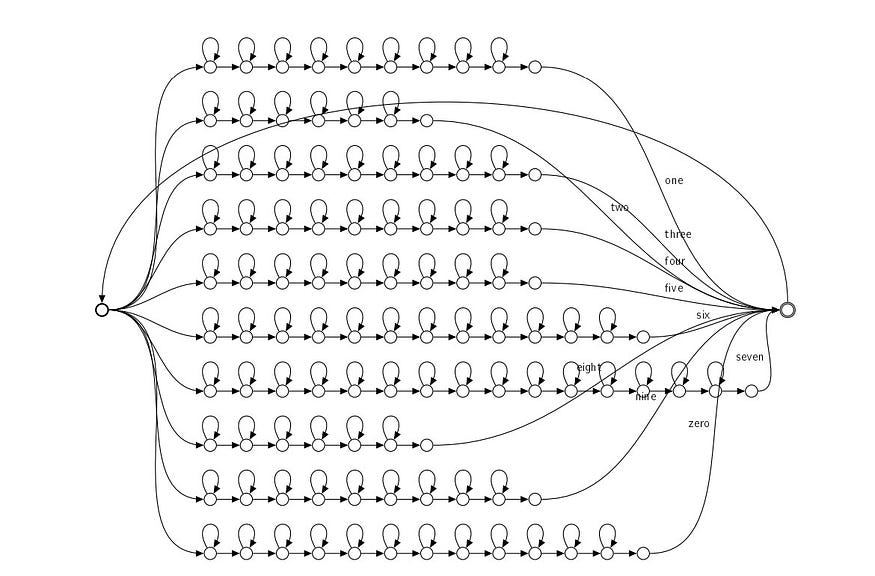
源
五、语言模型
即使音频剪辑在语法上可能不完美或跳过了单词,我们仍然假设我们的音频剪辑在语法和语义上是合理的。因此,如果我们在解码中包含语言模型,我们可以提高 ASR 的准确性。
双格拉姆模型
语言模型计算单词序列的可能性。

在双语(又名 2 克)语言模型中,当前单词仅取决于最后一个单词。
![]()
例如

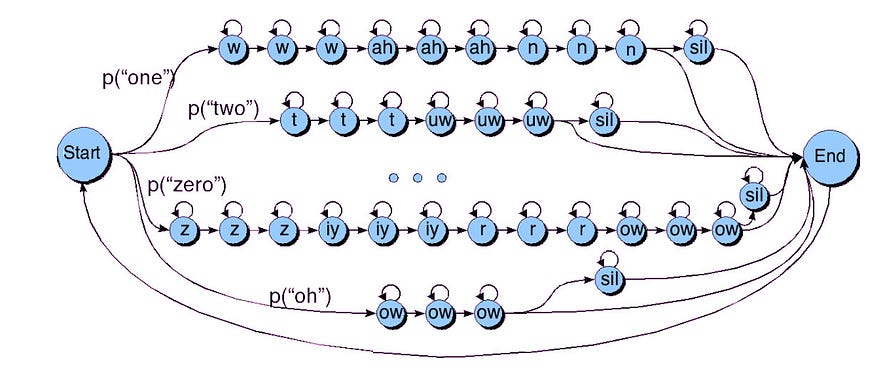
让我们看一下马尔可夫链,如果我们将双字母语言模型与发音词典集成在一起。下面的三个词典分别用于单词一、二和零。然后我们用双元语言模型将它们连接在一起,转移概率像p(one|two)。

源
计算 P(“零”|”二“),我们抓取语料库(例如来自包含 23M 字的《华尔街日报》语料库)并计算

如果语言模型依赖于最后 2 个单词,则称为三元组。

从源代码修改
n-gram 取决于最后的 n-1 个单词。这是双元组和三元组的状态图。对于三元组模型,每个节点表示具有最后两个单词的状态,而不仅仅是一个单词。
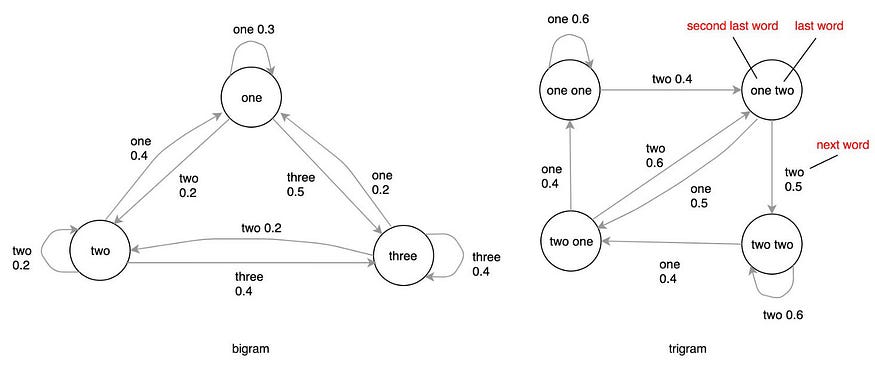
这是使用三元组语言模型的可视化。

六、平滑
即使23M个单词听起来也很多,但语料库仍然可能包含合法的单词组合。对于三元组或其他 n-gram,这种情况变得更糟。通常,三元组或 n 元语法模型的数据很少。如果我们将《华尔街日报》的尸体分成两半,一组数据中36.6%的三卦(4.32M / 11.8M)将不会在另一半中看到。这很糟糕,因为我们训练模型说这些合法序列的概率为零。
加一平滑
让我们先从 unigram 看问题。我们问题的一个解决方案是在所有计数中添加一个偏移量 k(比如 1)以调整 P(W) 的概率,这样即使我们没有在语料库中看到它们,P(W) 也会都是正数。以下是平滑计数和人为喷射计数后的平滑概率。

从源代码修改
但是很难确定k的正确值。但是让我们考虑一下平滑的原理是什么。如果我们没有足够的数据来做出估计,我们会回退到与原始统计数据密切相关的其他统计数据,并显示出更准确。然后,我们根据这些统计数据插值我们的最终答案。例如,如果在语料库中没有观察到双元词,我们可以从出现一次的双元词中借用统计数据。
良好的图灵平滑
让我们回到 n-gram 模型进行讨论。平滑的一般思想是重新插值训练数据中看到的计数,以伴随测试数据中看不见的单词组合。在这个过程中,我们重新洗牌计数并压缩看到的单词的概率,以适应看不见的n元语法。

一种可能性是将平滑计数 r* 和概率 p 计算为:
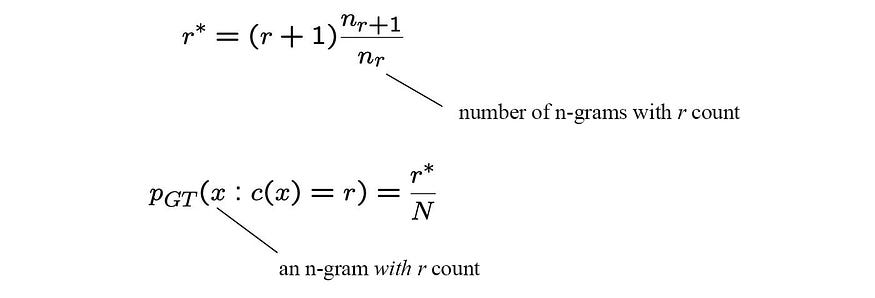
从源代码修改
直观地说,我们用具有“r + 1”计数的上层n元语法来平滑概率质量
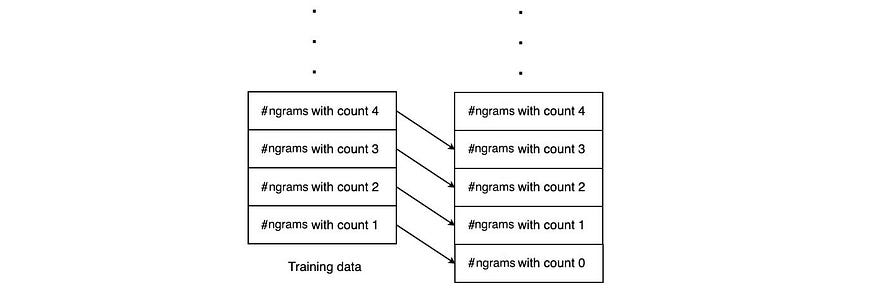
对于看不见的 n 元语法,我们通过使用具有单次出现的 n 元语法数 (n₁) 来计算其概率。
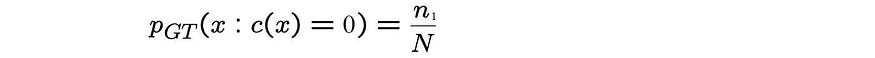
但在某些情况下,上层 (r+1) 的 n 元语法为零。我们将首先应用插值 S 来平滑计数。

目前,我们不需要进一步详细说明。我们将继续介绍另一种更有趣的平滑方法。但是,如果您对此方法感兴趣,可以阅读本文以获取更多信息。
卡茨平滑
Katz 平滑是在数据稀疏时平滑统计信息的常用方法之一。对于双元模型,平滑计数和概率的计算公式为:

此方法基于折扣概念,我们降低某些类别的计数,以将计数重新分配给训练数据集中计数为零的单词。

如果计数高于阈值(例如 5),则折扣 d 等于 1,即我们将使用实际计数。他们有足够的数据,因此相应的概率是可靠的。对于计数较低的单词组合,我们希望折扣 d 与好图灵平滑成正比。

此外,我们希望从折扣中保存的计数等于 n₁,Good-Tuuring 将其分配给零计数。

为了满足这两个限制,折扣变为

在良图灵平滑中,每个具有零计数的 n 元语法都具有相同的平滑计数。对于 Katz 平滑,我们会做得更好。α的选择是这样
![]()
因此,在重新洗牌计数后,双字母中第一个单词给出的总体统计数据将与统计数据相匹配。我们将平滑计数计算为:
![]()
因此,即使训练数据集中不存在单词对,如果第二个单词 wi 很受欢迎,我们将平滑计数调整得更高。
α等于

直观地说,如果有许多低计数的单词对以相同的第一个单词开头,则平滑计数会增加。

在这种情况下,我们预计(或预测)具有相同第一个单词的许多其他对将出现在测试中,而不是训练中。实证结果表明,Katz 平滑能够很好地平滑稀疏数据概率。同样,如果您想更好地了解平滑,请参阅本文。
退避模型
Katz 平滑是一个退避模型,当我们找不到任何 n 元语法的出现时,我们回退,即如果我们找不到 n-gram 的任何出现,我们用 n-1 克估计它。但是在 n-1 克中也没有出现,我们不断回落,直到找到非零出现计数。退避概率的计算公式为:

其中 α 和 P 定义为:
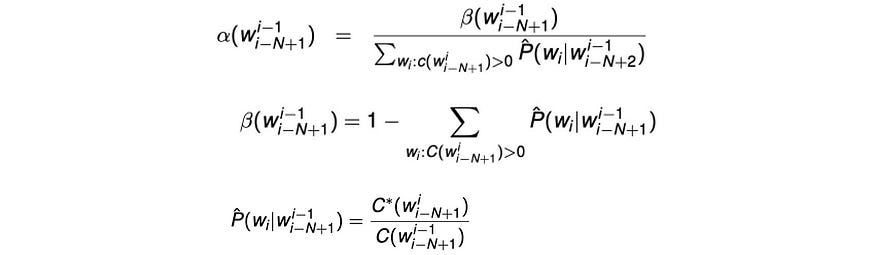
每当我们回退到较低跨度的语言模型时,我们都需要用α来缩放概率,以确保所有概率的总和为 1。
让我们举一个例子来阐明这个概念。假设我们从未在我们的训练语料库中找到 5 克的“第 10 个符号是 obelus”。因此,我们必须回退到 4 克模型来计算概率。

P(Obelus | 符号为 an) 通过计算以下相应的出现次数来计算:
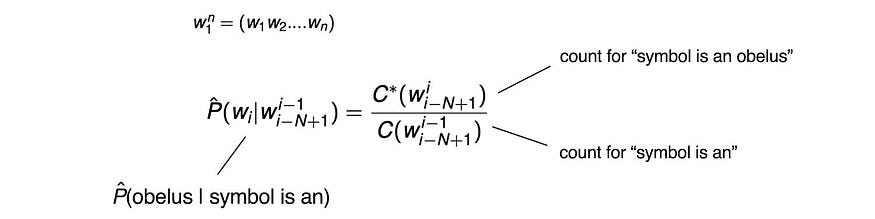
最后,我们计算α来重新规范概率。
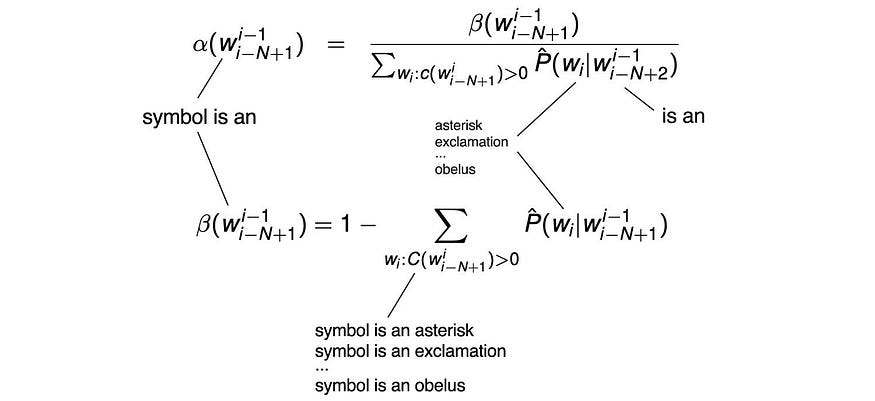
这是最终的平滑计数和概率。
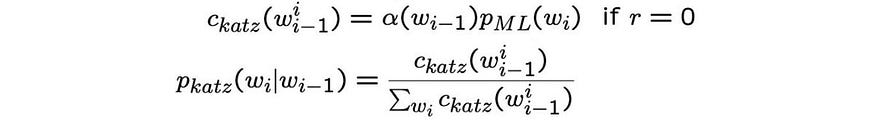
七、接下去的内容
现在,我们知道如何对 ASR 进行建模。但是,我们如何使用这些模型来解码话语呢?
相关文章:
【语音识别】- 声学,词汇和语言模型
一、说明 语音识别是指计算机通过处理人类语言的音频信号,将其转换为可理解的文本形式的技术。也就是说,它可以将人类的口语语音转换为文本,以便计算机能够进一步处理和理解。它是自然语言处理技术的一部分,被广泛应用于语音识别助…...
【考研英语语法及长难句】小结
【 考场攻略汇总 】 考点汇总 考场攻略 #1 断开长难句只看谓语动词,不考虑非谓语动词先找从句,先看主句 考场攻略 #2 抓住谓语动词,抓住句子最核心的表述动作或内容通过定位谓语动词,找到复杂多变的主语通过谓语动词的数量&…...

C# 反射
反射的概念:C#通过类型(Type)来创建对象,调用对象中的方法,属性等信息;B超就是利用了反射原理将超声波打在人的肚子上,然后通过反射波进行体内器官的成员; 反射提供的类:…...
Pytorch(二)
一、分类任务 构建分类网络模型 必须继承nn.Module且在其构造函数中需调用nn.Module的构造函数无需写反向传播函数,nn.Module能够利用autograd自动实现反向传播Module中的可学习参数可以通过named_parameters()返回迭代器 from torch import nn import torch.nn.f…...

Python 使用http时间同步设置系统时间源码
Python方式实现使用http时间同步设置系统时间源码,系统环境是ubuntu 12.04、Python2.7版本。需要使用到time、os及httplib方法。 Python使用http时间同步设置系统时间,源码如下: #-*-coding:utf8 -*- import httplib as client import time…...

golang sync.singleflight 解决热点缓存穿透问题
在 go 的 sync 包中,有一个 singleflight 包,里面有一个 singleflight.go 文件,代码加注释,一共 200 行出头。内容包括以下几块儿: Group 结构体管理一组相关的函数调用工作,它包含一个互斥锁和一个 map,map 的 key 是…...
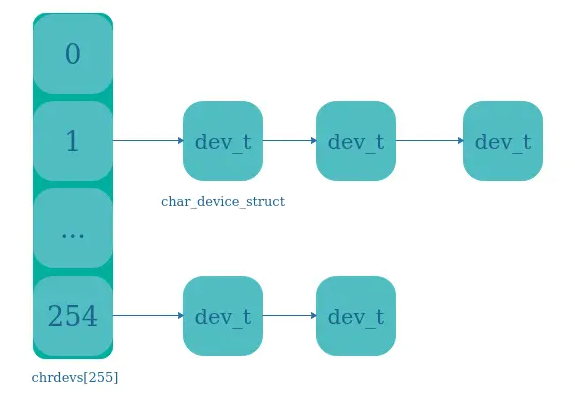
4、Linux驱动开发:设备-设备号设备号注册
目录 🍅点击这里查看所有博文 随着自己工作的进行,接触到的技术栈也越来越多。给我一个很直观的感受就是,某一项技术/经验在刚开始接触的时候都记得很清楚。往往过了几个月都会忘记的差不多了,只有经常会用到的东西才有可能真正记…...
调用Python)
C++(MFC)调用Python
环境: phyton版本:3.10 VS版本:VS2017 包含文件头:Python\Python310\include 包含库文件:Python\Python310\libs 程序运行期间,以下函数只需要调用一次即可,重复调用会导致崩溃 void Initial…...

深度学习实践——循环神经网络实践
系列实验 深度学习实践——卷积神经网络实践:裂缝识别 深度学习实践——循环神经网络实践 深度学习实践——模型部署优化实践 深度学习实践——模型推理优化练习 代码可见于: 深度学习实践——循环神经网络实践 0 概况1 架构实现1.1 RNN架构1.1.1 RNN架…...
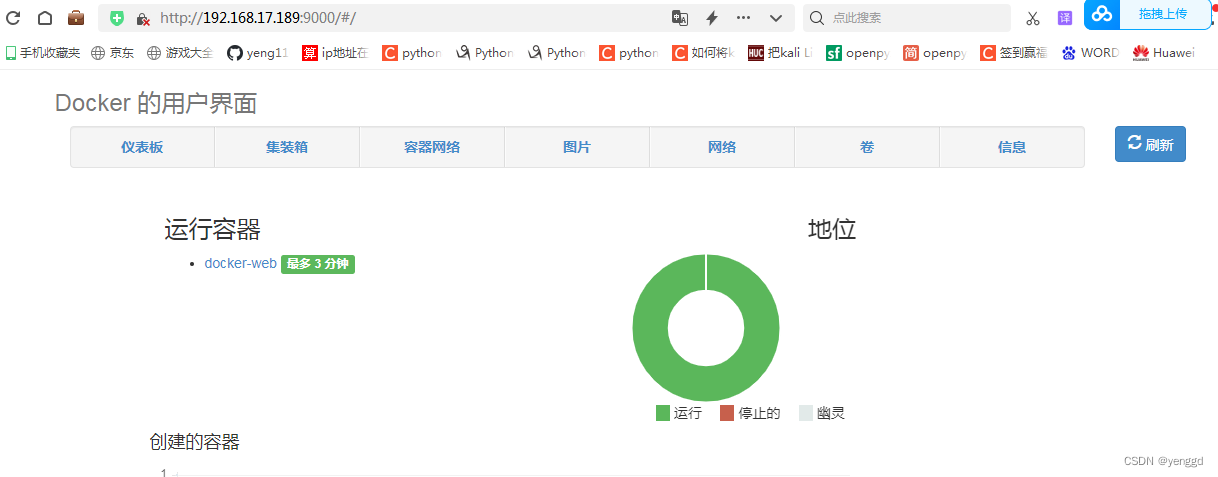
docker简单web管理docker.io/uifd/ui-for-docker
要先pull这个镜像docker.io/uifd/ui-for-docker 这个软件默认只能使用9000端口,别的不行,因为作者在镜像制作时已加入这一层 刚下下来镜像可以通过docker history docker.io/uifd/ui-for-docker 查看到这个端口已被 设置 如果在没有设置br0网关时&…...
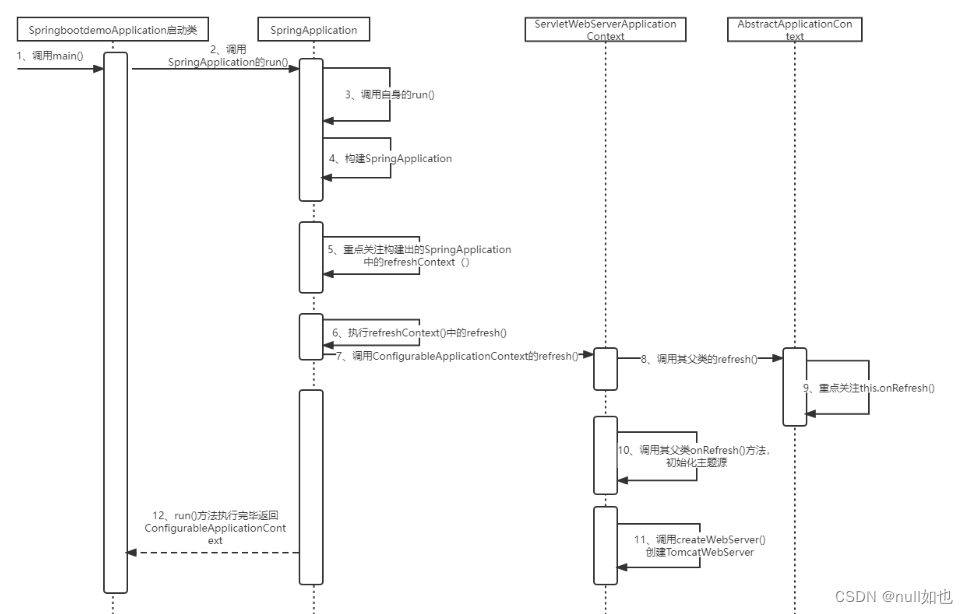
SpringBoot内嵌的Tomcat:
SpringBoot内嵌Tomcat源码: 1、调用启动类SpringbootdemoApplication中的SpringApplication.run()方法。 SpringBootApplication public class SpringbootdemoApplication {public static void main(String[] args) {SpringApplication.run(SpringbootdemoApplicat…...

企业级docker应用注意事项
现在很多企业使用容器化技术部署应用,绕不开的docker技术,在生产环境docker常用操作总结。参考:https://juejin.cn/post/7259275893796651069 1. 尽可能使用官方镜像 在docker hub 官方 使用后面带有 DOCKER OFFICIAL IMAGE 标签的镜像&…...

腾讯云高性能计算集群CPU服务器处理器说明
腾讯云高性能计算集群以裸金属云服务器为节点,通过RDMA互联,提供了高带宽和极低延迟的网络服务,能满足大规模高性能计算、人工智能、大数据推荐等应用的并行计算需求,腾讯云服务器网分享腾讯云服务器高性能计算集群CPU处理器说明&…...
tinkerCAD案例:23.Tinkercad 中的自定义字体
tinkerCAD案例:23.Tinkercad 中的自定义字体 原文 Tinkercad Projects Tinkercad has a fun shape in the Shape Generators section that allows you to upload your own font in SVG format and use it in your designs. I’ve used it for a variety of desi…...

Box-Cox 变换
Box-cox 变化公式如下: y ( λ ) { y λ − 1 λ λ ≠ 0 l n ( y ) λ 0 y^{(\lambda)}\left\{ \begin{aligned} \frac{y^{\lambda} - 1}{\lambda} && \lambda \ne 0 \\ ln(y) && \lambda 0 \end{aligned} \right. y(λ)⎩ ⎨ ⎧λyλ−1ln…...

Linux wc命令用于统计文件的行数,字符数,字节数
Linux wc命令用于计算字数。 利用wc指令我们可以计算文件的Byte数、字数、或是列数,若不指定文件名称、或是所给予的文件名为"-",则wc指令会从标准输入设备读取数据。 语法 wc [-clw][–help][–version][文件…] 参数: -c或–b…...
Python读取多个栅格文件并提取像元的各波段时间序列数据与变化值
本文介绍基于Python语言,读取文件夹下大量栅格遥感影像文件,并基于给定的一个像元,提取该像元对应的全部遥感影像文件中,指定多个波段的数值;修改其中不在给定范围内的异常值,并计算像元数值在每一景遥感影…...

Linux 之 wget curl
wget 命令 wget是非交互式的文件下载器,可以在命令行内下载网络文件 语法: wget [-b] url 选项: -b ,可选,background 后台下载,会将日志写入到 当前工作目录的wget-log文件 参数 url : 下载链…...

AngularJS 和 React区别
目录 1. 背景:2. 版本:3. 应用场景:4. 语法:5. 优缺点:6. 代码示例: AngularJS 和 React 是两个目前最为流行的前端框架之一。它们有一些共同点,例如都是基于 JavaScript 的开源框架,…...
【Solr】Solr搜索引擎使用
文章目录 一、什么是Solr?二 、数据库本身就支持搜索啊,干嘛还要搞个什么solr?三、如果我们想要使用solr那么首先我们得安装它 一、什么是Solr? 其实我们大多数人都使用过Solr,也许你不会相信我说的这句话,但是事实却是如此啊 ! 每当你想买自己喜欢的东东时,你可能会打开某…...

通过curl命令快速测试Taotoken多模型聚合接口的连通性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken多模型聚合接口的连通性 在接入大模型服务时,直接使用HTTP请求进行测试是一种高效且通用…...

独立开发者如何借助Taotoken低成本试验多种大模型效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助Taotoken低成本试验多种大模型效果 对于独立开发者或小微团队而言,在创意验证或产品原型阶段&#…...

为什么你的NotebookLM中文摘要总漏关键信息?3个被官方文档忽略的语言标记陷阱,90%用户正在踩坑
更多请点击: https://kaifayun.com 第一章:NotebookLM多语言支持 NotebookLM 原生支持多种语言的文档理解与对话生成,其底层模型经过多语言语料联合训练,可无缝处理中、英、日、韩、法、德、西等 20 种语言的混合输入。用户上传非…...

VideoDownloadHelper:打破网页视频下载壁垒的智能解决方案
VideoDownloadHelper:打破网页视频下载壁垒的智能解决方案 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 你是否曾遇到过这样的困…...

Bebas Neue字体完全指南:免费商用的现代设计利器
Bebas Neue字体完全指南:免费商用的现代设计利器 【免费下载链接】Bebas-Neue Bebas Neue font 项目地址: https://gitcode.com/gh_mirrors/be/Bebas-Neue 还在寻找一款能为你的设计项目增添专业感的免费字体吗?Bebas Neue字体库正是你需要的完美…...

OpenRocket:开源火箭设计与飞行仿真的终极指南
OpenRocket:开源火箭设计与飞行仿真的终极指南 【免费下载链接】openrocket Model-rocketry aerodynamics and trajectory simulation software 项目地址: https://gitcode.com/GitHub_Trending/op/openrocket 你是否曾经梦想设计自己的火箭,但又…...

使用Taotoken多模型API为嵌入式项目提供智能对话辅助
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken多模型API为嵌入式项目提供智能对话辅助 对于使用Keil5等传统IDE进行嵌入式开发的工程师而言,为设备增添自…...

3步掌握Sabaki围棋软件:从新手到高手的完整指南
3步掌握Sabaki围棋软件:从新手到高手的完整指南 【免费下载链接】Sabaki An elegant Go board and SGF editor for a more civilized age. 项目地址: https://gitcode.com/gh_mirrors/sa/Sabaki 在围棋的智慧世界里,一款优秀的软件能让您的学习和…...

从零开始接入 Taotoken,新用户注册到首次成功调用的全过程耗时
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从零开始接入 Taotoken,新用户注册到首次成功调用的全过程耗时 对于开发者而言,评估一个新工具或平台的接入…...

C166架构中idaata变量存储类别变更的解析与优化
1. 问题现象与背景解析最近在Keil C166开发环境中遇到了一个有趣的编译警告,代码看起来非常简单:void main(void) {int i;int j;int idata asdf; // 触发警告的变量声明i 100;j 1000;asdf i j; }编译时会出现如下警告:*** WARNING 189 I…...