深度学习实践——循环神经网络实践
系列实验
深度学习实践——卷积神经网络实践:裂缝识别
深度学习实践——循环神经网络实践
深度学习实践——模型部署优化实践
深度学习实践——模型推理优化练习
代码可见于:
深度学习实践——循环神经网络实践
- 0 概况
- 1 架构实现
- 1.1 RNN架构
- 1.1.1 RNN架构搭建
- 1.1.2 RNN超参数调整
- 1.2 GRU架构
- 1.2.1 GRU架构搭建
- 1.2.2 GRU超参数调整
- 1.3 LSTM架构
- 1.3.1 LSTM架构搭建
- 1.3.2 LSTM超参数调整
- 1.4 三种架构的对比
- 2 序列到序列学习
- 3 实验结论
0 概况
**方法:**实验主要通过python中的pytorch与d2l环境进行,利用了jupyter notebook编写代码。RNN、GRU、LSTM架构的实现基于d2l所提供的教程代码,数据集的使用选择了d2l中的“time machine”数据集。对于基本架构,我选择调整epoch次数、学习率、隐含层神经元数量来寻找更优的结果。除了实现基本的循环神经网络架构外,还学习了seq2seq,并基于d2l教程复现了seq2seq从训练到推理的过程,并尝试调整参数观察变化。
步骤:
- 搭建RNN架构并调整参数以达到较好结果
- 搭建GRU架构并调整参数以达到较好结果
- 搭建LSTM架构并调整参数以达到较好结果
- 实现seq2seq的训练与推理
1 架构实现
1.1 RNN架构
1.1.1 RNN架构搭建
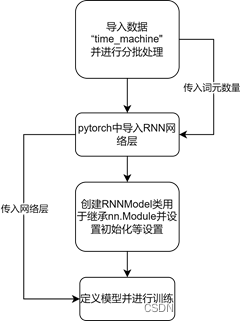
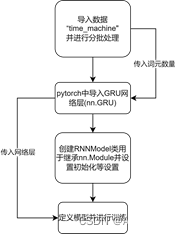
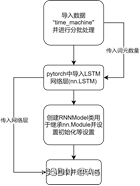
对于RNN架构的实现,我根据教材的指示使用了d2l中的“time machine(时间机器)”数据。此数据集是关于时间机器的一个短篇小说,可以用于进行小批量训练。而对于RNN的代码实现,则是通过pytorch与d2l库实现的。首先是利用d2l的数据加载模块,提供批量数与步长加载出“time machine”的数据。得到数据后,可以利用pytorch中的nn.RNN()来导入RNN神经层。在导入神经层后,构建一个RNNModel的类来继承nn.Module并设置一些训练时的规则与流程。最后定义一个RNNModel对象并传入RNN神经层与数据利用d2l的训练函数进行训练。由于代码较长故报告中不列出,详细代码可见于对应的.ipynb文件。下图为搭建RNN架构时的代码流程图。
初次训练使用的参数epochs次数为500次、学习率为1、隐含层数量256,下面为训练得到的结果。
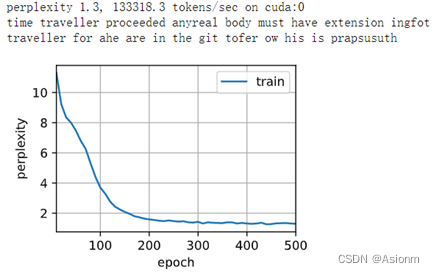
从上面的结果可以看出,在epochs为500,学习率为1时,图像在接近300时收敛,最后困惑度为1.3。从结果的输出可以看出,其语义基本是没有的,但是可以看出输出的单词,接近一半的单词是拥有正确拼写的。这说明了训练是有一定的效果,但是效果并不算太佳。那么下面将进行超参数地调整以达到更好的效果。
1.1.2 RNN超参数调整
以1.1.1中的训练参数作为基础参数,即epochs次数为500次、学习率为1、隐含层数量256,上下调整参数进行比较。
1 epochs次数
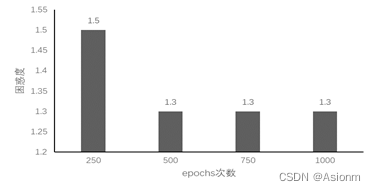
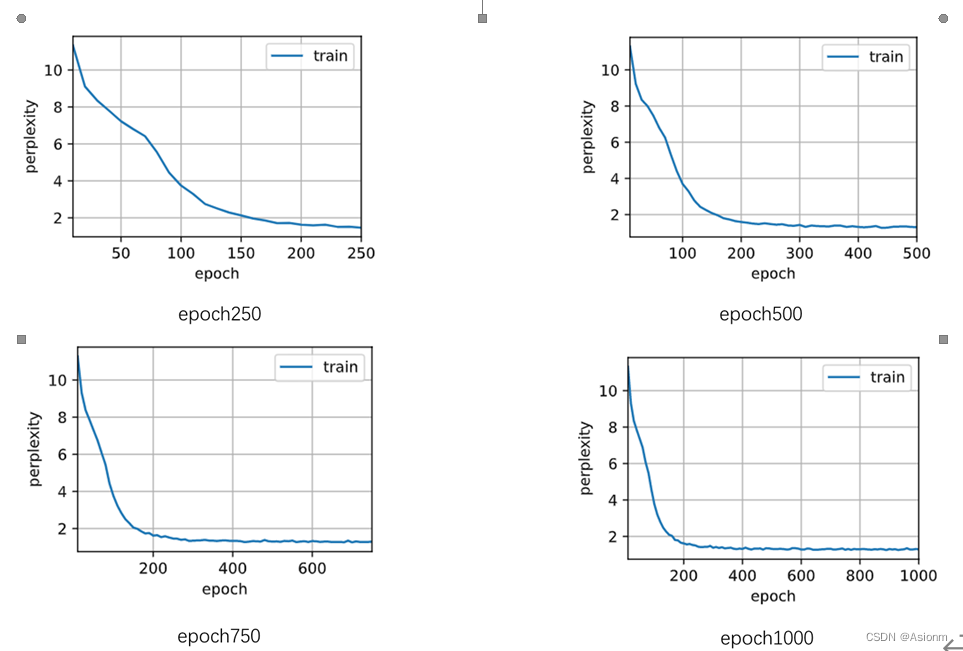
这里之所以选择epochs次数进行比较,其原因在于epochs次数对模型结果的收敛和对困惑度的影响十分大。一般来说次数越多那么梯度下降也越多,训练结果也越饱满同样效果会越好,同样也可能次数越多训练会过拟合。而如果次数很小那么效果也可能会非常差,因为训练并不足够。下面选取250、750、1000次进行实验以进行验证比较。(详细代码可见附加的文件,此处只展示结果)
对于“time traveller”的预测:
(1)Epoch250: time traveller held in his hant wald at ifgristtand why had wan
(2)Epoch500: time traveller proceeded anyreal body must have extension ingfot
(3)Epoch750: time traveller came back andfilby seane whyse the lyon at ingte
(4)Epoch1000: time traveller held in whack and hareare redohat de sam e sugod
从结果中可以看出当epoch较小时对模型训练的结果影响是较为显著的,会使得训练的效果较差,但是当epoch到达一定数量时训练的结果基本维持在一定范围内,影响将很小。
2 学习率
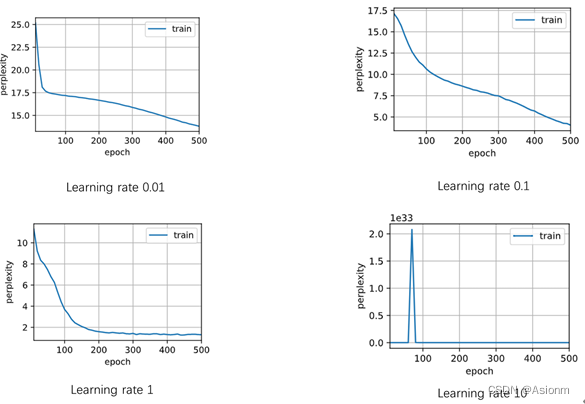
学习率对训练的结果是具有一定的影响的,学习率过大会使得结果的困惑度随着次数的增加每次都很大的不同,十分地混乱,而使得永远得不到较好结果。而如果学习率太低,那么在同样的次数下,其收敛的速度会更慢。下面选取学习率0.01、0.1、10进行实验比较,下面为运行结果。(详细代码可见附加的文件,此处只展示结果)
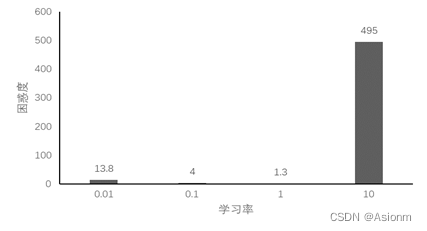
对于“time traveller”的预测:
(1)lr0.01: time traveller the the the the the the the the the the the the t
(2)lr0.1: time traveller thice dimensions al merice time al sicherenre thi
(3)lr1: time traveller proceeded anyreal body must have extension ingfot
(4)lr10: time travellerohc ohc ohc ohc ohc ohc ohc ohc ohc ohc ohc ohc oh
从结果中可以看出当学习率较小时模型的收敛速度会变慢,而其预测的结果中重复出现the也说明结果是很差的,而当学习率为0.1时虽然没有重复出现多个单词但是基本上单词的拼写全是错的。当学习率很大时,其困惑度也十分的大,其出现毫无语义的重复单词。最好的学习率是1在测试的中间,而学习率小时会使得训练地学习收到阻碍,而当学习率太大时会使得学习超过一定值而陷入一个无法寻找更优地循环中。
3 隐藏层神经元数量
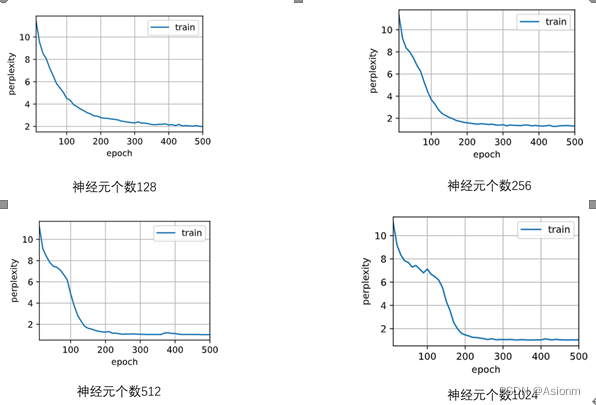
一般来说隐藏层神经元数量越多其拟合的效果会越好,而越少那么其结果可能会很差。因此隐藏层神经元数量是十分关键的,那么选取隐藏层神经元数量为128、512、1024进行比较,下面为运行结果。(详细代码可见附加的文件,此处只展示结果)
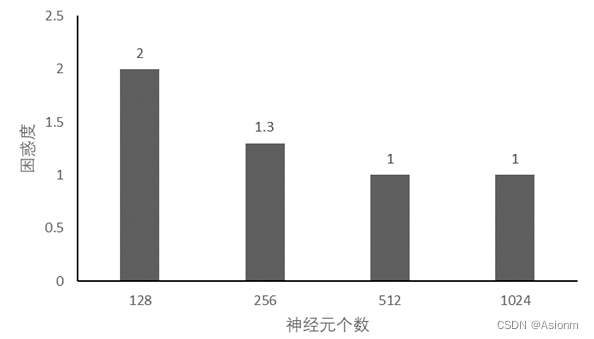
对于“time traveller”的预测:
(1)128: time travellerit s againstirad and the time travellerit s all ha
(2)256: time traveller proceeded anyreal body must have extension ingfot
(3)512: time travelleryou can show black is white by argument said filby
(4)1024: time traveller for so it will be convenient to speak of himwas e
从结果中可以看出当神经元个数增加时,其最终的困惑度会减小。其收敛的曲线也会存在一定的变化会存在极速下降的部分。而其预测的结果中神经元个数为512与1024的可以看出存在一定的语义,且拼写也都正确。之所以会这样,我个人认为是神经元个数与拟合效果有关。一般来说神经元个数越多其参数也越多对应的拟合效果一般也会越好。
基于上面的调参可以发现,最好的一组是神经元个数为512与1024的组合,其他的训练效果均差于基础参数。
1.2 GRU架构
1.2.1 GRU架构搭建
对于GRU架构的实现,同样使用了d2l中的“time machine(时间机器)”数据。GRU相对于RNN增加了一些控制单元,就好像电路那样限制了一些内容的输入同时保存了一些重要的内容。架构实现的代码主要参考于d2l,其代码基本与RNN的一致,不同的是改变了神经层。同样layer的调取也是通过pytorch的api,也就是与RNN构建不同的是layer从nn.RNN()变为了nn.GRU()。下面构建的流程图。(详细代码可见于.ipynb文件)
初次训练使用的参数epochs次数为500次、学习率为1、隐含层数量256,下面为训练得到的结果。
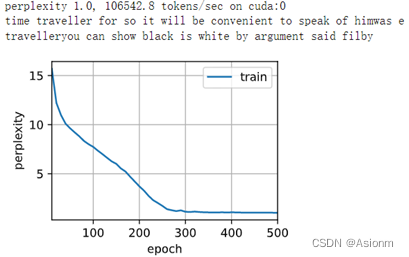
从上面的结果可以看出,在epochs为500,学习率为1时,图像在接近250时收敛,最后困惑度为1。从结果的输出可以看出,其拼写基本正确,且已经拥有一定的语义。这说明了训练是有一定的效果,且与RNN相比其效果更好。
1.2.2 GRU超参数调整
对于GRU超参数的调整基本与RNN的一致,其参数选取理由一致,下面为调参结果
1 epochs次数
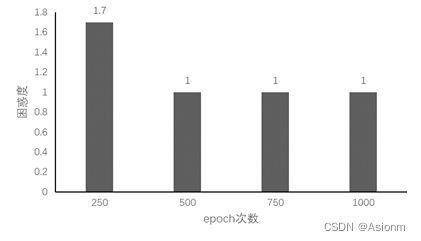
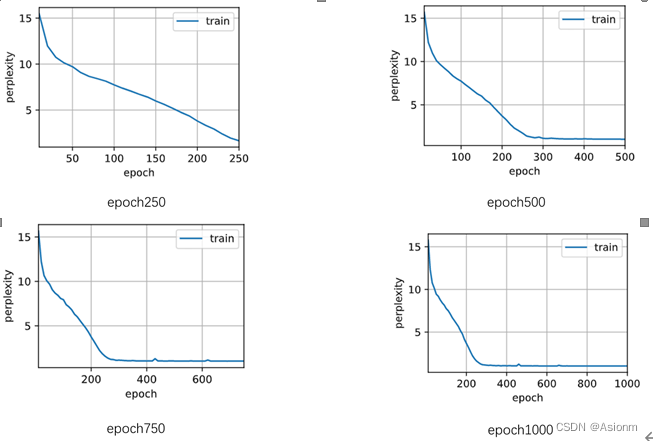
对于“time traveller”的预测:
(1)Epoch250: time travelleris cofr mensthe fourth dimension do net gout the l
(2)Epoch500: time traveller for so it will be convenient to speak of himwas e
(3)Epoch750: time traveller with a slight accession ofcheerfulness really thi
(4)Epoch1000: time traveller with a slight accession ofcheerfulness really thi
可以看出其规律基本与RNN的一致,但是其起点的效果就优于RNN。
2 学习率
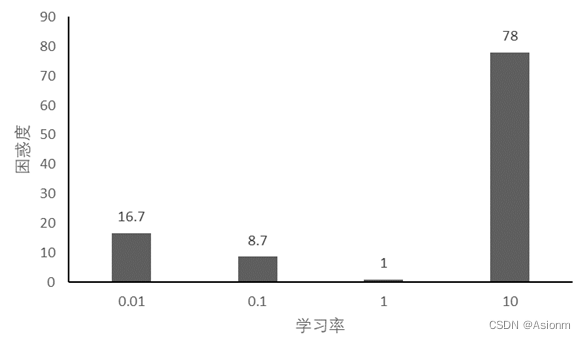
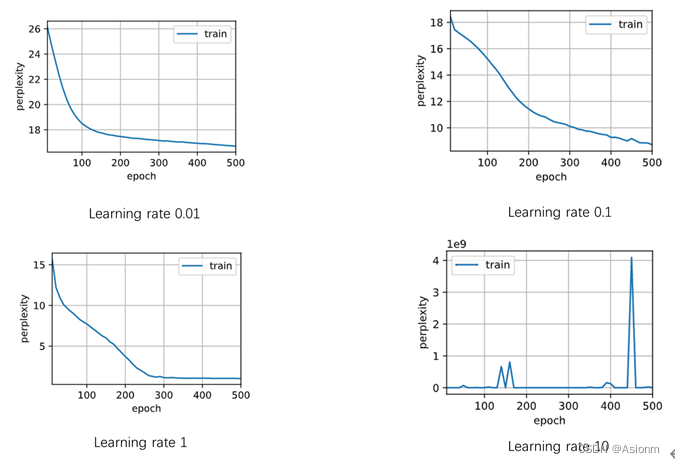
对于“time traveller”的预测:
(1)lr0.01: time traveller t e e t e e t e e t e e t e e t
(2)lr0.1: time travellere the the the the the the the the the the the the
(3)lr1: travelleryou can show black is white by argument said filby
(4)lr10: time travellerohc ohc ohc ohc ohc ohc ohc ohc ohc ohc ohc ohc oh
此结果基本与RNN的一致,不同点在于困惑度的大小。
3 隐藏层神经元数量
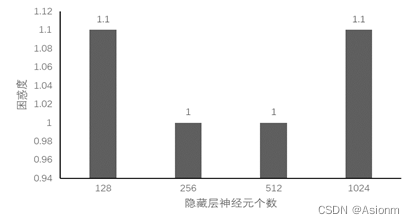
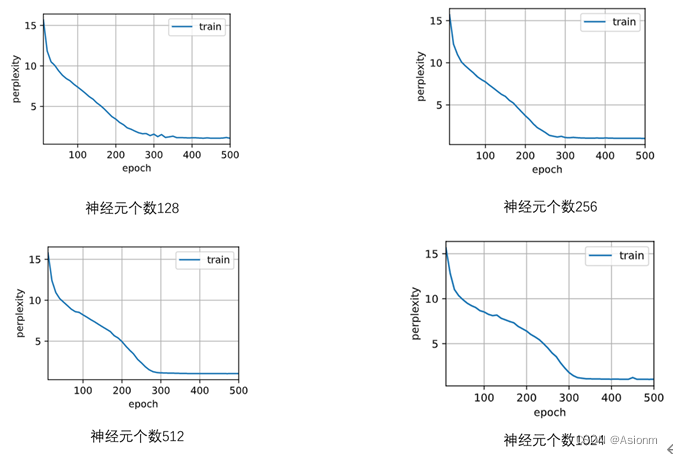
对于“time traveller”的预测:
(1)128: time travellerit s against reason said filbywhat is there is the
(2)256: travelleryou can show black is white by argument said filby
(3)512: time traveller for so it will be convenient to speak of himwas e
(4)1024: time traveller with a slight accession ofcheerfulness really thi
从结果中可以看出其结果基本一致,但是128与512的困惑度比其他两者低,而128可能是因为欠拟合的原因,而512则可能为过拟合。
基于上面的调参可以发现,最好的一组是神经元个数为512组合。
1.3 LSTM架构
1.3.1 LSTM架构搭建
对于LSTM架构的实现,同样使用了d2l中的“time machine(时间机器)”数据。LSTM也称为长短期记忆网络,它具有一定的记忆功能。LSTM相对于GRU更加地复杂,拥有更多的门控系统,因此同样的参数数据下LSTM的训练时间可能长于GRU,但是相应的训练效果可能会更好。下面利用d2l的LSTM模块快速搭建LSTM架构。(详细代码可见于.ipynb文件)
初次训练使用的参数epochs次数为500次、学习率为1、隐含层数量256,下面为训练得到的结果。
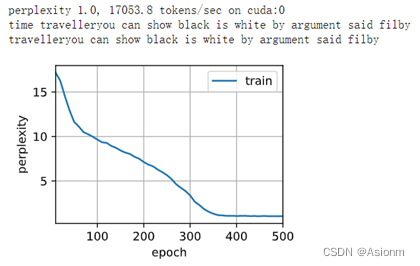
从上面的结果可以看出,在epochs为500,学习率为1时,图像在接近250时收敛,最后困惑度为1。从结果的输出可以看出,其拼写基本正确,且已经拥有一定的语义。这说明了训练是有一定的效果,且与RNN相比其效果更好,与GRU相比效果基本一致。
1.3.2 LSTM超参数调整
对于LSTM超参数的调整基本与RNN的一致,其参数选取理由一致,下面为调参结果。
1 epochs次数
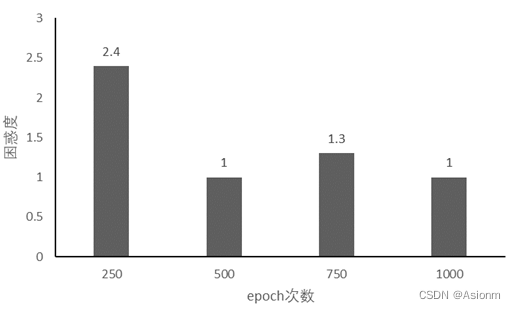
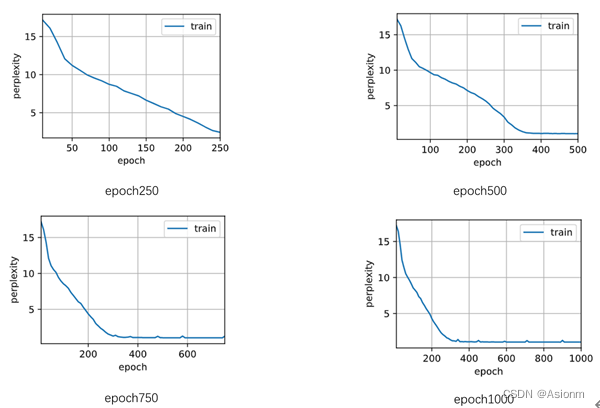
对于“time traveller”的预测:
(1)Epoch250: time traveller soud in the bertal it it as ingous doo doust hick
(2)Epoch500: time travelleryou can show black is white by argument said filby
(3)Epoch750: time traveller fich wi har hive tree yyinn waid the peos co vepr
(4)Epoch1000: time travelleryou can show black is white by argument said filby
可以看出基本呈现递减的形式,但是当为750时困惑度却较高预测结果也不是很好,这可能与偶然性有关需要更多实验以证明。
2 学习率
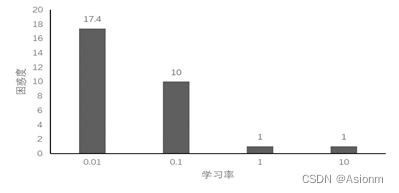
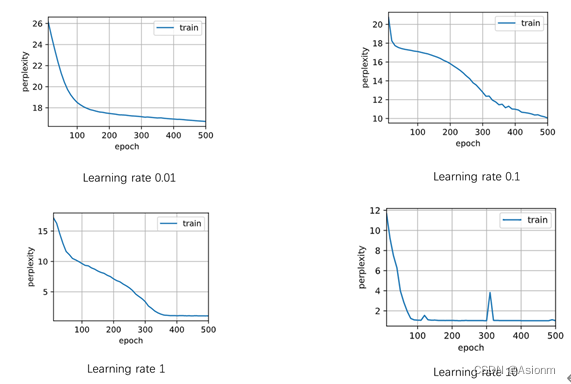
对于“time traveller”的预测:
(1)lr0.01: time traveller t e e t e e t e e t e e t e e t
(2)lr0.1: time travellere the the the the the the the the the the the the
(3)lr1: travelleryou can show black is white by argument said filby
(4)lr10: time traveller for so it will be convenient to speak of himwas e
可以看出训练效果随着学习率的增大而增大,与GRU与RNN不同的是,LSTM架构的学习率是学习率越大效果越好,而其他两者则是介于一个范围内。者可能与架构内部网络层有关。
3 隐藏层神经元数量
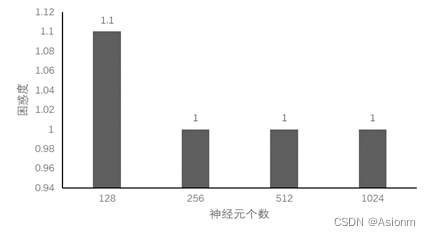
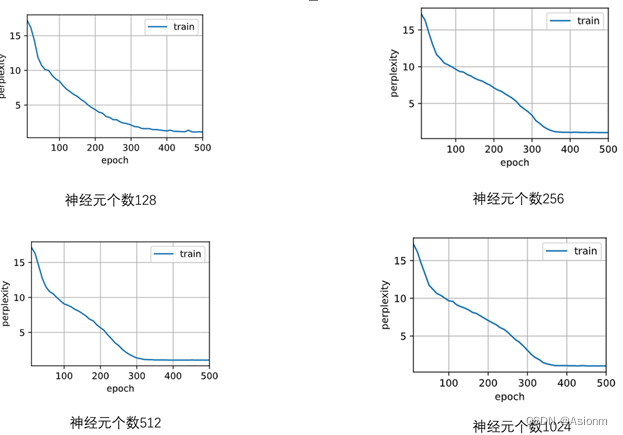
对于“time traveller”的预测:
(1)128: time travellerice withereal inhis fefclndiface traces along i ou
(2)256: travelleryou can show black is white by argument said filby
(3)512: time travelleryou can show black is white by argument said filby
(4)1024: time traveller for so it will be convenient to speak of himwas e
1.4 三种架构的对比
从上面的调参实验中可以看到,RNN明显是差于GRU与LSTM的。GRU与LSTM拥有更好的收敛能力,以及更好地效果,且其预测的有效性也更好。而GRU与LSTM的对比相对来说在以上实验中并不能明显看出,可能在更复杂的数据集中才可以测试出两组的优缺点。但是在调参实验中,GRU与LSTM在学习率调节方面存在明显的不同,在GRU中学习率最优的是为1时,最差为10时,而LSTM却是1与10同样的效果。而这可能是由于两者的网络层存在差异所照成的。
2 序列到序列学习
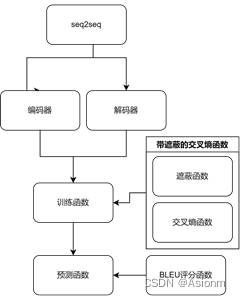
序列到序列模型是一个基于编码器与解码器的模型,可以用于解决输出序列与输入序列不一致的情况,一般用于翻译。对于序列到序列模型的构建训练,我是通过d2l教程进行的,在教程的代码中,首先需要定义编码器与解码器,用于处理输入与输出。其次设置带有遮蔽功能的交叉熵函数用于损失函数,并将其带入训练函数中。最后进行训练,然后定义BLEU评分函数用于预测时量化预测效果。其代码搭建的流程如下图所示。(具体代码见于.ipynb文件)
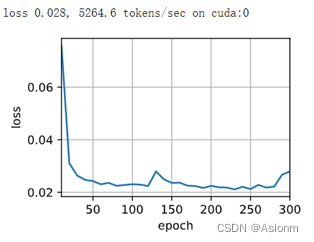
下面为隐藏层层数为2,神经元个数为256,学习率为0.005, epoch为300的结果。
下面为预测结果,

可知bleu越大越解决1那么其预测的效果越好,可以看到前两者的值为1,说明预测效果是很好的,但是后面两个的值却越来越小,而在查看正确翻译后发现输出的法语翻译效果是不佳的。而仔细观察其原因可以发现后两者稍微比前两者的单词个数要多长度要长,所以者可能是导致其效果不佳的原因,这说明此seq2seq模型拥有一定的优化空间。
3 实验结论
本次实验中构建了RNN、GRU、LSTM架构对“time machine”数据集进行了训练,在训练的过程中通过不断地调节epoch\学习率\神经元个数三个参数以获取较好的结果。除了不同参数外的对比,还进行了不同架构间的对比。除了构建三个经典的循环神经网络模型外,还学习了seq2seq这个含有编码器与解码器的模型,并进行训练推理得到相应结果。
最后的结果发现,epoch次数很小时会对实验的结果造成不利的影响,但是当epoch达到一定的大小后此影响将逐渐减小,甚至变得毫无影响。而学习率对于RNN与GRU来讲其最佳值在1附近,但是对于LSTM却发现,学习率为10时LSTM照样可以拥有较好的结果,但是其他两者学习率为10时效果却是最差的。对于神经元个数对结果的影响,从上面的实验内容可以看出,其影响是最为显著的,一般来说神经元个数越多其效果越好,而这也可能是因为神经元越多拟合效果越佳的原因。对于seq2seq的学习,在最后的训练预测结果中可以发现,模型对短句子的预测效果较好,但是对于较长的句子的效果却是十分差的,这也说明此模型具有一定的提升空间。
相关文章:
深度学习实践——循环神经网络实践
系列实验 深度学习实践——卷积神经网络实践:裂缝识别 深度学习实践——循环神经网络实践 深度学习实践——模型部署优化实践 深度学习实践——模型推理优化练习 代码可见于: 深度学习实践——循环神经网络实践 0 概况1 架构实现1.1 RNN架构1.1.1 RNN架…...
docker简单web管理docker.io/uifd/ui-for-docker
要先pull这个镜像docker.io/uifd/ui-for-docker 这个软件默认只能使用9000端口,别的不行,因为作者在镜像制作时已加入这一层 刚下下来镜像可以通过docker history docker.io/uifd/ui-for-docker 查看到这个端口已被 设置 如果在没有设置br0网关时&…...
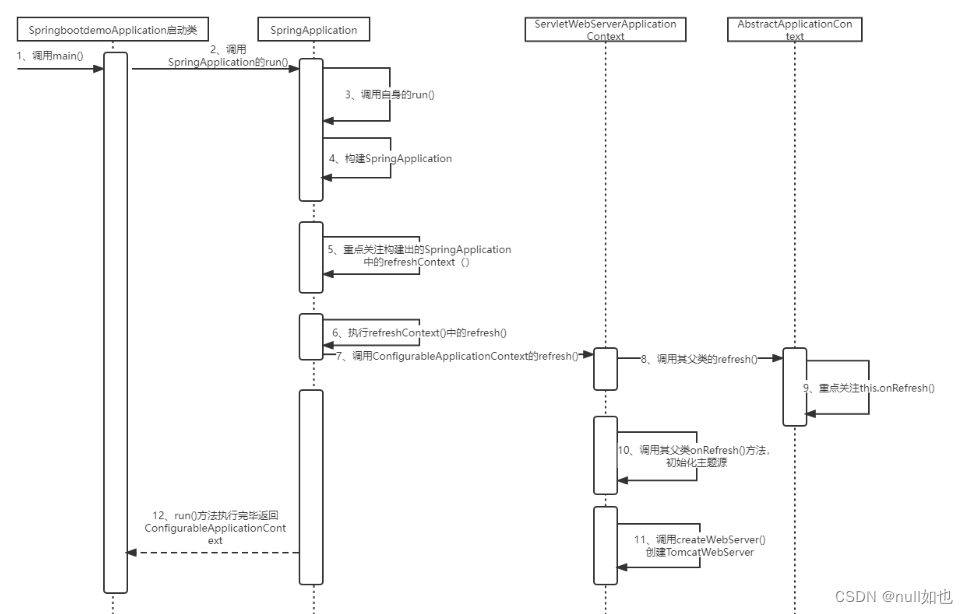
SpringBoot内嵌的Tomcat:
SpringBoot内嵌Tomcat源码: 1、调用启动类SpringbootdemoApplication中的SpringApplication.run()方法。 SpringBootApplication public class SpringbootdemoApplication {public static void main(String[] args) {SpringApplication.run(SpringbootdemoApplicat…...

企业级docker应用注意事项
现在很多企业使用容器化技术部署应用,绕不开的docker技术,在生产环境docker常用操作总结。参考:https://juejin.cn/post/7259275893796651069 1. 尽可能使用官方镜像 在docker hub 官方 使用后面带有 DOCKER OFFICIAL IMAGE 标签的镜像&…...

腾讯云高性能计算集群CPU服务器处理器说明
腾讯云高性能计算集群以裸金属云服务器为节点,通过RDMA互联,提供了高带宽和极低延迟的网络服务,能满足大规模高性能计算、人工智能、大数据推荐等应用的并行计算需求,腾讯云服务器网分享腾讯云服务器高性能计算集群CPU处理器说明&…...
tinkerCAD案例:23.Tinkercad 中的自定义字体
tinkerCAD案例:23.Tinkercad 中的自定义字体 原文 Tinkercad Projects Tinkercad has a fun shape in the Shape Generators section that allows you to upload your own font in SVG format and use it in your designs. I’ve used it for a variety of desi…...

Box-Cox 变换
Box-cox 变化公式如下: y ( λ ) { y λ − 1 λ λ ≠ 0 l n ( y ) λ 0 y^{(\lambda)}\left\{ \begin{aligned} \frac{y^{\lambda} - 1}{\lambda} && \lambda \ne 0 \\ ln(y) && \lambda 0 \end{aligned} \right. y(λ)⎩ ⎨ ⎧λyλ−1ln…...

Linux wc命令用于统计文件的行数,字符数,字节数
Linux wc命令用于计算字数。 利用wc指令我们可以计算文件的Byte数、字数、或是列数,若不指定文件名称、或是所给予的文件名为"-",则wc指令会从标准输入设备读取数据。 语法 wc [-clw][–help][–version][文件…] 参数: -c或–b…...
Python读取多个栅格文件并提取像元的各波段时间序列数据与变化值
本文介绍基于Python语言,读取文件夹下大量栅格遥感影像文件,并基于给定的一个像元,提取该像元对应的全部遥感影像文件中,指定多个波段的数值;修改其中不在给定范围内的异常值,并计算像元数值在每一景遥感影…...

Linux 之 wget curl
wget 命令 wget是非交互式的文件下载器,可以在命令行内下载网络文件 语法: wget [-b] url 选项: -b ,可选,background 后台下载,会将日志写入到 当前工作目录的wget-log文件 参数 url : 下载链…...

AngularJS 和 React区别
目录 1. 背景:2. 版本:3. 应用场景:4. 语法:5. 优缺点:6. 代码示例: AngularJS 和 React 是两个目前最为流行的前端框架之一。它们有一些共同点,例如都是基于 JavaScript 的开源框架,…...
【Solr】Solr搜索引擎使用
文章目录 一、什么是Solr?二 、数据库本身就支持搜索啊,干嘛还要搞个什么solr?三、如果我们想要使用solr那么首先我们得安装它 一、什么是Solr? 其实我们大多数人都使用过Solr,也许你不会相信我说的这句话,但是事实却是如此啊 ! 每当你想买自己喜欢的东东时,你可能会打开某…...
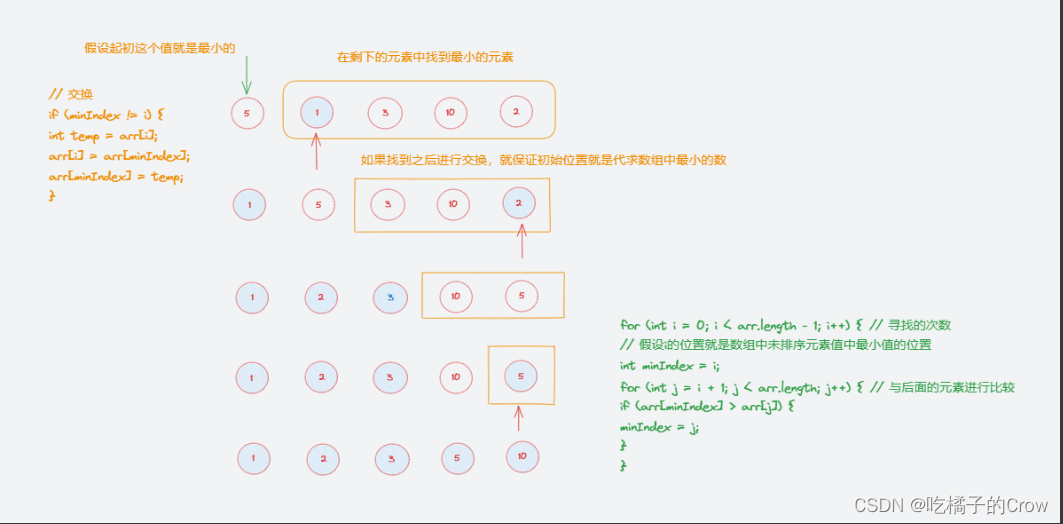
一起学算法(选择排序篇)
距离上次更新已经很久了,以前都是非常认真的写笔记进行知识分享,但是带来的情况并不是很好,一度认为发博客是没有意义的,但是这几天想了很多,已经失去了当时写博客的初心了,但是我觉得应该做点有意义的事&a…...

智能体的主观和能动
摘要 智能体的主动性是提升智能机器的能力的关键。围绕智能体的主动性存在很多思想迷雾,本文继续我们以前的工作,试图清理这些概念上的问题。我们的讨论显示:要研究主动性,并不一定需要研究意识,仅需要研究主观和能动就…...
AB 压力测试
服务器配置 阿里云Ubuntu 64位 CPU1 核 内存2 GB 公网带宽1 Mbps ab -c100 -n1000 http://127.0.0.1:9501/ -n:在测试会话中所执行的请求个数。默认时,仅执行一个请求。 -c:一次产生的请求个数。默认是一次一个。 ab -c 100 -n 200 ht…...
多旋翼物流无人机节能轨迹规划(Python代码实现)
目录 💥1 概述 📚2 运行结果 🌈3 Python代码实现 🎉4 参考文献 💥1 概述 多旋翼物流无人机的节能轨迹规划是一项重要的技术,可以有效减少无人机的能量消耗,延长飞行时间,提高物流效率…...

Vue通过指令 命令将打包好的dist静态文件上传到腾讯云存储桶 (保存原有存储目录结构)
1、在项目根目录创建uploadToCOS.js文件 (建议起简单的名字 方便以后上传输入命令方便) 2、uploadToCOS.js文件代码编写 const path require(path); const fs require(fs); const COS require(cos-nodejs-sdk-v5);// 配置腾讯云COS参数 const cos n…...

Linux 新硬盘分区,挂载
在Linux系统中,当你插入新的硬盘时,你需要进行一些步骤来使系统识别并使用它。以下是一些常见的步骤: 确保硬盘已正确连接到计算机。检查硬盘的电源和数据线是否牢固连接。 打开终端或命令行界面。 运行以下命令来扫描新硬盘: s…...
Stable Diffusion 开源模型 SDXL 1.0 发布
关于 SDXL 模型,之前写过两篇: Stable Diffusion即将发布全新版本Stable Diffusion XL 带来哪些新东西? 一晃四个月的时间过去了,Stability AI 团队终于发布了 SDXL 1.0。当然在这中间发布过几个中间版本,分别是 SDXL …...

NoSQL--------- Redis配置与优化
目录 一、关系型数据库与非关系型数据库 1.1关系型数据库 1.2非关系型数据库Nosql 1.3关系与非关系区别 1.4非关系产生的背景 1.5总结 二、Redis介绍 2.1Redis简介 2.3Redis优点 2.4 Redis为什么这么快? 三、Redis安装部署 3.1安装redis 3.2测试redis 3.3r…...

边缘多模态AI驱动的文档重构技术
1. 项目概述:当打印机和扫描仪开始“读懂”文档的真正意图你有没有遇到过这样的场景:客户用手机随手拍了一张合同,边缘歪斜、背景杂乱、光线不均,发到公司邮箱里;行政同事用老式扫描仪扫了一份带表格的报销单ÿ…...

达梦数据库-收缩数据库表空间步骤及示例记录总结
1达梦数据库-收缩数据库表空间步骤及示例记录总结 注:收缩表空间,如果空闲空间都在尾部,可以直接收缩成功,如果尾部不空闲,中部空闲,则需要移走使用尾部的表后再收缩,生产环境,如果…...

利用Taotoken模型广场为不同AI任务选择最佳模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken模型广场为不同AI任务选择最佳模型 在实际开发中,我们常常面临一个选择:面对内容生成、代码编…...

百度网盘macOS插件架构解析:基于运行时方法交换的SVIP权限模拟技术深度剖析
百度网盘macOS插件架构解析:基于运行时方法交换的SVIP权限模拟技术深度剖析 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 百度网盘macOS加…...

深入解析现代游戏修改框架的5大核心模块架构
深入解析现代游戏修改框架的5大核心模块架构 【免费下载链接】REFramework Mod loader, scripting platform, and VR support for all RE Engine games 项目地址: https://gitcode.com/GitHub_Trending/re/REFramework REFramework是一款专为RE引擎游戏设计的企业级游戏…...

前端实战:CSS 实现经典对联式悬浮广告
一、效果介绍对联广告是网页中非常经典的广告布局,特点:左右两侧各一个广告栏,像对联一样悬挂页面上下滚动,广告固定不动、悬浮跟随屏幕中间是网站主体内容,互不遮挡、互不影响核心技术:CSS fixed 固定定位…...

大麦网自动抢票神器:5分钟配置,告别抢票焦虑的终极指南
大麦网自动抢票神器:5分钟配置,告别抢票焦虑的终极指南 【免费下载链接】ticket-purchase 大麦自动抢票,支持人员、城市、日期场次、价格选择 项目地址: https://gitcode.com/GitHub_Trending/ti/ticket-purchase 还在为心仪演唱会门票…...

3个颠覆性技巧:重新定义现代界面字体的选择标准
3个颠覆性技巧:重新定义现代界面字体的选择标准 【免费下载链接】source-sans Sans serif font family for user interface environments 项目地址: https://gitcode.com/gh_mirrors/so/source-sans 你是否曾为网页上的文字不够清晰而烦恼?或是发…...

微服务限流实战:Nginx 漏桶与网关令牌桶
限流不是为了让系统“变慢”,而是为了让系统在突发流量、恶意请求或超过承载能力时,仍然能保住核心服务。 一句话概括:限流是在入口处控制请求速度或并发数量,Nginx 常用漏桶算法控制请求流出速率,Spring Cloud Gatewa…...

Dark Reader动态主题修复终极指南:自动化解决网站适配难题
Dark Reader动态主题修复终极指南:自动化解决网站适配难题 【免费下载链接】darkreader Dark Reader Chrome and Firefox extension 项目地址: https://gitcode.com/gh_mirrors/da/darkreader Dark Reader是一款广受欢迎的浏览器扩展,能帮助你将任…...