AI绘画Stable Diffusion原理之Autoencoder-Latent
前言
传送门:
stable diffusion:Git|论文
stable-diffusion-webui:Git
Google Colab Notebook:Git
kaggle Notebook:Git
今年AIGC实在是太火了,让人大呼许多职业即将消失,比如既能帮忙写代码,又能写文章的ChatGPT。当然,还有AI绘画,输入一段文本就能生成相关的图像,stable diffusion便是其中一个重要分支。自己对其中的原理比较感兴趣,因此开启这个系列的文章来对stable diffusion的原理进行学习(主要是针对“文生图”[text to image])。
上述的stable-diffusion-webui是AUTOMATIC1111开发的一套UI操作界面,可以在自己的主机上搭建,无限生成图像(实测2080ti完全能够胜任),如果没有资源,可以白嫖Google Colab或者kaggle的GPU算力。
其中stable diffusion的基础模型可以hugging face下载,而C站可以下载各种风格的模型。stable diffusion有一个很大的优势就是基于C站中各式各样的模型,我们可以进行不同风格的AI绘画。
而这篇文章,首先对其中的一个组件进行学习:Autoencoder。
原理简介
Stable Diffusion is a latent text-to-image diffusion model。stable diffusion本质是一种latent diffusion models(LDMs),隐向量扩散模型。diffusion models (DMs)将图像的形成过程分解为去噪自动编码器(denoising autoencoders)的一系列操作,但这些都是直接在像素空间上进行的操作,因此对于昂贵的计算资源,特别是高像素的图像。而LDMs则是引入隐向量空间,能够生成超高像素的图像。
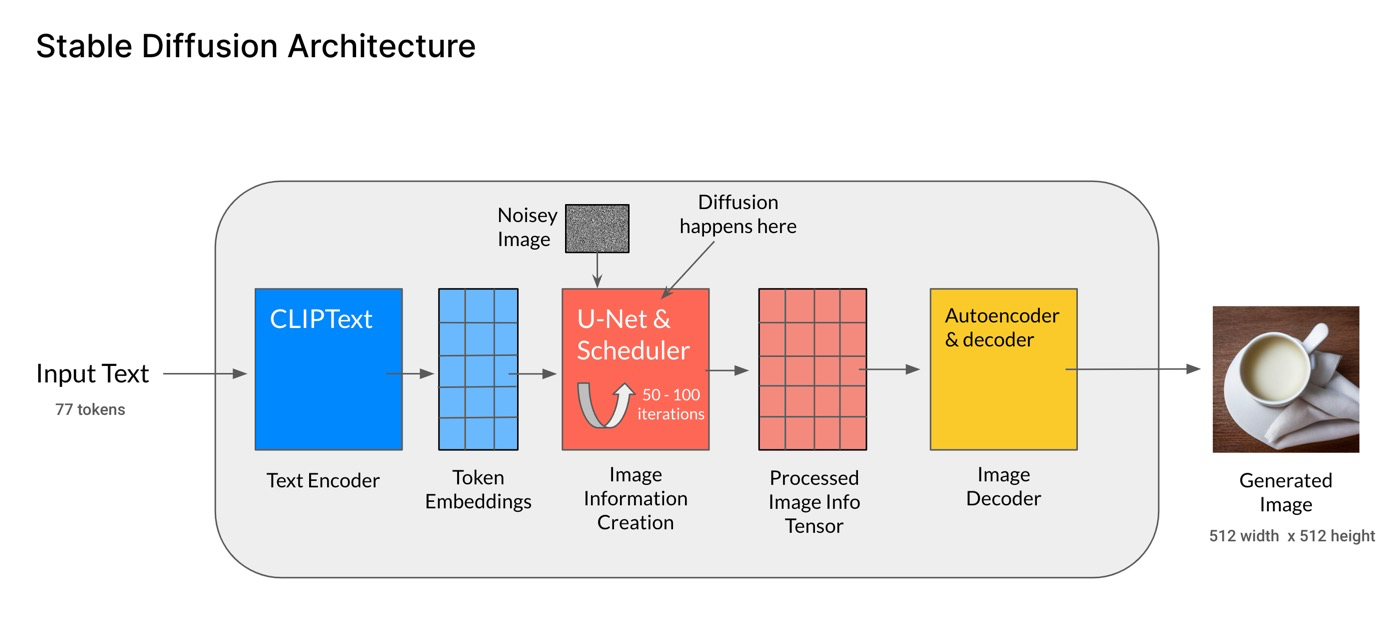
这里,我们先整体地来了解下stable diffusion的结构组成,后面再对每个组件进行拆开逐一理解。整体结构如下图[Stable Diffusion Architecture]:
- 文本编码器:人类输入的文本即prompt,经过CLIP模型中的Text Encoder,转化为语义向量(Token Embeddings);
- 图像生成器(Image information Creator):U-Net、采样器以及Autoencoder组成。由随机生成的纯噪声向量(即下图中的Noisey Image)开始,通过Autoencoder编码映射到低维的隐空间,文本语义向量作为控制条件进行指导,由U-Net和采样器不断迭代生成新的越具有丰富语义信息的隐向量,这就是扩散过程diffusion;
- 图像解码器(Image Decoder)- Autoencoder:迭代了一定次数之后,得到了包含丰富语义信息的隐向量(Processed Image Info Tensor),低维的隐向量经过Autoencoder解码到原始像素;
- 第2步就是LDMs和DMs的区别,LDMs是在latent space进行扩散,而DMs则是在pixel space,这也是性能提升的关键。
Autoencoder
[1] 论文:Taming Transformers for High-Resolution Image Synthesis
[2] Git:taming-transformers
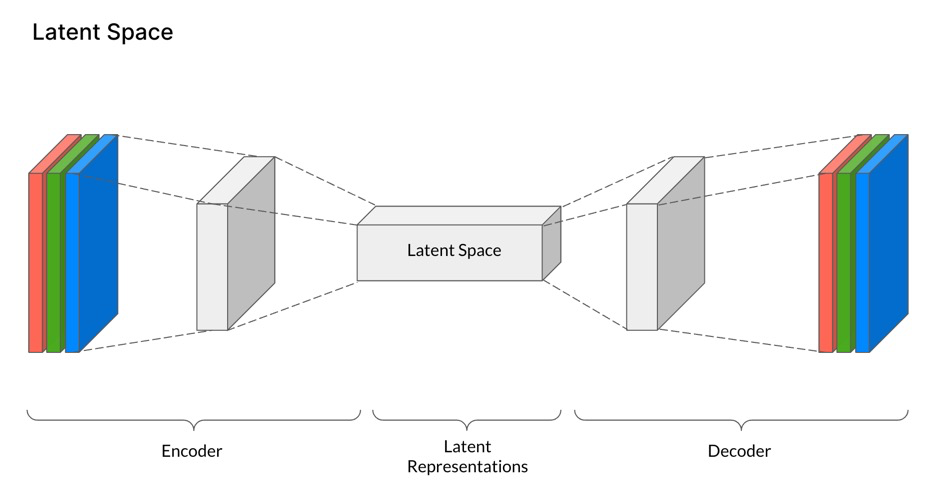
图片的隐空间表征从何而来:Autoencoder,既能够将图片从像素空间压缩到隐空间,让扩散过程在latent space中进行,又可以让图片从隐空间重建到像素空间(即图片重建),简化的过程如下图所示:
- 其中的encoder可以将一张图片从RGB空间即像素空间 x ∈ R H × W × 3 x\in \mathbb{R}^{H\times W \times 3} x∈RH×W×3,经过encoder编码到隐空间表征(latent representation) z = ε ( x ) z= \varepsilon(x) z=ε(x);
- decoder则是将隐空间表征重建到图片RGB x ~ = D ( z ) = D ( ε ( x ) ) \tilde{x}=D(z)=D(\varepsilon(x)) x~=D(z)=D(ε(x));
- 其中, z ∈ R h × w × c z\in \mathbb{R}^{h \times w \times c} z∈Rh×w×c,重要的是,控制隐空间大小的是编码器的下采样因子(downsampling factors): f = H / h = W / w , f = 2 m , m ∈ N f=H/h=W/w,f=2^m,m \in \mathbb{N} f=H/h=W/w,f=2m,m∈N
上述仅仅是从整体架构层面简单地描述了图片的隐空间与像素空间的转换与重建过程,但其实整个过程的细节还是比较复杂的,方法是出自VQGAN [ 1 ] ^{[1]} [1],其结构如下图所示:
- 论文认为高像素的图片合成需要模型能够理解图片的全局组成,使得局部和全局现实的生成能够保持一致。
- 因此,论文使用codebook来对图片的丰富视觉组成进行表征,而不是像素表征,codebook即是隐空间的表现形式。
- codebook可以大大减少的图片组成长度(相比像素),也使得能用transformer来高效地对图片内部的全局交互( global interrelations)进行建模。
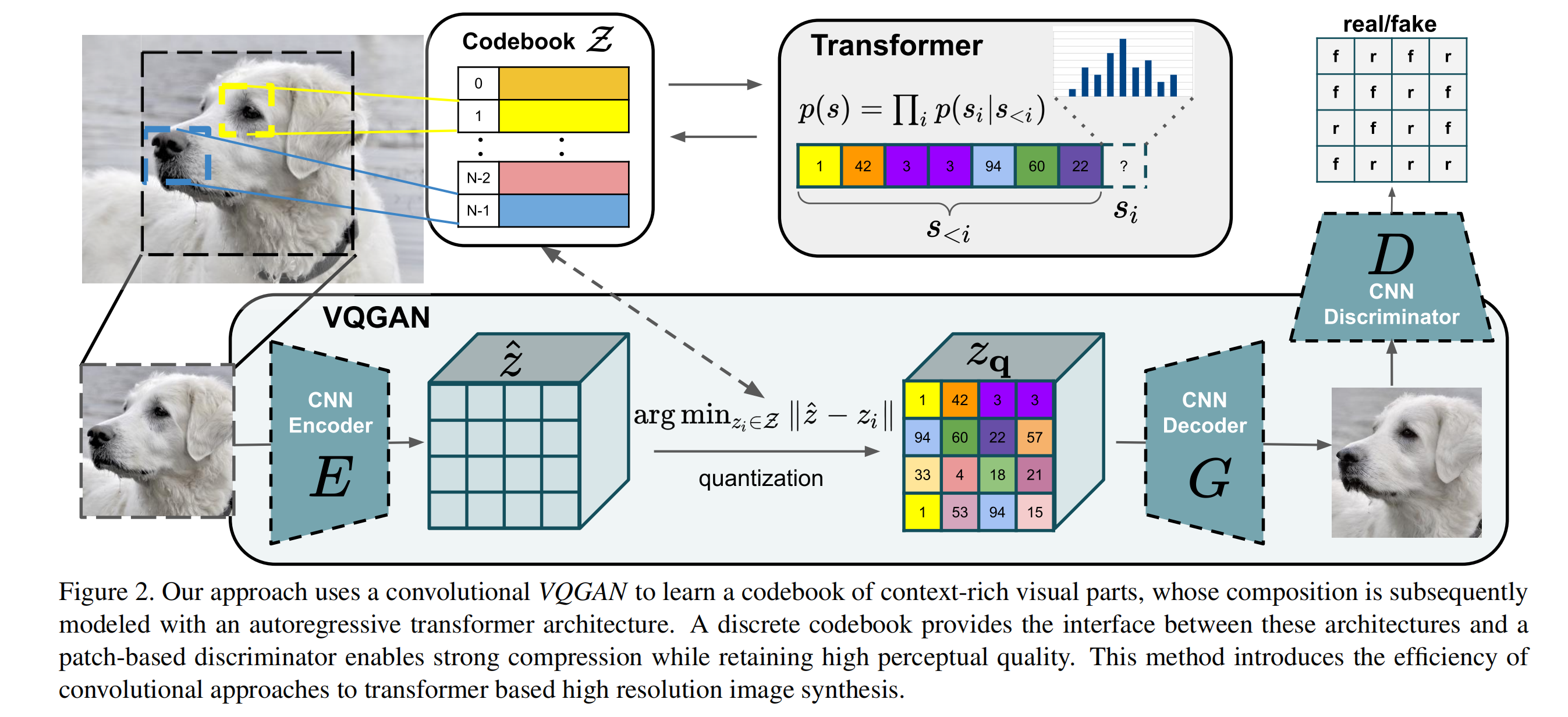
Codebook
给定一张图片 x ∈ R H × W × 3 x\in \mathbb{R}^{H\times W \times 3} x∈RH×W×3,需要将x表征为离散空间的codebook集合 z q ∈ R h × w × n z z_q \in \mathbb{R}^{h\times w \times n_z} zq∈Rh×w×nz,其中 h ⋅ w h \cdot w h⋅w可以认为是codebook中每个code的索引,而 n z n_z nz是code的维度。学习这样的codebook表征需要以下几个组件:
- 一个离散的codebook Z = { z k } k = 1 K ∈ R n z Z=\{z_k\}^K_{k=1} \in \mathbb{R}^{n_z} Z={zk}k=1K∈Rnz(可以当成embedding来理解,参数随机初始化,参与模型训练 ,但论文对这块没有清晰的描述,可以去看源码)
- CNN结构的encoder E,可以将图片 x x x编码为 z ^ ∈ R h × w × n z \hat{z} \in \mathbb{R}^{h\times w \times n_z} z^∈Rh×w×nz
- CNN结构的decoder G,能够将codebook z q z_q zq重建为图像 x ^ \hat{x} x^
- quantization操作,将 z ^ \hat{z} z^映射到 z q z_q zq
具体的 z q z_q zq编码过程为:编码器E将x转化为 z ^ = E ( x ) ∈ R h × w × n z \hat{z}=E(x) \in \mathbb{R}^{h\times w \times n_z} z^=E(x)∈Rh×w×nz,然后通过element-wise quantization q ( ⋅ ) q(\cdot) q(⋅)将每个离散的code z ^ i j ∈ R n z \hat{z}_{ij} \in \mathbb{R}^{n_z} z^ij∈Rnz编码到距离最近的codebook entry z k z_k zk(这里产生的最邻近的 z k z_k zk索引即为上图[VQGAN]的 s i s_i si,后续会用到)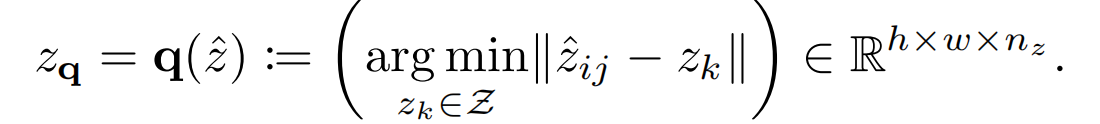
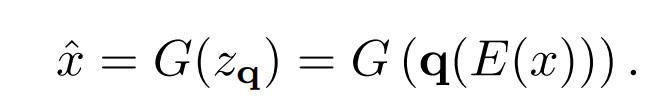
这部分的损失函数如下式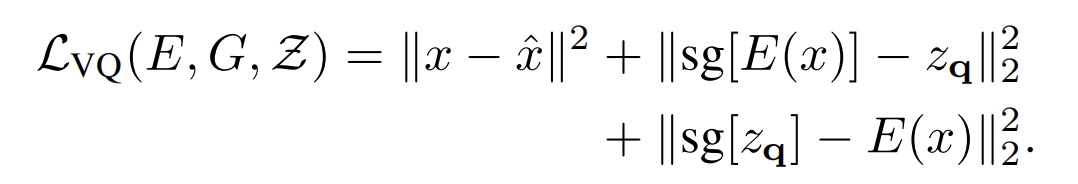
其中 L r e c = ∣ ∣ x − x ^ ∣ ∣ 2 L_{rec}=||x-\hat{x}||^2 Lrec=∣∣x−x^∣∣2为重建loss, s g [ ⋅ ] sg[\cdot] sg[⋅]为stop-gradient操作。由于 z q z_q zq的quantization操作是不可微分的,因此需要用到梯度拷贝(出自straight-through gradient estimator)
Discriminator
论文:Image-to-Image Translation with Conditional Adversarial Networks
Git:https://github.com/phillipi/pix2pix
使用transformer来表征图片的隐性图像成分的分布,需要进一步逼近图片压缩的极限和学习更富含信息的codebook,因此,论文还训练一个patch-based的判别器D,让它能够区分真实和重建的图片: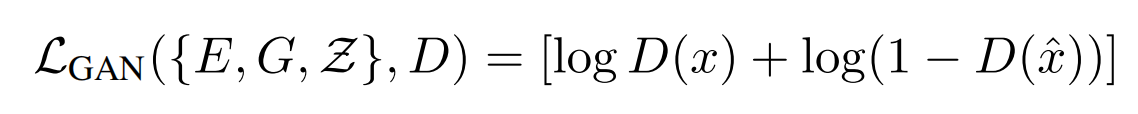
真实图像和重建图像都会经过一个CNN结构的Discriminator,然后得到每个patch的预估概率,模型的训练目标就是让真实图像的预估概率尽量都为1,而重建图像的预估概率尽量都为0,简而言之,就是让Discriminator能够识别每个patch是来自真实图像还是重建图像,如下图红框部分: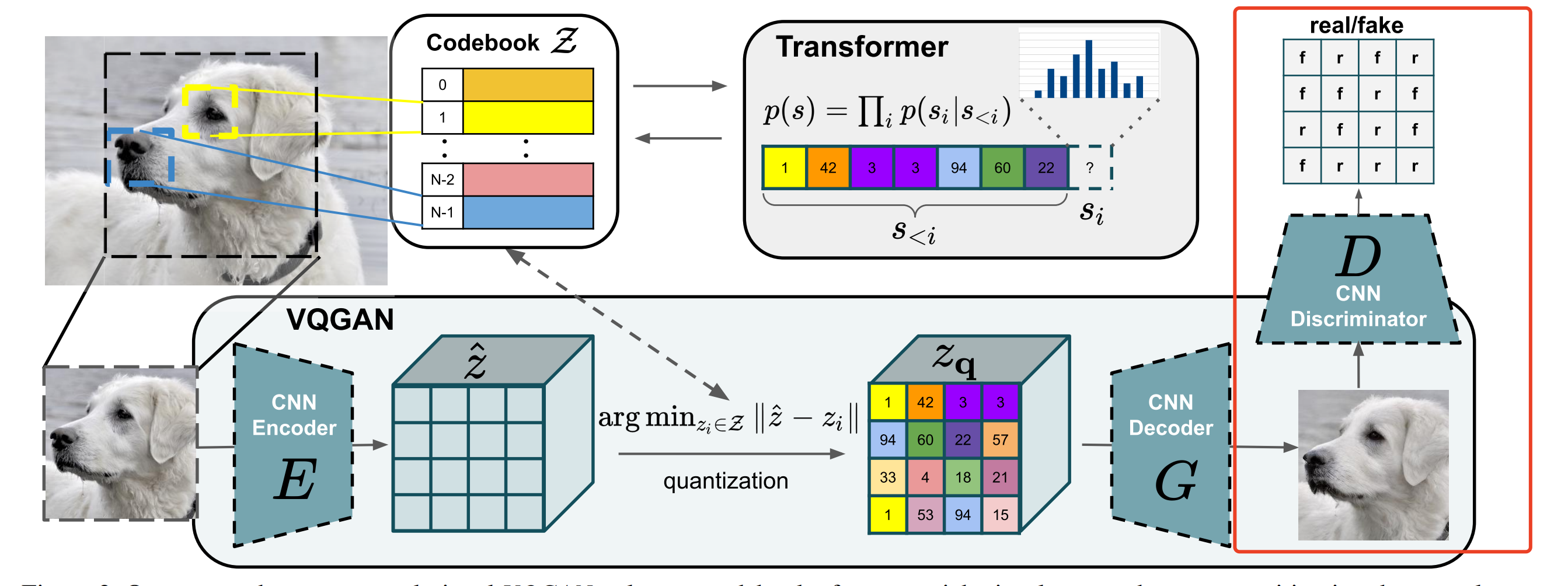
上述这两部分是联合训练:
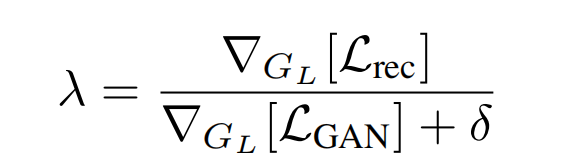
其中, ∇ G L [ ⋅ ] \nabla_{G_L}[\cdot] ∇GL[⋅]是decoder最后一层网络的梯度,而 δ = 1 0 − 6 \delta=10^{-6} δ=10−6。
Transformers
Latent Transformers.
编码器E和解码器G训练完成之后,按照上述同样的操作,通过E和quantization操作,可以将图片 x x x表征到codebook z q = q ( E ( x ) ) ∈ R h × w × n z z_q=q(E(x)) \in \mathbb{R}^{h \times w \times n_z} zq=q(E(x))∈Rh×w×nz, h ⋅ w h \cdot w h⋅w可以认为是codebook中每个code的索引 s i s_i si,然后将二维的索引变为一维的,相当于一个code序列 s ∈ { 0 , . . . , ∣ Z ∣ − 1 } h × w s \in \{0,...,|Z|-1\}^{h \times w} s∈{0,...,∣Z∣−1}h×w: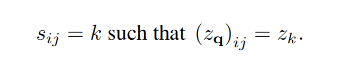
到这里,我们就可以按照NLP的自回归模型“预测下一个词”的思路来理解:给定code索引序列(上文) s < i s<i s<i,利用transformer来学习下一个code索引(下文)的概率分布 p ( s i ∣ s < i ) p(s_i|s<i) p(si∣s<i),最大化完整表征序列的似然估计 p ( s ) = ∏ i p ( s i ∣ s < i ) p(s)=\prod_ip(s_i|s<i) p(s)=∏ip(si∣s<i):
Conditioned Synthesis.
在许多图片合成任务中,往往会加入额外的信息来控制图片的合成过程,这个额外信息称为 c c c,它可以是一个对图片的标签描述或者另外的图片。那么,学习的似然估计则变为: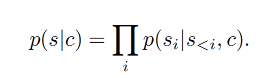
机制理解
在最后,通过源码仓库里的两个实操案例notebook来理解Autoencoder这些组建的工作机制。
图像重建.
VQGAN可以将图片输入编码到低维的codebook空间(隐空间),然后再对codebook空间重建为图片的像素空间,如下图所示。更重要的是,这个过程的中间产物-隐空间,相较于像素空间,能够以很小的特征空间来表征图片,可以迁移到attention机制底座的模型训练的下流任务,比如本文的主题:Stable Diffusion。
def reconstruct_with_vqgan(x, model):# could also use model(x) for reconstruction but use explicit encoding and decoding herez, _, [_, _, indices] = model.encode(x)print(f"VQGAN --- {model.__class__.__name__}: latent shape: {z.shape[2:]}")xrec = model.decode(z)return xrec

草图绘画.
这里主要是可以帮助理解VQGAN中Transformer的作用:
- 草图经过VQGAN的编码器得到codebook索引序列c- s i s_i si(c-仅是前缀,为了与成品图进行区分);
- 随机生成 成品图的codebook索引序列z- s i s_i si;
- 然后草图的索引序列c- s i s_i si作为控制条件,即上述提到Conditioned Synthesis章节中的 c c c,拼接在z- s i s_i si的前面(z- s i s_i si每次截取一段),输入到Transformer,去预测z- s i s_i si的每一个位置,预测得到的索引逐步替代随机生成的索引序列;
- 最后,这个生成的索引序列再进入解码器G重建为图片(成品图)。


相关文章:
AI绘画Stable Diffusion原理之Autoencoder-Latent
前言 传送门: stable diffusion:Git|论文 stable-diffusion-webui:Git Google Colab Notebook:Git kaggle Notebook:Git 今年AIGC实在是太火了,让人大呼许多职业即将消失,比如既能帮…...

C++核心知识点总结
学习一门新的程序设计语言得到最好方法就是练习编写程序! C基础 变量和基本类型 基本内置类型 定义解释 算术类型 整型:包括字符和布尔类型,bool、char、wchar_t、char16_t、char32_t、short、int、long、long long、 浮点型:…...
echart折线图,调节折线点和y轴的间距(亲测可用)
options代码: options {tooltip: {trigger: axis, //坐标轴触发,主要在柱状图,折线图等会使用类目轴的图表中使用。},xAxis: {type: category,//类目轴,适用于离散的类目数据,为该类型时必须通过 data 设置类目数据。…...

Power BI-云端报表定时刷新--ODBC、MySQL、Oracle等其他本地数据源的刷新(二)
ODBC数据源 一些小众的数据源无法直接连接,需要通过微软系统自带的应用“ODBC数据源”连接。 1.首次使用应安装对应数据库的ODBC驱动程序,Mysql的ODBC驱动需要手动安装 2.在web服务中进行数据源的配置 Mysql数据源 1.Powerbi与Gateway第一次连SQL…...

redis 淘汰策略和持久化
文章目录 一、淘汰策略1.1 背景1.2 淘汰策略 二、持久化2.1 AOF日志2.1.1 AOF配置2.1.2 AOF策略2.1.3 AOF缺点2.1.4 AOF Rewrite2.1.5 AOF Rewrite配置2.1.6 AOF Rewrite缺点2.1.7 fork进程时的写时复制2.1.8 大key对持久化的影响 2.2 RDB快照2.2.1 RDB配置2.2.2 RDB缺点 2.3 混…...
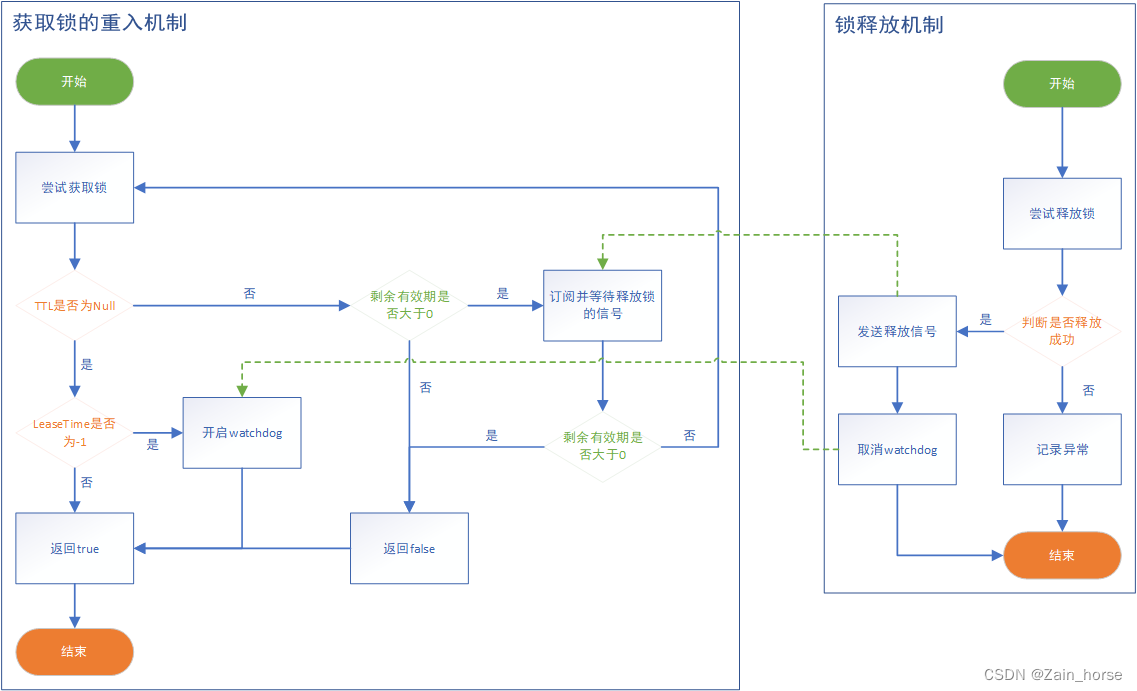
Redis学习路线(6)—— Redis的分布式锁
一、分布式锁的模型 (一)悲观锁: 认为线程安全问题一定会发生,因此在操作数据之前先获取锁,确保线程串行执行。例如Synchronized、Lock都属于悲观锁。 优点: 简单粗暴缺点: 性能略低 &#x…...
一、创建自己的docker python容器环境;支持新增python包并更新容器;离线打包、加载image
1、创建自己的docker python容器环境 参考:https://blog.csdn.net/weixin_42357472/article/details/118991485 首先写Dockfile,注意不要有txt等后缀 Dockfile # 使用 Python 3.9 镜像作为基础 FROM python:3.9# 设置工作目录 WORKDIR /app# 复制当前…...
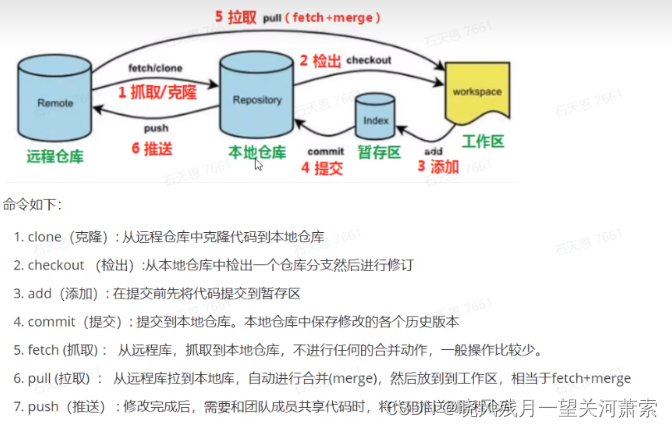
【Git】git企业开发命令整理,以及注意点
1.git企业开发过程 业务的分支大概有以下几个: master:代码随时可能上线 develop:代码最新 feature/xxx:实际业务开发分支 release/xxx:预发布分支 fix:修复bug分支 过程大概是这样的: 首…...

使用Django自带的后台管理系统进行数据库管理的实例
Django自带的后台管理系统主要用来对数据库进行操作和管理。它是Django框架的一个强大功能,可以让你快速创建一个管理界面,用于管理你的应用程序的数据模型。 使用Django后台管理系统,你可以轻松地进行以下操作: 数据库管理&…...
1254 - 1266 题)
leetcode解题思路分析(一百四十五)1254 - 1266 题
统计封闭岛屿的数目 二维矩阵 grid 由 0 (土地)和 1 (水)组成。岛是由最大的4个方向连通的 0 组成的群,封闭岛是一个 完全 由1包围(左、上、右、下)的岛。请返回 封闭岛屿 的数目。 BFS或者DFS…...

使用 GORM 连接数据库并实现增删改查操作
步骤 1:安装 GORM 首先,我们需要安装 GORM 包。在终端中运行以下命令: shell go get -u gorm.io/gorm 步骤 2:导入所需的包 在 Go 代码的开头导入以下包: import ("gorm.io/driver/mysql" // 如果你使用…...

kafka集群搭建(Linux环境)
zookeeper搭建,可以搭建集群,也可以单机(本地学习,没必要搭建zookeeper集群,单机完全够用了,主要学习的是kafka) 1. 首先官网下载zookeeper:Apache ZooKeeper 2. 下载好之后上传到…...
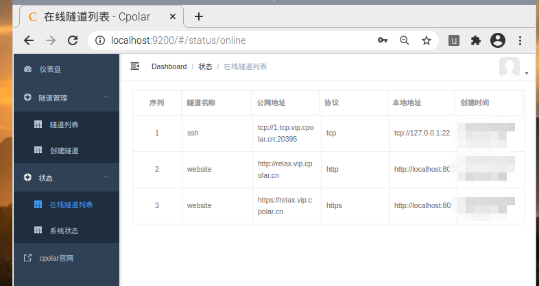
树莓派本地快速搭建web服务器,并发布公网访问
文章目录 树莓派本地快速搭建web服务器,并发布公网访问 树莓派本地快速搭建web服务器,并发布公网访问 随着科技的发展,电子工业也在不断进步,我们身边的电子设备也在朝着小型化和多功能化演进,以往体积庞大的电脑也在…...

集合中的数据结构
栈 先进后出入口跟出口在同一侧 队列 先进先出入口跟出口在不同的一层 数组 查询快、增删慢查询快是因为数组的地址是连续的,我们通过数组的首地址就可以找到数组,之后通过数组的下标就可以访问数组的每一个元素。增删慢是因为数组的长度是固定的&…...
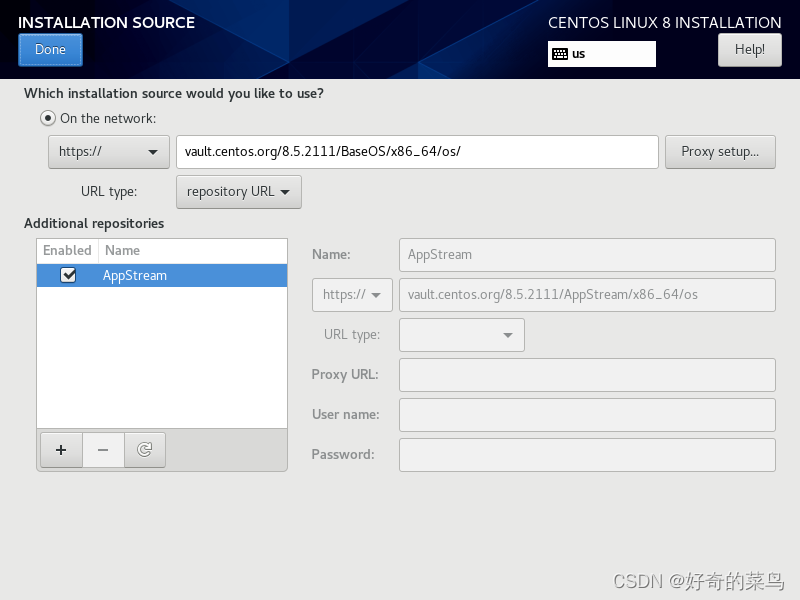
CentOS 8 错误: Error setting up base repository
配置ip、掩码、网关、DNS VMware网关可通过如下查看 打开网络连接 配置镜像的地址 vault.centos.org/8.5.2111/BaseOS/x86_64/os/...

java外观模式
在Java中,外观模式(Facade Design Pattern)用于为复杂的子系统提供一个简单的接口,以方便客户端的使用。外观模式是一种结构型设计模式,它隐藏了系统的复杂性,将多个类的复杂操作封装在一个外观类中&#x…...
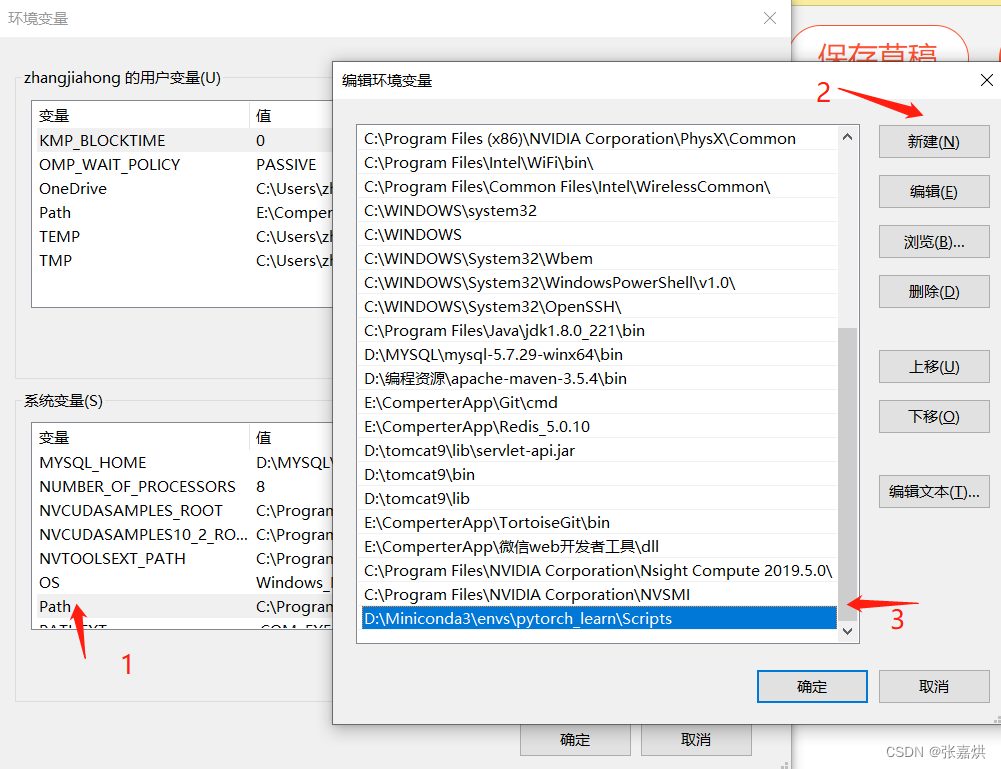
3秒快速打开 jupyter notebook
利用 bat 脚本,实现一键打开 minconda 特点: 1、可指定 python 环境 2、可指定 jupyter 目录 一、配置环境 minconda 可以搭建不同的 python 环境,所以我们需要找到 minconda 安装目录,把对应目录添加到电脑环境 PATH 中&#…...
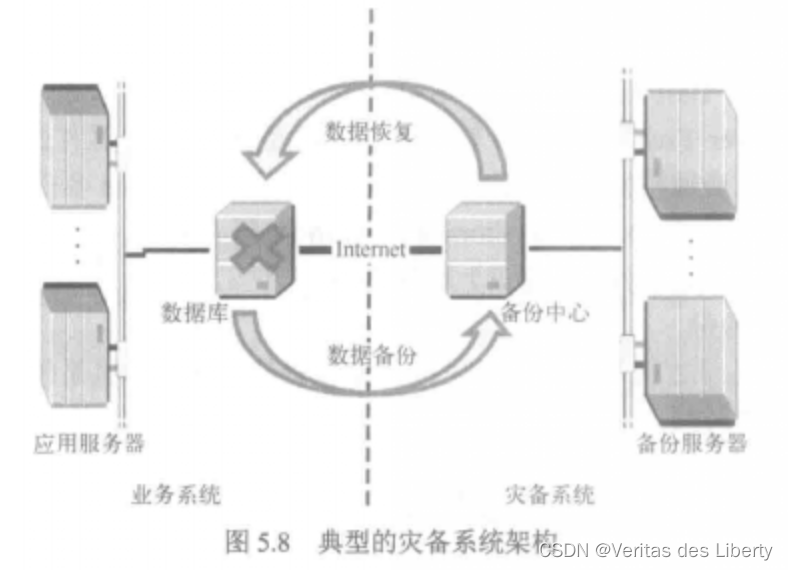
数据安全
数据的备份与恢复 1. 数据备份技术 任何数据在长期使用过程中,都存在一定的安全隐患。由于认为操作失误或系统故障,例如认为错误、程序出错、计算机失效、灾难和偷窃,经常造成数据丢失,给个人和企业造成灾难性的影响。在这种情况…...
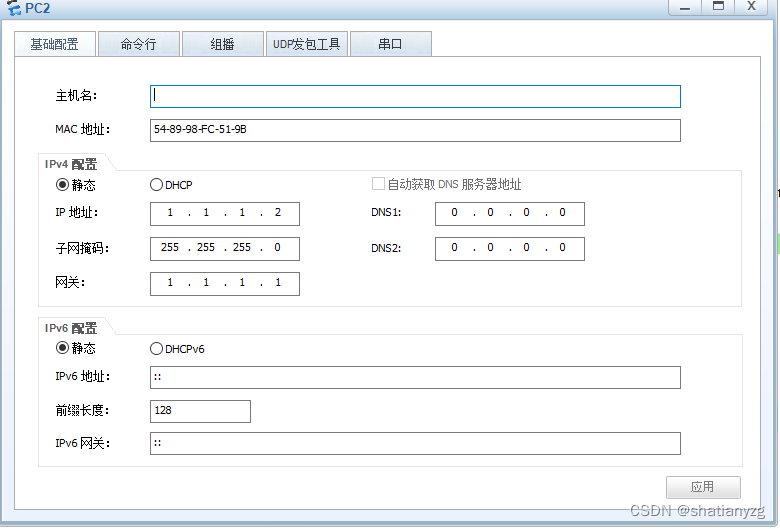
华为nat64配置
1.前期环境准备 环境拓扑 拓扑分为两个区域,左边为trust区域,使用IPv4地址互访,右边为untrust区域,使用IPv6地址互访 2.接口地址配置 pc1地址配置 pc2地址配置 FW接口配置 (1)首先进入防火墙配置界面 注:防火墙初始账号密码为user:admin,pwd:Admin@123,进入之后…...

从分片传输到并行传输之大文件传输加速技术
随着大文件的传输需求越来越多,传输过程中也会遇到很多困难,比如传输速度慢、文件安全性低等。为了克服这些困难,探讨各种大文件传输加速技术。其中,分片传输和并行传输是两种比较常见的技术,下面将对它们进行详细说明…...

Unity热更新本质与分层设计原理
1. 热更新不是“打补丁”,而是游戏生命周期的呼吸系统很多人第一次听说“Unity热更新”,脑子里立刻蹦出一个画面:玩家正在打Boss,突然弹出“检测到新版本,正在后台下载……3秒后重启生效”。然后下意识觉得——这不就是…...

【Lindy人力资源自动化方案】:20年HR Tech专家亲授,3大落地陷阱与5步零失败实施路径
更多请点击: https://codechina.net 第一章:Lindy人力资源自动化方案全景图 Lindy 是一款面向中大型企业的开源人力资源自动化平台,聚焦于招聘管理、员工生命周期编排、组织架构动态建模与合规性审计四大核心能力。其架构采用云原生设计&…...

通过Taotoken审计日志功能追踪与管理团队内部的API调用行为
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken审计日志功能追踪与管理团队内部的API调用行为 在团队协作使用大模型API进行开发时,一个常见的管理难题是…...

大麦抢票终极指南:告别手速焦虑,轻松锁定心仪演出门票
大麦抢票终极指南:告别手速焦虑,轻松锁定心仪演出门票 【免费下载链接】ticket-purchase 大麦自动抢票,支持人员、城市、日期场次、价格选择 项目地址: https://gitcode.com/GitHub_Trending/ti/ticket-purchase 面对热门演唱会门票&q…...

Yarn Spinner终极指南:10分钟学会编写专业游戏交互对话
Yarn Spinner终极指南:10分钟学会编写专业游戏交互对话 【免费下载链接】YarnSpinner The core compiler and engine-agnostic components for Yarn Spinner, the friendly dialogue tool. 项目地址: https://gitcode.com/gh_mirrors/ya/YarnSpinner Yarn Sp…...

如何用Easy Voice Toolkit轻松实现语音AI全流程:从识别到合成的完整指南
如何用Easy Voice Toolkit轻松实现语音AI全流程:从识别到合成的完整指南 【免费下载链接】Easy-Voice-Toolkit A user-friendly toolkit for voice recgonition/transcription/conversion etc. | 简单易用的语音工具箱 项目地址: https://gitcode.com/gh_mirrors/…...

Lindy HR自动化上线72小时后,员工自助率飙升83%:我们如何用1套规则引擎替代3个外包团队
更多请点击: https://intelliparadigm.com 第一章:Lindy人力资源自动化方案的诞生背景与核心价值 在数字化转型加速推进的今天,中大型企业普遍面临HR事务重复率高、跨系统数据割裂、员工自助能力薄弱等结构性挑战。传统HRIS平台虽能承载基础…...

Pandoc终极指南:如何用一款工具解决所有文档格式转换难题
Pandoc终极指南:如何用一款工具解决所有文档格式转换难题 【免费下载链接】pandoc Universal markup converter 项目地址: https://gitcode.com/gh_mirrors/pa/pandoc 你是否曾经为不同文档格式之间的转换而烦恼?是否需要在Markdown、Word、PDF、…...

Unity 2D跑酷开发全链路实战:从物理帧到对象池的工程化落地
1. 这不是“又一个跑酷游戏”,而是Unity 2D开发能力的完整压力测试 很多人点开“Unity跑酷游戏教程”时,心里想的是:拖几个Sprite,加个Rigidbody2D,写个Input.GetKeyDown(KeyCode.Space)跳一下,再配个背景滚…...

3大突破性技术:如何实现Cursor AI编程助手永久免费使用
3大突破性技术:如何实现Cursor AI编程助手永久免费使用 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tr…...