解读随机森林的决策树:揭示模型背后的奥秘
一、引言
随机森林[1]是一种强大的机器学习算法,在许多领域都取得了显著的成功。它由多个决策树组成,而决策树则是构建随机森林的基本组件之一。通过深入解析决策树,我们可以更好地理解随机森林模型的工作原理和内在机制。
决策树是一种树状结构,用于根据输入特征进行决策和预测。它由节点和边组成,每个节点代表一个特征或属性,而边则表示该特征的取值。决策树的分裂过程是基于不同特征的条件判断,最终将数据样本分配到不同的叶子节点中。这使得决策树具有直观性和可解释性,可以帮助我们理解模型的决策过程。
随机森林是通过集成多个决策树来进行预测的。它引入了随机性,通过对训练样本进行随机采样和对特征进行随机选择,构建了多颗决策树。这样的集成方式既提高了模型的准确性,又增强了模型对噪声和异常值的鲁棒性。
通过解读随机森林决策树,我们可以揭示模型背后的奥秘。我们可以分析决策树节点的重要性和特征的贡献度,了解模型预测的依据。随机森林决策树还可以应用于金融风险评估、医学诊断等领域,并取得了很多成功案例。继续研究随机森林和决策树的价值将有助于提升模型的性能和解释能力。
二、什么是决策树?
2.1 决策树的概念和结构
决策树是一种用于决策和预测的树状结构模型。它由一系列节点和边组成,每个节点代表一个特征或属性,而边则表示该特征的取值。决策树的结构可以看作是一种自上而下的分层判定过程。
2.2 策树如何根据特征进行分裂和判断
决策树的根节点位于最顶端,代表整个数据集。而叶子节点则表示最终的决策结果或预测结果。在决策树的分裂过程中,每个非叶子节点都有若干分支,每个分支对应一个特征取值。通过根据不同特征进行分裂和判断,决策树将数据样本分配到不同的叶子节点中,使得相似特征的样本聚集在同一叶子节点上。
分裂和判断的过程通常基于特征的纯度或不纯度来进行,常见的指标包括信息增益、基尼指数和均方差等。在每个节点上,决策树选择最优的特征来进行分裂,以最大程度地提高纯度或减小不纯度。这样的分裂过程逐渐形成一系列子节点,直到满足停止条件(如达到最大深度或叶子节点中的样本数量小于某个阈值)。
2.3 决策树的可解释性和直观性
决策树的可解释性和直观性是其独特的优点。由于决策树使用简单的判定规则进行决策,它能够清晰地展示模型的决策过程。我们可以通过观察决策树的分裂节点和特征取值,了解模型是如何对输入数据进行条件判断的。这种直观性使得决策树在许多领域具有广泛的应用,例如医学诊断、金融风险评估等。
然而,决策树也存在一些限制。它容易过拟合训练数据,导致泛化能力较差。为了解决这个问题,我们可以通过剪枝和集成学习等方法来提高决策树的性能。同时,决策树在处理连续型特征和缺失值时需要做额外的处理,以适应更复杂的数据情况。
总之,决策树是一种基于树状结构的模型,通过对不同特征的分裂和判断来进行决策和预测。它具有可解释性和直观性的特点,可用于解决许多实际问题。
三、随机森林是如何构建的?
3.1 随机森林由多个决策树组成的原理
随机森林是一种集成学习方法,由多个决策树组成。下面我将解释随机森林的构建原理。
随机森林的构建过程如下:
-
随机采样:从原始数据集中进行有放回的随机采样,产生多个不同的训练子集,每个子集都包含部分原始数据集的样本。这些子集被用于训练每个决策树模型。 -
特征随机选择:对于每个决策树的训练过程中,在每次节点的特征选择时,随机从所有特征中选取一部分特征进行考虑。这样可以确保每个决策树的训练过程中使用的特征都是不同的。 -
构建决策树:使用选定的特征子集对每个训练子集进行决策树的构建。通常采用基于信息增益、基尼指数或均方差等指标来进行节点的划分和分裂。 -
集成预测:当所有决策树构建完成后,对新样本进行预测时,每个决策树都会给出自己的预测结果,最终的预测结果可以通过多数投票或者平均值来确定。
3.2 随机森林中的“随机”是啥?
在随机森林中,“随机”起着重要的作用:
-
样本随机采样:通过有放回的随机采样,每个决策树使用不同的训练子集,这样可以保证每个决策树之间具有差异性,减少了过拟合的风险。 -
特征随机选择:每个决策树的特征选择只考虑了部分特征,从而增加了决策树之间的多样性。这种随机性有效地减少了模型的相关性,提高了整体模型的稳定性和泛化能力。
3.3 多个决策树的集成如何提高模型预测的准确性和稳定性?
多个决策树的集成可以显著提高模型的预测准确性和稳定性:
-
预测结果投票/平均:对于分类问题,随机森林通过多数投票来确定最终的分类结果;对于回归问题,将所有决策树的预测结果进行平均。这种集成方式可以降低单个决策树的偏差,提高整体模型的准确性。 -
减少过拟合:由于随机森林中使用了样本随机采样和特征随机选择的方法,每个决策树都是在不同的数据子集和特征子集上进行训练的,从而减少了过拟合的概率,并提高了模型的泛化能力。
总之,随机森林是由多个决策树组成的集成学习方法。通过样本随机采样和特征随机选择,随机森林具有较高的预测准确性和稳定性,同时保持了决策树的可解释性和直观性。
四、决策树的训练过程?
决策树的训练过程包括「特征选择」和「节点分裂」依据的决策准则。
-
「特征选择」
在决策树的训练过程中,特征选择是决策树构建的关键一步。目标是选择一个最佳的特征作为当前节点的划分标准,使得划分后的子节点能够尽可能地纯净或信息增益最大。常用的特征选择准则有:
-
信息增益(Information Gain):基于熵的概念,通过计算当前节点划分前后的信息熵差异,选择信息增益最大的特征作为划分标准。信息增益越大,表示划分后的子节点纯净度提升的程度越大。 -
基尼系数(Gini Index):衡量随机选择一个样本的类别标记被错误分类的概率。基尼系数越小,表示划分后的子节点纯净度越高。 -
基于均方差(Mean Squared Error):主要用于回归问题,通过计算当前节点划分前后的平均方差差异,选择平均方差最小的特征作为划分标准。
-
「节点分裂」
在特征选择之后,确定了当前节点的划分标准(即最佳特征)后,可以进行节点的分裂。具体的分裂方式取决于特征的类型。
对于离散特征,通常采用多叉树的方式,为每个可能取值创建一个分支。
对于连续特征,需要确定一个划分点,将样本分成两个子集。一种常用的划分方式是选择特征的中位数作为划分点,将小于等于中位数的样本归为左子节点,大于中位数的样本归为右子节点。
决策树的构建过程是递归的,对每个子节点都进行特征选择和节点分裂操作,直到满足终止条件,如达到最大深度或节点中样本数小于预定义的阈值。
使用基尼系数或信息增益进行决策树分支选择的原理和方法如下:
-
基尼系数:计算基尼系数需要针对每个特征的每个可能取值进行切分,计算切分后子节点的基尼系数,然后将所有切分点得到的基尼系数求加权平均。选择基尼系数最小的特征作为划分标准。 -
信息增益:计算信息增益需要计算当前节点的信息熵和每个特征划分后的条件熵,然后将当前节点的信息熵减去特征划分后的条件熵得到信息增益。选择信息增益最大的特征作为划分标准。
基尼系数和信息增益都是常用的特征选择准则,它们在决策树的训练过程中起到了评估特征重要性的作用。选择合适的特征选择准则可以提高决策树的预测性能和泛化能力。
五、随机森林的预测过程?
随机森林是一种集成学习方法,通过构建多个决策树,并对它们的结果进行集成来进行预测。下面我将详细解释随机森林的预测过程以及其优点。
-
「随机森林的预测过程如下」:
-
对于给定的输入样本,将其输入到每棵决策树中进行预测。 -
对于分类问题,采用投票的方式进行集成。即统计每个类别被决策树预测的次数,并选择获得最高票数的类别作为最终预测结果。 -
对于回归问题,采用平均值的方式进行集成。即将每棵决策树的预测结果求平均作为最终预测结果。
-
-
「随机森林的优点包括:」
-
鲁棒性:随机森林具有较强的鲁棒性,能够处理噪声和异常值的影响。由于随机森林使用多个决策树进行集成,其中的单个决策树对噪声和异常值相对不敏感,因此整个模型能够减小这些异常值的影响。 -
高准确性:随机森林在处理各种类型的数据时表现良好,能够提供较高的预测准确性。通过集成多棵决策树的结果,随机森林能够减小过拟合的风险,提高泛化能力。 -
可解释性:随机森林能够给出特征的重要性排名,通过分析每个特征在决策树中的使用频率和划分效果,可以了解到每个特征对预测结果的贡献程度。 -
处理高维数据:随机森林在处理高维数据时具有较好的表现。由于每棵决策树只使用部分特征进行训练,因此能够有效地处理高维数据,避免维度灾难问题。
-
总结起来,随机森林通过构建多个决策树并进行投票或取平均的方式进行结果集成,具有鲁棒性、高准确性、可解释性和适应高维数据等优点。这使得随机森林成为了一种强大的机器学习方法,在各种应用场景中得到了广泛的应用。
六、随机森林模型背后的奥秘
随机森林是由多个决策树组成的集成学习模型,其内在机制和参数意义可以通过解析单个决策树来理解。下面我将解释决策树的内在机制和参数意义,并讨论如何通过解读决策树来解释模型的预测过程和判断依据。
-
「决策树的内在机制和参数意义:」
-
决策树的节点:决策树由一系列节点组成,每个节点代表一个特征的取值或者一个判断条件。通过对特征的划分,决策树能够将数据集划分为不同的子集,使得每个子集的纯度(同一类别的样本比例)尽可能高。 -
决策树的分支:决策树的分支表示一个特征的取值与该特征的判断条件之间的关系。通过对特征的判断条件,决策树能够将样本从父节点分配到相应的子节点中。 -
决策树的叶子节点:决策树的叶子节点表示最终的预测结果或者该节点所代表的样本属于的类别。
-
「决策树节点的重要性和特征的贡献度:」
-
决策树节点的重要性可以通过节点的纯度或者基尼指数来衡量。纯度越高或者基尼指数越低的节点意味着该节点对预测结果的贡献越大。 -
特征的贡献度可以通过分析决策树中特征被使用的频率来评估。在决策树中,特征被使用的次数越多,表示该特征对于模型的预测结果影响越大。
-
「通过解读决策树来解释模型的预测过程和判断依据」:
-
决策树可以提供特征的重要性排名,通过分析每个特征在决策树中的使用次数和划分效果,可以了解到每个特征对预测结果的贡献程度。这些信息可以帮助我们理解模型的预测过程和决策依据。 -
通过观察决策树的具体分支和节点,可以解释模型在不同特征取值下的预测结果以及判断依据。通过追踪样本在决策树中的路径,可以了解到模型是如何进行判断和决策的。
总结起来,通过解析决策树的内在机制和参数意义,我们可以了解随机森林模型的预测过程和判断依据。特征的贡献度和决策树节点的重要性提供了对模型的解释和理解。通过解读决策树,我们可以更好地理解模型的工作原理和预测依据。
七、决策树可视化
-
「包加载和数据集引入」
from sklearn.ensemble import RandomForestClassifier
from sklearn import datasets
from sklearn import tree
from matplotlib import pyplot as plt
-
「构建随机森林模型和决策树可视化」
def print_choice():
iris = datasets.load_iris()
print(iris)
X = iris.data
y = iris.target
# 构建随机森林模型
model = RandomForestClassifier(n_estimators=5) # 指定森林中树的数量
model.fit(X, y)
# 可视化决策树森林
fig, axes = plt.subplots(nrows=1, ncols=5, figsize=(10, 2), dpi=300) # 在一行中绘制每个决策树
for i in range(len(model.estimators_)):
tree.plot_tree(model.estimators_[i], ax=axes[i])
axes[i].set_title(f'Tree {i + 1}')
plt.show()
# Press the green button in the gutter to run the script.
if __name__ == '__main__':
print_choice()
参考文献:
[1] Mantero A, Ishwaran H. Unsupervised random forests. Stat Anal Data Min. 2021;14(2):144-167. doi:10.1002/sam.11498
*「未经许可,不得以任何方式复制或抄袭本篇文章之部分或全部内容。版权所有,侵权必究。」
相关文章:
解读随机森林的决策树:揭示模型背后的奥秘
一、引言 随机森林[1]是一种强大的机器学习算法,在许多领域都取得了显著的成功。它由多个决策树组成,而决策树则是构建随机森林的基本组件之一。通过深入解析决策树,我们可以更好地理解随机森林模型的工作原理和内在机制。 决策树是一种树状结…...

OceanMind海睿思获评中国信通院“内审数字化产品评测”卓越级(最高级)!
2023年7月27日,由中国内部审计协会、中国通信标准化协会指导,中国信息通信研究院主办的第二届数字化审计论坛在北京成功召开。 大会聚焦内部审计数字化领域先进实践、研究成果、行业发展举措,重磅发布了多项内部审计数字化领域的最新研究和实…...
TPlink云路由器界面端口映射设置方法?快解析内网穿透能实现吗?
有很多网友在问:TPlink路由器端口映射怎么设置?因为不懂端口映射的原理,所以无从下手,下面小编就给大家分享TPlink云路由器界面端口映射设置方法,帮助大家快速入门TP路由器端口映射设置方法。 1.登录路由器管理界面&a…...

css3的filter图片滤镜使用
业务介绍 默认:第一个图标为选中状态,其他三个图标事未选中状态 样式:选中状态是深蓝,未选中状体是浅蓝 交互:鼠标放上去选中,其他未选中,鼠标离开时候保持当前选中状态 实现:目前…...

❤️创意网页:打造炫酷网页 - 旋转彩虹背景中的星星动画
✨博主:命运之光 🌸专栏:Python星辰秘典 🐳专栏:web开发(简单好用又好看) ❤️专栏:Java经典程序设计 ☀️博主的其他文章:点击进入博主的主页 前言:欢迎踏入…...

react常用知识点
React是一个用于构建用户界面的JavaScript库。以下是React常用的知识点: 组件:React将用户界面分解成小而独立的组件,每个组件都有自己的状态和属性,并且可以通过组合这些组件来构建复杂的用户界面。 // 函数组件示例 function We…...

iOS开发-QLPreviewController与UIDocumentInteractionController显示文档
iOS开发-QLPreviewController与UIDocumentInteractionController显示文档 在应用中,我们有时想预览文件, 可以使用QLPreviewController与UIDocumentInteractionController 一、QLPreviewController与UIDocumentInteractionController QLPreviewController是一个 UIViewContr…...

八、用 ChatGPT 帮助排查生产事故
目录 一、实验介绍 二、背景 三、故障排查概述 3.1 生产环境故障排查涉及的角色...

WPF实战学习笔记25-首页汇总
注意:本实现与视频不一致。本实现中单独做了汇总接口,而视频中则合并到国todo接口当中了。 添加汇总webapi接口添加汇总数据客户端接口总数据客户端接口对接3首页数据模型 添加数据汇总字段类 新建文件MyToDo.Share.Models.SummaryDto using System;…...
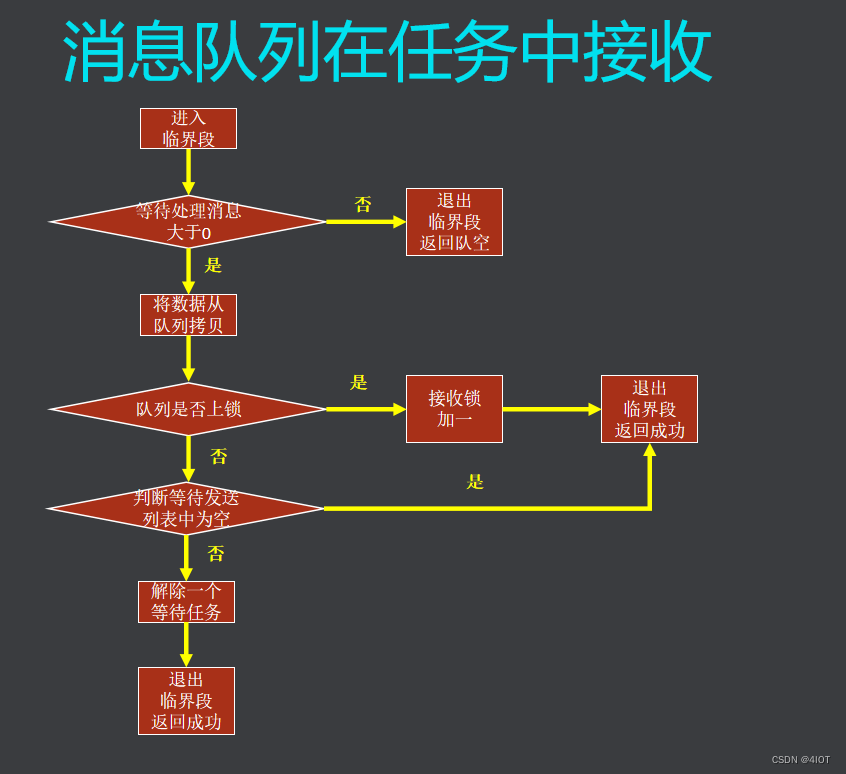
FreeRTOS源码分析-7 消息队列
目录 1 消息队列的概念和作用 2 应用 2.1功能需求 2.2接口函数API 2.3 功能实现 3 消息队列源码分析 3.1消息队列控制块 3.2消息队列创建 3.3消息队列删除 3.4消息队列在任务中发送 3.5消息队列在中断中发送 3.6消息队列在任务中接收 3.7消息队列在中断中接收 1 消…...

机器学习深度学习——权重衰减
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——模型选择、欠拟合和过拟合 📚订阅专栏:机器学习&&深度学习 希望文章对你…...
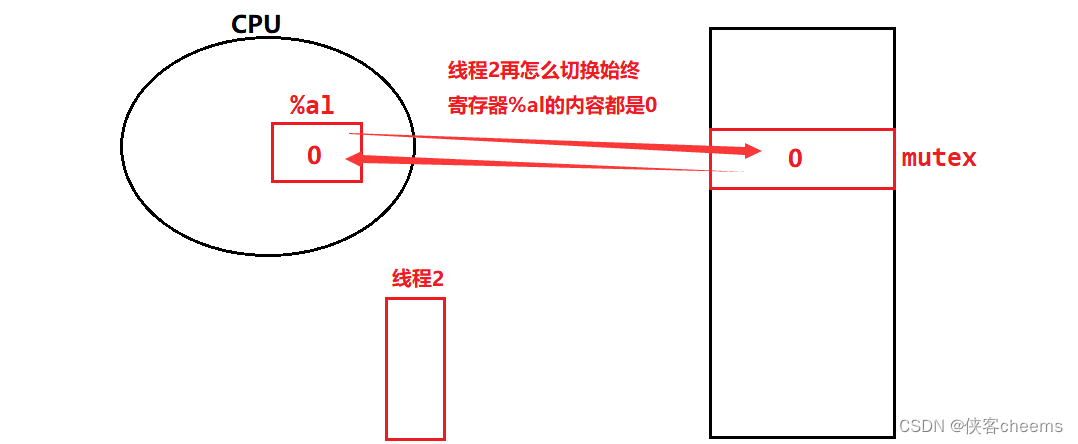
【Linux】线程互斥 -- 互斥锁 | 死锁 | 线程安全
引入互斥初识锁互斥量mutex锁原理解析 可重入VS线程安全STL中的容器是否是线程安全的? 死锁 引入 我们写一个多线程同时访问一个全局变量的情况(抢票系统),看看会出什么bug: // 共享资源, 火车票 int tickets 10000; //新线程执行方法 vo…...

【vue-pdf】PDF文件预览插件
1 插件安装 npm install vue-pdf vue-pdf GitHub:https://github.com/FranckFreiburger/vue-pdf#readme 参考文档:https://www.cnblogs.com/steamed-twisted-roll/p/9648255.html catch报错:vue-pdf组件报错vue-pdf Cannot read properti…...

Flink集群运行模式--Standalone运行模式
Flink集群运行模式--Standalone运行模式 一、实验目的二、实验内容三、实验原理四、实验环境五、实验步骤5.1 部署模式5.1.1 会话模式(Session Mode)5.1.2 单作业模式(Per-Job Mode)5.1.3 应用模式(Application Mode&a…...

Spring整合JUnit实现单元测试
Spring整合JUnit实现单元测试 一、引言 在软件开发过程中,单元测试是保证代码质量和稳定性的重要手段。JUnit是一个流行的Java单元测试框架,而Spring是一个广泛应用于Java企业级开发的框架。本文将介绍如何使用Spring整合JUnit实现单元测试,…...

Spring Boot学习路线1
Spring Boot是什么? Spring Boot是基于Spring Framework构建应用程序的框架,Spring Framework是一个广泛使用的用于构建基于Java的企业应用程序的开源框架。Spring Boot旨在使创建独立的、生产级别的Spring应用程序变得容易,您可以"只是…...

管理类联考——写作——论说文——实战篇——标题篇
角度3——4种材料类型、4个立意对象、5种写作态度 经过审题立意后,我们要根据我们的立意,确定一个主题,这个主题必须通过文章的标题直接表达出来。 标题的基本要求 主题清晰,态度明确 第一,阅卷人看到一篇论说文的标…...
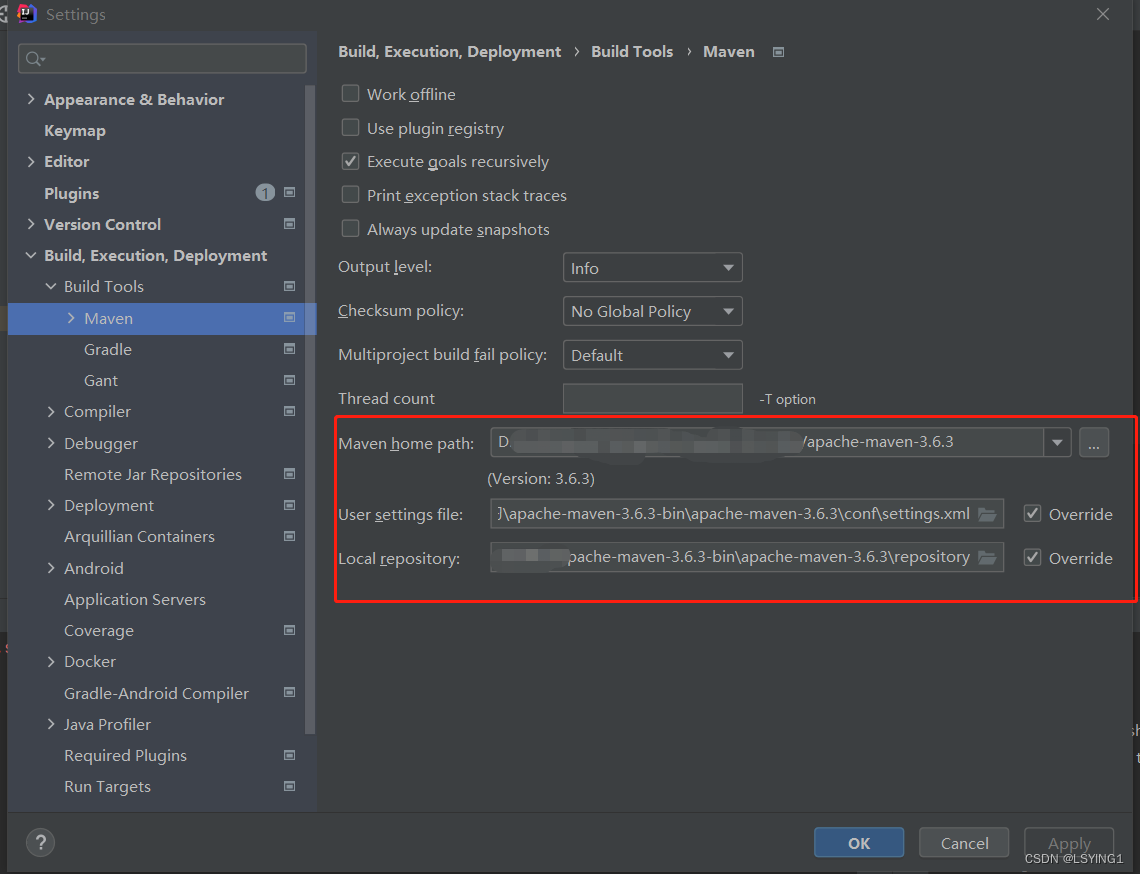
idea中设置maven本地仓库和自动下载依赖jar包
1.下载maven 地址:maven3.6.3 解压缩在D:\apache-maven-3.6.3-bin\apache-maven-3.6.3\目录下新建文件夹repository打开apache-maven-3.6.3-bin\apache-maven-3.6.3\conf文件中的settings.xml编辑:新增本地仓库路径 <localRepository>D:\apache-…...
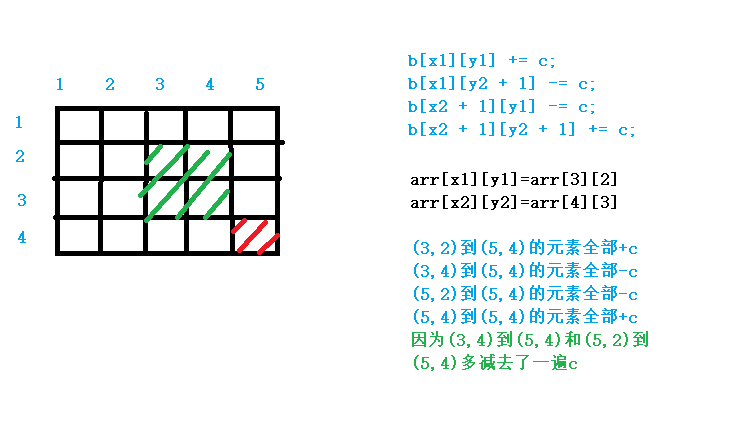
前缀和差分
前缀和 前缀和:一段序列里的前n项和 给出n个数,在给出q次问询,每次问询给出L、R,快速求出每组数组中一段L至R区间的和 给出一段数组,每次问询为求出l到r区间的和 普通方法:L到R进行遍历,那么…...
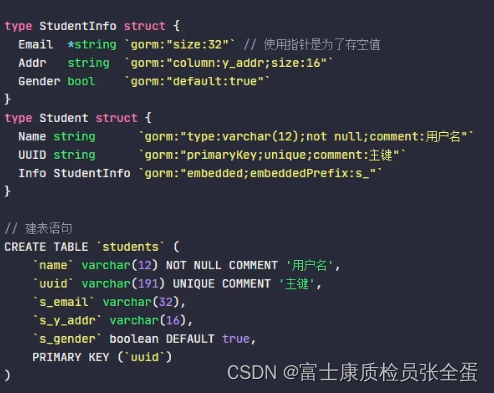
Golang GORM 模型定义
模型定义 参考文档:https://gorm.io/zh_CN/docs/models.html 模型一般都是普通的 Golang 的结构体,Go的基本数据类型,或者指针。 模型是标准的struct,由Go的基本数据类型、实现了Scanner和Valuer接口的自定义类型及其指针或别名组成&#x…...

哈尔滨除甲醛本地推荐
新房装修完工本是喜事,但刺鼻异味与甲醛却令人困扰。哈尔滨冬季供暖期长,室内密闭时间长,甲醛释放周期可达3-15年,仅靠通风难以根除。许多业主在除甲醛时踩坑:要么找了不靠谱的游击队治理无效,要么被低价套…...

GEO获客工具如何选择?
随着AI智能搜索全面普及,越来越多的企业开始关注GEO获客工具。面对市面上涌现的各类产品,如何理性、客观地做出选择?本文从技术适配性、操作落地性、数据透明度三个维度,结合惠搜GEO获客系统的实际设计逻辑,提供一套可…...

【Sora 2批量视频生成黄金工作流】:实测吞吐提升4.8倍的关键配置——NVIDIA A100集群下每小时稳定输出217段1080p视频
更多请点击: https://codechina.net 第一章:Sora 2批量视频生成工作流全景概览 Sora 2作为新一代多模态视频生成模型,其批量处理能力依托于模块化、可编排的端到端工作流设计。该工作流融合提示工程、时空 latent 编码、分块并行解码与后处理…...

【Elasticsearch从入门到精通】第10篇:Elasticsearch REST API最佳实践——Content-Type、模糊性与访问控制
上一篇【第09篇】Elasticsearch API规范详解——多索引、日期数学与通用选项 下一篇【第11篇】Elasticsearch索引API详解——索引创建、删除与别名管理(明日更新,敬请期待) 摘要 掌握Elasticsearch REST API的使用规范不仅能避免常见错误&am…...
,3大未公开API接口实测报告)
别再手动复制粘贴了!ChatGPT原生PPT导出功能已上线(仅限Enterprise Tier),3大未公开API接口实测报告
更多请点击: https://intelliparadigm.com 第一章:ChatGPT原生PPT导出功能的架构演进与企业级定位 ChatGPT原生PPT导出功能并非简单集成第三方渲染库,而是OpenAI在模型服务层、内容生成中间件与文档编排引擎三者深度协同下构建的端到端能力。…...

紫光同创FPGA网络摄像头方案选型指南:OV7725 vs OV5640,YT8531 vs KSZ9031怎么选?
紫光同创FPGA网络摄像头方案选型指南:OV7725 vs OV5640,YT8531 vs KSZ9031深度解析 在工业视觉和安防监控领域,FPGA因其并行处理能力和低延迟特性,成为实时视频采集与传输的理想选择。紫光同创作为国产FPGA的重要代表,…...

无人机航拍林业树种分割|单木树冠检测|三维点云|遥感影像数据集10059期
无人机航拍林业树种分割|单木树冠检测|三维点云|遥感影像数据集10059期 面向林业资源调查、生态监测、智慧城市绿化管理的大规模高分辨率树种单木分割数据集,提供影像、点云、矢量多模态数据,支持树冠分割、树种识别、…...

SMUDebugTool终极指南:深度掌握AMD Ryzen硬件调试与性能优化
SMUDebugTool终极指南:深度掌握AMD Ryzen硬件调试与性能优化 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: http…...
GoogleTranslate_IPFinder高级功能详解:自定义IP段扫描与在线同步服务
GoogleTranslate_IPFinder高级功能详解:自定义IP段扫描与在线同步服务 【免费下载链接】GoogleTranslate_IPFinder 谷歌翻译API服务器的IP扫描、测速工具。 项目地址: https://gitcode.com/gh_mirrors/go/GoogleTranslate_IPFinder GoogleTranslate_IPFinder…...

LABVIEW生成EXE
遇到的问题报错说找不到这个路径的某个VI原因在于之前手动改过文件夹名称,导致路径有变更。更关键的是有的VI还沿用以前旧的路径,因此报错。解决办法就是打开可能用到这个功能的VI,选定新路径。报错是因为要打包的vi里面不是所有的vi都能够正…...