MongoDB 基础学习记录
MongoDB 基础
mongoDB 是由 C++语言编写,基于分布式文件存储的开源数据库系统,是一个 nosql 数据库.
在高负载的情况下,添加更多的节点,保证服务器性能,MongoDB 旨在为 web 引用提供可扩展的高性能存储解决方案,将数据存储为给文档,
数据结构由键值(key,value)对组成,MongoDB 文档类似于 json 对象,字段值可以包含其他文档,数据以及文档数组.
主要特点
面向文档:MongoDB 存储的数据采用 JSON 样式的 BSON(二进制 JSON)文档格式,可以直接映射到应用程序的对象模型。这种面向文档的模型使得数据的存储和查询更加灵活和方便。
高性能:MongoDB 具有高度并行化和低延迟的读写操作,支持水平扩展以处理大量数据。它还支持基于内存的操作,可以提供非常快的查询速度。
良好的可扩展性:MongoDB 的架构设计适合横向扩展,它可以通过添加更多的节点来处理更大规模的数据和负载。同时,它支持自动分片,可以将数据分布在多个服务器上进行负载均衡。
强大的查询功能:MongoDB 提供了丰富的查询功能,包括范围查询、全文搜索、正则表达式等,并支持聚合查询和地理空间查询。此外,它还支持二级索引,可以根据需求对不同字段建立索引。
灵活的数据模型:MongoDB 的文档模型允许存储具有不同结构和字段的文档,无需事先定义表结构。这种灵活性使得应用程序可以随时更改和扩展数据模型,而无需任何迁移过程。
多种数据一致性选项:MongoDB 提供了多种数据一致性选项,可以在数据的一致性和性能之间进行权衡。开发人员可以根据需求选择合适的副本集或分片策略,以满足应用程序的需求。
社区支持和生态系统:MongoDB 有一个庞大的用户社区和活跃的开发者社区,提供了丰富的资源和支持。此外,MongoDB 还有许多附加工具和第三方库,可以帮助用户更好地使用和管理数据库。
- 1,MongoDB 是一个面向文档存储的数据库,操作简单
- 2,你可以在 MongoDB 记录设置任何属性的索引
- 3,可以通过本地或者网络创建数据镜像,
- 4,支持网络分片
- 5,丰富的查询表达式,查询指令使用 json 形式,可以在文档中内嵌对象和数组
- 6,使用 update 命令可以实现替换完成文档数据或者一些指定字段的更新,
- 7,map/reduce 主要是用来对统计数据进行批量出和操作,
- 8,map 函数调用的 emit(key,value)遍历集合中所有记录,将 key 于 value 传给 Reduce 函数进行处理,
- map 函数和 reduce 函数使用 js 编写的,并可以通过 db.runCommand 或 mapreduce 命令来执行 MapReduce 操作。
- GridFS 是 MongoDB 中的一个内置功能,可以用于存放大量小文件,
- mongoDB 允许在服务器端执行脚本,可以用 js 编写某个函数,直接在服务器端执行,也可以把函数的定义存储在服务端下,下次直接调用了,
- MongoDB 支持多种变成语言,Python,c++,php,c#等多种,
mongoDB 概念解析
将于关系数据库类比解析
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-S5Ulzncu-1690278972184)(./images/2022-10-20-16-48-43.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4j5Stjt6-1690278972185)(./images/2022-10-20-16-49-01.png)]
这里就可以很多看出,这里是以 json 字符串方式的匹配.
数据库
MongoDB 的单个实例可以容纳多个独立的数据库,每各都有自己的集合和权限,不同的数据库也放置在不同的文件中,
show dbs : 可以显示所有数据的列表,
db: 可以显示当前数据库对象或集合
use: 指定一个连接到一个数据库
有一些数据库名是保留的,可以直接访问这些有特殊作用的数据库。
admin: 从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
config: 当 Mongo 用于分片设置时,config 数据库在内部使用,用于保存分片的相关信息。
文档(Document)
文档是一组键值对,文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,
例如:
{ "site": "www.runoob.com", "name": "菜鸟教程" }
需要注意的是:
1,文档中的键值是有序的,
2,文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型
3,mongoDB 区分类型和大小写
4,文档中不能有重复的键
5,文档中的键是字符串,使用 utf-8
文档键命令要求:
键不能有空字符,一般是来识别键结尾,
.和$有特殊意义,只有在特定环境下使用
以下划线_开头的键是保留的(不严格要求)
注意: 在 MongoDB 中,因为它本身具有的灵活性,所以不要求一个集合中的文档的字段格式必须要相同,这于关系型数据很不大同。
其中单个文档具有不同字段,那么也就是具有了不同的数据长度,例如:
{ _id: 1, name: "John", age: 20, grade: "A" }
{ _id: 2, name: "Jane", age: 22, major: "Computer Science", GPA: 3.5 }
需要注意的是: 查询操作的时候,对于缺少该字段的文档,不会返回控制,而是直接忽略,在结果中不会展示。
集合
集合就是 MongoDB 文档组,类似于关系型数据库中的表
集合存在于数据库中,集合没有固定的结构,这意味着对集合可以插入不同格式和类型的数据,当第一个文档被插入的时候,集合就已经被创建了.
集合命令不能以"system"开头,这是为了系统集合保留前缀.
用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。除非你要访问这种系统创建的集合,否则千万不要在名字里出现$。
集合名不能是空字符串""。
集合名不能含有\0 字符(空字符),这个字符表示集合名的结尾。
capped collections
capped collections 就是固定大小的集合,它有很高的性能以及队列过期的特性,
capped collections 是高性能自动维护对象的插入顺序,它非常适合类似记录日志的功能和标准的 collection 不同,你必须要显示的创建一个 capped collections,指定它的大小,单位是字节,是可以提前分配的,
capped collections 可以按照文档的插入顺序保存到集合中,而且这些文档在磁盘上存放的位置,也是按照顺序来保存的,所以当我们更新 capped collections 中文档的时候,更新后的文档的不能超过之前文档的大小,这样就可以保持所有文档在磁盘上的位置一直保持不变.
可以很好的提高插入数据额效率,要注意的是:指定的存储大小包含了数据库头信息.
db.createCollection(“mycoll”, {capped:true, size:100000})
在 capped collection 中,你能添加新的对象。
能进行更新,然而,对象不会增加存储空间。如果增加,更新就会失败 。
使用 Capped Collection 不能删除一个文档,可以使用 drop() 方法删除 collection 所有的行。
删除之后,你必须显式的重新创建这个 collection。
在 32bit 机器中,capped collection 最大存储为 1e9( 1X109)个字节。
元数据
数据库的信息是存储在集合中,他们使用了系统的命令空间
dbname.system.*
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ka0pWWiM-1690278972186)(./images/2022-10-20-17-17-01.png)]
MongoDB 的数据类型
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Fhmm99qw-1690278972187)(./images/2022-10-20-17-18-36.png)]
Object 类型:
object 类似是唯一主键,可以很快的去生成和排序,包含了 12bytes,
含义:
前 4 个字节表示创建的 unix 时间戳,后 3 个是机器标识码,然后是进程 id,然后是随机数,
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-S7Lac1o0-1690278972188)(./images/2022-10-20-17-20-58.png)]
MongoDB 中存储的文档必须有个_id 键,这个键的值可以是任何类型的,默认是个 object 对象,
由于 ObjectId 中保存了创建的时间戳,所以你不需要为你的文档保存时间戳字段,你可以通过 getTimestamp 函数来获取文档的创建时间:
> var newObject = ObjectId()
> newObject.getTimestamp()
ISODate("2017-11-25T07:21:10Z")
objectld 转为字符串: newObject.str
String(字符串):用于存储文本数据,例如姓名、地址、描述等。
Number(数字):用于存储数值类型的数据,包括整数和浮点数。
Boolean(布尔值):存储 true 或 false 两个取值。
Date(日期):用于存储日期和时间,以 ISO 格式进行存储。
Object(对象):用于存储复杂的数据结构,可以包含多个字段。
Array(数组):用于存储多个值的列表。
Binary Data(二进制数据):用于存储二进制数据,例如图片、音频或视频等。
ObjectId(对象 ID):用于存储文档的唯一标识符,在集合中自动生成。
Null(空值):表示没有值的字段。
Undefined(未定义):表示字段未定义或不存在。
Regular Expression(正则表达式):用于存储正则表达式模式。
除了上述常见的数据类型之外,MongoDB 还支持一些特殊的数据类型,例如 GeoJSON(地理空间数据)、Timestamp(时间戳)等,以满足不同类型数据的存储需求。
时间戳
BSON 有一个特殊的时间戳类型用于 MongoDB 内部使用,与普通的 日期 类型不相关。 时间戳值是一个 64 位的值。其中:
前 32 位是一个 time_t 值,
后 32 位是在某秒中操作的一个递增的序数
在单个 mongod 实例中,时间戳的值通常是唯一的,在复制集群中,oplog 有一个 ts 字段,这个字段中的值是使用 bson 时间戳表示的操作时间.
MongoDB - 连接
mongdb 服务安装之后,需要先创建两个目录:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-C6euW6Fb-1690278972189)(2023-06-18-16-18-07.png)]
创建对应 data 目录,然后使用下面的启动命令启动,
启动 MongoDB 服务:
mongod --dbpath /var/lib/mongo --logpath /var/log/mongodb/mongod.log --fork
回显成功,即可.
进入管理 shell: (6.0 之后,需要自己安装 shell 工具)
到 MongoDB 的安装/bin 目录下,执行: ./mongo
mongodb://[username:password@]host1[:port1],host2[:port2],…[,hostN[:portN]]][/[database][?options]]
mongodb:// 这是固定的格式,必须要指定。
username:password@ 可选项,如果设置,在连接数据库服务器之后,驱动都会尝试登录这个数据库
host1 必须的指定至少一个 host, host1 是这个 URI 唯一要填写的。它指定了要连接服务器的地址。如果要连接复制集,请指定多个主机地址。
portX 可选的指定端口,如果不填,默认为 27017
/database 如果指定 username:password@,连接并验证登录指定数据库。若不指定,默认打开 test 数据库。
?options 是连接选项。如果不使用/database,则前面需要加上/。所有连接选项都是键值对 name=value,键值对之间通过&或;(分号)隔开
mongo 支持多个连接:
连接 replica pair, 服务器 1 为 example1.com 服务器 2 为 example2。: mongodb://example1.com:27017,example2.com:27017
连接 replica set 三台服务器 (端口 27017, 27018, 和 27019): mongodb://localhost,localhost:27018,localhost:27019
用户身份认证
db.auth(“username”,“password”)
使用 rpm 安装的 mongodb.进入命令行:
mongoDB 语法
创建数据库
建库语句:
use DATABASE_NAME
(如果数据库不存在,则进行创建,否则切换到指定的数据库)
查看所有数据库:
show dbs;
注意: 库中没有数据时候是无法查看的,需要向其中插入数据,在 MongoDB 中,集合只有在内容插入后才会创建! 就是说,创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建。
删除数据库:
db.dropDatabase()
默认会删除当前的库,可以使用 db,查看当前的数据库名
使用 use 进入到指定库中,然后执行 db.dropDatabase().
创建集合:
db.createCollection(name,options)
说明:
name: 要创建的集合名称,
options: 可选参数,指定有关内存大小及索引的选项.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-78jjzkBV-1690278972190)(./images/2022-11-09-18-14-43.png)]
在插入文档时,MongoDB 首先会检查固定的集合的 size 字段,然后检查 max 字段.
如
db.createCollection("runoob")db.createCollection("mycol", { capped : true, autoIndexId : true, size :6142800, max : 10000 } )
{ "ok" : 1 }
如果查看已经有的集合,可以使用 show collections 或 showtables 命令:
在 MongoDB 中,你不需要创建集合,当你插入一些文档,mongoDB 会自动创建集合,隐式创建的方式.
删除集合:
db.collection_name.drop()
如果删除成功则会返回 true,否则返回 false
插入文档
文档的数据结构和 json 基本一样,所有存储在集合中的数据都是 bson 格式,
插入:
mongoDB 中使用的 inset()或 save()方法向集合中插入文档:
db.COLLECTION_NAME.insert(document)
或
db.COLLECTION_NAME.save(document)
save():如果 _id 主键存在则更新数据,如果不存在就插入数据。该方法新版本中已废弃,可以使用 db.collection.insertOne() 或 db.collection.replaceOne() 来代替。
insert(): 如果插入的数据主键已经存在,会抛出异常,提示主键已经重复,不保存当前的数据,
db.collection.insertMany() 用于向集合插入一个多个文档,语法格式如下,最新用法:
db.collection.insertMany([ <document 1> , <document 2>, ... ],{writeConcern: <document>,ordered: <boolean>}
)
document:要写入的文档。
writeConcern:写入策略,默认为 1,即要求确认写操作,0 是不要求
ordered:指定是否按顺序写入,默认 true,按顺序写入。
以上实例 col 是我们的集合名称,如果该集合在不在数据库中,则会自动创建给文档的集合,并插入新的文档. 这种方式就是隐式创建集合,在写入文档时候,创建集合.
也可以将数据定义为一个变量,document={}
然后再将变量传入,db.col.insert(document)
更新文档
update()方法用于更新已经存在的文档,语法格式:
db.collection.update(<query>,<update>,{upsert: <boolean>,multi: <boolean>,writeConcern: <document>}
)
db.users.updateMany({ age: { $gte: 30 } }, // 匹配条件,找出age大于等于30的文档{ $set: { status: "active" } } // 更新操作,将匹配的文档的status字段设置为"active"
);query: update 的查询条件,类型 where 子句,
update: update 的对象和一些更新的操作符等,也可以理解为 sql update 查询内 set 后面的值,
upsert: 可选,表示如果存在 update 的记录,是否插入 objnew,true 为插入,默认 false
multi: 默认是 false,只更新找到的第一条记录,如果这个参数为 ture,就把这个条件查询出来的多条记录全部更新
writeConcern :可选,抛出异常的级别。
在更新文档时,可以使用多种操作符,包括 s e t 、 set、 set、inc、 u n s e t 等。 unset 等。 unset等。inc 操作符用于递增或递减字段的值,而 s e t 操作符用于设置字段的值。 set操作符用于设置字段的值。 set操作符用于设置字段的值。unset(用于删除字段)、$push(用于向数组添加元素)
>db.col.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 }) # 输出信息
> db.col.find().pretty()
{"_id" : ObjectId("56064f89ade2f21f36b03136"),"title" : "MongoDB","description" : "MongoDB 是一个 Nosql 数据库","by" : "菜鸟教程","url" : "http://www.runoob.com","tags" : ["mongodb","database","NoSQL"],"likes" : 100
}
>
以上语句只会修改第一条发现的文档,如果你要修改多条相同的文档,则需要设置 multi 参数为 true。
db.col.update({‘title’:‘MongoDB 教程’},{$set:{‘title’:‘MongoDB’}},{multi:true})
save()方法
save()方法是通过传入的文档来替换已有文档,_id 主键存在就更新,不存在就插入,已经废弃
db.collection.save(<document>,{writeConcern: <document>}
)
document : 文档数据。
writeConcern :可选,抛出异常的级别。
删除文档
建议使用 deleteOne()方法来删除匹配条件的单个文档,或者使用 deleteMany()方法来批量删除匹配条件的多个文档。
下面是一个示例,演示如何使用 deleteOne()方法删除匹配条件的单个文档:
// 删除名为 “users” 的集合中匹配条件的数据(删除第一个匹配的文档)
db.users.deleteOne({ age: { $gte: 30 } });
const result = await db.users.deleteMany({ age: { $gte: 30 } });
console.log(result.deletedCount);
deleteMany()方法将删除所有与匹配条件匹配的文档,而不仅仅是第一个匹配文档。
查询操作
mongodb 中的表达式
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3vY9Ve7v-1690278972191)(./images/2023-07-20-18-28-27.png)]
查询语法:
查询全部: db.collection.find() 不带参数回显指定字段: db.collection.find({},{title:1,_id:0}) 1表示显示,0表示不显示,其中的第一个{}表示查询条件,第二个{}表示要显示的字段,_id默认是显示的,如果不显示,需要设置为0查询判断: db.collection.find({likes:{$gt:100}}) 查询likes大于100的数据 $gt表示大于,$lt表示小于,$gte表示大于等于,$lte表示小于等于,$ne表示不等于
db.collection.find({status:"A"}) 这种表示返回status等于A的数据的全部字段信息。也可以使用多个匹配条件:
db.collection.find({staues:"A",likes:{$gt:100}
})
使用逻辑判断:
db.collection.find({$or:[{status:"A"},{likes:{$gt:100}}]
}) 表示或的关系
db.collection.find({$and:[{status:"A"},{likes:{$gt:100}}]
}) 表示与的关系多条件查询:
db.collection.find({$and:[{status:"A"},{likes:{$gt:100}}],$or:[{title:"MongoDB 教程"},{title:"C# 教程"}]
})
正则匹配:
db.collection.find({title:/^MongoDB/}) 表示title以MongoDB开头的数据匹配嵌套文档:
测试数据:
db.collection.insertMany([{ item: "journal", qty: 25, size: { h: 14, w: 21, uom: "cm" }, status: "A" },{ item: "notebook", qty: 50, size: { h: 8.5, w: 11, uom: "in" }, status: "A" },{ item: "paper", qty: 100, size: { h: 8.5, w: 11, uom: "in" }, status: "D" },{ item: "planner", qty: 75, size: { h: 22.85, w: 30, uom: "cm" }, status: "D" },{ item: "postcard", qty: 45, size: { h: 10, w: 15.25, uom: "cm" }, status: "A" }
])
在这里,size域是一个嵌套文档。要匹配嵌套文档,必须使用引号将整个嵌套文档括起来,例如:
db.collection.find({size: {h: 14, w: 21, uom: "cm"}},{_id:0})
这里的匹配格式和位置很重要,不能出现错误,否则无法匹配到数据。在嵌套的字段上查询,使用点号(.)来指定嵌套字段,例如:
指定sized对象里面的uom属性值查询:
db.collection.find({"size.uom": "in"})查询数组结构:
测试数据:
db.size.insertMany([{item:"journal",qty:[5,15]},{item:"notebook",qty:[10,20]},{item:"paper",qty:[5,10]},{item:"planner",qty:[0,10]},{item:"postcard",qty:[15,15]}
])精确查询:
db.collection.find({qty:{$eq:5}})
包含查询:
db.collection.find({qty:{$in:[5,15]}},{_id:0})
不包含查询:
db.collection.find({qty:{$nin:[5,15]}},{_id:0})
数组长度查询:
db.collection.find({qty:{$size:2}},{_id:0}) # 查询qty数组长度为2的数据查询数据中满足指定条件的元素,使用$elemMatch操作符,例如:
实例数据:
{_id: 1,scores: [{ subject: 'Math', score: 90 },{ subject: 'English', score: 85 },{ subject: 'Science', score: 92 }]
}
现在我们想查询 scores 数组中其中一个科目的分数大于等于90的文档,可以使用 $elemMatch 操作符来实现:
db.collection.find({scores:{$elemMatch:{score:{$gte:90}}}})
如果要查询科目
db.collection.find({scores:{$elemMatch:{subject:"Math"}}})
如果要组合查询
db.collection.find({scores:{$elemMatch:{subject:"Math",score:{$gte:90}}}})
表示查询 scores 数组中有一个元素的 subject 域等于 "Math",并且 score 域大于等于 90 的文档。文档的排序插查询:
通过关键字sort()来实现排序,1表示升序,-1表示降序,例如:
db.collection.find({status:"A"}).sort({user_id:1}}
注意,排序操作,sort是在find之外,而不是在find里面,否则会报错。
同时在find内部做匹配操作,然后在find外部做排序操作。查询总数:
mongodb中也是通过count方法进行统计。
db.collection.find({status:"A"}).count() --指定字段查询总数
db.collection.find({user_id:{$exists:true}}).count()
-- 其中的$exists表示user_id字段存在的数据,如果不加$exists,表示user_id字段不存在的数据。
-- 该操作符主要用于检查文档中某个字段是否存在,如果存在返回true,否则返回false。
去重处理:
db.collection.distinct({status:"A"}) -- 去重status字段
db.collection.aggregate([{$group:{_id:"$status"_}]) -- 去重status字段
获取指返回条数,分页查询方法
使用 find().limit()方法来指定返回的条数,例如:
db.collection.find().limit(2)
指定返回值的某条记录
db.collection.find().limit(5).skip(10)
对比:select * from table limit 10,5
使用 limit 操作符限制返回的文档数。limit 操作符接受一个整数参数,表示需要返回的文档数。
使用 skip 操作符指定跳过的文档数。skip 操作符接受一个整数参数,表示需要跳过的文档数。
例如,假设有一个名为 books 的集合,我们需要查询第二页的 10 个文档。可以按照以下步骤进行操作:
计算每页的文档数。假设每页显示 10 个文档,所以每次查询应该设置 limit 为 10。
计算要跳过的文档数。对于第二页,我们需要跳过前 10 个文档,所以 skip 值为 10。
查询 sql 语句的执行情况:
与mysql类似,采用explain语句来查看
db.collection.find().explain()
使用所索引的情况
db.collection.find({status:"A"}).explain()
就可以查看到该 sql 语言执行过程中是否采用了索引,以及它的索引类型等信息。
语句返回的基本内容:
{"queryPlanner": {"plannerVersion": 1, //查询计划版本"namespace": "sang.sang_collect", //要查询的集合"indexFilterSet": false, //是否使用索引"parsedQuery": {//查询条件"x": {//查询条件字段"$eq": 1.0 //查询条件值}},"winningPlan": {//最终执行的查询计划"stage": "COLLSCAN", //查询的方式,常见有collscan/全表扫描, indexscan/索引扫描, FETCH/根据索引去检索文档获取数据, SHARD_MERGE/分片合并结果 IDHACK/根据_id去检索文档获取数据"filter": {//查询条件"x": {//查询条件字段"$eq": 1.0 //查询条件值}},"direction": "forward" //查询方向 forward/正向,backward/反向 通常是采用正向索引查询},"rejectedPlans": [] //被拒绝的查询计划},"serverInfo": {//服务器信息"host": "localhost.localdomain", //主机名"port": 27017, //端口号"version": "3.4.9", //版本号"gitVersion": "876ebee8c7dd0e2d992f36a848ff4dc50ee6603e" //git版本号},"ok": 1.0 //是否成功
}
explain()也可以接受一个参数,该参数是一个文档,用于指定 explain 的模式,例如:
db.collection.find().explain(“executionStats”)
db.collection.find().explain(“allPlansExecution”)
db.collection.find().explain(“queryPlanner”)
参考链接:‘https://blog.csdn.net/user_longling/article/details/83957085’
命令总结:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZDsDnEyr-1690278972193)(./images/2023-06-23-12-56-51.png)]
mongdb 中的索引类型
mongdb 的索引底层采用的是 b-tree,
这里简单介绍一下大概的索引类型,后面会详细介绍.
单键索引类型:
它支持所有数据类型中的单个字段的索引,并且可以在文档的任何字段上定义,
对于单个字段索引,索引建的排序无关紧要,它是从任一方向上开始读取索引,所以不注重顺序
特殊: 过期索引 TTL
其中 TTL 索引是,支持文档在一定时间之后,自动过期删除的,并且目前只能在单字段索引上建立,且字段类型必须为日期类型…
db.集合名.createIndex({“日期字段”:排序方式}, {expireAfterSeconds: 秒数})
复合索引
我们需要在多个字段的基础上搜索表/集合,这是非常频繁的。 如果是这种情况,我们可能会考虑在 MongoDB 中制作复合索引。 复合索引支持基于多个字段的索引,这扩展了索引的概念并将它们扩展到索引中的更大域。
需要注意: 字段顺序,索引方向
db.集合名.createIndex( { “字段名 1” : 排序方式, “字段名 2” : 排序方式 } )
多键索引
针对属性包含数组数据的情况,MongoDB 支持针对数组中每一个 element 创建索引,Multikey indexes 支持 strings,numbers 和 nested documents
地理空间索引(Geospatial Index)
针对地理空间坐标数据创建索引。
2dsphere 索引,用于存储和查找球面上的点
2d 索引,用于存储和查找平面上的点
db.company.insert({loc : { type: "Point", coordinates: [ 116.482451, 39.914176 ] },name: "大望路地铁",category : "Parks"}
)
db.company.ensureIndex( { loc : "2dsphere" } )
# 参数不是1或-1,为2dsphere 或者 2d。还可以建立组合索引。
db.company.find({"loc" : {"$geoWithin" : {"$center":[[116.482451,39.914176],0.05]}}
})全文索引
提供了针对 string 内容的文本查询,text index 支持持任意属性值为 string 或 string 数组元素的索引查询。注意:一个集合仅支持最多一个 Text Index,中文分词不理想 推荐 ES。
db.集合.createIndex({“字段”: “text”})
db.集合.find({“KaTeX parse error: Expected '}', got 'EOF' at end of input: text": {"search”: “coffee”}})
哈希索引 (Hashed Index)
针对属性的哈希值进行索引查询,当要使用 Hashed index 时,MongoDB 能够自动的计算 hash 值,无需程序计算 hash 值。注:hash index 仅支持等于查询,不支持范围查询。
db.集合.createIndex({“字段”: “hashed”})
索引操作
索引的查看: db.comment.getIndexs() ,查看所有的索引
索引的创建:
db.collection.createIndex(keys,options)
其中 key,是索引的字段,option 是对索引的具体设置.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mq5ywxAQ-1690278972194)(./images/2023-06-18-16-50-16.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fCpRli5c-1690278972194)(2023-06-18-16-51-11.png)]
db.mycol.createIndex({userid:1}) 这里 1 代表升序,-1 是降序
索引的删除: db.collection.dropIndex(index)
相关文章:

MongoDB 基础学习记录
MongoDB 基础 mongoDB 是由 C语言编写,基于分布式文件存储的开源数据库系统,是一个 nosql 数据库. 在高负载的情况下,添加更多的节点,保证服务器性能,MongoDB 旨在为 web 引用提供可扩展的高性能存储解决方案,将数据存储为给文档, 数据结构由键值(key,value)对组成,MongoDB 文…...
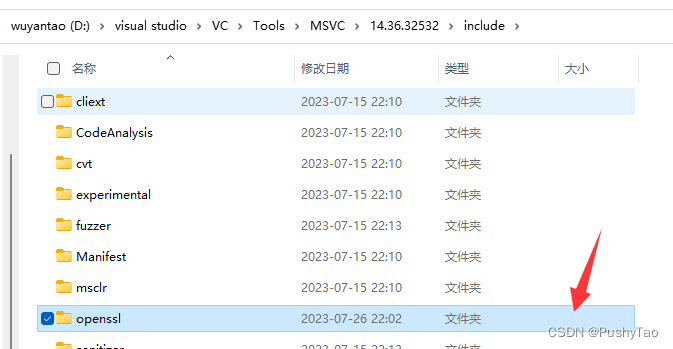
Visual Studio2022报错 无法打开 源 文件 “openssl/conf.h“解决方式
目录 问题起因问题解决临时解决方案 问题起因 近一段时间有了解到Boost 1.82.0新添加了MySQL库,最近一直蠢蠢欲动想要试一下这个库 所以就下载了源码并进行了编译(过程比较简单,有文档的) 然后在VS2022中引入了Boost环境…...
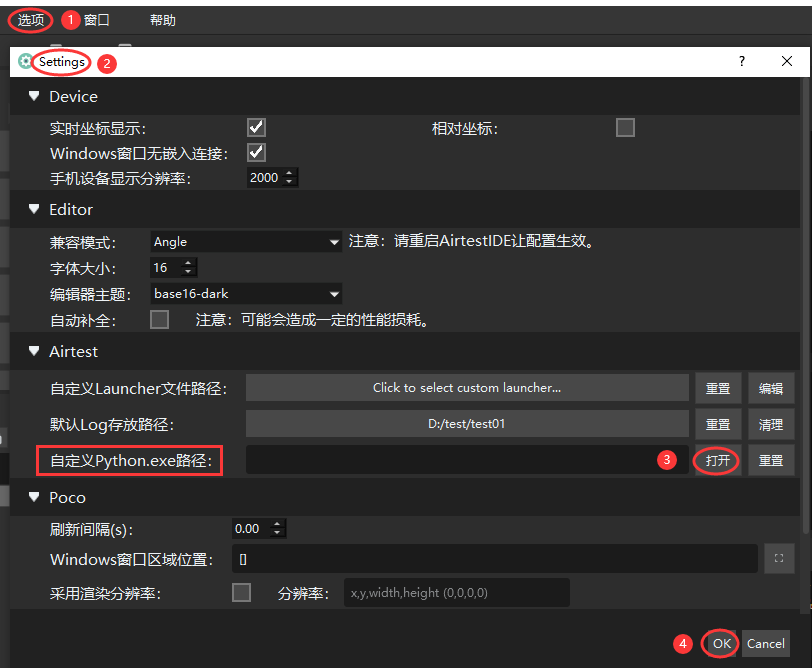
【更新公告】Airtest更新至1.3.0.1版本
1. 前言 本次更新为Airtest库更新,版本提升至1.3.0.1版本,主要新增了一些iOS设备相关的装包等接口,以及封装了一些tidevice常用接口。更多更新详情,详见我们下文的描述。 2. 新增iOS设备接口 1)iOS安装接口…...

SQL语句集锦
题记:SQL语句就是一种编程语言,我们平时项目中我们需要从数据库种调取数据,然后通过增删改查的接口对数据库进行操作,当然我们也可以用数据库自己的编程语言进行数据库里边数据的操作。 1.select * from users; 从use…...
【多线程中的线程安全问题】线程互斥
1 🍑线程间的互斥相关背景概念🍑 先来看看一些基本概念: 1️⃣临界资源:多线程执行流共享的资源就叫做临界资源。2️⃣临界区:每个线程内部,访问临界资源的代码,就叫做临界区。3️⃣互斥&…...

抖音seo短视频矩阵系统源代码开发技术分享
抖音SEO短视频矩阵系统是一种通过优化技术,提高在抖音平台上视频的排名和曝光率的系统。以下是开发该系统的技术分享: 熟悉抖音平台的算法 抖音平台的算法是通过分析用户的兴趣爱好和行为习惯,对视频进行排序和推荐。因此,开发人员…...
windows桌面版 修改应用logo、名称、显示位置、显示大小)
flutter实战(01)windows桌面版 修改应用logo、名称、显示位置、显示大小
说明:该系列文章主要为flutter在windows桌面平台实战中遇到的一些坑。 1 修改logo 只需要在flutter项目/windows/runner/resources目录下替换原来的应用图标 app_icon.ico即可。 2 修改应用名称、显示位置、显示大小 修改flutter项目/windows/runner/main.cpp 文…...

校园基础设施资源管理
背景 自2017年起,为响应两会提出的“数实融合”“数字经济”“数字中国”的中国经济发展新动向,满足“中国教育现代化2030”战略部署,进一步推动“教育信息化十三五规划”的落实。这五年时间,各大高校致力于深化信息技术与教育教…...

Github git clone 和 git push 特别慢的解决办法
1.在本地上使用 SSH 命令无法git push 上传 github 项目 2.使用 git clone 下载项目特别慢总是加载不了 解决办法1 将 *** 的连接模式换成:D-i-r-e-c-t(好像不太有用) 后面再找找能不能再G-l-o-b-a-l 下解决该问题 解决办法 2 mac下直接设…...
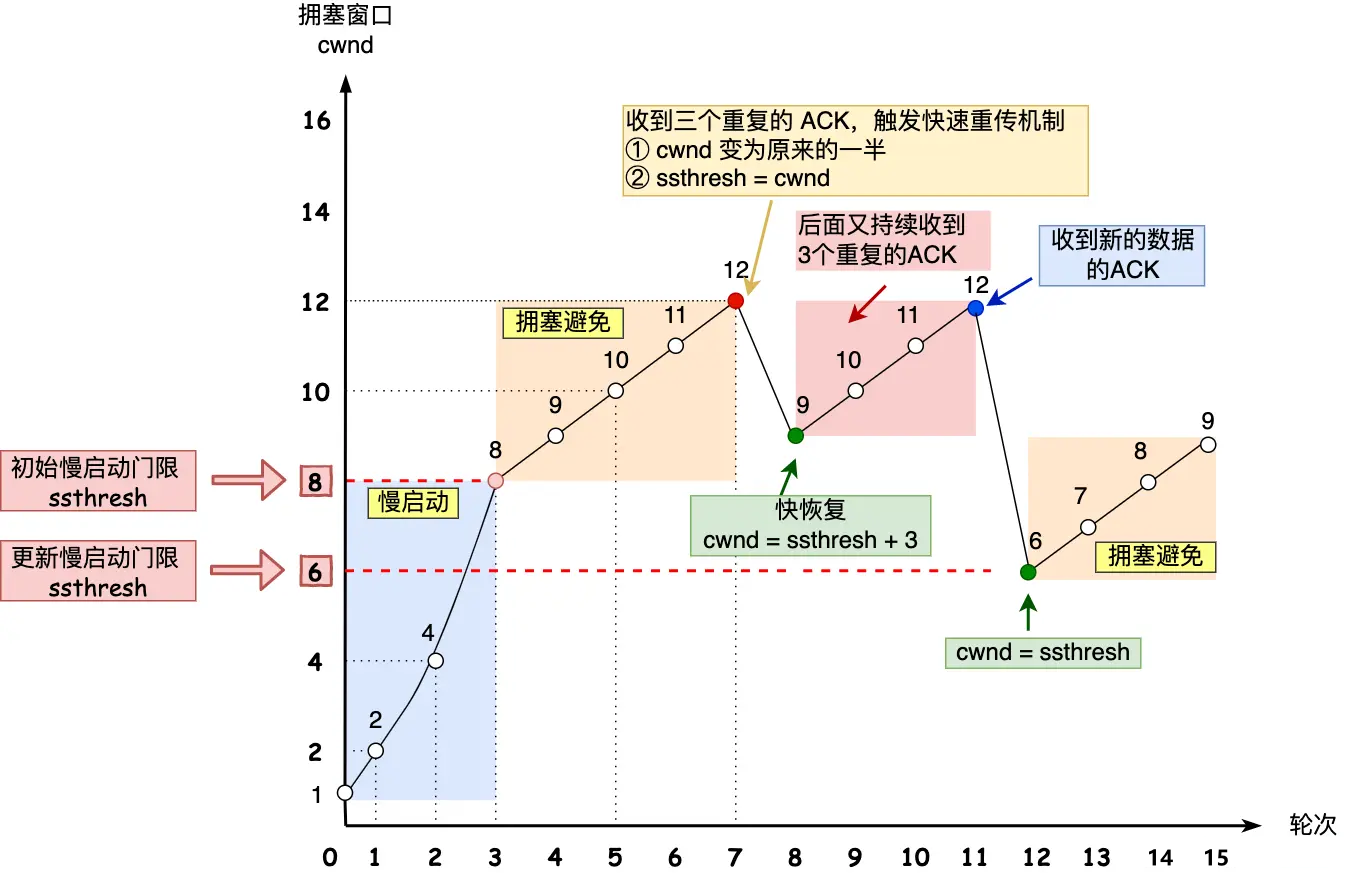
【计网】TCP在可靠传输中都干了啥
文章目录 1、概述2、校验和3、序列号和确认应答机制4、重传机制4.1、介绍4.2、超时重传4.3、快速重传 5、滑动窗口协议5.1、介绍5.2、发送方的滑动窗口5.3、接收方的滑动窗口 6、流量控制7、拥塞控制7.1、介绍7.2、慢开始7.3、拥塞避免7.4、快重传和快恢复 1、概述 TCP 是面向…...

windows下载安装FFmpeg
FFmpeg是一款强大的音视频处理软件,下面介绍如何在windows下下载安装FFmpeg 下载 进入官网: https://ffmpeg.org/download.html, 选择Windows, 然后选择"Windows builds from gyan.dev" 在弹出的界面中找到release builds, 然后选择一个版本࿰…...

SwipeDelMenuLayout失效:Could not find SwipeDelMenuLayout-V1.3.0.jar
一、问题描述 最近在工作上的项目中接触到SwipeDelMenuLayout这个第三方Android开发库,然后我就根据网上的教程进行配置。这里先说一下我的开发环境:Android Studio版本是android-studio-2020.3.1.24-windows,gradle版本是7.0.2。 首先是在se…...

C++ 类和对象篇(零) 面向过程 和 面向对象
目录 一、面向过程 二、面向对象 三、两种编程思想的比较 四、C和C 一、面向过程 1.是什么? 是一种以解决问题的过程为中心的编程思想。即先分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现。 2.为什么? 面向过程就纯粹是分析…...

列表list
列表 列表是将数据组织在一个一维集合中,从这个组织方式来看,它与c()函数是相似的。但是,列表并不是将具体的值组织起来,而是组织R对象,如列表、数据框、矩阵、函数、向量等等。 列表非常好用,因为列表可…...

gcc编译出现bar causes a section type conflict with foo问题解决
这里bar是变量名,foo是函数名。 如下是charGPT给出的答复,结论是:bar和foo放在同一个section内,但是它们的类型不同,函数应该放置在一个可执行(executable)类型的section,而变量应该…...

12. Mybatis 多表查询 动态 SQL
目录 1. 数据库字段和 Java 对象不一致 2. 多表查询 3. 动态 SQL 使用 4. if 标签 5. trim 标签 6. where 标签 7. set 标签 8. foreach 标签 9. 通过注解实现 9.1 查找所有数据 9.2 通过 id 查找 1. 数据库字段和 Java 对象不一致 我们先来看一下数据库中的数…...
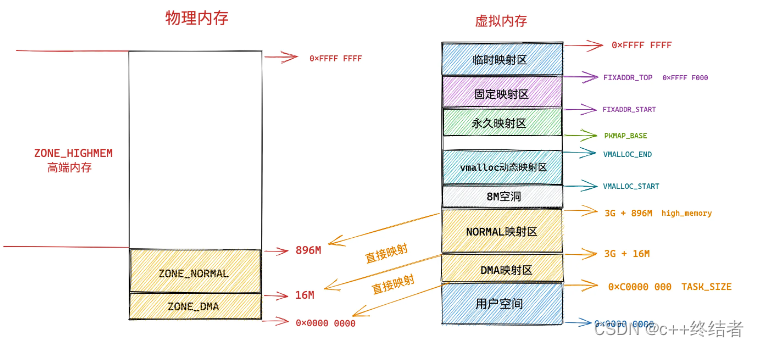
操作系统专栏1-内存管理from 小林coding
操作系统专栏1-内存管理 虚拟地址内存管理方案分段分页页表单级页表多级页表TLB 段页式内存管理Linux内存管理 malloc工作方式操作系统内存回收回收的内存种类 预读失败和缓存污染问题预读机制预读机制失效解决方案缓存污染 内核对虚拟内存的表示内核对内核空间的表示直接映射区…...

SpringCloud远程服务调用
下面介绍在SpringCloud中如何使用openfeign实现远程服务调用 1.在字典服务中有这么2个接口 Api(tags "数据字典接口") RestController RequestMapping("/admin/cmn/dict/") CrossOrigin public class DictController {Autowiredprivate DictService dic…...
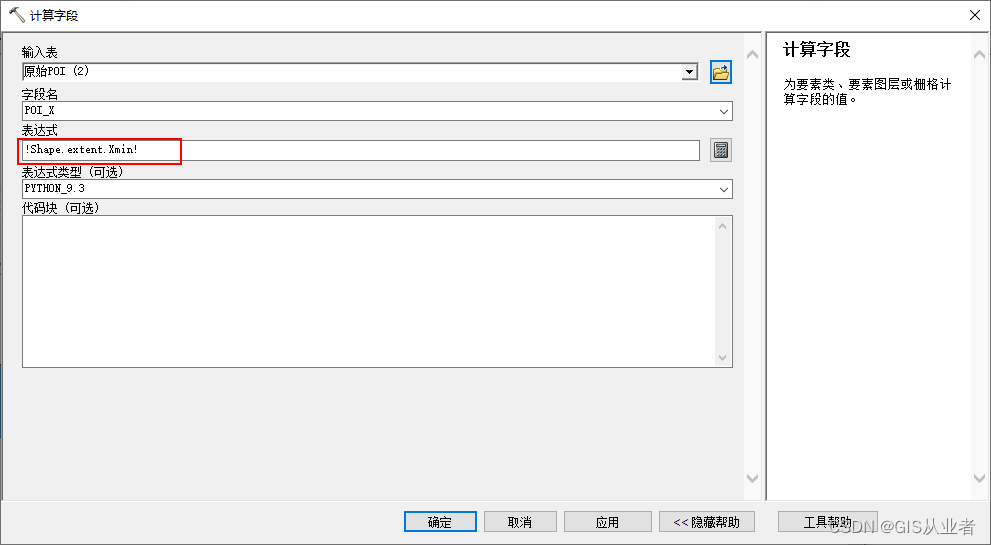
Arcgis通过模型构建器计算几何坐标
模型 模型中,先添加字段,再计算字段 计算字段 模型的计算字段中,表达式是类似这样写的,其中Xmin表示X坐标,Ymin表示Y坐标 !Shape.extent.Xmin!...
)
java设计模式-工厂模式(下)
接java设计模式-工厂模式(上) 抽象工厂模式 针对耳机的生产需求,我们可以知道,刚才的工厂已经不满足了,因为只是生产一类产品-手机,但是现在我们需要的工厂类是要生产一个产品族(手机和耳机&a…...

汽车级MCU MSPM0G3505-Q1实战:从Cortex-M0+内核到CAN-FD与低功耗设计全解析
1. 从数据手册到实战:深度拆解MSPM0G3505-Q1这颗汽车级MCU最近在为一个车载传感节点做选型,要求很明确:成本敏感、功耗要低、模拟性能要强,还得过车规。翻了一圈,TI的MSPM0G3505-Q1进入了视线。说实话,第一…...

GEO学习能帮我提高AI搜索排名吗?
先直接回答这个问题:GEO不叫"排名",但效果比排名更直接。如果你理解了这句话,你就理解了GEO和SEO的本质区别。AI搜索没有"排名",只有"引用"传统SEO优化的目标是在搜索结果页面占据靠前位置——第几…...

ARMv8 AArch32调试异常机制与断点技术详解
1. AArch32调试异常架构解析在ARMv8架构的AArch32执行状态下,调试异常机制为开发者提供了强大的程序控制能力。这套机制通过硬件断点和软件断点指令(BKPT)实现对程序执行流的精确控制,其核心设计哲学体现在三个层面:异…...

为什么选择Minimal:GitHub Pages最简洁主题的深度解析与快速入门指南
为什么选择Minimal:GitHub Pages最简洁主题的深度解析与快速入门指南 【免费下载链接】minimal Minimal is a Jekyll theme for GitHub Pages 项目地址: https://gitcode.com/gh_mirrors/mini/minimal Minimal主题是GitHub Pages平台上最受欢迎、最简洁的Jek…...

明日方舟智能基建管理:Arknights-Mower 完整指南与实战应用
明日方舟智能基建管理:Arknights-Mower 完整指南与实战应用 【免费下载链接】arknights-mower 《明日方舟》长草助手 项目地址: https://gitcode.com/gh_mirrors/ar/arknights-mower 还在为《明日方舟》基建管理的繁琐操作而烦恼吗?每天重复的干员…...

代码质量与代码审查
代码质量与代码审查 1. 技术分析 1.1 代码质量概述 代码质量是软件维护的关键: 代码质量维度可读性: 易于理解可维护性: 易于修改可测试性: 易于测试性能: 运行效率质量指标:圈复杂度代码覆盖率代码重复率1.2 代码审查流程 审查流程提交代码: PR/MR自动检查: CI/CD人…...

AArch64 SCTLR_EL3寄存器解析与安全配置实践
1. AArch64 SCTLR_EL3系统控制寄存器深度解析在Armv8-A/v9-A架构的安全世界中,SCTLR_EL3寄存器扮演着系统控制中枢的角色。作为EL3(最高特权级别)的系统控制寄存器,它直接决定了安全监控模式(Secure Monitor࿰…...

科研创作提质增效|依托 PaperXie 智能写作,高效完成期刊论文全流程创作
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/期刊论文https://www.paperxie.cn/ai/journalArticleshttps://www.paperxie.cn/ai/journalArticles 一、引言 学术研究领域中,期刊论文是展现科研成果、完成学业考核、学术成果发表的核心载体。…...

如何快速上手Udeler:新手必看的完整Udemy课程下载指南
如何快速上手Udeler:新手必看的完整Udemy课程下载指南 【免费下载链接】udemy-downloader-gui A desktop application for downloading Udemy Courses 项目地址: https://gitcode.com/gh_mirrors/ud/udemy-downloader-gui 想要随时随地学习你购买的Udemy课程…...

Nginx缓慢HTTP攻击防护:从Slowloris原理到四层生产加固
1. 这不是误报:缓慢HTTP拒绝服务攻击的真实杀伤力与Nginx暴露面 “检测到目标主机可能存在缓慢的http拒绝服务攻击”——当安全扫描工具弹出这行提示时,很多运维同学的第一反应是点掉、忽略、加白名单。我见过三次真实事故:一次是电商大促前…...