Mongodb 多文档聚合操作处理方法三(聚合管道)
聚合
聚合操作处理多个文档并返回计算结果。您可以使用聚合操作来:
-
将多个文档中的值分组在一起。
-
对分组数据执行操作以返回单个结果。
-
分析数据随时间的变化。
要执行聚合操作,您可以使用:
-
聚合管道
-
单一目的聚合方法
-
Map-reduce 函数
聚合管道
聚合管道由一个或多个处理文档的阶段组成:
-
除$out、$merge、$geoNear和$changeStream阶段之外的所有阶段都可以在管道中出现多次。
-
每个阶段都对输入文档执行操作。例如,阶段可以过滤文档、对文档进行分组以及计算值。
-
从一个阶段输出的文档将输入到下一阶段。
-
聚合管道可以返回文档组的结果。例如,返回总计、平均值、最大值和最小值。
聚合阶段
在db.collection.aggregate()方法和db.aggregate()方法中,管道阶段出现在数组中。文档按顺序经过这些阶段。
db.collection.aggregate( [ { <stage> }, ... ] )
常见几种阶段:
| 阶段 | 描述 |
|---|---|
| $group | 按指定的标识符表达式对输入文档进行分组,并在指定的情况下对每个组应用累加器表达式。消耗所有输入文档,并为每个不同的组输出一个文档。输出文档只包含标识符字段,如果指定的话,还包含累积字段。 |
| $limit | 将未修改的前n 个文档传递到管道,其中n是指定的限制。对于每个输入文档,输出一个文档(前n 个文档)或零个文档(前n 个文档之后)。 |
| $match | 过滤文档流以仅允许匹配的文档未经修改地传递到下一个管道阶段。 $match使用标准 MongoDB 查询。对于每个输入文档,输出一个文档(匹配)或零个文档(不匹配)。 |
| $merge | 将聚合管道的结果文档写入集合。该阶段可以将结果合并(插入新文档、合并文档、替换文档、保留现有文档、操作失败、使用自定义更新管道处理文档)结果到输出集合中。要使用该$merge阶段,它必须是管道中的最后一个阶段。 |
| $out | 将聚合管道的结果文档写入集合。要使用该$out阶段,它必须是管道中的最后一个阶段。 |
| $project | 重塑流中的每个文档,例如通过添加新字段或删除现有字段。对于每个输入文档,输出一个文档。 |
| $sort | 按指定的排序键对文档流重新排序。仅顺序发生变化;文件保持不变。对于每个输入文档,输出一个文档。 |
| $unwind | 从输入文档解构数组字段以输出每个元素的文档。每个输出文档都用一个元素值替换数组。对于每个输入文档,输出n个文档,其中n是数组元素的数量,对于空数组可以为零。 |
测试数据如下:
sit_rs1:PRIMARY> db.orders.find()
{ "_id" : 4, "cust_id" : "B", "ord_date" : ISODate("2023-06-18T00:00:00Z"), "price" : 26, "items" : [ { "sku" : "apple", "qty" : 10, "price" : 2.5 } ], "status" : "1" }
{ "_id" : 6, "cust_id" : "C", "ord_date" : ISODate("2023-06-19T00:00:00Z"), "price" : 38, "items" : [ { "sku" : "carrots", "qty" : 10, "price" : 1 }, { "sku" : "apples", "qty" : 10, "price" : 2.5 } ], "status" : "1" }
{ "_id" : 1, "cust_id" : "A", "ord_date" : ISODate("2023-06-01T00:00:00Z"), "price" : 15, "items" : [ { "sku" : "apple", "qty" : 5, "price" : 2.5 }, { "sku" : "apples", "qty" : 5, "price" : 2.5 } ], "status" : "1" }
{ "_id" : 2, "cust_id" : "A", "ord_date" : ISODate("2023-06-08T00:00:00Z"), "price" : 60, "items" : [ { "sku" : "apple", "qty" : 8, "price" : 2.5 }, { "sku" : "banana", "qty" : 5, "price" : 10 } ], "status" : "1" }
{ "_id" : 9, "cust_id" : "D", "ord_date" : ISODate("2023-06-20T00:00:00Z"), "price" : 51, "items" : [ { "sku" : "carrots", "qty" : 5, "price" : 1 }, { "sku" : "apples", "qty" : 10, "price" : 2.5 }, { "sku" : "apple", "qty" : 10, "price" : 2.5 } ], "status" : "1" }
{ "_id" : 3, "cust_id" : "B", "ord_date" : ISODate("2023-06-08T00:00:00Z"), "price" : 55, "items" : [ { "sku" : "apple", "qty" : 10, "price" : 2.5 }, { "sku" : "pears", "qty" : 10, "price" : 2.5 } ], "status" : "1" }
{ "_id" : 5, "cust_id" : "B", "ord_date" : ISODate("2023-06-19T00:00:00Z"), "price" : 40, "items" : [ { "sku" : "banana", "qty" : 5, "price" : 10 } ], "status" : "1" }
{ "_id" : 7, "cust_id" : "C", "ord_date" : ISODate("2023-06-20T00:00:00Z"), "price" : 21, "items" : [ { "sku" : "apple", "qty" : 10, "price" : 2.5 } ], "status" : "1" }
{ "_id" : 8, "cust_id" : "D", "ord_date" : ISODate("2023-06-20T00:00:00Z"), "price" : 76, "items" : [ { "sku" : "banana", "qty" : 5, "price" : 10 }, { "sku" : "apples", "qty" : 10, "price" : 2.5 } ], "status" : "1" }
{ "_id" : 10, "cust_id" : "D", "ord_date" : ISODate("2023-06-23T00:00:00Z"), "price" : 23, "items" : [ { "sku" : "apple", "qty" : 10, "price" : 2.5 } ], "status" : "1" }
示例一:
查询客户: “D” 的订单,按日期分组,返回每天的订单总价
$match 阶段:
- 匹配 “cust_id” : “D” 的记录。
- 将过滤后的文档输出到 group 阶段。
$group 阶段:
- 输入的文档按 ord_date 进行分组。
- 使用 $sum 运算符计算价格总和,并将结果存放聚合管道 sumPrice 字段中。
sit_rs1:PRIMARY> db.orders.aggregate( [
... { $match: { "cust_id" : "D" } },
... { $group: { _id: "$ord_date", sumPrice: { $sum: "$price" } } }
... ] )
{ "_id" : ISODate("2023-06-20T00:00:00Z"), "sumPrice" : 127 }
{ "_id" : ISODate("2023-06-23T00:00:00Z"), "sumPrice" : 23 }
示例二
按照客户进行分组,统计每个客户的订单总价,并总价降序排序。取前三名的客户,如下
$group 阶段:
- 输入的文档按 cust_id进行分组。
- 使用 $sum 运算符计算价格总和,并将结果存放聚合管道 sumPrice 字段中。
$sort 阶段:
- 按 sumPrice 字段以相反的顺序对这些文档进行排序。
$limit 阶段:
- 运算 $limit 仅包含前 3 个结果文档。
sit_rs1:PRIMARY> db.orders.aggregate(
... [
... { $group : { _id : "$cust_id" , sumPrice : { $sum : "$price" } } },
... { $sort : { sumPrice : -1 } },
... { $limit : 3 }
... ]
... )
{ "_id" : "D", "sumPrice" : 150 }
{ "_id" : "B", "sumPrice" : 121 }
{ "_id" : "A", "sumPrice" : 75 }
示例三
按照客户进行分组,统计每个客户的订单总价,并输出到结果集合:agg_cust_id_1 ,如下
$group 阶段:
- 输入的文档按 cust_id进行分组。
- 使用 $sum 运算符计算价格总和,并将结果存放聚合管道 value字段中。
$out 阶段
- 将输出写入集合 agg_cust_id_1
sit_rs1:PRIMARY> db.orders.aggregate([
... { $group: { _id: "$cust_id", value: { $sum: "$price" } } },
... { $out: "agg_cust_id_1" }
... ])# 查询 agg_cust_id_1 集合以验证结果:
sit_rs1:PRIMARY> db.agg_cust_id_1.find()
{ "_id" : "A", "value" : 75 }
{ "_id" : "D", "value" : 150 }
{ "_id" : "B", "value" : 121 }
{ "_id" : "C", "value" : 59 }sit_rs1:PRIMARY> db.orders.find({}, { "cust_id": 1, "price": 1})
{ "_id" : 4, "cust_id" : "B", "price" : 26 }
{ "_id" : 6, "cust_id" : "C", "price" : 38 }
{ "_id" : 1, "cust_id" : "A", "price" : 15 }
{ "_id" : 2, "cust_id" : "A", "price" : 60 }
{ "_id" : 9, "cust_id" : "D", "price" : 51 }
{ "_id" : 3, "cust_id" : "B", "price" : 55 }
{ "_id" : 5, "cust_id" : "B", "price" : 40 }
{ "_id" : 7, "cust_id" : "C", "price" : 21 }
{ "_id" : 8, "cust_id" : "D", "price" : 76 }
{ "_id" : 10, "cust_id" : "D", "price" : 23 }
示例四
计算某个SKU单品总共下了多少单,销售总数量,及平均每单数量是多少,如下:
首先查询日期大于等于 2023-03-01 的订单, 按数组 items 字段 分解文档(即如果数组包含N个元素,将分解为N个文档)。 再对 items.sku进行分组统计,并计算 qty 的数量总和。 orders_ids 把相同组的订单ID号添加到数组。
sit_rs1:PRIMARY> db.orders.aggregate( [
... { $match: { ord_date: { $gte: new Date("2023-03-01") } } },
... { $unwind: "$items" },
... { $group: { _id: "$items.sku", qty: { $sum: "$items.qty" }, orders_ids: { $addToSet: "$_id" } } },
... { $project: { value: { count: { $size: "$orders_ids" }, qty: "$qty", avg: { $divide: [ "$qty", { $size: "$orders_ids" } ] } } } },
... { $merge: { into: "agg_sku", on: "_id", whenMatched: "replace", whenNotMatched: "insert" } }
... ] )# 查询 agg_sku 集合以验证结果:
sit_rs1:PRIMARY> db.agg_sku.find()
{ "_id" : "apple", "value" : { "count" : 7, "qty" : 63, "avg" : 9 } }
{ "_id" : "banana", "value" : { "count" : 3, "qty" : 15, "avg" : 5 } }
{ "_id" : "apples", "value" : { "count" : 4, "qty" : 35, "avg" : 8.75 } }
{ "_id" : "carrots", "value" : { "count" : 2, "qty" : 15, "avg" : 7.5 } }
{ "_id" : "pears", "value" : { "count" : 1, "qty" : 10, "avg" : 10 } }
接下来,各阶段执行过程详细如下:
$match阶段
- 该阶段仅选择那些大于或等于2023-03-01 的文档,输出如下:
sit_rs1:PRIMARY> db.orders.aggregate( [
... { $match: { ord_date: { $gte: new Date("2023-03-01") } } }
... ] )
{ "_id" : 2, "cust_id" : "A", "ord_date" : ISODate("2023-06-08T00:00:00Z"), "price" : 60, "items" : [ { "sku" : "apple", "qty" : 8, "price" : 2.5 }, { "sku" : "banana", "qty" : 5, "price" : 10 } ], "status" : "1" }
{ "_id" : 3, "cust_id" : "B", "ord_date" : ISODate("2023-06-08T00:00:00Z"), "price" : 55, "items" : [ { "sku" : "apple", "qty" : 10, "price" : 2.5 }, { "sku" : "pears", "qty" : 10, "price" : 2.5 } ], "status" : "1" }
{ "_id" : 7, "cust_id" : "C", "ord_date" : ISODate("2023-06-20T00:00:00Z"), "price" : 21, "items" : [ { "sku" : "apple", "qty" : 10, "price" : 2.5 } ], "status" : "1" }
{ "_id" : 9, "cust_id" : "D", "ord_date" : ISODate("2023-06-20T00:00:00Z"), "price" : 51, "items" : [ { "sku" : "carrots", "qty" : 5, "price" : 1 }, { "sku" : "apples", "qty" : 10, "price" : 2.5 }, { "sku" : "apple", "qty" : 10, "price" : 2.5 } ], "status" : "1" }
{ "_id" : 1, "cust_id" : "A", "ord_date" : ISODate("2023-06-01T00:00:00Z"), "price" : 15, "items" : [ { "sku" : "apple", "qty" : 5, "price" : 2.5 }, { "sku" : "apples", "qty" : 5, "price" : 2.5 } ], "status" : "1" }
{ "_id" : 4, "cust_id" : "B", "ord_date" : ISODate("2023-06-18T00:00:00Z"), "price" : 26, "items" : [ { "sku" : "apple", "qty" : 10, "price" : 2.5 } ], "status" : "1" }
{ "_id" : 10, "cust_id" : "D", "ord_date" : ISODate("2023-06-23T00:00:00Z"), "price" : 23, "items" : [ { "sku" : "apple", "qty" : 10, "price" : 2.5 } ], "status" : "1" }
{ "_id" : 6, "cust_id" : "C", "ord_date" : ISODate("2023-06-19T00:00:00Z"), "price" : 38, "items" : [ { "sku" : "carrots", "qty" : 10, "price" : 1 }, { "sku" : "apples", "qty" : 10, "price" : 2.5 } ], "status" : "1" }
{ "_id" : 5, "cust_id" : "B", "ord_date" : ISODate("2023-06-19T00:00:00Z"), "price" : 40, "items" : [ { "sku" : "banana", "qty" : 5, "price" : 10 } ], "status" : "1" }
{ "_id" : 8, "cust_id" : "D", "ord_date" : ISODate("2023-06-20T00:00:00Z"), "price" : 76, "items" : [ { "sku" : "banana", "qty" : 5, "price" : 10 }, { "sku" : "apples", "qty" : 10, "price" : 2.5 } ], "status" : "1" }
$unwind阶段:
- 该阶段按 items 数组字段分解文档,items为每个数组元素输出一个文档。例如:
sit_rs1:PRIMARY> db.orders.aggregate( [
... { $match: { ord_date: { $gte: new Date("2023-03-01") } } },
... { $unwind: "$items" }
... ] )
{ "_id" : 2, "cust_id" : "A", "ord_date" : ISODate("2023-06-08T00:00:00Z"), "price" : 60, "items" : { "sku" : "apple", "qty" : 8, "price" : 2.5 }, "status" : "1" }
{ "_id" : 2, "cust_id" : "A", "ord_date" : ISODate("2023-06-08T00:00:00Z"), "price" : 60, "items" : { "sku" : "banana", "qty" : 5, "price" : 10 }, "status" : "1" }
{ "_id" : 3, "cust_id" : "B", "ord_date" : ISODate("2023-06-08T00:00:00Z"), "price" : 55, "items" : { "sku" : "apple", "qty" : 10, "price" : 2.5 }, "status" : "1" }
{ "_id" : 3, "cust_id" : "B", "ord_date" : ISODate("2023-06-08T00:00:00Z"), "price" : 55, "items" : { "sku" : "pears", "qty" : 10, "price" : 2.5 }, "status" : "1" }
{ "_id" : 7, "cust_id" : "C", "ord_date" : ISODate("2023-06-20T00:00:00Z"), "price" : 21, "items" : { "sku" : "apple", "qty" : 10, "price" : 2.5 }, "status" : "1" }
{ "_id" : 9, "cust_id" : "D", "ord_date" : ISODate("2023-06-20T00:00:00Z"), "price" : 51, "items" : { "sku" : "carrots", "qty" : 5, "price" : 1 }, "status" : "1" }
{ "_id" : 9, "cust_id" : "D", "ord_date" : ISODate("2023-06-20T00:00:00Z"), "price" : 51, "items" : { "sku" : "apples", "qty" : 10, "price" : 2.5 }, "status" : "1" }
{ "_id" : 9, "cust_id" : "D", "ord_date" : ISODate("2023-06-20T00:00:00Z"), "price" : 51, "items" : { "sku" : "apple", "qty" : 10, "price" : 2.5 }, "status" : "1" }
{ "_id" : 1, "cust_id" : "A", "ord_date" : ISODate("2023-06-01T00:00:00Z"), "price" : 15, "items" : { "sku" : "apple", "qty" : 5, "price" : 2.5 }, "status" : "1" }
{ "_id" : 1, "cust_id" : "A", "ord_date" : ISODate("2023-06-01T00:00:00Z"), "price" : 15, "items" : { "sku" : "apples", "qty" : 5, "price" : 2.5 }, "status" : "1" }
{ "_id" : 4, "cust_id" : "B", "ord_date" : ISODate("2023-06-18T00:00:00Z"), "price" : 26, "items" : { "sku" : "apple", "qty" : 10, "price" : 2.5 }, "status" : "1" }
{ "_id" : 10, "cust_id" : "D", "ord_date" : ISODate("2023-06-23T00:00:00Z"), "price" : 23, "items" : { "sku" : "apple", "qty" : 10, "price" : 2.5 }, "status" : "1" }
{ "_id" : 6, "cust_id" : "C", "ord_date" : ISODate("2023-06-19T00:00:00Z"), "price" : 38, "items" : { "sku" : "carrots", "qty" : 10, "price" : 1 }, "status" : "1" }
{ "_id" : 6, "cust_id" : "C", "ord_date" : ISODate("2023-06-19T00:00:00Z"), "price" : 38, "items" : { "sku" : "apples", "qty" : 10, "price" : 2.5 }, "status" : "1" }
{ "_id" : 5, "cust_id" : "B", "ord_date" : ISODate("2023-06-19T00:00:00Z"), "price" : 40, "items" : { "sku" : "banana", "qty" : 5, "price" : 10 }, "status" : "1" }
{ "_id" : 8, "cust_id" : "D", "ord_date" : ISODate("2023-06-20T00:00:00Z"), "price" : 76, "items" : { "sku" : "banana", "qty" : 5, "price" : 10 }, "status" : "1" }
{ "_id" : 8, "cust_id" : "D", "ord_date" : ISODate("2023-06-20T00:00:00Z"), "price" : 76, "items" : { "sku" : "apples", "qty" : 10, "price" : 2.5 }, "status" : "1" }
$group阶段
- 该阶段按 items.sku 进行分组,计算每个 sku 的总数量。
- order _ids 数组包括不相同的 items.sku 元素。
- $addToSet : 返回所有唯一值的数组,这些值来自每个文档(使用相同字段group by 的一组文档中)。输出数组中元素的顺序未指定。
sit_rs1:PRIMARY> db.orders.aggregate( [
... { $match: { ord_date: { $gte: new Date("2023-03-01") } } },
... { $unwind: "$items" },
... { $group: { _id: "$items.sku", qty: { $sum: "$items.qty" }, orders_ids: { $addToSet: "$_id" } } }
... ] )
{ "_id" : "carrots", "qty" : 15, "orders_ids" : [ 6, 9 ] }
{ "_id" : "apples", "qty" : 35, "orders_ids" : [ 1, 6, 9, 8 ] }
{ "_id" : "banana", "qty" : 15, "orders_ids" : [ 8, 5, 2 ] }
{ "_id" : "apple", "qty" : 63, "orders_ids" : [ 10, 1, 7, 4, 9, 2, 3 ] }
{ "_id" : "pears", "qty" : 10, "orders_ids" : [ 3 ] }
$project阶段
- 该阶段重塑输出文档以镜像映射缩减的输出,使其具有两个字段_id和 value。
- 运算符 $divide 计算 订单平均数量。 即将一个数字除以另一个数字并返回结果。将参数传递给在一个数组中。
- 使用 $size 来确定数组orders_ids的大小。
sit_rs1:PRIMARY> db.orders.aggregate( [
... { $match: { ord_date: { $gte: new Date("2023-03-01") } } },
... { $unwind: "$items" },
... { $group: { _id: "$items.sku", qty: { $sum: "$items.qty" }, orders_ids: { $addToSet: "$_id" } } },
... { $project: { value: { count: { $size: "$orders_ids" }, qty: "$qty", avg: { $divide: [ "$qty", { $size: "$orders_ids" } ] } } } }
... ] )
{ "_id" : "apples", "value" : { "count" : 4, "qty" : 35, "avg" : 8.75 } }
{ "_id" : "carrots", "value" : { "count" : 2, "qty" : 15, "avg" : 7.5 } }
{ "_id" : "pears", "value" : { "count" : 1, "qty" : 10, "avg" : 10 } }
{ "_id" : "banana", "value" : { "count" : 3, "qty" : 15, "avg" : 5 } }
{ "_id" : "apple", "value" : { "count" : 7, "qty" : 63, "avg" : 9 } }
$merge阶段
最后,$merge将输出写入集合 agg_sku 。如果现有文档_id与新结果具有相同的键,则该操作将覆盖现有文档。如果不存在具有相同键的现有文档,则该操作将插入该文档。
sit_rs1:PRIMARY> db.orders.aggregate( [
... { $match: { ord_date: { $gte: new Date("2023-03-01") } } },
... { $unwind: "$items" },
... { $group: { _id: "$items.sku", qty: { $sum: "$items.qty" }, orders_ids: { $addToSet: "$_id" } } },
... { $project: { value: { count: { $size: "$orders_ids" }, qty: "$qty", avg: { $divide: [ "$qty", { $size: "$orders_ids" } ] } } } },
... { $merge: { into: "agg_sku", on: "_id", whenMatched: "replace", whenNotMatched: "insert" } }
... ] )# 该操作返回以下文档:
sit_rs1:PRIMARY> db.agg_sku.find().sort( { _id: 1 } )
{ "_id" : "apple", "value" : { "count" : 7, "qty" : 63, "avg" : 9 } }
{ "_id" : "apples", "value" : { "count" : 4, "qty" : 35, "avg" : 8.75 } }
{ "_id" : "banana", "value" : { "count" : 3, "qty" : 15, "avg" : 5 } }
{ "_id" : "carrots", "value" : { "count" : 2, "qty" : 15, "avg" : 7.5 } }
{ "_id" : "pears", "value" : { "count" : 1, "qty" : 10, "avg" : 10 } }
聚合管道的限制
聚合管道对值类型和结果大小有一些限制:
-
该aggregate命令可以返回游标或将结果存储在集合中。结果集中的每个文档均受 16 MB BSON 文档大小限制。如果任何单个文档超过BSON 文档大小限制,聚合就会产生错误。该限制仅适用于返回的文件。在管道处理过程中,文档可能会超过此大小。该 db.collection.aggregate()方法默认返回一个游标。
-
每个单独的管道阶段的 RAM 限制为 100 MB。默认情况下,如果某个阶段超过此限制,MongoDB 会生成错误。$search
聚合阶段不限于 100 MB RAM,因为它在单独的进程中运行 -
如果管道阶段之一的结果$sort超出限制,请考虑添加 $limit stage 。
相关文章:
)
Mongodb 多文档聚合操作处理方法三(聚合管道)
聚合 聚合操作处理多个文档并返回计算结果。您可以使用聚合操作来: 将多个文档中的值分组在一起。 对分组数据执行操作以返回单个结果。 分析数据随时间的变化。 要执行聚合操作,您可以使用: 聚合管道 单一目的聚合方法 Map-reduce 函…...
Zabbix分布式监控配置和使用
目录 1 Zabbix监控的配置流程2 添加主机组3 添加模板4 添加主机5 配置图形6 配置大屏7 新建监控项7.1 简介7.2 添加监控项7.3 查看数据7.4 图表 8 新建触发器8.1 概述8.2 添加触发器8.3 显示触发器状态 1 Zabbix监控的配置流程 在Zabbix-Web管理界面中添加一个主机,…...
XCTF_very_easy_sql
简单的进行sql注入测试后发现不简单尝试一下按照提示 结合这句提示应该是内部访问,所以采用的手段应该是ssrf顺便看看包 唯一值得关注的是set-cookie说回ssrf唯一能使用的方式应该是Gopher协议找到了一个POST的python脚本 import urllib.parsepayload ""…...

[React]useMemoizedFn和useCallback对比
useMemoizedFn文档地址:https://ahooks.js.org/zh-CN/hooks/use-memoized-fn hooks组件内什么时候会更新自定义函数 在 React 中,自定义的 Hooks 内部的函数在以下常见的几种情况下会被重新赋值,导致更新引用: 组件重新渲染&…...

计算机毕设 深度学习人体跌倒检测 -yolo 机器视觉 opencv python
文章目录 0 前言1.前言2.实现效果3.相关技术原理3.1卷积神经网络3.1YOLOV5简介3.2 YOLOv5s 模型算法流程和原理4.数据集处理3.1 数据标注简介3.2 数据保存 5.模型训练 6 最后 0 前言 🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题…...

完全背包
动态规划解题步骤 : 动态规划问题一般从三个步骤进行考虑。 步骤一:集合和集合的状态 所谓的集合,就是一些方案的集合。 用 g[i][j] 表示从前 i 种物品中进行选择,且总体积不大于 j 的各个选法获得的价值的集合。注意:g[i][j] 不是一个数…...
【软件测试】webdriver常用API演示(Java+IDEA+chrome浏览器)
1.元素定位方法 对象的定位应该是自动化测试的核心,要想操作一个对象,首先应该识别这个对象。一个对象就是一个人一样,他会有各种的特征(属性),如比我们可以通过一个人的身份证号,姓名…...

Linux安装MySQL 8.1.0
MySQL是一个流行的开源关系型数据库管理系统,本教程将向您展示如何在Linux系统上安装MySQL 8.1.0版本。请按照以下步骤进行操作: 1. 下载MySQL安装包 首先,从MySQL官方网站或镜像站点下载MySQL 8.1.0的压缩包mysql-8.1.0-linux-glibc2.28-x…...

多线程面试相关的一些问题
面试题 1. 常见的锁策略相关的面试题 2. CAS相关的面试题 3. Synchronized 原理相关的面试题 4. Callable 接口相关的面试题 1. 常见的锁策略 乐观锁 vs 悲观锁 悲观锁: 总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都…...
【使用维纳滤波进行信号分离】基于维纳-霍普夫方程的信号分离或去噪维纳滤波器估计(Matlab代码实现)
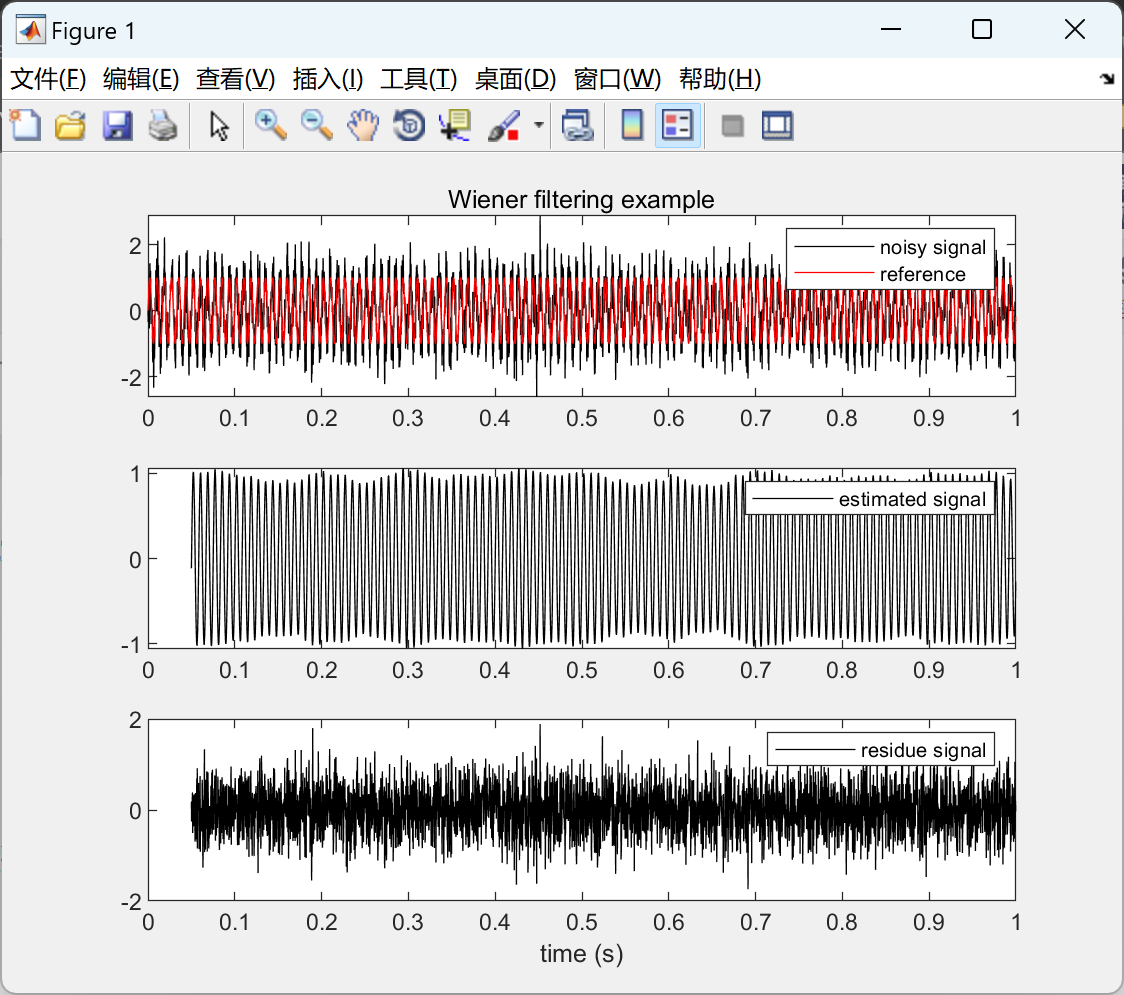
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

Vue+axios如何解决跨域
1、为什么会产生跨域? 出于浏览器的同源策略限制。 同源策略(Sameoriginpolicy)是一种约定,是浏览器的一种安全机…...
网络安全系统中的守护者:如何借助威胁情报 (TI) 提高安全性
在这篇哈巴尔网站上的推文中,我们将解释 TI 缩写背后的含义、为什么需要它、Positive Technologies 收集哪些网络威胁数据以及如何帮助企业预防网络威胁。我们将以四种情况为例,说明公司如何使用 PT Threat Intelligence Feeds 来发现恶意活动并预防攻击…...

并发编程 - CompletableFuture
文章目录 Pre概述FutureFuture的缺陷类继承关系功能概述API提交任务的相关API结果转换的相关APIthenApplyhandlethenRunthenAcceptthenAcceptBoththenCombinethenCompose 回调方法的相关API异常处理的相关API获取结果的相关API DEMO实战注意事项 Pre 每日一博 - Java 异步编程…...

IPIDEA参展ChinaJoy!探索未来创新科技的峰会之旅
中国最大的国际数码互动娱乐展会ChinaJoy即将于7月28日在上海举行,届时将聚集全球来自22个国家和地区的领先科技公司、创业者和技术专家,为参观者呈现一系列引人入胜的展览和活动。而IPIDEA作为参展商之一,将为参观者带来一场关于数字科技的奇…...

2023最新ChatGPT商业运营版网站源码+支持ChatGPT4.0+GPT联网+支持ai绘画(Midjourney)+支持Mind思维导图生成
本系统使用Nestjs和Vue3框架技术,持续集成AI能力到本系统! 支持GPT3模型、GPT4模型Midjourney专业绘画(全自定义调参)、Midjourney以图生图、Dall-E2绘画Mind思维导图生成应用工作台(Prompt)AI绘画广场自定…...
轮趣科技教育版ros小车键盘控制运动
我之前买的ros小车是单独买的底板,以为随便一个树莓派就可以,因为我以前有一个树莓派3B,后来买了单独的小车之后,发现只能使用树莓派4B,然后又单独买了一个树莓派4B,给装上镜像,安装ros-melodic…...
方法)
深入理解Python中的os.chdir()方法
深入理解Python中的os.chdir()方法 1. 简介 在Python中,os.chdir()方法用于改变当前的工作目录。工作目录是指当前正在执行的脚本所在的目录。通过使用os.chdir()方法,我们可以在脚本执行过程中切换到不同的目录。 在编写Python脚本时,我们…...

【Golang 接口自动化02】使用标准库net/http发送Post请求
目录 写在前面 发送Post请求 示例代码 源码分析 Post请求参数解析 响应数据解析 验证 发送Json/XMl Json请求示例代码 xml请求示例代码 总结 资料获取方法 写在前面 上一篇我们介绍了使用 net/http 发送get请求,因为考虑到篇幅问题,把Post单…...
LaTex语法(常用数学符号的语法和注意事项)
说明:[]括号表示把语法括起来,并不表示LaTex语法。 1. 求和符号(Σ) 这个符号的基本语法为:[\sum_{}^{}]。 符号有两种模式:内联数学模式(inside math mode)和显示数学模式(displayed math mode)。 内联数学模式:排版时使用各…...
Yunfly 一款高效、性能优异的node.js企业级web框架
介绍 Yunfly 一款高性能 Node.js WEB 框架, 使用 Typescript 构建我们的应用。 使用 Koa2 做为 HTTP 底层框架, 使用 routing-controllers 、 typedi 来高效构建我们的 Node 应用。 Yunfly 在 Koa 框架之上提升了一个抽象级别, 但仍然支持 Koa 中间件。在此基础之上, 提供了一…...

AArch64架构SMCR_EL3寄存器详解与SME向量计算优化
1. AArch64系统寄存器与SMCR_EL3概述在Armv8-A/v9架构中,系统寄存器是处理器状态和功能控制的核心枢纽。作为特权级软件与硬件交互的接口,每个系统寄存器都承担着特定的控制、配置或状态监控职责。SMCR_EL3(SME Control Register at EL3&…...

CVPR 2023五大技术断层:泛化性、实时性与边缘部署的工程真相
1. 这不是会议速记,而是一份“CVPR 2023技术脉络手绘地图”如果你在搜索引擎里输入“CVPR 2023 summary”,大概率会看到一堆标题党文章:什么“十大突破”、什么“最火模型TOP5”、什么“必看论文清单”。我翻过不下二十篇,结果发现…...

C++ 程序内存分区
C 程序运行时,操作系统会给进程分配虚拟地址空间,在 32/64 位系统中,逻辑上划分为 代码区、全局静态区、常量区、栈区、堆区 5 个区域。下面从存储内容、管理方式、生命周期、权限、代码示例、常见坑逐一拆解。一、代码区(Text 段…...

免费在线法线贴图生成器终极指南:3分钟为你的3D模型添加逼真细节
免费在线法线贴图生成器终极指南:3分钟为你的3D模型添加逼真细节 【免费下载链接】NormalMap-Online NormalMap Generator Online 项目地址: https://gitcode.com/gh_mirrors/no/NormalMap-Online 还在为3D模型表面过于平滑、缺乏真实感而烦恼吗?…...

意法半导体STM32F407VET6代理商
在当今快速发展的电子行业中,选择一家可靠且专业的微控制器(MCU)供应商至关重要。对于那些正在寻找意法半导体STM32F407VET6系列单片机解决方案的企业而言,深圳市粤科源兴科技有限公司凭借其优质的服务、合理的价格及充足的库存量…...

通讯的数学理论
1948年,香农在题为《通讯的数学理论》指出,信息是用来消除随机不定性的东西,创造宇宙万物的最基本单位是信息。...

KMS_VL_ALL_AIO:企业级Windows与Office智能激活解决方案深度解析
KMS_VL_ALL_AIO:企业级Windows与Office智能激活解决方案深度解析 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 在数字化办公环境中,Windows操作系统与Office办公套件的…...
 中 userdata 参数的正确用法与内存管理)
OpenCV鼠标事件避坑指南:setMouseCallback() 中 userdata 参数的正确用法与内存管理
OpenCV鼠标事件高阶实践:setMouseCallback()中userdata参数的安全使用与多线程陷阱 在计算机视觉开发中,交互式图像处理是一个常见需求。OpenCV提供的setMouseCallback()函数看似简单,但当开发者需要传递复杂数据结构或在多线程环境下使用时…...

5分钟免费搞定:让Windows资源管理器原生显示iPhone HEIC照片缩略图
5分钟免费搞定:让Windows资源管理器原生显示iPhone HEIC照片缩略图 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails 你…...
)
RAG 检索增强生成(全链路)
目录一、什么是RAG(Retrieval-augmented Generation)二、核心流程三、从零实战1. 环境准备2. 准备你的资料3. 代码4. 运行结果四、RAG全链路1. 文档切分(切块)2. Embedding 向量化3. 向量库存储4. 语义检索5. LLM生成回答必备5个工具(全免费&…...