音频深度学习变得简单:自动语音识别 (ASR),它是如何工作的
一、说明
在过去的几年里,随着Google Home,Amazon Echo,Siri,Cortana等的普及,语音助手已经无处不在。这些是自动语音识别 (ASR) 最著名的示例。此类应用程序从某种语言的语音音频剪辑开始,并将说出的单词提取为文本。因此,它们也称为语音转文本算法。
当然,像Siri和上面提到的其他应用程序,走得更远。他们不仅提取文本,而且还解释和理解所说的语义,以便他们可以用答案做出回应,或者根据用户的命令采取行动。
在本文中,我将重点介绍使用深度学习进行语音转文本的核心功能。我的目标不仅是了解某件事是如何工作的,而且是了解它为什么会这样工作。
在我的音频深度学习系列中,我还有一些文章可能会让你觉得有用。他们探讨了这个领域的其他引人入胜的主题,包括我们如何为深度学习准备音频数据,为什么我们将Mel频谱图用于深度学习模型以及如何生成和优化它们。
- 最先进的技术(什么是声音以及如何数字化。音频深度学习在我们的日常生活中解决了哪些问题。什么是频谱图以及为什么它们非常重要。
- 为什么 Mel 频谱图表现更好(在 Python 中处理音频数据。什么是梅尔频谱图以及如何生成它们)
- 数据准备和增强(通过超参数调优和数据增强增强频谱图功能以获得最佳性能)
- 声音分类(对普通声音进行分类的端到端示例和架构。适用于各种方案的基础应用程序。
- 波束搜索(语音转文本和NLP应用程序通常用于增强预测的算法)
二、语音转文本
可以想象,人类语音是我们日常个人和商业生活的基础,语音转文本功能具有大量的应用。人们可以使用它来转录客户支持或销售电话的内容,用于面向语音的聊天机器人,或记下会议和其他讨论的内容。
基本音频数据由声音和噪音组成。人类语言就是其中的一个特例。因此,我在文章中谈到的概念,例如我们如何数字化声音,处理音频数据以及为什么我们将音频转换为频谱图,也适用于理解语音。但是,语音更复杂,因为它对语言进行编码。
音频分类等问题从声音剪辑开始,并从一组给定的类中预测该声音属于哪个类。对于语音转文本问题,训练数据包括:
- 输入特征(X):口语的音频剪辑
- 目标标签 (y):所讲内容的文本记录

自动语音识别使用音频波作为输入特征,文本脚本作为目标标签(图片来源:作者)
该模型的目标是学习如何获取输入音频并预测所说的单词和句子的文本内容。
三、数据预处理
在声音分类文章中,我将逐步解释用于处理深度学习模型的音频数据的转换。对于人类语言,我们也遵循类似的方法。有几个Python库提供了执行此操作的功能,librosa是最受欢迎的库之一。
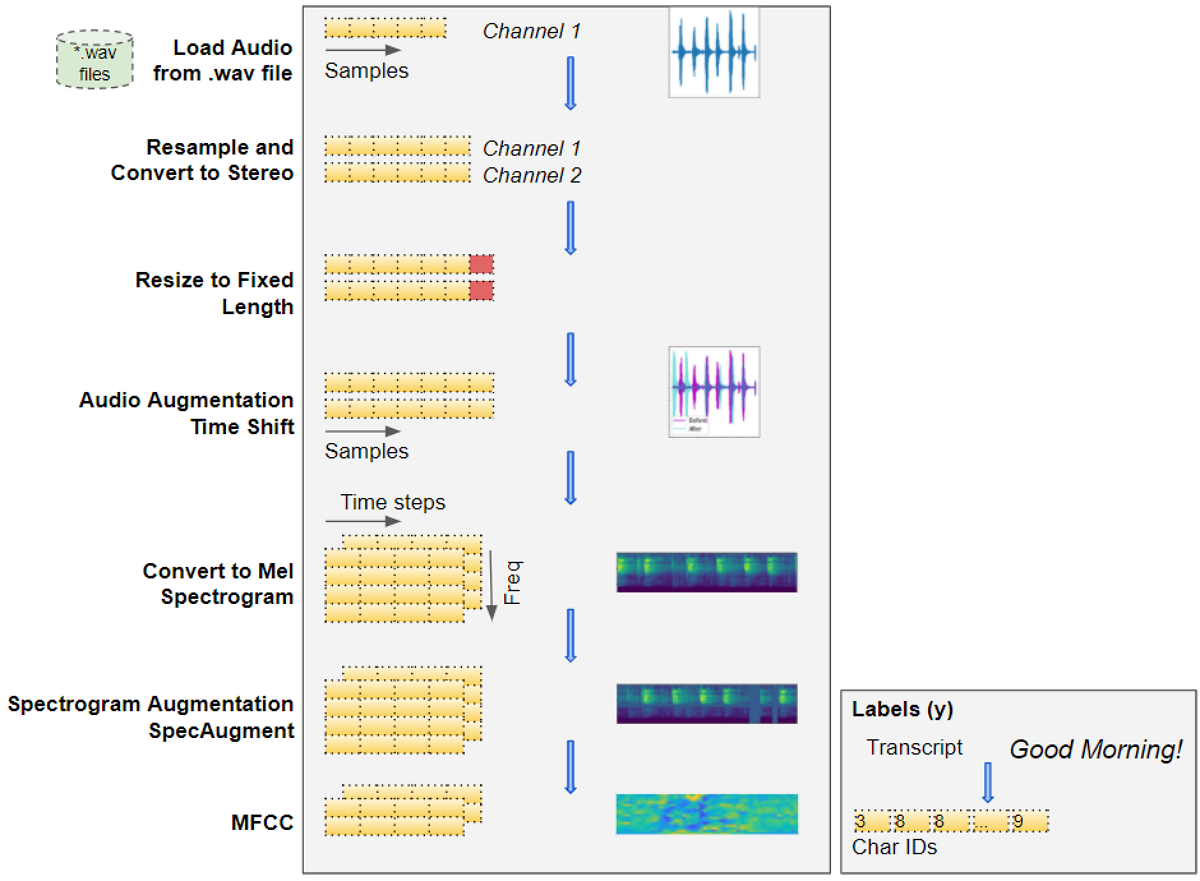
将原始音频波转换为频谱图图像以输入到深度学习模型(图片来自作者)
3.1 加载音频文件
- 从输入数据开始,该数据由音频格式(如“.wav”或“.mp3”)的语音的音频文件组成。
- 从文件中读取音频数据并将其加载到 2D Numpy 数组中。该数组由一系列数字组成,每个数字代表特定时刻声音强度或振幅的测量值。此类测量的数量由采样率决定。例如,如果采样率为 44.1kHz,则 Numpy 数组将有一行 44,100 个数字,用于 1 秒的音频。
- 音频可以有一个或两个声道,通常称为单声道或立体声。对于双声道音频,我们将为第二个声道提供另一个类似的振幅数字序列。换句话说,我们的 Numpy 数组将是 3D,深度为 2。
3.2 转换为统一尺寸:采样率、通道和持续时间
- 我们的音频数据项可能有很多变化。剪辑可能以不同的速率采样,或者具有不同数量的通道。剪辑很可能有不同的持续时间。如上所述,这意味着每个音频项目的尺寸会有所不同。
- 由于我们的深度学习模型期望所有输入项具有相似的大小,因此我们现在执行一些数据清理步骤来标准化音频数据的尺寸。我们对音频进行重新采样,以便每个项目都具有相同的采样率。我们将所有项目转换为相同数量的频道。所有项目也必须转换为相同的音频持续时间。这涉及填充较短的序列或截断较长的序列。
- 如果音频质量很差,我们可以通过应用噪声消除算法来消除背景噪声来增强它,以便我们可以专注于语音音频。
3.3 原始音频的数据增强
- 我们可以应用一些数据增强技术来为我们的输入数据添加更多种类,并帮助模型学会泛化到更广泛的输入。我们可以将音频随机向左或向右移动一小部分,或者将音频的音高或速度更改少量。
3.3 梅尔频谱图
- 此原始音频现在转换为 Mel 频谱图。频谱图通过将音频分解为其中包含的频率集来捕获音频作为图像的性质。
3.4 MFCC
- 特别是对于人类语音,有时采取一个额外的步骤并将梅尔频谱图转换为MFCC(梅尔频率倒谱系数)会有所帮助。MFCC 通过仅提取最基本的频率系数来生成 Mel 频谱图的压缩表示,这些频率系数对应于人类说话的频率范围。
3.5 频谱图的数据增强
- 我们现在可以使用一种称为SpecAugment的技术在Mel频谱图图像上应用另一个数据增强步骤。这涉及频率和时间掩码,随机掩盖任何一个垂直(即。时间掩码)或水平(即频率掩码)频谱图中的信息带。注意:我不确定这是否也适用于MFCC,以及这是否会产生良好的结果。
现在,经过数据清理和增强,我们已将原始原始音频文件转换为Mel频谱图(或MFCC)图像。
我们还需要从成绩单中准备目标标签。这只是由单词句子组成的常规文本,因此我们从成绩单中的每个字符构建词汇表,并将它们转换为字符 ID。
这为我们提供了输入功能和目标标签。这些数据已准备好输入到我们的深度学习模型中。
四、建筑
ASR 的深度学习架构有许多变体。两种常用的方法是:
- 一种 CNN(卷积神经网络)和基于 RNN(递归神经网络)的架构,它使用 CTC 损失算法来划分语音中单词的每个字符。例如。百度的深度语音模型。
- 一种基于 RNN 的序列到序列网络,它将频谱图的每个“切片”视为序列中的一个元素,例如。谷歌的Listen Attend Spell(LAS)模型。
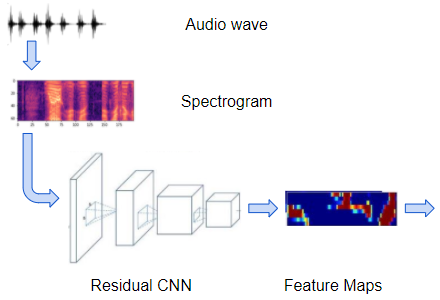
让我们选择上面的第一种方法,并更详细地探讨它是如何工作的。在高级别上,模型由以下块组成:
- 由几个残差 CNN 层组成的规则卷积网络,用于处理输入频谱图图像和这些图像的输出特征图。
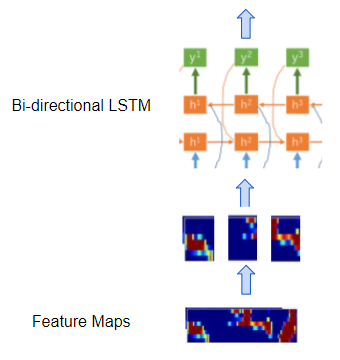
- 由几个双向 LSTM 层组成的常规循环网络,这些层将特征图处理为一系列不同的时间步长或“帧”,对应于我们所需的输出字符序列。(LSTM是一种非常常用的循环层类型,其完整形式是长短期记忆)。换句话说,它采用作为音频连续表示的特征图,并将它们转换为离散表示。
- 具有 softmax 的线性层,它使用 LSTM 输出为输出的每个时间步长生成字符概率。
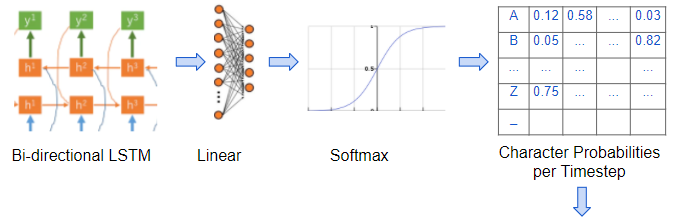
- 我们还有位于卷积网络和循环网络之间的线性层,有助于将一个网络的输出重塑为另一个网络的输入。
因此,我们的模型采用频谱图图像,并输出该频谱图中每个时间步长或“帧”的字符概率。
五、对齐序列
如果你稍微考虑一下,你就会意识到我们的拼图中仍然缺少一个主要的部分。我们的最终目标是将这些时间步或“帧”映射到目标成绩单中的单个字符。
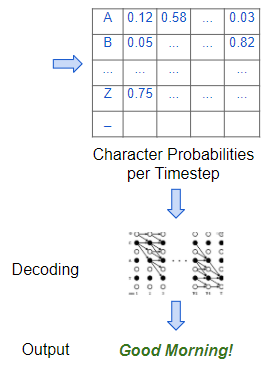
该模型解码字符概率以产生最终输出(图片来自作者)
但是对于特定的频谱图,我们怎么知道应该有多少帧?我们如何确切知道每个帧的边界在哪里?我们如何将音频与文本成绩单中的每个字符对齐?
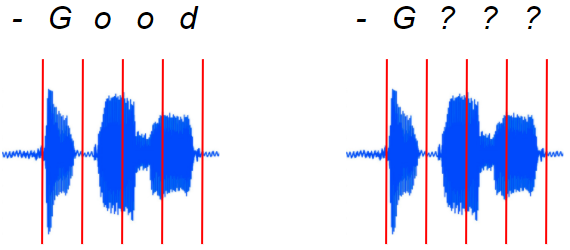
左边是我们需要的对齐方式。但是我们如何得到它呢?(图片来源:作者)
音频和频谱图图像没有预先分割以向我们提供此信息。
- 在口语音频中,因此在频谱图中,每个字符的声音可能具有不同的持续时间。
- 这些字符之间可能存在间隙和停顿。
- 几个字符可以合并在一起。
- 有些字符可以重复。例如。在“苹果”这个词中,我们怎么知道音频中的“P”音是否真的对应于成绩单中的一个或两个“P”?
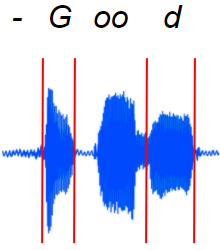
实际上,口语对我们来说并不整齐(图片来自作者)
这实际上是一个非常具有挑战性的问题,也是使ASR难以正确的原因。这是将 ASR 与其他音频应用(如分类等)区分开来的区别特征。
我们解决这个问题的方法是使用一种巧妙的算法,它有一个听起来很花哨的名字——它被称为连接主义时间分类,简称CTC。由于我不是“花哨的人”并且发现很难记住那个长名字,所以我只会用CTC这个名字来指代它😃。
六、CTC 算法 — 训练和推理
当输入连续且输出是离散的,并且没有明确的元素边界可用于将输入映射到输出序列的元素时,CTC 用于对齐输入和输出序列。
它之所以如此特别,是因为它会自动执行此对齐,而无需手动提供该对齐作为标记训练数据的一部分。这将使创建训练数据集的成本非常高。
正如我们上面所讨论的,在我们的模型中,卷积网络输出的特征图被切成单独的帧并输入到循环网络。每一帧对应于原始音频波的某个时间步长。但是,在设计模型时,由您选择帧数和每个帧的持续时间作为超参数。对于每一帧,循环网络后跟线性分类器,然后从词汇表中预测每个字符的概率。
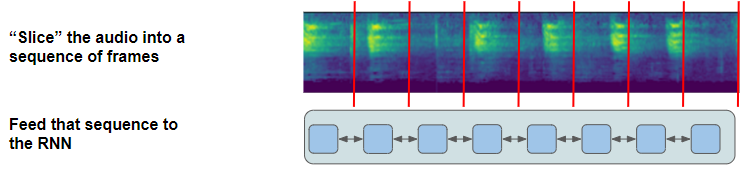
CTC 算法的工作是获取这些字符概率并导出正确的字符序列。
为了帮助它处理我们刚刚讨论的对齐和重复字符的挑战,它在词汇表中引入了“空白”伪字符(用“-”表示)的概念。因此,网络输出的字符概率还包括每帧空白字符的概率。
请注意,空白与“空格”不同。空格是真正的字符,而空白表示没有任何字符,有点像大多数编程语言中的“null”。它仅用于划分两个字符之间的边界。
CTC 以两种模式工作:
- CTC 损失(训练期间):它有一个地面真相目标成绩单,并尝试训练网络以最大限度地提高输出正确成绩单的概率。
- CTC 解码(在推理期间):在这里,我们没有可参考的目标脚本,并且必须预测最可能的字符序列。
让我们进一步探讨这些内容,以了解算法的作用。我们将从CTC解码开始,因为它更简单一些。
6.1 CTC解码
- 使用字符概率为每个帧选择最可能的字符,包括空白。例如。“呜呜呜”
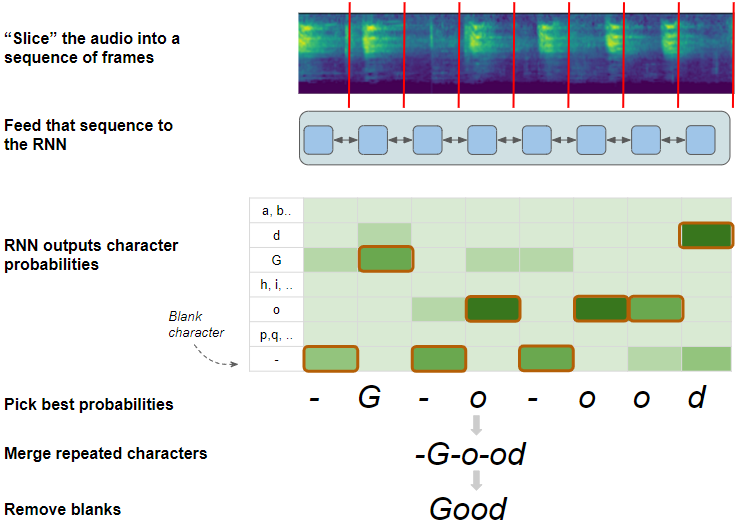
CTC解码算法(图片来自作者)
- 合并任何重复的字符,并且不要用空格分隔。例如,我们可以将“oo”合并为单个“o”,但我们不能合并“o-oo”。这就是反恐委员会如何能够区分有两个单独的“o”并产生用重复字符拼写的单词。例如。“-
- 最后,由于空白已达到其目的,因此它会删除所有空白字符。例如。“好”。
6.2 CTC损失
损失计算为网络预测正确序列的概率。为此,该算法列出了网络可以预测的所有可能序列,并从中选择与目标转录本匹配的子集。
为了从完整的可能序列集中识别该子集,该算法按如下方式缩小了可能性范围:
- 仅保留目标脚本中出现的字符的概率,并丢弃其余字符。它仅保留“G”、“o”、“d”和“-”的概率。
- 使用过滤的字符子集,对于每个帧,仅选择与目标脚本顺序相同的字符。例如。虽然“G”和“o”都是有效字符,但“Go”的顺序是有效的序列,而“oG”是无效序列。
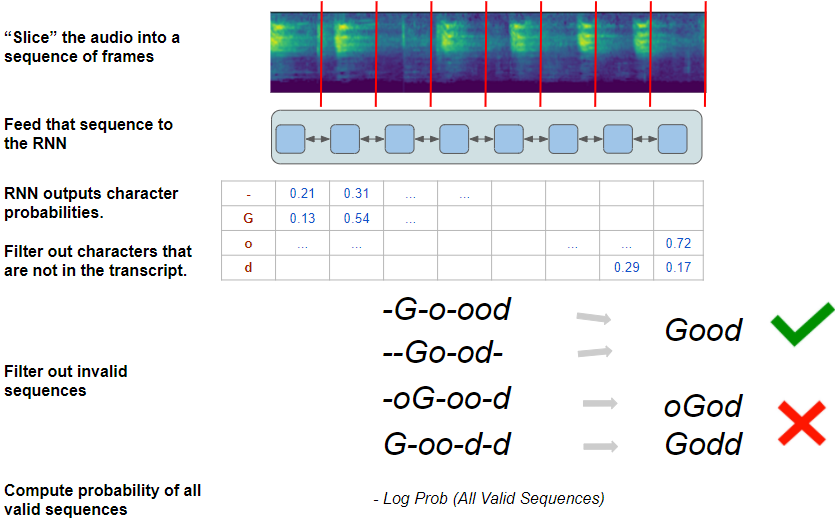
CTC损失算法(图片来自作者)
有了这些约束,算法现在有一组有效的字符序列,所有这些字符序列都将生成正确的目标脚本。例如。使用推理期间使用的相同步骤,“-G-o-ood”和“ — Go-od-”都将产生“Good”的最终输出。
然后,它使用每个帧的单个字符概率来计算生成所有这些有效序列的总体概率。网络的目标是学习如何最大化该概率,从而降低生成任何无效序列的概率。
严格来说,由于神经网络将损失最小化,因此CTC损失计算为所有有效序列的负对数概率。由于网络在训练期间通过反向传播将损失最小化,因此它会调整其所有权重以产生正确的序列。
然而,实际做到这一点比我在这里描述的要复杂得多。挑战在于有大量可能的角色组合来产生序列。仅通过我们的简单示例,我们每帧可以有 4 个字符。用 8 帧给我们 4 ** 8 种组合 (= 65536)。对于任何具有更多字符和更多帧的逼真成绩单,此数字呈指数级增长。这使得简单地详尽列出有效组合并计算其概率在计算上是不切实际的。
有效地解决这个问题是CTC如此创新的原因。这是一个引人入胜的算法,非常值得了解它如何实现这一目标的细微差别。这本身就值得写一篇完整的文章,我计划很快写。但就目前而言,我们专注于建立对CTC工作的直觉,而不是研究它是如何工作的。
七、指标 — 单词错误率 (WER)
训练我们的网络后,我们必须评估它的性能。语音转文本问题的常用指标是单词错误率(和字符错误率)。它逐字(或逐个字符)比较预测输出和目标成绩单,以找出它们之间的差异数量。
差异可以是脚本中存在但在预测中缺少的单词(计为删除)、不在脚本中但已添加到预测中的单词(插入),或者在预测和脚本之间更改的单词(替换)。

计算成绩单和预测之间的插入、删除和替换(图片来自作者)
指标公式相当简单。它是相对于单词总数的差异百分比。

单词错误率计算(图片来自作者)
八、语言模型
到目前为止,我们的算法已经将语音音频视为仅对应于某种语言的字符序列。但是,当这些字符组合成单词和句子时,这些字符是否真正有意义并有意义?
自然语言处理 (NLP) 中的一个常见应用是构建语言模型。它捕获了单词在语言中通常如何用于构造句子、段落和文档。它可以是关于英语或韩语等语言的通用模型,也可以是特定于特定领域(如医学或法律)的模型。
一旦你有了语言模型,它就可以成为其他应用程序的基础。例如,它可以用来预测句子中的下一个单词,辨别某些文本的情绪(例如,这是一篇积极的书评),通过聊天机器人回答问题,等等。
因此,当然,它也可用于通过指导模型生成更有可能根据语言模型的预测来选择性地提高 ASR 输出的质量。
九、波束搜索
在推理过程中描述 CTC 解码器时,我们隐含地假设它总是在每个时间步选择概率最高的单个字符。这被称为贪婪搜索。
但是,我们知道使用称为光束搜索的替代方法可以获得更好的结果。
虽然Beam Search通常经常用于NLP问题,但它并不是特定于ASR的,所以我在这里提到它只是为了完整。如果您想了解更多信息,请查看我的文章,其中详细介绍了Beam Search。
十、结论
希望现在这能让您了解用于解决 ASR 问题的构建块和技术。
在深度学习之前的旧时代,通过经典方法解决这些问题需要理解音素等概念以及许多特定于领域的数据准备和算法。
然而,正如我们刚刚在深度学习中看到的那样,我们几乎不需要任何涉及音频和语音知识的特征工程。然而,它能够产生出色的结果,继续让我们感到惊讶!
最后,如果你喜欢这篇文章,你可能还会喜欢我关于变形金刚、地理定位机器学习和图像标题架构的其他系列。
相关文章:
音频深度学习变得简单:自动语音识别 (ASR),它是如何工作的
一、说明 在过去的几年里,随着Google Home,Amazon Echo,Siri,Cortana等的普及,语音助手已经无处不在。这些是自动语音识别 (ASR) 最著名的示例。此类应用程序从某种语言的语音音频剪辑开始&…...
反射简述
什么是反射反射在java中起到什么样的作用获取class对象的三种方式反射的优缺点图 什么是反射 JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性&…...
Kotlin泛型的协变与逆变
以下内容摘自郭霖《第一行代码》第三版 泛型的协变 一个泛型类或者泛型接口中的方法,它的参数列表是接收数据的地方,因此可以称它为in位置,而它的返回值是输出数据的地方,因此可以称它为out位置。 先定义三个类: op…...

【后端面经】微服务构架 (1-6) | 隔离:如何确保心悦会员体验无忧?唱响隔离的鸣奏曲!
文章目录 一、前置知识1、什么是隔离?2、为什么要隔离?3、怎么进行隔离?A) 机房隔离B) 实例隔离C) 分组隔离D) 连接池隔离 与 线程池隔离E) 信号量隔离F) 第三方依赖隔离二、面试环节1、面试准备2、基本思路3、亮点方案A) 慢任务隔离B) 制作库与线上库分离三、章节总结 …...
复习之kickstart无人职守安装脚本
一、kickstart简介 kickstart是红帽发行版中的一种安装方式,它通过以配置文件的方式来记录linux系统安装的各项参数和想要安装的软件。只要配置正确,整个安装过程中无需人工交互参与,达到无人值守安装的目的。 二、kickstar文件的生成 进入/…...

CSS动画——实现波浪摇摆效果...
一、效果展示 以下主要实现四个动画: 元素上下摇摆动画波浪上下摇摆动画气泡上升及消失动画连续气泡右飘动画 二、实现思路 这里主要讲一下波浪上下摇摆动画和连续气泡右飘动画的实现思路 这里拿一张波浪图来举例解释实现波浪动画的思路: 波浪的摇…...
【MyBatis学习】Spring Boot(SSM)单元测试,不用打包就可以测试我们的项目了,判断程序是否满足需求变得如此简单 ? ? ?
前言: 大家好,我是良辰丫,在上一篇文章中我们学习了MyBatis简单的查询操作,今天来介绍一下Spring Boot(SSM)的一种单元测试,有人可能会感到疑惑,框架里面还有这玩意?什么东东呀,框架里面是没有这的,但是我们简单的学习一下单元测试,可以帮助我们自己测试代码,学习单元测试可以…...

JavaScript 类
本文内容学习于:后盾人 (houdunren.com) 1.可以使用类声明和赋值表达式定义类,推荐使用类声明来定义类 //类声明 class User {} console.log(new User()); //赋值表达式定义类 let Article class {}; console.log(new Article()); //类方法间不需要逗号…...

SpringBoot的static静态资源访问、参数配置、代码自定义访问规则
目录 1. 静态资源1.1 默认静态资源1.2 Controller高优先级1.3 修改静态资源的URL根路径1.4 修改静态资源的目录1.5 访问webjars依赖包的静态资源1.6 静态资源的关闭1.7 静态资源在浏览器的缓存1.8 静态资源实战1.9 通过代码自定义静态资源访问规则 1. 静态资源 查看源码如下&a…...
)
IO进、线程——线程(线程的创建、线程的退出、线程的回收、线程的分离和多线程并发编程)
线程 并发执行的轻量级进程 进程是资源分配的最小单位,线程是任务调度的最小单位 线程是进程的一部分,是任务调度的最小单位。一个进程可以包含多个线程,这些线程可以并发执行,共享进程的资源,但每个线程都有自己的…...

neo4j教程-Cypher操作
Cypher基础操作 Cypher是图形存储数据库Neo4j的查询语言,Cypher是通过模式匹配Neo4j数据库中的节点和关系,从而对数据库Neo4j中的节点和关系进行一系列的相关操作。 下面,通过一张表来介绍一下常用的Neo4j操作命令及相关说明,具…...

秋招算法备战第31天 | 贪心算法理论基础、455.分发饼干、376. 摆动序列、53. 最大子序和
贪心算法理论基础 贪心算法并没有固定的套路,唯一的难点就是如何通过局部最优,推出整体最优。如何验证可不可以用贪心算法呢?最好用的策略就是举反例,如果想不到反例,那么就试一试贪心吧。刷题或者面试的时候…...
页面生成图片或PDF node-egg
没有特别的幸运,那么就特别的努力!!! 中间件:页面生成图片 node-egg 涉及到技术node egg Puppeteer 解决文书智能生成多样化先看效果环境准备初始化项目 目录结构核心代码 完整代码https://gitee.com/hammer1010_ad…...

go常用知识点
go env -w GO111MODULEon go env -w GOPROXYhttps://goproxy.cn,direct 打包一个目录下的多个包时 go build ./… go install ./… 测试时,命令行:go test . //目录下所有单元测试都会执行 go test -v 目录 //测试覆盖率 go test -cover //使用cove…...
)
ComPDFKit PDF SDK(支持Web、Android、IOS、Windows、Server、API、跨平台)
1. SDK、API是什么? SDK是软件开发工具包的缩写,指的是一组用于开发软件应用的工具、库和文档。SDK包含一系列的函数、类和方法,开发人员可以使用这些工具和资源来开发、测试和部署应用程序。SDK可以提供各种功能和技术支持,如图…...

使用maven容器打包java项目
docker run --rm -v /path/to/your/microservice:/app -w /app maven:latest mvn clean package 解释一下上面的命令: docker run:运行Docker容器。--rm:在容器运行结束后自动删除容器,避免堆积未使用的容器。-v /path/to/you…...
超前端相关的学习网站和一些靠谱的小工具
CSS相关 1. CSS Battle - 在线比拼 CSS https://cssbattle.dev 在线比拼 CSS ,一个挺有趣的竞争性游戏,一共有12个级别,需要你用 HTML和 CSS 100%还原它给出的页面,然后再尽量减少代码,你也可以查看全球的排行榜&am…...

uniapp跳转到外部链接
// 一、先配置页面 {"path": "pages/webview/webview","style": {"navigationBarTitleText": ""} } // 二、编写页面 <template><web-view :src"src" /> </template><script> export def…...
初识DBT以及搭建第一个DBT工程
DBT是什么: 按照官方的说法,DBT 是一个数据转换流编排工具。个人理解就是,DBT是帮你编排SQL用的,你可以按照DBT的结构,构建好一个SQL的pipeline,然后让DBT帮你执行这个pipeline。我这里说的SQL pipeline的意…...
Python基于PyTorch实现卷积神经网络回归模型(CNN回归算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。 1.项目背景 卷积神经网络,简称为卷积网络,与普通神经网络的区别是它的卷积层内的神经元只覆…...

昇腾CANN amct:模型压缩工具的量化和部署实践
amct(Ascend Model Compression Toolkit)是 CANN 内置的模型压缩工具,不是 AtomGit 上的独立开源仓库——它在 CANN AOE 调优引擎里作为一个子模块运行。amct 做三件事:量化(INT8/FP16)、剪枝(结…...

Keil µVision TAB显示异常问题分析与解决方案
1. 问题现象与背景分析在Keil Vision集成开发环境中,部分用户遇到了编辑器界面显示异常的问题。具体表现为:当代码中包含TAB字符(制表符)时,屏幕上会出现奇怪的显示错乱,原本应该显示为空白缩进的区域&…...
)
DeepSeek微服务拆分实战:从单体到弹性集群的7步标准化迁移手册(含流量染色+灰度发布Checklist)
更多请点击: https://codechina.net 第一章:DeepSeek微服务架构演进的底层逻辑与决策框架 微服务架构并非技术堆砌的结果,而是业务复杂度、组织演进节奏与工程效能诉求三者动态博弈下的系统性解法。DeepSeek 在模型训练平台、推理网关、数据…...

基于GIS三维地球的全球指挥官推演沙盘软件军迷免费版 谷歌地球 数字孪生 自媒体创作 战术想定编辑
一套完全自主的、基于真实地理坐标系的沉浸式战术推演引擎,其技术栈的构建是对传统可视化与交互范式的系统性革新。 全球指挥官沙盘软件军迷免费版下载 一、 项目概述:一个核心命题与两项技术挑战 本项目源于一个明确的工程命题:构建一个允…...

GitHub Copilot X:AI编程助手如何重塑开发工作流与效率
1. 项目概述:当代码编辑器遇见“副驾驶”如果你和我一样,每天有超过一半的时间是在代码编辑器里度过的,那你一定对“效率”这个词有着近乎偏执的追求。从语法高亮、代码补全,到后来的LSP(Language Server Protocol&…...

基于瑞萨R8C MCU的180度电角度无感FOC BLDC电机控制方案详解
1. 项目概述与核心需求解析大家好,我是老王,一个在电机控制和嵌入式系统开发领域摸爬滚打了十几年的工程师。今天想和大家深入聊聊一个非常具体且有意思的项目:如何基于瑞萨电子的R8C系列MCU,来实现一套180度电角度控制的无刷直流…...

Windows热键冲突终极指南:如何用Hotkey Detective一键精准定位占用程序
Windows热键冲突终极指南:如何用Hotkey Detective一键精准定位占用程序 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detecti…...

视频硬字幕提取神器:3分钟将任何视频字幕转为可编辑SRT文件
视频硬字幕提取神器:3分钟将任何视频字幕转为可编辑SRT文件 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含字幕区域检测、字…...

Rufus技术演进:从Windows 7告别到现代USB启动盘工具的重构之路
Rufus技术演进:从Windows 7告别到现代USB启动盘工具的重构之路 【免费下载链接】rufus The Reliable USB Formatting Utility 项目地址: https://gitcode.com/GitHub_Trending/ru/rufus 在开源工具生态中,技术栈的更新换代往往伴随着兼容性的艰难…...

B站直播神器:神奇弹幕全方位操作指南
B站直播神器:神奇弹幕全方位操作指南 【免费下载链接】MagicalDanmaku 本仓库及所有相关项目已永久停止开发、维护和任何形式的分发。 项目地址: https://gitcode.com/gh_mirrors/bi/MagicalDanmaku 直播难题:为什么你需要智能弹幕助手 每个B站主…...