实训笔记7.28
实训笔记7.28
- 7.28笔记
- 一、Hive的基本使用
- 1.1 Hive的命令行客户端的使用
- 1.2 Hive的JDBC客户端的使用
- 1.2.1 使用前提
- 1.2.2 启动hiveserver2
- 1.2.3 使用方式
- 1.3 Hive的客户端中也支持操作HDFS和Linux本地文件
- 二、Hive中DDL语法
- 2.1 数据库的管理
- 2.1.1 创建语法
- 2.1.2 修改语法
- 2.1.3 查询语法
- 2.1.4 删除语法
- 2.2 数据表的管理
- 2.2.1 创建语法
- 2.2.2 修改语法
- 2.2.3 查询语法
- 2.2.4 删除语法
- 2.2.5 数据表字段类型
- 三、Hive中DML语法
- 3.1 Hive的DML操作分为两部分
- 3.1.1 正常的DML操作:对数据增加、删除、修改操作
- 3.1.2 import和export操作
- 四、代码示例
7.28笔记
一、Hive的基本使用
Hive采用类SQL语言HQL进行数据库和数据表的创建、修改、查询、删除等等操作。同时采用HQL语言对表数据进行查询统计分析等操作。表面上hive是通过HQL来进行操作的,但实际底层是基于HDFS、MapReduce、YARN的实现。
1.1 Hive的命令行客户端的使用
只能在Hive的安装节点上使用,无法远程操作。
使用语法:hive 【操作选项】
-
hive:会进入hive的交互式命令行窗口 -
hive -e "HQL语句":不需要进入交互式命令窗口也可以执行HQL语句 ,HQL语句也可以有多条,只要保证语句之间以分号分割即可,但是不建议这种方式执行多条HQL语句 -
hive -f xxx.sql --hiveconf key=value .... --hivevar key=value ......不需要进入交互式命令行窗口去执行多条HQL语句,只要保证多条HQL语句声明到一个SQL文件即可。多条语句以分号分割,同时SQL文件中注释必须以–空格的形式去声明。
--hiveconf --hivevar代表向SQL文件传递一个参数,传递的参数在SQL使用的时候,使用的语法:--hiveconf key=value : ${hiveconf:key}--hivevar key=value : ${hivevar:key}
1.2 Hive的JDBC客户端的使用
可以通过Java代码借助JDBC工具远程连接Hive数据仓库,然后通过网络传递HQL语句以及执行结果。
1.2.1 使用前提
必须启动hiveserver2,hiveserver2相等于是hive的远程连接服务,专门用来让我们通过JDBC远程连接的。hiveserver2启动之后会给我们提供一个网络端口10000(必须在hive-site.xml文件中配置hiveserver2的相关参数、core-site.xml中允许hiveserver2的用户操作Hadoop集群)。
1.2.2 启动hiveserver2
nohup hiveserver2 1>xxxx.log 2>&1 &
Hive服务的启动和关闭代码比较多的,因此我们可以启动和关闭的命令封装成为一个shell脚本,便于我们后期的操作 hs2.sh
【注意】我们每次开启虚拟机都需要开启hdfs、yarn、jobhistory、hiveserver2,扩展作业:把HDFS、YARN、Jobhistory、hiveserver2的开启封装到一个通用的脚本文件中。
1.2.3 使用方式
-
使用Java代码中的原始的JDBC去操作Hiveserver2
-
使用一些基于JDBC的工具\
- beeline–hive自带的jdbc客户端
- dbeaver–基于jdbc的数据库可视化工具
1.3 Hive的客户端中也支持操作HDFS和Linux本地文件
- Hive客户端操作HDFS:
dfs 选项操作 - Hive客户端操作Linux:
!Linux命令
二、Hive中DDL语法
Hive也有DDL语法,DDL语法就是hive用来管理数据库和数据表的语言。虽然Hive使用数据库和数据表来管理结构化数据,但是库和表的底层实现和正宗的数据库是没有任何的关系的。
Hive
2.1 数据库的管理
2.1.1 创建语法
create database 【if not exists】 database_name
【comment "注释"】
【location "hdfs的地址"】
【with dbproperties("key"="value","key"="value",........)】
2.1.2 修改语法
-
修改数据库的dbproperties:
alter database database_name set dbproperties(key=value.....) -
修改数据库的存储位置(hive2.2.1版本之后才支持):
alter database database_name set location "hdfs路径"
2.1.3 查询语法
show databases;desc database database_namedesc database extended database_name
2.1.4 删除语法
drop database database_namedrop database database_name cascade
2.2 数据表的管理
2.2.1 创建语法
- 语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name #external 外部的
[(col_name data_type [COMMENT col_comment], ...)] #表字段
[COMMENT table_comment] #表的备注
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] #hive中特有的数据表 分区表
[CLUSTERED BY (col_name, col_name, ...) #hive中特有的数据表 分桶表
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] #分桶表的信息
[ROW FORMAT row_format] #表字段之间的分隔符
[STORED AS file_format] #hdfs存储的文件的类型格式 默认是文本格式
[LOCATION hdfs_path] #单独指定数据表在hdfs上存储的目录,如果没有指定 那么就在表对应的数据库的路径下
-
hive数据表的分类
-
管理表/内部表——————删除表,表数据一并删除
-
外部表——————删除表,表数据在HDFS上依然存在
-
分区表
将表数据以分区目录的形式在HDFS上进行存储
分区表指定分区字段,分区字段不能是表字段,表字段是要在文件中存储的,分区字段是以目录的形式表示的
多级分区
-
分桶表
表字段数据最终是以文件的形式存放的,表数据以几个文件进行存储,分桶表的事情
分桶表指定分桶字段,分桶字段一定是表字段,分桶字段结合分桶格式使用hash取值的方式进行文件的分发
支持抽样取值tablesample
-
-
hive数据表底层存储文件的分隔符问题
row_format DELIMITED 说明 [FIELDS TERMINATED BY char [ESCAPED BY char]] 列和列之间的分隔符 [LINES TERMINATED BY char] 行和行之间分隔符 \n [COLLECTION ITEMS TERMINATED BY char] 集合、struct、数组等等结构元素之间的分隔符 [MAP KEYS TERMINATED BY char] map集合key value之间的分隔符 [NULL DEFINED AS char] null值用什么字符表示 -
hive支持指定HDFS存储目录、一般不建议指定
-
Hive中还有两种比较特殊的创建数据表的语法
-
根据查询语法创建数据表
create table table_name as select查询语句 -
根据另外一个数据表创建一个新的数据表
create table table_name like other_table_name创建的新表只有旧表的结构,没有旧表的数据
分区信息和分桶信息也会一并复制
-
2.2.2 修改语法
修改表字段
增加/删除表分区目录信息
2.2.3 查询语法
show tables;desc table_name;desc formatted table_name;
2.2.4 删除语法
drop table if not exists table_name;
2.2.5 数据表字段类型
| 类型 | |
|---|---|
| 整数类型 | tinyint |
| smallint | |
| int/integer | |
| bigint | |
| 布尔类型 | boolean |
| 小数类型 | float |
| double | |
| 字符串类型 | string |
| 时间日期有关的类型 | timestamp |
| 字节类型 | binary |
| 复杂的数据类型 | array-数组类型 |
| map-Java中map集合 | |
| struct—Java对象(可以存放多个数据,每个数据的类型都可以不一样) |
三、Hive中DML语法
Hive中存储的数据是以数据库和数据表的形式进行存储的,因此我们就可以使用DML操作对表数据进行相关的增加、删除、修改等操作。但是因为hive的特殊性,Hive对数据的修改和删除不是特别的支持。
3.1 Hive的DML操作分为两部分
3.1.1 正常的DML操作:对数据增加、删除、修改操作
-
增加数据的语法
-
普通的insert命令:底层会翻译成为MR程序执行
-
insert into table_name(表字段) 【partition(分区字段=分区值)】 values(字段对应的值列表),(值列表).......Hive中基本不用
-
insert into table_name(表字段) 【partition(分区字段=分区值)】 select 查询语句 -
insert overwrite table table_name(表字段) 【partition(分区字段=分区值)】 select 查询语句Hive比较常用 根据一个查询语句添加数据 要求 table_name后面跟的表字段的个数、类型、顺序 必须和查询语句的得到结果一致
-
多插入语法,从同一个表A查询回来不同范围的数据插入到另外一个表B
form Ainsert into/overwrite [table] table_name [partitio(分区字段=分区值)] select 查询字段 where筛选条件insert into/overwrite [table] table_name [partitio(分区字段=分区值)] select 查询字段 where另外一个筛选条件
-
-
如果向表中增加数据,除了insert语法以外,我们还可以通过一些手法来添加数据
-
按照表格的格式要求,将一个符合格式要求的数据文件上传到数据表的所在HDFS目录下
不建议使用
【注意事项】 如果不是分区表,数据上传成功,表会自动识别 如果是分区表,可能会出现数据上传成功,但是表不识别(分区目录是我们手动创建的),我们修复分区表
msck repair table table_name -
创建表的时候指定location, location位置可以存在
-
-
load装载命令
也是将文件装载到数据表当中(底层表现就是会把文件移动到数据表所在的目录下),load装载命令相比于手动上传文件而言,load不会出现数据上传无法识别的情况,因此load装载数据会走hive的元数据。
同时手动上传文件到数据表目录下,因为不走元数据,因此我们执行count()命令统计表中的数据行,结果不准确的,因为count()直接从元数据中获取结果。但是如果使用load装载,同样是将文件上传到hive数据表的存储目录,但是load走元数据。
load data [local] inpath "路径" [overwrite] into table table_name [partition(分区字段=分区值)]local 如果加了local 那么后面路径是linux的路径
如果没有加local 那么路径是HDFS的路径(如果是HDFS上的文件装载,把文件移动到数据表的目录下,原始文件不见)
【注意事项】load装载的文件的格式必须和数据表的分割符一致,列也是对应。否则会出现装载失败或者数据异常。
-
-
更新操作
Hive中创建的分区表、管理表、外部表、分桶表默认不支持更新操作
更新操作需要hive的一些特殊手段,hive的事务操作
-
删除操作
Hive中创建的这些表默认不支持删除部分数据操作,但是支持删除所有数据的操作。
如果要删除表中所有数据,必须使用truncate table table_name 命令是DDL命令
3.1.2 import和export操作
-
导出操作
将hive数据表中数据导出到指定的目录下存储
export table table_name [partition(分区=值)] to "路径" -
导入操作
将hive导出的数据导入到hive中
import [external] table table_name [partition(分区=值)] from "hdfs路径-必须是通过export导出的数据"如果导入指定分区,分区必须导出目录也存在
四、代码示例
create table demo(hobby array<string>,menu map<string,double>,students struct<name:string,age:int,sex:string>
)row format delimited
fields terminated by ","
collection items terminated by "_"
map keys terminated by ":"
lines terminated by "\n";
-- 1、根据查询语句创建数据表:创建的数据表字段会根据查询语句的字段自动确定,类型自动推断
use demo;
create table teacher as select teacher_number as tn,teacher_name from teacher1;
select * from teacher;
-- 2、根据其他表创建一张一样的数据表
create table teacher2 like teacher1;
select * from teacher2;
desc formatted teacher2;-- 3、创建一个具有复杂数据类型的数据表 必须指定复杂数据类型的元素的分割符
-- array map struct 三个类型都是有多条数据组成的,需要指定数据之间的分隔符
create table demo(hobby array<string>,menu map<string,double>,students struct<name:string,age:int,sex:string>
)row format delimited
fields terminated by ","
collection items terminated by "_"
map keys terminated by ":"
lines terminated by "\n";
-- 向数据表增加特殊数据 insert增加问题比较多,不用insert增加了,而是使用文件添加
select * from demo;
select hobby[0],menu["apple"],students.age from demo;-- DML操作语法
-- 1、insert增加单条或者多条数据
create table test(name string,age int
)row format delimited fields terminated by ",";
insert into test values("zs",20),("ww",30);
insert into test select name,age from test1;create table test1(name string,age int
)partitioned by (timestr string)
row format delimited fields terminated by ",";
insert into test1 partition(timestr="2022") values("zs",20),("ww",30);insert overwrite table test1 partition(timestr="2022") select name,age from test;
-- 多插入语法,根据多条增加语句增加数据,要求多条增加语句的查询是从同一张表查询过来
from test
insert overwrite table test1 partition(timestr="2022") select name,age
insert overwrite table test1 partition(timestr="2023") select name,age;-- 修复hive分区表的分区
msck repair table test1;
show partitions test1;相关文章:

实训笔记7.28
实训笔记7.28 7.28笔记一、Hive的基本使用1.1 Hive的命令行客户端的使用1.2 Hive的JDBC客户端的使用1.2.1 使用前提1.2.2 启动hiveserver21.2.3 使用方式 1.3 Hive的客户端中也支持操作HDFS和Linux本地文件 二、Hive中DDL语法2.1 数据库的管理2.1.1 创建语法2.1.2 修改语法2.1.…...

C 游游的二进制树
题目描述 游游拿到了一棵树,共有nnn个节点,每个节点都有一个权值:0或者1。这样,每条路径就代表了一个二进制数。 游游想知道,有多少条路径代表的二进制数在[l,r][l,r][l,r]区间范围内? (请注意…...
收发存和进销存有什么区别?
一、什么是收发存和进销存 1、收发存 收发存是供应链管理中的关键概念,用于描述企业在供应链中的物流和库存管理过程。 收发存代表了企业在采购、生产和销售过程中的物流活动和库存水平。 收(Receiving) 企业接收供应商送达的物料或产品…...

小程序 账号的体验版正式版的账号信息及相关配置
siteinfo.js // 正式环境 const releaseConfig {appID: "",apiUrl: "",imgUrl: "" }; // 测试环境(包含开发环境和体验环境) const developConfig {appID: "",apiUrl: "",imgUrl: "" }…...
和 Web3对比,未来发展)
AIGC(Artificial Intelligence Generated Content)和 Web3对比,未来发展
一、AIGC(Artificial Intelligence Generated Content)行业 历史背景 AIGC(Artificial Intelligence Generated Content)是指利用人工智能技术生成的内容。随着人工智能技术的不断发展,AIGC 行业逐渐兴起。早期的 AIG…...
机器学习之Boosting和AdaBoost
1 Boosting和AdaBoost介绍 1.1 集成学习 集成学习 (Ensemble Learning) 算法的基本思想就是将多个分类器组合,从而实现一个预测效果更好的集成分类器。 集成学习通过建立几个模型来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学…...

汇编语言预定义寄存器和协处理器
ARM汇编器对ARM的寄存器和协处理器进行了预定义(包括APCS对r0~r15寄存器的定义),所有的寄存器和协处理器名都是大小写敏感的。 (1)预定义寄存器名 下面列出了被ARM汇编器预定义的寄存器名。 r0ÿ…...

【前缀和】974. 和可被 K 整除的子数组
Halo,这里是Ppeua。平时主要更新C,数据结构算法,Linux与ROS…感兴趣就关注我bua! 974. 和可被 K 整除的子数组 题目:示例:题解: 题目: 示例: 题解: 本题与560.和为K的子数组高度相似 同样的,本题利用了前缀和的定理.当(pre[i]-…...
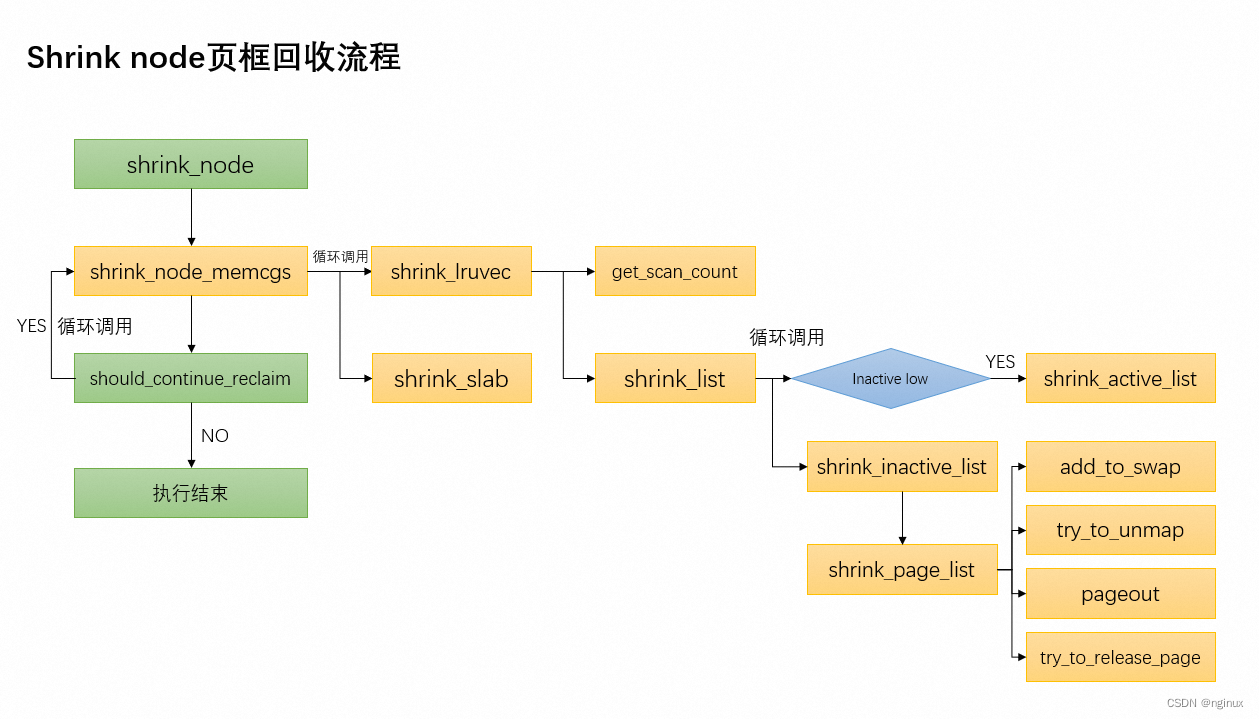
linux页框回收之shrink_node函数源码剖析
概述 《Linux内存回收入口_nginux的博客-CSDN博客》前文我们概略的描述了几种内存回收入口,我们知道几种回收入口最终都会调用进入shrink_node函数,本文将以Linux 5.9源码来描述shrink_node函数的源码实现。 函数调用流程图 scan_control数据结构 str…...

网络运维基础问题及解答
前言 本篇文章是对于网络运维基础技能的一些常见问题的解答,希望能够为进行期末复习或者对网络运维感兴趣的同学或专业人员提供一定的帮助。 问题及解答 1. 列举 3 种常用字符编码,简述怎样在 str 和 bytes 之间进行编码和解码。 答:常用的…...

【RabbitMQ】之保证数据不丢失方案
目录 一、数据丢失场景二、数据可靠性方案 1、生产者丢失消息解决方案2、MQ 队列丢失消息解决方案3、消费者丢失消息解决方案 一、数据丢失场景 MQ 消息数据完整的链路为:从 Producer 发送消息到 RabbitMQ 服务器中,再由 Broker 服务的 Exchange 根据…...

插入排序算法
插入排序 算法说明与代码实现: 以下是使用Go语言实现的插入排序算法示例代码: package mainimport "fmt"func insertionSort(arr []int) {n : len(arr)for i : 1; i < n; i {key : arr[i]j : i - 1for j > 0 && arr[j] > …...
Linux标准库API
目录 1.字符串函数 2.数据转换函数 3.格式化输入输出函数 4.权限控制函数 5.IO函数 6.进程控制函数 7.文件和目录函数 1.字符串函数 2.数据转换函数 3.格式化输入输出函数 #include<stdarg.h>void test(const char * format , ...){va_list ap;va_start(ap,format…...

腾讯云—自动挂载云盘
腾讯云,稍微麻烦了点。 腾讯云服务器,镜像为opencloudos 8。 ### 1、挂载云盘bash #首先通过以下命令,能够看到新的数据盘,如果不能需要通过腾讯云控制台卸载后,重新挂载,并重启服务器。 fdisk -l#为 /dev…...
为Win12做准备?微软Win11 23H2将集成AI助手:GPT4免费用
微软日前确认今年4季度推出Win11 23H2,这是Win11第二个年度更新。 Win11 23H2具体有哪些功能升级,现在还不好说,但它会集成微软的Copilot,它很容易让人想到多年前的“曲别针”助手,但这次是AI技术加持的,Co…...

Opencv Win10+Qt+Cmake 开发环境搭建
文章目录 一.Opencv安装二.Qt搭建opencv开发环境 一.Opencv安装 官网下载Opencv安装包 双击下载的软件进行解压 3. 系统环境变量添加 二.Qt搭建opencv开发环境 创建一个新的Qt项目(Non-Qt Project) 打开创建好的项目中的CMakeLists.txt,添加如下代码 # openc…...
)
Matlab实现光伏仿真(附上30个完整仿真源码)
光伏发电电池模型是描述光伏电池在不同条件下产生电能的数学模型。该模型可以用于预测光伏电池的输出功率,并为优化光伏电池系统设计和控制提供基础。本文将介绍如何使用Matlab实现光伏发电电池模型。 文章目录 1、光伏发电电池模型2、使用Matlab实现光伏发电电池模…...
与JSON.parse())
JSON.stringify()与JSON.parse()
JSON.parse() 方法用来解析 JSON 字符串 onst json {"result":true, "count":42}; const obj JSON.parse(json); console.log(typeof(json)) //string console.log(typeof(obj)) //objJSON.stringify() 方法将一个 JavaScript 对象或值转换为 JSON 字…...

neo4j教程-安装部署
neo4j教程-安装部署 Neo4j的关键概念和特点 •Neo4j是一个开源的NoSQL图形存储数据库,可为应用程序提供支持ACID的后端。Neo4j的开发始于2003年,自2007年转变为开源图形数据库模型。程序员使用的是路由器和关系的灵活网络结构,而不是静态表…...
网络面试合集
传输层的数据结构是什么? 就是在问他的协议格式:UDP&TCP 2.1.1三次握手 通信前,要先建立连接,确保双方都是在线,具有数据收发的能力。 2.1.2四次挥手 通信结束后,会有一个断开连接的过程࿰…...
)
别再死记硬背寄存器了!用Vivado SDK玩转Zynq 7010的GPIO(附MIO/EMIO/中断完整代码)
实战派Zynq 7010开发:从零玩转GPIO控制与中断处理 刚接触Zynq平台的开发者常被复杂的寄存器配置困扰,其实Xilinx提供的驱动库能大幅简化开发流程。本文将带你用Vivado SDK快速实现GPIO控制,避开底层细节直接产出可运行代码。 1. 环境搭建与基…...

职业会崩塌,岗位会消失,聪明的技术人该何去何从?
凌晨两点,写字楼的灯还亮着。我盯着屏幕上第 37 次运行的测试用例,咖啡杯里沉淀着今天的第三份浓缩。突然弹出一条消息:“系统架构升级,你的岗位可能被优化”。那一刻,我忽然意识到:我精心打磨的"职业…...

兄弟反目成仇?《易经》深挖人性:猜疑才是最大祸根
你有没有过这样的经历?关系最好的朋友或同事,因为一个误会,突然就成了“最熟悉的陌生人”。你解释,他觉得你掩饰;你沉默,他觉得你默认。最后,好好的关系,硬生生被“猜疑”这把刀&…...
)
从ENVI到MATLAB:高光谱图像处理工作流迁移指南(以真假彩色显示为例)
从ENVI到MATLAB:高光谱图像处理工作流迁移指南(以真假彩色显示为例) 对于长期使用ENVI进行遥感影像分析的研究者而言,MATLAB的编程环境提供了截然不同的工作流体验。本文将聚焦高光谱图像可视化这一基础但关键的操作,系…...

从B73到5000个RILs:手把手拆解玉米NAM群体构建的完整流程与关键决策
玉米NAM群体构建全流程解析:从亲本筛选到RILs优化的科学决策 站在玉米遗传研究的十字路口,我们常常面临一个核心挑战:如何在有限资源下构建既能捕获广泛遗传多样性,又能实现精准定位的群体?2009年,Buckler团…...

DataStore vs SharedPreferences 迁移指南:告别 ANR,拥抱类型安全
DataStore vs SharedPreferences 迁移指南:告别 ANR,拥抱类型安全 一句话收益:掌握从 SharedPreferences 迁移到 Jetpack DataStore 的完整路径,彻底消除主线程 I/O 阻塞与类型安全隐患。 适用版本:Android API 21&…...

免费文档下载终极方案:如何优雅获取百度文库等30+平台资源
免费文档下载终极方案:如何优雅获取百度文库等30平台资源 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档,该脚本就是为…...

10个sd-webui-regional-prompter实用技巧:从基础分割到高级2D区域配置
10个sd-webui-regional-prompter实用技巧:从基础分割到高级2D区域配置 【免费下载链接】sd-webui-regional-prompter set prompt to divided region 项目地址: https://gitcode.com/gh_mirrors/sd/sd-webui-regional-prompter sd-webui-regional-prompter是一…...

【收藏干货】2026年AI Coding全面爆发!程序员终极职业升级攻略,告别被替代焦虑
2026年,AI编码技术迎来规模化落地爆发期,行业彻底告别“人工纯编码”的传统模式。对于所有程序员而言,当下最核心的生存与发展策略,早已不是埋头敲代码,而是从“被动写代码的执行者”全面升级为“主动驾驭AI的价值创造…...
用C++实现信奥题 P8976 「DTOI-4」排列)
打卡信奥刷题(3292)用C++实现信奥题 P8976 「DTOI-4」排列
P8976 「DTOI-4」排列 题目背景 Update on 2023.2.1:新增一组针对 yuanjiabao 的 Hack 数据,放置于 #21。 Update on 2023.2.2:新增一组针对 CourtesyWei 和 bizhidaojiaosha 的 Hack 数据,放置于 #22。 构造一个排列 ppp&…...