自然语言处理从入门到应用——LangChain:提示(Prompts)-[提示模板:连接到特征存储]
分类目录:《自然语言处理从入门到应用》总目录
特征存储是传统机器学习中的一个概念,它确保输入模型的数据是最新和相关的。在考虑将LLM应用程序投入生产时,这个概念非常重要。为了个性化LLM应用程序,我们可能希望将LLM与特定用户的最新信息结合起来。特征存储可以是保持数据更新的好方法,而LangChain提供了一种将该数据与LLM结合的简单方式。
在下面的示例中,我们将展示如何将提示模板连接到特征存储。其基本思想是从提示模板中调用特征存储以检索值,然后将这些值格式化到提示中。
Feast
首先,我们将使用流行的开源特征存储框架Feast。首先,假设我们已经做完了Feast的入门步骤。紧接着,我们将基于入门示例构建,并创建一个LLMChain,用于驱动有关其最新统计信息。
加载 Feast 存储
根据Feast的README中的说明进行设置:
from feast import FeatureStore# 根据存储路径进行更新
feast_repo_path = "../../../../../my_feature_repo/feature_repo/"
store = FeatureStore(repo_path=feast_repo_path)
提示
在这里,我们将设置一个自定义的FeastPromptTemplate。这个提示模板将接收一个司机 ID,查找他们的统计数据,并将这些统计数据格式化到提示中。需要注意的是,这个提示模板的输入只有driver_id,因为这是唯一由用户定义的部分,所有的其它变量都在提示模板内部查找。
from langchain.prompts import PromptTemplate, StringPromptTemplate
template = """根据司机的最新统计数据,写一个便签将这些统计数据传达给他们。
如果他们的对话率超过0.5,请给他们一个赞美。否则,在最后讲一个关于鸡的愚蠢笑话,让他们感觉好一些。以下是司机的统计数据:
对话率:{conv_rate}
接受率:{acc_rate}
平均每日行程数:{avg_daily_trips}你的回复:"""
prompt = PromptTemplate.from_template(template)
class FeastPromptTemplate(StringPromptTemplate):def format(self, **kwargs) -> str:driver_id = kwargs.pop("driver_id")feature_vector = store.get_online_features(features=['driver_hourly_stats:conv_rate','driver_hourly_stats:acc_rate','driver_hourly_stats:avg_daily_trips'],entity_rows=[{"driver_id": driver_id}]).to_dict()kwargs["conv_rate"] = feature_vector["conv_rate"][0]kwargs["acc_rate"] = feature_vector["acc_rate"][0]kwargs["avg_daily_trips"] = feature_vector["avg_daily_trips"][0]return prompt.format(**kwargs)
prompt_template = FeastPromptTemplate(input_variables=["driver_id"])
print(prompt_template.format(driver_id=1001))
输出:
根据司机的最新统计数据,写一个便签将这些统计数据传达给他们。
如果他们的对话率超过0.5,请给他们一个赞美。否则,在最后讲一个关于鸡的愚蠢笑话,让他们感觉好一些。以下是司机的统计数据:
对话率:0.4745151400566101
接受率:0.055561766028404236
平均每日行程数:936你的回复:
在上面的例子中,我们创建了一个FeastPromptTemplate的实例,并使用format方法为特定的driver_id生成一个提示。使用store.get_online_features从特征存储中检索司机的特征向量,并将相关统计数据填充到提示模板中。现在,我们可以将生成的提示文本用于进一步处理或作为输入提供给您的语言模型。
在链式结构中使用
现在我们可以在链式结构中使用它,创建一个由特征存储支持的个性化链式结构:
from langchain.chat_models import ChatOpenAI
from langchain.chains import LLMChain
chain = LLMChain(llm=ChatOpenAI(), prompt=prompt_template)
chain.run(1001)
输出:
"嗨!我想向您更新一下您当前的统计数据。您的接受率为0.055561766028404236,平均每日行程数为936。虽然您当前的对话率为0.4745151400566101,但我相信只要再加一点努力,您就能超过0.5的标准!继续保持良好的工作!还记得,即使鸡无法总是穿过马路,但它们仍会尽力而为。"
以上是根据提供的统计数据生成的更新消息。消息中包含司机的接受率、平均每日行程数和对话率的信息。鼓励司机继续努力工作,并给予他们一些鸡的笑话来增加一些轻松的氛围。
Tecton
上面,我们展示了如何在LangChain中使用流行的开源自管特征存储Feast。下面的示例将展示如何使用Tecton进行类似的集成。Tecton是一个完全托管的特征平台,用于协调完整的ML特征生命周期,从转换到在线服务,具备企业级SLA。
前提条件
- Tecton部署
- 将
TECTON_API_KEY环境变量设置为有效的服务账户密钥
定义和加载特征
我们将使用Tecton教程中user_transaction_counts的Feature View作为Feature Service的一部分。为简单起见,我们只使用了一个Feature View;然而,更复杂的应用可能需要更多的Feature View来检索其提示所需的特征。
user_transaction_metrics = FeatureService(name="user_transaction_metrics",features=[user_transaction_counts]
)
上述Feature Service预计将被应用到实时工作空间中。在本示例中,我们将使用prod工作空间。
import tectonworkspace = tecton.get_workspace("prod")
feature_service = workspace.get_feature_service("user_transaction_metrics")
Prompts
在这里,我们将设置一个自定义的TectonPromptTemplate。该提示模板将接收一个用户ID,查找其统计数据,并将这些统计数据格式化为提示。需要注意的是,该提示模板的输入只有user_id,因为这是唯一由用户定义的部分,所有其他的变量都在提示模板内部查找。
from langchain.prompts import PromptTemplate, StringPromptTemplate
template = """给定供应商的最新交易统计数据,根据以下规则给他们写一封信:1. 如果他们在过去一天内有交易,向他们祝贺最近的销售成绩。
2. 如果过去一天没有交易,但过去30天内有交易,逗趣地鼓励他们多卖一些。
3. 最后总是加上一个关于鸡的愚蠢笑话。以下是供应商的统计数据:
过去一天的交易数量:{transaction_count_1d}
过去30天的交易数量:{transaction_count_30d}您的回复:"""
prompt = PromptTemplate.from_template(template)
class TectonPromptTemplate(StringPromptTemplate):def format(self, **kwargs) -> str:user_id = kwargs.pop("user_id")feature_vector = feature_service.get_online_features(join_keys={"user_id": user_id}).to_dict()kwargs["transaction_count_1d"] = feature_vector["user_transaction_counts.transaction_count_1d_1d"]kwargs["transaction_count_30d"] = feature_vector["user_transaction_counts.transaction_count_30d_1d"]return prompt.format(**kwargs)prompt_template = TectonPromptTemplate(input_variables=["user_id"])
print(prompt_template.format(user_id="user_469998441571"))
输出:
给定供应商的最新交易统计数据,根据以下规则给他们写一封信:如果他们在过去一天内有交易,向他们祝贺最近的销售成绩。
如果过去一天没有交易,但过去30天内有交易,逗趣地鼓励他们多卖一些。
最后总是加上一个关于鸡的愚蠢笑话。
以下是供应商的统计数据: 过去一天的交易数量:657 过去30天的交易数量:20326您的回复:
在链式模型中使用
现在我们可以在链式模型中使用它,创建一个通过Tecton Feature平台支持的个性化链式模型:
from langchain.chat_models import ChatOpenAI
from langchain.chains import LLMChain
chain = LLMChain(llm=ChatOpenAI(), prompt=prompt_template)
chain.run("user_469998441571")
输出:
'哇,恭喜您最近的销售成绩!您的业务就像热气球上的一只鸡一样飞得很高!继续保持良好的工作!'
Featureform
最后,我们将使用Featureform,一个开源的企业级特征存储,来运行相同的示例。Featureform允许我们使用Spark等基础设施或本地环境来定义特征转换。
初始化Featureform
我们可以按照README中的说明初始化Featureform中的转换和特征。
import featureform as ffclient = ff.Client(host="demo.featureform.com")
Prompts
在这里,我们将设置一个自定义的FeatureformPromptTemplate,该提示模板将使用用户每笔交易的平均金额作为输入。需要注意的是,该提示模板的输入只有avg_transaction,因为所有其他变量都在提示模板内部查找。
from langchain.prompts import PromptTemplate, StringPromptTemplate
template = """Given the amount a user spends on average per transaction, let them know if they are a high roller. Otherwise, make a silly joke about chickens at the end to make them feel betterHere are the user's stats:
Average Amount per Transaction: ${avg_transcation}Your response:"""
prompt = PromptTemplate.from_template(template)
class FeatureformPromptTemplate(StringPromptTemplate):def format(self, **kwargs) -> str:user_id = kwargs.pop("user_id")fpf = client.features([("avg_transactions", "quickstart")], {"user": user_id})return prompt.format(**kwargs)prompt_template = FeatureformPrompTemplate(input_variables=["user_id"])
print(prompt_template.format(user_id="C1410926"))
在对话链中使用
现在我们还可以将其用于对话链中,成功创建一个由Featureform Feature平台支持的个性化对话链。
from langchain.chat_models import ChatOpenAI
from langchain.chains import LLMChain
chain = LLMChain(llm=ChatOpenAI(), prompt=prompt_template)
chain.run("C1410926")
参考文献:
[1] LangChain 🦜️🔗 中文网,跟着LangChain一起学LLM/GPT开发:https://www.langchain.com.cn/
[2] LangChain中文网 - LangChain 是一个用于开发由语言模型驱动的应用程序的框架:http://www.cnlangchain.com/
相关文章:
-[提示模板:连接到特征存储])
自然语言处理从入门到应用——LangChain:提示(Prompts)-[提示模板:连接到特征存储]
分类目录:《自然语言处理从入门到应用》总目录 特征存储是传统机器学习中的一个概念,它确保输入模型的数据是最新和相关的。在考虑将LLM应用程序投入生产时,这个概念非常重要。为了个性化LLM应用程序,我们可能希望将LLM与特定用户…...
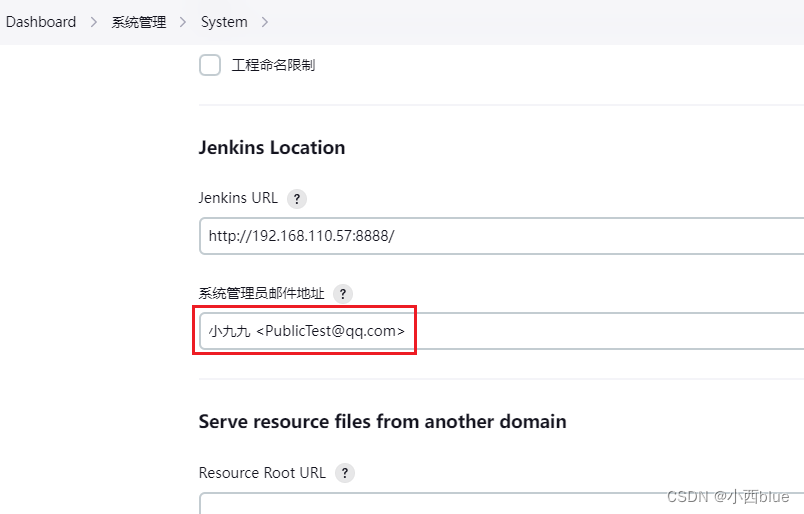
jenkins自定义邮件发送人姓名
jenkins发送邮件的时候发送人姓名默认的,如果要自定义发件人姓名,只需要修改如下信息即可: 系统管理-system-Jenkins Location下的系统管理员邮件地址 格式为:自定义姓名<邮件地址>...

SolidWorks二次开发---简单的连接solidworks
创建一个.net Framework的应用,正常4.0以上就可以了。 打开nuget包管理 在里面搜索paine 在版中选择对应的solidworks年份开头的,进行安装。 安装完之后 : 同时选中下面两个dll,把嵌入操作类型改为false 然后在按钮的单击事件中输入: Connect.Crea…...

docker 安装 active Mq
在安装完Docker的机器上,安装activeMQ。 拉取镜像: docker pull webcenter/activemq 查看镜像: docker images Docker运行ActiveMQ镜像 docker run --name activemq -d -p 8161:8161 -p 61616:61616 --privilegedtrue --restartalways …...
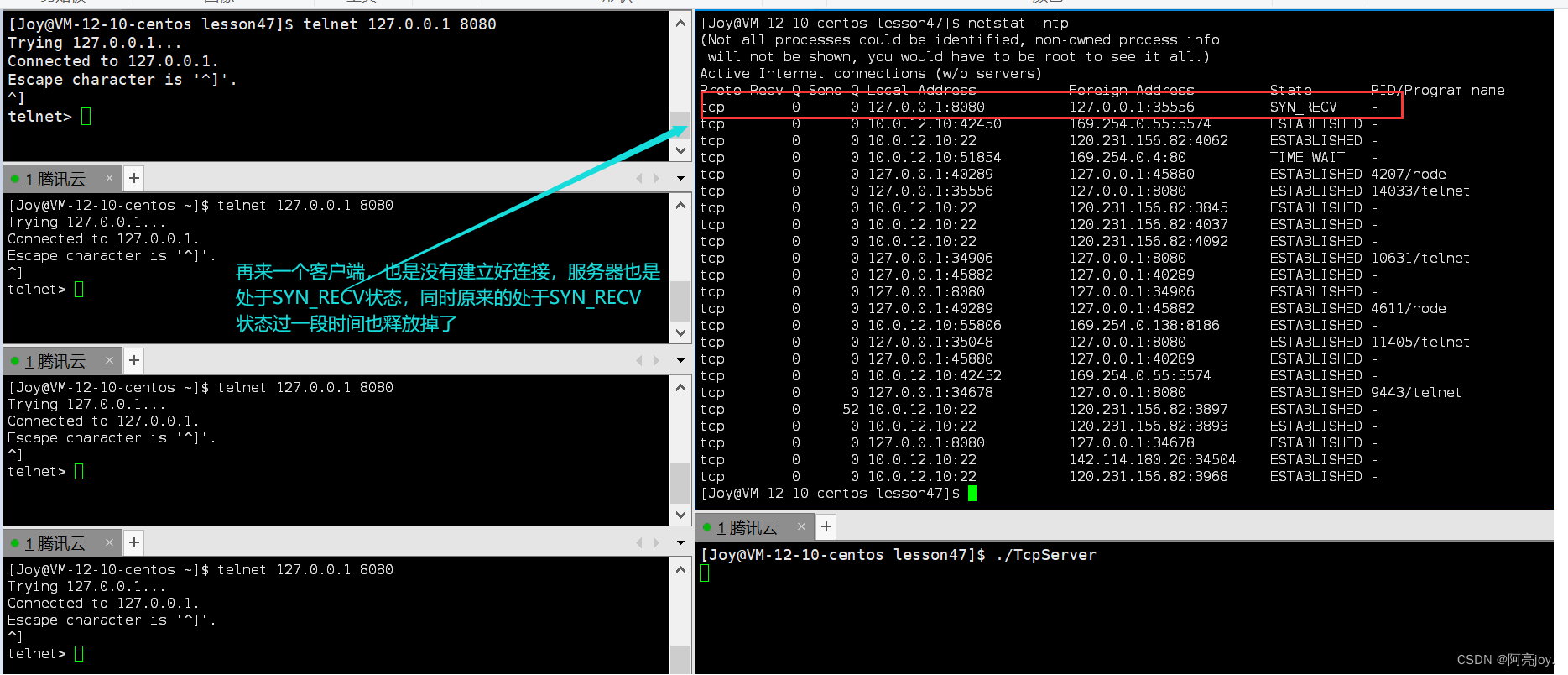
【Linux】TCP协议
🌠 作者:阿亮joy. 🎆专栏:《学会Linux》 🎇 座右铭:每个优秀的人都有一段沉默的时光,那段时光是付出了很多努力却得不到结果的日子,我们把它叫做扎根 目录 👉TCP协议&…...
DevOps系列文章之 自动化测试大全(单测和集成测试)
自动化测试业界主流工具 核心目标: 主要是功能测试和覆盖率测试 业界常用主流工具 GoogleTest GoogleTest是一个跨平台的(Liunx、Mac OS X、Windows 、Cygwin 、Windows CE and Symbian ) C单元测试框架,由google公司发布,为在不同平台上为编…...
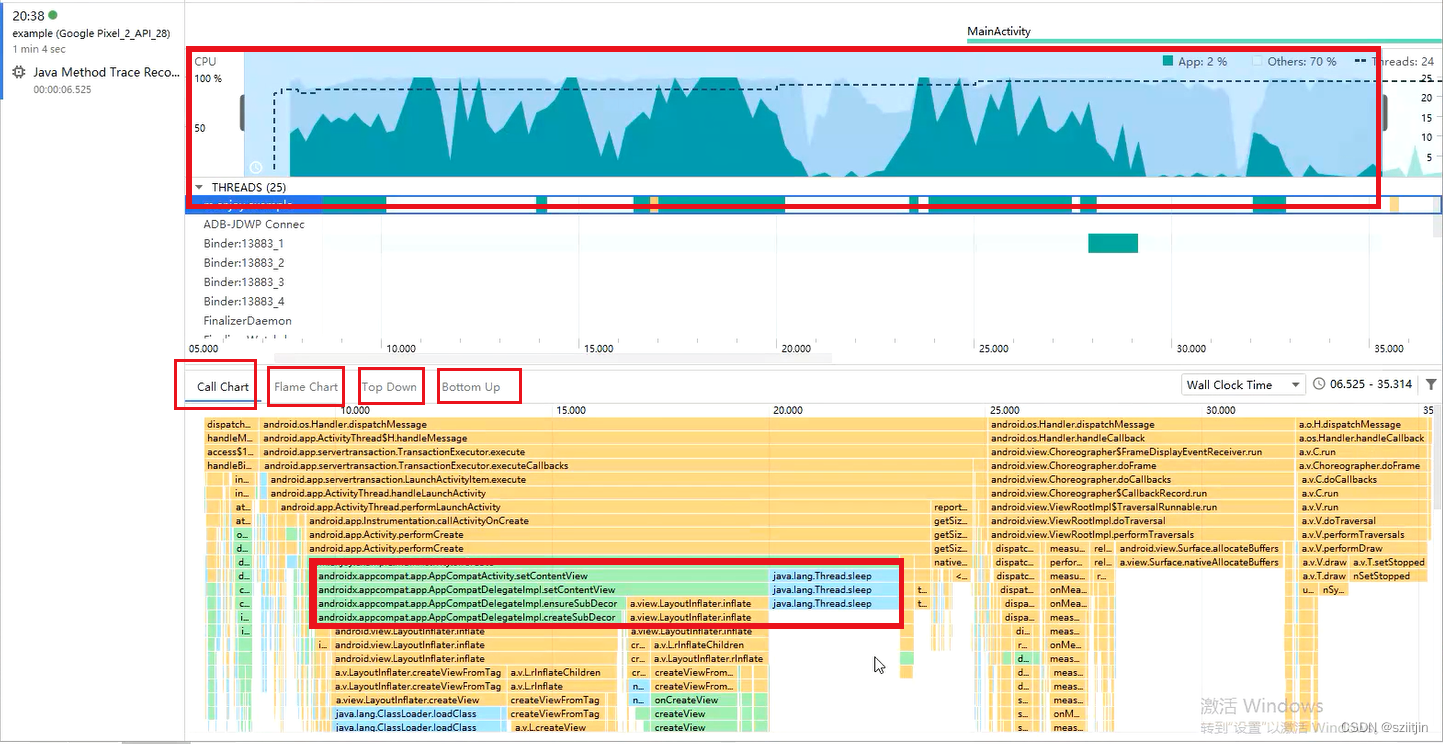
Android启动速度优化
本节主要内容:了解APP启动流程、启动状态、查看启动时间、CPU Profile定位启动耗时代码、StrictMode严苛模式检测不合理写法、解决启动黑白屏问题。 一、APP启动流程 ①用户点击桌面App图标,Launcher进程采用Binder IPC向system_server进程发起startAc…...

linux 日志 系统安全日志 web日志
web日志 LINUX日志系统之WEB日志(一)_dracut.log_麻子来了的博客-CSDN博客 系统安全日志 Linux系统安全日志详解_sinolover的博客-CSDN博客 wtmp和utmp文件都是二进制文件,需使用who、w、users、last和ac来操作这两个文件。 who /var/lo…...

SpringBoot 整合 MongoDB 连接 阿里云MongoDB
注:spring-boot-starter-data-mongodb 2.7.5;jdk 1.8 阿里云MongoDB是副本集实例的 在网上查找了一番,大多数都是教连接本地mongodb或者linux上的mongodb 阿里云上有java版连接教程,但它不是SpringBoot方法配置的,是手…...

Debeizum 增量快照
在Debeizum1.6版本发布之后,成功推出了Incremental Snapshot(增量快照)的功能,同时取代了原有的实验性的Parallel Snapshot(并行快照)。在本篇博客中,我将介绍全新快照方式的原理,以…...
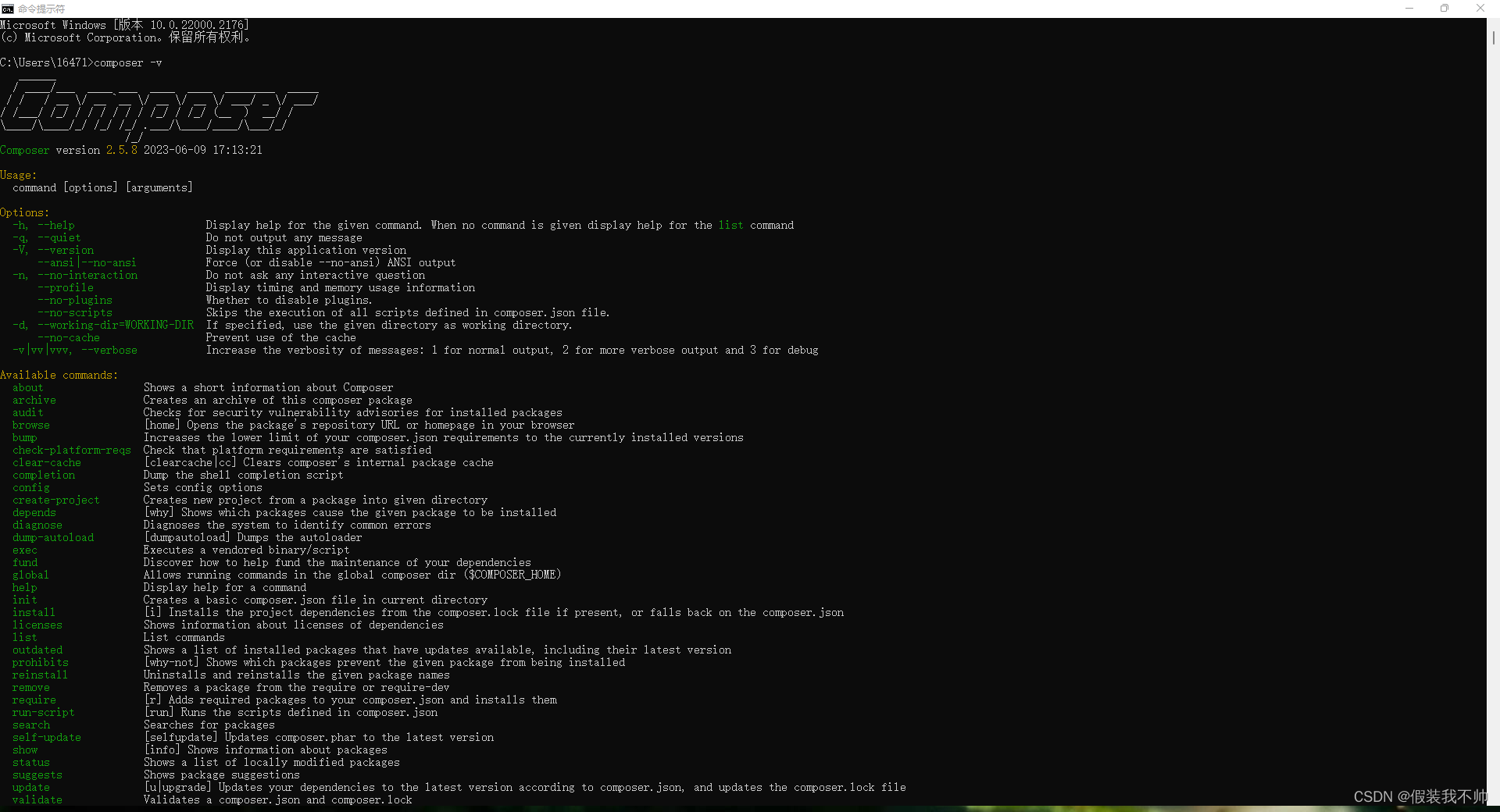
windows下安装composer
安装Php 教程 下载composer 官网 中文网站 exe下载地址 下载好exe 双击运行 找到php.ini注释一行代码 测试 composer -v说明安装成功 修改源 执行以下命令即可修改 composer config -g repo.packagist composer https://packagist.phpcomposer.com # 查看配置…...

企业游学进华秋,助力电子产业创新与发展
近日,淘IC企业游学活动,携20多位电子行业的企业家,走进了深圳华秋电子有限公司(以下简称“华秋”),进行交流学习、供需对接。华秋董事长兼CEO陈遂佰对华秋的发展历程、业务版块、产业布局等做了详尽的介绍&…...

玩转Tomcat:从安装到部署
文章目录 一、什么是 Tomcat二、Tomcat 的安装与使用2.1 下载安装2.2 目录结构2.3 启动 Tomcat 三、部署程序到 Tomcat3.1 Windows环境3.2 Linux环境 一、什么是 Tomcat 一看到 Tomcat,我们一般会想到什么?没错,就是他,童年的回忆…...

吃透《西瓜书》第四章 决策树定义与构造、ID3决策树、C4.5决策树、CART决策树
目录 一、基本概念 1.1 什么是信息熵? 1.2 决策树的定义与构造 二、决策树算法 2.1 ID3 决策树 2.2 C4.5 决策树 2.3 CART 决策树 一、基本概念 1.1 什么是信息熵? 信息熵: 熵是度量样本集合纯度最常用的一种指标,代表一个系统中蕴…...
)
复现宏景eHR存在任意文件上传漏洞(0day)
目录 一、漏洞描述 二、影响版本 三、资产测绘 四、漏洞复现 一、漏洞描述 北京宏景世纪软件股份有限公司(简称“宏景软件”)自成立以来始终专注于国有企事业单位人力与人才管理数智化(数字化、智能化)产品的研发和应用推广,是中国国有企事业单位人力与人才管理数智…...

unity连接MySQL数据库并完成增删改查
数据存储量比较大时,我就需要将数据存储在数据库中方便使用,尤其是制作管理系统时,它的用处就更大了。 在编写程序前,需要在Assets文件夹中创建plugins文件,将.dll文件导入,文件从百度网盘自取:…...

13个ChatGPT类实用AI工具汇总
在ChatGPT爆火后,各种工具如同雨后春笋一般层出不穷。以下汇总了13种ChatGPT类实用工具,可以帮助学习、教学和科研。 01 / ChatGPT for google/ 一个浏览器插件,可搭配现有的搜索引擎来使用 最大化搜索效率,对搜索体验的提升相…...
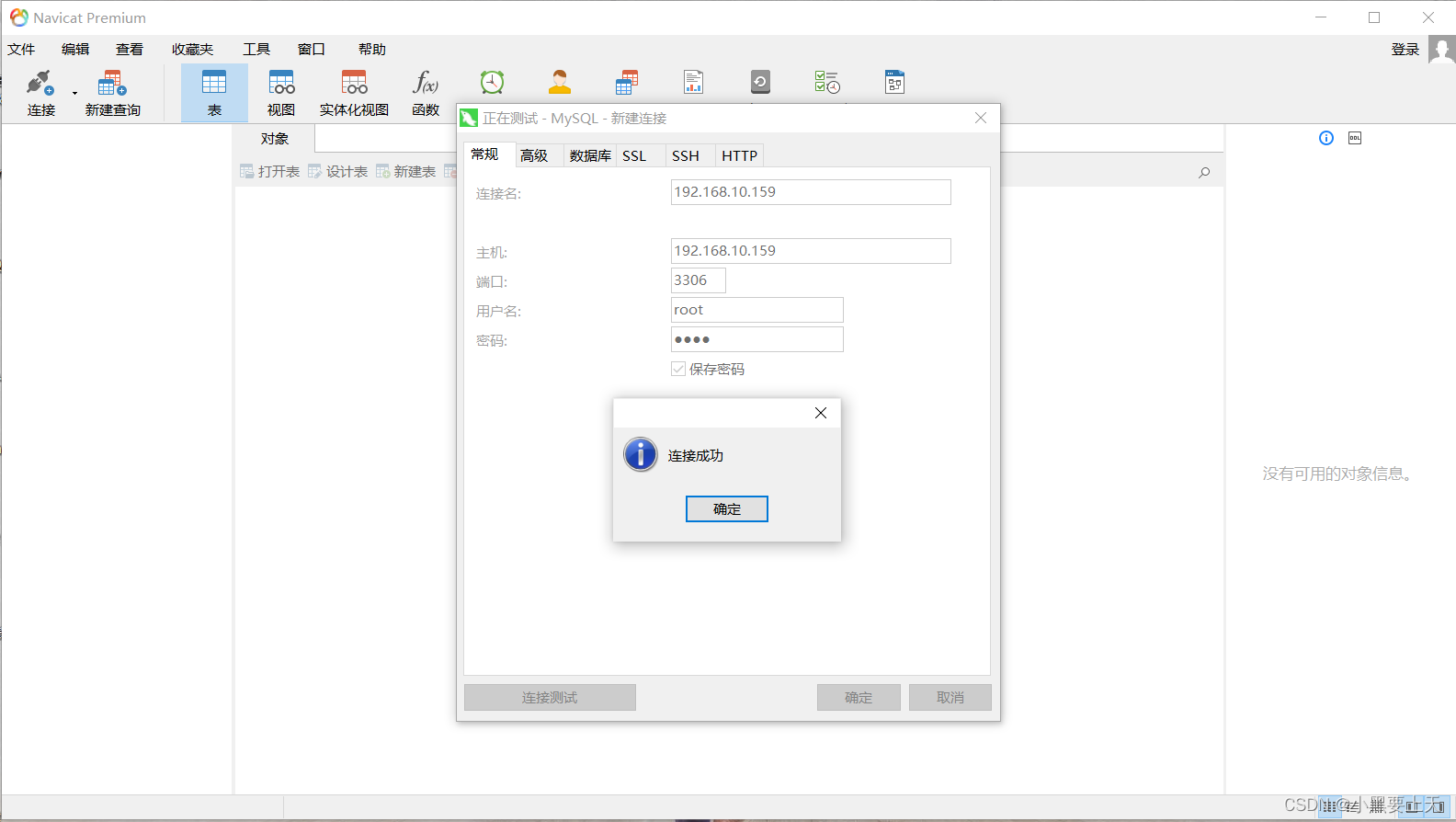
1-linux下mysql8.0.33安装
在互联网企业的日常工作/运维中,我们会经常用到mysql数据库,而linux下mysql的安装方式有三种: 1.mysql rpm安装 2.mysql二进制安装 3.mysql源码安装 今天就为大家讲讲linux下mysql8.0.33版本rpm方式的安装。 1.前提 1.1.系统版本 Cent…...
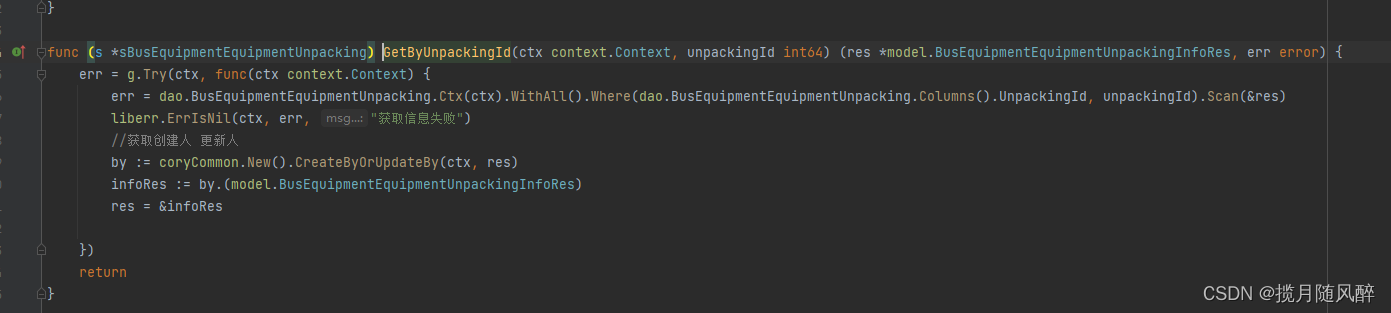
golang反射获取结构体的值和修改值
功能:根据id和反射技术封装 创建和更新人的查询 一、代码二、演示 一、代码 package coryCommonimport ("context""errors""github.com/gogf/gf/v2/container/gvar""github.com/tiger1103/gfast/v3/internal/app/system/dao&qu…...

中文大模型评估数据集——C-Eval
C-EVAL: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models https://arxiv.org/pdf/2305.08322v1.pdfhttps://github.com/SJTU-LIT/cevalhttps://cevalbenchmark.com/static/leaderboard.html Part1 前言 怎么去评估一个大语言模型呢? 在广泛…...
)
VLC隐藏玩法:结合Lua脚本实现智能视频播放(比如根据时间切换片单)
VLC隐藏玩法:结合Lua脚本实现智能视频播放 你是否厌倦了手动切换播放列表?VLC作为一款开源多媒体播放器,其真正的潜力远不止于基础播放功能。通过Lua脚本接口,我们可以解锁VLC的自动化能力,实现根据时间、文件存在与否…...

从B73到5000个RILs:手把手拆解玉米NAM群体构建的完整流程与关键决策
玉米NAM群体构建全流程解析:从亲本筛选到RILs优化的科学决策 站在玉米遗传研究的十字路口,我们常常面临一个核心挑战:如何在有限资源下构建既能捕获广泛遗传多样性,又能实现精准定位的群体?2009年,Buckler团…...

为什么你的DeepSeek微调收敛慢?揭秘Attention初始化偏差导致的3轮内loss震荡——附自动校准工具脚本
更多请点击: https://intelliparadigm.com 第一章:DeepSeek注意力机制优化 DeepSeek系列模型在长上下文建模中对标准Transformer注意力进行了系统性重构,核心聚焦于降低计算复杂度与提升内存局部性。其注意力优化并非单一技术点叠加…...

爆仓价格系数推导
多仓 爆仓条件:账户权益 < 维持保证金 即: Equity Maintenance Margin对于一个仓位: 多仓 权益: 权益 初始权益 (当前价 - 开仓价) 数量因为: 价格上涨赚钱。 空仓 权益: 权益 初始权益 (开仓价 -…...

终极QR码修复指南:三步让损坏的二维码“起死回生“
终极QR码修复指南:三步让损坏的二维码"起死回生" 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 你是否遇到过这样的尴尬场景?精心打印的会议签到二维码被咖…...

Linux字符设备驱动开发:从内核注册到/dev节点创建的完整实践
1. 项目概述:从零到一,理解Linux内核的“门牌号”管理在Linux的世界里,一切皆文件。这个哲学理念不仅体现在我们熟悉的普通文件上,更深刻地内嵌于设备管理中。当你敲下ls -l /dev命令,看到那些tty、null、random等文件…...

ncmdumpGUI:Windows平台免费NCM文件转换终极指南
ncmdumpGUI:Windows平台免费NCM文件转换终极指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 您是否在网易云音乐下载了喜爱的歌曲,…...

曼德勃罗集的 Three.js 实现
效果预览 经典的曼德勃罗集(Mandelbrot Set)分形渲染,配合动态缩放动画探索分形边界的无限细节。使用线性插值平滑着色,呈现出彩虹般的色彩过渡。 👉 点击查看《曼德勃罗集的》完整源码与效果演示 Shader 实现原理…...

为OpenClaw智能体工作流配置Taotoken聚合端点的教程
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为OpenClaw智能体工作流配置Taotoken聚合端点的教程 OpenClaw是一款功能强大的智能体开发工具,它允许开发者构建和编排…...

使用 TaoToken CLI 工具一键配置多开发环境的大模型端点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 TaoToken CLI 工具一键配置多开发环境的大模型端点 在团队协作或跨项目开发中,为不同的 AI 工具(如 C…...