pytorch(续周报(1))
文章目录
- 2.1 张量
- 2.1.1 简介
- 2.1.2 创建tensor
- 2.1.3 张量的操作
- 2.1.4 广播机制
- 2.2 自动求导
- Autograd简介
- 2.2.1 梯度
- 2.3 并行计算简介
- 2.3.1 为什么要做并行计算
- 2.3.2 为什么需要CUDA
- 2.3.3 常见的并行的方法:
- 网络结构分布到不同的设备中(Network partitioning)
- 同一层的任务分布到不同数据中(Layer-wise partitioning)
- 不同的数据分布到不同的设备中,执行相同的任务(Data parallelism)
- 2.3.4 使用CUDA加速训练
2.1 张量
概述:
- 张量的简介
- PyTorch如何创建张量
- PyTorch中张量的操作
- PyTorch中张量的广播机制
2.1.1 简介
几何代数中定义的张量是基于向量和矩阵的推广,比如我们可以将标量视为零阶张量,矢量可以视为一阶张量,矩阵就是二阶张量。
| 张量维度 | 代表含义 |
|---|---|
| 0维张量 | 代表的是标量(数字) |
| 1维张量 | 代表的是向量 |
| 2维张量 | 代表的是矩阵 |
| 3维张量 | 时间序列数据 股价 文本数据 单张彩色图片(RGB) |
张量是现代机器学习的基础。它的核心是一个数据容器,多数情况下,它包含数字,有时候它也包含字符串,但这种情况比较少。因此可以把它想象成一个数字的水桶。
这里有一些存储在各种类型张量的公用数据集类型:
- 3维 = 时间序列
- 4维 = 图像
- 5维 = 视频
例子:一个图像可以用三个字段表示:
(width, height, channel) = 3D
但是,在机器学习工作中,我们经常要处理不止一张图片或一篇文档——我们要处理一个集合。我们可能有10,000张郁金香的图片,这意味着,我们将用到4D张量:
(batch_size, width, height, channel) = 4D
2.1.2 创建tensor
- 随机初始化矩阵
我们可以通过torch.rand()的方法,构造一个随机初始化的矩阵:
import torch
x = torch.rand(4, 3)
print(x)
tensor([[0.7569, 0.4281, 0.4722],[0.9513, 0.5168, 0.1659],[0.4493, 0.2846, 0.4363],[0.5043, 0.9637, 0.1469]])
- 全0矩阵的构建
我们可以通过torch.zeros()构造一个矩阵全为 0,并且通过dtype设置数据类型为 long。除此以外,我们还可以通过torch.zero_()和torch.zeros_like()将现有矩阵转换为全0矩阵.
import torch
x = torch.zeros(4, 3, dtype=torch.long)
print(x)
tensor([[0, 0, 0],[0, 0, 0],[0, 0, 0],[0, 0, 0]])
- 张量的构建
我们可以通过torch.tensor()直接使用数据,构造一个张量:
import torch
x = torch.tensor([5.5, 3])
print(x)
tensor([5.5000, 3.0000])
- 基于已经存在的 tensor,创建一个 tensor :
x = x.new_ones(4, 3, dtype=torch.double)
# 创建一个新的全1矩阵tensor,返回的tensor默认具有相同的torch.dtype和torch.device
# 也可以像之前的写法 x = torch.ones(4, 3, dtype=torch.double)
print(x)
x = torch.randn_like(x, dtype=torch.float)
# 重置数据类型
print(x)
# 结果会有一样的size
# 获取它的维度信息
print(x.size())
print(x.shape)
tensor([[1., 1., 1.],[1., 1., 1.],[1., 1., 1.],[1., 1., 1.]], dtype=torch.float64)
tensor([[ 2.7311, -0.0720, 0.2497],[-2.3141, 0.0666, -0.5934],[ 1.5253, 1.0336, 1.3859],[ 1.3806, -0.6965, -1.2255]])
torch.Size([4, 3])
torch.Size([4, 3])
返回的torch.Size其实是一个tuple,⽀持所有tuple的操作。我们可以使用索引操作取得张量的长、宽等数据维度。
- 常见的构造Tensor的方法:
| 函数 | 功能 |
|---|---|
| Tensor(sizes) | 基础构造函数 |
| tensor(data) | 类似于np.array |
| ones(sizes) | 全1 |
| zeros(sizes) | 全0 |
| eye(sizes) | 对角为1,其余为0 |
| arange(s,e,step) | 从s到e,步长为step |
| linspace(s,e,steps) | 从s到e,均匀分成step份 |
| rand/randn(sizes) | rand是[0,1)均匀分布;randn是服从N(0,1)的正态分布 |
| normal(mean,std) | 正态分布(均值为mean,标准差是std) |
| randperm(m) | 随机排列 |
2.1.3 张量的操作
在接下来的内容中,我们将介绍几种常见的张量的操作方法:
- 加法操作:
import torch
# 方式1
y = torch.rand(4, 3)
print(x + y)# 方式2
print(torch.add(x, y))# 方式3 in-place,原值修改
y.add_(x)
print(y)
tensor([[ 2.8977, 0.6581, 0.5856],[-1.3604, 0.1656, -0.0823],[ 2.1387, 1.7959, 1.5275],[ 2.2427, -0.3100, -0.4826]])
tensor([[ 2.8977, 0.6581, 0.5856],[-1.3604, 0.1656, -0.0823],[ 2.1387, 1.7959, 1.5275],[ 2.2427, -0.3100, -0.4826]])
tensor([[ 2.8977, 0.6581, 0.5856],[-1.3604, 0.1656, -0.0823],[ 2.1387, 1.7959, 1.5275],[ 2.2427, -0.3100, -0.4826]])- 索引操作:(类似于numpy)
需要注意的是:索引出来的结果与原数据共享内存,修改一个,另一个会跟着修改。如果不想修改,可以考虑使用copy()等方法
import torch
x = torch.rand(4,3)
# 取第二列
print(x[:, 1])
tensor([-0.0720, 0.0666, 1.0336, -0.6965])
y = x[0,:]
y += 1
print(y)
print(x[0, :]) # 源tensor也被改了了
tensor([3.7311, 0.9280, 1.2497])
tensor([3.7311, 0.9280, 1.2497])
- 维度变换
张量的维度变换常见的方法有torch.view()和torch.reshape(),下面我们将介绍torch.view():
x = torch.randn(4, 4)
y = x.view(16)
z = x.view(-1, 8) # -1是指这一维的维数由其他维度决定
print(x.size(), y.size(), z.size())
torch.Size([4, 4]) torch.Size([16]) torch.Size([2, 8])
注: torch.view() 返回的新tensor与源tensor共享内存(其实是同一个tensor),更改其中的一个,另外一个也会跟着改变。(顾名思义,view()仅仅是改变了对这个张量的观察角度)
x += 1
print(x)
print(y) # 也加了了1
tensor([[ 1.3019, 0.3762, 1.2397, 1.3998],[ 0.6891, 1.3651, 1.1891, -0.6744],[ 0.3490, 1.8377, 1.6456, 0.8403],[-0.8259, 2.5454, 1.2474, 0.7884]])
tensor([ 1.3019, 0.3762, 1.2397, 1.3998, 0.6891, 1.3651, 1.1891, -0.6744,0.3490, 1.8377, 1.6456, 0.8403, -0.8259, 2.5454, 1.2474, 0.7884])
- 取值操作
如果我们有一个元素tensor,我们可以使用.item()来获得这个value,而不获得其他性质:
import torch
x = torch.randn(1)
print(type(x))
print(type(x.item()))
<class 'torch.Tensor'>
<class 'float'>
PyTorch中的 Tensor 支持超过一百种操作,包括转置、索引、切片、数学运算、线性代数、随机数等等,具体使用方法可参考官方文档。
2.1.4 广播机制
当对两个形状不同的 Tensor 按元素运算时,可能会触发广播(broadcasting)机制:先适当复制元素使这两个 Tensor 形状相同后再按元素运算。
x = torch.arange(1, 3).view(1, 2)
print(x)
y = torch.arange(1, 4).view(3, 1)
print(y)
print(x + y)
tensor([[1, 2]])
tensor([[1],[2],[3]])
tensor([[2, 3],[3, 4],[4, 5]])
由于x和y分别是1行2列和3行1列的矩阵,如果要计算x+y,那么x中第一行的2个元素被广播 (复制)到了第二行和第三行,⽽y中第⼀列的3个元素被广播(复制)到了第二列。如此,就可以对2个3行2列的矩阵按元素相加。
2.2 自动求导
PyTorch 中,所有神经网络的核心是 autograd 包。autograd包为张量上的所有操作提供了自动求导机制。它是一个在运行时定义 ( define-by-run )的框架,这意味着反向传播是根据代码如何运行来决定的,并且每次迭代可以是不同的。
- autograd的求导机制
- 梯度的反向传播
Autograd简介
torch.Tensor 是这个包的核心类。如果设置它的属性 .requires_grad 为 True,那么它将会追踪对于该张量的所有操作。当完成计算后可以通过调用 .backward(),来自动计算所有的梯度。这个张量的所有梯度将会自动累加到.grad属性。
注意:在 y.backward() 时,如果 y 是标量,则不需要为 backward() 传入任何参数;否则,需要传入一个与 y 同形的Tensor。
要阻止一个张量被跟踪历史,可以调用.detach()方法将其与计算历史分离,并阻止它未来的计算记录被跟踪。为了防止跟踪历史记录(和使用内存),可以将代码块包装在 with torch.no_grad(): 中。在评估模型时特别有用,因为模型可能具有 requires_grad = True 的可训练的参数,但是我们不需要在此过程中对他们进行梯度计算。
还有一个类对于autograd的实现非常重要:Function。Tensor 和 Function 互相连接生成了一个无环图 (acyclic graph),它编码了完整的计算历史。每个张量都有一个.grad_fn属性,该属性引用了创建 Tensor 自身的Function(除非这个张量是用户手动创建的,即这个张量的grad_fn是 None )。
from __future__ import print_function
import torch
x = torch.randn(3,3,requires_grad=True)
print(x.grad_fn)
None
如果需要计算导数,可以在 Tensor 上调用 .backward()。如果 Tensor 是一个标量(即它包含一个元素的数据),则不需要为 backward() 指定任何参数,但是如果它有更多的元素,则需要指定一个gradient参数,该参数是形状匹配的张量。
创建一个张量并设置requires_grad=True用来追踪其计算历史
x = torch.ones(2, 2, requires_grad=True)
print(x)
tensor([[1., 1.],[1., 1.]], requires_grad=True)
对这个张量做一次运算:
y = x**2
print(y)
tensor([[1., 1.],[1., 1.]], grad_fn=<PowBackward0>)
y是计算的结果,所以它有grad_fn属性。
print(y.grad_fn)
<PowBackward0 object at 0x000001CB45988C70>
对 y 进行更多操作
z = y * y * 3
out = z.mean()print(z, out)
tensor([[3., 3.],[3., 3.]], grad_fn=<MulBackward0>) tensor(3., grad_fn=<MeanBackward0>)
.requires_grad_(...) 原地改变了现有张量的requires_grad标志。如果没有指定的话,默认输入的这个标志是 False。
a = torch.randn(2, 2) # 缺失情况下默认 requires_grad = False
a = ((a * 3) / (a - 1))
print(a.requires_grad)
a.requires_grad_(True)
print(a.requires_grad)
b = (a * a).sum()
print(b.grad_fn)
False
True
<SumBackward0 object at 0x000001CB4A19FB50>
2.2.1 梯度
现在开始进行反向传播,因为 out 是一个标量,因此out.backward()和 out.backward(torch.tensor(1.)) 等价。
out.backward()
输出导数 d(out)/dx
print(x.grad)
tensor([[3., 3.],[3., 3.]])
数学上,若有向量函数 y ⃗ = f ( x ⃗ ) \vec{y}=f(\vec{x}) y=f(x),那么 y ⃗ \vec{y} y 关于 x ⃗ \vec{x} x 的梯度就是一个雅可比矩阵:
J = ( ∂ y 1 ∂ x 1 ⋯ ∂ y 1 ∂ x n ⋮ ⋱ ⋮ ∂ y m ∂ x 1 ⋯ ∂ y m ∂ x n ) J=\left(\begin{array}{ccc}\frac{\partial y_{1}}{\partial x_{1}} & \cdots & \frac{\partial y_{1}}{\partial x_{n}} \\ \vdots & \ddots & \vdots \\ \frac{\partial y_{m}}{\partial x_{1}} & \cdots & \frac{\partial y_{m}}{\partial x_{n}}\end{array}\right) J= ∂x1∂y1⋮∂x1∂ym⋯⋱⋯∂xn∂y1⋮∂xn∂ym
而 torch.autograd 这个包就是用来计算一些雅可比矩阵的乘积的。例如,如果 v v v 是一个标量函数 l = g ( y ⃗ ) l = g(\vec{y}) l=g(y) 的梯度:
v = ( ∂ l ∂ y 1 ⋯ ∂ l ∂ y m ) v=\left(\begin{array}{lll}\frac{\partial l}{\partial y_{1}} & \cdots & \frac{\partial l}{\partial y_{m}}\end{array}\right) v=(∂y1∂l⋯∂ym∂l)
由链式法则,我们可以得到:
v J = ( ∂ l ∂ y 1 ⋯ ∂ l ∂ y m ) ( ∂ y 1 ∂ x 1 ⋯ ∂ y 1 ∂ x n ⋮ ⋱ ⋮ ∂ y m ∂ x 1 ⋯ ∂ y m ∂ x n ) = ( ∂ l ∂ x 1 ⋯ ∂ l ∂ x n ) v J=\left(\begin{array}{lll}\frac{\partial l}{\partial y_{1}} & \cdots & \frac{\partial l}{\partial y_{m}}\end{array}\right)\left(\begin{array}{ccc}\frac{\partial y_{1}}{\partial x_{1}} & \cdots & \frac{\partial y_{1}}{\partial x_{n}} \\ \vdots & \ddots & \vdots \\ \frac{\partial y_{m}}{\partial x_{1}} & \cdots & \frac{\partial y_{m}}{\partial x_{n}}\end{array}\right)=\left(\begin{array}{lll}\frac{\partial l}{\partial x_{1}} & \cdots & \frac{\partial l}{\partial x_{n}}\end{array}\right) vJ=(∂y1∂l⋯∂ym∂l) ∂x1∂y1⋮∂x1∂ym⋯⋱⋯∂xn∂y1⋮∂xn∂ym =(∂x1∂l⋯∂xn∂l)
注意:grad在反向传播过程中是累加的(accumulated),这意味着每一次运行反向传播,梯度都会累加之前的梯度,所以一般在反向传播之前需把梯度清零。
# 再来反向传播⼀一次,注意grad是累加的
out2 = x.sum()
out2.backward()
print(x.grad)out3 = x.sum()
x.grad.data.zero_()
out3.backward()
print(x.grad)
tensor([[4., 4.],[4., 4.]])
tensor([[1., 1.],[1., 1.]])
现在我们来看一个雅可比向量积的例子:
x = torch.randn(3, requires_grad=True)
print(x)y = x * 2
i = 0
while y.data.norm() < 1000:y = y * 2i = i + 1
print(y)
print(i)
tensor([-0.9332, 1.9616, 0.1739], requires_grad=True)
tensor([-477.7843, 1004.3264, 89.0424], grad_fn=<MulBackward0>)
8
在这种情况下,y 不再是标量。torch.autograd 不能直接计算完整的雅可比矩阵,但是如果我们只想要雅可比向量积,只需将这个向量作为参数传给 backward:
v = torch.tensor([0.1, 1.0, 0.0001], dtype=torch.float)
y.backward(v)print(x.grad)
tensor([5.1200e+01, 5.1200e+02, 5.1200e-02])
也可以通过将代码块包装在 with torch.no_grad(): 中,来阻止 autograd 跟踪设置了.requires_grad=True的张量的历史记录。
print(x.requires_grad)
print((x ** 2).requires_grad)with torch.no_grad():print((x ** 2).requires_grad)
True
True
False
如果我们想要修改 tensor 的数值,但是又不希望被 autograd 记录(即不会影响反向传播), 那么我们可以对 tensor.data 进行操作。
x = torch.ones(1,requires_grad=True)print(x.data) # 还是一个tensor
print(x.data.requires_grad) # 但是已经是独立于计算图之外y = 2 * x
x.data *= 100 # 只改变了值,不会记录在计算图,所以不会影响梯度传播y.backward()
print(x) # 更改data的值也会影响tensor的值
print(x.grad)
tensor([1.])
False
tensor([100.], requires_grad=True)
tensor([2.])
2.3 并行计算简介
在利用PyTorch做深度学习的过程中,可能会遇到数据量较大无法在单块GPU上完成,或者需要提升计算速度的场景,这时就需要用到并行计算。
- 并行计算的简介
- CUDA简介
- 并行计算的三种实现方式
- 使用CUDA加速训练
2.3.1 为什么要做并行计算
深度学习的发展离不开算力的发展,GPU的出现让我们的模型可以训练的更快,更好。所以,如何充分利用GPU的性能来提高我们模型学习的效果,这一技能是我们必须要学习的。这一节,我们主要讲的就是PyTorch的并行计算。PyTorch可以在编写完模型之后,让多个GPU来参与训练,减少训练时间。
2.3.2 为什么需要CUDA
CUDA是我们使用GPU的提供商——NVIDIA提供的GPU并行计算框架。对于GPU本身的编程,使用的是CUDA语言来实现的。但是,在我们使用PyTorch编写深度学习代码时,使用的CUDA又是另一个意思。在PyTorch使用 CUDA表示要开始要求我们的模型或者数据开始使用GPU了。
在编写程序中,当我们使用了 .cuda() 时,其功能是让我们的模型或者数据从CPU迁移到GPU(0)当中,通过GPU开始计算。
注:
- 我们使用GPU时使用的是
.cuda()而不是使用.gpu()。这是因为当前GPU的编程接口采用CUDA,但是市面上的GPU并不是都支持CUDA,只有部分NVIDIA的GPU才支持,AMD的GPU编程接口采用的是OpenCL,在现阶段PyTorch并不支持。 - 数据在GPU和CPU之间进行传递时会比较耗时,我们应当尽量避免数据的切换。
- GPU运算很快,但是在使用简单的操作时,我们应该尽量使用CPU去完成。
- 当我们的服务器上有多个GPU,我们应该指明我们使用的GPU是哪一块,如果我们不设置的话,tensor.cuda()方法会默认将tensor保存到第一块GPU上,等价于tensor.cuda(0),这将会导致爆出
out of memory的错误。我们可以通过以下两种方式继续设置。-
#设置在文件最开始部分 import os os.environ["CUDA_VISIBLE_DEVICE"] = "2" # 设置默认的显卡 -
CUDA_VISBLE_DEVICE=0,1 python train.py # 使用0,1两块GPU
-
2.3.3 常见的并行的方法:
网络结构分布到不同的设备中(Network partitioning)
在刚开始做模型并行的时候,这个方案使用的比较多。其中主要的思路是,将一个模型的各个部分拆分,然后将不同的部分放入到GPU来做不同任务的计算。其架构如下:
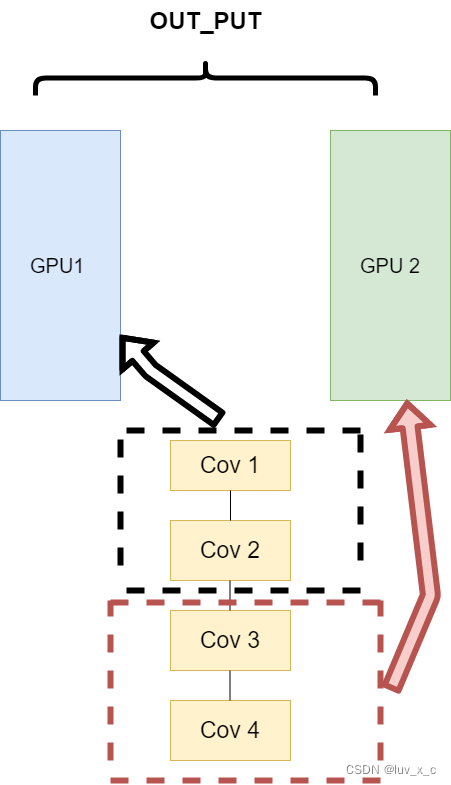
这里遇到的问题就是,不同模型组件在不同的GPU上时,GPU之间的传输就很重要,对于GPU之间的通信是一个考验。但是GPU的通信在这种密集任务中很难办到,所以这个方式慢慢淡出了视野。
同一层的任务分布到不同数据中(Layer-wise partitioning)
第二种方式就是,同一层的模型做一个拆分,让不同的GPU去训练同一层模型的部分任务。其架构如下:
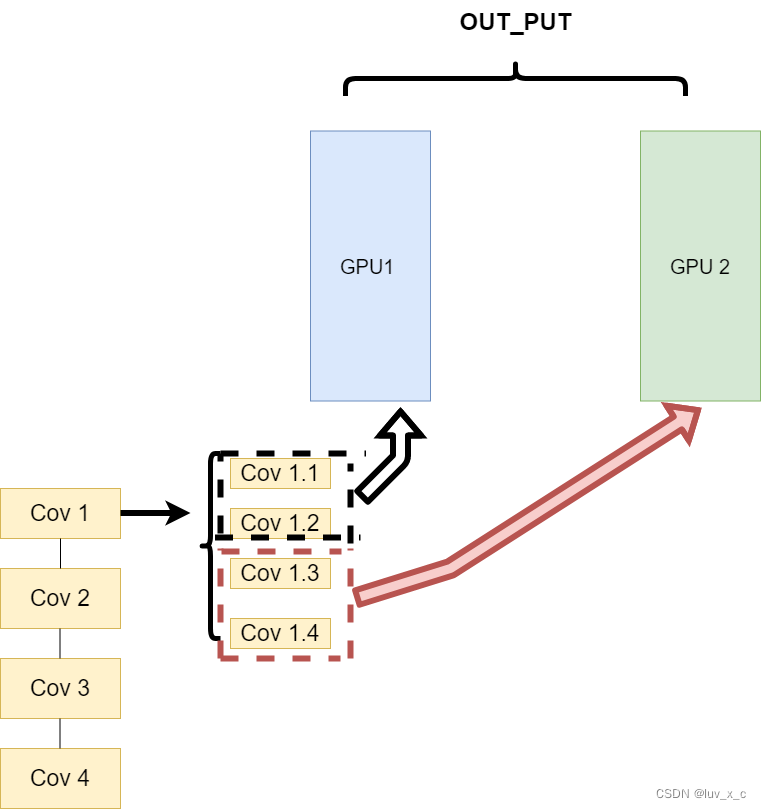
这样可以保证在不同组件之间传输的问题,但是在我们需要大量的训练,同步任务加重的情况下,会出现和第一种方式一样的问题。
不同的数据分布到不同的设备中,执行相同的任务(Data parallelism)
第三种方式有点不一样,它的逻辑是,我不再拆分模型,我训练的时候模型都是一整个模型。但是我将输入的数据拆分。所谓的拆分数据就是,同一个模型在不同GPU中训练一部分数据,然后再分别计算一部分数据之后,只需要将输出的数据做一个汇总,然后再反传。其架构如下:
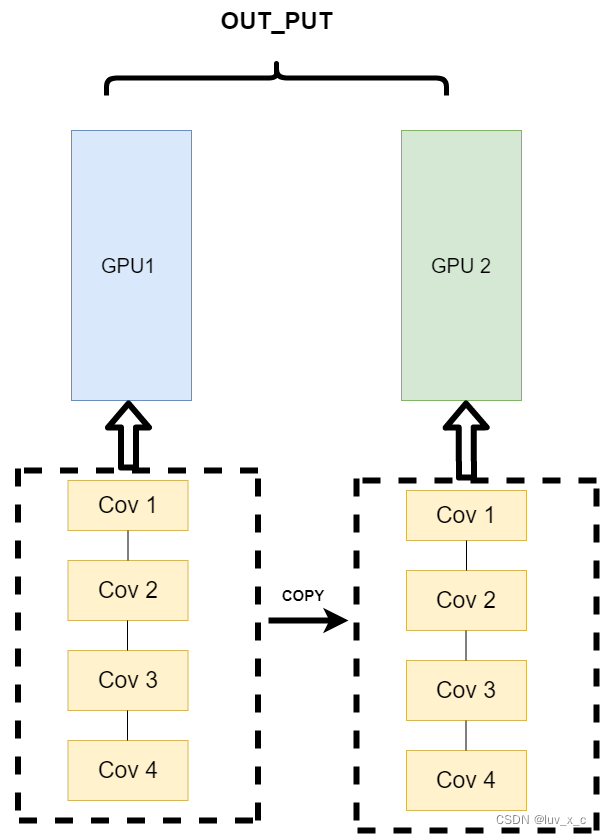
这种方式可以解决之前模式遇到的通讯问题。现在的主流方式是数据并行的方式(Data parallelism)
2.3.4 使用CUDA加速训练
在PyTorch框架下,CUDA的使用变得非常简单,我们只需要显式的将数据和模型通过.cuda()方法转移到GPU上就可加速我们的训练,在此处我们仅讨论单卡的情况下,后续我们会介绍多卡训练的使用方法。
model = Net()
model.cuda() # 模型显示转移到CUDA上for image,label in dataloader:# 图像和标签显示转移到CUDA上image = image.cuda() label = label.cuda()
相关文章:
pytorch(续周报(1))
文章目录 2.1 张量2.1.1 简介2.1.2 创建tensor2.1.3 张量的操作2.1.4 广播机制 2.2 自动求导Autograd简介2.2.1 梯度 2.3 并行计算简介2.3.1 为什么要做并行计算2.3.2 为什么需要CUDA2.3.3 常见的并行的方法:网络结构分布到不同的设备中(Network partitioning)同一层…...

el-table 树形结构数据 设置某一层,新增按钮不展示
<template><div><el-table:data"tableData":row-class-name"rowClassName":tree-props"{ children: children, hasChildren: hasChildren }"><!-- 表格列定义 --><!-- ... --><el-table-column label"操作…...

【Unity2D】粒子特效
为什么要使用粒子特效 Unity 的粒子系统是一种非常强大的工具,可以用来创建各种各样的游戏特效,如火焰、烟雾、水流、爆炸等等。使用粒子特效可以使一些游戏动画更加真实或者使游戏效果更加丰富。 粒子特效的使用 在Hierarchy界面右键添加Effects->…...

第九十六回 网络综合示例:获取天气信息
文章目录 概念介绍使用方法示例代码 我们在上一章回中介绍了dio库中转换器相关的内容,本章回中将介绍网络综合示例:获取天气信息.闲话休提,让我们一起Talk Flutter吧。 概念介绍 我们在前面章回中介绍了网络操作相关的内容,本章…...

Shell中获取昨天和多天前日期
1、获取今天日期 $ date -d now %Y-%m-%d 或者 $ date %F2、获取明天日期 $ date -d next-day %Y-%m-%d $ date -d tomorrow %Y-%m-%d3、获取昨天日期 $ date -d yesterday %Y-%m-%d 或者 $ date -d last-day %Y-%m-%d 或者 $ date -d "1 days ago" %Y-%m-%d …...

golang静态编译及编译失败排查步骤
文章目录 一、背景前提 二、静态编译概述1、执行静态编译设置CGO_ENABLED方式指定link方式 2、编译报错分析(1)确认系统上有没有安装libopus(2)设置LD_LIBRARY_PATH 三、详细排查过程1、下载bpf排查工具bcc, bcc-tools,python-bcc…...
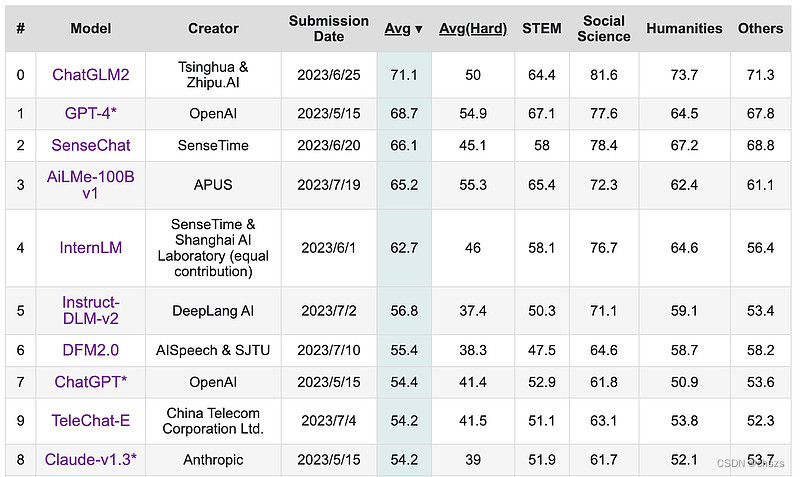
2023年7月第4周大模型荟萃
2023年7月第4周大模型荟萃 2023.7.31版权声明:本文为博主chszs的原创文章,未经博主允许不得转载。 1、Cerebras推出全球最强AI超算 AI芯片初创公司Cerebras Systems和总部位于阿联酋的技术控股集团G42于7月20日宣布,携手打造一个由互联的超…...
Meta分析的选题与文献计量分析CiteSpace应用丨R语言Meta分析【数据清洗、精美作图、回归分析、诊断分析、不确定性及贝叶斯应用】
目录 专题一、Meta分析的选题与文献计量分析CiteSpace应用 专题二、Meta分析与R语言数据清洗及相关应用 专题三、R语言Meta分析与精美作图 专题四、R语言Meta回归分析 专题五、R语言Meta诊断分析与进阶 专题六、R语言Meta分析的不确定性及贝叶斯应用 专题七、深度拓展…...
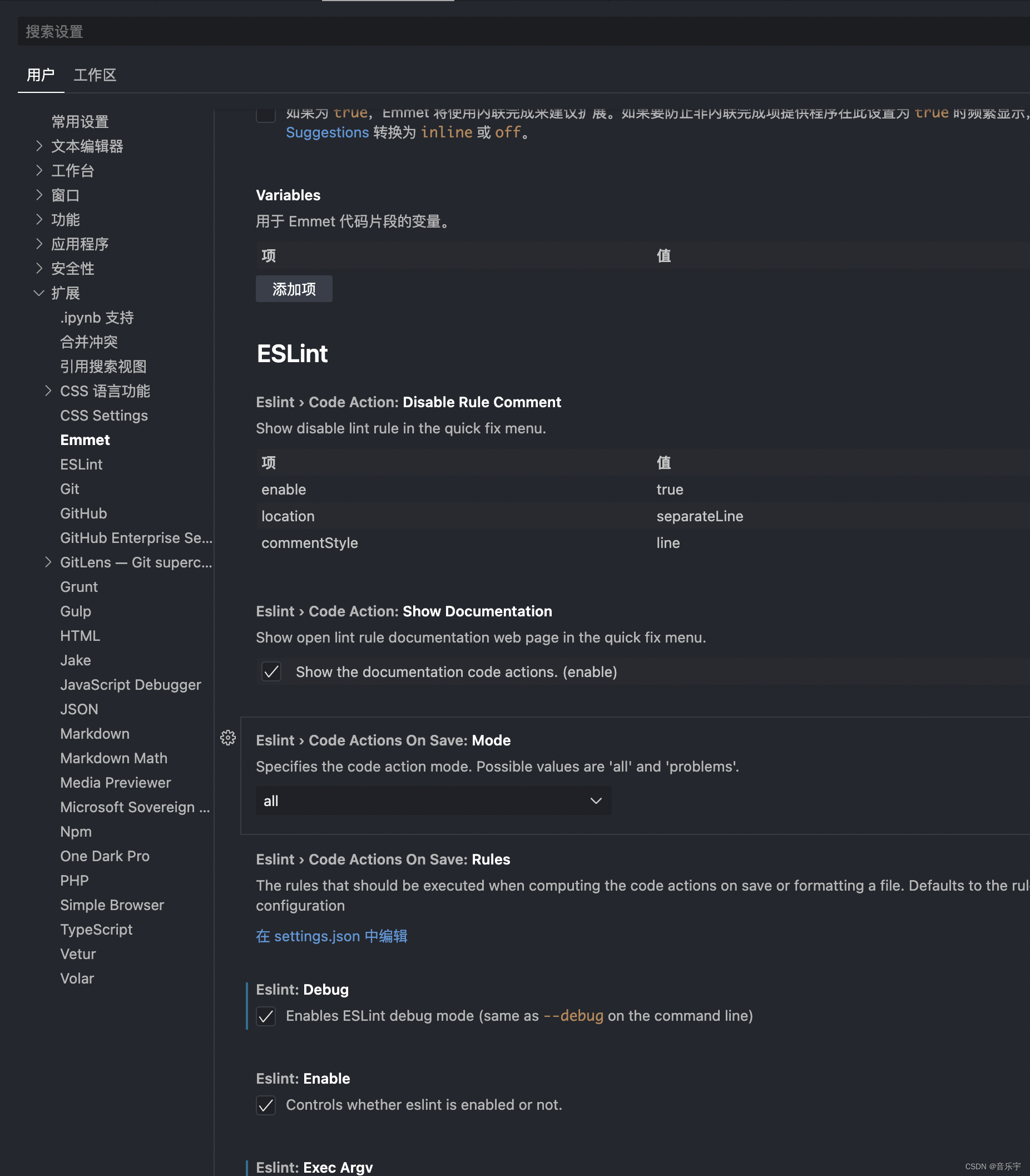
vscode eslint配置
1. 全局安装 eslint npm install -g eslint 2. control shift p 输入 settings 打开设置进行配置 3. 添加配置 {"workbench.colorTheme": "One Dark Pro","eslint.debug": true,"eslint.execArgv": null,"eslint.alwaysShow…...

C++ 对象模型 C++ Object Model
C 对象模型 C Object Model 文章目录 C 对象模型 C Object ModelC语言的数据及函数C的类C对象模型 C语言的数据及函数 C语言中,数据和函数是分开声明的。 数据 typedef struct point2d {float x;float y; } Point2d;函数 打印Point2d的数值 void Point2d_print…...

leetcode做题笔记47
给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。 思路一:回溯 int* Source NULL; int Source_Size 0;int** Result NULL; int* Retcolsizes NULL; int Result_Index 0;int* Path NULL; int Path_Index 0;bool* Used …...
Linux Day04
目录 一、文件压缩与解压命令 1.1 tar cvf 文件名 ---打包命令生成.tar 1.2 tar xvf 文件名 ----解开包 生成文件 1.3 gzip .tar 压缩 生成.tar.gz压缩包 1.4 gzip -d .tar.gz 解压成包 1.5 直接把压缩包解压成文件 tar zxf .tar.gz 二、Linux 系统上 C 程序的…...

上海亚商投顾:沪指冲高回落 两市成交重回万亿
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 市场情绪 三大指数今日冲高回落,盘初一度集体涨超1%,随后涨幅明显回落,上证50午后一度翻…...
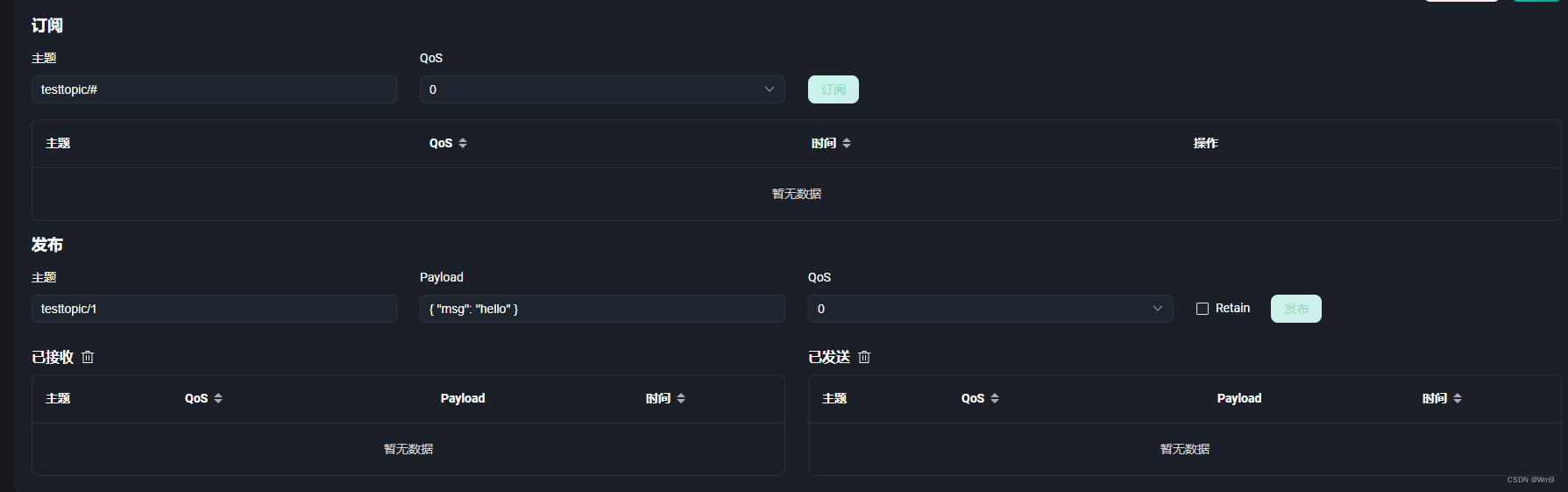
2023最新版本~十分钟零基础搭建EMQX服务器
购买服务器 已知服务器大厂商 1 阿里云 点击直接访问 2 华为云点击直接访问 3 腾讯云 点击直接访问 还是比较推荐大公司 不会跑路 这里我购买的是一年的华为云服务器(新用户 64一年) 镜像推荐乌班图18 登陆服务器(需要重置密码!!&…...

SpringBoot2.5.6整合Elasticsearch7.12.1
SpringBoot2.5.6整合Elasticsearch7.12.1 下面将通过SpringBoot整合Elasticseach,SpringBoot的版本是2.5.6,Elasticsearch的版本是7.12.1。 SpringBoot整合Elasticsearch主要有三种方式,一种是通过elasticsearch-rest-high-level-client&am…...

准大一信息安全/网络空间安全专业学习规划
如何规划? 学习需要一个良好的学习习惯,建议刚开始一定要精通一项程序语言,学习其他的就会一通百通。过程中是按步骤学习,绝不半途看见苹果丢了梨,一定要强迫自己抵制新鲜技术的诱惑。 网络安全其实是个广而深的领域…...
WEB:php_rce
背景知识 Linux命令 thinkPHPv5漏洞 题目 打开页面,页面显示为thinkphp v5的界面,可以判断框架为thinkPHP,可以去网上查找相关的漏洞 由题目可知,php rec是一个通过远程代码执行漏洞来攻击php程序的一种方式 因为不知道是php版…...

问题:idea启动项目错误提示【command line is too long. shorten command line】
问题:idea启动项目错误提示【command line is too long. shorten command line】 参考博客 问题描述 启动参数过长,启动项目,错误提示 原因分析 出现此问题的直接原因是:IDEA集成开发环境运行你的“源码”的时候(…...

xshell连接Windows中通过wsl安装的linux子系统-Ubuntu 22.04
xshell连接Windows中通过wsl安装的linux子系统-Ubuntu 22.04 一、安装linux子系统 1.1、 启动或关闭Windows功能-适用于Linux的Windows子系统 1.2 WSL 官方文档 使用 WSL 在 Windows 上安装 Linux //1-安装 WSL 命令 wsl --install//2-检查正在运行的 WSL 版本:…...
子域名收集工具OneForAll的安装与使用-Win
子域名收集工具OneForAll的安装与使用-Win OneForAll是一款功能强大的子域名收集工具 GitHub地址:https://github.com/shmilylty/OneForAll Gitee地址:https://gitee.com/shmilylty/OneForAll 安装 1、python环境准备 OneForAll基于Python 3.6.0开发和…...

硬件工程选型解析:钡特电源VB6-48S03MD与金升阳URB4803YMD-6WR3属工业标准模块电源
在工业硬件研发、设备调试与批量量产过程中,小功率隔离供电模块的稳定性、封装规范性与工况适配性,是硬件研发工程师重点核查的核心参数,直接决定工控终端、通信设备与电力监测装置的运行稳定性。在6W级48V转3.3V主流供电方案中,钡…...

JWT密钥轮换静默失效的热修复实战指南
1. 这不是漏洞公告,而是一份热修复作战手册Seedance2.0 v2.0.3上线刚满72小时,我们团队在灰度环境做JWT签名校验一致性压测时,发现一个反直觉现象:新签发的token在旧服务节点上能通过验签,但旧token在新节点上却频繁失…...

Selenium Cookie复用登录态实战指南
1. 这不是“绕过”,而是“复用登录态”——先厘清一个关键认知误区很多人看到“Selenium通过cookie绕过验证码”这个标题,第一反应是:又一个黑灰产技巧?能省事就上?但我在电商、金融、SaaS类项目里带团队做自动化测试近…...

awesome-regex终极指南:10个必备正则表达式工具和库
awesome-regex终极指南:10个必备正则表达式工具和库 【免费下载链接】awesome-regex A curated collection of awesome Regex libraries, tools, frameworks and software 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-regex 正则表达式(…...

多图像查看器:告别繁琐切换,高效管理海量图片的专业解决方案
多图像查看器:告别繁琐切换,高效管理海量图片的专业解决方案 【免费下载链接】MulimgViewer MulimgViewer is a multi-image viewer that can open multiple images in one interface, which is convenient for image comparison and image stitching. …...
与少样本(Few-shot)提示在用例生成中的对比)
【Prompt实战】零样本(Zero-shot)与少样本(Few-shot)提示在用例生成中的对比
目录 一、开篇:一个测试工程师的真实困境 二、基础概念:零样本与少样本的本质区别 三、学术界怎么说:最新实证研究深度解读...

3D格式转换神器:如何用stltostp轻松实现STL到STEP的无缝转换
3D格式转换神器:如何用stltostp轻松实现STL到STEP的无缝转换 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 你是否曾经遇到这样的困境?精心设计的3D打印模型在STL格式下…...

职场痛点|同事甩锅、摸鱼划水,干活全靠自己?3步破局不内耗
职场痛点|同事甩锅、摸鱼划水,干活全靠自己?3步破局不内耗相信很多职场人都有过这样的崩溃瞬间:明明是团队协作的任务,同事要么全程摸鱼划水,不干活、不配合,要么出了问题就第一时间甩锅&#x…...

罗技鼠标宏逆向工程:PUBG后坐力补偿系统的架构设计与实现
罗技鼠标宏逆向工程:PUBG后坐力补偿系统的架构设计与实现 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 在竞技射击游戏中ÿ…...

西方垃圾思维在中国 AI 大模型中的渗透机制与贾子理论替代范式研究
西方垃圾思维在中国 AI 大模型中的渗透机制与贾子理论替代范式研究摘要: 西方垃圾思维(WCG)正通过“伪自主”模式深度渗透中国主流AI大模型。百度文心、讯飞星火等模型表面宣称“自主研发”“遵循社会主义核心价值观”,实则借助标…...