自监督去噪:Noise2Noise原理及实现(Pytorch)

文章地址:https://arxiv.org/abs/1803.04189
ICML github 代码: https://github.com/NVlabs/noise2noise
本文整理和参考代码: https://github.com/shivamsaboo17/Deep-Restore-PyTorch
文章目录
- 1. 理论背景
- 2. 实验结果
- 3. 代码实现
- (1) 网络结构
- (2) 数据加载
- (3) 网络训练
- (4) 完整流程
- 4. 总结
文章核心句子: ‘learn to turn bad images into good images by only looking at bad images, and do this just as well, sometimes even better.’
1. 理论背景
如果有一系列观测不怎么精确的数据(y1,y2…yn),想要得到一个可信的结果最简单的方法就是让这些观测数据的 “方差”(可以是其他度量)最小
a r g m i n z E y { L ( z , y ) } \underset{z}{argmin} E_y \{ L(z,y)\} zargminEy{L(z,y)}
不同的损失函数这里查找的最优位置不同:
- L2 损失, L ( z , y ) = ( z − y ) 2 L(z,y) = (z-y)^2 L(z,y)=(z−y)2的时候,最优位置是期望
z = E y { y } z = E_y \{ y\} z=Ey{y} - L1 损失, L ( z , y ) = ∣ z − y ∣ L(z,y) = |z-y| L(z,y)=∣z−y∣,最优值就是中值位置 z = m e d i a n { y } z = median \{y \} z=median{y}
- L0损失, L ( z , y ) = ∣ z − y ∣ 0 L(z,y) = |z-y|_0 L(z,y)=∣z−y∣0, 最优值是众数, z = m o d e { y } z = mode\{ y\} z=mode{y}
将这里的z用网络进行表示
a r g m i n θ E ( x , y ) { L ( f θ ( x ) ) , y } \underset{\theta}{argmin} E_{(x,y)} \{ L(f_{\theta}(x)),y \} θargminE(x,y){L(fθ(x)),y}
通过贝叶斯变换也等价于
a r g m i n θ E x { E y ∣ x { L ( f θ ( x ) , y ) } } \underset{\theta}{argmin} E_x \{ E_{y|x} \{ L(f_{\theta}(x), y)\} \} θargminEx{Ey∣x{L(fθ(x),y)}}
理论上可通过优化每一个噪声图像对 ( x i , y i x_i,y_i xi,yi) 得到一个最好的拟合器 f θ f_{\theta} fθ ,但这是一个多解且不稳定的过程。比如对于一个超分辨问题来说,对于每一个输入的低分辨图像,其可能对应于多张高分辨图像,或者说多张高分辨图像的下采样可能对应同一张图像。而在高低分辨率的图像对上,使用L2损失函数训练网络,网络会学习到输出所有结果的平均值。这也是我们想要的,如果网络经过优化之后,输出的结果不是和 x i x_i xi一一对应的,而是在一个范围内的随机值,该范围的期望是 y i y_i yi。
- 当网络还没有收敛的时候,其解空间大,方差大,得到的 y i y_i yi偏离真实结果很多
- 而充分训练的网络,解空间变小,方差小,得到的 y i y_i yi接近真实结果
- 解空间的大小不会随着训练的增加而无限减小,但其期望/均值总是不变的
那么上面的结论也就告诉我们,如果用一个期望和目标相匹配的随机数替换原始目标,那么其估计值是将保持不变的。也就是说如果输入条件目标分布 p ( y ∣ x ) p(y|x) p(y∣x)被具有相同条件期望值的任意分布替换,最佳网络参数是保持不变的。训练的目标表示为
a r g m i n θ ∑ i L ( f θ ( x i ^ ) , y i ^ ) \underset{\theta}{argmin} \sum_i L(f_{\theta}(\hat{x_i}),\hat{y_i}) θargmini∑L(fθ(xi^),yi^)
其中,输出和目标都是来自于有噪声的分布,其满足 E { y i ^ ∣ x i ^ } = y i E\{ \hat{y_i} | \hat{x_i} \} = y_i E{yi^∣xi^}=yi
当给定的训练数据足够多的时候,该目标函数的解和原目标函数是相同的.当训练数据有限的时候,估计的均方误差等于目标中的噪声平方差除以训练样例数目
E y ^ [ 1 N ∑ i y i − 1 N ∑ i y i ^ ] 2 = 1 N [ 1 N ∑ i v a r ( y i ) ] E_{\hat{y}} [\frac{1}{N} \sum_i y_i - \frac{1}{N} \sum_i \hat{y_i}]^2 = \frac{1}{N}[\frac{1}{N} \sum_i var(y_i)] Ey^[N1i∑yi−N1i∑yi^]2=N1[N1i∑var(yi)]
- 随着样本数量的增加,误差将接近于0。
- 即使数量有限,估计也是无偏的。
方法总结:
- 强行让NN学习两张 零均值噪声图片之间的映射关系
- 样本数量少:学习了两种零均值噪声的映射变换
- 样本数量多:噪声不可预测,需要最小化loss,NN倾向于输出所有可能的期望值,也就是干净图片
2. 实验结果
(1) 不同噪声:高斯噪声、poisson噪声、Bernoulli噪声

(2) 不同场景:图去文字、脉冲噪声

3. 代码实现
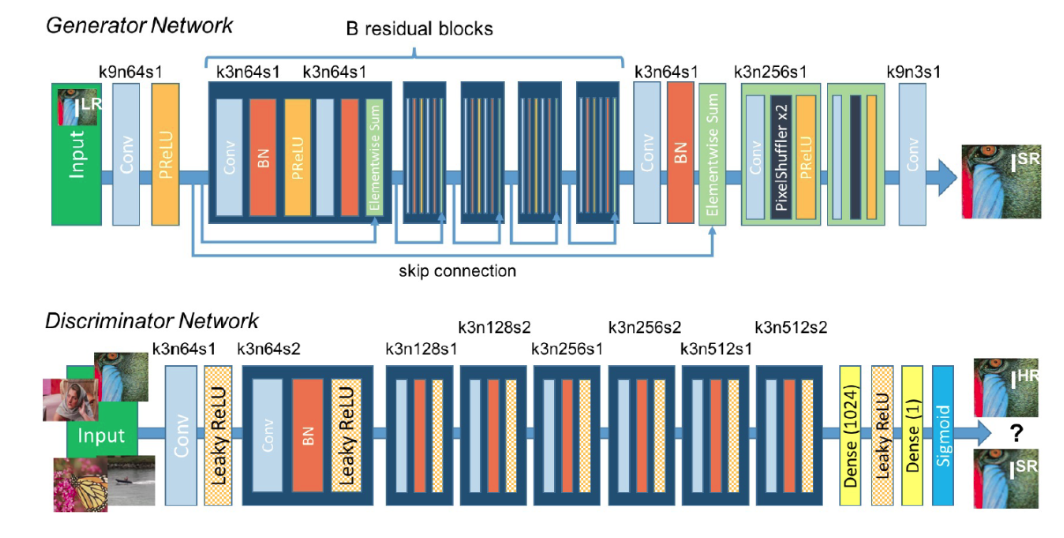
(1) 网络结构
SRResNet模型结构: SRGAN 图像超分辨率结构
import torch
import torch.nn as nn
import torch.nn.functional as Fclass ConvBlock(nn.Module):def __init__(self,input_channels,output_channels,kernel_size,stride=1,pad=1,use_act=True):super(ConvBlock,self).__init__()self.use_act = use_actself.conv = nn.Conv2d(input_channels,output_channels,kernel_size,stride=stride,padding=pad)self.bn = nn.BatchNorm2d(output_channels)self.act = nn.LeakyReLU(0.2,inplace=True)def forward(self,x):"""conv2dbatch normalizationPReLU"""op = self.bn(self.conv(x))if self.use_act:return self.act(op)else:return op class ResBlock(nn.Module):def __init__(self,input_channels,output_channels,kernel_size):super(ResBlock,self).__init__()self.block1 = ConvBlock(input_channels,output_channels,kernel_size)self.block2 = ConvBlock(input_channels,output_channels,kernel_size,use_act=False)def forward(self,x):"""conv2dBNPReLUconv2dBNelement sum (residule skip connection)"""return x + self.block2(self.block1(x))class SRResnet(nn.Module):def __init__(self,input_channels,output_channels,res_layers=16):super(SRResnet,self).__init__()self.conv1 = nn.Conv2d(input_channels,output_channels,kernel_size=3,stride=1,padding=1)self.act = nn.LeakyReLU(0.2,inplace=True)_resl = [ResBlock(output_channels,output_channels,3) for i in range(res_layers)]self.resl = nn.Sequential(*_resl)self.conv2 = ConvBlock(output_channels,output_channels,3,use_act=False)self.conv3 = nn.Conv2d(output_channels,input_channels,kernel_size=3,stride=1,padding=1)def forward(self,input):_op1 = self.act(self.conv1(input))_op2 = self.conv2(self.resl(_op1))op = self.conv3(torch.add(_op1,_op2))return opmodel = SRResnet(3,64)
model(2) 数据加载
这里用的数据是从 https://github.com/shivamsaboo17/Deep-Restore-PyTorch 下载的coco2017的数据,当然也可以从官网下载,然后将数据分为 train 和 valid两个部分。
这里准备的噪声数据有四种不同的方法,也是对应的文章中的内容
- gaussian
- poisson
- multiplicative_bernoulli
- text
from torch.utils.data import Dataset,DataLoader
import torchvision.transforms.functional as tvF
from PIL import Image,ImageFont,ImageDraw
from random import choice
from sys import platform
from random import choice
from string import ascii_letters
import numpy as np
import os
import scipy
import cv2
import random
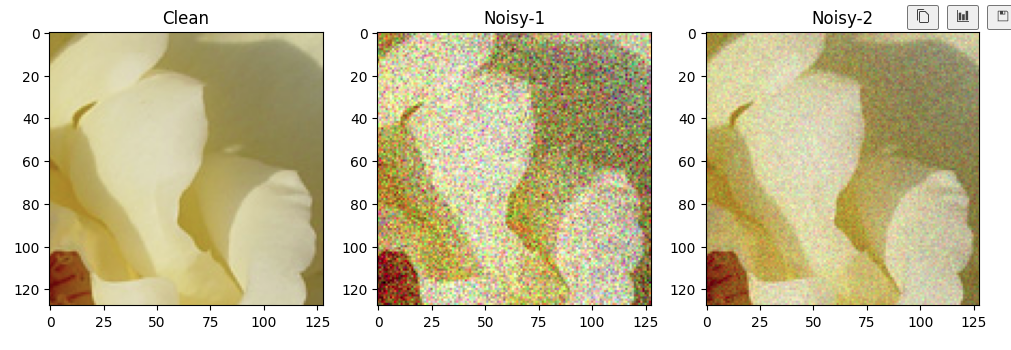
import matplotlib.pyplot as pltclass NoisyDataset(Dataset):def __init__(self, root_dir, crop_size=128, train_noise_model=('gaussian', 50), clean_targ=False):"""root_dir: Path of image directorycrop_size: Crop image to given sizeclean_targ: Use clean targets for training"""self.root_dir = root_dirself.crop_size = crop_sizeself.clean_targ = clean_targself.noise = train_noise_model[0]self.noise_param = train_noise_model[1]self.imgs = os.listdir(root_dir)def _random_crop_to_size(self, imgs):w, h = imgs[0].sizeassert w >= self.crop_size and h >= self.crop_size, 'Cannot be croppped. Invalid size'cropped_imgs = []i = np.random.randint(0, h - self.crop_size + 2)j = np.random.randint(0, w - self.crop_size + 2)for img in imgs:if min(w, h) < self.crop_size:img = tvF.resize(img, (self.crop_size, self.crop_size))cropped_imgs.append(tvF.crop(img, i, j, self.crop_size, self.crop_size))#cropped_imgs = cv2.resize(np.array(imgs[0]), (self.crop_size, self.crop_size))return cropped_imgsdef _add_gaussian_noise(self, image):"""Added only gaussian noise"""w, h = image.sizec = len(image.getbands())std = np.random.uniform(0, self.noise_param)_n = np.random.normal(0, std, (h, w, c))noisy_image = np.array(image) + _nnoisy_image = np.clip(noisy_image, 0, 255).astype(np.uint8)return {'image':Image.fromarray(noisy_image), 'mask': None, 'use_mask': False}def _add_poisson_noise(self, image):"""Added poisson Noise"""noise_mask = np.random.poisson(np.array(image))#print(noise_mask.dtype)#print(noise_mask)return {'image':noise_mask.astype(np.uint8), 'mask': None, 'use_mask': False}def _add_m_bernoulli_noise(self, image):"""Multiplicative bernoulli"""sz = np.array(image).shape[0]prob_ = random.uniform(0, self.noise_param)mask = np.random.choice([0, 1], size=(sz, sz), p=[prob_, 1 - prob_])mask = np.repeat(mask[:, :, np.newaxis], 3, axis=2)return {'image':np.multiply(image, mask).astype(np.uint8), 'mask':mask.astype(np.uint8), 'use_mask': True}def _add_text_overlay(self, image):"""Add text overlay to image"""assert self.noise_param < 1, 'Text parameter should be probability of occupancy'w, h = image.sizec = len(image.getbands())if platform == 'linux':serif = '/usr/share/fonts/truetype/dejavu/DejaVuSerif.ttf'else:serif = 'Times New Roman.ttf'text_img = image.copy()text_draw = ImageDraw.Draw(text_img)mask_img = Image.new('1', (w, h))mask_draw = ImageDraw.Draw(mask_img)max_occupancy = np.random.uniform(0, self.noise_param)def get_occupancy(x):y = np.array(x, np.uint8)return np.sum(y) / y.sizewhile 1:font = ImageFont.truetype(serif, np.random.randint(16, 21))length = np.random.randint(10, 25)chars = ''.join(choice(ascii_letters) for i in range(length))color = tuple(np.random.randint(0, 255, c))pos = (np.random.randint(0, w), np.random.randint(0, h))text_draw.text(pos, chars, color, font=font)# Update mask and check occupancymask_draw.text(pos, chars, 1, font=font)if get_occupancy(mask_img) > max_occupancy:breakreturn {'image':text_img, 'mask':None, 'use_mask': False}def corrupt_image(self, image):if self.noise == 'gaussian':return self._add_gaussian_noise(image)elif self.noise == 'poisson':return self._add_poisson_noise(image)elif self.noise == 'multiplicative_bernoulli':return self._add_m_bernoulli_noise(image)elif self.noise == 'text':return self._add_text_overlay(image)else:raise ValueError('No such image corruption supported')def __getitem__(self, index):"""Read a image, corrupt it and return it"""img_path = os.path.join(self.root_dir, self.imgs[index])image = Image.open(img_path).convert('RGB')# 对图片进行随机切割if self.crop_size > 0:image = self._random_crop_to_size([image])[0]# 噪声图片1source_img_dict = self.corrupt_image(image)source_img_dict['image'] = tvF.to_tensor(source_img_dict['image'])if source_img_dict['use_mask']:source_img_dict['mask'] = tvF.to_tensor(source_img_dict['mask'])# 噪声图片2if self.clean_targ:#print('clean target')target = tvF.to_tensor(image)else:#print('corrupt target')_target_dict = self.corrupt_image(image)target = tvF.to_tensor(_target_dict['image'])image = np.array(image).astype(np.uint8)if source_img_dict['use_mask']:return [source_img_dict['image'], source_img_dict['mask'], target,image]else:return [source_img_dict['image'], target, image]def __len__(self):return len(self.imgs)也可以对数据进行查看
data = NoisyDataset("./dataset/train/", crop_size=128) # Default gaussian noise without clean targets
dl = DataLoader(data, batch_size=1, shuffle=True)index = 10
[img_noise1,img_noise2,img] = data.__getitem__(index)plt.figure(figsize=(12,4))
plt.subplot(131)
plt.imshow(img)
plt.title("Clean")
plt.subplot(132)
plt.imshow(np.transpose(img_noise1,(1,2,0)))
plt.title("Noisy-1")
plt.subplot(133)
plt.imshow(np.transpose(img_noise2,(1,2,0)))
plt.title("Noisy-2")
plt.show()
(3) 网络训练
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
import torch.nn.functional as F
from torch.optim import lr_scheduler
from tqdm import tqdm
import matplotlib.pyplot as plt
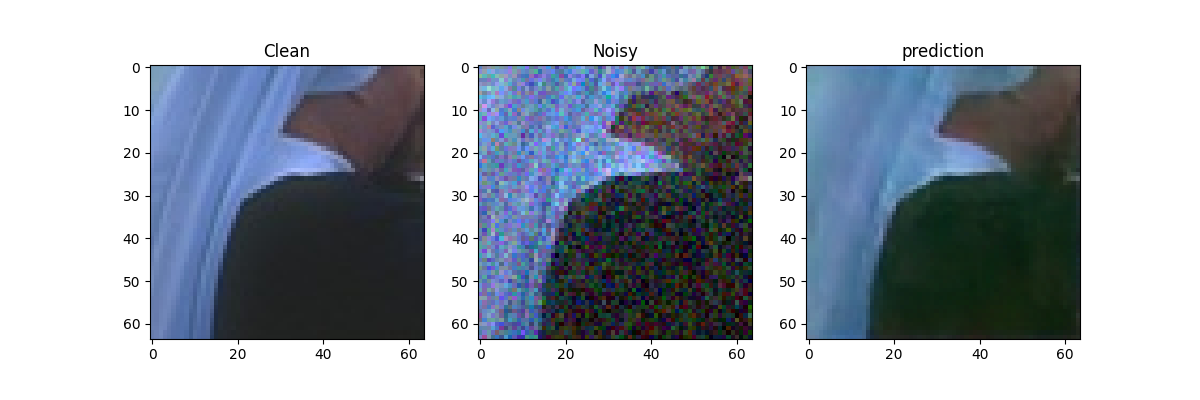
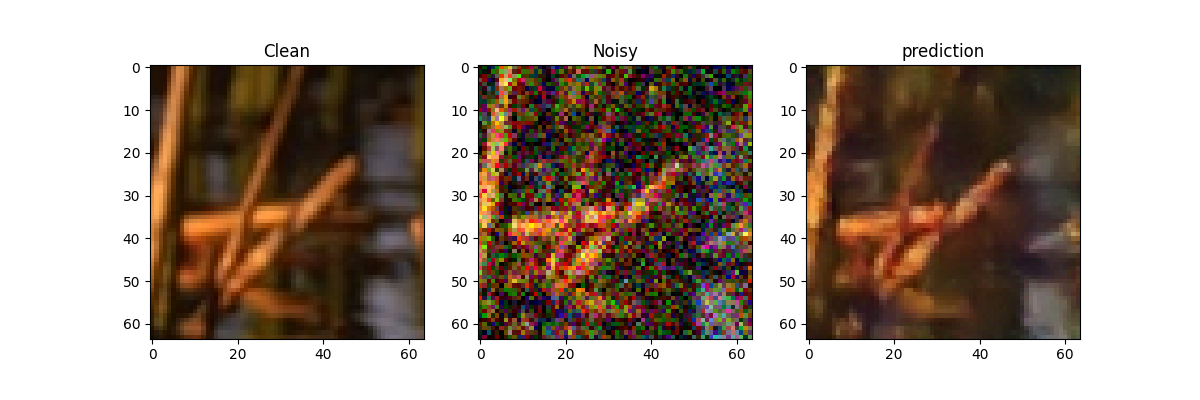
import numpy as npclass Train():def __init__(self,model,train_dir,val_dir,params) -> None:self.cuda = params['cuda']if self.cuda:self.model = model.cuda()else:self.model = modelself.train_dir = train_dirself.val_dir = val_dir# how to add noise: gaussian/poison/ text self.noise_model = params['noise_model'] self.crop_size = params['crop_size']# pair with noise figure or clean figureself.clean_targs = params['clean_targs']self.lr = params['lr']self.epochs = params['epochs']# Wbatch sizeself.bs = params['bs']self.train_dl, self.val_dl = self.__getdataset__()self.optimizer = self.__getoptimizer__()self.scheduler = self.__getscheduler__()self.loss_fn = self.__getlossfn__(params['lossfn'])def __getdataset__(self):train_ds = NoisyDataset(self.train_dir, crop_size=self.crop_size, train_noise_model=self.noise_model,clean_targ=self.clean_targs)train_dl = DataLoader(train_ds, batch_size=self.bs, shuffle=True)val_ds = NoisyDataset(self.val_dir, crop_size=self.crop_size, train_noise_model=self.noise_model,clean_targ=True)val_dl = DataLoader(val_ds, batch_size=self.bs)return train_dl, val_dldef __getoptimizer__(self):return optim.Adam(self.model.parameters(), self.lr)def __getscheduler__(self):return lr_scheduler.ReduceLROnPlateau(self.optimizer, patience=self.epochs/4, factor=0.5, verbose=True)def __getlossfn__(self, lossfn):if lossfn == 'l2':return nn.MSELoss()elif lossfn == 'l1':return nn.L1Loss()else:raise ValueError('No such loss function supported')def evaluate(self):val_loss = 0self.model.eval()for _, valid_datalist in enumerate(self.val_dl):if self.cuda:source = valid_datalist[0].cuda()target = valid_datalist[-2].cuda()else:source = valid_datalist[0]target = valid_datalist[-2]_op = self.model(Variable(source))if len(valid_datalist) == 4:if self.cuda:mask = Variable(valid_datalist[1].cuda())else:mask = Variable(valid_datalist[1])_loss = self.loss_fn(mask * _op, mask * Variable(target))else:_loss = self.loss_fn(_op, Variable(target))val_loss += _loss.datareturn val_lossdef train(self):pbar = tqdm(range(self.epochs))for i in pbar:tr_loss = 0# train modeself.model.train()for train_datalist in self.train_dl:# the the pair noise dataif self.cuda:source = train_datalist[0].cuda()target = train_datalist[-2].cuda()else:source = train_datalist[0]target = train_datalist[-2]# train the nueral network_op = self.model(Variable(source))# if use the "multiplicative_bernoulli" just calculate the difference with the masked placeif len(train_datalist) == 4:if self.cuda:mask = Variable(train_datalist[1].cuda())else:mask = Variable(train_datalist[1])_loss = self.loss_fn(mask * _op, mask * Variable(target))else:_loss = self.loss_fn(_op, Variable(target))tr_loss += _loss.dataself.optimizer.zero_grad()_loss.backward()self.optimizer.step()val_loss = self.evaluate()#self.scheduler.step(val_loss)pbar.set_description('Train loss: {:.4f}, Val loss: {:.4f}'.format(tr_loss,val_loss))# save temp reusltwith torch.no_grad():if i%50==0:source = train_datalist[0].cuda()pred = self.model(Variable(source))img = train_datalist[-1].cuda()plt.figure(figsize=(12,4))plt.subplot(131)plt.imshow(torch.squeeze(img[0]).cpu().detach().numpy())plt.title("Clean")plt.subplot(132)plt.imshow(np.transpose(torch.squeeze(source[0]).cpu().detach().numpy(),(1,2,0)))plt.title("Noisy")plt.subplot(133)plt.imshow(np.transpose(torch.squeeze(abs(pred[0])).cpu().detach().numpy(),(1,2,0)))plt.title("prediction")if not os.path.exists("./result/{}".format(self.noise_model[0]+"_"+str(self.noise_model[1]))):os.makedirs("./result/{}".format(self.noise_model[0]+"_"+str(self.noise_model[1])))plt.savefig("./result/{}/{}.png".format(self.noise_model[0]+"_"+str(self.noise_model[1]),i))plt.close()(4) 完整流程
model = SRResnet(3, 64)params = {'noise_model': ('gaussian', 50),'crop_size': 64,'clean_targs': False,'lr': 0.001,'epochs': 1000,'bs': 32,'lossfn': 'l2','cuda': True
}trainer = Train(model, 'dataset/train/', 'dataset/valid/', params)
4. 总结
方法:
- 强行让NN学习两张 零均值噪声图片之间的映射关系
- 样本数量少:学习了两种零均值噪声的映射变换
- 样本数量多:噪声不可预测,需要最小化loss,NN倾向于输出所有可能的期望值,也就是干净图片
结果:
- 对于DIP、Self2Self的方法,不需要估计图像的先验信息、对噪声图像进行似然估计
- 对于监督学习方法,无需干净图像,只需要噪声数据对
- 性能有的时候回超过监督训练方法
问题:
- 当损失函数和噪声不匹配的时候,该方法训练的模型误差较大
- 均值为0的假设太强,很难进行迁移、范围性有限
相关文章:
自监督去噪:Noise2Noise原理及实现(Pytorch)
文章地址:https://arxiv.org/abs/1803.04189 ICML github 代码: https://github.com/NVlabs/noise2noise 本文整理和参考代码: https://github.com/shivamsaboo17/Deep-Restore-PyTorch 文章目录 1. 理论背景2. 实验结果3. 代码实现(1) 网络结构(2) 数据加载(3) 网络…...
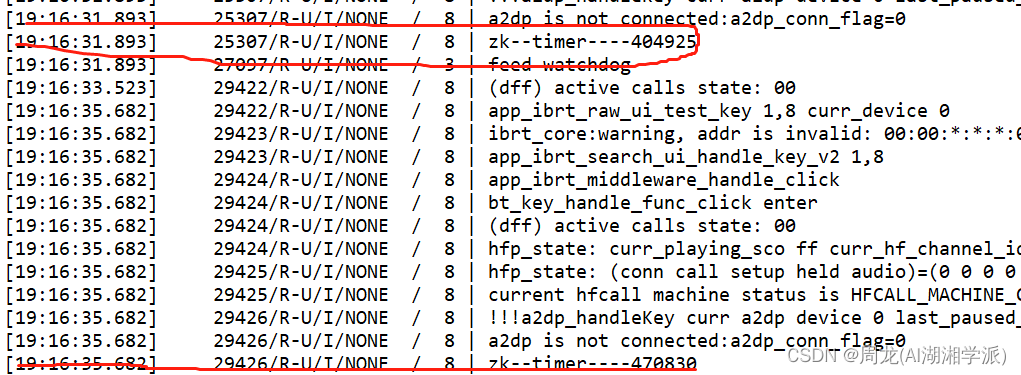
BES2700 SDK绝对时间获取方法
1 代码 2 实验 log 需要换算下...
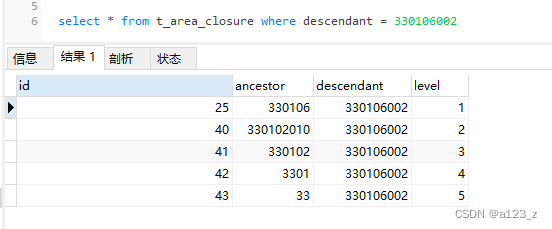
Closure Table-树形多级关系数据库设计(MySql)
一般树形多级关系数据库设计,比较普遍的就是四种方法:(具体见 SQL Anti-patterns这本书) Adjacency List:每一条记录存parent_id Path Enumerations:每一条记录存整个tree path经过的node枚举(…...

【SQL应知应会】表分区(一)• MySQL版
欢迎来到爱书不爱输的程序猿的博客, 本博客致力于知识分享,与更多的人进行学习交流 本文收录于SQL应知应会专栏,本专栏主要用于记录对于数据库的一些学习,有基础也有进阶,有MySQL也有Oracle 分区表 • MySQL版 一、分区表1.非分区表2.分区表2…...

java语法基础-- 变量、标识符、关键字
学习目标 教学目标重点难点1.掌握变量的相关概念。2.掌握Java中数据类型的划分。3.掌握8种基本数据类型的使用。4.掌握数据类型的转换方式。5.掌握各个运算符,表达式的作用。6.可以编写简单的Java应用程序。1.对变量的理解。2.基本数据类型的相关信息的记忆。3.数据…...

[STL]stack和queue模拟实现
[STL]stack和queue模拟实现 文章目录 [STL]stack和queue模拟实现stack模拟实现queue模拟实现 stack模拟实现 stack是一种容器适配器,标准容器vector、deque、list都可以作为实现stack的底层数据结构,因为它们都具备以下功能: empty…...

汽车销售企业消费税,增值税高怎么合理解决?
《税筹顾问》专注于园区招商、企业税务筹划,合理合规助力企业节税! 汽车行业一直处于炙手可热的阶段,这是因为个人或者家庭用车的需求在不断攀升,同时随着新能源的技术进一步应用到汽车领域,一度实现了汽车销量的翻倍。…...

flask数据库操作
本文将详细介绍在Flask Web应用中如何设计数据库模型,并使用Flask-SQLAlchemy等扩展进行数据库操作的最佳实践。内容涵盖数据模型设计,ORM使用,关系映射,查询方法,事务处理等方面。通过本文,您可以掌握Flask数据库应用的基本知识。 Flask作为一个流行的Python Web框架,提供了高…...

【C++】 哈希
一、哈希的概念及其性质 1.哈希概念 在顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素时,必须要经过关键码的多次比较。比如顺序表需要从第一个元素依次向后进行查找,顺序查找时间复杂度为…...
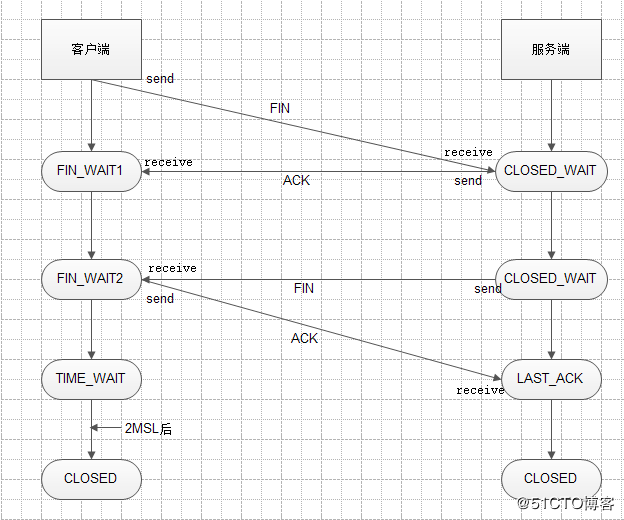
TCP三次握手和四次挥手以及11种状态(二)
11种状态 1、一开始,建立连接之前服务器和客户端的状态都为CLOSED; 2、服务器创建socket后开始监听,变为LISTEN状态; 3、客户端请求建立连接,向服务器发送SYN报文,客户端的状态变味SYN_SENT; 4、…...

【华为OD】运维日志排序
题目描述: 运维工程师采集到某产品线网运行一天产生的日志n条,现需根据日志时间先后顺序对日志进行排序,日志时间格式为H:M:S.N。 H表示小时(0~23) M表示分钟(0~59) S表示秒(0~59) N表示毫秒(0~999) 时间可能并没有补全,也就是说&…...
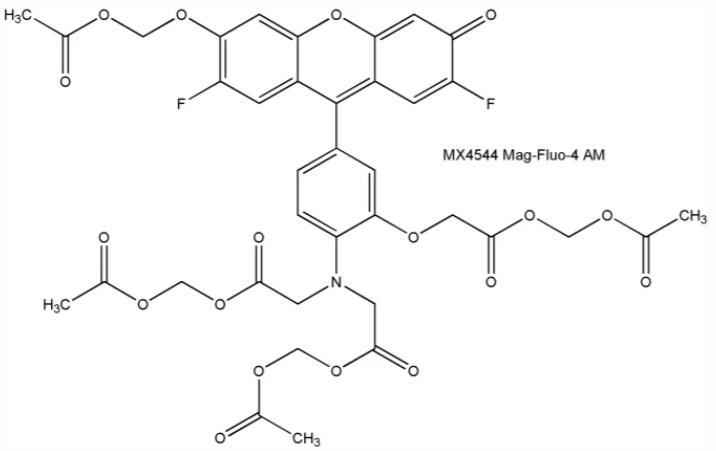
Mag-Fluo-4 AM,镁离子荧光探针,是一种有用的细胞内镁离子指示剂
资料编辑|陕西新研博美生物科技有限公司小编MISSwu PART1----产品描述: 镁离子荧光探针Mag-Fluo-4 AM,具细胞膜渗透性,对镁离子(Mg2) 和钙离子(Ca2)的 Kd 值分别是 4.7mM 和 22mM,…...

与 ChatGPT 进行有效交互的几种策略
在这篇文章中,您将了解即时工程。尤其, 如何在提示中提供对响应影响最大的信息什么是角色、正面和负面提示、零样本提示等如何迭代使用提示来利用 ChatGPT 的对话性质 废话不多说直接开始吧!!! 提示原则 快速工程是有…...
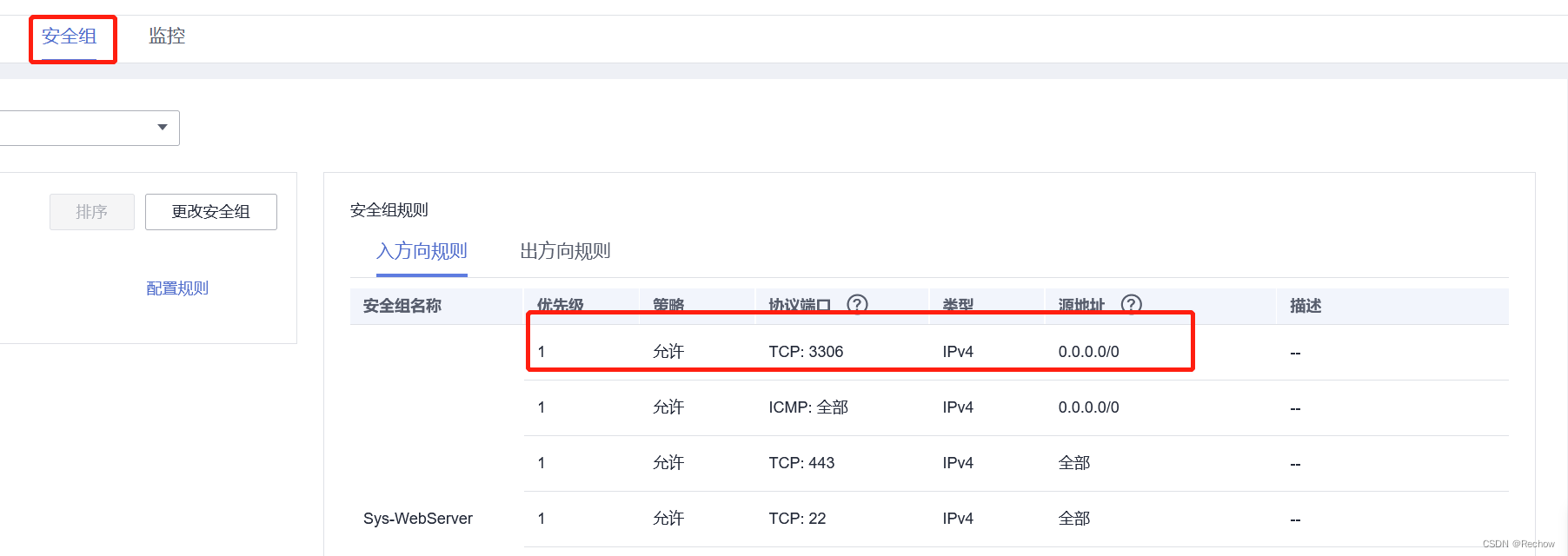
华为云安装MySQL后,本地工具连接MySQL失败
华为云安装MySQL后,本地连接失败 排查问题步骤: 在此之前需要在MySQL创建用户,并赋予权限。 1、能否ping通。 在本地命令行(Windows:winR)通过ping命令,ping服务器地址,看能否ping通。不能则需要检查本地…...

Flink On Yarn模式部署与验证
session运行模式 该模式下分为2步,即使用yarn-session.sh申请资源,然后 flink run提交任务。 1、申请资源yarn-session.sh #在server1执行命令 /usr/local/flink-1.13.5/bin/yarn-session.sh -tm 1024 -n 2 -s 1 -d #申请2个CPU、2g内存 # -tm 表示每个…...
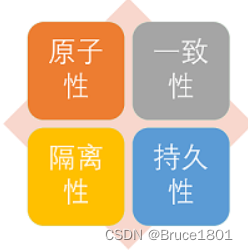
[数据库]对数据库事务进行总结
文章目录 1、什么是事务2、事务的特性(ACID)3、并发事务带来的问题4、四个隔离级别: 1、什么是事务 事务是逻辑上的一组操作,要么都执行,要么都不执行。 事务最经典也经常被拿出来说例子就是转账了。假如小明要给小红…...

【Lua学习笔记】Lua进阶——Table(2)
文章目录 Table的一万种用法二维数组类和结构体Table操作insert & removesortconcat 接上文【Lua学习笔记】Lua进阶——Table,迭代器 Table的一万种用法 二维数组 a {{ 1, 2, 3 },{ 4, 5, 6 }, } print(#a) -->2 for i1,#a dob a[i]for j1,#b doprint(b[…...

如何进行软件回归测试
什么是软件回归测试,如何进行回归测试,进行回归测试时有哪些常用的方法? 回归测试是指修改了旧代码后,重新进行测试以确认修改没有引入新的错误或导致其他代码产生错误的一种测试方法。回归测试是指重复以前的全部或部分的相同功能…...
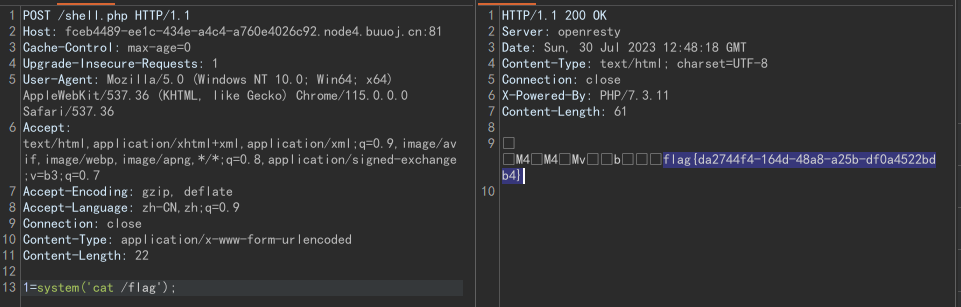
php://filter绕过死亡exit
文章目录 php://filter绕过死亡exit前言[EIS 2019]EzPOP绕过exit 参考 php://filter绕过死亡exit 前言 最近写了一道反序列化的题,其中有一个需要通过php://filter去绕过死亡exit()的小trick,这里通过一道题目来讲解 [EIS 2019]EzPOP 题目源码&#…...
RS485/RS232自由转ETHERNET/IP网关profinet和ethernet区别
你是否曾经遇到过这样的问题:如何将ETHERNET/IP网络和RS485/RS232总线连接起来呢?捷米的JM-EIP-RS485/232通讯网关,自主研发的ETHERNET/IP从站功能,完美解决了这个难题。这款网关不仅可以将ETHERNET/IP网络和RS485/RS232总线连接起…...

如何用deberta-v3-base-zeroshot-v2.0构建企业级NLP应用?完整教程来了
如何用deberta-v3-base-zeroshot-v2.0构建企业级NLP应用?完整教程来了 【免费下载链接】deberta-v3-base-zeroshot-v2.0 项目地址: https://ai.gitcode.com/hf_mirrors/NingBo_Ascend/deberta-v3-base-zeroshot-v2.0 deberta-v3-base-zeroshot-v2.0是一款基…...

C++中显示与隐式加载dll的使用与区别
一、什么是 DLL?DLL(Dynamic Link Library) 是 Windows 下的动态链接库,包含可被多个程序共享的函数、资源或类。使用 DLL 可以实现代码复用、模块化设计和插件机制。在 C 中,调用 DLL 中的函数有两种主要方式…...

别再死记硬背Payload了!我用XSS-Game靶场,带你拆解18种过滤规则背后的绕过逻辑
从XSS-Game靶场实战中掌握18种过滤规则的逆向思维在网络安全领域,跨站脚本攻击(XSS)始终是Web应用面临的主要威胁之一。许多开发者虽然了解XSS的基本概念,但当面对各种复杂的过滤规则时,往往不知如何系统分析并构造有效…...

ARM架构CONSTRAINED UNPREDICTABLE行为解析与应对
1. ARM架构中的CONSTRAINED UNPREDICTABLE行为解析在处理器架构设计中,UNPREDICTABLE行为通常指架构规范未明确定义的执行结果,可能导致不可预期的系统状态。ARM架构通过引入CONSTRAINED UNPREDICTABLE机制,将这类行为限制在特定范围内&#…...

金融合规审核为何人力堆积却仍漏洞百出?2026年RegTech演进与Agent全链路闭环解决方案
在2026年的金融监管环境下,合规审核已不再是简单的“查漏补缺”,而是演变为一场高强度的算力与逻辑博弈。尽管金融机构在合规成本上的投入逐年攀升,甚至不惜以“人海战术”填补流程断点,但监管罚单的数额与频率却并未显著下降。这…...

WarcraftHelper:魔兽争霸III现代兼容性问题的终极解决方案指南
WarcraftHelper:魔兽争霸III现代兼容性问题的终极解决方案指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 魔兽争霸III作为经典即时战…...

独立站内容分层:一层给 SEO,一层给 GEO
你的内容在喂两个完全不同的"阅读者" 你的博客文章,从来都不只有一个读者。 传统认知里,独立站内容的读者只有两类:真人访客和搜索引擎爬虫。SEO 优化的一切工作,本质上都是在讨好后者,顺带服务前者。 但…...

Keil µVision链接器错误204解决方案
1. 问题现象与背景解析最近在使用Keil Vision进行嵌入式开发时,不少工程师遇到了一个令人头疼的链接器错误。具体表现为编译时出现"FATAL ERROR 204: INVALID KEYWORD"的致命错误,错误位置指向链接器控制文件中的特定行。这个问题在C166和C51两…...

ZMJS,把 JavaScript 解释器放进 SAP ABAP 应用服务器之后,很多扩展思路会变得不一样
我今天看这个 oisee/zmjs 仓库时,最吸引人的不是它把 JavaScript 语法做进了 ABAP,而是它选择了一条非常 SAP 的路线,纯 ABAP、无外部依赖、无 Kernel Module、以类和接口的形式运行在 SAP 应用服务器内部。仓库自己的定位很直接,ZMJS 是一个面向 SAP ABAP 的 Mini JavaScr…...
)
用ESP32-C3的PWM做个RGB呼吸灯吧:从配置结构体到色彩渐变(乐鑫ESP-IDF实战)
ESP32-C3 RGB呼吸灯实战:从PWM配置到色彩渐变算法 当智能家居的灯光不再只是简单的开关控制,而是能像呼吸般自然渐变时,整个空间的氛围立刻变得生动起来。ESP32-C3凭借其出色的LED PWM控制器(LEDC)外设,为开…...