【SQL应知应会】表分区(一)• MySQL版

欢迎来到爱书不爱输的程序猿的博客, 本博客致力于知识分享,与更多的人进行学习交流
本文收录于SQL应知应会专栏,本专栏主要用于记录对于数据库的一些学习,有基础也有进阶,有MySQL也有Oracle

分区表 • MySQL版
- 一、分区表
- 1.非分区表
- 2.分区表
- 2.1 概念
- 2.2 MySQL数据库表分区
- 2.2.1 InnoDB 逻辑存储结构
- 2.2.2 段(segment)
- 2.2.3 区(extent)
- 2.2.4 页(page)
- 2.3 MySQL数据库分区的由来
- 2.4 为什么对表进行分区?
- 2.4.1 表分区要解决的问题
- 2.4.2 表分区有如下优点:
- 2.5 MySQL的分区形式
- 2.5.1 水平分区(HorizontalPartitioning)
- 2.5.2 垂直分区(VerticalPartitioning)
- 2.6 MySQL分区的类型
- 2.6.1 range分区:范围表分区,按照一定的范围值来确定每个分区包含的数据
一、分区表
1.非分区表
CREATE TABLE IF NOT EXISTS student(id INT, name VARCHAR(50), age INT, address VARCHAR(100));或CREATE TABLE IF NOT EXISTS `student`( `id` INT, `name` VARCHAR(50), `age` INT, `address` VARCHAR(100) ) ;
- 注意: 数据库名、表名、字段名反勾号` 是系统导出DDL语句自带格式,也可以不写。
2.分区表
2.1 概念
分区是一种表的设计模式,通俗地讲表分区是将一大表,根据条件分割成若干个小表。
但是对于应用程序来讲,分区的表和没有分区的表是一样的。
换句话来讲,分区对于应用是透明的,只是数据库对于数据的重新整理。
MySQL在创建表的时候可以通过使用PARTITION BY子句定义每个分区存放的数据。在执行查询的时候,优化器根据分区定义过滤那些没有我们需要的数据的分区,这样查询就可以无需扫描所有分区,只需要查找包含需要数据的分区即可。
分区的另一个目的是将数据按照一个较粗的粒度分别存放在不同的表中。这样做可以将相关的数据存放在一起,另外,当我们想要一次批量删除整个分区的数据也会变得很方便(可以单独truncate分区)
delete 要记录日志,如果开启事务的话,可以进行回滚,一行一行的删除,效率慢
truncate 直接删除底层的数据页,MySQL的物理结构底层是数据页
2.2 MySQL数据库表分区
2.2.1 InnoDB 逻辑存储结构
- InnoDB存储引擎的逻辑存储结构和Oracle大致相同,所有数据都被逻辑地存放在一个空间中,我们称之为表空间(tablespace。表空间又由段(segment)、区(extent)、页(page) 组成。
- 页在一些文档中有时也称为块(block),1 extent = 64 pages
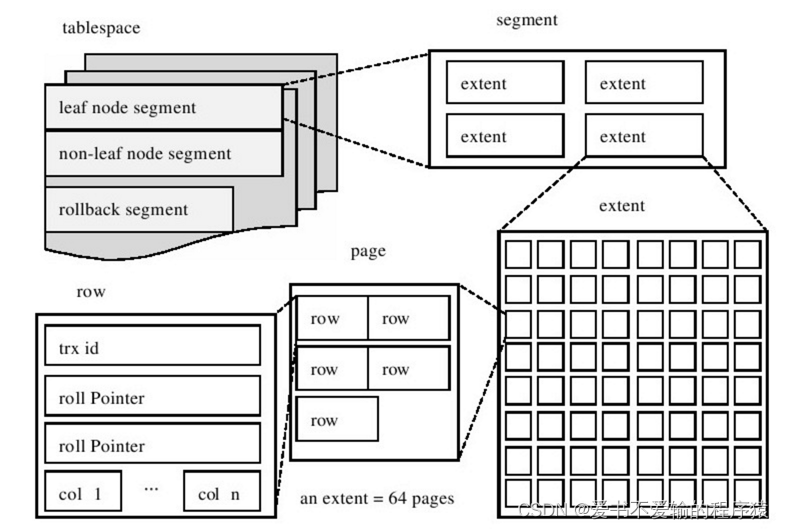
2.2.2 段(segment)
表空间是由各个段组成的,常见的段有数据段、索引段、回滚段等。
- 对于回滚段,进行delete后可以回滚数据,所以delete既占空间也耗时间,truncate相当于直接将页格式化了(不要再讲truncate是讲表删除后又重建了一个,不太恰当)
InnoDB存储引擎表是索引组织的(index
organized),因此数据即索引,索引即数据。那么数据段即为B+树的页节点(上图的leaf node
segment),索引段即为B+树的非索引节点(上图的non-leaf node segment)。与Oracle不同的是,InnoDB存储引擎对于段的管理是由引擎本身完成,这和Oracle的自动段空间管理(ASSM)类似,没有手动段空间管理(MSSM)的方式,这从一定程度上简化了DBA的管理。
- 需要注意的是,并不是每个对象都有段。因此更准确地说,表空间是由分散的页和段组成。
2.2.3 区(extent)
区是由64个连续的页组成的,每个页大小为16KB,即每个区的大小为1MB。对于大的数据段,InnoDB存储引擎最多每次可以申请4个区,以此来保证数据的顺序性能。
在我们启用了参数innodb_file_per_talbe后,创建的表默认大小是96KB。
区是64个连续的页,那创建的表的大小至少是1MB才对啊?其实这是因为在每个段开始时,先有32个页大小的碎片页(fragment page)来存放数据,当这些页使用完之后才是64个连续页的申请。这样做得目的是,对于一些小表或者undo类的段,可以开始申请较小的空间,节约磁盘开销
2.2.4 页(page)
页就是上图的page区域,也可以叫块。
页是InnoDB磁盘管理的最小单位。默认大小为16KB,可以通过参数innodb_page_size来设置
常见的页类型有:数据页,undo页,系统页,事务数据页,插入缓冲位图页,插入暖冲空闲列表页,未压缩的二进制大对象页,压缩的二进制大对象页等。
2.3 MySQL数据库分区的由来
- 传统不分区数据库痛点
mysql数据库中的数据是以文件的形式存在磁盘上的,默认放在/mysql/data下面(可以通过my.cnf中的datadir来查看),一张表主要对应着三个文件,一个是frm存放表结构的,一个是myd存放表数据的,一个是myi存表索引的。(这是myisam引攀,如果是innodb,则是frm和ibd文件,索引和数据在一起)
2.4 为什么对表进行分区?
为了改善大型表以及具有各种访问模式的表的可伸缩性,可管理性和提高数据库效率。
2.4.1 表分区要解决的问题
当表非常大,或者表中有大量的历史记录,而“热数据“却位于表的末尾。如日志系统、新闻…此时就可以考虑分区表。(热数据就是经常使用的数据)
【注:此处也可以使用分表,但是会增加业务的复杂性】
2.4.2 表分区有如下优点:
- 与单个磁盘或文件系统分区相比,可以存储更多的数据
- 对于那些已经失去保存意义的数据,通常可以通过删除与那些数据有关的分区,很容易地删除那些数据。
- 相反地,在某些情况下,添加新数据的过程又可以通过为那些新数据专门增加一个新的分区,来很方便地实现。
- 同样的,你可以很快的通过删除分区来移除旧数据,还可以优化、检查、修复个别分区
- 一些查询可以得到极大的优化。可以把一些归类的数据放在一个分区中,可以减少服务器检查数据的数量加快查询。
- 这主要是借助于满足一个给定WHERE语句的数据可以只保存在一个或多个分区内,这样在查找时就不用查找其他剩余的分区。
PS:因为分区可以在创建了分区表后进行修改,所以在第一次配置分区方案时还不曾这么做时,可以重新组织数据,来提高那些常用查询的效率。
- 涉及到例如SUM()和COUNT()这样聚合函数的查询,可以很容易地进行并行处理。
- 通过“并行”,这意味着该查询可以在每个分区上同时进行,最终结果只需通过总计所有分区得到的结果。
这种查询的一个简单例子如
SELECT salesperson_id,COUNT (orders) as order_total FROM sales GROUP BY salesperson_id
- 通过跨多个磁盘来分散数据查询,来获得更大的查询吞吐量
2.5 MySQL的分区形式
2.5.1 水平分区(HorizontalPartitioning)
- 这种形式的分区是对根据表的行进行分区,通过这样的方式不同分组里面的物理列分割的数据集得以组合,从而进行个体分别(单分区)或集体分别(1个或多个分区)
- 所有在表中定义的列在每个数据集中都能找到,所以表的特性依然得以保持
- 水平分区一定要通过某个属性列来分别,常见的有年份、日期
2.5.2 垂直分区(VerticalPartitioning)
- 这种分区方式一般来说是通过对表的垂直划分来减少目标表的宽度,是某些特定的列被划分到特定的分区,每个分区都包含了其中的列所对应的所有行
2.6 MySQL分区的类型
-
根据所使用的不同分区规则可以分成几大分区类型

-
MySql默认是支持表分区的,可以通过语句查询是否开启表分区功能:
show plugins
2.6.1 range分区:范围表分区,按照一定的范围值来确定每个分区包含的数据
- 语法如下:
partition by range(id) partition p0 values less than() - 示例:
create table user(id int(11) not null,name varchar(32) not null) -- 正常的创建语句
partition by range(id) -- 根据表字段id来创建分区 <--分区的定义
( -- 分区实例 -->partition p0 values less than(10), -- 第一个分区p0,范围~-9partition p1 values less than(20), -- 第二个分区p1,范围10-19partition p2 values less than(30), -- 第三个分区p2,范围20-29partition p3 values less than maxvalue -- 第四个分区p3,范围30-~
) -- 需要注意的是分区字段“id”的取值范围等于分区取值范围
maxvalue只是可以这么做,但是实际情况不可能把后面的所有数据都放在同一个分区,如果进行删除的话,那就是直接将后面的所有数据都删除了,不符合业务逻辑- range分区,一般用于生产运维、比较固化的调度场景,很少进行补数据的操作,如果涉及到补数据
- 根据上面的分区,假设要把范围15-19的放在一个新的分区,这就需要用到其他的手段,如重组分区
recognation,如果是Oracle的话,还需要进行split,对分区进行一个分割 - 以后想补旧的数据的时候,假设对第一个分区进行再分割,很不方便,之后会用存储过程进行存取数据的操作,存储过程的变量定义都是写死的,很难去增加一个范围分区(往后增加可以,比如上面的maxvalue,但是不能往前增加,比如上面的第一个分区的前面)
- 根据上面的分区,假设要把范围15-19的放在一个新的分区,这就需要用到其他的手段,如重组分区

相关文章:
【SQL应知应会】表分区(一)• MySQL版
欢迎来到爱书不爱输的程序猿的博客, 本博客致力于知识分享,与更多的人进行学习交流 本文收录于SQL应知应会专栏,本专栏主要用于记录对于数据库的一些学习,有基础也有进阶,有MySQL也有Oracle 分区表 • MySQL版 一、分区表1.非分区表2.分区表2…...

java语法基础-- 变量、标识符、关键字
学习目标 教学目标重点难点1.掌握变量的相关概念。2.掌握Java中数据类型的划分。3.掌握8种基本数据类型的使用。4.掌握数据类型的转换方式。5.掌握各个运算符,表达式的作用。6.可以编写简单的Java应用程序。1.对变量的理解。2.基本数据类型的相关信息的记忆。3.数据…...

[STL]stack和queue模拟实现
[STL]stack和queue模拟实现 文章目录 [STL]stack和queue模拟实现stack模拟实现queue模拟实现 stack模拟实现 stack是一种容器适配器,标准容器vector、deque、list都可以作为实现stack的底层数据结构,因为它们都具备以下功能: empty…...

汽车销售企业消费税,增值税高怎么合理解决?
《税筹顾问》专注于园区招商、企业税务筹划,合理合规助力企业节税! 汽车行业一直处于炙手可热的阶段,这是因为个人或者家庭用车的需求在不断攀升,同时随着新能源的技术进一步应用到汽车领域,一度实现了汽车销量的翻倍。…...

flask数据库操作
本文将详细介绍在Flask Web应用中如何设计数据库模型,并使用Flask-SQLAlchemy等扩展进行数据库操作的最佳实践。内容涵盖数据模型设计,ORM使用,关系映射,查询方法,事务处理等方面。通过本文,您可以掌握Flask数据库应用的基本知识。 Flask作为一个流行的Python Web框架,提供了高…...

【C++】 哈希
一、哈希的概念及其性质 1.哈希概念 在顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素时,必须要经过关键码的多次比较。比如顺序表需要从第一个元素依次向后进行查找,顺序查找时间复杂度为…...
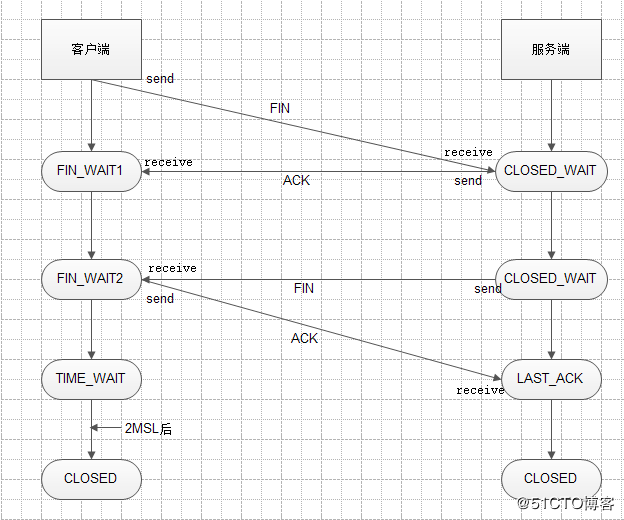
TCP三次握手和四次挥手以及11种状态(二)
11种状态 1、一开始,建立连接之前服务器和客户端的状态都为CLOSED; 2、服务器创建socket后开始监听,变为LISTEN状态; 3、客户端请求建立连接,向服务器发送SYN报文,客户端的状态变味SYN_SENT; 4、…...

【华为OD】运维日志排序
题目描述: 运维工程师采集到某产品线网运行一天产生的日志n条,现需根据日志时间先后顺序对日志进行排序,日志时间格式为H:M:S.N。 H表示小时(0~23) M表示分钟(0~59) S表示秒(0~59) N表示毫秒(0~999) 时间可能并没有补全,也就是说&…...
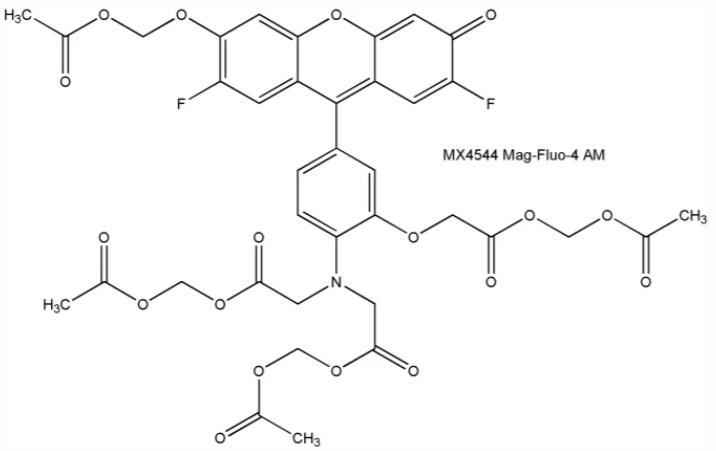
Mag-Fluo-4 AM,镁离子荧光探针,是一种有用的细胞内镁离子指示剂
资料编辑|陕西新研博美生物科技有限公司小编MISSwu PART1----产品描述: 镁离子荧光探针Mag-Fluo-4 AM,具细胞膜渗透性,对镁离子(Mg2) 和钙离子(Ca2)的 Kd 值分别是 4.7mM 和 22mM,…...

与 ChatGPT 进行有效交互的几种策略
在这篇文章中,您将了解即时工程。尤其, 如何在提示中提供对响应影响最大的信息什么是角色、正面和负面提示、零样本提示等如何迭代使用提示来利用 ChatGPT 的对话性质 废话不多说直接开始吧!!! 提示原则 快速工程是有…...
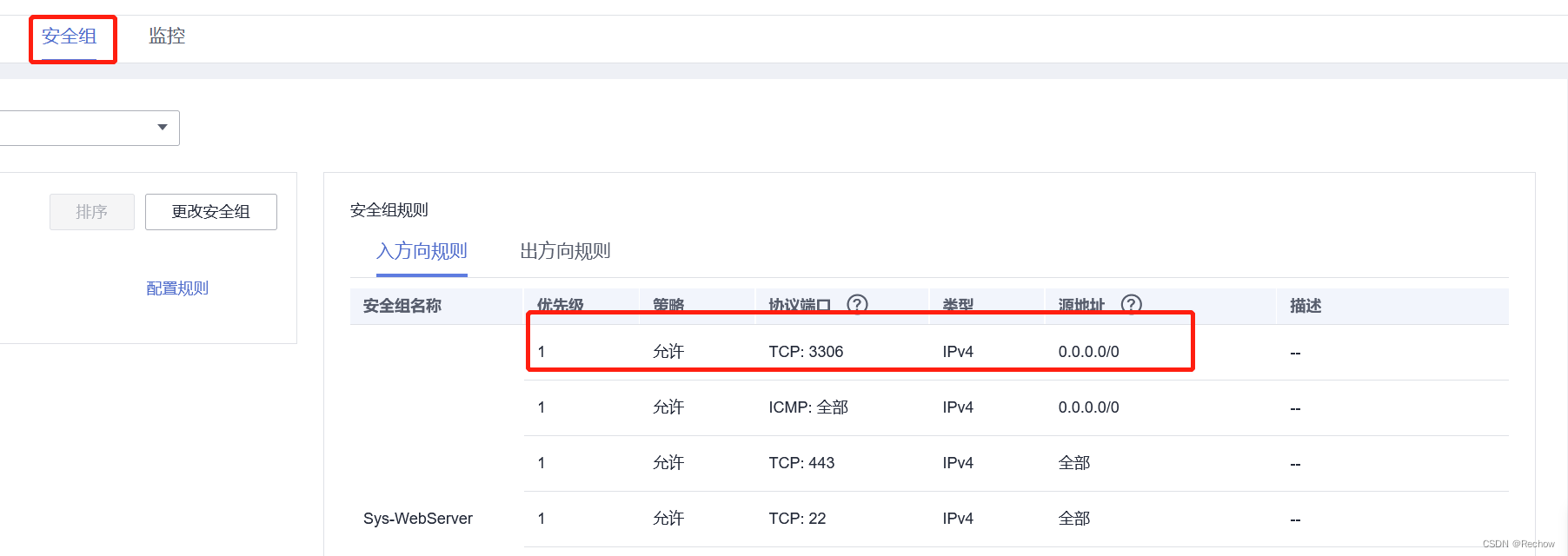
华为云安装MySQL后,本地工具连接MySQL失败
华为云安装MySQL后,本地连接失败 排查问题步骤: 在此之前需要在MySQL创建用户,并赋予权限。 1、能否ping通。 在本地命令行(Windows:winR)通过ping命令,ping服务器地址,看能否ping通。不能则需要检查本地…...

Flink On Yarn模式部署与验证
session运行模式 该模式下分为2步,即使用yarn-session.sh申请资源,然后 flink run提交任务。 1、申请资源yarn-session.sh #在server1执行命令 /usr/local/flink-1.13.5/bin/yarn-session.sh -tm 1024 -n 2 -s 1 -d #申请2个CPU、2g内存 # -tm 表示每个…...
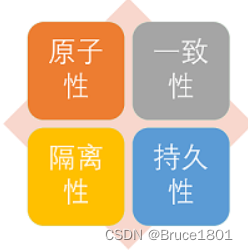
[数据库]对数据库事务进行总结
文章目录 1、什么是事务2、事务的特性(ACID)3、并发事务带来的问题4、四个隔离级别: 1、什么是事务 事务是逻辑上的一组操作,要么都执行,要么都不执行。 事务最经典也经常被拿出来说例子就是转账了。假如小明要给小红…...

【Lua学习笔记】Lua进阶——Table(2)
文章目录 Table的一万种用法二维数组类和结构体Table操作insert & removesortconcat 接上文【Lua学习笔记】Lua进阶——Table,迭代器 Table的一万种用法 二维数组 a {{ 1, 2, 3 },{ 4, 5, 6 }, } print(#a) -->2 for i1,#a dob a[i]for j1,#b doprint(b[…...

如何进行软件回归测试
什么是软件回归测试,如何进行回归测试,进行回归测试时有哪些常用的方法? 回归测试是指修改了旧代码后,重新进行测试以确认修改没有引入新的错误或导致其他代码产生错误的一种测试方法。回归测试是指重复以前的全部或部分的相同功能…...
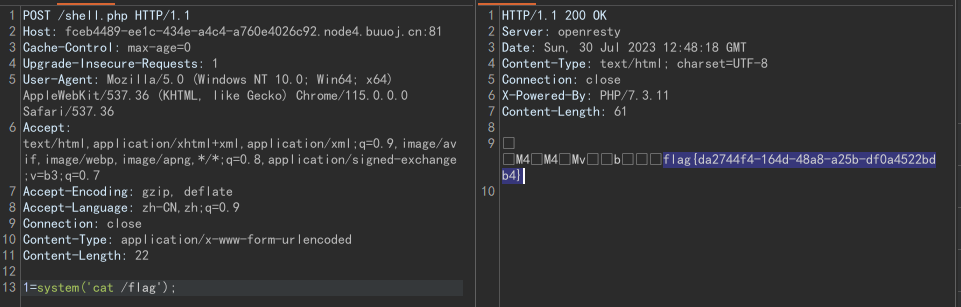
php://filter绕过死亡exit
文章目录 php://filter绕过死亡exit前言[EIS 2019]EzPOP绕过exit 参考 php://filter绕过死亡exit 前言 最近写了一道反序列化的题,其中有一个需要通过php://filter去绕过死亡exit()的小trick,这里通过一道题目来讲解 [EIS 2019]EzPOP 题目源码&#…...
RS485/RS232自由转ETHERNET/IP网关profinet和ethernet区别
你是否曾经遇到过这样的问题:如何将ETHERNET/IP网络和RS485/RS232总线连接起来呢?捷米的JM-EIP-RS485/232通讯网关,自主研发的ETHERNET/IP从站功能,完美解决了这个难题。这款网关不仅可以将ETHERNET/IP网络和RS485/RS232总线连接起…...
Hadoop_HDFS_常见的文件组织格式与压缩格式
参考资料 1. HDFS中的常用压缩算法及区别_大数据_王知无_InfoQ写作社区 2. orc格式和parquet格式对比-阿里云开发者社区 3.Hadoop 压缩格式 gzip/snappy/lzo/bzip2 比较与总结 | 海牛部落 高品质的 大数据技术社区 4. Hive中的文件存储格式TEXTFILE、SEQUENCEFILE、RCFILE…...
算法与数据结构(四)--排序算法
一.冒泡排序 原理图: 实现代码: /* 冒泡排序或者是沉底排序 *//* int arr[]: 排序目标数组,这里元素类型以整型为例; int len: 元素个数 */ void bubbleSort (elemType arr[], int len) {//为什么外循环小于len-1次?//考虑临界情况…...

【C/C++】C++11 在各编译器版本支持详情
C11 是在 2011 年发布的 C 标准,各编译器对 C11 的支持情况如下: GCC:GCC 4.8 及以上版本支持 C11。Clang:Clang 3.3 及以上版本支持 C11。Visual Studio:Visual Studio 2010 及以上版本支持部分 C11 特性,…...

tools.simonwillison.net图像处理工具集:从裁剪到优化的完整指南
tools.simonwillison.net图像处理工具集:从裁剪到优化的完整指南 【免费下载链接】tools Assorted useful tools, almost entirely generated using LLMs 项目地址: https://gitcode.com/gh_mirrors/tools23/tools tools.simonwillison.net图像处理工具集是一…...

Vulnhub-DC-1
1.信息收集 使用工具nmap扫描主机端口 这是Drupal是使用PHP语言编写的开源内容管理框架(CMF),它由内容管理系统(CMS)和PHP开发框架(Framework)共同构成 Web指纹扫描 发现是:drupal…...

组态王通用扫码枪配置
使用组态王扫码枪驱动,是绑定变量,扫码后直接就可以显示扫码内容。解决每次扫码输入数据时必须先用鼠标点进输入框内的问题。驱动安装先添加驱动,亚控网站的文件为 barcodescanner,这个文件是组态王通用扫码枪的驱动,但…...

基于ATmega2560与ISD1700的智能语音时钟:硬件选型、软件架构与避坑指南
1. 项目概述与核心价值去年折腾那个用ATMega328驱动三块显示屏的时钟时,我主要精力都花在了如何在320x240的TFT屏幕上把时间、日期和图标画得又准又好看上。项目在《Elektor》杂志上发表后,一位热心的读者给我提了个新想法:能不能做个会“说话…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...

DragonBones与Godot集成:骨骼动画的可编程化实践
1. 为什么在Godot里用DragonBones不是“锦上添花”,而是“绕不开的刚需” 去年上线一个横版动作手游Demo时,美术团队交来一套20个角色、每个角色含8套动画(待机/跑动/跳跃/攻击/受击/死亡/闪避/必杀)的Spine资源。我兴冲冲导入God…...

Spring Security OAuth2 /oauth/token 401原因与Content-Type规范
1. 问题现场还原:一个看似简单却让开发停摆两小时的/oauth/token请求刚接手一个老项目做安全加固,第一件事就是验证OAuth2密码模式的token获取流程。我照着文档写了一条curl命令:curl -X POST http://localhost:8080/oauth/token回车执行&…...

为你的Hermes Agent自定义Provider,接入Taotoken多模型池
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为你的Hermes Agent自定义Provider,接入Taotoken多模型池 在构建复杂的AI应用时,开发者常常面临一个核心挑…...

Codex使用API Key授权无法使用插件?
小伙伴们,大家好,我是小溪,见字如面。对于没有ChatGPT账号的小伙伴来说,虽然可以通过API Key授权的方式使用Codex桌面端,但是会有一些限制。比如无法使用插件功能,无法使用Codex移动端进行远程控制等。为了…...

3步快速解密中兴光猫配置:ZET工具终极实战指南
3步快速解密中兴光猫配置:ZET工具终极实战指南 【免费下载链接】ZET-Optical-Network-Terminal-Decoder 项目地址: https://gitcode.com/gh_mirrors/ze/ZET-Optical-Network-Terminal-Decoder 中兴光猫配置解密工具是每个网络管理员必备的神器!Z…...